In this section, we first describe two datasets for empirical studies. All of the data are available online. Then, the parameter settings of model and evaluation metrics are introduced in our studies. Finally, the proposed M-TCN model against different baseline models is compared.
4.1. Datasets
Two benchmark datasets are used which are publicly available.
Table 2 summarizes the corpus statistics.
Beijing PM2.5 Dataset (available online:
https://archive.ics.uci.edu/ml/datasets/Beijing+PM2.5+Data): It contains hourly PM2.5 data and the associated meteorological data in Beijing, China. The exogenous time series include dew point, temperature, and atmospheric pressure, combined wind direction, cumulated wind speed, hours of snow, and hours of rain. In total, we have 43,824 multivariable sequences. For this dataset, the hourly PM2.5 data are used as a predictive value.
ISO-NE Dataset (available online:
https://www.iso-ne.com/isoexpress/web/reports/load-and-demand): The time range of the dataset is between March 2003 and December 2014. The ISO-NE Dataset includes hourly demand, prices, weather data and system load. The dataset contains two variables, which are hourly electricity demand in MW and dry-bulb temperature in
F. For this dataset, the hourly electricity demand is used as a predictive value.
In our experiments, ISO-NE datasets have been split into training set (from 1 March 2003 to 31 December 2012), valid set (the whole year of 2013) and test set (the whole year of 2014) in a chronological order. In addition, the Beijing PM2.5 Dataset has been split into a training set (from January 2, 2010 to December 31, 2012), valid set (the whole year of 2013) and test set (the whole year of 2014) in a chronological order.
4.2. Data Processing
According to the characteristics of each dataset, it is necessary to preprocess the data. Each of the datasets is normalized with a mean of 0 and a standard deviation of 1.
For the Beijing PM2.5 Dataset, PM2.5 is NA in the first 24 h. We will, therefore, need to remove the first row of data. There are also a few scattered “NA” values later in the dataset, and we use zero to fill in missing values. The wind speed feature is label encoded (integer encoded). We apply the new dataset to every algorithm in later experiments.
4.4. Walk-Forward Validation
In the test set, the Walk-Forward Validation method is adopted, but the model is not updated. In this case, a model is needed to predict a period of time, and then the actual data of the current period is provided to the model, so that it can be used as the basis for the prediction of subsequent periods. This is not only applicable to the way the model is used in practice, but also conducive to the model using the best available data.
In the experiment, the output length is set to 24. For multi-step prediction problems, we evaluate each prediction time step separately.
Table 3 summarizes the actual value and predicted value. Models can be trained and evaluated as follows.
Step 1: Starting at the beginning of the test set, the last set of observations in the training set is used as input of the model to predict the next set of data (the first set of true values in the validation set).
Step 2: The model makes a prediction for the next time step.
Step 3: Get real observation and add to history for predicting the next time.
Step 4: The prediction is stored and evaluated against the real observation.
Step 5: Go to step 1.
4.5. Experimental Details
To be more specific, most models chose input length from
, and the batch size is set to 100. The mean squared error is the default loss function for forecasting tasks. Adam [
35] is adopted as optimization strategy, with an initial learning rate set to 0.001. In addition, the learning rate is reduced by a factor of every 10 epochs of no improvement in the validation score, until the final learning rate was reached.
For the LSTM model, a single hidden layer with
units is defined. The number of units in the hidden layer is unrelated to the number of time steps in the input sequences. Finally, an output layer will directly predict a vector with 24 elements, one for each hour in the output sequence. SGD [
36] is adopted as an optimizer. The learning rate is set to 0.05 with a reduction rate by a factor of 0.3.
