More Rule than Exception: Parallel Evidence of Ancient Migrations in Grammars and Genomes of Finno-Ugric Speakers


 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Genomic Dataset
2.2. Dataset Preparation
2.3. Principal Component Analysis
2.4. Genomic Distances
2.5. Linguistic Dataset
2.6. Linguistic Distances and Phylogenies
2.7. ChromoPainter and fineSTRUCTURE
2.8. Outgroup f3-Statistics
2.9. Modelling Admixture
3. Results
3.1. Linguistic Analyses
Syntactic Comparison
3.2. Genetic Comparison
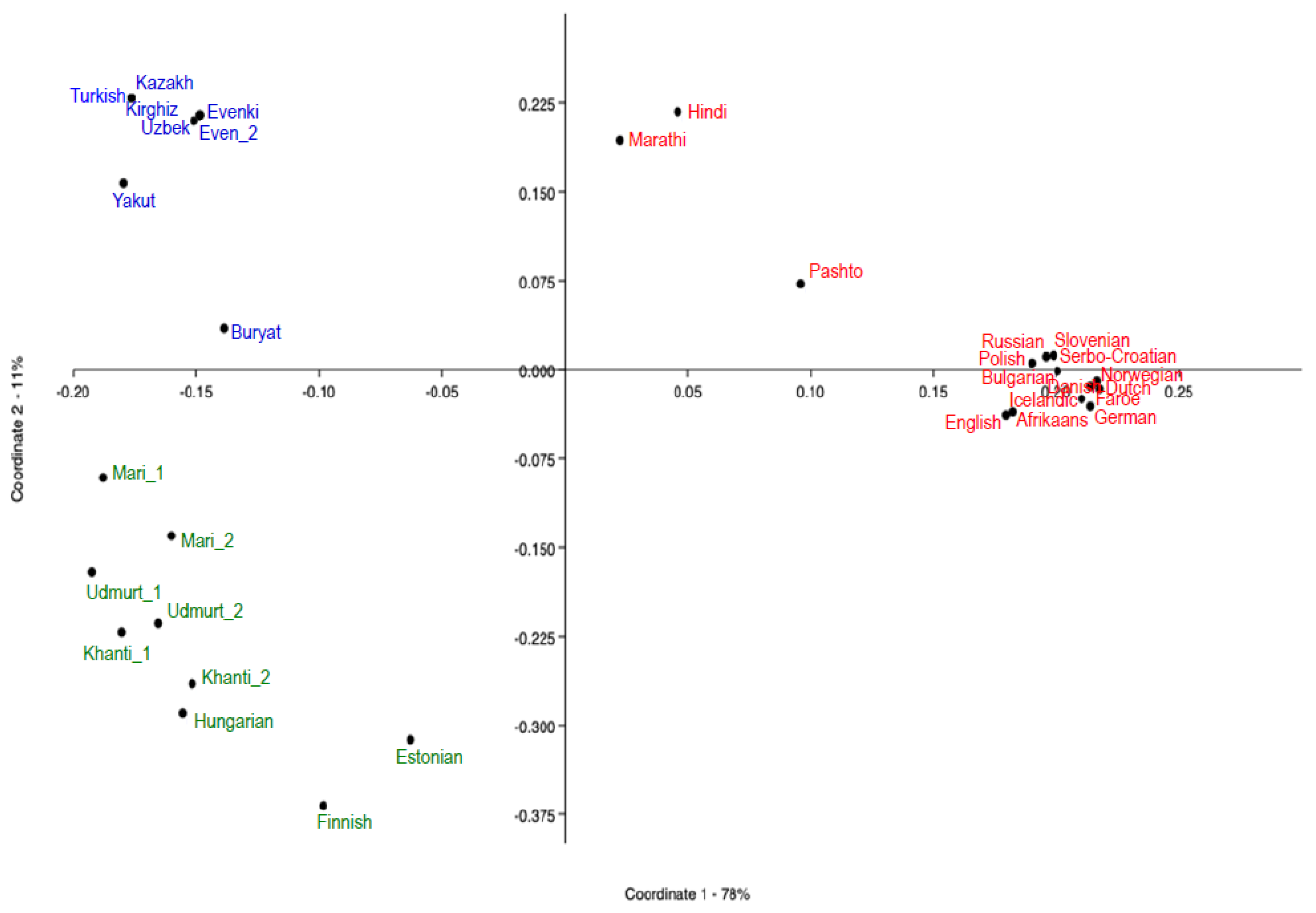
3.2.1. Population Structuring in Eurasia
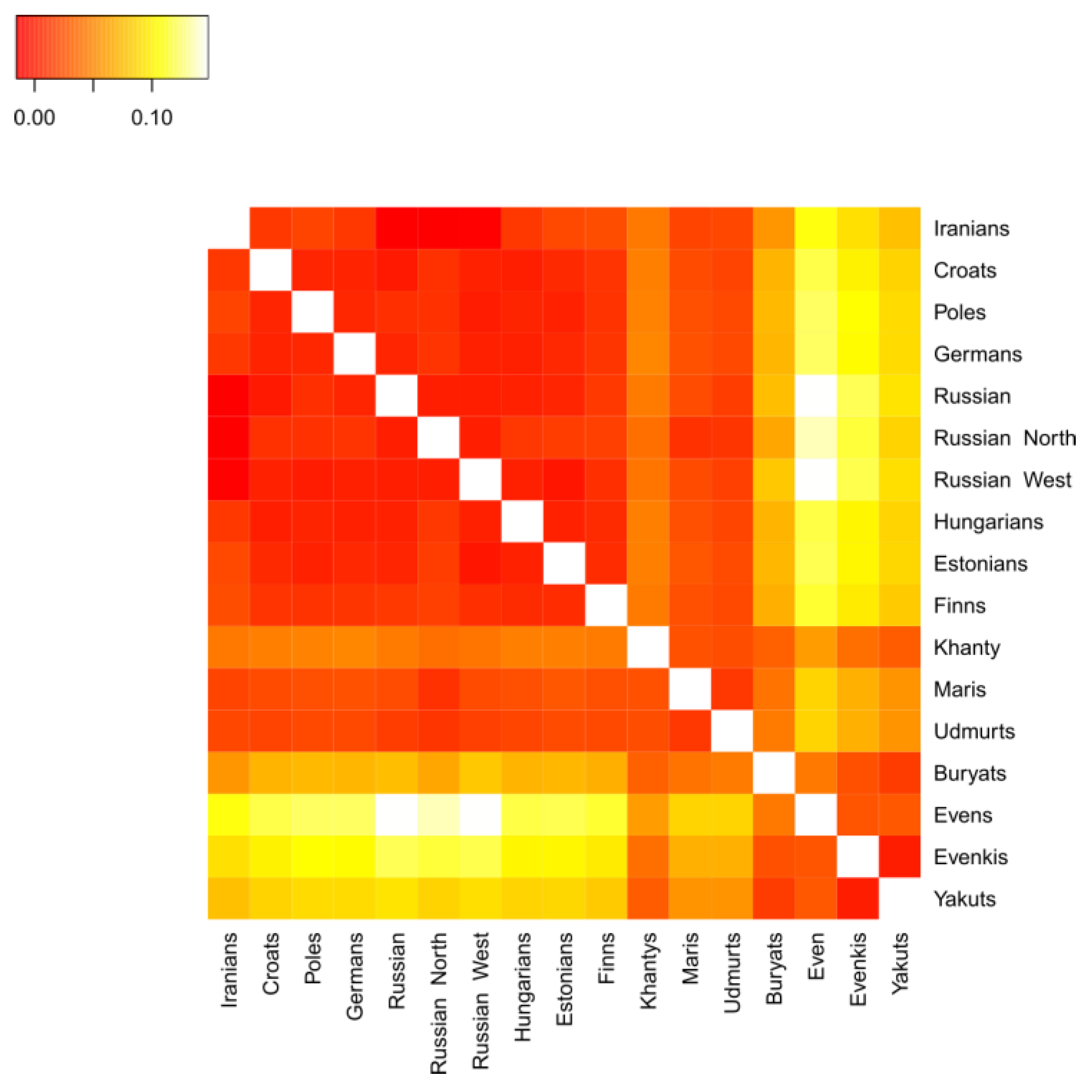
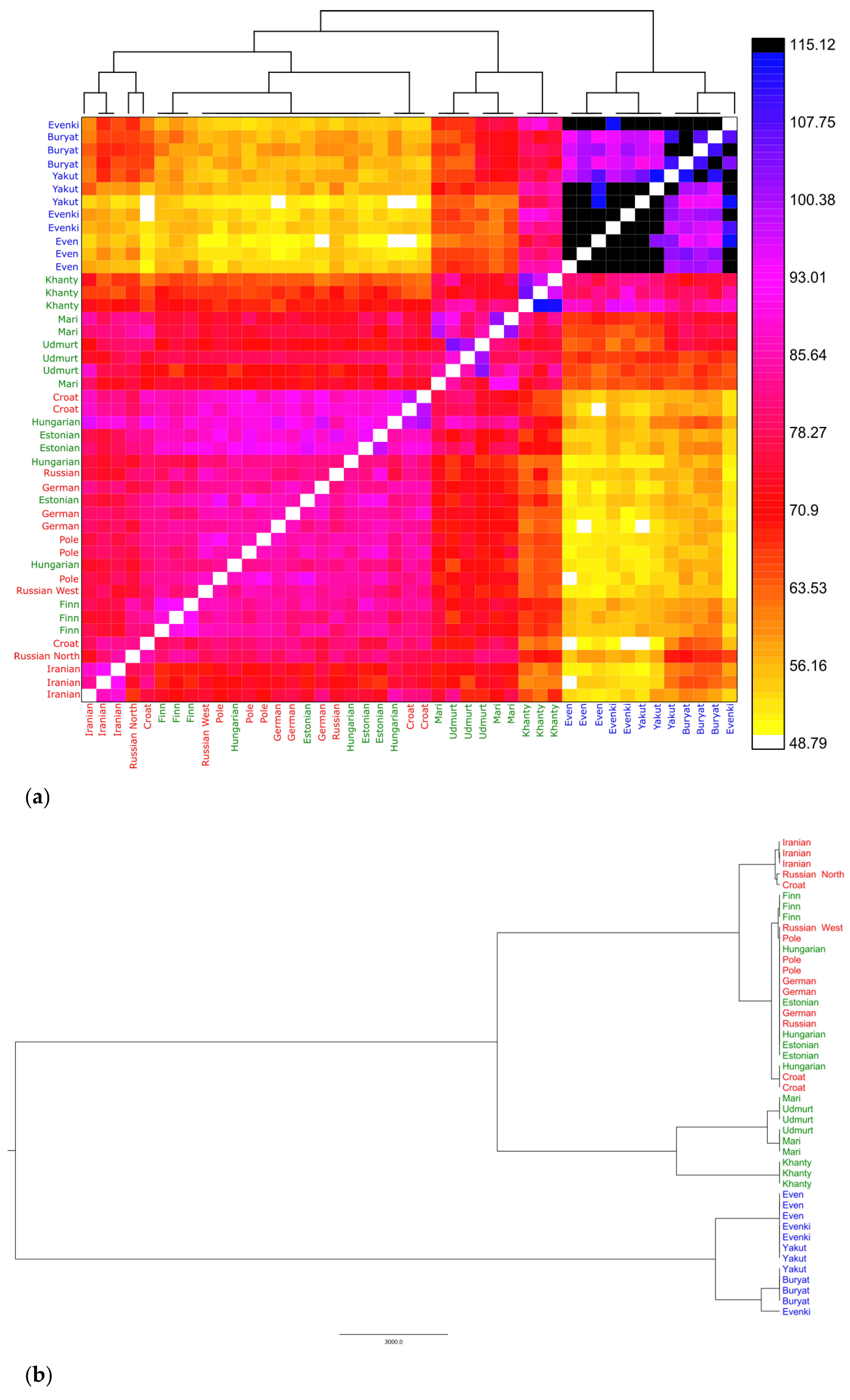
3.2.2. Genetic Distances between Populations
3.2.3. Shared Haplotypes
3.2.4. Affinities between Modern and Ancient Populations
4. Discussion
4.1. Syntactic Diversity
4.2. Genome Diversity
4.3. Comparison of Genetic and Linguistic Results
4.4. Demographic Scenarios: Linguistic and Genetic Evidence
4.5. Speculations on the Diffusion of IE into Europe
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Darwin, C. On the Origin of Species by Means of Natural Selection, or the Preservation of Favoured Races in the Struggle for Life; John Murray: London, UK, 1859. [Google Scholar]
- Sokal, R.R. Genetic, geographic, and linguistic distances in Europe. Proc. Natl. Acad. Sci. USA 1988, 85, 1722–1726. [Google Scholar] [CrossRef] [Green Version]
- Barbujani, G.; Pilastro, A. Genetic evidence on origin and dispersal of human populations speaking languages of the Nostratic macrofamily. Proc. Natl. Acad. Sci. USA 1993, 90, 4670–4673. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Longobardi, G.; Ghirotto, S.; Guardiano, C.; Tassi, F.; Benazzo, A.; Ceolin, A.; Barbujani, G. Across language families: Genome diversity mirrors linguistic variation within Europe. Am. J. Phys. Anthr. 2015, 157, 630–640. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Creanza, N.; Ruhlen, M.; Pemberton, T.J.; Rosenberg, N.A.; Feldman, M.W.; Ramachandran, S. A comparison of worldwide phonemic and genetic variation in human populations. Proc. Natl. Acad. Sci. USA 2015, 112, 1265–1272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Renfrew, C. Archaeology, Genetics and Linguistic Diversity. R. Anthropol. Inst. Gt. Br. Irel. 1992, 27, 445. [Google Scholar] [CrossRef]
