1. Introduction
Remote sensing satellite data analysis plays an essential role in providing helpful information for urban planning and decision-making [
1]. In addition, the recent sustainability research studies of smart cities depend on remote sensing data analysis [
2]. Remote sensing data are presented in multi-modal form, e.g., aerial images, multispectral images, light detection and ranging (LiDAR) sensors, hyperspectral, and synthetic aperture radar (SAR) sensors [
3]. The satellite image analysis is one of the most critical information analysis in satellite data [
4]. Furthermore, human analysis - techniques for extracting building information are very tedious and inaccurate for the involvement of human expertise quality degree [
5]. Therefore, computer-based systems are more accurate, save time, and save cost, especially in high-resolution satellite images. Computer vision is a computer-based image analysis system that utilizes image content information such as intensities, edges, textures, and morphological [
6]. Such information is beneficial to enhance, segment, detect, or recognize objects inside these images. In the last decade, several computer vision algorithms were introduced for satellite image analysis applications [
7].
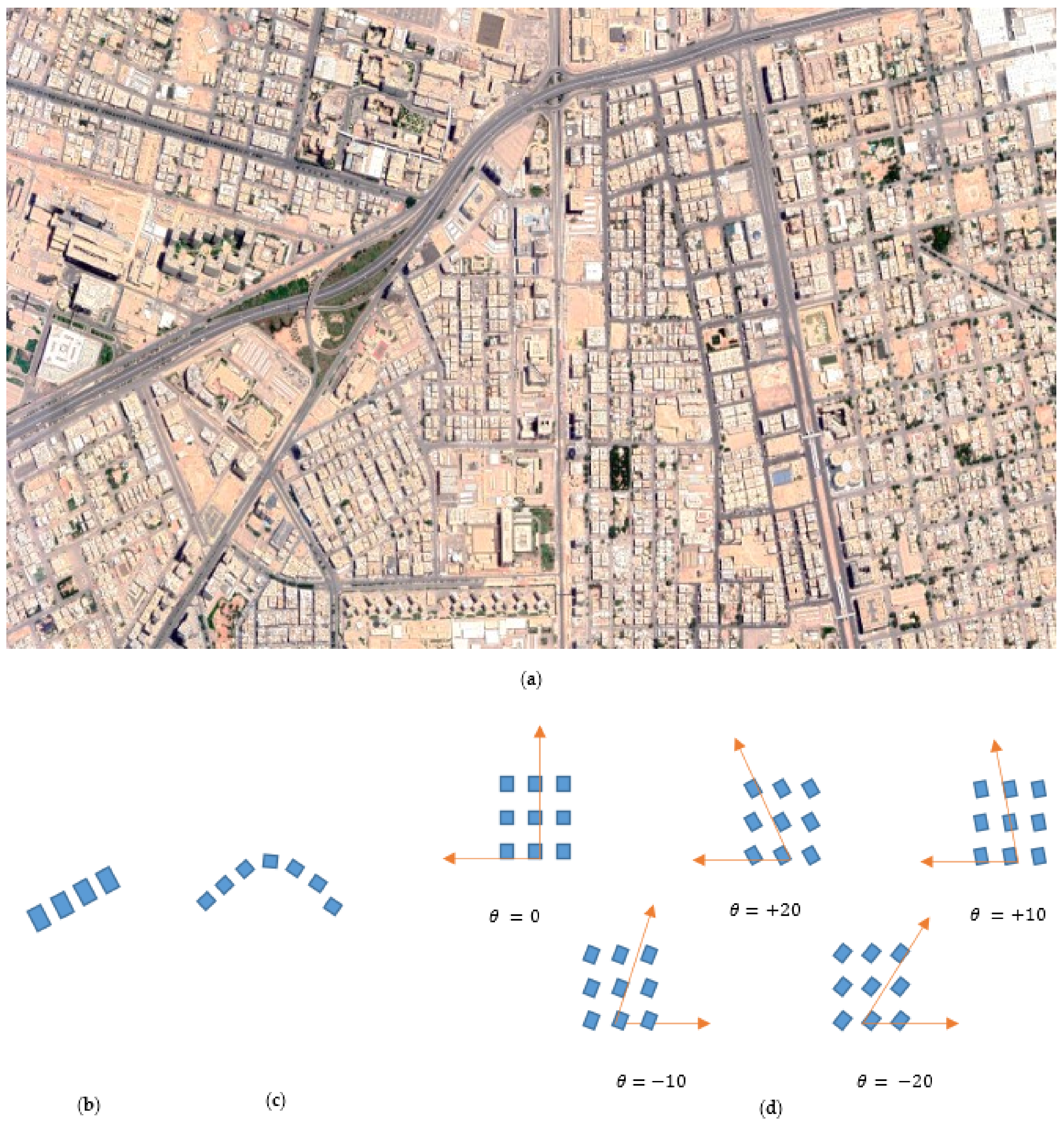
Automated building boundary extraction plays a crucial role in urban planning. The topographic data of building clusters are summarized into linear alignments, and non-linear alignments [
8]. The linear alignments are divided into collinear, curvilinear, and align-along-road. The non-linear alignments are divided into grid and unstructured. These variations of building clusters inside urban planning make it challenging to accurately detect the angle of building orientation inside the satellite high-resolution images to obtain an optimum building boundary extraction. Therefore, the correct building orientation angle plays an essential role in the overall building detection algorithms. A sample of dense buildings satellite image at different building orientation angles (−20, 0, +10, +20) from Riyadh city is shown in
Figure 1a. Different buildings alignments can be modeled such as linear as shown in
Figure 1b, curvilinear as shown in
Figure 1c and grid with different orientation angles as shown in
Figure 1d. There are two main kinds of approaches for applying computer vision applications in satellite images, which are the traditional image processing approaches and deep learning approaches [
9]. There is a challenge to employ recent approaches to analyze the building orientation angle.
Deep learning has been introduced by LeCun [
10] as a subfield of artificial intelligence (AI), in which the computer algorithm learns tasks and distinguishes patterns with just constrained preparing information. Deep learning models can automatically extract the features with no need for feature extraction process [
11]. Deep learning calculations learn designs by advancing through layers in a neural system to reach inferences. These advantages have made the utilization of deep learning a powerful tool in computer vision algorithms. Recently, deep learning shows exponential growing trend in compute vision tasks such as estimation [
12], enhancement [
13], segmentation [
14], detection [
15], and classification [
16]. Deep learning is a powerful tool for a large amount of satellite image analysis tasks [
17]. The deep learning algorithms have been employed in several satellite image analysis such as building detection [
18], ship detection [
19], vehicle detection [
20], crop detection [
21], and water detection [
22]. There is a real need to employ deep learning to estimate some building characteristics in the remote satellite image.
This paper focuses on the building’s orientation angle as an essential characteristic for urban planning and automated building detection algorithms. Our proposed approach is based on the deep learning technique, which has proven its power compared with the traditional computer vision techniques. Deep learning is employed to estimate the angle of building orientation for buildings in Riyadh city collected during this study.
In this paper, our contributions are as follows:
- (1)
We have proposed two deep learning approaches to estimate the building orientation angle in high-resolution satellite images.
- (2)
The first approach based on deep transfer learning was examined using recent deep learning architectures.
- (3)
The second approach is based on a lightweight deep learning architecture called DCRN to estimate building orientation angle.
- (4)
A new early gradient layer has been proposed to overcome the drawbacks of building images and enhance the DCRN architecture performance.
- (5)
A grid search hyper-parameters optimization has been applied to achieve the best performance for the DCRN architecture.
- (6)
We have collected a dataset for Riyadh city that consisted of thousands of building images with different angles to achieve our task.
- (7)
The two proposed approaches has been evaluated using our buildings dataset. Then, we compared our findings with the traditional and deep learning approaches in the literature.
The remainder of this paper is organized as follows.
Section 2 presents the related works of building angle detection, including (1) traditional computer vision techniques, (2) deep learning techniques.
Section 3 introduces our proposed material and methods in detail.
Section 4 presents the experimental section with the proposed approach performance analysis with benchmarking against previous algorithms over our Riyadh-city building datasets.
Section 5 introduces the discussion of our experimental results. Finally, the conclusion is introduced in
Section 6.
2. Related Works
Buildings are one of the most important four patterns inside satellite images that need to be analyzed for optimum urban planning Zhang et al. [
8]. Deep semantic segmentation for buildings received great attention last years Hatamizadeh et al. [
23], Sun et al. [
24], Yi et al. [
25], Liu et al. [
26], Abdollahi et al. [
27], Yi et al. [
25] and Wang and Li [
28].
Another research dimension for building included the deep detection networks Shahin and Almotairi [
29]. In Li et al. [
30], the authors have introduced a building damage detection system based on deep learning. They have utilized the single-shot deep learning detector to detect the damaged area. They have utilized a Hurricane-Sandy dataset collected in 2012 in their study. The study has included only 350 images and achieved 77% average precision. In Zhang et al. [
31], the authors have introduced a deep learning detection algorithm based on masked-RCNN. The authors have combined a fusion image to increase the system performance. The experiments have been applied to Chinese cities. The system achieved intersection over union (IOU) 87.8%. In Ma et al. [
32], the authors have proposed a deep learning detection algorithm based on YOLOv3 for collapsed Buildings in Post-Earthquake. The dataset was collected after the 2008 Wenchuan and the 2010 Yushu earthquakes. The proposed algorithm reached 90.89% average precision.
However, these algorithms were employed for buildings area extraction alone. In addition, they neglected the other building characteristics which are essential in urban planning, such as height, orientation, and damage degree. Furthermore, the deep semantic segmentation techniques usually consume high processing time. The authors did not discuss the building orientation angle characteristic from a regression problem perspective, as challenging to construct a dataset for each building characteristic separately or transform the deep segmentation networks for other estimation tasks.
Several articles have been also introduced for buildings characteristics analysis such as building heights detection Liasis and Stavrou [
33], building roof detection Nemoto et al. [
34], building change detection More et al. [
35], and building damage detection Li et al. [
30]. Several estimation problems has been solved using deep learning approaches for buildings as shown in
Table 1. The buildings heights estimation has been deeply investigated in several previous works Karatsiolis et al. [
36], Li et al. [
37], Liu et al. [
38], and Cao and Huang [
39].
