Performance of Kernel Estimator and Johnson SB Function for Modeling Diameter Distribution of Black Alder (Alnus glutinosa (L.) Gaertn.) Stands


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Diameter Distribution Models
2.3. Model Evaluation and Validation
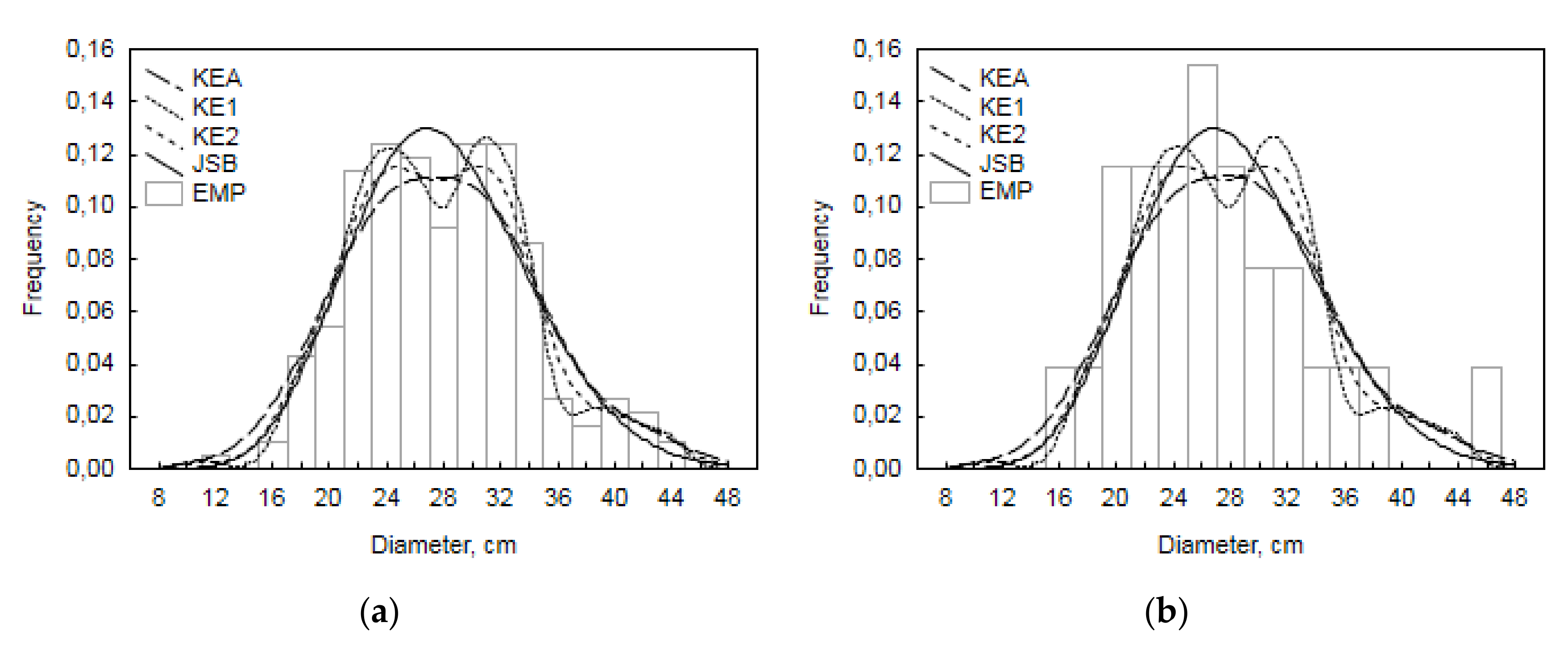
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bruchwald, A.; Dmyterko, E.; Dudzińska, M.; Wirowski, M. Constant height curves for black alder stands. Sylwan 2001, 145, 15–19. (In Polish) [Google Scholar]
- Orzeł, S.; Pogoda, P.; Ochał, W. Generalized height-diameter model for black alder (Alnus glutinosa (L.) Gaertn.) in the western part of the Sandomierz Basin. Sylwan 2014, 158, 840–849. (In Polish) [Google Scholar]
- Hasenauer, H.; Monserud, R.A. A crown ratio model for Austrian forests. For. Ecol. Manag. 1996, 84, 49–60. [Google Scholar] [CrossRef]
- Rédei, K.; Veperdi, I. Study of the relationships between crown and volume production of black locust trees (Robinia pseudoacacia L.). Lesn. Časopis For. J. 2001, 47, 135–142. [Google Scholar]
- Bruchwald, A. Methods of determination of current volume increment of tree stands using fL/3. Folia For. Pol. Ser. A For. 1971, 18, 99–131. (In Polish) [Google Scholar]
- Kelly, J.F.; Beltz, R.C. A comparison of tree volume estimation models for forest inventory. A Comp. Tree Vol. Estim. Models For. Inventory 1987, 233, 13. [Google Scholar] [CrossRef] [Green Version]
- Tewari, V.P.; Singh, B. Total and merchantable wood volume equations for Eucalyptus hybrid trees in Gujarat State, India. Arid Land Res. Manag. 2006, 20, 147–159. [Google Scholar] [CrossRef]
- Zianis, D.; Muukkonen, P.; Mäkipää, R.; Mencuccini, M. Biomass and stem volume equations for tree species in Europe. Silva. Fenn. 2005, 4, 63. [Google Scholar]
- Ochał, W.; Socha, J.; Grabczyński, S. Accuracy of empirical formulas for determining aboveground biomass of black alder (Alnus glutinosa (L.) Gaertn.). Sylwan 2014, 158, 431–442. (In Polish) [Google Scholar]
- Malek, S.; Miglietta, F.; Gobakken, T.; Næsset, E.; Gianelle, D.; Dalponte, M. Prediction of stem diameter and biomass at individual tree crown level with advanced machine learning techniques. Iforest 2019, 12, 323–329. [Google Scholar] [CrossRef] [Green Version]
- Rupšys, P.; Petrauskas, E.; Mažeika, J.; Deltuvas, R. The Gompertz type stochastic growth law and a tree diameter distribution. Balt. For. 2007, 13, 197–206. [Google Scholar]
- Newton, P.F.; Lei, Y.; Zhang, S.Y. A parameter recovery model for estimating black spruce diameter distributions within the context of a stand density management diagram. For. Chron. 2004, 80, 349–358. [Google Scholar] [CrossRef] [Green Version]
- Rauscher, H.M.; Reynolds, K.; Vacik, H. Decision-support systems for forest management. Comput. Electron. Agric. 2005, 49, 1–5. [Google Scholar] [CrossRef]
- Reynolds, K.M.; Twery, M.; Lexer, M.J.; Vacik, H.; Ray, D.; Shao, G.; Borges, J.G. Decision support systems in forest management. In Handbook on Decision Support Systems 2: Variations; Burstein, F., Holsapple, C.W., Eds.; International Handbooks Information System, Springer: Berlin/Heidelberg, Germany, 2008; pp. 499–533. [Google Scholar] [CrossRef]
- Borges, J.G.; Nordström, E.M.; Garcia-Gonzalo, J.; Hujala, T.; Trasobares, A. Computer-Based Tools for Supporting Forest Management. The Experience and the Expertise World-Wide; Department of Forest Resource Management, Swedish University of Agricultural Sciences: Umeå, Sweden, 2014; p. 503. [Google Scholar]
