
Formation of the Codon Degeneracy during Interdependent Development between Metabolism and Replication

Ministry of Education Key Laboratory for Non-Equilibrium Synthesis and Modulation of Condensed Matter, Shaanxi Province Key Laboratory of Advanced Functional Materials and Mesoscopic Physics, School of Physics, Xi’an Jiaotong University, Xi’an 710049, China
Genes 2021, 12(12), 2023; https://0-doi-org.brum.beds.ac.uk/10.3390/genes12122023
Submission received: 3 November 2021
/
Revised: 30 November 2021
/
Accepted: 3 December 2021
/
Published: 20 December 2021
(This article belongs to the Section Molecular Genetics and Genomics)
Abstract
:Nirenberg’s genetic code chart shows a profound correspondence between codons and amino acids. The aim of this article is to try to explain the primordial formation of the codon degeneracy. It remains a puzzle how informative molecules arose from the supposed prebiotic random sequences. If introducing an initial driving force based on the relative stabilities of triplex base pairs, the prebiotic sequence evolution became innately nonrandom. Thus, the primordial assignment of the 64 codons to the 20 amino acids has been explained in detail according to base substitutions during the coevolution of tRNAs with aaRSs; meanwhile, the classification of aaRSs has also been explained.
1. Introduction
The difficulty in the field of the origin of the genetic code is due to the lack of key experiments to reproduce the primordial scenario of evolution of life. The debate about the nature of life even makes it difficult to reach a consensus on the definition of life. Pragmatically, we need to put together the few following well-established and enlightening observations to have a deep insight into the transition from non-living to living phenomena. Wong values that Phase I amino acids appeared earlier than Phase II amino acids in prebiotic evolution [1,2]. Pouplana and Schimmel prefer aminoacyl-tRNA synthetases (aaRSs) to clues to establishment of the genetic code [3,4]. Woese divided cellular life into three domains [5], which helps to comprehend last universal common ancestor (LUCA). In addition, a living JCVI-syn1.0 cell has been created by combining a cytoplasm without natural DNA and a chemically synthesised chromosome with Venter’s watermark [6]. Verily, potential contradictions, as will be explained next, have yet appeared in the few above common sense observations, which urges us to be serious in collecting experimental observations and extremely cautious in interpreting them.
Pouplana and Schimmel have overlooked the above two phases of amino acids. By comparing sequences and structures, the 20 aaRSs are divided into two distinct classes, each of which is subdivided into three subclasses. Pouplana and Schimmel assumed simultaneous association of two aaRSs on a single tRNA to interpret the symmetrical subclasses between the two classes of aaRSs, where the aaRS pairs, namely (subclass Ia) and (IIa), (Ib) and (IIb), and (Ic) and (IIc), can cover the tRNA acceptor stem without major steric clashes and, meanwhile, link together the specific subclasses. However, as a Phase II amino acid recruited much later than as a Phase I amino acid [7,8]. It becomes suspicious to associate and on a single tRNA simultaneously.
The creation of JCVI-syn1.0 is quite different from the primordial picture for supposed LUCA, where the former was synthesised rapidly, while the latter evolved during a long period. Moreover, a new cell can be certainly recreated anytime in JCV institute if a synthesised cell dies, but the evolution of life has to be halted if LUCA died. Life is a phenomenon rather than eternal matter, which emerged from interdependent development between metabolism and replication. The cell JCVI-syn1.0 was created by combining a cytoplasm without natural DNA and a chemically synthesised chromosome, whose life was acquired by integrating metabolism in cytoplasm and replication of chromosome, so JCVI-syn1.0 belongs to “cell without living parents” (CwoP). The apparatuses in JCV institute can play the role of “‘the Hand that feeds you’ for CwoPs” (HfC). In such an “HfC-CwoP” mechanism, the long-lasting non-living HfC is able to rapidly create various ephemeral living CwoPs at any time. The successful creation of the cell JCVI-syn1.0 is just a contemporary transition from non-living to living phenomena, whose mechanism can enlighten the prebiotic transition from non-living to living phenomena. LUCA followed Darwin’s vague idea of common ancestor. Many popular theories have yet forgotten to explain the viability of simple LUCA during the geologically long period. In fact, only living LUCA can hardly survive such a geologically long period. However, an “HfC-CwoP”-like mechanism is feasible to bridge the gap between the nonliving and living by continually generating viable systems, where an auxiliary non-living HfC evolved during the geologically long period to create various living CwoPs at any appropriate time. It is logical to assume that the molecular ancestors, at different times, had the same chemical characteristics given the same source of primordial matter. Thus, death of an individual CwoP and extinction in its offsprings cannot interrupt the process of evolution of life. When numerous CwoPs and their offsprings gathered and formed into a continuously evolving ecosystem, the HfC-like apparatus stepped down and vanished.
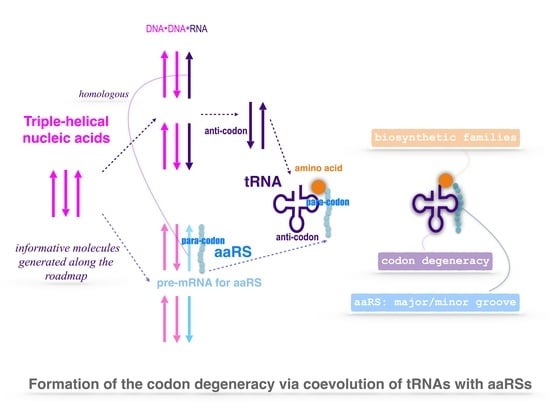
Nirenberg’s genetic code chart [9] revealed a profound correspondence between amino acids and codons. It is still a mystery how the codon degeneracy formed yet. If introducing an HfC-like apparatus during the evolution of tRNAs with aaRSs, the symmetrical subclasses of aaRSs can also be explained without the above redundant complex of two aaRSs on a single tRNA. The crux in the coevolution of aaRSs and tRNAs is how to continually generate and maintain non-random sequences in the geologically long period. In this paper, I propose that certain primordial polymer molecules played the role of HfC in the prebiotic evolution. Triple-helical nucleic acids provide a possible picture. Hence, non-random sequences were generated routinely based on the triplex base substitutions, where low stable triplex bases were substituted spontaneously by more stable triplex base pairs [10,11]. Numerous non-random DNA sequences were generated, along which aaRSs and tRNAs coevolved. Remarkably, the evolution of complementary strands also accounts for the symmetrical subclasses of aaRSs. This process is intricate but elegant; thus, both the codon degeneracy and the two classes, as well as their symmetrical subclasses of aaRSs, have been explained thoroughly.
The interesting property of triplex base pairs in triple-helical nucleic acids has been often ignored in the field of the origin of life. In experiments, the homopurine and homopyrimidine strands tend to form triple helix [10,12,13] besides double helix. It is not unreasonable to introduce triplex nucleic acids in the prebiotic evolution, considering the substantial role of triplex DNAs within recA fibers in the fundamental process of recombination. Furthermore, the triplex base pairs remained in tRNAs [14] also indicate that the origin of tRNAs depended on stability of triplex base pairs, which hints the rationality of this scenario. The prebiotic reciprocal impact between the HfC-like triplex DNAs and the CwoP-like systems with evolving genetic code is essential for the emergence of life where the evolution of prebiotic informative molecules was driven by the triplex DNAs whose evolution in return needed the help of prebiotic informative molecules, which is analogous to the reciprocal impact between Wilkinson’s boring machine and Watt’s steam engine in the industrial revolution, where a boring machine was driven by the steam engine whose improved cylinder in return needed to be bored by a boring machine. In such an interim scenario, the “chicken-egg” problem becomes an opportunity rather than a dilemma that RNA world theory tends to avoid.
The synthesis of adenine from hydrogen cyanide by Oro initiated the prebiotic chemistry of nucleic acids [2,15]. HCN tetramer is polymerised to a intractable solid, from which adenine and guanine can be recovered [16]. There are also HCN-independent routes of purine synthesis [17]. Cyanoacetylene, via electrically discharging nitrogen and methane, reacts with cyanic acid to give cytosine. Hydrolysis of cytosine yields uracil [16,18,19]. Progress in the prebiotic synthesis of the pyrimidine ribonucleosides [20], together with recent advances in non-enzymatic RNA replication [21], have given credence to the RNA world theory. So far, progress towards the abiotic synthesis of purine nucleosides has to use disputable starting materials [22]. The nature of the first genetic polymer is the subject of major debate. A prebiotic scenario for coexistence and co-evolution of RNA and DNA has been investigated [23,24]. Synthesis under prebiotic conditions gives credence to the idea that DNA could appear concurrently with RNA, instead of being its later descendent [25]. Purine deoxyribonucleosides and pyrimidine ribonucleosides may have coexisted before the emergence of life [26]. Resently, Xu et al. demonstrated a high-yielding, completely stereo-, regio-, and furanosyl-selective prebiotic synthesis of the purine deoxyribonucleosides, leading to a mixture of deoxyadenosine, deoxyinosine, cytidine, and uridine [27]. Considering that the homopurine and homopyrimidine RNA and DNA strands tend to form triple helix [10], substitutions of triplex base pairs among the prebiotic triplex nucleic acids also contribute to the prebiotic evolution.
Although numerous theories have attempted to explain the origin of the genetic code in literature [3,28], a candidate theoretical framework must at least be able to explain: (i) the driving force in the prebiotic sequence evolution, (ii) the degeneracies 6, 4, 3, 2, and 1 for the respective 20 amino acids, and (iii) the two classes of aaRSs to recognise tRNAs from either major or minor groove sides. These are the tasks of this article. I found that the evolution of triple-helical nucleic acids driven by the spontaneous substitutions of triplex base pairs provides an elegant roadmap picture for the prebiotic evolution. Accordingly, the assignment of the 64 codons to the 20 amino acids has been explained one by one based on the coevolution of aaRSs and tRNAs, where the symmetrical subclasses of aaRSs need the help of palindromic para-codons. There are many profound and amazing relationships among traditionally separate fields, summarised as follows. The coevolution of tRNAs with aaRSs along the roadmap that is established by the relative stabilities of triplex base pairs [10,11] agrees with both the codon degeneracy [29,30] and two classes of aaRSs [31] in observations. The earliest amino acids recruited in the initiation stage of the roadmap agrees with phase I amino acids in Miller-Urey experiment [32] and carbonaceous chondrites [33,34,35], and see Chapter 6 in [2]. The recruitment orders of amino acids and codons on the roadmap agrees with the variation trends of amino acid frequencies in proteomes [36] and codon position content variation [37]. The expansion of codons along the roadmap agrees with biosynthetic families of amino acids [1]. All the above agreements between predictions and observations prompted the formation of the present hypothesis on the origin of the genetic code.
2. Materials and Methods
2.1. Triplex Picture
The genetic code is a common and essential feature of life, which can be regarded as a relic of the prebiotic emergence of informative molecules. The complexity of the problem for the origin of the genetic code may exceed all the theoretical estimations, such as frozen accident, error minimisation, stereochemical interaction, amino acid biosynthesis, expanding codons, etc. [1,38,39,40,41,42,43,44,45,46,47,48]. So far, it can hardly describe the evolution of the genetic code step by step so as to explain the formation of the codon degeneracy in detail. Here, a triplex picture is proposed to describe the intricate evolution of the genetic code thoroughly, by which both the formation of the codon degeneracy and the classification of aaRSs have been explained in a same theoretical framework. The complexity of the following explanation of the codon degeneracy is comparable to that of a symphony score. The simplest method of score-reading is to concentrate on an individual voice part that can be heard particularly well and then going over to section-by-section or selective reading. Similarly, here are some suggestions for reading the following technical explanation of the codon degeneracy in the triplex picture. Please watch the Supplementary Movie S1 and start from Figure 1 and then figures on tRNAs and aaRSs so as to understand the recruitment of the 20 amino acids during coevolution of tRNAs with aaRSs.
Guessing the right prebiotic picture is the key for understanding the origin of the genetic code. Here, I propose a triplex picture for the prebiotic sequence evolution. There are 8 kinds of triplex nucleic acids (‘·’ represents a Watson-Crick base pair, while ‘∗’ a Hoogsteen base pair), where the strands can be either DNA or RNA [49,50,51], such as the triplex DNA and the triplex nucleic acids mixed with DNA and RNA , etc. The triplex DNA is supposed as the initial physical conditions for the evolution of the genetic code. The 64 codons have been recruited one by one with the sequence evolution by alternative separation and recombination of the three strands in the periodic changing environments. Such sequence evolution in the prebiotic evolution was driven by the substitutions of triplex base pairs according to their relative stabilities. The sequence evolution of led to the evolution of the genetic code, while the RNA strands separated from the coevolving yielded tRNAs and the template RNAs for aaRSs. The tRNAs and aaRSs were generated in accompany with the recruitment of the corresponding codons, respectively. So, the triplex picture gives a physical basis for the coevolution of the genetic code with the corresponding tRNAs and aaRSs.
Nomenclature and Notation
- Notations for the 20 amino acids, 20 aaRSs, and the corresponding tRNAs (): amino acid ↔↔ tRNA , , , , , , where the amino acids from to are, respectively, as follows: , , , , , , , , , , , , , , , , , , , , and are, respectively, as follows: (namely ), (namely ), and so on.
- Triplex DNAs (): , and the inverse triplex DNAs: , , where Y, y stands for pyrimidine strands, and R, r purine strands.
- Triplex DNA·DNA*RNA (): , , , , where two types of tRNAs can be generated by linking the RNA strands or , and aaRSs can approach tRNAs from major groove side (M) or minor groove side (m).
- Codon pairs: , etc.; pair connections: , etc.; route dualities: , etc., where the numbers () indicates the positions on the roadmap
2.2. Origin of the Genetic Code
2.2.1. The Roadmap
In the triplex picture, I obtained a roadmap for the evolution of the genetic code (or the roadmap for short). The validity of the roadmap depends essentially on the experimental data of triplex base pairs. The stabilities of the 16 triplex base pairs in triplex DNA are listed from instability (−), weak (+) to strong (, , ) as follows [10,11]:
The above stability order in experiments played a significant role in the primordial evolution of triplex DNA. The substitutions of triplex base pairs from weak to strong provided the principal driving force in the prebiotic sequence evolution.
At the beginning of the evolution of the genetic code, there existed single-stranded DNA and , which tended to form a triplex DNA (Figure 1a,b) [10,13]. is a usual triplex DNA, which is combined by triplex base pair (Figure 1b and Supplementary Movie S1). The sequences evolved via substitutions of triplex base pairs in the procedure of alternative combining and separating for the strands of triple-stranded DNA. Only three kinds of substitutions of triplex base pairs are practically required on the roadmap: (1) substitution of by [10,11], with the transition from G to A in the third R strand. This is of the most common substitution on the roadmap by which all the codons in and most codons in were recruited (Figure 1a); (2) substitution of by , with the transversion from G to C in the third R strand, which blazed a new path at , , for the recruitment of codons in , respectively (Figure 1a); (3) substitution of by , with the transition from C to T in the third R strand at , , (Figure 1a and Figure 2), by which the remaining codons in were recruited (Figure 1a). Thus, all the 64 codons have been recruited following the roadmap (Figure 1a, Figure 3a and Figure 4b).
According to the base substitutions on the roadmap, the recruitment order of the codon pairs from to is as follows (Figure 1a):
, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ;
and the recruitment order of the amino acids from to is as follows (Figure 1a):
, , , , , , , , , , , , , , , , , , , .
The evolution of the genetic code can be divided into three stages (Figure 1a): the initiation stage (), the midway stage (, ), and the ending stage (, ). All the amino acids recruited in the initiation stage belong to phase I. The recruitment of amino acids along the roadmap is described step by step hereinafter, and the pair connections and route dualities on the roadmap will be explained according to the evolution of tRNAs and aaRSs in the following.
- Initiation
- step 1: 1GlyVacant #1
- step 2: 1Gly Vacant #1 1Gly Vacant #2
- step 3: 1Gly Vacant #1 1Gly 2Ala #2
- step 4: 1Gly Vacant #1 1Gly 2Ala #2 1Gly Vacant #3
- step 5: 1Gly Vacant #1 1Gly 2Ala #2 1Gly Vacant #3 3Glu Vacant #4
- step 6: 1Gly Vacant #1 1Gly 2Ala #2 1Gly Vacant #3 3Glu Vacant #4 4Asp Vacant #5
- step 7: 1Gly Vacant #1 1Gly 2Ala #2 1Gly Vacant #3 3Glu Vacant #4 4Asp 5Val #5
- step 8: 1Gly 6Pro #1 1Gly 2Ala #2 1Gly Vacant #3 3Glu Vacant #4 4Asp 5Val #5
- step 9: 1Gly 6Pro #1 1Gly 2Ala #2 1Gly 7Ser #3 3Glu Vacant #4 4Asp 5Val #5
- step 10: 1Gly 6Pro #1 1Gly 2Ala #2 1Gly 7Ser #3 3Glu 8Leu #4 4Asp 5Val #5
- step 11: 1Gly 6Pro #1 1Gly 2Ala #2 1Gly 7Ser #3 3Glu 8Leu #4 4Asp 5Val #5 1Gly Vacant #6
- step 12: 1Gly 6Pro #1 1Gly 2Ala #2 1Gly 7Ser #3 3Glu 8Leu #4 4Asp 5Val #5 1Gly 9Thr #6
- Midway & ending
- step 13: (#1 ∼ #6 are fully filled by 1Gly to 9Thr, the same below for the following steps) 2Ala 10Arg #7
- and the following steps (omitting the previously fully filled #1 ∼ #(n-1) codon pairs in step #n, from #8 to #32):
- 7Ser 2Ala #8; 2Ala 11Cys #9; 10Arg 6Pro #10; 10Arg 6Pro #11; 12Trp 6Pro #12; 10Arg 7Ser #13; 10Arg 7Ser #14; stop 7Ser #15; 9Thr 10Arg #16; 7Ser 9Thr #17; 9Thr 11Cys #18; 5Val 13His #19; 14Gln 8Leu #20; 4Asp 15Ile #21; 16Met 13His #22; 3Glu 17Phe #23; 5Val 18Tyr #24; stop 8Leu #25; 19Asn 5Val #26; 20Lys 8Leu #27; 14Gln 8Leu #28; 15Ile 18Tyr #29; 19Asn 15Ile #30; stop 8Leu #31; 20Lys 17Phe #32.
2.2.2. Initiation
In the beginning, there was an R (R denotes purine) single-stranded DNA (Figure 1a,b, ). By complementary base pairing formed a (Y denotes pyrimidine) double-stranded DNA . Furthermore, by triplex base pairing formed a triple-stranded DNA (Figure 1a,b, ). The third strand separated out of this triple-stranded DNA, which then formed a new double-stranded DNA . So far, there was only initial codon pair (Figure 1a,b, ).
In the initiation stage of the roadmap, the codon pairs from to were recruited along the roadmap, which constituted the initial subset of the genetic code:
, , ,
, , .
And in this stage were recruited the earliest 9 amino acids in order: , , , , , , , , , all of which belong to phase I amino acids [7,8]. For example, at codon pair position on the roadmap, and are encoded by the codon pair in strand and in strand, respectively. Although the initial subset is concise, two essential features of the roadmap, pair connection and route duality, had taken shape in this initiation stage (Figure 1a and Figure 3a).