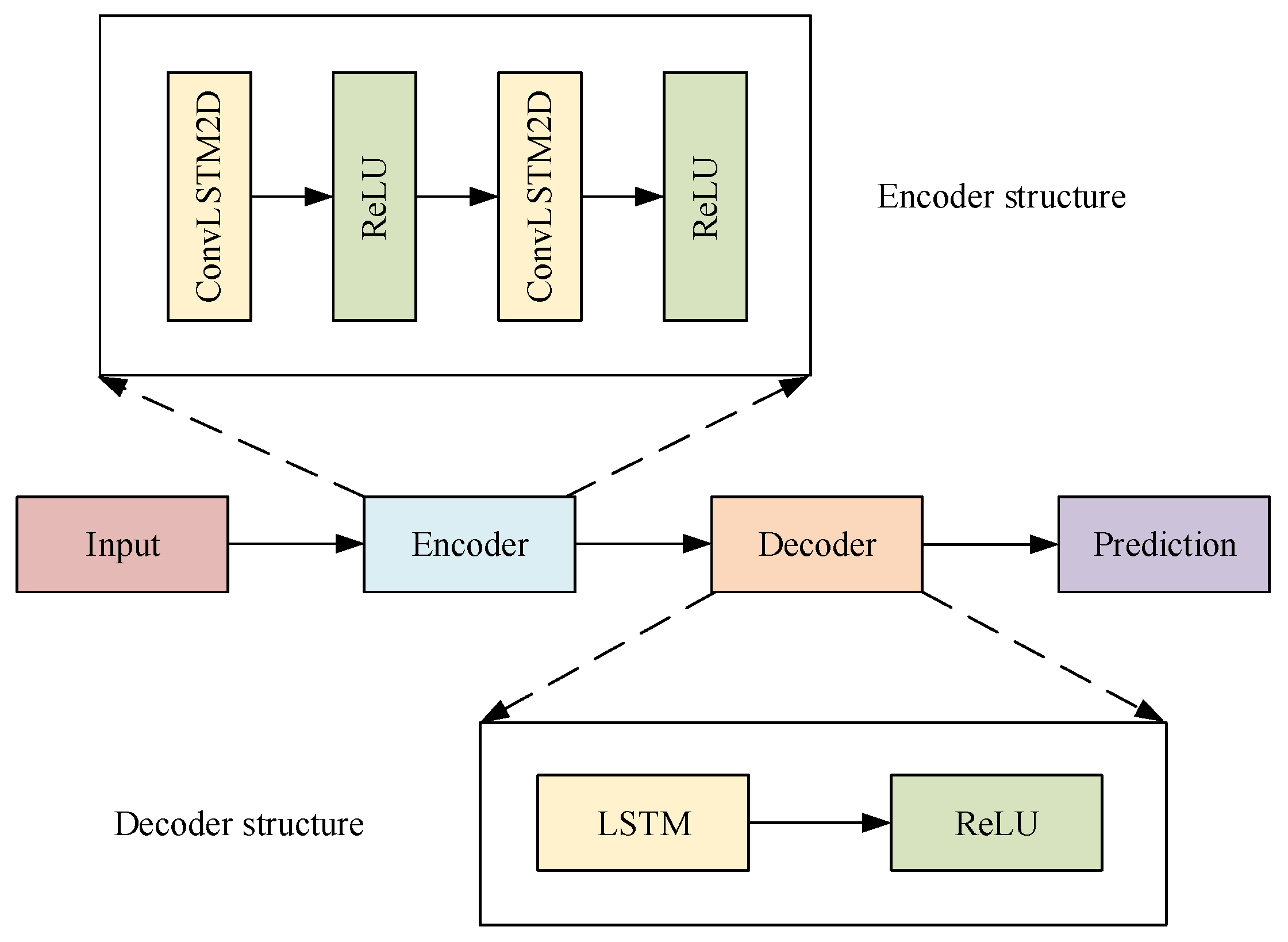
In the ConvLSTM Encoder–Decoder model, input data have the shape of [timestep, row, column, channel]. Timestep is chosen from . Row is set to 1. Column is chosen from . Channel is chosen from . SGD is adopted as the optimization algorithm. The learning rate is set as the same in LSTM. For this network, the 1-layer network contains one ConvLSTM layer with 64 hidden states, the 2-layer network contains one ConvLSTM layer with 128 hidden states, and the 3-layer network has 200 hidden states in the LSTM layers. All the input-to-state and state-to-state kernels are of size .
