Artificial Neural Networks and Linear Regression Reduce Sample Intensity to Predict the Commercial Volume of Eucalyptus Clones

 , and
, and
Abstract
:1. Introduction
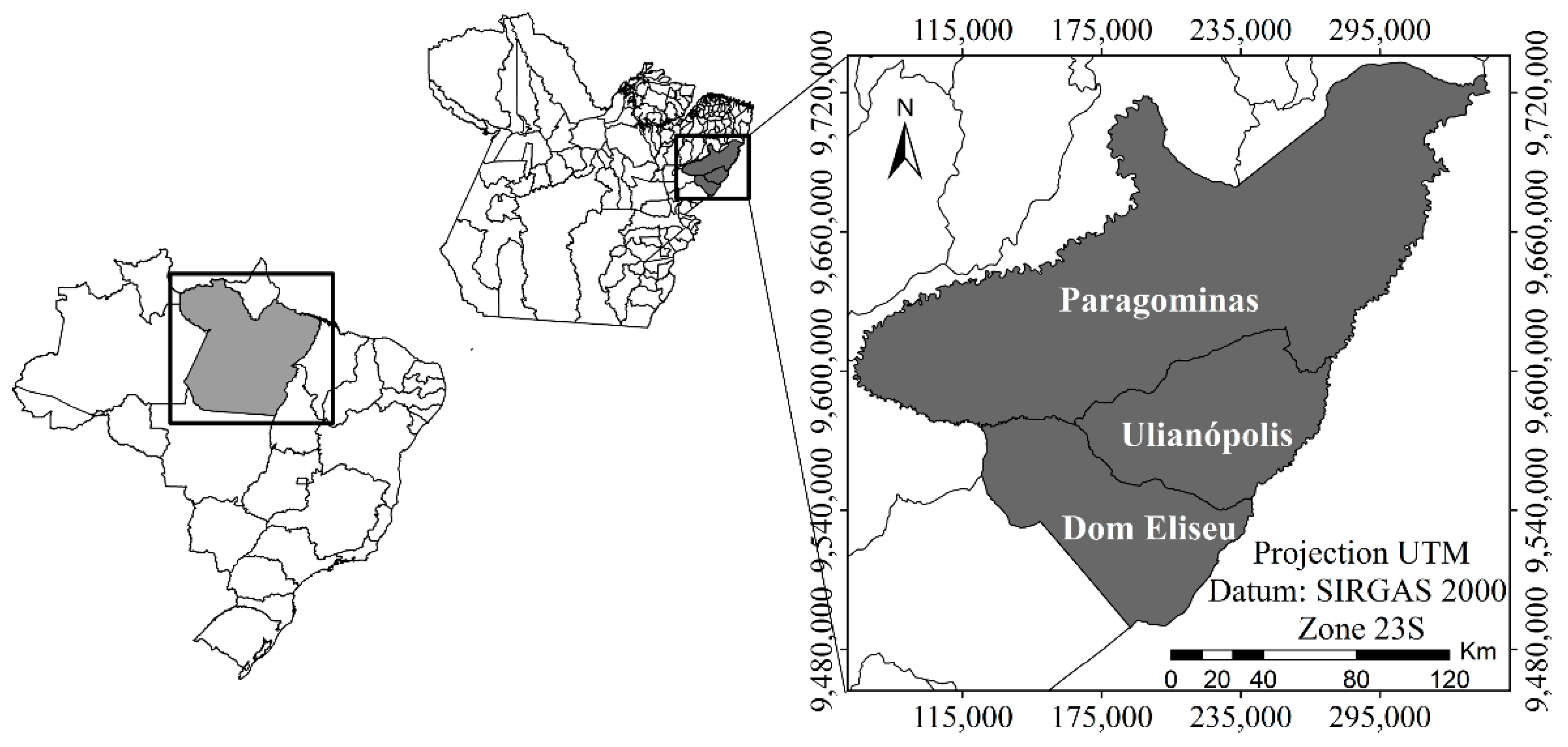
2. Materials and Methods
2.1. Data
Methods for Estimation of the Tree Attributes
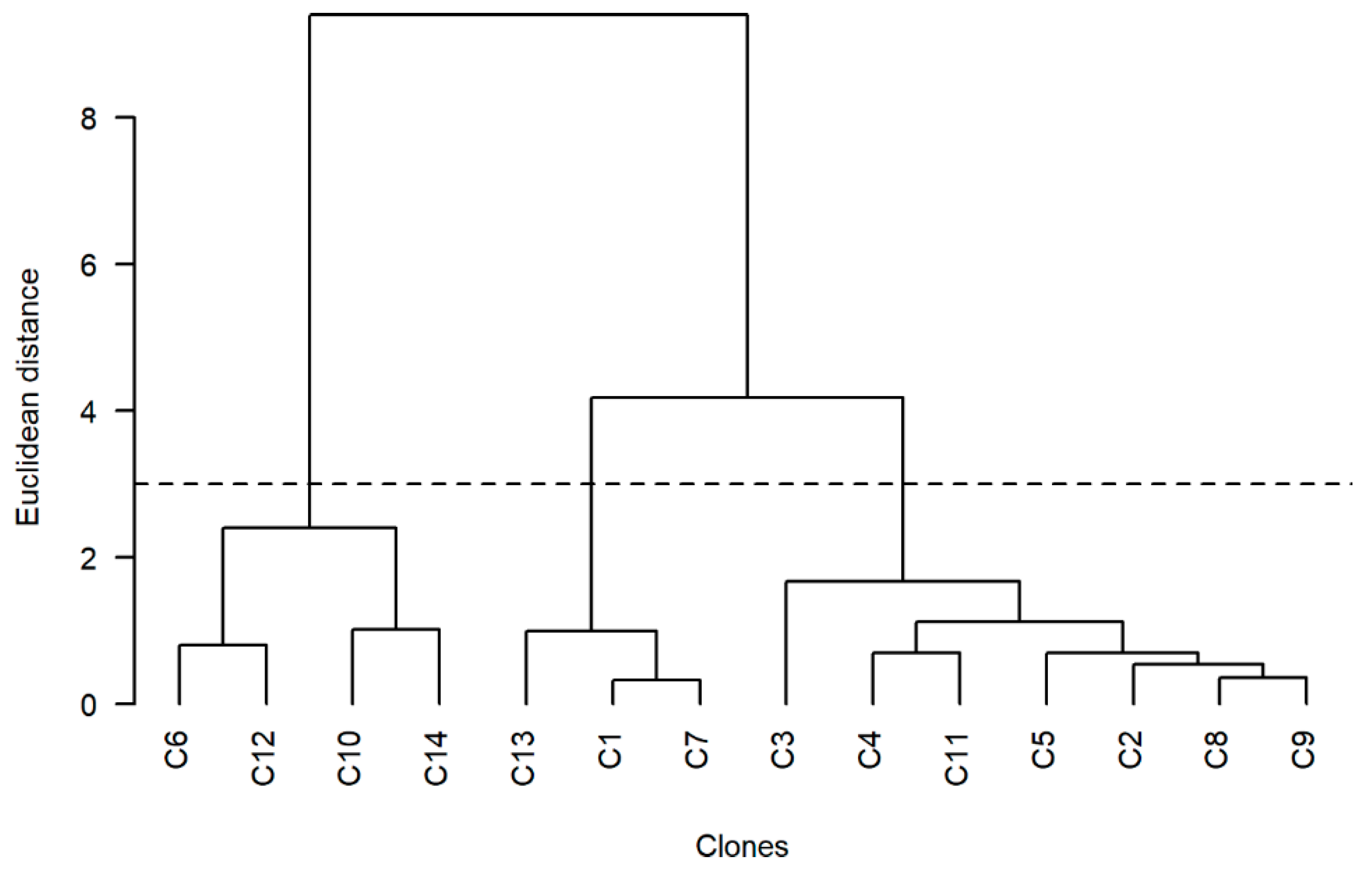
2.2. Clone Cluster Analysis
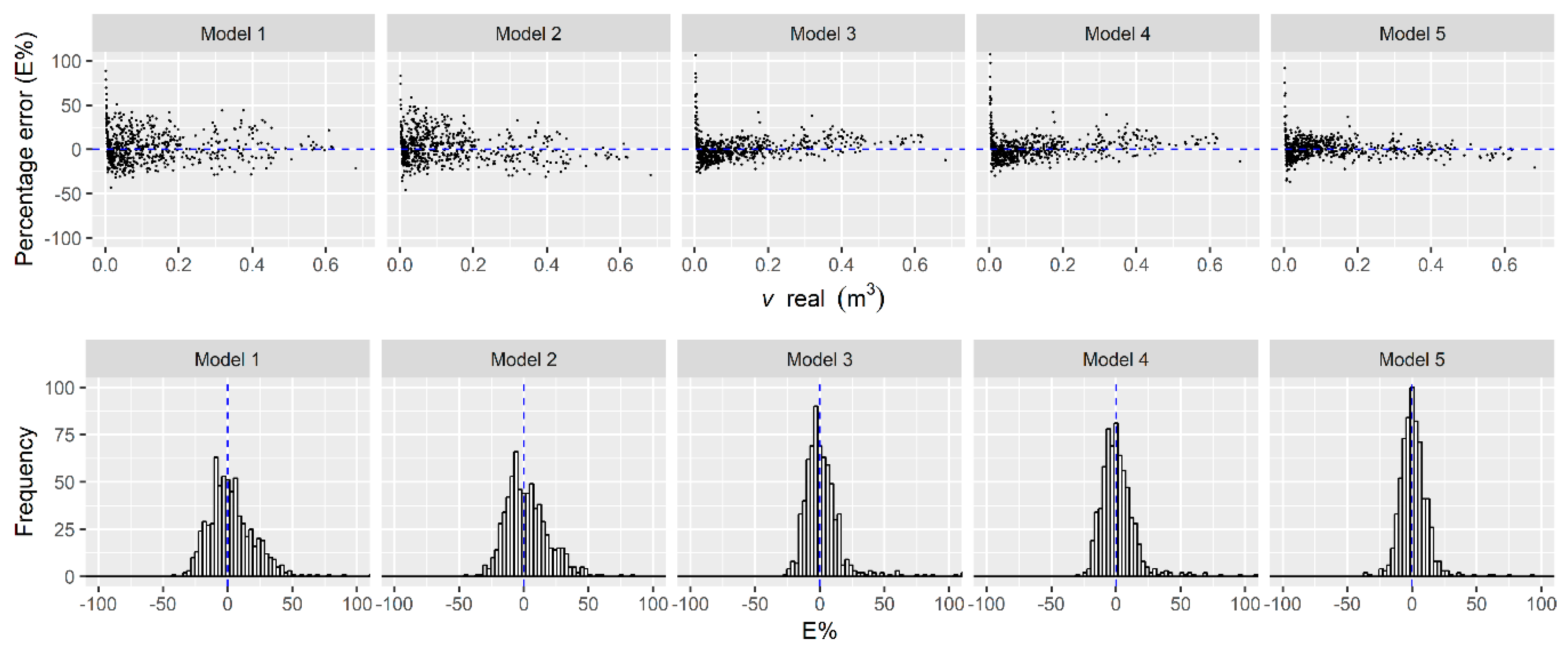
2.3. Settings to Select the Best Model
2.4. ANN Training
Selection of the Best ANN
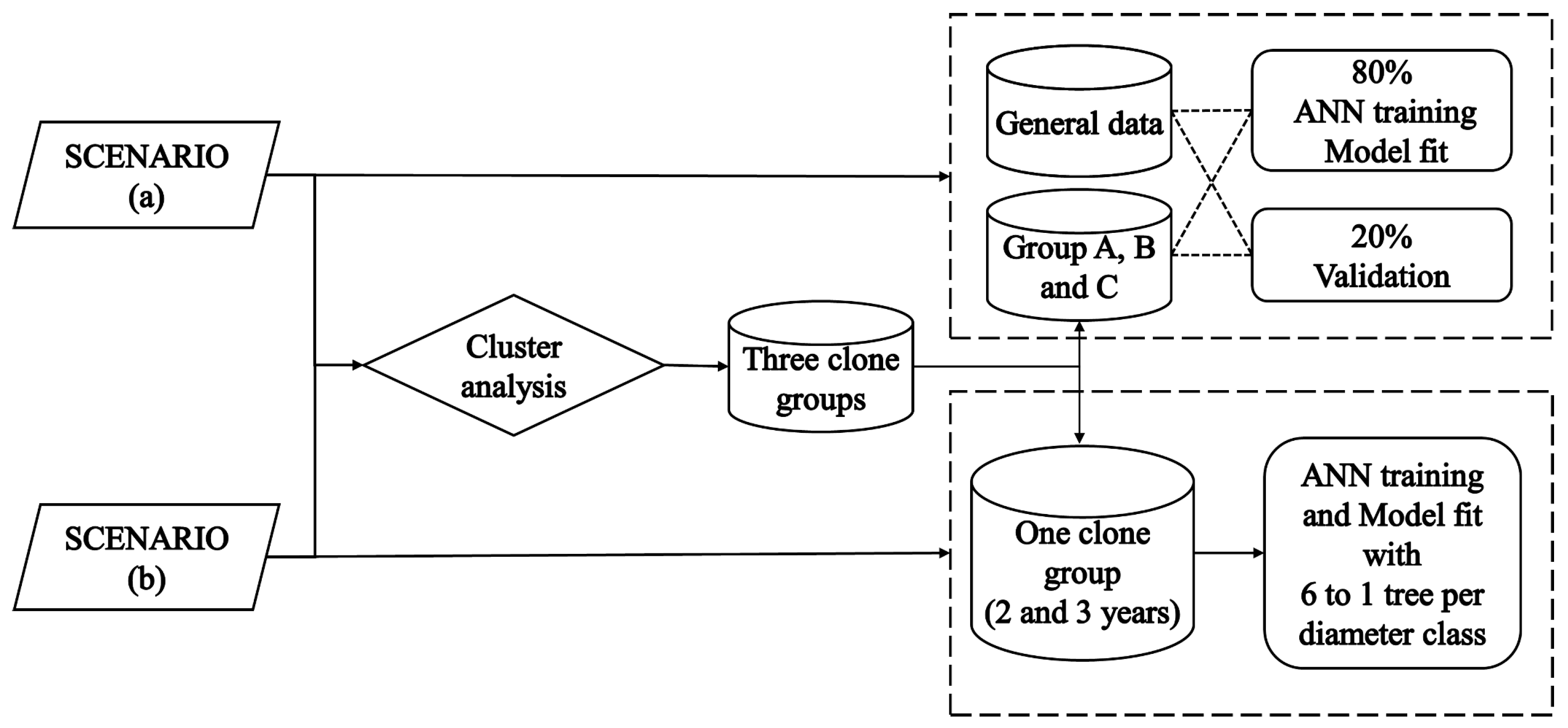
2.5. Experimental Scenarios
2.6. Methods Analysis
2.7. Methods Validation
3. Results
3.1. Clone Grouping
3.2. Best Model Selection
3.3. ANN Retained in Scenarios (a) and (b)
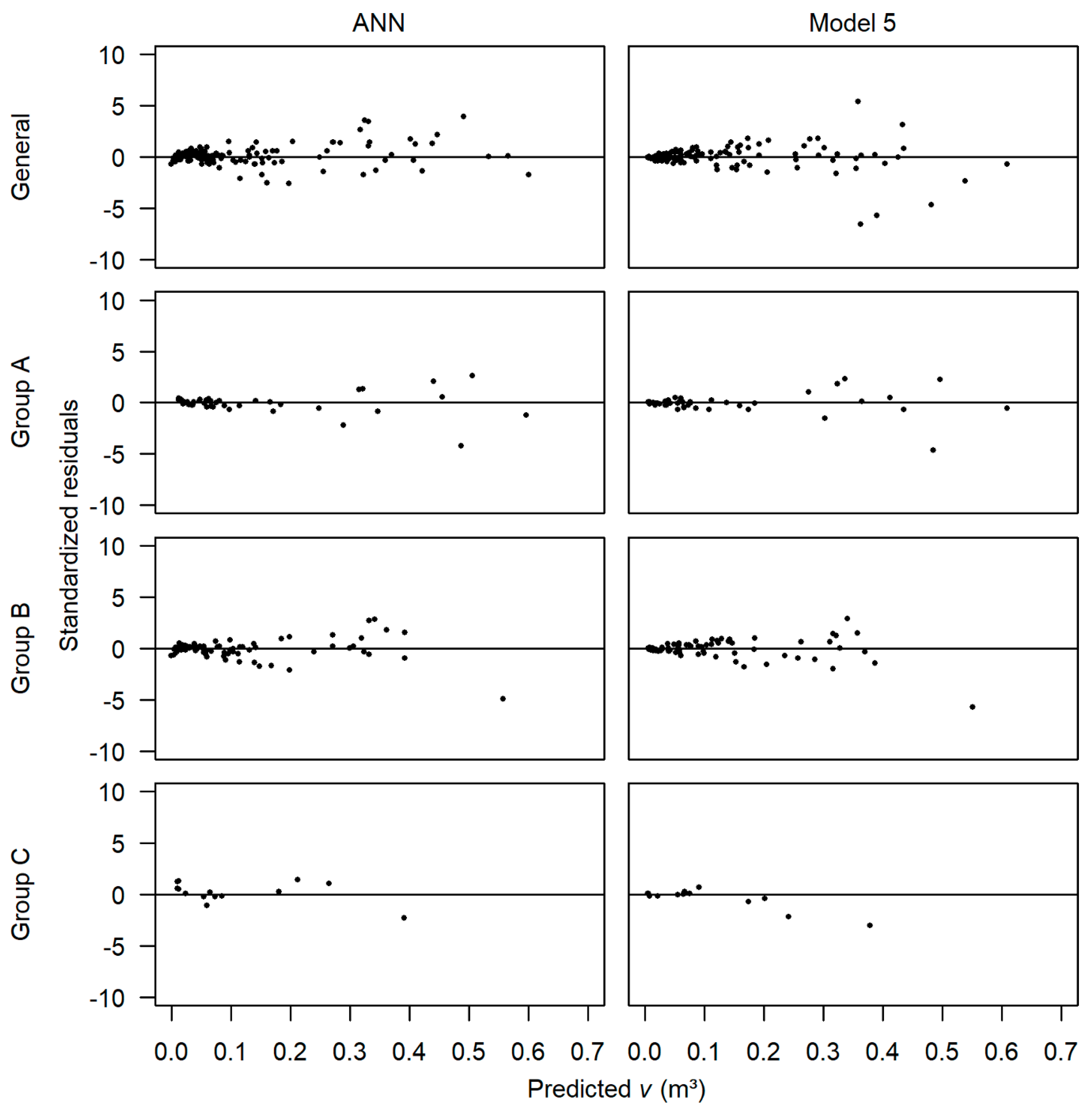
3.4. Predictions Assessment in Scenario (a)
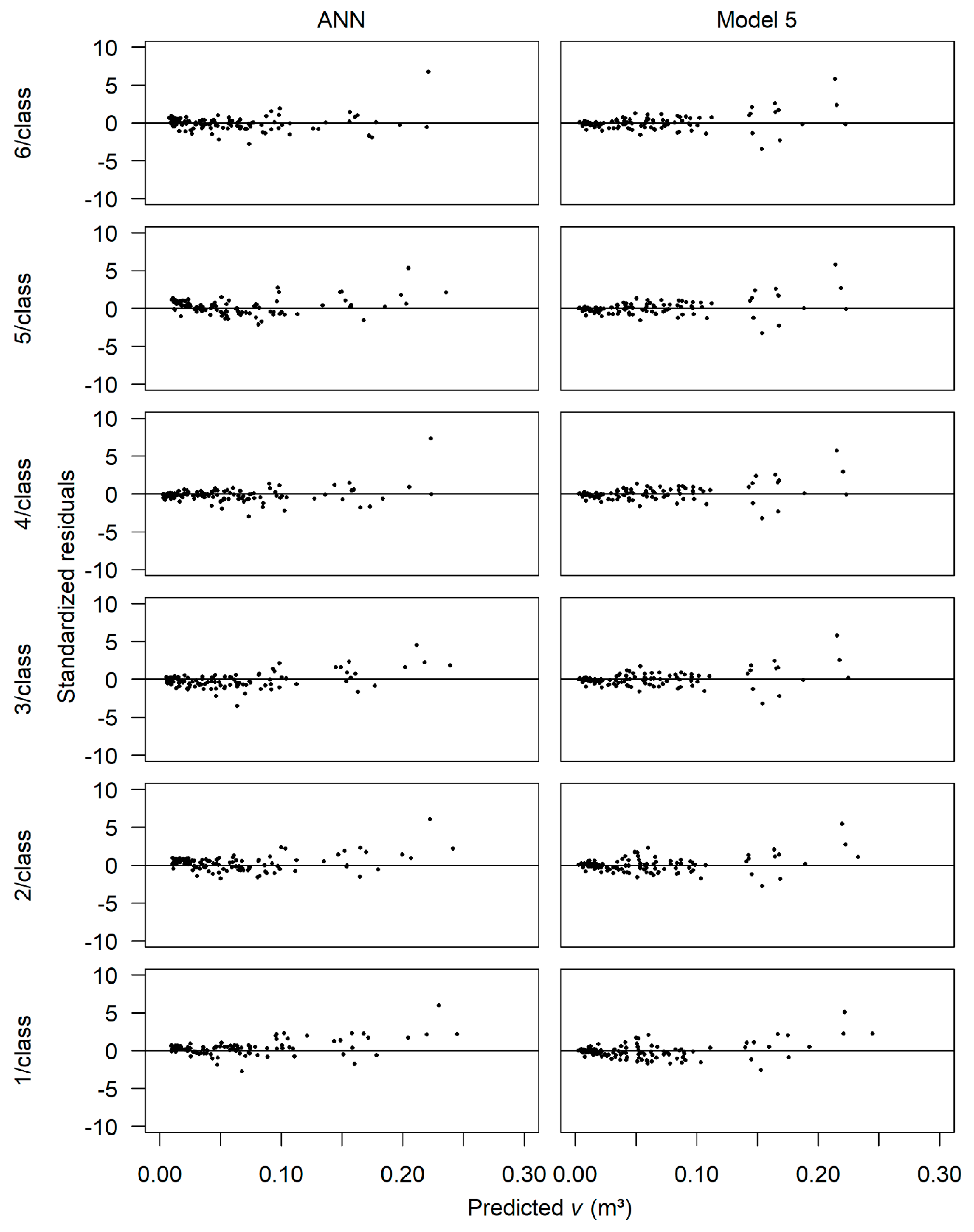
3.5. Predictions Assessment in Scenario (b)
3.6. Variance Analysis for Means in Scenario (b)
3.7. Predictions Validation in Both Scenarios
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clone | Species/Hybrid | n |
|---|---|---|
| C1 | Eucalyptus grandis W. Hill ex Maiden × Eucalyptus urophylla S.T. Blake | 339 |
| C2 | Eucalyptus grandis W. Hill ex Maiden × Eucalyptus urophylla S.T. Blake | 42 |
| C3 | Eucalyptus grandis W. Hill ex Maiden × Eucalyptus urophylla S.T. Blake | 113 |
| C4 | Eucalyptus grandis W. Hill ex Maiden | 43 |
| C5 | Eucalyptus platyphylla F. Muell. | 2 |
| C6 | Eucalyptus platyphylla F. Muell. | 2 |
