On a Generalization of the Jensen–Shannon Divergence and the Jensen–Shannon Centroid


Sony Computer Science Laboratories, Tokyo 141-0022, Japan
Entropy 2020, 22(2), 221; https://0-doi-org.brum.beds.ac.uk/10.3390/e22020221
Submission received: 5 December 2019
/
Revised: 14 February 2020
/
Accepted: 14 February 2020
/
Published: 16 February 2020
(This article belongs to the Special Issue Divergence Measures: Mathematical Foundations and Applications in Information-Theoretic and Statistical Problems)
Abstract
:The Jensen–Shannon divergence is a renown bounded symmetrization of the Kullback–Leibler divergence which does not require probability densities to have matching supports. In this paper, we introduce a vector-skew generalization of the scalar -Jensen–Bregman divergences and derive thereof the vector-skew -Jensen–Shannon divergences. We prove that the vector-skew -Jensen–Shannon divergences are f-divergences and study the properties of these novel divergences. Finally, we report an iterative algorithm to numerically compute the Jensen–Shannon-type centroids for a set of probability densities belonging to a mixture family: This includes the case of the Jensen–Shannon centroid of a set of categorical distributions or normalized histograms.
1. Introduction
Let be a measure space [1] where denotes the sample space, the -algebra of measurable events, and a positive measure; for example, the measure space defined by the Lebesgue measure with Borel -algebra for or the measure space defined by the counting measure with the power set -algebra on a finite alphabet . Denote by the Lebesgue space of measurable functions, the subspace of positive integrable functions f such that and for all , and the subspace of non-negative integrable functions f such that and for all .
We refer to the book of Deza and Deza [2] and the survey of Basseville [3] for an introduction to the many types of statistical divergences met in information sciences and their justifications. The Kullback–Leibler Divergence (KLD) is an oriented statistical distance (commonly called the relative entropy in information theory [4]) defined between two densities p and q (i.e., the Radon–Nikodym densities of -absolutely continuous probability measures P and Q) by
Although with equality iff. -a. e. (Gibb’s inequality [4]), the KLD may diverge to infinity depending on the underlying densities. Since the KLD is asymmetric, several symmetrizations [5] have been proposed in the literature.
A well-grounded symmetrization of the KLD is the Jensen–Shannon Divergence [6] (JSD), also called capacitory discrimination in the literature (e.g., see [7]):
The Jensen–Shannon divergence can be interpreted as the total KL divergence to the average distribution . The Jensen–Shannon divergence was historically implicitly introduced in [8] (Equation (19)) to calculate distances between random graphs. A nice feature of the Jensen–Shannon divergence is that this divergence can be applied to densities with arbitrary support (i.e., with the convention that and ); moreover, the JSD is always upper bounded by . Let and denote the supports of the densities p and q, respectively, where . The JSD saturates to whenever the supports and are disjoints. We can rewrite the JSD as
where denotes Shannon’s entropy. Thus, the JSD can also be interpreted as the entropy of the average distribution minus the average of the entropies.
The square root of the JSD is a metric [9] satisfying the triangle inequality, but the square root of the JD is not a metric (nor any positive power of the Jeffreys divergence, see [10]). In fact, the JSD can be interpreted as a Hilbert metric distance, meaning that there exists some isometric embedding of into a Hilbert space [11,12]. Other principled symmetrizations of the KLD have been proposed in the literature: For example, Naghshvar et al. [13] proposed the extrinsic Jensen–Shannon divergence and demonstrated its use for variable-length coding over a discrete memoryless channel (DMC).
Another symmetrization of the KLD sometimes met in the literature [14,15,16] is the Jeffreys divergence [17,18] (JD) defined by
However, we point out that this Jeffreys divergence lacks sound information-theoretical justifications.
For two positive but not necessarily normalized densities and , we define the extended Kullback–Leibler divergence as follows:
The Jensen–Shannon divergence and the Jeffreys divergence can both be extended to positive (unnormalized) densities without changing their formula expressions:
However, the extended divergence is upper-bounded by instead of for normalized densities (i.e., when ).
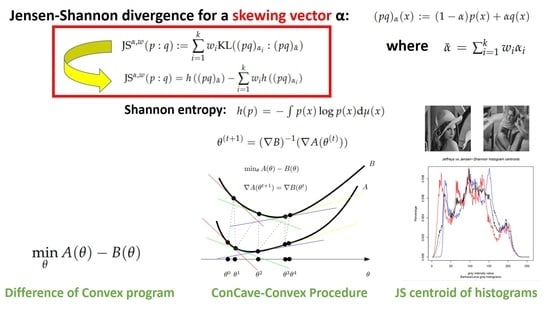
Let denote the statistical weighted mixture with component densities p and q for . The asymmetric -skew Jensen–Shannon divergence can be defined for a scalar parameter by considering the weighted mixture as follows:
Then, both the Jensen–Shannon divergence and the Jeffreys divergence can be rewritten [20] using as follows:
since , and .
The ordinary Jensen–Shannon divergence is recovered for .
In general, skewing divergences (e.g., using the divergence instead of the KLD) have been experimentally shown to perform better in applications like in some natural language processing (NLP) tasks [21].
The α-Jensen–Shannon divergences are Csiszár f-divergences [22,23,24]. An f-divergence is defined for a convex function f, strictly convex at 1, and satisfies as:
We can always symmetrize f-divergences by taking the conjugate convex function (related to the perspective function): is a symmetric divergence. The f-divergences are convex statistical distances which are provably the only separable invariant divergences in information geometry [25], except for binary alphabets (see [26]).
The Jeffreys divergence is an f-divergence for the generator , and the -Jensen–Shannon divergences are f-divergences for the generator family . The f-divergences are upper-bounded by . Thus, the f-divergences are finite when .
The main contributions of this paper are summarized as follows:
- First, we generalize the Jensen–Bregman divergence by skewing a weighted separable Jensen–Bregman divergence with a k-dimensional vector in Section 2. This yields a generalization of the symmetric skew -Jensen–Shannon divergences to a vector-skew parameter. This extension retains the key properties for being upper-bounded and for application to densities with potentially different supports. The proposed generalization also allows one to grasp a better understanding of the “mechanism” of the Jensen–Shannon divergence itself. We also show how to directly obtain the weighted vector-skew Jensen–Shannon divergence from the decomposition of the KLD as the difference of the cross-entropy minus the entropy (i.e., KLD as the relative entropy).
- Second, we prove that weighted vector-skew Jensen–Shannon divergences are f-divergences (Theorem 1), and show how to build families of symmetric Jensen–Shannon-type divergences which can be controlled by a vector of parameters in Section 2.3, generalizing the work of [20] from scalar skewing to vector skewing. This may prove useful in applications by providing additional tuning parameters (which can be set, for example, by using cross-validation techniques).