- Gove, J.H.; Patil, G.P. Modeling the basal area-size distribution of forest stands: A compatible approach. For. Sci. 1998, 44, 285–297. [Google Scholar]
- Wikström, P. A solution method for uneven-aged management applied to Norway Spruce. For. Sci. 2000, 46, 452–463. [Google Scholar]
- Sterba, H. Equilibrium curves and growth models to deal with forests in transition to uneven-aged structure-Application in two sample stands. Silva Fenn. 2004, 38, 413–423. [Google Scholar] [CrossRef] [Green Version]
- Gorgoso, J.J.; Álvarez González, J.G.; Rojo, A.; Grandas-Arias, J.A. Modelling diameter distributions of Betula alba L. stands in northwest Spain with the two-parameter Weibull function. Investig. Agrar. Sist. Y Recur. For. 2007, 16, 113–123. [Google Scholar] [CrossRef] [Green Version]
- Surový, P.; Kuželka, K. Acquisition of forest attributes for decision support at the forest enterprise level using remote-sensing techniques-a review. Forests 2019, 10, 273. [Google Scholar] [CrossRef] [Green Version]
- Von Gadow, K.; Zhang, C.Y.; Wehenkel, C.; Pommerening, A.; Corral-Rivas, J.; Korol, M.; Myklush, S.; Hui, G.Y.; Kiviste, A.; Zhao, X.H. Forest structure and diversity. In Continuous Cover Forestry. Managing Forest Ecosystems; Pukkala, T., Von Gadow, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 29–84. [Google Scholar] [CrossRef]
- Nanos, N.; Sjöstedt de Luna, S. Fitting diameter distribution models to data from forest inventories with concentric plot design. For. Syst. 2017, 26, e01S. [Google Scholar] [CrossRef] [Green Version]
- García, O. What is a diameter distribution? In Proceedings of the Symposium on Integrated Forest Management Information Systems—An International Symposium; Minowa, M., Tsuyuki, S., Eds.; Japan Society of Forest Planning Press: Tokyo, Japan, 1992; pp. 11–29. [Google Scholar]
- García, O. Scale and spatial structure effects on tree size distributions: Implications for growth and yield modelling. Can. J. For. Res. 2006, 36, 2983–2993. [Google Scholar] [CrossRef] [Green Version]
- Bollandsås, O.M.; Maltamo, M.; Gobakken, T.; Naesset, E. Comparing parametric and non-parametric modelling of diameter distributions on independent data using airborne laser scanning in a boreal conifer forest. Forestry 2013, 86, 493–501. [Google Scholar] [CrossRef] [Green Version]
- Mulverhill, C.; Coops, N.C.; White, J.C.; Tompalski, P.; Marshall, P.L.; Bailey, T. Enhancing the estimation of stem-size distributions for unimodal and bimodal stands in boreal mixedwood forest with airborne laser scanning data. Forests 2018, 9, 95. [Google Scholar] [CrossRef] [Green Version]
- Peuhkurinen, J.; Tokola, T.; Plevak, K.; Sirparanta, S.; Kedrov, A.V.; Pyankov, S. Predicting tree diameter distributions from airborne laser scanning, SPOT 5 Satellite, and field sample data in the Perm Region, Russia. Forests 2018, 9, 639. [Google Scholar] [CrossRef] [Green Version]
- Maltamo, M.; Hauglin, M.; Næsset, E.; Gobakken, T. Estimating stand level stem diameter distribution utilizing harvester data and airborne laser scanning. Silva Fenn. 2019, 53, 19. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, B.; Min, Z. Stand diameter distribution modeling and prediction based on maximum entropy principle. Forests 2019, 10, 859. [Google Scholar] [CrossRef] [Green Version]
- Mønness, E. Diameter distributions and height curves in even-aged stands of Pinus sylvestris L. Rep. Nor. For. Res. Inst. 1982, 36, 1–40. [Google Scholar]