Pair connection is an essential feature of the roadmap. A connected codon pair on the roadmap generally encode a common amino acid (Figure 1a and Figure 3b). For instance, the pair connection indicates that both in and in encode the common amino acid . Pair connections reveal the close relationship between recruitment of codons and recruitment of amino acids, which will be explained later according to the evolution of tRNAs.
Route duality is another essential feature of the roadmap, which shows the relationship of pair connections between different routes (Figure 1a and Figure 3b). For instance, the route duality
indicates that the pair connection in and the pair connection in are dual, which encode a common amino acid . Route dualities generally exist between and , or between and (Figure 3b), which will be explained later according to the evolution of aaRSs.
Glycine, the simplest amino acid, is encoded by the cytosine triplet, the simplest nitrogen base. Glycine has been identified in the coma of comet [52] and could be the first amino acid on earth. Here, glycine is also the first amino acid recruited on the roadmap. In the initiation stage of the roadmap, the non-chiral helped to create the first pair connection , recruiting chiral at (Figure 1a). Furthermore, the non-chiral also helped to create the first route duality on the roadmap (Figure 1a):
This route duality played a central role in the initiation stage; consequently, the initial subset played a central role in the midway stage (Figure 3a). The chirality was required at the beginning of the roadmap by the triplex DNA itself (Figure 1a,b). Even so, there was still a transition period from non-chirality to chirality, in consideration of the special role of non-chiral . Competition between opposite homochiral roadmap systems resulted in the homochirality by a winner-take-all game [53].
2.2.3. Midway
The genetic codes evolved along four routes , respectively, where 8 codon pairs in each route evolved in the order of four hierarchies , respectively (Figure 1a). The roadmap can be divided into two groups: the early hierarchies and the late hierarchies . It can also be divided into two groups: the initial route (all-purine codons pairing with all-pyrimidine codons) and the expanded routes (purine-pyrimidine-mixing codons).
In the midway stage of the roadmap, the genetic codes expanded spontaneously from the initial subset (Figure 1a and Figure 3a). Each of the 6 codon pairs in the initial subset expanded to three additional codon pairs, respectively, by route dualities. Details are as follows. The codon pair in the initial subset expanded to the three continual codon pairs , and by route duality
the codon pair in the initial subset expanded to the three continual codon pairs , , and by route duality
the codon pair in the initial subset expanded to the three continual codon pairs , , and by route duality
the codon pair in the initial subset expanded to the three continual codon pairs , , and by route duality
the codon pair in the initial subset expanded to the three codon pairs , , and by route duality
and the codon pair in the initial subset expanded to the three codon pairs , , and by route duality
The recruitment order of the codon pairs and the recruitment order of the amino acids are intricately well organised and coherent, according to the subtle roadmap (Figure 1a and Figure 3a). In the initiation stage, firstly, the amino acid was recruited with the codon pair , remaining a vacant position. Subsequently, and were recruited with the codon pair ; was recruited with the codon pair , remaining a vacant position; was recruited with the codon pair , remaining a vacant position; and were recruited with the codon pair ; filled up the vacant position of ; filled up the vacant position of ; filled up the vacant position of ; and were recruited with the codon pair (Figure 3a). Thus, the framework of the genetic code had been established at the end of the initiation stage. From on, the latecomer amino acids no longer jumped the queue in recruitment so that there were no more vacant positions in the recruited codon pairs. Details are as follows. and amino acids were recruited with the codon pair ; and, subsequently, and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with ; and were recruited with (Figure 3a).
Take, for example, from to , the evolution of the genetic code along the roadmap can be described in details as follows (Figure 1a,b and Supplementary Movie S1). Starting from the position (Figure 1b, #1), an R single-stranded DNA brought about a double-stranded DNA; next, the double-stranded DNA brought about a triple-stranded DNA (the number 1 denotes , similar below); next, an single-stranded DNA departed from the triple-stranded DNA; next, the single-stranded DNA brought about a double-stranded DNA. Thus, the codon pair were achieved at . At the beginning of (Figure 1b, #7), the double-stranded DNA was renamed as double-stranded DNA, where the rotation in writing did not change the right-handed helix; next, the double-stranded DNA brought about a triple-stranded DNA, through the transversion from G to C, where the stability of increased to the stability of ; next, an single-stranded DNA departed from the triple-stranded DNA; next, the single-stranded DNA brought about a double-stranded DNA. Thus, the codon pair were achieved at . The case of is similar to (Figure 1b, #19); the codon pair were achieved through the transition from C to T, where the stability of increased to the stability of . The case of is also similar to (Figure 1b, #24); the codon pair were achieved through the common transition from G to A, where the stability of increased to the stability of . At the position (Figure 1b, #29), the codon pair in are non-palindromic in consideration that both and do not read the same backwards as forwards. In this case, a reverse operation is necessary so that the obtained codon pair in read reversely the same as the codon pair in . The process from to is still similar to the case of ; the codon pair were achieved through the transition from G to A, where the stability of increased to the stability of . Other processes on the roadmap are similar to the above example (Figure 1a,b). The reverse operation is unnecessary in the cases of , , , , , , , , , , , , after palindromic codon pairs and the last one (Figure 1a), whereas the reverse operation is necessary in the remaining cases of , , , , , , , , , , , , , , , , (Figure 1a).
2.2.4. The Ending
So far, the genetic code table had been expanded from the 6 codon pairs in the initial subset to the codon pairs by route duality; the remaining 8 codon pairs were recruited into the genetic code table in the ending stage of the roadmap (Figure 1a and Figure 3a). There were 2 codon pairs remained in each of the four routes , respectively. They satisfied pair connections as follows: , , , (Figure 3a). Two of them satisfied route duality (Figure 3a):
The last two stop codons appeared in the pair connection (Figure 1a and Figure 3a). When the last two amino acids were recruited through the base pairs and , the codon at had to be selected as a stop codon. The codon at was selected as the last stop codon, due to lack of corresponding tRNA.
The non-standard codons also satisfy codon pairs and route dualities on the roadmap (Figure 1a). The codon pairs pertaining to non-standard codons are as follows: , in ; none in ; in ; , , , in . Majority of non-standard codons appear in the last (Figure 1a). Route dualities of non-standard codons exist between and (Figure 1a):
where the first stop codon at is dual to the non-standard stop codons in .
The choice of the genetic code was by no means random, which resulted from the increasing stabilities of triplex base pairs in the substitutions [10,11], where the rotation of the single glycosidic bond between base and deoxiribose has been considered in the opposite direction. It had been emphasised that the roadmap followed the strict rule that the stabilities of triplex base pairs monotonically increase (Figure 2). Note that the roadmap had tried its best to avoid the unstable triplex DNA. The roadmap (Figure 1a) is the only possible one that has avoided the unstable triplex base pairs (−) , and , as shown in Table 1, while other eliminated possible roadmaps cannot avoid.
Among the 16 possible triplex base pairs, there are three relatively unstable triplex base pairs. So, the statistical ratio of instability for the triplex base pairs is . However, the ratio of instability for the triplex base pairs on the roadmap is much smaller. There are 49 triplex DNAs through to on the roadmap, which involve triplex base pairs (Figure 1a). The relatively unstable triplex base pairs and have not appeared on the roadmap; only the relatively unstable triplex base pair has appeared inevitably for 7 times in the reverse operations so as to fulfil all the permutations of 64 codons (Figure 1a). The ratio of instability on the roadmap is much smaller than the ratio of instability by the statistical requirement. When the relatively unstable appears at the positions , , , , , , and , both stabilities of the other two triplex base pairs in the triplex DNA are (Figure 1a), which compensates the instability of the triplex DNA to some extent. The amino acid , whose degeneracy uniquely is three, occupied three positions , , and among those 7 positions. In addition, the three stop codons occupied other three neighbour positions , and (Figure 1a). The first stop codon appeared at the position , where the relatively unstable appeared firstly (Figure 1a). According to the primordial translation mechanism, the weak combination of might help to assign stop codons. The route dualities played significant roles in the midway stage, where the remnant codons were chosen as the stop codons (Figure 1a and Figure 3a). The stop codon appeared as early as the midway of the evolution of the genetic code (Figure 1a and Figure 3a), which indicates that the genetic code had been taken shape around the midway to promote the formation of the primitive life. Not until the fulfilment of the genetic code did the translation efficiency increase notably by recognising all the 64 codons.
2.3. Origin of tRNA
The roadmap illustrates the coevolution of the genetic code with the amino acids, where tRNAs and aaRSs play an intermediary role. The expansion of the genetic code along the roadmap can be explained by the coevolution of tRNAs with aaRSs (Figure 5c, Figure 6b and Figure 7). The cloverleaf shape of tRNA can be explained by assembling the two complementary RNA strands separated from triplex nucleic acid in the triplex picture (Figure 6a). The origin of aaRS will be explained next.
2.3.1. Anti-Codon
When studying the evolution of the genetic code, we were focused on only three bases in the triplex DNA. However, when studying the origin of tRNAs, it is necessary to study the evolution of entire sequences of both triplex DNA and triplex nucleic acid , where the third RNA strands in can be used to assemble tRNAs (Figure 5a,b and Figure 6a). According to the order of the relative stabilities of for the 8 kinds of triplex nucleic acids: , , , >, , [50,54], the relative stabilities of and are greater than the relative stabilities of other kinds of triplex nucleic acids. The choice of triplex DNA for the roadmap and the choice of for the origin of tRNAs are based on the observed relative stabilities. And the other kinds of triplex nucleic acids can be neglected due to their less probabilities to appear.
There are four types of RNA strands for assembling tRNAs that were generated by the triplex base pairing of triplex nucleic acids : via the triplex nucleic acid , via the triplex nucleic acid (Figure 5a,c), and via the triplex nucleic acid , via the triplex nucleic acid (Figure 5b,c), where the subscript t indicates that theses RNA strands , and , are used to assemble tRNA (Figure 5a,b and Figure 6a). The sequences , are the respective reverse sequences of and . There is a difference in the sequence evolution along the roadmap between purine strands and pyrimidine strands. The pyrimidine sequences , and the purine sequences , are complementary, respectively, owing to the triplex pairing with the purine DNA strand and the pyrimidine DNA stand in the triplex nucleic acids , respectively. These tRNA strands coevolved with the triplex DNA along the roadmap. Therefore, the evolution of the anti-codons on tRNAs can be explained according to the evolution of the genetic code along the roadmap. The evolution of aaRSs should be considered next. After separating from the triplex nucleic acids , the pair of complementary single RNA strands and , or and , can concatenate and fold into a cloverleaf-shaped tRNA [55,56,57,58,59], whose anti-codon corresponds to the codon of the triplex DNA on the roadmap (Figure 6a). Owing to the different positions of anti-codons in the RNA strands, either near to -ends or near to -ends, it must be seriously considered for the different reading directions between , and , (Figure 6a). There were two types of tRNAs: the type tRNA and the type tRNA (Figure 5a,b), where the anti-codons are near to the -end of the RNA strand and the -end of the RNA strand , respectively. The other concatenated RNA strands and cannot evolve together with the above two types of tRNAs because the corresponding triplets would be on the acceptor arms rather than on the anti-codon loops.
It is possible to explain the sequence evolution of tRNAs in detail along the roadmap (Figure 5a–c and Figure 6a). For example, the tRNA for can form by concatenating and , which are generated by triplex base parings and at the branch node . The anti-codon near the -end of the strand is palindromic. The two complementary strands and can combine into a cloverleaf-shaped type tRNA by concatenating, pairing, and folding (Figure 6a). Thus, anti-codon arm of contains the anti-codon , which corresponds to , with the help of aaRS; consequently, the codon at the R DNA strand in is assigned to . The sequences evolve from to along the roadmap. As another example, the codons at the position is non-palindromic, where the type tRNA and the type tRNA are assembled by concatenating and for and by concatenating and for , respectively (Figure 6a). Hence, the codon at and the reversely complimentary codon at are assigned to and , respectively.
There are 4 pairs of palindromic codons: , , , in the 16 branch nodes of the roadmap (Figure 1a). Accordingly there are 12 non-palindromic codons among the branch nodes at the positions , , , , , , , , , , , and . The sets of complementary pairs of RNA strands are the same for the two routes because of the bijection between and in the sense of reverse relationship (Figure 1a). Thus, there are totally pairs of complementary single RNA strands (4 palindromic codons, and the 12 non-palindromic codons minus 4 identities between and ), which can assemble into 20 groups of cognate tRNAs, respectively. This could be among the reasons why there are 20 canonical amino acids.
There is another reason at the sequence level for the number “20” of the canonical amino acids (Figure 6b). There are 64 triple permutations for the 4 bases, which accounts for the number 64 of the codons. However, little attention has been paid to the 20 triple combinations for the 4 bases. The products () are the same, respectively, for the 20 groups of combinations for the 4 bases (Figure 6b), owing to the multiplication exchange law, where denotes the base compositions for . The products determine the average interval distances of codons in genome sequences. Therefore, there are 20 classes of genomic codon interval distributions according to the 20 combinations rather than the 64 permutations of the 4 bases [53]. Consequently, there are 20 cognate tRNA-synthetase systems so as to improve the translation efficiency for tRNAs to recognise the corresponding codons, considering the 20 average interval distances of codons. So, the number “20” of the canonical amino acids actually should be attributed to a statistical origin at the sequence level. The 20 combinations of the 4 bases can be divided into 4 groups: , , , . and correspond and ; and correspond to and . Their positions on the roadmap are , , , . Each group can be divided into 5 combinations, which correspond to or , respectively. In the case , and belong to ; , , and belong to , and it is similar for the other cases , , . These 20 combinations roughly correspond to the 20 cognate tRNAs (Figure 6b). This rough correspondence shows that the codons, especially those in , are assigned to the tRNAs based on the combinations, considering that the codons in are -rich, and the context sequences tend to form -rich repeats. Concretely speaking, the group of codons in the combinations , , , , , , , , , , , , , , are assigned, respectively, to , and , , and , and and , and , , , , , , , , , (Figure 6b). In addition, the first stop codon appeared halfway in the evolution of tRNAs (Figure 6b). The order of combinations are simply organised by the bases in the order “G”, “C”, “A”, “U” (Figure 6b), considering the substitutions “G to C”, “G to A”, “C to U” on the roadmap (Figure 1a). And the amino acids are in the recruitment order. Then, a rough diagonal distribution of tRNAs has been obtained (Figure 6b), which is due to the evolutionary relationship between the genetic code and amino acids.
2.3.2. Evolution of tRNA
There was a post-initiation-stage stagnation (Figure 1a) between the initiation stage and the midway stage of the roadmap. Such a stagnation in the prebiotic evolution was just to await the birth of functional macromolecules. In this period, oligonucleotides with arbitrary finite sequences can be generated via the base substitutions G to A, G to C, and C to T in the triplex picture. The primordial sequences of the prototype tRNAs and the template RNAs of prototype aaRSs can be generated along the roadmap. In the light of complicated interactions between oligonucleotides and amino acids, some early tRNAs with certain anti-codons can be generated in the sequence evolution along the roadmap so as to carry the corresponding prebiotically synthetised phase I amino acids, respectively. These tRNAs were not necessarily homologous, as long as they were capable of fulfilling their respective tasks. There are two independent codon systems for tRNAs: the anti-codons and the para-codons. The anti-codons evolved along the roadmap, while the para-codons evolved with aaRSs (Figure 5c and Figure 7). When the para-codons did not evolve but the anti-codons evolved, only cognate tRNAs originated. However, when both the para-codons and the anti-codons evolved, more new tRNAs originated to carry the remaining amino acids.
There exists an assignment scheme for the genetic code. The 64 codons can be assigned to the 20 amino acids and stop codons with the help of approximate four dozens of tRNAs: , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , (Figure 5c and Figure 6b). The naming rules for tRNAs are as follows. The tRNA series numbers are named after the recruitment order of the respective canonical amino acids. The prime tRNAs ∼ are the early recruited tRNAs that coevolve with the corresponding aaRSs. The derivative tRNAs are the cognate tRNAs expanded within the codon boxes, namely with the same first two bases in codons. The derivative tRNAs are the cognate tRNAs expanded outside the codon boxes. The derivative tRNAs , and are the cognate tRNAs needed by wobble pairing rules. The bracket in “” indicates the same tRNA . It is also possible to generate more or less new tRNAs in the triplex picture for different species, so the numbers of tRNAs are different among species.
On one side, the tRNAs can recognise the respective codons according to the genetic code evolution along the roadmap. On the other side, they can recognise the respective aaRSs to combine with the respective aminoacyls. Among the 20 prime tRNAs ∼, there are 13 type tRNAs (, , , , , , , , , , , , ) and 7 type tRNAs (, , , , , , ) (Figure 5c). The codons for the type prime tRNAs are situated in the purine strand on the roadmap, whose first base are purine, except , , , while the codons for the type prime tRNAs are situated in the Y strand on the roadmap, whose first base are pyrimidine. In total, there are 6 prime tRNAs (, , , , , ) in , 3 prime tRNAs (, , ) in , 8 prime tRNAs (, , , , , , , ) in , and 3 prime tRNAs (, , ) in (Figure 5c). The majority of prime tRNAs situated in the branch nodes, except , , , (Figure 5c). For each amino acid, several cognate tRNAs can be generated at certain steps of the roadmap.
| , , | ||
| , , | ||
| , | ||
| , , | ||
| , , | ||
| , , , | ||
| , , , , | ||
| , , | ||
| ,,,, | ||
| , | ||
| , | ||
| , |
The following evolution of derivative tRNAs can be explained by the base substitution G to A along the roadmap (Figure 5c): to , to , to , to , to , to , to , to , to , to , to , to , to . Moreover, the following evolution of derivative tRNAs can be explained by the base substitution G to C along the roadmap (Figure 5c): to , to , to , to , to , to , to . However, the following tRNAs can recognise the respective two codons whose third bases are C or U, owing to the wobble pairing (Figure 5c): , , , , , , , , , , , , , , , .
The wobble pairing rules can be explained by the origin and evolution of tRNAs in the triplex picture. The transition from C to T occurred at the position on the roadmap, which resulted in the wobble pairing rule . Taking as a template, with is formed by the triplex base pairing, while with and with are formed, where the transition from C to U occurred in the formation of . The complementary strands and combine into a tRNA with anti-codon , where G at the first position of the anti-codon of the tRNA is paired with U at the third position of the triple code of an additional single strand . It implies that the wobble pairing rule had been established as early as the end of the initiation stage of the roadmap. The transition from C to T occurred at the position , which resulted in the wobble pairing rule . Taking as a template, with is formed by the triplex base pairing, and with and with are also formed, where the transition from C to U occurred in the formation of . The complementary strands and combine into a tRNA with anti-codon , where U at the first position of the anti-codon of the tRNA is paired with G at the third position of the triple code of an additional single strand . The above explanation of the wobble pairing rules by tRNA mutations is supported by the observations of nonsense suppressor. For instance, the wobble pairing rule for a suppressor can be established by a transition from G to A at the position of . The wobble pairing rules and had been established early in the evolution of the genetic code, which continued to flourish so as to make full use of the short supply tRNAs.
