
Influence of Car Configurator Webpage Data from Automotive Manufacturers on Car Sales by Means of Correlation and Forecasting


Abstract
:1. Introduction
2. Related Works
2.1. State-of-the Art Review
2.2. Research Gap
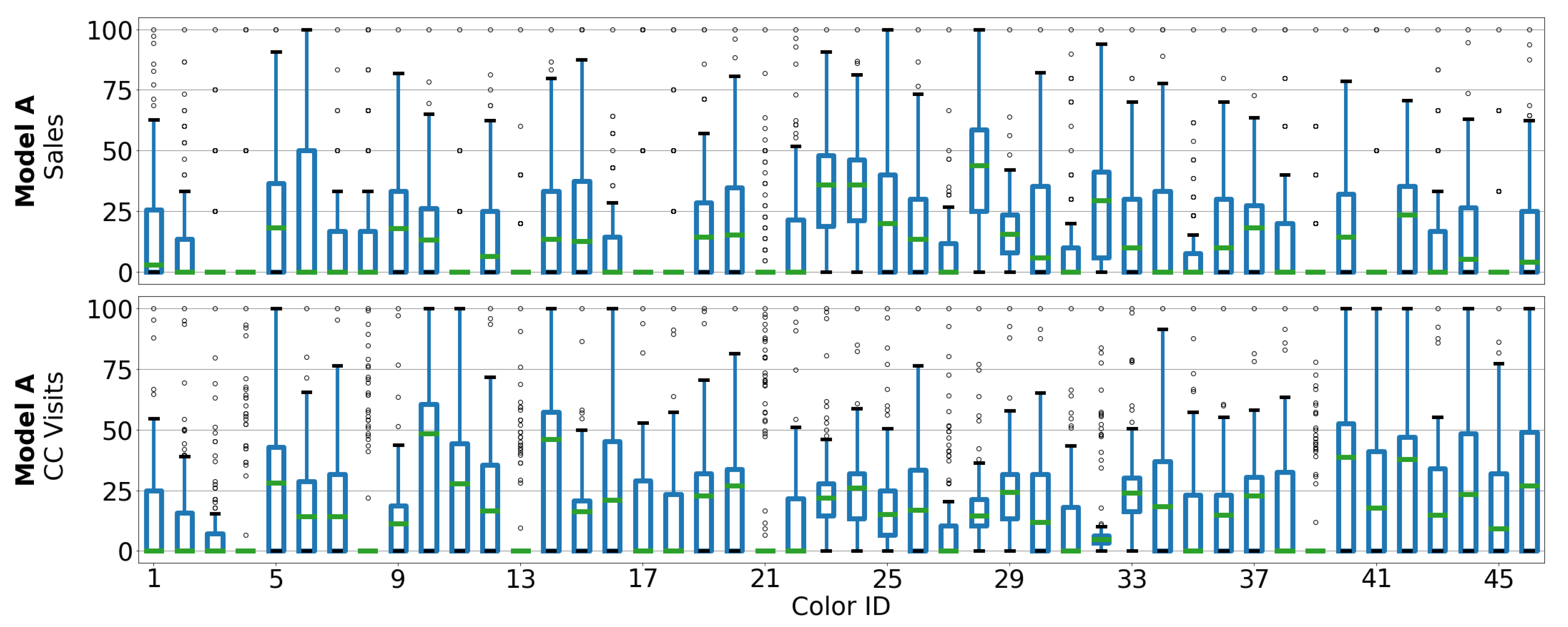
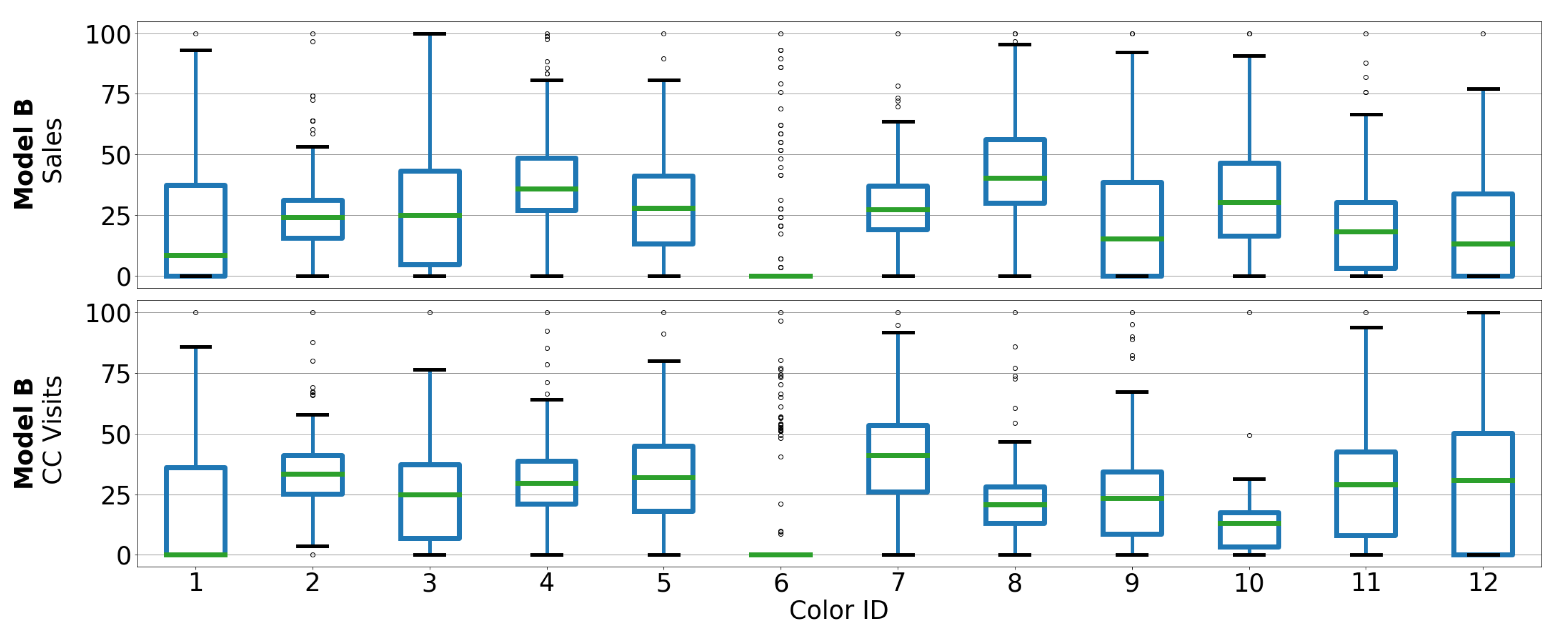
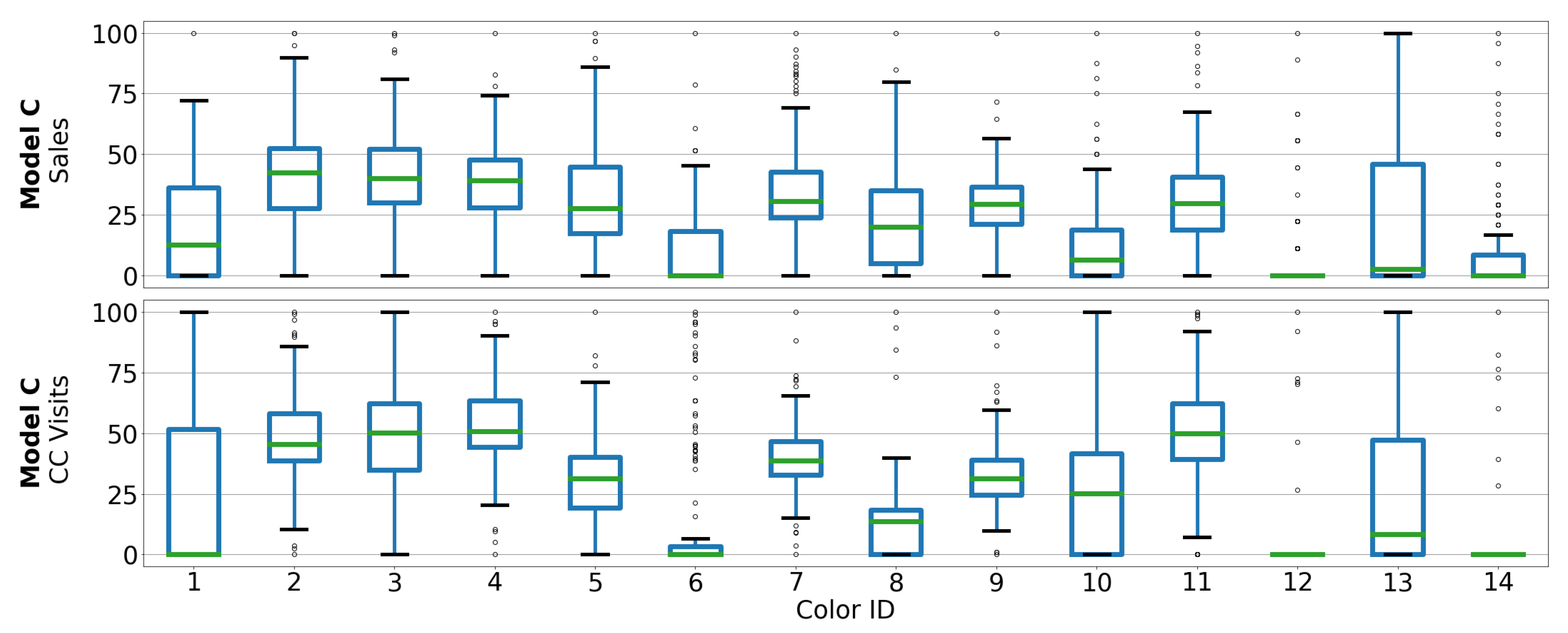
