
Hybrid Machine Learning Approaches and a Systematic Model Selection Process for Predicting Soot Emissions in Compression Ignition Engines

 , ,
, ,  and
and
Abstract
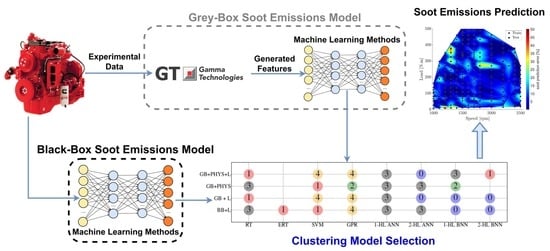
:
1. Introduction
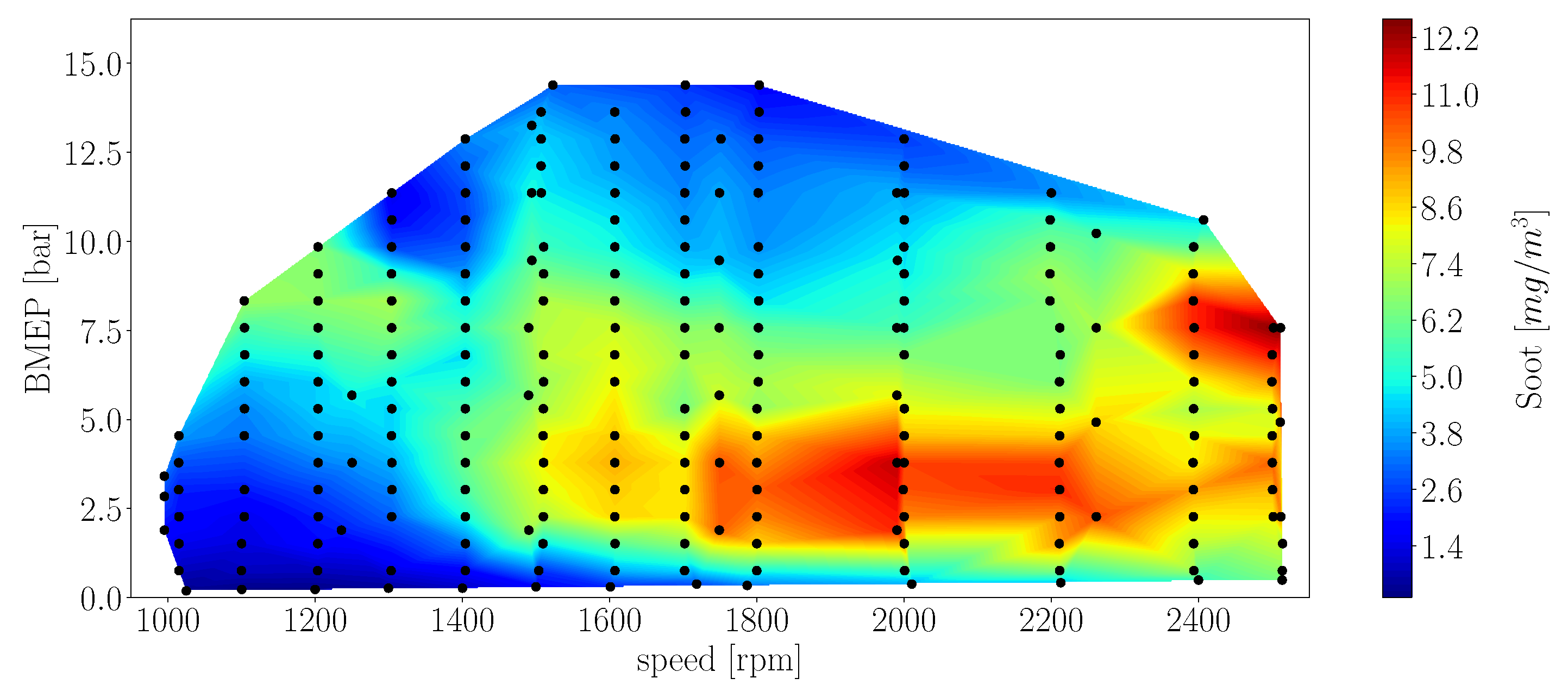
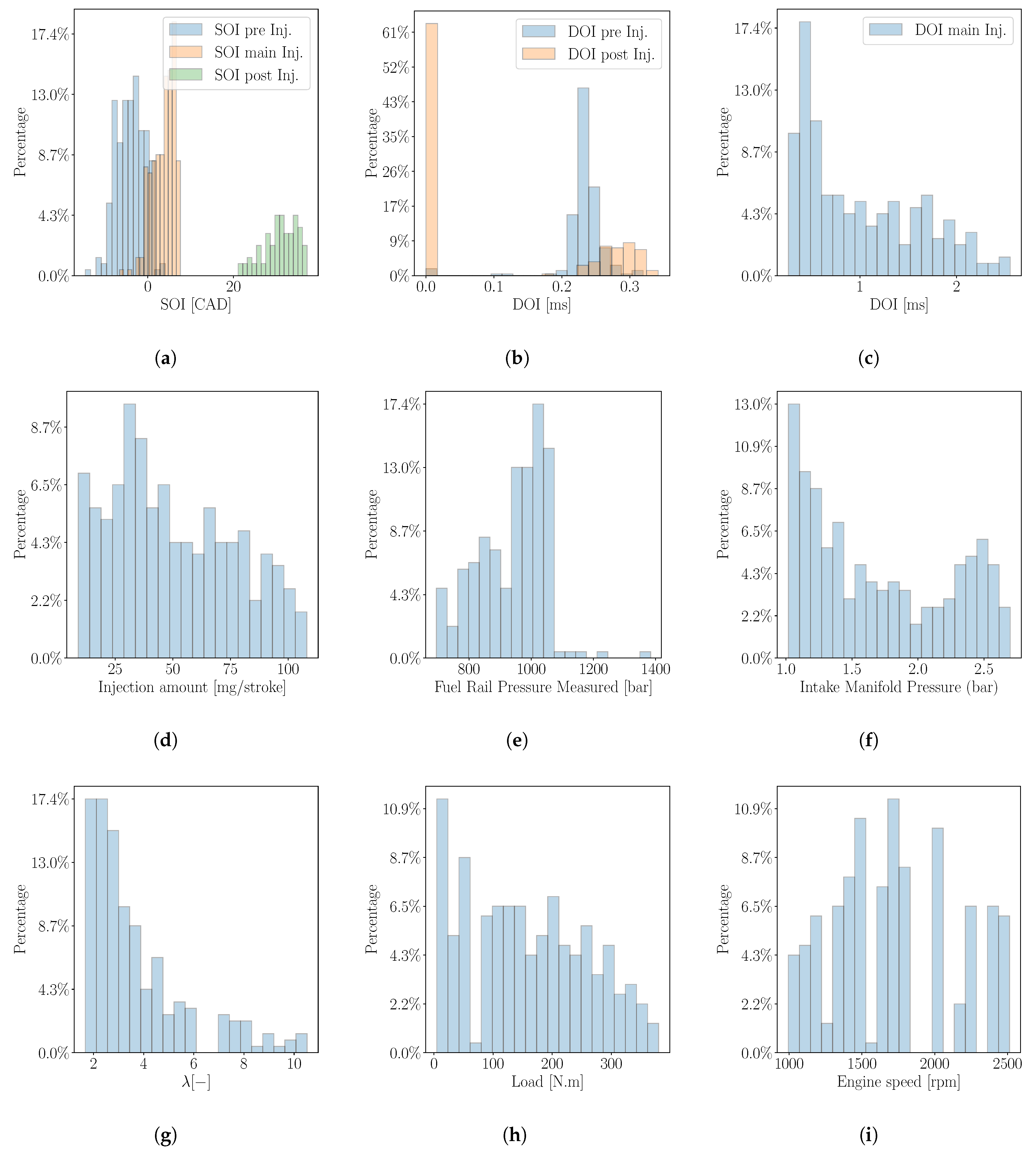
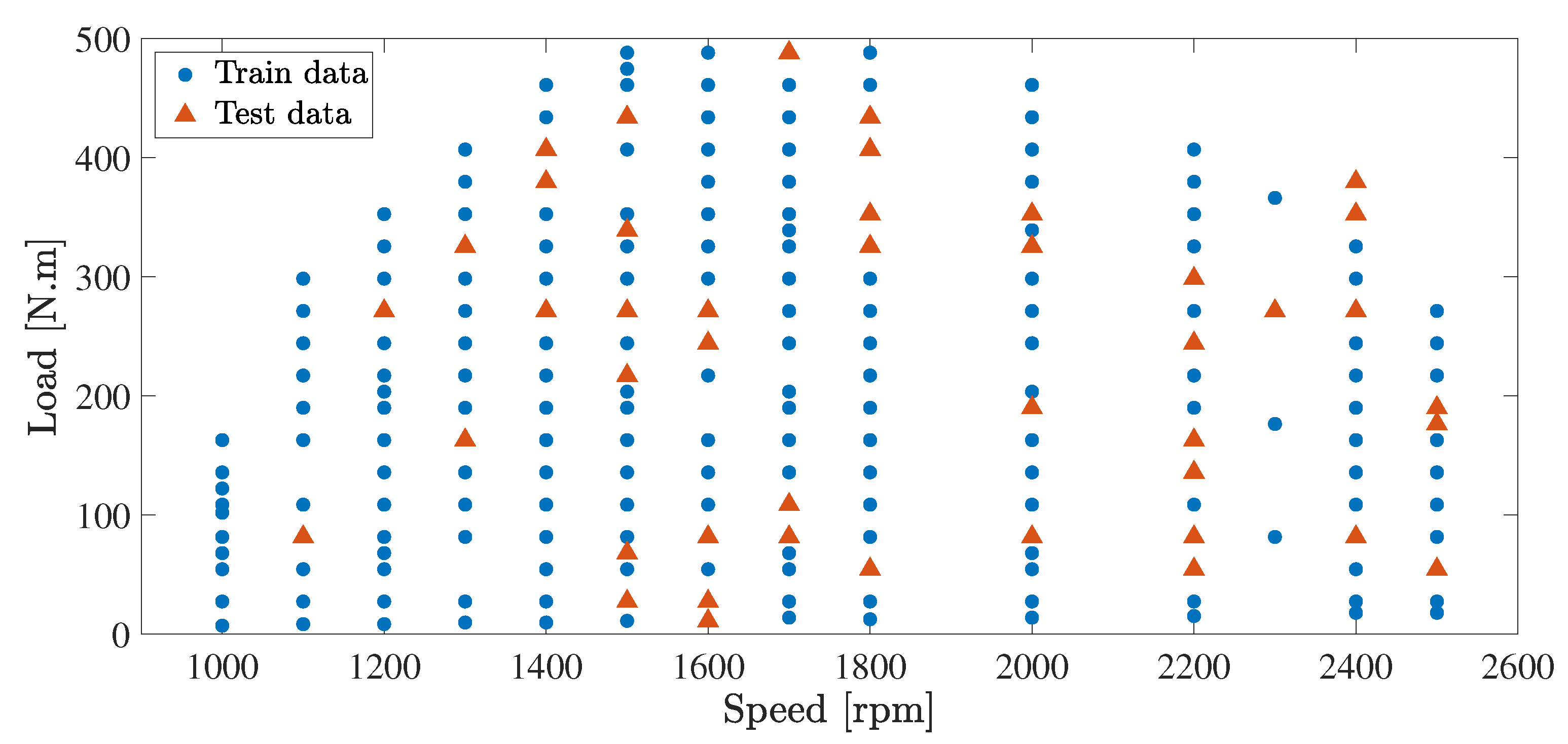
- Although some papers investigated the effects of different parameters on emission production of diesel engines, e.g., effect of fuel properties [30] there is limited published soot emissions data for "full" speed-load maps from medium-duty diesel compression ignition engines in the literature. This is because it is difficult and costly to measure soot emissions accurately and it involves substantial calibration efforts for emission analyzers. In this work, the soot emissions data for full speed-load map of a 4.5 L 4-cylinder diesel engine is measured. This dataset provides a benchmark to test different modeling methods in this study.
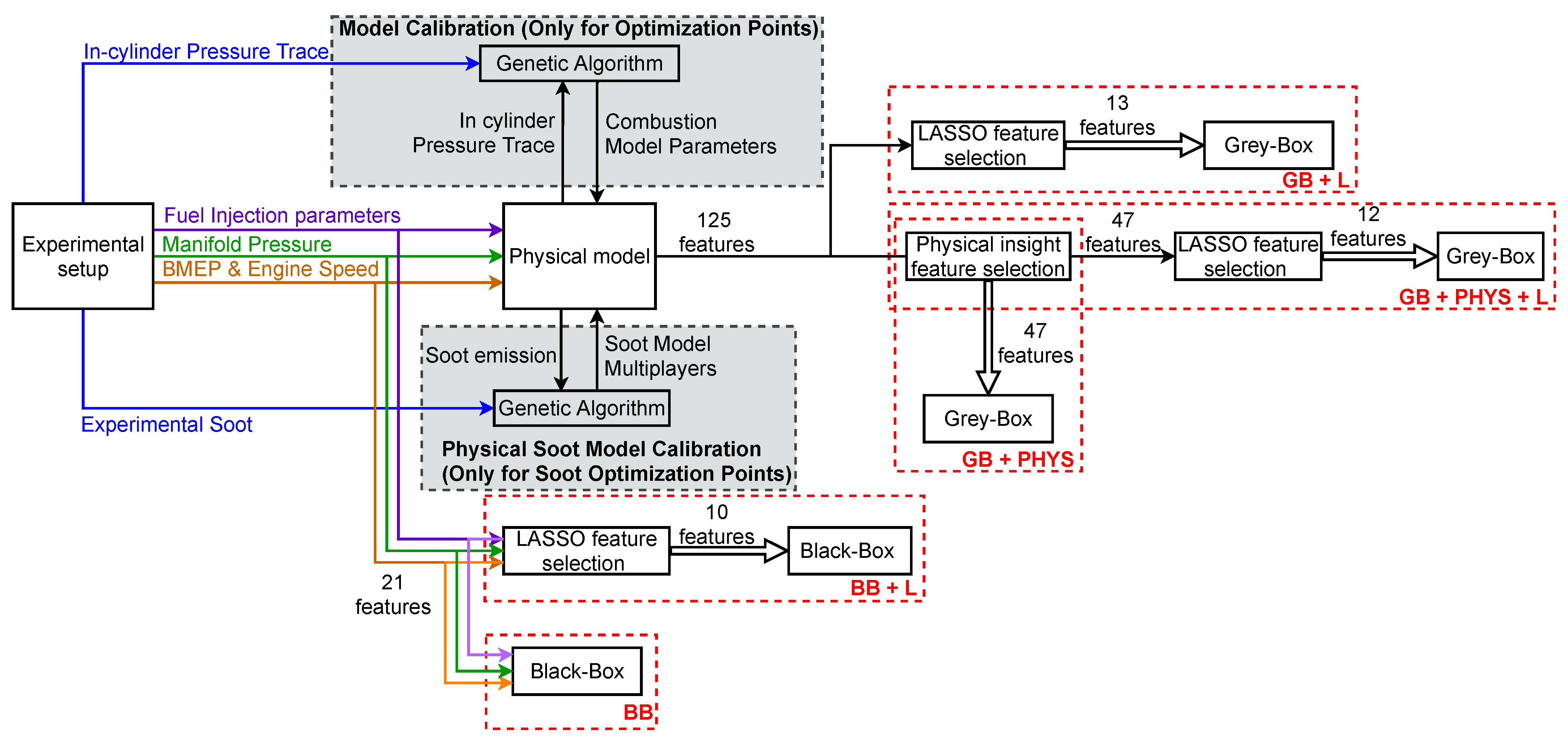
- The performance of ML methods is highly dependent on the input feature set. In emission modeling using ML methods, it is common to mainly use physical knowledge to choose the input feature set. Using physical knowledge has the risk of missing some crucial features due to unknown and misunderstood physical relations. This is especially important in gray-box emission modeling because it generates many features making it difficult to choose a subset based on physical knowledge. In this paper, different input feature sets based on ML feature selection and physical knowledge are investigated to select the optimal input features.
- Previous studies used conventional ML methods such as SVM and ANN and GPR with fixed input feature set for soot emissions modeling. There is a lack of comprehensive studies that investigate different ML methods and feature sets for soot emissions modeling. In this paper, eight different ML methods with five different input feature sets (40 models in total) are used for soot emissions modelling.