- Third, we consider the calculation of the Jensen–Shannon centroids in Section 3 for densities belonging to mixture families. Mixture families include the family of categorical distributions and the family of statistical mixtures sharing the same prescribed components. Mixture families are well-studied manifolds in information geometry [25]. We show how to compute the Jensen–Shannon centroid using a concave–convex numerical iterative optimization procedure [27]. The experimental results graphically compare the Jeffreys centroid with the Jensen–Shannon centroid for grey-valued image histograms.
2. Extending the Jensen–Shannon Divergence
2.1. Vector-Skew Jensen–Bregman Divergences and Jensen Diversities
Recall our notational shortcut: . For a k-dimensional vector , a weight vector w belonging to the -dimensional open simplex , and a scalar , let us define the following vector skew α-Jensen–Bregman divergence (-JBD) following [28]:
where is the Bregman divergence [29] induced by a strictly convex and smooth generator F:
with denoting the Euclidean inner product (dot product). Expanding the Bregman divergence formulas in the expression of the -JBD and using the fact that
we get the following expression:
The inner product term of Equation (21) vanishes when
Thus, when (assuming at least two distinct components in so that ), we get the simplified formula for the vector-skew -JBD:
This vector-skew Jensen–Bregman divergence is always finite and amounts to a Jensen diversity [30] induced by Jensen’s inequality gap:
The Jensen diversity is a quantity which arises as a generalization of the cluster variance when clustering with Bregman divergences instead of the ordinary squared Euclidean distance; see [29,30] for details. In the context of Bregman clustering, the Jensen diversity has been called the Bregman information [29] and motivated by rate distortion theory: Bregman information measures the minimum expected loss when encoding a set of points using a single point when the loss is measured using a Bregman divergence. In general, a k-point measure is called a diversity measure (for ), while a distance/divergence is the special case of a 2-point measure.
Conversely, in 1D, we may start from Jensen’s inequality for a strictly convex function F:
Let us notationally write , and define and (i.e., assuming at least two distinct values). We have the barycenter which can be interpreted as the linear interpolation of the extremal values for some . Let us write for and proper values of the s. Then, it comes that
so that .
2.2. Vector-Skew Jensen–Shannon Divergences
Let be a strictly smooth convex function on . Then, the Bregman divergence induced by this univariate generator is
the extended scalar Kullback–Leibler divergence.
We extend the scalar-skew Jensen–Shannon divergence as follows: for h, the Shannon’s entropy [4] (a strictly concave function [4]).
Definition 1
(Weighted vector-skew -Jensen–Shannon divergence). For a vector and a unit positive weight vector , the -Jensen–Shannon divergence between two densities is defined by:
with , where denotes the Shannon entropy [4] (i.e., is strictly convex).
This definition generalizes the ordinary JSD; we recover the ordinary Jensen–Shannon divergence when , , , and with : .
Let . Then, we have . Using this -KLD, we have the following identity:
since , where is a k-dimensional vector of ones.
A very interesting property is that the vector-skew Jensen–Shannon divergences are f-divergences [22].
Theorem 1.
The vector-skew Jensen–Shannon divergences are f-divergences for the generator with .
Proof.
First, let us observe that the positively weighted sum of f-divergences is an f-divergence: for the generator .
Now, let us express the divergence as an f-divergence:
with generator
Thus, it follows that
Therefore, the vector-skew Jensen–Shannon divergence is an f-divergence for the following generator:
where .
When and , we recover the f-divergence generator for the JSD:
Observe that , where .
We also refer the reader to Theorem 4.1 of [31], which defines skew f-divergences from any f-divergence. □
Remark 1.
Since the vector-skew Jensen divergence is an f-divergence, we easily obtain Fano and Pinsker inequalities following [32], or reverse Pinsker inequalities following [33,34] (i.e., upper bounds for the vector-skew Jensen divergences using the total variation metric distance), data processing inequalities using [35], etc.
Next, we show that (and ) are separable convex divergences. Since the f-divergences are separable convex, the divergences and the divergences are separable convex. For the sake of completeness, we report a simplex explicit proof below.
Theorem 2
(Separable convexity). The divergence is strictly separable convex for and .
Proof.
Let us calculate the second partial derivative of with respect to x, and show that it is strictly positive:
for . Thus, is strictly convex on the left argument. Similarly, since , we deduce that is strictly convex on the right argument. Therefore, the divergence is separable convex. □
It follows that the divergence is strictly separable convex, since it is a convex combination of weighted divergences.
Another way to derive the vector-skew JSD is to decompose the KLD as the difference of the cross-entropy minus the entropy h (i.e., KLD is also called the relative entropy):
where and (self cross-entropy). Since (for ), it follows that
Here, the “trick” is to choose in order to “convert” the cross-entropy into an entropy: when . Then, we end up with
When with and and , we have , and we recover the Jensen–Shannon divergence:
Notice that Equation (13) is the usual definition of the Jensen–Shannon divergence, while Equation (48) is the reduced formula of the JSD, which can be interpreted as a Jensen gap for Shannon entropy, hence its name: The Jensen–Shannon divergence.
Moreover, if we consider the cross-entropy/entropy extended to positive densities and :
we get:
Next, we shall prove that our generalization of the skew Jensen–Shannon divergence to vector-skewing is always bounded. We first start by a lemma bounding the KLD between two mixtures sharing the same components:
Lemma 1
(KLD between two w-mixtures). For and , we have:
Proof.
For , we have
Indeed, by considering the two cases (or equivalently, ) and (or equivalently, ), we check that and . Thus, we have . Therefore, it follows that:
Notice that we can interpret as the ∞-Rényi divergence [36,37] between the following two two-point distributions: and . See Theorem 6 of [36].
A weaker upper bound is . Indeed, let us form a partition of the sample space into two dominance regions:
- and
- .
We have for and for . It follows that
That is, . Notice that we allow but not to take the extreme values (i.e., ). □
In fact, it is known that for both , amount to compute a Bregman divergence for the Shannon negentropy generator, since defines a mixture family [38] of order 1 in information geometry. Hence, it is always finite, as Bregman divergences are always finite (but not necessarily bounded).
By using the fact that
we conclude that the vector-skew Jensen–Shannon divergence is upper-bounded:
Lemma 2
(Bounded -Jensen–Shannon divergence). is bounded by where .
Proof.
We have . Since , it follows that we have
Notice that we also have
□
The vector-skew Jensen–Shannon divergence is symmetric if and only if for each index there exists a matching index such that and .
For example, we may define the symmetric scalar α-skew Jensen–Shannon divergence as
since it holds that for any . Note that .
Remark 2.
