
Novel Deep Convolutional Neural Network-Based Contextual Recognition of Arabic Handwritten Scripts

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Related Works
3. OAHR General Framework
3.1. Data Acquisition
3.2. Pre-Processing
3.3. Segmentation
3.4. Feature Extraction
3.5. Classification
3.6. Post-Processing
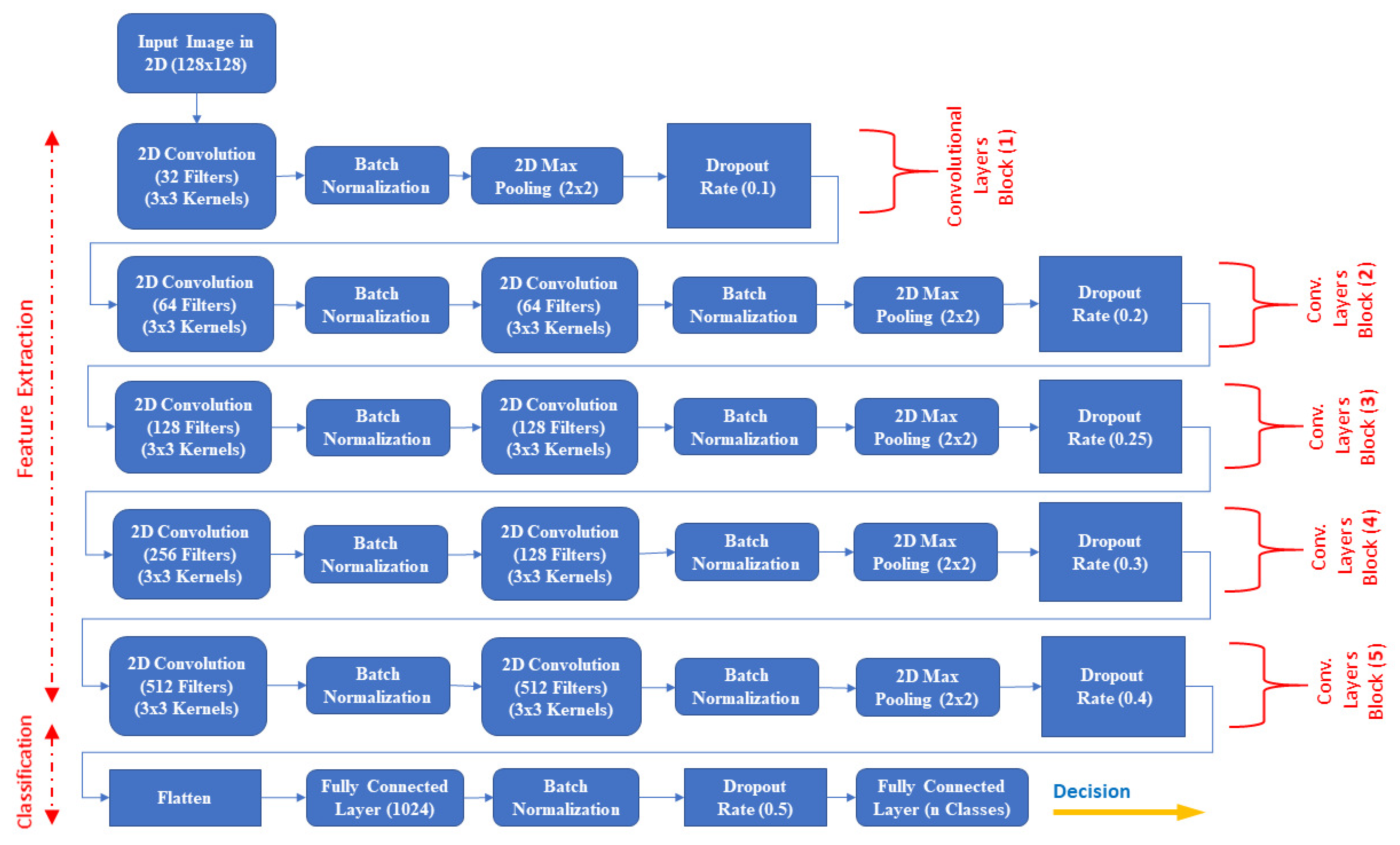
4. Proposed DCNN Model
4.1. Design Methodology
4.2. Feature Extraction Phase
4.3. Classification Phase
5. Experiments and Discussion
5.1. Details About Arabic Handwritten Databases
5.2. Experimental Setup and Pre-Processing
5.3. Results and Discussion
5.3.1. Evaluation Criteria
5.3.2. Incremental Approach to Proposed Model Design
5.3.3. Comparative Study
5.3.4. Generalization Tests on Offline English Handwritten Digits
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- El Qacimy, B.; Kerroum, M.A.; Hammouch, A. Word-based Arabic handwritten recognition using SVM classifier with a reject option. In Proceedings of the 2015 15th international conference on intelligent systems design and applications (ISDA), Marrakech, Morocco, 14–16 December 2015; pp. 64–68. [Google Scholar]
- Asebriy, Z.; Raghay, S.; Bencharef, O.; Chihab, Y. Comparative systems of handwriting Arabic character recognition. In Proceedings of the 2014 Second World Conference on Complex Systems (WCCS), Agadir, Morocco, 10–12 November 2014; pp. 90–93. [Google Scholar]
- El Qacimy, B.; Hammouch, A.; Kerroum, M.A. A review of feature extraction techniques for handwritten Arabic text recognition. In Proceedings of the 2015 International Conference on Electrical and Information Technologies (ICEIT), Marrakech, Morocco, 25–27 March 2015; pp. 241–245. [Google Scholar]
- Patel, S.R.; Jha, J. Notice of Removal: Handwritten character recognition using machine learning approach-A survey. In Proceedings of the 2015 International Conference on Electrical, Electronics, Signals, Communication and Optimization (EESCO), Visakhapatnam, India, 24–25 January 2015; pp. 1–5. [Google Scholar]
- Hussain, R.; Raza, A.; Siddiqi, I.; Khurshid, K.; Djeddi, C. A comprehensive survey of handwritten document benchmarks: Structure, usage and evaluation. EURASIP J. Image Video Process. 2015, 2015, 46. [Google Scholar] [CrossRef] [Green Version]
- AlKhateeb, J.H. A database for Arabic handwritten character recognition. Procedia Comput. Sci. 2015, 65, 556–561. [Google Scholar] [CrossRef] [Green Version]
- Khorsheed, M.S. Off-line Arabic character recognition–a review. Pattern Anal. Appl. 2002, 5, 31–45. [Google Scholar] [CrossRef]
- El Moubtahij, H.; Halli, A.; Satori, K. Review of feature extraction techniques for offline handwriting arabic text recognition. Int. J. Adv. Eng. Technol. 2014, 7, 50. [Google Scholar]
- El-Sawy, A.; Hazem, E.B.; Loey, M. CNN for handwritten arabic digits recognition based on LeNet-5. In International Conference on Advanced Intelligent Systems and Informatics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 566–575. [Google Scholar]
- Loey, M.; El-Sawy, A.; El-Bakry, H. Deep learning autoencoder approach for handwritten arabic digits recognition. arXiv 2017, arXiv:1706.06720. [Google Scholar]
- ElAdel, A.; Ejbali, R.; Zaied, M.; Amar, C.B. Dyadic multi-resolution analysis-based deep learning for Arabic handwritten character classification. In Proceedings of the 2015 IEEE 27th International Conference on Tools with Artificial Intelligence (ICTAI), Vietri sul Mare, Italy, 9–11 November 2015; pp. 807–812. [Google Scholar]
- Myers, L. Aliterate Community College Remedial Students and Their Attitudes toward Reading: A Phenomenological Examination. Master’s Thesis, California State University, Long Beach, CA, USA, 2013. [Google Scholar]
- Manisha, C.N.; Reddy, E.S.; Krishna, Y. Role of offline handwritten character recognition system in various applications. Int. J. Comput. Appl. 2016, 135, 30–33. [Google Scholar] [CrossRef]
- Muhammad’Arif Mohamad, D.N.; Hassan, H.; Haron, H. A review on feature extraction and feature selection for handwritten character recognition. Int. J. Adv. Comput. Sci. Appl. 2015, 6, 204–212. [Google Scholar]
- Dashtipour, K.; Poria, S.; Hussain, A.; Cambria, E.; Hawalah, A.Y.; Gelbukh, A.; Zhou, Q. Multilingual sentiment analysis: State of the art and independent comparison of techniques. Cogn. Comput. 2016, 8, 757–771. [Google Scholar] [CrossRef] [Green Version]
