
Effective Voting Ensemble of Homogenous Ensembling with Multiple Attribute-Selection Approaches for Improved Identification of Thyroid Disorder

 , ,
, ,  , , and
, , and
Abstract
:1. Introduction
1.1. Research Contribution
- Researchers achieved a lot of success in detecting thyroid illnesses, however, it is advised to utilize several parameters to diagnose thyroid problems. More criteria would necessitate more clinical testing for patients, which would be both costly and time-demanding. As a result, predictive models must be constructed which use as few parameters as feasible in detecting the illnesses while preserving both money and time for patients. When compared to prior studies, the dataset of this research contributes fewer, but very crucial and effective characteristics for better diagnosis of the disease;
- It is critical to clean the sample data before modeling to assure that the data best reflect the situation. A dataset may comprise the missing and extreme values that are outside of the anticipated range and differ from the rest of the data. These are known as outliers, while the understanding and elimination of these outlier values may frequently enhance the performance of the machine-learning models. Therefore, in this study, the early preprocessing includes the detection and replacement of the missing values and the outliers with the mean values of the used features;
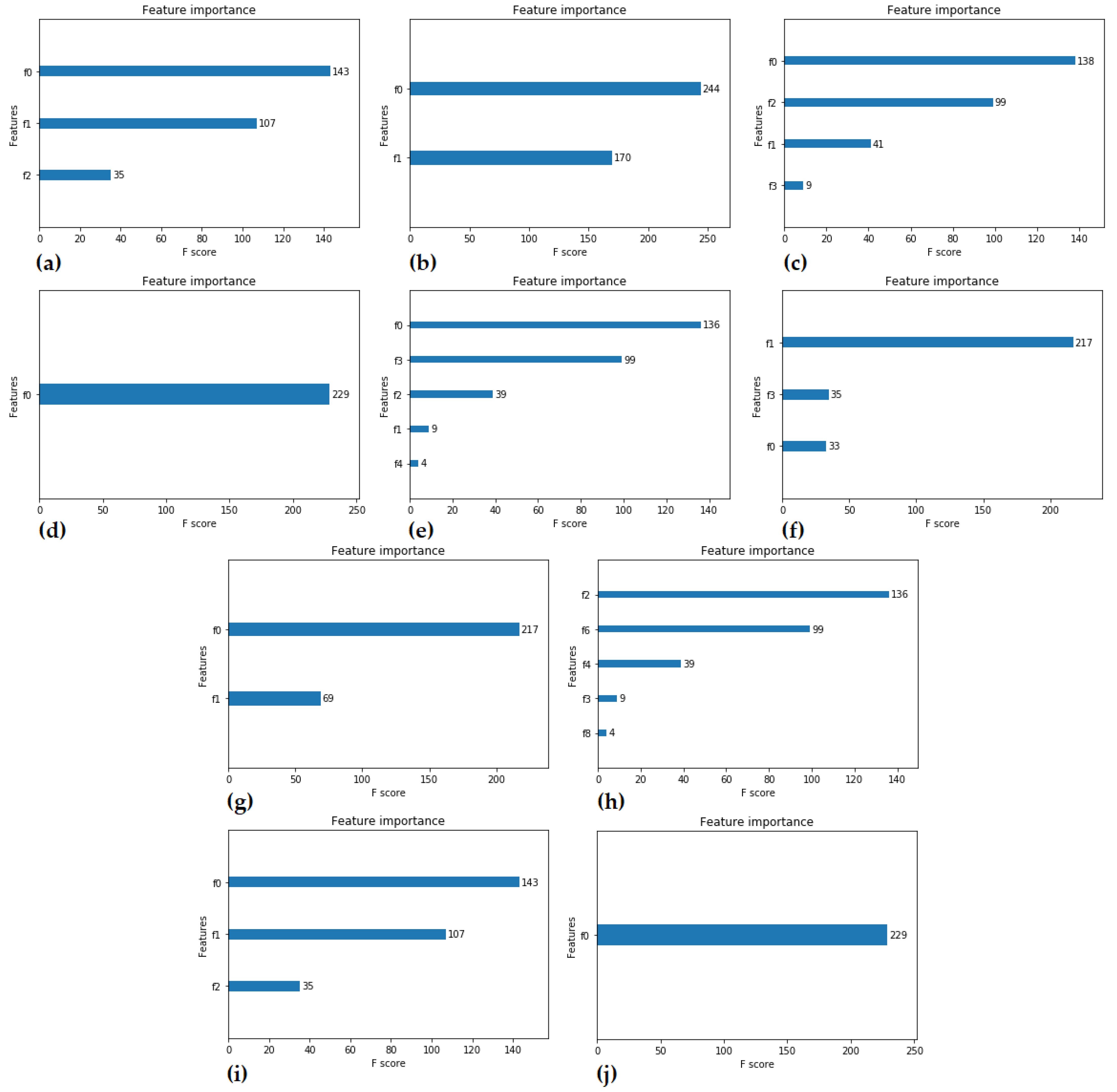
- The feature-selection process uses feature significance ratings with the help of estimated feature importance from the used dataset. The training dataset is used to choose features, and then the model is trained using the selected features and evaluated on the test set. Both datasets were subjected to the XGBoost (XGB) feature importance to acquire a clear picture of the attribute relevance before selection;
- Feature selection is a procedure in which you automatically pick those characteristics in your dataset that contribute the most to the output variables. The presence of irrelevant characteristics in your data might reduce the performance of many models. Feature selection before modeling not only improves accuracy but also reduces training time and the likelihood of overfitting. In this study, we implemented three popular attribute-selection techniques which are; SFM, RFE, and SKB;
- The concept of a multilevel ensemble is introduced in this experimental work where the predictions of the bagging and boosting ensemble classifiers further undergo the voting ensemble with soft and hard voting. This methodology obtained state-of-the-art results on both proposed and open source datasets. For performance evaluation, multiple metrics such as recall, hamming loss, precision, etc., have been used.
