The Fisher–Rao Distance between Multivariate Normal Distributions: Special Cases, Bounds and Applications


1
Center of Exact and Technological Sciences, University of Reconcavo of Bahia, Cruz das Almas 44380-000, Brazil
2
School of Applied Sciences, University of Campinas, Limeira 13484-350, Brazil
3
Institute of Mathematics, University of Campinas, Campinas 13083-859, Brazil
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(4), 404; https://0-doi-org.brum.beds.ac.uk/10.3390/e22040404
Submission received: 26 January 2020
/
Revised: 6 March 2020
/
Accepted: 11 March 2020
/
Published: 1 April 2020
Abstract
:The Fisher–Rao distance is a measure of dissimilarity between probability distributions, which, under certain regularity conditions of the statistical model, is up to a scaling factor the unique Riemannian metric invariant under Markov morphisms. It is related to the Shannon entropy and has been used to enlarge the perspective of analysis in a wide variety of domains such as image processing, radar systems, and morphological classification. Here, we approach this metric considered in the statistical model of normal multivariate probability distributions, for which there is not an explicit expression in general, by gathering known results (closed forms for submanifolds and bounds) and derive expressions for the distance between distributions with the same covariance matrix and between distributions with mirrored covariance matrices. An application of the Fisher–Rao distance to the simplification of Gaussian mixtures using the hierarchical clustering algorithm is also presented.
1. Introduction
A proper measure to determine the dissimilarity between probability distributions has been approached in many problems and applications. The Fisher–Rao distance is a very special metric for statistical models of probability distributions. This distance is invariant by reparametrization of the sample space and covariant by reparameterization of the parameter space [1]. Moreover, the Fisher–Rao metric is preserved under Markov morphisms and under centain conditions it is, up to a scaling factor, the unique Riemannian metric satisfying this condition [2,3]. Markov morphisms are associated with the notion of statistical sufficiency which express the criterion of passing from one statistical model to another with no loss of information [4,5,6]. Therefore it is natural to require the invariance of the geometric structures of statistical models under Markov morphisms. Between finite sample size simplex model , a Markov morphism is a linear map , where , with , is a matrix with non-negative entries such that every row sums to 1 and every column has precisely one non-zero element. The mapping corresponds to probabilistic refining of the event space where the refinement occurs with probability [7]. Chentsov [8,9] has proved the Fisher–Rao uniqueness invariance property under Markov morphisms for the finite sample spaces. The extension of this result to more general statistical models requires careful formulations of statistical sufficiency and Markov morphisms and has been evolved since then [3,10]. More recently in [5,6] it is shown this uniqueness of the Fisher–Rao metric under an assumption of strong continuity of the information metric.
After previous papers [11,12,13] connecting geometry and statistics, C. R.Rao in an independent landmark paper [14] considered statistical models with the metric induced by the information matrix defined by R. Fisher in 1921 [15]. This work encouraged several authors to calculate the Fisher–Rao metric distance between other probability distributions [16,17,18] as well as stimulated approaches to other dissimilarity measures such as Kullback-Leibler divergence [19], total variation and Wasserstein distances [20]. Amari [3,4,21] unified the information geometry theory by organizing and introducing other concepts regarding statistical models [2].
An explicit form for the Fisher–Rao distance in the univariate normal distribution space is known via an association with the classical model of the hyperbolic plane [14,16,18,22]. It was applied to quantization of hyperspectral images [23] and to the space of projected lines in the paracatadioptric images [24]. This Fisher–Rao model was used to simplify Gaussian mixtures through the k-means method [25] and a hierarchical clustering technique [26].
An expression for the geodesic curve (initial value problem) in the multivariate normal distributions space was derived in [27] and in [28]. However, the calculus of the Fisher–Rao distance requires solving non-trivial differential equations under boundary conditions to find the geodesic connecting two distributions and then to calculate the integral along the geodesic. A closed form for this distance in the general case is still an open problem. Expressions for the distance are known only in special cases [16,17,18].
The Fisher–Rao distance between multivariate normal distributions in specific cases, such as distributions with a common mean, was considered in diffusion tensor image analysis [29,30,31], in color texture discrimination in several classification experiments [32], in the problem of distributed estimation fusion with unknown correlations [33], and in the machine learning technique [34]. In [35,36], the authors described shapes representing landmarks by a Gaussian model with diagonal covariance matrices and used the Fisher–Rao distance to quantify the difference between two shapes. In [17], this model was applied to statistical inference. Bounds for the Fisher–Rao distance were used to track quality monitoring [37].
This paper is organized as follows. In Section 2, we gather known results (closed forms for special cases and bounds) for the Fisher–Rao distance between multivariate normal distributions. In Section 3, we describe a closed form for the Fisher–Rao distance between distributions with the same covariance matrix and a non-linear system to find the distance between distributions with mirrored covariance matrices. An application of the Fisher–Rao distance to the simplification of Gaussian mixtures using the hierarchical clustering algorithm is presented in Section 4. Some conclusions and perspectives are drawn in Section 5.
2. The Fisher–Rao Distance in the Multivariate Normal Distribution Space: Special Submanifolds and Bounds
In this section, as in [38], we summarize previous results regarding the Fisher–Rao distance in the space of multivariate normal distributions including closed forms for this distance restricted to submanifolds and general bounds.
Given a statistical model , a natural Riemannian structure [21] can be provided by the Fisher information matrix :
where is the expected value with respect to the distribution . This matrix can also be viewed as the Hessian matrix of the Shannon entropy (concave function) [39],
and is used to establish connections between inequalities in information theory and geometrical inequalities.
The Fisher–Rao distance, , between two distributions and in , identified with their parameters and , is given by the shortest length of a curve in the parameter space connecting these distributions, , where . Note that this is in fact a metric, since for any , , and in , we have: (i) and if only if ; (ii) ; (iii) . A curve that provides the shortest length is called a geodesic and is given by the solutions of the differential equations
where are the Christoffel symbols,
and is the inverse matrix of the Fisher information matrix.
