
Co-Optimizing Battery Storage for Energy Arbitrage and Frequency Regulation in Real-Time Markets Using Deep Reinforcement Learning



Abstract
:1. Introduction
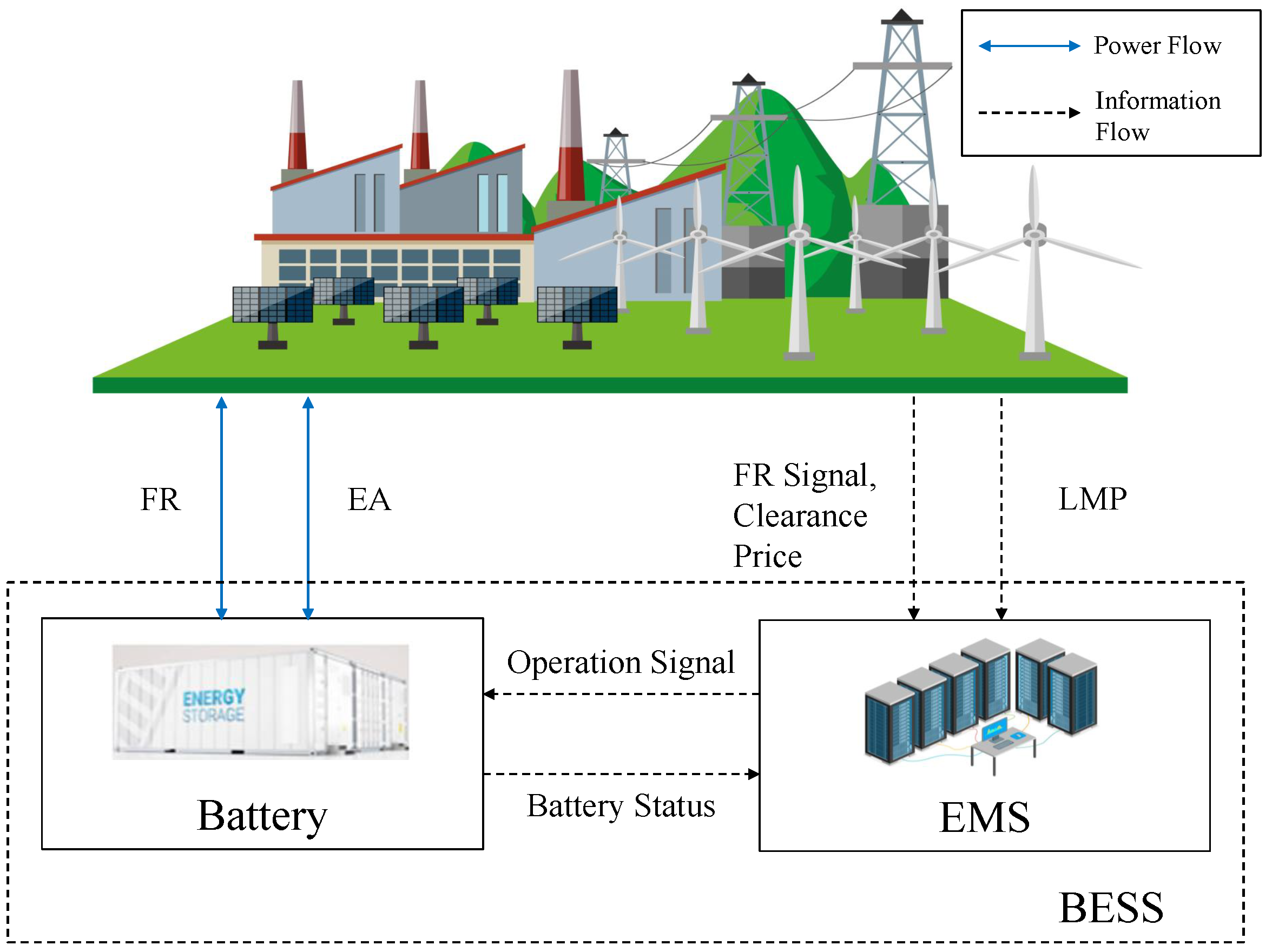
- A novel co-optimization scheme is proposed to handle the multitimescale problem. The BESS decides an optimal EA action every five minutes to maximize its revenue due to the total amount of energy change, and every two seconds the BESS decides an optimal FR action to maximize the total reward including the revenue due to energy change and FR settlement reward. Based on the FR action, the EA action has to be adjusted based on the power constraints of the BESS to maximize the total revenue of the day on the two-second level.
- The TDD–ND algorithm is proposed to solve the co-optimization problem. To the best of our knowledge, the TDD algorithm [34] is for the first time used for energy storage. Our proposed method combines the TDD algorithm with ND policy to improve the exploration during the training, and thus to achieve the higher total revenue.
- Real-time data are used to evaluate the performance of the proposed TDD–ND co-optimization approach. Simulation results show that our proposed DRL approach with the co-optimization scheme performs better than studied policies.