The evolutionary relationship between tRNAs that corresponds to pairs of different amino acids can also be explained according to the evolution of tRNAs along the roadmap. For example, based on the substitution G to A, can evolve to , and based on the substitution G to C, can evolve to , and so on (Figure 5c). However, this kind of evolution of tRNAs involves not only anti-codons but also para-codons because it inevitably needs extra help from aaRSs. There is a close relationship between the evolution of tRNAs and the biosynthetic families of amino acids, so the sequences of tRNAs coevolved with the sequences of aaRSs at each step of the roadmap. The recognition between tRNAs and aaRSs will be explained next, where there are many technical details, and each step needs to be straightened out in order to draw a comprehensive conclusion.
The evolution of tRNAs played significant roles to implement the number of canonical amino acids as 20. There is an important difference between the early prime tRNAs and the late derivative tRNAs . Generally speaking, the wobble pairing rules apply to the late derivative tRNAs rather than to the early prime tRNAs (Figure 6b). The early prime tRNAs do not need wobble pairings so as to accurately implement the number of bases in codons as 3, whereas the late derivative tRNAs need wobble pairings so as to improve translation efficiency via codon degeneracy. This was a dynamic process to achieve that the number of canonical amino acids equals to the combination number of bases, which can hardly be fulfilled in lack of tRNAs but can be adjusted by choosing among the numerous candidates of tRNAs.
2.3.3. Palindrome
Palindromic sequences play significant roles not only in contemporary molecular biology but also in the prebiotic evolution. Palindromic or non-palindromic codons on the roadmap can produce different effects in the origin and evolution of informative macromolecules. The cloverleaf secondary structure of tRNAs can be explained by the complementary palindrome in assembling tRNAs. Furthermore, the evolution of aaRSs also depended strongly on the evolution of palindromic para-codons along the roadmap, which will be explained next.
There are two types of tRNAs: type and type , where the two single RNA strands and , and are complementary to each other. A D-loop and an anti-codon loop situate in the -end RNA strand ( for type and for type ), while a TC loop and a missing loop situate in the -end RNA strand ( for type or for type ) (Figure 6a). The strand pair and or and can form two pairs of hairpins in the complementary double-stranded RNA, where the D-loop and the TC loop constitute a pair of hairpins, and the anti-codon loop and the missing complementary loop constitute another pair of hairpins (Figure 6a). When the missing loop has been deleted, the three other loops form a cloverleaf-shaped tRNA (Figure 6a). A palindromic nucleotide sequence can form a hairpin, and palindromic complementary double RNA sequences can form a pair of hairpins, which can account for the cloverleaf secondary structure of tRNAs (Figure 6a and Figure 8). If there are palindromic sequence intervals in the -end RNA strand, there will also be the corresponding palindromic sequence intervals in the complementary -end RNA strand. A D-loop and an anti-codon loop can form in the -end RNA strand, owing to the complementarity in the palindromic sequence intervals. Accordingly, a TC loop and a missing loop can also form in the -end RNA strand, which correspond to the D-loop and the anti-codon loop, respectively. After deleting the missing loop, a catenated RNA strand with three loops can form a cloverleaf secondary structure, and consequently, a stable tertiary structure can form. Therefore, palindromic sequences contribute to the formation of stable RNA structures in the prebiotic evolution. It is easy to generate palindromic oligonucleotides according to the base substitutions along the roadmap (Figure 5a,b). So, it tended to generate pairs of palindromic single RNA strands so as to assemble cloverleaf-shaped tRNA candidates. Numerous tRNA candidates can be produced by such an assembly line during the prebiotic evolution, where several qualified tRNAs with proper anti-codons and para-codons can be selected to carry the respective amino acids. Although it is difficult for the origin of aaRSs in the prebiotic evolution (Figure 8), it is not too difficult for the origin of tRNAs and amino acids. The early aaRSs had chance to adapt by choosing among the numerous tRNA candidates and amino acid candidates. Thus, the degree of difficulty for the origin of life can be reduced to some extent. Yet, if both tRNAs and aaRSs had been rare, there would have been little opportunity to establish the correspondence relationship between aaRSs and tRNAs.
2.4. Origin of aaRS
2.4.1. Para-Codon
On one hand, an aaRS is able to recognise cognate tRNAs by para-codons (Figure 6b and Figure 8). On the other hand, the aaRS is able to catalyse the esterification of proper amino acid to its cognate tRNA (Figure 8). The origin of aaRS is one of the most difficult events in the origin of life because a primordial mechanism must be invented to generate the earliest proteins in absence of ribosome, and, meanwhile, aaRSs have to possess both para-codons and enzyme activity. It should be a rare critical event for the emergence of the first aaRS with enzyme activity in primordial sequence evolution. Following this process, the enzyme activity can transmit from the common ancestor of aaRSs to all the descendant aaRSs, either to the class I or class II aaRSs. Thus, the evolution of para-codons became to play a leading role in the evolution of aaRSs. The evolution of aaRS closely related to both the evolution of tRNA and the biosynthesis families of amino acids. The evolution of para-codons can be explained in the triplex picture. The para-codons of aaRSs coevolved with the sequences of tRNAs along the roadmap. The abilities to recognise certain amino acids came from the coevolution within the biosynthetic families of amino acids. According to the sequence evolution in the triplex picture, the recognition of tRNA by aaRS can be explained by the sequence homology between the template RNA of aaRS and the corresponding major or minor groove side sequence of tRNA. The recognition between aaRS and its template RNA led to the recognition between aaRS and the corresponding tRNA.
There are two types of tRNA according to the generation process of tRNA along the roadmap: type and type (Figure 5a,b), where the side corresponds to the minor groove, while the side to the major groove. Additionally, the aaRSs can combine with the two types of tRNAs from either minor groove or major groove (Figure 5c and Figure 8). Thus, there are four classes of aaRSs: class aaRS, class aaRS, class aaRS, class aaRS (Figure 5c and Figure 7). The four symbols indicate that aaRSs combine with tRNAs, respectively, from the minor groove (m) side (y) of type tRNA, from the major groove (M) side (r) of type tRNA, from the minor groove (m) side (R) of type tRNA, and from the major groove (M) side (Y) of type tRNA.
The evolution of aaRSs occurred between the four classes of aaRSs (Figure 7). The sequences of para-codon can evolved between the homologous strands, and it can also evolve between the complementary strands when the sequences of para-codons are palindromic (Figure 7). According to the evolution of palindromic para-codons and the origin of the template RNA of aaRS (Figure 8), the class aaRS can be complementary with the class aaRS owing to the complementary two strands and that combine into the type tRNA (Figure 5a), and the class aaRS can be complementary with the class aaRS owing to the complementary two strands and that combine into the type tRNA (Figure 5b). According to the evolution of palindromic para-codons and the coevolution of the template RNAs of aaRSs with tRNAs (Figure 7 and Figure 8), the class aaRS can be complementary with the class aaRS, and the class aaRS can be complementary with the class aaRS. The class aaRS can be homologous to the class aaRS, and the class aaRS can be homologous to the class aaRS. These relationships are useful for studying the evolution of aaRS along the roadmap.
The aaRSs are denoted in evolutionary order as to instead of to for convenience, according to the recruitment order of the corresponding amino acids from to , respectively. The ancestor of aaRSs, namely the major groove , belongs to the class aaRS, which catalysed pairing between the amino acid and the tRNA and which approaches to the type tRNA from the major groove side (Figure 7). The evolved into the same class and the class (Figure 7). The evolved into . According to the evolution of the biosynthesis family, evolved into , , , and, furthermore, , and evolved into (Figure 7). According to the evolution of the biosynthesis family, evolved into , , and, furthermore, , , and (Figure 7). According to the evolution of the biosynthesis family, evolved into and . According to the evolution of the biosynthesis family, evolved into , . According to the evolution of the biosynthesis family, evolved into and . In general, the evolutions via the and biosynthesis families took place in and , corresponding to the codons whose second bases are G or C, while the evolutions via the , and biosynthesis families took place in and , corresponding to the codons whose second bases are A or U (Figure 5c). This result accounts for the observation that the second bases of codons relate to the biosynthesis families of amino acids (Figure 4c).
The evolution of aaRSs depends strongly on the para-codon evolution (Figure 7 and Figure 8). Some para-codons of aaRS are homologous but not complementary to the previous para-codons. However, the para-codons of aaRSs that are complementary to the previous para-codons had to be palindromic. Some evolutions occurred between the same classes, which includes from to , from to , from to , from to , from to , from to (Figure 7). Some evolutions of palindromic para-codons occurred between class and class , which includes from to , from to , from to , from to , from to (Figure 7). Some evolutions of palindromic para-codons occurred between class and class , which includes from to , from to (Figure 7). In addition, from to occurred between class and class ; from to occurred between class and class ; from to , from and from to occurred between class and class ; from to occurred between class and class (Figure 7).
The evolution of aaRSs along the roadmap helps to clarify the traditional classifications of aaRSs in the literature (Figure 4c), such as the major groove (M), minor groove (m) classification [31], or the class I (, , ), class (, , ) classification (Gesteland et al. 2006). The four classes , , , classification here makes clear some confused ideas in the above classifications. The majority of class aaRSs correspond to class aaRSs, and the majority of class aaRSs correspond to class aaRSs, which indicates an evolution from to due to the reverse sequence relationship between the RNA templates of class aaRS and class aaRS (Figure 7). The majority of aaRSs correspond to class aaRSs, which were from the homologous aaRSs. In addition, the majority of class aaRSs correspond to class or aaRSs, which were from the complementary aaRSs due to evolution of palindromic para-codons (Figure 7). The traditional classification of aaRSs by the major groove and minor groove are reasonable in practice because the template RNAs of aaRSs are complementary between the major groove class and the minor groove class, where the para-codons are palindromic to link the two classes. Meanwhile, the traditional classification of aaRS by classes A, B, and C reflects some reasonable evolutionary relationships between aaRSs based on the evolution of the biosynthetic families.
2.4.2. Coevolution of tRNA with aaRS
A comprehensive study of the evolution of the genetic code inevitably involves the origins of tRNAs and aaRSs. The intricate evolutionary relationships between tRNAs and aaRSs can be explained step by step for each codon in the triplex picture (Figure 7). The initiation stage on the roadmap played a fundamental role. At the end of the initiation stage, arbitrary finite sequences can be generated, which provided opportunities to generate complex RNAs, such as tRNAs, the template RNAs for aaRSs, ribozymes and the prototype of rRNAs, coding and non-coding RNAs, etc. The primordial translation mechanism were invented during the evolution of the genetic code. There were a junior stage and a senior stage of the primordial translation mechanism (Figure 8). The ancestor of aaRSs originated in the junior stage when no tRNAs were involved (Figure 8). However, the tRNAs and ribosomes were indispensable in the senior stage of the primordial translation mechanism, as well as in the modern translation mechanism. Certainly, the translation efficiency was low in the junior stage, was medium in the senior stage, and was high in the modern translation mechanism. There exists non-standard translation in experiments, such as direct translation from DNA to protein [60,61].
The benefits to explain the origins of tRNAs and aaRSs in the triplex picture are as follows. First, the ancestors of tRNAs and aaRSs did not originate from the random sequences; the sequence evolution along the roadmap was recurrent so the informative molecules were generated recurrently and accumulated in the prebiotic surroundings. Second, the evolutionary relationships between tRNAs and aaRSs can be naturally explained by the relationships of the homologous strands of the evolving triplex DNAs. The sequence of the template of the ancestor aaRS can be generated in the triplex picture by the junior stage of the primordial translation mechanism; meanwhile, the sequence of ribozyme can also be generated by the other strand of the same triplex nucleic acid. Thus, the earliest proteins, such as the ancestor of aaRSs, can be generated by the complex consisting of the ribozyme, the RNA template of aaRS, as well as a triplex DNA. Such a complex itself was the product of sequence evolution of triplex nucleic acids based on specific substitutions of triplex base pairs, where both the sequence for ribozyme and the sequence for the template of ancestor aaRS with enzyme activity were generated in different strands of the same triplex DNA by chance. Although the efficiency to produce proteins was low in this junior stage, it was feasible to generate a small number of proteins by this complex consisting only nucleic acids. The ancestor of aaRS with enzyme activity can be generated by this complex, which naturally tends to combine with the corresponding RNA template.
If the sequence of tRNA is homologous to the above RNA template, the ancestor aaRS also tends to combine with the tRNA. Furthermore, the above requirement can be reduced to homologous para-codons. Thus, in the triplex picture, the aaRSs coevolved with the para-codons, while the tRNAs coevolved with the codons. When considering the homologous or complementary sequence relationships, the reverse sequence relationships and the base substitution relationships in the strands of triplex nucleic acids, the intricate evolutionary relationships between tRNAs and aaRSs can be revealed in detail (Figure 5c and Figure 7). It is more difficult to generate aaRSs than to generate tRNAs, so there existed numerous tRNAs candidates in the prebiotic surroundings. Only the tRNAs that were recognised by aaRSs can be recruited into the living system. For example, the RNA were recognised by the class , so it was chosen as the first tRNA to transport . The prime RNAs were recognised by , so they were chosen as the tRNAs to transport amino acids (Figure 5c and Figure 7), respectively. Similarly, the derivative RNAs , , , , , with non-palindromic or palindromic para-codons homologous to the para-codons of , were recognised by , so they became the tRNAs to transport amino acids, respectively. Para-codons are the key factors for the recognition between tRNAs and aaRSs. The types of tRNAs are not necessarily same for the cognate tRNAs. Generally, the aaRSs combine with the cognate tRNAs from the same side. For example, combines with the type cognate tRNAs , , , , and from the minor groove side, where the para-codons can be non-palindromic (Figure 7); combines with the type tRNAs , , and the type tRNAs from the major groove side, where the para-codons of the two types of tRNAs have to be palindromic (Figure 7). However, combines with the type tRNAs , and the type tRNA from the minor groove side, while combine with the type tRNAs and from the major groove side, where the para-codons also need to be palindromic (Figure 7).
The biosynthetic families played essential roles in the evolution of aaRSs when both anti-codon and para-codon had changed (Figure 7). There were far more than 20 amino acids in the prebiotic surroundings. Only the amino acids that were recognised by aaRSs can be recruited into the living system. When involved to , recognised , as well as , from the major groove side, which inherited from that recognised , as well as , from the major groove side. When involved to , recognised , as well as , from the minor groove side owing to the palindromic para-codons, which inherited from that recognised , as well as , from the major groove side. When aaRSs involved in the same biosynthetic families: family, family, family, family, and family, the new aaRSs tended to recruit the new amino acids with the similar chemical properties in the same biosynthetic family. When aaRSs evolved from to , the enzyme activity transmitted between the aaRSs, and the recognised tRNAs to and the recognised amino acids to were recruited, where the evolving non-palindromic or palindromic para-codons linked these evolutions.
The evolutionary pairs of aaRSs combining two sides of the same tRNAs along the roadmap agree with the results based on structures: and , () and , and and [4,62], and additionally and . The aaRS pair and (namely and ) corresponds to an evolution from to . The aaRS pair and (namely and ) corresponds to an evolution from to . The aaRS pair and (namely and ) corresponds to an evolution from to . The aaRS pair and (namely and ) corresponds to an evolution from to .
The recruitment order of the 20 amino acids from to can be obtained by the roadmap (Figure 3a and Figure 9), which meets the basic requirement that Phase I amino acids appeared earlier than the Phase II amino acids [1,2]. The species with complete genome sequences are sorted by the order according to their amino acid frequencies, where the order is defined as the ratio of the average amino acid frequencies for the last 10 amino acids to that for the first 10 amino acids [8,36,63,64,65]. Along the evolutionary direction indicated by the increasing , the amino acid frequencies vary in different monotonous manners for the 20 amino acids, respectively (Figure 9). For the early amino acids , , , , , the amino acid frequencies tend to decrease greatly, except for to increase slightly (Figure 9); for the midterm amino acids , , , , , , , the amino acid frequencies tend to vary slightly, except for to decrease greatly (Figure 9); for the late amino acids , , , , , the amino acid frequencies tend to increase greatly, except for to increase slightly (Figure 9). In the recruitment order from to , the variation trends of the amino acid frequencies increase in general; namely, the later the amino acids recruited, the more greatly the amino acid frequencies tend to increase (Figure 9). The recruitment order of the amino acids from to is supported not only by the previous roadmap theory but also by this pattern of amino acid frequencies based on genomic data.
2.5. Recruitment of Codons
The roadmap only provided a logical substitution relationship of the 64 codons based on the stabilities of triplex base pairs (Figure 1a). It was the tRNAs and aaRSs that gave the genetic significance to the 64 codons (Figure 5c). The pair connections and route dualities observed in the recruitment of codons along the roadmap should be explained based on the coevolution of tRNAs with aaRSs (Figure 5b and Figure 7). The standard genetic code table can be comprehended in a biological context. Incidentally, the non-standard codons can also be explained.
2.5.1. Pair Connection
The pair connections can be explained by the coevolution of tRNAs with aaRSs when recognise, respectively, both the prime tRNAs (in bold in the following pair connections and route dualities) and the corresponding derivative tRNAs , and , where the anti-codons of tRNAs change but the para-codons of tRNAs do not change, or when have the efficient ability to recognise similar codons by wobble pairings (Figure 7c and Figure 7). Taking as an example, the type tRNA and the class originated at on the roadmap, and the same type tRNA appeared at on the roadmap. The for can recognise both the same type tRNAs and via the same para-codon. Namely, tRNAs and recognise, respectively, the codons at and at on the purine stands (R) on the roadmap (Figure 5c).
The following pair connections are due to wobble pairings or the tRNA evolution from to , both of which can be recognised by the respective same (Figure 5c, Figure 6b and Figure 7).
| 1Gly, aaRS1, t1→t1’: #1 R-Gly-#3 R | 2Ala, aaRS2, t2→t2’: #7 R-Ala-#9 R |
| 3Glu, aaRS3, t3→t3’: #4 R-Glu-#23 R | 4Asp, aaRS4, t4 wobbling: #5 R-Asp-#21 R |
| 5Val, aaRS5, t5→t5’: #19 R-Val-#24 R | 6Pro, aaRS6, t6 wobbling: #1 Y-Pro-#11 Y |
| 7Ser, aaRS7, t7 wobbling: #3 Y-Ser-#14 Y | 8Leu, aaRS8, t8→t8’: #20 Y-Leu-#25 Y |
| 9Thr, aaRS9, t9→t9’: #16 R-Thr-#18 R | 10Arg, aaRS10, t10→t10’: #10 R-Arg-#13 R |
| 11Cys, aaRS11, t11 wobbling: #9 Y-Cys-#18 Y | 12Trp, aaRS12, t12 wobbling: #12 R-Trp-#(15 R) |
| 13His, aaRS13, t13 wobbling: #19 Y-His-#22 Y | 14Gln, aaRS14, t14→t14’: #20 R-Gln-#28 R |
| 15Ile/16Met,aaRS15/16,t15/t16:#29R-Ile/Met-#22R | 17Phe, aaRS17, t17 wobbling: #23 Y-Phe-#32 Y |
| 18Tyr, aaRS18, t18 wobbling: #24 Y-Tyr-#29 Y | 19Asn, aaRS19, t19 wobbling: #26 R-Asn-#30 R |
| 20Lys, aaRS20, t20→t20’: #27 R-Lys-#32 R | stop, no aaRS, no tRNA: #25 R-stop-#31 R |
Especially, in the pair connection , for evolved to for , and the corresponding evolved to by changing both anti-codon and para-codon.
