
A Methodology Based on FT-IR Data Combined with Random Forest Model to Generate Spectralprints for the Characterization of High-Quality Vinegars

 ,
,  , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Samples
2.2. Fourier-Transform Infrared Spectra Acquisition
2.3. Data Analysis
3. Results
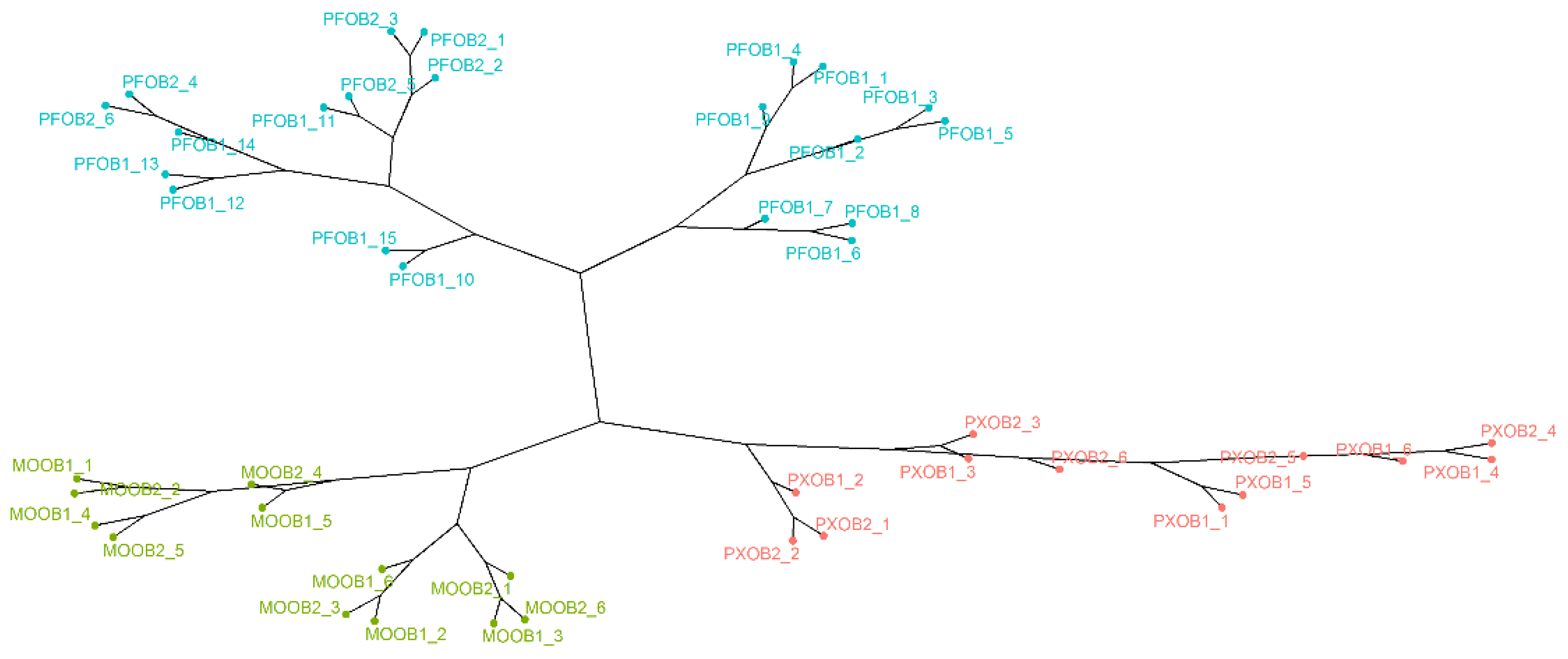
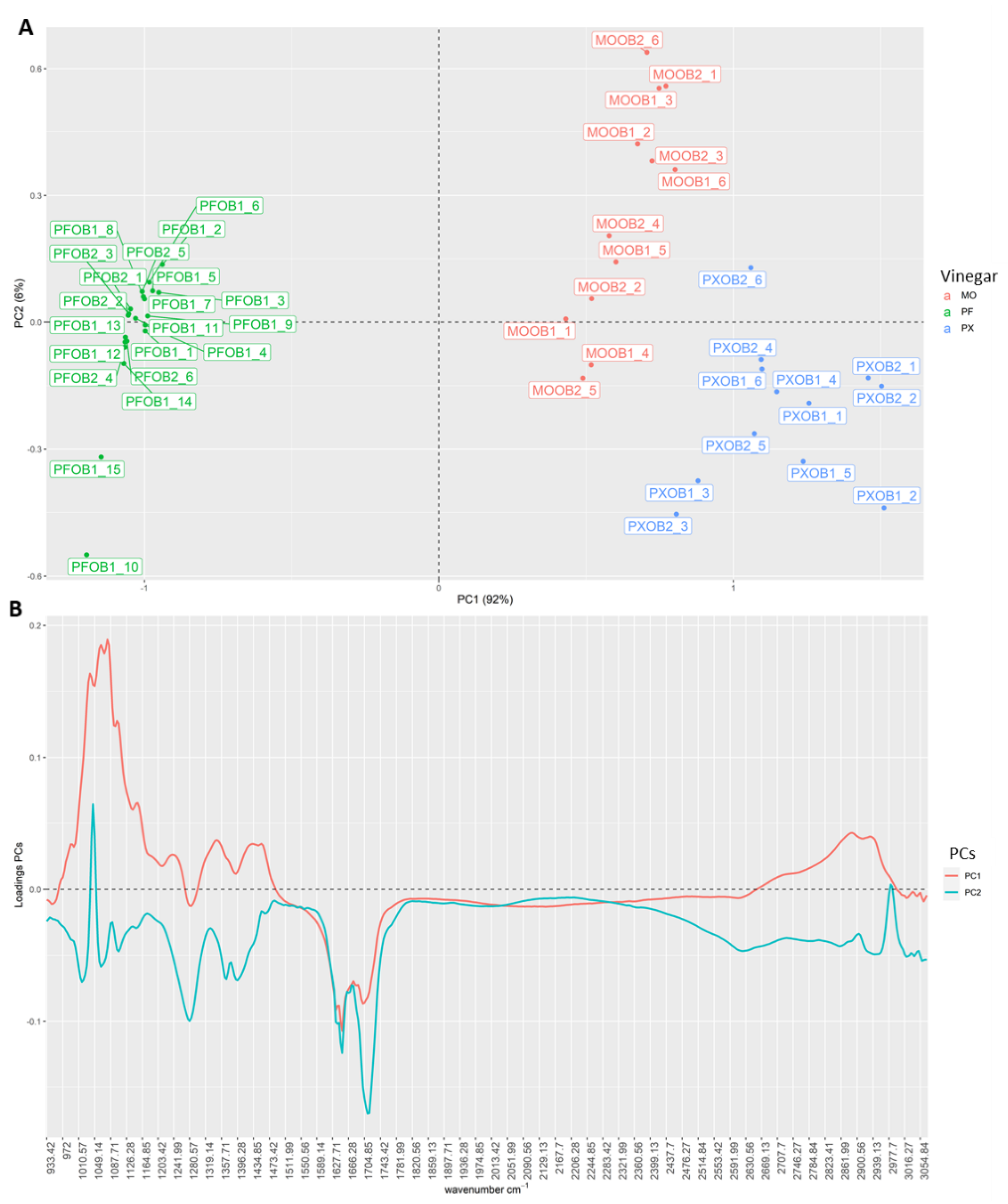
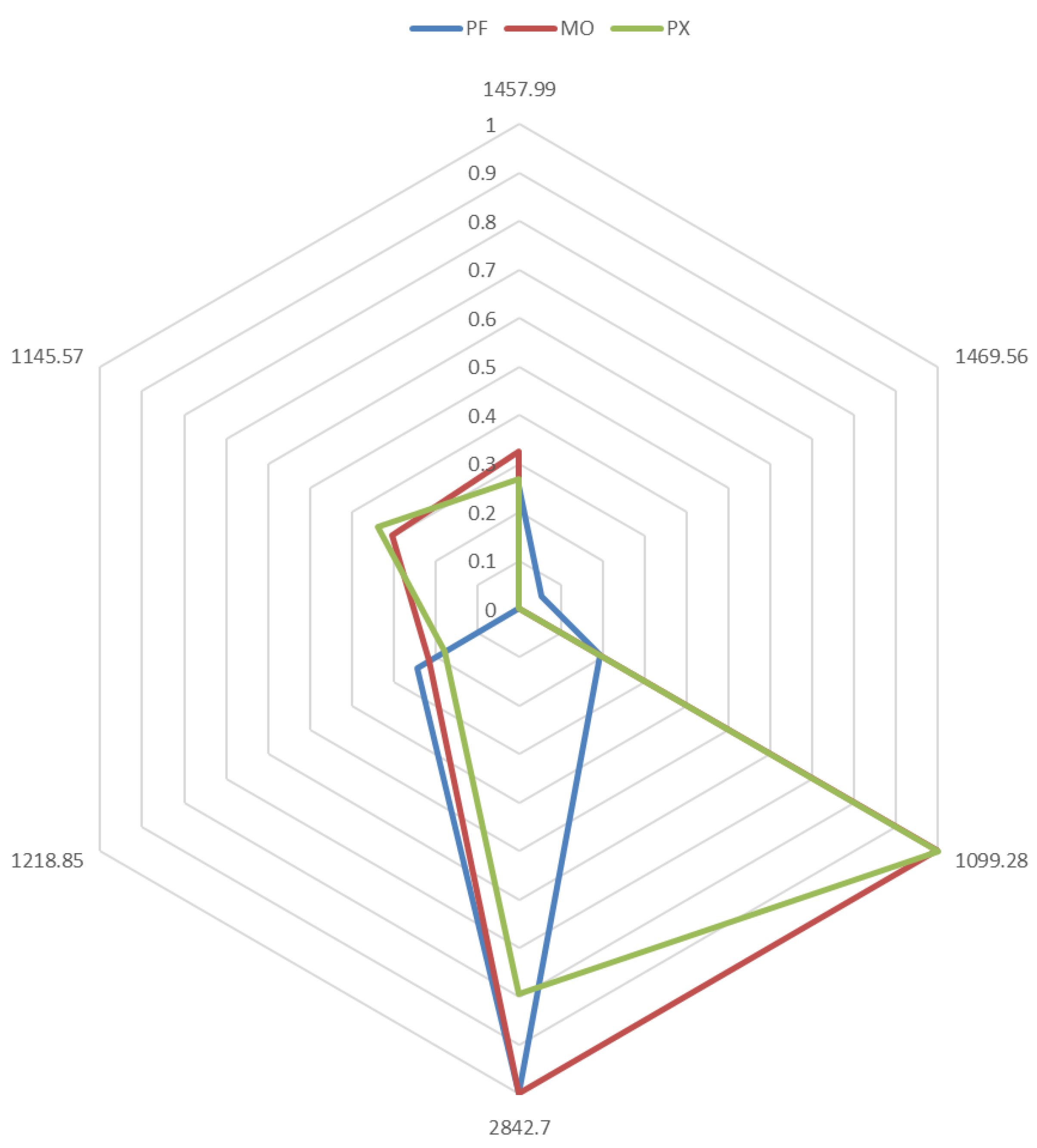
3.1. Exploratory Analysis
3.2. Supervised Techniques
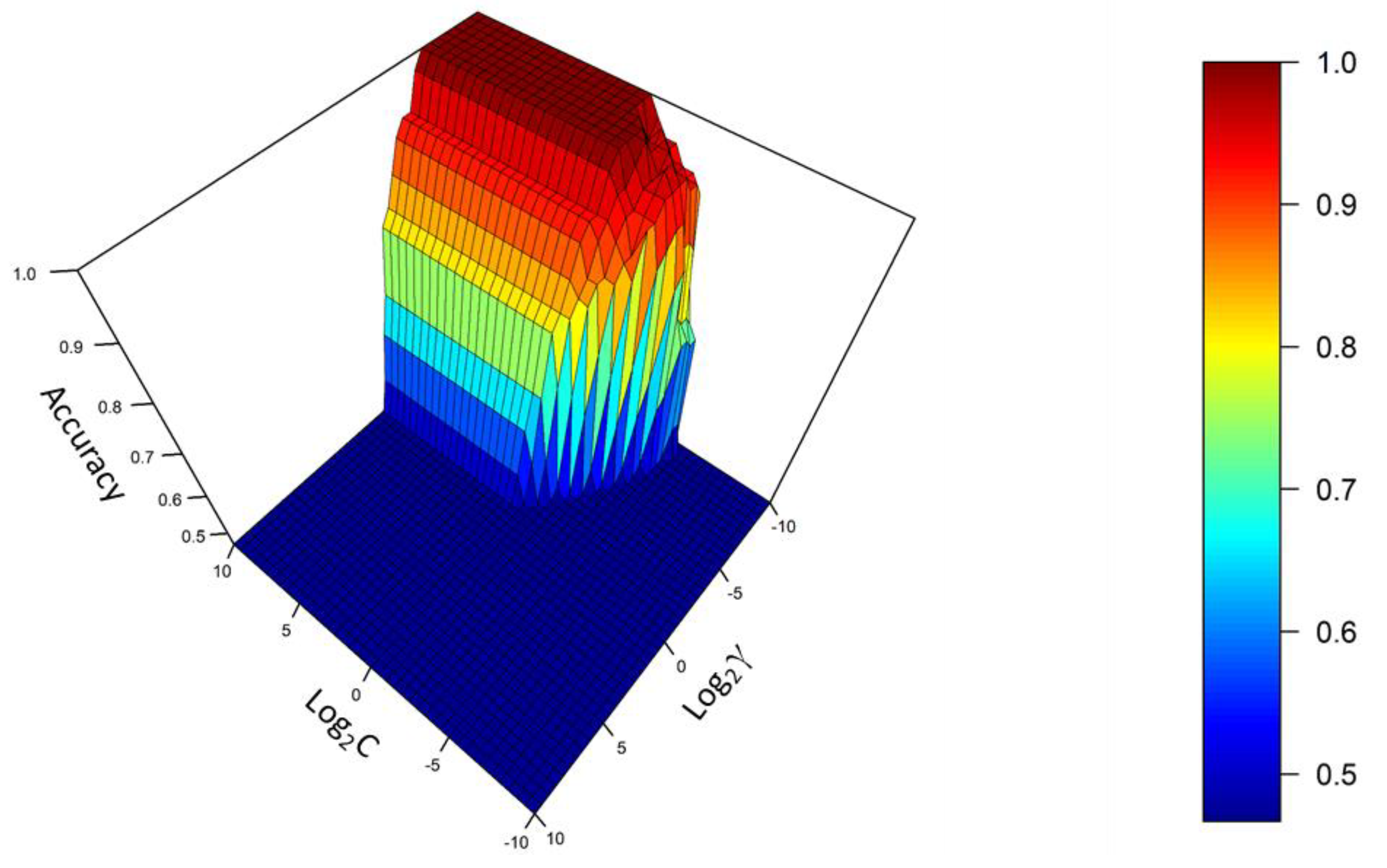
3.2.1. Support Vector Machine (SVM)
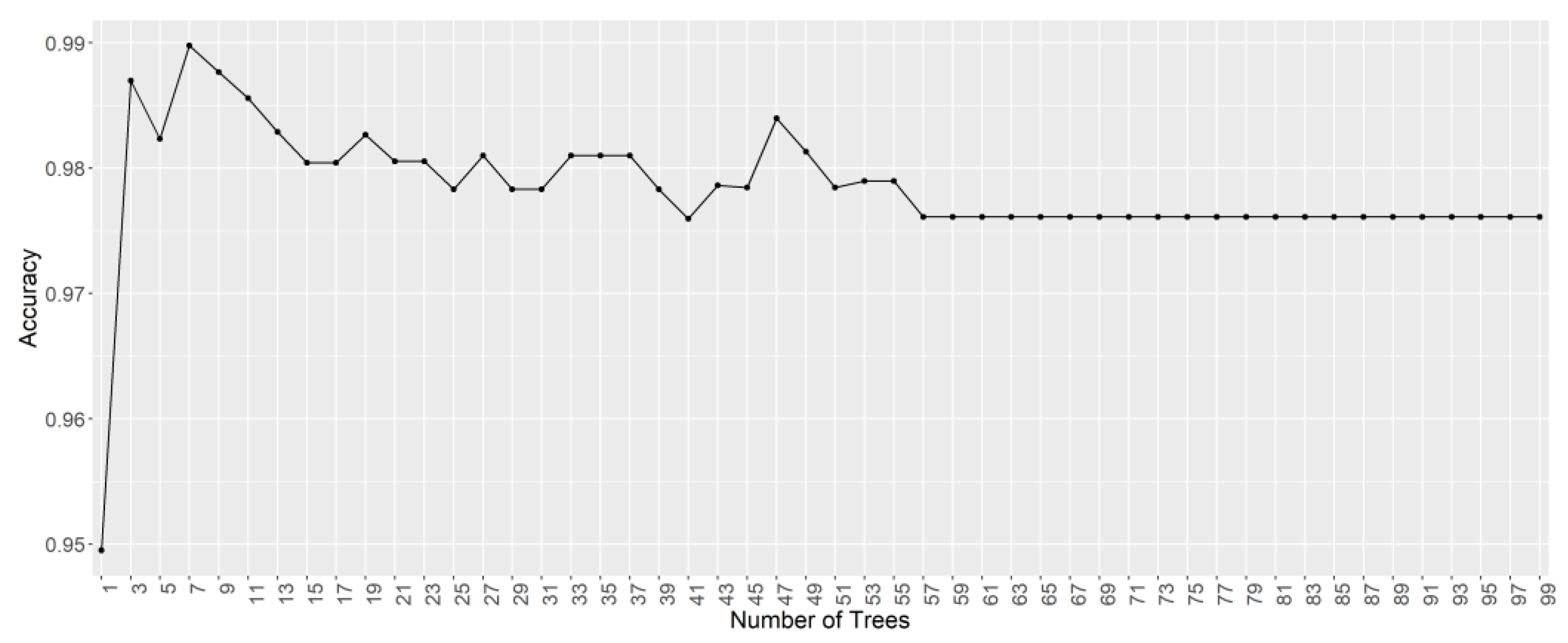
3.2.2. Random Forest (RF)
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiménez-Sánchez, M.; Durán-Guerrero, E.; Rodríguez-Dodero, M.C.; Barroso, C.G.; Castro, R. Use of ultrasound at a pilot scale to accelerate the ageing of sherry vinegar. Ultrason. Sonochem. 2020, 69, 105244. [Google Scholar] [CrossRef] [PubMed]
- Ríos-Reina, R.; Callejón, R.M.; Oliver-Pozo, C.; Amigo, J.M.; González, D.G. ATR-FTIR as a potential tool for controlling high quality vinegar categories. Food Control. 2017, 78, 230–237. [Google Scholar] [CrossRef]
- Quirós, J.M. La elaboración de vinagre de calidad de Jerez. Quad. Vitic. Enol. Univ. Torino 1990, 2, 115–129. [Google Scholar]
- BOJA 15/10. Inscripción de la Denominación de Origen Protegida “Vinagre de Jerez”. Boletín Oficial de la Junta de Andalucía, 2008; Volume 184, pp. 29–35. Available online: https://www.juntadeandalucia.es/organismos/agriculturapescaydesarrollorural/areas/industrias-agroalimentaria (accessed on 1 January 2021).