2. PJM Frequency Regulation Market
3. Nested System Model and Problem Formulation
3.1. The Five-Minute MDP Submodel Formulation
3.1.1. State
3.1.2. Action
3.1.3. Degradation Cost and Reward
3.2. The Two-Second MDP Submodel Formulation
3.2.1. State
3.2.2. Action
3.2.3. Reward
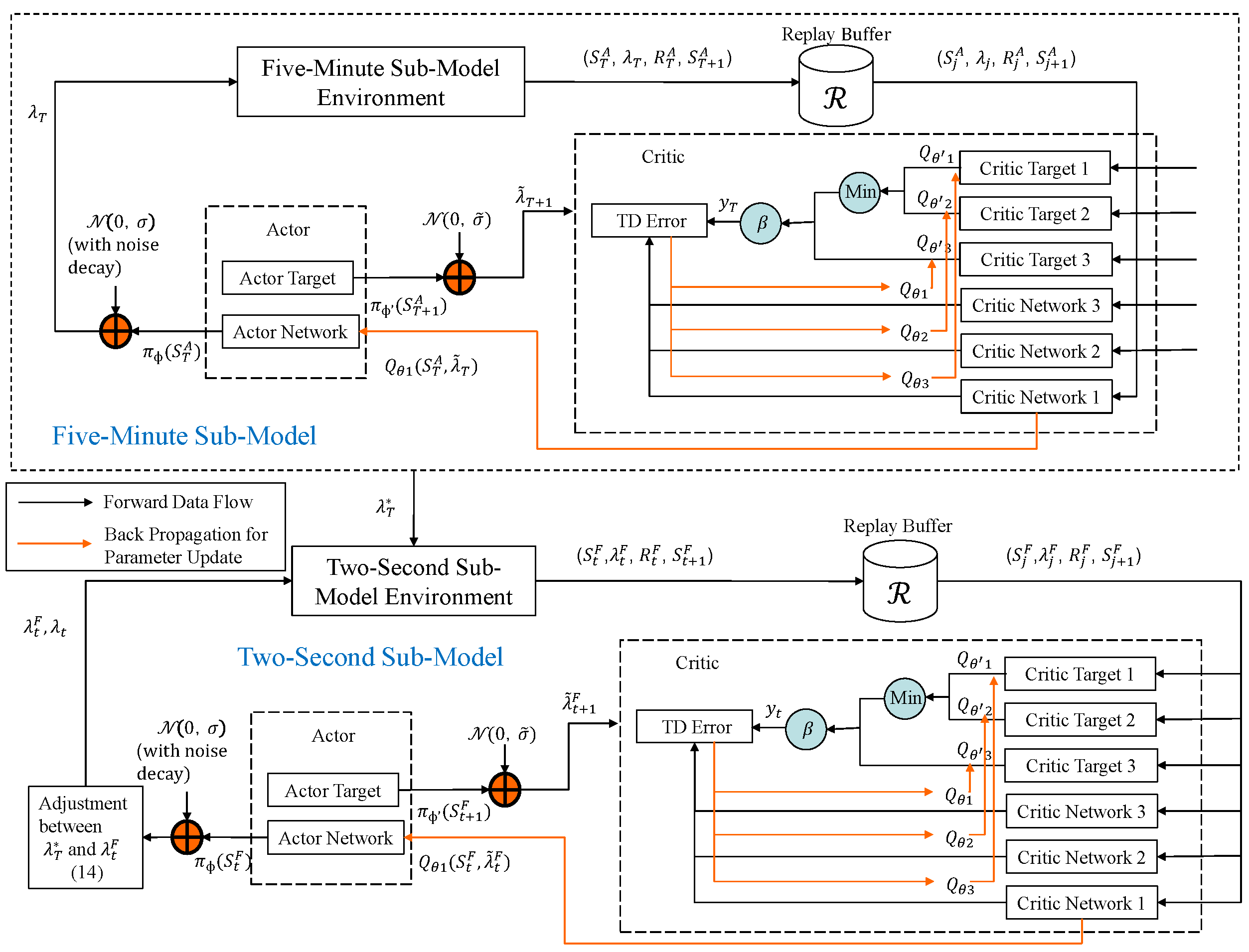
3.3. Proposed Co-Optimization Scheme
4. Proposed Triplet Deep Deterministic Policy Gradient with Exploration Noise Decay Approach
4.1. Triplet Deep Deterministic Policy Gradient Algorithm
4.2. Proposed TDD–ND Co-Optimization Approach
| Algorithm 1: The TDD–ND training process for five-minute submodel optimization |
Initialize the actor network , the actor target network , the size R of replay buffer , and the mini-batch size m. Initialize the three critic networks , and , and three critic target networks , and .