We can always symmetrize a vector-skew Jensen–Shannon divergence by doubling the dimension of the skewing vector. Let and w be the vector parameters of an asymmetric vector-skew JSD, and consider and w to be the parameters of . Then, is a symmetric skew-vector JSD:
Since the vector-skew Jensen–Shannon divergence is an f-divergence for the generator (Theorem 1), we can take generator to define the symmetrized f-divergence, where denotes the convex conjugate function. When yields a symmetric f-divergence , we can apply the generic upper bound of f-divergences (i.e., ) to get the upper bound on the symmetric vector-skew Jensen–Shannon divergences:
since
For example, consider the ordinary Jensen–Shannon divergence with and . Then, we find , the usual upper bound of the JSD.
As a side note, let us notice that our notation allows one to compactly write the following property:
Property 1.
We have for any , and for any .
Proof.
Clearly, for any . Now, we have
□
2.3. Building Symmetric Families of Vector-Skewed Jensen–Shannon Divergences
We can build infinitely many vector-skew Jensen–Shannon divergences. For example, consider and . Then, , and
Interestingly, we can also build infinitely many families of symmetric vector-skew Jensen–Shannon divergences. For example, consider these two examples that illustrate the construction process:
- Consider . Let denote the weight vector, and the skewing vector. We have . The vector-skew JSD is symmetric iff. (with ) and . In that case, we have , and we obtain the following family of symmetric Jensen–Shannon divergences:
- Consider , weight vector , and skewing vector for . Then, , and we get the following family of symmetric vector-skew JSDs:
- We can similarly carry on the construction of such symmetric JSDs by increasing the dimensionality of the skewing vector.
In fact, we can define
with
3. Jensen–Shannon Centroids on Mixture Families
3.1. Mixture Families and Jensen–Shannon Divergences
Consider a mixture family in information geometry [25]. That is, let us give a prescribed set of linearly independent probability densities defined on the sample space . A mixture family of order D consists of all strictly convex combinations of these component densities:
For example, the family of categorical distributions (sometimes called “multinouilli” distributions) is a mixture family [25]:
where is the Dirac distribution (i.e., for and for ). Note that the mixture family of categorical distributions can also be interpreted as an exponential family.
Notice that the linearly independent assumption on probability densities is to ensure to have an identifiable model: .
The KL divergence between two densities of a mixture family amounts to a Bregman divergence for the Shannon negentropy generator (see [38]):
On a mixture manifold , the mixture density of two mixtures and of also belongs to :
where we extend the notation to vectors and : .
Thus, the vector-skew JSD amounts to a vector-skew Jensen diversity for the Shannon negentropy convex function :
3.2. Jensen–Shannon Centroids
Given a set of n mixture densities of , we seek to calculate the skew-vector Jensen–Shannon centroid (or barycenter for non-uniform weights) defined as , where is the minimizer of the following objective function (or loss function):
where is the weight vector of densities (uniform weight for the centroid and non-uniform weight for a barycenter). This definition of the skew-vector Jensen–Shannon centroid is a generalization of the Fréchet mean (the Fréchet mean may not be unique, as it is the case on the sphere for two antipodal points for which their Fréchet means with respect to the geodesic metric distance form a great circle) [39] to non-metric spaces. Since the divergence is strictly separable convex, it follows that the Jensen–Shannon-type centroids are unique when they exist.
Plugging Equation (82) into Equation (88), we get that the calculation of the Jensen–Shannon centroid amounts to the following minimization problem:
This optimization is a Difference of Convex (DC) programming optimization, for which we can use the ConCave–Convex procedure [27,40] (CCCP). Indeed, let us define the following two convex functions:
Both functions and are convex since F is convex. Then, the minimization problem of Equation (89) to solve can be rewritten as:
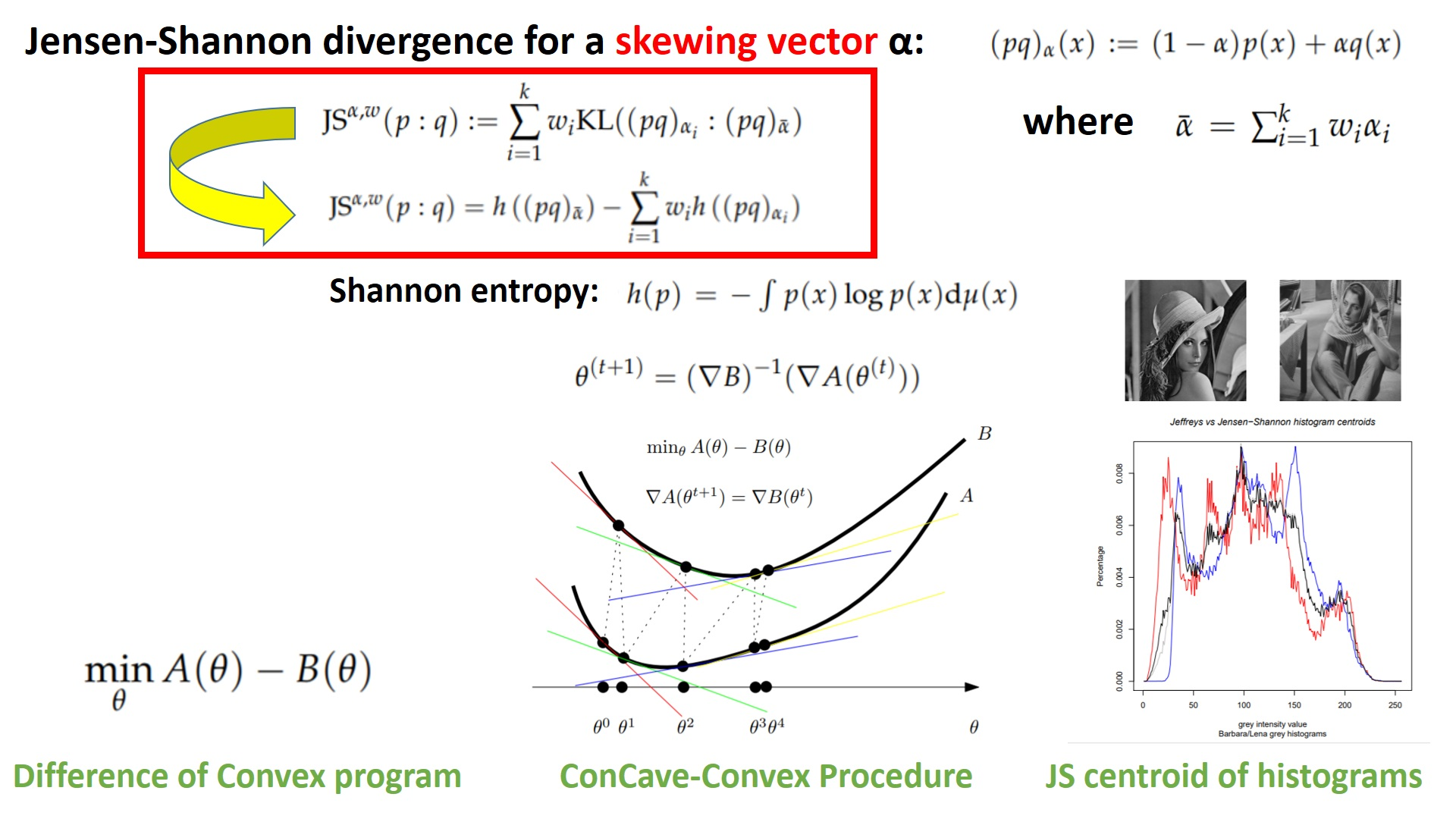
This is a DC programming optimization problem which can be solved iteratively by initializing to an arbitrary value (say, the centroid of the s), and then by updating the parameter at step t using the CCCP [27] as follows:
Compared to a gradient descent local optimization, there is no required step size (also called “learning” rate) in CCCP.