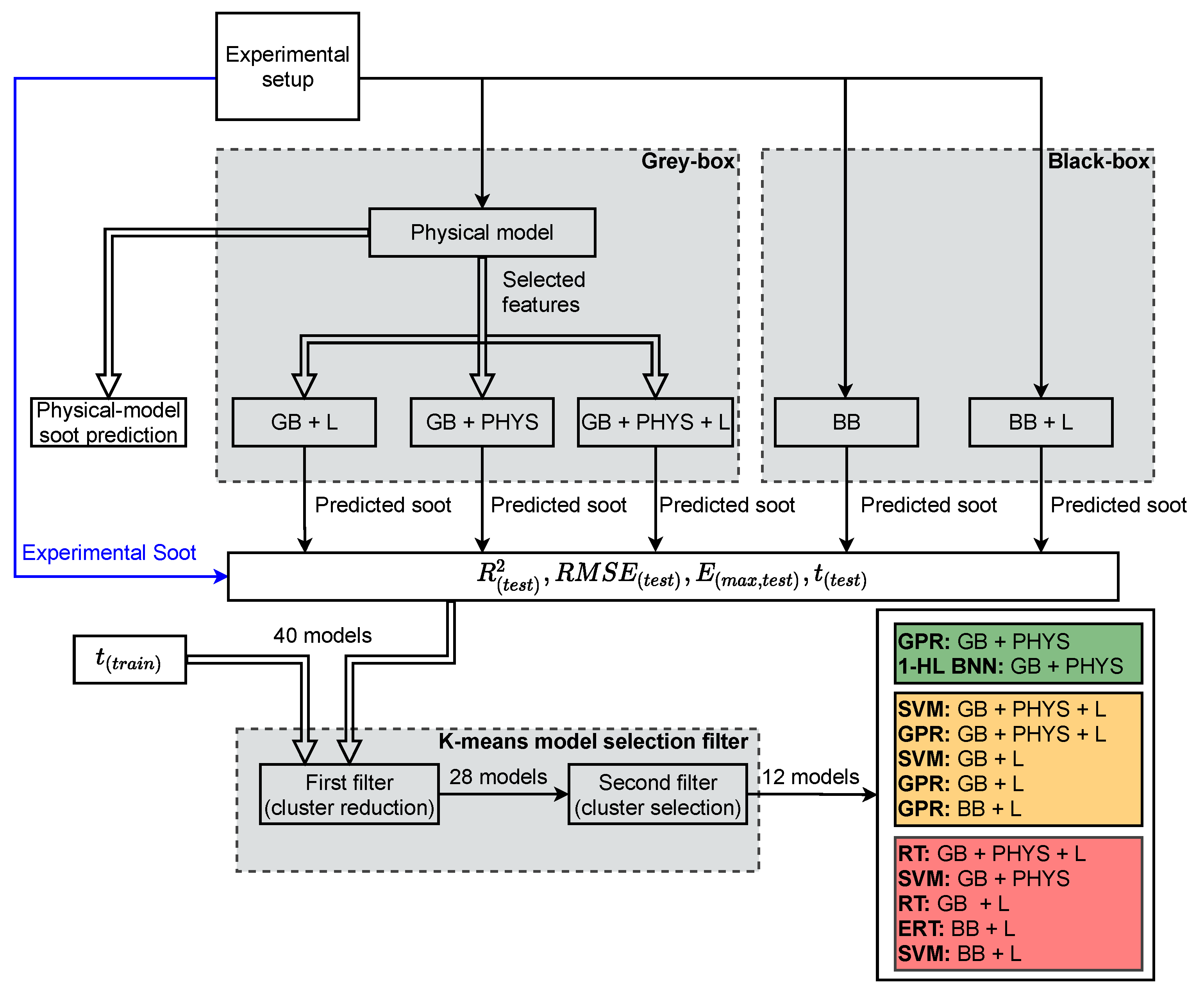
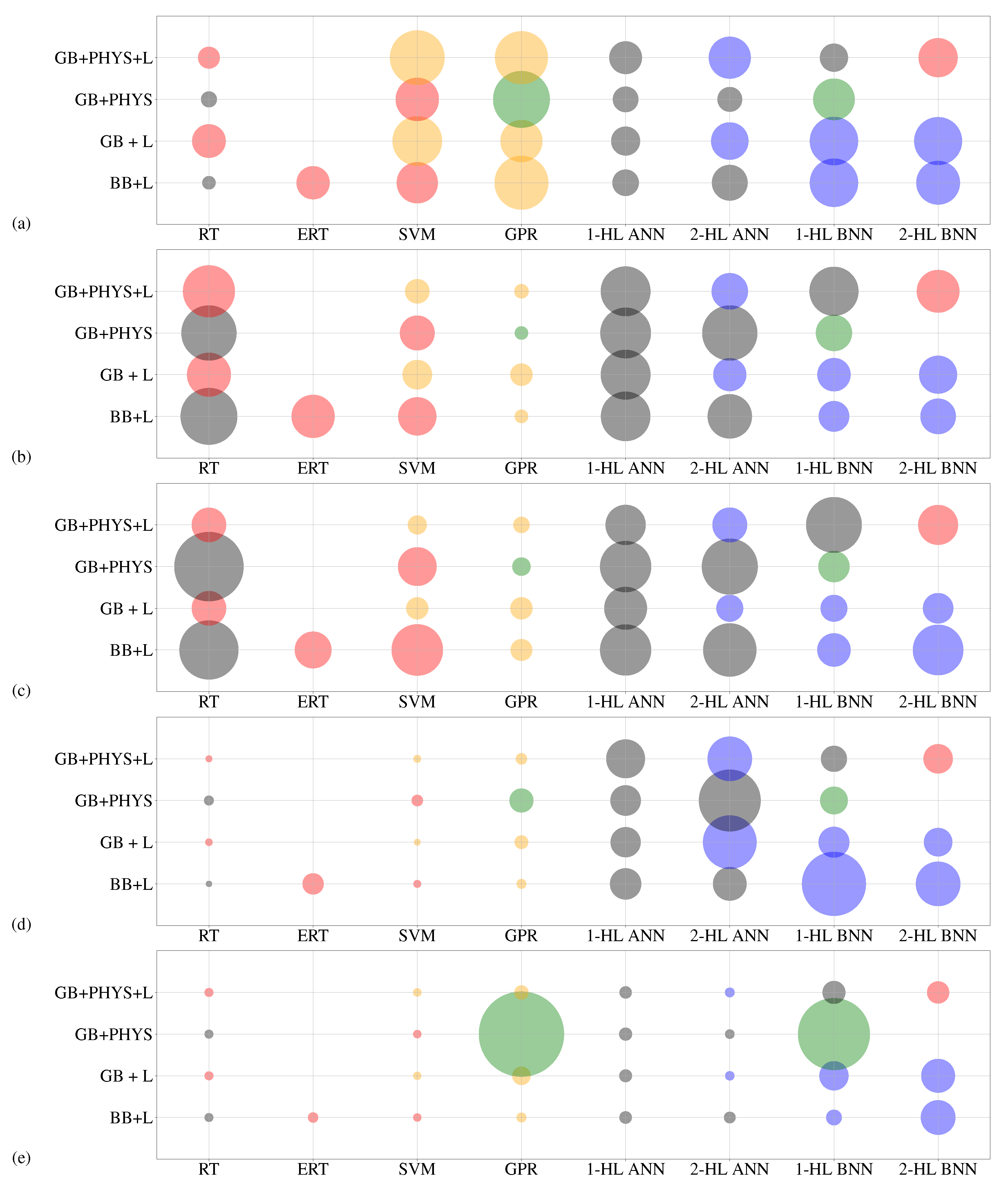
- Post processing methods for analysing the results and method selection have not been used in the previous soot emissions modeling studies. In this paper, a systematic unsupervised ML method is used for analyzing and comparing different engine soot emissions models. Two K-means clustering algorithms that perform as filters are used to select the best soot emissions models. This method could also be used for other engine modeling studies.