|
5. Experimental Results
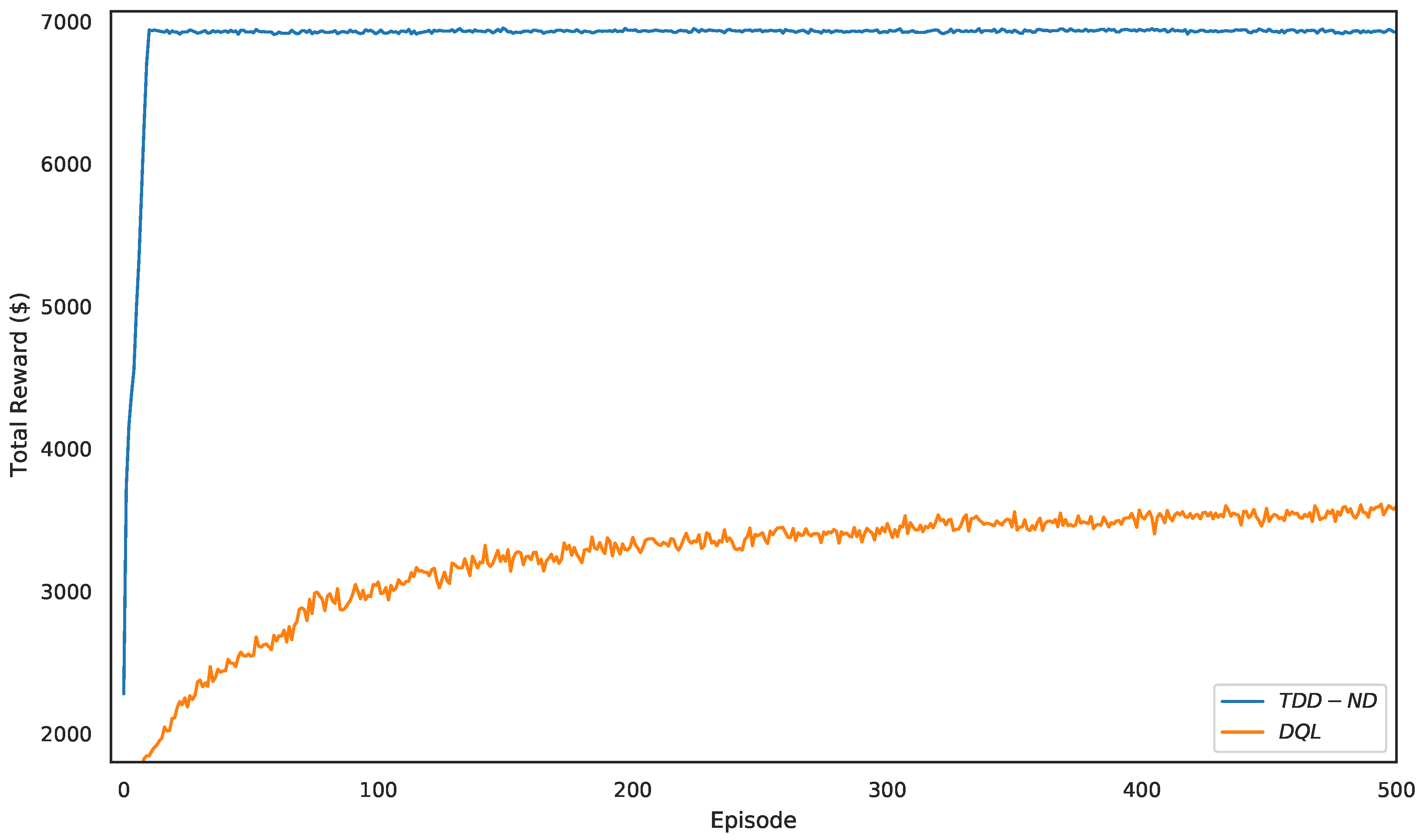
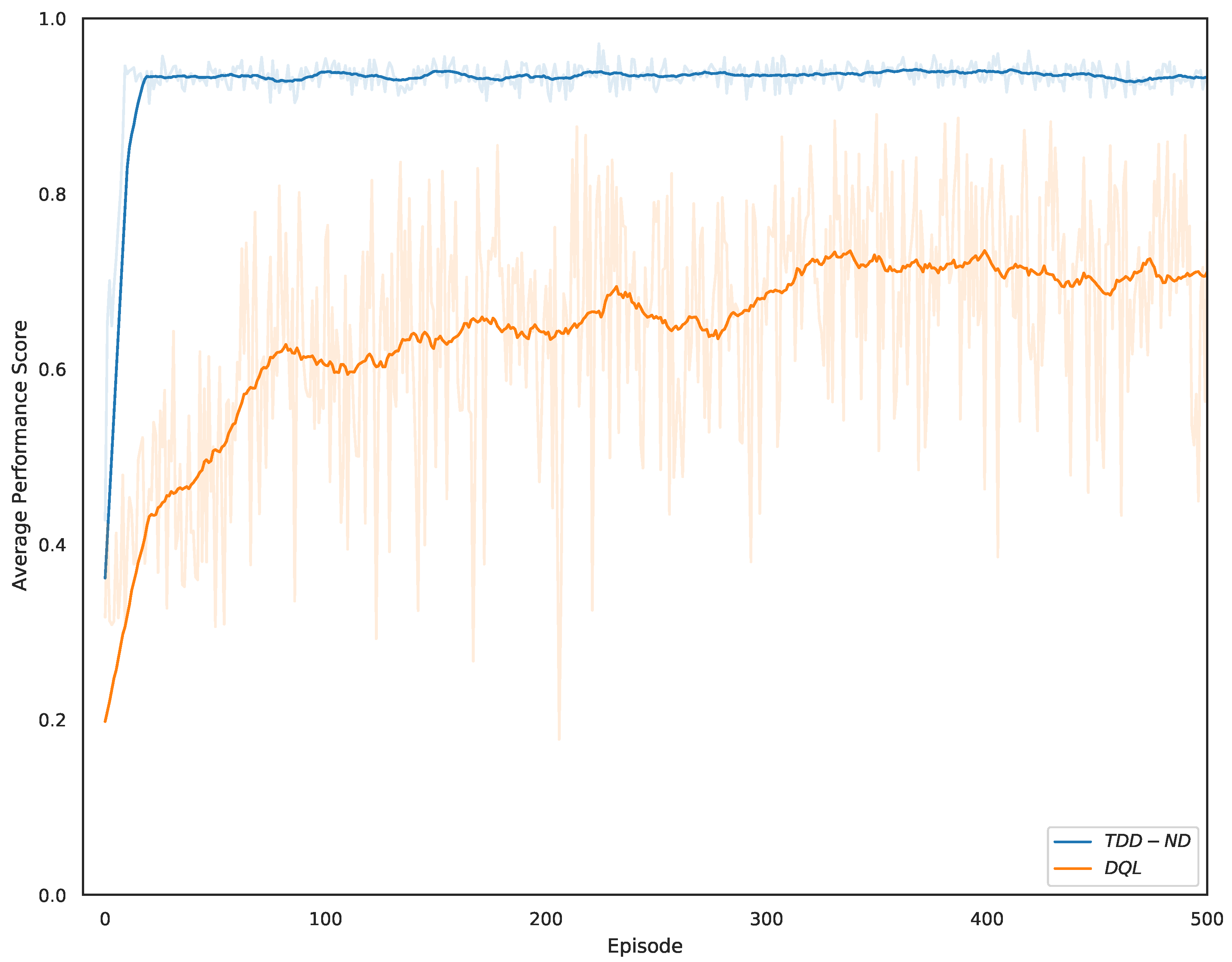
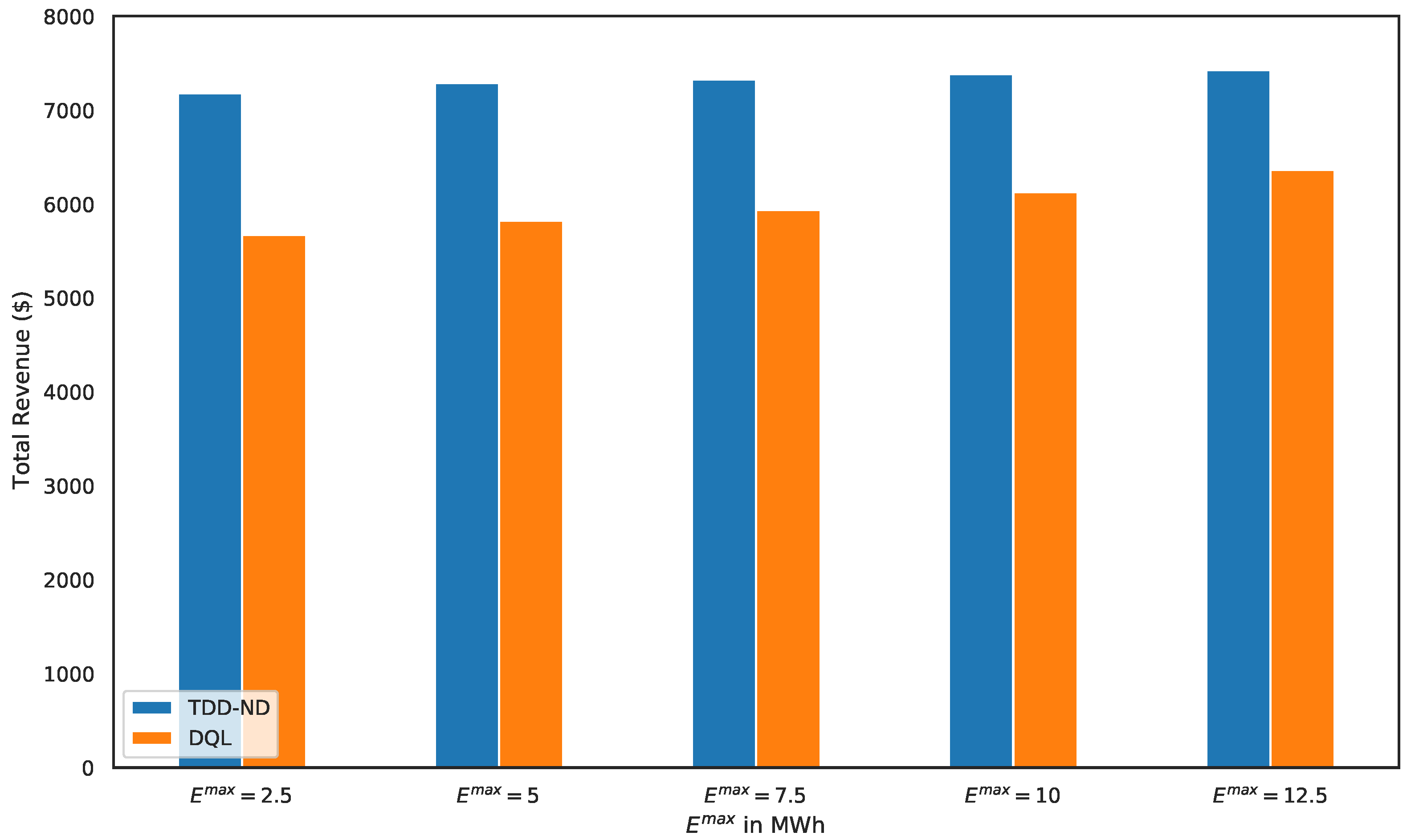
5.1. Performance Evaluation of the Proposed TDD–ND Algorithm
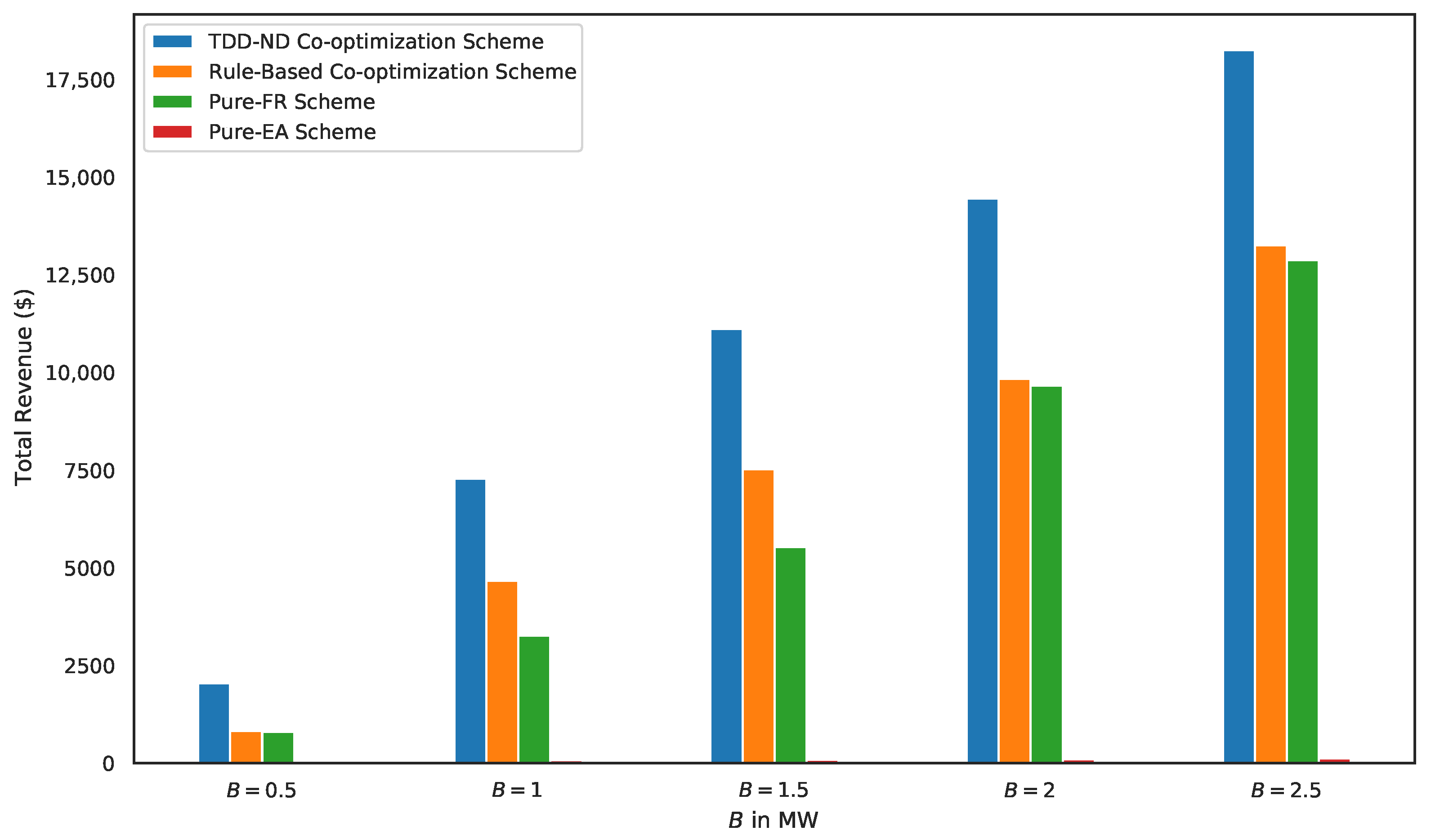
5.2. Performance Comparison of Various Schemes
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| The maximum regulation capacity in MW assigned by PJM | |
| B | The maximum power capacity of the BESS in MW |
| The linearized battery degradation cost co-efficient | |
| Energy level of the BESS in MWh at time T in five-minute submodel | |
| Energy level of the BESS in MWh at time t in two-second submodel | |
| The maximum energy capacity of the BESS in MWh | |
| The degradation cost | |
| m | The mini-batch size |
| N | The number of cycles that the BESS |
| The real-time electricity price at time T | |
| The average value of electricity prices in the past day | |
| The price of the battery cell in the BESS | |
| Dynamic signal for fast regulation, which is a measure of the imbalance between sources and uses of power in MW in the grid | |
| The regulation signal (RegD) sent by PJM at time t to the BESS to provide regulation service | |
| The five-minute regulation settlement | |
| The reward for performing an action state in five-minute submodel | |
| The reward for performing action at state in two-second submodel | |
| The real-time regulation settlement reward within the two-second interval | |
| Average performance score within a five-minute period indicating the performance of FR | |
| The two-second performance score at time t | |
| The state of five-minute submodel at time T | |
| The state of two-second submodel at time t | |
| T | The time indicator in five-minute submodel |
