
Asymptotic and Finite Sample Properties for Multivariate Rotated GARCH Models



1
Faculty of Economics, Soka University, Tokyo 192-8577, Japan
2
Department of Applied Economics, National Chung Hsing University, Taichung City 402, Taiwan
3
Department of Finance, National Chung Hsing University, Taichung City 402, Taiwan
4
Department of Finance, College of Management, Asia University, Taichung City 41354, Taiwan
5
Department of Bioinformatics and Medical Engineering, College of Information and Electrical Engineering, Asia University, Taichung City 41354, Taiwan
6
Discipline of Business Analytics, University of Sydney Business School, Darlington 2006, Australia
7
Econometric Institute, Erasmus School of Economics, Erasmus University Rotterdam, 3062 PA Rotterdam, The Netherlands
8
Department of Economic Analysis and ICAE, Complutense University of Madrid, 28040 Madrid, Spain
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Econometrics 2021, 9(2), 21; https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics9020021
Submission received: 24 December 2020
/
Revised: 18 March 2021
/
Accepted: 27 April 2021
/
Published: 4 May 2021
Abstract
:This paper derives the statistical properties of a two-step approach to estimating multivariate rotated GARCH-BEKK (RBEKK) models. From the definition of RBEKK, the unconditional covariance matrix is estimated in the first step to rotate the observed variables in order to have the identity matrix for its sample covariance matrix. In the second step, the remaining parameters are estimated by maximizing the quasi-log-likelihood function. For this two-step quasi-maximum likelihood (2sQML) estimator, this paper shows consistency and asymptotic normality under weak conditions. While second-order moments are needed for the consistency of the estimated unconditional covariance matrix, the existence of the finite sixth-order moments is required for the convergence of the second-order derivatives of the quasi-log-likelihood function. This paper also shows the relationship between the asymptotic distributions of the 2sQML estimator for the RBEKK model and variance targeting quasi-maximum likelihood estimator for the VT-BEKK model. Monte Carlo experiments show that the bias of the 2sQML estimator is negligible and that the appropriateness of the diagonal specification depends on the closeness to either the diagonal BEKK or the diagonal RBEKK models. An empirical analysis of the returns of stocks listed on the Dow Jones Industrial Average indicates that the choice of the diagonal BEKK or diagonal RBEKK models changes over time, but most of the differences between the two forecasts are negligible.
1. Introduction
The BEKK model of Baba et al. (1985) and Engle and Kroner (1995) is widely used for estimating and forecasting time-varying conditional covariance dynamics, especially in the empirical analysis of the multiple asset returns of financial time series (Bauwens et al. 2006; Laurent et al. 2012; McAleer 2005; Silvennoinen and Teräsvirta 2009). The BEKK model is a natural extension of the ARCH/GARCH models of Engle (1082) and Bollerslev (1986). One of the features of the BEKK model is that it guarantees the positive definiteness of the covariance matrix. However, as it does not satisfy suitable regularity conditions, the corresponding estimators do not possess asymptotic properties, except under restrictive conditions (Chang and McAleer 2019; Comte and Lieberman 2003; McAleer et al. 2008). To overcome this problem, Hafner and Preminger (2009) showed the asymptotic properties of the quasi-maximum likelihood (QML) estimator under moderate regularity conditions.
Similar to other multivariate GARCH models, a drawback of the BEKK model is that it contains a large number of parameters, even for moderate dimensions. To reduce the number of parameters, the so-called scalar BEKK and diagonal BEKK specifications are used in empirical analyses (Chang and McAleer 2019). Recently, Noureldin et al. (2014) suggested the rotated BEKK (RBEKK) model to handle the high-dimensional BEKK model. They proposed the estimation of the unconditional covariance matrix of the observed variables in the first step to rotate the variables in order to have unit sample variance and zero sample correlation coefficients. In the second step, they considered simplified BEKK models for the QML estimation. We call this procedure the two-step QML (2sQML) estimation. One of the major advantages of the RBEKK model is that it can reduce the number of parameters in the optimization step, while another is that it is more natural to consider simplified specifications after the rotation than to simplify the structure directly without the rotation.
2sQML is closely related to the variance targeting (VT) specification analyzed by Francq et al. (2011) and Pedersen and Rahbek (2014), among others. The VT-QML estimation also uses the estimated unconditional covariance matrix in the first step to reduce the number of parameters in the QML maximization step. Pedersen and Rahbek (2014) showed the consistency and asymptotic normality of the VT-QML estimator under finite sixth-order moments. As Noureldin et al. (2014) discussed the general framework for the asymptotic distribution of the 2sQML estimator for the RBEKK model, it is thus worth examining the detailed moment condition, as in Pedersen and Rahbek (2014).
In this study, we show the consistency and asymptotic normality of the 2sQML estimator for the RBEKK model by extending the approach of Pedersen and Rahbek (2014). For asymptotic normality, we need to impose sixth-order moment restrictions, as in Hafner and Preminger (2009) and Pedersen and Rahbek (2014). We also derive the asymptotic relationship between the VT-QML estimator for the BEKK model and the 2sQML estimator for the RBEKK model. We conduct Monte Carlo experiments to check the finite sample properties of the 2sQML estimator and compare the performance of the estimated diagonal BEKK and diagonal RBEKK models. The proofs of the propositions and corollaries are given in Appendix A. We present an empirical result based on the returns of stocks listed on the Dow Jones Industrial Average.
There are several works related to the idea of Noureldin et al. (2014). First, the transformation suggested by Noureldin et al. (2014) is related to the (generalized) orthogonal GARCH models of Alexander (2001), van der Weide (2002), and Lanne and Saikkonen (2007). While these authors attempt to find orthogonal or unconditionally uncorrelated components in the raw returns, which can then be modeled individually through univariate variance models, Noureldin et al. (2014) suggest fitting flexible multivariate models to the rotated returns using the VT approach. Second, the symmetric square root rotation of Noureldin et al. (2014) is not the most general type of rotation one could use—see, for instance, the hyper-rotation suggested by Asai and McAleer (2020) and the structural multivariate GARCH approach of Hafner et al. (2020). Both use generalized rotations that are not necessarily symmetric. From the structure, we can infer that these works are not based on the VT approach.
We use the following notation throughout the paper. For a matrix A, we define . With , the n eigenvalues of a matrix A, , is the spectral radius of A. The Frobenius norm of the matrix, or vector A, is defined as . For a positive matrix A, we define the square root, , by the spectral decomposition of A. For an matrix A, the commutation matrix has the property .
2. RBEKK-GARCH Model
As in Hafner and Preminger (2009) and Pedersen and Rahbek (2014), we focus on a simple specification of the BEKK model defined by:
where , , and are d-dimensional square matrices, is a d-dimensional positive definite matrix, and is an sequence of random variables.
We begin with the following assumption.
Assumption 1.
- (a)
- The distribution of is absolutely continuous with respect to the Lebesgue measure of and zero is an interior point of the support of the distribution.
- (b)
- The matrices and satisfy .
From Theorem 2.4 of Boussama et al. (2011), Assumption 1 implies the existence of a unique stationary and ergodic solution to the model in (1) and (2). Furthermore, the stationary solution has finite second-order moments, , and variance , with positive definite , which is the solution to:
Lemma 2.4 and Proposition 4.3 of Boussama et al. (2011) indicate that the necessary and sufficient conditions for (3) to have a solution of a positive definite matrix is Assumption 1(b). As in Pedersen and Rahbek (2014), we obtain the VT specification by substituting in (3) into the model (2), giving:
Based on this specification, Noureldin et al. (2014) suggested the RBEKK model, which is obtained by setting and in (2), where A and B are d-dimensional square matrices. The transformation yields:
with the rotated vector , which gives . As discussed by Noureldin et al. (2014), the specification provides a natural interpretation for considering the diagonal matrices A and B to reduce the number of parameters. Rather than the special case with these diagonal matrices, we consider general A and B for asymptotic theory. With respect to the initial values, we consider the estimation conditional on the initial values and , where h is a positive definite matrix. Under this structure, it is natural to replace Assumption 1(b) with the following assumption.
Assumption 2.
The matrices A and B satisfy .
Lemma A2 in Appendix A.2 shows that Assumption 2 is equivalent to Assumption 1(b).
In the next section, we consider the 2sQML estimation for the RBEKK model (1) and (5), as in Noureldin et al. (2014) and Pedersen and Rahbek (2014).
