1. Introduction
Traditionally, the role of a distribution system has been to receive power from the power grid, supply it to consumers in a certain area, and operate it smoothly. However, as the distribution system changes due to distributed power sources such as photovoltaic (PV) generation, wind turbine generation, and the energy storage system (ESS), the concept of the distribution system is changing [
1,
2]. In other words, while stably supplying electricity generated from large-scale power plants to consumers was important in the past, the acceptance of distributed power sources near demand sides and flexibility for new distribution systems such as microgrids and DC distribution systems are gradually emerging as a new issue in the distribution system [
3,
4]. Additionally, despite the load concentration phenomenon due to urbanization and the limitations of new distribution facilities, consumers continuously want to receive a high-quality and reliable power supply.
Distribution planning is a technique that acquires and evaluates system operability, stability, and reliability at a minimal cost for improving and expanding existing power distribution systems in response to future power demand [
5]. As mentioned above, as the need for connection of distributed power sources is rapidly increasing, and digital loads are expanding, there are customers’ increasing demands for a reliable and high-quality supply of power, and the complexity and uncertainties of the distribution system are also increasing. Accordingly, as investment costs for distribution facilities continue to increase, the importance of an efficient distribution plan is growing. That is, as various distributed power sources such as renewable energy resources, electric vehicles, and ESSs increase in the distribution system, a complicated transformation of the distribution system is occurring, and thus in response to this transformation, the importance of research in the field of distribution planning to maintain the reliability and power quality of the distribution system at minimum cost is increasing.
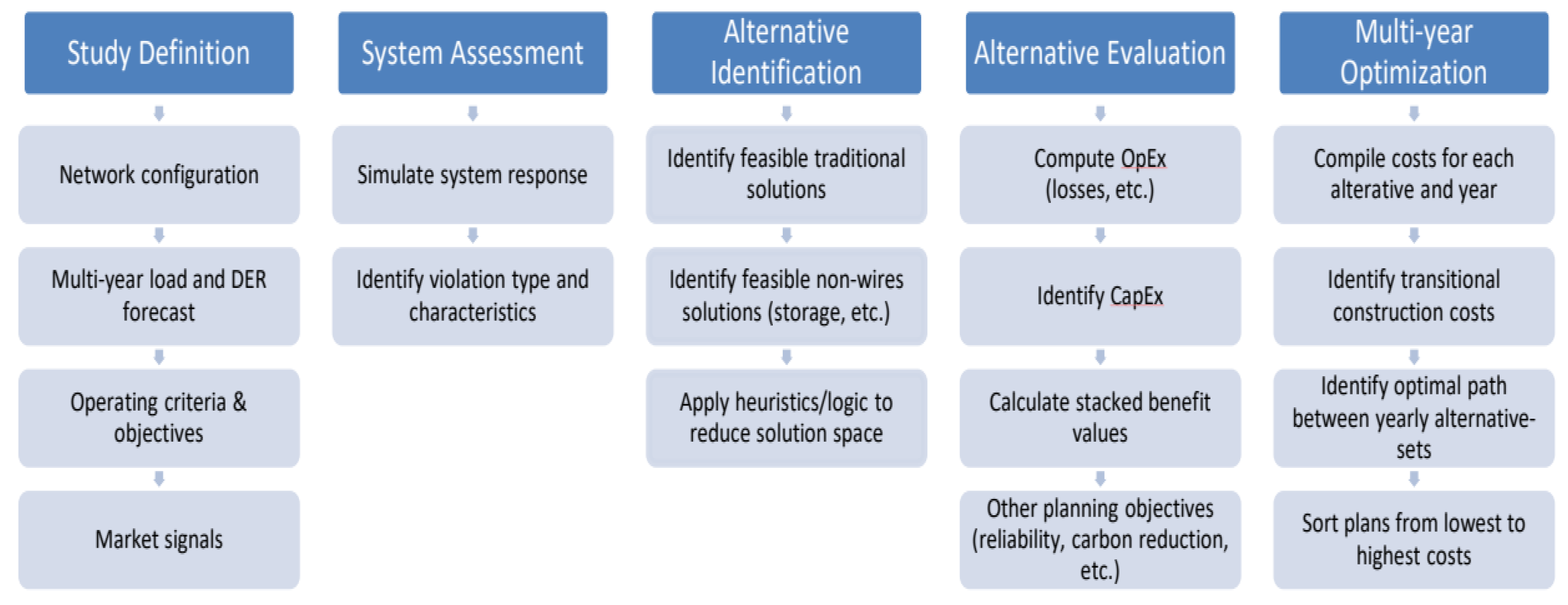
As shown in
Figure 1 [
2], for deciding the size and timing of the distribution facility installation in the future, the distribution line capacity should be planned in consideration of the load. Hence, it is important to forecast future loads [
6]. Recently, the renewable energy connection to the distribution system is a factor that makes such forecasts more difficult. In the modern distribution plan, since it is necessary to finally establish a mid- to long-term expansion plan for distribution facilities by synthesizing the results of the forecasting renewable energy sources and loads [
7], the accuracy of load forecasting for distribution lines is becoming more important than in the past, being the basis for effective and economic planning.
While the short-term load forecasting of distribution lines is necessary for operating distribution systems, the mid- to long-term load forecasting provides very important information for operation, planning, and investment [
6]. In the past distribution plans, load forecasting assumed a constant increase in load; however, this assumption was insufficient in distribution plans because the mid- to long-term load forecast has a non-linear characteristic. Therefore, in addition to power data, statistical models such as the regression model and the auto-regressive integrated moving average (ARIMA) model that use population information and economic indicators as input variables were used, and currently, machine learning models such as the artificial neural network (ANN) and support vector machine (SVM) are used for load forecast [
8,
9]. Recently, hybrid models that combine two or more models to solve the bias problems in machine learning models and improve forecasting accuracy are being developed [
10,
11,
12].
