Multivariate Pointwise Information-Driven Data Sampling and Visualization


Los Alamos National Laboratory, Los Alamos, NM 87545, USA
*
Author to whom correspondence should be addressed.
Entropy 2019, 21(7), 699; https://0-doi-org.brum.beds.ac.uk/10.3390/e21070699
Submission received: 8 May 2019
/
Revised: 25 June 2019
/
Accepted: 6 July 2019
/
Published: 16 July 2019
(This article belongs to the Special Issue Information Theory Application in Visualization)
Abstract
:With increasing computing capabilities of modern supercomputers, the size of the data generated from the scientific simulations is growing rapidly. As a result, application scientists need effective data summarization techniques that can reduce large-scale multivariate spatiotemporal data sets while preserving the important data properties so that the reduced data can answer domain-specific queries involving multiple variables with sufficient accuracy. While analyzing complex scientific events, domain experts often analyze and visualize two or more variables together to obtain a better understanding of the characteristics of the data features. Therefore, data summarization techniques are required to analyze multi-variable relationships in detail and then perform data reduction such that the important features involving multiple variables are preserved in the reduced data. To achieve this, in this work, we propose a data sub-sampling algorithm for performing statistical data summarization that leverages pointwise information theoretic measures to quantify the statistical association of data points considering multiple variables and generates a sub-sampled data that preserves the statistical association among multi-variables. Using such reduced sampled data, we show that multivariate feature query and analysis can be done effectively. The efficacy of the proposed multivariate association driven sampling algorithm is presented by applying it on several scientific data sets.
1. Introduction
The size of the scientific data sets is increasing rapidly with ever-increasing computing capabilities. Modern-day supercomputers can generate data in the order of petabytes and soon we will enter the era of exascale computing [1,2]. As the size of the data sets keeps growing, traditional analysis and visualization techniques using full resolution raw data will soon become prohibitive since storing, parsing, and analyzing the full resolution raw data will not be a viable option anymore [3,4,5,6]. This is primarily due to the gap between the disk I/O speed and the data generation speed. Recent studies show that the velocity at which data is being generated is significantly higher compared to the speed at which the data can be stored into the disks [3,6,7]. Therefore, only a small subset of the data can be moved to the permanent storage for exploratory post-hoc analysis.
Since the data triage is going to be a necessary step in the near future to facilitate flexible, exploratory, and timely post-hoc analysis, the important question now is that how the data should be reduced such that the stored subset of the data retains important information about the scientific simulations and is able to answer the queries performed by domain scientists. Large-scale simulations nowadays output data sets containing multiple variables over time. During the analysis phase of such multivariate data sets, application scientists often explore two or more variables simultaneously instead of looking at each variable individually to investigate the modeled physical phenomena in their simulation. For example, to understand the complex turbulent chemical processes of combustion, scientists have acknowledged that the exploration of multiple variables together is essential and analyzing variables individually is not sufficient [8]. By exploring multiple variables together, scientists found that during the combustion process, high valued hydroxyl regions are located where the stoichiometric mixture fraction isosurfaces are convoluted. Similarly, in the climate science domain, while studying the impact of a hurricane in a region, climatologists often look at variables like Pressure and Velocity together since the hurricane eye, an important feature of the hurricane system, can be located by querying for the regions that have low Pressure and low to moderate Velocity [9,10]. Therefore, it is essential to preserve the relationship among variables while performing data reduction such that multivariate feature analysis, as mentioned above, can be performed during the post-hoc analysis phase.
As previous researchers have shown, relationships among multiple variables in the scientific data sets can be complicated [11,12,13] and so, effective summarization of such large multivariate data sets is a challenging task. Since not all the data values are equally important, the application scientists often employ query-driven analysis techniques where a different range of values of multiple variables are queried and analyzed simultaneously [9,10,14]. The query can involve two or more variables and the result of the query on multiple variables can be combined using boolean clauses such as AND/OR. The query ranges can also be further refined as the experts gain knowledge from the exploratory analyses. As a result, a primary requirement of such summarization process will be to preserve the salient regions (i.e., regions where multiple variables demonstrate specific trends) of the data with high fidelity such that query-driven multivariate analysis and visualization can be done efficiently using the reduced subset of the data. Scientists in the past have proposed several data reduction approaches such as distribution-based [6,10,15,16,17], image-based [3,5], wavelet compression based [18,19,20], data compression by functional approximations [21] etc. However, a majority of these techniques perform data reduction on each variable individually and overlook the relationship among variables. Therefore, even though the above techniques have achieved promising results for summarizing data variables individually, multivariate relationship-aware data summarization techniques that can facilitate query-driven visual analysis during the post-hoc analysis phase are still missing.
In this work, we propose a multivariate data summarization technique that selects a small fraction of the original data set (i.e., subsamples the data) considering multiple variables simultaneously and picks data points with higher fidelity from the regions where the selected variables show a strong association. The benefits of sampling-based data representations for a single variable has been shown by the researchers in the past [22,23,24,25]. In this work, we pursue a novel sampling-based data summarization scheme and extend the sampling capability to the multi-variable domain. The proposed sampling technique uses information theoretic measure pointwise mutual information (PMI) [26] (for bivariate sampling) and its multivariate generalization specific correlation [27] to assign importance to each data point based on their multivariate associativity. Given a data point containing multiple values from different variables, pointwise mutual information allows us to quantify the strength of associativity of the data point. We leverage statistical distribution-based data sampling technique to produce a sub-sampled data set where the data points are sampled according to the strength of their statistical association values. Using pointwise statistical association as a multivariate sampling criterion, we generate a sub-sampled data where more samples are taken from regions with strong associativity and fewer samples are taken from regions that demonstrate weak dependence among the selected variables. We demonstrate the usefulness of the proposed sampling algorithm by applying it to several scientific data sets. Furthermore, to study the effectiveness of the proposed method, we compare it both qualitatively and quantitatively to the traditional random sampling technique. In our study, we demonstrate the applications where the proposed method is desirable over random sampling and also report its potential limitations compared to the random sampling. Therefore, our contributions to this work are threefold:
- We propose a new multivariate association-driven data sampling algorithm for large-scale data summarization.
- Given a user-specified sampling fraction, we use pointwise information measures and statistical distribution-based sampling techniques to generate a sub-sampled data that preserves the important multivariate features.
- We perform a detailed qualitative and quantitative study to demonstrate the efficacy of the proposed sampling scheme.
2. Related Works
2.1. Information Theory in Visualization
In computer graphics and visualization, information theory [28,29,30] has been used to solve a variety of problems in the past decades. In particular, the concepts of entropy and mutual information (MI) have been very popular for applications that use ideas ranging from information quantification to information overlap. Viola et al. [31] used MI for finding the best viewpoints for a given scene and achieving its smooth transition. MI has also been applied successfully for data fusion and image registration [32,33,34,35,36]. Previously, MI has further been used by researchers for understanding scene [37] and shape complexity [38], as well as understanding and analyzing mesh properties [39]. For scalar datasets, Bruckner et al. [40] used MI to identify the isosurface similarities. Wei et al. [41] used MI to compute representativeness of isosurfaces via a level-sets for volumetric data. Bramon et al. [42] used MI between data values and color pixels to compute information transfer. MI has also been used on the vector datasets for the selection of streamlines [43,44]. In recent years, decompositions of MI such as specific mutual information (SMI) and pointwise mutual information (PMI) have become popular for characterizing properties of individual scalars of a dataset. For fusing data from multiple sources, Bramon et al. [45] used SMI and showed the trade-off of different fusion operations. Biswas et al. [12] used entropy-based methods for salient variable selection and applied SMI for identification of salient isosurfaces from such variables. SMI has also been used for transfer function design [46]. PMI was used by Haidacher et al. [47] for understanding and extracting inverse associations from the datasets. PMI was also used by Dutta et al. [48] for exploration of time-varying multivariate datasets. For more detailed reviews regarding use of information theory in visualization, we refer the readers to [49,50,51,52,53].
2.2. Sampling for Data Analysis and Visualization
Sampling has been a very widely popular approach for selecting a subset of values from a given population. Visualization researchers have used sampling primarily in the context of data reduction such that fast data analysis and visualization can be performed. A stratified random sampling based scheme was proposed by Woodring et al. [24] where the authors used cosmology simulation as their application and enabled interactive visualization of the large-scale data. Using bitmap indices and information entropy, Wei et al. [23] extended the standard stratified random sampling for in situ data reduction. Previous to this work, Su et al. [25] used bit map indices for sampling to enable fast user queries on the datasets. Recently, visualization aware sampling methods are starting to gain more importance [54]. In this work, Park et al. [54] generated samples for scatter plot and map plot to still retain important visualization properties. Nguyen and Song [55] proposed a sampling approach that used the centrality-driven clustering for getting higher performance and quality over existing simple random sampling methods. Use of information theory has also been an important direction for researchers [56,57,58] while finding the optimal subset of the original data. Biswas et al. [22] used similar ideas of entropy maximization for inventing an in situ data-driven sampling scheme that can preserve important properties of the data. They used probability distribution of the original datasets to find important samples in a generic sampling scheme.
2.3. Multivariate Data Analysis and Visualization
Multivariate data analysis and visualization have historically been very important for researchers. A study of local correlation coefficients among multiple variables for visualization purposes was provided by Sauber et al. [59]. For multivariate datasets, Bethel et al. [60] further used correlations for enabling query-driven analysis and visualization. Such query-driven methods were extended by Gosink et al. [9] where they used local statistical data properties. Jänicke et al. [13] used local statistical complexities for finding out the interesting regions of multivariate datasets. Despite the works, multivariate data analysis remains a challenging task and there exists no sampling approach that specifically uses multivariate information for data reduction purposes. For a detailed overview of this topic, we refer the interested readers to the works of Wong et al. [61] and Fuchs et al. [62].
3. Method
In this section, we briefly discuss existing generic sampling techniques and then introduce the proposed multivariate association-driven sampling algorithm. Statistical data sampling has been shown to be effective in summarizing and analyzing data sets by researchers in the past [22,63]. One key advantage of sampling-based data summarization over sophisticated data modeling-based approaches is that the sampling techniques keep a true subset of representative points selected from the original raw data. Therefore, the observed variable values at these selected point locations are accurate, whereas using statistical models such as distributions, the values at such spatial locations will have to be inferred from the model and may contain uncertainties. Furthermore, the sub-sampled data sets can be analyzed and visualized directly without any further processing, whereas, data summarized by statistical models often need to perform reconstruction of data first which may be an expensive operation. Also, sampling techniques are expected to be computationally less expensive compared to the sophisticated statistical modeling algorithms where iterative processes are employed for model parameter estimation. To generate a representative sub-sampled data, a simple technique is to sample the data at regular intervals. This technique is called regular sampling. Regular sampling does not consider any data properties while selecting samples and due to the regular nature of sample selection, it produces artifacts and discontinuities during sample-based visual analysis [17,22].
3.1. Random Sampling
Another well-known and widely used sampling technique is random sampling. Random sampling for data summarization has been a promising approach among scientists and is being used extensively since the sub-sampled data set preserves the overall distribution of the data along with statistical quantities such as mean, standard deviation, etc. In the random sampling algorithm, each data sample has an equal probability for getting picked and hence it does not consider any variable relationship while selecting points. Random sampling operates independently on each data point and can be performed by applying the rejection sampling algorithm [64] for selecting data points uniformly randomly. Given a user-specified sampling fraction (), for each data point we generate a sample s () drawn from a standard uniform distribution . If then the current data point is selected. Since the random sampling technique does not consider variable relationships while selecting data points, the sampled output does not warrant any feature preservation. In the following section, we provide a new multivariate sampling scheme that exploits statistical association among multiple variables while sampling data points and hence is able to preserve important features in the data with higher accuracy.
3.2. Proposed Multivariate Statistical Association-Driven Sampling
Our primary goal in this work is to develop a data sub-sampling algorithm that considers multiple variables such that the reduced sampled data set preserves the statistical association among those variables with higher fidelity. To achieve this, the proposed sampling scheme samples densely from regions where a subset of selected data variables show a strong statistical association. It has been shown previously [11,48] that such associative regions often represent a multivariate feature in scientific data sets where a range of values of multiple variables tends to co-occur frequently. Therefore, considering two variables and a pair of the scalar value selected from them, the existence of a strong statistical association between the value pair can be comprehended if they demonstrate high co-occurrence and the distribution of these value pairs in the spatial domain represents a joint statistical feature. The proposed sampling algorithm samples data points by following such multivariate statistical association and selects more samples from such feature regions such that the feature regions are well preserved. At the end of the sampling process, the output is an unstructured non-uniform set of points. Before we present the details of the sampling technique, first we introduce the information theoretic measure pointwise mutual information that allows us to quantify multivariate associativity for each data point and then present the sampling algorithm that uses pointwise information as the sample selection criterion.
3.2.1. Multivariate Pointwise Information Characterization
To perform multivariate statistical association driven sampling, characterization of importance of each data point is essential. In the multivariate data set, each data point has a value tuple consisting of values from each data variable associated with it. Consider a bivariate example where X and Y are two variables and at each data point, we have a value pair . Here, x is a specific value of variable X and y for variable Y. For each such value pair, the shared information needs to be quantified so that we can identify data points (associated with each value pair) having a higher statistical association. Information theoretic measure pointwise mutual information (PMI) allows us to quantify such shared information. Given two random variables X and Y, if x is an observation of X and y for Y, then the PMI value for the value pair is expressed as:
where is the probability of a particular occurrence x of X, is the probability of y of variable Y and, is their joint probability. PMI was first introduced by Church and Hanks [26] for the quantification of word association directly from computer readable corpora. When , , which means x and y have higher information sharing between them. If , then indicating the two observations follow complementary distribution. When x and y do not have any significant information overlap then and 0. In this case, x and y are considered as statistically independent. Note that, the mutual information yields the expected PMI value over all possible instances of variable X and Y [27].
By estimating PMI values for each value pair, the shared information content for each value pair can be quantified and since each data point is associated with a value pair, we can now quantify the importance of each data point by analyzing its PMI value. If the value pair associated with a data point has high PMI value, then it is considered more important in our sampling algorithm since high PMI value indicates strong co-occurrence and therefore strong statistical association [26]. Furthermore, previous researchers also showed that such high PMI valued regions in multivariate data sets generally correspond to multivariate features [48] where multiple variables demonstrate a strong statistical association. Hence, using PMI the strength of statistical association for each data point can be quantified effectively.
In Figure 1, renderings of two scalar fields, Pressure, and Velocity, of Hurricane Isabel data set is shown to illustrate the usefulness of PMI values in characterizing multivariate association. As PMI values can be computed for each value pair of two variables, a 2-D PMI plot can be obtained where the PMI values of all value pairs can be studied. Such a PMI plot for Pressure and Velocity variables is shown in Figure 2a. The x-axis of the plot contains values of Pressure and the y-axis contains values of Velocity (Note that, the computation of PMI values are done on a histogram space and hence, the axes in plot Figure 2a show the bin ids. The scalar value that represents the bin center for each bin can be trivially computed from the range of data values for each variable). The white regions in the plot represent value pairs with zero PMI value. As we can see from this plot, the lower values of Pressure and moderate to high values of Velocity has higher PMI values (seen from the red regions in the plot). Now, since each spatial point in the data set has a Pressure and Velocity value associated with it, we can easily construct a new scalar field, called PMI field as suggested in [48] by assigning the PMI value at each grid point. Visualization of such a PMI field is provided in Figure 2b. This PMI field can be considered as an association field between Pressure and Velocity, and high PMI valued regions in this field will indicate regions that demonstrate a higher statistical association. From Figure 2b, we can observe that the high PMI valued data points are located on the eyewall of the hurricane (the dark reddish region at the center in Figure 2b). This is an important feature in Isabel data set and the eyewall of a hurricane typically represents the region where the most destructive high-velocity wind exists. Hence, the above discussion demonstrates the effectiveness of PMI in quantifying statistical association for each data point in the spatial domain. To preserve such statistical associative features while performing data sampling, in this work, we use PMI values as the sampling criterion for determining whether data point will be selected or not. The proposed sampling algorithm selects data points densely where the data points have high PMI values. In Section 3.2.3 the proposed pointwise information-driven sampling algorithm is presented in detail.