In Karatsiolis et al. [
36], the authors introduced a deep learning model that combines architectural characteristics extracted through U-NET supported with residual connections and learned the height estimation by mapping the aerial RGB images. They achieved an RMSE value of 1.6. However, their model could not predict their heights in the DFC2018 dataset. In addition, the tall and thin buildings were rarely detected. The model sometimes failed to estimate their heights correctly. In some buildings cases, the model also failed to detect them. In Li et al. [
37], the authors introduced a deep regression network that captured building height information with no need for multi-remote sensing perspectives. As a result, their model achieved the lowest RMSE value of 1.4. However, to achieve this target, they employed the ResNet architecture as a feature extractor backbone, then they fine-tuned the end of the network with a regression layer to fit the problem. In Liu et al. [
38], the authors presented an IM2ELEVATION deep learning model based on the multi-sensor fusion of aerial RGB images and lidar data. They have achieved an RMSE value of 3.05. However, the network was very complex, which increased its inference time. Besides that, lidar data is not always available. In Cao and Huang [
39], the authors introduced the M3Net deep learning model based on learning multi-spectral images, RGB images, and near-infrared bands. Moreover, they fed their network with multi-view images nadir, forward, and backward images). As a result, their model achieved an RMSE value of 3.3. Furthermore, their model was compared with single-task networks for height estimation, and they achieved a lower RMSE with the multi-task branching technique. However, the availability of all remote sensing information is challenging to be obtained for each city. In Sun et al. [
40], the authors introduced an orientation estimation Network for outdoor RGB images. They have proposed a model based on fine-tuned MobileNet. They evaluated their model based on the average error, which was relatively high. Their dataset included buildings but not specifically for buildings images. In Amini and Arefi [
41], the authors presented a deep CNN network to detect the collapsed buildings after an earthquake using height estimation. They employed both RGB images and lidar data pre-event satellite image as well as post-event. Their model was evaluated by overall quality metric which has achieved a value of 91.5%.
In this study, we focus on the building analysis in the high-resolution satellite image, especially the studies including building orientation angle calculation. Building orientation angle estimation is an active research point; there are three approaches in the previous studies to detect building boundaries involved with its orientation angle in high-resolution satellite RGB images. The first approach is based on the traditional image processing techniques. This approach has been proposed during building boundary detection, which is based on morphological binary processing. After binary thresholding of the building image, several pre-processing operations have been applied to remove artifacts. The major binary blob was utilized to extract the building boundary edges. Then, the orientation angle has been calculated as in Ghandour and Jezzini [
42]:
where
are two opposites vectors in the building and
is the angle between them.
In Ghandour and Jezzini [
42], the authors proposed a building boundary detection algorithm based on building shadow verification. They have utilized traditional image processing techniques for building roof boundary extraction. They utilized The SztaKi–Inria and Istanbul cities datasets. They have utilized a fusion idea to increase their system performance, which reached 95.8% of accuracy. However, the proposed algorithm lacked robustness in the case of changing the color nature of roof buildings. In Nguyen et al. [
43], the authors have proposed an un-supervised automatic building detection algorithm based on an active contour algorithm. Their experiments have been applied on a dataset collected from Quebec City and Vaihingen City, Germany. The authors utilized LiDAR information to increase the system performance that reached 91.12% intersection of union (IOU).
The second approach is based on the Hough transform Wang et al. [
3]. Hough lines in the Hough transform approach can detect the best fitting line from a set of 2-D points where each pixel in the spatial domain is represented into a sinusoidal curve in Hough space. The algebraic distance from the origin to the line (
) is defined as in Wang et al. [
3]:
where (
x;
y) are coordinates of a point on the line in a Cartesian system,
is the angle of the line’s normal with respect to the x-axis.
In Wang et al. [
3], the authors have utilized the Hough transform approach for LIDAR information to extract the building boundary. Their experiments have been applied to three urban sites: Quantities Village site, Osaka city, and Toronto city. The average accuracy achieved through their proposed system has been 90%. In Bachiller-Burgos et al. [
44], the authors have introduced a building boundary detection based on Hough transform. They have combined corners, segments, and polylines for the detected boundary. They have evaluated their proposed system based on qualitative analysis with no quantitative measurement of their proposed system.
The third approach is dependent on the supervised learning approach. In Kadhim and Mourshed [
45], the authors have introduced a system for building heights detection based on traditional image processing. The authors have utilized graph fuzzy morphological processing to extract the building heights. The algorithm has been examined on seven urban sites in Cardiff, UK. They achieved a mean square error of the overall system reached 21%.
To our knowledge, in the literature, the building orientation angle has not been investigated through a deep learning framework as the main task. However, we have noticed that the learning of the object angle orientation based on deep learning has been discussed in the previous articles as a stage for arbitrary-oriented object detection Chen et al. [
46], Wang et al. [
47], and Tang et al. [
48]. Their orientation estimation networks were based on VGG16 architecture. In Chen et al. [
46], the authors investigated the buildings at three angles only. In Wang et al. [
47], the authors introduced a ship detection model that neglected the evaluation of the ship’s orientation angle estimation accuracy. In Tang et al. [
48], the authors investigated the vehicles orientation angle estimation in the vehicles detection model. However, the achieved RMSE value was very high and reached a value of 74.38. On the other hand, the convolutional regression networks have been previously introduced to estimate the orientation angles in several applications. In Hara et al. [
49], the authors introduced a continuous object orientation estimation for pedestrians, which requires prediction of 0
to 360
degrees. In Phisannupawong et al. [
50], the authors proposed a regression network based on Xception architecture for satellite orientation estimation from the image. However, they employed a simulated images dataset to train their model due to the insufficiency of dataset size. All these previous articles proved the efficiency of deep regression networks for the orientation angle estimation task.
On the other hand, there was a study to detect building orientation angles through SAR information Li et al. [
51]. The authors proposed a mathematical model to estimate the building orientation angle from SAR information in several regions of interest. Their proposed system measured the overall building’s orientation angles inside each region of interest. However, there were several disadvantages of their proposed system. First, their results have been investigated using only the estimated angle’s mean and standard deviation values on limited case studies. Second, the high standard deviation values of the estimated angles of the buildings and the utilized dataset lacked uniform distribution of the buildings’ orientation angles which is more suitable for urban planning. Third, SAR information is produced by generating consequence pulses of radio waves to illuminate the target, and the space-based illuminators equipped with SAR radar lack the continuous availability of the transmitter to illuminate the target Maslikowski et al. [
52].
Several drawbacks have been founded in the previous studies as follows: the dependency on the LIDAR sensor fusion with image information which increased system-processing complexity, the dependency on the traditional image processing for color building roof detection, which lacked robustness, the absence of building detection in a desert environment with no building roof color and low contrast image appearance. Furthermore, the high-resolution satellite RGB images can be captured instantly and provide separate data for each building information suitable for urban planning tasks. Such drawbacks could be tackled using deep learning approaches. In addition, all previous deep learning approaches for building detection neglected the building orientation angle as the main task. In the previous studies, building detection algorithms were involved with building orientation angle detection, which decreased the system performance Chen et al. [
46]. Furthermore, the complexity of roof appearance made the prediction based on roof morphological appearance. Therefore, there is a complexity to modify the loss function of the deep learning detectors. However, the previous datasets lacked a dessert nature like in Saudi Arabia cities, which decreased the image contrast. Therefore, there is a real need to estimate the orientation angle of the building in remote sensing images in the desert environment.
4. Results
We perform our proposed system based on MATLAB 2020a. The system platform contains Quad-Core 2.9 GHz Intel i5 with 16 GB RAM. The GPU computation is done through NVIDIA Quadro 5000 with 16 GB internal RAM and computing capability 6.1. We design seven main experiments to prove our findings as follows: (1) We investigate the performance of our first proposed approach, (2) We investigate the best depth for our proposed DCRN architecture, (3) We investigate the SG layer effect on DCRN architectures with different optimization algorithms, (4) We investigate the performance of DCRN architecture after the hyper-parameters grid-search optimization, (5) We compare between our optimized DCRN approach and the other methods in the literature, (6) We perform a computational cost analysis for our approach vs. the previous methods, and (7) We visualize several examples to answer how each algorithm makes its decision to estimate the correct orientation angle.
In this section, we assess our experimental results based on quantitative and qualitative results. We use the root mean square error (RMSE) value as defined in Equation (
17), mean absolute error (MAE) as defined in Equation (
18) and Adjusted R-Squared value as defined in Equation (
19). Furthermore, we perform a computational cost analysis for our proposed DCRN network. On the other hand, we visualize the learning curves for both training and validation cycles for our proposed DCRN network. In addition, we visualize the activation of our proposed DCRN network.
where
where
is the predicted building orientation angle for instance
i,
is the correct building orientation angle for instance
i with a given
n samples of the test dataset.
K is the number of independent variables.