Currently, Korea Electric Power Corporation (KEPCO) is applying the simple linear regression method in the mid- to long-term load forecasting for the expansion plan of distribution lines, so improving accuracy is needed [
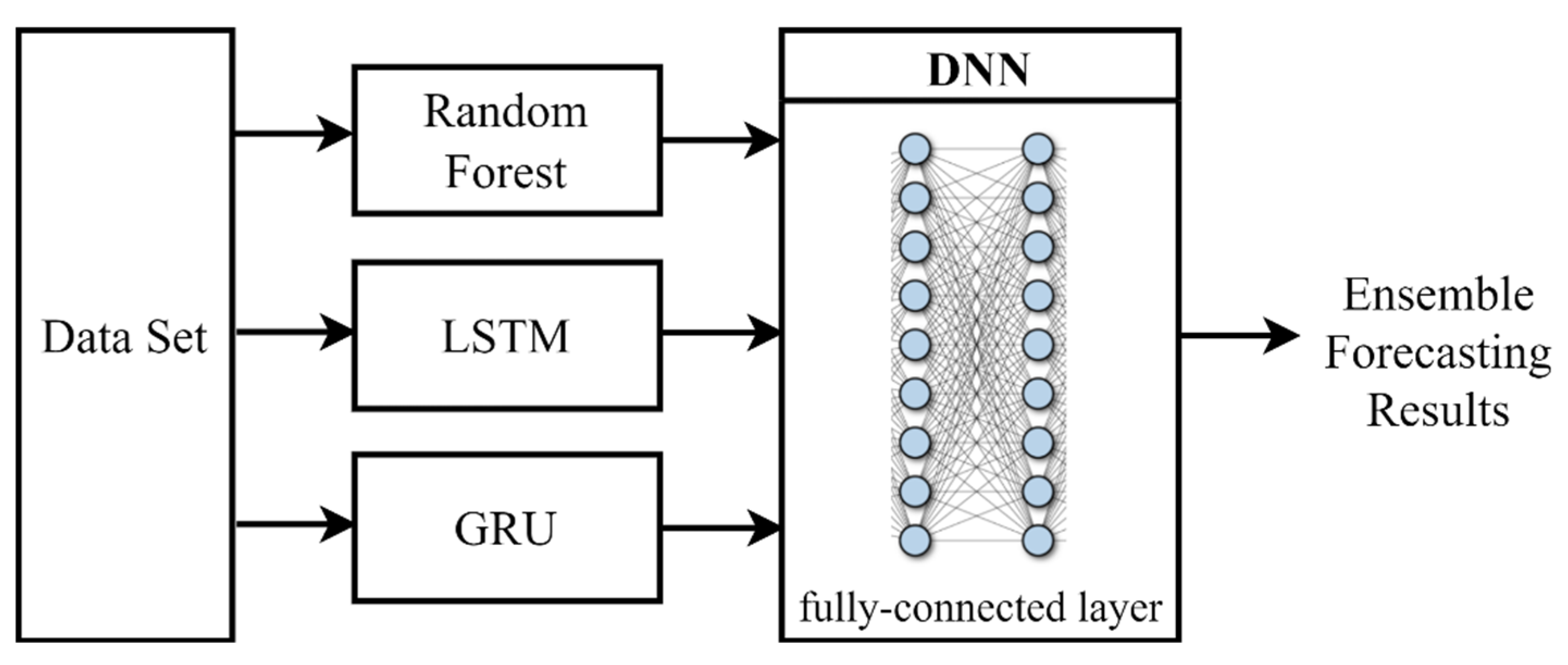
13]. Therefore, it is necessary to analyze the mid- to long-term load forecasting method for the existing distribution planning. This paper derived optimal individual forecasting models based on selecting input variables for load forecasting through correlation analysis. Then, ensemble load forecasting using combining individual models was developed. In addition, this paper proposed a method for improving forecasting results by considering the characteristics of each distribution line, and the process of the mid- to long-term distribution line load peak forecasting for distribution planning was also presented. In the end, this paper verified the performance of the proposed method by comparing the forecasting with their actual values.