3. 2sQML Estimation
Let , denote the parameter vector of the RBEKK model, which is defined by , where and with and . We also define the parameter space . As in Hafner and Preminger (2009) and Pedersen and Rahbek (2014), we emphasize the dependence of and on the parameters and by writing and , respectively. In addition, we emphasize the initial value of the covariance matrix, h, by denoting and . Now, we restate the RBEKK model as:
with the given initial values and .
As mentioned above, we consider the 2sQML estimation, which comprises two steps. In the first step, we estimate using the sample covariance matrix, while the second step conducts the QML estimation by optimizing the log-likelihood function for conditional on the estimates of . For the RBEKK model, the Gaussian log-likelihood function is given by:
with the tth contribution to the log-likelihood given as:
excluding the constant. In the first step, we estimate the unconditional covariance matrix by:
to rotate and as:
Note that the sample covariance matrix is positive definite, since the structure confirms the positive semi-definiteness, and since guarantees that the rank of is d. By definition, we have . The conditional log-likelihood function is given by:
which is equivalent to . Hence, the second step of the estimator is given by:
We derive the asymptotic theory for the 2sQML estimator, which consists of (10) and (11).
Following Comte and Lieberman (2003), Hafner and Preminger (2009), and Pedersen and Rahbek (2014), we make the following conventional assumptions.
Assumption 3.
- (a)
- The process is strictly stationary and ergodic.
- (b)
- The true parameters and Θ are compact.
- (c)
- For , if , then almost surely, for all .
For Assumption 3(a), Assumptions 1(a) and 2 imply the existence of a strictly stationary ergodic solution in the RBEKK model. Regarding Assumption A3(c), one of the conditions is that the first element in the matrices A and B should be strictly positive, which is a sufficient condition for the parameter identification, as shown by Engle and Kroner (1995).
We now state the following result on the consistency of the 2sQML estimator, .
Proposition 1.
Under Assumptions 1(a), 2, and 3, as , .
Assumptions 1(a) and 2 imply the finite second-order moments of , which are necessary for estimating with the sample covariance matrix. As shown by Hafner and Preminger (2009), the consistency of the QML estimator for the BEKK model (1) and (2) does not require the finite second-order moment of .
We make the following assumption about the asymptotic normality of the 2sQML estimator.
Assumption 4.
- (a)
- .
- (b)
- is in the interior of Θ.
As in Pedersen and Rahbek (2014), we need to assume finite sixth-order moments to show that the second-order derivatives of the log-likelihood function converge uniformly on the parameter space. This is different than the univariate case, which only requires finite fourth-order moments (Francq et al. 2011).
Proposition 2.
Under Assumptions 1(a) and 2–4, as ,
where
with the matrix and non-singular matrices and defined by:
using
Remark 1.
The structure of the asymptotic covariance matrix is similar to that of the VT-QML estimator for Equations (2) and (4), derived by Pedersen and Rahbek (2014). The major difference comes from the model structure, as the RBEKK further assumes that and depend on the non-linear function of .
Remark 2.
We can estimate , , and using the sample outer product of the gradient and Hessian matrices as follows:
