
Revisiting Symptom-Based Fault Tolerant Techniques against Soft Errors

 , ,
, ,
Abstract
:1. Introduction
2. Background and Motivation
2.1. Protection Schemes against Soft Errors
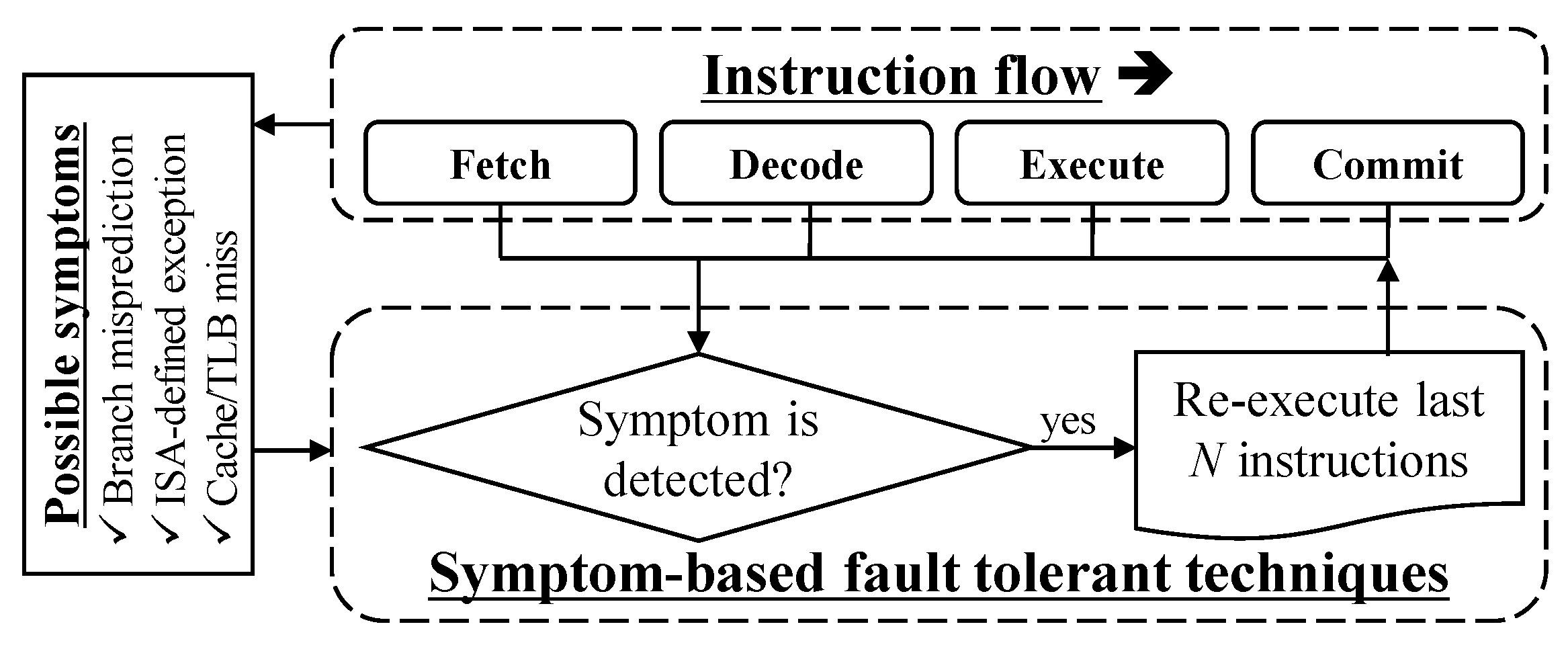
2.2. Symptom-Based Fault Tolerant Schemes
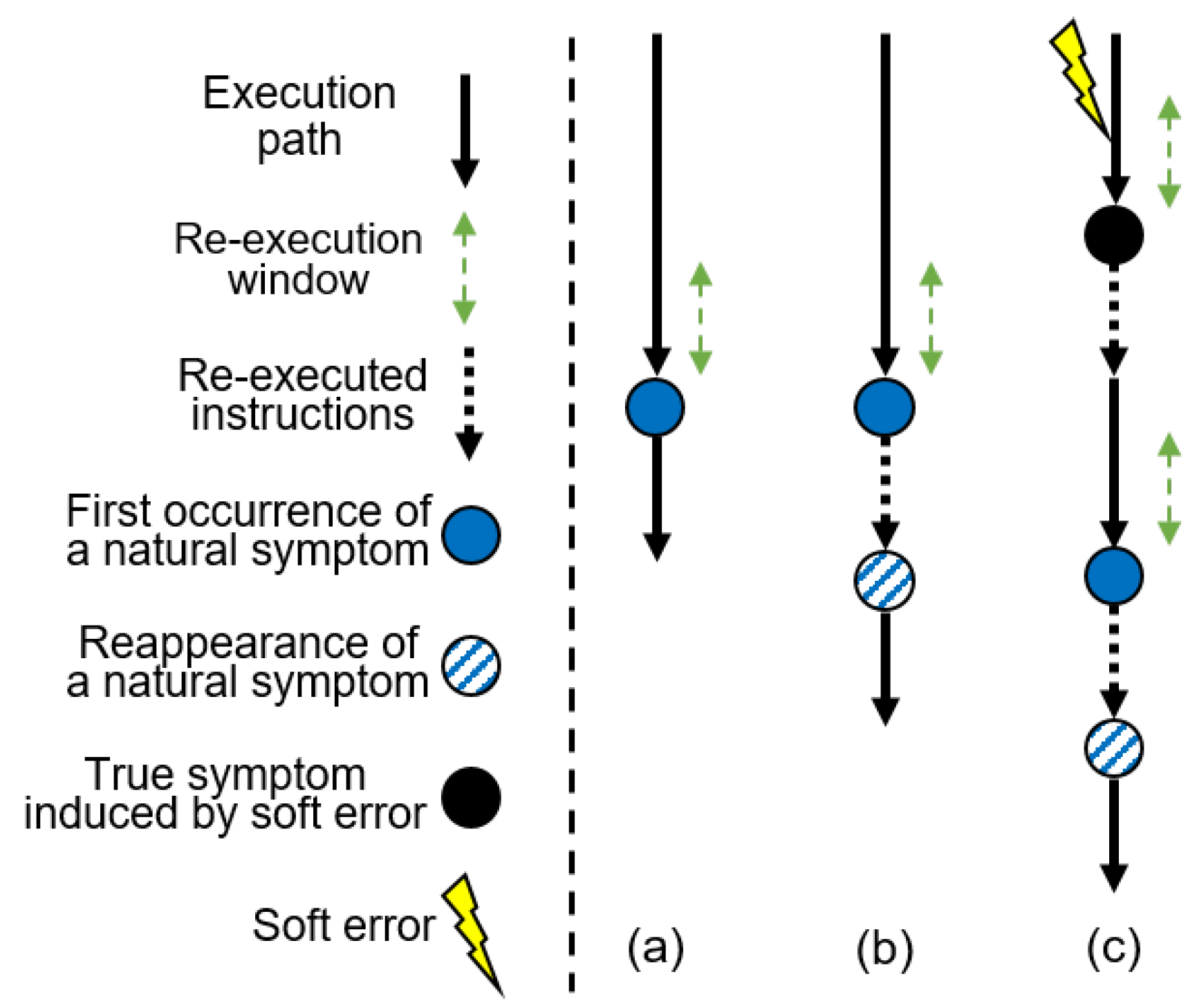
2.3. Reconsidering Low-Level Symptoms
3. Fault Coverage: Overview of Results
4. Fault Coverage Analysis
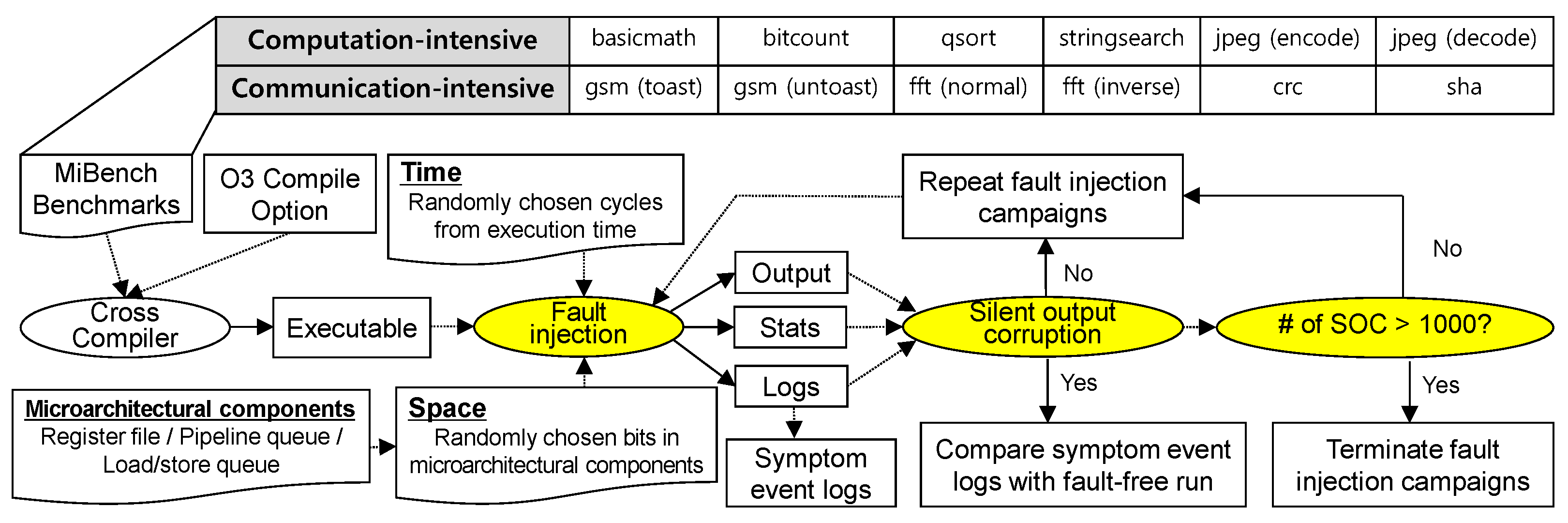
5. Experimental Setup
6. Experimental Results
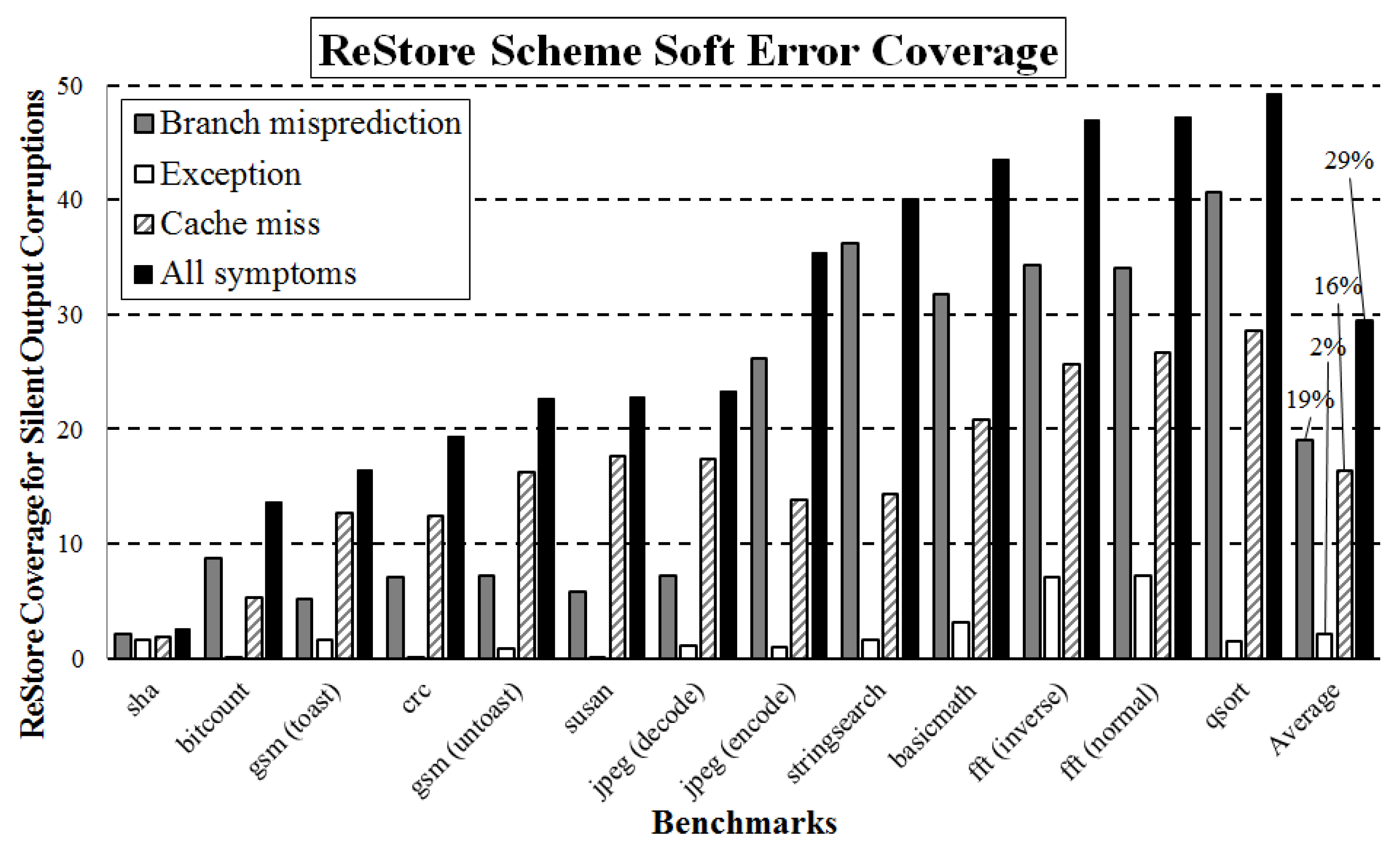
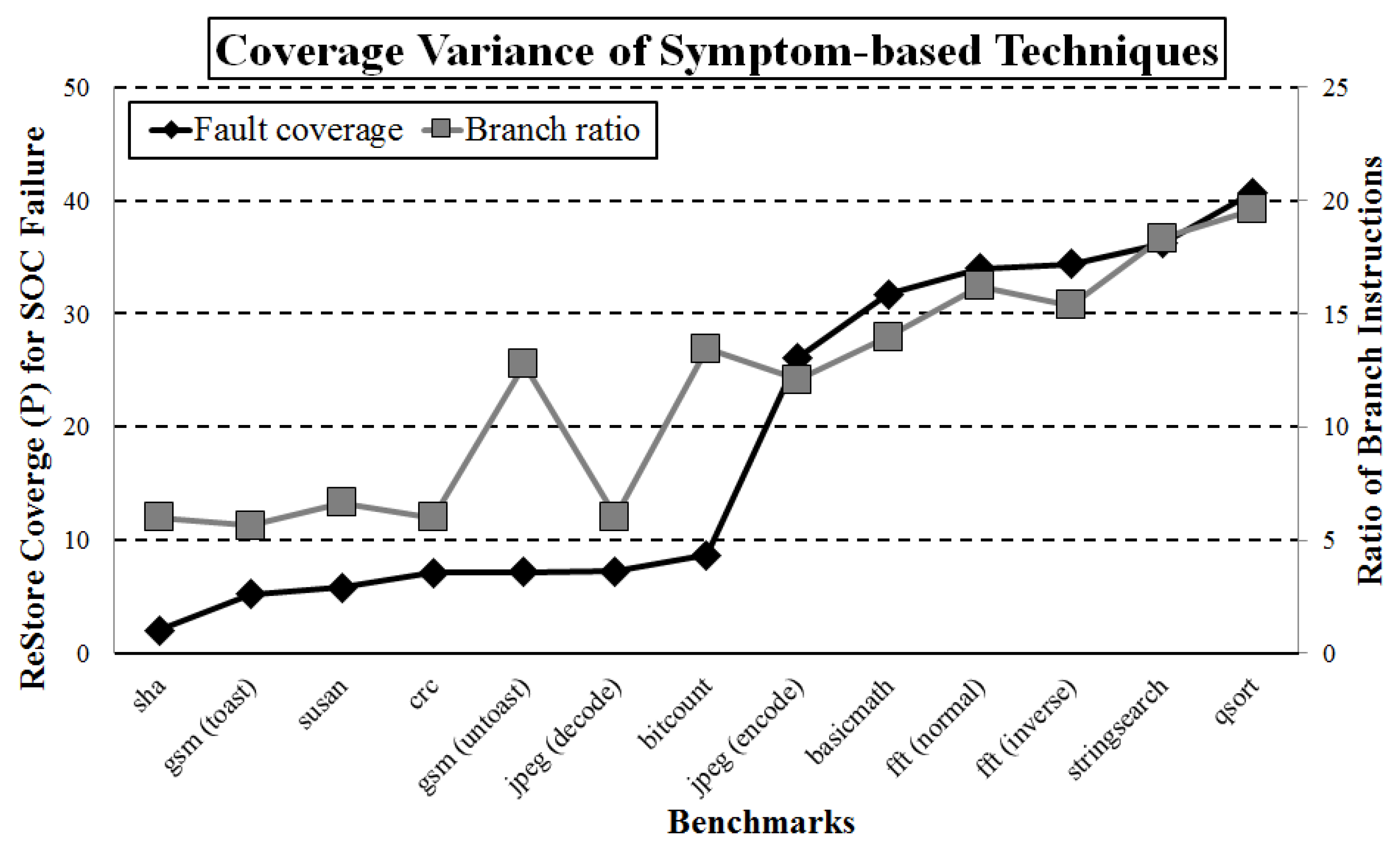
6.1. Ineffective Failure Coverage
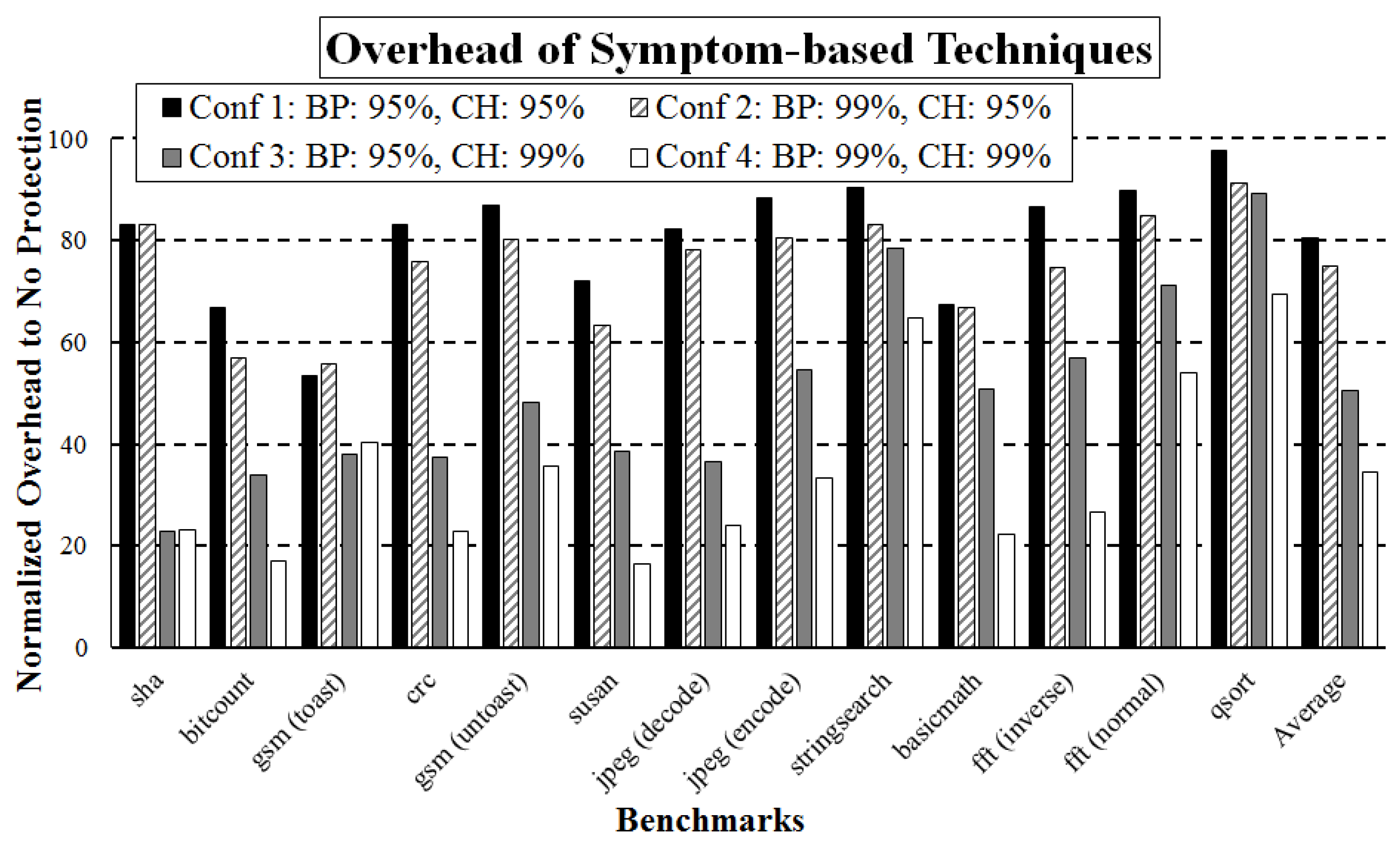
6.2. Considerable Performance Overhead
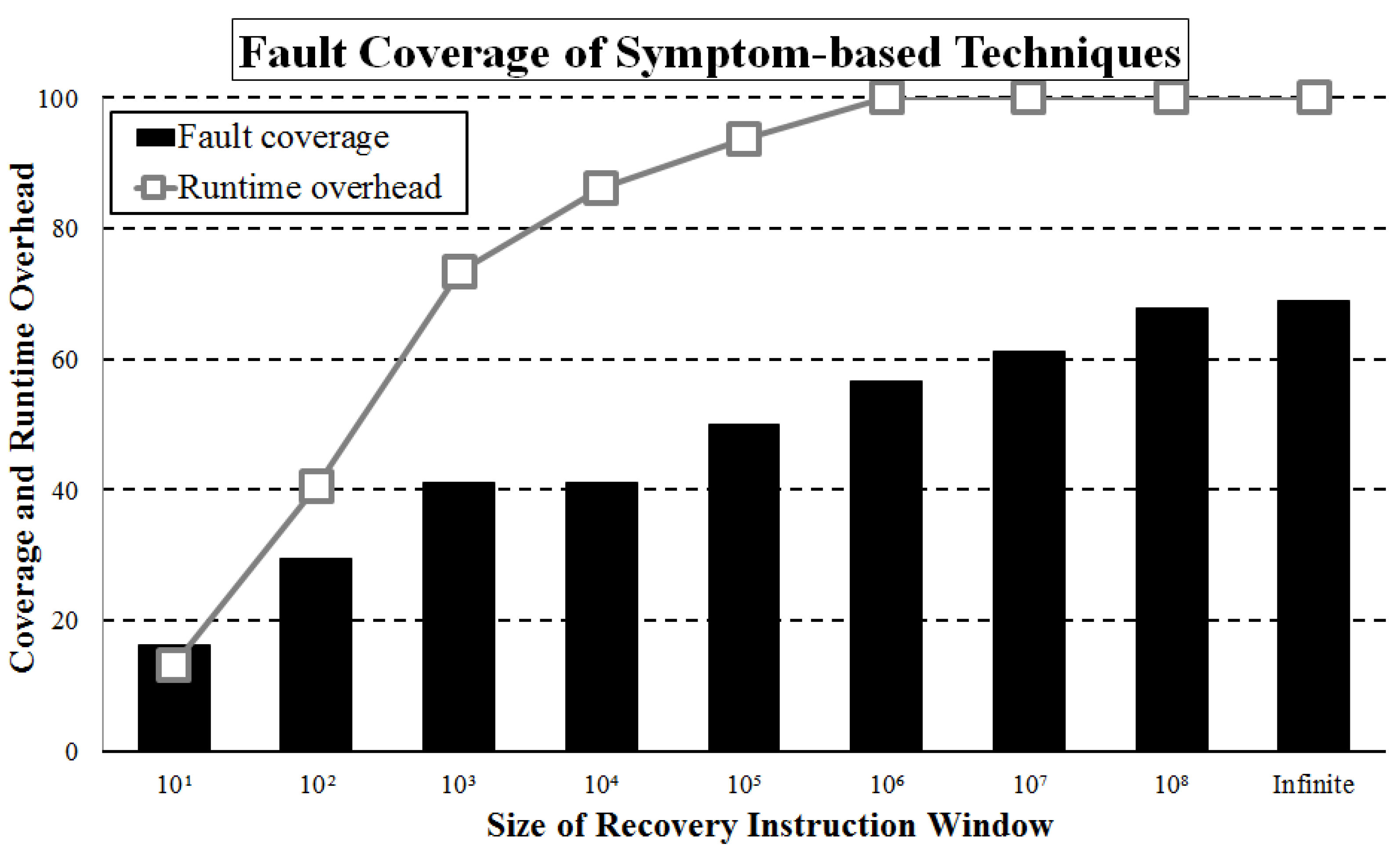
6.3. Recovery Window Size Slightly Improves Coverage and Drastically Hurts Overhead
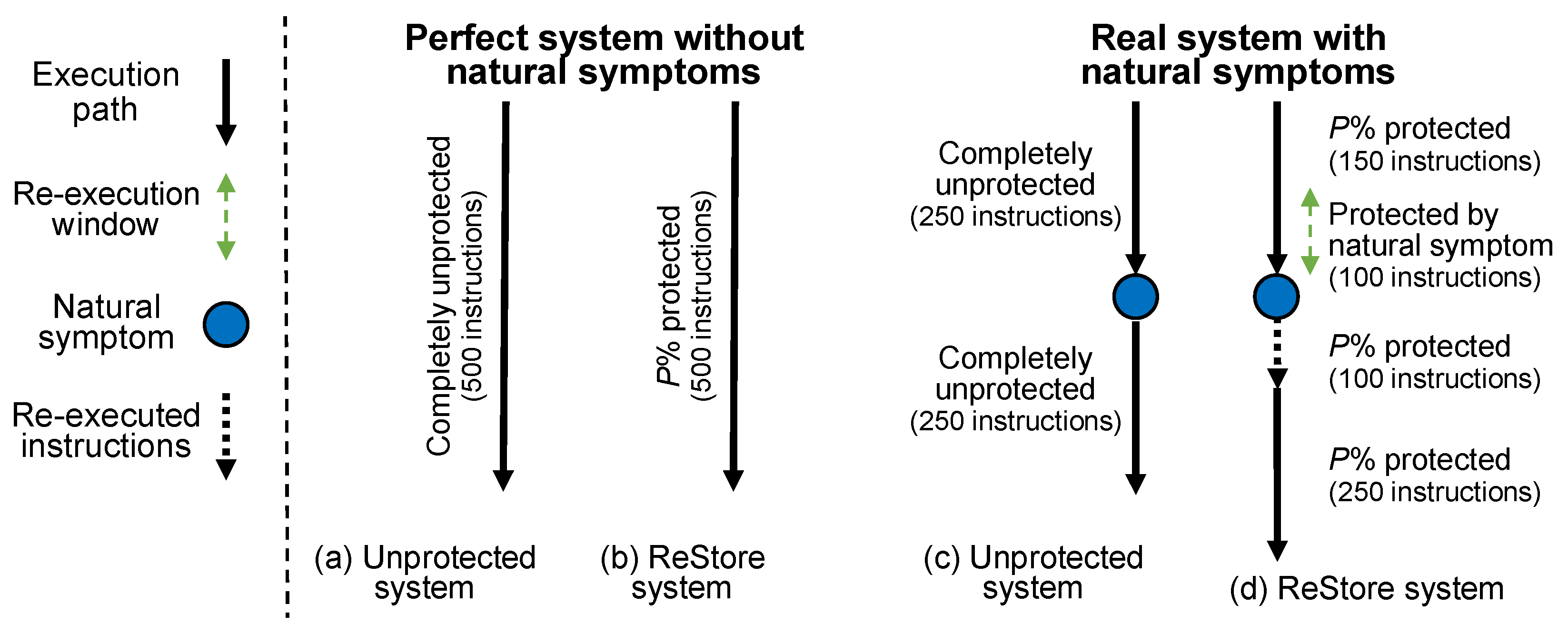
6.4. Quantifying the Negative Impact of the Program-Level Masking Effects
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shivakumar, P.; Kistler, M.; Keckler, S.W.; Burger, D.; Alvisi, L. Modeling the effect of technology trends on the soft error rate of combinational logic. In Proceedings of the IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Washington, DC, USA, 23–26 June 2002; pp. 389–398. [Google Scholar]
- Mukherjee, S.S.; Weaver, C.; Emer, J.; Reinhardt, S.K.; Austin, T. A systematic methodology to compute the architectural vulnerability factors for a high-performance microprocessor. In Proceedings of the 36th Annual IEEE/ACM International Symposium on Microarchitecture, San Diego, CA, USA, 5 December 2003; pp. 29–40. [Google Scholar]
- Wang, N.; Fertig, M.; Patel, S. Y-branches: When you come to a fork in the road, take it. In Proceedings of the IEEE International Conference on Parallel Architecture and Compilation Techniques (PACT), New Orleans, LA, USA, 27 September–1 October 2003; pp. 56–66. [Google Scholar]