1.2. Literature Review
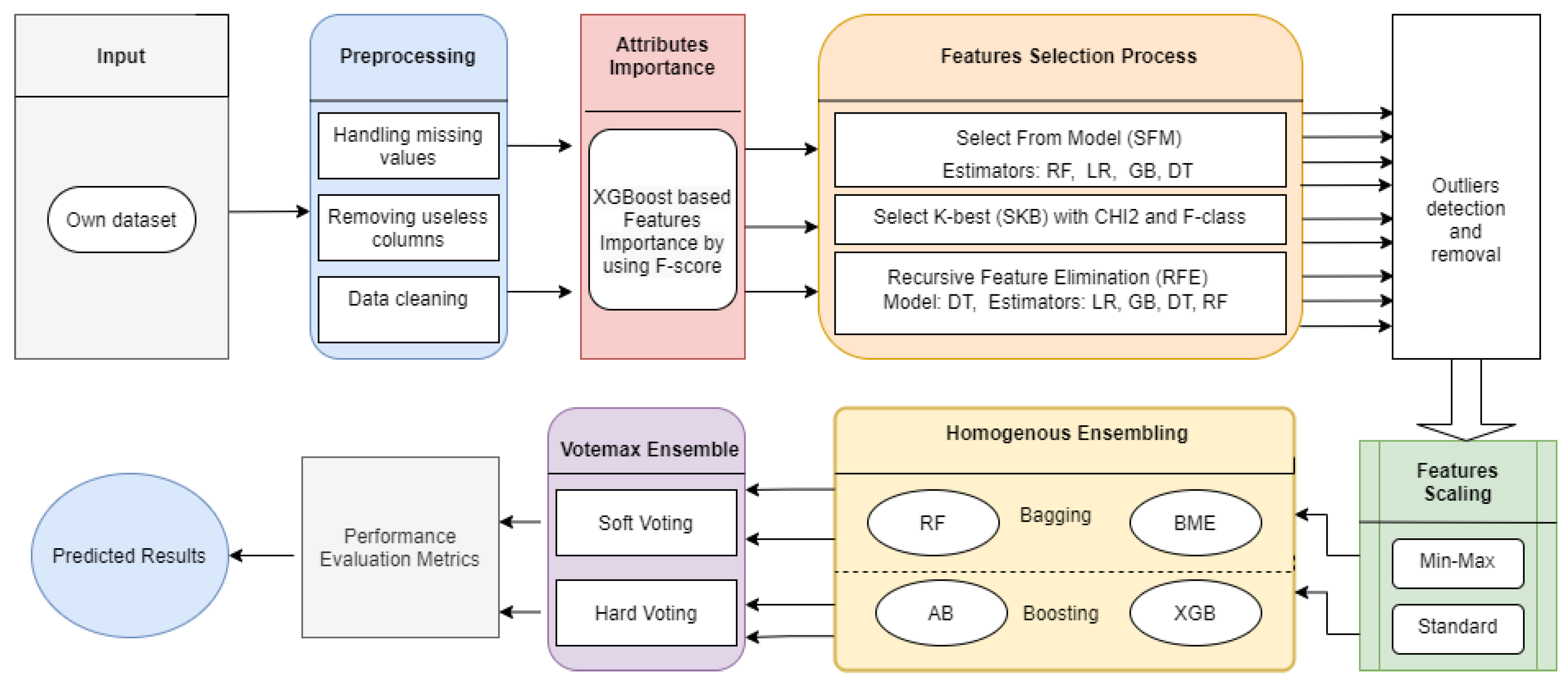
2. Materials and Methods
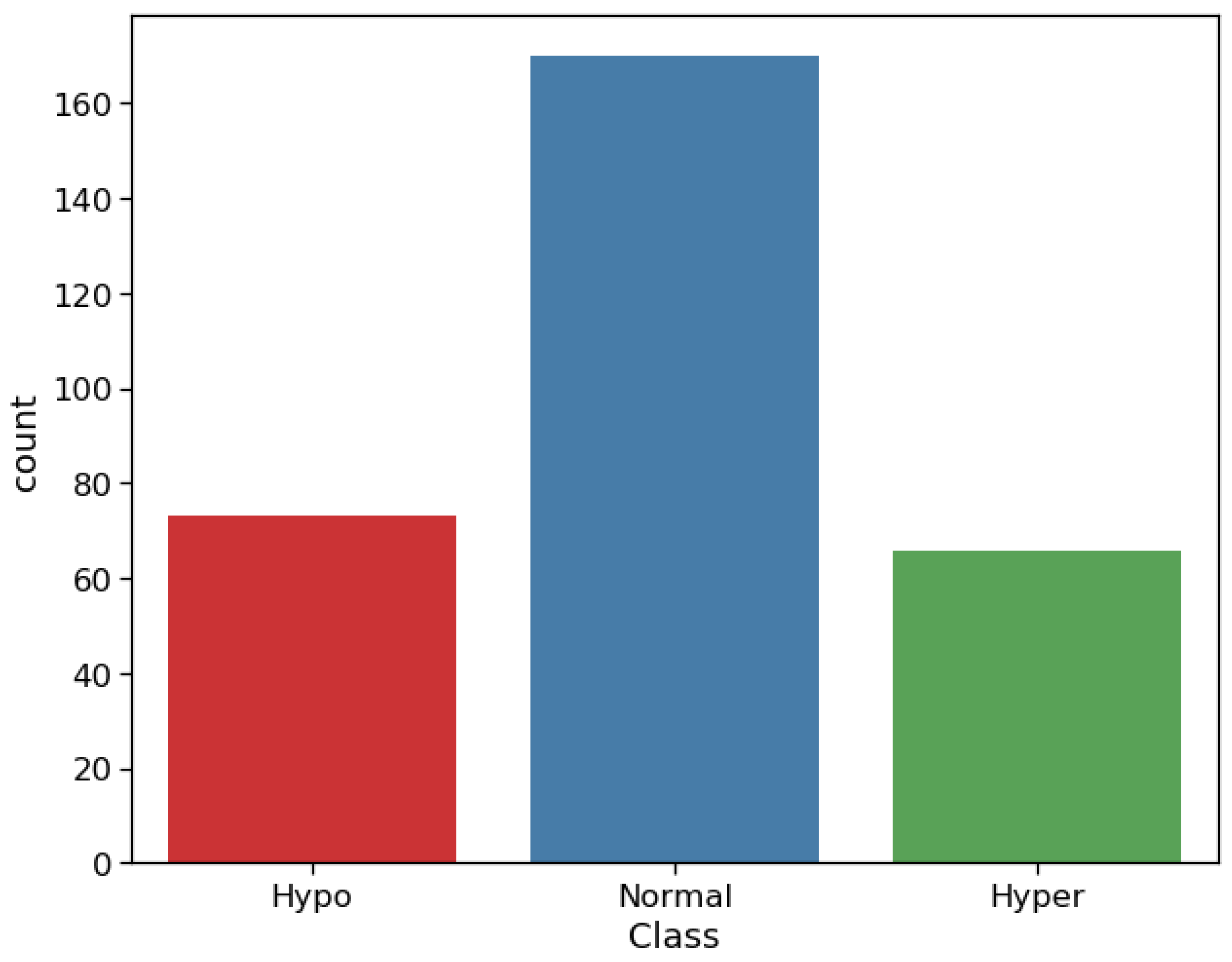
2.1. Dataset Description
2.2. Data Preprocessing
2.3. XGBoost-Based Feature Importance by Using F-Score
2.4. Attribute Selection Approaches
2.4.1. Selection from Model (SFM)
2.4.2. Recursive Feature Elimination (RFE)
2.4.3. Univariate Feature Selection Based Select K-Best (SKB)
2.5. Automatic Outlier Detection and Removal using Isolation Forest (ISO)
2.6. Homogenous Ensemble
2.6.1. Bagging
2.6.2. Boosting
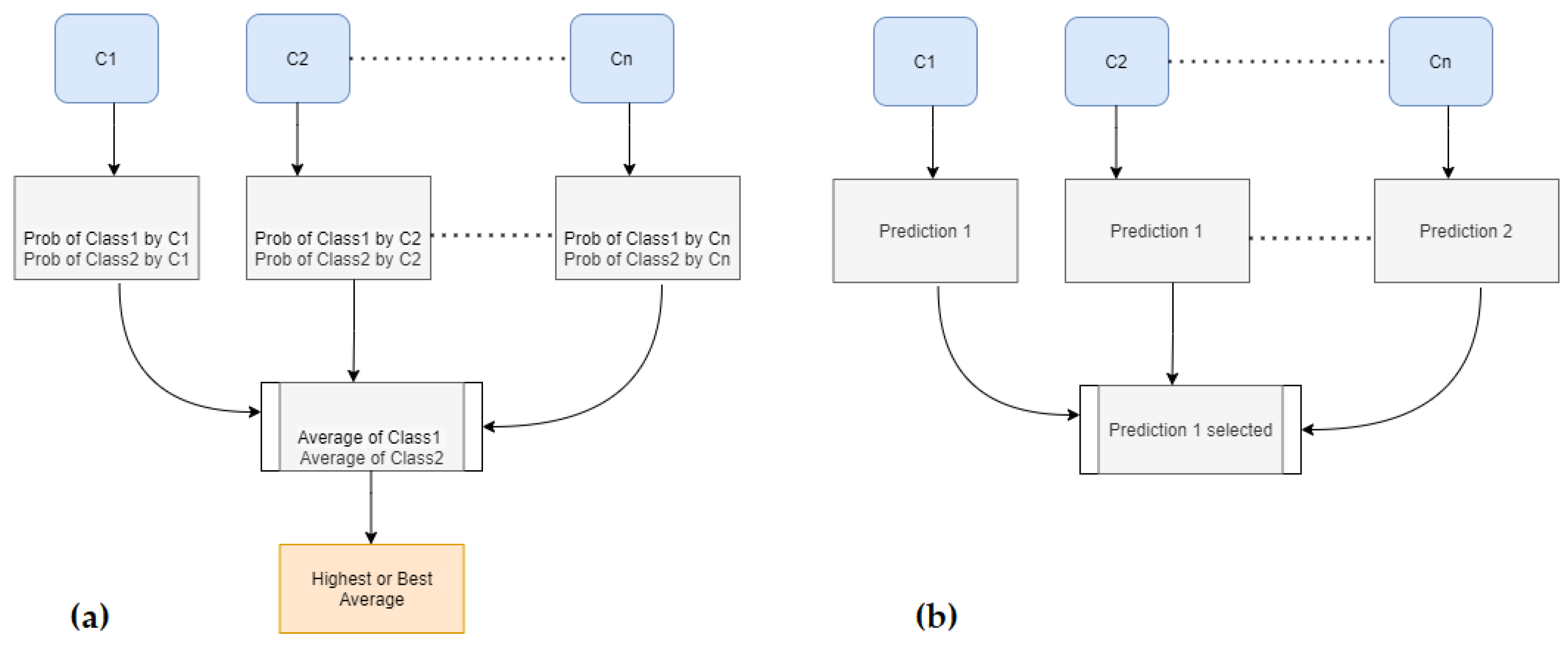
2.7. Voting Ensemble of Homogenous Ensemble
2.7.1. Soft Voting Ensemble
2.7.2. Hard Voting Ensemble
2.8. Performance Assessment Metrics
2.8.1. Confusion Matrix-Based Metrics
2.8.2. Statistical Test
2.8.3. Loss and Error Finding
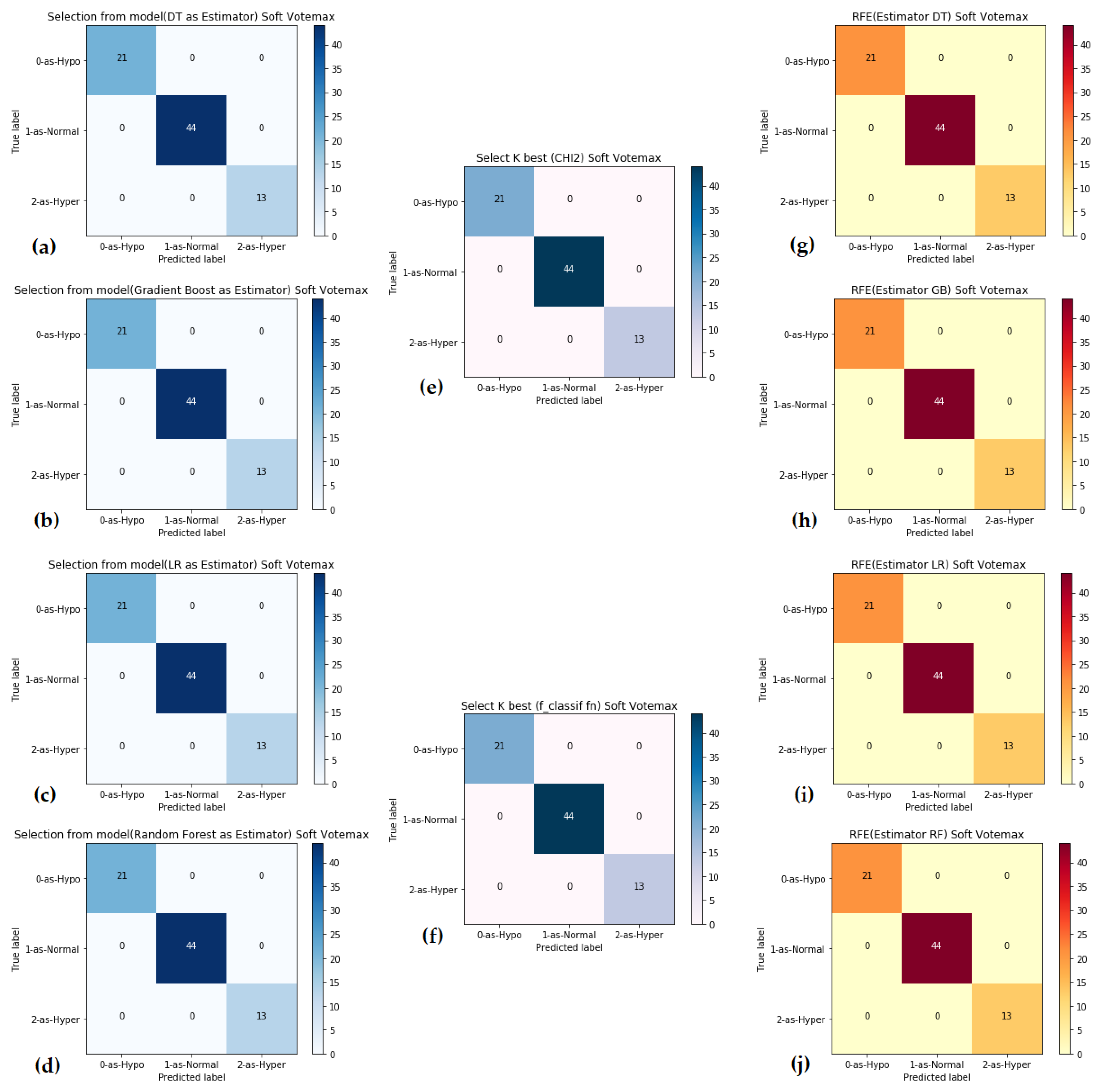