where
Given the asymptotic distribution of , we can show the asymptotic distribution of the 2sQML estimator of in the VT representation of the BEKK. Define , where .
Proposition 3.
Remark 3.
The difference in the asymptotic covariance matrix for the 2sQML and VT-QML estimators depends on and . While is a symmetric matrix, is a square matrix in general. The definiteness of is undetermined.
From Proposition 3 and the delta method, we provide the asymptotic distribution of the 2sQML estimator for in the original BEKK model. Define , , and .
Corollary 1.
Under the assumptions of Proposition 2, as ,
where
Remark 4.
From Proposition 1, we can estimate and using the 2sQML estimate, .
4. Monte Carlo Experiments
4.1. Experimental Framework
In this section, we illustrate the theoretical results presented in the previous section using Monte Carlo experiments for d-dimensional rotated diagonal GARCH models. We use the diagonal GARCH model for the model comparison because the number of parameters to be estimated is the same. It is difficult to estimate the fully parametrized BEKK model when d takes a higher value such as , which gives the number of parameters for and as . On the contrary, rotated and unrotated diagonal GARCH models use parameters. We consider four experiments to examine the (i) finite sample property of the 2sQML estimator, (ii) difference between the true and estimated covariance matrices, (iii) approximation of the fully parametrized BEKK model via the diagonal models, and (iv) finite sample property of the 2sQML estimator when fourth moments of do not exist. We generate from for all the experiments.
4.2. Performance of the 2sQML Estimator
In the first Monte Carlo experiment, we consider the bivariate case () for the data-generating processes (DGPs) with the following structure in (5):
We consider two types of parameter sets:
which are used to obtain for the DGPs from (1) and (2). We use for the initial value to generate observations. We set the number of replications to 2000. Table 1 and Table 2 provide the values of and corresponding values of , respectively. While DGP1 describes the positive unconditional correlation, DGP2 uses the negative correlation. Using this specification, we can verify that . From this setting, we examine the finite sample property of the 2sQML estimator for .
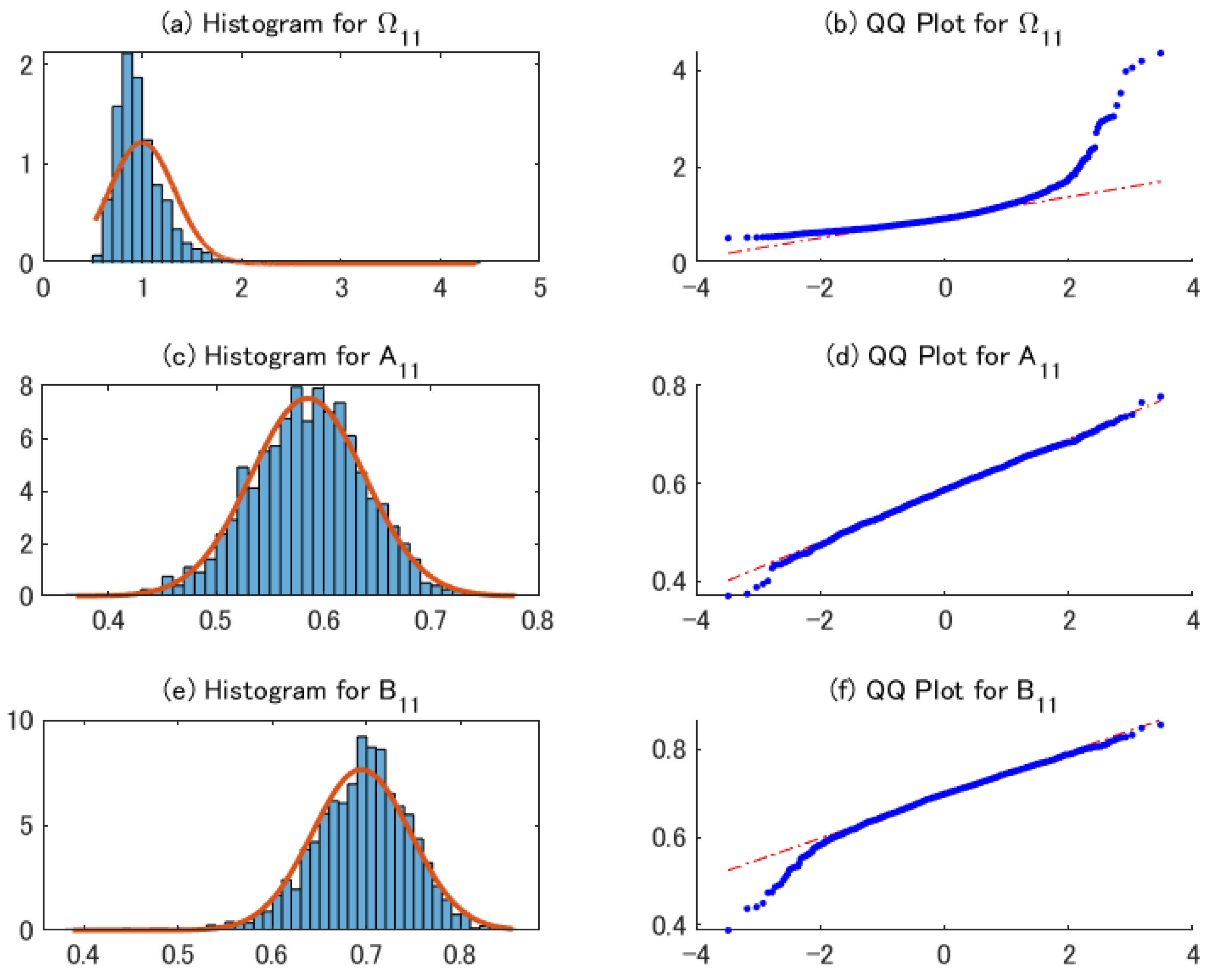
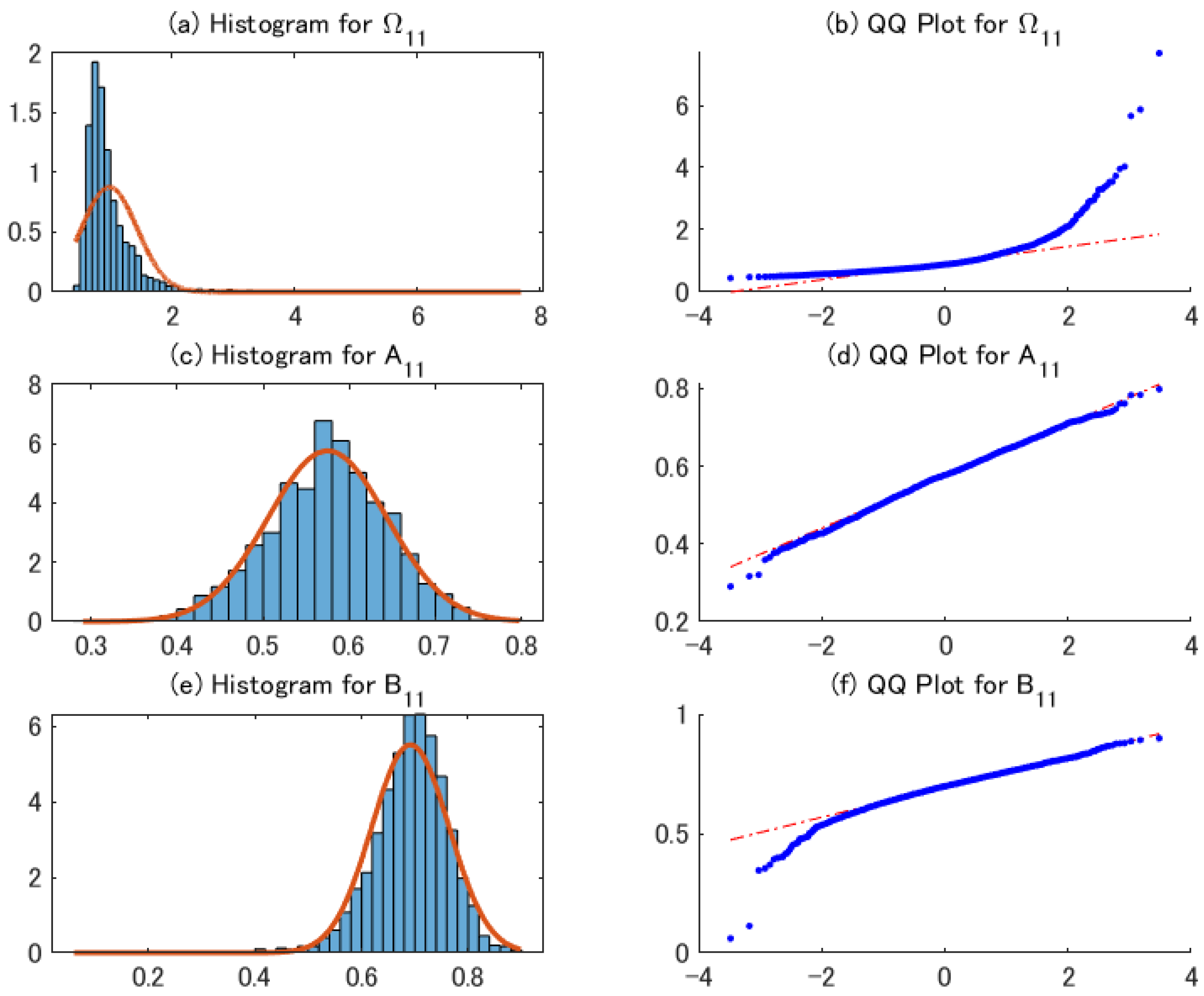
Table 1 shows the sample mean, standard deviations, and root mean squared error of the 2sQML estimates. The table indicates that the bias of the estimators is negligible, even for . The standard deviation for the sample covariance matrix is relatively large for DGP1, which is expected to decrease as the sample size increases. Figure 1 shows the histograms and QQ Plots of 2sQML estimates for representative parameters. As the estimate of is obtained from the sample covariance matrix, its distribution is skewed to the right. By contrast, the distributions of the 2sQML estimates of and are close to the normal distribution.
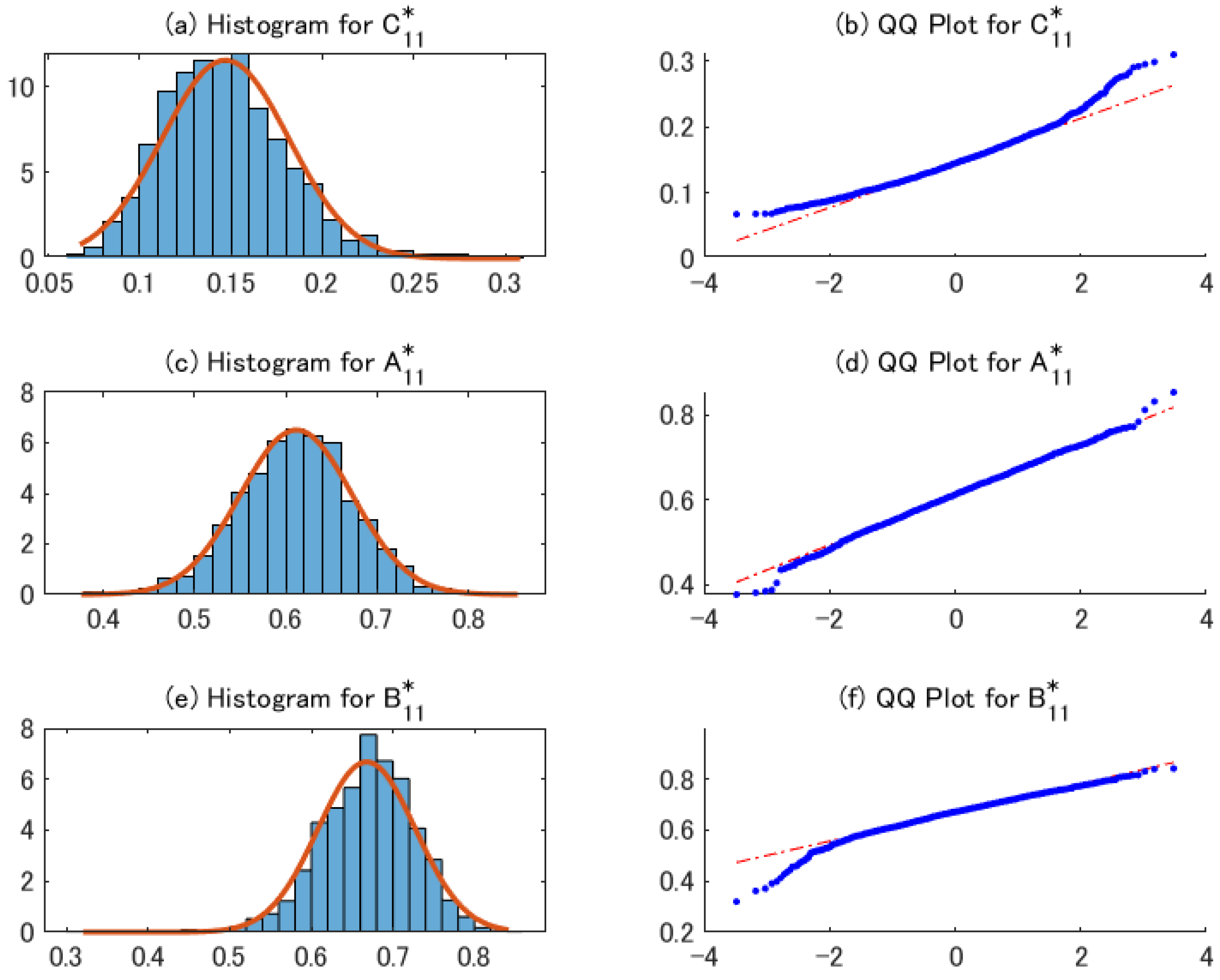
We also check the effects of the transformation from to , as shown in Corollary 1. Table 2 shows the sample mean, standard error, and root mean squared error of the transformed estimator. As in Table 1, the bias of the estimators is negligible. Figure 2 indicates that the transformed estimators for the full BEKK specification can be approximated using the normal distribution.