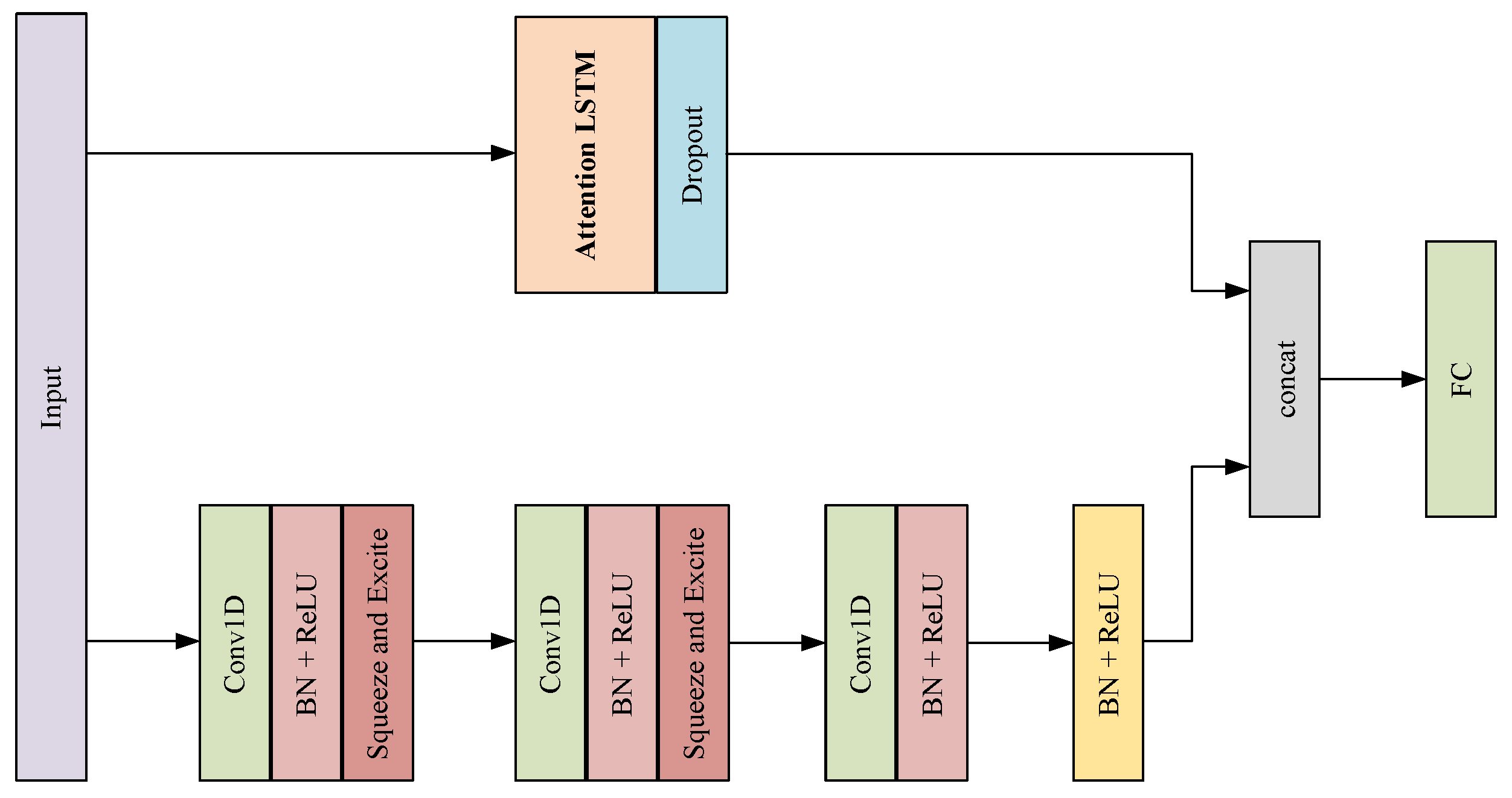
For the MALSTM-FCN network, the optimal number of LSTM hidden states for each dataset was found via grid search over
. The FCN block is comprised of three blocks of 128-256-128 filters. The models are trained using a batch size of 128. The convolution kernels are initialized following the work of [
24].
For the TCN network, the optimal number of hidden units per layer for each dataset was found via grid search over . The convolution kernels are of size .
In our M-TCN model, Adam is adopted as an optimization strategy with an initial learning rate set to 0.001(ISO-NE Dataset), while, for Beijing PM2.5, SGD is adopted as an optimization strategy with an initial learning rate set to 0.05.
The implementations of M-TCN are built based on Keras library with the Tensorflow backend. We run all the experiments on a computer with a single NVIDIA 1080 GPU (Santa Clara, CA, USA).
4.7. Spectrum Analysis
In order to further study the performance of the model, we analyzed the spectrum of the test set and the prediction data. Spectrum refers to the representation of a time domain signal in frequency domain, which can be used for discrete Fourier transform of sequence data. Discrete Fourier Transform (DFT) of
k points are computed as:
where
is the time series.
More detailed calculations include:
where
is signal time,
is the frequency interval,
N is the number of signal sampling, and
is the signal sampling interval time.