4.1. Experiment 1
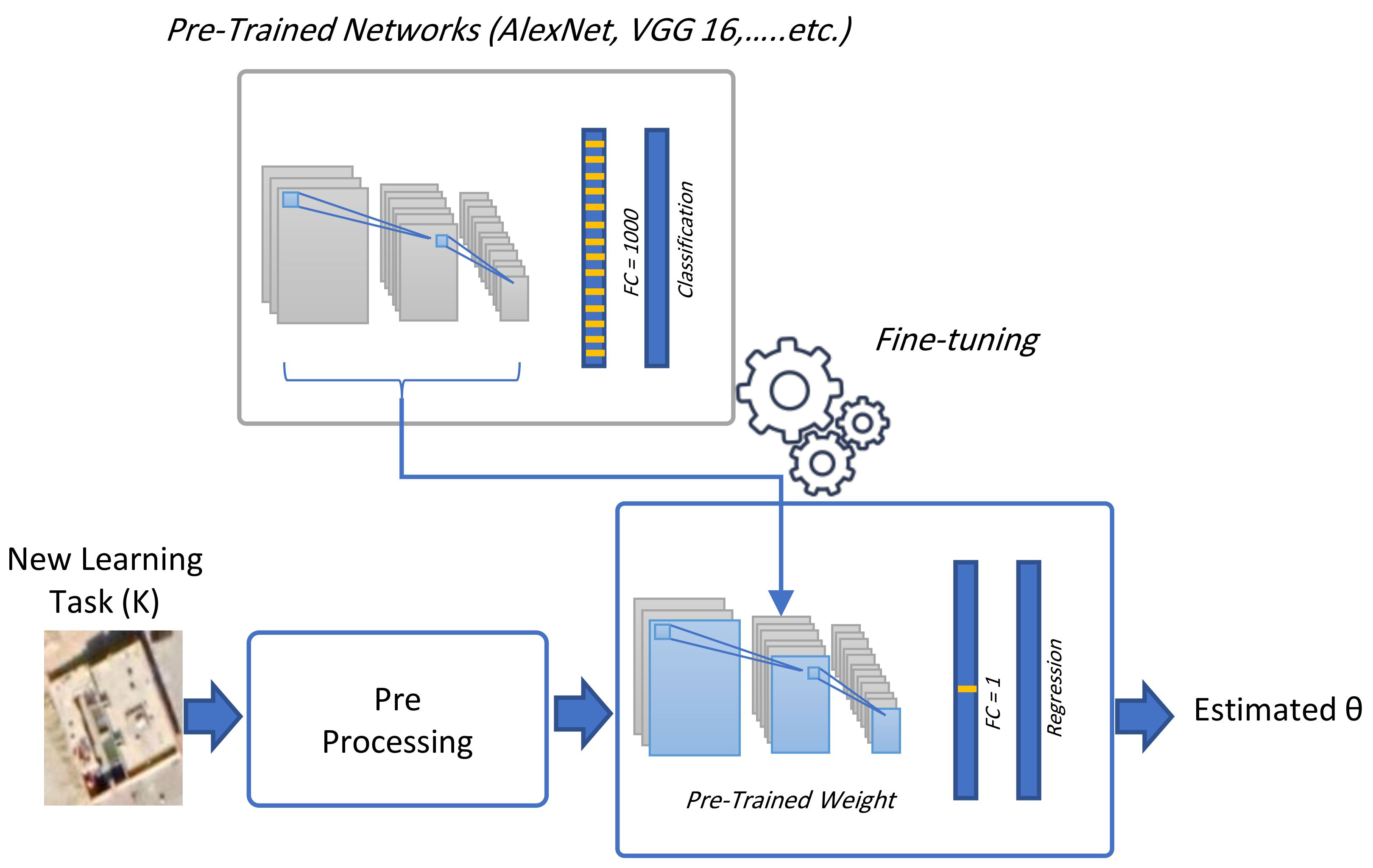
In this experiment, we investigate the transfer learning approach, as shown in
Figure 3. We utilize AlexNet, VGG16, VGG19, GoogleNet, ResNet18, ResNet50, ResNet101, MobileNetV2, and EfficientNet. We employ the RMSE value to compare different pre-trained networks. We have also compared two optimization algorithms during this experiment: adaptive moment estimation (ADAM) and root mean square (RMS). ALL network training parameters are set as follows: learning rate: 0.001, epochs: 30, minimum batch size: 64. As shown in
Table 3, MobileNetV2 has achieved the lowest RMSE value (2.14) with ADAM optimizer and (2.43) with RMS optimizer. EfficientNet has achieved the second rank of the RMSE value (2.18) with RMS optimizer and (2.44) RMSE value with ADAM optimizer. ALL ResNet architectures have achieved low RMS values as follows: ResNet18 (2.31) RMSE value with ADAM optimizer and (2.44) RMSE value with RMS optimizer, ResNet50 (2.67) RMSE value with ADAM optimizer and (2.76) RMSE value with RMS optimizer, and ResNet101 (2.65) RMSE value with ADAM optimizer and (2.58) RMSE value with RMS optimizer. AlexNet has achieved a high RMSE value (5.06) with the ADAM optimizer and (4.21) RMSE value with the RMS optimizer. On the contrary, both VGGNet models have achieved the worst RMSE values. VGGNet16 has achieved the highest RMSE value (147.48) with ADAM optimizer and (79.98) RMSE value with RMS optimizer. VGGNet19 has achieved a high RMS value (103.14) with ADAM optimizer and (34.5) RMSE value with RMS optimizer.
4.2. Experiment 2
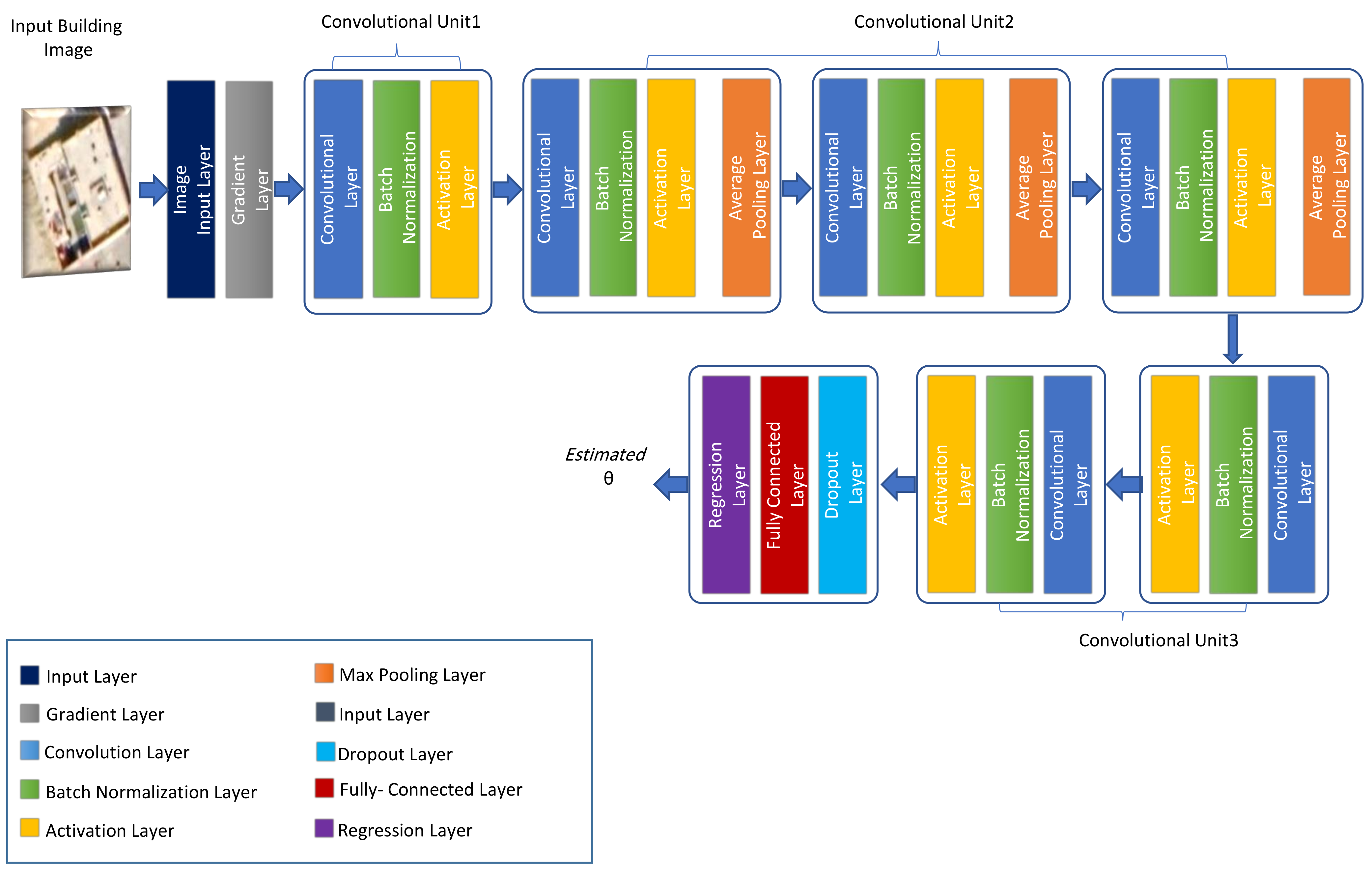
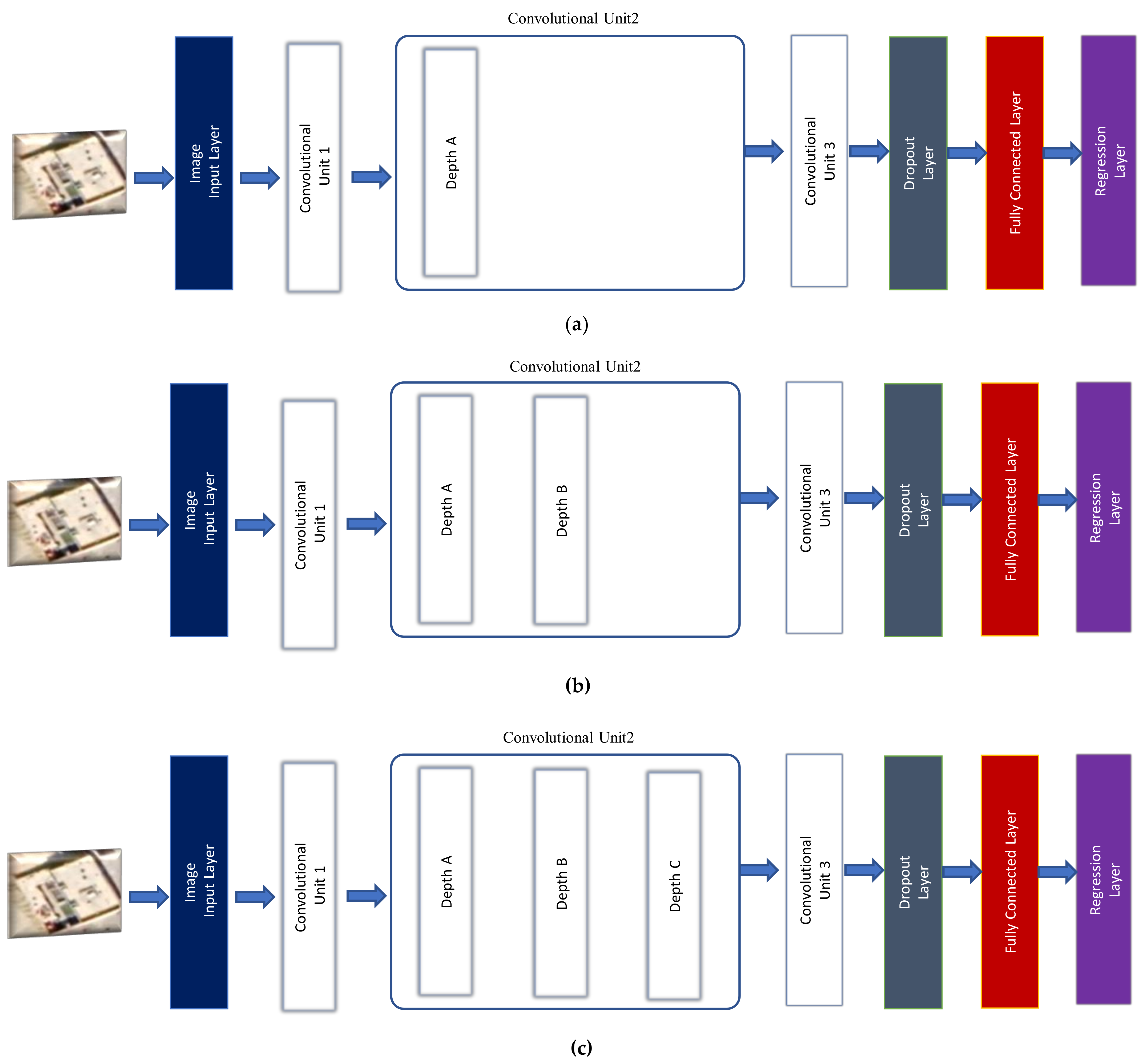
In this experiment, we investigate the performance of the second proposed DCRN approach. The network’s depth is considered an important parameter to determine the network performance. Therefore, we investigate the depth of convolutional unit 2 variation. This experimental setup utilizes the RMSE value to compare different depths, as shown in
Figure 6. The network training parameters setup is as follows: learning rate: 0.001, epochs: 30, minimum batch size: 64.