- Dashtipour, K.; Hussain, A.; Zhou, Q.; Gelbukh, A.; Hawalah, A.Y.; Cambria, E. PerSent: A freely available Persian sentiment lexicon. In Lecture Notes in Computer Science, Proceedings of the International Conference on Brain Inspired Cognitive Systems, Beijing, China, 28–30 November 2016; Springer: Cham, Switzerland, 2016; pp. 310–320. [Google Scholar]
- Gogate, M.; Dashtipour, K.; Bell, P.; Hussain, A. Deep Neural Network Driven Binaural Audio Visual Speech Separation. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Gogate, M.; Adeel, A.; Dashtipour, K.; Derleth, P.; Hussain, A. Av speech enhancement challenge using a real noisy corpus. arXiv 2019, arXiv:1910.00424. [Google Scholar]
- Elbashir, M.K.; Mustafa, M.E. Convolutional neural network model for arabic handwritten characters recognition. Int. J. Adv. Res. Comput. Commun. Eng. 2018, 7, 1–5. [Google Scholar] [CrossRef]
- Al-Helali, B.M.; Mahmoud, S.A. Arabic Online Handwriting Recognition (AOHR) A Survey. ACM Comput. Surv. (CSUR) 2017, 50, 1–35. [Google Scholar] [CrossRef]
- Adeel, A.; Gogate, M.; Farooq, S.; Ieracitano, C.; Dashtipour, K.; Larijani, H.; Hussain, A. A survey on the role of wireless sensor networks and IoT in disaster management. In Geological Disaster Monitoring Based on Sensor Networks; Springer: Berlin/Heidelberg, Germany, 2019; pp. 57–66. [Google Scholar]
- Younis, K.S. Arabic handwritten character recognition based on deep convolutional neural networks. Jordanian J. Comput. Inf. Technol. (JJCIT) 2017, 3, 186–200. [Google Scholar] [CrossRef]
- Maalej, R.; Kherallah, M. Convolutional neural network and BLSTM for offline Arabic handwriting recognition. In Proceedings of the 2018 International Arab conference on information technology (ACIT), Werdanye, Lebanon, 28–30 November 2018; pp. 1–6. [Google Scholar]
- Bahashwan, M.A.; Bakar, S.A.A. A database of Arabic handwritten characters. In Proceedings of the 2014 IEEE International Conference on Control System, Computing and Engineering (ICCSCE 2014), Penang, Malaysia, 28–30 November 2014; pp. 632–635. [Google Scholar]
- Lorigo, L.M.; Govindaraju, V. Offline Arabic handwriting recognition: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 712–724. [Google Scholar] [CrossRef] [PubMed]
- Dashtipour, K. Novel Symbolic and Sub-Symbolic Approaches for Text Based and Multimodal Sentiment Analysis. Ph.D. Thesis, University of Stirling, Stirling, UK, 2019. [Google Scholar]
- Elleuch, M.; Maalej, R.; Kherallah, M. A new design based-SVM of the CNN classifier architecture with dropout for offline Arabic handwritten recognition. Procedia Comput. Sci. 2016, 80, 1712–1723. [Google Scholar] [CrossRef] [Green Version]
- Elleuch, M.; Mokni, R.; Kherallah, M. Offline Arabic Handwritten recognition system with dropout applied in Deep networks based-SVMs. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3241–3248. [Google Scholar]
- Dashtipour, K.; Hussain, A.; Gelbukh, A. Adaptation of sentiment analysis techniques to Persian language. In Lecture Notes in Computer Science, Proceedings of the International Conference on Computational Linguistics and Intelligent Text Processing, Budapest, Hungary, 17–23 April 2017; Springer: Cham, Switzerland, 2017; pp. 129–140. [Google Scholar]
- Boufenar, C.; Kerboua, A.; Batouche, M. Investigation on deep learning for off-line handwritten Arabic character recognition. Cogn. Syst. Res. 2018, 50, 180–195. [Google Scholar] [CrossRef]
- Dashtipour, K.; Gogate, M.; Adeel, A.; Ieracitano, C.; Larijani, H.; Hussain, A. Exploiting deep learning for Persian sentiment analysis. In Lecture Notes in Computer Science, Proceedings of the International Conference on Brain Inspired Cognitive Systems, Xi’an, China, 7–8 July 2018; Springer: Cham, Switzerland, 2018; pp. 597–604. [Google Scholar]
- Jiang, F.; Kong, B.; Li, J.; Dashtipour, K.; Gogate, M. Robust visual saliency optimization based on bidirectional Markov chains. Cogn. Comput. 2020, 13, 69–80. [Google Scholar] [CrossRef]
- Musa, M.E. Arabic handwritten datasets for pattern recognition and machine learning. In Proceedings of the 2011 5th International Conference on Application of Information and Communication Technologies (AICT), Baku, Azerbaijan, 12–14 October 2011; pp. 1–3. [Google Scholar]
- Gogate, M.; Dashtipour, K.; Hussain, A. Visual Speech In Real Noisy Environments (VISION): A Novel Benchmark Dataset and Deep Learning-based Baseline System. Proc. Interspeech 2020 2020, 2020, 4521–4525. [Google Scholar]
- Alqarafi, A.S.; Adeel, A.; Gogate, M.; Dashitpour, K.; Hussain, A.; Durrani, T. Toward’s Arabic multi-modal sentiment analysis. In International Conference in Communications, Signal Processing, and Systems; Springer: Singapore, 2017; pp. 2378–2386. [Google Scholar]