2. Analysis of Load Forecasting Method for the Current Distribution Planning
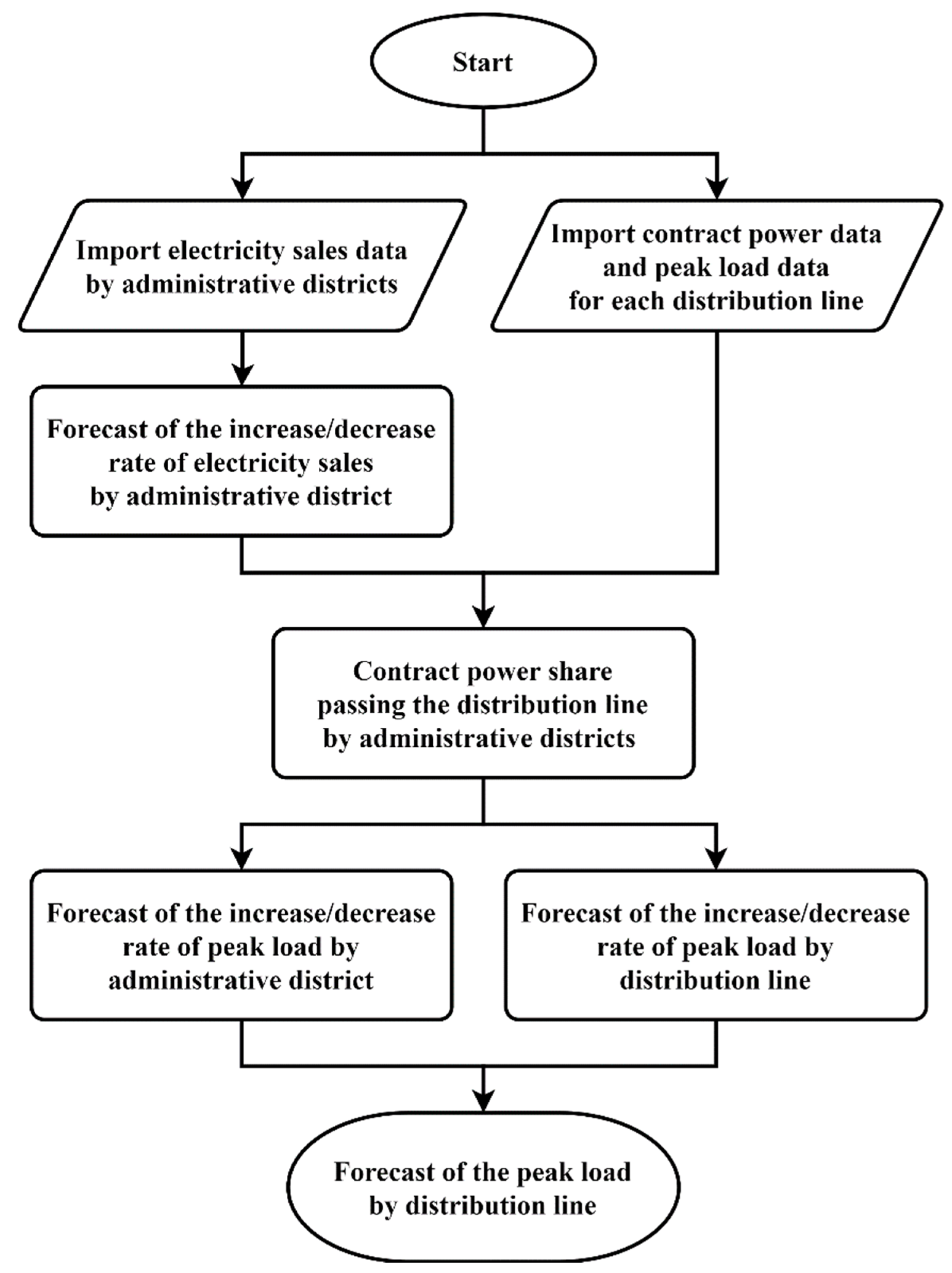
The mid- to long-term distribution line peak load forecasting process currently used by KEPCO is briefly shown in
Figure 2. The algorithm forecasts the increase and decrease in the rate of electricity sales by applying the simple linear regression method to the amount of electricity sold in each administrative district. By deriving the share of contract power in each administrative district, the amount of electricity that the distribution line is responsible for by the district is calculated. Then, the increase and decrease rate of the peak load for each administrative district and each distribution line are forecasted, and then the peak loads of distribution lines are forecasted by applying these rates to each distribution line. The reason for calculating the peak loads of distribution lines is to reinforce power facilities to maintain the safety and reliability of the distribution system in mid- to long-term [
13].
However, problems related to forecasting and synthesizing the peak load for each distribution line can occur. In general, the load does not increase evenly for each distribution line, and the increase and decrease rate of the load is not simple to express as a simple linear function. If distribution line peak loads are forecasted by simply applying the increase and decrease rates of the load, there is a possibility that a large error may occur. When comparing forecasting values from 2011 to 2020 according to the current distribution line peak load forecasting method as of 2010 with the real distribution line peak load values obtained from the substation operating results management system (SOMAS) within the same period, it is analyzed that the error rate increased from an average of 19% to 52% as the forecasting year approached 2020.
It can be observed from these results that the present load forecasting algorithm based on the simple linear regression method has a limitation in the optimal distribution planning. The linear regression method has the advantage of high robustness when the prediction period is long and when data are small; however, it may reach a limit in forecasting accuracy as non-linear characteristics occur in mid- to long-term forecasting because of various external variables such as weather and economy affecting the load in the distribution system. Therefore, if a machine learning technique that can improve accuracy while reflecting the influence of various external variables is applied, improved accuracy can be expected for the mid- to long-term peak load forecasting for distribution lines.