- Shiver, B.D. Sample sizes and estimation methods for the Weibull distribution for unthinned slash pine plantation diameter distributions. For. Sci. 1988, 34, 809–814. [Google Scholar]
- Maltamo, M.; Puumalainen, J.; Päivinen, R. Comparison of beta and Weibull functions for modelling basal area diameter distribution in stands of Pinus sylvestris and Picea abies. Scand. J. For. Res. 1995, 10, 284–295. [Google Scholar] [CrossRef]
- Orzeł, S.; Rutkowska, L. Diameter structure in pine stands growing in different zones of industrial damage. Sylwan 2000, 144, 55–63. (In Polish) [Google Scholar]
- Ochał, W.; Pająk, M.; Pietrzykowski, M. Diameter structure of selected pine stands growing on post-mining sites reclaimed for forestry. Sylwan 2010, 154, 323–332. (In Polish) [Google Scholar]
- Zasada, M. Evaluation of the double normal distribution for tree diameter distribution modeling. Silva Fenn. 2013, 47, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Bailey, R.L.; Dell, T.R. Quantifying diameter distribution with the Weibull function. For. Sci. 1973, 19, 97–104. [Google Scholar]
- Hafley, W.L.; Schreuder, H.T. Statistical distributions for fitting diameter and height data in even-aged stands. Can. J. For. Res. 1977, 7, 481–487. [Google Scholar] [CrossRef]
- Orzeł, S.; Pogoda, P.; Ochał, W. Evaluation of usefulness of selected functions for modeling distribution of breast height diameter in black alder stands (Alnus glutinosa (L.) Gaertn.). Sylwan 2017, 161, 101–113. (In Polish) [Google Scholar]
- Zhag, L.; Gove, J.H.; Liu, C.; Leak, W.B. A finite mixture of two Weibull distributions for modeling the diameter distributions of rotated-sigmoid, uneven-aged stands. Can. J. For. Res. 2001, 31, 1654–1659. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, L.; Davis, C.J.; Solomon, D.S.; Gove, J.H. A finite mixture model for characterizing the diameter distributions of mixed-species forest stands. For. Sci. 2002, 48, 653–661. [Google Scholar]
- Zhang, L.; Liu, C. Fitting irregular diameter distributions of forest stands by Weibull, modified Weibull, and mixture Weibull models. J. For. Res. 2006, 11, 369–372. [Google Scholar] [CrossRef]
- Jaworski, A.; Podlaski, R. Modelling irregular and multimodal tree diameter distributions by finite mixture models: An approach to stand structure characterization. J. For. Res. 2012, 17, 79–88. [Google Scholar] [CrossRef]
- Wand, M.P.; Jones, M.C. Kernel Smoothing; Chapman and Hall: London, UK, 1995; p. 3. [Google Scholar]
- Borders, B.E.; Souter, R.A.; Bailey, R.L.; Ware, K.D. Percentile-based distributions characterize forest stand tables. For. Sci. 1987, 33, 570–576. [Google Scholar]
- Kangas, A.; Maltamo, M. Percentile based basal area diameter distribution models for Scots pine, Norway spruce and birch species. Silva Fenn. 2000, 34, 371–380. [Google Scholar] [CrossRef] [Green Version]
- Pogoda, P.; Ochał, W.; Orzeł, S. Modeling diameter distribution of black alder (Alnus glutinosa (L.) Gaertn.) stands in Poland. Forests 2019, 10, 412. [Google Scholar] [CrossRef] [Green Version]
- Haara, A.; Maltamo, M.; Tokola, T. The k-nearest-neighbour method for estimating basal-area diameter distribution. Scand. J. For. Res. 1997, 12, 200–208. [Google Scholar] [CrossRef]
- Maltamo, M.; Kangas, A. Methods based on k-nearest neighbor regression in the prediction of basal area diameter distribution. Can. J. For. Res. 1998, 28, 1107–1115. [Google Scholar] [CrossRef]