3.2.2. Generalized Pointwise Information
In the above section, we introduced the information theoretic measure PMI which allows quantification of statistical association for each data point which is applicable for two variables only. In this section, we provide a generalized extension of PMI which enables us to use more than two variables while analyzing statistical association for data points for sampling. Watanabe in their work [65] first quantified the total shared information among multiple variables as:
The quantity is termed as total correlation where n represents the number of variables, represents the probability of a specific value of variable , and indicates the joint probability of the value tuple . Note that, total correlation quantifies the total shared information among multiple variables and does quantify importance for each data point. Later, from the above definition, Tim Van de Cruys defined a new information theoretic measure called specific correlation [27], which is analogous to PMI for multiple variables:
As can be seen, specific correlation () presented in Equation (4) is a natural extension of bi-variate PMI depicted in Equation (2). Specific correlation measure follows similar statistical properties as PMI discussed above, and higher values of specific correlation indicate stronger statistical association.
3.2.3. Pointwise Information-Guided Multivariate Sampling
In the above section, we presented pointwise mutual information (PMI) and a generalized extension of it which allows us to quantify the importance of each data point in terms of their statistical association considering multiple variables. In the following, we propose a novel sampling algorithm, which uses such pointwise information measure as a sampling criterion such that multivariate statistical association driven sampling can be done. Using pointwise information assigned to each data point, the proposed sampling scheme accepts data points with higher likelihood when the pointwise information value is high indicating a high statistical association. As a result, the sub-sampled data set is able to preserve the multivariate association with higher fidelity and facilitates efficient visual query and analysis.
Given a user-specified sampling fraction () as an input parameter to the sampling algorithm, the proposed sampling scheme outputs a sub-sampled data set containing points where N is the total number of data points. In order to sample data points using their pointwise information, in this work, we use a multivariate distribution-based approach. Consider a bivariate example, where X and Y are two data variables using which sampling will be done. Firstly, the joint probability distribution of these two variables is estimated using a histogram. The univariate histograms of variable X and Y can be estimated by marginalizing the joint histogram. Since we are considering two variables to describe the sampling algorithm in this example, the joint histogram, in this case, is a 2D histogram. Each bin center in this 2D histogram represents a value pair for the two variables for the bin . Also, given the joint and univariate distributions of variables X and Y, the PMI value for each value pair for the bin ( where B is the number of bins) can be estimated by following Equation (1). Therefore, a PMI value is assigned to each 2D histogram bin. Since each bin contains multiple data points, all the data points belonging to a specific 2D histogram bin is assigned with the PMI value of the current bin. In this way, all the data points are assigned a PMI value, same as its bin center’s PMI value. Finally, the normalized PMI values assigned to each 2D histogram bin is treated as the acceptance probability for the data points in that bin. For example, if a bin in the 2D histogram has normalized PMI value , then of the data points from this bin will be selected. Since the sampling criterion, i.e., the normalized PMI value represents the strength of statistical association for multivariate data, this sampling technique will accept more sample points from the 2D histogram bins where the value of PMI is high. As a result, the final sub-sampled data set will preserve the strong statistically associative regions with higher fidelity.
The above sampling technique is similar in spirit to the importance sampling algorithms in statistics [66,67] where Monte Carlo methods are used for estimating statistical expectations of one distribution by sampling from another distribution. In our algorithm, we use PMI values as the importance criterion while selecting data points. The selection of points from each 2D histogram bin is done using rejection sampling method [64]. To determine whether to select a data point belonging to bin having normalized PMI value , first we generate a sample s drawn from a standard uniform distribution . If then the data point is selected. This sample selection process is repeated for all the data points for each bin. It is to be noted that, since the sampling algorithm is expected to store n data points according to the user-specified sampling fraction , the proposed sampling scheme first scales the normalized PMI values by applying a scaling factor such that the following condition is satisfied:
where is the frequency of the 2D histogram bin and B is the number of histogram bins. The scaling factor scales the PMI values to ensure that the total number of data points selected finally meets the desired sampling fraction . Estimation of for a given sampling fraction is straightforward. First we compute the number of data points that would be picked without any scaling by evaluating . If then scaling factor , else scaling factor . Please note that the above sampling algorithm naturally extends to multi-variable domain (i.e., more than two variables) and for the characterization of the statistical association in such cases, the generalized definition of pointwise statistical association, i.e., the specific correlation measure presented in Equation (4) can be used without the loss of any generality.
An example of the proposed sampling algorithm is provided in Figure 3 using Isabel data set where Pressure and Velocity variables are used while sampling data points. The sampling fraction for this example is set to , i.e., of total data points are selected in the sub-sampled data. In Figure 3a a point rendering of the sampled data produced by the random sampling algorithm is shown and Figure 3b depicts the point samples picked by the proposed association driven sampling algorithm. It can be observed that, since given the variables Pressure and Velocity, the eyewall region of hurricane Isabel data set has a higher statistical association (as observed in the PMI field in Figure 2b), the proposed sampling algorithm selects data points densely from such multivariate feature regions to preserve the feature more accurately. Another example of the proposed sampling algorithm applied to three variables (QGraup, QCloud, and Precipitation) of Hurricane Isabel data is shown in Figure 4. Figure 4a–c provide the visualization of the raw data for the three variables respectively and in Figure 4d we show the sample points selected by the proposed multivariate sampling algorithm. Note that, since this example uses three variables together, we have used the generalized pointwise information measure, specific correlation presented in Equation (4) for computing the multivariate statistical association for the data points considering three variables. It can be seen that the cloud and rain bands show strong statistical association and as a result, more data points are selected from such regions (the dark black regions in Figure 4d).
4. Results
In this section, we present the results of the case studies using several scientific simulation data sets to show the effectiveness of the proposed sampling algorithm. To demonstrate the applicability of the sub-sampled data set, in this work, we employ three important analysis tasks: (1) multivariate query-driven analysis, (2) reconstruction-based visualization of sampled data sets, and (3) Multivariate correlation analysis. While computing the multivariate histograms we studied the impact of a number of bins by varying it from 64 to 256. As the number of bins increases, the multivariate histogram becomes more refined as can be seen from Figure 5a–c. In Figure 5, we show the results when different bin numbers are used for Isabel data set considering variables Pressure and Velocity. As can be seen that the pattern in the PMI plots changes only slightly, but the overall pattern remains similar. Also, from Figure 5d–f it is observed that the changes in the number of bins do not impact the proposed sampling algorithm significantly. Therefore, to maintain consistency, for all the experiments presented in this paper, we set the bin number to 128. The detailed results of the case studies are discussed below.
4.1. Sample-Based Multivariate Query-Driven Visual Analysis
Query-driven visualization (QDV) is a well-known technique to understand and discover multivariate features in scientific datasets [10,14,60]. QDV is effective because it can reduce the computation workload significantly and help the domain experts to focus on the regions of interest. In this work, to help scientists to perform efficient multivariate query-driven feature exploration and visual analysis, we employ QDV to the sampled data sets directly. By performing a multivariate query on the sampled data set, experts can quickly analyze and visualize the important features in the data set. After analyzing the results of one specific query, the experts can refine the query for performing a more detailed exploration. However, note that, since the QDV is applied to the sampled data, the result we obtain is an approximation. Given a user-specified query, e.g., the value of variable P⩾ x AND Q⩽ y, we first extract the data points that satisfy this query. To visualize the results interactively, we use point rendering techniques to directly visualize the query results in the spatial domain. It is to be noted that, since the proposed sampling method prioritizes the data samples based on their PMI values, which reflects the existence of the multivariate association, the proposed technique aims at primarily preserving such statistically associated regions with a higher precession compared to the regions in the data set where the statistical association is weak. Below we present results of QDV from several multivariate scientific data sets and demonstrate the effectiveness of the proposed method.
4.1.1. Hurricane Isabel Data
We first apply the QDV analysis to Hurricane Isabel data set. Hurricane Isabel data set is used to study the impact of the hurricane Isabel on the coastal regions of the United States. The dataset is courtesy of NCAR and the U.S. National Science Foundation (NSF) and was created using the Weather Research and Forecast (WRF) model. The spatial resolution of the data is . The data set has 13 variables and we have used Pressure and Velocity field for this study. To understand the strength of the storm, scientists often explore the moderate to high-velocity regions. Furthermore, the low-Pressure region at the eye of the hurricane also is an indicating factor for the strength of the storm [9,10]. Therefore, we perform the query: −100 < Pressure < −4900 AND Velocity > 10 to analyze the low Pressure and moderate to high-Velocity regions in the sampled data set.
In Figure 6 the results of the above query is presented. Figure 6a shows all the sample points (sampling fraction ) that are selected initially before the query by applying the proposed information-driven sampling algorithm. The points are colored using Pressure variable. As can be seen that the information-driven sampling algorithm sampled points more densely where Pressure and Velocity show a strong statistical association. When the above multivariate query is applied on the original raw data, it returns a set of points shown in Figure 6b which is considered as the ground truth. Figure 6c provides the result of the same query when it is performed on the sub-sampled data (sampling fraction ) generated using our proposed algorithm, and in Figure 6d we show the result of the query when applied on a randomly sampled data set (sampling fraction ). It can be observed from Figure 6c,d that the proposed sampling algorithm is able to answer the query more accurately compared to the randomly sampled data set since the proposed method returns a denser set of points close to the true result shown in Figure 6b. Since the random sampling method does not consider relationships among variables while selecting data points, it is unable to preserve such important features with high fidelity and results in a sparse set of points as can be seen in Figure 6d.
4.1.2. Turbulent Combustion Data
Next, the QDV analysis is applied to a Turbulent Combustion data set. This dataset is a turbulent simulation and consists of 5 variables. Among them, the mixfrac variable is an important variable and denotes the proportion of fuel and oxidizer mass and this value generally provides the location of the flame where the chemical reaction rate exceeds the turbulent mixing rate [8,12]. The spatial resolution of this dataset is . Another important variable in this simulation is the mass fraction of the hydroxyl radical denoted as Y_OH. Since it was previously observed that the mixfrac values around represent the flame region and Y_OH field is nonuniform in the flame region [8,10], we performed a multivariate query 0.3 < mixfrac < 0.7 AND 0.0006 < Y_OH < 0.1 on the sampled data set.
Figure 7a shows the initial set of points selected by the proposed sampling method when a sampling fraction of is used. The result of the above query when performed on the raw data is shown in Figure 7b. Figure 7c,d presents the results of the same query when performed on the sub-sampled data produced by the proposed method and on the randomly sampled data. For this experiment, the value of the sampling fraction is set to . As can be seen, the result obtained from the samples generated by the proposed sampling method (Figure 7c) generates higher quality compared to the result obtained from the randomly sampled data.
4.1.3. Asteroid Impact Data
Finally, we apply the query-driven analysis to the Asteroid impact data set. The Deep Water Impact dataset [68] represents an ensemble of simulations run at the Los Alamos National Laboratory to study Asteroid Generated Tsunami or AGT. To evaluate our sampling scheme, we have used one of the ensemble members in this work where the spatial resolution of the data is . We have used the volume fraction of water variable, denoted by v02 and the temperature variable denoted by tev to perform sub-sampling of the data. The value of v02 lies between 0.0 and 1.0, where 1.0 means pure water. The goal is to study the phenomena of ablation and ejecta material as the asteroid enters and subsequently impacts the water, sending a plume of material into the surrounding area and up into the atmosphere [69]. Since the temperature increases as the asteroid enters the atmosphere, in this work, we perform the following query to study the interaction between tev and v02: 0.13 < tev < 0.5 AND 0.45 < v02 < 1.0.
The results of the query-driven analysis are presented in Figure 8. Figure 8a shows the point rendering of all the sub-sampled data points selected by the proposed sampling algorithm when a sampling fraction of is used. It can be seen that by analyzing the statistical association between tev and v02, the proposed method selects samples more densely from the regions where the two variables show a high statistical association. The query result obtained from the sub-sampled data produced by the proposed method (Figure 8c) is similar to the true query result produced from the raw data shown in Figure 8b. It can be also seen that the query result performed on the randomly sampled data is sparse and misses some important features which are preserved well in the results obtained by the proposed sampling method.
4.1.4. Quantitative Evaluation of Query-Driven Analysis
To study the accuracy of the query-driven analysis quantitatively, in this work, we have used the similarity measure Jaccard index [70]. The Jaccard similarity index has been used extensively in the research community to measure the similarity between sample sets. Essentially, it measures the similarity between two finite sets and can be estimated as below:
where P and Q are two finite sets. The value of lies between 0 and 1, with 1 means P and Q are identical. In our study of the query-driven analysis, set P is the point set resulted from the query applied on the raw data and Q is the point set resulted from either the proposed method or from the query applied on the randomly sampled data. Higher values of Jaccard index indicate more accurate query results. In Table 1, we provide the accuracy results of a range of queries that have been performed on Isabel data set using different variable combinations. As can be seen that the proposed method performs well for all the queries compared to random sampling method. Note that, the query presented in the second row of the Table 1, where the query involves Pressure value range outside of the hurricane eye region (i.e., the negative Pressure values), the accuracy of the random sampling method is very similar to the proposed information-driven sampling method. This is due to the fact that in such regions, the proposed sampling method did not pick samples densely due to the existence of a weak statistical association between Pressure and Velocity. Therefore, in such weakly associated regions, random sampling based QDV can result in similar accuracy to that of the proposed method. Table 1 also shows QDV results for Pressure and QVapor variables of Isabel data set. As can be seen that, for a different range of Pressure and QVapor values, the proposed method performs well. In Table 2 and Table 3, we provide the results of several QDV for Turbulent Combustion and Asteroid data sets respectively. Similar to the Isabel data set, it can be seen that the proposed method performs well for each of these data sets compared to the random sampling method for a range of values for different variables.
4.2. Reconstruction-Based Visualization of Sampled Data
Besides query-driven analysis, to visualize the data at its entirety at full resolution, we also perform reconstruction of the data from the sub-sampled data points. In this work, we have adopted a linear interpolation based technique for data reconstruction such that the features in the data can be effectively visualized using volume visualization techniques. To linearly interpolate the data, first, a 3D convex hull is generated using all the sampled points. Next, the points are converted to a polygonal mesh by using Delaunay triangulation. Finally, for each grid point in the reconstruction grid, the value is calculated by linearly interpolating scalar values from the vertices of the simplex that encloses the current grid point. After reconstruction, the traditional raycasting-based volume rendering algorithm is used to visualize the features in the data set. In the following, we first present the visualization of the reconstructed data for several multivariate data sets and then provide a quantitative image-based study of the visual quality of the results to demonstrate the efficacy of the proposed method.