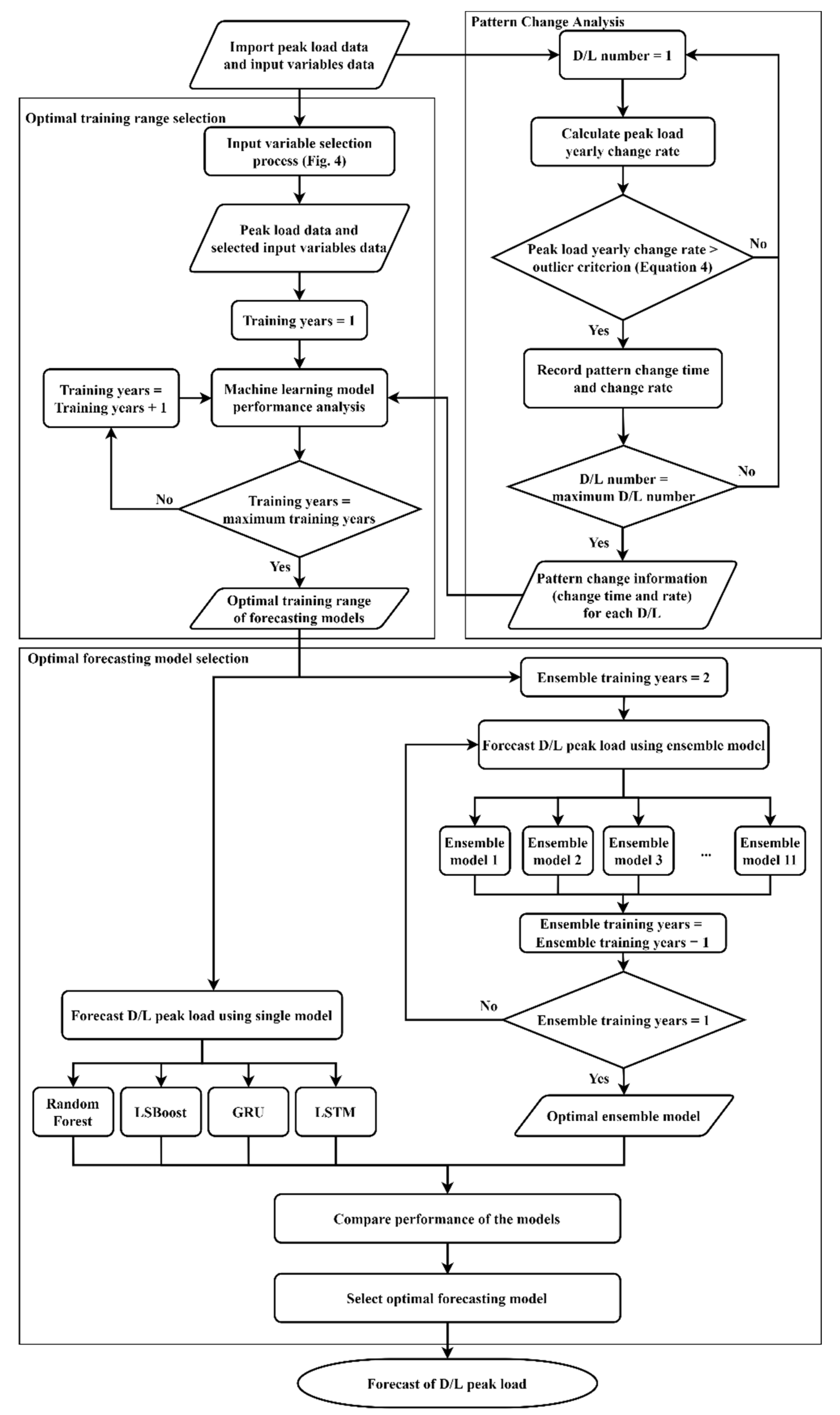
5. Development of Peak Load Forecasting Process Considering Distribution Line Characteristics
As in
Table 8, the proposed mid- to long-term distribution line peak load ensemble forecasting model has improved forecasting accuracy compared to the previous linear regression-based peak load forecasting method. However, a distribution line may not meet the learning period of the forecasting model because many new distribution lines are newly built every year or may change owing to load switching. This learning period problem may impair forecasting accuracy, so a peak load forecasting process that reflects the characteristics of such distribution lines is required.
5.1. Forecasting Model Reflecting Load Fluctuations of Distribution Lines
In the distribution system, a new distribution line may cause load transfer and movement, thus changing distribution line loads. As a result, the peak load pattern of the distribution line may also change significantly. In such a case, even if the proposed ensemble model is applied, the forecasting accuracy may be impaired because external input variables do not cause the change.