- Cristian, F.; Dancey, B.; Dehn, J. Fault-tolerance in the advanced automation system. In Proceedings of the ACM SIGOPS European Workshop, Bologna, Italy, 3–5 September 1990; pp. 6–17. [Google Scholar]
- LaBel, K.A.; Barnes, C.E.; Marshall, P.W.; Marshall, C.J.; Johnston, A.H.; Reed, R.A.; Barth, J.L.; Seidleck, C.M.; Kayali, S.A.; O’Bryan, M.V. A roadmap for NASA’s radiation effects research in emerging microelectronics and photonics. In Proceedings of the 2000 IEEE Aerospace Conference, Big Sky, MT, USA, 25 March 2000; Volume 5. [Google Scholar]
- Katz, D.S.; Some, R.R. NASA advances robotic space exploration. Computer 2003, 36, 52–61. [Google Scholar] [CrossRef]
- IRC. International Technology Roadmap for Semiconductors 2.0-Executive Summary. 2015. Available online: http://www.itrs2.net/itrs-reports.html (accessed on 2 December 2021).
- Wang, N.J.; Patel, S.J. ReStore: Symptom-based soft error detection in microprocessors. IEEE Trans. Dependable Secur. Comput. (TDSC) 2006, 3, 188–201. [Google Scholar] [CrossRef]
- Sahoo, S.K.; Li, M.L.; Ramachandran, P.; Adve, S.V.; Adve, V.S.; Zhou, Y. Using likely program invariants to detect hardware errors. In Proceedings of the IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Anchorage, AK, USA, 24–27 June 2008; pp. 70–79. [Google Scholar]
- Yalcin, G.; Unsal, O.S.; Cristal, A.; Hur, I.; Valero, M. SymptomTM: Symptom-based error detection and recovery using hardware transactional memory. In Proceedings of the IEEE International Conference on Parallel Architecture and Compilation Techniques (PACT), Galveston, TX, USA, 10–14 October 2011; pp. 199–200. [Google Scholar]
- Hari, S.K.S.; Li, M.L.; Ramachandran, P.; Choi, B.; Adve, S.V. mSWAT: Low-cost hardware fault detection and diagnosis for multicore systems. In Proceedings of the 2009 42nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), New York, NY, USA, 12–16 December 2009; pp. 122–132. [Google Scholar]