- Cavalli-Sforza, L.L.; Piazza, A.; Menozzi, P.; Mountain, J. Reconstruction of human evolution: Bringing together genetic, archaeological, and linguistic data. Proc. Natl. Acad. Sci. USA 1988, 85, 6002–6006. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Poloni, E.S.; Passarino, G.; Santachiara-Benerecetti, A.S.; Langaney, A.; Excoffier, L.; Poloni, E. Human Genetic Affinities for Y-Chromosome P49a,f/Taql Haplotypes Show Strong Correspondence with Linguistics. Am. J. Hum. Genet. 1997, 61, 1015–1035. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Belle, E.M.S.; Barbujani, G. Worldwide analysis of multiple microsatellites: Language diversity has a detectable influence on DNA diversity. Am. J. Phys. Anthr. 2007, 133, 1137–1146. [Google Scholar] [CrossRef]
- Henn, B.M.; Botigué, L.R.; Gravel, S.; Wang, W.; Brisbin, A.; Byrnes, J.K.; Fadhlaoui-Zid, K.; Zalloua, P.A.; Moreno-Estrada, A.; Bertranpetit, J.; et al. Genomic ancestry of North Africans supports back-to-Africa migrations. PLoS Genet. 2012, 8, e1002397. [Google Scholar] [CrossRef] [Green Version]
- Gyarmathi, S. Affinitas Linguae Hungaricae Cum Linguis Fennicae Originis Grammatice Demonstrata; J.C. Dieterich: Göttingen, Germany, 1799. [Google Scholar]
- Ceolin, A. Significance testing of the Altaic family. Diachronica 2019, 36, 299–336. [Google Scholar] [CrossRef]
- Marcantonio, A. The Uralic Language Family: Facts, Myths and Statistics; Blackwell: Oxford, UK, 2002. [Google Scholar]
- Nettle, D.; Harriss, L. Genetic and Linguistic Affinities between Human Populations in Eurasia and West Africa. Hum. Biol. 2003, 75, 331–344. [Google Scholar] [CrossRef] [PubMed]
- Ringe, D.; Warnow, T.; Taylor, A. Indo-European and computational cladistics. Trans. Philol. Soc. 2002, 100, 59–129. [Google Scholar] [CrossRef] [Green Version]
- Gray, R.D.; Atkinson, Q.D. Language-tree divergence times support the Anatolian theory of Indo-European origin. Nature 2003, 426, 435–439. [Google Scholar] [CrossRef] [PubMed]
- Gray, R.D.; Drummond, A.J.; Greenhill, S.J. Language phylogenies reveal expansion pulses and pauses in Pacific settlement. Science 2009, 323, 479–483. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jäger, G. Support for linguistic macrofamilies from weighted sequence alignment. Proc. Natl. Acad. Sci. USA 2015, 112, 12752–12757. [Google Scholar] [CrossRef] [Green Version]
- Longobardi, G. Methods in parametric linguistics and cognitive history. Linguistic Var. Yearb. 2003, 3, 101–138. [Google Scholar] [CrossRef]
- Guardiano, C.; Longobardi, G. Parametric comparison and language taxonomy. In Grammaticalization and Parametric Variation; Battlori, M., Picallo, C., Roca, F., Eds.; Oxford University Press: Oxford, UK, 2005. [Google Scholar]
- Longobardi, G.; Guardiano, C. Evidence for syntax as a signal of historical relatedness. Lingua 2009, 119, 1679–1706. [Google Scholar] [CrossRef]