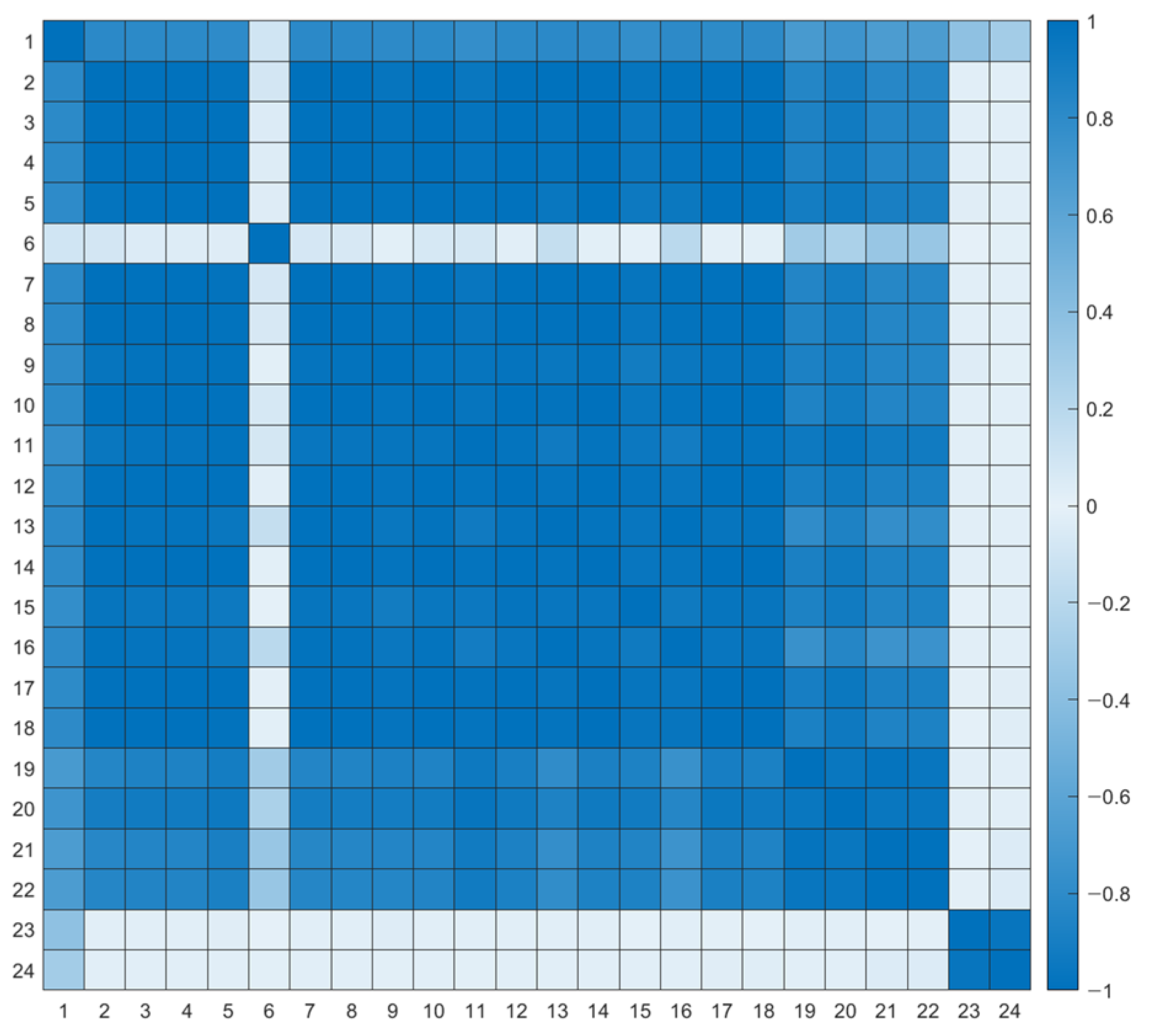
For solving this problem, an outlier detection algorithm is applied in a statistical manner. The annual maximum load change rate for each power distribution line was derived, and the outlier of the change rate was derived. Then, outliers can be detected by Equation (4), which is based on the outliers scaled by multiplying the constant by the MAD as used in the statistical outlier calculation method [
29].
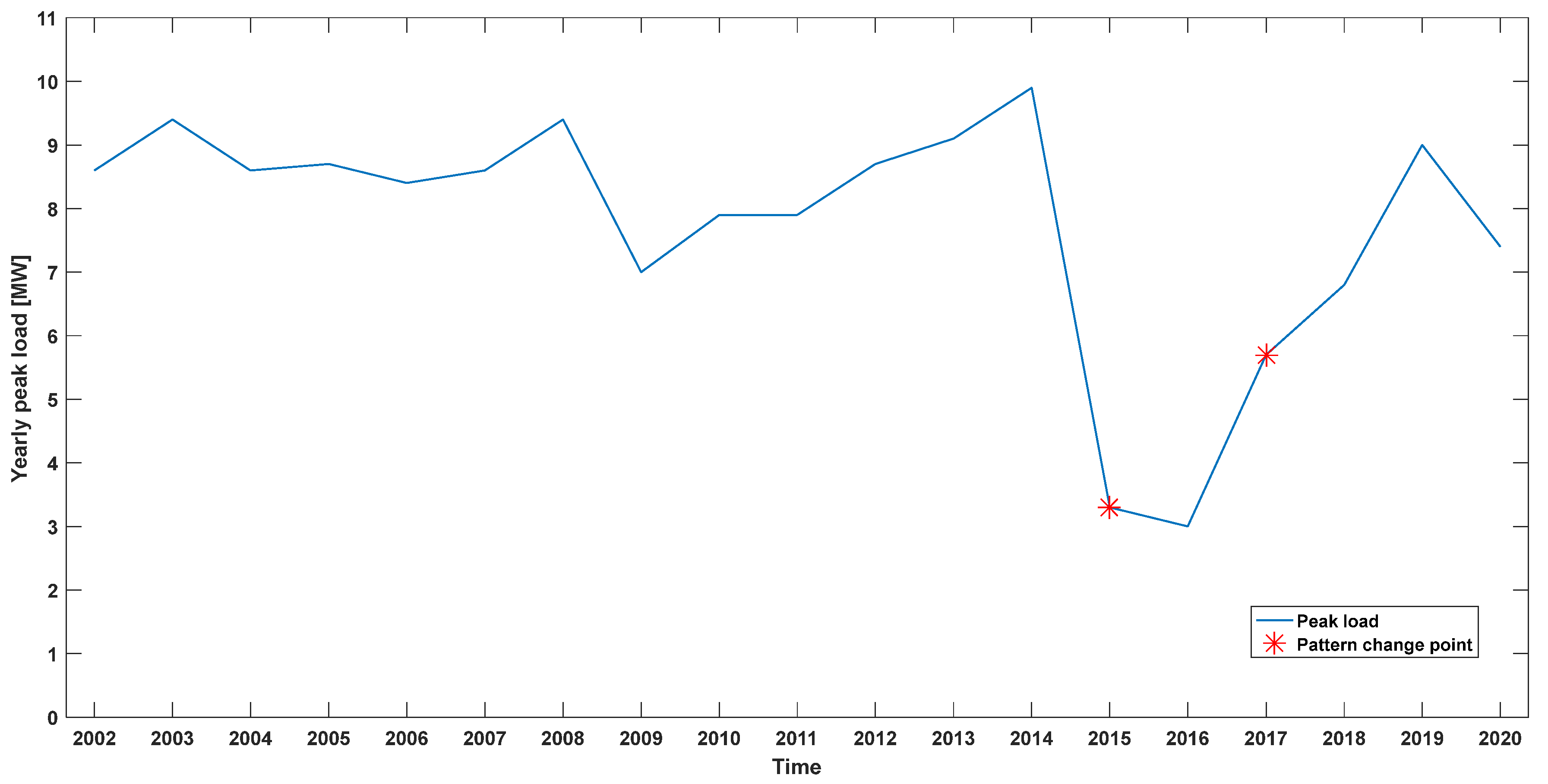
Since the pattern characteristics are different for each distribution line, outlier criteria were selected by the rate of yearly peak change for each distribution line. The rate of change in the monthly peak average was defined as the rate of change in the interval based on the period when the annual peak rate of change was large. As shown in
Figure 11, the pattern change was applied by displaying the pattern and calculating the average value ratio between the pattern change intervals.