4.3. Performance of Conditional Covariance Matrix Estimator
In the second experiment, we consider higher-dimensional cases with . Denoting by , we simulate the uniform distribution on :
where , , and . We discard the parameters which do not satisfy the stationarity condition. Based on the simulated parameters, we generate for the sample size , and estimate the diagonal RBEKK and diagonal BEKK models to calculate the average of the Frobenius norm of the difference in the conditional covariance matrices:
where is the estimated covariance matrix and is the true covariance matrix. While for the diagonal BEKK model, is similarly defined for the diagonal BEKK model. We use the common random parameters for the two models and repeat the procedure 100 times with different random parameters.
Table 3 shows the sample means of the average distances. The values of the measure for are expected to take values approximately four times larger than those for , as implied by the dimension of . Table 3 supports this result. As the sample size increases, the average distance decreases. Compared with the diagonal BEKK model, the diagonal RBEKK model has a smaller distance measure.
4.4. Effects of Diagonal Specification
In the third experiment, we examine the effects of the diagonal specification for the BEKK and RBEKK models when the true model is full BEKK. For this purpose, we consider several measures to check the distance from the diagonal BEKK and RBEKK models to the full BEKK model. The non-diagonal indices are defined as:
where creates a diagonal matrix from the square matrix Y. Using the non-diagonal indices, we can calculate the theoretical distance of the diagonal BEKK and RBEKK models. For the remaining measures, we use the estimated values of the parameters of these models. The maximized log-likelihood is used, as is the average of the Frobenius norm of the difference of the conditional covariance matrices, as explained above.
Using these measures, the following Monte Carlo simulations investigate the effects of the diagonal specification of the BEKK and RBEKK models when the true model is bivariate full BEKK. For this purpose, we consider the specification for (4):
for , where , , , and are diagonal matrices. When , the specification reduces to the diagonal BEKK model, while it becomes the diagonal RBEKK model for . Except for these endpoints, the full BEKK specification provides a non-diagonal structure for and in (4) and and in (5). For the specification in (4), the non-diagonal indices provide the linear functions of w:
where
to calculate the theoretical distances. Consider the parameter settings for the DGPs as:
Set to examine 11 cases, with and the number of replications set to 100. We estimate the diagonal RBEKK model using the 2sQML method, while VT-QML is used for the diagonal BEKK model.
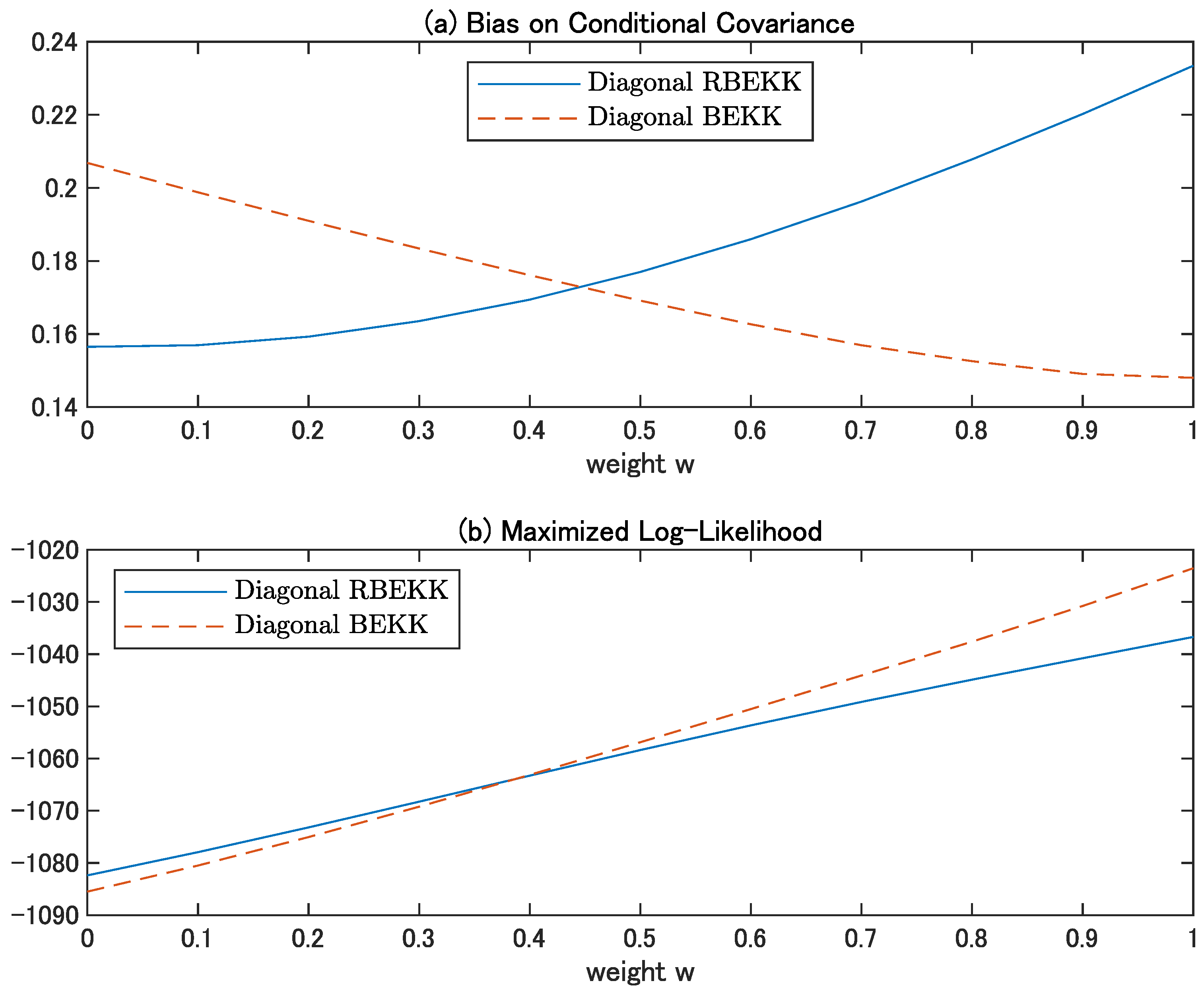
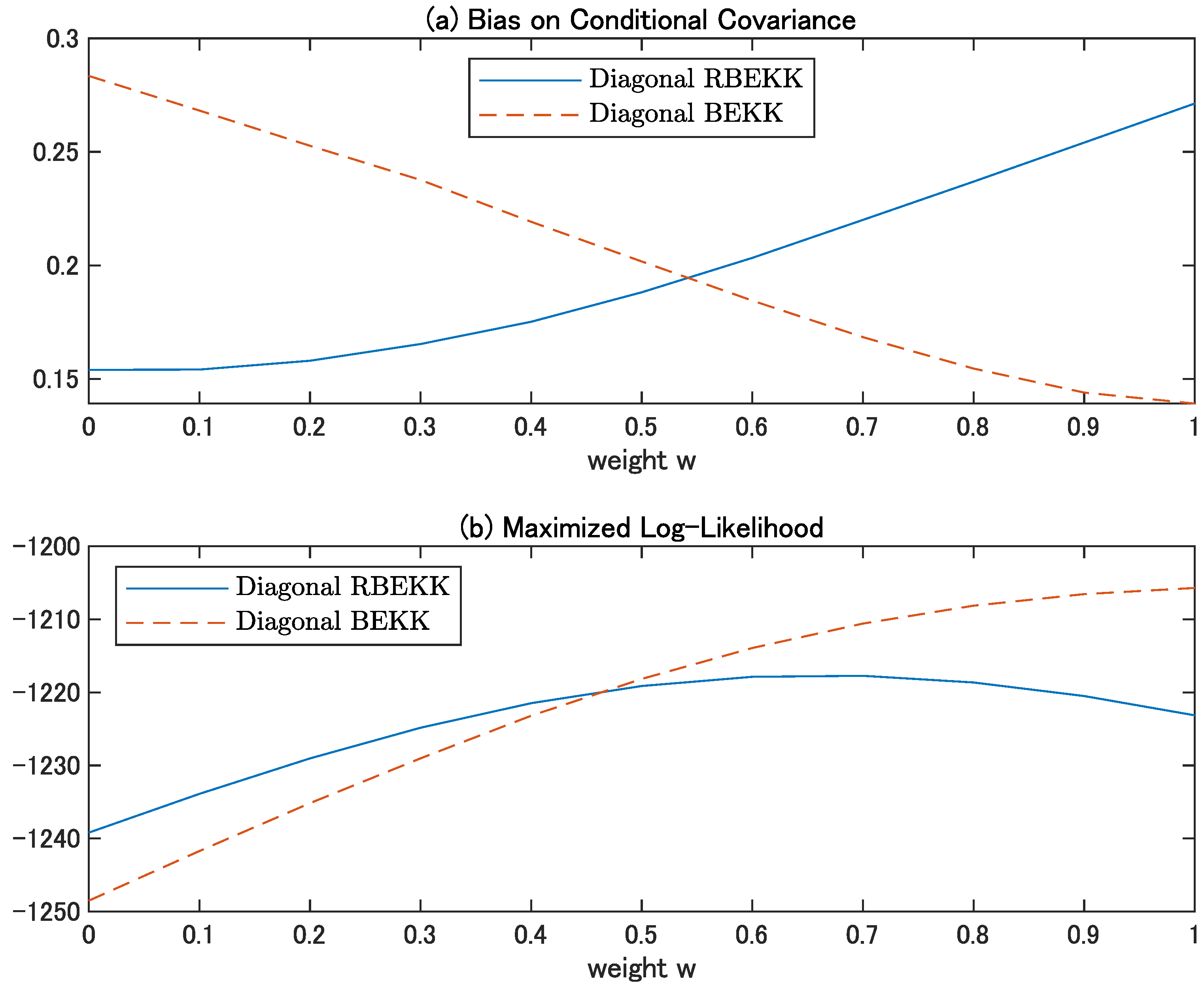
Figure 3 and Figure 4 show the sample means of the average bias for the conditional covariance matrices and sample means of the maximized log-likelihood function for DGP3 and DGP4, respectively. As expected from the structure, the superiority of the diagonal models depends on the structure of the true BEKK model. If w is closer to zero, the diagonal RBEKK model is preferred. The non-diagonality indices are
and these theoretical values of correspond to the intersections shown in Figure 3b and Figure 4b, respectively. The Akaike information criterion and Bayesian information criterion lead to the same conclusion, as the numbers of parameters in these two models are the same.