- Marrufo-Curtido, A.; Bastante, M.J.C.; Durán-Guerrero, E.; Mejias, R.C.; Natera-Marín, R.; Chinnici, F.; Barroso, C.G. Characterization and differentiation of high quality vinegars by stir bar sorptive extraction coupled to gas chromatography-mass spectrometry (SBSE-GC-MS). LWT Food Sci. Technol. 2012, 47, 332–341. [Google Scholar] [CrossRef]
- Ríos-Reina, R.; Morales, M.L.; González, D.G.; Amigo, J.M.; Callejón, R.M. Sampling methods for the study of volatile profile of PDO wine vinegars. A comparison using multivariate data analysis. Food Res. Int. 2018, 105, 880–896. [Google Scholar] [CrossRef]
- Pizarro, C.; Esteban-Díez, I.; Sáenz-González, C.; Sáiz, J.M.G. Vinegar classification based on feature extraction and selection from headspace solid-phase microextraction/gas chromatography volatile analyses: A feasibility study. Anal. Chim. Acta 2008, 608, 38–47. [Google Scholar] [CrossRef] [PubMed]
- Cejudo-Bastante, C.; Durán-Guerrero, E.; García-Barroso, C.; Mejias, R.C. Comparative study of submerged and surface culture acetification process for orange vinegar. J. Sci. Food Agric. 2018, 98, 1052–1060. [Google Scholar] [CrossRef]
- Paneque, P.; Morales, M.L.; Burgos, P.; Ponce, L.; Callejón, R.M. Elemental characterisation of Andalusian wine vinegars with protected designation of origin by ICP-OES and chemometric approach. Food Control. 2017, 75, 203–210. [Google Scholar] [CrossRef]
- Boffo, E.F.; Tavares, L.A.; Ferreira, M.M.C.; Ferreira, A.G. Classification of Brazilian vinegars according to their 1H NMR spectra by pattern recognition analysis. LWT Food Sci. Technol. 2009, 42, 1455–1460. [Google Scholar] [CrossRef]
- Viskić, M.; Bandić, L.M.; Korenika, A.-M.J.; Jeromel, A. NMR in the Service of Wine Differentiation. Foods 2021, 10, 120. [Google Scholar] [CrossRef]
- Valcárcel, M.; Cárdenas, S. Vanguard-rearguard analytical strategies. TrAC Trends Anal. Chem. 2005, 24, 67–74. [Google Scholar] [CrossRef]
- Ríos-Reina, R.; Camiña, J.M.; Callejón, R.M.; Azcarate, S.M. Spectralprint techniques for wine and vinegar characterization, authentication and quality control: Advances and projections. TrAC Trends Anal. Chem. 2021, 134, 116121. [Google Scholar] [CrossRef]
- Durán, E.; Palma, M.; Natera, R.; Castro, R.; Barroso, C.G. New FT-IR method to control the evolution of the volatile constituents of vinegar during the acetic fermentation process. Food Chem. 2010, 121, 575–579. [Google Scholar] [CrossRef]
- Kansiz, M.; Gapes, J.R.; McNaughton, D.; Lendl, B.; Schuster, K.C. Mid-infrared spectroscopy coupled to sequential injection analysis for the on-line monitoring of the acetone–butanol fermentation process. Anal. Chim. Acta 2001, 438, 175–186. [Google Scholar] [CrossRef]
- Ferreiro-González, M.; Barbero, G.F.; Álvarez, J.A.; Ruiz, A.; Palma, M.; Ayuso, J. Authentication of virgin olive oil by a novel curve resolution approach combined with visible spectroscopy. Food Chem. 2017, 220, 331–336. [Google Scholar] [CrossRef] [PubMed]
- Ríos-Reina, R.; Callejón, R.M.; Savorani, F.; Amigo, J.M.; Cocchi, M. Data fusion approaches in spectroscopic characterization and classification of PDO wine vinegars. Talanta 2019, 198, 560–572. [Google Scholar] [CrossRef] [Green Version]