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- American Thyroid Association. Thyroid Function Tests. Available online: https://www.thyroid.org/thyroid-function-tests/ (accessed on 15 August 2021).
- Shroff, S.; Pise, S.; Chalekar, P.; Panicker, S.S. Thyroid Disease Diagnosis: A Survey. In Proceedings of the 2015 IEEE 9th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 9–10 January 2015; pp. 1–6. [Google Scholar]
- Thyroid Cancer. Available online: https://seer.cancer.gov/statfacts/html/thyro.html (accessed on 1 September 2021).
- Ioniţă, I.; Ioniţă, L. Prediction of Thyroid Disease Using Data Mining Techniques. BRAIN Broad Res. Artif. Intell. Neurosci. 2016, 7, 115–124. [Google Scholar]
- Medline Plus. Hyperthyroidism, Graves, Disease, Overactive Thyroid, MedlinePlus. Available online: https://medlineplus.gov/hyperthyroidism.html (accessed on 15 August 2021).
- Sampath, P.; Packiriswamy, G.; Pradeep Kumar, N.; Shanmuganathan, V.; Song, O.Y.; Tariq, U.; Nawaz, R. IoT Based health—Related topic recognition from emerging online health community (med help) using machine learning technique. Electronics. 2020, 9, 1469. [Google Scholar] [CrossRef]
- Reid, J.R.; Wheeler, S.F. Hyperthyroidism: Diagnosis and Treatment. Am. Fam. Physician 2005, 72, 623–630. [Google Scholar]
- Pal, R.; Anand, T.; Dubey, S.K. Evaluation and Performance Analysis of Classification Techniques for Thyroid Detection. Int. J. Bus. Inf. Syst. 2018, 28, 163–177. [Google Scholar] [CrossRef]
- Prasad, V.; Rao, T.S.; Babu, M.S.P. Thyroid Disease Diagnosis via Hybrid Architecture Composing Rough Data Sets Theory and Machine Learning Algorithms. Soft Comput. 2016, 20, 1179–1189. [Google Scholar] [CrossRef]
- Healthline. Thyroid Functions Tests. Available online: https://www.healthline.com/health/thyroid-function-tests (accessed on 15 August 2021).