We consider here the space of the multivariate normal distributions given by:
where is the variable vector, is the mean vector, and is the covariance matrix in , the space of order n positive definite symmetric matrices.
In this case, the model is a statistical -dimensional manifold.
In this case, the model is a statistical manifold of dimension . Considering a parametrization of the model , the Fisher information matrix is given by [40]
The metric provided by this matrix is invariant with respect to affine transformations. In other words, for any , where is the group of non-singular n-square matrices, the mapping:
is an isometry in [16]. Consequently, the Fisher–Rao distance between and in satisfies:
for any . In particular, for and , , the Fisher–Rao distance admits the form:
where , is the n-order identity matrix, and is the null vector.
The geodesic equations in can be expressed as [17]:
and could be partially integrated [27]:
where , , and B is a symmetric matrix. The initial conditions for this problem can be taken as:
Eriksen [27] and Calvo and Oller [28], in independent works, solved this initial value problem. An explicit solution to the geodesic curve in [28] is:
where is an n-order identity matrix, , and is the generalized inverse square matrix of G, that is .
Due the fact that the geodesic curve has constant velocity at any point, given in the tangent space of , the Fisher–Rao distance between and is:
where is the standard Euclidean norm. Note that the above expression provides the Fisher–Rao distance between two distributions only if we can determine the initial value problem from the boundary conditions, which usually is very difficult.
Han and Park in [31] presented a numerical shooting method for computing the minimum geodesic distance between two normal distributions, through parallel transport of a vector field defined along the geodesic curve given in Equation (15).
A closed form for the Fisher–Rao distance between two normal distributions in is still an important open question. Next, we present closed forms for this distance in some submanifolds of .
2.1. Closed Forms for the Fisher–Rao Distance in Submanifolds of
In this subsection, we consider submanifolds with the distance induced by the Fisher–Rao metric in . It is important to remark that, in general, given two distributions and in , the distance between and when restricted to a submanifold is bigger than the distance between and in , that is . This is due to the fact that to get , we consider the minimum length of restricted curves, which are the ones contained in the submanifold . We say that is totally geodesic if only if , for any , which means that the geodesic in connecting and is contained in .
2.1.1. The Submanifold Where Is Constant
In the n-dimensional manifold composed by multivariate normal distributions with common covariance matrix , , the Fisher–Rao distance between two distributions and is [18]:
This distance is equal to the Mahalanobis distance [11], which is equal to the Euclidean distance between the image of and under the transformation , where is the Cholesky decomposition [18]. This distance was one of the first dissimilarity measures between datasets with some correlation. Note that this submanifold is not totally geodesic, as it can be seen even in the space of univariate normal distributions [22] and in Example 1 in the next section.
A geodesic curve in connecting and can be provided by:
2.1.2. The Submanifold Where Is Constant
A totally geodesic submanifold of is given by of dimension composed by distributions that have the same mean vector . The Fisher–Rao distance in was studied by several authors in different contexts [16,18,30,41] and for and is given by:
where are the eigenvalues of .
An expression for the geodesic curve connecting these two distributions is [30]:
2.1.3. The Submanifold Where Is Diagonal
Let , the submanifold of composed by distributions with a diagonal covariance matrix. If we consider the parameter , it can be shown [22] that the metric in the parametric space of is equal to the product metric:
where is the Fisher–Rao distance in the univariate case given by [22]:
In this space, a curve is a geodesic if, and only if, is a geodesic curve in the univariate case, for all . The geodesic curves in the univariate normal distributions space (upper half plane ) are half-vertical lines and half-ellipses centered at , with eccentricity [22].
It is important to note that is not totally geodesic. The submanifold of composed only by normal distributions with covariance matrices which are multiples of the identity (round normals) is totally geodesic [22]. In fact, this submanifold of round normals is also contained in the totally geodesic submanifold described next.
2.1.4. The Submanifold Where Is Diagonal and Is an Eigenvector of
Let be the -dimensional submanifold composed by distributions with the mean vector for some (the canonical basis of ) and diagonal covariance matrix , and without loss of generality, we shall assume that . An analytic expression for the distance in is:
We proved in [42] that this submanifold is totally geodesic.
2.2. Bounds for the Fisher–Rao in
As mentioned, a closed form for the Fisher–Rao distance between two general normal distributions is not known. In this subsection, we present some bounds for this distance.
2.2.1. A Lower Bound
Calvo and Oller [43] derived a lower bound for the Fisher–Rao distance through an isometric embedding of the parametric space into the manifold of the positive definite matrices.
Proposition 1.
[43] Given and , let:
. A lower bound for the distance between and is:
where , , are the eigenvalues of .
We note that this bound satisfies the distance proprieties in . In [44], through a similar approach, a lower bound for the Fisher–Rao distance was obtained in the more general space of elliptical distributions, restricted to normal distributions, is the above bound.
2.2.2. The Upper Bound
In [45], we proposed an upper bound based on an isometry (8) in the manifold and on the distance in the non-totally geodesic submanifold (21), as follows:
Proposition 2.
[45] The Fisher–Rao distance between two multivariate normal distributions and is upper bounded by,
where are the diagonal terms of the matrix Λ given by the eigenvalues of , are the coordinates of , Q is the orthogonal matrix whose columns are the eigenvectors of A and is the Fisher–Rao distance between univariate normal distributions given in Equation (22).
2.2.3. The Upper Bounds and
Considering the Fisher–Rao distance in the totally geodesic submanifold and the triangular inequality, we propose another upper bound [42].