2. Experimental Setup
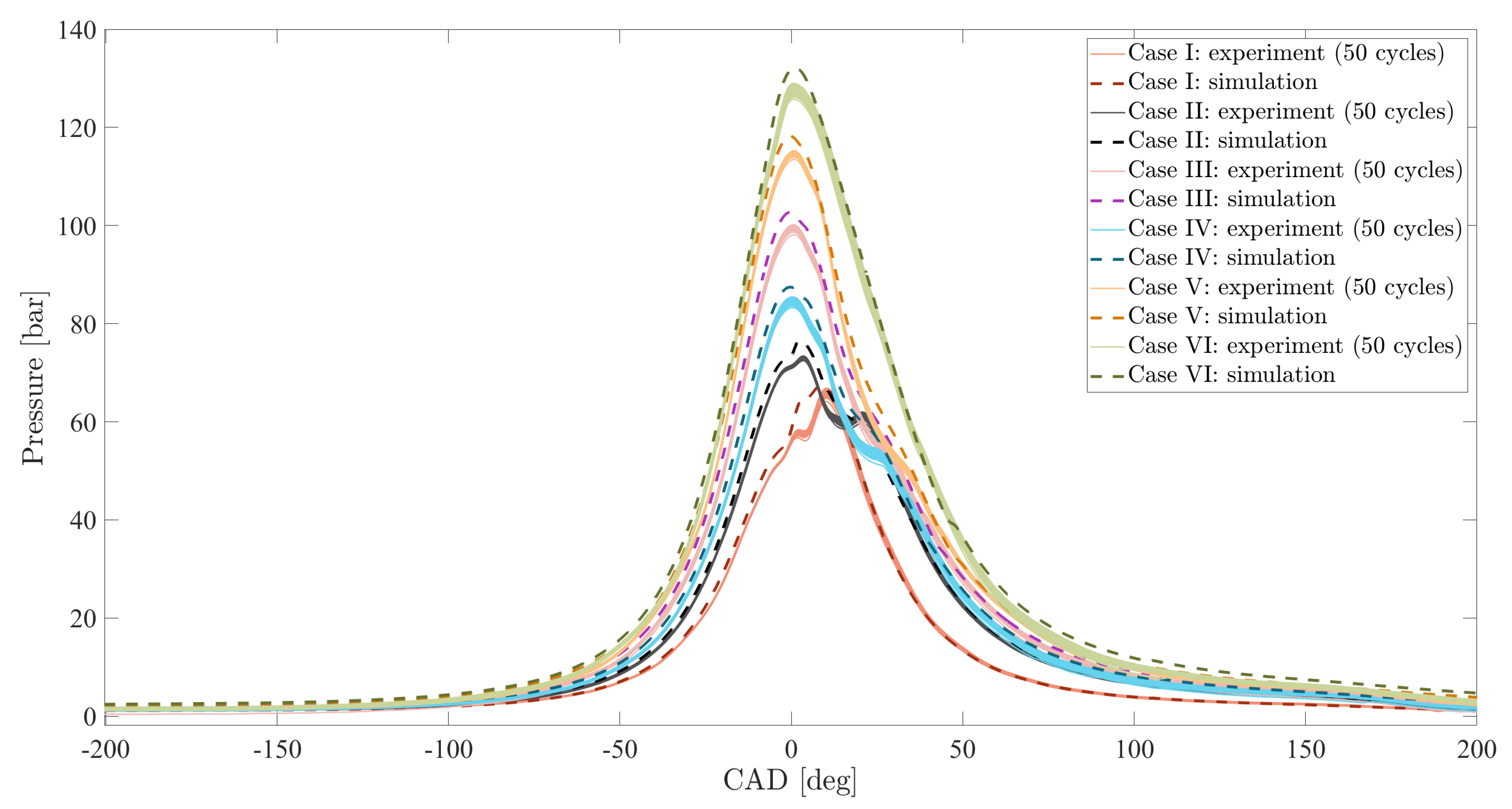
3. Gray-Box and Black-Box Models
4. Machine Learning Methods
4.1. Pre-Processing: Feature Selection
4.2. Regression Models
4.2.1. K-Fold Cross Validation
4.2.2. Hyperparameters Optimization
4.2.3. Regression Tree (RT)
4.2.4. Ensemble of Regression Trees (ERT)
4.2.5. Support Vector Machine (SVM)
4.2.6. Gaussian Process Regression (GPR)
4.2.7. Neural Network (NN)
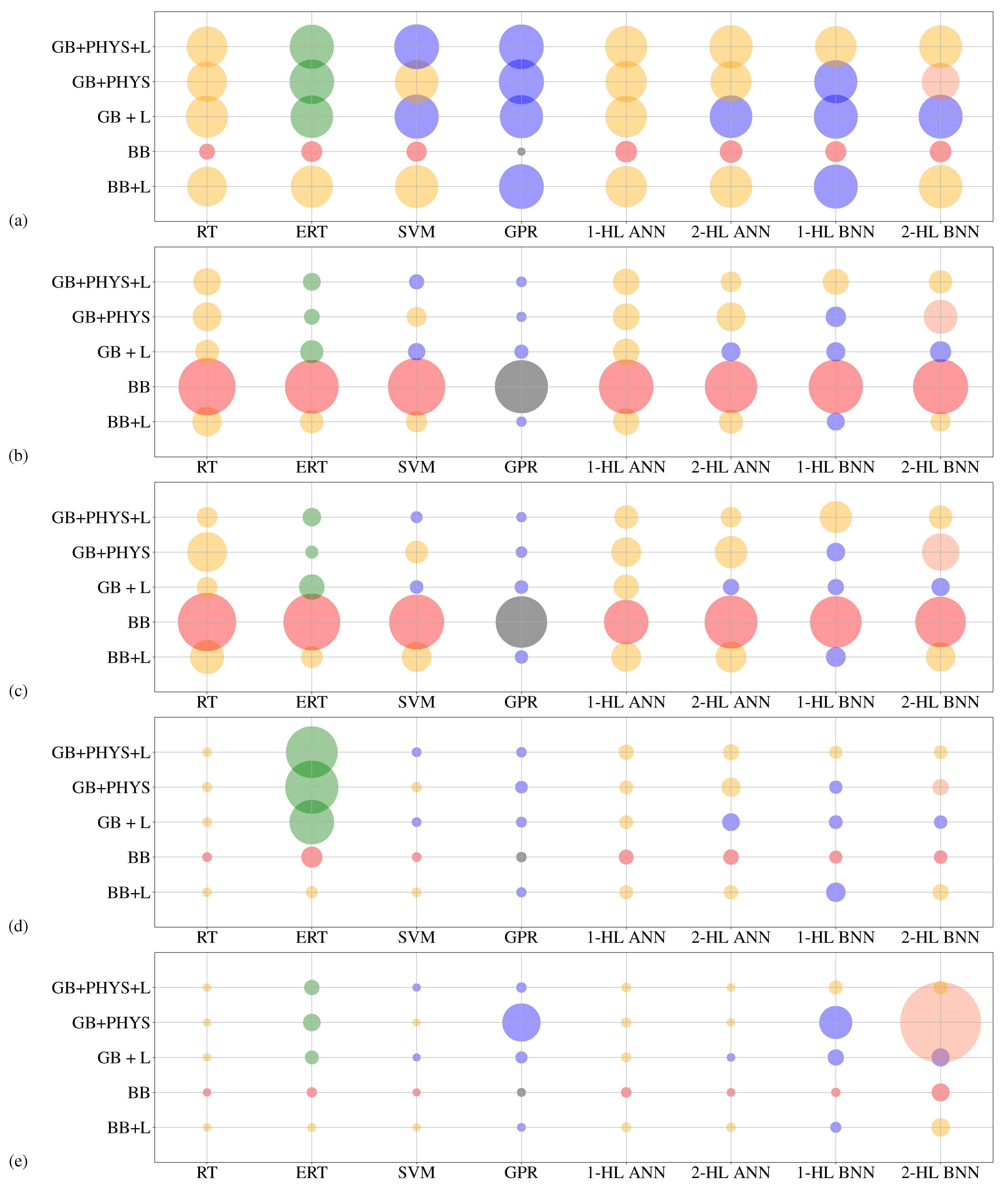
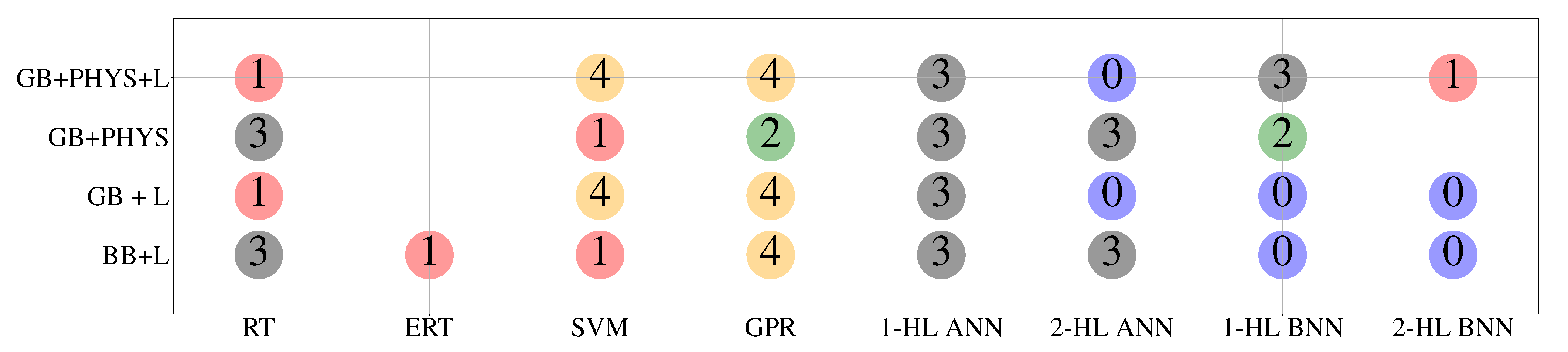
4.3. Post-Processing: Model Selection
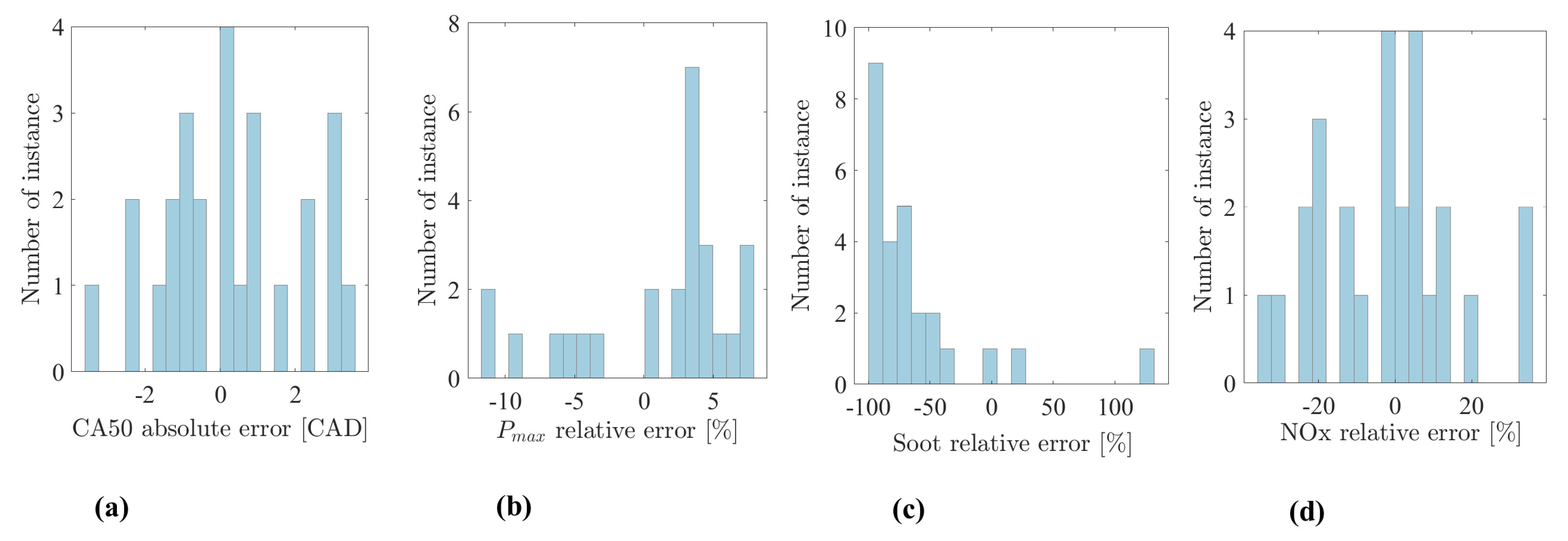
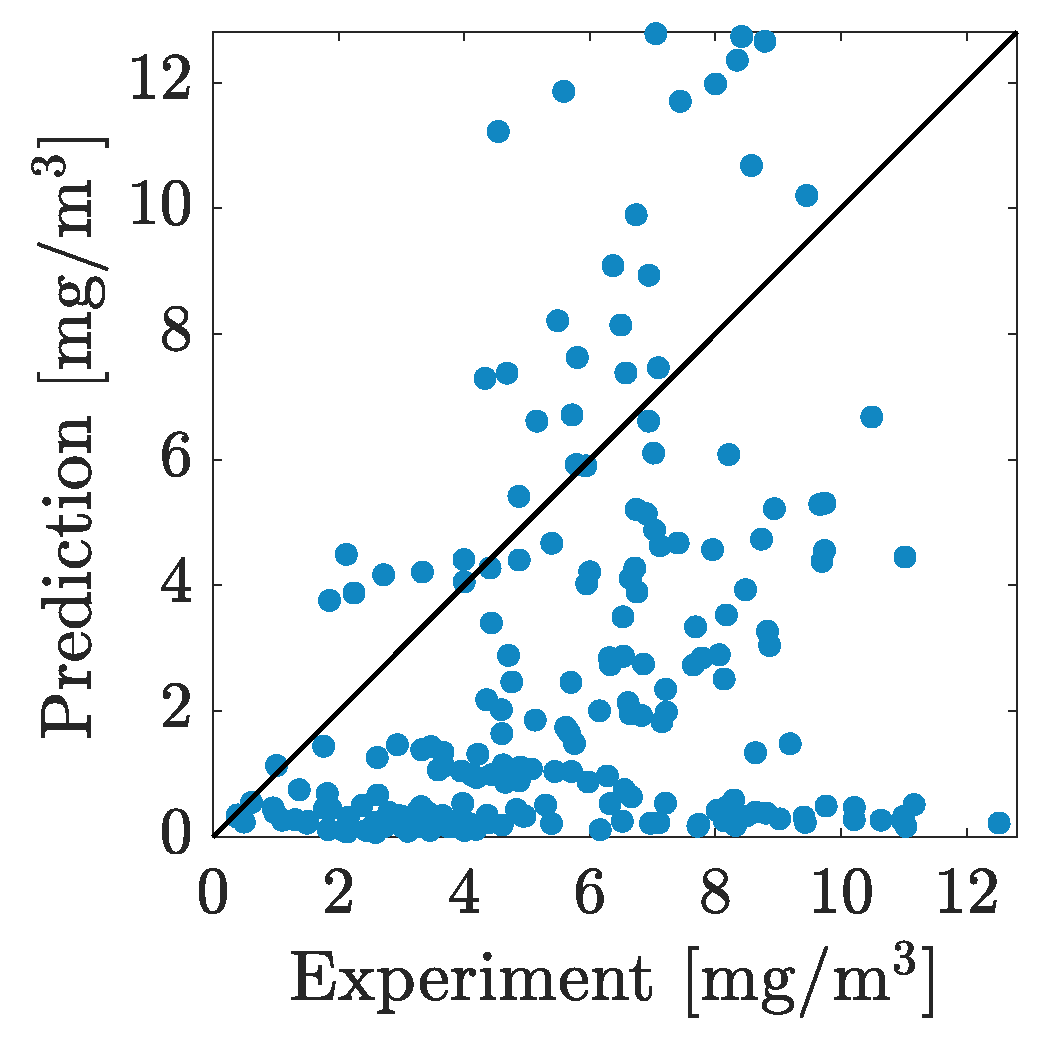
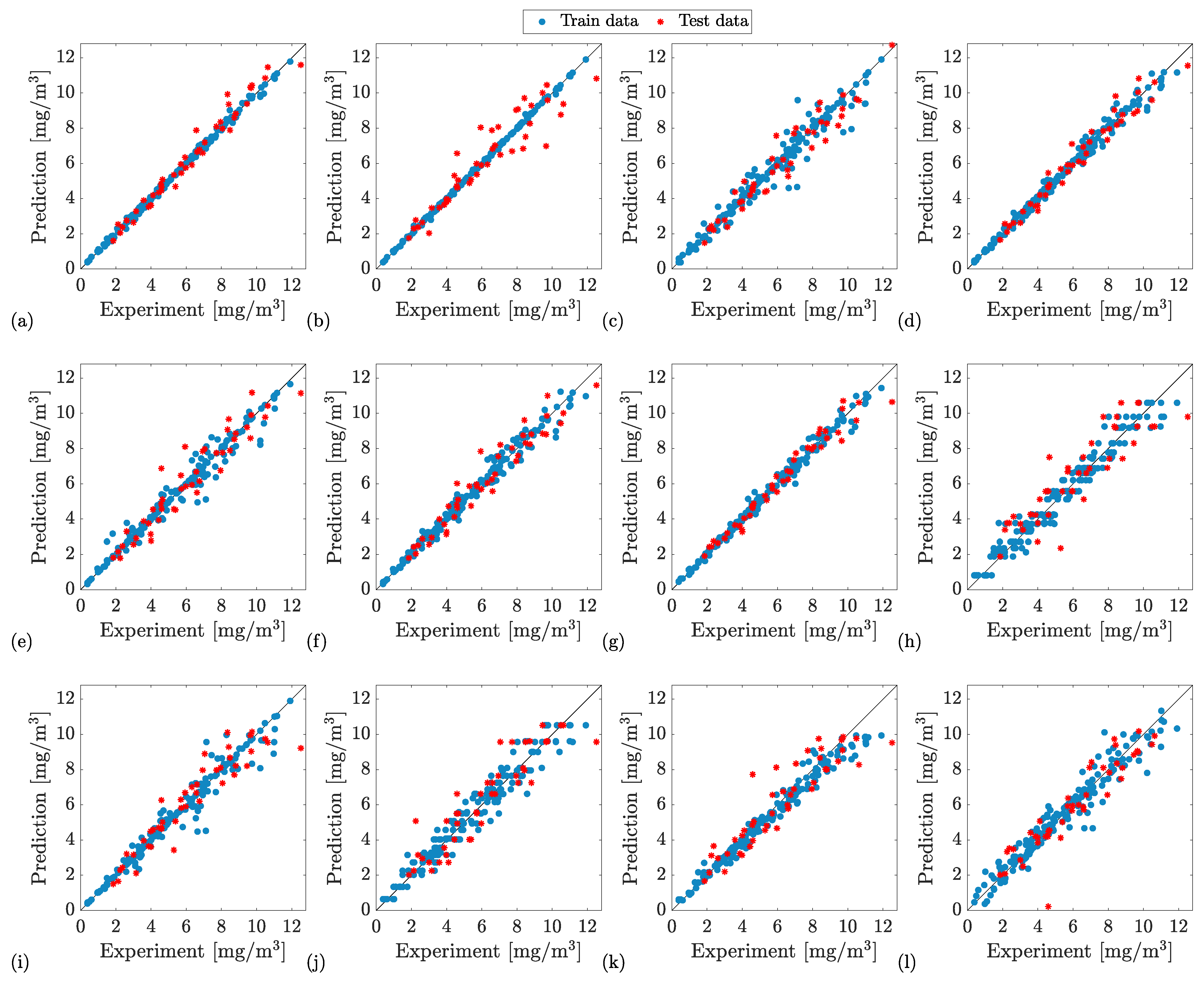
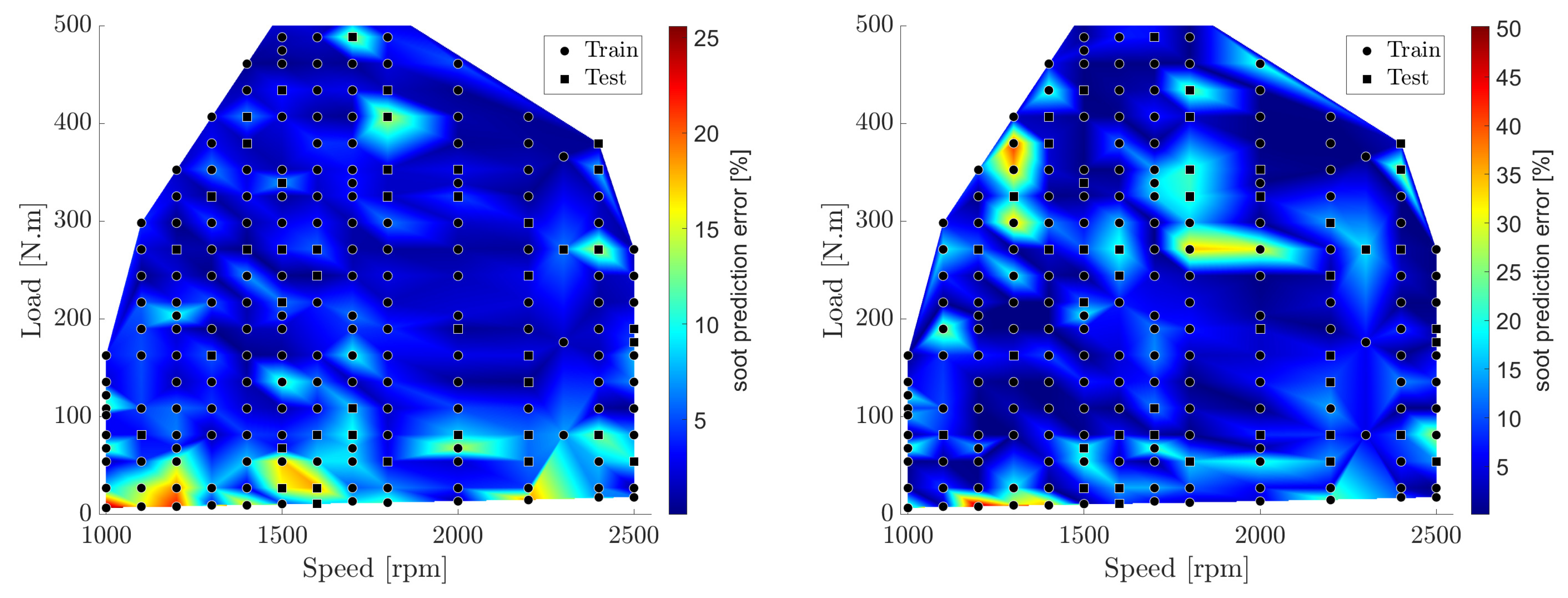
5. Results and Discussion
- 1.
- The coefficient of determination of test data ;
- 2.
- Root Mean Square of Error of test data ;
- 3.
- Maximum of absolute prediction error of test data ;
- 4.
- Training time ;
- 5.
- Prediction time .
6. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Norouzi, A.; Heidarifar, H.; Shahbakhti, M.; Koch, C.R.; Borhan, H. Model Predictive Control of Internal Combustion Engines: A Review and Future Directions. Energies 2021, 14, 6251. [Google Scholar] [CrossRef]
- Omidvarborna, H.; Kumar, A.; Kim, D.S. Recent studies on soot modeling for diesel combustion. Renew. Sustain. Energy Rev. 2015, 48, 635–647. [Google Scholar] [CrossRef]
- Zheng, Z.; Yue, L.; Liu, H.; Zhu, Y.; Zhong, X.; Yao, M. Effect of two-stage injection on combustion and emissions under high EGR rate on a diesel engine by fueling blends of diesel/gasoline, diesel/n-butanol, diesel/gasoline/n-butanol and pure diesel. Energy Convers. Manag. 2015, 90, 1–11. [Google Scholar] [CrossRef]
- Yi, W.; Liu, H.; Feng, L.; Wang, Y.; Cui, Y.; Liu, W.; Yao, M. Multiple optical diagnostics on effects of fuel properties on spray flames under oxygen-enriched conditions. Fuel 2021, 291, 120129. [Google Scholar] [CrossRef]
- EuroVI. Commission Regulation (EU) 2016/646 of 20 April 2016 Amending Regulation (EC) NO692/2008 as Regards Emissions from Light Passenger and Commercial Vehicles (Euro 6); European Union, Euro 6 Regulation: 2016. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32016R0646 (accessed on 10 November 2021).
