OTL-Classifier: Towards Imaging Processing for Future Unmanned Overhead Transmission Line Maintenance

 , ,
, ,
Abstract
:1. Introduction
2. Methodology
2.1. Problem Statement
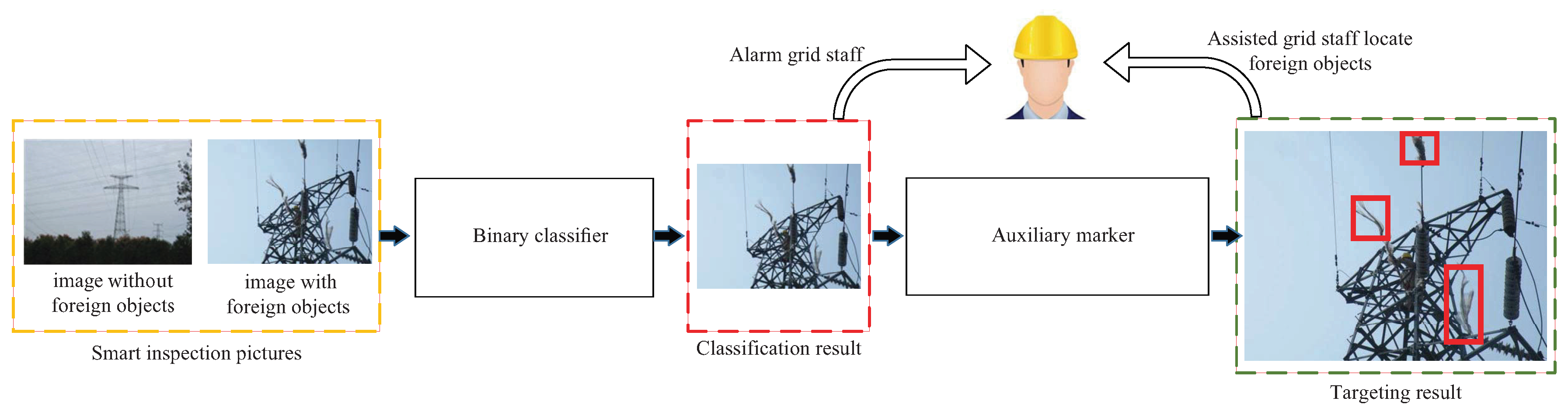
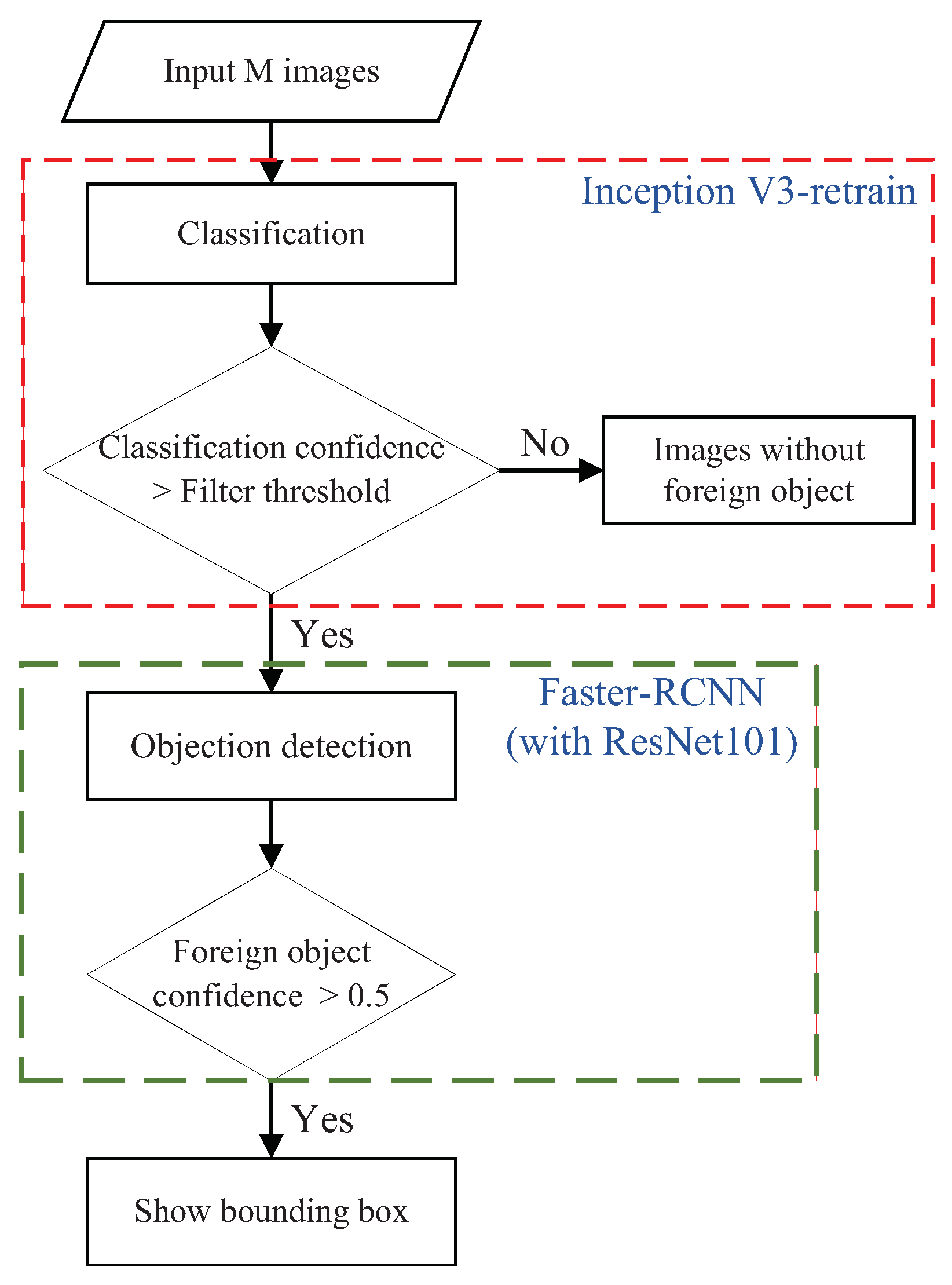
2.2. Warning–Review Strategy
2.3. Binary Classification Module
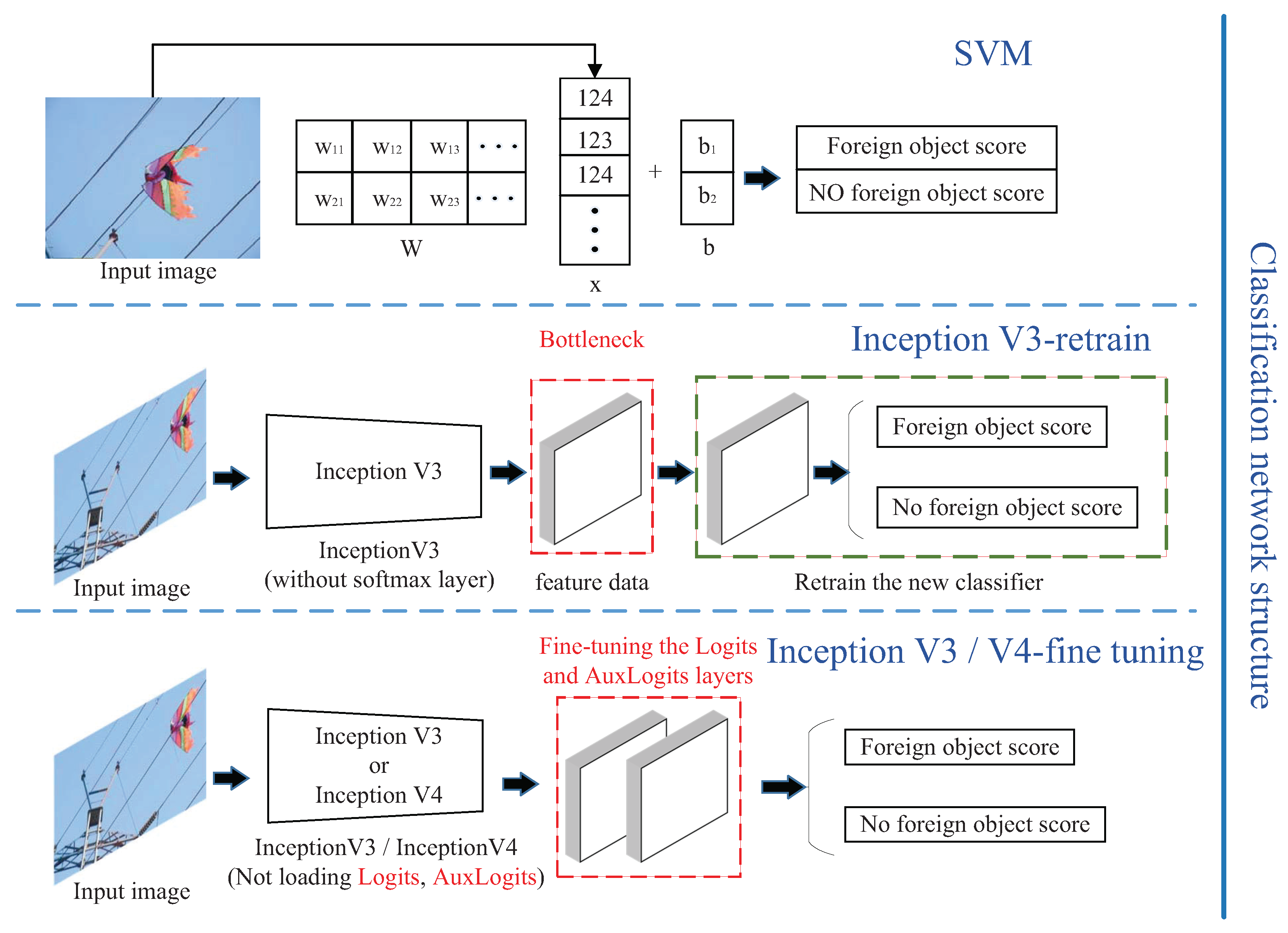
2.3.1. SVM
2.3.2. Inception Retrain
2.3.3. Inception Fine-Tuning