The following pair connections are due to wobble pairings or the tRNA evolution from to , both of which can be recognised by the respective same (Figure 5c, Figure 6b, and Figure 7).
| 1Gly, aaRS1, wobbling: #2 R-Gly-#6 R | 2Ala, aaRS2, wobbling: #2 Y-Ala-#8 Y |
| 5Val, aaRS5, wobbling: #5 Y-Val-#26 Y | 6Pro, aaRS6, →: #10 Y-Pro-#12 Y |
| 7Ser, aaRS7, →: #13 Y-Ser-#15 Y | 8Leu, aaRS8, wobbling: #4 Y-Leu-#27 Y |
| 9Thr, aaRS9, wobbling: #6 Y-Thr-#17 Y | 10Arg, aaRS10, wobbling: #7 Y-Arg-#16 Y |
| 15Ile, aaRS15, wobbling: #21 Y-Ile-#30 Y |
The following pair connections are due to wobble pairings or the tRNA evolution from to , both of which can be recognised by the respective same (Figure 5c, Figure 6b, and Figure 7).
| 7Ser, aaRS7, wobbling: #8 R-Ser-#17 R | 8Leu, aaRS8, → : #28 Y-Leu-#31 Y |
| 10Arg, aaRS10, → : #11 R-Arg-#14 R |
The pair connections between non-standard codons are also due to the non-standard tRNA evolution. The non-standard tRNAs with non-standard anti-codons can also be recognised by . The existence of non-standard codons indicates a variety of possibilities to choose tRNAs among the candidate tRNAs by the aaRSs during the evolution of the genetic code. The non-standard genetic code system can exist in case of certain metabolic cycle (Figure 5c and Figure 7).
| 7Ser, aaRS7, → : #11 R-Ser-#14 R | stop, no aaRS, no tRNA: #11 R-Ser-#14 R |
| 9Thr, aaRS9, wobbling: #4 Y-Thr-#27 Y | 9Thr, aaRS9, →: #20 Y-Thr-#25 Y |
| 14Gln, aaRS14, → : #25 R-Gln-#31 R |
2.5.2. Route Duality
Route duality refers to the relationships between pair connections in different routes. The route duality can also be explained by the coevolution of tRNAs with aaRSs when recognise both the prime tRNAs and the corresponding derivative tRNAs and , respectively. Taking the route duality ∼, for example, there were two pair connections: connecting via the type tRNA , and connecting via the type tRNA . The route duality between in and in is due to the fact that for recognises both the tRNAs , and the different type tRNAs by same para-codon.
The following route dualities are due to the tRNA evolution from to or , all of which can be recognised by the respective same (Figure 5c, Figure 6b and Figure 7).
| 1Gly, aaRS1, t1 → | #1-Gly-#3 (Route 0) ∼ #2-Gly-#6 (Route 1) |
| 2Ala, aaRS2, t2 → | #7-Ala-#9 (Route 2) ∼ #2-Ala-#8 (Route 1) |
| 5Val, aaRS5, t5 → | #19-Val-#24 (Route 2) ∼ #5-Val-#26 (Route 1) |
| 6Pro, aaRS6, t6 → | #1-Pro-#11 (Route 0) ∼ #10-Pro-#12 (Route 3) |
| 7Ser, aaRS7, t7 → | #3-Ser-#14 (Route 0) ∼ #13-Ser-#15 (Route 3) |
| and t7 → | #3-Ser-#14 (Route 0) ∼ #8-Ser-#17 (Route 1) |
| 8Leu, aaRS8, t8 → | #20-Leu-#25 (Route 3) ∼ #4-Leu-#27 (Route 0) |
| and t8 → | #20-Leu-#25 (Route 3) ∼ #28-Leu-#31 (Route 3) |
| 9Thr, aaRS9, t9 → | #16-Thr-#18 (Route 2) ∼ #6-Thr-#17 (Route 1) |
| 10Arg, aaRS10, t10 → | #10-Arg-#13 (Route 3) ∼ #7-Arg-#16 (Route 2) |
| and t10 → | #10-Arg-#13 (Route 3) ∼ #11-Arg-#14 (Route 0) |
The relationship between pair connections via aaRS evolution can be regarded as quasi route dualities (Figure 5c, Figure 6b and Figure 7).
| 3Glu/4Asp, /, aaRS3 → aaRS4 | #4-Glu-#23 (Route 0) ∼#5-Asp-#21 (Route 1) |
| 7Ser/10Arg, /, aaRS7 / aaRS10 | #8-Ser-#17 (Route 1) ∼ #11-Arg-#14 (Route 0) |
| 11Cys/12Trp, /, aaRS11 → aaRS12 | #9-Cys-#18 (Route 2) ∼#12-Trp-(#15) (Route 3) |
| 13His/14Gln, /, aaRS13 → aaRS14 | #19-His-#22 (Route 2) ∼#20-Gln-#28 (Route 3) |
| 15Ile/16Met,,/,aaRS15→aaRS16 | #29-Ile/Met-#22 (Route 2) ∼ #21-Ile-#30 (Route 1) |
| 8Leu/17Phe, /, aaRS8 → aaRS17 | #28-Leu-#31 (Route 3) ∼ #23-Phe-#32 (Route 0) |
| 18Tyr/stop, t18, aaRS18 | #24-Tyr-#29 (Route 2) ∼#25-stop-#31 (Route 3) |
| 19Asn/20Lys, /, aaRS19 → aaRS20 | #26-Asn-#30 (Route 1) ∼#27-Lys-#32 (Route 0) |
The route dualities between non-standard pair connections are also due to the non-standard tRNA evolution. The non-standard tRNAs and with non-standard anti-codons can also be recognised by the respective same (Figure 5c and Figure 7). The phenomenon of non-standard genetic code is due to alternative choice of tRNAs by aaRSs as small probability events in the fulfilment of the genetic code.
| 7Ser, aaRS7, → | #8-Ser-#17 (Route 1) ∼ #11-(Ser)-#14 (Route 0) |
| 9Thr, aaRS9, → | #4-(Thr)-#27 (Route 0) ∼ #20-(Thr)-#25 (Route 3) |
| stop | #11-(stop)-#14 (Route 0) ∼ #15-stop-#31 (Route 3) |
The codon boxes in the standard genetic code table come from the 8 route dualities and the 8 quasi route dualities (Table 2 and Figure 4a,b), where the pair connections are from to , from to , and from to , only. And the route dualities only exist between and , between and , between and , and between and , but not between and and and (Figure 4a,b).
2.6. Codon Degeneracy
The degeneracies 6, 4, 3, 2, or 1 for the 20 amino acids can be explained one by one according to pair connections and route dualities on the roadmap based on the coevolution of tRNAs with aaRSs in the triplex picture (Figure 5c, Figure 6b and Figure 7). Especially, the evolution of aaRSs based on the biosynthetic families played significant roles in the expansion of the genetic code. The degeneracy 2 mainly results from pair connections. The degeneracy 4 or 6 mainly result from the expansion of the genetic code from the initial subset by route dualities for , , , , , and (Figure 3a,b).
The degeneracy 6 for , , and can be explained by pair connections and route dualities (Figure 1a, Figure 3b, Figure 5c, Figure 6b and Figure 7), where and belong to the initial subset, and was recruited immediately after the initial subset. All of them have appeared in . The 6 codons of satisfy both the route duality and pair connection
The 6 codons of satisfy both the route duality and pair connection
The 6 codons of satisfy both the route duality and pair connection
The degeneracy 4 for , , , , and can be explained by route dualities (Figure 1a and Figure 3b). All of them belong to the initial subset. The degeneracy 4 for satisfy the route duality:
The degeneracy 4 for satisfy the route duality:
The degeneracy 4 for satisfy the route duality:
The degeneracy 4 for satisfy the route duality:
The degeneracy 4 for satisfy the route duality:
The degeneracy 2 for , , , , , , , , and can be explained by pair connections (Figure 1a and Figure 3b). They satisfy the following pair connections, respectively: , , , , , , , , . The degeneracy 3 for and the degeneracy 1 for satisfies the route duality (Figure 1a, Figure 3b, Figure 5c, Figure 6b and Figure 7).
3. Results
3.1. Driving Force in the Prebiotic Sequence Evolution
First, I propose an elegant roadmap for the evolution of the genetic code (Figure 1a). Around the middle of the last century, double helix DNAs, the genetic code, as well as triplex DNAs, were discovered, the former two of which greatly enhanced our understanding of life. There are indeed profound relationships among the above three discoveries. Although triple-helical nucleic acids are rare in vivo, they might be the unsung heroes in the origin of life. According to the substitutions of triplex base pairs from weak to strong along the roadmap, the recruitment of the 64 codons has been described from initiation to expansion and, finally, to the ending, and, hence, the perplexing codon degeneracy has been obtained.
The whole process is complicated and cumbersome, and has been explained step by step in the Methods section. Here is an overview of the basic process. Concretely speaking, the stability of the 16 triplex base pairs in triplex DNAs are from instability (−), weak (+) to strong (, , ) [10,11]. This stability order in experiments is crucial to establish a roadmap for the evolution of the genetic code. is a common and easily formed triplex DNA [10,13], which is bound together by triplex base pair . The sequences evolved via substitutions between triplex base pairs when the strands of triplex DNAs combined and separated alternatively. Only three kinds of substitutions between triplex base pairs are practically required to obtain a complete set of 64 codons on the roadmap (Figure 1 and Figure 2): (1) substitution of by (transition from G to A with increasing stability from + to ). This is the most common substitution on the roadmap by which all the codons in and most codons in were recruited; (2) substitution of by (transversion from G to C with increasing stability from + to ), which blazed a new path at , , for the recruitment of codons in , respectively; (3) substitution of by (transition from C to T with increasing stability from + to ) at , , , by which the remaining codons in were recruited.
Hence, a roadmap has been obtained with 4 Routes and 4 Hierarchies (Figure 1a, Figure 3b and Figure 4a). This unique roadmap has narrowly avoided those unstable triplex base pairs that can hinder the sequence evolution of triplex DNAs. The roadmap describes recruitments of both the 64 codons and the 20 amino acids in proper order during coevolution of tRNAs with aaRSs. The initial codon pair () corresponds the amino acid pair and , and the consequent codon pair (G to C at ) corresponds a new amino acid pair and . The obtained pair connection indicates that the common is encoded by in the former pair and in the latter pair. Pair connections appear step by step along the roadmap, which relates to the evolution of the corresponding tRNAs. In addition, there are route dualities between pair connections, which relate to the evolution of the corresponding aaRSs. The expansion of codons along the roadmap has been explained by route dualities from the Phase I amino acids [34] , , , , , and , which are due to recognition of tRNAs by the corresponding aaRSs step by step. In addition, stop codons and non-standard genetic code often occur at the ending stage. Thus, the intricate codon degeneracy has been obtained based on the incremental stability of triplex base pairs. In the triplex picture for the prebiotic evolution, the base substitution of triplex DNA drives both the recruitment of the 64 codons and the corresponding coevolution of tRNAs and aaRSs, step by step.
The benefit of the triplex picture is that nonrandom sequences can be generated routinely in the prebiotic evolution. The modification of homopolymers became a routine process in forming the codon degeneracy. This non-living apparatus based on sequence evolution of triplex DNAs was able to maintain during geologically long period, by which similar nonrandom sequences can be statistically generated again and again under selective pressure at any appropriate time. Hence, the nonrandom sequences, e.g., tRNAs and aaRSs, were able to emerge more efficiently than any mechanism to choose informative molecules from random sequences. Such an HfC-like apparatus based on sequence evolution of triplex DNAs had vanished after the establishment of the genetic code system, whose relic may have remained in the triplex base pairs in tRNAs at present.
3.2. Explanation of Two Classes of aaRSs According to Coevolution of tRNAs with aaRSs
Then, I explain the coevolution of tRNAs with aaRSs (Figure 5, Figure 6 andFigure 7), by which the two classes of aaRSs [31] and the anti-codons and para-codons of tRNAs have been explained in detail. A comprehensive study of the evolution of the genetic code inevitably involves the intricate evolutionary relationships between tRNAs and aaRSs. The evolution of triple-helical nucleic acids and (D for DNA, R for RNA) [10] created conditions for coevolution of tRNAs and aaRSs along the roadmap. The third RNA strand R and its complementary strand can carry codons and anti-codons in sequence evolution along the roadmap, which, hence, accounts for that the tRNAs can be assembled by pairs of these complementary RNAs [66] whose anti-codons evolved along the roadmap (Figure 5a,b and Figure 6a). Meanwhile, genes of aaRSs also evolved along the roadmap, which were homologous to the complementary [67,68] templates of major or minor groove sides of tRNAs. The recognition of a tRNA by certain aaRS came from the combining ability between the aaRS and its gene that is homologous to the corresponding side of the tRNA. Hence, the recognition of tRNAs by aaRSs kept pace with the evolution of the genetic code along the roadmap. The tRNAs were relatively easy to be assembled, so there existed numerous candidate tRNAs. Only tRNAs that were recognised by aaRSs had been recruited into the living system. The genes of aaRSs are scarce, whose enzyme activity came from a common ancestor. The genes of the two classes of aaRSs evolved alternatively in two complementary strands. Palindrome enabled recognition of tRNA via choosing its appropriate side by the corresponding aaRS.
The intricate relationships between tRNAs and aaRSs along the roadmap has been explained, which agrees with both the anti-codons of tRNAs and the two classes of aaRSs in observations (Figure 5). The evolution of aaRSs along the roadmap in the triplex picture helps to clarify the traditional classifications of aaRSs in the literature. The major/minor groove classification of aaRSs [31] can be accounted for by the complementary strands of the template RNAs of aaRSs, and the A/B/C sub-classification of aaRSs [69] relates to the impact from biosynthetic families of amino acids. In most cases, the aaRSs combine with the cognate tRNAs from the same side, whose classes are fixed. As a special case, combines with the type tRNAs , and the type tRNA from the minor groove side, while combine with the type tRNAs and from the major groove side, where the para-codons need to be palindromic. In the evolution from to , for instance, recognised from major groove side of , whose class follows the former to recognise from major groove side of . In addition, in the consequent evolution from to , recognised yet from minor groove side of due to the palindromic para-codons. The biosynthetic families played significant roles in the evolution of aaRSs when both anti-codon and palindromic or non-palindromic para-codon evolved. When aaRSs involved in the same biosynthetic families, the new aaRSs tended to recruit amino acids in same biosynthetic family with similar chemical properties. Thus, the observed recognition of tRNAs from major or minor groove sides by aaRSs have been explained for respective amino acids in detail (Figure 7). The aaRS pair supposed to combine both sides of tRNA simultaneously [4,62] should be amended as new aaRS pair that combined one side of a tRNA and evolved to the other side. The pairs - and - appear both in the above literature and here. However, the pair - in the above literature should be changed to -. In addition, the pair - appeared here was missing in the above literature.
3.3. Explanation of the Codon Degeneracy on the Genetic Code Chart
As the main result, the codon degeneracy should be explained based on the roadmap for the evolution of the genetic code (Figure 1) and the coevolution of tRNAs with aaRSs (Figure 5 and Figure 7). The intricate codon degeneracies are just the relics of learning process for the recognition of tRNAs by aaRSs. The pair connections and route dualities on the roadmap result from the evolution of tRNAs and the recognition of tRNAs by aaRSs (Figure 5). Especially, homologous aaRSs often evolved within the biosynthetic families of amino acids by combining either the same side or the opposite side of tRNAs (Figure 7). The codon boxes in the standard genetic code table came from the 8 route dualities and the 8 quasi route dualities (Figure 1).
The degeneracies 6, 4, 3, 2, or 1 for the 20 amino acids have been explained, respectively, according to the corresponding pair connections and route dualities (Figure 1, Figure 5 and Figure 7). The large degeneracy 4 or 6 mainly results from the expansion of codons for the amino acids recruited in the initiation stage: , , , , , and . The degeneracy 6 for , , and is due to the following route dualities and pair connections, respectively: The degeneracy 4 for , , , and is due to the following route dualities, respectively: , , , , . In addition, the degeneracy 2 for , , , , , , , , and is due to the following pair connections, respectively: , , , , , , , , . The degeneracies 3 for and 1 for are due to the route duality The degeneracy 1 for satisfies the pair connection with non-standard genetic code . This pair connection includes a stop codon; the other stop codons satisfy the pair connection: . Incidentally, the route dualities for non-standard codons are also due to recognition of non-standard tRNAs by the corresponding aaRSs: , , .
4. Conclusions
In the present prebiotic picture with selective pressure, both the codon degeneracy and the major/minor groove classification of aaRSs have been explained together within the scope of literature.
Supplementary Materials
The following are available online at https://0-www-mdpi-com.brum.beds.ac.uk/article/10.3390/genes12122023/s1, Movie S1: Substitutions of triplex base pairs along the roadmap.
Funding
Supported by the Fundamental Research Funds for the Central Universities (xjtu08143058).
Acknowledgments
My warm thanks go to Jinyi Li for valuable discussions. The author thanks the anonymous reviewers for their helpful comments.