Figure 6 shows the details of variation of convolutional unit 2 in its depth. We keep the remind of DCRN fixed without using the SG layer.
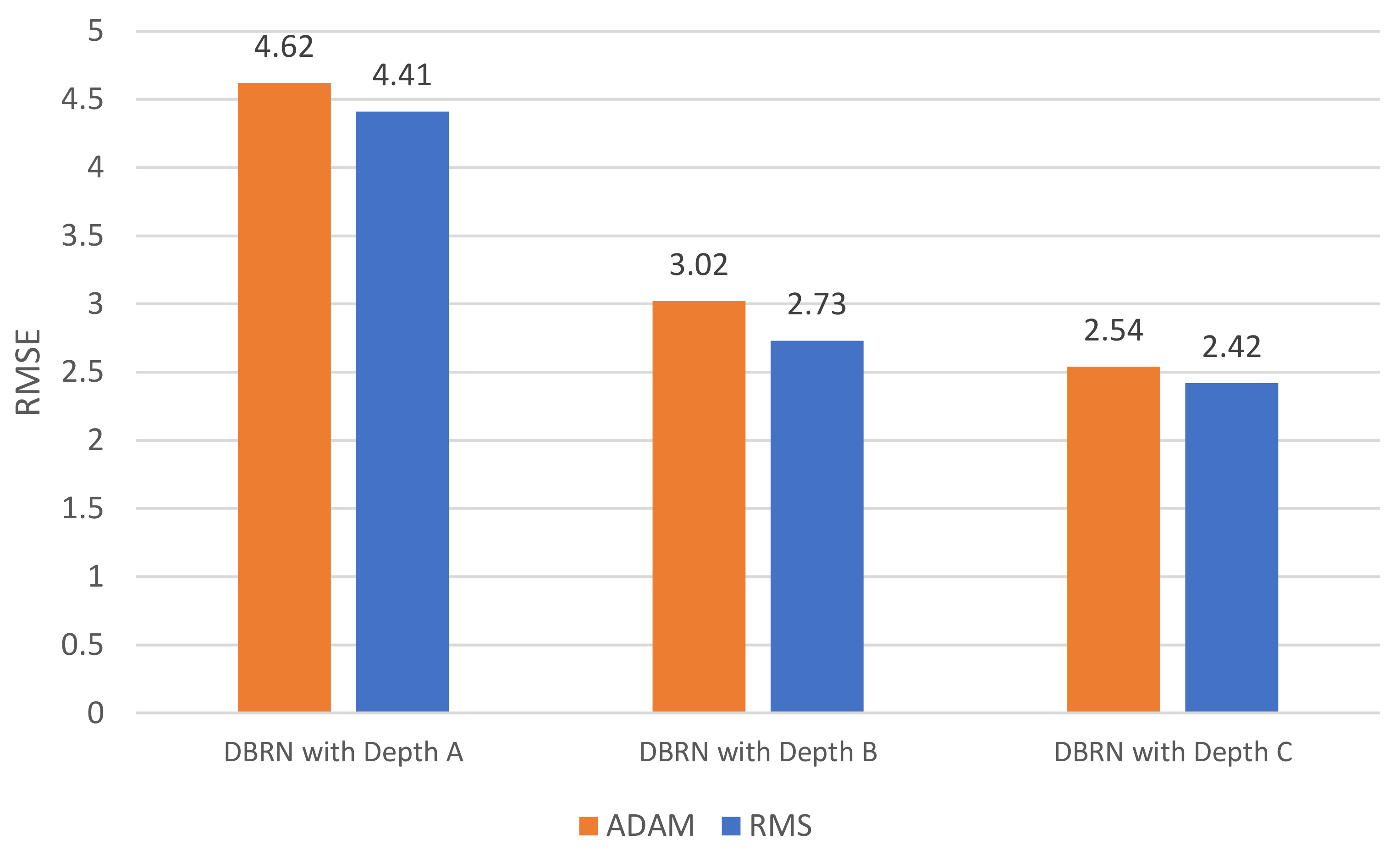
As shown in
Figure 7, the DCRN with depth A has achieved the highest RMSE values with both utilized optimizers. The ADAM optimizer has achieved 4.62 RMSE value and RMS has achieved 4.41 RMSE value.DCRN with depth B has achieved 3.02 with ADAM optimizer and has achieved 2.73 with RMS optimizer. The lowest RMSE values have been achieved by using DCRN with depth C. The DCRN architecture with depth C has achieved 2.54 with ADAM optimizer and has achieved 2.42 with RMS optimizer.
4.3. Experiment 3
In this experiment, we investigate the SG layer effect on the proposed DCRN architecture. The network training setup is as follows: learning rate: 0.001, minimum batch size: 64, and epochs: 30. As shown in