- Gogate, M.; Adeel, A.; Hussain, A. Deep learning driven multimodal fusion for automated deception detection. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–6. [Google Scholar]
- Elleuch, M.; Tagougui, N.; Kherallah, M. Towards unsupervised learning for Arabic handwritten recognition using deep architectures. In Lecture Notes in Computer Science, Proceedings of the International Conference on Neural Information Processing, Istanbul, Turkey, 9–12 November 2015; Springer: Cham, Switzerland, 2015; pp. 363–372. [Google Scholar]
- El-Sawy, A.; Loey, M.; El-Bakry, H. Arabic handwritten characters recognition using convolutional neural network. WSEAS Trans. Comput. Res. 2017, 5, 11–19. [Google Scholar]
- Gogate, M.; Adeel, A.; Marxer, R.; Barker, J.; Hussain, A. DNN driven speaker independent audio-visual mask estimation for speech separation. arXiv 2018, arXiv:1808.00060. [Google Scholar]
- Adeel, A.; Gogate, M.; Hussain, A.; Whitmer, W.M. Lip-reading driven deep learning approach for speech enhancement. IEEE Trans. Emerg. Top. Comput. Intell. 2019. [Google Scholar] [CrossRef] [Green Version]
- Gillot, P.; Benois-Pineau, J.; Zemmari, A.; Nesterov, Y. Increasing Training Stability for Deep CNNS. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3423–3427. [Google Scholar]
- Adeel, A.; Gogate, M.; Hussain, A. Contextual deep learning-based audio-visual switching for speech enhancement in real-world environments. Inf. Fusion 2020, 59, 163–170. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Huan, J.; Li, B. Data dropout: Optimizing training data for convolutional neural networks. In Proceedings of the 2018 IEEE 30th International Conference on Tools with Artificial Intelligence (ICTAI), Volos, Greece, 5–7 November 2018; pp. 39–46. [Google Scholar]
- Gogate, M.; Adeel, A.; Hussain, A. A novel brain-inspired compression-based optimised multimodal fusion for emotion recognition. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–7. [Google Scholar]
- Nisar, S.; Tariq, M.; Adeel, A.; Gogate, M.; Hussain, A. Cognitively inspired feature extraction and speech recognition for automated hearing loss testing. Cogn. Comput. 2019, 11, 489–502. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Ashiquzzaman, A.; Tushar, A.K. Handwritten Arabic numeral recognition using deep learning neural networks. In Proceedings of the 2017 IEEE International Conference on Imaging, Vision & Pattern Recognition (icIVPR), Dhaka, Bangladesh, 13–14 February 2017; pp. 1–4. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Latif, G.; Alghazo, J.; Alzubaidi, L.; Naseer, M.M.; Alghazo, Y. Deep convolutional neural network for recognition of unified multi-language handwritten numerals. In Proceedings of the 2018 IEEE 2nd International Workshop on Arabic and Derived Script Analysis and Recognition (ASAR), London, UK, 12–14 March 2018; pp. 90–95. [Google Scholar]
- Gogate, M.; Dashtipour, K.; Adeel, A.; Hussain, A. CochleaNet: A Robust Language-independent Audio-Visual Model for Speech Enhancement. Inf. Fusion 2020, 63, 273–285. [Google Scholar] [CrossRef]
- Howard, N.; Adeel, A.; Gogate, M.; Hussain, A. Deep Cognitive Neural Network (DCNN). US Patent Application 16/194,721, 23 May 2019. [Google Scholar]
- Ieracitano, C.; Adeel, A.; Gogate, M.; Dashtipour, K.; Morabito, F.C.; Larijani, H.; Raza, A.; Hussain, A. Statistical analysis driven optimized deep learning system for intrusion detection. In Lecture Notes in Computer Science, Proceedings of the International Conference on Brain Inspired Cognitive Systems, Xi’an, China, 7–8 July 2018; Springer: Cham, Switzerland, 2018; pp. 759–769. [Google Scholar]
- Dashtipour, K.; Ieracitano, C.; Morabito, F.C.; Raza, A.; Hussain, A. An Ensemble Based Classification Approach for Persian Sentiment Analysis. In Progresses in Artificial Intelligence and Neural Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 207–215. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 2483–2493. [Google Scholar]
- Li, Z.; Gong, B.; Yang, T. Improved dropout for shallow and deep learning. arXiv 2016, arXiv:1602.02220. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Jiang, F.; Dashtipour, K.; Hussain, A. A survey on deep learning for the routing layer of computer network. In Proceedings of the 2019 UK/China Emerging Technologies (UCET), Glasgow, UK, 21–22 August 2019; pp. 1–4. [Google Scholar]