| C7 | Eucalyptus grandis W. Hill ex Maiden × Eucalyptus urophylla S.T. Blake | 2 |
| C8 | Eucalyptus grandis W. Hill ex Maiden × Eucalyptus urophylla S.T. Blake | 2 |
| C9 | Eucalyptus grandis W. Hill ex Maiden × Eucalyptus urophylla S.T. Blake | 13 |
| C10 | Eucalyptus urophylla S.T. Blake | 11 |
| C11 | Eucalyptus urophylla S.T. Blake | 7 |
| C12 | Eucalyptus urophylla S.T. Blake | 54 |
| C13 | Eucalyptus urophylla S.T. Blake | 32 |
| C14 | Eucalyptus camaldulensis Dehnh. × Eucalyptus urophylla S.T. Blake | 4 |
| Total | 666 |
| dbh Class (cm) | n |
|---|---|
| 4–6 | 23 |
| 6–8 | 28 |
| 8–10 | 28 |
| 10–12 | 27 |
| 12–14 | 21 |
| 14–16 | 13 |
| 16–18 | 10 |
| 18–20 | 1 |
| Total | 151 |
| Intensity Sample | Treatment | n | Original Value | Transformed Value | ||||
|---|---|---|---|---|---|---|---|---|
| Lilliefors | p-Value | Bartlett | p-Value | Lilliefors | p-Value | |||
| Real | 108 | 0.13486 * | 0.00005 | 0.07881 ns | >0.01 | |||
| 6/class | ANN | 108 | 0.15964 * | 0.00038 | 0.14973 ns | >0.01 | 0.07341 ns | >0.01 |
| Model 5 | 108 | 0.14441 * | 0.00861 | 0.08355 ns | >0.01 | |||
| 5/class | ANN | 108 | 0.16288 * | 0.00019 | 0.21673 ns | >0.01 | 0.07269 ns | >0.01 |
| Model 5 | 108 | 0.14355 ns | >0.01 | 0.09035 ns | >0.01 | |||
| 4/class | ANN | 108 | 0.14298 ns | >0.01 | 0.21918 ns | >0.01 | 0.08726 ns | >0.01 |
| Model 5 | 108 | 0.14409 * | 0.00917 | 0.08969 ns | >0.01 | |||
| 3/class | ANN | 108 | 0.16724 * | 0.00007 | 0.40207 ns | >0.01 | 0.07236 ns | >0.01 |