- Li, M. Designing Resilient Hardware by Treating Software Anomalies. Ph.D. Thesis, University of Illinois Urbana-Champaign, Champaign, IL, USA, 2009. [Google Scholar]
- Ramachandran, P. Detecting and Recovering from In-Core Hardware Faults through Software Anomaly Treatment. Ph.D. Thesis, University of Illinois Urbana-Champaign, Champaign, IL, USA, 2011. [Google Scholar]
- Mahmoud, A.; Venkatagiri, R.; Ahmed, K.; Misailovic, S.; Marinov, D.; Fletcher, C.W.; Adve, S.V. Minotaur: Adapting software testing techniques for hardware errors. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, Providence, RI, USA, 13–17 April 2019; pp. 1087–1103. [Google Scholar]
- Venkatagiri, R.; Ahmed, K.; Mahmoud, A.; Misailovic, S.; Marinov, D.; Fletcher, C.W.; Adve, S.V. gem5-Approxilyzer: An open-source tool for application-level soft error analysis. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), New York, NY, USA, 12–16 December 2019; pp. 214–221. [Google Scholar]
- Venkatagiri, R.; Mahmoud, A.; Hari, S.K.S.; Adve, S.V. Approxilyzer: Towards a systematic framework for instruction-level approximate computing and its application to hardware resiliency. In Proceedings of the IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–14. [Google Scholar]
- Feng, S.; Gupta, S.; Ansari, A.; Mahlke, S.A.; August, D.I. Encore: Low-cost, fine-grained transient fault recovery. In Proceedings of the IEEE/ACM International Symposium on Microarchitecture (MICRO), Porto Alegre, Brazil, 3–7 December 2011; pp. 398–409. [Google Scholar]
- Wang, N.J.; Mahesri, A.; Patel, S.J. Examining ACE analysis reliability estimates using fault-injection. In Proceedings of the 34th Annual International Symposium on Computer Architecture, San Diego, CA, USA, 9–13 June 2007; Volume 35, pp. 460–469. [Google Scholar]