- Ahmed, A.A.; Darwish, S.M.S.; El-Sherbiny, M.M. A novel automatic CNN architecture design approach based on genetic algorithm. In International Conference on Advanced Intelligent Systems and Informatics; Springer: Cham, Switzerland, 2019; pp. 473–482. [Google Scholar]
- Jaafra, Y.; Laurent, J.L.; Deruyver, A.; Naceur, M.S. Reinforcement learning for neural architecture search: A review. Image Vis. Comput. 2019, 89, 57–66. [Google Scholar] [CrossRef]
- Albelwi, S.; Mahmood, A. A framework for designing the architectures of deep convolutional neural networks. Entropy 2017, 19, 242. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. Completely automated CNN architecture design based on blocks. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1242–1254. [Google Scholar] [CrossRef]
- Sahoo, S.; Lakshmi, R. Offline handwritten character classification of the same scriptural family languages by using transfer learning techniques. In Proceedings of the 2020 3rd International Conference on Emerging Technologies in Computer Engineering: Machine Learning and Internet of Things (ICETCE), Jaipur, India, 7–8 February 2020; pp. 1–4. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Nguyen, K.; Fookes, C.; Sridharan, S. Improving deep convolutional neural networks with unsupervised feature learning. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec, QC, Canada, 27–30 September 2015; pp. 2270–2274. [Google Scholar]
- Nair, R.R.; Sankaran, N.; Kota, B.U.; Tulyakov, S.; Setlur, S.; Govindaraju, V. Knowledge transfer using Neural network based approach for handwritten text recognition. In Proceedings of the 2018 13th IAPR International Workshop on Document Analysis Systems (DAS), Vienna, Austria, 24–27 April 2018; pp. 441–446. [Google Scholar]
- Ribani, R.; Marengoni, M. A survey of transfer learning for convolutional neural networks. In Proceedings of the 2019 32nd SIBGRAPI Conference on Graphics, Patterns and Images Tutorials (SIBGRAPI-T), Rio de Janeiro, Brazil, 28–31 October 2019; pp. 47–57. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Yan, R.; Peng, L.; Furuhata, A.; Ding, X. Multi-layer recurrent neural network based offline Arabic handwriting recognition. In Proceedings of the 2017 1st International Workshop on Arabic Script Analysis and Recognition (ASAR), Nancy, French, 3–5 April 2017; pp. 6–10. [Google Scholar]
- Gogate, M.; Hussain, A.; Huang, K. Random Features and Random Neurons for Brain-Inspired Big Data Analytics. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019; pp. 522–529. [Google Scholar]
- Hussien, I.O.; Dashtipour, K.; Hussain, A. Comparison of sentiment analysis approaches using modern Arabic and Sudanese Dialect. In Lecture Notes in Computer Science, Proceedings of the International Conference on Brain Inspired Cognitive Systems, Xi’an, China, 7–8 July 2018; Springer: Cham, Switzerland, 2018; pp. 615–624. [Google Scholar]
- Ahmed, R.; Dashtipour, K.; Gogate, M.; Raza, A.; Zhang, R.; Huang, K.; Hawalah, A.; Adeel, A.; Hussain, A. Offline Arabic Handwriting Recognition Using Deep Machine Learning: A Review of Recent Advances. In Lecture Notes in Computer Science, Proceedings of the International Conference on Brain Inspired Cognitive Systems, Guangzhou, China, 13–14 July 2019; Springer: Cham, Switzerland, 2019; pp. 457–468. [Google Scholar]
- Adeel, A.; Gogate, M.; Hussain, A. Towards next-generation lipreading driven hearing-aids: A preliminary prototype demo. In Proceedings of the International Workshop on Challenges in Hearing Assistive Technology (CHAT-2017), Stockholm, Sweden, 19 August 2017; Stockholm University: Stockholm, Sweden, 2017. [Google Scholar]
- Dashtipour, K.; Gogate, M.; Adeel, A.; Algarafi, A.; Howard, N.; Hussain, A. Persian named entity recognition. In Proceedings of the 2017 IEEE 16th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), Oxford, UK, 26–28 July 2017; pp. 79–83. [Google Scholar]
- Dashtipour, K.; Raza, A.; Gelbukh, A.; Zhang, R.; Cambria, E.; Hussain, A. Persent 2.0: Persian sentiment lexicon enriched with domain-specific words. In Lecture Notes in Computer Science, Proceedings of the International Conference on Brain Inspired Cognitive Systems, Guangzhou, China, 13–14 July 2019; Springer: Cham, Switzerland, 2019; pp. 497–509. [Google Scholar]
- Hussain, A.; Tahir, A.; Hussain, Z.; Sheikh, Z.; Gogate, M.; Dashtipour, K.; Ali, A.; Sheikh, A. Artificial intelligence-enabled analysis of UK and US public attitudes on Facebook and Twitter towards COVID-19 vaccinations. medRxiv 2020. [Google Scholar] [CrossRef]
- Taylor, W.; Abbasi, Q.H.; Dashtipour, K.; Ansari, S.; Shah, S.A.; Khalid, A.; Imran, M.A. A Review of the State of the Art in Non-Contact Sensing for COVID-19. Sensors 2020, 20, 5665. [Google Scholar] [CrossRef]