- Merkisz, J.; Bielaczyc, P.; Pielecha, J.; Woodburn, J. RDE Testing of Passenger Cars: The Effect of the Cold Start on the Emissions Results; SAE: Warrendale, PA, USA, 2019. [Google Scholar] [CrossRef]
- Liu, H.; Ma, S.; Zhang, Z.; Zheng, Z.; Yao, M. Study of the control strategies on soot reduction under early-injection conditions on a diesel engine. Fuel 2015, 139, 472–481. [Google Scholar] [CrossRef]
- Norouzi, A.; Gordon, D.; Aliramezani, M.; Koch, C.R. Machine Learning-based Diesel Engine-Out NOx Reduction Using a plug-in PD-type Iterative Learning Control. In Proceedings of the IEEE Conference on Control Technology and Applications (CCTA), Montreal, QC, Canada, 24–26 August 2020; pp. 450–455. [Google Scholar] [CrossRef]
- Norouzi, A.; Ebrahimi, K.; Koch, C.R. Integral discrete-time sliding mode control of homogeneous charge compression ignition (HCCI) engine load and combustion timing. IFAC-PapersOnLine 2019, 52, 153–158. [Google Scholar] [CrossRef]
- Gordon, D.; Norouzi, A.; Blomeyer, G.; Bedei, J.; Aliramezani, M.; Andert, J.; Koch, C.R. Support Vector Machine Based Emissions Modeling using Particle Swarm Optimization for Homogeneous Charge Compression Ignition Engine. Int. J. Engine Res. 2021, in press. [Google Scholar] [CrossRef]
- Aliramezani, M.; Koch, C.R.; Shahbakhti, M. Modeling, Diagnostics, Optimization, and Control of Internal Combustion Engines via Modern Machine Learning Techniques: A Review and Future Directions. Prog. Energy Combust. Sci. 2021, 88, 100967. [Google Scholar] [CrossRef]
- Singalandapuram Mahadevan, B.; Johnson, J.H.; Shahbakhti, M. Development of a Kalman filter estimator for simulation and control of particulate matter distribution of a diesel catalyzed particulate filter. Int. J. Engine Res. 2020, 21, 866–884. [Google Scholar] [CrossRef]
- Gao, Z.; Schreiber, W. A phenomenologically based computer model to predict soot and NOx emission in a direct injection diesel engine. Int. J. Engine Res. 2001, 2, 177–188. [Google Scholar] [CrossRef]
- Amani, E.; Akbari, M.; Shahpouri, S. Multi-objective CFD optimizations of water spray injection in gas-turbine combustors. Fuel 2018, 227, 267–278. [Google Scholar] [CrossRef]