- Singh, N.; Jindal, A.A. Segmentation Method and Comparison of Classification Methods for Thyroid Ultrasound Images. Int. J. Comput. Appl. 2012, 50, 43–49. [Google Scholar] [CrossRef]
- Erol, R.; Oğulata, S.N.; Şahin, C.; Alparslan, Z.N. A Radial Basis Function Neural Network (RBFNN) Approach for Structural Classification of Thyroid Diseases. J. Med. Syst. 2008, 32, 215–220. [Google Scholar] [CrossRef] [PubMed]
- Begum, A.; Parkavi, A. Prediction of Thyroid Disease Using Data Mining Techniques. In Proceedings of the 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Coimbatore, India, 15–16 March 2019; pp. 342–345. [Google Scholar]
- Mushtaq, Z.; Yaqub, A.; Sani, S.; Khalid, A. Effective K-Nearest Neighbor Classifications for Wisconsin Breast Cancer Data Sets. J. Chin. Inst. Eng. 2020, 43, 80–92. [Google Scholar] [CrossRef]
- Shivastuti, H.K.; Manhas, J.; Sharma, V. Performance Evaluation of SVM and Random Forest for the Diagnosis of Thyroid Disorder. Int. J. Res. Appl. Sci. Eng. Technol. 2021, 9, 945–947. [Google Scholar]
- Zhang, B.; Tian, J.; Pei, S.; Chen, Y.; He, X.; Dong, Y.; Zhang, L.; Mo, X.; Huang, W.; Cong, S. Machine Learning—Assisted System for Thyroid Nodule Diagnosis. Thyroid 2019, 29, 858–867. [Google Scholar] [CrossRef]
- Sonuç, E. Thyroid Disease Classification Using Machine Learning Algorithms. J. Phys. Conf. Ser. 2021, 1963, 012140. [Google Scholar]
- Yadav, D.C.; Pal, S. Thyroid Prediction Using Ensemble Data Mining Techniques. Int. J. Inf. Technol. 2019, 1–11. [Google Scholar] [CrossRef]
- Poudel, P.; Illanes, A.; Ataide, E.J.; Esmaeili, N.; Balakrishnan, S.; Friebe, M. Thyroid Ultrasound Texture Classification Using Autoregressive Features in Conjunction with Machine Learning Approaches. IEEE Access 2019, 7, 79354–79365. [Google Scholar] [CrossRef]
- Zhu, L.-C.; Ye, Y.-L.; Luo, W.-H.; Su, M.; Wei, H.-P.; Zhang, X.-B.; Wei, J.; Zou, C.-L. A model to Discriminate Malignant from Benign Thyroid Nodules Using Artificial Neural Network. PLoS ONE 2013, 8, e82211. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.K. A Comparative Study on Disease Classification Using Machine Learning Algorithms. In Proceedings of the 2nd International Conference on Advanced Computing and Software Engineering (ICACSE), Sultanpur, India, 8–9 February 2019. [Google Scholar]
- Kousarrizi, M.N.; Seiti, F.; Teshnehlab, M. An Experimental Comparative Study on Thyroid Disease Diagnosis Based on Feature Subset Selection and Classification. Int. J. Electr. Comput. Sci. IJECS-IJENS 2012, 12, 13–20. [Google Scholar]
- Mousavi, S.S.Z.; Zanjireh, M.M.; Oghbaie, M. Applying Computational Classification Methods to Diagnose Congenital Hypothyroidism: A Comparative Study. Inf. Med. Unlocked 2020, 18, 100281. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Kang, J.K.; Pham, T.D.; Batchuluun, G.; Park, K.R. Ultrasound Image-Based Diagnosis of Malignant Thyroid Nodule Using Artificial Intelligence. Sensors 2020, 20, 1822. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geetha, K.; Baboo, S.S. An Empirical Model for Thyroid Disease Classification Using Evolutionary Multivariate Bayseian Prediction Method. Glob. J. Comput. Sci. Technol. 2016, 16, 1–10. [Google Scholar]
- Chaubey, G.; Bisen, D.; Arjaria, S.; Yadav, V. Thyroid Disease Prediction Using Machine Learning Approaches. Natl. Acad. Sci. Lett. 2021, 44, 233–238. [Google Scholar] [CrossRef]
- Chen, H.-L.; Yang, B.; Wang, G.; Liu, J.; Chen, Y.-D.; Liu, D.-Y. A Three-Stage Expert System Based on Support Vector Machines for Thyroid Disease Diagnosis. J. Med. Syst. 2012, 36, 1953–1963. [Google Scholar] [CrossRef]
- Fedushko, S.; Ustyianovych, T.; Gregus, M. Real-Time High-Load Infrastructure Transaction Status Output Prediction Using Operational Intelligence and Big Data Technologies. Electronics 2020, 9, 668. [Google Scholar] [CrossRef] [Green Version]
- Dogantekin, E.; Dogantekin, A.; Avci, D. An Expert System Based on Generalized Discriminant Analysis and Wavelet Support Vector Machine for Diagnosis of Thyroid Diseases. Expert Syst. Appl. 2011, 38, 146–150. [Google Scholar] [CrossRef]
- Keleş, A.; Keleş, A. ESTDD: Expert System for Thyroid Diseases Diagnosis. Expert Syst. Appl. 2008, 34, 242–246. [Google Scholar] [CrossRef]
- Ozyilmaz, L.; Yildirim, T. Diagnosis of Thyroid Disease Using Artificial Neural Network Methods. In Proceedings of the 9th International Conference on Neural Information Processing, 2002. ICONIP’02, Singapore, 18–22 November 2002; pp. 2033–2036. [Google Scholar]
- Valko, M.; Hauskrecht, M. Feature Importance Analysis for Patient Management Decisions. Stud. Health Technol. Inform. 2010, 160, 861. [Google Scholar]
- Abbad Ur Rehman, H.; Lin, C.-Y.; Mushtaq, Z. Effective K-Nearest Neighbor Algorithms Performance Analysis of Thyroid Disease. J. Chin. Inst. Eng. 2021, 44, 77–87. [Google Scholar] [CrossRef]
- Brownlee, J. Feature Importance and Feature Selection with XGBoost in Python. Machine Learning Mastery. Available online: https://machinelearningmastery.com/feature-importance-and-feature-selection-with-xgboost-in-python/ (accessed on 15 October 2021).
