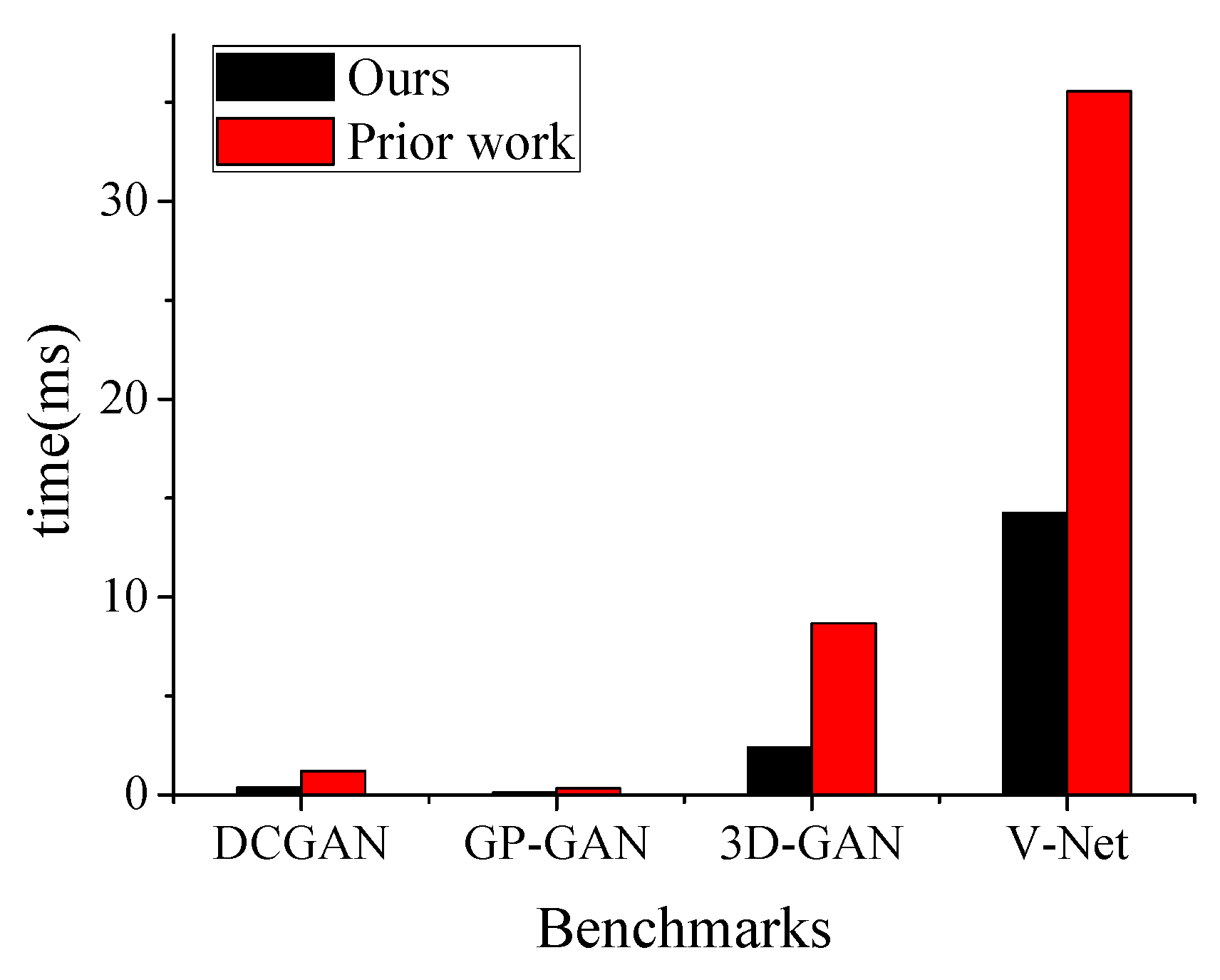
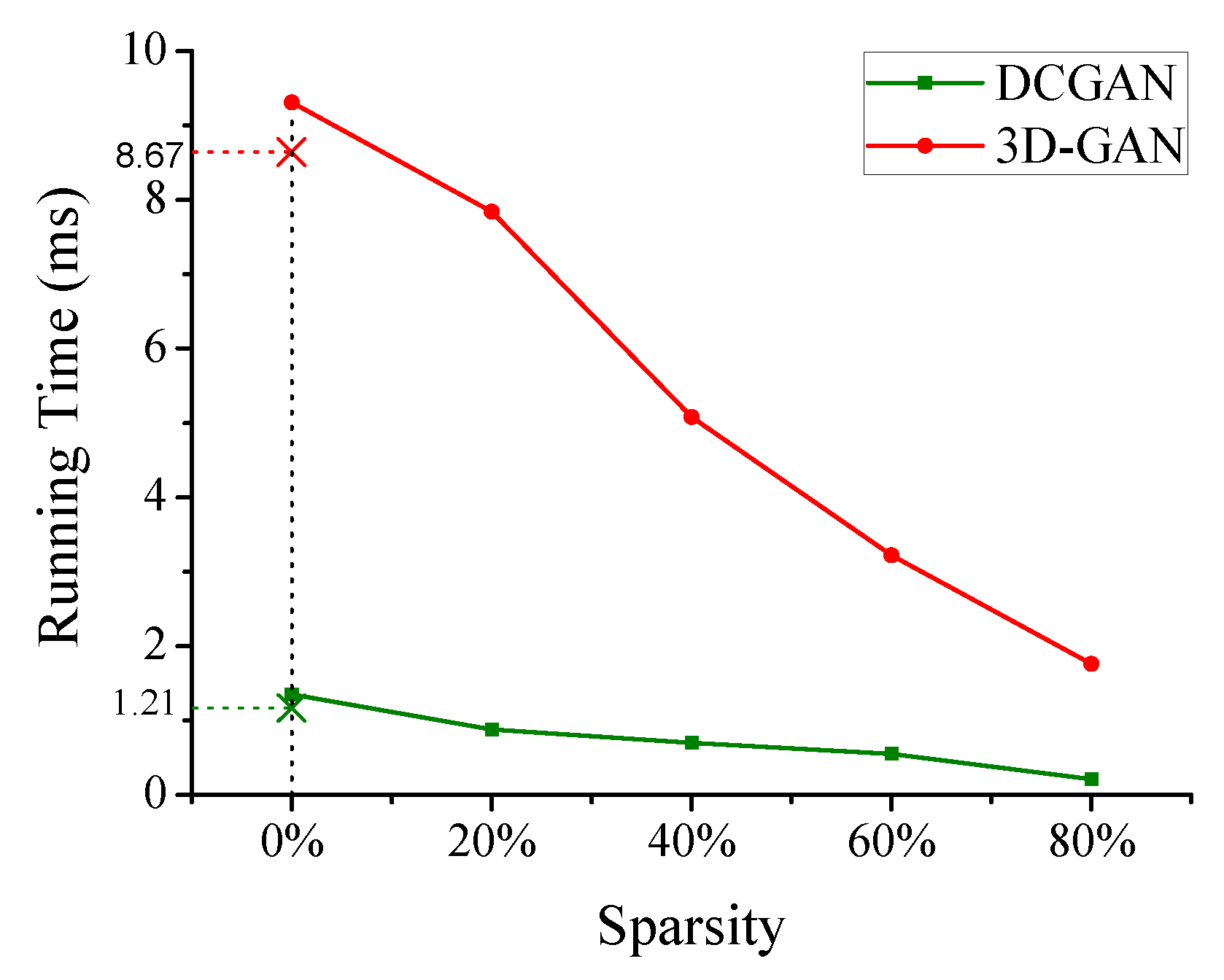
4.1. Architecture Overview
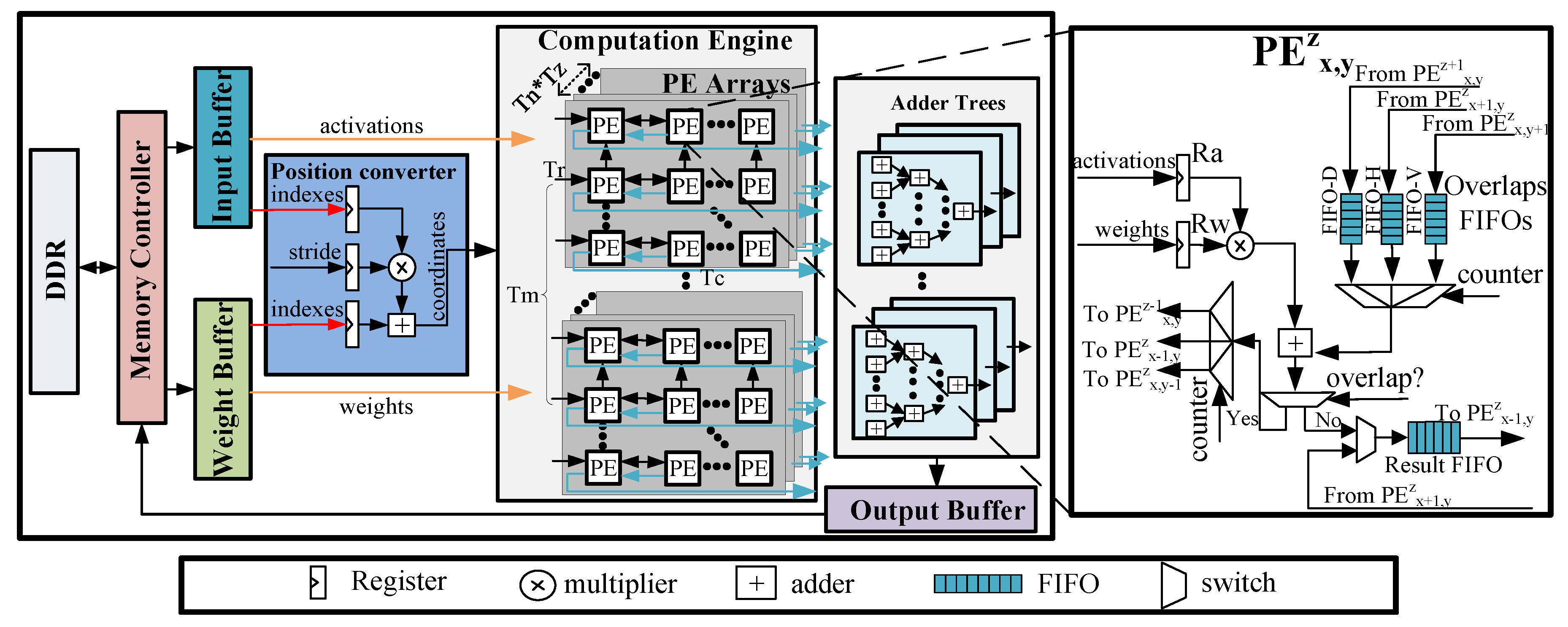
Figure 6 presents an overview of our proposed uniform architecture for accelerating both 2D and 3D sparse DCNNs. The accelerator mainly consists of a memory controller, three types of on-chip buffers, a kernel computation engine, a position converter and the adder trees. Due to a limited amount of on-chip memory of FPGAs, input images, compressed parameters and final results are stored in the off-chip memory (i.e., the dual date rate (DDR) memory). The memory controller is used to fetch the input feature maps and compressed weights from the DDR to the on-chip buffers, and storing the results into the DDR when they are available. One output feature map involves
(i.e., input channels) input feature maps. However, due to the limited on-chip memory, it is difficult to cache all the input data needed for one feature map on chip. Hence, we use a blocking method to resolve this issue. Input feature maps and compressed weights are divided into some tiling blocks. We adopt three separate on-chip buffers to store tiled input feature maps, output feature maps and compressed weights.
The computation engine is a significant component of our accelerator, which consists of a group of PEs. In each group, the PEs are organized as a 3D mesh architecture, which contains 2D PE planes. In this work, we regard the PE plane as a PE array with PEs. All PEs have direct connections to the input buffers and weight buffers. Those PEs which process the input activations belonging to the same input feature maps share the same weights.
Different from our prior work [
11], a position converter is added into the architecture. The position converter computes the coordinates of results yield by the computation engine according the indexes of input activations and weights. The architecture of the position converter module includes three register files, as well as an adder and a multiplier. The three register files are used to buffer input activations indexes and weights indexes, as well as to buffer sliding window stride S. The adder trees handle the additions of the results with the same positions but different input channels.
adders are integrated in the adder trees to support a higher degree of parallelism.