- Shahpouri, S.; Houshfar, E. Nitrogen oxides reduction and performance enhancement of combustor with direct water injection and humidification of inlet air. Clean Technol. Environ. Policy 2019, 21, 667–683. [Google Scholar] [CrossRef]
- Rezaei, R.; Hayduk, C.; Alkan, E.; Kemski, T.; Delebinski, T.; Bertram, C. Hybrid Phenomenological and Mathematical-Based Modeling Approach for Diesel Emission Prediction; SAE World Congress Experience, SAE Paper No. 2020-01-0660; SAE: Warrendale, PA, USA, 2020. [Google Scholar] [CrossRef]
- Oppenauer, K.S.; Alberer, D. Soot formation and oxidation mechanisms during diesel combustion: Analysis and modeling impacts. Int. J. Engine Res. 2014, 15, 954–964. [Google Scholar] [CrossRef]
- Gao, J.; Kuo, T.W. Toward the accurate prediction of soot in engine applications. Int. J. Engine Res. 2019, 20, 706–717. [Google Scholar] [CrossRef]
- Kavuri, C.; Kokjohn, S.L. Exploring the potential of machine learning in reducing the computational time/expense and improving the reliability of engine optimization studies. Int. J. Engine Res. 2020, 21, 1251–1270. [Google Scholar] [CrossRef]
- Khurana, S.; Saxena, S.; Jain, S.; Dixit, A. Predictive modeling of engine emissions using machine learning: A review. Mater. Today Proc. 2021, 38, 280–284. [Google Scholar] [CrossRef]
- Grahn, M.; Johansson, K.; McKelvey, T. Data-driven emission model structures for diesel engine management system development. Int. J. Engine Res. 2014, 15, 906–917. [Google Scholar] [CrossRef] [Green Version]
- Niu, X.; Yang, C.; Wang, H.; Wang, Y. Investigation of ANN and SVM based on limited samples for performance and emissions prediction of a CRDI-assisted marine diesel engine. Appl. Therm. Eng. 2017, 111, 1353–1364. [Google Scholar] [CrossRef]
- Shahpouri, S.; Norouzi, A.; Hayduk, C.; Rezaei, R.; Shahbakhti, M.; Koch, C.R. Soot Emission Modeling of a Compression Ignition Engine Using Machine Learning. IFAC-PapersOnLineModeling. Estimation and Control Conference (MECC 2021), Austin, Texas, USA. Available online: https://www.researchgate.net/publication/355718550 (accessed on 10 November 2012).