We have and .
The CCCP converges to a local optimum where the support hyperplanes of the function graphs of A and B at are parallel to each other, as depicted in Figure 1. The set of stationary points is . In practice, the delicate step is to invert . Next, we show how to implement this algorithm for the Jensen–Shannon centroid of a set of categorical distributions (i.e., normalized histograms with all non-empty bins).
3.2.1. Jensen–Shannon Centroids of Categorical Distributions
To illustrate the method, let us consider the mixture family of categorical distributions [25]:
The Shannon negentropy is
We have the partial derivatives
Inverting the gradient requires us to solve the equation so that we get . We find that
Table 1 summarizes the dual view of the family of categorical distributions, either interpreted as an exponential family or as a mixture family.
We have for and , where
is the Jensen divergence [40]. Thus, to compute the Jensen–Shannon centroid of a set of n densities of a mixture family (with ), we need to solve the following optimization problem for a density :
The CCCP algorithm for the Jensen–Shannon centroid proceeds by initializing (center of mass of the natural parameters), and iteratively updates as follows:
We iterate until the absolute difference between two successive and goes below a prescribed threshold value. The convergence of the CCCP algorithm is linear [41] to a local minimum that is a fixed point of the equation
where is a vector generalization of the formula of the quasi-arithmetic means [30,40] obtained for the generator . Algorithm 1 summarizes the method for approximating the Jensen–Shannon centroid of a given set of categorical distributions (given a prescribed number of iterations). In the pseudo-code, we used the notation instead of in order to highlight the conversion procedures of the natural parameters to/from the mixture weight parameters by using superscript notations for coordinates.
| Algorithm 1: The CCCP algorithm for computing the Jensen–Shannon centroid of a set of categorical distributions. |
 |
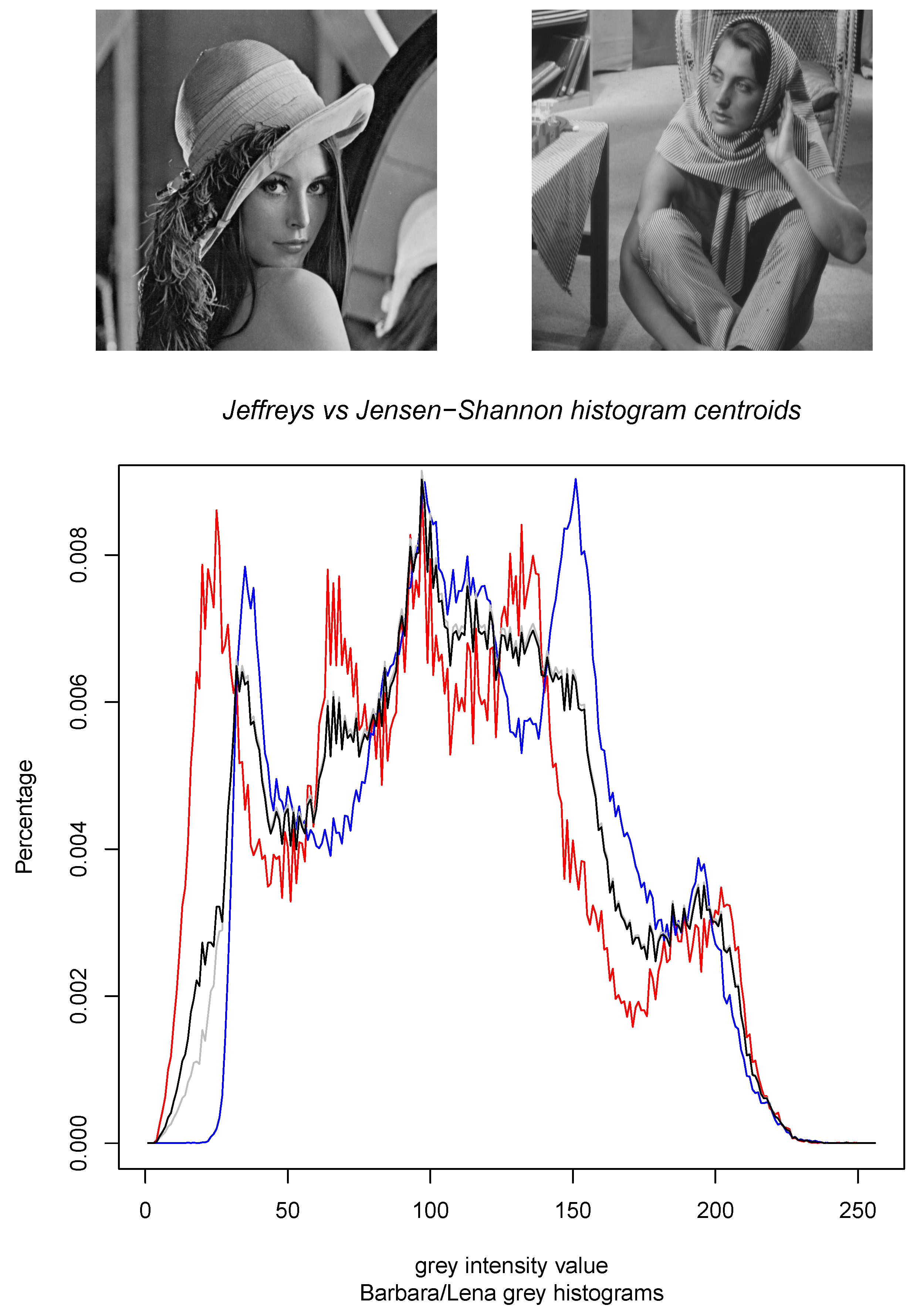
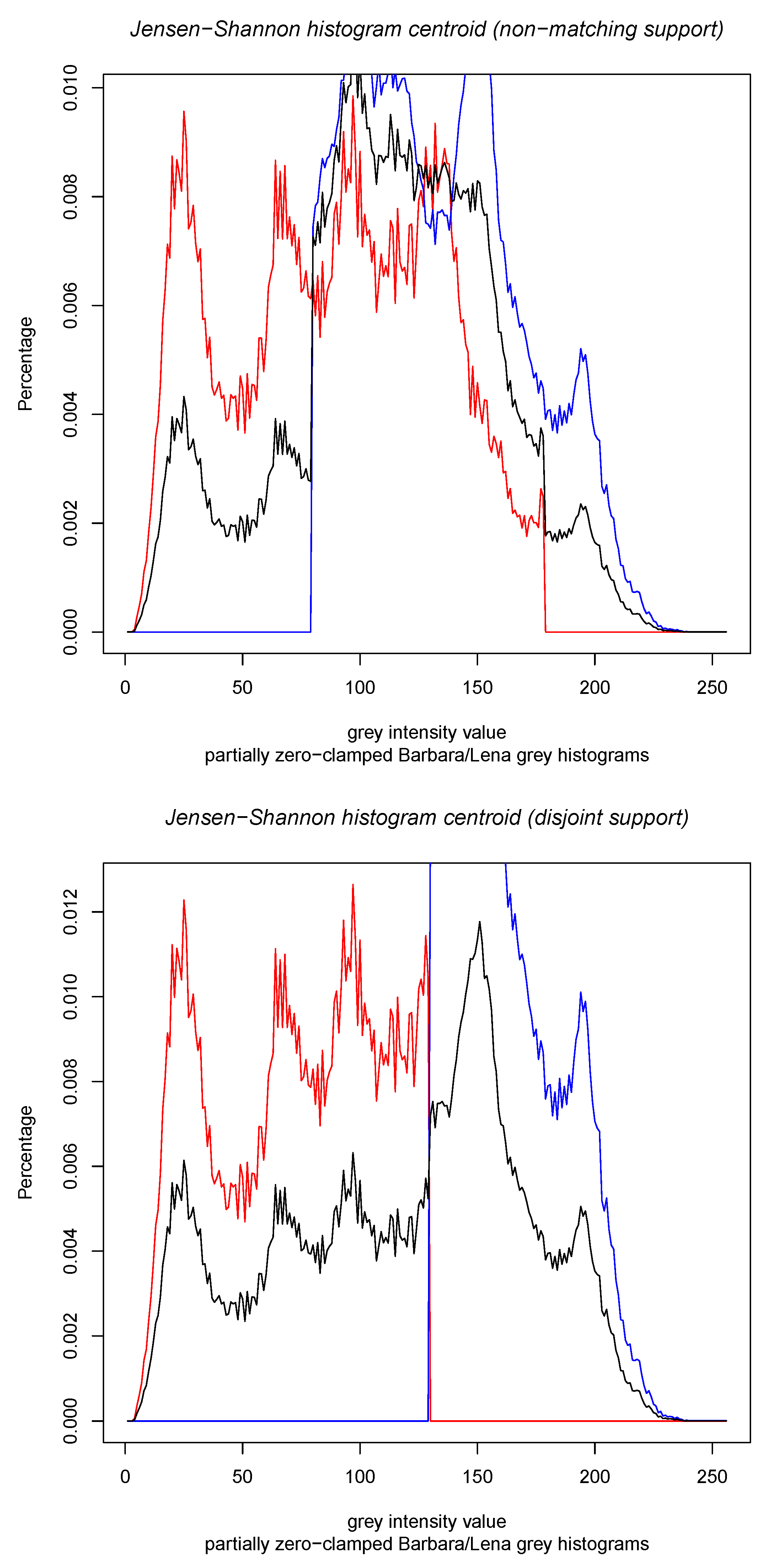
Figure 2 displays the results of the calculations of the Jeffreys centroid [18] and the Jensen–Shannon centroid for two normalized histograms obtained from grey-valued images of Lena and Barbara. Figure 3 show the Jeffreys centroid and the Jensen–Shannon centroid for the Barbara image and its negative image. Figure 4 demonstrates that the Jensen–Shannon centroid is well defined even if the input histograms do not have coinciding supports. Notice that on the parts of the support where only one distribution is defined, the JS centroid is a scaled copy of that defined distribution.
3.2.2. Special Cases
Let us now consider two special cases:
- For the special case of , the categorical family is the Bernoulli family, and we have (binary negentropy), (and ) and . The CCCP update rule to compute the binary Jensen–Shannon centroid becomes
- Since the skew-vector Jensen–Shannon divergence formula holds for positive densities:we can relax the computation of the Jensen–Shannon centroid by considering 1D separable minimization problems. We then normalize the positive JS centroids to get an approximation of the probability JS centroids. This approach was also considered when dealing with the Jeffreys’ centroid [18]. In 1D, we have , and .