2.4. Auxiliary Marking Module
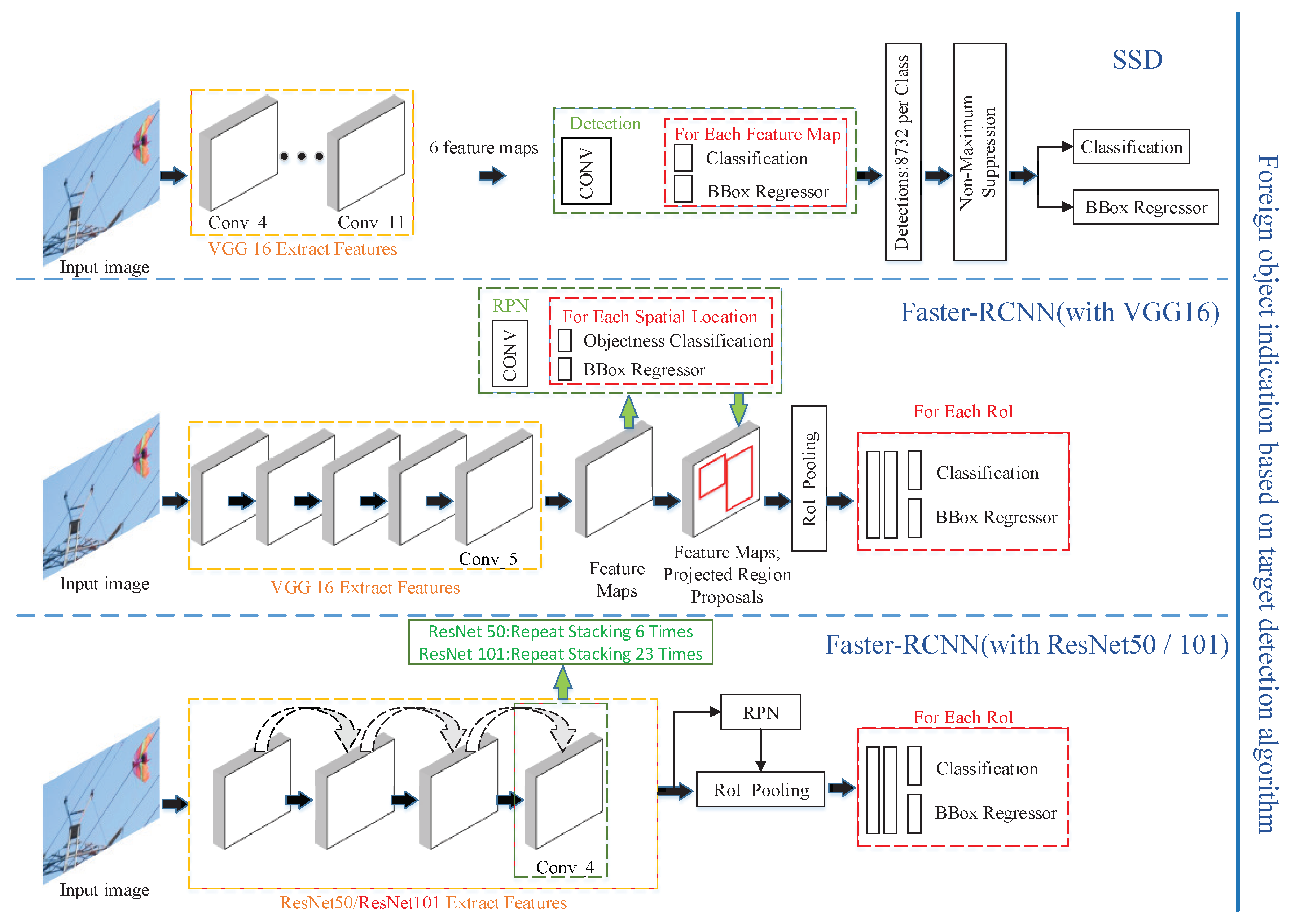
2.4.1. SSD with VGG16
2.4.2. Faster-RCNN with VGG16
2.4.3. ResNet
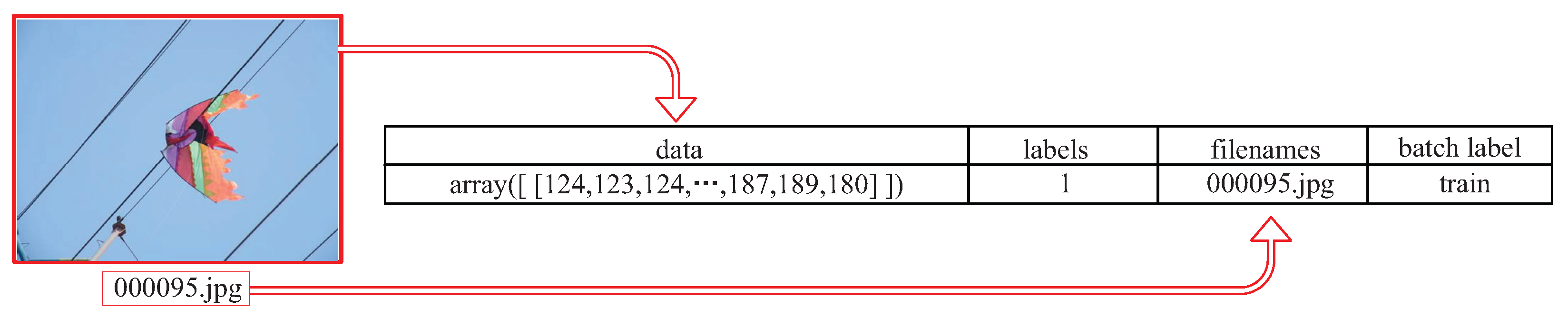
3. Data Set Preparation
4. Results
4.1. Calculation of Various Evaluation Indicators
4.1.1. Calculation Formula for Classifier Evaluation
4.1.2. Calculation Formula for Evaluation of Foreign Object Indicator