Conflicts of Interest
The author declares no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Wong, J.T. A coevolution theory of the genetic code. Proc. Natl. Acad. Sci. USA 1975, 72, 1909–1912. [Google Scholar] [CrossRef] [Green Version]
- Wong, J.T.; Lazcano, A. Prebiotic Evolution and Astrobiology; Landes Bioscience: Austin, TX, USA, 2009. [Google Scholar]
- De Pouplana, L.R. (Ed.) The Genetic Code and the Origin of Life; Kluwer Academic: New York, NY, USA, 2004. [Google Scholar]
- De Pouplana, L.R.; Schimmel, P. Aminoacyl-tRNA synthetases: Potential markers of genetic code development. Trends Biochem. Sci. 2001, 26, 591–596. [Google Scholar] [CrossRef]
- Woese, C.R.; Kandler, O.; Wheelis, M.L. Towards a natural system of organisms: Proposal for the domains Archaea, Bacteria, and Eucarya. Proc. Natl. Acad. Sci. USA 1990, 87, 4576–4579. [Google Scholar] [CrossRef] [Green Version]
- Gibson, D.G.; Glass, J.I.; Lartigue, C.; Noskov, V.N.; Chuang, R.Y.; Algire, M.A.; Benders, G.A.; Montague, M.G.; Ma, L.; Moodie, M.M.; et al. Creation of a bacterial cell controlled by a chemically synthesized genome. Science 2010, 329, 52–56. [Google Scholar] [CrossRef] [Green Version]
- Wong, J.T. Coevolution theory of the genetic code at age thirty. BioEssays 2005, 27, 416–425. [Google Scholar] [CrossRef]
- Trifonov, E.N.; Gabdank, I.; Barash, D.; Sobolevsky, Y. Primordia vita. deconvolution from modern sequences. Orig. Life Evol. Biosph. 2006, 36, 559–565. [Google Scholar] [CrossRef]
- Reznick, J.S. Embracing the future as stewards of the past: Charting a course forward for historical medical libraries and archives. RBM 2014, 15, 111–123. [Google Scholar] [CrossRef] [Green Version]
- Soyfer, V.N.; Potaman, V.N. Triple-Helical Nucleic Acids; Springer: New York, NY, USA, 1996. [Google Scholar]
- Belotserkovskii, B.P.; Veselkov, A.G.; Filippov, S.A.; Dobrynin, V.N.; Mirkin, S.M.; Frank-Kamenetskii, M.D. Formation of intramolecular triplex in homopurine-homopyrimidine mirror repeats with point substitutions. Nucleic Acids Res. 1990, 18, 6621–6624. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sklenář, V.; Felgon, J. Formation of a stable triplex from a single DNA strand. Nature 1990, 345, 836–838. [Google Scholar] [CrossRef] [PubMed]
- Frank-Kamenetskii, M.D. Triplex DNA structrutures. Annu. Rev. Biochem. 1995, 64, 65–95. [Google Scholar] [CrossRef] [PubMed]
- Robertus, J.D.; Ladner, J.E.; Finch, J.T.; Rhodes, D.; Brown, R.S.; Clark, B.F.C.; Klug, A. Structure of yeast phenylalanine tRNA at 3Å resolution. Nature 1974, 250, 546–551. [Google Scholar] [CrossRef] [PubMed]
- Oro, J. Mechanism of synthesis of adenine from hydrogen cyanide under possible primitive Earth conditions. Nature 1961, 191, 1193–1194. [Google Scholar] [CrossRef] [PubMed]
- Orgel, L.E. Prebiotic chemistry and the origin of the RNA world. Crit. Rev. Biochem. Mol. Biol. 2006, 39, 99–123. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miyakawa, S.; Murasawa, K.; Kobayashi, K.; Sawaoka, A.B. Abiotic synthesis of guanine with high temperature plasma. Orig. Life Evol. Biosph. 2000, 30, 557–566. [Google Scholar] [CrossRef] [PubMed]
- Ferris, J.P.; Sanchez, R.A.; Orgel, L.E. Studies in prebiotic synthesis. 3. Synthesis of pyrimidines from cyanoacetylene and cyanate. J. Mol. Biol. 1968, 33, 693–704. [Google Scholar] [CrossRef]
- Sanchez, R.; Ferris, J.P.; Orgel, L.E. Cyanoacetylene in prebiotic synthesis. Science 1966, 154, 784–785. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Tsanakopoulou, M.; Magnani, C.J.; Szabla, R.; Šponer, J.E.; Šponer, J.; Góra, R.W.; Sutherland, J.D. A prebiotically plausible synthesis of pyrimidine β-ribonucleosides and their phosphate derivatives involving photoanomerization. Nat. Chem. 2017, 9, 303–309. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Prywes, N.; Tam, C.P.; O’flaherty, D.K.; Lelyveld, V.S.; Izgu, E.C.; Pal, A.; Szostak, J.W. Enhanced nonenzymatic RNA copying with 2-aminoimidazole activated nucleotides. J. Am. Chem. Soc. 2017, 139, 1810–1813. [Google Scholar] [CrossRef]
- Becker, S.; Feldmann, J.; Wiedemann, S.; Okamura, H.; Schneider, C.; Iwan, K.; Crisp, A.; Rossa, M.; Amatov, T.; Carell, T. Unified prebiotically plausible synthesis of pyrimidine and purine RNA ribonucleotides. Science 2019, 366, 76–82. [Google Scholar] [CrossRef] [Green Version]
- Powner, M.W.; Zheng, S.; Szostak, J.W. Multicomponent assembly of proposed DNA precursors in water. J. Am. Chem. Soc. 2012, 134, 13889–13895. [Google Scholar] [CrossRef]
- Trevinoa, S.G.; Zhanga, N.; Elenkoa, M.P.; Luptákb, A.; Szostak, J.W. Evolution of functional nucleic acids in the presence of nonheritable backbone heterogeneity. Proc. Natl. Acad. Sci. USA 2011, 108, 13492–13497. [Google Scholar] [CrossRef] [Green Version]
- Bhowmik, S.; Krishnamurthy, R. The role of sugar-backbone heterogeneity and chimeras in the simultaneous emergence of RNA and DNA. Nat. Chem. 2019, 11, 1009–1018. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Green, N.J.; Gibard, C.; Krishnamurthy, R.; Sutherl, J.D. Prebiotic phosphorylation of 2-thiouridine provides either nucleotides or DNA building blocks via photoreduction. Nat. Chem. 2019, 11, 457–462. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Chmela, V.; Green, N.J.; Russell, D.A.; Janicki, M.J.; Góra, R.W.; Szabla, R.; Bond, A.D.; Sutherland, J.D. Selective prebiotic formation of RNA pyrimidine and DNA purine nucleosides. Nature 2020, 582, 60–66. [Google Scholar] [CrossRef] [PubMed]
- Wong, J.T.; Ng, S.; Mat, W.; Hu, T.; Xue, H. Coevolution theory of the genetic code at age forty: Pathway to translation and synthetic life. Life 2016, 6, 12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nirenberg, M.W.; Matthaei, J.H. The dependence of cell-free protein synthesis in E. coli upon naturally occurring or synthetic polyribonucleotides. Proc. Natl. Acad. Sci. USA 1961, 47, 1588–1602. [Google Scholar] [CrossRef] [Green Version]
- Crick, F.H.C. Codon-anticodon pairing: The wobble hypothesis. J. Mol. Biol. 1966, 19, 548–555. [Google Scholar] [CrossRef]
- Eriani, G.; Delarue, M.; Poch, O.; Gangloff, J.; Moras, D. Partition of tRNA synthetases into two classes based on mutually exclusive sets of sequence motifs. Nature 1990, 347, 203–206. [Google Scholar] [CrossRef] [PubMed]
- Miller, S.L.; Urey, H.C. Organic compound synthes on the primitive earth. Science 1959, 130, 245–251. [Google Scholar] [CrossRef] [PubMed]
- Engel, M.H.; Macko, S.A. Isotopic evidence for extraterrestrial non-racemic amino acids in the Murchison meteorite. Nature 1997, 389, 265–268. [Google Scholar] [CrossRef]
- Wong, J.T. Coevolution of the genetic code and amino acid biosynthesis. Trends Biochem. Sci. 1981, 6, 33–36. [Google Scholar] [CrossRef]
- Kobayashi, K.; Kaneko, T.; Saito, T.; Oshima, T. Amino acid formation in gas mixtures by high energy particle irradiation. Orig. Life Evol. Biosph. 1998, 28, 155–165. [Google Scholar] [CrossRef]
- Li, D.J.; Zhang, S. Genetic code evolution as an initial driving force for molecular evolution. Phys. A 2009, 388, 3809–3825. [Google Scholar] [CrossRef] [Green Version]
- Muto, A.; Osawa, S. The guanine and cytosine content of genomic DNA and bacterial evolution. Proc. Natl. Acad. Sci. USA 1987, 84, 166–169. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woese, C.R.; Dugre, D.H.; Dugre, S.A.; Kondo, M.; Saxinger, W.C. On the fundamental nature and evolution of the genetic code. Cold Spring Harbour. Symp. Quant. Biol. 1966, 31, 723–736. [Google Scholar] [CrossRef]
- Crick, F.H.C. The origin of the genetic code. J. Mol. Biol. 1968, 38, 367–379. [Google Scholar] [CrossRef]
- Yarus, M. A specific amino acid binding site composed of RNA. Science 1988, 240, 1751–1758. [Google Scholar] [CrossRef]
- Di Giulio, M. The Extension Reached by the Minimization of the Polarity Distances during the Evolution of the Genetic Code. J. Mol. Evol. 1989, 29, 288–293. [Google Scholar] [CrossRef]
- Di Giulio, M. Some Aspects of the Organization and Evolution of the Genetic Code. J. Mol. Evol. 1989, 29, 191–201. [Google Scholar] [CrossRef]
- Osawa, S.; Jukes, T.H. Codon Reassignment (Codon Capture) in Evolution. J. Mol. Evol. 1989, 28, 271–278. [Google Scholar] [CrossRef] [PubMed]
- Root-Bernstein, R. Simultaneous origin of homochirality, the genetic code and its directionality. Bioessays 2007, 29, 689–698. [Google Scholar] [CrossRef]
- Rodin, A.S.; Szathmáry, E.; Rodin, S.N. One ancestor for two codes viewed from the perspective of two complementary modes of tRNA aminoacylation. Biol. Direct 2009, 4, 4. [Google Scholar] [CrossRef] [Green Version]
- Knight, R.D.; Freel, S.J.; Landweber, L.F. Rewiring the keyboard: Evolvability of the genetic code. Nat. Rev. Genet. 2001, 2, 49–58. [Google Scholar] [CrossRef] [PubMed]
- Sengupta, S.; Higgs, P.G. Pathways of Genetic Code Evolution in Ancient and Modern Organisms. J. Mol. Evol. 2015, 80, 229–243. [Google Scholar] [CrossRef] [PubMed]
- Sengupta, S.; Yang, X.; Higgs, P.G. The Mechanisms of Codon Reassignments in Mitochondrial Genetic Codes. J. Mol. Evol. 2007, 64, 662–688. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Escudé, C.; Francçois, J.C.; Sun, J.S.; Ott, G.; Sprinzl, M.; Garestier, T.; Heélene, J.C. Stability of triple helices containing RNA and DNA strands: Experimental and molecular modeling studies. Nucleic Acids Res. 1993, 21, 5547–5553. [Google Scholar] [CrossRef]
- Han, H.; Dervan, P.B. Sequence-specific recognition of double helical RNA and RNA·DNA by triple helix formation. Proc. Natl. Acad. Sci. USA 1993, 90, 3806–3810. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, S.; Kool, E.T. Relative stabilities of triple helices composed of combinations of DNA, RNA and 2’-O-methyl-RNA backbones: Chimeric circular oligonucleotides as probes. Nucleic Acids Res. 1995, 23, 1157–1164. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Altwegg, K.; Balsiger, H.; Bar-Nun, A.; Berthelier, J.J.; Bieler, A.; Bochsler, P.; Briois, C.; Calmonte, U.; Combi, M.R.; Cottin, H.; et al. Prebiotic chemicals–amino acid and phosphorus–in the coma of comet 67P/Churyumov-Gerasimenko. Sci. Adv. 2016, 2, e1600285. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, D.J. Concurrent origins of the genetic code and the homochirality of life, and the origin and evolution of biodiversity Part I: Observations and explanations. bioRxiv 2015. [Google Scholar] [CrossRef] [Green Version]
- Roberts, R.W.; Crothers, D.M. Stability and properties of double and triple helices: Dramatic effects of RNA or DNA backbone composition. Science 1992, 258, 1463–1466. [Google Scholar] [CrossRef]
- Di Giulio, M. On the origin of the transfer RNA molecule. J. Theor. Biol. 1992, 159, 199–214. [Google Scholar] [CrossRef]
- Di Giulio, M. Was it an ancient gene codifying for a hairpin RNA that, by means of direct duplication, gave rise to the primitive tRNA molecule? J. Theor. Biol. 1995, 177, 95–101. [Google Scholar] [CrossRef]
- Di Giulio, M. The nonmonophyletic origin of tRNA molecule. J. Theor. Biol. 1999, 197, 403–414. [Google Scholar] [CrossRef]
- Di Giulio, M. The origin of the tRNA molecule: Implications for the origin of protein synthesis. J. Theor. Biol. 2004, 226, 89–93. [Google Scholar] [CrossRef]
- Di Giulio, M. Nanoarchaeum equitans is a living fossil. J. Theor. Biol. 2006, 242, 257–260. [Google Scholar] [CrossRef] [PubMed]
- McCarthy, B.J.; Holl, J.J. Denatured DNA as a Direct Template for in vitro Protein Synthesis. Proc. Natl. Acad. Sci. USA 1965, 54, 880–886. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Uzawa, T.; Yamagishi, A.; Oshima, T. Polypeptide Synthesis Directed by DNA as a Messenger in Cell-Free Polypeptide Synthesis by Extreme Thermophiles, Thermus thermophilus HB27 and Sulfolobus tokodaii Strain 7. J. Biochem. 2002, 131, 849–853. [Google Scholar] [CrossRef]
- Schimmel, P. Development of tRNA synthetases and connection to genetic code and disease. Protein Sci. 2008, 17, 1643–1652. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Trifonov, E.N. Consensus temporal order of amino acids and evolution of the triplet code. Gene 2000, 261, 139–151. [Google Scholar] [CrossRef]
- Trifonov, E.N. The triplet code from first principles. J. Biomol. Struct. Dyn. 2004, 22, 1. [Google Scholar] [CrossRef]
- Trifonov, E.N.; Kirzhner, A.; Kirzhner, V.M.; Berezovsky, I.N. Distinc stage of protein evolution as suggested by protein sequence analysis. J. Mol. Evol. 2001, 53, 394–401. [Google Scholar] [CrossRef] [PubMed]
- Widmann, J.; Di Giulio, M.; Yarus, M.; Knight, R. tRNA creation by hairpin duplication. J. Mol. Evol. 2005, 61, 524–530. [Google Scholar] [CrossRef] [PubMed]
- Rodin, S.N.; SOhno, S. Two types of aminoacyl-trna synthetases could be originally encoded by complementary strands of the same nucleic acid. Orig. Life Evol. Biosph. 1995, 25, 565–589. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Rodriguez, L.; Erdogan, O.; Jimenez-Rodriguez, M.; Gonzalez-Rivera, K.; Williams, T.; Li, L.; Weinreb, V.; Collier, M.; Chandrasekaran, S.N.; Ambroggio, X.; et al. Functional class I and II amino acid-activating enzymes can be coded by opposite strands of the same gene. J. Biol. Chem. 2015, 290, 19710–19725. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gestel, R.F. (Ed.) The RNA World, 3rd ed.; Cold Spring Harbor Laboratory: New York, NY, USA, 2006. [Google Scholar]
Figure 1.
The origin of the genetic code. (a) The roadmap for the evolution of the genetic code. The 64 codons formed from base substitutions in triplex DNAs are in red. Only three-base-length segments of the triplex DNAs are shown explicitly; the whole length right-handed triplex DNAs are indicated in Figure 1b. In each position (), the codon pair on , and is in red. The relative stabilities of the triplex base pairs (−, +, ++, 4+) are written to the right of the base triplexes, where the increased relative stabilities of triplex base pairs in base substitutions are indicated in green. Each triplex DNA is denoted by three arrows, whose directions are from 5’ to 3’. The triplex DNAs are in pink, and the triplex DNAs in azure. The recruitment order of codon pairs are from to , and the recruitment order of the 20 amino acids are to the left of them, respectively. Non-standard genetic codes are indicated by brackets beside the corresponding amino acids. The and are indicated to the right of and below the roadmap, respectively. The evolution of the genetic code are denoted by black arrows, beside which pair connections are indicated by the corresponding amino acids. Refer to an example in Figure 1b to understand details of the roadmap; refer to Figure 2 to understand the critical role of relative stabilities of triplex base pairs in achieving the real genetic code; refer to Figure 5a,b to see the origin of tRNAs; refer to Figure 3a to see the coherent relationship between the recruitment orders of codons and amino acids; refer to Figure 3b to see the codon degeneracy in the symmetric roadmap. (b) A detailed description of the roadmap (see Supplementary Movie S1). Taking, for example, from to , the evolution of the genetic code from , to , to , to , and, at last, to are explained in detail in the upper boxes, and the corresponding right-handed single-stranded, double-stranded, and triple-stranded DNAs are shown in the lower boxes, respectively.
Figure 1.
The origin of the genetic code. (a) The roadmap for the evolution of the genetic code. The 64 codons formed from base substitutions in triplex DNAs are in red. Only three-base-length segments of the triplex DNAs are shown explicitly; the whole length right-handed triplex DNAs are indicated in Figure 1b. In each position (), the codon pair on , and is in red. The relative stabilities of the triplex base pairs (−, +, ++, 4+) are written to the right of the base triplexes, where the increased relative stabilities of triplex base pairs in base substitutions are indicated in green. Each triplex DNA is denoted by three arrows, whose directions are from 5’ to 3’. The triplex DNAs are in pink, and the triplex DNAs in azure. The recruitment order of codon pairs are from to , and the recruitment order of the 20 amino acids are to the left of them, respectively. Non-standard genetic codes are indicated by brackets beside the corresponding amino acids. The and are indicated to the right of and below the roadmap, respectively. The evolution of the genetic code are denoted by black arrows, beside which pair connections are indicated by the corresponding amino acids. Refer to an example in Figure 1b to understand details of the roadmap; refer to Figure 2 to understand the critical role of relative stabilities of triplex base pairs in achieving the real genetic code; refer to Figure 5a,b to see the origin of tRNAs; refer to Figure 3a to see the coherent relationship between the recruitment orders of codons and amino acids; refer to Figure 3b to see the codon degeneracy in the symmetric roadmap. (b) A detailed description of the roadmap (see Supplementary Movie S1). Taking, for example, from to , the evolution of the genetic code from , to , to , to , and, at last, to are explained in detail in the upper boxes, and the corresponding right-handed single-stranded, double-stranded, and triple-stranded DNAs are shown in the lower boxes, respectively.


Figure 2.
The driving force in the evolution of the genetic code based on the relative stabilities of triplex base pairs. The base substitutions on the roadmap occur when the relative stabilities of triplex base pairs increase. The roadmap is the best result to avoid the unstable triplex base pairs. So, the universal genetic code is a narrow choice by the relative stabilities of triplex base pairs. The relative stability increases from (+) of the triplex base pair to (4+) of the triplex base pair at , , and that initiates , respectively. (+) changes to (++) at , , and , and (+) changes to (++) at other positions on the roadmap.
Figure 2.
The driving force in the evolution of the genetic code based on the relative stabilities of triplex base pairs. The base substitutions on the roadmap occur when the relative stabilities of triplex base pairs increase. The roadmap is the best result to avoid the unstable triplex base pairs. So, the universal genetic code is a narrow choice by the relative stabilities of triplex base pairs. The relative stability increases from (+) of the triplex base pair to (4+) of the triplex base pair at , , and that initiates , respectively. (+) changes to (++) at , , and , and (+) changes to (++) at other positions on the roadmap.

Figure 3.
(a) Cooperative recruitment of codons and amino acids. Codon pairs are plotted from left to right according to their recruitment order. The initial subset plays a crucial role in the expansion of the genetic code along the roadmap. The 6 biosynthetic families of the amino acid are distinguished by different colours. (b) The cubic roadmap. This is a revised roadmap Figure 1a to indicate the symmetry in the evolution of the genetic code. The four routes are represented by four cubes, respectively. Pair connections are marked besides the evolutionary arrows. Route dualities are indicated by same colours for the corresponding pair connections.
Figure 3.
(a) Cooperative recruitment of codons and amino acids. Codon pairs are plotted from left to right according to their recruitment order. The initial subset plays a crucial role in the expansion of the genetic code along the roadmap. The 6 biosynthetic families of the amino acid are distinguished by different colours. (b) The cubic roadmap. This is a revised roadmap Figure 1a to indicate the symmetry in the evolution of the genetic code. The four routes are represented by four cubes, respectively. Pair connections are marked besides the evolutionary arrows. Route dualities are indicated by same colours for the corresponding pair connections.

Figure 4.