- Longobardi, G.; Guardiano, C.; Silvestri, G.; Boattini, A.; Ceolin, A. Toward a syntactic phylogeny of modern Indo-European languages. J. Hist. Linguist. 2013, 3, 122–152. [Google Scholar] [CrossRef] [Green Version]
- Longobardi, G.; Guardiano, C. Phylogenetic reconstruction in syntax: The Parametric Comparison Method. In The Cambridge Handbook of Historical Syntax; Ledgeway, A., Roberts, I., Eds.; Cambridge University Press: Cambridge, UK, 2017; pp. 241–272. ISBN 9781107049604. [Google Scholar]
- Ceolin, A.; Guardiano, C.; Irimia, M.-A.; Longobardi, G. Formal syntax and deep history. Front. Psychol. 2020, 11, 2384. [Google Scholar]
- Kylstra, A.D.; Hahmo, S.-L.; Hofstra, T.; Nikkilä, O. Lexikon der 2110 Älteren Germanischen Lehnwörter in den Ostseefinnischen Sprachen. In Band I: A-J; Rodopi: Amsterdam, The Netherlands, 1991. [Google Scholar]
- Koivulehto, J. The earliest contacts between Indo-European and Uralic speakers in the light of lexical loans. In Early Contacts between Uralic and Indo-European: Linguistic and Archaeological Considerations; Carpelan, C., Parpola, A., Petteri, K., Eds.; Suomalais-Ugrilainen Seura: Helsinki, Finland, 2001; pp. 235–263. [Google Scholar]
- Sammalahti, P. The Indo-European loanwords in Saami. In Early Contacts between Uralic and Indo-European: Linguistic and Archaeological Considerations; Carpelan, C., Parpola, A., Petteri, K., Eds.; Suomalais-Ugrilainen Seura: Helsinki, Finland, 2001; pp. 397–415. [Google Scholar]
- Kallio, P. Phonetic Uralisms in Indo-European. In Early Contacts between Uralic and Indo-European: Linguistic and Archaeological Considerations; Carpelan, C., Parpola, A., Petteri, K., Eds.; Suomalais-Ugrilainen Seura: Helsinki, Finland, 2001; pp. 221–234. [Google Scholar]
- Kallio, P. The Diversification of Proto-Finnic. In Fibula, Fabula, Fact: The Viking Age in Finland; Ahola, J., Frog, C.T., Eds.; Studia Finnica: Helsinki, Finland, 2014; pp. 155–168. [Google Scholar]
- Gimbutas, M. The Three Waves of Kurgan People into Old Europe, 4500–2500 BC. Archives Suisses D’anthropologie Genérale 1979, 43, 113–137. [Google Scholar]
- Anthony, D. The Horse, the Wheel and Language: How Bronze-Age Riders from the Eurasian Steppes Shaped the Modern World; Princeton University Press: Princeton, NJ, USA, 2007. [Google Scholar]
- Ammerman, A.J.; Cavalli-Sforza, L.L. The Neolithic Transition and the Genetics of Populations in Europe; Princeton University Press: Princeton, NJ, USA, 1984. [Google Scholar]