| t | The time indicator in two-second submodel |
| The one-day horizon of five-minute submodel | |
| The one-day horizon of two-second submodel | |
| The five-minute time interval | |
| The two-second time interval | |
| The action of the total amount of power change in MW due to EA and FR at time T in five-minute submodel | |
| The action in MW of BESS response to the RegD signal at time t in two-second submodel | |
| The optimal action of five-minute submodel at time T | |
| The total amount of power change at time t due to EA and FR in two-second submodel | |
| The charging efficiency of the BESS | |
| The discharging efficiency of the BESS, | |
| learning rate for actor | |
| learning rate for critic | |
| The maximum standard deviation value in the exploration noise | |
| The minimum standard deviation value in the exploration noise | |
| The decay of standard deviation value in the exploration noise decay policy | |
| The discount factor for future rewards | |
| Replay buffer | |
| R | The size of replay buffer |
| Clipped Gaussian noise | |
| The actor network in TDD–ND | |
| The actor target network in TDD–ND | |
| Critic networks in TDD–ND | |
| Target networks in TDD–ND |
References
- Chatzinikolaou, E.; Rogers, D.J. A comparison of grid-connected battery energy storage system designs. IEEE Trans. Power Electron. 2017, 32, 6913–6923. [Google Scholar] [CrossRef]
- He, G.; Chen, Q.; Kang, C.; Pinson, P.; Xia, Q. Optimal bidding strategy of battery storage in power markets considering performance-based regulation and battery cycle life. IEEE Trans. Smart Grid 2016, 7, 2359–2367. [Google Scholar] [CrossRef] [Green Version]