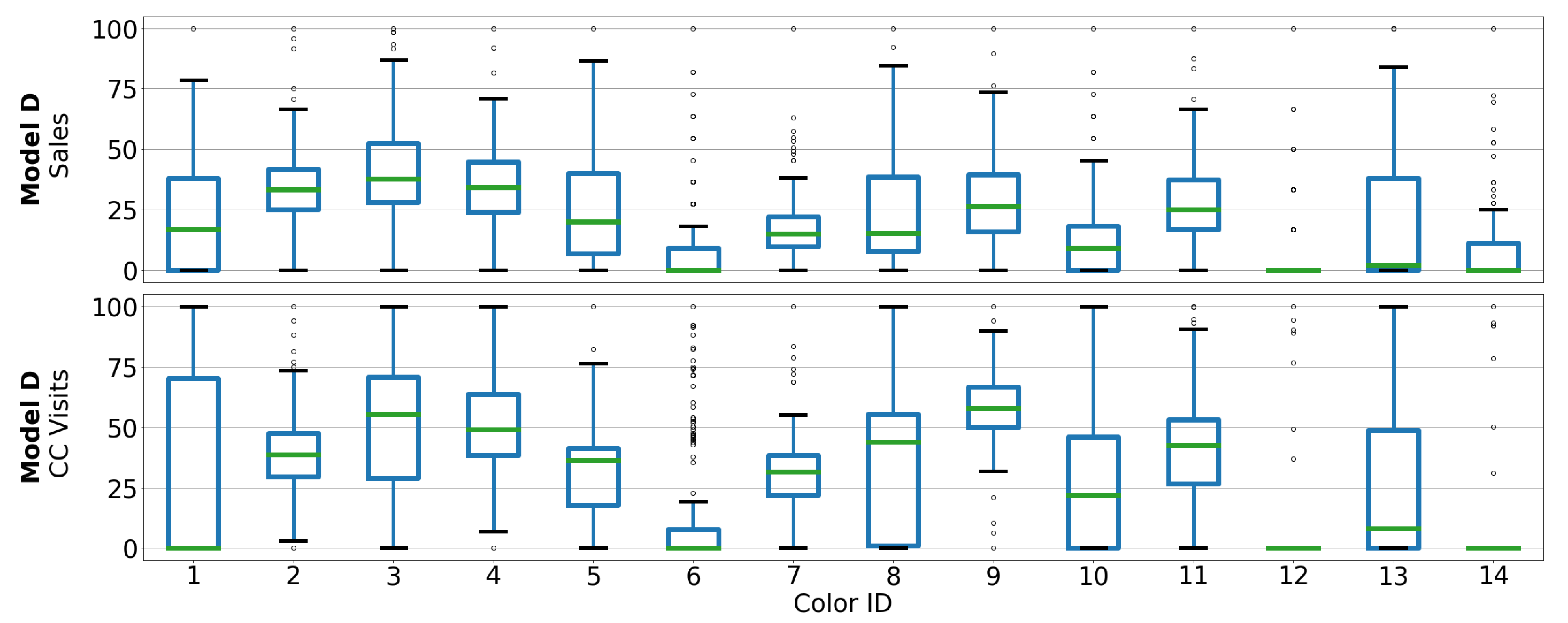
3. Dataset Description
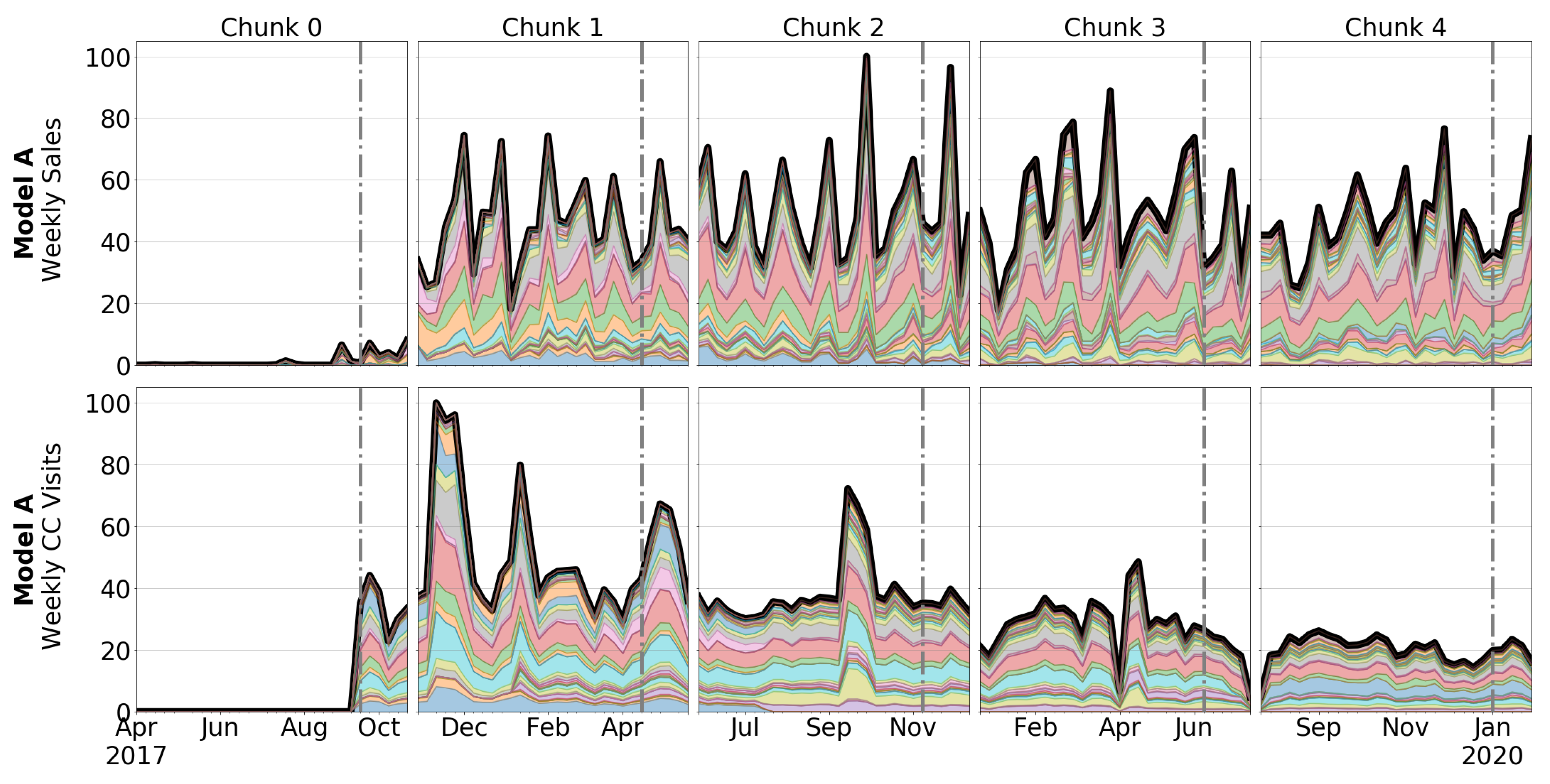
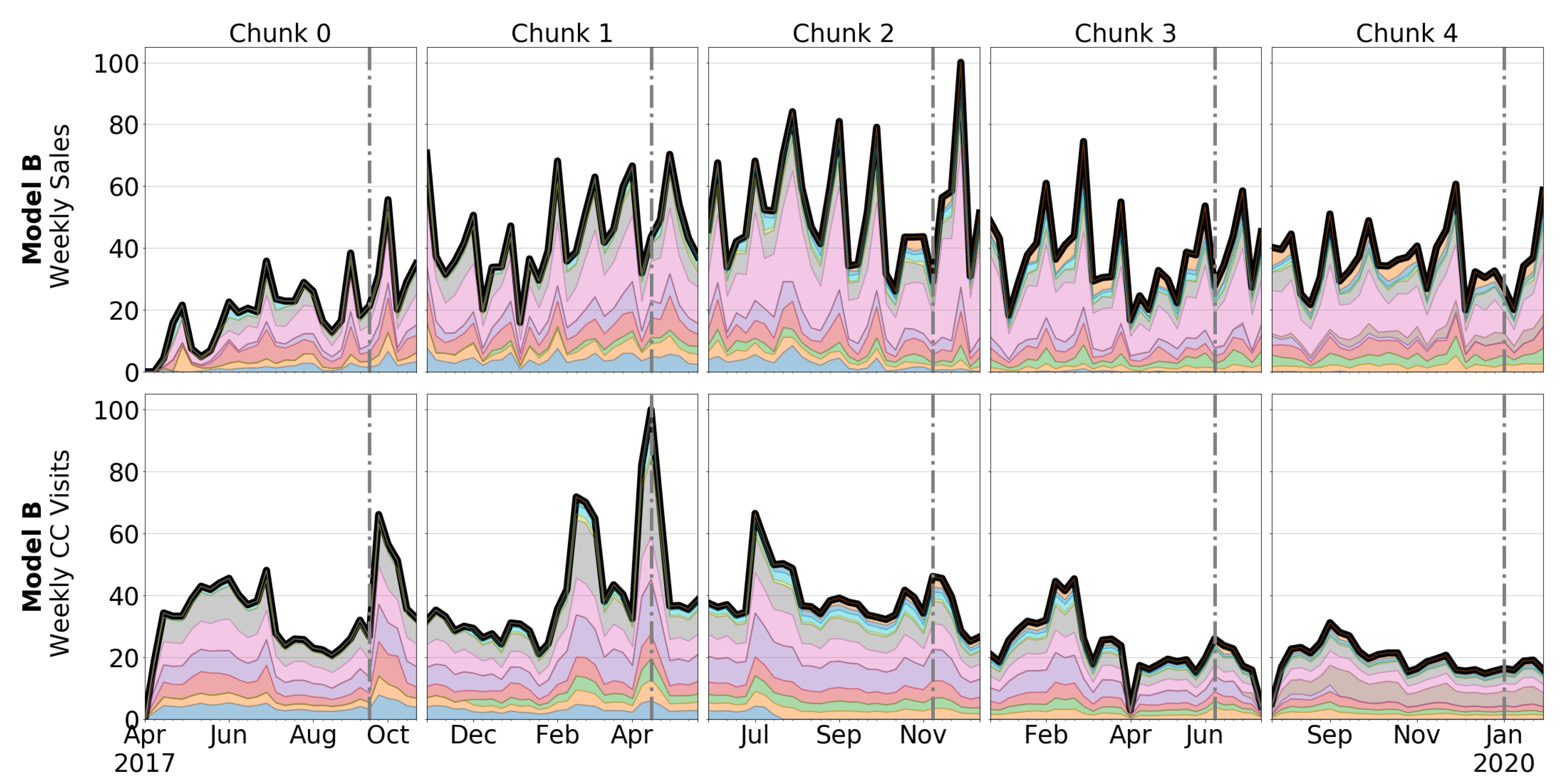
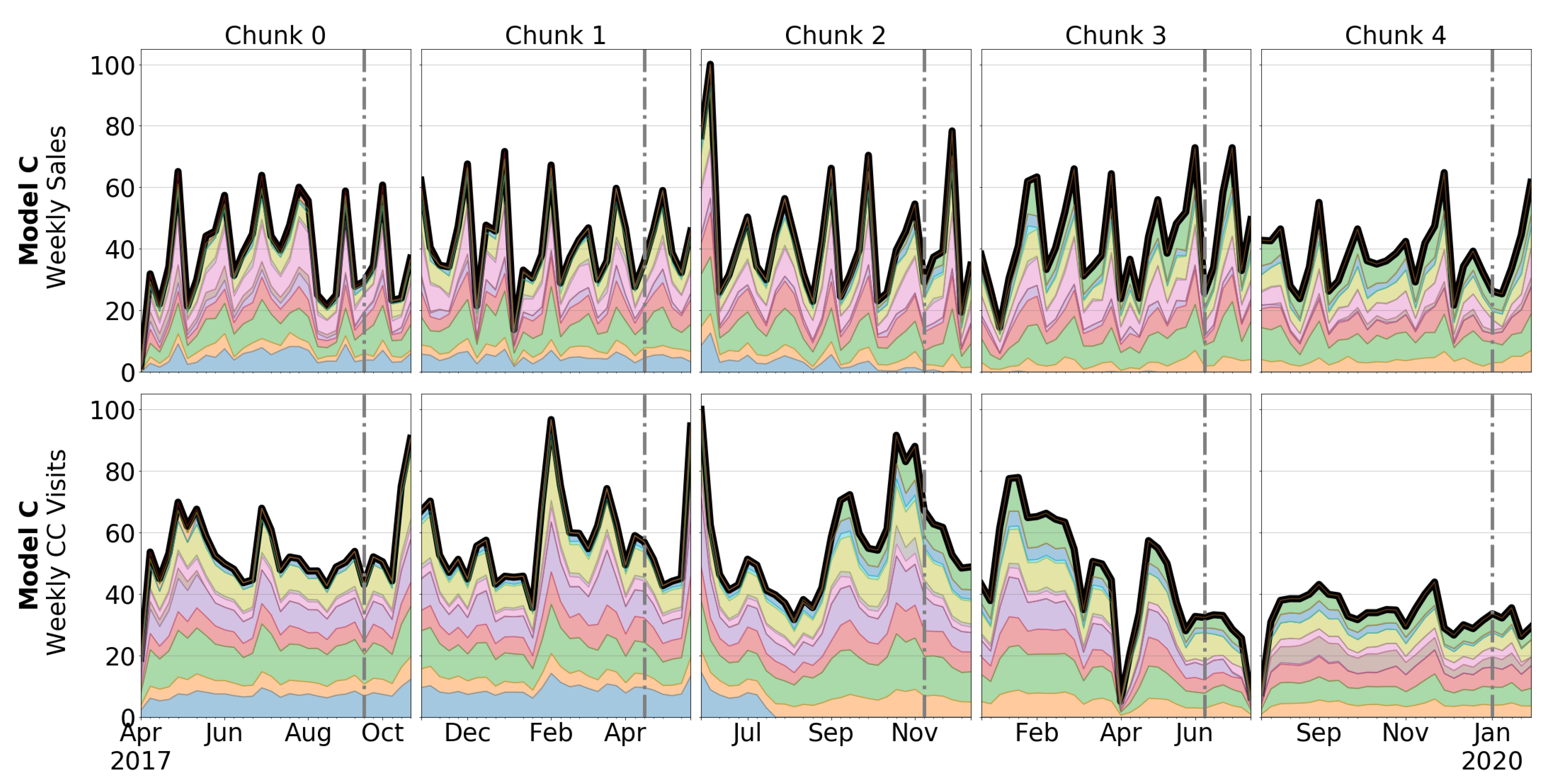
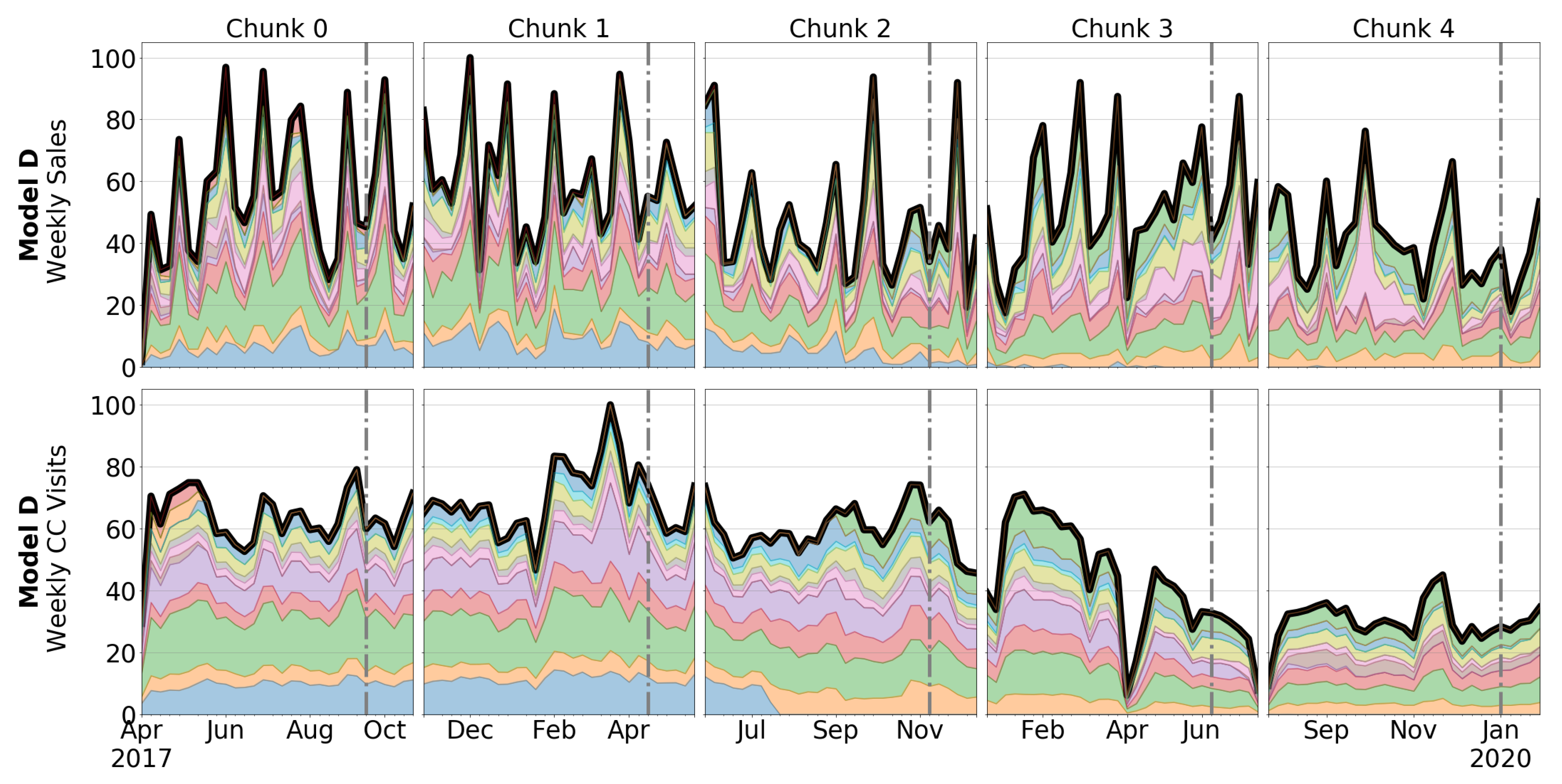
3.1. Automotive OEM and Car Model Description
3.2. Dataset Description
4. Methodology