Table 4, the proposed DCRN has achieved the RMSE value (1.8914) using the RMS optimizer. However, the proposed DCRN has achieved an RMSE value (1.9372) using the ADAM optimizer. The RMS optimizer has achieved the Adjusted R-squared value (0.9104). However, the ADAM optimizer has achieved the lowest Adjusted R-squared value (0.9025) with our proposed DCRN architecture.
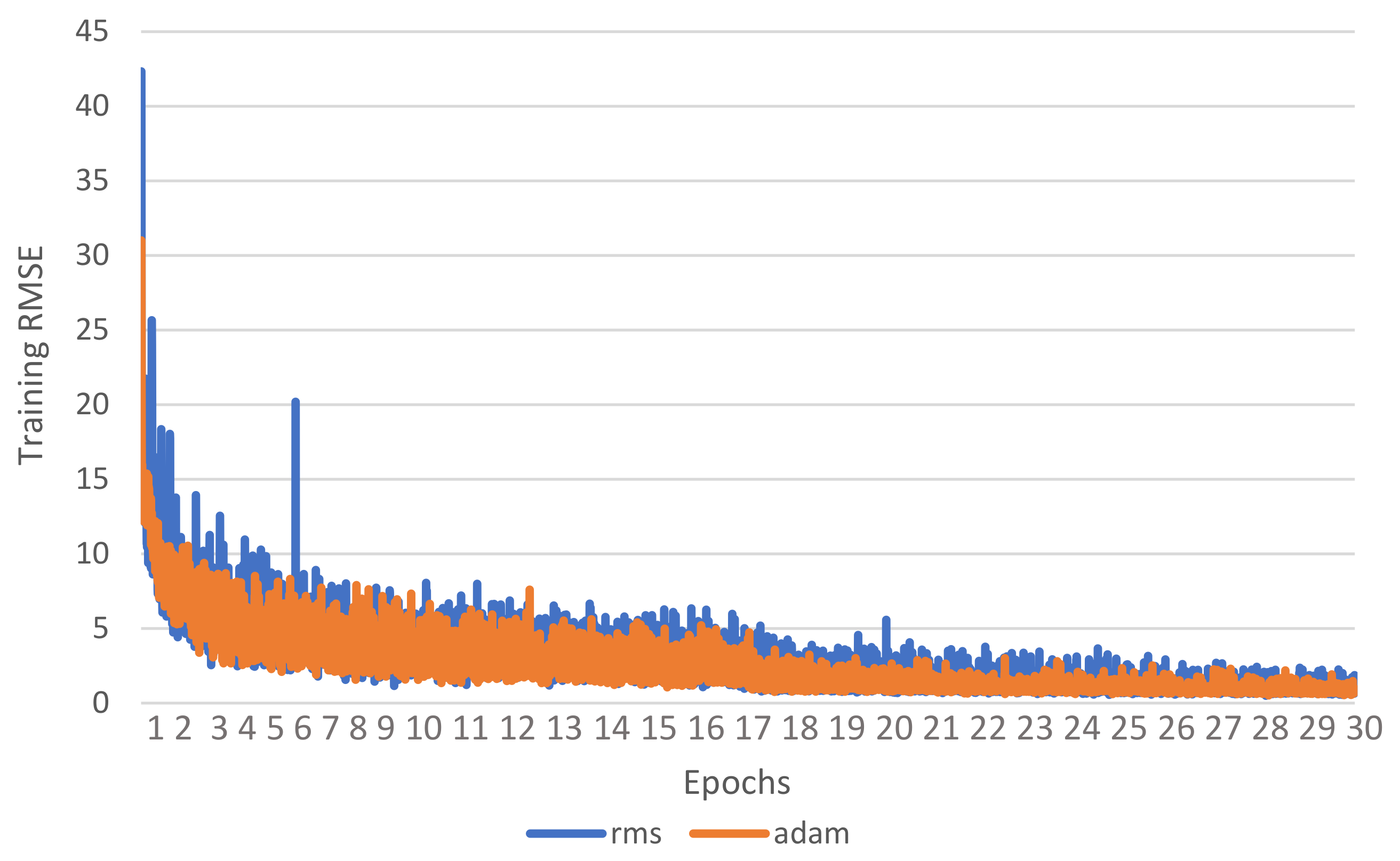
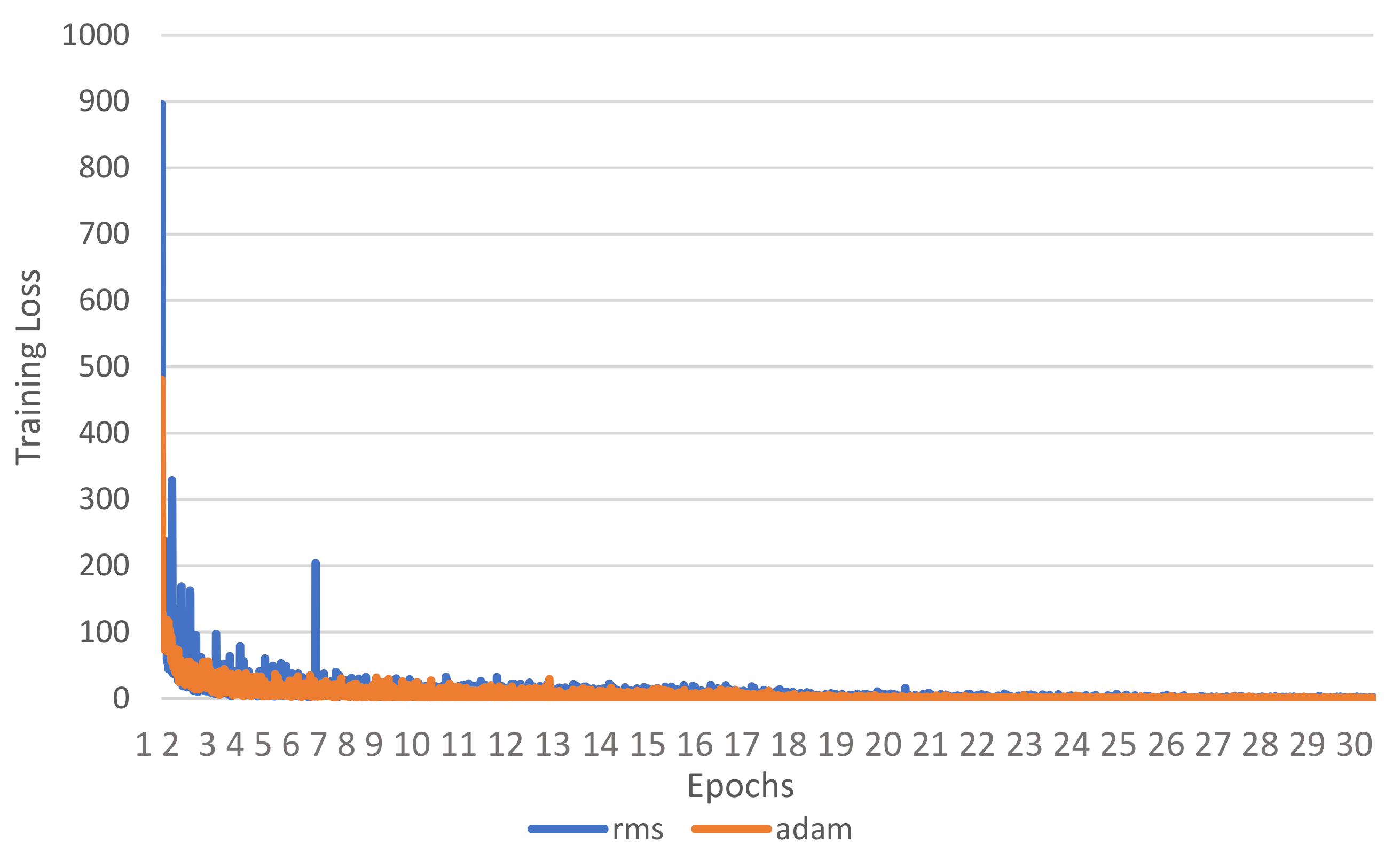
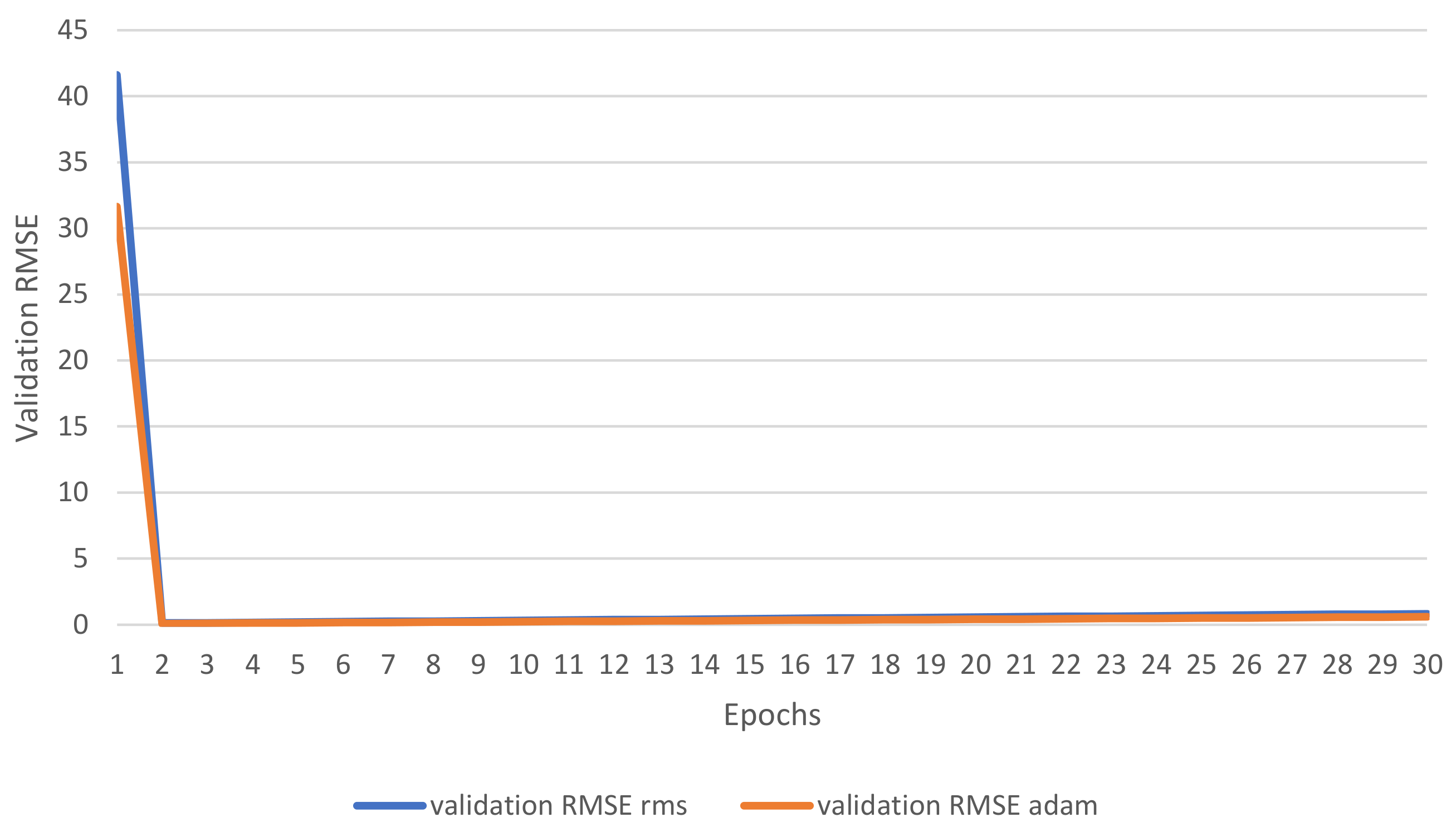
Also, in this experiment, we investigate both loss and RMS learning curves using our proposed SG layer with the architecture of depth c based on RMS and ADAM optimizers. The loss and RMS for the training set are shown in
Figure 8 and
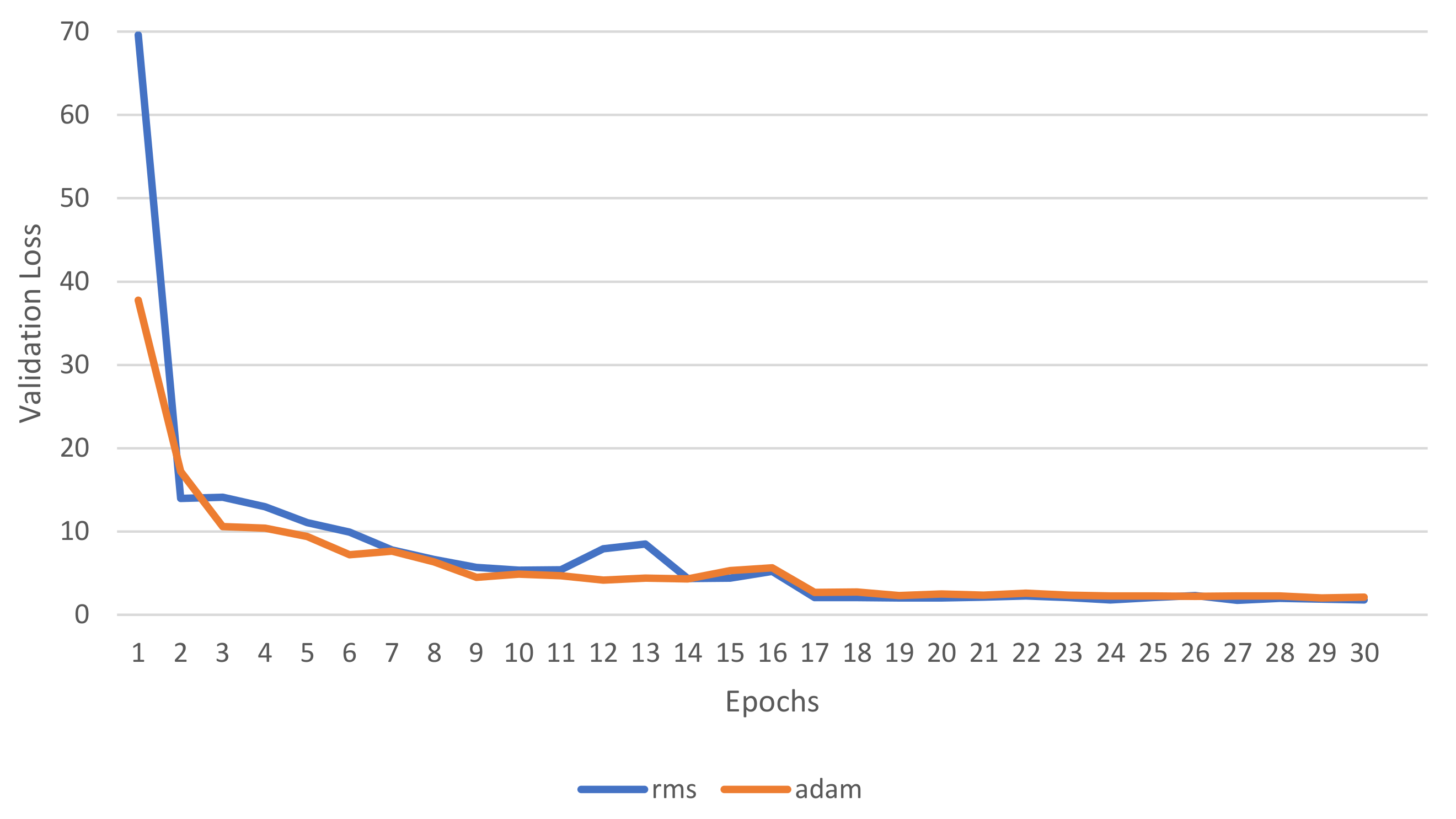
Figure 9. The loss and RMS for the validation set are shown in
Figure 10 and
Figure 11.