Given and , we consider the Fisher–Rao distance between and as in Equation (10). Let ; by the triangular inequality, it follows that:
To calculate this bound, we choose appropriately. For , note that . Let P be an orthogonal matrix such that and a diagonal matrix. We will consider and . By the isometry , given in Equation (9), for and , it follows:
Then, combining Inequality (27) and Equation (28), the left side of the equation below is an upper bound for the Fisher–Rao distance between and ,
In [42], we derived the upper bound:
through a numerical minimization process by considering the diagonal elements of D as a vector that minimizes ,
We also derive an analytic upper bound by minimizing of the distance . By expressing this distance in terms of the parameters , we can show that it reaches the minimum at:
The lower bound of Section 2.2.1 and the upper bounds of Section 2.2.2 and Section 2.2.3 are summarized in Table 1.
Upper and lower bounds have been used to estimate the Fisher–Rao distance in applications such as [37].
2.2.4. Comparisons of the Bounds
In this section, as in [42], we illustrate comparisons between the bounds presented previously.
We consider the bivariate normal distributions model () and distributions and , where:
From (10), we can see that there always exists an isometry that converts any two pairs of bivariate distributions into a pair of distributions as above.
We present next a comparison between the lower bound “LB” (25), the upper bounds (26), (31), and (32), and the numerical solution given by the geodesic shooting algorithm (GS) [31] in specific situations.
In Figure 1, we consider the eigenvalues , , and to be fixed and varying from zero to . We note that the upper bound is very near the lower bound and to the numerical solution . The other upper bounds are bigger than the bound . In Figure 2, it is considered and the previous eigenvalues. Now, the best performance is of bounds and , which are similar. In Figure 3a, we again keep the eigenvalues; the rotation angle is fixed ; and varies from zero to 10. We can see similar performances of and , which are better than for larger values of .
We may also consider the upper bound:
3. Fisher–Rao Distance Between Special Distributions
In this section, we describe the Fisher–Rao distance in the full space between special kinds of distributions.
3.1. The Fisher–Rao Distance Between Distributions with Common Covariance Matrices
The Fisher–Rao distance between distributions with common covariance matrices given in Section 2.1.1 was restricted to non-totally geodesic submanifold . We show next that using the isometry given in (8) and the distance in the submanifold , it is possible to find a closed form for the distance between two distributions with the same covariance matrix, in the full manifold .
Proposition 3.
Given two distributions and in , let P be an orthogonal matrix such that , and consider the decomposition of the matrix ,
where U is an upper triangular matrix with all diagonal entries equal to one and D is a diagonal matrix. The Fisher–Rao distance between and is given by:
Proof.
By considering the isometries and and the decomposition given by Equation (35), it follows from Equation (9) that:
Since the distributions and belong to the submanifold , we conclude that:
□
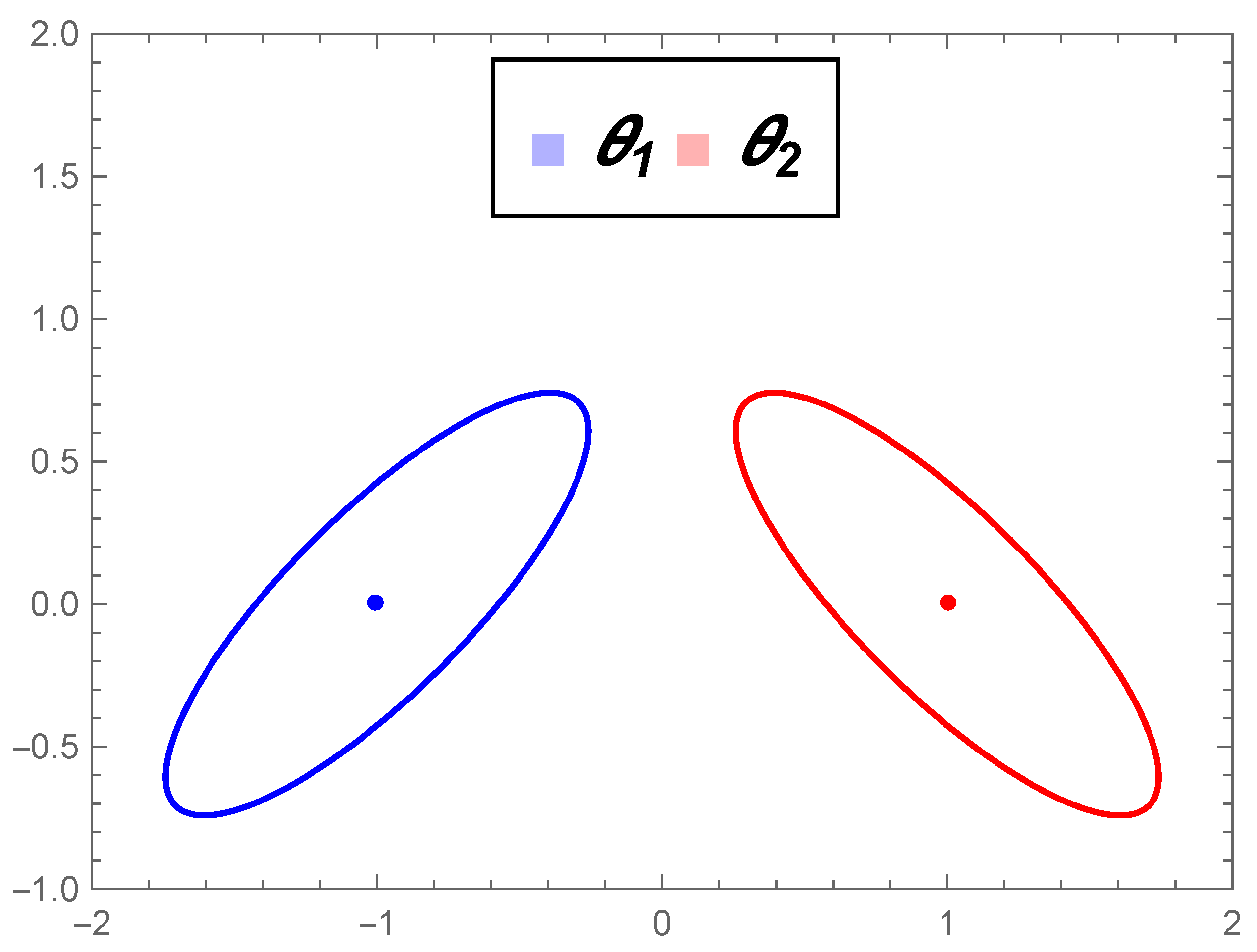
Example 1.