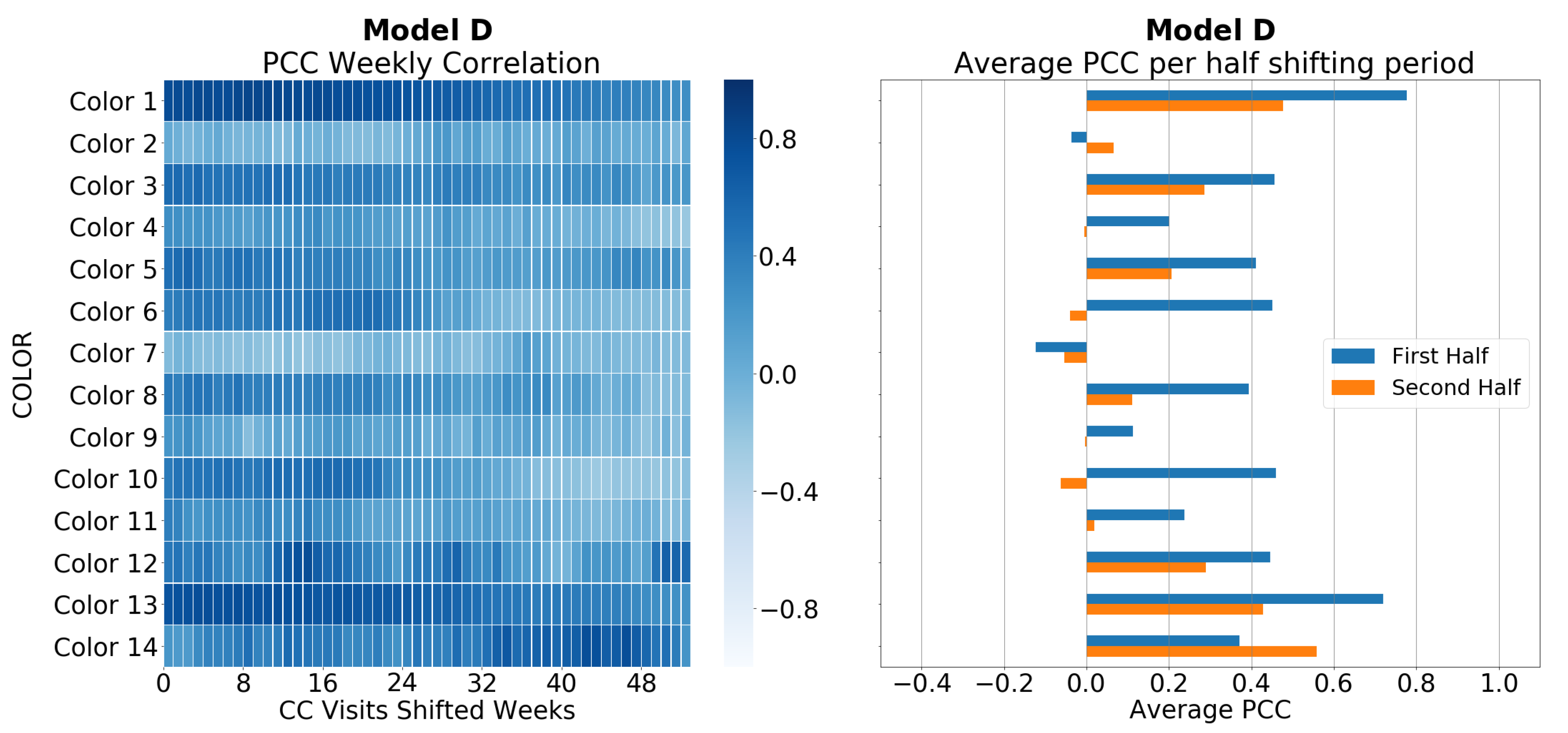
4.1. Correlation between Sales and CC Data
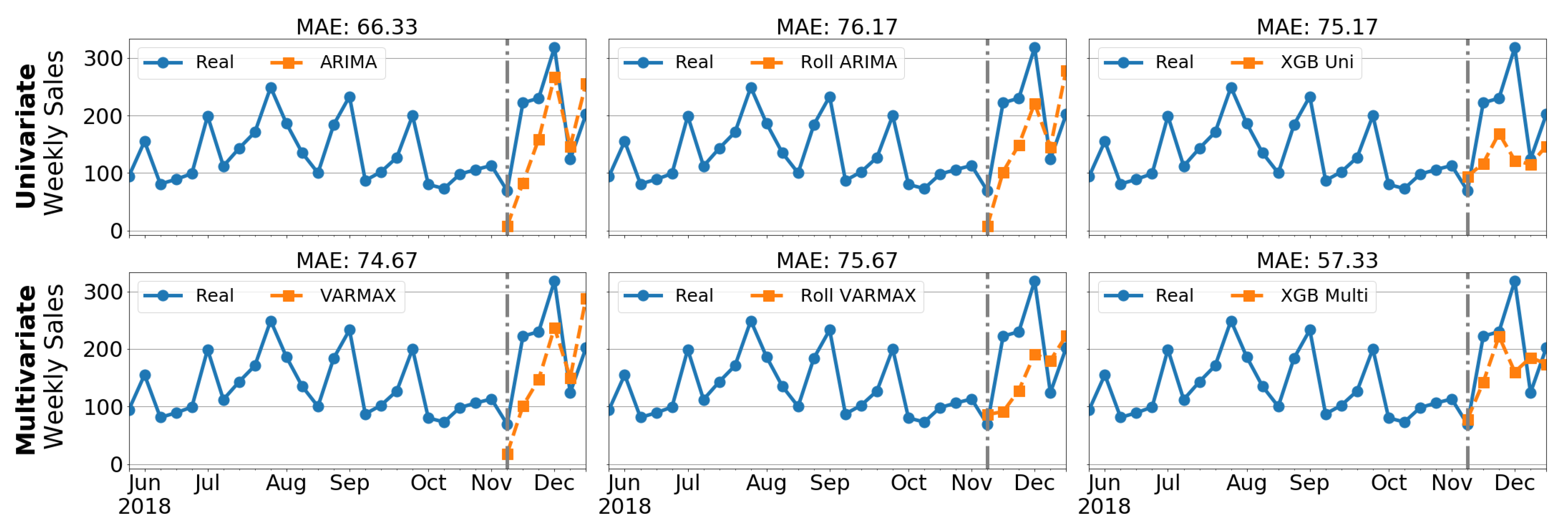
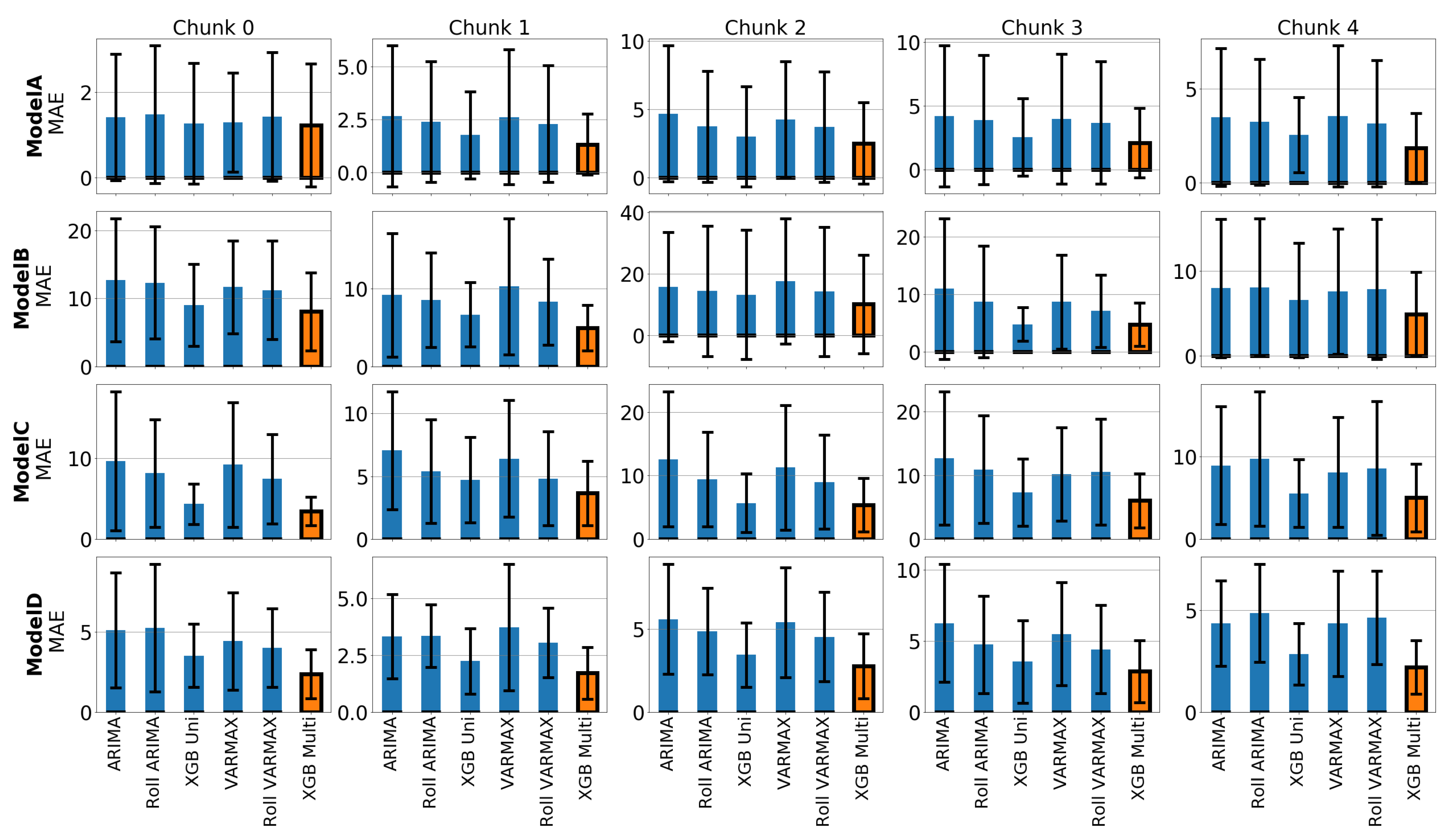
4.2. Forecasting Techniques
- (Roll) ARIMA—Univariate: Statistical model constructed by (p) the dependent relationship between an observation and some number of lagged observations; (d) the use of differencing of raw observations; (q) the dependency between an observation and a residual error from a moving average model applied to lagged observations. Future estimations come from past data, not from independent variables. See [38] for a detailed explanation of the algorithm.