4.5. Heavy Tails and Moment Conditions
The last experiment uses DGPs 1 and 2 with the multivariate standardized t distribution and the degree-of-freedom parameter (denoted by ), instead of the multivariate standard normal distribution. We consider three cases: (i) a heavy-tailed distribution (), which satisfies Assumption 4(a); (ii) DGPs in which the sixth moments are not finite (); and (iii) DGPs in which the fourth moments are not finite (). The latter two cases imply that the 2sQML estimator is consistent, but its asymptotic normality is not guaranteed. As an alternative approach, we may use the parameter condition derived from Theorem 3 of Hafner (2003). To save space, we omitted the tables for the sample mean, standard deviations, and root mean squared error of the 2sQML estimates, which are available in the Supplementary Materials.
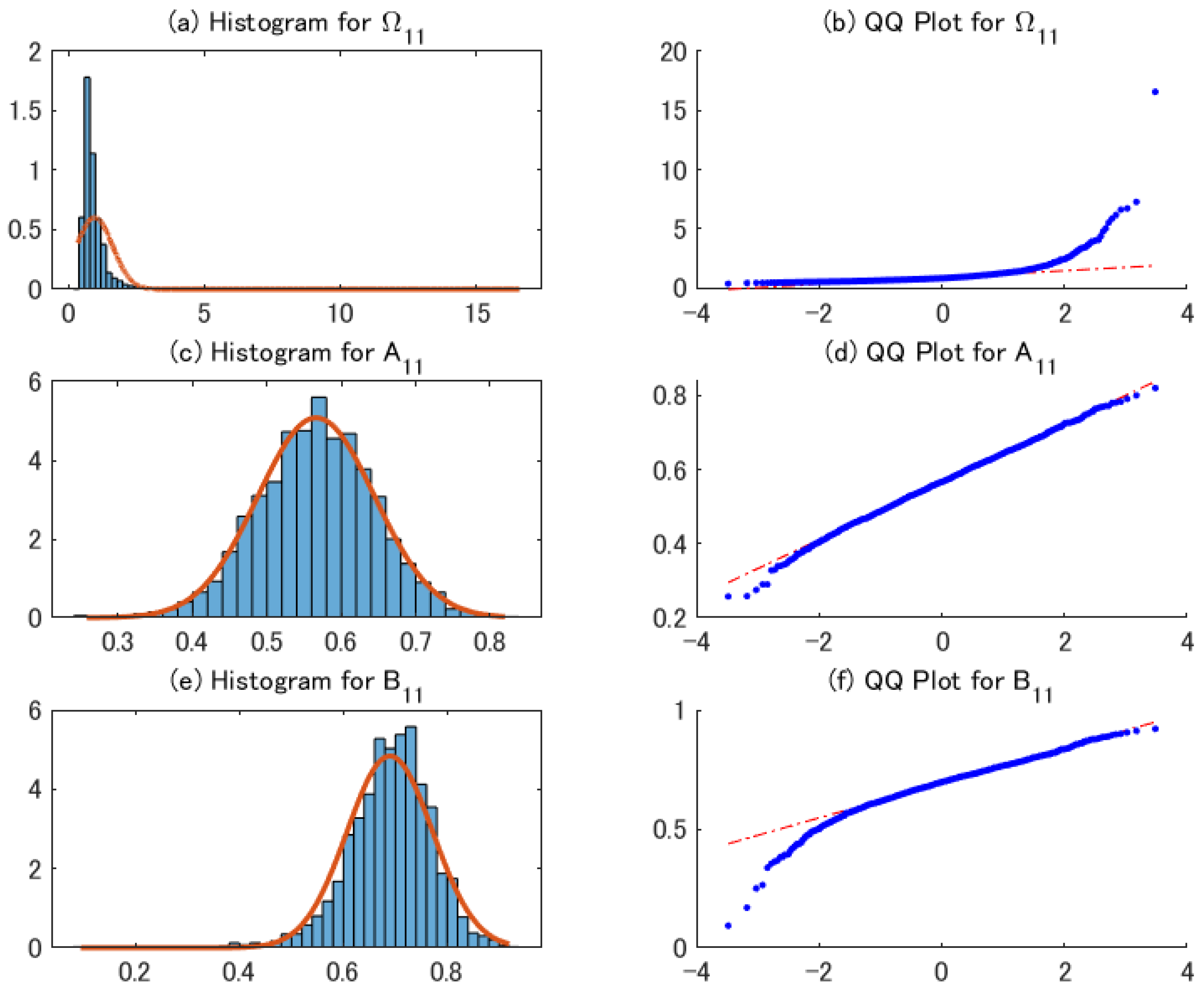
Figure 5 shows the histograms and QQ plots of 2sQML estimates for DGP1 with . The Monte Carlo results indicate that the bias is negligible, and the standard deviations are larger than in the case of standard normal distribution. The distributions of the estimates of , , and are similar to those of Figure 1. This result supports Proposition 2.
Figure 6 shows the histograms and QQ plots of 2sQML estimates for DGP1 with . Although the sixth moments are not finite, the distributions of the estimates of , , and are close to those of Figure 5. This result implies that we can relax Assumption 4 to guarantee asymptotic normality for the second-step estimator.
