1. Introduction
The fuzzy set theory [
1] was first introduced to describe the uncertainty and fuzziness of things. In order to reflect the objective world as faithfully as possible, many people offered some extended forms of the fuzzy set, such as interval-valued hesitant fuzzy sets (IVHFSs), type-2 fuzzy sets (T2FSs), and intuitionistic fuzzy sets (IFSs) [
2]. The IFS theory was proposed by Atanassov [
2] in 1986 as an important extension of the classical fuzzy set theory. The research on its theory and application has achieved extensive research results in the field of fuzzy set theory [
3,
4,
5,
6,
7,
8,
9]. However, when using IFSs to make decisions, the following situation may occur: the membership degree plus the non-membership degree of the scheme satisfying attributes given by the decision makers is greater than 1. Based on this, in 2013, American scholar Yager [
10] proposed the Pythagorean fuzzy set (PFSs), which makes membership degree plus non-membership degree greater than 1, but the sum of squares does not exceed 1. Therefore, the decision maker (DM) does not need to modify the values of membership and non-membership, can be more accurate and gives a detailed description of the reality [
11,
12,
13,
14,
15,
16,
17].
After the PFSs were proposed, a large number of researchers combined the PFSs [
10] with various methods and applied these proposed methods to multiple attribute decision making (MADM) issues. Zhang and Xu [
18] firstly put forward the mathematical expression of PFSs, and then they tied the PFSs and Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) method together. Zhang [
19] presented a Pythagorean fuzzy QUALItative FLEXible multiple criteria method (QUALIFLEX) method with the closeness index to address the layered multi-criteria decision-making issue under PFSs on the basis of PFNs and interval-valued Pythagorean fuzzy numbers (IVPFNs). Ren et al. [
20] provided a case of choosing the governor of Asian Infrastructure Investment Bank by using the Pythagorean fuzzy TODIM (PF-TODIM) method to observe the feasibility of the model. Bolturk [
21] expanded the COmbinative Distance-based Assessment (CODAS) model to PFSs to propose a novel method, which is PF-CODAS. They addressed a MADM problem of supplier selection utilizing the new method to show its validity and effectiveness. Chen [
22] defined a new VIseKriterijumska Optimizacija I KOmpromisno Resenje (VIKOR)-based method for MADM analysis containing PFSs. PFSs have certain advantages over un-normalized fuzzy sets such as IFS in dealing with fuzziness and complex uncertainty. Based on this, a Pythagorean fuzzy VIKOR method based on distance index is proposed, which is quite different from the existing VIKOR method. Huang and Wei [
23] put forward a new extended TODIM to deal with the MADM issue. Ilbahar et al. [
24] proposed the three methods of Fine Kinney, Pythagorean fuzzy analytic hierarchy process and PFPRA. Khan et al. [
25] presented an extension of TOPSIS under the interval value Pythagorean fuzzy context, using the interval-valued Pythagorean fuzzy Choquet integral geometric (IVPFCIG) operator and distance formula based on the Choquet integral to aggregate all fuzzy decision matrixes. Perez-Dominguez et al. [
26] combined ratio analysis-based multiple objective optimization under PFSs to select an appropriate alternative. A novel Linear Programming Technique for Multidimensional Analysis of Preference (LINMAP) method was expanded by Xue et al. [
27] to the PFSs.
The Taxonomy method was originally proposed by Adanson in 1763 and was developed in 1950 by a group of Polish mathematicians. In 1968, Zyegnant Hellwing from the Wroclaw High School released this method as a method of classifying and determining the degree of development. Based on the state’s level of development and resources, and the structure of skilled employees, Hellwig [
28] applied the method to national classifications. Afterwards, Hellwig [
29] evaluated high-level manpower by means of this method. Due to the internal diversity of Germany in terms of social and economic development, Barbara Jurkowska [
30] utilized the Taxonomy method to analyze the level of German social and economic development, making it possible to determine the development direction of a particular country. Bienkowska [
31] did a study that used the Taxonomy method to determine the level of development of Polish local municipalities and the actions the authorities took to promote entrepreneurship.
Based on previous studies, this paper tries to propose a new approach, so we joined the 2-tuple linguistic variable to Pythagorean fuzzy numbers and then combined it with the Taxonomy method. This paper utilized the P2TL-Taxonomy model for supplier selection in medical instrument industries by using relevant assessment criteria. Our goal in this article is to combine the origin Taxonomy with Pythagorean 2-tuple linguistic numbers (P2TLNs) to address MAGDM issues. The innovativeness of the paper can be summarized as follows: (1) the Taxonomy method is extended by P2TLSs; (2) the Pythagorean 2-tuple linguistic Taxonomy (P2TL-Taxonomy) method is proposed to solve the Pythagorean 2-tuple linguistic MAGDM problems; (3) a numerical example for supplier selection in medical instrument industries is supplied to show the developed approach; and (4) some comparative studies are provided with the existing methods to give effect to the rationality of P2TL-Taxonomy.