In general, calculating the negentropy for a mixture family with continuous densities sharing the same support is not tractable because of the log-sum term of the differential entropy. However, the following remark emphasizes an extension of the mixture family of categorical distributions:
3.2.3. Some Remarks and Properties
Remark 3.
Consider a mixture family (for a parameter θ belonging to the D-dimensional standard simplex) of probability densities defined respectively on the supports . Let . Assume that the support s of the s are mutually non-intersecting( for all implying that the densities are linearly independent) so that for all , and let . Consider Shannon negative entropy as a strictly convex function. Then, we have
Note that the term is affine in θ, and Bregman divergences are defined up to affine terms so that the Bregman generator F is equivalent to the Bregman generator of the family of categorical distributions. This example generalizes the ordinary mixture family of categorical distributions where the s are distinct Dirac distributions. Note that when the support of the component distributions are not pairwise disjoint, the (neg)entropy may not be analytic [42] (e.g., mixture of the convex weighting of two prescribed distinct Gaussian distributions). This contrasts with the fact that the cumulant function of an exponential family is always real-analytic [43]. Observe that the term can be interpreted as a conditional entropy: where and .
Notice that we can truncate an exponential family [25] to get a (potentially non-regular [44]) exponential family for defining the s on mutually non-intersecting domains s. The entropy of a natural exponential family with cumulant function and natural parameter space Θ is , where , and is the Legendre convex conjugate [45]: .
In general, the entropy and cross-entropy between densities of a mixture family (whether the distributions have disjoint supports or not) can be calculated in closed-form.
Property 2.
The entropy of a density belonging to a mixture family is , and the cross-entropy between two mixture densities and is .
Proof.
Following [45], we deduce that and for a constant c. Since by definition, it follows that and that where . □
Thus, we can numerically compute the Jensen–Shannon centroids (or barycenters) of a set of densities belonging to a mixture family. This includes the case of categorical distributions and the case of Gaussian Mixture Models (GMMs) with prescribed Gaussian components [38] (although in this case, the negentropy needs to be stochastically approximated using Monte Carlo techniques [46]). When the densities do not belong to a mixture family (say, the Gaussian family, which is an exponential family [25]), we face the problem that the mixture of two densities does not belong to the family anymore. One way to tackle this problem is to project the mixture onto the Gaussian family. This corresponds to an m-projection (mixture projection) which can be interpreted as a Maximum Entropy projection of the mixture [25,47]).