- Renfrew, C. Archaeology and Language: The Puzzle of Indo-European Origins; Jonathan Cape: Lonon, UK, 1987. [Google Scholar]
- Heggarty, P. Indo-European and the Ancient DNA Revolution. In Proceedings of the Workshop on Indo-European Origins Held at the Max Planck Institute for Evolutionary Anthropology, Leipzig, Germany, 2–3 December 2013. [Google Scholar]
- Haak, W.; Lazaridis, I.; Patterson, N.; Rohland, N.; Mallick, S.; Llamas, B.; Brandt, G.; Nordenfelt, S.; Harney, E.; Stewardson, K.; et al. Massive migration from the steppe was a source for Indo-European languages in Europe. Nature 2015, 522, 207–211. [Google Scholar] [CrossRef] [Green Version]
- Allentoft, M.E.; Sikora, M.; Sjögren, K.-G.; Rasmussen, S.; Rasmussen, M.; Stenderup, J.; Damgaard, P.B.; Schroeder, H.; Ahlström, T.; Vinner, L.; et al. Population genomics of Bronze Age Eurasia. Nature 2015, 522, 167–172. [Google Scholar] [CrossRef]
- Narasimhan, V.M.; Patterson, N.; Moorjani, P.; Rohland, N.; Bernardos, R.; Mallick, S.; Lazaridis, I.; Nakatsuka, N.; Olalde, I.; Lipson, M.; et al. The formation of human populations in South and Central Asia. Science 2019, 365, eaat7487. [Google Scholar] [CrossRef]
- De Barros Damgaard, P.; Martiniano, R.; Kamm, J.; Moreno-Mayar, J.V.; Kroonen, G.; Peyrot, M.; Barjamovic, G.; Rasmussen, S.; Zacho, C.; Baimukhanov, N.; et al. The first horse herders and the impact of early Bronze Age steppe expansions into Asia. Science 2018, 360, eaar7711. [Google Scholar] [CrossRef] [Green Version]
- Janhunen, J. Indo-Uralic and Ural-Altaic: On the diachronic implications of areal typology. In Early Contacts between Uralic and Indo-European: Linguistic and Archaeological Considerations; Carpelan, C., Parpola, A., Petteri, K., Eds.; Suomalais-Ugrilainen Seura: Helsinki, Finland, 2001; pp. 207–220. [Google Scholar]
- Pagani, L.; Lawson, J.; Jagoda, E.; Mörseburg, A.; Clemente, F.; Hudjashov, G.; DeGiorgio, M.; Eriksson, A.; Saag, L.; Wall, J.; et al. Genomic analyses inform on migration events during the peopling of Eurasia. Nature 2016. [Google Scholar] [CrossRef] [Green Version]
- Mathieson, I.; Lazaridis, I.; Rohland, N.; Mallick, S.; Patterson, N.; Roodenberg, S.A.; Harney, E.; Stewardson, K.; Fernandes, D.; Novak, M.; et al. Genome-wide patterns of selection in 230 ancient Eurasians. Nature 2015, 528, 499–503. [Google Scholar] [CrossRef] [Green Version]
- Delaneau, O.; Ongen, H.; Brown, A.A.; Fort, A.; Panousis, N.I.; Dermitzakis, E.T. A complete tool set for molecular QTL discovery and analysis. Nat. Commun. 2017, 8, 15452. [Google Scholar] [CrossRef] [Green Version]