- (Roll) VARMAX—Multivariate: Extension of the VARMA model that also includes the modeling of exogenous variables. The latter ones are also called covariates and can be thought of as parallel input sequences that have observations at the same time steps as the original series, see [39] for a detailed explanation of the algorithm.
- XGBoost—Univariate/Multivariate: Efficient implementation of gradient boosting algorithm. Gradient boosting refers to a class of ensemble machine learning constructed from decision tree models. Trees are added one at a time to the ensemble and fit to correct the prediction errors made by prior models. Models are fit using any arbitrary differentiable loss function and gradient descent optimization algorithm, see [40] for a detailed explanation of the algorithm.
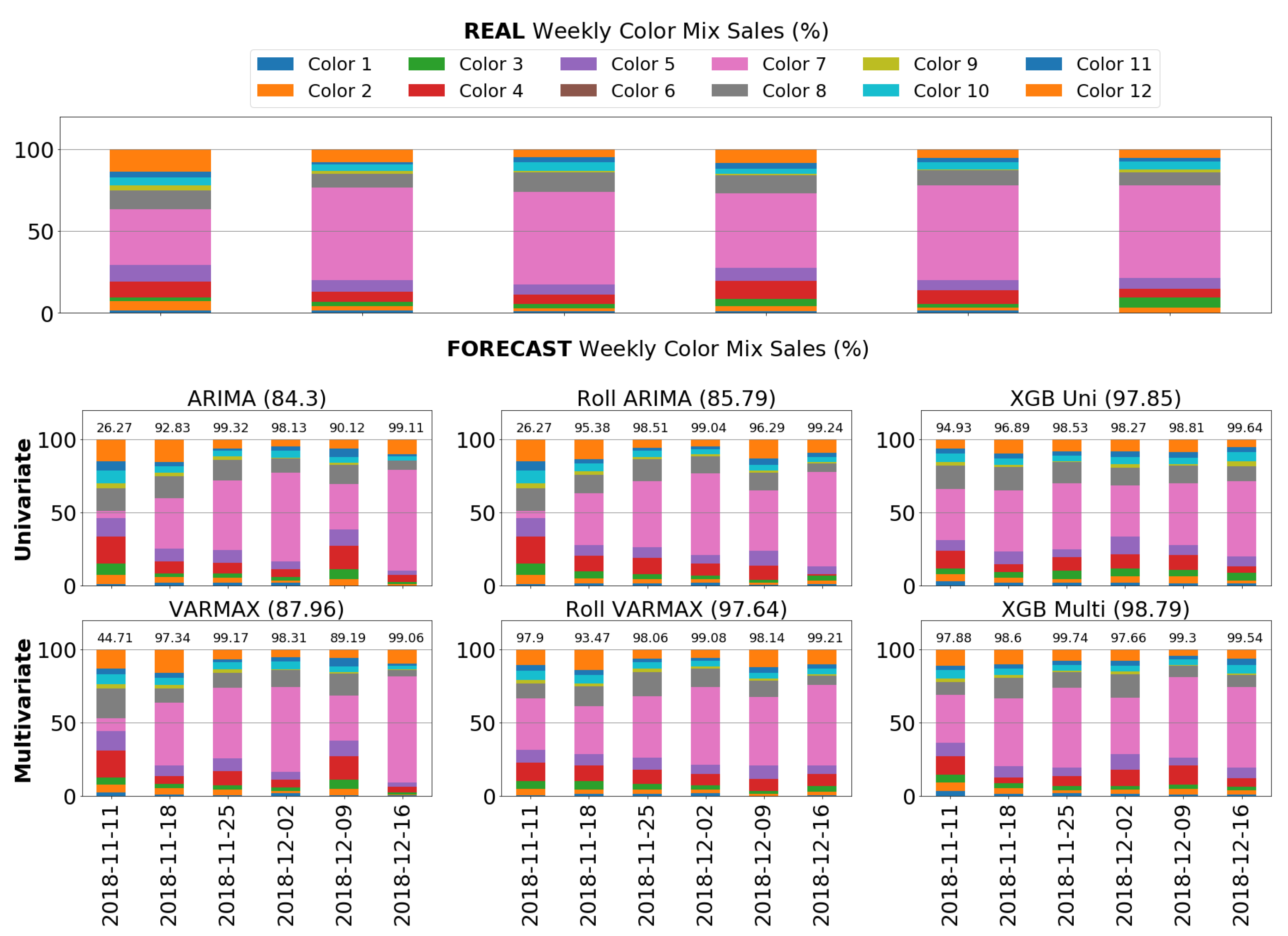
4.3. Weekly Color Mix Sales Procedure
5. Results
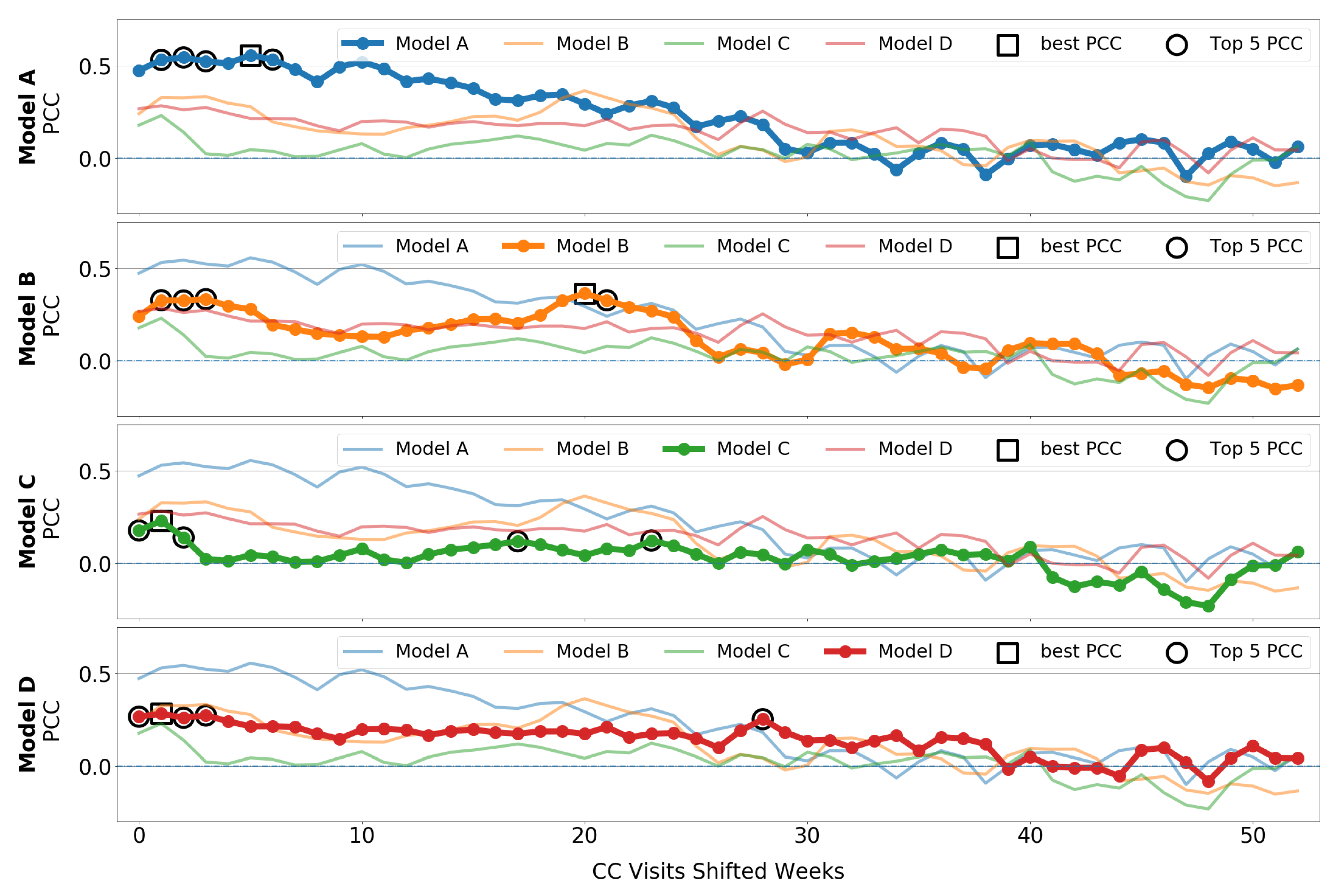
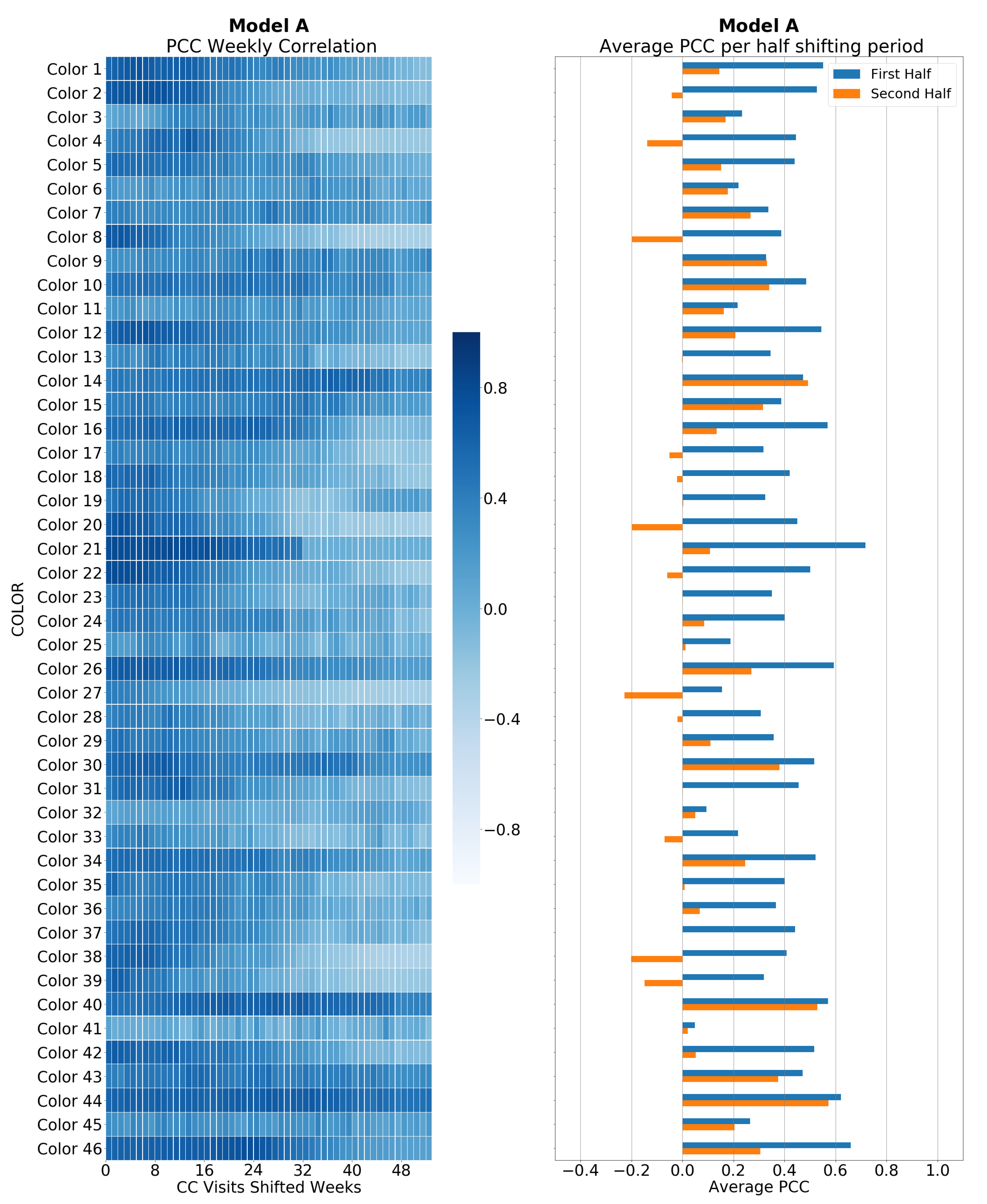
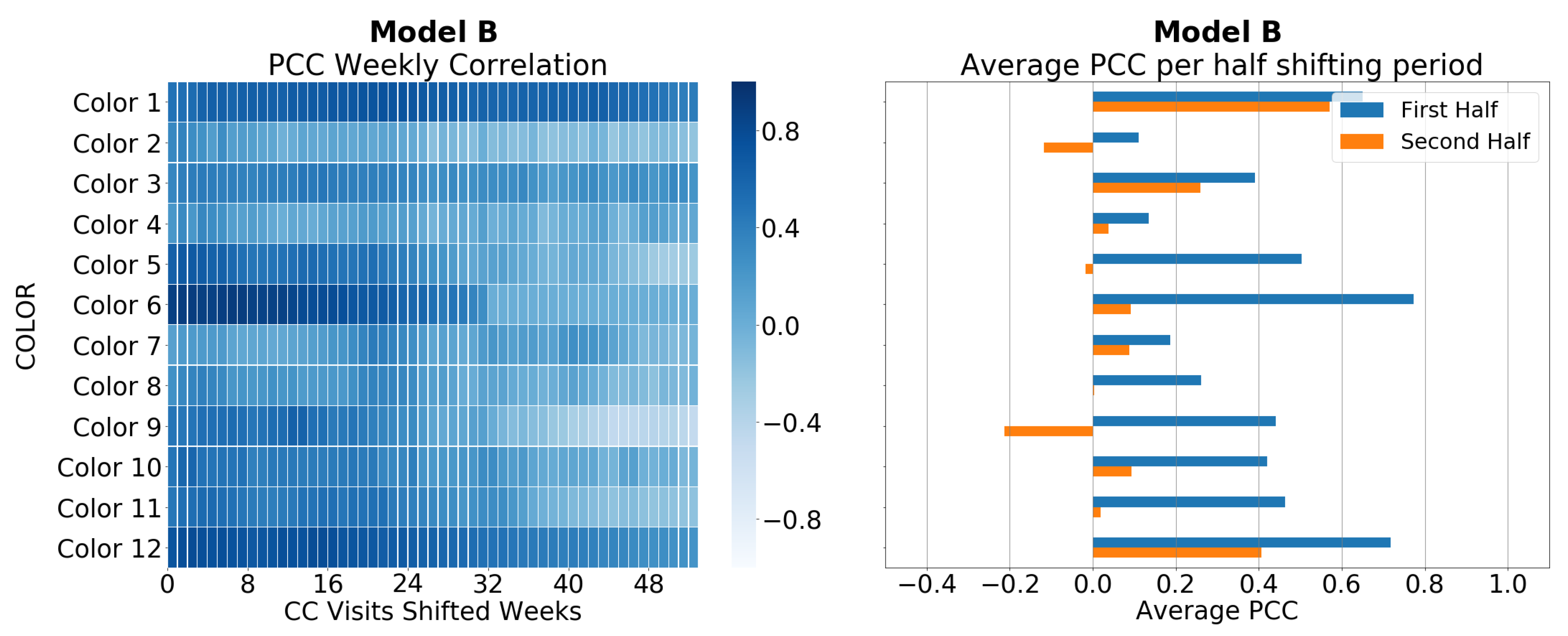
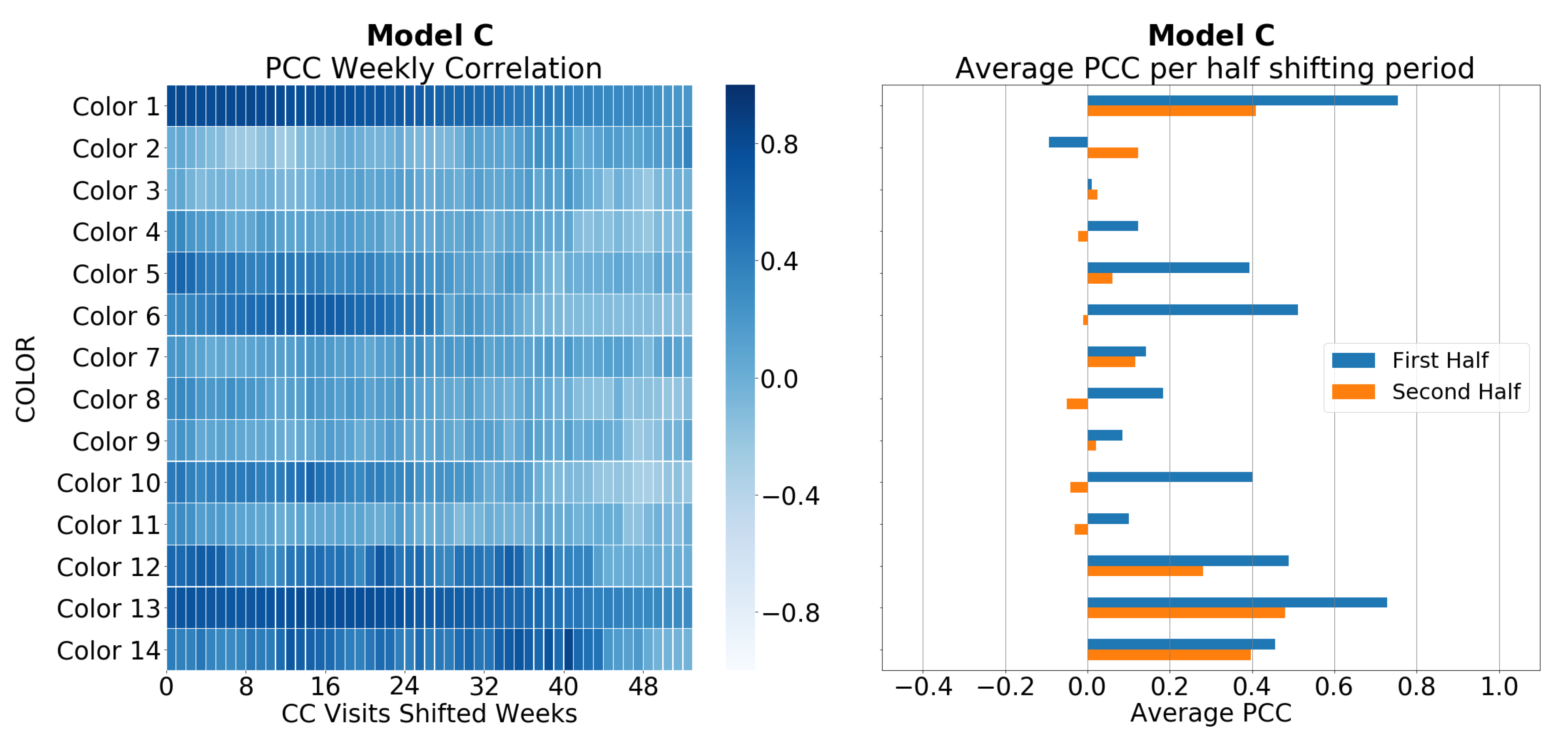
5.1. Correlation between Sales and CC Data
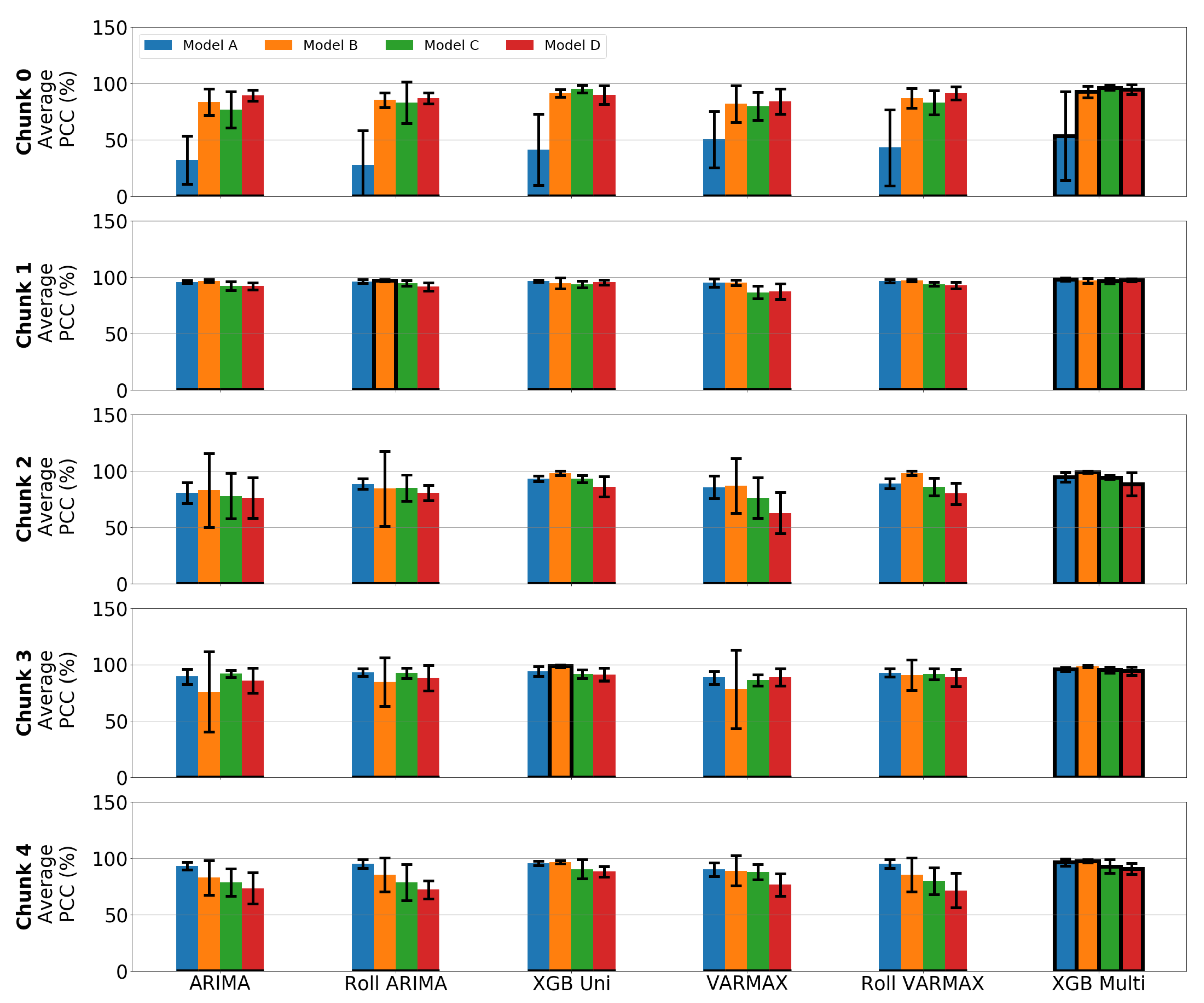
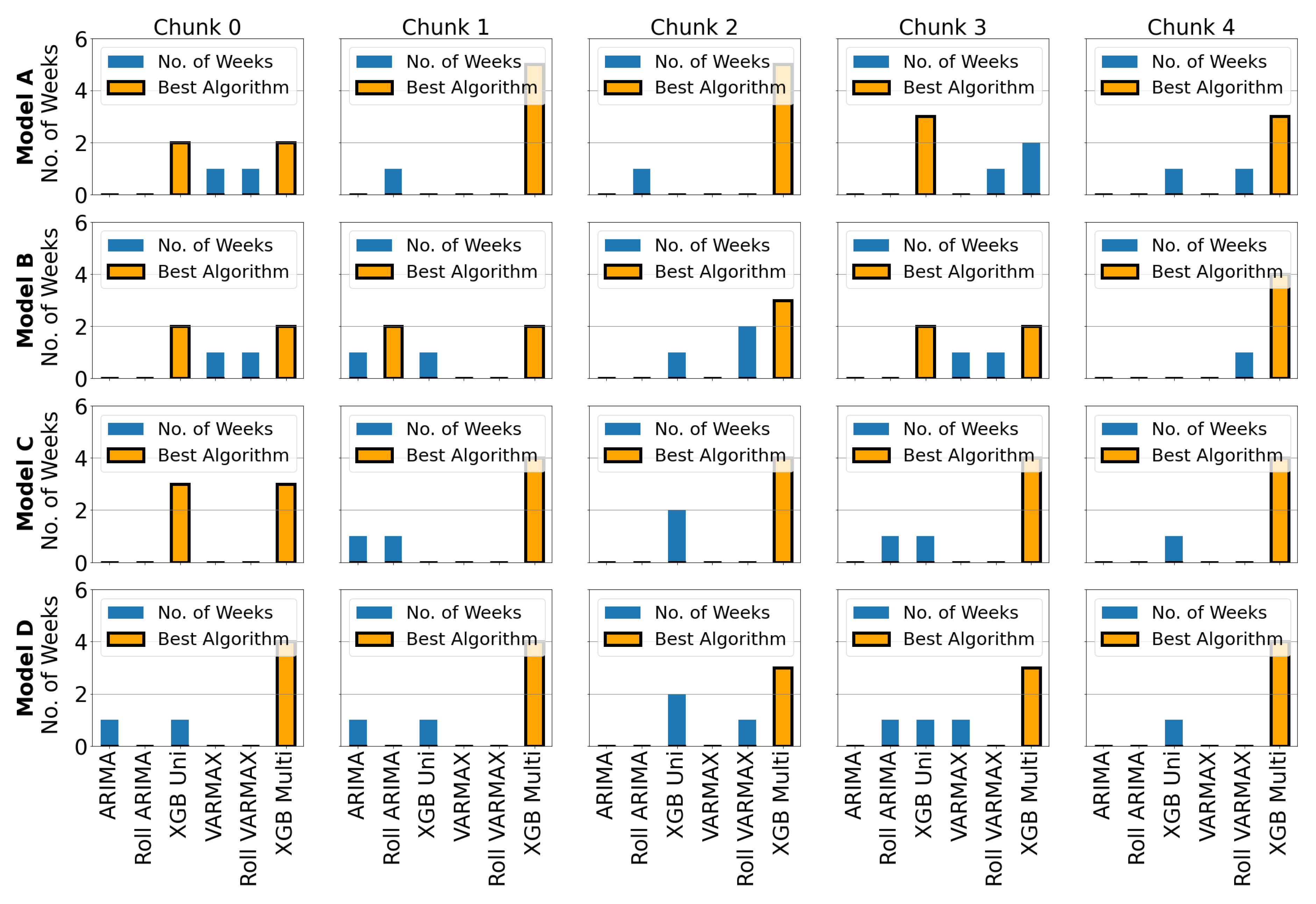
5.2. Forecasting Performance
5.3. Weekly Color Mix Sales Assessment
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| ARIMA | AutoRegressive Integrated Moving Average |
| BTS | Build-to-Stock |
| CC | Car Configurator |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| ML | Machine Learning |
| OEMs | Original Equipment Manufacturers |
| PCC | Pearson Correlation Coefficient |
| RMSE | Root Mean Squared Error |
| VARMAX | Vector AutoRegressive Moving Average eXogenous |
| XGBoost | eXtreme Gradient Boosting |
References