- Maltamo, M.; Malinen, J.; Kangas, A.; Härkönen, S.; Pasanen, A.M. Most similar neighbour-based stand variable estimation for use in inventory by compartments in Finland. Forestry 2003, 76, 449–463. [Google Scholar] [CrossRef] [Green Version]
- Gorgoso-Varela, J.J.; Rojo-Alboreca, A.; Álvarez-González, J.G. Using a nonparametric method to describe diameter distributions of birch (Betula pubescens EHRH.) stands in northwest Spain. Silva Balc. 2015, 16, 62–75. [Google Scholar]
- Borowski, M. Przyrost Drzew i Drzewostanów; PWRIL: Warszawa, Poland, 1974; pp. 182–186. [Google Scholar]
- Leduc, D.J.; Matney, T.G.; Belli, K.L.; Baldwin, V.C. Predicting Diameter Distributions of Longleaf Pine Plantations: A Comparison between Artificial Neural Networks and other Accepted Methodologies; Department of Agriculture, Forest Service, Southern Research Station: Asheville, NC, USA, 2001; Volume 25, p. 24.
- Ercanli, Í.; Bolat, F. Diameter distribution modelling based on artificial neural networks for Kunduz Forests. Presented at the International Symposium on New Horizons in Forestry, Isparta, Turkey, 18–20 October 2017. [Google Scholar]
- Uutera, J.; Maltamo, M. Impact of regeneration method on stand structure prior to first thinning. Comparative study North Karelia, Finland vs. Republic of Karelia, Russian Federation. Silva Fenn. 1995, 29, 267–285. [Google Scholar] [CrossRef]
- Uusitalo, J. Pre-harvest measurement of pine stands for sawing production planning. Acta For. Fenn. 1997, 259, 1–59. [Google Scholar] [CrossRef]
- Podlaski, R. Parametric and nonparametric approximation of the DBH distribution in the stands of different vertical structure. Acta Agrar. Silvestria Ser. Silvestris 2013, 51, 27–44. (In Polish) [Google Scholar]
- Podlaski, R. Forest modeling: The gamma shape mixture model and simulation of tree diameter distributions. Ann. For. Sci. 2017, 74, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Podlaski, R.; Roesch, F.A. Approximation of the breast height diameter distribution of two-cohort stands by mixture models. III. Kernel density estimators vs. mixture models. Sylwan 2014, 158, 414–422. (In Polish) [Google Scholar]
- Wandresen, R.R.; Netto, S.P.; Koehler, H.S.; Sanquetta, C.R.; Behling, A. Nonparametric method: Kernel density estimation applied to forestry data. Floresta 2019, 49, 561–570. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman and Hall: London, UK, 1986. [Google Scholar]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Téllez, A.E.; Grande Ortiz, M.Á.; González García, C.; Martin Fernández, Á.J.; García, A.I. The kernel estimation in biosystems engineering. JSCI 2008, 6, 23–27. [Google Scholar]
- Taubert, F.; Hartig, F.; Dobner, H.-J.; Huth, A. On the challenge of fitting tree size distributions in ecology. PLoS ONE 2013, 8, e58036. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- López-de-Ullibarri, I. Bandwidth selection in kernel distribution function estimation. Stata J. 2015, 15, 784–795. [Google Scholar] [CrossRef] [Green Version]
- Pogoda, P.; Ochał, W.; Orzeł, S. Bandwidth of kernel estimator of DBH distribution in black alder (Alnus glutinosa (L.) Gaertn.) stands from west part of the Sandomierz Basin. Sylwan 2018, 162, 411–421. (In Polish) [Google Scholar]
- Zambom, A.Z.; Dias, R. A review of kernel density estimation with applications to econometrics. Stats 2012, 5, 1–35. Available online: https://arxiv.org/abs/1212.2812 (accessed on 2 June 2020).