| Model 5 | 108 | 0.14370 * | 0.00989 | 0.08892 ns | >0.01 | |||
| 2/class | ANN | 108 | 0.16676 * | 0.00008 | 0.16563 ns | >0.01 | 0.06155 ns | >0.01 |
| Model 5 | 108 | 0.14492 * | 0.00781 | 0.09548 ns | >0.01 | |||
| 1/class | ANN | 108 | 0.16423 * | 0.00014 | 0.46086 ns | >0.01 | 0.06843 ns | >0.01 |
| Model 5 | 108 | 0.15562 * | 0.00090 | 0.10664 * | 0.00416 | |||
| Source of Variance | df | SS | MS | Fcal |
|---|---|---|---|---|
| Treatments | 2 | 0.6 | 0.293 | 0.303 ns |
| Intensities | 4 | 1.2 | 0.295 | 0.305 ns |
| Treatments × Intensities | 8 | 2 | 0.246 | 0.254 ns |
| Residuals | 1605 | 1549.8 | 0.966 | |
| Total | 1619 | 1553.6 |
| Scenario | Approach | n | ANN | Model 5 | ||
|---|---|---|---|---|---|---|
| Dcal | p-Value | Dcal | p-Value | |||
| A | General | 133 | 0.0526 ns | >0.01 | 0.0376 ns | >0.01 |
| A | Group A | 44 | 0.1136 ns | >0.01 | 0.0682 ns | >0.01 |
| A | Group B | 74 | 0.0405 ns | >0.01 | 0.0541 ns | >0.01 |
| A | Group C | 14 | 0.2857 ns | >0.01 | 0.1429 ns | >0.01 |
| B | 6/class | 108 | 0.0648 ns | >0.01 | 0.0556 ns | >0.01 |
| B | 5/class | 108 | 0.1389 ns | >0.01 | 0.0648 ns | >0.01 |
| B | 4/class | 108 | 0.0556 ns | >0.01 | 0.0648 ns | >0.01 |
| B | 3/class | 108 | 0.0648 ns | >0.01 | 0.0463 ns | >0.01 |
| B | 2/class | 108 | 0.1389 ns | >0.01 | 0.0556 ns | >0.01 |
| B | 1/class | 108 | 0.1111 ns | >0.01 | 0.0648 ns | >0.01 |
References
- Ferraz Filho, A.C.; Mola-Yudego, B.; Ribeiro, A.; Scolforo, J.R.S.; Loos, R.A.; Scolforo, H.F. Height-diameter models for eucalyptus sp. plantations in Brazil. Cerne 2018, 24, 9–17. [Google Scholar] [CrossRef]