- Snir, M.; Wisniewski, R.W.; Abraham, J.A.; Adve, S.V.; Bagchi, S.; Balaji, P.; Belak, J.; Bose, P.; Cappello, F.; Carlson, B.; et al. Addressing failures in exascale computing. Sage Int. J. High Perform. Comput. Appl. (IJHPCA) 2014, 28, 129–173. [Google Scholar] [CrossRef] [Green Version]
- Sastry Hari, S.K.; Venkatagiri, R.; Adve, S.V.; Naeimi, H. GangES: Gang error simulation for hardware resiliency evaluation. ACM Sigarch Comput. Archit. News 2014, 42, 61–72. [Google Scholar] [CrossRef]
- Wang, N.J.; Patel, S.J. ReStore: Symptom based soft error detection in microprocessors. In Proceedings of the IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Yokohama, Japan, 28 June–1 July 2005; pp. 30–39. [Google Scholar]
- Li, M.L.; Ramachandran, P.; Sahoo, S.K.; Adve, S.V.; Adve, V.S.; Zhou, Y. Understanding the propagation of hard errors to software and implications for resilient system design. ACM Sigarch Comput. Archit. News 2008, 36, 265–276. [Google Scholar] [CrossRef]
- Li, M.L.; Ramachandran, P.; Sahoo, S.K.; Adve, S.V.; Adve, V.S.; Zhou, Y. SWAT: An error resilient system. In Proceedings of the Workshop on Silicon Errors in Logic (SELSE), Austin, TX, USA, 26–27 March 2008. [Google Scholar]
- Lepak, K.M.; Lipasti, M.H. Silent stores for free. In Proceedings of the IEEE/ACM International Symposium on Microarchitecture (MICRO), Monterey, CA, USA, 10–13 December 2000; pp. 22–31. [Google Scholar]
- Bell, G.B.; Lepak, K.M.; Lipasti, M.H. Characterization of silent stores. In Proceedings of the IEEE International Conference on Parallel Architecture and Compilation Techniques (PACT), Philadelphia, PA, USA, 15–19 October 2000; pp. 133–144. [Google Scholar]
- Guthaus, M.R.; Ringenberg, J.S.; Ernst, D.; Austin, T.M.; Mudge, T.; Brown, R.B. MiBench: A free, commercially representative embedded benchmark suite. In Proceedings of the IEEE International Workshop on Workload Characterization (WWC), Austin, TX, USA, 2 December 2001; pp. 3–14. [Google Scholar]