The remainder of this article is organized as follows:
Section 2 introduces some basic definitions of P2TLNs;
Section 3 extends the Taxonomy method with P2TLNs; in
Section 4, a case study for supplier selection in medical instrument industries and contrastive analysis is given; and
Section 5 supplies the conclusions.
3. Taxonomy Method for P2TL-MAGDM Issues
Suppose that and are respectively m alternatives and n criteria. Let be the criteria’s weighting vector that satisfies and . Let be the group of DMs, be the weight of DMs, with and . Construct a decision matrix , where means the performance of the alternative with respect to criteria by expert using a P2TLN, and
In view of both the P2TLN theories and procedures from the Taxonomy method [
34], we put forward a P2TL-Taxonomy method to deal with the problem of MAGDM effectively. The new model can be shown below:
Step 1. Shift the cost attribute into the beneficial attribute.
Step 2. Set up a decision-making group composed of several experts, choose the best attributes to measure alternatives, and finally get a P2TL fuzzy decision matrix series
from each decision maker.
where
denotes the fuzzy performance value of the
alternative (
) with respect to the
criterion (
) and the
decision-maker (
).
Step 3. Utilize the P2TLWA operator or the P2TLWG operator to fuse assessment information, then the P2TL fuzzy decision matrix
group can be obtained by the calculation.
or
where
means the average fuzzy performance value of the
alternative relative to the
criterion.
Step 4. Equations (11) and (12) are used to calculate the mean and standard deviation of the attributes.
In Equation (12),
means the normalized Hamming distance between two P2TLNs.
Step 5. The standard matrix:
Remark. In the decision matrix, the alternatives are represented based on attributes with different metrics, such as the unit differences. Therefore, this step uses Equation (13) to change the decision matrix to a standard matrix . Here, denotes the standardized performance value of the alternative in the attributes.
Step 6: The composite distances matrix:
Remark. In this step, use Equation (15) to calculate the distance between each alternative and the other alternative under each attribute. We will get a composite distance matrix between the alternatives.
Step 7: Homogenizing the alternatives:
Remark. The minimum distance of each row is selected by the composite distance matrix determined in the previous step. Then, calculate the mean and standard deviation of the minimum distance value for each line according to Equation (17) and Equation (18). The homogeneity range of the composite distance matrix is calculated based on the mean and standard deviation according to Equation (19). If the minimum distance value for each row is not within the range, then they are inhomogeneous and eliminated, and then the mean and standard deviation of the values are calculated again.
Step 8: The development pattern:
Remark. In this step, through Equation (19), using the matrix obtained in Step 4, the alternative development pattern is determined, where represents the ideal value for the attribute. If is a cost attribute, is the minimum value of this column. Conversely, if is a benefit attribute, selects the maximum value of this column. indicates the standardized value of the attribute for the alternative, and illustrates the development pattern for the attribute.
Step 9: The final ranking of alternatives:
Remark. According to the mean and standard deviation of , the high limit of development is initially calculated. The number of obtained from Equation (22) is between 0 and 1, and the smaller the value, the higher the ranking.