(a) The distribution of codons from R- and Y-strands of in the genetic code table. The pattern of the codon boxes for the degenerate codons relates to such a distribution of the four routes, owing to the evolution of the genetic code along the roadmap. (b) The genetic code table. The clusterings of biosynthetic families (Glu, Asp, Val, Ser, Phe) in the genetic code table. Such nice clusterings are correspondingly observed in the R- and Y-strands of in Figure 3b (denoted in the same group of colour as in the present figure). The clusterings of biosynthetic families in the present figure are closely related to the distribution of codons from R- and Y-strands of , owing to the recruitment of amino acids along the roadmap. Generally speaking, the amino acids are arranged properly in the recruitment order from to along the direction from G, C to A, U in the genetic code table. (c) The distribution of types of aaRSs in the genetic code table. The aaRSs can be divided into and , which can be divided into subclasses , , and , , , respectively. The aaRSs can also be divided into minor groove ones (m) and major groove ones (M).
Figure 4.
(a) The distribution of codons from R- and Y-strands of in the genetic code table. The pattern of the codon boxes for the degenerate codons relates to such a distribution of the four routes, owing to the evolution of the genetic code along the roadmap. (b) The genetic code table. The clusterings of biosynthetic families (Glu, Asp, Val, Ser, Phe) in the genetic code table. Such nice clusterings are correspondingly observed in the R- and Y-strands of in Figure 3b (denoted in the same group of colour as in the present figure). The clusterings of biosynthetic families in the present figure are closely related to the distribution of codons from R- and Y-strands of , owing to the recruitment of amino acids along the roadmap. Generally speaking, the amino acids are arranged properly in the recruitment order from to along the direction from G, C to A, U in the genetic code table. (c) The distribution of types of aaRSs in the genetic code table. The aaRSs can be divided into and , which can be divided into subclasses , , and , , , respectively. The aaRSs can also be divided into minor groove ones (m) and major groove ones (M).

Figure 5.
The origin and evolution of tRNAs along the roadmap. (a) The evolution of the type tRNAs by the triplex base pairings and . (b) The evolution of the type tRNAs by the triplex base pairings , and and . The node numbers on the roadmap may exchange within or between routes because the sequences of Y and R are reverse to the sequences of y and r, respectively. (c) The coevolution of tRNAs with aaRSs along the roadmap, which determines the pair connections and route dualities. The aaRSs to combine, respectively, with the tRNAs to from certain major/minor groove side. The complementary relationship between the pyrimidine strand of the type tRNAs and the purine strand of the type tRNAs agrees with the complementary relationship between G and C for the second bases of the consensus genes of tRNAs, especially for the early tRNAs in and in .
Figure 5.
The origin and evolution of tRNAs along the roadmap. (a) The evolution of the type tRNAs by the triplex base pairings and . (b) The evolution of the type tRNAs by the triplex base pairings , and and . The node numbers on the roadmap may exchange within or between routes because the sequences of Y and R are reverse to the sequences of y and r, respectively. (c) The coevolution of tRNAs with aaRSs along the roadmap, which determines the pair connections and route dualities. The aaRSs to combine, respectively, with the tRNAs to from certain major/minor groove side. The complementary relationship between the pyrimidine strand of the type tRNAs and the purine strand of the type tRNAs agrees with the complementary relationship between G and C for the second bases of the consensus genes of tRNAs, especially for the early tRNAs in and in .



Figure 6.