The architecture of the PE is presented in the right part of
Figure 6. It consists of two register files (i.e., Ra and Rw) to buffer the input activations and weights. In addition, three Overlap First-In-First-Outs (FIFOs) (i.e., FIFO-Vs, FIFO-Hs and FIFO-Ds) are designed to deliver the overlap of the results data from the adjacent PEs. The position converter can gain the position of results and control the data transfer between PEs. The products yielded by the multipliers are conditionally added with the data from the Overlap FIFOs. Once the current results are determined to be overlap by the position converter, they will be sent to the Overlap FIFOs of adjacent PEs, waiting to be added. Otherwise, they will be sent to the local Result FIFOs. The results in the local FIFO of the current PE will be sent to the left PE once they have stored all the local results.
4.3. 3D IOM Method
Previous studies [
19,
20] have adopted the output oriented mapping (OOM, i.e., mapping each output computation task to each PE) for the computation of deconvolution layers. This method, however, does not eliminate useless operations thereby resulting in low computational efficiency of PEs. In [
7], Yan et al. proposed a novel mapping method called IOM, which can efficiently overcome the inefficiency of PE computation. Motivated by [
7], we propose a 3D version of IOM for the mapping of 3D deconvolution on the accelerator.
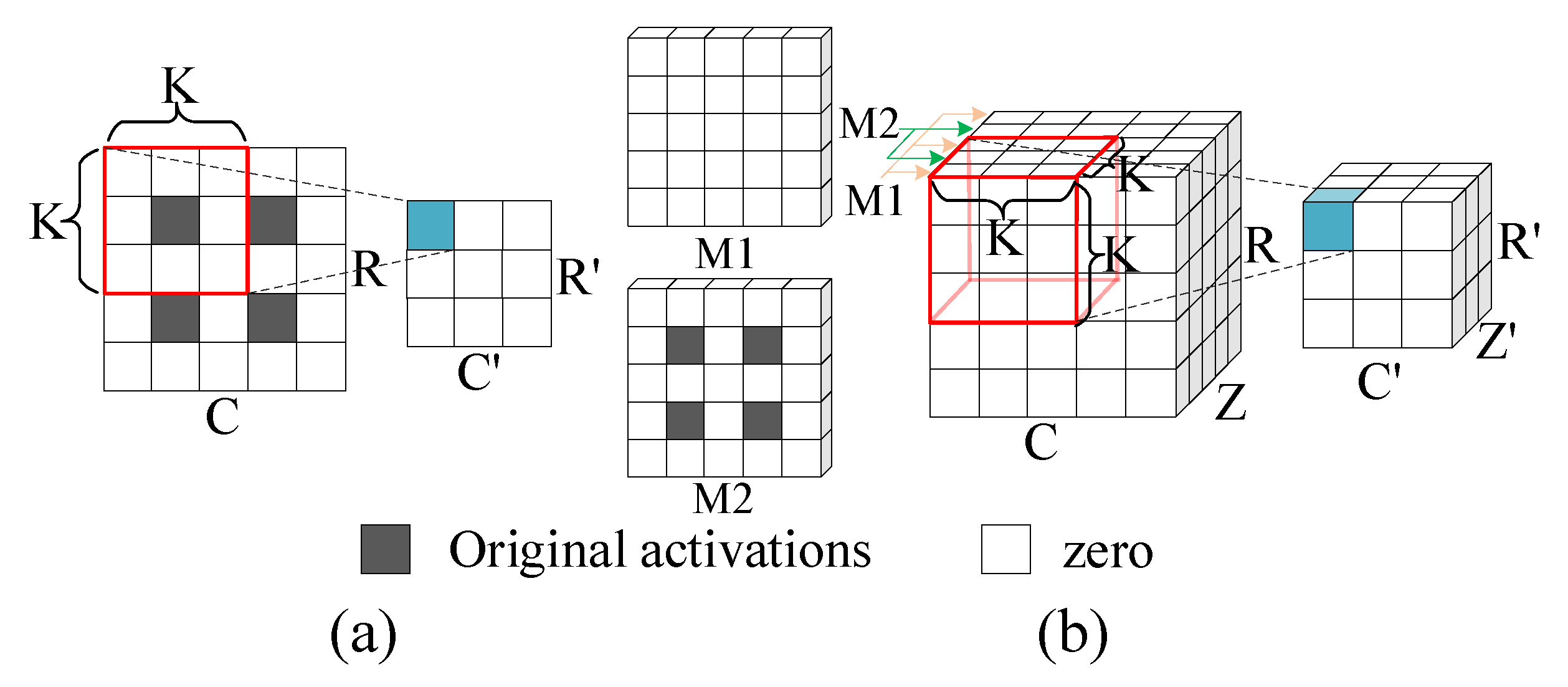
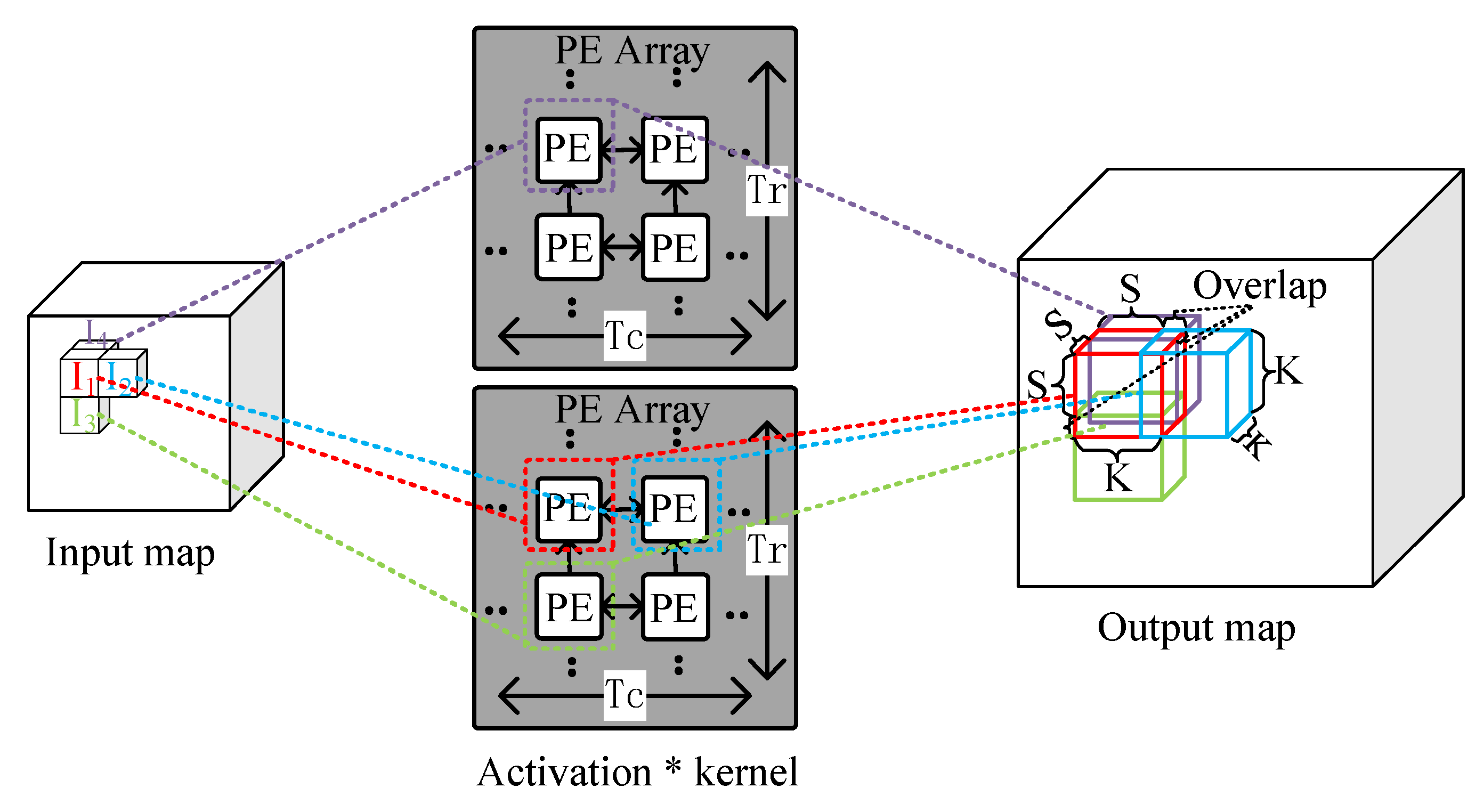
Figure 7 illustrates the 3D IOM method.