- Hao, J.; Ho, T.K. Machine Learning Made Easy: A Review of Scikit-Learn Package in Python Programming Language. J. Educ. Behav. Stat. 2019, 44, 348–361. [Google Scholar] [CrossRef]
- Seddik, A.F.; Shawky, D.M. Logistic Regression Model for Breast Cancer Automatic Diagnosis. In Proceedings of the 2015 SAI Intelligent Systems Conference (IntelliSys), London, UK, 10–11 November 2015; pp. 150–154. [Google Scholar]
- Dikshit, A.; Pradhan, B.; Alamri, A.M. Short-Term Spatio-Temporal Drought Forecasting Using Random Forests Model at New South Wales, Australia. Appl. Sci. 2020, 10, 4254. [Google Scholar] [CrossRef]
- Chowdhary, C.L.; Mittal, M.; Pattanaik, P.; Marszalek, Z. An Efficient Segmentation and Classification System in Medical Images Using Intuitionist Possibilistic Fuzzy C-Mean Clustering and Fuzzy SVM Algorithm. Sensors 2020, 20, 3903. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Gong, G.; Li, N. Automated Recognition of Epileptic EEG States Using a Combination of Symlet Wavelet Processing, Gradient Boosting Machine, and Grid Search Optimizer. Sensors 2019, 19, 219. [Google Scholar] [CrossRef] [Green Version]
- Brownlee, J. Data Preparation for Machine Learning: Data Cleaning, Feature Selection, and Data Transforms in Python. Machine Learning Mastery. 2020. Available online: https://machinelearningmastery.com/data-preparation-for-machine-learning/ (accessed on 15 October 2021).
- Lal, A.; Datta, B. Performance Evaluation of Homogeneous and Heterogeneous Ensemble Models for Groundwater Salinity Predictions: A regional-Scale Comparison Study. Water Air Soil Pollut. 2020, 231, 1–21. [Google Scholar] [CrossRef]
- Wen, L.; Hughes, M. Coastal Wetland Mapping Using Ensemble Learning Algorithms: A Comparative Study of Bagging, Boosting and Stacking Techniques. Remote Sens. 2020, 12, 1683. [Google Scholar] [CrossRef]
- Alam, M.Z.; Rahman, M.S.; Rahman, M.S. A Random Forest Based Predictor for Medical Data Classification Using Feature Ranking. Inform. Med. Unlocked 2019, 15, 100180. [Google Scholar] [CrossRef]
- Palacios-Navarro, G.; Hogan, N. Head-Mounted Display-Based Therapies for Adults Post-Stroke: A Systematic Review and Meta-Analysis. Sensors 2021, 21, 1111. [Google Scholar] [CrossRef] [PubMed]
- Shen, Z.; Wu, Q.; Wang, Z.; Chen, G.; Lin, B. Diabetic Retinopathy Prediction by Ensemble Learning Based on Biochemical and Physical Data. Sensors 2021, 21, 3663. [Google Scholar] [CrossRef] [PubMed]
- Liew, X.Y.; Hameed, N.; Clos, J. An Investigation of XGBoost-Based Algorithm for Breast Cancer Classification. Mach. Learn. Appl. 2021, 6, 100154. [Google Scholar] [CrossRef]
- Brownlee, J. How to Develop Voting Ensembles with Python. Machine Learning Mastery. Available online: https://machinelearningmastery.com/voting-ensembles-with-python/ (accessed on 15 October 2021).