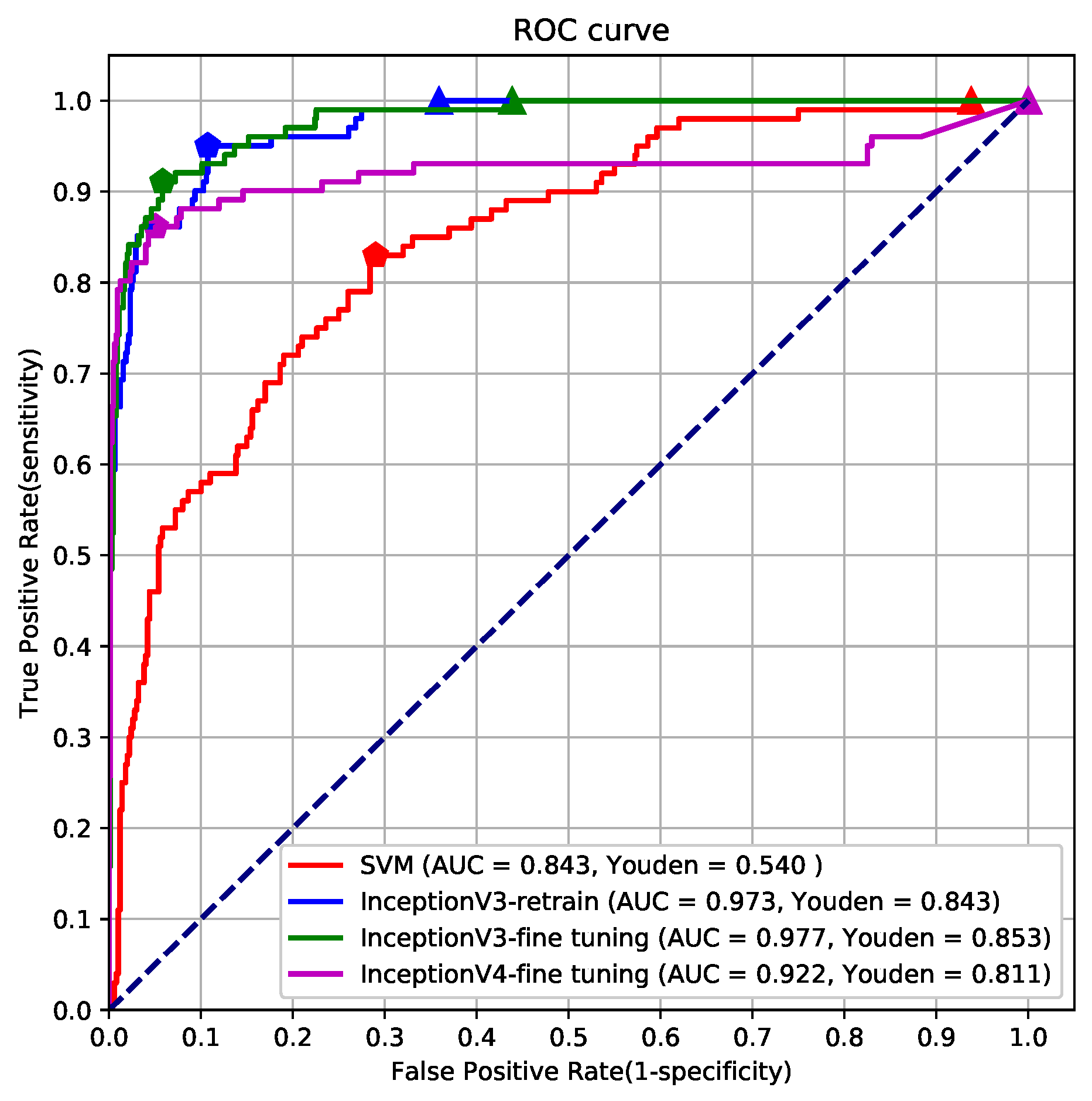
4.2. Classification Performance Evaluation
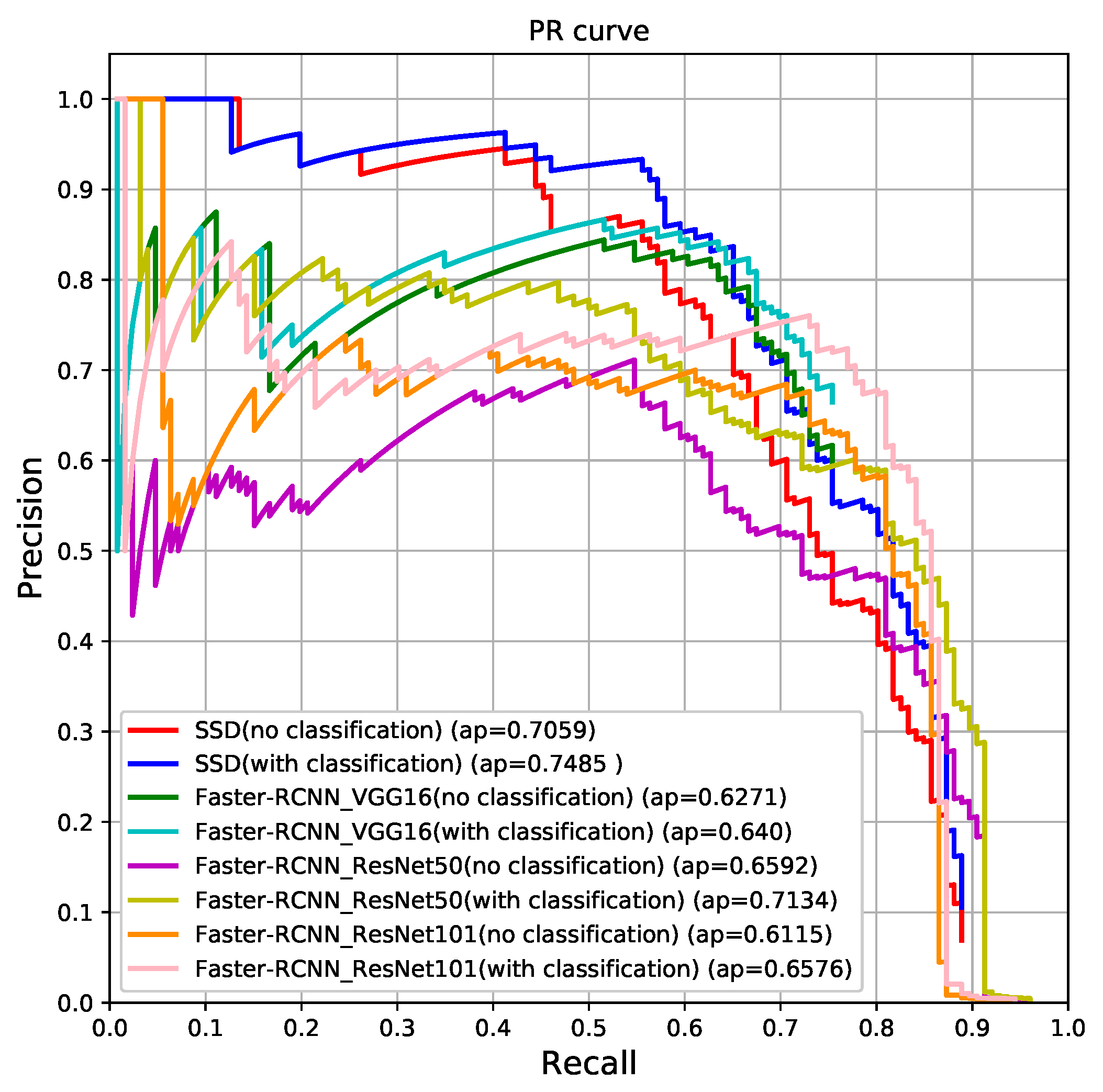
4.3. Automate Marking Performance Evaluation
5. Conclusions
- Our OTL-Classifier module can classify images with and without foreign objects. However, recent research only processes images with foreign objects; they focused on detecting the type and location of the foreign objects in the abnormal images. However, aerial images return by drones and robots inspection include much more normal images than abnormal images. Searching abnormal images manually is not only time-consuming, but also has poor precision due to attention feature of human. Therefore, it is much more important to design a module which could automatically extract abnormal images directly from original images returned by unmanned vehicles.
- During the evaluation phase, we consider recall rate as more important than precision in our application. A sudden wide-area outage caused by even one undetected foreign object will affect people’s lives and industrial production seriously and may lead to a lot of economic loss. Therefore, we think it is very critical to have a recall rate of 100%, so no abnormal images will be missed during classification.
- Most recent research evaluated detection speed. For example, RCNN4SPL module spends 230 ms per frame, YOLOv3 based module is 46 ms in average, Morphology based module is 95.8 ms in average, and Motion compensation-based module is 64 ms. We didn’t test execution time because it is highly dependent on the hardware. In addition, in our application, we don’t have a very high timing requirement as path planning for automatic drive.