4.2.1. Hurricane Isabel Data
Figure 9 shows the reconstructed data visualization of Velocity field for Hurricane Isabel data set. The visualization is focused on the feature in the data set, i.e., the hurricane eye region. The eye of the hurricane is an important feature where strong wind exists indicated by the dark reddish regions in the image. At the core of the eye, the velocity is low as seen from the blue color and around it the eyewall is generally the region where the destructive winds exist. In Figure 9, by comparing the Figure 9a, which shows the visualization of the Velocity field generated using the full resolution raw data, we can observe that the visualization produced by the proposed sampling technique (Figure 9b) matches quite well to the raw data image. However, it can be seen that the image produced from randomly sampled data presented in Figure 9c is missing some fine details around the hurricane eye region as shown by the dotted black lines in the images which are preserved more accurately by the proposed sampling algorithm.
4.2.2. Turbulent Combustion Data
The reconstruction based visualization for mixfrac and Y_OH fields of Turbulent Combustion data is shown in Figure 10 and Figure 11 respectively. In this case, the visualization of the turbulent mixing region is considered as an important feature since the mixfrac and Y_OH fields interact with each other in these regions. Scientists often try to find regions where the high Y_OH values exist and how are the high Y_OH values distributed on mixture fraction surfaces to study the flame structure [8]. The sampling fraction used in this experiment is for all the sampling algorithms. For the mixfrac field, both the proposed sampling technique (Figure 10b) and the random sampling technique (see Figure 10c) produce images which are visually very similar to that of the raw data image provided in Figure 10a. There are some minor differences in the images as highlighted by the black dotted lines. However, the proposed multivariate association-based sampling technique produces more accurate visualization for the Y_OH field compared to the random sampling algorithm. By comparing Figure 11b,c, it is observed that the regions where Y_OH values are high (indicated by the black dotted lines) are more accurate in Figure 11b obtained by our proposed sampling scheme. Furthermore, as mentioned above, such high valued regions are important since the scientists often study such high Y_OH valued regions and study its relationship with the mixture fraction values [8].
4.2.3. Asteroid Impact Data
Finally, we show the reconstruction-based visualizations of tev (temperature) field in Figure 12. Sampling fraction of is used for this study. In this visualization, the dark orange regions indicate the places where the temperature value is high and is often indicative of the existence of the asteroid. This is due to the fact that as the asteroid enters the atmosphere, the temperature increases due to the friction with the atmosphere. On the lower right side, the region shows the impact of the asteroid with the surface of the water. Figure 12b shows the reconstructed image when the sampled data from the proposed method is used and by comparing it with raw data image (Figure 12a), we can observe that the reconstructed image matches quite well to the raw data image. Figure 12c shows the visualization produced using the randomly sampled data. It is seen that even though the image quality of the random sampling method is good, however, the proposed method preserves the fine structures in the image better (as highlighted by the dotted black regions) compared to the image obtained by randomly sampled data.
4.2.4. Image-Based Quantitative Evaluation of Reconstruction-Based Visualization
After the above qualitative analysis of reconstruction-based data visualization, in this section, we provide a comprehensive study of the quality of the images generated by both the proposed sampling method and random sampling method. To study the quality, we performed an image-based comparison of the results obtained from both the sampling technique to the ground truth generated from the full resolution raw data under varying sampling fractions. Note that, for the generation of images, the same rendering parameters are used for each data set. To study the image quality quantitatively, we have used the Structural Similarity Index (SSIM) [71]. SSIM is a well-known image similarity measure frequently used in the Computer Vision community and measures the distortion between an image with respect to a reference image. This method exploits the fact that human visual perception is highly adapted for extracting structural information from an image and is designed to capture the degradation of structural information. SSIM compares the images based on the variation of luminance, contrast, and structural information. Therefore, the SSIM measure [71] between two images and is represented as:
where represents luminance similarity, denotes contrast similarity and contains the structural information. In the above equation, a, b, and c are three parameters used to assign the relative importance to the three corresponding components in the measure and the default value for those parameters are set to 1 indicating equal importance. Using SSIM, the comparison between the images are done on local patches first and finally the mean values of all SSIM values from all the patches are computed which represents the final SSIM between two images. Besides SSIM, we have also used Mean Squared Error (MSE) as our second image quality comparison measure. Note that higher values of SSIM indicate better similarity between the test image and the reference image and since MSE estimates an error quantity, lower values are considered more accurate for this measure. In our study, the raw images are considered as the reference image and images produced by the proposed sampling algorithm and random sampling are compared against the reference image.
The results of the image-based quality comparison for Hurricane Isabel data set is presented in Table 4 and Table 5. Table 4 shows results when Pressure and Velocity fields are used for sampling, and Table 5 depicts results when Pressure and QVapor variables are used. Table 6 summarizes the results of image-based comparison for Turbulent Combustion data where mixfrac and Y_OH fields are used and Table 7 shows results for Asteroid Impact data using tev and v02 field. From all the results obtained by these three multivariate data sets, it can be observed that the proposed method has produced better image quality consistently for the similarity measures across different sampling fractions which demonstrates the superiority of the proposed multivariate association-driven sampling algorithm over the existing popular random sampling algorithm. We also observe that for v02 field of Asteroid data set (Table 7), MSE measures are slightly better for random sampling algorithm, however, when the structural similarity is estimated through SSIM measure, the proposed sampling algorithm produces more accurate results than random sampling technique. This indicates that the proposed sampling algorithm is able to preserve the structure of the features in the visualization more accurately.
4.3. Multivariate Correlation Analysis of the Proposed Sampling Method
In this section, we evaluate the proposed method in preserving the multivariate association among selected variables. Since the proposed PMI-based sampling technique prioritizes data points based on their shared information, the technique aims at preserving the relationship between variable combinations in the strongly associated regions. More specifically, the proposed technique aims at recovering back the statistical association in the important regions where a strong local dependence among variables exists. Note that, as shown above, these strongly statistically associated regions often indicate important scientific features in the data set where multiple variables interact with each other. For example, in Hurricane Isabel data set, we have shown that the low Pressure valued regions (i.e., negative Pressure regions) and moderate to high wind velocity regions show the important feature “hurricane eye”. The proposed technique in this work aims at preserving such regions with higher fidelity such that the multivariate dependence among variables in such regions can be recovered. Therefore, to evaluate the quality of the preservation of statistical association, we have used two measures in this work. The first measure is Pearson’s correlation coefficient, which measures the linear correlation between variables. In addition, since the variables can have non-linear dependence, we have also used distance correlation [72] to estimate the non-linear correlation among variables using the reconstructed fields. While Pearson’s correlation coefficient takes values between −1.0 and 1.0 where −1.0 indicates total negative correlation and 1.0 indicates the total positive correlation, distance correlation takes values only between 0 and 1.0 where 0 indicates independence.
The first evaluation is done on the reconstructed data set by specifically focusing on the important feature regions of the data sets. In Figure 13, we present the regions of interest (ROI) for each data set used in this study. The black box shown in the images indicates the ROI where the correlation study is performed. Note that, for Hurricane Isabel data, we have selected the Hurricane eye region (see Figure 13a), for Combustion data, we have selected the turbulent flame region as our ROI (Figure 13b), and in the Asteroid impact data set, we have used the region where the asteroid has impacted the sea surface and the water is ejected into the atmosphere (Figure 13c). Table 8 provides the different correlation values that we obtained from different data sets when the correlation measures are computed in the reconstructed fields considering only the feature regions indicated by the ROIs in Figure 13. As can be seen from Table 8, the proposed method is able to preserve both the linear and non-linear correlation better compared to the random sampling method. Next, we estimated these two correlation measures by considering the full reconstructed data. The results are shown in Table 9. As we can see that when the full reconstructed data is considered, for Isabel and Combustion data set, the proposed information-driven technique is performing better than the random sampling technique. However, the random sampling technique achieves a more accurate result in the Asteroid data. These results demonstrate that, when full data is considered, both these techniques are competitive. However, since the proposed method is designed to preserve the important statistically associated regions with higher fidelity, it is able to recover the linear and non-linear dependence between variables accurately compared to random sampling.
5. Discussion, Limitations, and Future Works
In this work, we propose a new multivariate statistical association driven data sub-sampling algorithm that aims at preserving the statistically associated regions in the multivariate data sets with higher accuracy in the form of a reduced sub-sampled data set. To achieve this, the proposed technique first uses pointwise information theoretic measures to compute the strength of statistical association for each data point in the spatial domain and then uses a multivariate distribution-based approach to sample data points according to the strength of their multivariate association. Therefore, such a sampling technique produces a sub-sampled data set where stronger statistically associated regions are sampled densely compared to the regions that demonstrate weaker association among selected variables. We show several visualization and analysis tasks such as (a) multivariate feature query, (b) reconstruction based feature visualization and (c) recovery of multivariate correlation and dependence for important regions of interest in the data sets where the proposed sampling technique can be preferred over the traditional random sampling algorithms. This is primarily due to the fact that the random sampling technique samples the whole data set randomly and the importance of all the data points are equal. Hence, it does not sample any region densely.
However, when experts want to preserve the overall data distribution and statistical quantities like mean, standard deviation, random sampling technique can be preferred over the proposed method. Furthermore, as we have observed from Table 9, when we are considering the full data, random sampling based technique is able to perform almost similarly to the proposed method in recovering the correlations. Therefore, it can be concluded that both the proposed sampling technique and the random sampling technique have their own advantages and limitations. The proposed method does not recommend replacing random sampling completely, rather, they can be used in a complementary fashion depending on the demands of the application tasks. Hence, it can be concluded that the proposed technique is able to preserve the features (identified as statistically associated regions) in the scientific data sets more accurately compared to the random sampling methods, however, for preserving the overall statistical data properties and distributions, random sampling can still be used.
Another potential limitation of the proposed method in its current state is the use of multivariate histograms whose dimension increases with the number of variables used during sampling. When the number of variables is large, creating a high-dimensional histogram can be challenging and also memory consuming. Therefore, to overcome this issue, we plan to first cluster the variables using their shared information content into smaller sub-groups as was proposed in [12] and then apply the proposed sampling algorithm. Furthermore, we wish to compare the performance and efficacy of the proposed method with more sophisticated data sampling techniques such as stratified random sampling, importance driven sampling algorithms, etc.
In addition to the above goals, another future task is to apply the proposed sampling method to the distributed parallel environment such that the sampling algorithm can be run in situ while the simulation is running and the generated data resides in the supercomputer memory. This will lead to an effective in situ statistical sampling-based data summarization technique and the reduced sub-sampled data can be explored timely in the post-hoc analysis phase. In order to perform the sampling in a distributed environment, we need to compute the global joint data distributions and we plan to leverage the optimized multivariate histogram computation technique provided in [73] for estimating compact multivariate distributions. We also plan to apply our sampling algorithm to other scientific applications and obtain user feedback to further improve the quality of the sampling technique.
6. Conclusions
In summary, this paper presents a new multivariate association driven data sampling technique for summarization of large-scale scientific data sets. We use pointwise information theoretic measures to assign importance to data points based on their statistical association and then perform data sub-sampling according to such multivariate importance criterion. The proposed sampling algorithm is applied to several scientific data sets to conduct multivariate feature analysis. Through comprehensive quantitative and qualitative query-driven analysis and reconstruction-based visualization, the usefulness of the proposed sampling algorithm is justified.
Author Contributions
S.D. was responsible for conceiving the idea, designing all the experiments, performing the studies, and writing the paper. A.B. helped in conceiving the idea and in the editing of the manuscript. J.A. supervised the work and helped in guiding the research overall.
Funding
This research was funded by U.S. Department of Energy and Alpine Exascle Computing Project.
Acknowledgments
The authors wish to thank the anonymous reviewers for their insightful and detailed comments. Also, the authors thank Francesca Samsel for her help with the colormaps. This research was supported by the Exascale Computing Project (ECP), Project Number: 17-SC-20-SC, a collaborative effort of two DOE organizations - the Office of Science and the National Nuclear Security Administration. This work is published under LA-UR-19-24243 v2.
Conflicts of Interest
The authors declare no conflict of interest for this work.