∼
are adjacent activations of the input map, and they are sent to four adjacent PEs of two PE arrays. In the PEs, each activation is multiplied by the
kernel and generates a
result block. The results are added to the corresponding location of the output maps. It is worth noting that some locations may overlap in the output maps and the overlapped elements of the same locations should be added up to form the resulting output maps. The overlap results from the PEs which are responsible for processing
∼
are sent to the PE which is responsible for processing
, and point-wise addition is performed. In each block, the length of the overlapping part is
K-
S, where S is the stride.
In 3D deconvolution, the output feature map size is given by Equation (
1). Note that
represent the height, width and depth of the input maps and output maps. However, at the edge of the output feature map, there is additional data padded. Thus, the padded data are removed from the final output feature map. The final result is equal to traditional convolution with ‘zero’ inserted into the original input map. The 3D deconvolution algorithm is illustrated in Algorithm 1, where
[
m][
][
][
],
[
n][
][
][
] and
W[
m][
n][
][
][
] represent the elements of output feature maps, input feature maps and weights, respectively:
| Algorithm 1 Pseudo code for 3D deconvolution. |
- 1:
for (; ; m ++) - 2:
for (; ; n ++) - 3:
for (; ; ++) - 4:
for (; ; ++) - 5:
for (; ; ++) - 6:
fo r(; ; ++) - 7:
for (; ; ++) - 8:
for (; ; ++) - 9:
; - 10:
; - 11:
; - 12:
[m][][][] += [n][][][] × W[m][n][][][];
|
We divide the dataflow in the PE arrays into three steps:
Loading activations and weights: Input blocks and weight blocks are firstly fetched into the input and weight buffers, and activations and weights are fed into the computation engine. Each PE in the 3D PE mesh load a input activation from input buffers, and PEs which process the input activations of the same input feature map share the same weight from weight buffers. Input activations are multiplied by all the compressed non-zero weights of the corresponding kernels. After that, the arithmetic operations of the current weights and input activations are completed in PEs, the next weights of current convolutional kernels are then fed into the computation engine. In addition, when the the arithmetic operations of the current input activations and convolutional kernels are finished, the next group activations are fed into the computation engine.
Computing: After input activations and weights are fed into the PEs, they are immediately sent to the multiplier to yield products in each PE. The results are then sent to the FIFOs. If the results overlap, they are sent to Overlap FIFOs, else they are sent to Result FIFOs. When the PEs process the overlapped part of the result blocks, the PEs load the overlapped elements from their Overlap FIFOs, and perform multiplication and additions. For 3D deconvolution, each input activation produces a result block. In result blocks, except for those results yielded by PEs, the remaining part of result blocks are regarded as zero. When the computation process in the direction of input channels (i.e., ) is completed, the position converter computes the positions of results yield by the computation engine according to the index of input activations and weights; then, results with the same locations are accumulated by the adder trees.
Writing Back: When all the activations of input blocks are completed and the overlap is accumulated, the final results (i.e., the output feature map) is transferred to output buffers. The results are accumulated until the input channels are completed, and the final outputs of output feature maps are then transferred to the external memory.