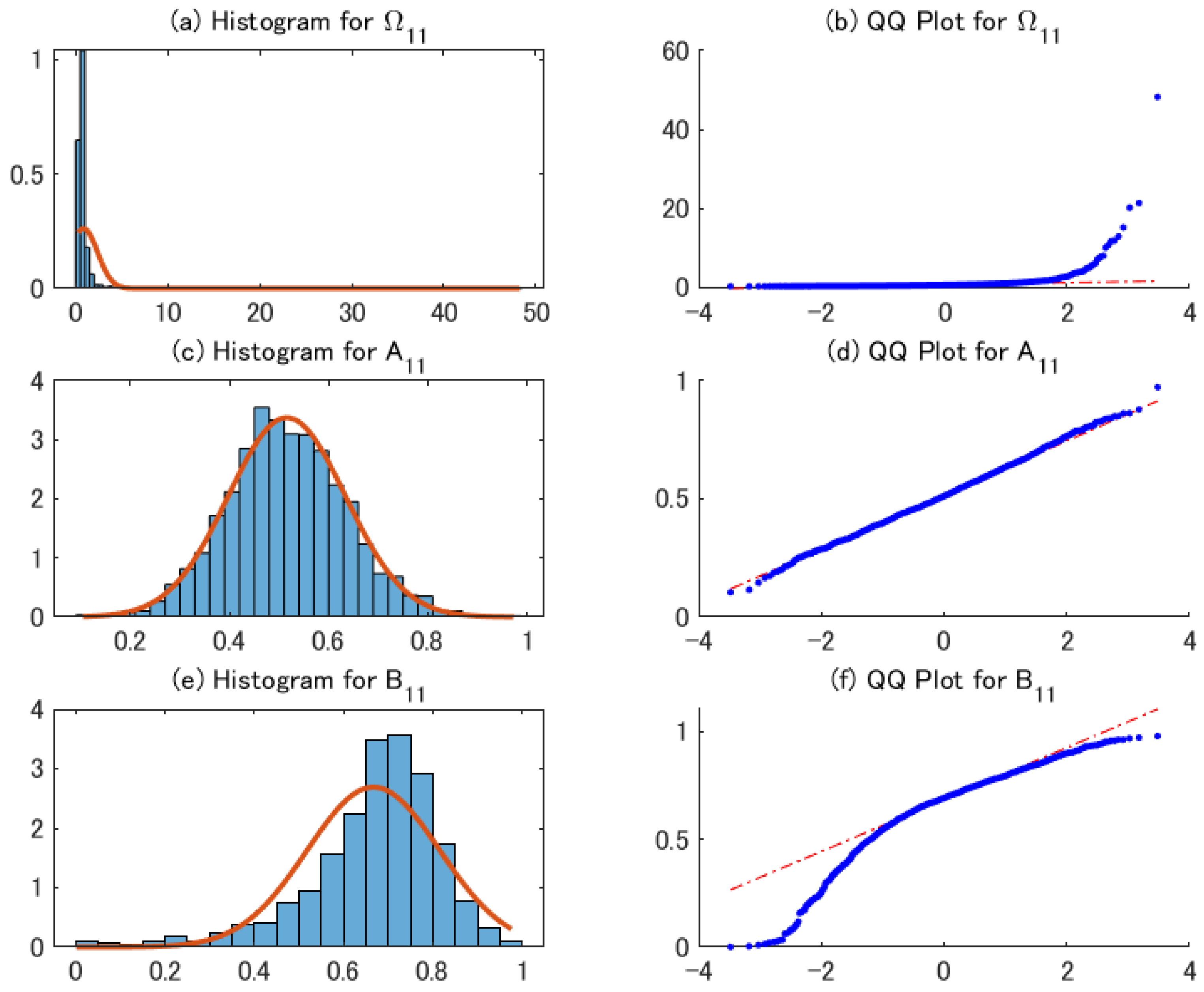
For the DGPs with , the Monte Carlo result shown in the Supplementary Materials indicates that the bias of the estimators for and A are relatively small, compared with those of and . Figure 7 shows the histograms and QQ plots of 2sQML estimates for DGP1 with . The QQ plot of Figure 7a shows the instability of the first-step estimator. The instability affects the standard deviations of the second-step estimator. Figure 7e implies that the effects are more serious on the estimates of , with a pressure towards zero. The result indicates that a larger sample size is required in order to improve the estimates for the parameters of B.
The Monte Carlo experiments show that the finite sample properties of the 2sQML estimator are satisfactory and that the average distance between the true and estimated covariance matrices indicates that the difference between the two diagonal BEKK models is not negligible. Because it is difficult to estimate the fully parametrized BEKK model for higher d, it is necessary to examine the model specifications, as in Noureldin et al. (2014), using parsimonious specifications. The Monte Carlo experiments indicate that we may relax the assumption for the sixth moments for the second step estimator.
5. Empirical Analysis
In this section, we assess the diagonal specification of the RBEKK model compared with the diagonal BEKK model. For this purpose, we focus on the out-of-sample forecasts evaluation, adopting the approach of Engle and Colacito (2006), for the mean-variance portfolio. We calculate the returns of stocks listed on the Dow Jones Industrial Average, except for Dow Inc. (), for the period starting from 18 February 2010 to 23 January 2020, yielding 2500 observations. We exclude Dow Inc. since it went public on April 1, 2019. Fixing the sample size as , we use rolling windows to obtain one-step-ahead forecasts for the last 500 observations for model i, denoted by . While Model 1 is the diagonal RBEKK model, Model 2 is the diagonal BEKK.
For our portfolio analysis, we consider the minimum variance portfolio, which gives the weight vector for model i chosen at the end of time , , where is the vector of ones. Engle and Colacito (2006) show that the realized portfolio volatility is the smallest one when the variance-covariance matrices are correctly specified. We define the distance based on the difference of the squared returns of the two portfolios as:
Since the portfolio variances are the same if the forecasts of the covariance matrices are the same, we examine the null hypothesis using the Diebold and Mariano (1995) test. In this case, the test can be constructed in the following manner. Consider the linear regression model given by with , and test using the heteroskedasticity- and autocorrelation-consistent standard errors. If the mean of is negative (positive), the diagonal RBEKK (the diagonal BEKK) model is preferred.
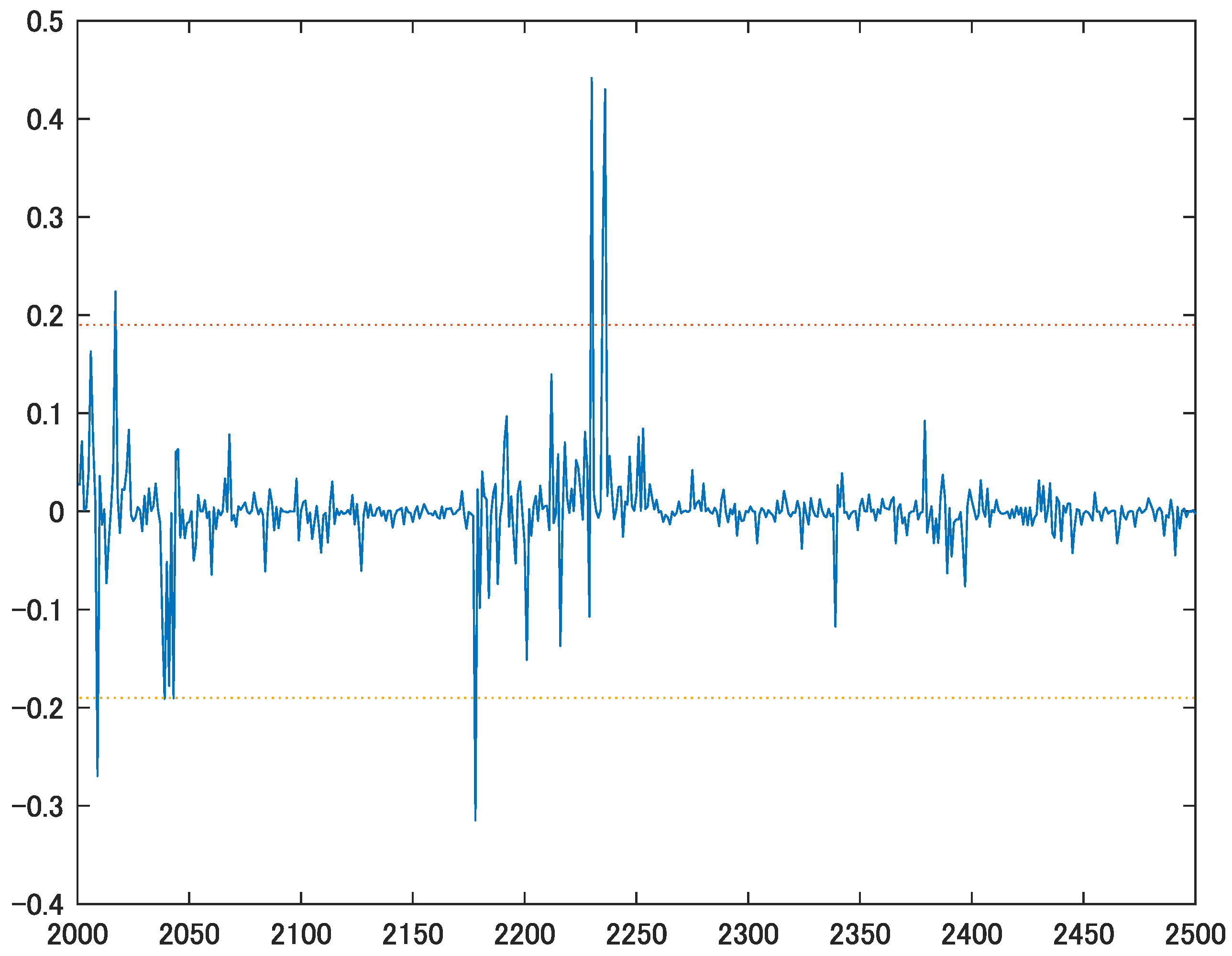
Table 4 indicates that the Engle and Colacito (2006) test fails to reject the null hypothesis that the two forecasts are equivalent. Figure 8 shows the difference of squared portfolio returns, defined by Equation (15), accompanied by the 95% confidence interval. With a few exceptions, there is no significant difference between the two portfolio weights calculated by the forecasts of the two different models. For instance, at time , the forecast by the diagonal RBEKK is preferred. As discussed in Section 4.4, the choice of the diagonal RBEKK or the diagonal BEKK model depends on the true structure of the full BEKK. Figure 8 supports the result of the Engle and Colacito (2006) test in Table 4. To improve the forecasting performance, we may consider a more general rotation matrix, as in Asai and McAleer (2020) and Hafner et al. (2020).