Notice that we can perform fast k-means clustering without centroid calculations using a generalization of the k-means++ probabilistic initialization [48,49]. See [50] for details of the generalized k-means++ probabilistic initialization defined according to an arbitrary divergence.
Finally, let us notice some decompositions of the Jensen–Shannon divergence and the skew Jensen divergences.
Remark 4.
We have the following decomposition for the Jensen–Shannon divergence:
where
and . This decomposition bears some similarity with the KLD decomposition viewed as the cross-entropy minus the entropy (with the cross-entropy always upper-bounding the entropy).
Similarly, the α-skew Jensen divergence
can be decomposed as the sum of the information minus the cross-information :
Notice that the information is the self cross-information: . Recall that the convex information is the negentropy where the entropy is concave. For the Jensen–Shannon divergence on the mixture family of categorical distributions, the convex generator is the Shannon negentropy.
Finally, let us briefly mention the Jensen–Shannon diversity [30] which extends the Jensen–Shannon divergence to a weighted set of densities as follows:
where . The Jensen–Shannon diversity plays the role of the variance of a cluster with respect to the KLD. Indeed, let us state the compensation identity [51]: For any q, we have
Thus, the cluster center defined as the minimizer of is the centroid , and
4. Conclusions and Discussion
The Jensen–Shannon divergence [6] is a renown symmetrization of the Kullback–Leibler oriented divergence that enjoys the following three essential properties:
- It is always bounded,
- it applies to densities with potentially different supports, and
- it extends to unnormalized densities while enjoying the same formula expression.
This JSD plays an important role in machine learning and in deep learning for studying Generative Adversarial Networks (GANs) [52]. Traditionally, the JSD has been skewed with a scalar parameter [19,53] . In practice, it has been experimentally demonstrated that skewing divergences may significantly improve the performance of some tasks (e.g., [21,54]).
In general, we can symmetrize the KLD by taking an abstract mean (we require a symmetric mean with the in-betweenness property: ) M between the two orientations and :
We recover the Jeffreys divergence by taking the arithmetic mean twice (i.e., where ), and the resistor average divergence [55] by taking the harmonic mean (i.e., where ). When we take the limit of Hölder power means, we get the following extremal symmetrizations of the KLD:
In this work, we showed how to vector-skew the JSD while preserving the above three properties. These new families of weighted vector-skew Jensen–Shannon divergences may allow one to fine-tune the dissimilarity in applications by replacing the skewing scalar parameter of the JSD by a vector parameter (informally, adding some “knobs” for tuning a divergence). We then considered computing the Jensen–Shannon centroids of a set of densities belonging to a mixture family [25] by using the convex–concave procedure [27].
In general, we can vector-skew any arbitrary divergence D by using two k-dimensional vectors and (with ) by building a weighted separable divergence as follows:
This bi-vector-skew divergence unifies the Jeffreys divergence with the Jensen–Shannon -skew divergence by setting the following parameters:
We have shown in this paper that interesting properties may occur when the skewing vector is purposely correlated to the skewing vector : Namely, for the bi-vector-skew Bregman divergences with and , we obtain an equivalent Jensen diversity for the Jensen–Bregman divergence, and, as a byproduct, a vector-skew generalization of the Jensen–Shannon divergence.
Funding
This research received no external funding.
Acknowledgments
The author is very grateful to the two Reviewers and the Academic Editor for their careful reading, helpful comments, and suggestions which led to this improved manuscript. In particular, Reviewer 2 kindly suggested the stronger bound of Lemma 1 and hinted at Theorem 1.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Billingsley, P. Probability and Measure; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Deza, M.M.; Deza, E. Encyclopedia of Distances; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Basseville, M. Divergence measures for statistical data processing—An annotated bibliography. Signal Process. 2013, 93, 621–633. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Nielsen, F. On the Jensen–Shannon Symmetrization of Distances Relying on Abstract Means. Entropy 2019, 21, 485. [Google Scholar] [CrossRef] [Green Version]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef] [Green Version]
- Sason, I. Tight bounds for symmetric divergence measures and a new inequality relating f-divergences. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Wong, A.K.; You, M. Entropy and distance of random graphs with application to structural pattern recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1985, 7, 599–609. [Google Scholar] [CrossRef]
- Endres, D.M.; Schindelin, J.E. A new metric for probability distributions. IEEE Trans. Inf. Theory 2003, 49, 1858–1860. [Google Scholar] [CrossRef] [Green Version]
- Kafka, P.; Österreicher, F.; Vincze, I. On powers of f-divergences defining a distance. Stud. Sci. Math. Hung. 1991, 26, 415–422. [Google Scholar]
- Fuglede, B. Spirals in Hilbert space: With an application in information theory. Expo. Math. 2005, 23, 23–45. [Google Scholar] [CrossRef] [Green Version]
- Acharyya, S.; Banerjee, A.; Boley, D. Bregman divergences and triangle inequality. In Proceedings of the 2013 SIAM International Conference on Data Mining, Austin, TX, USA, 2–4 May 2013; pp. 476–484. [Google Scholar]
- Naghshvar, M.; Javidi, T.; Wigger, M. Extrinsic Jensen–Shannon divergence: Applications to variable-length coding. IEEE Trans. Inf. Theory 2015, 61, 2148–2164. [Google Scholar] [CrossRef] [Green Version]
- Bigi, B. Using Kullback-Leibler distance for text categorization. In European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2003; pp. 305–319. [Google Scholar]
- Chatzisavvas, K.C.; Moustakidis, C.C.; Panos, C. Information entropy, information distances, and complexity in atoms. J. Chem. Phys. 2005, 123, 174111. [Google Scholar] [CrossRef] [Green Version]
- Yurdakul, B. Statistical Properties of Population Stability Index. Ph.D. Thesis, Western Michigan University, Kalamazoo, MI, USA, 2018. [Google Scholar]
- Jeffreys, H. An invariant form for the prior probability in estimation problems. Proc. R. Soc. Lond. A 1946, 186, 453–461. [Google Scholar]
- Nielsen, F. Jeffreys centroids: A closed-form expression for positive histograms and a guaranteed tight approximation for frequency histograms. IEEE Signal Process. Lett. 2013, 20, 657–660. [Google Scholar] [CrossRef] [Green Version]