- Benazzo, A.; Panziera, A.; Bertorelle, G. 4P: Fast computing of population genetics statistics from large DNA polymorphism panels. Ecol. Evol. 2015, 5, 172–175. [Google Scholar] [CrossRef]
- Guardiano, C.; Longobardi, G. Parameter theory and parametric comparison. In The Oxford Handbook of Universal Grammar; Roberts, I., Ed.; Oxford University Press: Oxford, UK, 2017; pp. 377–398. [Google Scholar]
- Guardiano, C.; Longobardi, G.; Cordoni, G.; Crisma, P. Formal syntax as a phylogenetic method. In The Handbook of Historical Linguistics II; Janda, R.D., Joseph, B.D., Vance, B.S., Eds.; John Wiley & Sons, Inc: New York, NY, USA, 2020; pp. 145–182. [Google Scholar]
- Crisma, P.; Guardiano, C.; Longobardi, G. Syntactic parameters and language learnability. Stud. Saggi Linguist. 2020, 58, 99–130. [Google Scholar]
- Hammer, O.; Harper, D.; Ryan, P. PAST: Paleontological Statistics Software Package for Education and Data Analysis. Palaeontol. Electron. 2001, 4, 1–9. [Google Scholar]
- Felsenstein, J.; Felenstein, J. Inferring Phylogenies; Sinauer Associates: Sunderland, MA, USA, 2004. [Google Scholar]
- Maddison, W.P.; Maddison, D.R. Mesquite: A Modular System for Evolutionary Analysis; Version 1. 2004. Available online: http://www.mesquiteproject.org (accessed on 11 December 2020).
- Bouckaert, R.; Vaughan, T.G.; Barido-Sottani, J.; Duchêne, S.; Fourment, M.; Gavryushkina, A.; Heled, J.; Jones, G.; Kühnert, D.; De Maio, N.; et al. BEAST 2.5: An advanced software platform for Bayesian evolutionary analysis. PLoS Comput. Biol. 2019, 15, e1006650. [Google Scholar] [CrossRef] [Green Version]
- Lawson, D.J.; Hellenthal, G.; Myers, S.; Falush, D. Inference of population structure using dense haplotype data. PLoS Genet. 2012, 8, 11–17. [Google Scholar] [CrossRef] [Green Version]
- Salminen, T. Problems in the taxonomy of the Uralic languages in the light of modern comparative studies. In Лингвистический беспредел: Сборник Статей к 70-летию АИ Кузнецовой; Издательство Московского университета: Moscow, Russia, 2002; pp. 44–55. [Google Scholar]
- Pimenoff, V.N.; Comas, D.; Palo, J.U.; Vershubsky, G.; Kozlov, A.; Sajantila, A. Northwest Siberian Khanty and Mansi in the junction of West and East Eurasian gene pools as revealed by uniparental markers. Eur. J. Hum. Genet. 2008, 16, 1254–1264. [Google Scholar] [CrossRef]
- Lazaridis, I.; Nadel, D.; Rollefson, G.; Merrett, D.C.; Rohland, N.; Mallick, S.; Fernandes, D.; Novak, M.; Gamarra, B.; Sirak, K.; et al. Genomic insights into the origin of farming in the ancient Near East. Nature 2016, 536, 419–424. [Google Scholar] [CrossRef] [Green Version]