- Bidarvatan, M.; Thakkar, V.; Shahbakhti, M.; Bahri, B.; Aziz, A.A. Grey-box modeling of HCCI engines. Appl. Therm. Eng. 2014, 70, 397–409. [Google Scholar] [CrossRef]
- Lang, M.; Bloch, P.; Koch, T.; Eggert, T.; Schifferdecker, R. Application of a combined physical and data-based model for improved numerical simulation of a medium-duty diesel engine. Automot. Engine Technol. 2020, 5, 1–20. [Google Scholar] [CrossRef]
- Mohammad, A.; Rezaei, R.; Hayduk, C.; Delebinski, T.O.; Shahpouri, S.; Shahbakhti, M. Hybrid Physical and Machine Learning-Oriented Modeling Approach to Predict Emissions in a Diesel Compression Ignition Engine; SAE World Congress Experience, SAE Paper No. 2021-01-0496; SAE: Warrendale, PA, USA, 2020. [Google Scholar] [CrossRef]
- Le Cornec, C.M.; Molden, N.; van Reeuwijk, M.; Stettler, M.E. Modelling of instantaneous emissions from diesel vehicles with a special focus on NOx: Insights from machine learning techniques. Sci. Total Environ. 2020, 737, 139625. [Google Scholar] [CrossRef] [PubMed]
- Shamsudheen, F.A.; Yalamanchi, K.; Yoo, K.H.; Voice, A.; Boehman, A.; Sarathy, M. Machine Learning Techniques for Classification of Combustion Events under Homogeneous Charge Compression Ignition (HCCI) Conditions; SAE Technical Paper, No. 2020-01-1132; SAE: Warrendale, PA, USA, 2020. [Google Scholar] [CrossRef]
- Zhou, H.; Soh, Y.C.; Wu, X. Integrated analysis of CFD data with K-means clustering algorithm and extreme learning machine for localized HVAC control. Appl. Therm. Eng. 2015, 76, 98–104. [Google Scholar] [CrossRef]
- Liu, H.; Ma, J.; Dong, F.; Yang, Y.; Liu, X.; Ma, G.; Zheng, Z.; Yao, M. Experimental investigation of the effects of diesel fuel properties on combustion and emissions on a multi-cylinder heavy-duty diesel engine. Energy Convers. Manag. 2018, 171, 1787–1800. [Google Scholar] [CrossRef]
- Tarabet, L.; Loubar, K.; Lounici, M.; Khiari, K.; Belmrabet, T.; Tazerout, M. Experimental investigation of DI diesel engine operating with eucalyptus biodiesel/natural gas under dual fuel mode. Fuel 2014, 133, 129–138. [Google Scholar] [CrossRef]
- Hiroyasu, H.; Kadota, T.; Arai, M. Development and use of a spray combustion modeling to predict diesel engine efficiency and pollutant emissions: Part 1 combustion modeling. Bull. JSME 1983, 26, 569–575. [Google Scholar] [CrossRef] [Green Version]
- Deb, K.; Jain, H. An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: Solving problems with box constraints. IEEE Trans. Evol. Comput. 2013, 18, 577–601. [Google Scholar] [CrossRef]
- Rao, L.; Zhang, Y.; Kook, S.; Kim, K.S.; Kweon, C.B. Understanding the soot reduction associated with injection timing variation in a small-bore diesel engine. Int. J. Engine Res. 2021, 22, 1001–1015. [Google Scholar] [CrossRef]
- Farhan, S.M.; Pan, W.; Yan, W.; Jing, Y.; Lili, L. Effect of post-injection strategies on regulated and unregulated harmful emissions from a heavy-duty diesel engine. Int. J. Engine Res. 2020, 1468087420980917. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Newton, MA, USA, 2019. [Google Scholar]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Automated Machine Learning: Methods, Systems, Challenges: Chapter 3—Neural Architecture Search; Springer Nature: Berlin/Heidelberg, Germany, 2019. [Google Scholar] [CrossRef] [Green Version]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. 2012, 2, 2951–2959. [Google Scholar]
- Berk, R.A. Statistical Learning from a Regression Perspective: Chapter 3—Classification and Regression Trees (CART); Springer: Berlin/Heidelberg, Germany, 2008; Volume 14. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Aliramezani, M.; Norouzi, A.; Koch, C.R. Support vector machine for a diesel engine performance and NOx emission control-oriented model. IFAC-PapersOnLine 2020, 53, 13976–13981. [Google Scholar] [CrossRef]
- Norouzi, A.; Aliramezani, M.; Koch, C.R. A correlation-based model order reduction approach for a diesel engine NOx and brake mean effective pressure dynamic model using machine learning. Int. J. Engine Res. 2021, 22, 2654–2672. [Google Scholar] [CrossRef]
- Aliramezani, M.; Norouzi, A.; Koch, C. A grey-box machine learning based model of an electrochemical gas sensor. Sens. Actuators Chem. 2020, 321, 128414. [Google Scholar] [CrossRef]
- Seeger, M. Gaussian processes for machine learning. Int. J. Neural Syst. 2004, 14, 69–106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hassoun, M.H. Fundamentals of Artificial Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Foresee, F.D.; Hagan, M.T. Gauss–Newton approximation to Bayesian learning. In Proceedings of the International Conference on Neural Networks (ICNN’97), Houston, TX, USA, 12 June 1997; Volume 3, pp. 1930–1935. [Google Scholar] [CrossRef]
- Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Open: Berlin/Heidelberg, Germany, 2017. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Engine type | In-Line, 4-Cylinder |
| Displacement | 4.5 L |
| Bore × Stroke | 102 mm × 120 mm |
| Peak torque | 624 N.m @ 1500 rpm |
| Peak power | 123 kW @ 2000 rpm |
| Aspiration | Turbocharged and Charge Air Cooled |
| Certification Level | Tier 3/Stage IIIA |
| Parameter | Value |
|---|---|
| Sensor temperature | 200 °C |
| Extracted sample temperature | −40 up to 850 °C |
| Dilution | No need |
| Time response | 0.2 s |
| Measured particle size range | 10 nm and up |
| Trap voltage | 60 V (10 nm lower cut) 400 V (23 nm lower cut, default) 2 kV (90 nm lower cut) |
| Particle number range | 300 up to 109 |
| Particle mass range | 10−3 up to 300 |
| Sample pressure | −20 kPa to +100 kPa |
| Clean air/Nitrogen supply | 10 LPM @ 0.15 MPa |
| Operating voltage | 24 V |
| Power consumption | 6 W |
| Method | Opt. Method | Opt. Hyperparameters | Model Type | Opt. Model Configuration |