- Binkley, D.; Campoe, O.C.; Alvares, C.; Carneiro, R.L.; Cegatta, I.; Stape, J.L. The interactions of climate, spacing and genetics on clonal Eucalyptus plantations across Brazil and Uruguay. For. Ecol. Manag. 2017, 405, 271–283. [Google Scholar] [CrossRef]
- Dasgupta, M.G.; Dharanishanthi, V. Identification of PEG-induced water stress responsive transcripts using co-expression network in Eucalyptus grandis. Gene 2017, 627, 393–407. [Google Scholar] [CrossRef] [PubMed]
- Rocha, J.E.C.; Brasil Neto, A.B.; Noronha, N.C.; Gama, M.A.P.; Carvalho, E.J.M.; Silva, A.R.; Santos, C.R.C. Organic matter and physical-hydric quality of an oxisol under eucalypt planting and abandoned pasture. Cerne 2016, 22, 381–388. [Google Scholar] [CrossRef]
- Santana, R.C.; Barros, N.F.; Leite, H.G.; Comerford, N.B.; Novais, R.F. Estimativa de biomassa de plantios de eucalipto no Brasil. Rev. Árvore 2008, 32, 697–706. [Google Scholar] [CrossRef] [Green Version]
- Matos, G.S.B.; Silva, G.R.; Gama, M.A.P.; Vale, R.S.; Rocha, J.E.C. Desenvolvimento inicial e estado nutricional de clones de eucalipto no nordeste do Pará. Acta Amazon. 2012, 42, 491–500. [Google Scholar] [CrossRef]
- Ounban, W.; Puangchit, L.; Diloksumpun, S. Development of general biomass allometric equations for Tectona grandis Linn.f. and Eucalyptus camaldulensis Dehnh. plantations in Thailand. Agric. Nat. Resour. 2016, 50, 48–53. [Google Scholar] [CrossRef]