References
- Ahern, S.; Shoshani, A.; Ma, K.L.; Choudhary, A.; Critchlow, T.; Klasky, S.; Pascucci, V.; Ahrens, J.; Bethel, E.; Childs, H. Scientific Discovery at the Exascale. In Proceedings of the The DOE ASCR 2011 Workshop on Exascale Data Management, Houston, TX, USA, 22–23 February 2011. [Google Scholar]
- Childs, H. Data Exploration at the Exascale. Supercomput. Front. Innov. 2015, 2, 5–13. [Google Scholar]
- Ahrens, J.; Jourdain, S.; OLeary, P.; Patchett, J.; Rogers, D.H.; Petersen, M. An Image-Based Approach to Extreme Scale in Situ Visualization and Analysis. In Proceedings of the SC14: International Conference for High Performance Computing, Networking, Storage and Analysis, New Orleans, LA, USA, 16–21 November 2014; pp. 424–434. [Google Scholar] [CrossRef]
- Nouanesengsy, B.; Woodring, J.; Patchett, J.; Myers, K.; Ahrens, J. ADR visualization: A generalized framework for ranking large-scale scientific data using Analysis-Driven Refinement. In Proceedings of the 2014 IEEE 4th Symposium on Large Data Analysis and Visualization (LDAV), Paris, France, 9–10 November 2014; pp. 43–50. [Google Scholar] [CrossRef]
- Tikhonova, A.; Correa, C.D.; Ma, K. Explorable images for visualizing volume data. In Proceedings of the 2010 IEEE Pacific Visualization Symposium (PacificVis), Taipei, Taiwan, 2–5 March 2010; pp. 177–184. [Google Scholar] [CrossRef]
- Dutta, S.; Chen, C.M.; Heinlein, G.; Shen, H.W.; Chen, J.P. In Situ Distribution Guided Analysis and Visualization of Transonic Jet Engine Simulations. IEEE Trans. Vis. Comput. Graph. 2017, 23, 811–820. [Google Scholar] [CrossRef] [PubMed]
- Woodring, J.; Petersen, M.; Schmeiβer, A.; Patchett, J.; Ahrens, J.; Hagen, H. In Situ Eddy Analysis in a High-Resolution Ocean Climate Model. IEEE Trans. Vis. Comput. Graph. 2016, 22, 857–866. [Google Scholar] [CrossRef] [PubMed]
- Akiba, H.; Ma, K.; Chen, J.H.; Hawkes, E.R. Visualizing Multivariate Volume Data from Turbulent Combustion Simulations. Comput. Sci. Eng. 2007, 9, 76–83. [Google Scholar] [CrossRef] [Green Version]
- Gosink, L.J.; Garth, C.; Anderson, J.C.; Bethel, E.W.; Joy, K.I. An Application of Multivariate Statistical Analysis for Query-Driven Visualization. IEEE Trans. Vis. Comput. Graph. 2011, 17, 264–275. [Google Scholar] [CrossRef] [PubMed]
- Hazarika, S.; Dutta, S.; Shen, H.; Chen, J. CoDDA: A Flexible Copula-based Distribution Driven Analysis Framework for Large-Scale Multivariate Data. IEEE Trans. Vis. Comput. Graph. 2019, 25, 1214–1224. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Shen, H.W. Association Analysis for Visual Exploration of Multivariate Scientific Data Sets. IEEE Trans. Vis. Comput. Graph. 2016, 22, 955–964. [Google Scholar] [CrossRef] [PubMed]
- Biswas, A.; Dutta, S.; Shen, H.; Woodring, J. An Information-Aware Framework for Exploring Multivariate Data Sets. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2683–2692. [Google Scholar] [CrossRef] [PubMed]
- Jänicke, H.; Wiebel, A.; Scheuermann, G.; Kollmann, W. Multifield visualization using local statistical complexity. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1384–1391. [Google Scholar] [CrossRef]
- Stockinger, K.; Shalf, J.; Wu, K.; Bethel, E.W. Query-driven visualization of large data sets. In Proceedings of the IEEE Visualization 2005 (VIS 05), Minneapolis, MN, USA, 23–28 October 2005; pp. 167–174. [Google Scholar] [CrossRef]
- Wang, K.; Shareef, N.; Shen, H. Image and Distribution Based Volume Rendering for Large Data Sets. In Proceedings of the 2018 IEEE Pacific Visualization Symposium (PacificVis), Kobe, Japan, 10–13 April 2018; pp. 26–35. [Google Scholar] [CrossRef]
- Wang, K.; Wei, T.; Shareef, N.; Shen, H. Statistical visualization and analysis of large data using a value-based spatial distribution. In Proceedings of the 2017 IEEE Pacific Visualization Symposium (PacificVis), Seoul, Korea, 18–21 April 2017; pp. 161–170. [Google Scholar] [CrossRef]
- Dutta, S.; Woodring, J.; Shen, H.W.; Chen, J.P.; Ahrens, J. Homogeneity guided probabilistic data summaries for analysis and visualization of large-scale data sets. In Proceedings of the 2017 IEEE Pacific Visualization Symposium (PacificVis), Seoul, Korea, 18–21 April 2017; pp. 111–120. [Google Scholar] [CrossRef]
- Clyne, J.; Mininni, P.; Norton, A.; Rast, M. Interactive desktop analysis of high resolution simulations: application to turbulent plume dynamics and current sheet formation. New J. Phys. 2007, 9, 301. [Google Scholar] [CrossRef]
- Li, S.; Sane, S.; Orf, L.; Mininni, P.; Clyne, J.; Childs, H. Spatiotemporal Wavelet Compression for Visualization of Scientific Simulation Data. In Proceedings of the 2017 IEEE International Conference on Cluster Computing (CLUSTER), Honolulu, HI, USA, 5–8 September 2017; pp. 216–227. [Google Scholar] [CrossRef]
- Li, S.; Gruchalla, K.; Potter, K.; Clyne, J.; Childs, H. Evaluating the efficacy of wavelet configurations on turbulent-flow data. In Proceedings of the 2015 IEEE 5th Symposium on Large Data Analysis and Visualization (LDAV), Chicago, IL, USA, 25–26 October 2015; pp. 81–89. [Google Scholar] [CrossRef]
- Lakshminarasimhan, S.; Shah, N.; Ethier, S.; Klasky, S.; Latham, R.; Ross, R.; Samatova, N.F. Compressing the Incompressible with ISABELA: In-situ Reduction of Spatio-temporal Data. In Euro-Par 2011 Parallel Processing; Jeannot, E., Namyst, R., Roman, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 366–379. [Google Scholar]
- Biswas, A.; Dutta, S.; Pulido, J.; Ahrens, J. In Situ Data-driven Adaptive Sampling for Large-scale Simulation Data Summarization. In Proceedings of the Workshop on In Situ Infrastructures for Enabling Extreme-Scale Analysis and Visualization, Dallas, TX, USA, 12 November 2018; ACM: New York, NY, USA, 2018; pp. 13–18. [Google Scholar] [CrossRef]
- Wei, T.; Dutta, S.; Shen, H. Information Guided Data Sampling and Recovery Using Bitmap Indexing. In Proceedings of the 2018 IEEE Pacific Visualization Symposium (PacificVis), Kobe, Japan, 10–13 April 2018; pp. 56–65. [Google Scholar] [CrossRef]
- Woodring, J.; Ahrens, J.; Figg, J.; Wendelberger, J.; Habib, S.; Heitmann, K. In-situ Sampling of a Large-scale Particle Simulation for Interactive Visualization and Analysis. In Proceedings of the 13th Eurographics/IEEE—VGTC Conference on Visualization, Bergen, Norway, 1–3 June 2011; pp. 1151–1160. [Google Scholar] [CrossRef]
- Su, Y.; Agrawal, G.; Woodring, J.; Myers, K.; Wendelberger, J.; Ahrens, J. Taming Massive Distributed Datasets: Data Sampling Using Bitmap Indices. In Proceedings of the 22nd International Symposium on High-performance Parallel and Distributed Computing, New York, NY, USA, 17–21 June 2013; ACM: New York, NY, USA, 2013; pp. 13–24. [Google Scholar] [CrossRef]
- Church, K.W.; Hanks, P. Word association norms, mutual information, and lexicography. In Proceedings of the 27th Annual Meeting on Association for Computational Linguistics, Vancouver, BC, Canada, 26–29 June 1989; Association for Computational Linguistics: Stroudsburg, PA, USA, 1989; pp. 76–83. [Google Scholar] [CrossRef]
- Van de Cruys, T. Two multivariate generalizations of pointwise mutual information. In Proceedings of the Workshop on Distributional Semantics and Compositionality, Portland, OR, USA, 24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 16–20. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley Series in Telecommunications and Signal Processing; Wiley-Interscience: New York, NY, USA, 2006. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Verdú, S. Fifty years of Shannon theory. Inf. Theory IEEE Trans. 1998, 44, 2057–2078. [Google Scholar] [CrossRef]
- Viola, I.; Feixas, M.; Sbert, M.; Gröller, M.E. Importance-Driven Focus of Attention. IEEE Trans. Vis. Comput. Graph. 2006, 12, 933–940. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Collignon, A.; Maes, F.; Delaere, D.; Vandermeulen, D.; Suetens, P.; Marchal, G. Automated multi-modality image registration based on information theory. Inf. Process. Med. Imaging 1995, 3, 263–274. [Google Scholar]
- Hill, D.L.G.; Batchelor, P.G.; Holden, M.; Hawkes, D.J. Medical image registration. Phys. Med. Biol. 2001, 46, R1. [Google Scholar] [CrossRef] [PubMed]
- Wells, W.M., III; Viola, P.; Atsumi, H.; Nakajima, S.; Kikinis, R. Multi-modal volume registration by maximization of mutual information. Med. Image Anal. 1996, 1, 35–51. [Google Scholar] [CrossRef]
- Maes, F.; Collignon, A.; Vandermeulen, D.; Marchal, G.; Suetens, P. Multimodality image registration by maximization of mutual information. IEEE Trans. Med. Imaging 1997, 16, 187–198. [Google Scholar] [CrossRef]
- Pluim, J.P.W.; Maintz, J.B.A.; Viergever, M.A. Mutual-information-based registration of medical images: A survey. IEEE Trans. Med. Imaging 2003, 22, 986–1004. [Google Scholar] [CrossRef] [PubMed]
- Feixas, M.; Acebo, E.D.; Bekaert, P.; Sbert, M. An Information Theory Framework for the Analysis of Scene Complexity. In Computer Graphics Forum; Blackwell Publishers, Ltd.: Oxford, UK; Boston, MA, USA, 1999. [Google Scholar]
- Rigau, J.; Feixas, M.; Sbert, M. Shape complexity based on mutual information. In Proceedings of the 2005 International Conference on Shape Modeling and Applications, Cambridge, MA, USA, 13–17 June 2005; pp. 355–360. [Google Scholar] [CrossRef]
- Feixas, M.; Sbert, M.; González, F. A unified information-theoretic framework for viewpoint selection and mesh saliency. ACM Trans. Appl. Percept. 2009. [Google Scholar] [CrossRef]
- Bruckner, S.; Möller, T. Isosurface Similarity Maps. Comput. Graph. Forum 2010, 29, 773–782. [Google Scholar] [CrossRef] [Green Version]
- Wei, T.H.; Lee, T.Y.; Shen, H.W. Evaluating Isosurfaces with Level-set-based Information Maps. In Proceedings of the 15th Eurographics Conference on Visualization, Leipzig, Germany, 17–21 June 2013; Eurographics Association: Aire-la-Ville, Switzerland, 2013; pp. 1–10. [Google Scholar] [CrossRef]
- Bramon, R.; Ruiz, M.; Bardera, A.; Boada, I.; Feixas, M.; Sbert, M. An Information-Theoretic Observation Channel for Volume Visualization. Comput. Graph. Forum 2013, 32, 411–420. [Google Scholar] [CrossRef]
- Ma, J.; Wang, C.; Shene, C.K. Coherent view-dependent streamline selection for importance-driven flow visualization. Proc. SPIE 2013, 8654. [Google Scholar] [CrossRef]
- Tao, J.; Ma, J.; Wang, C.; Shene, C.K. A Unified Approach to Streamline Selection and Viewpoint Selection for 3D Flow Visualization. IEEE Trans. Vis. Comput. Graph. 2013, 19, 393–406. [Google Scholar] [CrossRef] [PubMed]
- Bramon, R.; Boada, I.; Bardera, A.; Rodriguez, J.; Feixas, M.; Puig, J.; Sbert, M. Multimodal Data Fusion Based on Mutual Information. IEEE Trans. Vis. Comput. Graph. 2012, 18, 1574–1587. [Google Scholar] [CrossRef] [PubMed]
- Bramon, R.; Ruiz, M.; Bardera, A.; Boada, I.; Feixas, M.; Sbert, M. Information Theory-Based Automatic Multimodal Transfer Function Design. IEEE J. Biomed. Health Inform. 2013, 17, 870–880. [Google Scholar] [CrossRef] [PubMed]
- Haidacher, M.; Bruckner, S.; Kanitsar, A.; Gröller, M.E. Information-based Transfer Functions for Multimodal Visualization. In Proceedings of the First Eurographics conference on Visual Computing for Biomedicine, Delft, The Netherlands, 6–7 October 2008; Botha, C.P., Kindlmann, G., Niessen, W., Preim, B., Eds.; Eurographics Association: Geneva, Switzerland, 2008; pp. 101–108. [Google Scholar]
- Dutta, S.; Liu, X.; Biswas, A.; Shen, H.W.; Chen, J.P. Pointwise Information Guided Visual Analysis of Time-varying Multi-fields. In Proceedings of the SIGGRAPH Asia 2017 Symposium on Visualization, Bangkok, Thailand, 27–30 November 2017; ACM: New York, NY, USA, 2017; pp. 17:1–17:8. [Google Scholar] [CrossRef]
- Chen, M.; Feixas, M.; Viola, I.; Bardera, A.; Shen, H.W.; Sbert, M. Information Theory Tools for Visualization; A K Peters: Natick, MA, USA; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Chen, M.; Jänicke, H. An Information-theoretic Framework for Visualization. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1206–1215. [Google Scholar] [CrossRef] [Green Version]
- Rigau, J.; Feixas, M.; Sbert, M. Informational Aesthetics Measures. IEEE Comput. Graph. Appl. 2008, 28, 24–34. [Google Scholar] [CrossRef] [Green Version]
- Sbert, M.; Feixas, M.; Rigau, J.; Chover, M.; Viola, I. Information Theory Tools for Computer Graphics; Synthesis Lectures on Computer Graphics and Animation; Morgan and Claypool Publishers: Fort Collins, CO, USA, 2009. [Google Scholar]
- Wang, C.; Shen, H.W. Information Theory in Scientific Visualization. Entropy 2011, 13, 254–273. [Google Scholar] [CrossRef] [Green Version]
- Park, Y.; Cafarella, M.J.; Mozafari, B. Visualization-Aware Sampling for Very Large Databases. arXiv 2015, arXiv:1510.03921. [Google Scholar]
- Nguyen, T.T.; Song, I. Centrality clustering-based sampling for big data visualization. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1911–1917. [Google Scholar] [CrossRef]
- Chen, X.H.; Dempster, A.P.; Liu, J.S. Weighted Finite Population Sampling to Maximize Entropy. Biometrika 1994, 81, 457–469. [Google Scholar] [CrossRef]
- Ko, C.W.; Lee, J.; Queyranne, M. An Exact Algorithm for Maximum Entropy Sampling. Oper. Res. 1995, 43, 684–691. [Google Scholar] [CrossRef]
- Shewry, M.C.; Wynn, H.P. Maximum entropy sampling. J. Appl. Stat. 1987, 14, 165–170. [Google Scholar] [CrossRef]
- Sauber, N.; Theisel, H.; Seidel, H.P. Multifield-Graphs: An Approach to Visualizing Correlations in Multifield Scalar Data. IEEE Trans. Vis. Comput. Graph. 2006, 12, 917–924. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gosink, L.; Anderson, J.; Bethel, W.; Joy, K. Variable Interactions in Query-Driven Visualization. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1400–1407. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wong, P.C.; Bergeron, R.D. 30 Years of Multidimensional Multivariate Visualization. In Scientific Visualization, Overviews, Methodologies, and Techniques; IEEE Computer Society: Washington, DC, USA, 1997; pp. 3–33. [Google Scholar]
- Fuchs, R.; Hauser, H. Visualization of Multi-Variate Scientific Data. InComputer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2009; Volume 28, pp. 1670–1690. [Google Scholar] [CrossRef]
- Lohr, S. Sampling: Design and Analysis; Advanced, Cengage Learning: Boston, MA, USA, 2009. [Google Scholar]
- Albert, J. Bayesian Computation with R; Use R; Springer: New York, NY, USA, 2009. [Google Scholar]
- Watanabe, S. Information theoretical analysis of multivariate correlation. IBM J. Res. Dev. 1960, 4, 66–82. [Google Scholar] [CrossRef]
- Doucet, A.; Godsill, S.; Andrieu, C. On Sequential Monte Carlo Sampling Methods for Bayesian Filtering. Stat. Comput. 2000, 10, 197–208. [Google Scholar] [CrossRef]
- Lawrence, E.; Wiel, S.V.; Bent, R. Model Bank State Estimation for Power Grids Using Importance Sampling. Technometrics 2013, 55, 426–435. [Google Scholar] [CrossRef]
- Patchett, J.; Gisler, G. Deep Water Impact Ensemble Data Set. Los Alamos National Laboratory, LA-UR-17-21595. 2017. Available online: https://oceans11.lanl.gov/deepwaterimpact/ (accessed on 16 July 2019).
- Gisler, G.R.; Heberling, T.; Plesko, C.S.; Weaver, R.P. Three-dimensional simulations of oblique asteroid impacts into water. J. Space Saf. Eng. 2018, 5, 106–114. [Google Scholar] [CrossRef]
- Levandowsky, M.; Winter, D. Distance between Sets. Nature 1971, 234. [Google Scholar] [CrossRef]
- Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Székely, G.J.; Rizzo, M.L.; Bakirov, N.K. Measuring and Testing Dependence by Correlation of Distances. Ann. Stat. 2007, 35, 2769–2794. [Google Scholar] [CrossRef]
- Lu, K.; Shen, H. A compact multivariate histogram representation for query-driven visualization. In Proceedings of the 2015 IEEE 5th Symposium on Large Data Analysis and Visualization (LDAV), Chicago, IL, USA, 25–26 October 2015; pp. 49–56. [Google Scholar] [CrossRef]
Figure 1.