- Zhang, Y.; Hara, T. Predicting E-commerce Item Sales With Web Environment Temporal Background. In Proceedings of the 24th International Conference on Business Information Systems, BIS 2021, Hannover, Germany, 15–17 June 2021; Abramowicz, W., Auer, S., Lewanska, E., Eds.; 2021; pp. 233–243. [Google Scholar] [CrossRef]
- Huang, Y.T.; Pai, P.F. Using the Least Squares Support Vector Regression to Forecast Movie Sales with Data from Twitter and Movie Databases. Symmetry 2020, 12, 625. [Google Scholar] [CrossRef] [Green Version]
- Ling, L.; Zhang, D.; Chen, S.; Mugera, A. Can online search data improve the forecast accuracy of pork price in China? J. Forecast. 2020, 39, 671–686. [Google Scholar] [CrossRef]
- Havranek, T.; Zeynalov, A. Forecasting tourist arrivals: Google Trends meets mixed-frequency data. Tour. Econ. 2019, 27, 129–148. [Google Scholar] [CrossRef] [Green Version]
- Sujo, J.; Ribé, E.; Cardona, X. CAIT: A Predictive Tool for Supporting the Book Market Operation Using Social Networks. Appl. Sci. 2021, 12, 366. [Google Scholar] [CrossRef]
- Beracha, E.; Wintoki, M.B. Forecasting residential real estate price changes from online search activity. J. Real Estate Res. 2013, 35, 283–312. [Google Scholar] [CrossRef]
- Sun, D.; Du, Y.; Xu, W.; Zuo, M.; Zhang, C.; Zhou, J. Combining Online News Articles and Web Search to Predict the Fluctuation of Real Estate Market in Big Data Context. Pac. Asia J. Assoc. Inf. Syst. 2013, 6, 19–37. [Google Scholar] [CrossRef]
- Dietzel, M.; Braun, N.; Schäfers, W. Sentiment-based commercial real estate forecasting with Google search volume data. J. Prop. Invest. Financ. 2014, 32, 540–569. [Google Scholar] [CrossRef] [Green Version]
- Wei, Y.; Cao, Y. Forecasting house prices using dynamic model averaging approach: Evidence from China. Econ. Model. 2017, 61, 147–155. [Google Scholar] [CrossRef]