- Paul, K.I.; Roxburgh, S.H.; Chave, J.; England, J.R.; Zerihun, A.; Specht, A.; Lewis, T.; Bennett, L.T.; Baker, T.G.; Adams, M.A.; et al. Testing the generality of above-ground biomass allometry across plant functional types at the continent scale. Glob. Chang. Biol. 2016, 22, 2106–2124. [Google Scholar] [CrossRef]
- Forrester, D.I.; Tachauer, I.H.H.; Annighoefer, P.; Barbeito, I.; Pretzsch, H.; Ruiz-Peinado, R.; Stark, H.; Vacchiano, G.; Zlatanov, T.; Chakraborty, T.; et al. Generalized biomass and leaf area allometric equations for European tree species incorporating stand structure, tree age and climate. For. Ecol. Manag. 2017, 396, 160–175. [Google Scholar] [CrossRef]
- Fortier, J.; Truax, B.; Gagnon, D.; Lambert, F. Allometric equations for estimating compartment biomass and stem volume in mature hybrid poplars: General or site-specific? Forests 2017, 8, 309. [Google Scholar] [CrossRef]
- García-Espinoza, G.G.; Aguirre-Calderón, O.A.; Quiñonez-Barraza, G.; Alanís-Rodríguez, E.; De Los Santos-Posadas, H.M.; García-Magaña, J.J. Taper and volume systems based on ratio equations for Pinus pseudostrobus Lindl. in Mexico. Forests 2018, 9, 344. [Google Scholar] [CrossRef]
- IBÁ. INDÚSTRIA BRASILEIRA DE ÁRVORES. Report IBÁ-2017. Indicators of Performance of the National Sector of Planted Trees for the Year 2016. Available online: http://iba.org/images/shared/Biblioteca/IBA_RelatorioAnual2017.pdf (accessed on 10 August 2018).