- Dixit, A.; Wood, A. The impact of new technology on soft error rates. In Proceedings of the 2011 International Reliability Physics Symposium, Monterey, CA, USA, 10–14 April 2011. [Google Scholar]
- Schirmeier, H.; Borchert, C.; Spinczyk, O. Avoiding pitfalls in fault-injection based comparison of program susceptibility to soft errors. In Proceedings of the IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Rio de Janeiro, Brazil, 22–25 June 2015; pp. 319–330. [Google Scholar]
- May, T.C.; Woods, M.H. Alpha-particle-induced soft errors in dynamic memories. IEEE Trans. Electron Devices (T-ED) 1979, 26, 2–9. [Google Scholar] [CrossRef]
- Lee, S.; Kim, I.; Ha, S.; Yu, C.S.; Noh, J.; Pae, S.; Park, J. Radiation-induced soft error rate analyses for 14 nm FinFET SRAM devices. In Proceedings of the IEEE International Reliability Physics Symposium (IRPS), Monterey, CA, USA, 19–23 April 2015. [Google Scholar]
- Hubert, G.; Artola, L.; Regis, D. Impact of scaling on the soft error sensitivity of bulk, FDSOI and FinFET technologies due to atmospheric radiation. Integr. VLSI J. 2015, 50, 39–47. [Google Scholar] [CrossRef]
- Hazucha, P.; Karnik, T.; Walstra, S.; Bloechel, B.A.; Tschanz, J.W.; Maiz, J.; Soumyanath, K.; Dermer, G.E.; Narendra, S.; De, V.; et al. Measurements and analysis of SER-tolerant latch in a 90-nm dual-VT CMOS process. IEEE J. Solid-State Circuits 2004, 39, 1536–1543. [Google Scholar] [CrossRef]
- Mukherjee, S.S.; Emer, J.; Reinhardt, S.K. The soft error problem: An architectural perspective. In Proceedings of the 11th International Symposium on High-Performance Computer Architecture, San Francisco, CA, USA, 12–16 February 2005; pp. 243–247. [Google Scholar] [CrossRef]
- Chen, C.L.; Hsiao, M.Y. Error-Correcting Codes for Semiconductor Memory Applications: A State-of-the-Art Review. IBM J. Res. Dev. 1984, 28, 124–134. [Google Scholar] [CrossRef] [Green Version]