- Lee, L. Measures of Distributional Similarity. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics on Computational Linguistics, ACL ’99; Association for Computational Linguistics: Stroudsburg, PA, USA, 1999; pp. 25–32. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. A family of statistical symmetric divergences based on Jensen’s inequality. arXiv 2010, arXiv:1009.4004. [Google Scholar]
- Lee, L. On the effectiveness of the skew divergence for statistical language analysis. In Proceedings of the 8th International Workshop on Artificial Intelligence and Statistics (AISTATS 2001), Key West, FL, USA, 4–7 January 2001. [Google Scholar]
- Csiszár, I. Information-type measures of difference of probability distributions and indirect observation. Stud. Sci. Math. Hung. 1967, 2, 229–318. [Google Scholar]
- Ali, S.M.; Silvey, S.D. A general class of coefficients of divergence of one distribution from another. J. R. Stat. Soc. Ser. B (Methodol.) 1966, 28, 131–142. [Google Scholar] [CrossRef]
- Sason, I. On f-divergences: Integral representations, local behavior, and inequalities. Entropy 2018, 20, 383. [Google Scholar] [CrossRef] [Green Version]
- Amari, S.I. Information Geometry and Its Applications; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Jiao, J.; Courtade, T.A.; No, A.; Venkat, K.; Weissman, T. Information measures: The curious case of the binary alphabet. IEEE Trans. Inf. Theory 2014, 60, 7616–7626. [Google Scholar] [CrossRef]
- Yuille, A.L.; Rangarajan, A. The concave-convex procedure (CCCP). In Proceedings of the Neural Information Processing Systems 2002, Vancouver, BC, Canada, 9–14 December 2002; pp. 1033–1040. [Google Scholar]
- Nielsen, F.; Nock, R. Skew Jensen-Bregman Voronoi diagrams. In Transactions on Computational Science XIV; Springer: Berlin/Heidelberg, Germany, 2011; pp. 102–128. [Google Scholar]
- Banerjee, A.; Merugu, S.; Dhillon, I.S.; Ghosh, J. Clustering with Bregman divergences. J. Mach. Learn. Res. 2005, 6, 1705–1749. [Google Scholar]
- Nielsen, F.; Nock, R. Sided and symmetrized Bregman centroids. IEEE Trans. Inf. Theory 2009, 55, 2882–2904. [Google Scholar] [CrossRef] [Green Version]
- Melbourne, J.; Talukdar, S.; Bhaban, S.; Madiman, M.; Salapaka, M.V. On the Entropy of Mixture distributions. Available online: http://box5779.temp.domains/~jamesmel/publications/ (accessed on 16 February 2020).
- Guntuboyina, A. Lower bounds for the minimax risk using f-divergences, and applications. IEEE Trans. Inf. Theory 2011, 57, 2386–2399. [Google Scholar] [CrossRef]
- Sason, I.; Verdu, S. f-divergence Inequalities. IEEE Trans. Inf. Theory 2016, 62, 5973–6006. [Google Scholar] [CrossRef]
- Melbourne, J.; Madiman, M.; Salapaka, M.V. Relationships between certain f-divergences. In Proceedings of the 57th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA , 24–27 September 2019; pp. 1068–1073. [Google Scholar]
- Sason, I. On Data-Processing and Majorization Inequalities for f-Divergences with Applications. Entropy 2019, 21, 1022. [Google Scholar] [CrossRef] [Green Version]
- Van Erven, T.; Harremos, P. Rényi divergence and Kullback-Leibler divergence. IEEE Trans. Inf. Theory 2014, 60, 3797–3820. [Google Scholar] [CrossRef] [Green Version]
- Xu, P.; Melbourne, J.; Madiman, M. Infinity-Rényi entropy power inequalities. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2985–2989. [Google Scholar]
- Nielsen, F.; Nock, R. On the geometry of mixtures of prescribed distributions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2861–2865. [Google Scholar]
- Fréchet, M. Les éléments aléatoires de nature quelconque dans un espace distancié. Ann. De L’institut Henri PoincarÉ 1948, 10, 215–310. [Google Scholar]
- Nielsen, F.; Boltz, S. The Burbea-Rao and Bhattacharyya centroids. IEEE Trans. Inf. Theory 2011, 57, 5455–5466. [Google Scholar] [CrossRef] [Green Version]
- Lanckriet, G.R.; Sriperumbudur, B.K. On the convergence of the concave-convex procedure. In Proceedings of the Advances in Neural Information Processing Systems 22 (NIPS 2009), Vancouver, BC, Canada, 7–10 December 2009; pp. 1759–1767. [Google Scholar]
- Nielsen, F.; Sun, K. Guaranteed bounds on information-theoretic measures of univariate mixtures using piecewise log-sum-exp inequalities. Entropy 2016, 18, 442. [Google Scholar] [CrossRef] [Green Version]
- Springer Verlag GmbH, European Mathematical Society. Encyclopedia of Mathematics. Available online: https://www.encyclopediaofmath.org/ (accessed on 19 December 2019).
- Del Castillo, J. The singly truncated normal distribution: A non-steep exponential family. Ann. Inst. Stat. Math. 1994, 46, 57–66. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F.; Nock, R. Entropies and cross-entropies of exponential families. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 3621–3624. [Google Scholar]
- Nielsen, F.; Hadjeres, G. Monte Carlo information geometry: The dually flat case. arXiv 2018, arXiv:1803.07225. [Google Scholar]
- Schwander, O.; Nielsen, F. Learning mixtures by simplifying kernel density estimators. In Matrix Information Geometry; Springer: Berlin/Heidelberg, Germany, 2013; pp. 403–426. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA’07), New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Nielsen, F.; Nock, R.; Amari, S.I. On clustering histograms with k-means by using mixed α-divergences. Entropy 2014, 16, 3273–3301. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F.; Nock, R. Total Jensen divergences: Definition, properties and clustering. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015; pp. 2016–2020. [Google Scholar]
- Topsøe, F. Basic concepts, identities and inequalities-the toolkit of information theory. Entropy 2001, 3, 162–190. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Yamano, T. Some bounds for skewed α-Jensen-Shannon divergence. Results Appl. Math. 2019, 3, 100064. [Google Scholar] [CrossRef]
- Kotlerman, L.; Dagan, I.; Szpektor, I.; Zhitomirsky-Geffet, M. Directional distributional similarity for lexical inference. Nat. Lang. Eng. 2010, 16, 359–389. [Google Scholar] [CrossRef]
- Johnson, D.; Sinanovic, S. Symmetrizing the Kullback-Leibler distance. IEEE Trans. Inf. Theory 2001, 1–8. [Google Scholar]
Figure 1.
The Convex–ConCave Procedure (CCCP) iteratively updates the parameter by aligning the support hyperplanes at . In the limit case of convergence to , the support hyperplanes at are parallel to each other. CCCP finds a local minimum.
Figure 1.
The Convex–ConCave Procedure (CCCP) iteratively updates the parameter by aligning the support hyperplanes at . In the limit case of convergence to , the support hyperplanes at are parallel to each other. CCCP finds a local minimum.

Figure 2.
The Jeffreys centroid (grey histogram) and the Jensen–Shannon centroid (black histogram) for two grey normalized histograms of the Lena image (red histogram) and the Barbara image (blue histogram). Although these Jeffreys and Jensen–Shannon centroids look quite similar, observe that there is a major difference between them in the range where the blue histogram is zero.