Consider two bivariate normal distributions and with the same covariance matrix:
Figure 4a illustrates the normal distributions in the geodesic curve connecting connecting and in , and Figure 4b illustrates the geodesic in the submanifold . We observe that in , the shape of the ellipses (contour curves) changes along the path. Furthermore, the Fisher–Rao distance between and is , which is less than the Mahalanobis distance given in Equation (17), , as expected, since the submanifold is not totally geodesic.
3.2. The Fisher–Rao Distance Between Mirrored Distributions
We consider here two mirrored normal distributions; that is, without loss of generality, if we consider up rotation, the line connecting and as parallel to the -axis, and the covariance matrices and satisfying:
This condition implies also the same eigenvalues for both matrices.
For bivariate normal distributions, we then should have:
see Figure 5.
After several experiments using the algorithm geodesic shooting for the and , we have observed that for the geodesic curve connecting these distributions (, with and ), satisfies
where , , and are real values; see Figure 6.
The focus here is the “shape” of these distributions. Note that at , the distribution appears as , which has a diagonal covariance matrix, and the tangent vector appears as , which is composed by a mean vector with the second entry equal to zero and by a symmetric covariance matrix with a null diagonal.
This observation inspired us to get an explicit expression for the geodesic connecting two mirrored distributions. Starting with the bi-dimensional case again, we will prove that in fact we have equality in Expressions (41) and (42).
Let , , and the geodesic curve in connecting and , and consider that and . Given the isometry , we define:
Then:
and:
Applying the natural changing of parameters:
it follows that:
Then, given that ,
That is, at , the tangent vector is equal to the tangent vector in (46). Furthermore, the distributions and are also mirrored . In fact,
and by similar arguments, we obtain:
Figure 7 illustrates the distributions , , and .
Conversely, by considering:
in the initial value problem given in Equations (13) and (14), it follows that the matrix is diagonal. Therefore, the geodesic curve with initial value and tangent vector given in Equation (15) can be simplified as follows:
From the parity of the functions and , it is possible to show that, given , the distributions:
are also mirrored.
By the above discussion, we conclude that it is possible to calculate the geodesic curve connecting and making and . That is, we need to find the values of , , and of the isometry and the values of such that:
Since the two equations above are equivalent, it is enough to solve the equation:
This is equivalent to solving the system:
where .
The above non-linear system has five equations and five variables and can be solved by an iterative method. With the solution of this system, we can determine the geodesic curve connecting the distributions and . Moreover, by Equation (16), the Fisher–Rao distance is:
We also remark that the curve of the means (and therefore, ) satisfies the equation of a hyperbola; in fact:
Summarizing the above discussion, we have:
Proposition 4.
- (i)
- (ii)
- The plane curve given by the coordinates of the mean vector in the geodesic connecting two of these distributions is a hyperbola.
Table 2 shows a time comparison between the numerical method proposed here and the geodesic shooting to obtain the Fisher–Rao distance. The distributions used in this experiment were:
for different values of .
The method proposed here uses a non-linear system for the calculus of the Fisher–Rao distance, so it is faster the geodesic shooting algorithm. Furthermore, we remark that for , the geodesic shooting requires additional adaptation to convergence.
Next, we generalize the results of Proposition 4 to pairs of general multivariate normal mirrored distributions. Without loss of generality, we may assume:
with as in (39), that is:
Proposition 5.
The Fisher–Rao distance between a pair of multivariate mirrored normal distributions and (65) is:
where:
The values x and , the non-zero entries of , are obtained by the solution of the order non-linear system:
where , L is the Cholesky factor of the matrix , with D a symmetric order matrix, , and is the geodesic curve with initial value and tangent vector given in Equation (15).
Let , , be the geodesic curve in connecting and . The proof is similar to the bivariate case, by considering ,
and where .
with .
Table 3 collects the results in Section 2.1 and the new results of this section.
4. Hierarchical Clustering for Diagonal Gaussian Mixture Simplification
A parameterized Gaussian mixture model f is a weighted sum of m multivariate normal distributions, that is,
where , , , are normal distributions and , , are mixture, . In this paper, we call the diagonal Gaussian mixture model (DGMM) the mixture composed only by distributions with diagonal covariance matrices.
Gaussian mixture models (GMM) are used in modeling datasets: image processing, signal processing, and density estimation problems [46,47,48]. In many applications involving mixture models, the computational requirements are of a very high level due to the large number of mixture components. This can be handled if we reduce the number of components of the mixture: given a mixture f of m components, we want to find a mixture g of l components, , such that g is a good approximation of f with respect to a similarity measure [49]. Gaussian mixture simplification was considered in statistical inference in [50] and to decode low-density lattice codes [51].
In [49] was proposed a hierarchical clustering algorithm to simplify an exponential family mixture model based on Bregman divergences. This section describes an agglomerative hierarchical clustering method based on the Fisher–Rao distance in the submanifold (21) to simplify DGMM, and we present an application to image segmentation, complementing what was developed in [52]. We start by introducing the concept of the centroid for a set of distributions in .
4.1. Centroids in the Submanifold
In [53], Galperin described centroids in the two-dimensional Minkowski model, which can be translated also to the Klein disk and Poincare half-plane models. Given a set of points in the Minkowski model, with associated weights , the centroid is computed and normalized as:
To calculate the centroid of a subset of points , , the isometries presented in [25] and the relation between the media × standard deviation plane of parameters of univariate normal distributions and the Poincare half-plane given in [22] are used.
Given a dataset , where are distributions in , the centroid of is:
where , , is the centroid of given in Equation (66).
4.2. Hierarchical Clustering Algorithm
Let a DGMM f with parameters .