- Mushtaq, Z.; Yaqub, A.; Hassan, A.; Su, S.F. Performance Analysis of Supervised Classifiers Using PCA Based Techniques on Breast Cancer. In Proceedings of the 2019 International Conference on Engineering and Emerging Technologies (ICEET), Lahore, Pakistan, 21–23 February 2019; pp. 1–6. [Google Scholar]
- Sahu, B.; Mohanty, S.; Rout, S. A Hybrid Approach for Breast Cancer Classification and Diagnosis. EAI Endorsed Trans. Scalable Inf. Syst. 2019, 6, e2. [Google Scholar] [CrossRef]
- Arif, S.; Khan, M.J.; Naseer, N.; Hong, K.-S.; Sajid, H.; Ayaz, Y. Vector Phase Analysis Approach for Sleep Stage Classification: A Functional Near-Infrared Spectroscopy-Based Passive Brain-Computer Interface. Front. Hum. Neurosci. 2021, 15, 658444. [Google Scholar] [CrossRef]
- Arif, S.; Arif, M.; Munawar, S.; Ayaz, Y.; Khan, M.J.; Naseer, N. EEG Spectral Comparison between Occipital and Prefrontal Cortices for Early Detection of Driver Drowsiness. In Proceedings of the 2021 International Conference on Artificial Intelligence and Mechatronics Systems (AIMS), Bandung, Indonesia, 28–30 April 2021; pp. 1–6. [Google Scholar]
- Rehman, H.A.U.; Lin, C.-Y.; Mushtaq, Z.; Su, S.-F. Performance Analysis of Machine Learning Algorithms for Thyroid Disease. Arab. J. Sci. Eng. 2021, 46, 9437–9449. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Thyroid Dataset | |
|---|---|
| Attributes Names | Range of Features |
| Serial Numbers | 1 to 309 |
| Hospital Reference IDs | Unique Number |
| Pregnancy | Yes, No |
| Body Mass Index (BMI) | Overweight Optimal Underweight |
| Blood Pressure (BP) | Low Healthy High |
| Pulse Rate (PR) | 50 to 110 |
| T3 | 0.15 TO 3.7 (Having 13 Missing values denoted by ‘?’) |
| TSH | 0.05 to 100 |
| T4 | 0.015 to 30 |
| Gender | Female Male |
| Age | 6 to 62 |
| Class | ‘0’ as Hypo ‘1’ as Hyper ‘2’ as Normal |
| Features Selection Techniques | Estimators or Functions Used | Total Features in the Dataset after Cleaning | Selected Features | Time Required for Features Selection (s) |
|---|---|---|---|---|
| Select From Model (SFM) | LR | 09 | 02 | 0.010 |
| RF | 09 | 03 | 0.135 | |
| DT | 09 | 01 | 0.032 | |
| GB | 09 | 04 | 0.154 | |
| Select K Best (SKB) | Chi2 | 09 | 05 | 0.014 |
| FCI | 09 | 03 | 0.006 | |
| Recursive Feature Elimination (RFE) | LR | 09 | 05 | 0.092 |
| RF | 09 | 02 | 0.235 | |
| DT | 09 | 01 | 0.010 | |
| GB | 09 | 03 | 1.172 |
| Feature-Selection Technique | Estimator or Function Used | Total Features in the Dataset after Cleaning | Total Entries Present in the Dataset | Entities in 75% Training of the Data | Number of Selected Features | Outliers Detected in the Selected Features | MAE Values |
|---|---|---|---|---|---|---|---|
| Select From Model (SFM) | LR | 09 | 309 | 231 | 02 | 23 | 0.0001 |
| RF | 09 | 309 | 231 | 03 | 23 | 0.0001 | |
| DT | 09 | 309 | 231 | 01 | 0 | 0.0001 | |
| GB | 09 | 309 | 231 | 04 | 23 | 0.0001 | |
| Select K Best (SKB) | Chi2 | 09 | 309 | 231 | 05 | 23 | 0.0001 |
| FCI | 09 | 309 | 231 | 03 | 22 | 0.026 | |
| Recursive Feature Elimination (RFE) | LR | 09 | 309 | 231 | 05 | 23 | 0.0001 |
| RF | 09 | 309 | 231 | 02 | 19 | 0.295 | |
| DT | 09 | 309 | 231 | 01 | 0 | 0.0001 | |
| GB | 09 | 309 | 231 | 03 | 23 | 0.0001 |
| Homogenous Ensemble (Bagging) | ||||||
|---|---|---|---|---|---|---|
| Feature-Selection Techniques | Estimators or Functions Used | Selected Features | Bagging Classifiers | Accuracy (%) | Training Time (s) | Prediction Time (s) |
| Select From Model (SFM) | LR | 02 | RF | 98.71 | 0.2869 | 0.0029 |
| BME | 100.0 | 0.0149 | 0.0020 | |||
| RF | 03 | RF | 100.0 | 0.0861 | 0.0079 | |
| BME | 100.0 | 0.0139 | 0.0009 | |||
| DT | 01 | RF | 100.0 | 0.3040 | 0.0029 | |
| BME | 100.0 | 0.0269 | 0.0019 | |||
| GB | 04 | RF | 100.0 | 0.0873 | 0.0079 | |
| BME | 100.0 | 0.2844 | 0.0009 | |||
| Select K Best (SKB) | Chi2 | 05 | RF | 100.0 | 0.0643 | 0.0039 |
| BME | 100.0 | 0.0108 | 0.0019 | |||
| FCI | 03 | RF | 100.0 | 0.0743 | 0.0049 | |
| BME | 100.0 | 0.0329 | 0.0050 | |||
| Recursive Feature Elimination (RFE) | LR | 05 | RF | 100.0 | 0.0289 | 0.0030 |
| BME | 100.0 | 0.0089 | 0.0009 | |||
| RF | 02 | RF | 100.0 | 0.0259 | 0.0029 | |
| BME | 100.0 | 0.0129 | 0.0019 | |||
| DT | 01 | RF | 100.0 | 0.0320 | 0.0039 | |
| BME | 100.0 | 0.0129 | 0.0009 | |||
| GB | 03 | RF | 100.0 | 0.0329 | 0.0049 | |
| BME | 100.0 | 0.0129 | 0.0020 | |||
| Homogenous Ensemble (Boosting) | ||||||
|---|---|---|---|---|---|---|
| Feature-Selection Techniques | Estimators or Functions Used | Selected Features | Boosting Classifiers | Accuracy (%) | Training Time (s) | Prediction Time (s) |
| Select From Model (SFM) | LR | 02 | AB | 100.0 | 0.1037 | 0.0049 |
| XGB | 100.0 | 0.9898 | 0.0009 | |||
| RF | 03 | AB | 100.0 | 0.1047 | 0.0050 | |
| XGB | 100.0 | 1.3160 | 0.0019 | |||
| DT | 01 | AB | 100.0 | 0.0490 | 0.0059 | |
| XGB | 100.0 | 1.3354 | 0.0009 | |||
| GB | 04 | AB | 100.0 | 0.1187 | 0.0049 | |
| XGB | 100.0 | 0.9752 | 0.0008 | |||