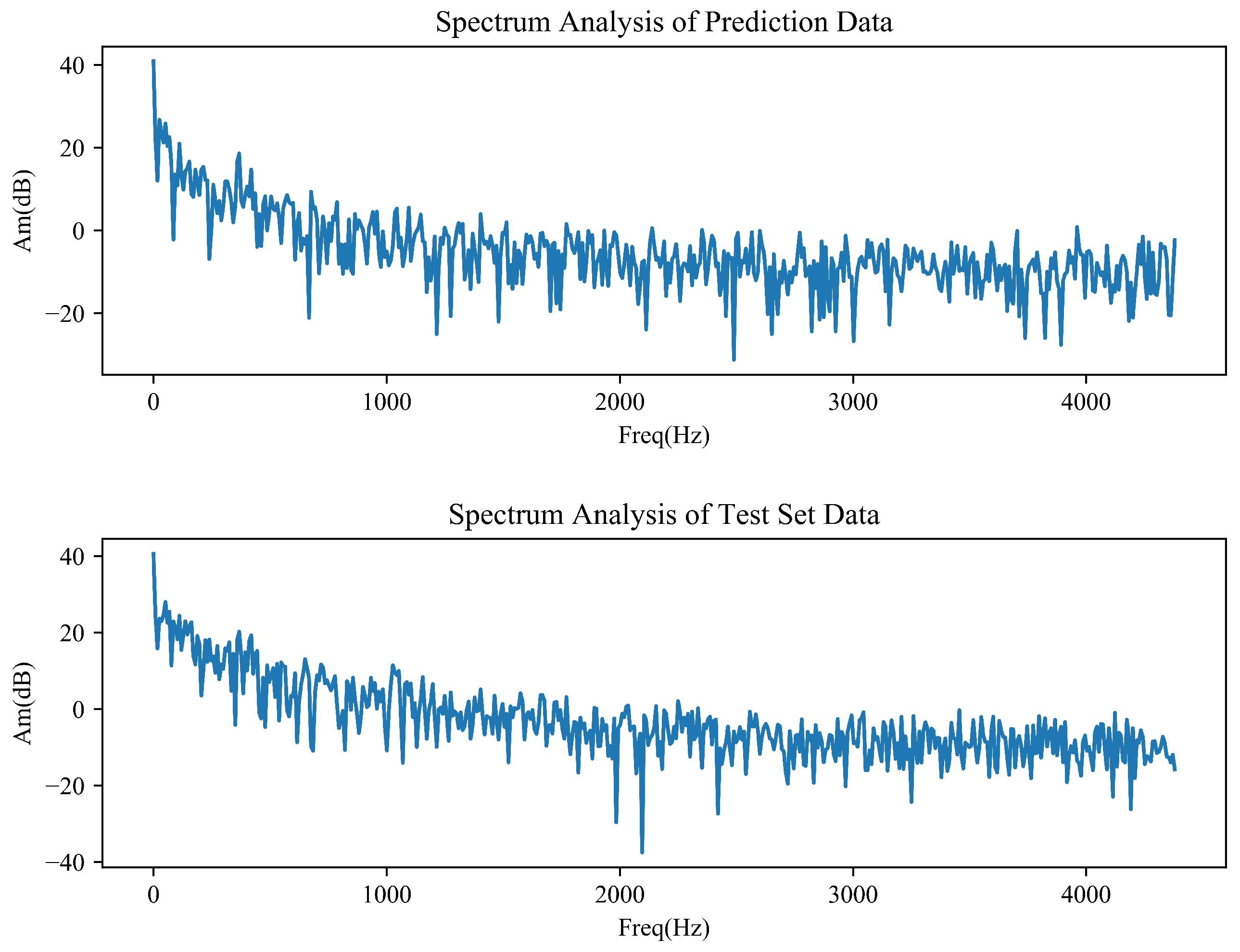
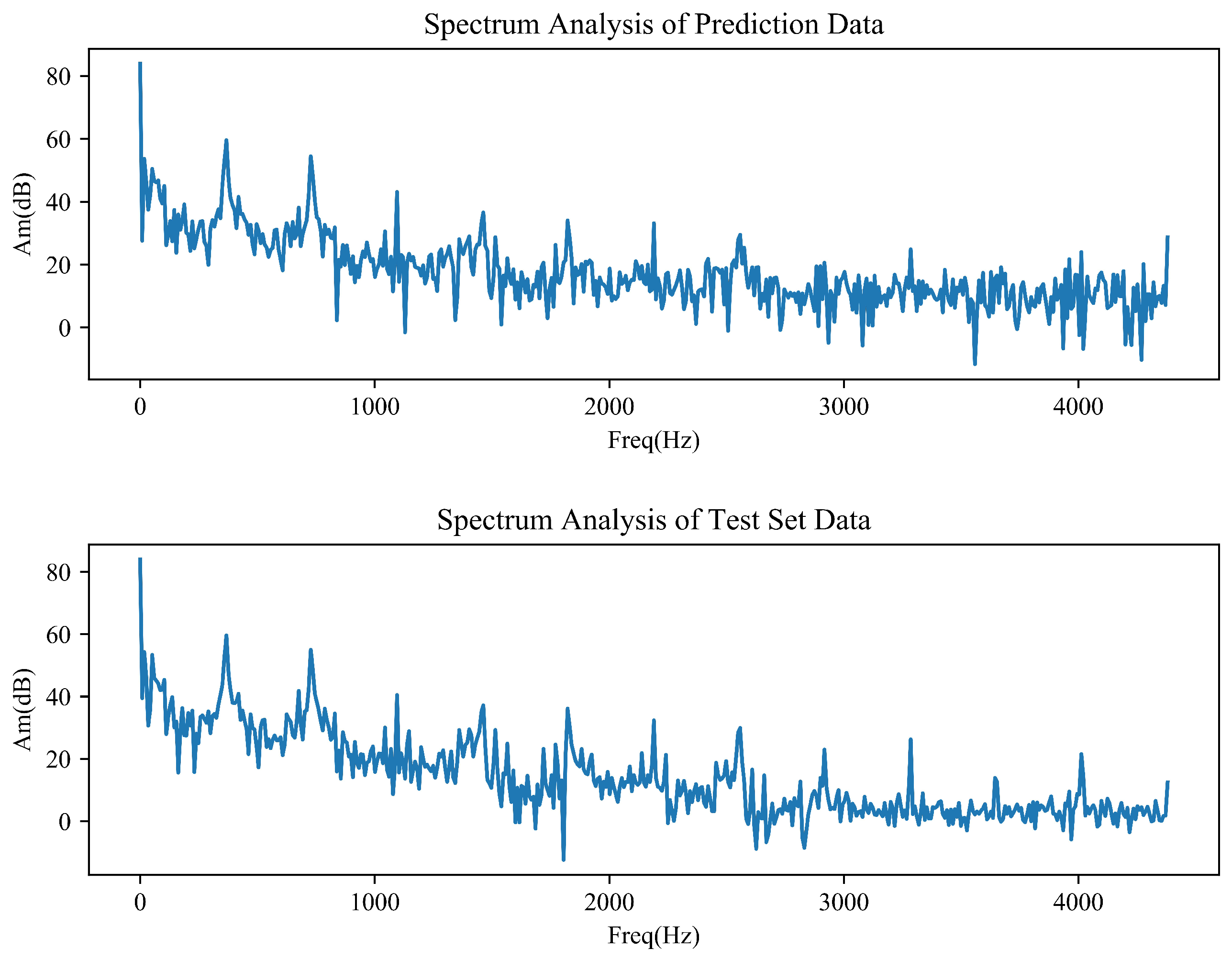
The amplitude spectrum analysis of these datasets is performed, so as to check the existence of repetitive patterns in the datasets. The hourly PM2.5 and ISO-NE data of test set and predictions are plotted in the frequency domain as shown in
Figure 10 and
Figure 11 separately, where
Freq is the frequency with a unit of 1/Hour and Am is the amplitude in dB. Sampling frequency is set to 8760 (the same as test set time variable length). Sampling frequency is set to 8760 (the same as the time variable length set by the test), which ensures that the frequency and time correspond to each other numerically. Both figures show that frequency domain is irregular continuous waveform indicating a non-periodic of PM2.5 and ISO-NE datasets. As can be clearly seen, PM2.5 data have no periodicity, which brings great errors to accurate prediction. Since the ISO-NE data change regularly from 1 to 1000 h, the prediction effect is the best.