- Rosewater, D.; Baldick, R.; Santoso, S. Risk-Averse Model Predictive Control Design for Battery Energy Storage Systems. IEEE Trans. Smart Grid 2020, 11, 2014–2022. [Google Scholar] [CrossRef]
- Shi, Y.; Xu, B.; Wang, D.; Zhang, B. Using battery storage for peak shaving and frequency regulation: Joint optimization for superlinear gains. IEEE Trans. Power Syst. 2018, 33, 2882–2894. [Google Scholar] [CrossRef] [Green Version]
- Meng, L.; Zafar, J.; Khadem, S.K.; Collinson, A.; Murchie, K.C.; Coffele, F.; Burt, G.M. Fast Frequency Response from Energy Storage Systems—A Review of Grid Standards, Projects and Technical Issues. IEEE Trans. Smart Grid 2020, 11, 1566–1581. [Google Scholar] [CrossRef] [Green Version]
- Arévalo, P.; Tostado-Véliz, M.; Jurado, F. A novel methodology for comprehensive planning of battery storage systems. J. Energy Storage 2021, 37, 102456. [Google Scholar] [CrossRef]
- Mohamed, N.; Aymen, F.; Ben Hamed, M.; Lassaad, S. Analysis of battery-EV state of charge for a dynamic wireless charging system. Energy Storage 2020, 2, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Antoniadou-Plytaria, K.; Steen, D.; Tuan, L.A.; Carlson, O.; Fotouhi Ghazvini, M.A. Market-Based Energy Management Model of a Building Microgrid Considering Battery Degradation. IEEE Trans. Smart Grid 2021, 12, 1794–1804. [Google Scholar] [CrossRef]
- Avula, R.R.; Chin, J.X.; Oechtering, T.J.; Hug, G.; Mansson, D. Design Framework for Privacy-Aware Demand-Side Management with Realistic Energy Storage Model. IEEE Trans. Smart Grid 2021, 12, 3503–3513. [Google Scholar] [CrossRef]
- Arias, N.B.; Lopez, J.C.; Hashemi, S.; Franco, J.F.; Rider, M.J. Multi-Objective Sizing of Battery Energy Storage Systems for Stackable Grid Applications. IEEE Trans. Smart Grid 2020, 3053, 1–14. [Google Scholar] [CrossRef]