In order to apply the hierarchical clustering algorithm, we need to consider the distance between two subsets A and B. The three most common distances are called linkage criteria and are given by [54]:
- Single linkage:
- Complete linkage:
- Group average linkage:where is the distance in the submanifold and is the number of elements of a set X.
A summary of the hierarchical clustering algorithm (Algorithm 1) [49] using one of these distances is given next.
| Algorithm 1: Hierarchical Clustering Algorithm |
|
The simplified DGMM:
of l components is built from the l subsets , …, remaining after the iteration of the hierarchical clustering algorithm. In this work, we choose the parameters of in two ways: as the centroid in the submanifold (Fisher–Rao hierarchical clustering) and as the Bregman left-sided centroid [49] (Bregman–Fisher–Rao hierarchical clustering) of the subset with weights .
As remarked in [49], the hierarchical clustering algorithm allows introducing a method to learn the optimal number of components in the simplified mixture g. Thus, g must be as compact as possible and reach a minimum prescribed quality , where is the Kullback–Leibler divergence.
4.3. Experiments in Image Segmentation
We can apply the Fisher–Rao and the Bregman–Fisher–Rao hierarchical clusterings to simplify a mixture of exponential families in the context of clustering-based image segmentation as was done in [49] for the Bregman hierarchical clustering. Given an input color image I, we adapt the Bregman soft clustering algorithm to generate a DGMM f of 32 components, which models the image pixels. We point out that the restriction considered in this paper (only DGMM) is also used in many applications due its much lower computational cost. We consider here a pixel as a point in , where , , and are the RGB color information. For image segmentation, we can say that the image pixel belongs to the class when:
Thus, the segmented image is illustrated by replacing the color value of the pixel by the mean of the Gaussian .
Using the the Fisher–Rao and the Bregman–Fisher–Rao hierarchical clusterings, we simplify the mixture f into mixtures g of l components with . Each mixture gives one image segmentation. The linkage criterion used here was the complete linkage (68), which has presented better results in our simulations. Figure 8 shows the segmentation of the Baboon, Lena, and Clown input images given by the Bregman–Fisher–Rao hierarchical clustering. The number of colors in each image is equal to the number of components in the simplified mixture g.
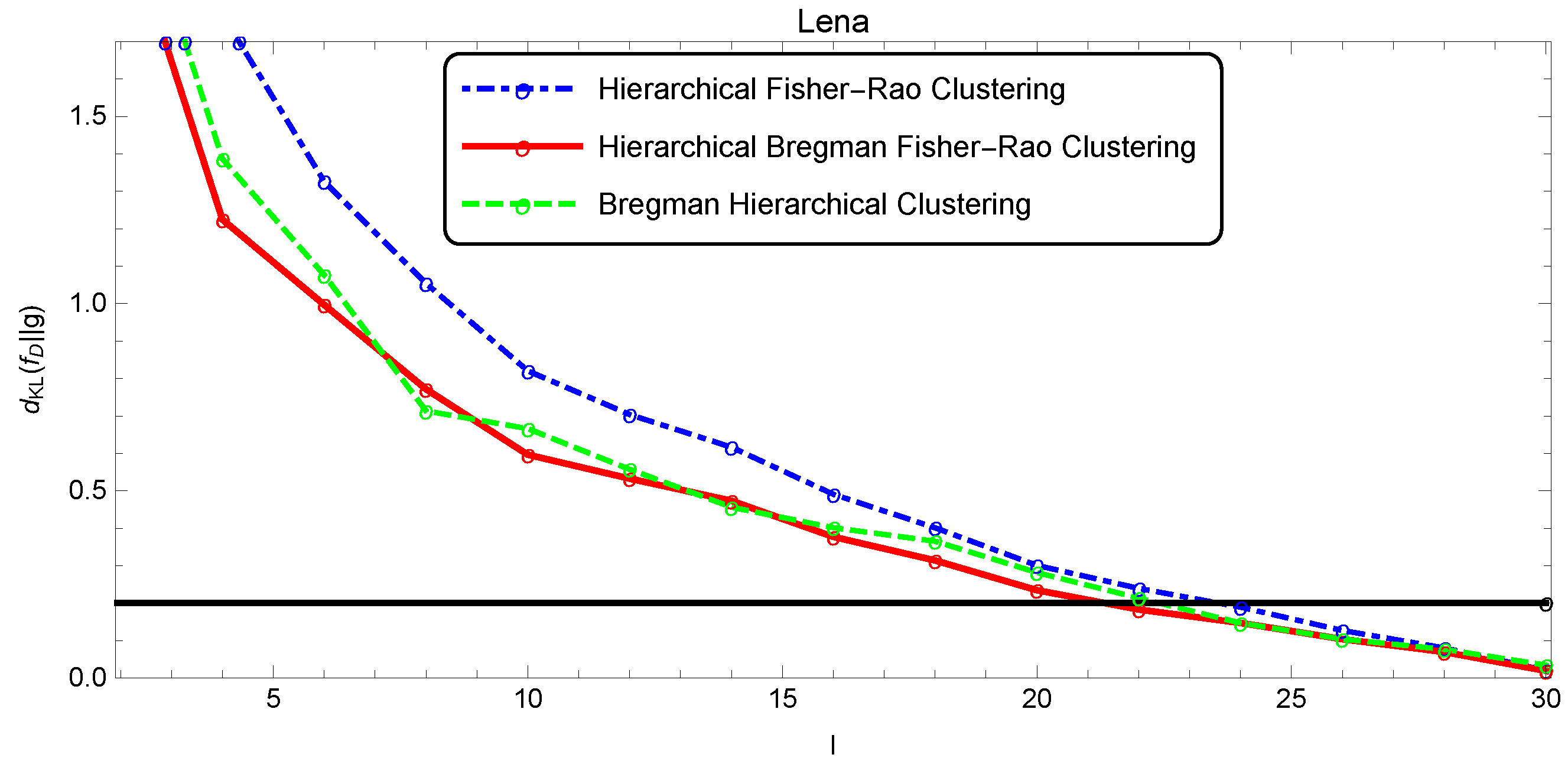
The quality of the segmentation was analyzed as a function of l through the Kullback–Leibler divergence estimated by the Monte Carlo method, since there was no closed form for this measure (five thousand points were randomly drawn to estimate ). Figure 9, Figure 10 and Figure 11 show the evolution of the simplification quality as a function of the number of components l for the Baboon, Lena, and Clown images, using the Bregman, the Fisher–Rao, and the Bregman–Fisher–Rao hierarchical clustering algorithms. We observed that the image quality increased ( decreased) with l, as expected, and the behavior was similar in all clustering algorithms. In general, the Bregman–Fisher–Rao hierarchical clustering algorithm presented better results. Considering the constraint , the learning process provided, for the Bregman–Fisher–Rao hierarchical clustering, mixtures of 19, 21, and 21 as optimal simplifications for the images of the Baboon, Lena, and Clown, respectively.