4.8. Ablation Tests
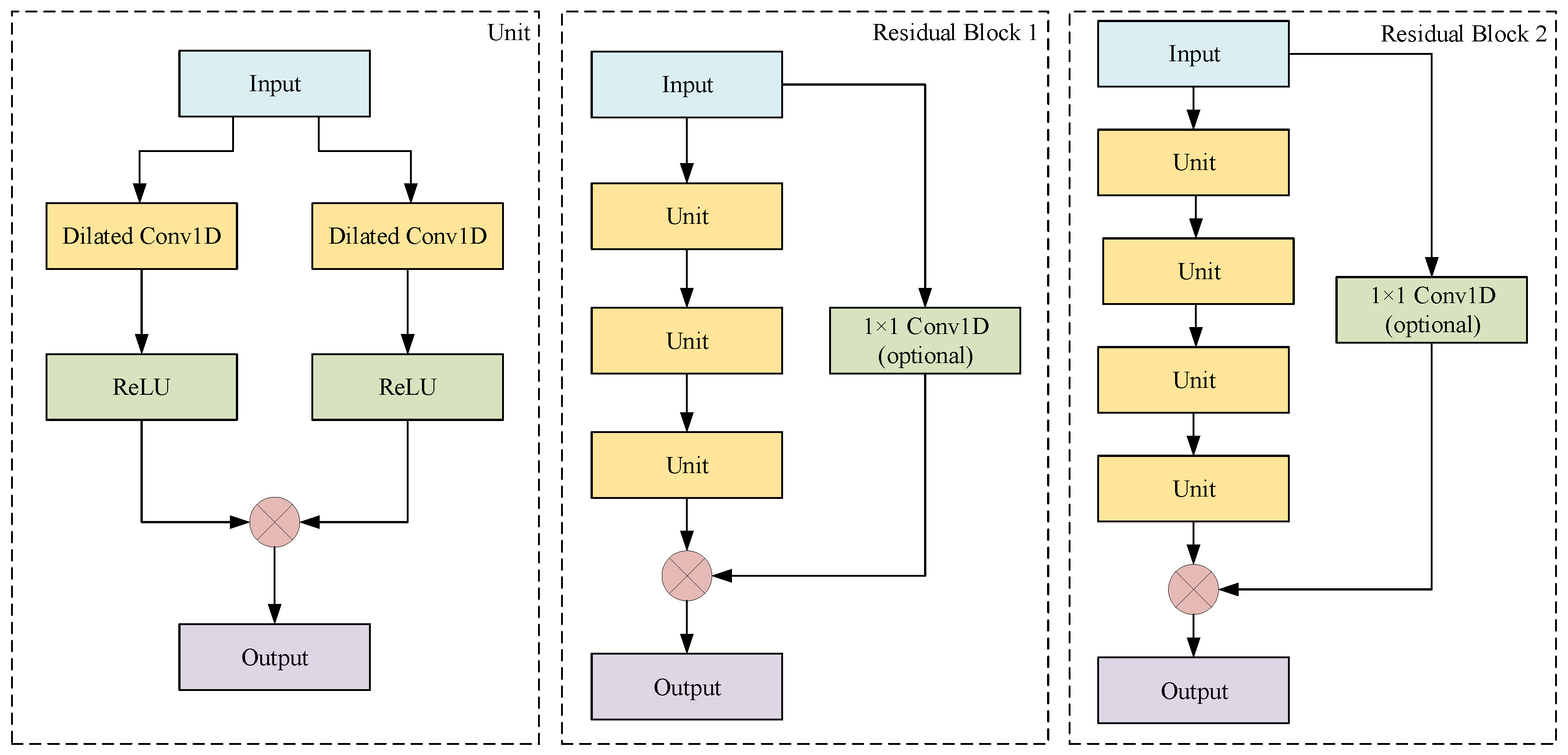
Furthermore, to demonstrate the efficiency of our model structure, a careful further study is performed. Specifically, we add each component one at a time in our framework. M-TCN with different components are defined as follows:
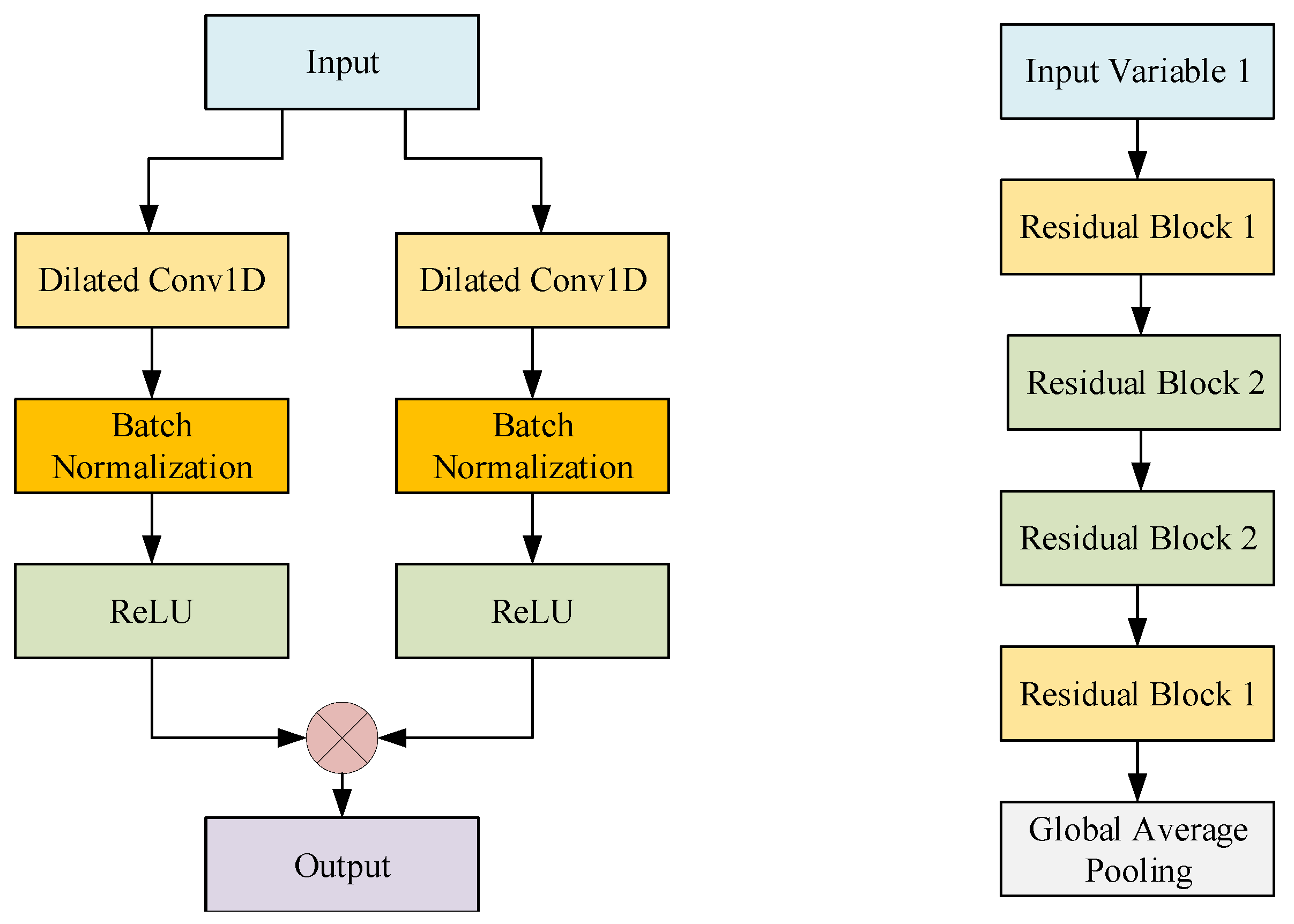
Model/w/BN: The model adds a Batch Normalization (BN) [