6. Conclusions
For the RBEKK-GARCH model, we show the consistency and asymptotic normality of the 2sQML estimator under weak conditions. The 2sQML estimation uses the unconditional covariance matrix for the first step and rotates the observed vector to have the identity matrix for its sample covariance matrix. The second step conducts the QML estimation for the remaining parameters. While we require second-order moments for consistency because of the estimation of the covariance matrix, we need finite sixth-order moments for asymptotic normality, as in Pedersen and Rahbek (2014). We also show the asymptotic relation of the 2sQML estimator for the RBEKK model and the VT-QML estimator for the VT-BEKK model. The Monte Carlo results show that the finite sample properties of the 2sQML estimator are satisfactory, and that the adequacy of the diagonal RBEKK depends on the structure of the true parameters. The empirical result for the returns of stocks listed on the DOW30 indicates that the diagonal RBEKK and diagonal BEKK models are competitive, with the superiority of each model changing over time.
As an extension of the dynamic conditional correlation (DCC) model of Engle (2002), Noureldin et al. (2014) suggested rotated DCC models (for a caveat about the regularity conditions underlying DCC, see McAleer (2018)). We can apply the rotation to the different kinds of correlation models suggested by McAleer et al. (2008) and Tse and Tsui (2002). Together with such extensions, the derivation of asymptotic theory for the rotated DCC models is an important direction for future research.
Supplementary Materials
The following are available at https://0-www-mdpi-com.brum.beds.ac.uk/article/10.3390/econometrics9020021/s1.
Author Contributions
All authors contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
Japan Society for the Promotion of Science (19K01594).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors are most grateful to the editor, four anonymous reviewers, and Yoshihisa Baba for very helpful comments and suggestions. The first author acknowledges the financial support of the Japan Ministry of Education, Culture, Sports, Science and Technology, Japan Society for the Promotion of Science, and the Australian Academy of Science. The second author thanks the Ministry of Science and Technology (MOST) for financial support. The third author is most grateful for the financial support of the Australian Research Council, Ministry of Science and Technology (MOST), Taiwan, and the Japan Society for the Promotion of Science.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analysis, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| 2sQML | Two-step quasi-maximum likelihood |
| ARCH | Autoregressive conditional heteroskedasticity |
| BEKK | Baba, Engle, Kraft, and Kroner |
| DCC | Dynamic conditional correlation |
| GARCH | Generalized autoregressive conditional heteroskedasticity |
| QML | Quasi-maximum likelihood |
| RBEKK | Rotated BEKK |
| VT | Variance targeting |
Appendix A
Appendix A.1. Derivatives of the Log-Likelihood Function
Although Pedersen and Rahbek (2014) demonstrated the derivatives with respect to , , and , they are not applicable, as and in (2) depend on and in the RBEKK models (6) and (7), respectively. Related to this issue, we need the following lemma to show the derivatives of the log-likelihood function.
Lemma A1.
Proof.
The gradient and Hessian matrices of the log-likelihood function are given by
Applying the chain rule and product rule, we obtain
where is the ith element of :
The first equation of (A2) uses 10.3.2(23) and 10.3.3(10) of Lütkepohl (1996), while we apply 10.6.1(1) for the second equation.
From Lemma A1, the product rule, and the chain rule, we obtain the first derivatives:
and
where is the commutation matrix, which consists of one and zero satisfying .
Similarly, the second derivatives of are given by
where is a vector of zeros except for the jth element, which takes one. We omit the derivatives of .
Before we proceed, we show the equivalence of Assumptions 1(b) and 2.
Appendix A.2. Proofs of Propositions 1–3
For notational convenience, let .
Proof of Propositions 1 and 2.
Using the log-likelihood function as well as the gradient and Hessian matrices in Appendix A.1, we can show strong consistency and asymptotic normality using similar arguments as in the proofs of Theorems 4.1 and 4.2 of Pedersen and Rahbek (2014), respectively. See the Supplementary Materials for the details. □
Lemma A3.
Under the assumptions of Proposition 2, as ,
where
with and as stated in Proposition 2.
Proof of Lemma A3.
From the definition of and and rule of vectorization, and . Define . From Proposition 2 and the delta method, . Since
applying Lemma A1 under the true vector yields and in Lemma A3. □
Lemma A4.
Under the assumptions of Proposition 2, the stated in Proposition 2 can be written as
where
with
Proof of Lemma A4.
Using an argument similar to the proof of Lemma B.8 in Pedersen and Rahbek (2014), we can show
which implies the equivalence of the asymptotic covariance matrices on both sides. □
Lemma A5.
Under the assumptions of Proposition 2, the asymptotic covariance matrix for the VT-QML estimator of Pedersen and Rahbek (2014) is given by , where
with
and
Proof of Lemma A5.
We can verify the result using Theorem 4.2 of Pedersen and Rahbek (2014). □
Proof Proposition 3.
Lemma A3 shows the asymptotic distribution of and corresponding asymptotic covariance matrix. Lemma A5 provides the asymptotic covariance matrix of the VT estimator. In the following, we show an alternative representation of the latter asymptotic covariance matrix.
By definition, we obtain , where
First, consider the second derivatives of the tth contribution to the likelihood function to obtain
Then, we obtain and . For defined by Lemma A4,
where
with , which is evaluated at the true value .
References
- Alexander, Carol, ed. 2001. Orthogonal GARCH. In Mastering Risk. Hoboken: Financial Times-Prentice Hall, pp. 21–28. [Google Scholar]
- Asai, Manabu, and Michael McAleer. 2020. Multivariate Hyper-Rotated GARCH-BEKK: Asymptotic Theory and Practice. Tokyo: Soka University, Unpublished Paper. [Google Scholar]
- Baba, Yoshihisa, Robert. F. Engle, Dennis Kraft, and Kenneth F. Kroner. 1985. Multivariate Simultaneous Generalized ARCH. San Diego: University of California, Unpublished Paper. [Google Scholar]
- Bauwens, Luc, Sébastian Laurent, and Jeroen K. V. Rombouts. 2006. Multivariate GARCH models: A survey. Journal of Applied Econometrics 21: 79–109. [Google Scholar] [CrossRef] [Green Version]
- Bollerslev, Tim. 1986. Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef] [Green Version]
- Boussama, Farid, Florian Fuchs, and Robert Stelzer. 2011. Stationarity and geometric ergodicity of BEKK multivariate GARCH models. Stochastic Processes and Their Applications 121: 2331–60. [Google Scholar] [CrossRef] [Green Version]
- Chang, Chia-Lin, and Michael McAleer. 2019. The fiction of full BEKK: Pricing fossil fuels and carbon emissions. Finance Research Letters 28: 11–19. [Google Scholar] [CrossRef]
- Comte, Fabienne, and Offer Lieberman. 2003. Asymptotic theory for multivariate GARCH processes. Journal of Multivariate Analysis 84: 61–84. [Google Scholar] [CrossRef] [Green Version]
- Diebold, Francis X., and Roberto S. Mariano. 1995. Comparing predictive accuracy. Journal of Business & Economic Statistics 13: 253–63. [Google Scholar]