- Venkataraman, M.; Panchapagesan, V.; Jalan, E. Does internet search intensity predict house prices in emerging markets? A case of India. Prop. Manag. 2018, 36, 103–118. [Google Scholar] [CrossRef]
- Rizun, N.; Baj-Rogowska, A. Can Web Search Queries Predict Prices Change on the Real Estate Market? IEEE Access 2021, 9, 70095–70117. [Google Scholar] [CrossRef]
- Fogliatto, F.S.; da Silveira, G.J.C.; Borenstein, D. The mass customization decade: An updated review of the literature. Int. J. Prod. Econ. 2012, 138, 14–25. [Google Scholar] [CrossRef]
- Pil, F.; Holweg, M. The Second Century Reconnecting Customer and Value Chain through Build-to-Order Moving beyond Mass and Lean Production in the Auto Industry; The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar] [CrossRef]
- Zhang, L.; Lee, C.; Akhtar, P. Towards customization: Evaluation of integrated sales, product, and production configuration. Int. J. Prod. Econ. 2020, 229, 107775. [Google Scholar] [CrossRef]
- Sa-Ngasoongsong, A.; Bukkapatnam, S.; Kim, J.; Iyer, P.; Suresh, R.P. Multi-step sales forecasting in automotive industry based on structural relationship identification. Int. J. Prod. Econ. 2012, 140, 875–887. [Google Scholar] [CrossRef]
- Wochner, S.; Grunow, M.; Staeblein, T.; Stolletz, R. Planning for Ramp-ups and New Product Introductions in the Automotive Industry: Extending Sales and Operations Planning. Int. J. Prod. Econ. 2016, 182, 372–383. [Google Scholar] [CrossRef]
- Irwin, J. Survey Shows Color Key Factor for 88% of Vehicle Shoppers. Available online: https://www.wardsauto.com/dealers/survey-shows-color-key-factor-88-vehicle-shoppers (accessed on 23 June 2021).