- Jones, M.C.; Marron, J.S.; Sheather, S.J. A brief survey of bandwidth selection for density estimation. J. Am. Stat. Assoc. 1996, 91, 401–407. [Google Scholar] [CrossRef]
- Altman, N.; Léger, C. Bandwidth selection for kernel distribution function estimation. J. Stat. Plan. Inference 1995, 46, 195–214. [Google Scholar] [CrossRef] [Green Version]
- Sheather, S.J. Density estimation. Stat. Sci. 2004, 19, 588–597. [Google Scholar] [CrossRef]
- Pandey, R.; Dhall, S.P.; Kumar, R. Cross-validation-a tool for forest modelers. Indian For. 1999, 125, 1224–1227. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 532–538. [Google Scholar]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Statist. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Reynolds, M.R.; Burk, T.E.; Huang, W. Goodness-of-fit tests and model selection procedures for diameter distribution models. For. Sci. 1988, 34, 373–399. [Google Scholar]
- Yang, Y.; Huang, S. Suitability of five cross validation methods for performance evaluation of nonlinear mixed-effects forest models-a case study. Forestry 2014, 87, 654–662. [Google Scholar] [CrossRef]
- Poudel, K.P.; Cao, Q.V. Evaluation of methods to predict Weibull parameters for characterizing diameter distributions. For. Sci. 2013, 59, 243–252. [Google Scholar] [CrossRef]
- Wang, X.F. sROC: Nonparametric Smooth ROC Curves for Continuous Data. Available online: https://CRAN.R-project.org/package=sROC (accessed on 8 January 2020).
- Wheeler, B. SuppDists: Supplementary Distributions. Available online: https://CRAN.R-project.org/package=SuppDists (accessed on 8 January 2020).
- R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 8 January 2020).
- Pond, N.C.; Froese, R.E. Interpreting stand structure through diameter distributions. For. Sci. 2015, 61, 429–437. [Google Scholar] [CrossRef]
- Hui, G.; Zhang, G.; Zhao, Z.; Yang, A. Methods of forest structure research: A review. Curr. For. Rep. 2019, 5, 142–154. [Google Scholar] [CrossRef]
- Kiviste, A.; Nilson, A.; Hordo, M.; Merenäkk, M. Diameter distribution models and height-diameter equations for Estonian forests. Model. For. Syst. 2003, 169–179. [Google Scholar] [CrossRef]
- Khongor, T.; Lin, C.; Tsogot, Z. Diameter structure analysis of forest stands and selection of suitable model. Mong. J. Biol. Sci. 2011, 9, 19–22. [Google Scholar]
- Özçelik, R.; Fidalgo Fonseca, T.J.; Parresol, B.R.; Eler, Ü. Modeling the diameter distributions of Brutian Pine stands using Johnson’s SB distribution. For. Sci. 2016, 62, 587–593. [Google Scholar] [CrossRef] [Green Version]
- Ogana, F.N.; Itam, E.S.; Osho, J.S.A. Modeling diameter distributions of Gmelina arborea plantation in Omo Forest Reserve, Nigeria with Johnson’s SB. J. Sustain. For. 2017, 36, 121–133. [Google Scholar] [CrossRef]
- Mayrinck, R.C.; Filho, A.C.F.; Ribeiro, A.; De Oliveira, X.M.; De Lima, R.R. A comparison of diameter distribution models for Khaya ivorensis A. Chev. plantations in Brazil. South For. 2018, 80, 373–380. [Google Scholar] [CrossRef]
- Zasada, M. The assessment of the goodness of fit of the dbh distributions in fir stands to some theoretical distributions. Sylwan 1995, 139, 61–69. (In Polish) [Google Scholar]