We have noticed that both learning curves during the training cycle are oscillating and starting with high values as shown in
Figure 8 and
Figure 9. In
Figure 10 and
Figure 11, we visualize both learning curves during the validation cycle. In this experiment, the RMS optimizer loss and RMSE value have started highly during the first epochs However, the performance of both optimizers are very similar at the end of the epochs.
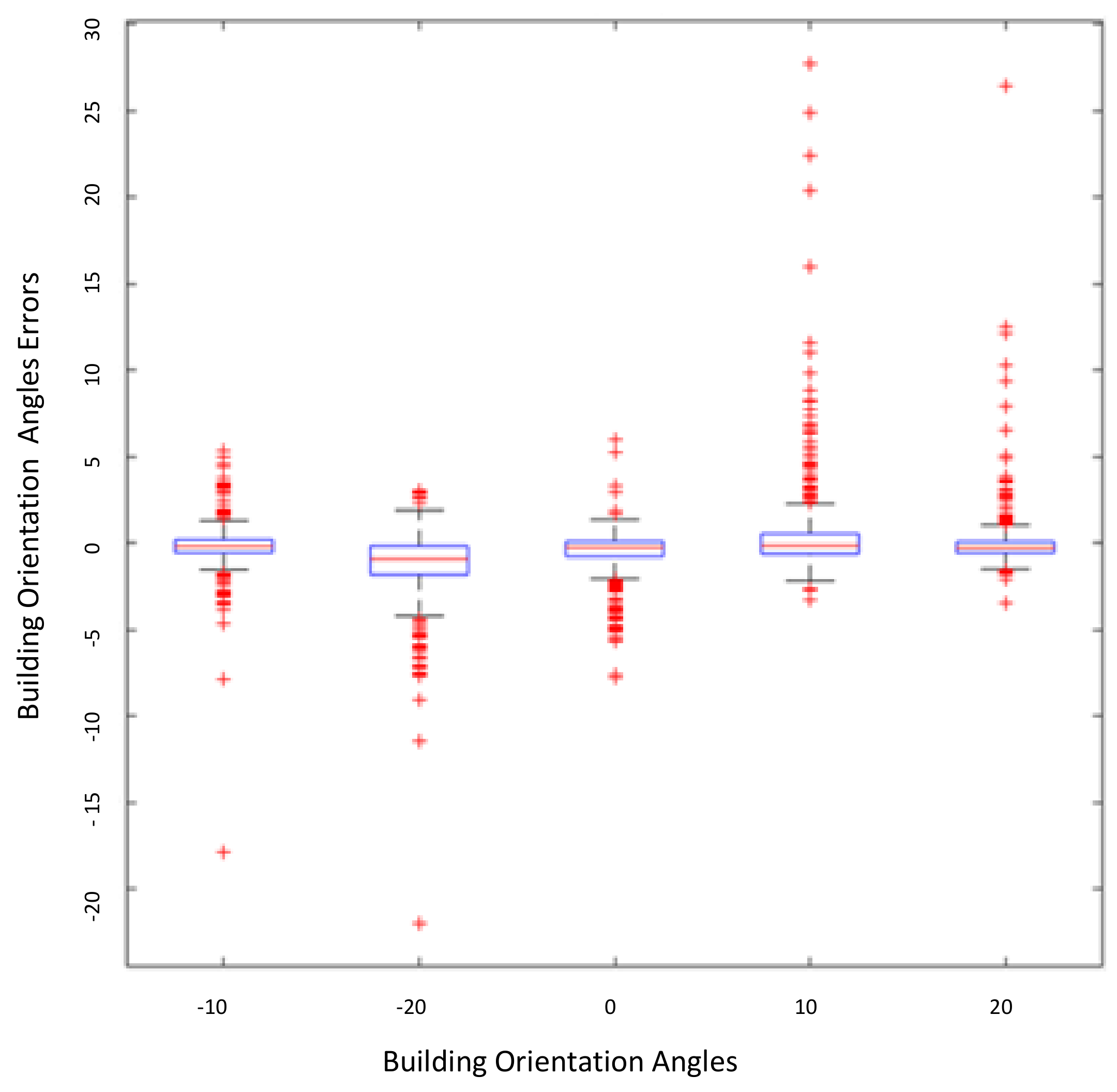
We visualize the residual plots of our proposed optimized DCRN approach for estimating the different building orientation angles as shown in
Figure 12. The building orientation angle 0 has achieved the smallest boxplot with the lowest angle error variation between the angles. Similar boxplots are noticed for the estimation of angles (10, 20, and −10). However, the boxplots represent the estimation of (−20) angle is the largest boxplot. The angle 10 represents the largest variation between the angle’s errors.
In this experiment, we visualize the robustness of our proposed method with the variation of the building image contrast as shown in
Figure 13. We apply our proposed algorithm by simulating several contrast values in range [0–1]. The contrast variation is applied to the five angles in the test set.
4.4. Experiment 4
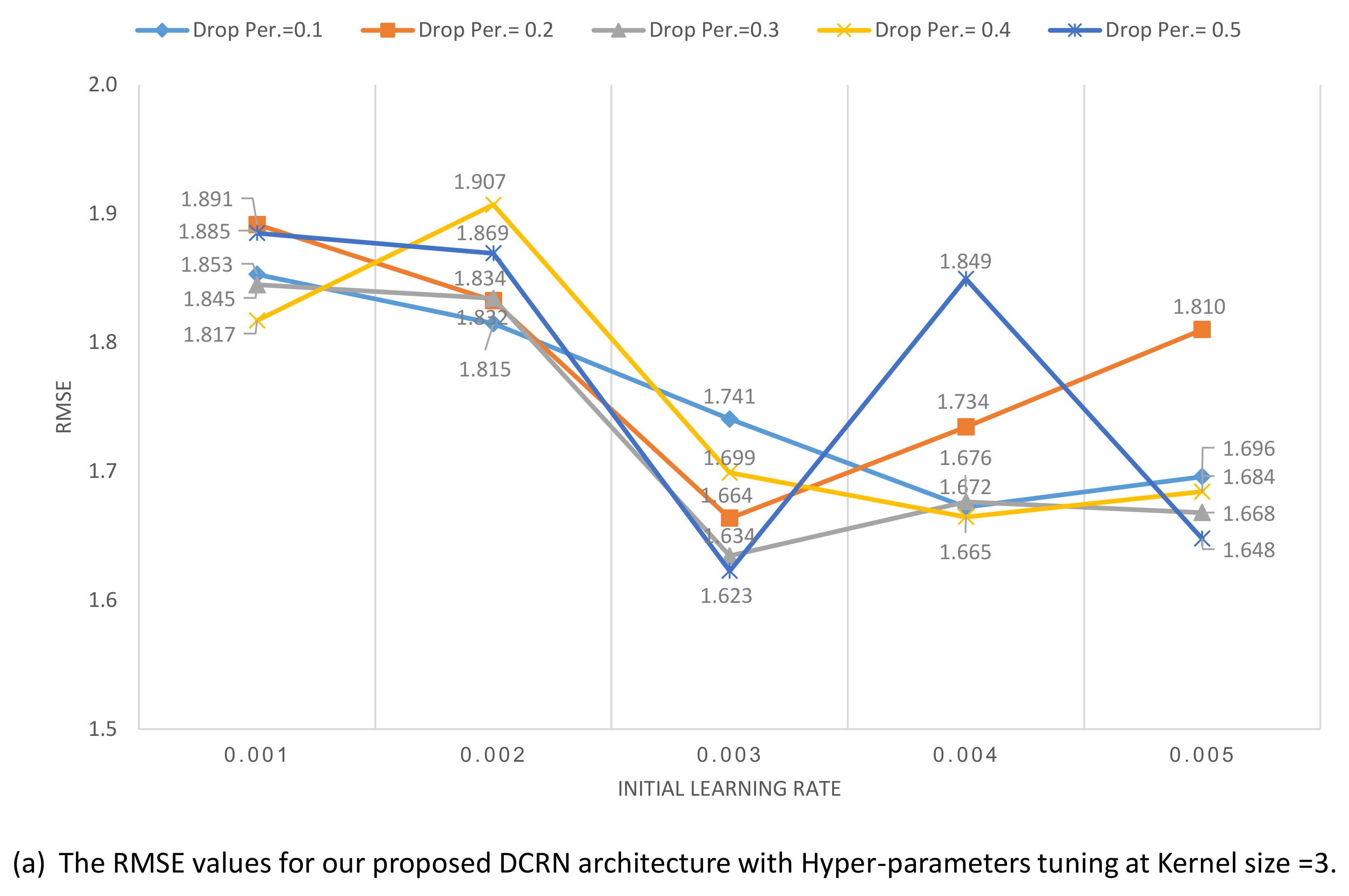
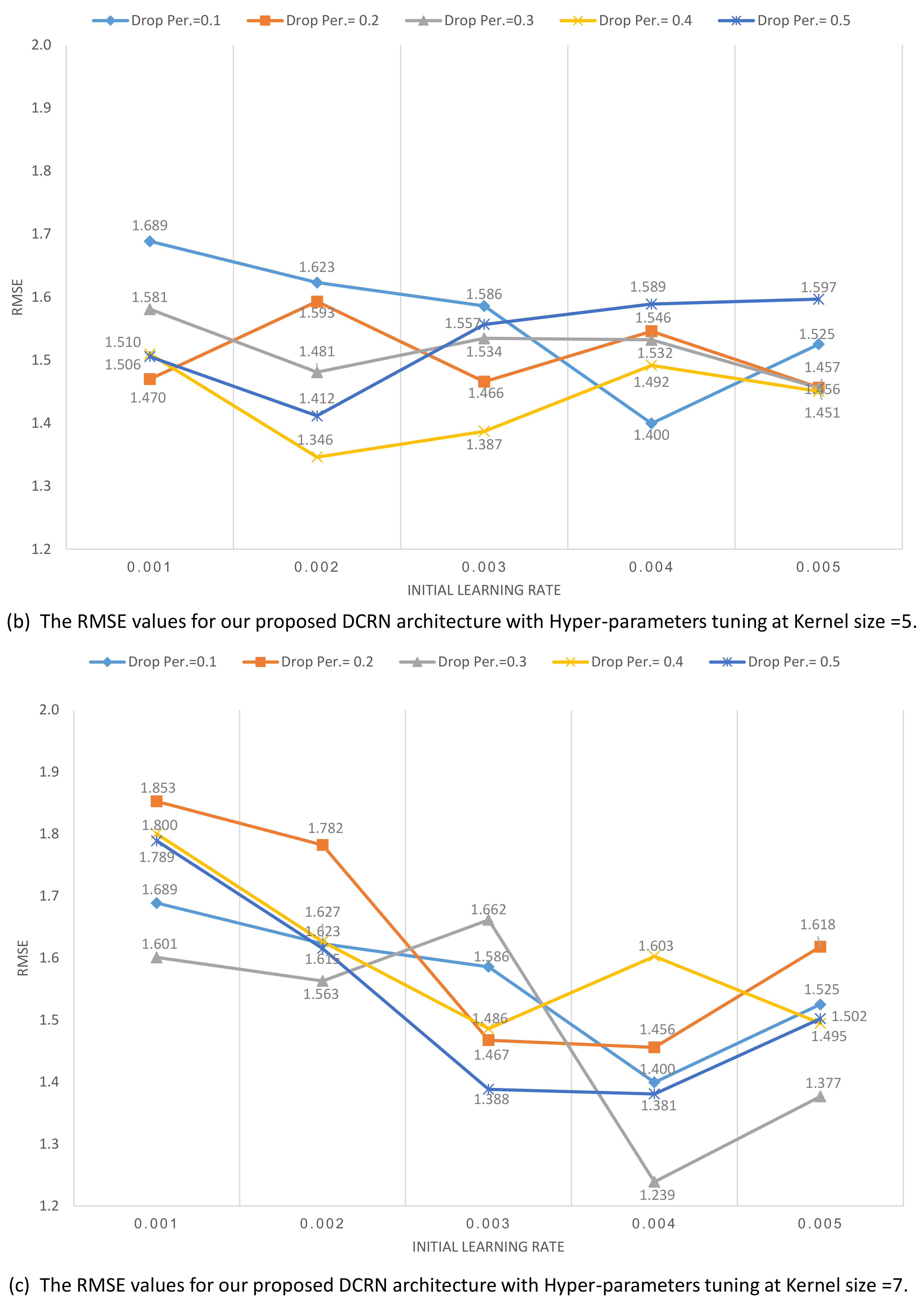
After investigating the DCRN depth layers and the best optimizer that working with it. We investigate the other hyper-parameters for DCRN architecture as shown in
Figure 14. We investigate the dropout percentage, initial learning rate, and kernel sizes in each layer. The investigated hyper-parameters were examined as follows: dropout percentage (0.1, 0.2, 0.3, 0.4, 0.5), kernel size (3, 5, 7), and Initial learning rate (0.001, 0.002, 0.003, 0.004, 0.005). The results of hyper-parameters tuning of our proposed DCRN at kernel size = 3, 5, and 7 are shown in
Figure 14a–c, respectively.
In this experiment, we have utilized the Experiment Manager tool in MATLAB 2020a which has generated 75 individual experiments. The lowest RMSE value (1.239) has been achieved with kernel size 7, initial learning rate 0.004, and drop percentage 0.3. Moreover, the optimized DCRN has achieved an Adjusted R-squared value of 0.99. The highest RMSE value (1.906) is achieved with kernel size 3 initial learning rate 0.002 and drop percentage 0.4.
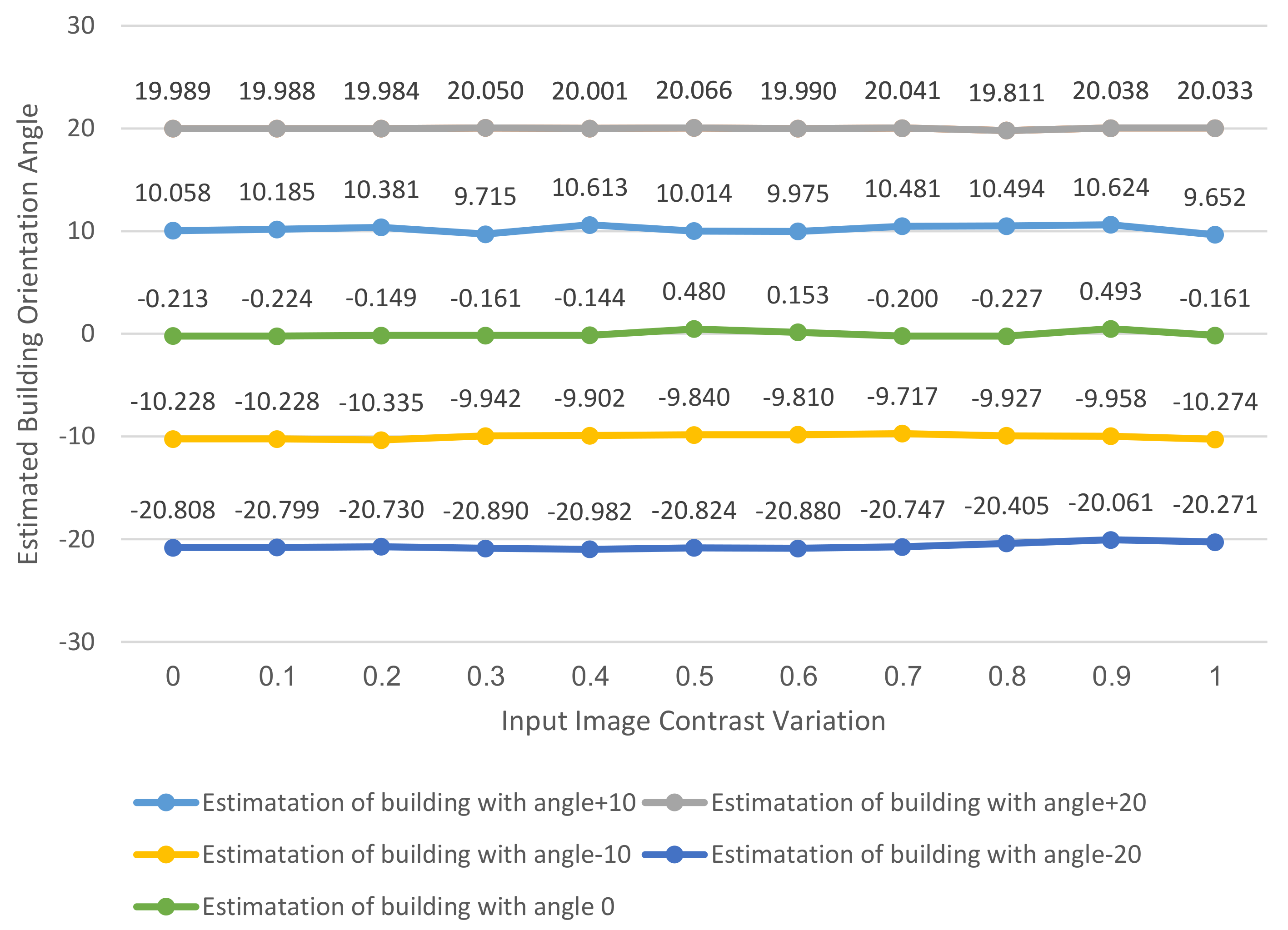
In
Table 5, we calculate the mean and the standard deviation (SD) values for the estimated angles results with the contrast variation of the input images. The estimation of buildings with orientation angle −10 has achieved the nearest mean value of 10.01 and the estimation of buildings with orientation angle 20 has achieved the lowest SD error. The estimation of buildings with orientation angle −20 has achieved a mean value of −20.61. On the contrary, the estimation of buildings with orientation angle +10 has achieved the largest SD value of 0.33.