5. Concluding Remarks
The Fisher–Rao distance was approached here in the space of multivariate normal distributions. Initially, as in [38], we summarized some known closed forms for this distance in submanifolds of this model and some bounds for the general case. A closed form for the Fisher–Rao distance between distributions with the same covariance matrix was obtained in Proposition 3, and we also have derived a non-linear system characterizing the distance between two distributions with mirrored covariance matrices in Proposition 5. Some perspectives for future research related to this topic include deriving new bounds for the Fisher–Rao distance in the general case, by using these special distributions, to characterize as non-linear systems the distances between other types of distributions and to extend the closed forms and bounds presented here to the space of elliptical distributions. Finally, we have extended the analysis of the Bregman–Fisher–Rao hierarchical clustering algorithm to simplify Gaussian mixtures in the context of clustering-based image segmentation given in [52] with comparative results that encourage the use of the Fisher–Rao distance in other clustering or classification algorithms.
Author Contributions
All authors contributed equally to the research and the writing of the manuscript. All authors read and approved the final manuscript.
Acknowledgments
The authors are thankful to the referees, as their comments and suggestions have contributed to improve the presentation of the text. The authors were partially supported by grants FAPESP (13/25977-7) and CNPq (313326/2017-7) foundations.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Calin, O.; Udriste, C. Geometric Modeling in Probability and Statistics. In Mathematics and Statistics; Springer International: Cham, Switzerland, 2014. [Google Scholar]
- Nielsen, F. An elementary introduction to information geometry. arXiv 2018, arXiv:1808.08271. [Google Scholar]
- Amari, S.; Nagaoka, H. Methods of Information Geometry. In Translations of Mathematical Monographs; Oxford University Press: Oxford, UK, 2000; Volume 191. [Google Scholar]
- Amari, S. Information Geometry and Its Applications; Springer: Tokyo, Japan, 2016. [Google Scholar]
- Ay, N.; Jost, J.; Vân Lê, H.; Schwachhöfer, L. Information geometry and sufficient statistics. Probab. Theory Relat. Fields 2015, 162, 327–364. [Google Scholar] [CrossRef] [Green Version]
- Vân Lê, H. The uniqueness of the Fisher metric as information metric. Ann. Inst. Stat. Math. 2017, 69, 879–896. [Google Scholar]
- Gibilisco, P.; Riccomagno, E.; Rogantin, M.P.; Wynn, H.P. Algebraic and Geometric Methods in Statistics; Cambridge University Press: New York, NY, USA, 2010. [Google Scholar]
- Chentsov, N.N. Statistical Decision Rules and Optimal Inference; AMS Bookstore: Providence, RI, USA, 1982; Volume 53. [Google Scholar]
- Campbell, L.L. An extended Cencov characterization of the information metric. Proc. Am. Math. Soc. 1986, 98, 135–141. [Google Scholar]
- Vân Lê, H. Statistical manifolds are statistical models. J. Geom. 2006, 84, 83–93. [Google Scholar]
- Mahalanobis, P.C. On the generalized distance in statistics. Proc. Natl. Inst. Sci. 1936, 2, 49–55. [Google Scholar]
- Bhattacharyya, A. On a measure of divergence between two statistical populations defined by their probability distributions. Bull. Calcutta Math. Soc. 1943, 35, 99–110. [Google Scholar]
- Hotelling, H. Spaces of statistical parameters. Bull. Am. Math. Soc. (AMS) 1930, 36, 191. [Google Scholar]
- Rao, C.R. Information and the accuracy attainable in the estimation of statistical parameters. Bull. Calcutta Math. Soc. 1945, 37, 81–91. [Google Scholar]
- Fisher, R.A. On the mathematical foundations of theoretical statistics. Philos. Trans. R. Soc. Lond. 1921, 222, 309–368. [Google Scholar]
- Burbea, J. Informative geometry of probability spaces. Expo. Math. 1986, 4, 347–378. [Google Scholar]
- Skovgaard, L.T. A Riemannian geometry of the multivariate normal model. Scand. J. Stat. 1984, 11, 211–223. [Google Scholar]
- Atkinson, C.; Mitchell, A.F.S. Rao’s Distance Measure. Sankhyã Indian J. Stat. 1981, 43, 345–365. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Villani, C. Optimal Transport, Old and New. In Grundlehren der Mathematischen Wissenschaften; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Amari, S. Differential Geometrical Methods in Statistics; Springer: Berlin, Germany, 1985. [Google Scholar]
- Costa, S.I.R.; Santos, S.A.; Strapasson, J.E. Fisher information distance: A geometrical reading. Discret. Appl. Math. 2015, 197, 59–69. [Google Scholar] [CrossRef]
- Angulo, J.; Velasco-Forero, S. Morphological processing of univariate Gaussian distribution-valued images based on Poincaré upper-half plane representation. In Geometric Theory of Information; Springer International Publishing: Cham, Switzerland, 2014; pp. 331–366. [Google Scholar]
- Maybank, S.J.; Ieng, S.; Benosman, R. A Fisher–Rao metric for paracatadioptric images of lines. Int. J. Comput. Vis. 2012, 99, 147–165. [Google Scholar] [CrossRef] [Green Version]
- Schwander, O.; Nielsen, F. Model centroids for the simplification of kernel density estimators. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012. [Google Scholar]
- Taylor, S. Clustering Financial Return Distributions Using the Fisher Information Metric. Entropy 2019, 21, 110. [Google Scholar] [CrossRef] [Green Version]