- Cosenza, D.N.; Leite, H.G.; Marcatti, G.E.; Binoti, D.H.B.; Alcântara, A.E.M.; Rode, R. Classificação da capacidade produtiva de sítios florestais utilizando máquina de vetor de suporte e rede neural artificial. Sci. For. 2015, 43, 955–963. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, L.; Ye, Q.; Ruan, H. Robust learning-based prediction for timber-volume of living trees. Comput. Electron. Agric. 2017, 136, 97–110. [Google Scholar] [CrossRef]
- Görgens, E.B.; Leite, H.G.; Gleriani, J.M.; Soares, C.P.B.; Ceolin, A. Influência da arquitetura na estimativa de volume de árvores individuais por meio de redes neurais artificiais. Rev. Árvore 2014, 38, 289–295. [Google Scholar] [CrossRef] [Green Version]
- Görgens, E.B.; Leite, H.G.; Santos, H.N.; Gleriani, J.M. Estimação do volume de árvores utilizando redes neurais artificiais. Rev. Árvore 2009, 33, 1141–1147. [Google Scholar] [CrossRef] [Green Version]
- Binoti, M.L.M.S.; Binoti, D.H.B.; Leite, H.G.; Garcia, S.L.R.; Ferreira, M.Z.; Rode, R.; Silva, A.A.L. Redes neurais artificiais para estimação do volume de árvores. Rev. Árvore 2014, 38, 283–288. [Google Scholar] [CrossRef] [Green Version]
- Cosenza, D.N.; Soares, A.A.V.; de Alcântara, A.E.M.; da Silva, A.A.L.; Rode, R.; Soares, V.P.; Leite, H.G. Site classification for eucalypt stands using artificial neural network based on environmental and management features. Cerne 2017, 23, 310–320. [Google Scholar] [CrossRef]
- Özçelik, R.; Diamantopoulou, M.J.; Crecente-Campo, F.; Eler, U. Estimating Crimean juniper tree height using nonlinear regression and artificial neural network models. For. Ecol. Manag. 2013, 306, 52–60. [Google Scholar] [CrossRef]
- Diamantopoulou, M.J.; Özçelik, R.; Crecente-Campo, F.; Eler, Ü. Estimation of Weibull function parameters for modelling tree diameter distribution using least squares and artificial neural networks methods. Biosyst. Eng. 2015, 133, 33–45. [Google Scholar] [CrossRef]
- Vahedi, A.A. Artificial neural network application in comparison with modeling allometric equations for predicting above-ground biomass in the Hyrcanian mixed-beech forests of Iran. Biomass Bioenergy 2016, 88, 66–76. [Google Scholar] [CrossRef]
- Reis, L.P.; Souza, A.L.; Mazzei, L.; Reis, P.C.M.; Leite, H.G.; Soares, C.P.B.; Torres, C.M.M.E.; Silva, L.F.; Ruschel, A.R. Prognosis on the diameter of individual trees on the eastern region of the amazon using artificial neural networks. For. Ecol. Manag. 2016, 382, 161–167. [Google Scholar] [CrossRef]
- Ribeiro, R.B.S.; Gama, J.R.V.; Souza, A.L.; Leite, H.G.; Soares, C.P.B.; Silva, G.F. Métodos para estimar o volume de fustes e galhos na Floresta Nacional do Tapajós. Rev. Árvore 2016, 40, 81–88. [Google Scholar] [CrossRef]
- Rocha, S.J.S.S.; Torres, C.M.M.E.; Jacovine, L.A.G.; Leite, H.G.; Gelcer, E.M.; Neves, K.M.; Schettini, B.L.S.; Villanova, P.H.; da Silva, L.F.; Reis, L.P.; et al. Artificial neural networks: Modeling tree survival and mortality in the Atlantic Forest biome in Brazil. Sci. Total Environ. 2018, 645, 655–661. [Google Scholar] [CrossRef] [PubMed]
- Husch, B.; Beers, T.W.; Kershaw, J.A., Jr. Forest Mensuration, 4th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2003; 443p. [Google Scholar]
- Mesquita, D.P.P.; Gomes, J.P.P.; Souza Junior, A.H.; Nobre, J.S. Euclidean distance estimation in incomplete datasets. Neurocomputing 2017, 248, 11–18. [Google Scholar] [CrossRef]
- Ward, J.H., Jr. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Camolesi, J.F.; Scolforo, J.R.S.; Oliveira, A.D.; Acerbi Júnior, F.W.; Rufini, A.L.; Mello, J.M. Ajuste, seleção e teste de identidade de modelo para volume e número de moirões da candeia (Eremanthus erythropappus). Cerne 2010, 16, 431–441. [Google Scholar] [CrossRef]
- Schneider, P.R.; Tonini, H. Utilização de variáveis dummy em equações de volume para Acacia mearnsii De Wild. Ciênc. Florest. 2003, 13, 121–129. [Google Scholar] [CrossRef]
- Rolim, S.G.; Couto, H.T.Z.; Jesus, R.M.; França, J.T. Modelos volumétricos para a Floresta Nacional do Tapirapé-Aquirí, Serra dos Carajás (PA). Acta Amazon. 2006, 36, 107–114. [Google Scholar] [CrossRef]
- Meyer, H.A. A Correction for a Systematic Error Occurring in the Application of the Logarithmic Volume Equation; Forestry School Research: Scranton, PA, USA, 1941; 15p.