(a) The assembly of tRNAs. The tRNAs - with anti-codons (Figure 5c) are listed here to carry the amino acids from to , respectively. The two complimentary single-stranded RNAs for each tRNA join together and fold into a cloverleaf shape by taking advantage of the complementarity between the two strands. The joining position of the two strands is near to the 3 side of the anti-codon loop, which agrees with the position of introns in tRNA genes in observations. The anti-codons situate in the -ends of the strand or strand. The palindromic sequences tend to form loops of the tRNAs. The para-codon of tRNA are non-palindromic or palindromic which adapt to the aaRSs (Figure 7 and Figure 8). (b) The cognate tRNAs. Explanation of the number of canonical amino acids as 20 based on the relationship between the types of cognate tRNAs and the 20 types of base combinations. The primer tRNAs generally appeared earlier than the derivative tRNAs. The primer tRNAs generally distribute along the diagonal line due to the chronological arrangements for both the 20 amino acids and the 20 base combinations, considering the substitution order G, C, A, U along the roadmap. The codon degeneracies 6, 4, 3, 2, and 1 are due to the tRNA evolution from to and , as well as from to , etc., all of which can be recognised by the corresponding .
Figure 6.
(a) The assembly of tRNAs. The tRNAs - with anti-codons (Figure 5c) are listed here to carry the amino acids from to , respectively. The two complimentary single-stranded RNAs for each tRNA join together and fold into a cloverleaf shape by taking advantage of the complementarity between the two strands. The joining position of the two strands is near to the 3 side of the anti-codon loop, which agrees with the position of introns in tRNA genes in observations. The anti-codons situate in the -ends of the strand or strand. The palindromic sequences tend to form loops of the tRNAs. The para-codon of tRNA are non-palindromic or palindromic which adapt to the aaRSs (Figure 7 and Figure 8). (b) The cognate tRNAs. Explanation of the number of canonical amino acids as 20 based on the relationship between the types of cognate tRNAs and the 20 types of base combinations. The primer tRNAs generally appeared earlier than the derivative tRNAs. The primer tRNAs generally distribute along the diagonal line due to the chronological arrangements for both the 20 amino acids and the 20 base combinations, considering the substitution order G, C, A, U along the roadmap. The codon degeneracies 6, 4, 3, 2, and 1 are due to the tRNA evolution from to and , as well as from to , etc., all of which can be recognised by the corresponding .


Figure 7.
The coevolution of tRNAs with aaRSs. The coevolution of the four classes of aaRSs and the corresponding two types of tRNAs in accordance with the biosynthetic families indicated in certain colours. The ancestor of aaRS, namely , corresponding to the non-chiral amino acid , belongs to the class. The codon degeneracy are due to the coevolution of tRNAs with aaRSs, where the surplus tRNAs were chosen by the rare aaRSs. There are some truths in the traditional classifications of aaRSs, but the evolutionary relationships of aaRSs are so intricate, as shown here. The start and stop codons generally appear in the positions corresponding to class. The non-standard codons also evolved as alternative choices of tRNAs by aaRSs.
Figure 7.
The coevolution of tRNAs with aaRSs. The coevolution of the four classes of aaRSs and the corresponding two types of tRNAs in accordance with the biosynthetic families indicated in certain colours. The ancestor of aaRS, namely , corresponding to the non-chiral amino acid , belongs to the class. The codon degeneracy are due to the coevolution of tRNAs with aaRSs, where the surplus tRNAs were chosen by the rare aaRSs. There are some truths in the traditional classifications of aaRSs, but the evolutionary relationships of aaRSs are so intricate, as shown here. The start and stop codons generally appear in the positions corresponding to class. The non-standard codons also evolved as alternative choices of tRNAs by aaRSs.

Figure 8.
The origin and evolution of four classes of early aaRSs in the junior stage of the primordial translation mechanism in absent of tRNA and ribosome. The first aaRS can be produced through the non-random evolution of the triplex DNA and the corresponding RNAs. At the beginning of the translation mechanism, DNAs are the carrier of information, and RNAs develop the functions of life.
Figure 8.
The origin and evolution of four classes of early aaRSs in the junior stage of the primordial translation mechanism in absent of tRNA and ribosome. The first aaRS can be produced through the non-random evolution of the triplex DNA and the corresponding RNAs. At the beginning of the translation mechanism, DNAs are the carrier of information, and RNAs develop the functions of life.

Figure 9.