- Elleuch, M.; Tagougui, N.; Kherallah, M. Arabic handwritten characters recognition using deep belief neural networks. In Proceedings of the 2015 IEEE 12th International Multi-Conference on Systems, Signals & Devices (SSD15), Mahdia, Tunisia, 16–19 March 2015; pp. 1–5. [Google Scholar]
- Elleuch, M.; Tagougui, N.; Kherallah, M. Deep learning for feature extraction of Arabic handwritten script. In Lecture Notes in Computer Science, Proceedings of the International Conference on Computer Analysis of Images and Patterns, Valletta, Malta, 2–4 September 2015; Springer: Cham, Switzerland, 2015; pp. 371–382. [Google Scholar]
- Amrouch, M.; Rabi, M.; Es-Saady, Y. Convolutional feature learning and CNN based HMM for Arabic handwriting recognition. In Lecture Notes in Computer Science, Proceedings of the International Conference on Image and Signal Processing, Cherbourg, France, 2–4 July 2018; Springer: Cham, Switzerland, 2018; pp. 265–274. [Google Scholar]
- Elleuch, M.; Kherallah, M. Boosting of deep convolutional architectures for Arabic handwriting recognition. Int. J. Multimed. Data Eng. Manag. (IJMDEM) 2019, 10, 26–45. [Google Scholar] [CrossRef]
- Ashiquzzaman, A.; Tushar, A.K.; Rahman, A.; Mohsin, F. An efficient recognition method for handwritten arabic numerals using CNN with data augmentation and dropout. In Data Management, Analytics and Innovation; Springer: Berlin/Heidelberg, Germany, 2019; pp. 299–309. [Google Scholar]
- Mustafa, M.E.; Elbashir, M.K. A Deep Learning Approach for Handwritten Arabic Names Recognition. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 678–682. [Google Scholar] [CrossRef] [Green Version]
- Al Abodi, J.; Li, X. An effective approach to offline Arabic handwriting recognition. Comput. Electr. Eng. 2014, 40, 1883–1901. [Google Scholar] [CrossRef]
- Manwatkar, P.M.; Singh, K.R. A technical review on text recognition from images. In Proceedings of the 2015 IEEE 9th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 9–10 January 2015; pp. 1–5. [Google Scholar]
- Alsanousi, W.A.; Adam, I.S.; Rashwan, M.; Abdou, S. Review about off-line handwriting Arabic text recognition. Int. J. Comput. Sci. Mob. Comput 2017, 6, 4–14. [Google Scholar]
- Iqbal, A.; Zafar, A. Offline Handwritten Quranic Text Recognition: A Research Perspective. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 125–128. [Google Scholar]
- Meddeb, O.; Maraoui, M.; Aljawarneh, S. Hybrid modeling of an offline arabic handwriting recognition system AHRS. In Proceedings of the 2016 International Conference on Engineering & MIS (ICEMIS), Agadir, Morocco, 22–24 September 2016; pp. 1–8. [Google Scholar]
- Impedovo, D.; Pirlo, G.; Vessio, G.; Angelillo, M.T. A handwriting-based protocol for assessing neurodegenerative dementia. Cogn. Comput. 2019, 11, 576–586. [Google Scholar] [CrossRef]
- Elleuch, M.; Lahiani, H.; Kherallah, M. Recognizing Arabic handwritten script using support vector machine classifier. In Proceedings of the 2015 15th International Conference on Intelligent Systems Design and Applications (ISDA), Marrakech, Morocco, 14–16 December 2015; pp. 551–556. [Google Scholar]
- Stąpor, K. Evaluating and comparing classifiers: Review, some recommendations and limitations. In International Conference on Computer Recognition Systems; Springer: Cham, Switzerland, 2017; pp. 12–21. [Google Scholar]
- Hossin, M.; Sulaiman, M. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]
- Dalianis, H. Evaluation metrics and evaluation. In Clinical Text Mining; Springer: Berlin/Heidelberg, Germany, 2018; pp. 45–53. [Google Scholar]
- Kayumov, Z.; Tumakov, D.; Mosin, S. Hierarchical convolutional neural network for handwritten digits recognition. Procedia Comput. Sci. 2020, 171, 1927–1934. [Google Scholar] [CrossRef]
- Ahlawat, S.; Choudhary, A. Hybrid CNN-SVM classifier for handwritten digit recognition. Procedia Comput. Sci. 2020, 167, 2554–2560. [Google Scholar] [CrossRef]
- Zhao, H.h.; Liu, H. Multiple classifiers fusion and CNN feature extraction for handwritten digits recognition. Granul. Comput. 2020, 5, 411–418. [Google Scholar] [CrossRef] [Green Version]
- Ali, S.; Sakhawat, Z.; Mahmood, T.; Aslam, M.S.; Shaukat, Z.; Sahiba, S. A robust CNN model for handwritten digits recognition and classification. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020; pp. 261–265. [Google Scholar]
- Hussain, A.; Cambria, E. Semi-supervised learning for big social data analysis. Neurocomputing 2018, 275, 1662–1673. [Google Scholar] [CrossRef] [Green Version]