- Eriksen, P.S. Geodesics Connected with the Fischer Metric on the Multivariate Normal Manifold; Institute of Electronic Systems, Aalborg University Centre: Aalborg, Denmark, 1986. [Google Scholar]
- Calvo, M.; Oller, J.M. An explicit solution of information geodesic equations for the multivariate normal model. Stat. Decis. 1991, 9, 119–138. [Google Scholar] [CrossRef]
- Lenglet, C.; Rousson, M.; Deriche, R.; Faugeras, O. Statistics on the manifold of multivariate normal distributions. Theory and application to diffusion tensor MRI processing. J. Math. Imaging Vis. 2006, 25, 423–444. [Google Scholar] [CrossRef]
- Moakher, M.; Mourad, Z. The Riemannian geometry of the space of positive-definite matrices and its application to the regularization of positive-definite matrix-valued data. J. Math. Imaging Vis. 2011, 40, 171–187. [Google Scholar] [CrossRef]
- Han, M.; Park, F.C. DTI Segmentation and Fiber Tracking Using Metrics on Multivariate Normal Distributions. J. Math. Imaging Vis. 2014, 49, 317–334. [Google Scholar] [CrossRef]
- Verdoolaege, G.; Scheunders, P. Geodesics on the manifold of multivariate generalized Gaussian distributions with an application to multicomponent texture discrimination. Int. J. Comput. Vis. 2011, 95, 265. [Google Scholar] [CrossRef] [Green Version]
- Tang, M.; Rong, Y.; Zhou, J.; Li, X.R. Information geometric approach to multisensor estimation fusion. IEEE Trans. Signal Process. 2018, 67, 279–292. [Google Scholar] [CrossRef]
- Poon, C.; Keriven, N.; Peyré, G. Support Localization and the Fisher Metric for off-the-grid Sparse Regularization. arXiv 2018, arXiv:1810.03340. [Google Scholar]
- Gattone, S.A.; De Sanctis, A.; Puechmorel, S.; Nicol, F. On the geodesic distance in shapes K-means clustering. Entropy 2018, 20, 647. [Google Scholar] [CrossRef] [Green Version]
- Gattone, S.A.; De Sanctis, A.; Russo, T.; Pulcini, D. A shape distance based on the Fisher–Rao metric and its application for shapes clustering. Phys. A Stat. Mech. Appl. 2017, 487, 93–102. [Google Scholar] [CrossRef]
- Pilté, M.; Barbaresco, F. Tracking quality monitoring based on information geometry and geodesic shooting. In Proceedings of the 2016 17th International Radar Symposium (IRS), Krakow, Poland, 10–12 May 2016. [Google Scholar]
- Pinele, J.; Costa, S.I.; Strapasson, J.E. On the Fisher–Rao Information Metric in the Space of Normal Distributions. In International Conference on Geometric Science of Information; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; pp. 676–684. [Google Scholar]
- Burbea, J.; Rao, C.R. Entropy differential metric, distance and divergence measures in probability spaces: A unified approach. J. Multivar. Anal. 1982, 12, 575–596. [Google Scholar] [CrossRef] [Green Version]
- Porat, B.; Benjamin, F. Computation of the exact information matrix of Gaussian time series with stationary random components. IEEE Trans. Acoust. Speech Signal Process. 1986, 34, 118–130. [Google Scholar] [CrossRef]
- Siegel, C.L. Symplectic geometry. Am. J. Math. 1943, 65, 1–86. [Google Scholar] [CrossRef]
- Strapasson, J.E.; Pinele, J.; Costa, S.I.R. A totally geodesic submanifold of the multivariate normal distributions and bounds for the Fisher–Rao distance. In Proceedings of the IEEE Information Theory Workshop (ITW), Cambridge, UK, 11–14 September 2016; pp. 61–65. [Google Scholar]
- Calvo, M.; Oller, J.M. A distance between multivariate normal distributions based in an embedding into the Siegel group. J. Multivar. Anal. 1990, 35, 223–242. [Google Scholar] [CrossRef] [Green Version]
- Calvo, M.; Oller, J.M. A distance between elliptical distributions based in an embedding into the Siegel group. J. Comput. Appl. Math. 2002, 145, 319–334. [Google Scholar] [CrossRef] [Green Version]
- Strapasson, J.E.; Porto, J.; Costa, S.I.R. On bounds for the Fisher–Rao distance between multivariate normal distributions. Aip Conf. Proc. 2015, 1641, 313–320. [Google Scholar]
- Zhang, K.; Kwok, J.T. Simplifying mixture models through function approximation. IEEE Trans. Neural Netw. 2010, 21, 644–658. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davis, J.V.; Dhillon, I.S. Differential entropic clustering of multivariate gaussians. In Proceedings of the 2006 Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006. [Google Scholar]
- Goldberger, J.; Greenspan, H.K.; Dreyfuss, J. Simplifying mixture models using the unscented transform. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1496–1502. [Google Scholar] [CrossRef]
- Garcia, V.; Nielsen, F. Simplification and hierarchical representations of mixtures of exponential families. Signal Process. 2010, 90, 3197–3212. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Li, X. Estimation and Tracking: Principles, Techniques and Software; Artech House: Norwood, MA, USA, 1993. [Google Scholar]
- Kurkoski, B.; Dauwels, J. Message-passing decoding of lattices using Gaussian mixtures. In Proceedings of the 2008 IEEE International Symposium on Information Theory, Toronto, ON, Canada, 6–11 July 2008. [Google Scholar]
- Strapasson, J.E.; Pinele, J.; Costa, S.I.R. Clustering using the Fisher–Rao distance. In Proceedings of the IEEE Sensor Array and Multichannel Signal Processing Workshop, Rio de Janerio, Brazil, 10–13 July 2016. [Google Scholar]
- Galperin, G.A. A concept of the mass center of a system of material points in the constant curvature spaces. Commun. Math. Phys. 1993, 154.1, 63–84. [Google Scholar] [CrossRef]
- Nielsen, F. Introduction to HPC with MPI for Data Science. In Undergraduate Topics in Computer Science; Springer: Cham, Switzerland, 2016. [Google Scholar]
Figure 1.