- Tambets, K.; Yunusbayev, B.; Hudjashov, G.; Ilumäe, A.M.; Rootsi, S.; Honkola, T.; Vesakoski, O.; Atkinson, Q.; Skoglund, P.; Kushniarevich, A.; et al. Genes reveal traces of common recent demographic history for most of the Uralic-speaking populations. Genome Biol. 2018, 19, 139. [Google Scholar] [CrossRef] [Green Version]
- Jeong, C.; Balanovsky, O.; Lukianova, E.; Kahbatkyzy, N.; Flegontov, P.; Zaporozhchenko, V.; Immel, A.; Wang, C.C.; Ixan, O.; Khussainova, E.; et al. The genetic history of admixture across inner Eurasia. Nat. Ecol. Evol. 2019, 3, 966–976. [Google Scholar] [CrossRef]
- Saag, L.; Laneman, M.; Varul, L.; Malve, M.; Valk, H.; Razzak, M.A.; Shirobokov, I.G.; Khartanovich, V.I.; Mikhaylova, E.R.; Kushniarevich, A.; et al. The Arrival of Siberian Ancestry Connecting the Eastern Baltic to Uralic Speakers further East. Curr. Biol. 2019, 29, 1701–1711.e16. [Google Scholar] [CrossRef]
- Lamnidis, T.C.; Majander, K.; Jeong, C.; Salmela, E.; Wessman, A.; Moiseyev, V.; Khartanovich, V.; Balanovsky, O.; Ongyerth, M.; Weihmann, A.; et al. Ancient Fennoscandian genomes reveal origin and spread of Siberian ancestry in Europe. Nat. Commun. 2018, 9, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Lehtinen, J.; Honkola, T.; Korhonen, K.; Syrjänen, K.; Wahlberg, N.; Vesakoski, O. Behind Family Trees: Secondary Connections in Uralic Language Networks. Lang. Dyn. Chang. 2014, 4, 189–221. [Google Scholar] [CrossRef]
- Honkola, T.; Vesakoski, O.; Korhonen, K.; Lehtinen, J.; Syrjänen, K.; Wahlberg, N. Cultural and climatic changes shape the evolutionary history of the Uralic languages. J. Evol. Biol. 2013, 26, 1244–1253. [Google Scholar] [CrossRef]
- Janhunen, J. Proto-Uralic: What, where, and when? In The Quasquicentennial of the Finno-Ugrian Society; Suomalais-Ugrilainen Seura: Helsinki, Finland, 2009. [Google Scholar]
- Kallio, P. Suomen kantakielen absoluuttista kronologiaa. Virittäjä 2006, 110, 2–25. [Google Scholar]
- Jones, E.R.; Zarina, G.; Moiseyev, V.; Lightfoot, E.; Nigst, P.R.; Manica, A.; Pinhasi, R.; Bradley, D.G. The Neolithic Transition in the Baltic Was Not Driven by Admixture with Early European Farmers. Curr. Biol. 2017, 27, 576–582. [Google Scholar] [CrossRef] [Green Version]
- Kivikoski, E. Suomen Historia I: Suomen Esihistoria; Werner-Söderström Oy: Porvoo, Finland, 1961. [Google Scholar]
- Miettinen, T. Suomenlahden ulkosaarten esihistoriaa. In Suomenlahden ulkosaaret: Lavansaari, Seiskari, Suursaari, Tytärsaari; Hamari, R., Korhonen, M., Timo, M., Talve, I., Eds.; Suomalaisen Kirjallisuuden Seura: Helsinki, Finland, 1996. [Google Scholar]