- Bravais, A. Analyse Mathématique sur les Probabilités des Erreurs de Situation d’un Point; Impr. Royale: Paris, France, 1844. [Google Scholar]
- Spearman, C. The proof and measurement of association between two things. By C. Spearman, 1904. Am. J. Psychol. 1987, 100, 441–471. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Sun, S.; Zhang, C.; Zhang, Y. Traffic Flow Forecasting Using a Spatio-temporal Bayesian Network Predictor. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; pp. 273–278. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, W.; Ghadimi, N. Electricity Load Forecasting by an Improved Forecast Engine for Building Level Consumers. Energy 2017, 139, 18–30. [Google Scholar] [CrossRef]
- Sheugh, L.; Alizadeh, S. A note on pearson correlation coefficient as a metric of similarity in recommender system. In Proceedings of the 2015 AI & Robotics (IRANOPEN), Qazvin, Iran, 12 April 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Goel, S.; Hofman, J.M.; Lahaie, S.; Pennock, D.M.; Watts, D.J. Predicting consumer behavior with Web search. Proc. Natl. Acad. Sci. USA 2010, 107, 17486–17490. [Google Scholar] [CrossRef] [Green Version]
- Bordino, I.; Battiston, S.; Caldarelli, G.; Cristelli, M.; Ukkonen, A.; Weber, I. Web Search Queries Can Predict Stock Market Volumes. PLoS ONE 2012, 7, e040014. [Google Scholar] [CrossRef] [Green Version]
- Wei, D.; Geng, P.; Ying, L.; Shuaipeng, L. A prediction study on e-commerce sales based on structure time series model and web search data. In Proceedings of the 26th Chinese Control and Decision Conference (2014 CCDC), Changsha, China, 31 May–2 June 2014; pp. 5346–5351. [Google Scholar] [CrossRef]
- Punjabi, S.; Shetty, V.; Pranav, S.; Yadav, A. Sales Prediction using Online Sentiment with Regression Model. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; pp. 209–212. [Google Scholar] [CrossRef]
- Pai, P.F.; Liu, C.H. Predicting Vehicle Sales by Sentiment Analysis of Twitter Data and Stock Market Values. IEEE Access 2018, 6, 57655–57662. [Google Scholar] [CrossRef]
- Varian, H.; Choi, H. Predicting the Present with Google Trends. Econ. Rec. 2009, 88, 2–9. [Google Scholar] [CrossRef] [Green Version]
- Kim, D.; Woo, J.; Shin, J.; Lee, J.; Kim, Y. Can search engine data improve accuracy of demand forecasting for new products? Evidence from automotive market. Ind. Manag. Data Syst. 2019, 119, 1089–1103. [Google Scholar] [CrossRef]
- Wachter, P.; Widmer, T.; Klein, A. Predicting Automotive Sales using Pre-Purchase Online Search Data. ACSIS 2019, 18, 569–577. [Google Scholar] [CrossRef] [Green Version]
- Fantazzini, D.; Toktamysova, Z. Forecasting German car sales using Google data and multivariate models. Int. J. Prod. Econ. 2015, 170, 97–135. [Google Scholar] [CrossRef] [Green Version]
- Graevenitz, G.; Helmers, C.; Millot, V.; Turnbull, O. Does Online Search Predict Sales? Evidence from Big Data for Car Markets in Germany and the UK. SSRN Electron. J. 2016. [Google Scholar] [CrossRef]
- Wijnhoven, F.; Plant, O. Sentiment Analysis and Google Trends Data for Predicting Car Sales. In Proceedings of the 38th International Conference on Information Systems, Seoul, Korea, 10 December 2017; pp. 1–16. [Google Scholar]
- Zhang, C.; Tian, Y.X.; Fan, L.W. Improving the Bass model’s predictive power through online reviews, search traffic and macroeconomic data. Ann. Oper. Res. 2020, 295, 881–922. [Google Scholar] [CrossRef]
- SEAT, S.A. (2020, February 12) Informe Anual 2019. Available online: https://www.seat.es/content/dam/countries/es/seat-website/sobre-seat/reporte-anual/pdf/others-annual_report_2019_full-NA-NA-NA-march-2020.pdf (accessed on 29 June 2022).
- Gonçalves, J.; Cortez, P.; Carvalho, M.; Frazão, N. A multivariate approach for multi-step demand forecasting in assembly industries: Empirical evidence from an automotive supply chain. Decis. Support Syst. 2020, 142, 113452. [Google Scholar] [CrossRef]
- Perktold, J.; Seabold, S.; Taylor, J. statsmodels.tsa.arima.model.ARIMA. Available online: https://www.statsmodels.org/devel/generated/statsmodels.tsa.arima.model.ARIMA.html (accessed on 29 June 2022).
- Perktold, J.; Seabold, S.; Taylor, J. statsmodels.tsa.statespace.varmax.VARMAX. Available online: https://www.statsmodels.org/devel/generated/statsmodels.tsa.statespace.varmax.VARMAX.html?highlight=varmax (accessed on 29 June 2022).
- XGBoost Developers. (Revision 5d92a7d9) XGBoost Documentation. Available online: https://xgboost.readthedocs.io/en/stable/index.html (accessed on 29 June 2022).
- Perktold, J.; Seabold, S.; Taylor, J. statsmodels.tsa.stattools.acf. Available online: https://www.statsmodels.org/devel/generated/statsmodels.tsa.stattools.acf.html?highlight=acf (accessed on 29 June 2022).
- Perktold, J.; Seabold, S.; Taylor, J. statsmodels.tsa.stattools.pacf. Available online: https://www.statsmodels.org/devel/generated/statsmodels.tsa.stattools.pacf.html?highlight=pacf (accessed on 29 June 2022).
- Perktold, J.; Seabold, S.; Taylor, J. statsmodels.tsa.stattools.adfuller. Available online: https://www.statsmodels.org/devel/generated/statsmodels.tsa.stattools.adfuller.html?highlight=adfuller (accessed on 29 June 2022).




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Car Model | Car Segment | Number of Colors |
|---|---|---|
| Model A | B | 46 |
| Model B | B | 12 |
| Model C | C | 14 |
| Model D | C | 14 |
| Year | Sales | CC Visits | Car Model | Sales | CC Visits |
|---|---|---|---|---|---|
| 2017 | 19.61% | 26.79% | Model A | 26.08% | 23.12% |
| 2018 | 40.55% | 44.44% | Model B | 32.04% | 30.68% |
| 2019 | 36.53% | 26.70% | Model C | 28.16% | 30.93% |
| 2020 | 3.31% | 2.06% | Model D | 13.72% | 15.26% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
García Sánchez, J.M.; Vilasís Cardona, X.; Lerma Martín, A. Influence of Car Configurator Webpage Data from Automotive Manufacturers on Car Sales by Means of Correlation and Forecasting. Forecasting 2022, 4, 634-653. https://0-doi-org.brum.beds.ac.uk/10.3390/forecast4030034
García Sánchez JM, Vilasís Cardona X, Lerma Martín A. Influence of Car Configurator Webpage Data from Automotive Manufacturers on Car Sales by Means of Correlation and Forecasting. Forecasting. 2022; 4(3):634-653. https://0-doi-org.brum.beds.ac.uk/10.3390/forecast4030034
Chicago/Turabian StyleGarcía Sánchez, Juan Manuel, Xavier Vilasís Cardona, and Alexandre Lerma Martín. 2022. "Influence of Car Configurator Webpage Data from Automotive Manufacturers on Car Sales by Means of Correlation and Forecasting" Forecasting 4, no. 3: 634-653. https://0-doi-org.brum.beds.ac.uk/10.3390/forecast4030034