- Zasada, M. A comparison of dbh distribution in birch stands with the selected theoretical distributions. Sylwan 2000, 144, 43–51. (In Polish) [Google Scholar]
- Jagiełło, R.; Beker, C.; Jagodziński, A.M. Goodness of fit evaluation of the breast height diameter distributions of beech stands differing in age with selected theoretical distributions. Sylwan 2016, 160, 107–119. (In Polish) [Google Scholar]
- Rymer-Dudzińska, T.; Dudzińska, M. An analysis of the tree dbh distribution in beech stands. Sylwan 1999, 143, 5–24. (In Polish) [Google Scholar]
- Rymer-Dudzińska, T.; Dudzińska, M. Dbh distribution in the lowland beech stands. Sylwan 2001, 145, 13–22. (In Polish) [Google Scholar]
- Siekierski, K. Evaluation of the goodness of fit of some statistical distributions to tree diameter distributions. Ann. Wars. Agric. Univ. SGGW AR For. Wood Technol. 1992, 43, 7–14. [Google Scholar]
- De Lima, R.A.F.; Batista, J.L.F.; Prado, P.I. Modeling tree diameter distributions in natural forests: An evaluation of 10 statistical models. For. Sci. 2015, 61, 320–327. [Google Scholar] [CrossRef]
- George, F.; Ramachandran, K.M. Estimation of parameters of Johnson’s system of distributions. J. Mod. Appl. Stat. Methods 2011, 10, 494–504. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Packard, K.C.; Liu, C. A comparison of estimation methods for fitting Weibull and Johnson’s SB distributions to mixed spruce-fir stands in northeastern North America. Can. J. For. Res. 2003, 33, 1340–1347. [Google Scholar] [CrossRef]
- Mehtätalo, L. An algorithm for ensuring compatibility between estimated percentiles of diameter distribution and measured stand variables. For. Sci. 2004, 50, 20–32. [Google Scholar]
- Siipilehto, J.; Lindeman, H.; Vastaranta, M.; Yu, X.; Uusitalo, J. Reliability of the predicted stand structure for clear-cut stands using optional methods: Airborne laser scanning-based methods, smartphone-based forest inventory application Trestima and pre-harvest measurement tool EMO. Silva Fenn. 2016, 50, 1568. [Google Scholar] [CrossRef] [Green Version]
- Siipilehto, J.; Rajala, M. Model for diameter distribution from assortments volumes: Theoretical formulation and a case application with a sample of timber trade data for clear-cut sections. Silva Fenn. 2019, 53, 10062. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
| Attribute | Minimum | First Quartile | Median | Third Quartile | Maximum | Mean | Standard Deviation |
|---|---|---|---|---|---|---|---|
| Number of measured trees | 138 | 181 | 206 | 260 | 359 | 219 | 51 |
| Density (stems ha−1) | 348 | 424 | 570 | 914 | 1505 | 725 | 377 |
| Reineke stand density index (stems ha−1) | 249 | 414 | 506 | 584 | 692 | 504 | 103 |
| Quadratic mean diameter (cm) | 11.1 | 15.7 | 24.1 | 30.0 | 35.0 | 23.1 | 8.2 |
| Basal area (m2 ha−1) | 9.83 | 17.57 | 25.17 | 30.95 | 39.49 | 24.78 | 8.01 |
| Method | ME | RMSE | KS | AD | ME | RMSE | KS | AD |
|---|---|---|---|---|---|---|---|---|
| Training Sets | Test Sets | |||||||
| KEA | 0.0059 (0.001) | 0.0268 (0.004) | 0.0569 (0.009) | 1.1252 (0.138) | 0.0128 (0.016) | 0.1426 (0.046) | 0.2440 (0.068) | 3.0245 (1.745) |