- We proposed an OTL-Classifier module; it can classify images with and without foreign objects. It can work in either Warning-Review mode or Normal mode.
- In the normal mode, the OTL-Classifier works the same as most common classification tasks, the module uses optimal parameters that balances recall rate and error rate. It can achieve a recall rate of 95% and an error rate of 10.7%.
- In the Warning-Review mode, the OTL-Classifier achieves a recall rate of 100% and an error rate of 35.9%. It has a two-stage workflow. In the first stage, the binary classifier module provides the warning. In the second stage, the automated marker module helps electric workers review the image quickly. This strategy can prevent outage caused by foreign objects and save more than half of the time on image checking. Our future work will focus on decreasing the error rate with a recall rate of 100%.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Menéndez, O.; Pérez, M.; Auat Cheein, F. Visual-Based Positioning of Aerial Maintenance Platforms on Overhead Transmission Lines. Appl. Sci. 2019, 9, 165. [Google Scholar] [CrossRef]
- Baik, H.; Valenzuela, J. Unmanned Aircraft System Path Planning for Visually Inspecting Electric Transmission Towers. J. Intell. Robot. Syst. 2019, 95, 1097–1111. [Google Scholar] [CrossRef]
- Campbell, J.F.; Corberán, Á.; Plana, I.; Sanchis, J.M. Drone arc routing problems. Networks 2018, 72, 543–559. [Google Scholar] [CrossRef] [Green Version]
- Lu, M.; Bagheri, M.; James, A.P.; Phung, T. Wireless Charging Techniques for UAVs: A Review, Reconceptualization, and Extension. IEEE Access 2018, 6, 29865–29884. [Google Scholar] [CrossRef]
- Citroni, R.; Di Paolo, F.; Livreri, P. A Novel Energy Harvester for Powering Small UAVs: Performance Analysis, Model Validation and Flight Results. PubMed 2019, 19, 1771. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Fei, Z.; Zhang, Y. UAV Communications for 5G and Beyond: Recent Advances and Future Trends. IEEE Internet Things J. 2019, 6, 2241–2263. [Google Scholar] [CrossRef]
- Richard, P.L.; Pouliot, N.; Morin, F.; Lepage, M.; Hamelin, P.; Lagac, M.; Sartor, A.; Lambert, G.; Montambault, S. LineRanger: Analysis and Field Testing of an Innovative Robot for Efficient Assessment of Bundled High-Voltage Powerlines. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9130–9136. [Google Scholar]
- Zhang, Y.; Li, J.; Li, C.; Tao, Q.; Xiong, X. Development of foreign matter removal robot for overhead transmission lines. In Proceedings of the 2nd International Conference on Mechanical, Electric and Industrial Engineering, Hangzhou, China, 25–27 May 2019. [Google Scholar]
- Disyadej, T.; Promjan, J.; Poochinapan, K.; Mouktonglang, T.; Grzybowski, S.; Muneesawang, P. High Voltage Power Line Maintenance & Inspection by Using Smart Robotics. In Proceedings of the 2019 IEEE Power and Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 18–21 February 2019. [Google Scholar] [CrossRef]
- Seok, K.H.; Kim, Y.S. A State of the Art of Power Transmission Line Maintenance Robots. J. Electr. Eng. Technol. 2016, 9, 1412–1422. [Google Scholar] [CrossRef]
- Qin, X.; Wu, G.; Lei, J.; Fan, F.; Ye, X.; Mei, Q. A Novel Method of Autonomous Inspection for Transmission Line based on Cable Inspection Robot LiDAR Data. Sensors 2018, 18, 596. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Wang, X.; Yao, H.; Tian, M.; Jian, Z. Power Line Extraction From Aerial Images Using Object-Based Markov Random Field With Anisotropic Weighted Penalty. IEEE Access 2019, 7, 125333–125356. [Google Scholar] [CrossRef]
- Cao, Z.; Ma, J.; Lin, P.; Peng, Z. Morphology-Based Visual Detection of Foreign Object on Overhead Line Tower. In Proceedings of the 2018 3rd IEEE International Conference on Image, Vision and Computing, ICIVC 2018, Chongqing, China, 27–29 June 2018; pp. 468–472. [Google Scholar]