Figure 2.
The Jeffreys centroid (grey histogram) and the Jensen–Shannon centroid (black histogram) for two grey normalized histograms of the Lena image (red histogram) and the Barbara image (blue histogram). Although these Jeffreys and Jensen–Shannon centroids look quite similar, observe that there is a major difference between them in the range where the blue histogram is zero.

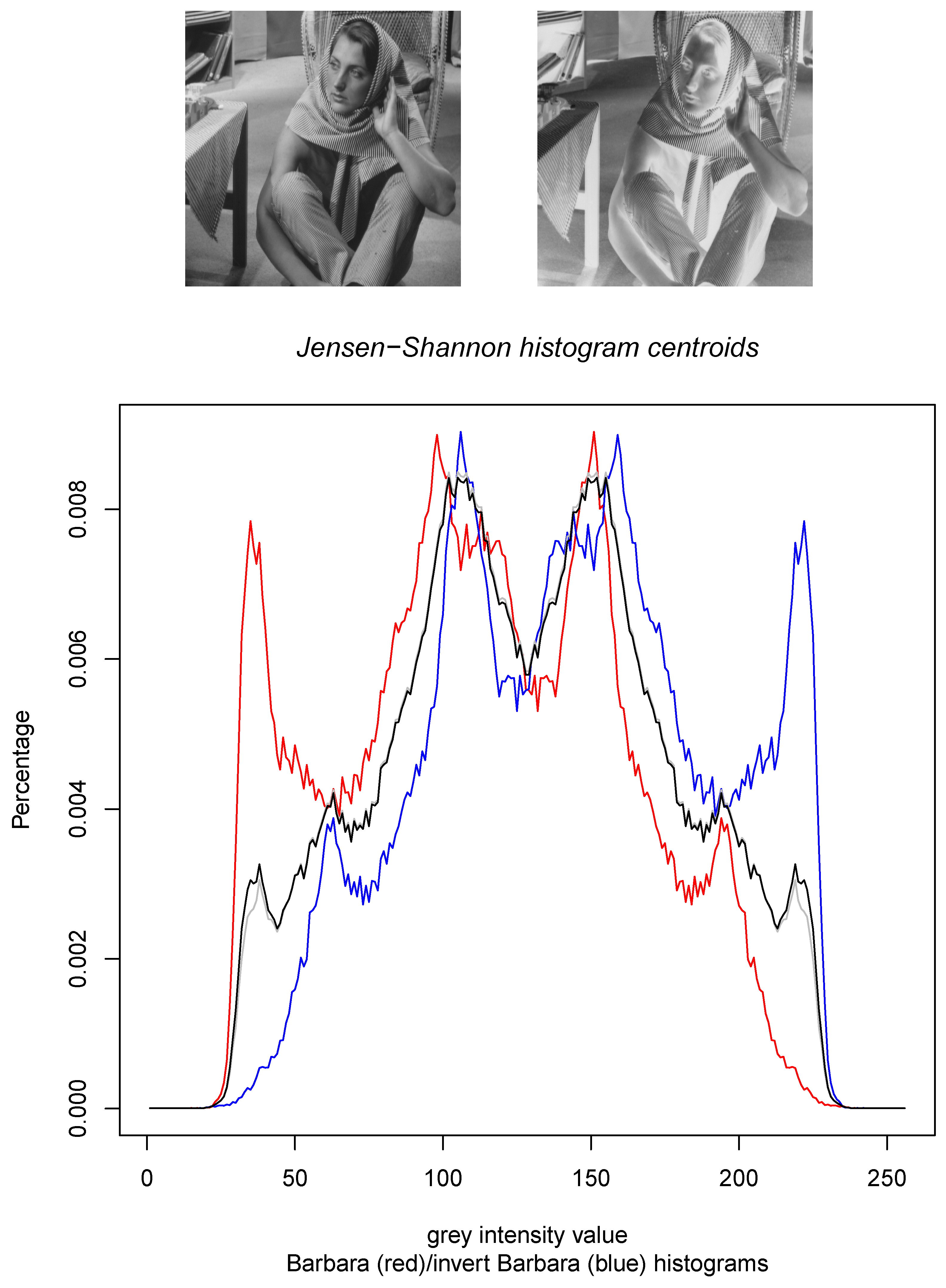
Figure 3.
The Jeffreys centroid (grey histogram) and the Jensen–Shannon centroid (black histogram) for the grey normalized histogram of the Barbara image (red histogram) and its negative image (blue histogram which corresponds to the reflection around the vertical axis of the red histogram).
Figure 3.
The Jeffreys centroid (grey histogram) and the Jensen–Shannon centroid (black histogram) for the grey normalized histogram of the Barbara image (red histogram) and its negative image (blue histogram which corresponds to the reflection around the vertical axis of the red histogram).

Figure 4.
Jensen–Shannon centroid (black histogram) for the clamped grey normalized histogram of the Lena image (red histograms) and the clamped gray normalized histogram of Barbara image (blue histograms). Notice that on the part of the sample space where only one distribution is non-zero, the JS centroid scales that histogram portion.
Figure 4.
Jensen–Shannon centroid (black histogram) for the clamped grey normalized histogram of the Lena image (red histograms) and the clamped gray normalized histogram of Barbara image (blue histograms). Notice that on the part of the sample space where only one distribution is non-zero, the JS centroid scales that histogram portion.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Two views of the family of categorical distributions with d choices: An exponential family or a mixture family of order . Note that the Bregman divergence associated to the exponential family view corresponds to the reverse Kullback–Leibler (KL) divergence, while the Bregman divergence associated to the mixture family view corresponds to the KL divergence.
Table 1.
Two views of the family of categorical distributions with d choices: An exponential family or a mixture family of order . Note that the Bregman divergence associated to the exponential family view corresponds to the reverse Kullback–Leibler (KL) divergence, while the Bregman divergence associated to the mixture family view corresponds to the KL divergence.
| Exponential Family | Mixture Family | |
|---|---|---|
| primal | ||
| dual | ||
| primal | ||
| Bregman divergence | ||
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Nielsen, F. On a Generalization of the Jensen–Shannon Divergence and the Jensen–Shannon Centroid. Entropy 2020, 22, 221. https://0-doi-org.brum.beds.ac.uk/10.3390/e22020221
AMA Style
Nielsen F. On a Generalization of the Jensen–Shannon Divergence and the Jensen–Shannon Centroid. Entropy. 2020; 22(2):221. https://0-doi-org.brum.beds.ac.uk/10.3390/e22020221
Chicago/Turabian StyleNielsen, Frank. 2020. "On a Generalization of the Jensen–Shannon Divergence and the Jensen–Shannon Centroid" Entropy 22, no. 2: 221. https://0-doi-org.brum.beds.ac.uk/10.3390/e22020221
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.