- Palo, J.U.; Ulmanen, I.; Lukka, M.; Ellonen, P.; Sajantila, A. Genetic markers and population history: Finland revisited. Eur. J. Hum. Genet. 2009, 17, 1336–1346. [Google Scholar] [CrossRef] [Green Version]
- Csányi, B.; Bogácsi-Szabó, E.; Tömöry, G.; Czibula, Á.; Priskin, K.; Csõsz, A.; Mende, B.; Langó, P.; Csete, K.; Zsolnai, A.; et al. Y-Chromosome Analysis of Ancient Hungarian and Two Modern Hungarian-Speaking Populations from the Carpathian Basin. Ann. Hum. Genet. 2008, 72, 519–534. [Google Scholar] [CrossRef]
- Cavalli-Sforza, L.L. Genes, Peoples, and Languages; University of California Press: Berkeley, CA, USA; Los Angeles, CA, USA, 1997. [Google Scholar]
- Neparáczki, E.; Kocsy, K.; Tóth, G.E.; Maróti, Z.; Kalmár, T.; Bihari, P.; Nagy, I.; Pálfi, G.; Molnár, E.; Raskó, I.; et al. Revising mtDNA haplotypes of the ancient Hungarian conquerors with next generation sequencing. PLoS ONE 2017, 12, e0174886. [Google Scholar] [CrossRef] [Green Version]
- Bouckaert, R.; Lemey, P.; Dunn, M.; Greenhill, S.J.; Alekseyenko, A.V.; Drummond, A.J.; Gray, R.D.; Suchard, M.A.; Atkinson, Q.D. Mapping the origins and expansion of the Indo-European language family. Science 2012, 337, 957–960. [Google Scholar] [CrossRef] [Green Version]
- Menozzi, P.; Piazza, A.; Cavalli-Sforza, L. Synthetic Maps of Human Gene Frequencies in Europeans. Science 1978, 201, 786–792. [Google Scholar] [CrossRef]
- Sokal, R.R.; Oden, N.L.; Legendre, P.; Fortin, M.-J.; Kim, J.; Thomson, B.A.; Vaudor, A.; Harding, R.M.; Barbujani, G. Genetics and Language in European Populations. Am. Nat. 1990, 135, 157–175. [Google Scholar] [CrossRef]
- Olalde, I.; Mallick, S.; Patterson, N.; Rohland, N.; Villalba-Mouco, V.; Silva, M.; Dulias, K.; Edwards, C.J.; Gandini, F.; Pala, M.; et al. The genomic history of the Iberian Peninsula over the past 8000 years. Science 2019, 363, 1230–1234. [Google Scholar] [CrossRef] [Green Version]
- Chikhi, L.; Nichols, R.A.; Barbujani, G.; Beaumont, M.A. Y genetic data support the Neolithic demic diffusion model. Proc. Natl. Acad. Sci. USA 2002, 99, 10008–10013. [Google Scholar] [CrossRef] [Green Version]
- Ning, C.; Wang, C.-C.; Gao, S.; Yang, Y.; Zhang, X.; Wu, X.; Zhang, F.; Nie, Z.; Tang, Y.; Robbeets, M.; et al. Ancient Genomes Reveal Yamnaya-Related Ancestry and a Potential Source of Indo-European Speakers in Iron Age Tianshan. Curr. Biol. 2019, 29, 2526–2532.e4. [Google Scholar] [CrossRef]