- Lyons, R.E.; Vanderkulk, W. The Use of Triple-Modular Redundancy to Improve Computer Reliability. IBM J. Res. Dev. 1962, 6, 200–209. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, Y.; Wang, H.; Bai, M.; Liu, Z.; Wang, J.; Yang, Z.; Chen, Z. Soft error resilience of deep residual networks for object recognition. IEEE Access 2020, 8, 19490–19503. [Google Scholar] [CrossRef]
- Quinn, H.; Baker, Z.; Fairbanks, T.; Tripp, J.L.; Duran, G. Software resilience and the effectiveness of software mitigation in microcontrollers. IEEE Trans. Nucl. Sci. (TNS) 2015, 62, 2532–2538. [Google Scholar] [CrossRef]
- Didehban, M.; Shrivastava, A. nZDC: A Compiler technique for near zero silent data corruption. In Proceedings of the ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 5–9 June 2016; p. 48. [Google Scholar]
- Oh, N.; Shirvani, P.P.; McCluskey, E.J. Error detection by duplicated instructions in super-scalar processors. IEEE Trans. Reliab. (TR) 2002, 51, 63–75. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Shrivastava, A.; Issenin, I.; Dutt, N.; Venkatasubramanian, N. Partially protected caches to reduce failures due to soft errors in multimedia applications. IEEE Trans. Very Large Scale Integr. Syst. (TVLSI) 2009, 17, 1343–1347. [Google Scholar]
- Lee, J.; Ko, Y.; Lee, K.; Youn, J.M.; Paek, Y. Dynamic code duplication with vulnerability awareness for soft error detection on VLIW architectures. Acm Trans. Archit. Code Optim. (TACO) 2013, 9, 1–24. [Google Scholar] [CrossRef]
- Oh, N.; Shirvani, P.P.; McCluskey, E.J. Control-flow checking by software signatures. IEEE Trans. Reliab. (TR) 2002, 51, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Rehman, S.; Shafique, M.; Henkel, J. Instruction scheduling for reliability-aware compilation. In Proceedings of the ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 3–7 June 2012; pp. 1288–1296. [Google Scholar]
- Shrivastava, A.; Rhisheekesan, A.; Jeyapaul, R.; Wu, C.J. Quantitative analysis of control flow checking mechanisms for soft errors. In Proceedings of the ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 1–5 June 2014. [Google Scholar]