- Sioshansi, R.; Denholm, P.; Jenkin, T.; Weiss, J. Estimating the value of electricity storage in PJM: Arbitrage and some welfare effects. Energy Econ. 2009, 31, 269–277. [Google Scholar] [CrossRef]
- Cao, J.; Harrold, D.; Fan, Z.; Morstyn, T.; Healey, D.; Li, K. Deep Reinforcement Learning-Based Energy Storage Arbitrage with Accurate Lithium-Ion Battery Degradation Model. IEEE Trans. Smart Grid 2020, 11, 4513–4521. [Google Scholar] [CrossRef]
- Eyer, J.M.; Iannucci, J.J.; Corey, G.P.; SANDIA. Energy storage benefits and markets analysis handbook. In A Study for DOE Energy Storage Systems Program; Sandia National Laboratories: Albuquerque, NM, USA; Livermore, CA, USA, 2004; p. 105. [Google Scholar]
- Wang, H.; Zhang, B. Energy storage arbitrage in real-time markets via reinforcement learning. In Proceedings of the IEEE Power and Energy Society General Meeting, Portland, OR, USA, 5–9 August 2018; pp. 1–5. [Google Scholar]
- Abdulla, K.; De Hoog, J.; Muenzel, V.; Suits, F.; Steer, K.; Wirth, A.; Halgamuge, S. Optimal operation of energy storage systems considering forecasts and battery degradation. IEEE Trans. Smart Grid 2018, 9, 2086–2096. [Google Scholar] [CrossRef]
- Chen, Y.; Hashmi, M.U.; Deka, D.; Chertkov, M. Stochastic Battery Operations using Deep Neural Networks. In Proceedings of the 2019 IEEE Power and Energy Society Innovative Smart Grid Technologies Conference, ISGT 2019, Washington, DC, USA, 18–21 February 2019; pp. 7–11. [Google Scholar]
- Krishnamurthy, D.; Uckun, C.; Zhou, Z.; Thimmapuram, P.R.; Botterud, A. Energy storage arbitrage under day-ahead and real-time price uncertainty. IEEE Trans. Power Syst. 2017, 33, 84–93. [Google Scholar] [CrossRef]
- Grid Energy Storage; Tech. Rep.; Dept. Energy: Washington, DC, USA, 2013.