A comparison between the bounds , , , , and . (, , and are fixed, and varies from zero to ).
Figure 1.
A comparison between the bounds , , , , and . (, , and are fixed, and varies from zero to ).

Figure 2.
A comparison between the bounds , , , , and . (, , and are fixed, and varies from zero to ).
Figure 2.
A comparison between the bounds , , , , and . (, , and are fixed, and varies from zero to ).

Figure 3.
(a) A comparison between the bounds , , , , and . (, , and the rotation angle are fixed, and varies from zero to 10). (b) A comparison between the bounds , , and . (, , and the rotation angle are fixed, and varies from zero to 10).
Figure 3.
(a) A comparison between the bounds , , , , and . (, , and the rotation angle are fixed, and varies from zero to 10). (b) A comparison between the bounds , , and . (, , and the rotation angle are fixed, and varies from zero to 10).

Figure 4.
(a) Level curves of the distributions in the geodesic curve connecting the bivariate normal distributions and in . (b) Level curves of the distributions in the geodesic curve connecting the bivariate normal distributions and in .
Figure 4.
(a) Level curves of the distributions in the geodesic curve connecting the bivariate normal distributions and in . (b) Level curves of the distributions in the geodesic curve connecting the bivariate normal distributions and in .

Figure 5.
Example of level curves of mirrored distributions where and are given by Equation (40).
Figure 5.
Example of level curves of mirrored distributions where and are given by Equation (40).

Figure 6.
Approximation of the geodesic curve connecting and via the geodesic shooting algorithm. The level curve of is the dashed one.
Figure 6.
Approximation of the geodesic curve connecting and via the geodesic shooting algorithm. The level curve of is the dashed one.

Figure 7.
Contour curves of distributions and .

Figure 8.
Illustration of the mixture simplification using the Fisher–Rao clustering, where l is the number of components of the mixture (the last column is the original figure).
Figure 8.
Illustration of the mixture simplification using the Fisher–Rao clustering, where l is the number of components of the mixture (the last column is the original figure).

Figure 9.
Illustration of the simplification quality of the mixture modeling Baboon image.

Figure 10.
Illustration of the simplification quality of the mixture modeling Lena image.

Figure 11.
Illustration of the simplification quality of the mixture modeling Clown image.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The lower bound and the upper bounds , and for the Fisher–Rao distance, , between distributions and in . is the distance between univariate normal distributions given in Equation (22).
Table 1.
The lower bound and the upper bounds , and for the Fisher–Rao distance, , between distributions and in . is the distance between univariate normal distributions given in Equation (22).
Table 2.
A time comparison between the numerical method proposed here and the geodesic shooting to calculate the distance between two mirrored distributions.
Table 2.
A time comparison between the numerical method proposed here and the geodesic shooting to calculate the distance between two mirrored distributions.
| Time Systems (s) | Time G.Shooting (s) | ||
|---|---|---|---|
| 1 | 2.77395 | 0.046875 | 4.70313 |
| 2 | 3.67027 | 0.046875 | 5.60938 |
| 3 | 4.52933 | 0.0625 | 7.10938 |
| 4 | 5.26093 | 0.078125 | 9.17188 |
| 5 | 5.87480 | 0.046875 | 12.5313 |
| 6 | 6.39439 | 0.0625 | 18.4219 |
| 7 | 6.84043 | 0.078125 | 492.563 |
| 8 | 7.22903 | 0.0625 | 574.422 |
| 9 | 7.57221 | 0.046875 | 917.859 |
| 10 | 7.87896 | 0.046875 | 1007.13 |
Table 3.
Closed forms for the Fisher–Rao distance in submanifolds of and the distance in between pairs of special distributions.
Table 3.
Closed forms for the Fisher–Rao distance in submanifolds of and the distance in between pairs of special distributions.
| Distance in Non-totally Geodesic Submanifolds | |
|---|---|
| Submanifold | Distance |
| Distance in Totally Geodesic Submanifolds | |
| , where are the eigenvalues of | |
| Distance Between Special Distributions in | |
| Distributions with Common Covariance Matrices, | , where P is an orthogonal matrix such that and |
| Mirrored Distributions, and , with | , where x and are obtained by the solution of Equation (63) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pinele, J.; Strapasson, J.E.; Costa, S.I.R. The Fisher–Rao Distance between Multivariate Normal Distributions: Special Cases, Bounds and Applications. Entropy 2020, 22, 404. https://0-doi-org.brum.beds.ac.uk/10.3390/e22040404
AMA Style
Pinele J, Strapasson JE, Costa SIR. The Fisher–Rao Distance between Multivariate Normal Distributions: Special Cases, Bounds and Applications. Entropy. 2020; 22(4):404. https://0-doi-org.brum.beds.ac.uk/10.3390/e22040404
Chicago/Turabian StylePinele, Julianna, João E. Strapasson, and Sueli I. R. Costa. 2020. "The Fisher–Rao Distance between Multivariate Normal Distributions: Special Cases, Bounds and Applications" Entropy 22, no. 4: 404. https://0-doi-org.brum.beds.ac.uk/10.3390/e22040404
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.