37] component. In this test, Batch Normalization was applied to the input of each nonlinearity, in a convolutional way, while keeping the rest of the architecture constant.
Figure 12 (left) describes this model in detail.
Model/r/GAP: In the model, the full connection layer is replaced by the global average pooling.
Figure 12 (right) describes this model in detail.
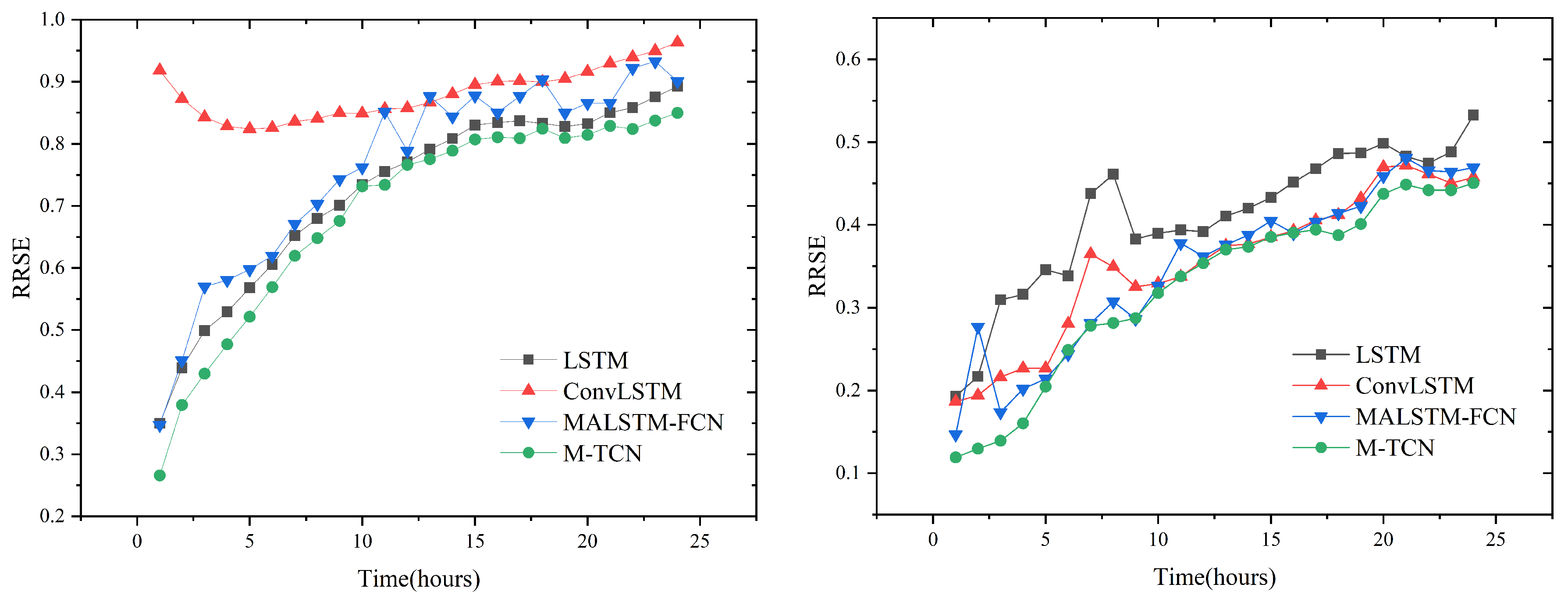
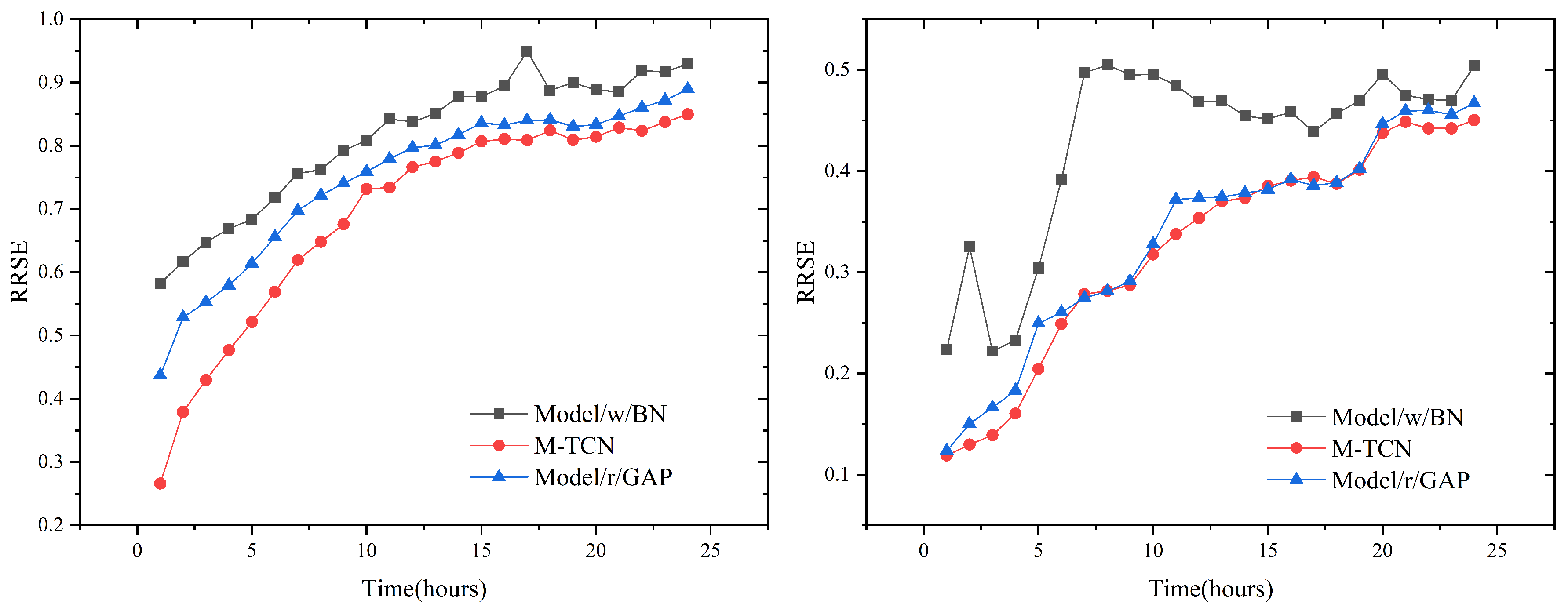
The test results measured using RRSE are shown in
Figure 13. Comparing the results, we see that, in both datasets, BN cannot help the network achieve higher accuracy. Adding the BN components in (Model/w/BN) caused big performance drops on both datasets. All of the components of the M-TCN model together lead to the robust performance of our approach on the Beijing PM2.5 dataset.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}