The recruitment orders of amino acids and codon pairs on the roadmap are supported by the variation of the amino acid frequencies. The 20 amino acids are arranged in the recruitment order on the roadmap Figure 1a. The 20 amino acid frequencies for each of the 803 species are obtained, respectively, based on the genomic data in NCBI. The 803 amino acid frequencies (green dots) for each of the 20 amino acids are all arranged properly in the order [36], respectively. The variation trend of the amino acid frequencies for each of the 20 amino acids is obtained by the regression line (denoted in red). Generally speaking, the variation trends for the earlier amino acids tend to decrease, and the variation trends for the latecomers to increase.
Figure 9.
The recruitment orders of amino acids and codon pairs on the roadmap are supported by the variation of the amino acid frequencies. The 20 amino acids are arranged in the recruitment order on the roadmap Figure 1a. The 20 amino acid frequencies for each of the 803 species are obtained, respectively, based on the genomic data in NCBI. The 803 amino acid frequencies (green dots) for each of the 20 amino acids are all arranged properly in the order [36], respectively. The variation trend of the amino acid frequencies for each of the 20 amino acids is obtained by the regression line (denoted in red). Generally speaking, the variation trends for the earlier amino acids tend to decrease, and the variation trends for the latecomers to increase.


{kind=link}
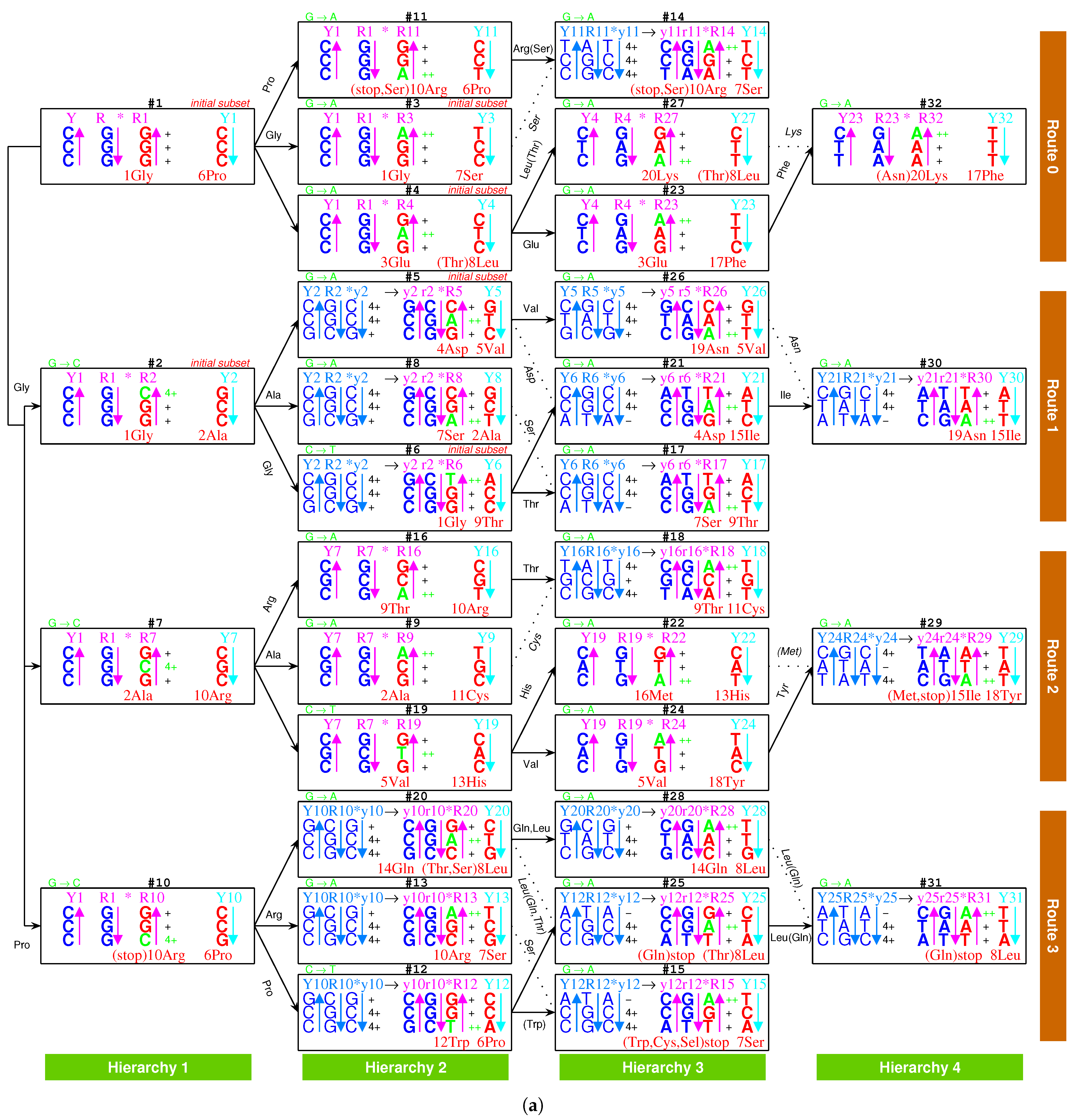{kind=link}
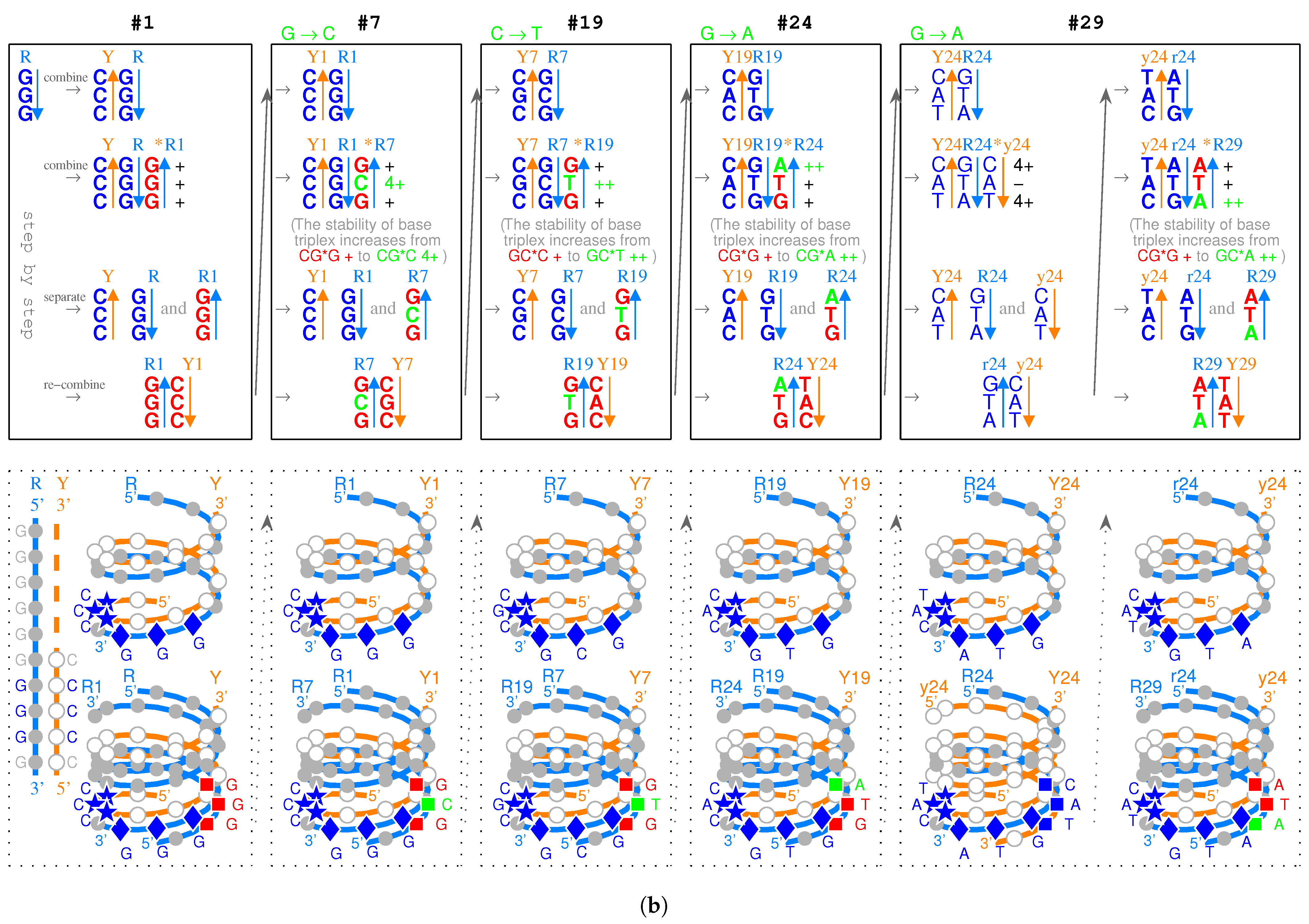{kind=link}
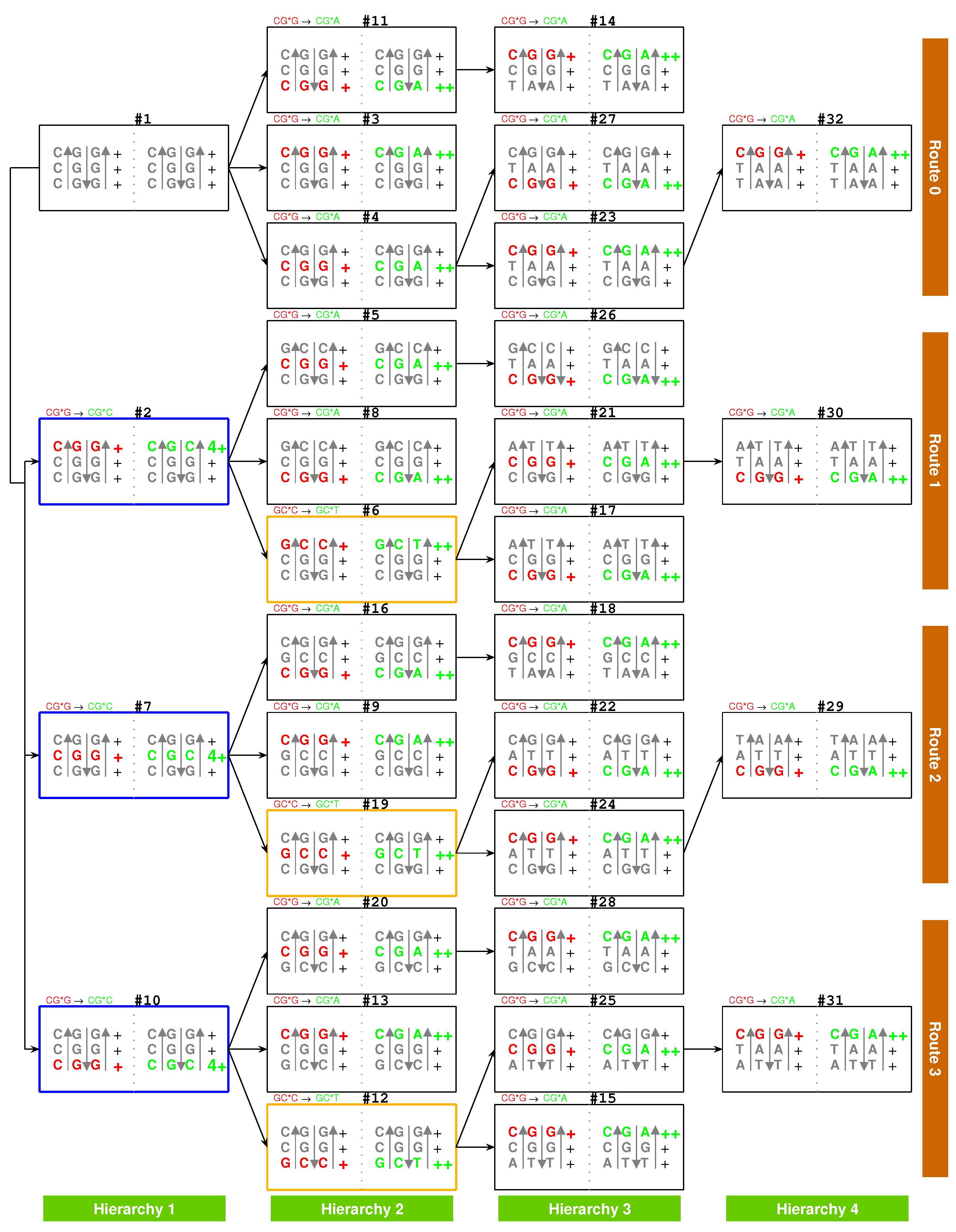{kind=link}
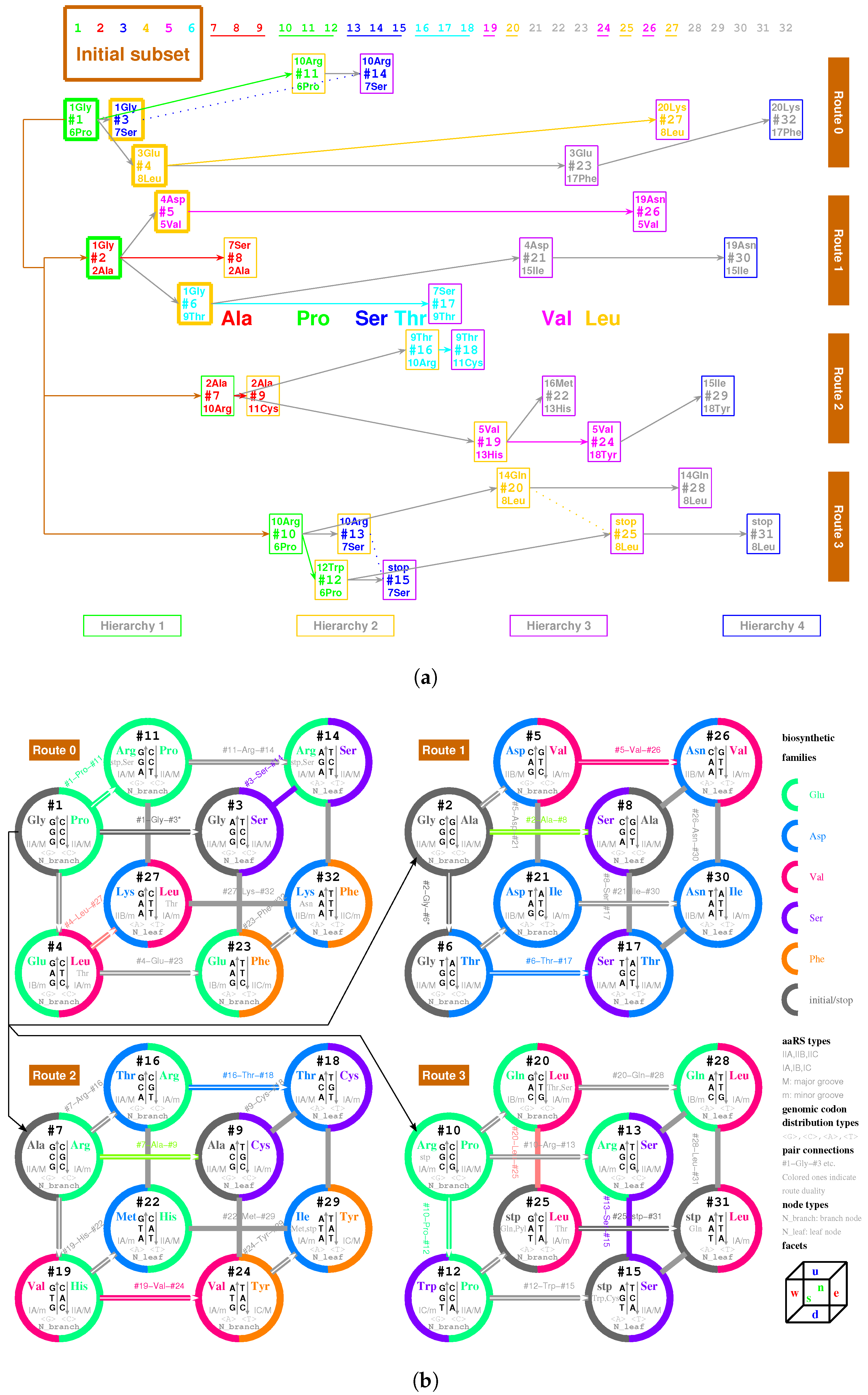{kind=link}
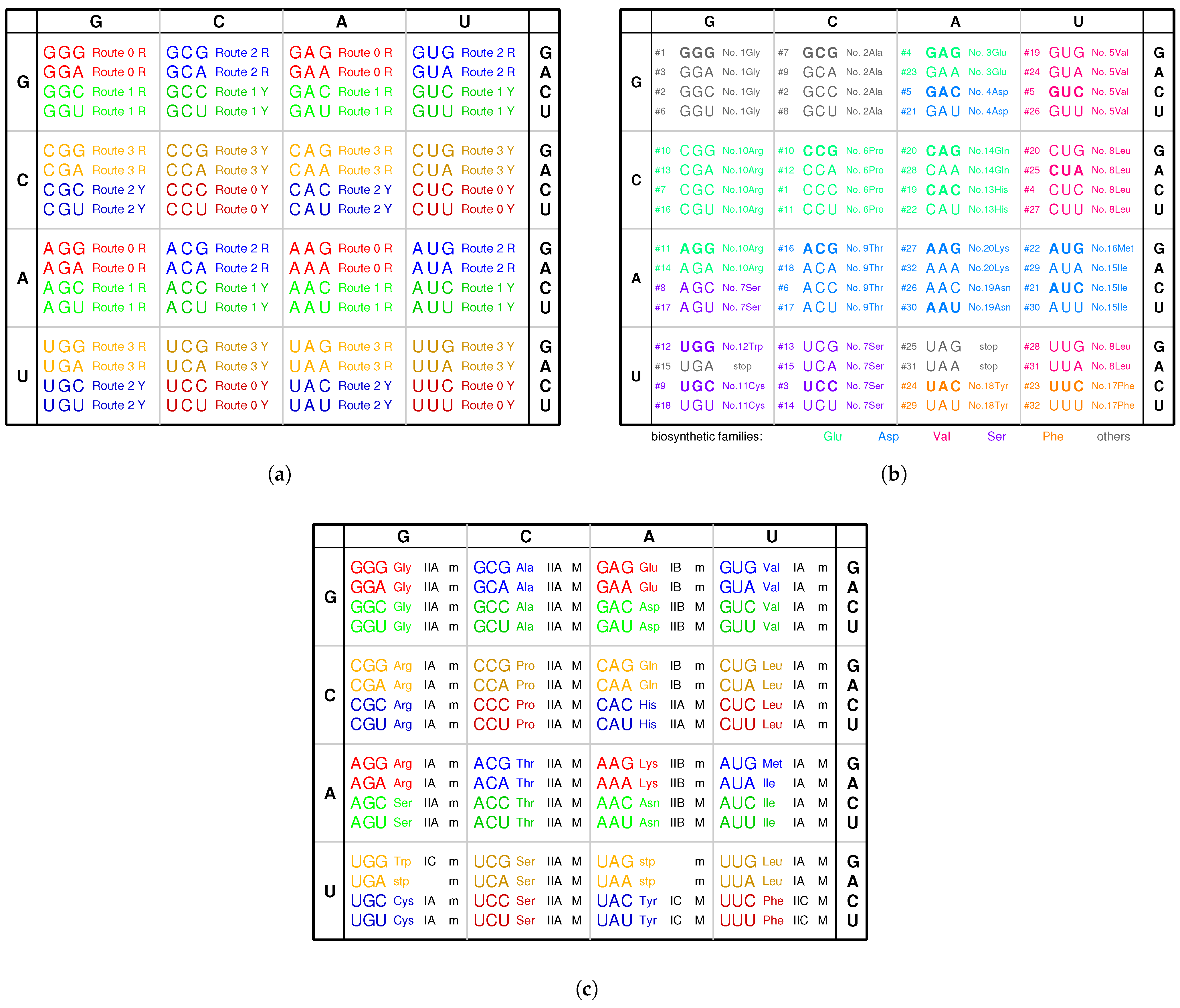{kind=link}
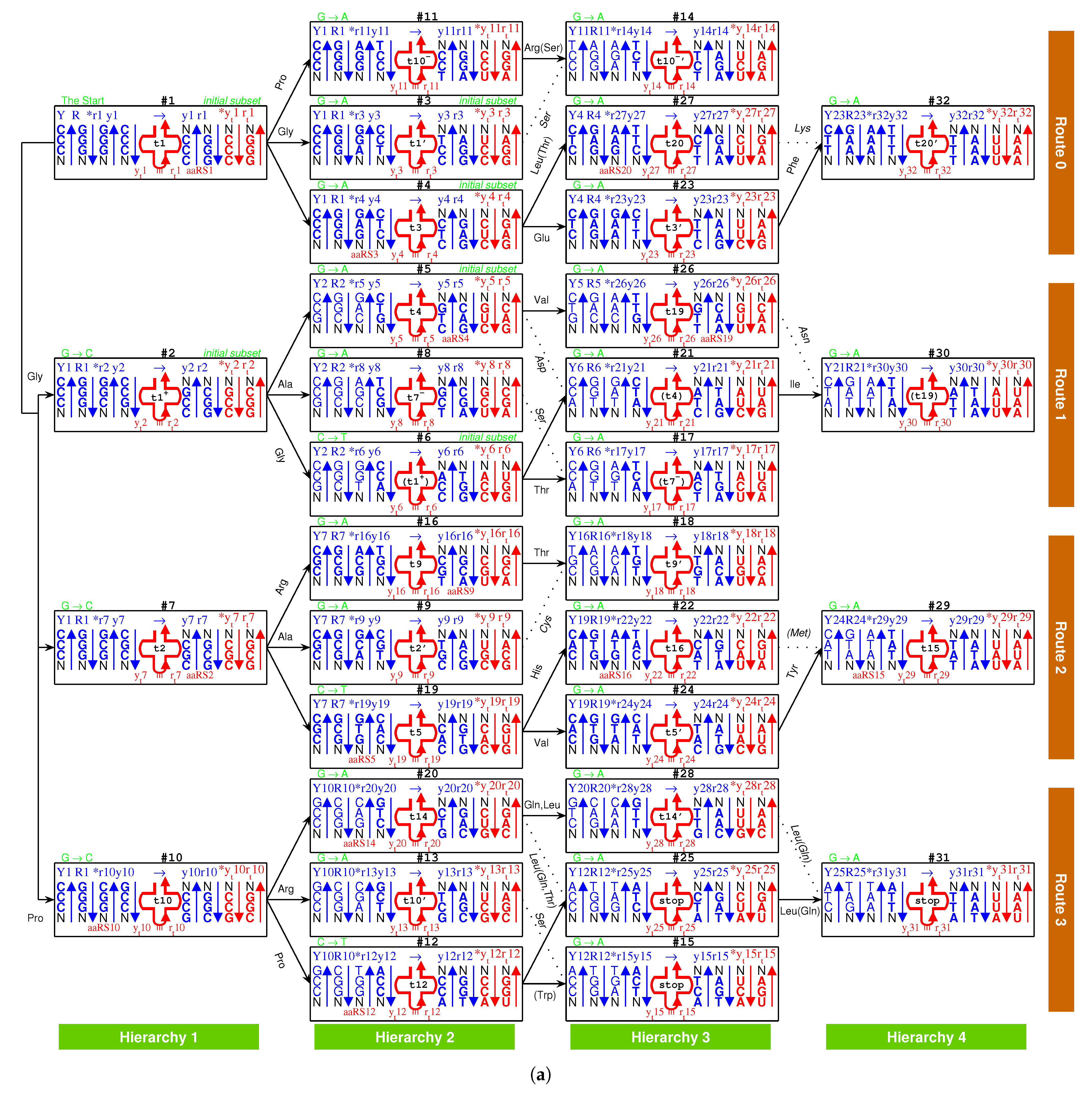{kind=link}
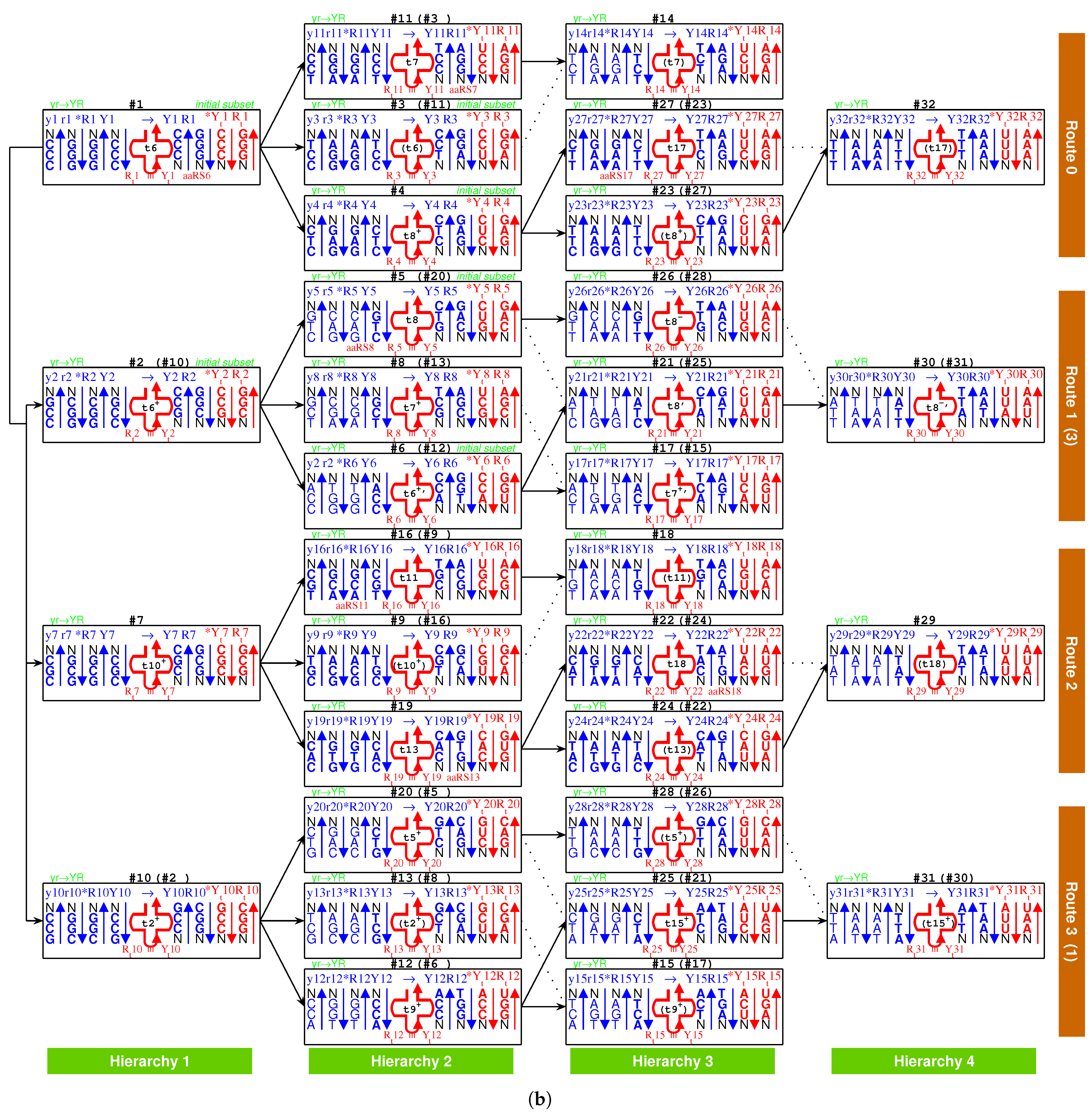{kind=link}
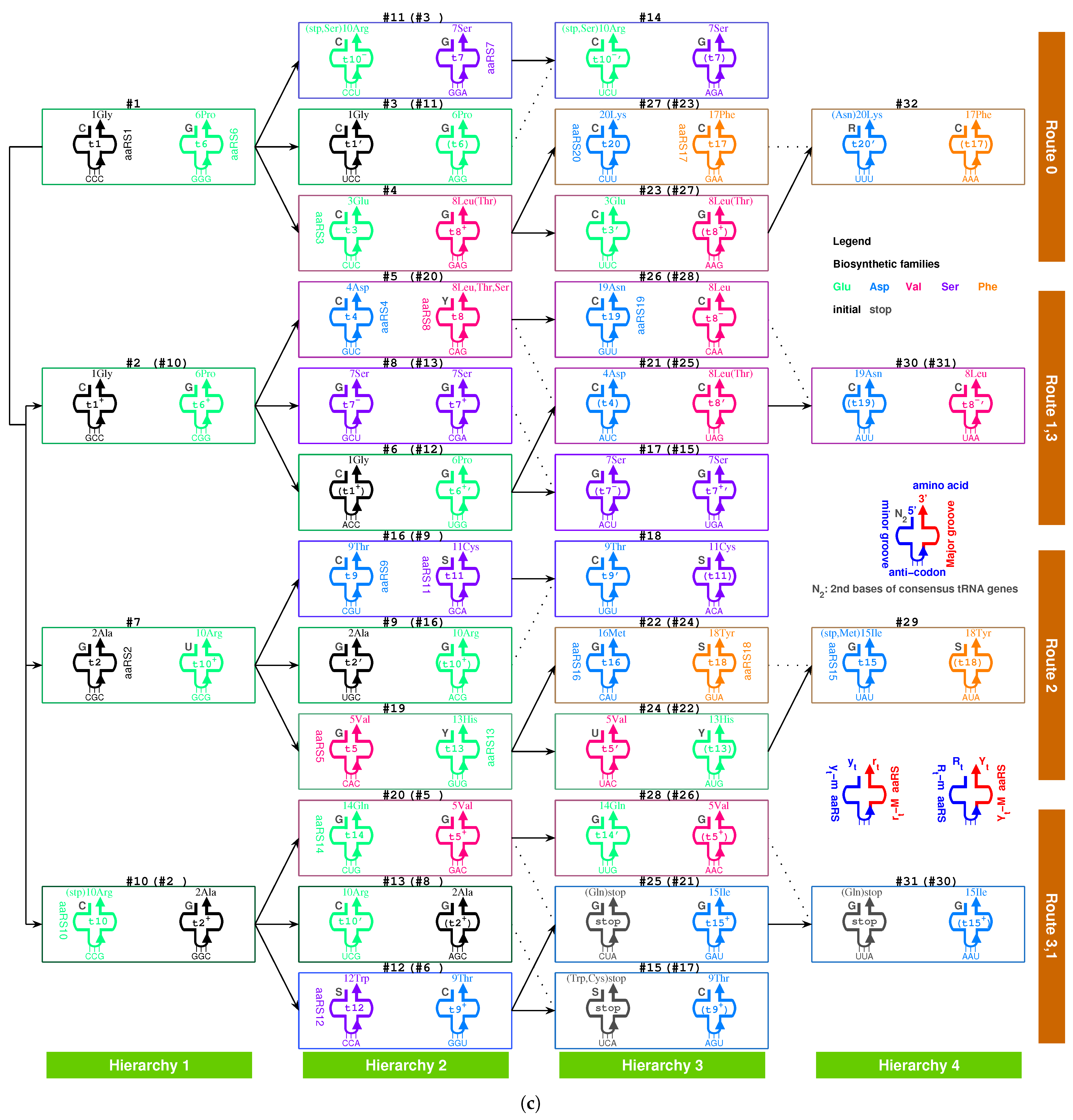{kind=link}
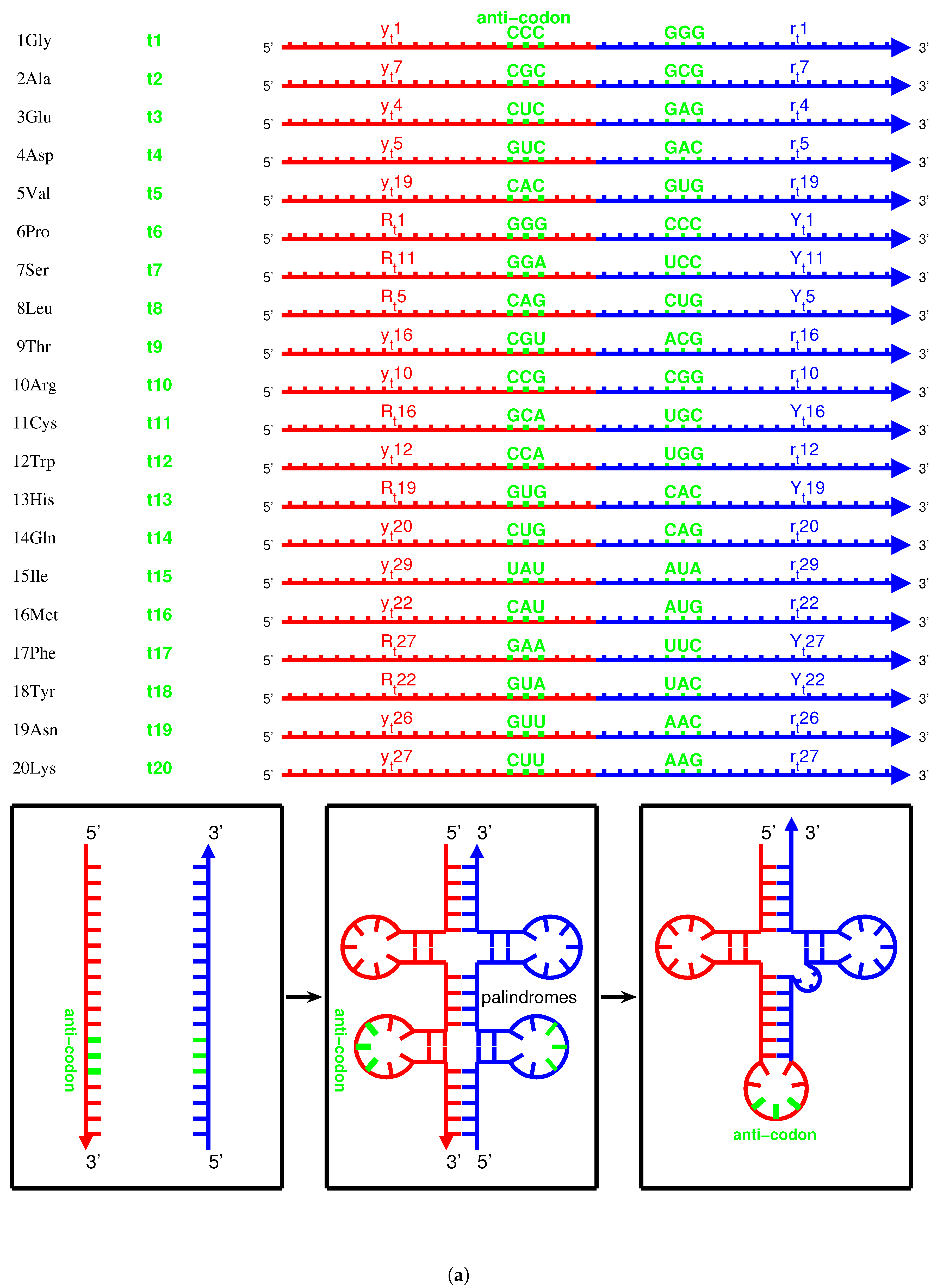{kind=link}
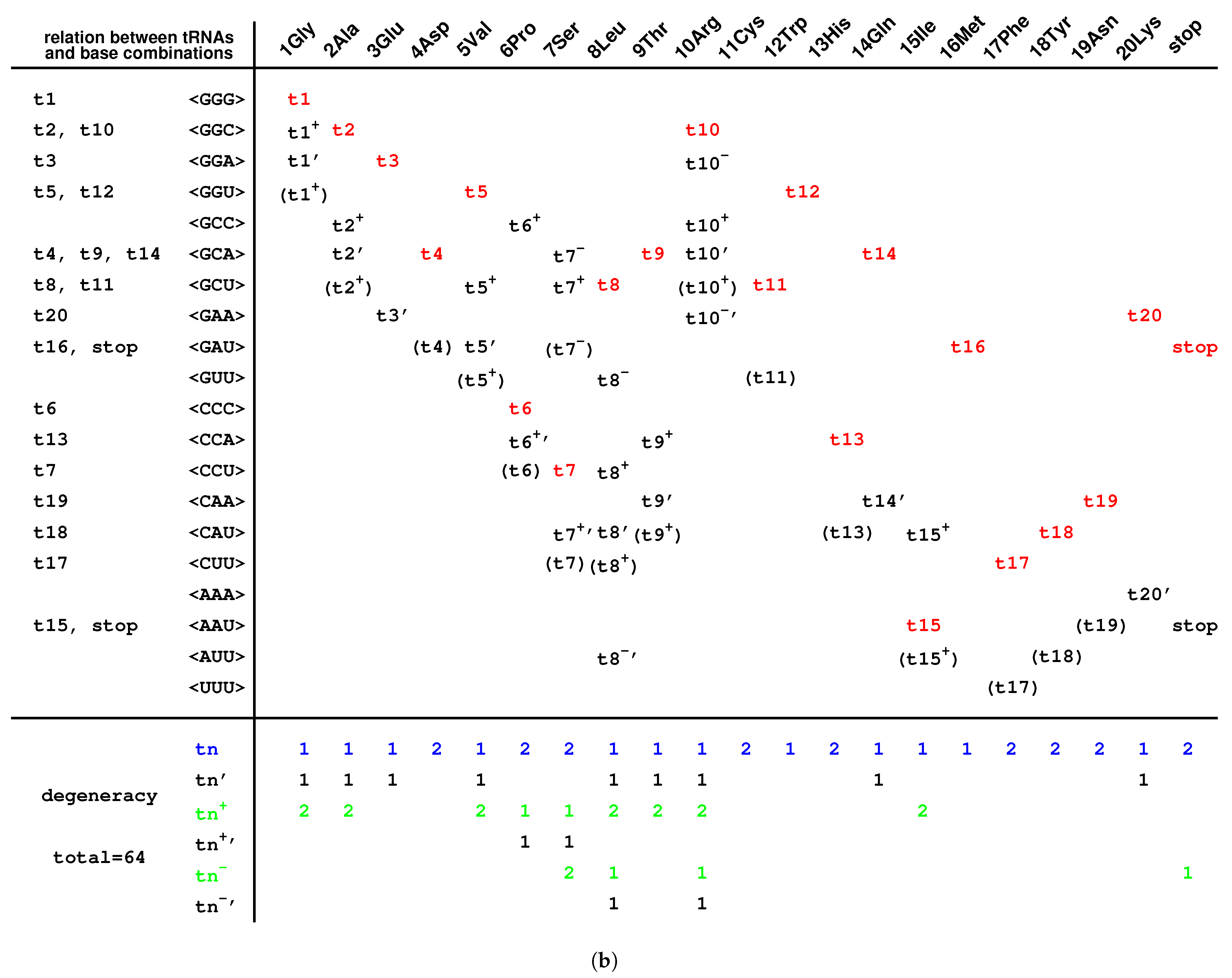{kind=link}
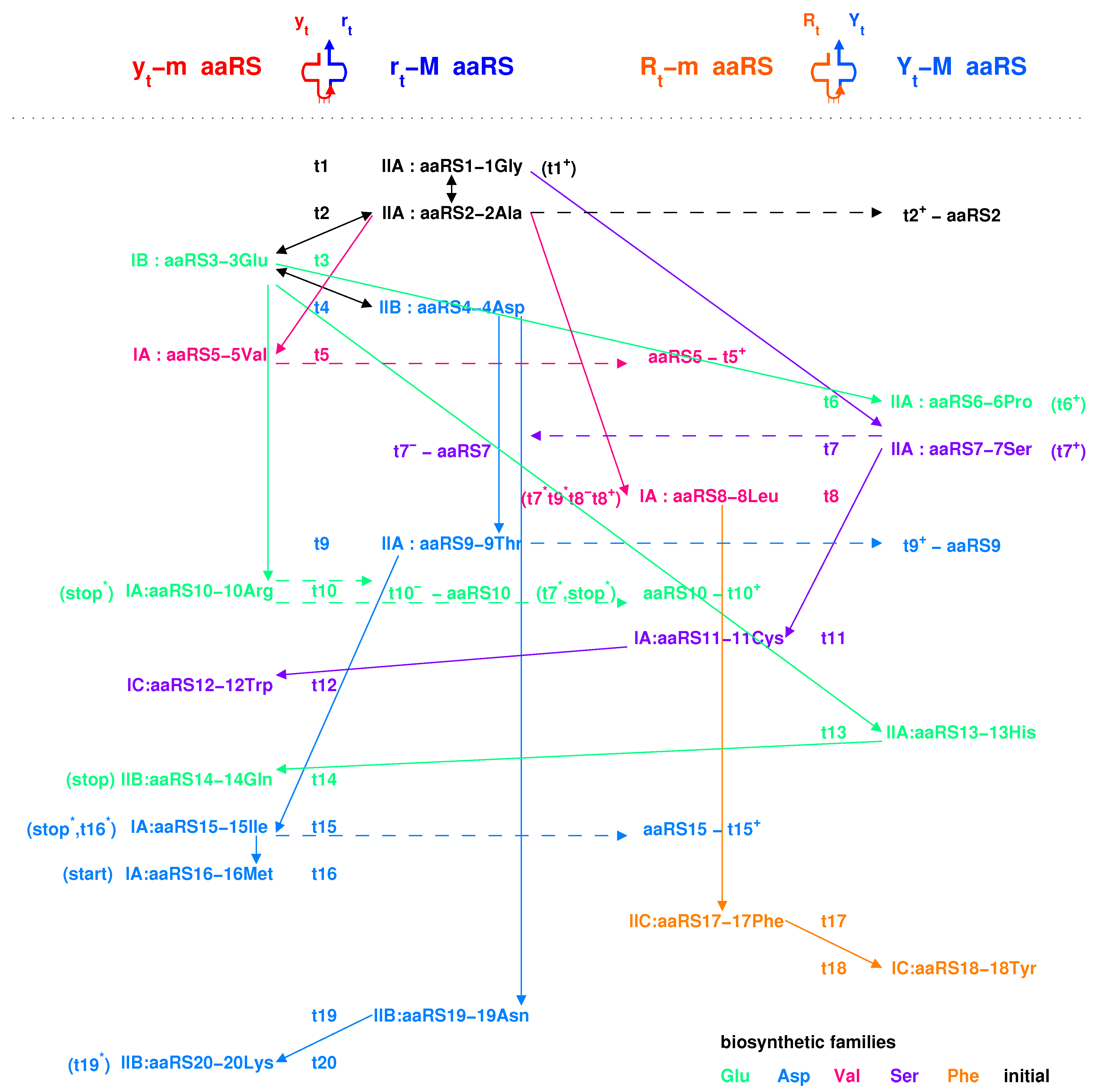{kind=link}
{kind=link}
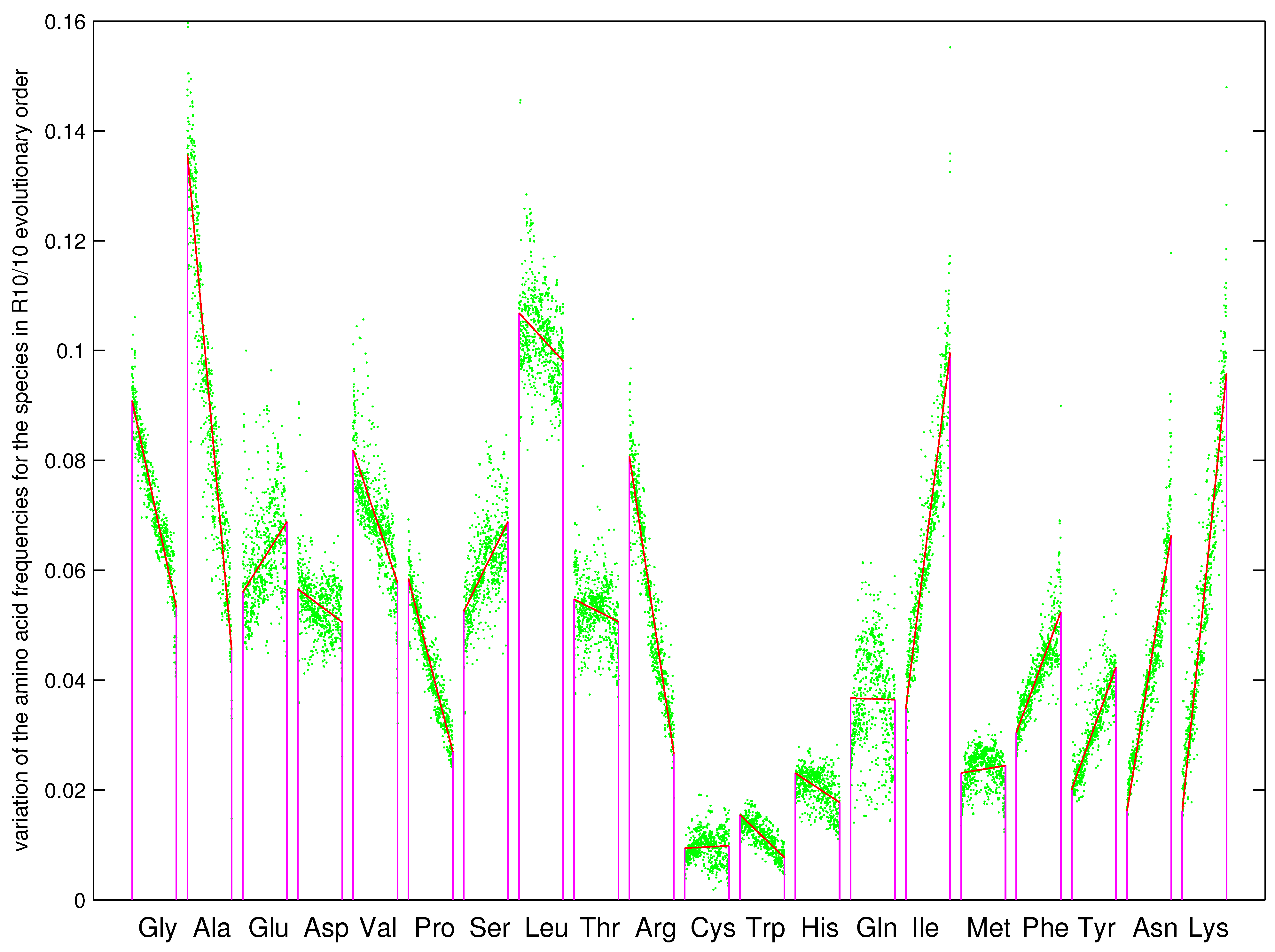{kind=link}
Table 1.
Selective pressure due to the unique roadmap with increasing stability.
| Stability | CG*N | GC*N | TA*N | AT*N |
|---|---|---|---|---|
| (−) | GC*A | AT*C AT*A | ||
| (+) | CG*G | GC*C GC*G | TA*C TA*G TA*A | AT*T |
| (++) | CG*A CG*T | GC*T | ||
| (3+) | AT*G | |||
| (4+) | CG*C | TA*T | ||
| (+)CG*G → (++)CG*A increase in stability | (+)GC*C → (−)GC*A unstable | (+)TA*A → (+)TA*G no increase in stability | (+)AT*T → (3+)AT*G | |
| (+)CG*G → (4+)CG*C increase in stability | (+)GC*C → (+)GC*G no increase in stability | (+)TA*A → (4+)TA*T | (+)AT*T → (−)AT*A unstable | |
| (+)GC*C → (++)GC*T increase in stability | (+)CG*G → (++)CG*T | (+)AT*T → (+)AT*C no increase in stability | (+)TA*A → (+)TA*C no increase in stability | |
| POSSIBLE (Roadmap) | Impossible | Impossible | Impossible | |
| (+)CG*G → (++)CG*T | (+)GC*C → (++)GC*T | (+)TA*A → (+)TA*C no increase in stability | (+)AT*T → (−)AT*C unstable | |
| (+)CG*G → (4+)CG*C | (+)GC*C → (+)GC*G no increase in stability | (+)TA*A → (4+)TA*T | (+)AT*T → (−)AT*A unstable | |
| (+)GC*C → (−)GC*A unstable | (+)CG*G → (++)CG*A | (+)AT*T → (3+)AT*G | (+)TA*A → (+)TA*G no increase in stability | |
| Impossible | Impossible | Impossible | Impossible |
Table 2.
Formation of the codon boxes via (quasi) route dualities.
| Hierarchy 1 to Hierarchy 2 | Hierarchy 2 to Hierarchy 3 | Hierarchy 3 to Hierarchy 4 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Route 0 | 1Gly | 6Pro | 3Glu | 7Ser | 8Leu | 10Arg | 17Phe | 20Lys | ||||||||
| Route 1 | 1Gly | 2Ala | 4Asp | 5Val | 9Thr | 7Ser | 15Ile | 19Asn | ||||||||
| Route 2 | 2Ala | 10Arg | 5Val | 9Thr | 11Cys | 13His | 16Met | 18Tyr | ||||||||
| Route 3 | 6Pro | 10Arg | 7Ser | 8Leu | 12Trp | 14Gln | 8Leu | stop | ||||||||
| Codon box | GGN | GCN | CCN | CGN | GAN | GUN | UCN | CUN | ACN | AGN | UGN | CAN | AUN | UUN | UAN | AAN |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Li, D.J. Formation of the Codon Degeneracy during Interdependent Development between Metabolism and Replication. Genes 2021, 12, 2023. https://0-doi-org.brum.beds.ac.uk/10.3390/genes12122023
AMA Style
Li DJ. Formation of the Codon Degeneracy during Interdependent Development between Metabolism and Replication. Genes. 2021; 12(12):2023. https://0-doi-org.brum.beds.ac.uk/10.3390/genes12122023
Chicago/Turabian StyleLi, Dirson Jian. 2021. "Formation of the Codon Degeneracy during Interdependent Development between Metabolism and Replication" Genes 12, no. 12: 2023. https://0-doi-org.brum.beds.ac.uk/10.3390/genes12122023
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.