Visualization of Pressure and Velocity field of Hurricane Isabel data set. The hurricane eye at the center of Pressure field and the high velocity region around the hurricane eye can be observed.
Figure 1.
Visualization of Pressure and Velocity field of Hurricane Isabel data set. The hurricane eye at the center of Pressure field and the high velocity region around the hurricane eye can be observed.

Figure 2.
PMI computed from Pressure and Velocity field of Hurricane Isabel data set is visualized. (a) shows the 2D plot of PMI values for all value pairs of Pressure and Velocity, (b) provides the PMI field for analyzing the PMI values in the spatial domain. It can be seen that around the hurricane eye, the eyewall is highlighted as high PMI-valued region which indicates a joint feature in the data set involving Pressure and Velocity field.
Figure 2.
PMI computed from Pressure and Velocity field of Hurricane Isabel data set is visualized. (a) shows the 2D plot of PMI values for all value pairs of Pressure and Velocity, (b) provides the PMI field for analyzing the PMI values in the spatial domain. It can be seen that around the hurricane eye, the eyewall is highlighted as high PMI-valued region which indicates a joint feature in the data set involving Pressure and Velocity field.

Figure 3.
Sampling result on Isabel data set when Pressure and Velocity variables are used. (a) shows results of random sampling and (b) shows results of the proposed pointwise information driven sampling results for sampling fraction . By observing the PMI field presented in Figure 2b, it can be seen that the proposed sampling method samples densely from the regions where statistical association between Pressure and Velocity is stronger (b).
Figure 3.
Sampling result on Isabel data set when Pressure and Velocity variables are used. (a) shows results of random sampling and (b) shows results of the proposed pointwise information driven sampling results for sampling fraction . By observing the PMI field presented in Figure 2b, it can be seen that the proposed sampling method samples densely from the regions where statistical association between Pressure and Velocity is stronger (b).

Figure 4.
Sampling result for Isabel data set when three variables (QGraup, QCloud, and Precipitation) are used to perform sampling. In this case, the generalized specific correlation measure presented in Equation is used to compute multivariate associativity for the data points considering all three variables. (a–c) show the rendering of QGraup, QCloud, and Precipitation fields respectively. (d) presents the rendering of sampled data points when the proposed multivariate sampling algorithm is applied to these three variables. It can be seen that the cloud and the rain bands show stronger statistical association among three variables and hence are sampled densely. The sampling fraction used in this example is .
Figure 4.
Sampling result for Isabel data set when three variables (QGraup, QCloud, and Precipitation) are used to perform sampling. In this case, the generalized specific correlation measure presented in Equation is used to compute multivariate associativity for the data points considering all three variables. (a–c) show the rendering of QGraup, QCloud, and Precipitation fields respectively. (d) presents the rendering of sampled data points when the proposed multivariate sampling algorithm is applied to these three variables. It can be seen that the cloud and the rain bands show stronger statistical association among three variables and hence are sampled densely. The sampling fraction used in this example is .

Figure 5.
Results of the proposed sampling technique when the number of histogram bins is varied while computing the information theoretic measure PMI. It is observed that the overall result remains similar without impacting the outcome of the sampling algorithm significantly.
Figure 5.
Results of the proposed sampling technique when the number of histogram bins is varied while computing the information theoretic measure PMI. It is observed that the overall result remains similar without impacting the outcome of the sampling algorithm significantly.

Figure 6.
Visualization of multivariate query-driven analysis performed on the sampled data using Hurricane Isabel data set. The multivariate query −100 < Pressure < −4900 AND Velocity > 10 is applied on the sampled data sets. (a) shows all the points selected by the proposed sampling algorithm by using Pressure and Velocity variable. (b) shows the data points selected by the query when applied to raw data. (c) shows the points selected when the query is performed on the sub-sampled data produced by the proposed sampling scheme and (d) presents the result of the query when applied to a randomly sampled data set. The sampling fraction used in this experiment is .
Figure 6.