|---|---|---|---|---|
| RT | Bayesian | Min samples leaf (MSL) | BB | MSL = 13 |
| BB + L | MSL = 1 | |||
| GB + L | MSL = 5 | |||
| GB + PHYS | MSL = 5 | |||
| GB + PHYS + L | MSL = 5 | |||
| ERT | Bayesian | Ensemble method, min samples leaf, and number of learners | BB | Boosting, 75 Learners, and MSL = 2 |
| BB + L | Boosting, 28 Learners, and MSL = 4 | |||
| GB + L | Boosting, 35 Learners, and MSL = 5 | |||
| GB + PHYS | Boosting, 488 Learners, and MSL = 47 | |||
| GB + PHYS + L | Boosting, 487 Learners, and MSL = 2 | |||
| SVM | Bayesian | Kernel function and | BB | Cubic, , |
| BB + L | Quadratic, , | |||
| GB + L | Gaussian, , | |||
| GB + PHYS | Quadratic, , | |||
| GB + PHYS + L | Cube, , | |||
| GPR | Bayesian | Kernel function, initial value for the noise standard deviation () | BB | Rational quadratic, |
| BB + L | Rational quadratic, | |||
| GB + L | Matérn 5/2, | |||
| GB + PHYS | Matérn 5/2, | |||
| GB + PHYS + L | Matérn 5/2, | |||
| 1-HL ANN | Grid search | Number of neurons in each layer | BB | Network conf.: [25] |
| BB + L | Network conf.: [19] | |||
| GB + L | Network conf.: [4] | |||
| GB + PHYS | Network conf.: [4] | |||
| GB + PHYS + L | Network conf.: [19] | |||
| 2-HL ANN | Grid search | Number of neurons in each layer | BB | Network conf.: [7, 25] |
| BB + L | Network conf.: [25, 31] | |||
| GB + L | Network conf.: [4, 13] | |||
| GB + PHYS | Network conf.: [7,13] | |||
| GB + PHYS + L | Network conf.: [16, 19] | |||
| 1-HL BNN | Grid search | Number of neurons in each layer | BB | Network conf.: [7] |
| BB + L | Network conf.: [31] | |||
| GB + L | Network conf.: [31] | |||
| GB + PHYS | Network conf.: [13] | |||
| GB + PHYS + L | Network conf.: [25] | |||
| 2-HL BNN | Grid search | Number of neurons in each layer | BB | Network conf.: [7, 28] |
| BB + L | Network conf.: [16, 13] | |||
| GB + L | Network conf.: [10, 22] | |||
| GB + PHYS | Network conf.: [22, 22] | |||
| GB + PHYS + L | Network conf.: [10, 19] |
| Model | Criteria | RT | ERT | SVM | GPR | 1-HL NN | 2-HL NN | 1-HL BNN | 2-HL BNN |
|---|---|---|---|---|---|---|---|---|---|
| BB | 0.85 | 0.95 | 0.86 | 0.87 | 0.86 | 0.86 | 0.88 | 0.90 | |
| 0.41 | 0.51 | 0.50 | 0.27 | 0.52 | 0.54 | 0.51 | 0.52 | ||
| 1.41 | 0.90 | 1.39 | 1.35 | 1.44 | 1.38 | 1.27 | 1.21 | ||
| 2.52 | 2.38 | 2.53 | 2.35 | 2.41 | 2.32 | 2.39 | 2.43 | ||
| 8.7 | 8.5 | 8.2 | 7.7 | 6.6 | 7.9 | 7.7 | 7.5 | ||
| 2.23 | 16.73 | 2.08 | 3.11 | 8.66 | 9.53 | 6.47 | 6.93 | ||
| 0.74 | 3.50 | 0.40 | 1.56 | 3.77 | 1.11 | 2.07 | 14.31 | ||
| BB + L | 0.98 | 0.99 | 0.97 | 1 | 0.97 | 0.98 | 0.99 | 0.99 | |
| 0.87 | 0.91 | 0.93 | 0.96 | 0.90 | 0.92 | 0.95 | 0.94 | ||
| 0.48 | 0.52 | 0.66 | 0.28 | 0.66 | 0.63 | 0.22 | 0.20 | ||
| 1.33 | 1.07 | 0.98 | 0.51 | 1.19 | 1.10 | 0.83 | 0.93 | ||
| 5.02 | 3.14 | 4.37 | 1.87 | 4.35 | 4.53 | 2.85 | 4.3 | ||
| 1.94 | 5.26 | 2.27 | 2.73 | 7.49 | 8 | 14.7 | 10.4 | ||
| 0.75 | 1.57 | 0.44 | 1.32 | 2.80 | 2.33 | 4.57 | 15.13 | ||
| GB + L | 0.97 | 0.99 | 0.98 | 0.99 | 0.96 | 0.96 | 0.99 | 0.99 | |
| 0.92 | 0.93 | 0.95 | 0.94 | 0.90 | 0.92 | 0.95 | 0.95 | ||
| 0.62 | 0.06 | 0.48 | 0.38 | 0.73 | 0.72 | 0.34 | 0.09 | ||
| 1.09 | 1.00 | 0.81 | 0.67 | 1.2 | 0.88 | 0.88 | 0.97 | ||
| 2.9 | 3.7 | 1.9 | 1.9 | 3.6 | 2.3 | 2.3 | 2.6 | ||
| 2.21 | 47.16 | 2.05 | 3.59 | 7.24 | 12.42 | 7.39 | 6.86 | ||
| 0.79 | 8.57 | 0.37 | 6.1 | 2.97 | 1.04 | 12.10 | 14.66 | ||
| GB + PHYS | 0.98 | 0.99 | 0.98 | 0.99 | 0.97 | 0.98 | 0.99 | 0.99 | |
| 0.87 | 0.96 | 0.94 | 0.97 | 0.90 | 0.89 | 0.93 | 0.83 | ||
| 0.54 | 0.01 | 0.57 | 0.13 | 0.70 | 0.6 | 0.07 | 0.01 | ||
| 1.3 | 0.74 | 0.91 | 0.5 | 1.2 | 0.94 | 1.2 | 1.06 | ||
| 5.88 | 1.8 | 3.3 | 1.58 | 4.35 | 4.76 | 2.67 | 5.52 | ||
| 2.74 | 58.19 | 3.1 | 5.87 | 7.3 | 14.22 | 6.69 | 10.63 | ||
| 0.75 | 13.90 | 0.46 | 43.24 | 3.09 | 1.11 | 35.87 | 103.90 | ||
| GB + PHYS + L | 0.98 | 0.99 | 0.98 | 0.99 | 0.95 | 0.98 | 0.99 | 0.99 | |
| 0.89 | 0.95 | 0.97 | 0.96 | 0.91 | 0.94 | 0.90 | 0.93 | ||
| 0.60 | 0.01 | 0.57 | 0.31 | 0.87 | 0.49 | 0.13 | 0.08 | ||
| 1.24 | 0.83 | 0.71 | 0.52 | 1.2 | 0.94 | 1.19 | 1.06 | ||
| 2.94 | 2.65 | 1.64 | 1.41 | 3.42 | 2.97 | 4.73 | 3.4 | ||
| 2.06 | 56.31 | 2.28 | 3.08 | 9.13 | 10.4 | 6.32 | 7.06 | ||
| 0.79 | 10.65 | 0.52 | 3.77 | 2.70 | 1.22 | 8.59 | 8.22 |
| Cluster | Model | Accuracy | Reliability | Less Complexity | Real-Time Control | Virtual Test |
|---|---|---|---|---|---|---|
| 2 | GPR: GB + PHYS | × | × | × | ||
| 2 | 1-HL BNN: GB + PHYS | × | ||||
| 4 | SVM: GB + PHYS + L | × | × | × | × | |
| 4 | GPR: GB + PHYS + L | × | × | × | × | |
| 4 | SVM: GB + L | × | × | × | × | |
| 4 | GPR: GB + L | × | × | × | ||
| 4 | GPR: BB + L | × | × | × | × | |
| 1 | RT: GB + PHYS + L | × | ||||
| 1 | SVM: GB + PHYS | × | ||||
| 1 | RT: GB + L | × | ||||
| 1 | ERT: BB + L | |||||
| 1 | SVM: BB + L | × | × |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shahpouri, S.; Norouzi, A.; Hayduk, C.; Rezaei, R.; Shahbakhti, M.; Koch, C.R. Hybrid Machine Learning Approaches and a Systematic Model Selection Process for Predicting Soot Emissions in Compression Ignition Engines. Energies 2021, 14, 7865. https://0-doi-org.brum.beds.ac.uk/10.3390/en14237865
Shahpouri S, Norouzi A, Hayduk C, Rezaei R, Shahbakhti M, Koch CR. Hybrid Machine Learning Approaches and a Systematic Model Selection Process for Predicting Soot Emissions in Compression Ignition Engines. Energies. 2021; 14(23):7865. https://0-doi-org.brum.beds.ac.uk/10.3390/en14237865
Chicago/Turabian StyleShahpouri, Saeid, Armin Norouzi, Christopher Hayduk, Reza Rezaei, Mahdi Shahbakhti, and Charles Robert Koch. 2021. "Hybrid Machine Learning Approaches and a Systematic Model Selection Process for Predicting Soot Emissions in Compression Ignition Engines" Energies 14, no. 23: 7865. https://0-doi-org.brum.beds.ac.uk/10.3390/en14237865