- Cheng, B.; Powell, W.B. Co-optimizing battery storage for the frequency regulation and energy arbitrage using multi-scale dynamic programming. IEEE Trans. Smart Grid 2018, 9, 1997–2005. [Google Scholar] [CrossRef]
- Cheng, B.; Asamov, T.; Powell, W.B. Low-rank value function approximation for co-optimization of battery storage. IEEE Trans. Smart Grid 2018, 9, 6590–6598. [Google Scholar] [CrossRef]
- Walawalkar, R.; Apt, J.; Mancini, R. Economics of electric energy storage for energy arbitrage and regulation in New York. Energy Policy 2007, 35, 2558–2568. [Google Scholar] [CrossRef]
- Perekhodtsev, D. Two Essays on Problems of Deregulated Electricity Markets. Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, 2004; p. 94. [Google Scholar]
- Engels, J.; Claessens, B.; Deconinck, G. Optimal Combination of Frequency Control and Peak Shaving with Battery Storage Systems. IEEE Trans. Smart Grid 2019, 11, 3270–3279. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Bahrami, S.; Wong, V.W.; Lampe, L. Chance-constrained frequency regulation with energy storage systems in distribution networks. IEEE Trans. Smart Grid 2020, 11, 215–228. [Google Scholar] [CrossRef]
- Jiang, T.; Ju, P.; Wang, C.; Li, H.; Liu, J. Coordinated Control of Air-Conditioning Loads for System Frequency Regulation. IEEE Trans. Smart Grid 2021, 12, 548–560. [Google Scholar] [CrossRef]
- Tian, Y.; Bera, A.; Benidris, M.; Mitra, J. Stacked Revenue and Technical Benefits of a Grid-Connected Energy Storage System. IEEE Trans. Ind. Appl. 2018, 54, 3034–3043. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep reinforcement learning for multi-agent systems: A review of challenges, solutions and applications. IEEE Trans. Cybern. 2018, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, T.; Bu, S.; Liu, X.; Kang, J.; Yu, F.R.; Han, Z. Peer-to-Peer Energy Trading and Energy Conversion in Interconnected Multi-Energy Microgrids Using Multi-Agent Deep Reinforcement Learning. IEEE Trans. Smart Grid 2021. [Google Scholar] [CrossRef]
- Wang, B.; Li, Y.; Ming, W.; Wang, S. Deep Reinforcement Learning Method for Demand Response Management of Interruptible Load. IEEE Trans. Smart Grid 2020, 11, 3146–3155. [Google Scholar] [CrossRef]
- Wu, J.; Wei, Z.; Li, W.; Wang, Y.; Li, Y.; Sauer, D.U. Battery Thermal-and Health-Constrained Energy Management for Hybrid Electric Bus Based on Soft Actor-Critic DRL Algorithm. IEEE Trans. Ind. Inform. 2021, 17, 3751–3761. [Google Scholar] [CrossRef]
- Wu, J.; Wei, Z.; Liu, K.; Quan, Z.; Li, Y. Battery-Involved Energy Management for Hybrid Electric Bus Based on Expert-Assistance Deep Deterministic Policy Gradient Algorithm. IEEE Trans. Veh. Technol. 2020, 69, 12786–12796. [Google Scholar] [CrossRef]