This pattern change point and interval average change were applied to the ensemble forecasting model. As shown in
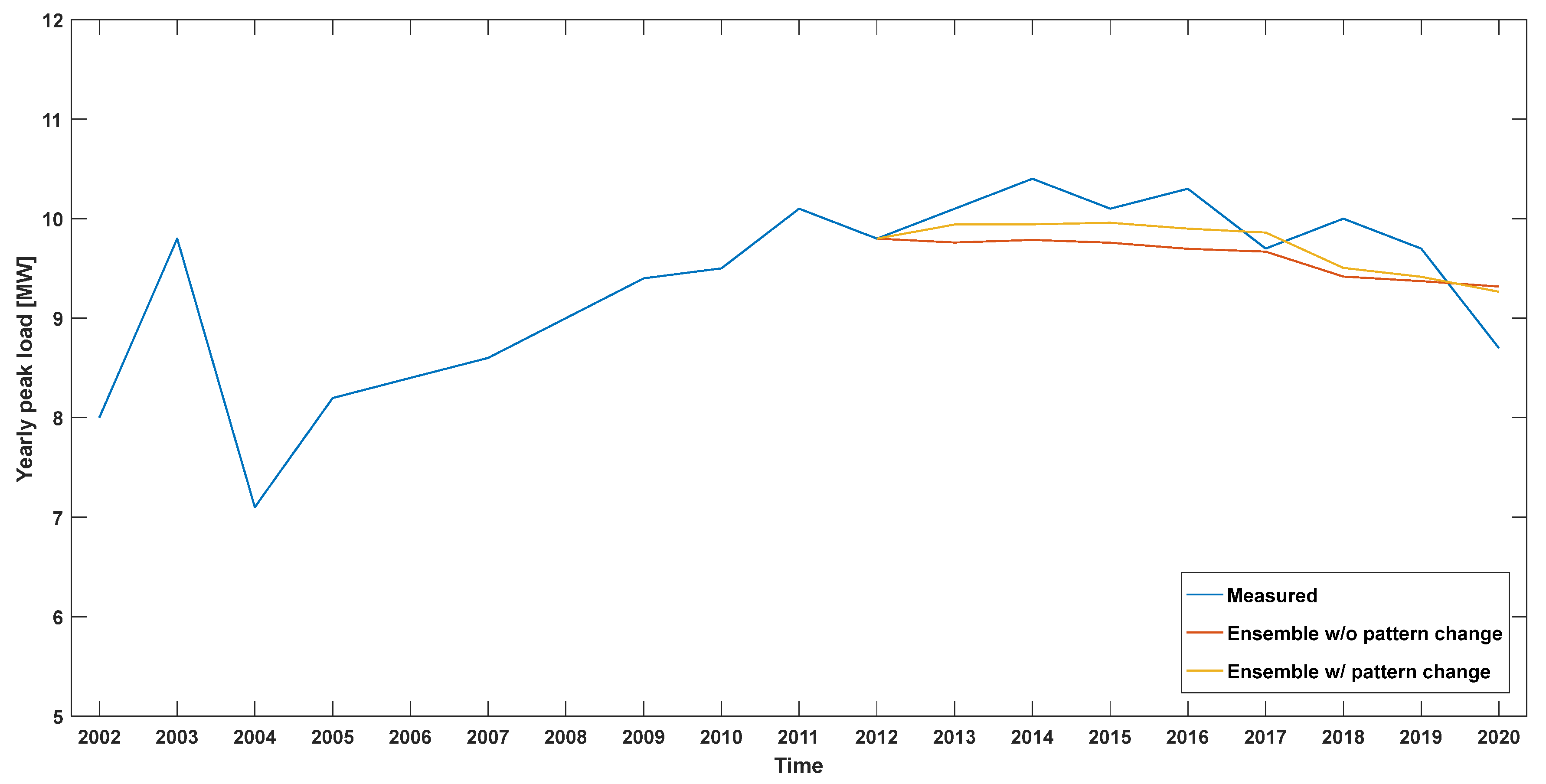
Figure 12, pattern changes occur within the learning period. In this case, the entire learning data are integrated into the latest pattern to follow it. This approach does not learn irrelevant patterns and provides sufficient learning data for one pattern. As shown in
Figure 12, when one of the distribution lines belonged to the Gimje substation, the overall peak load change was minor, but large pattern changes were found in 2004 and 2005.
Figure 12 shows the result of comparing the forecasting model with and without applying the pattern change algorithm to the distribution line. By correcting 15 distribution lines at the Gimje substation with the pattern change algorithm, it was confirmed that the forecasting performance improved, as shown in
Table 9.