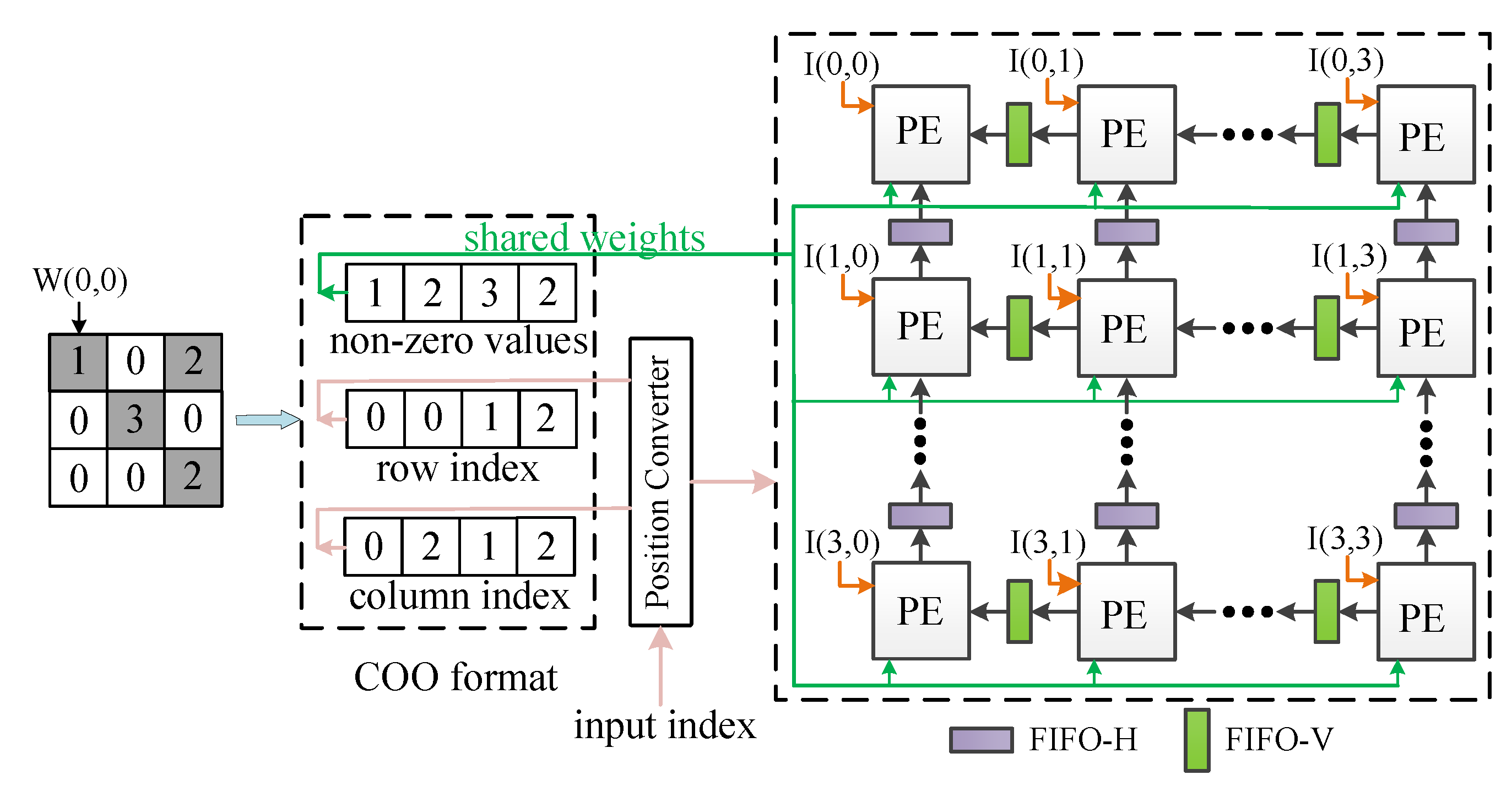
To explain this concept in more detail, we illustrate the dataflow of applying the 3D IOM method on the architecture in
Figure 8. For the sake of simplicity,
Figure 8 only shows the dataflow in a PE array, and the dataflow in other PE arrays is analogous.
Table 2 lists the definitions used in the explanation of the dataflow.
Initially, a pruned kernel is encoded in COO format. Weights are singly fed into the PE array in sequence and are shared by all PEs of the array, assuming that the size of the PE array is . In cycle 1, the first non-zero encoded weight and the input activations ∼ are fed to the PE array; the activations are then multiplied by the weight and the computation results are arranged in the output feature map according to their coordinates. The results coordinates are then computed by the position converter, as illustrated in lines 9–11 of Algorithm 1. There will be some results that have the same coordinates, leading to overlap. These computation results are overlapped in the vertical and sent to FIFO-Vs.
In cycle 2, the second non-zero weight is loaded into the PE array, which is also shared by all PEs. The weight is multiplied by the activations ∼; the computation results are then arranged in the output feature map according to their coordinates (generated by the position converter). These results have the same coordinates as the results generated in cycle 1; they are then added to the overlap loaded from FIFO-Vs (i.e., the computation results of cycle 1). These results are overlapped in the horizontal direction and sent to FIFO-Hs.
In cycle 3, the next non-zero weight is loaded into the PE array and is shared by all PEs. The weight is multiplied by the activations ∼ and the computation results are arranged in the output feature map according to their coordinates. These computation results are not overlapped and are sent to Result FIFOs.