Visualization of multivariate query-driven analysis performed on the sampled data using Hurricane Isabel data set. The multivariate query −100 < Pressure < −4900 AND Velocity > 10 is applied on the sampled data sets. (a) shows all the points selected by the proposed sampling algorithm by using Pressure and Velocity variable. (b) shows the data points selected by the query when applied to raw data. (c) shows the points selected when the query is performed on the sub-sampled data produced by the proposed sampling scheme and (d) presents the result of the query when applied to a randomly sampled data set. The sampling fraction used in this experiment is .

Figure 7.
Visualization of multivariate query-driven analysis performed on the sampled data using Turbulent Combustion data set. The multivariate query 0.3 < mixfrac < 0.7 AND 0.0006 < Y_OH 0.1 is applied on the sampled data sets. (a) shows all the points selected by the proposed sampling algorithm by using mixfrac and Y_OH variable. (b) shows the data points selected by the query when applied to raw data. (c) shows the points selected when the query is performed on the sub-sampled data produced by the proposed sampling scheme and (d) presents the result of the query when applied to a randomly sampled data set. The sampling fraction used in this experiment is .
Figure 7.
Visualization of multivariate query-driven analysis performed on the sampled data using Turbulent Combustion data set. The multivariate query 0.3 < mixfrac < 0.7 AND 0.0006 < Y_OH 0.1 is applied on the sampled data sets. (a) shows all the points selected by the proposed sampling algorithm by using mixfrac and Y_OH variable. (b) shows the data points selected by the query when applied to raw data. (c) shows the points selected when the query is performed on the sub-sampled data produced by the proposed sampling scheme and (d) presents the result of the query when applied to a randomly sampled data set. The sampling fraction used in this experiment is .

Figure 8.
Visualization of multivariate query driven analysis performed on the sampled data using Asteroid impact data set. The multivariate query 0.13 < tev < 0.5 AND 0.45 < v02 1.0 is applied on the sampled data sets. (a) shows all the points selected by the proposed sampling algorithm by using tev and v02 variable. (b) shows the data points selected by the query when applied to raw data. (c) shows the points selected when the query is performed on the sub-sampled data produced by the proposed sampling scheme and (d) presents the result of the query when applied to a randomly sampled data set. The sampling fraction used in this experiment is .
Figure 8.
Visualization of multivariate query driven analysis performed on the sampled data using Asteroid impact data set. The multivariate query 0.13 < tev < 0.5 AND 0.45 < v02 1.0 is applied on the sampled data sets. (a) shows all the points selected by the proposed sampling algorithm by using tev and v02 variable. (b) shows the data points selected by the query when applied to raw data. (c) shows the points selected when the query is performed on the sub-sampled data produced by the proposed sampling scheme and (d) presents the result of the query when applied to a randomly sampled data set. The sampling fraction used in this experiment is .

Figure 9.
Reconstruction-based visualization of Velocity field of Hurricane Isabel data set. Linear interpolation is used to reconstruct the data from the sub-sampled data sets. (a) shows the result from the original raw data. (b) provides the reconstruction result from the sub-sampled data generated by the proposed method, and (c) presents the result of reconstruction from random sampled data. The sampling fraction used in this experiment is .
Figure 9.
Reconstruction-based visualization of Velocity field of Hurricane Isabel data set. Linear interpolation is used to reconstruct the data from the sub-sampled data sets. (a) shows the result from the original raw data. (b) provides the reconstruction result from the sub-sampled data generated by the proposed method, and (c) presents the result of reconstruction from random sampled data. The sampling fraction used in this experiment is .

Figure 10.
Reconstruction-based visualization of mixfrac field of Turbulent Combustion data set. Linear interpolation is used to reconstruct the data from the sub-sampled data sets. (a) shows the result from the original raw data. (b) provides the reconstruction result from the sub-sampled data generated by the proposed method, and (c) presents the result of reconstruction from random sampled data. The sampling fraction used in this experiment is .
Figure 10.
Reconstruction-based visualization of mixfrac field of Turbulent Combustion data set. Linear interpolation is used to reconstruct the data from the sub-sampled data sets. (a) shows the result from the original raw data. (b) provides the reconstruction result from the sub-sampled data generated by the proposed method, and (c) presents the result of reconstruction from random sampled data. The sampling fraction used in this experiment is .