4.5. Experiment 5
In this experiment, we compare our proposed optimized DCRN and the previous methods. The first method is based on morphological binary processing [
42], the second method is based on Hough transform processing [
3], and the remind methods are based on deep regression networks [
46,
49,
59,
60]. Firstly, to prove the generalization ability of our proposed approach, we visualize the building orientation angles mean ± variance values through all test set as shown in
Table 6. Secondly, we have selected random test samples with different building sizes, building designs, roof shapes, and roof colors to visualize our proposed approach robustness with buildings shape and color change.
The morphological processing approach has achieved its best performance when estimating angle −10 with a mean value of −13.44. However, the variance error has a value of 1692.43. The morphological processing approach has failed to estimate the building orientation angles 0, 20, and −20. The Hough transform approach has achieved its best performance when estimating angles −20 with a value of −23.03. However, the variance error of the estimation of angles −20 was high. The Hough transform approach has failed to estimate the orientation angles for angles 0, 10, and 20. The deep learning approach1 [
46] has achieved its best performance during the estimation of buildings’ angles with a value of −10. However, the variance error was high at 22.74. It has achieved the worst results during the estimation of angle −20 with the highest variance value of 33.94. The deep learning approach2 [
59] has achieved its best performance during the estimation of buildings’ angles with a value of −10. The deep learning approach3 [
49] has achieved its best performance during the estimation of buildings’ angles with a value of 10. The deep learning approach4 [
60] has achieved its best performance during the estimation of buildings’ angles with a value of 0. The deep learning approach4 has achieved the nearest mean value for estimating the building’s orientation angle 0. Our proposed approach has achieved the nearest mean values compared to the previous methods for estimating buildings with orientation angles −10, −20, and 20. For the estimation of angle −10, our optimized DCRN approach has achieved an average estimated value of −10.03 with a low variance error of 0.62. For the estimation of angle −20, our optimized DCRN approach has achieved an average estimated value of −19.8 with a low variance error of 1.03. For the estimation of angle 20, our optimized DCRN approach has achieved an average estimated value of 19.97 with a low variance error of 1.01. Finally, Our optimized DCRN approach has achieved the lowest mean absolute error for the angles’ means values with a value of 0.16.