- Haykin, S. Neural Networks and Learning Machines; Pearson: Hoboken, NJ, USA, 2009; ISBN 9780131471399. [Google Scholar]
- Thomas, C.; Andrade, C.M.; Schneider, P.R.; Finger, C.A.G. Comparação de equações volumétricas ajustadas com dados de cubagem e análise de tronco. Ciênc. Florest. 2006, 16, 319–327. [Google Scholar] [CrossRef]
- Lek, S.; Guégan, J.F. Artificial neural networks as a tool in ecological modelling, an introduction. Ecol. Model. 1999, 120, 65–73. [Google Scholar] [CrossRef]
- Diamantopoulou, M.J. Artificial neural networks as an alternative tool in pine bark volume estimation. Comput. Electron. Agric. 2005, 48, 235–244. [Google Scholar] [CrossRef]
- Che, S.; Tan, X.; Xiang, C.; Sun, J.; Hu, X.; Zhang, X.; Duan, A.; Zhang, J. Stand basal area modelling for Chinese fir plantations using an artificial neural network model. J. For. Res. 2018. [Google Scholar] [CrossRef]
- Reis, L.P.; Souza, A.L.; Reis, P.C.M.; Mazzei, L.; Soares, C.P.B.; Torres, C.M.M.E.; Silva, L.F.; Ruschel, A.R.; Rêgo, L.J.S. Estimation of mortality and survival of individual trees after harvesting wood using artificial neural networks in the amazon rain forest. Ecol. Eng. 2018, 112, 140–147. [Google Scholar] [CrossRef]
- Diamantopoulou, M.J. Assessing a reliable modeling approach of features of trees through neural network models for sustainable forests. Sustain. Comput. Inform. Syst. 2012, 2, 190–197. [Google Scholar] [CrossRef]
- Soares, F.A.A.M.N.; Flôres, E.L.; Cabacinha, C.D.; Carrijo, G.A.; Veiga, A.C.P. Recursive diameter prediction and volume calculation of eucalyptus trees using Multilayer Perceptron Networks. Comput. Electron. Agric. 2011, 78, 19–27. [Google Scholar] [CrossRef]
- Sabatia, C.O.; Burkhart, H.E. Predicting site index of plantation loblolly pine from biophysical variables. For. Ecol. Manag. 2014, 326, 142–156. [Google Scholar] [CrossRef]
- Ebling, Â.A.; Péllico Netto, S. Modelagem de ocorrência de coortes na estrutura diamétrica da Araucaria angustifolia (Bertol.) Kuntze. Cerne 2015, 21, 251–257. [Google Scholar] [CrossRef]
- Campos, J.C.C.; Leite, H.G. Mensuração Florestal: Perguntas e Respostas, 4rd ed.; Editora UFV: Viçosa, Brazil, 2013; pp. 491–493. ISBN 978-85-7269-465-0. [Google Scholar]
- Cysneiros, V.C.; Pelissari, A.L.; Machado, S.A.; Figueiredo Filho, A.; Souza, L. Modelos genéricos e específicos para estimativa do volume comercial em uma floresta sob concessão na Amazônia. Sci. For. 2017, 45, 295–304. [Google Scholar] [CrossRef]
- Návar, J.; Ríos-Saucedo, J.; Pérez-Verdín, G.; Rodríguez-Flores, F.J.; Domínguez-Calleros, P.A. Regional aboveground biomass equations for North American arid and semi-arid forests. J. Arid Environ. 2013, 97, 127–135. [Google Scholar] [CrossRef]
- Sales, F.C.V.; Silva, J.A.A.; Ferreira, R.L.C.; Gadelha, F.H.L. Ajustes de modelos volumétricos para o clone Eucalyptus grandis x E. urophylla cultivados no agreste de Pernambuco. Floresta 2015, 45, 663–670. [Google Scholar] [CrossRef]
- Gimenez, B.O.; Santos, L.T.; Gebara, J.; Celes, C.H.S.; Durgante, F.M.; Lima, A.J.N.; Santos, J.; Higuchi, N. Tree climbing techniques and volume equations for Eschweilera (Matá-Matá), a hyperdominant genus in the Amazon forest. Forests 2017, 8, 154. [Google Scholar] [CrossRef]
- Özçelik, R.; Diamantopoulou, M.J.; Brooks, J.R.; Wiant Junior, H. Estimating tree bole volume using artificial neural network models for four species in Turkey. J. Environ. Manag. 2010, 91, 742–753. [Google Scholar] [CrossRef]
- Nunes, M.H.; Görgens, E.B. Artificial intelligence procedures for tree taper estimation within a complex vegetation mosaic in Brazil. PLoS ONE 2016, 11. [Google Scholar] [CrossRef]
- Vahedi, A.A. Monitoring soil carbon pool in the Hyrcanian coastal plain forest of Iran: Artificial neural network application in comparison with developing traditional models. Catena 2017, 152, 182–189. [Google Scholar] [CrossRef]
- Diamantopoulou, M.J.; Milios, E. Modelling total volume of dominant pine trees in reforestations via multivariate analysis and artificial neural network models. Biosyst. Eng. 2010, 105, 306–315. [Google Scholar] [CrossRef]
- Silva, M.L.M.; Binoti, D.H.B.; Gleriani, J.M.; Leite, H.G. Ajuste do modelo de Schumacher e Hall e aplicação de redes neurais artificiais para estimar volume de árvores de eucalipto. Rev. Árvore 2009, 33, 1133–1139. [Google Scholar] [CrossRef] [Green Version]
- Bhering, L.L.; Cruz, C.D.; Peixoto, L.A.; Rosado, A.M.; Laviola, B.G.; Nascimento, M. Application of neural networks to predict volume in eucalyptus. Crop Breed. Appl. Biotechnol. 2015, 15, 125–131. [Google Scholar] [CrossRef] [Green Version]
- David, H.C.; Otávio, R.; Miranda, V.; Welker, J.; Fiorentin, L.D.; Ebling, Â.A.; Henrique, P.; Martins, B.; Silva, D. Strategies for stem measurement sampling: A statistical approach of modelling individual tree volume. Cerne 2016, 22, 249–260. [Google Scholar] [CrossRef]