- Engle, Robert F. 1982. Autoregressive conditional heteroskedasticity with estimates of the variance of United Kingdom inflation. Econometrica 50: 987–1007. [Google Scholar] [CrossRef]
- Engle, Robert F. 2002. Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models. Journal of Business & Economic Statistics 20: 339–50. [Google Scholar]
- Engle, Robert F., and Kenneth F. Kroner. 1995. Multivariate simultaneous generalized ARCH. Econometric Theory 11: 122–50. [Google Scholar] [CrossRef]
- Engle, Robert F., and Riccardo Colacito. 2006. Testing and valuing dynamic correlations for asset allocation. Journal of Business & Economic Statistics 24: 238–53. [Google Scholar]
- Francq, Christian, Lajos Horváth, and Jean-Michel Zakoïan. 2011. Merits and drawbacks of variance targeting in GARCH models. Journal of Financial Econometrics 9: 619–56. [Google Scholar] [CrossRef] [Green Version]
- Hafner, Christian M. 2003. Fourth moment structure of multivariate GARCH models. Journal of Financial Econometrics 1: 26–54. [Google Scholar] [CrossRef]
- Hafner, Christian M., Helmut Herwartz, and Simone Maxand. 2020. Identification of structural multivariate GARCH models. Journal of Econometrics. [Google Scholar] [CrossRef]
- Hafner, Christian M., and Arie Preminger. 2009. On asymptotic theory for multivariate GARCH models. Journal of Multivariate Analysis 100: 2044–54. [Google Scholar] [CrossRef] [Green Version]
- Lanne, Markku, and Pentti Saikkonen. 2007. A multivariate generalized orthogonal factor GARCH model. Journal of Business & Economic Statistics 25: 61–75. [Google Scholar]
- Laurent, Sébastian, Jeroen V. K. Rombouts, and Francesco Violante. 2012. On the forecasting accuracy of multivariate GARCH models. Journal of Applied Econometrics 27: 934–55. [Google Scholar] [CrossRef] [Green Version]
- Lütkepohl, Helmut. 1996. Handbook of Matrices. New York: John Wiley & Sons. [Google Scholar]
- McAleer, Michael. 2005. Automated inference and learning in modeling financial volatility. Econometric Theory 21: 232–61. [Google Scholar] [CrossRef] [Green Version]
- McAleer, Michael. 2018. Stationarity and invertibility of a dynamic correlation matrix. Kybernetika 54: 363–74. [Google Scholar] [CrossRef] [Green Version]
- McAleer, Michael, Felix Chan, Suhejla Hoti, and Offer Lieberman. 2008. Generalized autoregressive conditional correlation. Econometric Theory 24: 1554–83. [Google Scholar] [CrossRef] [Green Version]
- Noureldin, Diaa, Neil Shephard, and Kevin Sheppard. 2014. Multivariate rotated ARCH models. Journal of Econometrics 179: 16–30. [Google Scholar] [CrossRef] [Green Version]
- Pedersen, Rasmus S., and Anders Rahbek. 2014. Multivariate variance targeting in the BEKK-GARCH model. Econometrics Journal 17: 24–55. [Google Scholar] [CrossRef] [Green Version]
- Silvennoinen, Annastiina, and Timo Teräsvirta. 2009. Multivariate GARCH models. In Handbook of Financial Time Series. Edited by Toben G. Andersen, Richard A. Davis, Jens-Peter Kreiss and Thomas Mikosch. New York: Springer, pp. 201–29. [Google Scholar]
- Tse, Y. K., and Albert K. C. Tsui. 2002. A multivariate generalized autoregressive conditional heteroscedasticity model with time-varying correlations. Journal of Business & Economic Statistics 20: 351–61. [Google Scholar]
- van der Weide, Roy. 2020. GO-GARCH: A multivariate generalized orthogonal GARCH model. Journal of Applied Econometrics 17: 549–64. [Google Scholar] [CrossRef]
Figure 1.
Histograms and QQ plots of 2sQML estimates for DGP1.

Figure 2.
Histograms and QQ plots of 2sQML estimates for DGP1 with full BEKK parameters.

Figure 3.
Comparison of the diagonal specifications for the BEKK and RBEKK models: DGP4.

Figure 4.
Comparison of the diagonal specifications for the BEKK and RBEKK models: DGP5.

Figure 5.
Histograms and QQ plots of 2sQML estimates for DGP1 with .

Figure 6.
Histograms and QQ plots of 2sQML estimates for DGP1 with .

Figure 7.
Histograms and QQ plots of 2sQML estimates for DGP1 with .

Figure 8.
Difference of squared portfolio returns. Note: The solid line shows the value of , defined by Equation (15), while the dotted lines indicate the confidence interval.
Figure 8.
Difference of squared portfolio returns. Note: The solid line shows the value of , defined by Equation (15), while the dotted lines indicate the confidence interval.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Finite sample properties of the 2sQML estimator for the diagonal RBEKK model.
| Parameters | DGP1 | DGP2 | ||||||
|---|---|---|---|---|---|---|---|---|
| True | Mean | Std. Dev. | RMSE | True | Mean | Std. Dev. | RMSE | |
| 1.00 | 1.0150 | 0.5831 | 0.5832 | 0.640 | 0.6375 | 0.2031 | 0.2031 | |
| 0.54 | 0.5492 | 0.3654 | 0.3654 | −0.264 | −0.2635 | 0.0552 | 0.0552 | |
| 0.81 | 0.8250 | 0.7143 | 0.7143 | 1.210 | 1.2067 | 0.1474 | 0.1474 | |
| 0.60 | 0.5853 | 0.0531 | 0.0551 | 0.600 | 0.5855 | 0.0567 | 0.0586 | |
| 0.40 | 0.3921 | 0.0424 | 0.0431 | −0.300 | −0.3032 | 0.0523 | 0.0524 | |
| 0.70 | 0.6939 | 0.0593 | 0.0596 | 0.700 | 0.6920 | 0.0710 | 0.0714 | |
| 0.90 | 0.8921 | 0.0463 | 0.0470 | −0.900 | −0.8666 | 0.1025 | 0.1078 | |
Table 2.
Finite sample properties of the 2sQML estimator for the full BEKK model.
| Parameters | DGP1 | DGP2 | ||||||
|---|---|---|---|---|---|---|---|---|
| True | Mean | Std. Dev. | RMSE | True | Mean | Std. Dev. | RMSE | |
| 0.1392 | 0.1469 | 0.0346 | 0.0354 | 0.0950 | 0.1007 | 0.0262 | 0.0268 | |
| 0.0505 | 0.0559 | 0.0175 | 0.0183 | −0.0319 | −0.0396 | 0.0174 | 0.0190 | |
| 0.0351 | 0.0433 | 0.0165 | 0.0184 | 0.1220 | 0.1707 | 0.1185 | 0.1281 | |
| 0.6249 | 0.6113 | 0.0613 | 0.0628 | 0.6212 | 0.6072 | 0.0582 | 0.0599 | |
| 0.0706 | 0.0685 | 0.0260 | 0.0261 | −0.1644 | −0.1656 | 0.0281 | 0.0281 | |
| −0.0794 | −0.0817 | 0.0375 | 0.0375 | 0.1187 | 0.1181 | 0.0230 | 0.0230 | |
| 0.3751 | 0.3661 | 0.0487 | 0.0495 | −0.3212 | −0.3250 | 0.0542 | 0.0543 | |
| 0.6751 | 0.6678 | 0.0597 | 0.0601 | 0.7376 | 0.7313 | 0.0613 | 0.0616 | |
| −0.0706 | −0.0714 | 0.0266 | 0.0266 | −0.2922 | −0.2912 | 0.0521 | 0.0521 | |
| 0.0794 | 0.0824 | 0.0303 | 0.0304 | 0.2110 | 0.2067 | 0.0360 | 0.0363 | |
| 0.9249 | 0.9195 | 0.0311 | 0.0315 | −0.9376 | −0.9045 | 0.1073 | 0.1123 | |
Table 3.
Average distance between the true and estimated covariance matrices.
| Sample Size | Diagonal RBEKK | Diagonal BEKK | ||||
|---|---|---|---|---|---|---|
| 1.1377 | 3.9358 | 41.047 | 1.5176 | 6.3447 | 64.909 | |
| 0.7883 | 2.7948 | 24.570 | 1.3800 | 5.9794 | 57.433 | |
Table 4.
Engle and Colacito (2006) test.
Table 4.
Engle and Colacito (2006) test.
| Parameter | Estimate | HAC S.E. | t-Value |
|---|---|---|---|
| 0.0010 | 0.0043 | 0.2192 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Asai, M.; Chang, C.-L.; McAleer, M.; Pauwels, L. Asymptotic and Finite Sample Properties for Multivariate Rotated GARCH Models. Econometrics 2021, 9, 21. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics9020021
AMA Style
Asai M, Chang C-L, McAleer M, Pauwels L. Asymptotic and Finite Sample Properties for Multivariate Rotated GARCH Models. Econometrics. 2021; 9(2):21. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics9020021
Chicago/Turabian StyleAsai, Manabu, Chia-Lin Chang, Michael McAleer, and Laurent Pauwels. 2021. "Asymptotic and Finite Sample Properties for Multivariate Rotated GARCH Models" Econometrics 9, no. 2: 21. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics9020021
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.