5. Conclusions
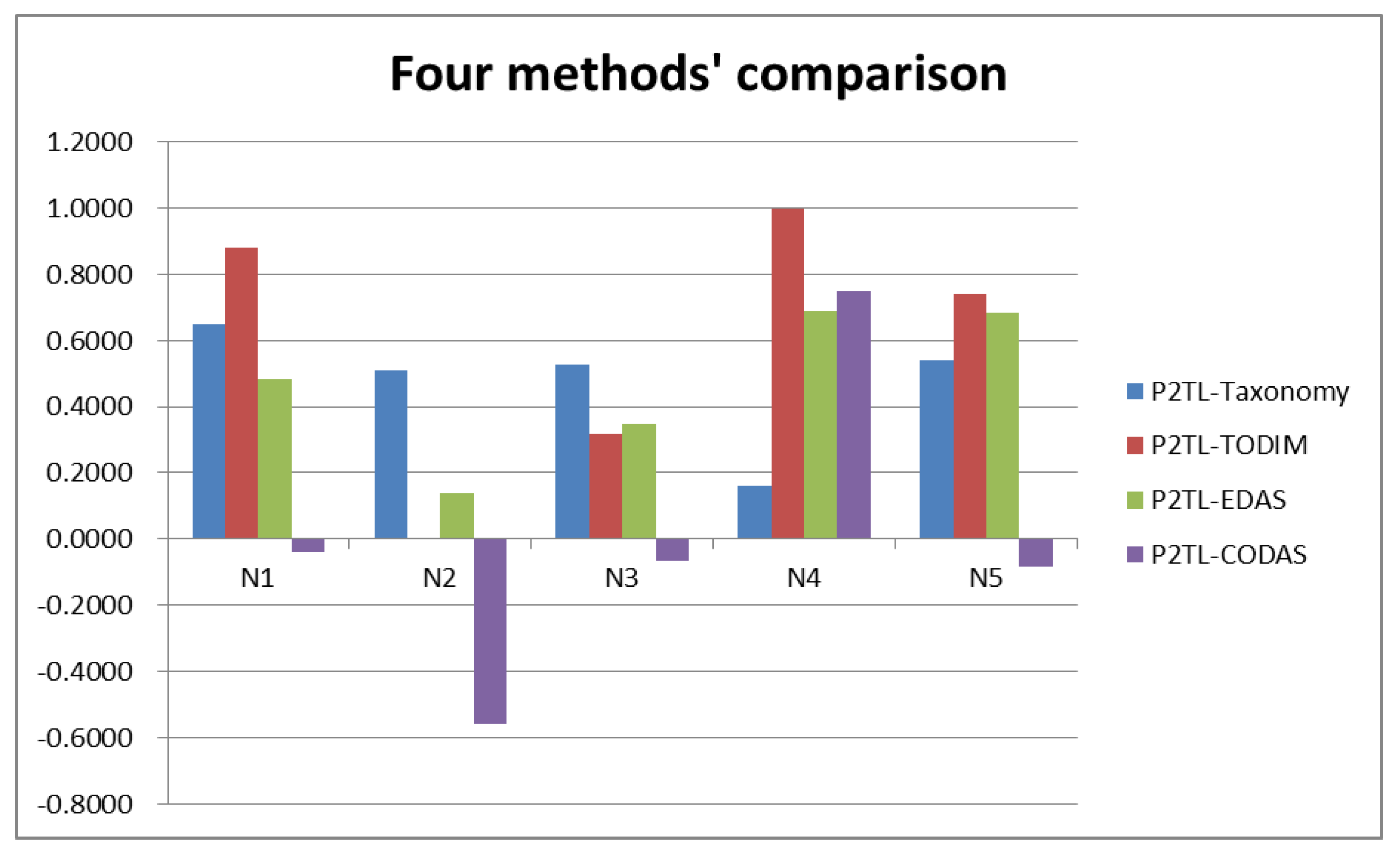
The P2TLSs can reflect uncertain or fuzzy information well and solve these kind of problems, and the original Taxonomy is very appropriate for comparing different alternatives with respect to their advantages from studied attributes. In this paper, a Taxonomy method is designed for MAGDM with P2TLNs. First, the basic definition of P2TLNs is introduced. Second, the optimal alternative(s) are determined by calculating the smallest development attribute values with P2TLNs from the Pythagorean 2-tuple linguistic positive ideal solution (P2TLPIS). Finally, a numerical example for supplier selection in medical instrument industries is used to illustrate the use of the proposed method. This comparative study shows that the proposed MAGDM algorithm is feasible. This method is very effective and useful for decision making issues.
The main contributions of this study are three fold: (1) the Pythagorean 2-tuple linguistic Taxonomy (P2TL-Taxonomy) method is designed to tackle the Pythagorean 2-tuple linguistic MAGDM issues; (2) a case study for supplier selection in medical instrument industries is designed to show the developed approach; and (3) some comparative studies are provided with the existing methods to give effect to the rationality of P2TL-Taxonomy. Finally, the proposed method can also contribute to the successful selection of suitable alternatives in other selection issues.
In the future, the proposed method can be expanded to deal with other decision-making issues [
39,
40,
41,
42,
43], such as the selection of green suppliers [
44,
45,
46,
47,
48,
49,
50], the location of waste disposal stations, and so on, and the developed approaches can also be extended to further unpredictable and uncertain information. Further studies could also aim at applying different distance measures in the decision making issues and the Monte Carlo simulations could also be carried out in order to identify the best performing settings.




{kind=link}