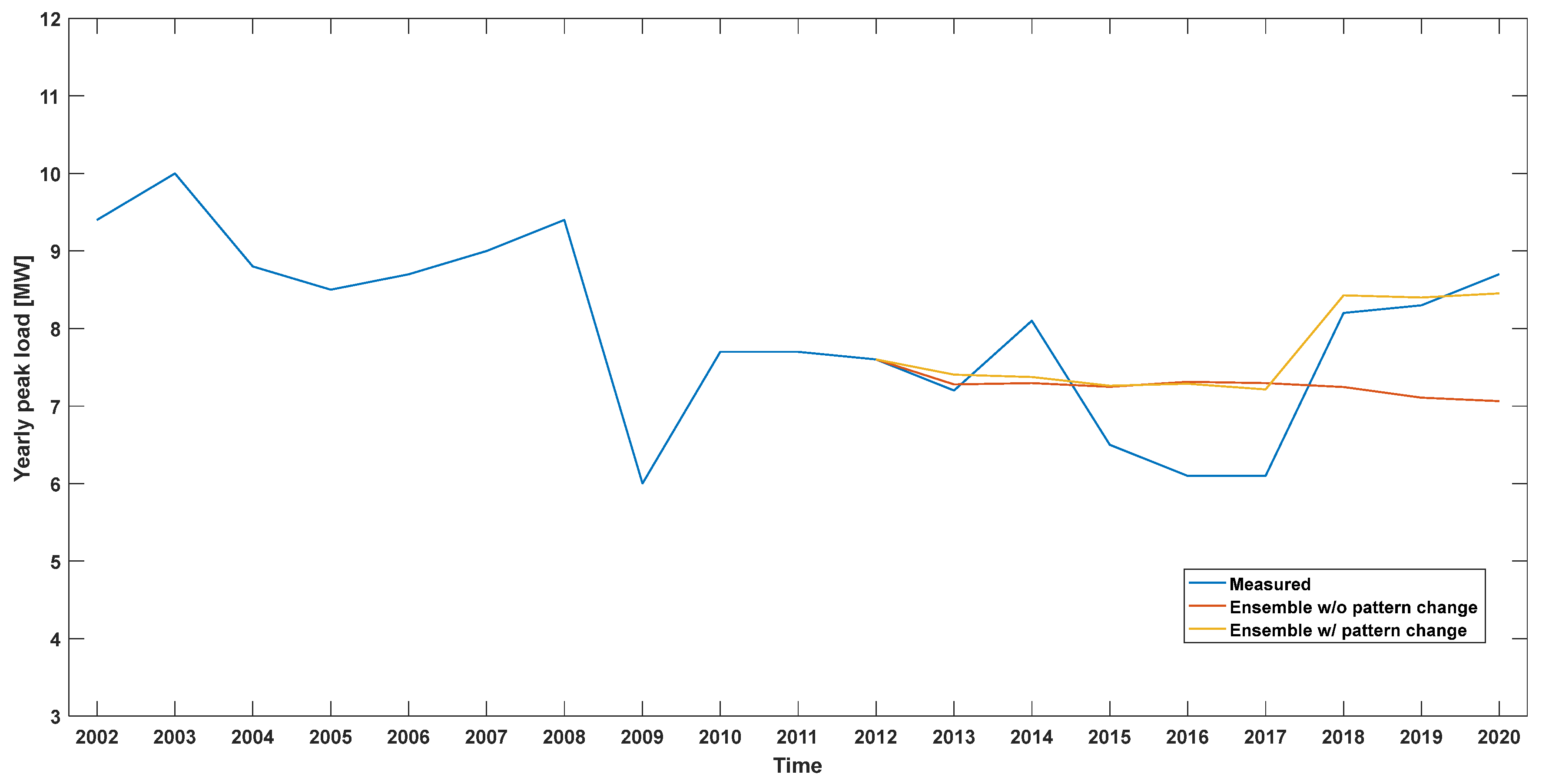
Another noticeable case is when a pattern change occurs during the forecast period. In this case, the timing and rate of change of the load pattern are known since the load transfer and movement of distribution lines are planned. There is no pattern change during the learning period, thus learning the data as they are. Instead, a pattern change with an average change rate during the forecast period is applied to forecast output values. It can be seen from
Figure 13 that a pattern change occurs during the forecast period of one of the distribution lines at the Gimje substation. When applying the pattern change approach proposed, the same verification period for eight years, from 2013 to 2020, was analyzed for the ensemble model.
Table 10 shows that the forecast results improve as compared with the case where pattern change was not applied. In the end, it was verified that the pattern change algorithm could further improve the forecast accuracy in the case of load transfer or movement, which is the characteristic of the distribution line.
5.2. Forecasting Model of Distribution Lines with Insufficient Learning Period
The proposed peak load forecasting requires ten years of the training period, comprising eight years of individual model training and two years of ensemble model training. However, since many new distribution lines are installed every year, some distribution lines inevitably lack the learning period. Therefore, the distribution line with an insufficient learning period should be separated in the load forecasting process, and a separate load forecasting model should be applied to the distribution line. A machine learning model with better performance than the previous regression method needs to be used when the learning period is short.