Figure 11.
Reconstruction-based visualization of Y_OH field of Turbulent Combustion data set. Linear interpolation is used to reconstruct the data from the sub-sampled data sets. (a) shows the result from the original raw data. (b) provides the reconstruction result from the sub-sampled data generated by the proposed method, and (c) presents the result of reconstruction from random sampled data. The sampling fraction used in this experiment is .
Figure 11.
Reconstruction-based visualization of Y_OH field of Turbulent Combustion data set. Linear interpolation is used to reconstruct the data from the sub-sampled data sets. (a) shows the result from the original raw data. (b) provides the reconstruction result from the sub-sampled data generated by the proposed method, and (c) presents the result of reconstruction from random sampled data. The sampling fraction used in this experiment is .

Figure 12.
Reconstruction-based visualization of tev field of Asteroid impact data set. Linear interpolation is used to reconstruct the data from the sub-sampled data sets. (a) shows the result from the original raw data. (b) provides the reconstruction result from the sub-sampled data generated by the proposed method, and (c) presents the result of reconstruction from random sampled data. The sampling fraction used in this experiment is .
Figure 12.
Reconstruction-based visualization of tev field of Asteroid impact data set. Linear interpolation is used to reconstruct the data from the sub-sampled data sets. (a) shows the result from the original raw data. (b) provides the reconstruction result from the sub-sampled data generated by the proposed method, and (c) presents the result of reconstruction from random sampled data. The sampling fraction used in this experiment is .

Figure 13.
Regions of interest (ROI) of different data sets used for analysis. (a) shows the ROI in Isabel data set, where the hurricane eye feature is selected. (b) shows the ROI for Combustion data set, where the turbulent flame region is highlighted. Finally, in (c) the ROI for asteroid data set is shown. The ROI selected in this example indicates the region where the asteroid has impacted the ocean surface and the splash of the water is ejected to the environment.
Figure 13.
Regions of interest (ROI) of different data sets used for analysis. (a) shows the ROI in Isabel data set, where the hurricane eye feature is selected. (b) shows the ROI for Combustion data set, where the turbulent flame region is highlighted. Finally, in (c) the ROI for asteroid data set is shown. The ROI selected in this example indicates the region where the asteroid has impacted the ocean surface and the splash of the water is ejected to the environment.


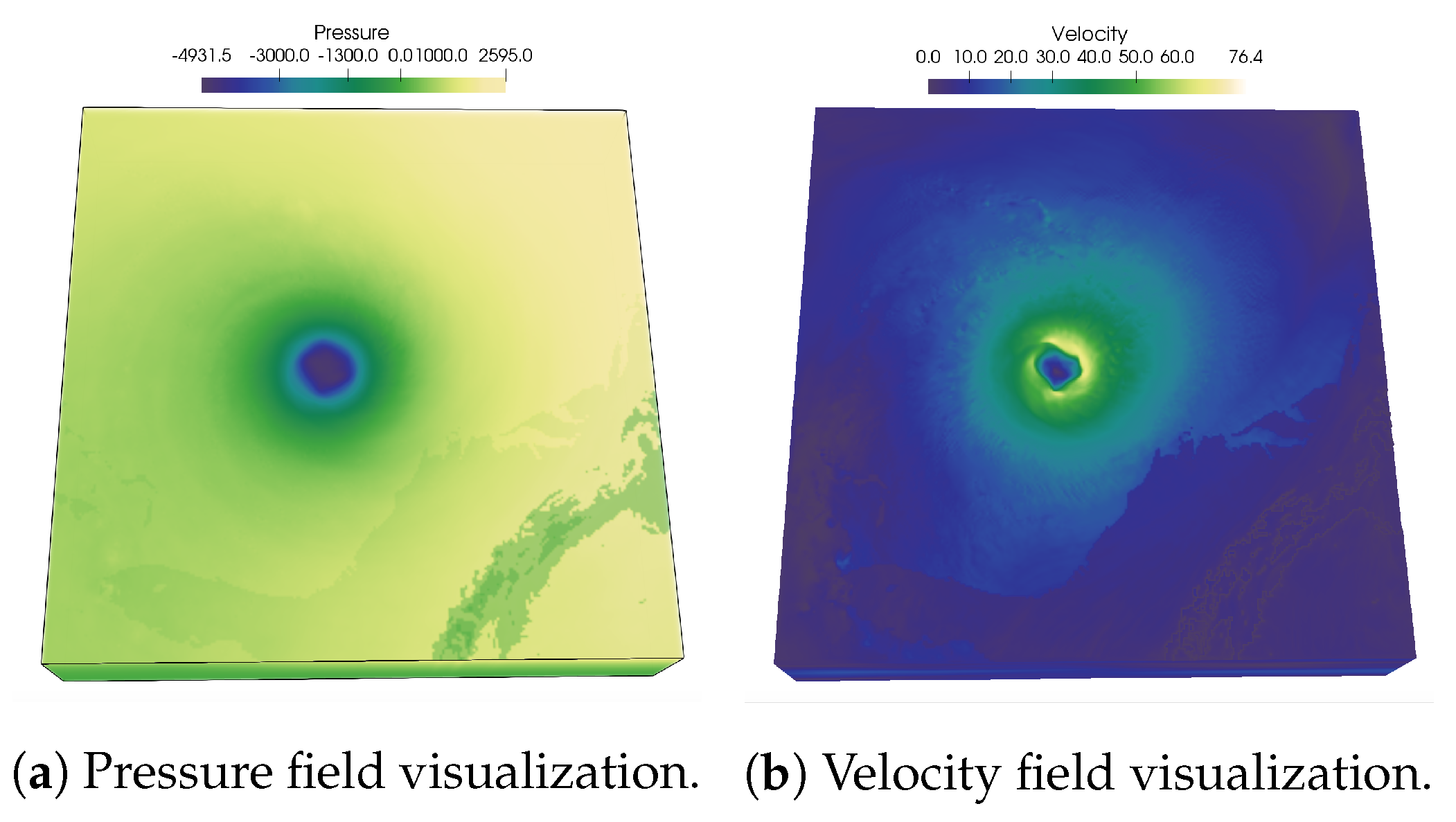{kind=link}
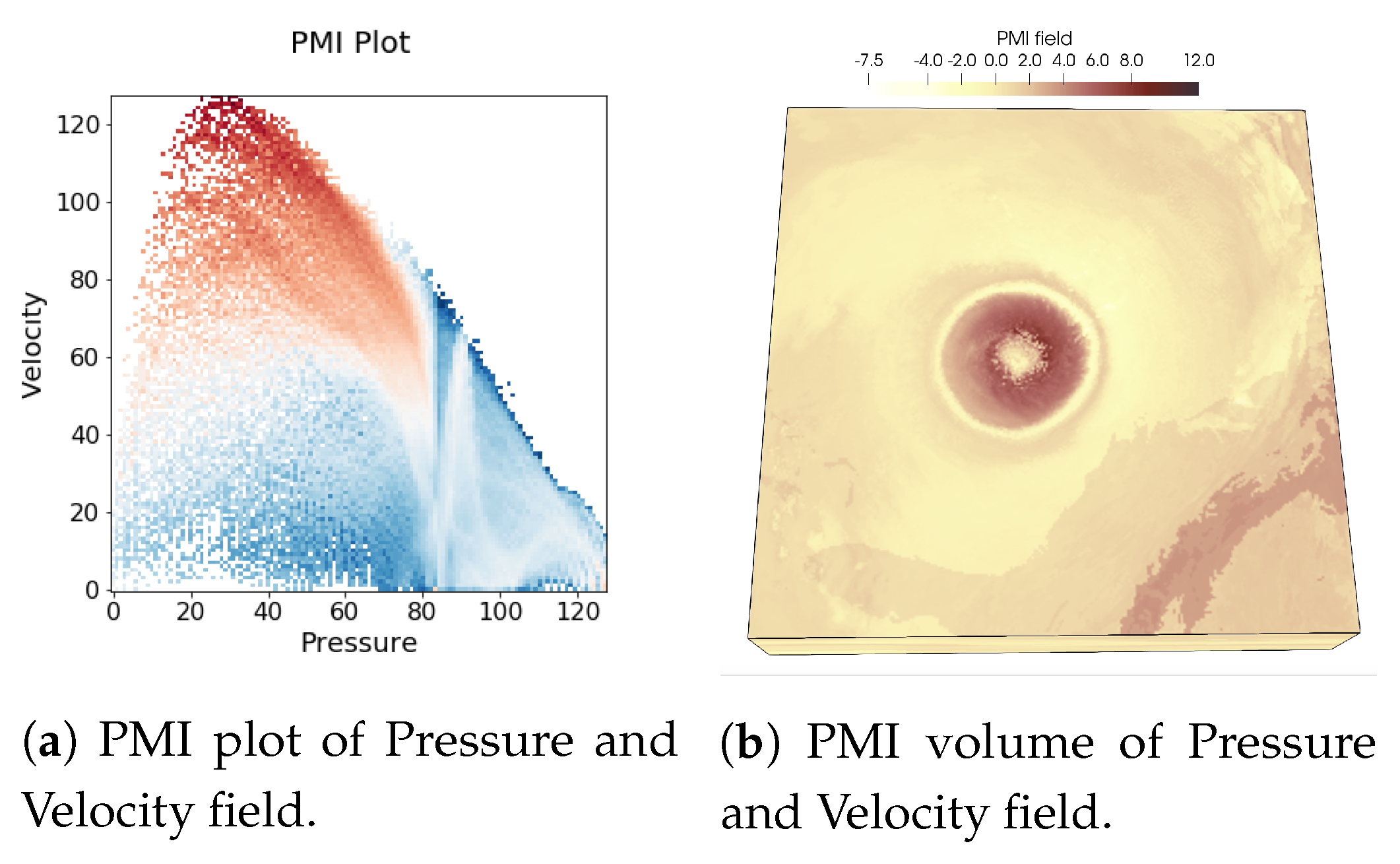{kind=link}
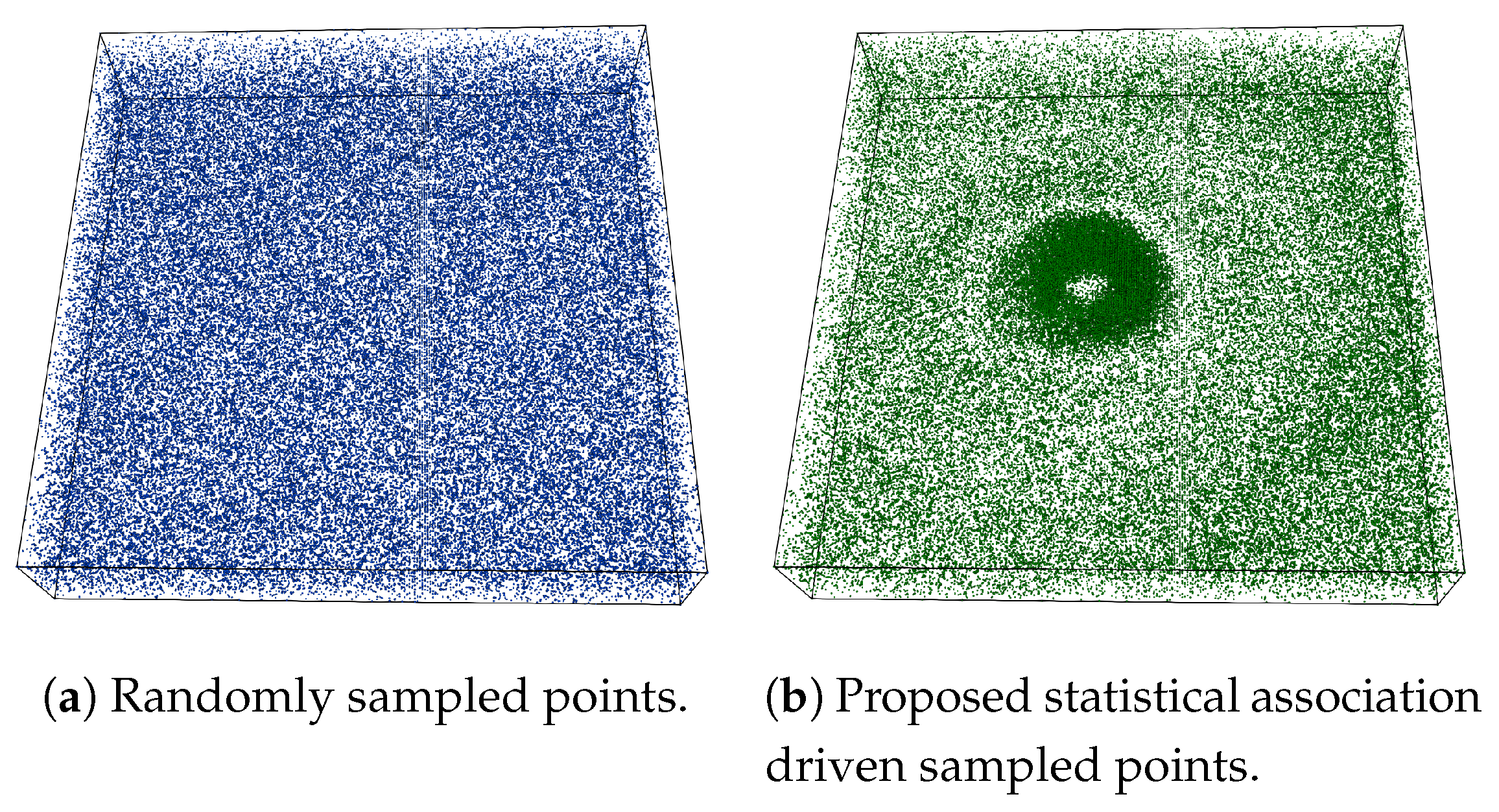{kind=link}
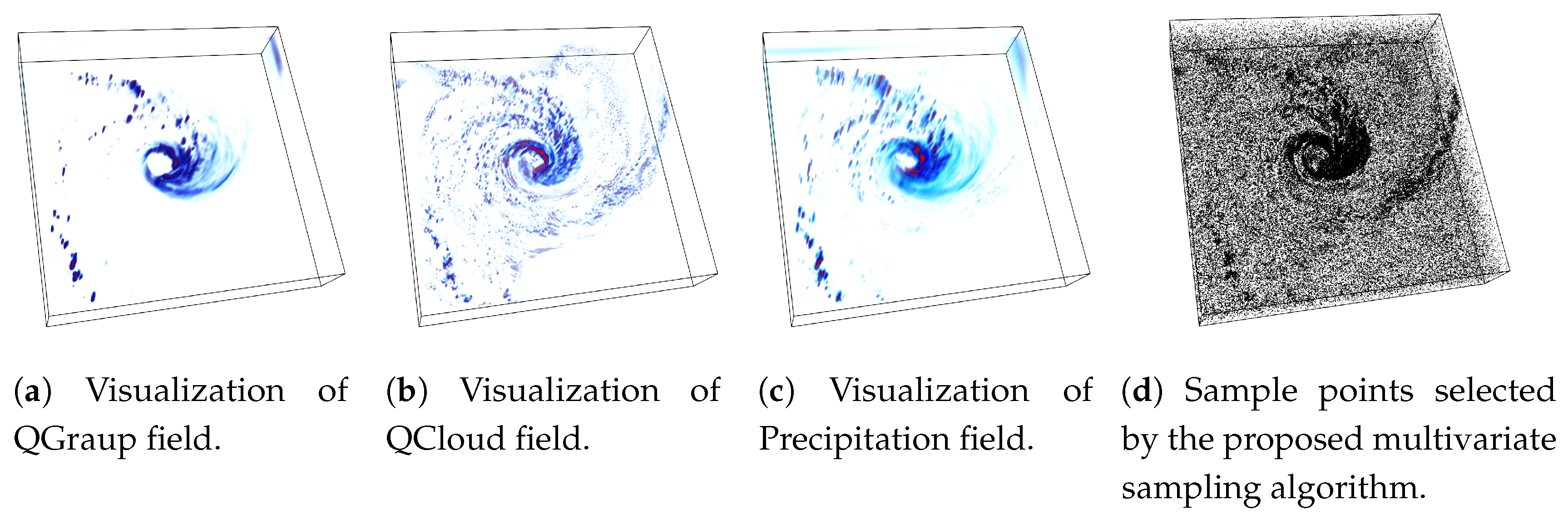{kind=link}
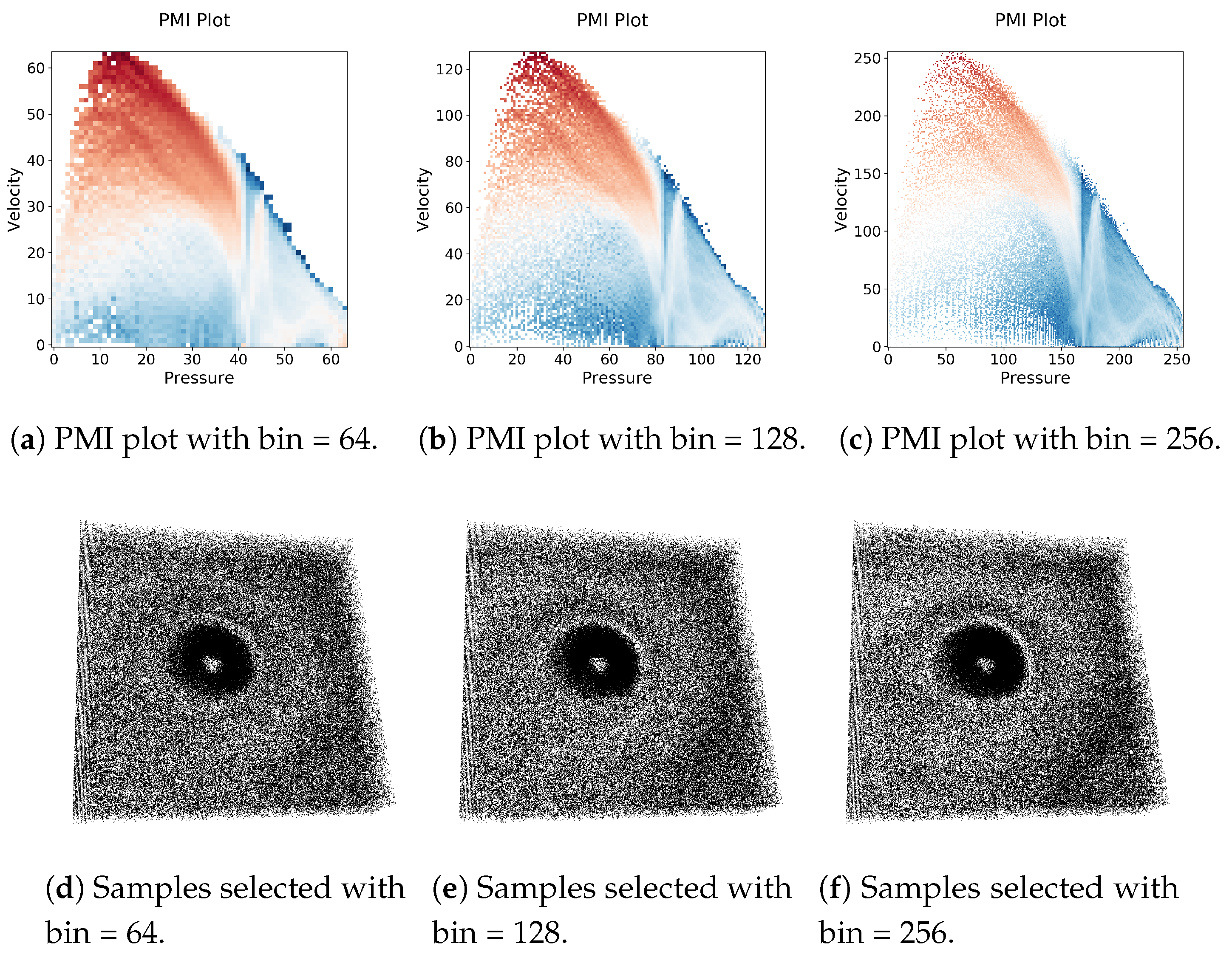{kind=link}
{kind=link}
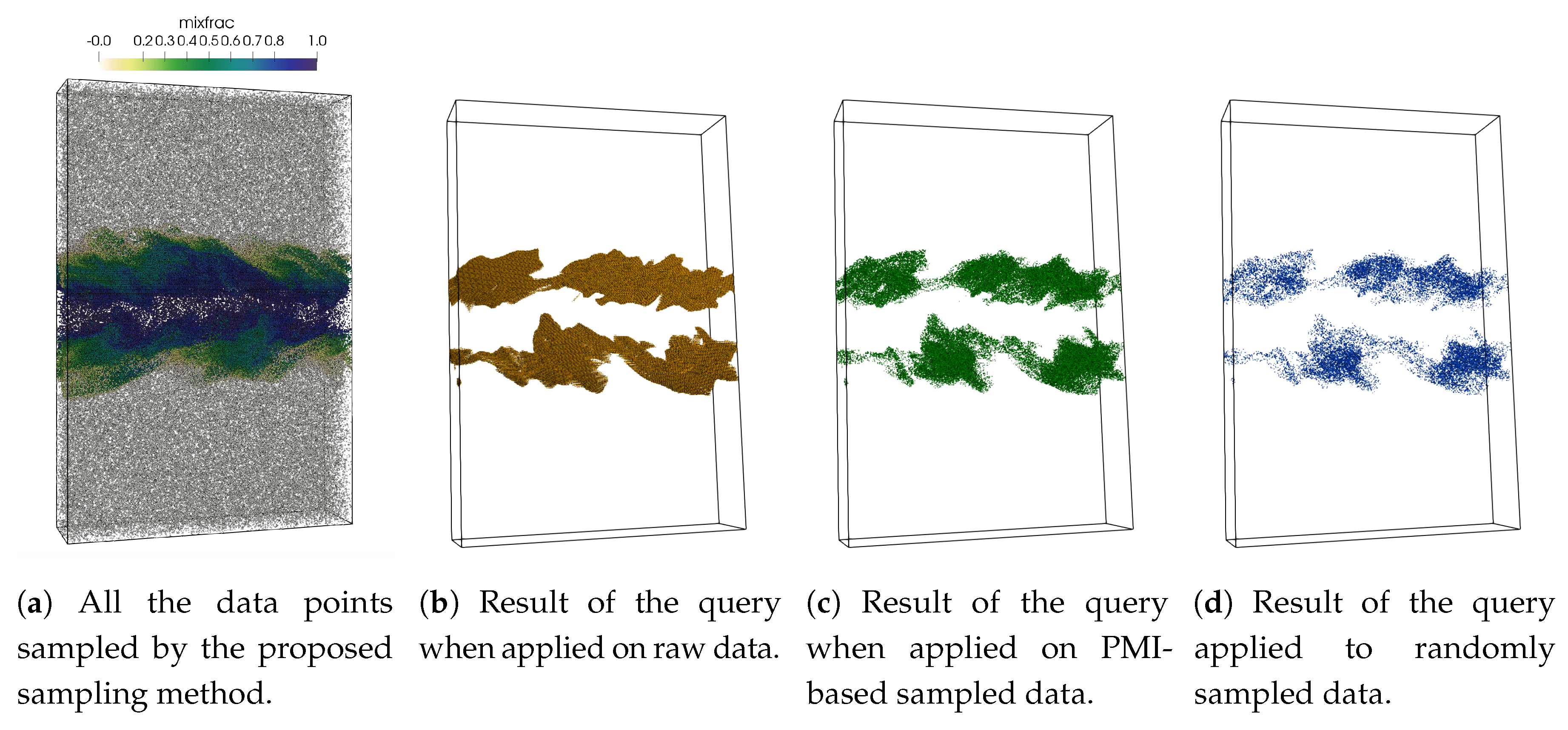{kind=link}
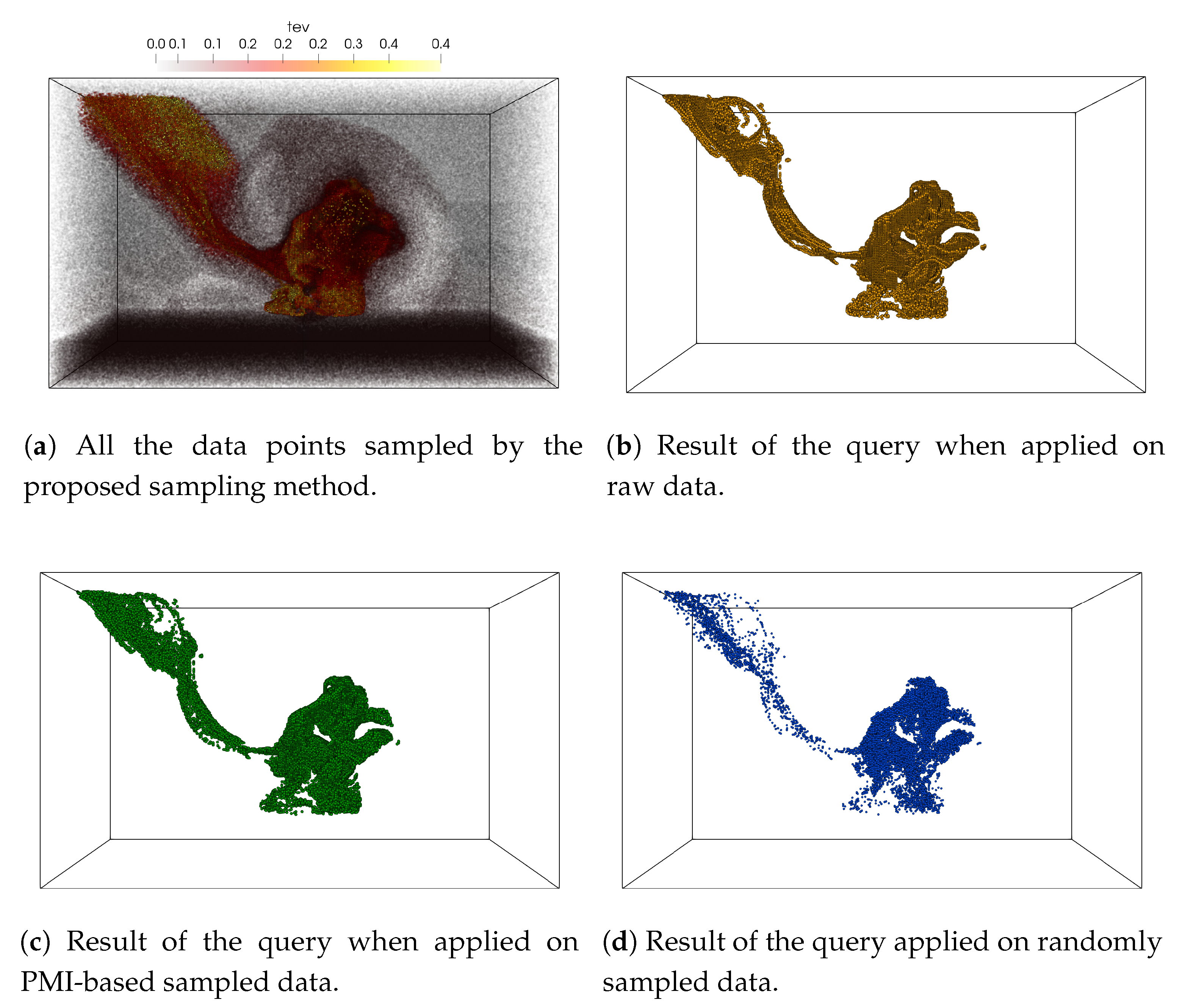{kind=link}
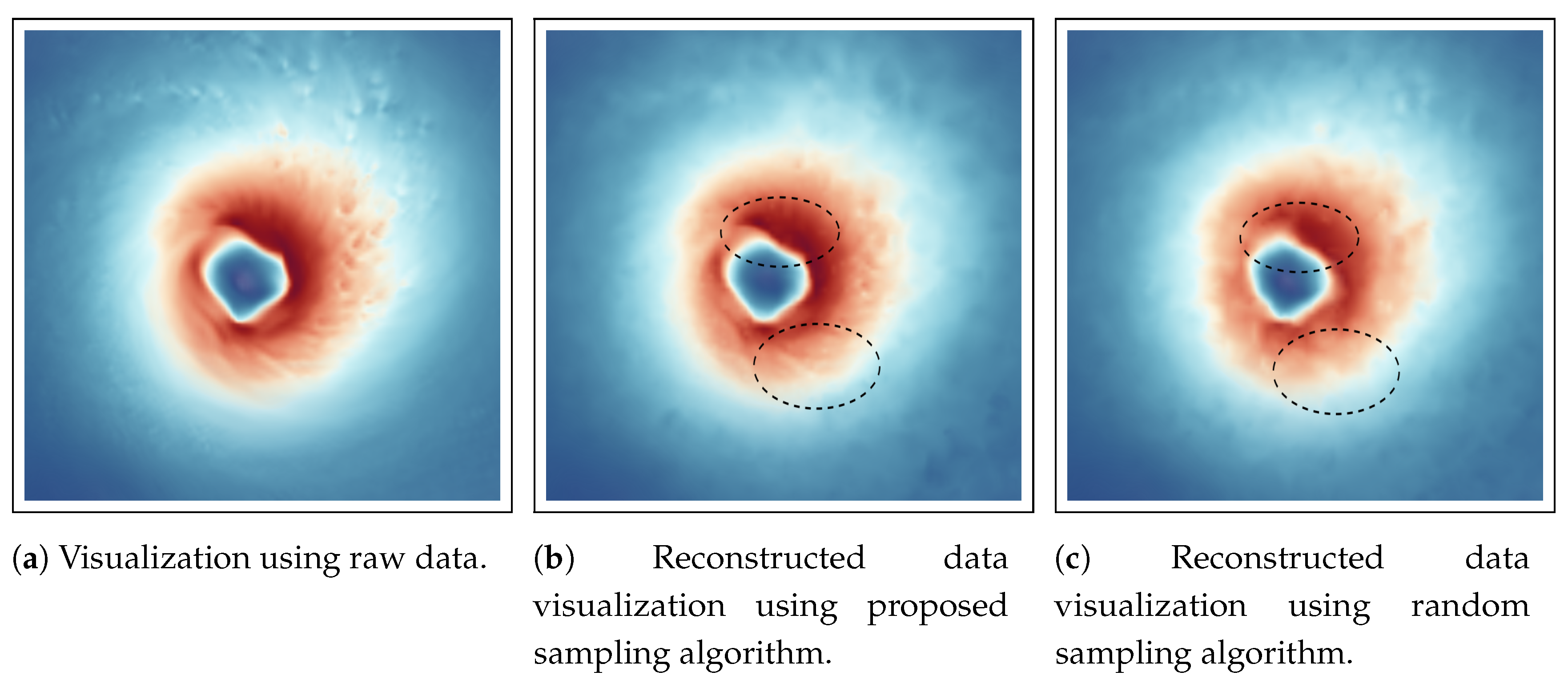{kind=link}
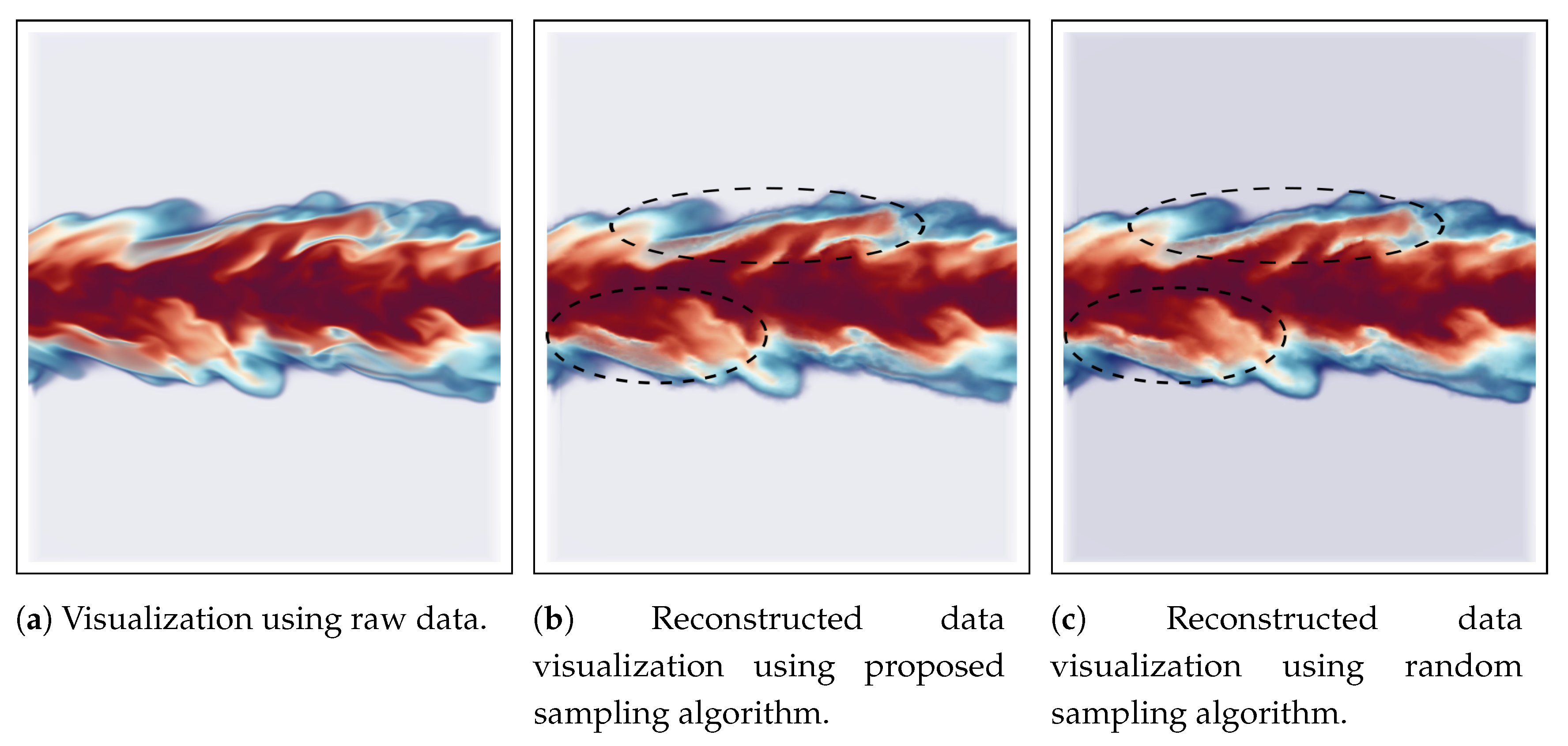{kind=link}
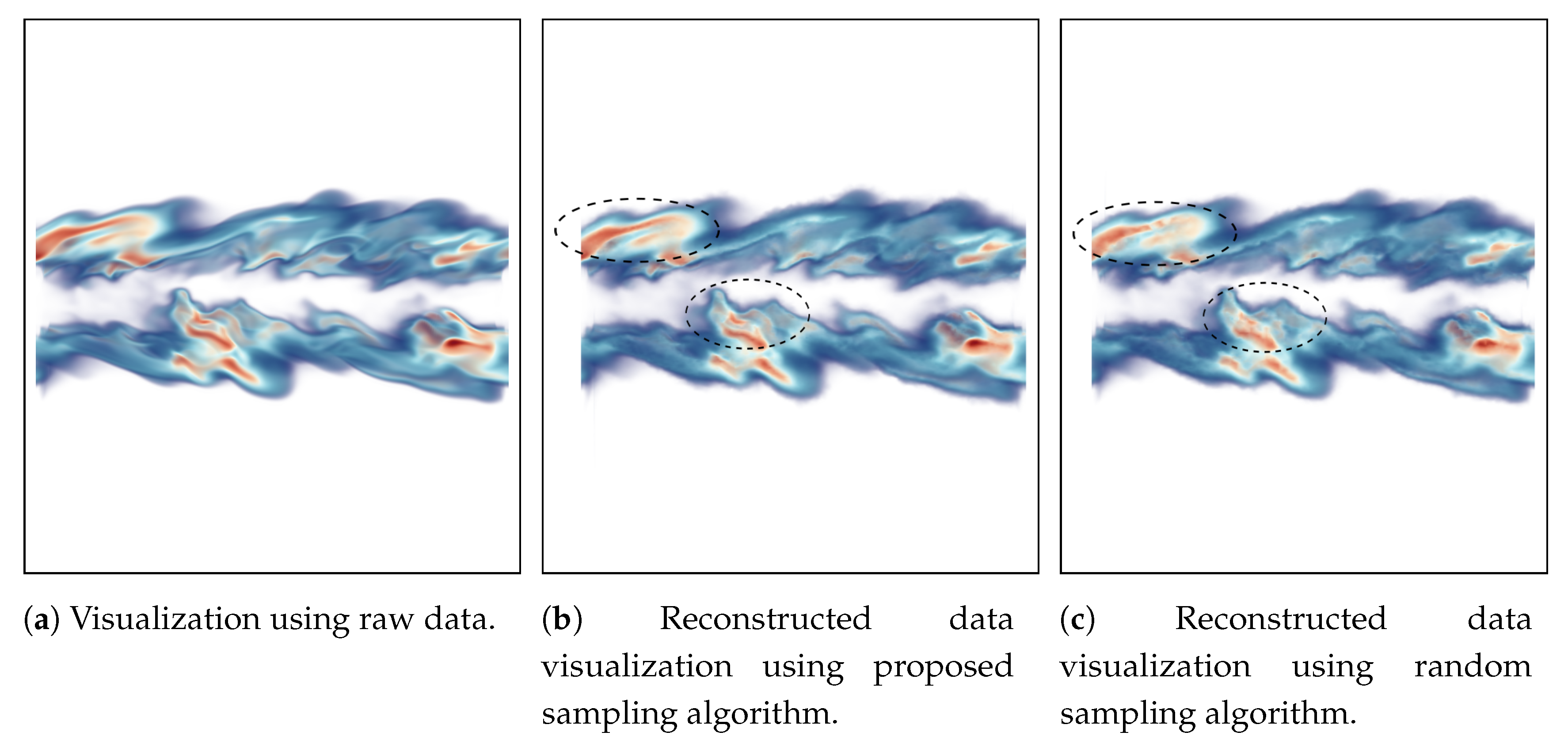{kind=link}
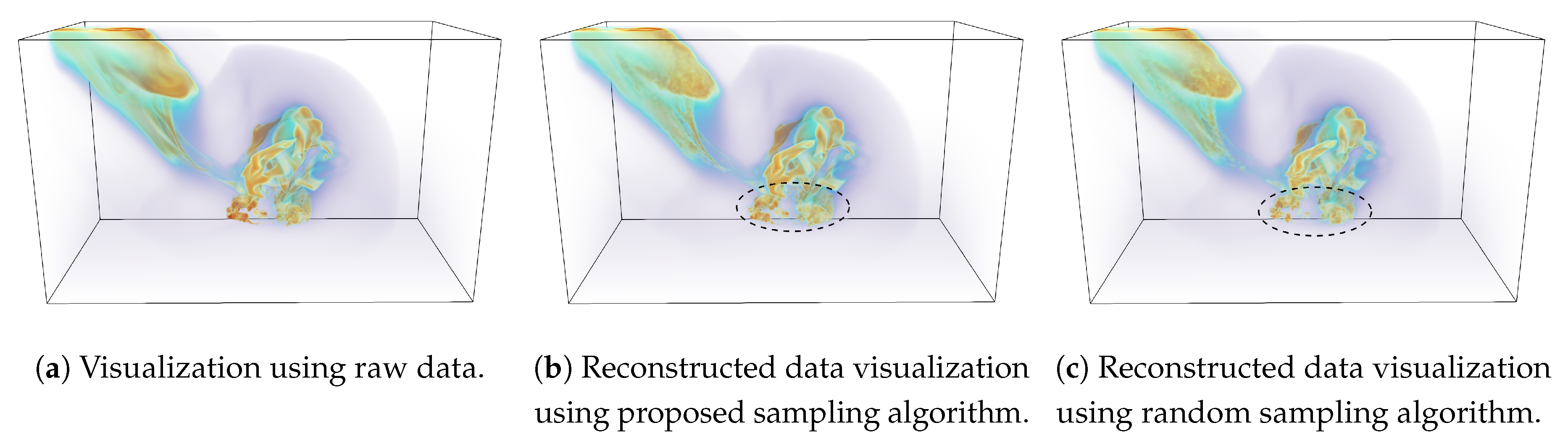{kind=link}
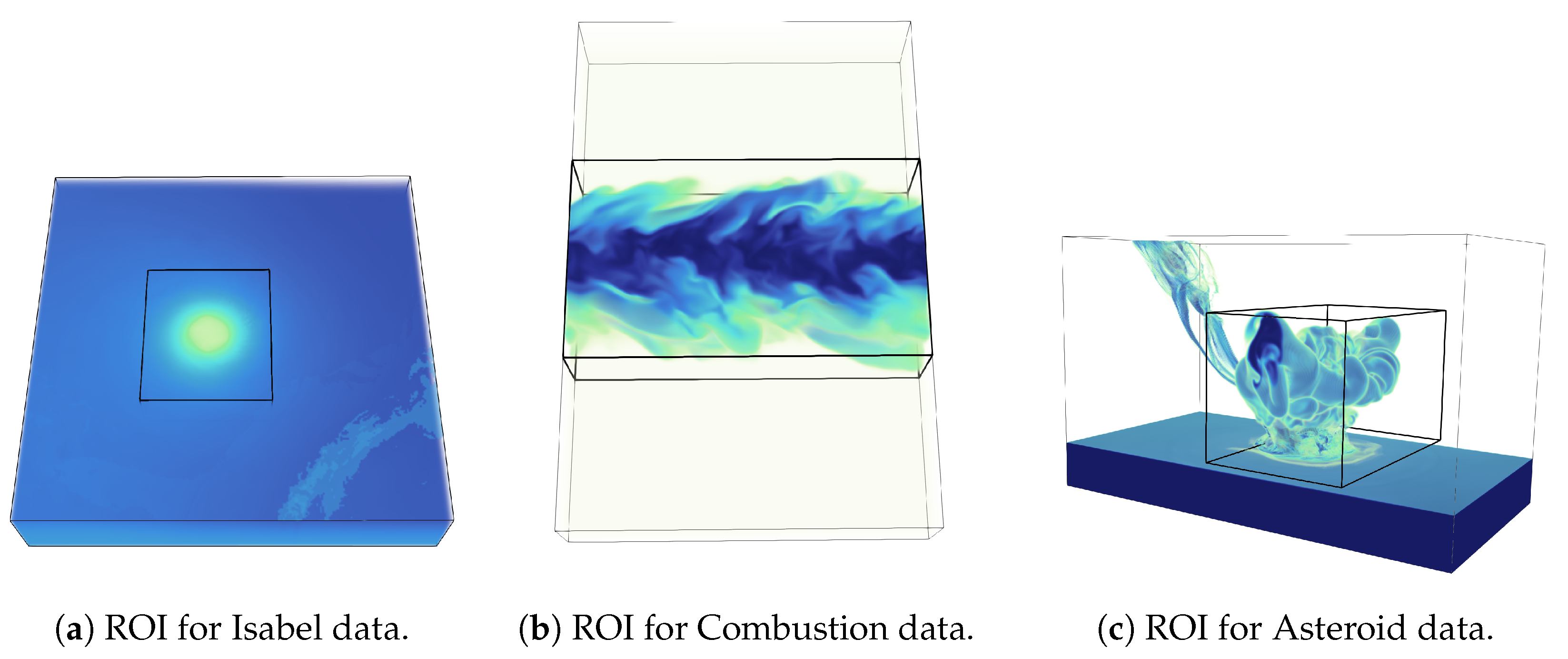{kind=link}
Table 1.
Accuracy study of multivariate query-driven analysis for Isabel data.
| samp. frac: 0.01 | samp. frac: 0.03 | samp. frac: 0.05 | samp. frac: 0.07 | samp. frac: 0.09 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Random | Proposed | Random | Proposed | Random | Proposed | Random | Proposed | Random | Proposed | |
| Isabel data (−100 < Pres < −4900 & Vel > 10) | 0.0096 | 0.0468 | 0.029 | 0.143 | 0.048 | 0.233 | 0.0676 | 0.315 | 0.0846 | 0.388 |
| Isabel data (0 < Pres < 1500 & 10 < Vel < 35) | 0.0116 | 0.0103 | 0.0293 | 0.0332 | 0.05 | 0.0524 | 0.0724 | 0.078 | 0.0842 | 0.0969 |
| Isabel data (−100 < Pres < −4900 & Qva > 0.017) | 0.0086 | 0.0912 | 0.033 | 0.163 | 0.05 | 0.266 | 0.0637 | 0.284 | 0.086 | 0.314 |
| Isabel data (Pres > 300 & 0.02 < Qva < 0.03) | 0.0088 | 0.023 | 0.0159 | 0.0585 | 0.062 | 0.1241 | 0.0726 | 0.1507 | 0.0975 | 0.2446 |
Table 2.
Accuracy study of multivariate query-driven analysis for Combustion data.
| samp. frac: 0.01 | samp. frac: 0.03 | samp. frac: 0.05 | samp. frac: 0.07 | samp. frac: 0.09 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Random | Proposed | Random | Proposed | Random | Proposed | Random | Proposed | Random | Proposed | |
| Combustion data (0.3 < mixfrac < 0.7 & 0.0006 < Y_OH < 0.1) | 0.0099 | 0.0275 | 0.029 | 0.081 | 0.048 | 0.135 | 0.0671 | 0.191 | 0.0862 | 0.244 |
| Combustion data (0.7 < mixfrac < 1.0 & 0.0005 < Y_OH < 0.0019) | 0.00884 | 0.0329 | 0.0291 | 0.1139 | 0.0474 | 0.1892 | 0.0686 | 0.2636 | 0.0877 | 0.3518 |
Table 3.