| Select K Best (SKB) | Chi2 | 05 | AB | 100.0 | 0.0757 | 0.0049 |
| XGB | 100.0 | 1.0682 | 0.0216 | |||
| FCI | 03 | AB | 100.0 | 0.0678 | 0.0069 | |
| XGB | 97.43 | 1.0034 | 0.0009 | |||
| Recursive Feature Elimination (RFE) | LR | 05 | AB | 100.0 | 0.0594 | 0.0059 |
| XGB | 100.0 | 1.0484 | 0.0009 | |||
| RF | 02 | AB | 100.0 | 0.0628 | 0.0059 | |
| XGB | 100.0 | 1.0614 | 0.0009 | |||
| DT | 01 | AB | 100.0 | 0.0927 | 0.0049 | |
| XGB | 100.0 | 1.1596 | 0.0009 | |||
| GB | 03 | AB | 100.0 | 0.0638 | 0.0059 | |
| XGB | 100.0 | 1.0472 | 0.0019 | |||
| Ensemble of the Homogenous Ensemble (Voting Classifier) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Feature-Selection Techniques | Estimators or Functions used | Selected Features | Voting Classifiers | Accuracy (%) | Training Time (s) | Prediction Time (s) | Recall (%) | Precision (%) | F1-score (%) | MCC (%) | Cohen Kappa (%) | MSE (%) | MAE (%) | Hamming Loss (%) |
| Select From Model (SFM) | LR | 02 | Soft | 100.0 | 1.062 | 0.007 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 |
| Hard | 100.0 | 1.103 | 0.007 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |||
| RF | 03 | Soft | 100.0 | 0.176 | 0.010 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |
| Hard | 100.0 | 0.152 | 0.009 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |||
| DT | 01 | Soft | 100.0 | 1.415 | 0.010 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |
| Hard | 100.0 | 1.216 | 0.014 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |||
| GB | 04 | Soft | 100.0 | 0.190 | 0.009 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |
| Hard | 100.0 | 1.060 | 0.009 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |||
| Select K Best (SKB) | Chi2 | 05 | Soft | 100.0 | 0.208 | 0.015 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 |
| Hard | 100.0 | 0.375 | 0.008 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |||
| FCI | 03 | Soft | 100.0 | 0.159 | 0.013 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |
| Hard | 100.0 | 0.175 | 0.022 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |||
| Recursive Feature Elimination (RFE) | LR | 05 | Soft | 100.0 | 1.095 | 0.031 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 |
| Hard | 100.0 | 1.138 | 0.009 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |||
| RF | 02 | Soft | 100.0 | 1.125 | 0.009 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |
| Hard | 100.0 | 1.363 | 0.011 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |||
| DT | 01 | Soft | 100.0 | 1.102 | 0.011 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |
| Hard | 100.0 | 1.230 | 0.010 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |||
| GB | 03 | Soft | 100.0 | 1.087 | 0.016 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |
| Hard | 100.0 | 1.073 | 0.011 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 0.0 | |||
| Ref. | Methodology | Accuracy (%) | Recall (%) | F1-Score (%) | Training Time (s) | Prediction Time (s) | Dataset |
|---|---|---|---|---|---|---|---|
| [52] | KNN + WLSVC (L1) | 97.8 | 96 | 97 | 0.53 | 0.361 | DHQ, DG Khan, Pakistan |
| DT + WLSVC (L2) | 76.9 | 67 | 61 | 0.681 | 0.372 | ||
| SVM + WLSVC (L2) | 86.0 | 79 | 85 | 0.511 | 0.361 | ||
| [33] | KNN (Euclidean) + WCHI | 100 | 100 | 100 | 1.032 | 0.806 | DHQ, DG Khan, Pakistan |
| KNN (Minkowski) + WCHI | 99.3 | 99 | 99 | 1.18 | 0.827 | ||
| KNN (Chebyshev) + WCHI | 98.7 | 97 | 98 | 1.11 | 0.808 | ||
| KNN (Manhattan) + WCHI | 99.3 | 99 | 99 | 1.01 | 0.749 | ||
| KNN (Correlation) + WCHI | 77.3 | 76 | 76 | 0.899 | 0.655 | ||
| This study | Homogenous ensemble + Voting (hard) + SFM (RF) | 100 | 100 | 100 | 0.152 | 0.009 | DHQ, DG Khan, Pakistan |
| Homogenous ensemble + Voting (soft) + SKB (FCI) | 100 | 100 | 100 | 0.159 | 0.013 | ||
| Bagging (BME) + RFE (DT) | 100 | 100 | 100 | 0.0129 | 0.0009 | ||
| Homogenous ensemble + Voting (hard) + RFE (GB) | 100 | 100 | 100 | 1.073 | 0.011 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akhtar, T.; Gilani, S.O.; Mushtaq, Z.; Arif, S.; Jamil, M.; Ayaz, Y.; Butt, S.I.; Waris, A. Effective Voting Ensemble of Homogenous Ensembling with Multiple Attribute-Selection Approaches for Improved Identification of Thyroid Disorder. Electronics 2021, 10, 3026. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10233026
Akhtar T, Gilani SO, Mushtaq Z, Arif S, Jamil M, Ayaz Y, Butt SI, Waris A. Effective Voting Ensemble of Homogenous Ensembling with Multiple Attribute-Selection Approaches for Improved Identification of Thyroid Disorder. Electronics. 2021; 10(23):3026. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10233026
Chicago/Turabian StyleAkhtar, Tehseen, Syed Omer Gilani, Zohaib Mushtaq, Saad Arif, Mohsin Jamil, Yasar Ayaz, Shahid Ikramullah Butt, and Asim Waris. 2021. "Effective Voting Ensemble of Homogenous Ensembling with Multiple Attribute-Selection Approaches for Improved Identification of Thyroid Disorder" Electronics 10, no. 23: 3026. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10233026