- Dashtipour, K.; Gogate, M.; Li, J.; Jiang, F.; Kong, B.; Hussain, A. A hybrid Persian sentiment analysis framework: Integrating dependency grammar based rules and deep neural networks. Neurocomputing 2020, 380, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Xiong, F.; Sun, B.; Yang, X.; Qiao, H.; Huang, K.; Hussain, A.; Liu, Z. Guided policy search for sequential multitask learning. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 216–226. [Google Scholar] [CrossRef]
- Mahmud, M.; Kaiser, M.S.; Hussain, A.; Vassanelli, S. Applications of deep learning and reinforcement learning to biological data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2063–2079. [Google Scholar] [CrossRef] [Green Version]




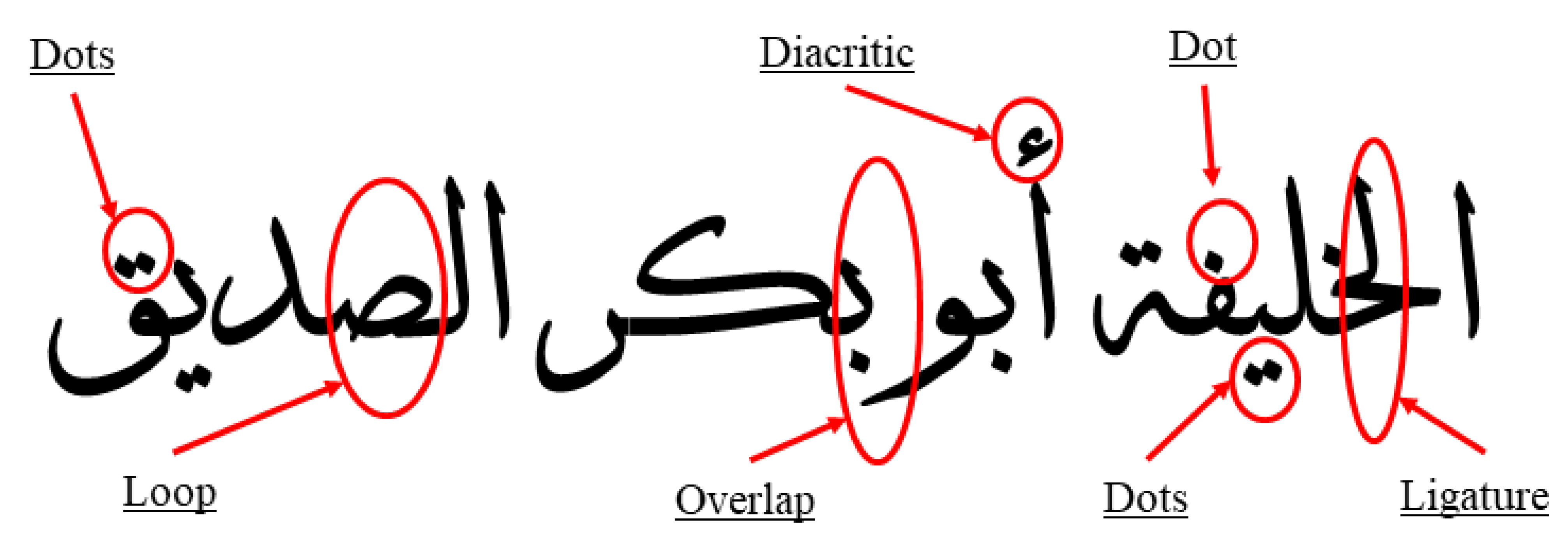{kind=link}
{kind=link}
{kind=link}
| Literature/ Year | Findings | Outline |
|---|---|---|
| Elleuch et al. [85]/2015 | The DBNN method obtained an ECR of 2.1% and an accuracy of 97.9% on the HACDB characters database. | Generalization was not tested for Arabic digits and words. Accuracy requires enhancement. |
| Elleuch et al. [37]/2015 | The DBN method obtained an ECR of 1.67% and 3.64% and an accuracy of 98.33% and 96.36% on the HACDB database with 24 characters and the HACDB database with 66 characters, respectively. | Generalization was not tested for Arabic digits and words. Accuracy requires enhancement. |
| Elleuch et al. [37]/2015 | The CNN method obtained an ECR of 5% and 14.71% and an accuracy of 95% and 85.29% on the HACDB database with 24 characters and the HACDB database with 66 characters, respectively. | Generalization was not tested for Arabic digits and words. Accuracy requires enhancement. |
| ElAdel et al. [11]/2015 | The DCNWN method obtained an ECR of 2.1% and an accuracy of 93.92% on the IESKarDB characters database. | Generalization was not tested for Arabic digits and words. Accuracy requires enhancement. |
| Elleuch et al. [86]/2015 | The DBN method obtained an ECR of 6.08% and an accuracy of 97.9% on the HACDB database with 66 characters. | Generalization was not tested for Arabic digits and words. Accuracy requires enhancement. |
| Elleuch et al. [86]/2015 | The CDBN method obtained an ECR of 1.82% and 16.3% and an accuracy of 98.18% and 83.7% on the HACDB (24) characters and the IFN/ENIT words databases, respectively. | Generalization was not tested for Arabic digits and characters. Accuracy requires enhancement. |
| El-Sawy et al. [9]/2016 | The CNN method obtained an ECR of 12% and an accuracy of 88% on the MADBase digits database. | Generalization wa not tested for Arabic characters and words. Accuracy requires enhancement. |
| Elleuch et al. [28]/2016 | The DSVM method obtained an ECR of 5.68% and an accuracy of 94.32% on the HACDB (66) characters database. | Generalization was not tested for Arabic digits and words. Accuracy requires enhancement. |
| Elleuch et al. [27]/2016 | The CNN-SVM method obtained an ECR of 2.09%, 5.83%, and 7.05% and an accuracy of 97.91%, 94.17%, and 92.95% on the HACDB database with 24 characters, the HACDB database with 66 characters, the IFN/ENIT (56) words databases, respectively. | Generalization was not tested for Arabic digits. Accuracy requires enhancement. |
| Loey et al. [10]/2017 | The SAE method obtained an ECR of 2.6% and an accuracy of 98.5% on the CMATERDB 3.3.1 digits database. | Generalization was not tested for Arabic characters and words. Accuracy requires enhancement. |
| Ashiquzzaman et al. [47]/2017 | The CNN method obtained an ECR of 1.5% and an accuracy of 97.4% on the MADBase digits database. | Generalization was not tested for Arabic characters and words. Accuracy requires enhancement. |
| Chen et al. [76]/2017 | The RRN-GRU method obtained an ECR of 13.51% and an accuracy of 86.49% on the IFN/ENIT words database. | Generalization was not tested for Arabic digits and characters. Accuracy requires enhancement. |
| M. Amrouch et al. [87]/2018 | The CNN-based HMM method obtained an ECR of 11.05% and 10.77% and an accuracy of 88.95% and 89.23% on the IFN/ENIT words database with “abd-e” protocol and the IFN/ENIT words database with “abcd-e”, respectively. | Generalization was not tested for Arabic digits and characters. Accuracy requires enhancement. |
| Elbashir et al. [19]/2018 | The CNN method obtained an ECR of 6.5% and an accuracy of 93.5% on the SUST-ALT characters database. | Generalization was not tested for Arabic digits and words. Accuracy requires enhancement. |