- Feng, S.; Gupta, S.; Ansari, A.; Mahlke, S. Shoestring: Probabilistic soft error reliability on the cheap. ACM Sigarch Comput. Archit. News 2010, 38, 385–396. [Google Scholar] [CrossRef]
- Khudia, D.S.; Wright, G.; Mahlke, S. Efficient soft error protection for commodity embedded microprocessors using profile information. ACM Sigplan Not. 2012, 47, 99–108. [Google Scholar] [CrossRef] [Green Version]
- Reis, G.A.; Chang, J.; Vachharajani, N.; Rangan, R.; August, D.I. SWIFT: Software implemented fault tolerance. In Proceedings of the IEEE International Symposium on Code Generation and Optimization (CGO), San Jose, CA, USA, 20–23 March 2005. [Google Scholar]
- Yang, N.; Wang, Y. Identify silent data corruption vulnerable instructions using SVM. IEEE Access 2019, 7, 40210–40219. [Google Scholar] [CrossRef]
- Laguna, I.; Schulz, M.; Richards, D.F.; Calhoun, J.; Olson, L. IPAS: Intelligent protection against silent output corruption in scientific applications. In Proceedings of the IEEE International Symposium on Code Generation and Optimization (CGO), Barcelona, Spain, 12–18 March 2016; pp. 227–238. [Google Scholar]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The gem5 simulator. ACM Sigarch Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Wang, N.J.; Quek, J.; Rafacz, T.M. Characterizing the effects of transient faults on a high-performance processor pipeline. In Proceedings of the International Conference on Dependable Systems and Networks, Florence, Italy, 8 June–1 July 2004; p. 61. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Descriptions | Coverage | Possible Symptoms | Concerns |
|---|---|---|---|
| Low-level hardware symptoms for error detection [8,21] | • Soft errors • Low-detection latency | • Branch mispredictions • Exceptions • TLB/cache misses | • Frequent false alarm by natural symptoms • HW support for checkpointing interval of 100 s of instructions |