- Jiao, S.; Wang, H. The Research of Transmission Line Foreign Body Detection Based on Motion Compensation. In Proceedings of the 2016 First, International Conference on Multimedia and Image Processing (ICMIP), Bandar Seri Begawan, Brunei, 1–3 June 2016; pp. 10–14. [Google Scholar]
- Nguyen, V.N.; Jenssen, R.; Roverso, D. Automatic autonomous vision-based power line inspection: A review of current status and the potential role of deep learning. Int. J. Electr. Power Energy Syst. 2018, 99, 107–120. [Google Scholar] [CrossRef] [Green Version]
- Miao, X.; Liu, X.; Chen, J.; Zhuang, S.; Fan, J.; Jiang, H. Insulator Detection in Aerial Images for Transmission Line Inspection Using Single Shot Multibox Detector. IEEE Access 2019, 7, 9945–9956. [Google Scholar] [CrossRef]
- Michalski, P.; Ruszczak, B.; Lorente, P.J.N. The Implementation of a Convolutional Neural Network for the Detection of the Transmission Towers Using Satellite Imagery. In Proceedings of the 40th Anniversary International Conference on Information Systems Architecture and Technology, Wrocław, Poland, 15–17 September 2019; pp. 287–299. [Google Scholar]
- Dong, J.; Chen, W.; Xu, C. Transmission line detection using deep convolutional neural network. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference, Chongqing, China, 24–26 May 2019; pp. 97–980. [Google Scholar]
- Xia, P.; Yin, J.; He, J. Neural Detection of Foreign Objects for Transmission Lines in Power Systems. J. Phys. Conf. Ser. 2019, 1267, 012043. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, X.; Yuan, J. RCNN-based foreign object detection for securing power transmission lines (RCNN4SPTL). In Proceedings of the International Conference on Identification, Information and Knowledge in the Internet of Things (IIKI), Beijing, China, 19–21 October 2018; pp. 331–337. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556v6. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CCVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-Resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First, AAAI Conference on Artificial Intelligence (AAAI-17), San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Foreign Object | No Foreign Object | |
|---|---|---|
| Training set | 305 | 500 |
| Testing set | 101 | 652 |
| Total | 406 | 1152 |
| SVM | InceptionV3-Retrain | InceptionV3-Fine-Tuning | InceptionV4-Fine-Tuning | ||
|---|---|---|---|---|---|
| Recall 100% | recall rate | 100% | 100% | 100% | 100% |
| error rate | 94% | 35.9% | 43.9% | 100% | |
| threshold | 0.264 | 0.102 | 0.092 | 0.0 | |
| Optimal threshold | recall rate | 83% | 95% | 91% | 86% |
| error rate | 29% | 10.7% | 5.8% | 5% | |
| Yoden index | 0.54 | 0.843 | 0.853 | 0.811 | |
| threshold | 0.428 | 0.546 | 0.503 | 0.4 |
| Total Box | TP Number | Missed Target | Target Detection Precision | Target Detection Recall | |
|---|---|---|---|---|---|
| ResNet50 | 218 | 106 | 20 | 48.62% | 84.13% |
| ResNet101 | 183 | 106 | 20 | 57.92% | 84.13% |
| VGG16 | 122 | 90 | 36 | 73.77% | 71.43% |
| SSD | 150 | 93 | 33 | 62.0% | 73.81% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Fan, Y.; Cai, T.; Liu, W.; Hu, Z.; Wang, N.; Wu, M. OTL-Classifier: Towards Imaging Processing for Future Unmanned Overhead Transmission Line Maintenance. Electronics 2019, 8, 1270. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics8111270
Zhang F, Fan Y, Cai T, Liu W, Hu Z, Wang N, Wu M. OTL-Classifier: Towards Imaging Processing for Future Unmanned Overhead Transmission Line Maintenance. Electronics. 2019; 8(11):1270. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics8111270
Chicago/Turabian StyleZhang, Fan, Yalei Fan, Tao Cai, Wenda Liu, Zhongqiu Hu, Nengqing Wang, and Minghu Wu. 2019. "OTL-Classifier: Towards Imaging Processing for Future Unmanned Overhead Transmission Line Maintenance" Electronics 8, no. 11: 1270. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics8111270