| KE1 | 0.0059 (0.001) | 0.0121 (0.004) | 0.0293 (0.008) | 0.2594 (0.303) | 0.0121 (0.016) | 0.1450 (0.048) | 0.2458 (0.069) | 3.4159 (2.071) |
| KE2 | 0.0059 (0.001) | 0.0231 (0.011) | 0.0514 (0.022) | 1.1853 (1.480) | 0.0126 (0.016) | 0.1441 (0.047) | 0.2446 (0.068) | 3.2046 (1.918) |
| JSB | 0.0039 (0.046) | 0.0326 (0.059) | 0.0666 (0.103) | 4.2440 (16.432) | 0.0079 (0.030) | 0.1431 (0.049) | 0.2427 (0.069) | 3.4290 (2.128) |
| Method | KEA | KE1 | KE2 | JSB | KEA | KE1 | KE2 | JSB |
|---|---|---|---|---|---|---|---|---|
| Group of Stands | Training Sets | Test Sets | ||||||
| MMB | 0.0585 (0.008) | 0.0304 (0.009) | 0.0523 (0.027) | 0.0517 (0.038) | 0.2607 (0.089) | 0.2625 (0.092) | 0.2617 (0.090) | 0.2529 (0.095) |
| MB | 0.0544 (0.010) | 0.0286 (0.007) | 0.0552 (0.022) | 0.0876 (0.106) | 0.2204 (0.051) | 0.2214 (0.051) | 0.2209 (0.050) | 0.2213 (0.052) |
| AS | 0.0577 (0.009) | 0.0289 (0.009) | 0.0466 (0.018) | 0.0841 (0.124) | 0.2510 (0.056) | 0.2534 (0.057) | 0.2511 (0.056) | 0.2508 (0.055) |
| 20 | 0.0561 (0.011) | 0.0405 (0.009) | 0.0847 (0.019) | 0.0393 (0.011) | 0.2000 (0.041) | 0.2008 (0.041) | 0.2011 (0.039) | 0.2041 (0.041) |
| 40 | 0.0525 (0.008) | 0.0274 (0.003) | 0.0459 (0.006) | 0.0963 (0.131) | 0.2108 (0.047) | 0.2120 (0.048) | 0.2105 (0.047) | 0.2123 (0.052) |
| 60 | 0.0596 (0.009) | 0.0255 (0.003) | 0.0384 (0.006) | 0.1303 (0.159) | 0.2949 (0.078) | 0.2977 (0.080) | 0.2958 (0.079) | 0.2915 (0.089) |
| 80 | 0.0592 (0.006) | 0.0239 (0.002) | 0.0364 (0.004) | 0.0422 (0.003) | 0.2705 (0.055) | 0.2726 (0.057) | 0.2709 (0.057) | 0.2587 (0.059) |
| Method | KEA | KE1 | KE2 | JSB | KEA | KE1 | KE2 | JSB |
|---|---|---|---|---|---|---|---|---|
| Group of Stands | Training Sets | Test Sets | ||||||
| MMB | 1.1730 (0.196) | 0.2875 (0.362) | 1.1527 (1.257) | 1.0390 (2.355) | 3.3959 (2.313) | 3.9156 (2.782) | 3.6743 (2.605) | 3.5222 (2.858) |
| MB | 1.1247 (0.071) | 0.3409 (0.358) | 1.6664 (1.895) | 7.9067 (19.147) | 2.5227 (1.004) | 2.7436 (1.142) | 2.5922 (1.049) | 2.8625 (1.292) |
| AS | 1.0780 (0.110) | 0.1498 (0.102) | 0.7368 (0.760) | 7.5225 (21.186) | 3.1548 (1.700) | 3.5886 (1.951) | 3.3474 (1.773) | 3.8371 (2.091) |
| 20 | 1.2658 (0.124) | 0.6775 (0.355) | 3.2760 (1.598) | 0.4296 (0.288) | 2.1975 (0.936) | 2.3119 (1.099) | 2.2198 (0.935) | 2.4966 (1.152) |
| 40 | 1.0813 (0.096) | 0.1690 (0.080) | 0.8240 (0.500) | 11.1023 (23.287) | 2.5412 (1.895) | 2.8149 (2.130) | 2.5891 (1.913) | 3.1441 (2.539) |
| 60 | 1.1104 (0.143) | 0.1074 (0.026) | 0.3755 (0.146) | 11.7151 (24.138) | 3.9786 (2.016) | 4.5411 (2.317) | 4.2709 (2.148) | 4.4073 (2.423) |
| 80 | 1.0434 (0.075) | 0.0836 (0.022) | 0.2657 (0.102) | 0.2946 (0.071) | 3.3805 (1.611) | 3.9957 (2.018) | 3.7389 (1.954) | 3.6024 (2.131) |
| Method | KEA | KE1 | KE2 | JSB | KEA | KE1 | KE2 | JSB |
|---|---|---|---|---|---|---|---|---|
| Group of Stands | Training Sets | Test Sets | ||||||
| MMB | 0.0271 (0.004) | 0.0120 (0.004) | 0.0223 (0.011) | 0.0242 (0.024) | 0.1525 (0.062) | 0.1554 (0.065) | 0.1547 (0.063) | 0.1478 (0.068) |