- Ríos-Reina, R.; Elcoroaristizabal, S.; Ocaña-González, J.A.; González, D.G.; Amigo, J.M.; Callejón, R.M. Characterization and authentication of Spanish PDO wine vinegars using multidimensional fluorescence and chemometrics. Food Chem. 2017, 230, 108–116. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferreiro-González, M.; Ruiz-Rodríguez, A.; Barbero, G.F.; Ayuso, J.; Álvarez, J.A.; Palma, M.; Barroso, C.G. FT-IR, Vis spectroscopy, color and multivariate analysis for the control of ageing processes in distinctive Spanish wines. Food Chem. 2019, 277, 6–11. [Google Scholar] [CrossRef] [PubMed]
- Guerrero, E.D.; Mejias, R.C.; Marín, R.N.; Lovillo, M.P.; Barroso, C.G. A new FT-IR method combined with multivariate analysis for the classification of vinegars from different raw materials and production processes. J. Sci. Food Agric. 2010, 90, 712–718. [Google Scholar] [CrossRef]
- Ríos-Reina, R.; Azcarate, S.M.; Camiña, J.; Callejón, R.M. Assessment of UV–visible spectroscopy as a useful tool for determining grape-must caramel in high-quality wine and balsamic vinegars. Food Chem. 2020, 323, 126792. [Google Scholar] [CrossRef] [PubMed]
- Dankowska, A.; Kowalewski, W. Tea types classification with data fusion of UV-Vis, synchronous fluorescence and NIR spectroscopies and chemometric analysis. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 211, 195–202. [Google Scholar] [CrossRef] [PubMed]
- Jia, W.; Liang, G.; Tian, H.; Sun, J.; Wan, C. Electronic Nose-Based Technique for Rapid Detection and Recognition of Moldy Apples. Sensors 2019, 19, 1526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Patle, A.; Chouhan, D.S. SVM kernel functions for classification. In Proceedings of the 2013 International Conference on Advances in Technology and Engineering (ICATE), Mumbai, India, 23–25 January 2013; pp. 1–9. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn and TensorFlow, 2nd ed.; Roumeliotis, R.N.T., Ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Olmo, M.C.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy (%) | |||
|---|---|---|---|
| Training Set | OOB Set | LOOCV | |
| Complete RF | 100 | 97.24 | 100 |
| Reduced RF | 100 | 100 | 100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calle, J.L.P.; Ferreiro-González, M.; Ruiz-Rodríguez, A.; Barbero, G.F.; Álvarez, J.Á.; Palma, M.; Ayuso, J. A Methodology Based on FT-IR Data Combined with Random Forest Model to Generate Spectralprints for the Characterization of High-Quality Vinegars. Foods 2021, 10, 1411. https://0-doi-org.brum.beds.ac.uk/10.3390/foods10061411
Calle JLP, Ferreiro-González M, Ruiz-Rodríguez A, Barbero GF, Álvarez JÁ, Palma M, Ayuso J. A Methodology Based on FT-IR Data Combined with Random Forest Model to Generate Spectralprints for the Characterization of High-Quality Vinegars. Foods. 2021; 10(6):1411. https://0-doi-org.brum.beds.ac.uk/10.3390/foods10061411
Chicago/Turabian StyleCalle, José Luis P., Marta Ferreiro-González, Ana Ruiz-Rodríguez, Gerardo F. Barbero, José Á. Álvarez, Miguel Palma, and Jesús Ayuso. 2021. "A Methodology Based on FT-IR Data Combined with Random Forest Model to Generate Spectralprints for the Characterization of High-Quality Vinegars" Foods 10, no. 6: 1411. https://0-doi-org.brum.beds.ac.uk/10.3390/foods10061411