| dbh Class (cm) | n | dbh (cm) | h (m) | v (m3) |
|---|---|---|---|---|
| 4–6 | 85 | 5.09 (0.50) | 9.23 (1.19) | 0.0069 (0.0028) |
| 6–8 | 87 | 6.86 (0.48) | 11.46 (1.42) | 0.0185 (0.0047) |
| 8–10 | 90 | 8.99 (0.54) | 13.35 (2.02) | 0.0381 (0.0090) |
| 10–12 | 92 | 10.77 (0.54) | 14.86 (2.00) | 0.0617 (0.0126) |
| 12–14 | 86 | 12.83 (0.54) | 17.04 (2.09) | 0.0995 (0.0199) |
| 14–16 | 71 | 14.95 (0.56) | 19.02 (1.88) | 0.1492 (0.0236) |
| 16–18 | 55 | 16.83 (0.53) | 21.56 (2.70) | 0.2155 (0.0432) |
| 18–20 | 35 | 18.92 (0.61) | 24.92 (1.96) | 0.3203 (0.0451) |
| 20–22 | 35 | 20.83 (0.68) | 26.23 (2.32) | 0.3804 (0.0570) |
| 22–24 | 22 | 22.95 (0.63) | 26.20 (2.34) | 0.4671 (0.0864) |
| 24–26 | 8 | 24.54 (0.58) | 29.53 (1.40) | 0.5929 (0.0257) |
| No. | Author * | Model |
|---|---|---|
| 1 | Husch | Ln(v) = β0 + β1Ln(dbh) + εi |
| 2 | Brenac | Ln(v) = β0 + β1Ln(dbh) + β2dbh−1 + εi |
| 3 | Spurr | Ln(v) = β0 + β1Ln(dbh2h) + εi |
| 4 | Schumacher-Hall | Ln(v) = β0 + β1Ln(dbh) + β2Ln(h) + εi |
| 5 | Prodan | Ln(v) = β0 + β1Ln(dbh) + β2Ln2(dbh) + β3Ln(h) + β4Ln2(h) + εi |
| Model No. | R2adj | Sy.x | VC% | AIC | Estimated Parameters | ||||
|---|---|---|---|---|---|---|---|---|---|
| β0 | β1 | β2 | β3 | β4 | |||||
| 1 | 0.9582 | 0.02773 | 23.39 | −439.13 | −9.606008 * (±0.0361) | 2.855458 * (±0.0148) | |||
| 2 | 0.9642 | 0.02568 | 21.64 | −509.33 | −7.834555 * (±0.2062) | 2.329743 * (±0.0620) | −5.061533 * (±0.5809) | ||
| 3 | 0.9777 | 0.02028 | 17.10 | −742.82 | −10.67147 * (±0.0330) | 1.049066 * (±0.0043) | |||
| 4 | 0.9771 | 0.02055 | 17.32 | −756.89 | −10.50457 * (±0.0527) | 2.227204 * (±0.0332) | 0.875632 * (±0.0433) | ||
| 5 | 0.9894 | 0.01395 | 11.74 | −1051.54 | −10.39049 * (±0.2743) | 4.890782 * (±0.1599) | −0.598349 * (±0.0352) | −1.508759 * (±0.2963) | 0.471110 * (±0.0551) |
| Scenario | Approach | Network | Neurons 1 | ryŷ | Activation Function | WV | |
|---|---|---|---|---|---|---|---|
| HL 2 | OL 3 | ||||||
| A | General | ANN 2 | 48–25–1 | 0.9977 | Exponential | H. tangent 4 | 5 |
| A | Group A | ANN 5 | 30–3–1 | 0.9940 | Logistic | Logistic | 5 |
| A | Group B | ANN 5 | 36–9–1 | 0.9955 | H. tangent | Identity | 4 |
| A | Group C | ANN 2 | 22–3–1 | 0.9992 | Exponential | Exponential | 6 |
| B | 6/class | ANN 5 | 19–30–1 | 0.9901 | H. tangent | Exponential | 5 |
| B | 5/class | ANN 1 | 18–12–1 | 0.9933 | Exponential | Logistic | 8 |
| B | 4/class | ANN 3 | 17–1–1 | 0.9912 | Logistic | Identity | 5 |
| B | 3/class | ANN 3 | 16–9–1 | 0.9888 | Exponential | Exponential | 7 |
| B | 2/class | ANN 2 | 15–4–1 | 0.9880 | Exponential | Exponential | 7 |
| B | 1/class | ANN 5 | 13–1–1 | 0.9861 | Exponential | Exponential | 6 |
| Method | Statistic | Approach | |||
|---|---|---|---|---|---|
| General | Group A | Group B | Group C | ||
| ANN | ryŷ | 0.9977 | 0.9940 | 0.9955 | 0.9992 |
| RMSE% | 7.87 | 12.70 | 9.95 | 4.99 | |
| Bias | 0.00187 | −0.00046 | −0.00176 | 0.00127 | |
| EV | 0.00009 | 0.00031 | 0.00014 | 0.00003 | |
| Model 5 | ryŷ | 0.9952 | 0.9947 | 0.9959 | 0.9994 |
| RMSE% | 11.08 | 11.83 | 9.59 | 8.32 | |
| Bias | 0.00006 | −0.0005 | −0.00168 | −0.00275 | |
| EV | 0.00018 | 0.00027 | 0.00013 | 0.00007 | |
| Method | Statistic | Sample Intensity | |||||
|---|---|---|---|---|---|---|---|
| 6/Class | 5/Class | 4/Class | 3/Class | 2/Class | 1/Class | ||
| ANN | ryŷ | 0.9901 | 0.9933 | 0.9912 | 0.9888 | 0.9880 | 0.9861 |
| RMSE% | 12.12 | 10.33 | 11.73 | 14.46 | 14.31 | 17.09 | |
| Bias | −0.00039 | 0.00154 | −0.00099 | −0.00136 | 0.00222 | 0.00339 | |
| EV | 0.00005 | 0.00003 | 0.00005 | 0.00007 | 0.00011 | 0.00009 | |
| Model 5 | ryŷ | 0.9914 | 0.9913 | 0.9910 | 0.9907 | 0.9871 | 0.9843 |
| RMSE% | 11.78 | 12.17 | 12.42 | 12.32 | 14.33 | 16.21 | |
| Bias | −0.00001 | 0.00051 | 0.00047 | 0.00009 | 0.00001 | −0.00095 | |
| EV | 0.00005 | 0.00005 | 0.00005 | 0.00005 | 0.00007 | 0.00009 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tavares Júnior, I.d.S.; Rocha, J.E.C.d.; Ebling, Â.A.; Chaves, A.d.S.; Zanuncio, J.C.; Farias, A.A.; Leite, H.G. Artificial Neural Networks and Linear Regression Reduce Sample Intensity to Predict the Commercial Volume of Eucalyptus Clones. Forests 2019, 10, 268. https://0-doi-org.brum.beds.ac.uk/10.3390/f10030268
Tavares Júnior IdS, Rocha JECd, Ebling ÂA, Chaves AdS, Zanuncio JC, Farias AA, Leite HG. Artificial Neural Networks and Linear Regression Reduce Sample Intensity to Predict the Commercial Volume of Eucalyptus Clones. Forests. 2019; 10(3):268. https://0-doi-org.brum.beds.ac.uk/10.3390/f10030268
Chicago/Turabian StyleTavares Júnior, Ivaldo da Silva, Jonas Elias Castro da Rocha, Ângelo Augusto Ebling, Antônio de Souza Chaves, José Cola Zanuncio, Aline Araújo Farias, and Helio Garcia Leite. 2019. "Artificial Neural Networks and Linear Regression Reduce Sample Intensity to Predict the Commercial Volume of Eucalyptus Clones" Forests 10, no. 3: 268. https://0-doi-org.brum.beds.ac.uk/10.3390/f10030268