Accuracy study of multivariate query-driven analysis for Asteroid data.
| samp. frac: 0.01 | samp. frac: 0.03 | samp. frac: 0.05 | samp. frac: 0.07 | samp. frac: 0.09 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Random | Proposed | Random | Proposed | Random | Proposed | Random | Proposed | Random | Proposed | |
| Asteroid data (0.13 < tev < 0.5 & 0.45 < v02 < 1.0) | 0.013 | 0.067 | 0.029 | 0.202 | 0.0479 | 0.328 | 0.0678 | 0.431 | 0.086 | 0.52 |
| Asteroid data (0.1 < tev < 0.3 & 0.01 < v02 < 0.6) | 0.0097 | 0.0827 | 0.0302 | 0.2497 | 0.0491 | 0.4154 | 0.0668 | 0.5777 | 0.0866 | 0.7083 |
Table 4.
Image-based comparison of Pressure and Velocity field of Isabel data set.
| Isabel Pressure Field | samp. frac: 0.01 | samp. frac: 0.03 | samp. frac: 0.05 | |||
| Random | Proposed | Random | Proposed | Random | Proposed | |
| SSIM | 0.9844 | 0.9915 | 0.9916 | 0.9931 | 0.9926 | 0.9939 |
| MSE | 6.5563 | 1.9267 | 2.5239 | 1.2559 | 2.0576 | 0.8961 |
| Isabel Velocity Field | samp. frac: 0.01 | samp. frac: 0.03 | samp. frac: 0.05 | |||
| Random | Proposed | Random | Proposed | Random | Proposed | |
| SSIM | 0.9234 | 0.9559 | 0.9427 | 0.9649 | 0.9516 | 0.9702 |
| MSE | 13.9638 | 8.492 | 10.6865 | 6.0452 | 8.1166 | 5.0213 |
Table 5.
Image-based comparison of Pressure and QVapor field of Isabel data set.
| Isabel Pressure Field | samp. frac: 0.01 | samp. frac: 0.03 | samp. frac: 0.05 | |||
| Random | Proposed | Random | Proposed | Random | Proposed | |
| SSIM | 0.9834 | 0.9919 | 0.9915 | 0.9926 | 0.9916 | 0.9929 |
| MSE | 6.5982 | 2.3903 | 3.0432 | 2.0518 | 3.0987 | 1.9561 |
| Isabel QVapor Field | samp. frac: 0.01 | samp. frac: 0.03 | samp. frac: 0.05 | |||
| Random | Proposed | Random | Proposed | Random | Proposed | |
| SSIM | 0.7495 | 0.7726 | 0.7745 | 0.7899 | 0.7838 | 0.80521 |
| MSE | 12.7532 | 11.8243 | 10.2122 | 9.2676 | 9.262 | 8.2 |
Table 6.
Image-based comparison of Mixfrac and Y_OH field of Combustion data set.
| Combustion mixfrac Field | samp. frac: 0.01 | samp. frac: 0.03 | samp. frac: 0.05 | |||
| Random | Proposed | Random | Proposed | Random | Proposed | |
| SSIM | 0.8913 | 0.9138 | 0.9373 | 0.9538 | 0.9452 | 0.9708 |
| MSE | 14.5252 | 12.2813 | 9.376 | 7.9371 | 18.141 | 5.7753 |
| Combustion Y_OH Field | samp. frac: 0.01 | samp. frac: 0.03 | samp. frac: 0.05 | |||
| Random | Proposed | Random | Proposed | Random | Proposed | |
| SSIM | 0.8868 | 0.9061 | 0.9401 | 0.9565 | 0.955 | 0.9739 |
| MSE | 14.4677 | 13.6179 | 9.111 | 8.0836 | 7.4155 | 5.9128 |
Table 7.
Image-based comparison of tev and v02 field of Asteroid data set.
| Asteroid tev Field | samp. frac: 0.01 | samp. frac: 0.03 | samp. frac: 0.05 | |||
| Random | Proposed | Random | Proposed | Random | Proposed | |
| SSIM | 0.9746 | 0.9813 | 0.9808 | 0.9885 | 0.9849 | 0.9908 |
| MSE | 4.93 | 4.3499 | 3.8366 | 3.1976 | 3.2674 | 2.7139 |
| Asteroid v02 Field | samp. frac: 0.01 | samp. frac: 0.03 | samp. frac: 0.05 | |||
| Random | Proposed | Random | Proposed | Random | Proposed | |
| SSIM | 0.7898 | 0.8121 | 0.7972 | 0.8213 | 0.8064 | 0.8326 |
| MSE | 31.27 | 32.91 | 26.301 | 27.656 | 23.9335 | 25.4177 |
Table 8.
Evaluation of multivariate correlation for feature regions.
| Raw Data Correlation | PMI-Based Sampling | Random Sampling | ||||
|---|---|---|---|---|---|---|
| Pearson’s Correlation | Distance Correlation | Pearson’s Correlation | Distance Correlation | Pearson’s Correlation | Distance Correlation | |
| Isabel Data (Pressure and QVapor) | −0.19803 | 0.3200 | −0.19805 | 0.3205 | −0.1966 | 0.3213 |
| Combustion Data (mixfrac and Y_OH) | 0.01088 | 0.4012 | 0.01624 | 0.4054 | 0.02123 | 0.4071 |
| Asteroid Data (tev and v02) | 0.2116 | 0.2938 | 0.2273 | 0.2994 | 0.2382 | 0.31451 |
Table 9.
Evaluation of multivariate correlation for full data.
| Raw Data | PMI-Based Sampling | Random Sampling | ||||
|---|---|---|---|---|---|---|
| Pearson’s Correlation | Distance Correlation | Pearson’s Correlation | Distance Correlation | Pearson’s Correlation | Distance Correlation | |
| Isabel Data (Pressure and QVapor) | 0.3725 | 0.5470 | 0.3735 | 0.5530 | 0.3686 | 0.5480 |
| Combustion Data (mixfrac and Y_OH) | 0.3462 | 0.5113 | 0.3588 | 0.5248 | 0.3663 | 0.5321 |
| Asteroid Data (tev and v02) | −0.028 | 0.3622 | −0.0209 | 0.1795 | −0.0259 | 0.1797 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Dutta, S.; Biswas, A.; Ahrens, J. Multivariate Pointwise Information-Driven Data Sampling and Visualization. Entropy 2019, 21, 699. https://0-doi-org.brum.beds.ac.uk/10.3390/e21070699
AMA Style
Dutta S, Biswas A, Ahrens J. Multivariate Pointwise Information-Driven Data Sampling and Visualization. Entropy. 2019; 21(7):699. https://0-doi-org.brum.beds.ac.uk/10.3390/e21070699
Chicago/Turabian StyleDutta, Soumya, Ayan Biswas, and James Ahrens. 2019. "Multivariate Pointwise Information-Driven Data Sampling and Visualization" Entropy 21, no. 7: 699. https://0-doi-org.brum.beds.ac.uk/10.3390/e21070699
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.