| MB | 0.0253 (0.004) | 0.0129 (0.004) | 0.0257 (0.013) | 0.0449 (0.061) | 0.1289 (0.035) | 0.1302 (0.036) | 0.1297 (0.035) | 0.1300 (0.037) |
| AS | 0.0281 (0.003) | 0.0113 (0.003) | 0.0213 (0.010) | 0.0419 (0.080) | 0.1466 (0.038) | 0.1496 (0.039) | 0.1480 (0.038) | 0.1482 (0.038) |
| 20 | 0.0253 (0.005) | 0.0175 (0.003) | 0.0398 (0.009) | 0.0173 (0.006) | 0.1136 (0.028) | 0.1142 (0.028) | 0.1152 (0.026) | 0.1163 (0.029) |
| 40 | 0.0259 (0.004) | 0.0114 (0.001) | 0.0214 (0.003) | 0.0502 (0.075) | 0.1191 (0.034) | 0.1203 (0.034) | 0.1192 (0.034) | 0.1212 (0.038) |
| 60 | 0.0290 (0.003) | 0.0103 (0.001) | 0.0169 (0.003) | 0.0705 (0.089) | 0.1784 (0.052) | 0.1825 (0.055) | 0.1804 (0.0504) | 0.1781 (0.060) |
| 80 | 0.0272 (0.002) | 0.0091 (0.001) | 0.0143 (0.002) | 0.0161 (0.002) | 0.1595 (0.038) | 0.1632 (0.040) | 0.1618 (0.040) | 0.1528 (0.044) |
| Group of Stands | Statistic | χ2 | p |
|---|---|---|---|
| MMB | KS | 22.5214/0.2970 | 0.0001/0.9606 |
| AD | 20.9270/0.4461 | 0.0001/0.9306 | |
| RMSE | 28.8302/0.2932 | 0.0000/0.9613 | |
| ME | 0.2846/0.0900 | 0.9629/0.9930 | |
| MB | KS | 22.4515/18.9881 | 0.0001/0.0003 |
| AD | 15.7228/0.5850 | 0.0013/0.8998 | |
| RMSE | 19.5009/0.0264 | 0.0002/0.9989 | |
| ME | 26.4907/0.2372 | 0.0000/0.9714 | |
| AS | KS | 23.3006/0.1037 | 0.0000/0.9914 |
| AD | 26.2651/1.0981 | 0.0000/0.7775 | |
| RMSE | 26.8973/0.2249 | 0.0000/0.9735 | |
| ME | 2.4891/2.9956 | 0.4773/0.3923 | |
| 20 | KS | 22.0410/0.1732 | 0.0001/0.9818 |
| AD | 25.3904/0.7377 | 0.0000/0.8643 | |
| RMSE | 24.3173/0.3894 | 0.0000/0.9424 | |
| ME | 2.2152/0.1612 | 0.5290/0.9836 | |
| 40 | KS | 19.9688/0.2954 | 0.0002/0.9609 |
| AD | 18.3556/0.3430 | 0.0004/0.9518 | |
| RMSE | 19.8372/0.0541 | 0.0002/0.9967 | |
| ME | 1.1652/0.7631 | 0.7614/0.8583 | |
| 60 | KS | 25.8482/0.0746 | 0.0000/0.9947 |
| AD | 24.7631/0.7852 | 0.0000/0.8530 | |
| RMSE | 26.1388/0.2393 | 0.0000/0.9710 | |
| ME | 0.0704/3.0270 | 0.9951/0.3875 | |
| 80 | KS | 31.5405/0.4695 | 0.0000/0.9255 |
| AD | 29.6987/1.6026 | 0.0000/0.6588 | |
| RMSE | 30.4795/0.7417 | 0.0000/0.8633 | |
| ME | 0.0831/0.4294 | 0.9938/0.9341 | |
| All data | KS | 66.9480/0.1140 | <0.0001/0.9901 |
| AD | 60.2600/0.9725 | <0.0001/0.8079 | |
| RMSE | 69.6550/0.1521 | <0.0001/0.9849 | |
| ME | 0.0429/1.0486 | 0.9977/0.7895 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pogoda, P.; Ochał, W.; Orzeł, S. Performance of Kernel Estimator and Johnson SB Function for Modeling Diameter Distribution of Black Alder (Alnus glutinosa (L.) Gaertn.) Stands. Forests 2020, 11, 634. https://0-doi-org.brum.beds.ac.uk/10.3390/f11060634
Pogoda P, Ochał W, Orzeł S. Performance of Kernel Estimator and Johnson SB Function for Modeling Diameter Distribution of Black Alder (Alnus glutinosa (L.) Gaertn.) Stands. Forests. 2020; 11(6):634. https://0-doi-org.brum.beds.ac.uk/10.3390/f11060634
Chicago/Turabian StylePogoda, Piotr, Wojciech Ochał, and Stanisław Orzeł. 2020. "Performance of Kernel Estimator and Johnson SB Function for Modeling Diameter Distribution of Black Alder (Alnus glutinosa (L.) Gaertn.) Stands" Forests 11, no. 6: 634. https://0-doi-org.brum.beds.ac.uk/10.3390/f11060634