| Elleuch et al. [88]/2019 | The CDBN method obtained an ECR of 1.14%, 8.45%, and 7.1% and an accuracy of 98.86%, 91.55%, and 92.9% on HACDB database with 66 characters, the IFN/ENIT words database with “abd-e” protocol, and the IFN/ENIT words database with “abc-d” protocol, respectively. | Generalization was not tested for Arabic digits. Accuracy requires enhancement. |
| Ashiquzzaman et al. [89]/2019 | The CNN method obtained an ECR of 0.6% and an accuracy of 99.4% on the CMATERDB 3.3.1digits database. | Generalization was not tested for Arabic characters and words. |
| Mustafa et al. [90]/2020 | The CNN method obtained an ECR of 0.86% and an accuracy of 99.14% on the SUST-ALT words database. | Generalization was not tested for Arabic digits and characters. |
| Number Name | Machine Form | MADBase Database | CMATERDB Database | SUST-ALT Digits |
|---|---|---|---|---|
| Zero |  |  |  |  |
| One |  |  |  |  |
| Two |  |  |  |  |
| Three |  |  |  |  |
| Four |  |  |  |  |
| Five |  |  |  |  |
| Six |  |  |  |  |
| Seven |  |  |  |  |
| Eight |  |  |  |  |
| Nine |  |  |  |  |
| Character Name | Machine Form | HACDB Database | SUST-ALT Characters Database |
|---|---|---|---|
| Alif |  |  |  |
| Raa |  |  |  |
| Seen |  |  |  |
| Saad |  |  |  |
| Ayn |  |  |  |
| Faa |  |  |  |
| Meem |  |  |  |
| Noon |  |  |  |
| Haa |  |  |  |
| Waw |  |  |  |
| Name in English | Machine Form | SUST-ALT Names Database |
|---|---|---|
| Ahmed |  |  |
| Ali |  |  |
| Ebraheem |  |  |
| Taha |  |  |
| Soliman |  |  |
| Eman |  |  |
| Fatema |  |  |
| Rian |  |  |
| Marwa |  |  |
| Samah |  |  |
| Stacked Blocks Count | Training Time (in Minutes) | Precision | Recall | F-Measure | Accuracy |
|---|---|---|---|---|---|
| One | 586 | 0.991 | 0.991 | 0.991 | 0.9982 |
| Two | 628 | 0.994 | 0.994 | 0.994 | 0.9988 |
| Three | 654 | 0.9945 | 0.9945 | 0.9945 | 0.9989 |
| Four | 717 | 0.9951 | 0.9951 | 0.9951 | 0.99902 |
| Five (Final Model) | 548 | 0.9953 | 0.9953 | 0.9953 | 0.99906 |
| Stacked Blocks Count | Training Time (in Minutes) | Precision | Recall | F-Measure | Accuracy |
|---|---|---|---|---|---|
| One | 24 | 0.96833 | 0.96833 | 0.96833 | 0.99367 |
| Two | 25 | 0.975 | 0.975 | 0.975 | 0.99 |
| Three | 26 | 0.97 | 0.97 | 0.97 | 0.994 |
| Four | 27 | 0.98542 | 0.98542 | 0.98542 | 0.99708 |
| Five (Final Model) | 22 | 0.98608 | 0.98608 | 0.98608 | 0.99722 |
| Stacked Blocks Count | Training Time (in Minutes) | Precision | Recall | F-Measure | Accuracy |
|---|---|---|---|---|---|
| One | 288 | 0.96061 | 0.96061 | 0.96061 | 0.99212 |
| Two | 350 | 0.9885 | 0.9885 | 0.9885 | 0.9977 |
| Three | 491 | 0.99283 | 0.99283 | 0.99283 | 0.99857 |
| Four | 343 | 0.99391 | 0.99391 | 0.99391 | 0.99878 |
| Five (Final Model) | 282 | 0.99107 | 0.99107 | 0.99107 | 0.99821 |
| Stacked Blocks Count | Training Time (in Minutes) | Precision | Recall | F-Measure | Accuracy |
|---|---|---|---|---|---|
| One | 52 | 0.70833 | 0.70833 | 0.70833 | 0.99116 |
| Two | 53 | 0.93561 | 0.93561 | 0.93561 | 0.99805 |
| Three | 59 | 0.95909 | 0.95909 | 0.95909 | 0.99876 |
| Four | 60 | 0.97197 | 0.97197 | 0.97197 | 0.99915 |
| Five (Final Model) | 53 | 0.96967 | 0.96967 | 0.96967 | 0.99908 |
| Stacked Blocks Count | Training Time (in Minutes) | Precision | Recall | F-Measure | Accuracy |
|---|---|---|---|---|---|
| One | 393 | 0.82687 | 0.82687 | 0.82687 | 0.98982 |
| Two | 573 | 0.95338 | 0.95338 | 0.95338 | 0.99726 |
| Three | 400 | 0.9733 | 0.9733 | 0.9733 | 0.99843 |
| Four | 611 | 0.97799 | 0.97799 | 0.97799 | 0.99871 |
| Five (Final Model) | 344 | 0.97591 | 0.97591 | 0.97591 | 0.99858 |
| Stacked Blocks Count | Training Time (in Minutes) | Precision | Recall | F-Measure | Accuracy |
|---|---|---|---|---|---|
| One | 1079 | 0.67788 | 0.67788 | 0.67788 | 0.98389 |
| Two | 1345 | 0.96213 | 0.96213 | 0.96213 | 0.99811 |
| Three | 504 | 0.98725 | 0.98725 | 0.98725 | 0.99936 |
| Four | 508 | 0.9895 | 0.9895 | 0.9895 | 0.99948 |
| Five (Final Model) | 534 | 0.99038 | 0.99038 | 0.99038 | 0.99952 |
| Database/Type | Four Blocks | Five Blocks | ||||
|---|---|---|---|---|---|---|
| Best Accuracy | Best Precision | Less Training Time | Best Accuracy | Best Precision | Less Training Time | |
| MADBase (Digits) | No | No | No | Yes | Yes | Yes |
| CMATERDB (Digits) | No | No | No | Yes | Yes | Yes |
| SUST-ALT (Digits) | Yes | Yes | No | No | No | Yes |
| HACDB (Characters) | Yes | Yes | No | No | No | Yes |
| SUST-ALT (Characters) | Yes | Yes | No | No | No | Yes |
| SUST-ALT (Words) | No | No | Yes | Yes | Yes | No |