- Tassi, F.; Vai, S.; Ghirotto, S.; Lari, M.; Modi, A.; Pilli, E.; Brunelli, A.; Susca, R.R.; Budnik, A.; Labuda, D.; et al. Genome diversity in the Neolithic Globular Amphorae culture and the spread of Indo-European languages. Proc. R. Soc. B Boil. Sci. 2017, 284, 20171540. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Syntax | Modern Genomes | Ancient Genomes | |
|---|---|---|---|
| 1 | AL languages form a cluster | AL speakers form a cluster | Higher Siberian component in AL speakers than in all the other populations |
| 2 | Indo-Iranian languages distinct from European IE languages | Indo-Iranian speakers distinct from other IE speakers | Higher Anatolian component in Indo-Iranian speakers than in other IE speakers |
| 3 | FU languages separated from IE and AL | In the tree, FU speakers and IE speakers fall in the same cluster | Yamnaya and Anatolian components similar in western FU speakers and their European IE-speaking neighbors |
| 4 | Estonian closer to IE and more distant than Finnish from other FU languages | Estonians closer to IE speakers than Finns | Siberian component lower in Estonians than in Finns |
| 5 | Mari, Khanty and Udmurt closer to AL than to IE languages | Mari, Khanty and Udmurt speakers more distant from IE speakers than Finns, Estonians and Hungarians | Higher Siberian component in Mari, Khanty and Udmurt speakers than in any other FU population |
| 6 | Easternmost FU Khanty least distant from easternmost Yakut of all AL languages | Khanty speakers halfway between the Mari/Udmurt speakers and eastern AL populations | Khanty speakers have the Siberian and Yamnaya component, but no Anatolian one |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santos, P.; Gonzàlez-Fortes, G.; Trucchi, E.; Ceolin, A.; Cordoni, G.; Guardiano, C.; Longobardi, G.; Barbujani, G. More Rule than Exception: Parallel Evidence of Ancient Migrations in Grammars and Genomes of Finno-Ugric Speakers. Genes 2020, 11, 1491. https://0-doi-org.brum.beds.ac.uk/10.3390/genes11121491
Santos P, Gonzàlez-Fortes G, Trucchi E, Ceolin A, Cordoni G, Guardiano C, Longobardi G, Barbujani G. More Rule than Exception: Parallel Evidence of Ancient Migrations in Grammars and Genomes of Finno-Ugric Speakers. Genes. 2020; 11(12):1491. https://0-doi-org.brum.beds.ac.uk/10.3390/genes11121491
Chicago/Turabian StyleSantos, Patrícia, Gloria Gonzàlez-Fortes, Emiliano Trucchi, Andrea Ceolin, Guido Cordoni, Cristina Guardiano, Giuseppe Longobardi, and Guido Barbujani. 2020. "More Rule than Exception: Parallel Evidence of Ancient Migrations in Grammars and Genomes of Finno-Ugric Speakers" Genes 11, no. 12: 1491. https://0-doi-org.brum.beds.ac.uk/10.3390/genes11121491