- Wei, Z.; Quan, Z.; Wu, J.; Li, Y.; Pou, J.; Zhong, H. Deep Deterministic Policy Gradient-DRL Enabled Multiphysics-Constrained Fast Charging of Lithium-Ion Battery. IEEE Trans. Ind. Electron. 2021. [Google Scholar] [CrossRef]
- Fujimoto, S.; Van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; Volume 4, pp. 2587–2601. [Google Scholar]
- Wu, D.; Dong, X.; Shen, J.; Hoi, S.C. Reducing Estimation Bias via Triplet-Average Deep Deterministic Policy Gradient. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4933–4945. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016—Conference Track Proceedings, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Shi, Q.; Lam, H.K.; Xuan, C.; Chen, M. Adaptive neuro-fuzzy PID controller based on twin delayed deep deterministic policy gradient algorithm. Neurocomputing 2020, 402, 183–194. [Google Scholar] [CrossRef]
- PJM. PJM Manual 11: Services, Ancillary Operations, Market Operations, Real-Time Market; PJM: Valley Forge, PA, USA, 2019. [Google Scholar]
- Croop, D. PJM—Performance Scoring, Regulation Market Issues Senior Task Force; PJM: Valley Forge, PA, USA, 2016. [Google Scholar]
- Operations, B.; Pilong, C. PJM Manual 12: Regulation; PJM: Valley Forge, PA, USA, 2016. [Google Scholar]
- PJM. Real-Time Five Minute LMPs; PJM: Valley Forge, PA, USA, 2019. [Google Scholar]
- PJM. Ancillary Services; PJM: Valley Forge, PA, USA, 2019. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
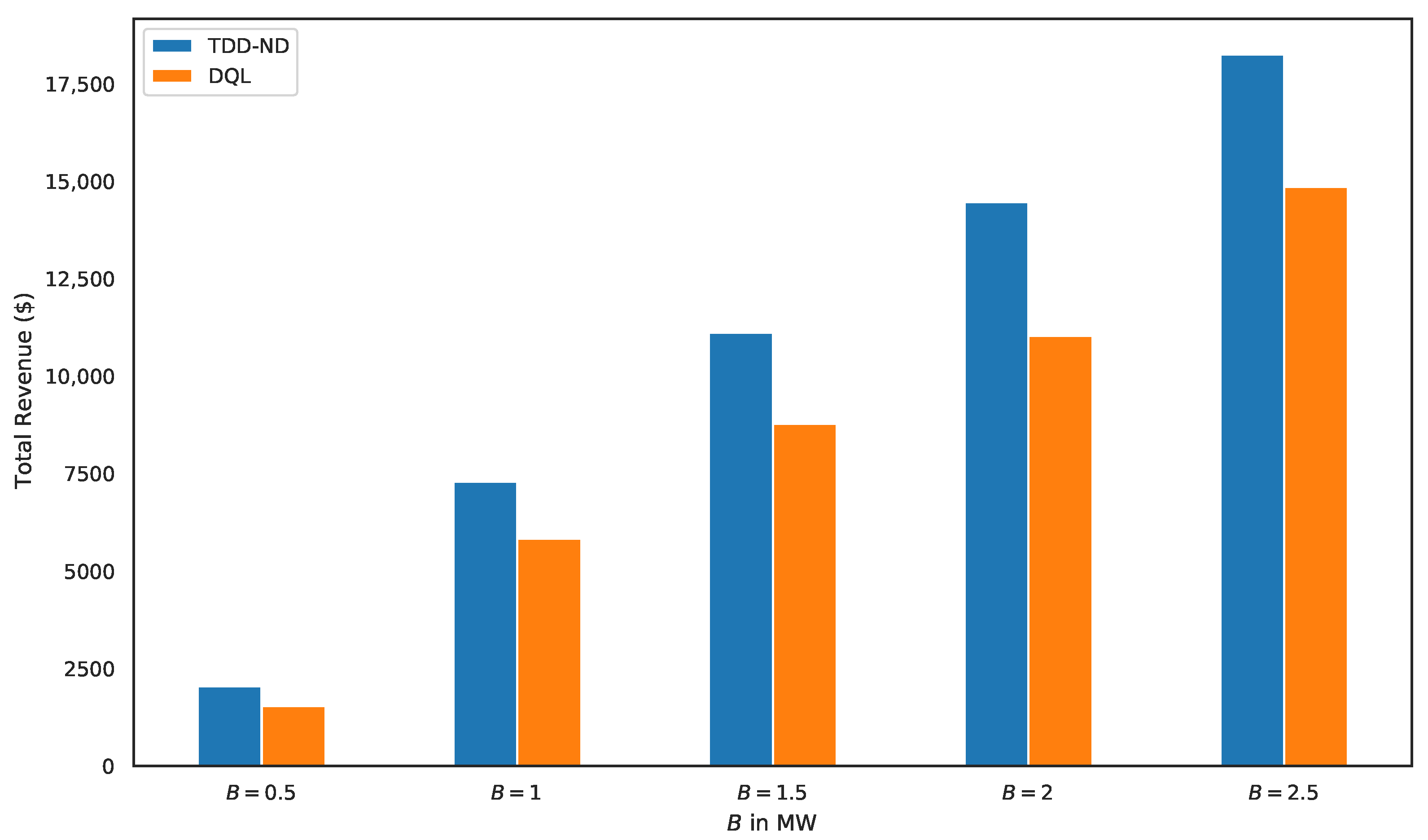{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| PJM historical real-time LMP from 00:00:00 AM to 11:55:00 PM, 30 July 2021 [40] | |
| PJM historical real-time clearance price for FR from 00:00:00 AM to 11:55:00 PM, 30 July 2021 [40] | |
| Historical real-time RegD signal from 00:00:00 AM to 11:59:58 PM, 30 July 2021 [41] | |
| 5 MWh | |
| B, | 1 MW |
| 4/MWh |
| Parameters | Value |
|---|---|
| 0.99 | |
| 1 | |
| 0.01 | |
| R | |
| m |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miao, Y.; Chen, T.; Bu, S.; Liang, H.; Han, Z. Co-Optimizing Battery Storage for Energy Arbitrage and Frequency Regulation in Real-Time Markets Using Deep Reinforcement Learning. Energies 2021, 14, 8365. https://0-doi-org.brum.beds.ac.uk/10.3390/en14248365
Miao Y, Chen T, Bu S, Liang H, Han Z. Co-Optimizing Battery Storage for Energy Arbitrage and Frequency Regulation in Real-Time Markets Using Deep Reinforcement Learning. Energies. 2021; 14(24):8365. https://0-doi-org.brum.beds.ac.uk/10.3390/en14248365
Chicago/Turabian StyleMiao, Yushen, Tianyi Chen, Shengrong Bu, Hao Liang, and Zhu Han. 2021. "Co-Optimizing Battery Storage for Energy Arbitrage and Frequency Regulation in Real-Time Markets Using Deep Reinforcement Learning" Energies 14, no. 24: 8365. https://0-doi-org.brum.beds.ac.uk/10.3390/en14248365