In cycle 4, the final non-zero weight is loaded into the PE array and is multiplied by the activations ∼. These results have the same coordinates as the results generated in cycle 2; they are then added to the overlap loaded from FIFO-Hs (i.e., the added results of cycle 2). Then, the added results of cycle 4 are sent to Result FIFOs. Finally, the computation process of these input activations is completed, the next group of activations is fed into the PE array.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
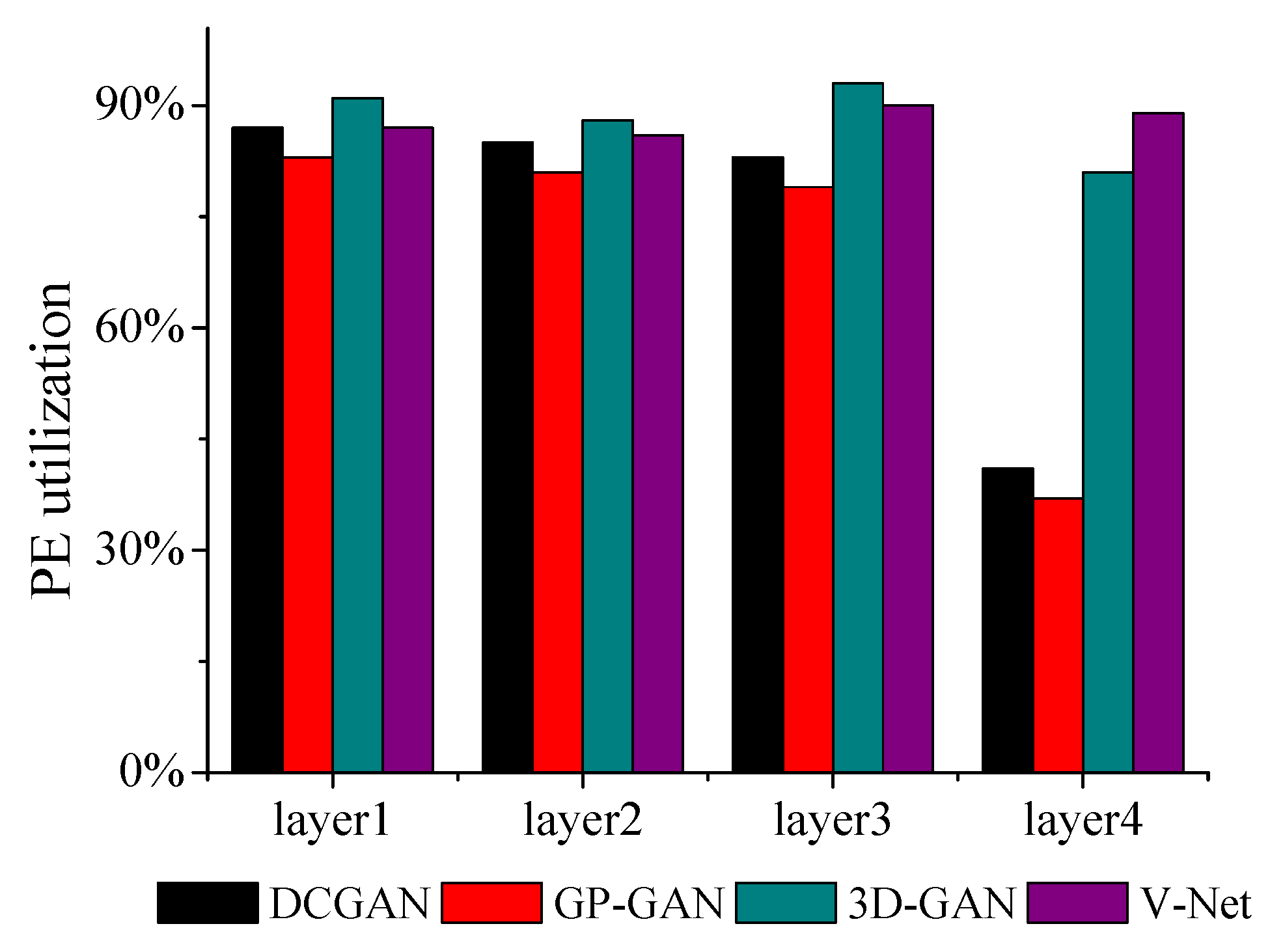{kind=link}
{kind=link}
{kind=link}