| OS-level symptoms for error detection [22] | • Soft errors and hard errors • High-detection latency | • Fatal traps • High OS activity • Hang/segmentation faults | • Offline profiling • Sophisticated HW support for rollback to 10 s of millions |
| Application-level symptoms for error detection [11,23] | • Soft and hard errors, | • Range-based invariant | • Offline profiling • Application-level modification |
| Benchmarks | BM | EX | CM | All Symptoms |
|---|---|---|---|---|
| sha | 62 | 49 | 56 | 76 |
| bitcount | 261 | 1 | 158 | 407 |
| gsm (toast) | 157 | 49 | 378 | 493 |
| crc | 213 | 2 | 371 | 579 |
| gsm (untoast) | 216 | 27 | 488 | 679 |
| susan | 175 | 4 | 529 | 683 |
| jpeg (decode) | 217 | 31 | 523 | 699 |
| jpeg (encode) | 785 | 27 | 412 | 1062 |
| stringsearch | 1087 | 48 | 431 | 1203 |
| basicmath | 951 | 93 | 624 | 1305 |
| fft (inverse) | 1031 | 212 | 768 | 1410 |
| fft (normal) | 1021 | 217 | 799 | 1417 |
| qsort | 1221 | 44 | 858 | 1478 |
| Average | 569 | 62 | 492 | 884 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
So, H.; Didehban, M.; Ko, Y.; Jeyapaul, R.; Kim, J.; Kim, Y.; Lee, K.; Shrivastava, A. Revisiting Symptom-Based Fault Tolerant Techniques against Soft Errors. Electronics 2021, 10, 3028. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10233028
So H, Didehban M, Ko Y, Jeyapaul R, Kim J, Kim Y, Lee K, Shrivastava A. Revisiting Symptom-Based Fault Tolerant Techniques against Soft Errors. Electronics. 2021; 10(23):3028. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10233028
Chicago/Turabian StyleSo, Hwisoo, Moslem Didehban, Yohan Ko, Reiley Jeyapaul, Jongho Kim, Youngbin Kim, Kyoungwoo Lee, and Aviral Shrivastava. 2021. "Revisiting Symptom-Based Fault Tolerant Techniques against Soft Errors" Electronics 10, no. 23: 3028. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10233028