For more explanation, we visualize ten different samples of building images as shown in
Table 7. The second column represents the original image sample, the third column represents the correct orientation angle of the building sample, the fourth column represents the estimated orientation angle based on morphological processing approach, the fifth column represents the estimated orientation angle based on the Hough transform processing approach, from sixth to ninth columns represent the estimated orientation angles based on the previous deep learning networks. Finally, the last column represents the estimated orientation angles based on our optimized DCRN approach.
4.6. Experiment 6
In this experiment, we perform a computational cost analysis for our proposed approach vs. the previous methods at two levels. In the first level, all methods are compared based on training and inference processes. We compare our proposed DCRN approach vs. the previous deep learning approaches, as shown in
Table 8. In the second level, all methods are compared based on inference process only. we compare our proposed DCRN approach and the other buildings’ angle orientation estimation techniques based on traditional image processing, as shown in
Table 9.
Our proposed DCRN approach has achieved the lowest training time, with 19 min. On the other hand, the deep learning approach2 has achieved the second rank for training time with 20 min. The deep learning approach1 has achieved the third rank of the training time with 31 min. The deep learning approach4 has achieved a high training time of 38 min. The deep learning approach3 has achieved the highest training time with 248 min. Our proposed DCRN and the deep learning approach2 have achieved the lowest inference time with 0.01 s. Our proposed DCRN approach and deep learning approach2 have achieved the lowest inference time with a value of 0.01 s. The deep learning approach3 has achieved the highest inference time with a value of 0.03 s. Our proposed DCRN approach has achieved a low training/inference ratio with a value of 1.14 × . The deep learning approach4 has achieved a similar training/inference ratio similar to our proposed DCRN approach. The deep learning approach1 has achieved the lowest training/inference ratio with a value of 9.3 × .
As shown in
Table 9, our proposed DCRN approach has achieved the highest performance of mean value 0.01 s of the processing inference time. The Morphological processing approach has achieved the mean value of 0.29 s of the processing inference time with the least variance value. The Hough transform approach has achieved the highest mean value of 0.56 s of the processing inference time.
4.7. Experiment 7
In this experiment, we try to answer the question of “how is the decision-making in each algorithm?” Each algorithm follows some procedures to get the ordination angle of the building. We visualize ten different samples of building images as shown in
Table 10. The second column represents the original image sample, the third column represents the morphological processing approach, the third column represents the Hough transform processing approach, and the last column represents our proposed DCRN approach. In each algorithm, the estimated orientation angle is calculated by different methodologies. In the morphological approach, the angle is detected through the biggest binary blob in the image. In the Hough transform approach, the angle is detected through the average orientation angles of lines detected on the corners. In our proposed approach, the angle is detected through the convolutional filters, which are applied to the input images. Then, the filters construct their learnable parameters through the training process. In our proposed DCRN approach, we visualize the strongest activation kernel. As the complexity of building roof appearance, the unsupervised approaches reflects the low performance of estimated orientation angle. However, CNN features in most of the images reflect the main edges of the building, which reflect on the effectiveness of orientation angle estimation.
5. Discussion
In experiment 1, the plain networks have demonstrated a low performance. Furthermore, the VGGNet architecture failed to estimate building orientation angle after fine-tuning. AlexNet has achieved a high RMSE value with both utilized optimizers. Inception GoogleNet architecture has achieved a better performance than plain networks. Moreover, GoogleNet has achieved a lower RMSE value than ResNet18 architecture with ADAM optimizer. However, ResNet18 architecture has achieved a lower RMSE value than GoogleNet architecture. Both of EffiicentNet and ResNet18 have achieved a similar RMSE value with the RMS optimizer. We have concluded that the RMS optimizer has increased the effectiveness of deep plain networks such as AlexNet, VGG16, and VGG19. Besides that, the RMS optimizer has also increased the performance of ResNet101 architecture. Moreover, the ADAM optimizer has enhanced the performance of GoogleNet, ResNet18, ResNet50, MobileNetv2, and EfficientNet. We have concluded that the transfer-learning approach from image classification task to image regression task has some limitations in its accuracy and consumes long training time. The need to highly upsampling of the input image size to fit the pre-trained networks may decrease the estimation accuracy. The boundary of the buildings which visually detect each building orientation angle has low contrast in color images which makes a real need to increase the buildings’ boundary using image processing sharpening techniques.
In experiment 2, the proposed DCRN architecture with depth c has achieved the highest performance with the RMS optimizer. This means that increasing the network depth increased the overall system performance. We have concluded that DCRN architecture C has achieved the best performance that confirmed that the increase of DCRN architecture depth has increased the proposed model performance. However, DCRN with depth A and depth B has achieved a lower accuracy than architecture with depth C. On the other hand, our proposed DCRN architecture has achieved the lowest performance with depth A. In our proposed DCRN, the RMS optimizer has worked better with different DCRN depths. We have found that our proposed DCRN approach achieved lower RMS value than transfer-learning approach. From experiment 2, it is demonstrated that training a deep regression network from scratch is better than pre-trained networks fine-tuning. The color information for building orientation angle estimation is not useful. The low image input layer for the deep network as in our proposed DCRN network has performed better than the high size image input layer in the pre-trained networks.
In experiment3, our proposed SG layer has enhanced the performance of DCRN architecture as expected from experiments 1 and 2. The proposed gradient layer has solved the shadows, poor building edges appearance, and low contrast problems. Moreover, the SG layer has worked better with the RMS optimizer and has achieved the highest performance. We have found that the RMS optimizer during training and validation phases has highly oscillated more than ADAM optimizer. However, it achieved a 1.8 RMSE value lower than the ADAM optimizer in the existence of the SG layer. Both evaluation metrics RMSE and Adjusted R-squared values have proven the superior performance of the RMS optimizer with our estimation task. The gradient layer was very efficient and help the deep network to extract more discriminated features.
In experiment 4, we have performed the hyper-parameters tuning for our proposed DCRN architecture to achieve the best performance. The lowest RMSE values have been achieved with the high kernel size (7), the second rank of the lowest RMSE value has been achieved with kernel size (5). Experiment 4 has demonstrated that the small kernel size has increased the RMSE value for our proposed DCRN architecture and has decreased its performance. Furthermore, the lowest RMSE value has been achieved with the high initial learning rate (0.004), the second rank of the lowest RMSE value has been achieved with the initial learning rate (0.003). Experiment 4 has demonstrated that the low learning initial rate value has increased the RMSE value for our proposed DCRN architecture and consequently has decreased its performance. Finally, the lowest RMSE value has been achieved with the low drop percentage (0.3), the second rank of the lowest RMSE value has achieved with drop percentage (0.1). Furthermore, the high drop percentage value has increased the RMSE value for our proposed DCRN architecture and has decreased its performance. We have concluded that the hyper-parameters tuning plays a crucial role in our proposed DCRN network performance. The residual plots error variation through the estimated angles reflect the low performance during the estimation of −20 angle. However, the error variation in all other angles is accepted. This provides an additional evidence for the superior capabilities of deep regression networks to extract building characteristics from high-resolution satellite images. We have proved the robustness of our proposed approach with the variation of building image contrast. We have noticed the stability of our building orientation angle estimation approach with different contrast conditions. We have noticed that each building orientation angle estimation has been varied individually with the contrast variation.
In experiment 5, we compare our proposed approach and the traditional image processing techniques and the other deep learning techniques. The results showed that the high superiority of our proposed DCRN architecture compared with the previous methods. The morphological-based approach lacked robustness and achieved the highest error values. This bad performance of traditional morphological binary processing refers to the sensitivity of the algorithm to the details inside the building roof, the design of the building, and the shadows effect. Furthermore, Hough transform-based approach has achieved better performance than the morphological processing approach in some of the angles estimation results. However, the Hough lines are very sensitive to non-real corners of the building because of the variation of roof design. In some samples, the two previous approaches failed to estimate the direction of orientation angles. The deep learning approach1 based on VGG16 and the deep learning approach2 based on AlexNet have achieved the worst estimation results among the other deep learning approaches. The deep learning approach3 based on ResNet101 architecture and the deep learning approach4 based on Xception architecture have achieved better results than VGG16 and AlexNet Architectures. On the other hand, our optimized DCRN approach has achieved the best results in most samples. Our proposed approaches have achieved the lowest error values. The deep learning approach presented in [
46] was embedded with the detection task. This proves that a separated network for object orientation detection is better than the embedded one [
46]. Our optimized DCRN approach reflects its super-capability in the estimation of building orientation angle with the minimum error values from different angles after hyper-parameters optimization.
In experiment 6, we have performed a computational cost analysis for our proposed approach and the other approaches in the literature. The findings clearly has indicated that the plain networks have achieved the lowest training time, inference time, and training/inference ratio. Furthermore, our proposed DCRN architecture has achieved the lowest training and inference time. The deep learning approach2 based on AlexNet architecture has a similar inference time as our proposed DCRN approach. However, the deep learning approach4 based on Xception architecture has the same training/inference ratio as our proposed DCRN approach. Our Proposed DCRN architecture has achieved a lower processing time than the Hough transform-based and morphological-based approaches. The morphological-based approach has achieved the highest error values with a high variance of processing time. However, our proposed DCRN has achieved the lowest error values with the lowest variance of the processing time.
In experiment 7, we visualize the CNN features aiming to ensure the effectiveness of our proposed DCRN architecture. The visualization of the previous methods has ensured that the problems found in these methods required more processes, which increased the algorithm’s complexity. The building’s roof shapes are very complex, and finding the edges of such shapes is very difficult. Furthermore, sharped corners and the variations in building roof design generated corners, which confused the Hough transform algorithm. However, the visualized activated kernels of the highest kernels show that the correct edges of the building with correct orientation angles were detected.





































































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}