| Database Name/Type | Training Time (Minutes) | Training Loss (%) | Training Accuracy (%) | Validation Loss (%) | Validation Accuracy (%) | ECR (%) | Accuracy (%) |
|---|---|---|---|---|---|---|---|
| MADBase/Digits | 548 | 0.46 | 99.88 | 1.41 | 99.73 | 0.09 | 99.91 |
| CMATERDB/ Digits | 22 | 3.43 | 98.85 | 6.66 | 98.96 | 0.28 | 99.72 |
| SUST-ALT/ Digits | 282 | 1.15 | 99.65 | 3.24 | 99.34 | 0.18 | 99.82 |
| HACDB/ Characters | 53 | 6.84 | 97.49 | 9.25 | 96.97 | 0.09 | 99.91 |
| SUST-ALT/ Characters | 344 | 3.71 | 98.73 | 9.18 | 97.97 | 0.14 | 99.86 |
| SUST-ALT/ Words | 534 | 1.86 | 99.48 | 3.97 | 99.13 | 0.05 | 99.95 |
| DatabaseName | DatabaseType | Precision | Recall | F-Measure | Accuracy |
|---|---|---|---|---|---|
| MADBase | Digits | 0.9953 | 0.9953 | 0.9953 | 0.99906 |
| CMATERDB | Digits | 0.98608 | 0.98608 | 0.98608 | 0.99722 |
| SUST-ALT | Digits | 0.99107 | 0.99107 | 0.99107 | 0.99821 |
| HACDB | Characters | 0.96967 | 0.96967 | 0.96967 | 0.99908 |
| SUST-ALT | Characters | 0.97591 | 0.97591 | 0.97591 | 0.99858 |
| SUST-ALT | Words | 0.99038 | 0.99038 | 0.99038 | 0.99952 |
| Database Name | Database Type | Training Time (in Minutes) | Precision | Recall | F-Measure | Accuracy |
|---|---|---|---|---|---|---|
| MADBase | Digits | 964 | 0.9921 | 0.9921 | 0.9921 | 0.99842 |
| CMATERDB | Digits | 32 | 0.97667 | 0.97667 | 0.97667 | 0.99533 |
| SUST-ALT | Digits | 423 | 0.98755 | 0.98755 | 0.98755 | 0.99751 |
| HACDB | Characters | 70 | 0.91439 | 0.91439 | 0.91439 | 0.99741 |
| SUST-ALT | Characters | 606 | 0.93002 | 0.93002 | 0.93002 | 0.99588 |
| SUST-ALT | Words | 892 | 0.866 | 0.866 | 0.866 | 0.9933 |
| Database Name | Database Type | Training Time (in Minutes) | Precision | Recall | F-Measure | Accuracy |
|---|---|---|---|---|---|---|
| MADBase | Digits | 548 | 0.8221 | 0.8221 | 0.8221 | 0.96442 |
| CMATERDB | Digits | 19 | 0.41167 | 0.41167 | 0.41167 | 0.88233 |
| SUST-ALT | Digits | 263 | 0.29088 | 0.29088 | 0.29088 | 0.85818 |
| HACDB | Characters | 42 | 0.19697 | 0.19697 | 0.19697 | 0.97567 |
| SUST-ALT | Characters | 330 | 0.1456 | 0.1456 | 0.1456 | 0.94974 |
| SUST-ALT | Words | 275 | 0.915 | 0.915 | 0.915 | 0.95458 |
| Literature | Method Name | Database Name (Classes) | Database Type | ECR/ WER | Accuracy |
|---|---|---|---|---|---|
| Elleuch et al. [85] | DBNN | HACDB (66) | Characters | 2.10% | 97.90% |
| Elleuch et al. [86] | DBN | HACDB (66) | Characters | 2.10% | 97.90% |
| Elleuchet al. [86] | CDBN | HACDB (66) | Characters | 1.82% | 98.18% |
| Elleuch et al. [37] | CNN | HACDB (66) | Characters | 14.71 | 85.29% |
| Elleuch et al. [37] | DBN | HACDB (66) | Characters | 3.64% | 96.36% |
| Elleuch et al. [27] | CNN based-SVM | HACDB (66) | Characters | 5.83% | 94.17% |
| Elleuch et al. [28] | DSVM | HACDB (66) | Characters | 5.68% | 94.32% |
| Elleuch et al. [88] | CDBN | HACDB (66) | Characters | 1.14% | 98.86% |
| Present Work | DCNN | HACDB (66) | Characters | 0.09% | 99.91% |
| El-Sawy et al. [9] | CNN | MADBase (10) | Digits | 12% | 88% |
| Loey et al. [10] | SAE | MADBase (10) | Digits | 1.50% | 98.50% |
| Present Work | DCNN | MADBase (10) | Digits | 0.09% | 99.91% |
| Ashiquzzaman et al. [47] | CNN | CMATERDB (10) | Digits | 2.60% | 97.40% |
| Ashiquzzaman et al. [89] | CNN | CMATERDB (10) | Digits | 0.60% | 99.40% |
| Present Work | DCNN | CMATERDB (10) | Digits | 0.28% | 99.72% |
| Elbashir et al. [19] | CNN | SUST-ALT (40) | Words | 6.50% | 93.50% |
| Mustafa et al. [90] | CNN | SUST-ALT (20) | Words | 0.86% | 99.14% |
| Present Work | DCNN | SUST-ALT (40) | Words | 0.05% | 99.95% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, R.; Gogate, M.; Tahir, A.; Dashtipour, K.; Al-tamimi, B.; Hawalah, A.; El-Affendi, M.A.; Hussain, A. Novel Deep Convolutional Neural Network-Based Contextual Recognition of Arabic Handwritten Scripts. Entropy 2021, 23, 340. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030340
Ahmed R, Gogate M, Tahir A, Dashtipour K, Al-tamimi B, Hawalah A, El-Affendi MA, Hussain A. Novel Deep Convolutional Neural Network-Based Contextual Recognition of Arabic Handwritten Scripts. Entropy. 2021; 23(3):340. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030340
Chicago/Turabian StyleAhmed, Rami, Mandar Gogate, Ahsen Tahir, Kia Dashtipour, Bassam Al-tamimi, Ahmad Hawalah, Mohammed A. El-Affendi, and Amir Hussain. 2021. "Novel Deep Convolutional Neural Network-Based Contextual Recognition of Arabic Handwritten Scripts" Entropy 23, no. 3: 340. https://0-doi-org.brum.beds.ac.uk/10.3390/e23030340