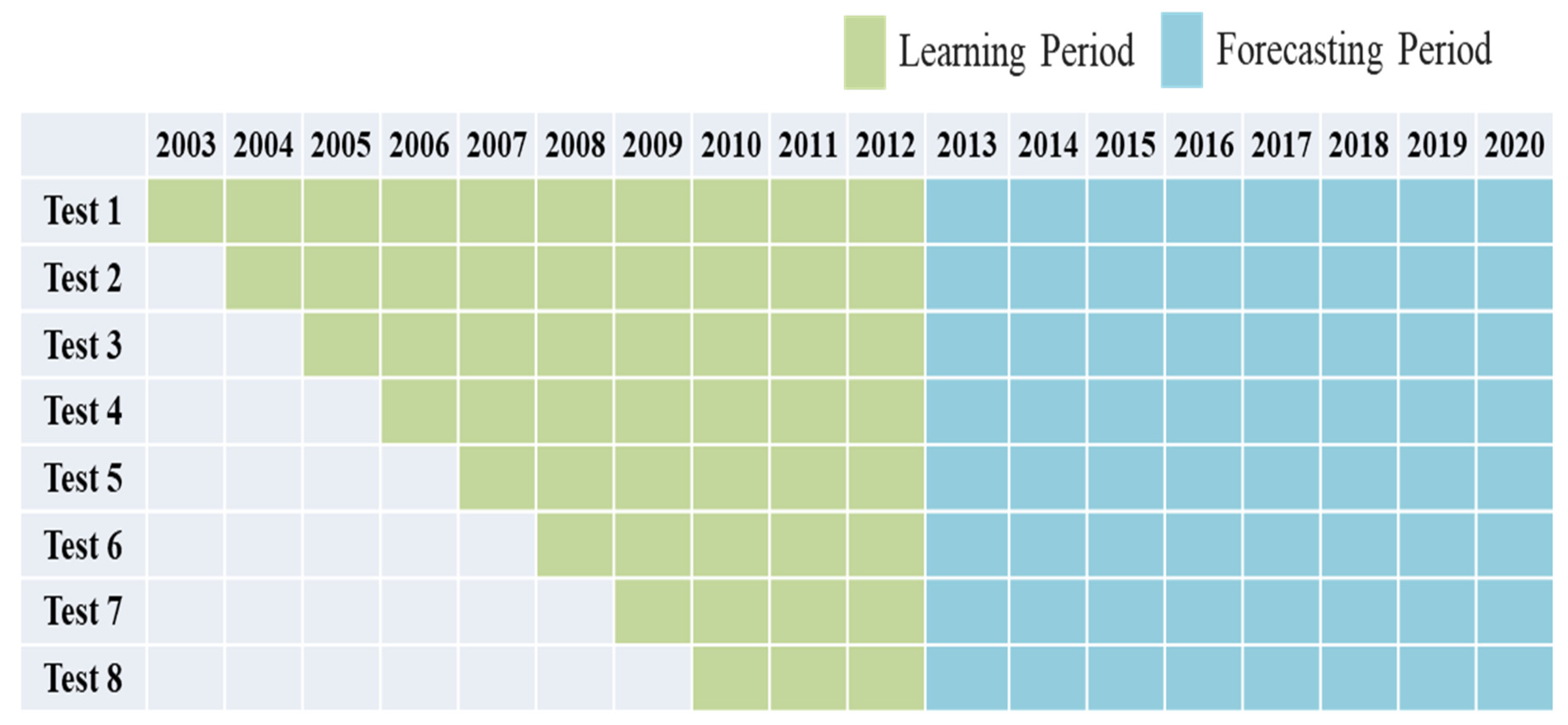
The 170 distribution lines of KEPCO’s Gunsan branch office were considered for the case study.
Table 11 lists the number of distribution lines that can be forecasted according to the different learning periods; to be specific, the test number is identical to the years assigned for the learning period.
Table 11 indicates that the number of distribution lines that could be forecasted decreased with the learning period since there was a limited period of total data collected.
Table 12 lists the performance test results of single machine learning models for different learning periods. The verification period was eight years, from 2013 to 2020. Since the learning period was insufficient, tests with various learning periods were required. As shown in
Table 12, the LSBoost model with the best performance results was selected as the load forecasting model for distribution lines with a short learning period.
Table 13 shows the performance comparison between the existing regression forecasting model and the proposed LSBoost forecasting model for the 170 distribution lines of KEPCO’s Gunsan branch office, where learning data exists for more than one year.
Table 13 indicates that the average error of 32% was significantly improved to 17% when the LSBoost model was used. All in all, with the distribution line that lacks the training period, the single LSBoost model has superior forecasting performance compared with the conventional regression method.
5.3. Distribution Line Peak Load Forecasting Process for Mid- to Long-Term Distribution Planning
Figure 14 shows the proposed mid- to long-term distribution line peak load forecasting process for distribution planning based on the ensemble model. This process improved the forecasting accuracy for the load fluctuation and lack of learning period of the distribution line while providing improved predictions compared to the conventional load forecasting method for all distribution lines.
Table 14 shows the forecasting verification results for all 22 distribution lines connected to the KEPCO Gimje substation using the proposed load peak forecasting process. The 22 distribution lines of the Gimje substation had severe load fluctuations and insufficient learning periods. As shown in
Table 14, the 8-year accuracy of the distribution line peak load forecasting was 87% on average.
Table 15 compares forecast performance between the existing regression forecasting and the proposed model, indicating that the MAE, MSE, and error rate were significantly improved. It was verified that the proposed peak load forecasting process for mid- to long-term presented higher forecast accuracy than the existing method. The efficiency of investment can be improved by the accuracy of the timing and capacity in distribution planning with the proposed forecasting process.
6. Conclusions
As the environment of the distribution system changes rapidly due to the expansion of renewable energy, the importance of distribution planning is growing. Therefore, this paper proposed the model and process for load forecasting, which is the essential element in distribution planning. The optimal ensemble machine learning model was derived to overcome the limitations of the non-linear characteristics of the existing linear regression load forecasting method for the mid- to long-term. The optimal input variables and the learning period were selected. This paper presented the ensemble model for forecasting the peak load for the mid- to long-term distribution lines and verified the result through KEPCO’s power data. The proposed method also reflected distribution line characteristics such as load fluctuations and lack of the learning period for its application to all distribution lines of power utilities. Its performance was verified by actual data from distribution lines at the KEPCO Gimje substation. In the future, KEPCO plans to implement the distribution load forecasting system based on the proposed process of updating power data and external data. Additionally, it will be used to plan the distribution planning for the mid-to long-term. In particular, it will help to make investment decisions for distribution substations and feeders. It will be expected that efficient and economical distribution planning will be enabled even in a distribution system situation where uncertainty increases.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}