
Virtual Reality-Based Fuzzy Spatial Relation Knowledge Extraction Method for Observer-Centered Vague Location Descriptions

Abstract
:1. Introduction
2. Related Works
2.1. Spatial Relation Extraction from Vague Location Descriptions
2.2. Geographic Scenes Simulated by VR Technology
2.3. Challenges When Processing Observer-Centered Vague Location Descriptions
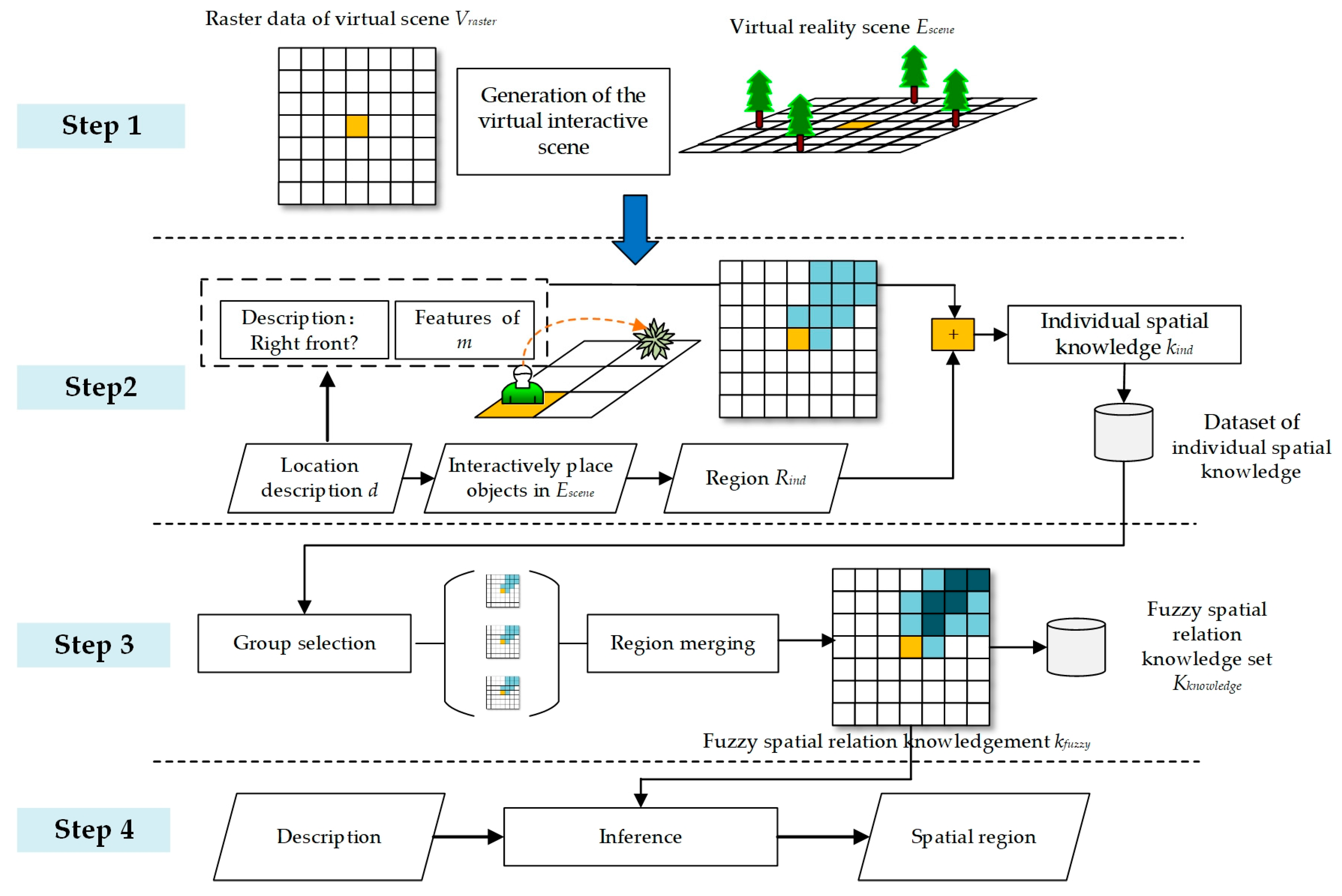
3. Methodology
3.1. Overall Process of the Method
3.2. Generation of the Virtual Interactive Scene
| Algorithm 1 Interactive VR scene generation algorithm (IVRSG) |
| Input:Vraster, Escene, m, d Output: Vraster, Escene |
| Begin Initialize all ei in Escene = {e1, e2, …, en} based on Vraster; while (m needs to make further changes in the region) for i = 1 to length(Vraster) vi = Vraster[i]; ei = Escene[i]; if (the content and membership of vi have changed) vi.renderstyle = Determined based on the content and membership of vi; ei.rendercontent = Determined based on the renderstyle of vi; Update ei in Escene; m places objects in Escene that conform to the spatial relations in d; Modify the content and membership of each element in Vraster based on the placed objects; Return Vraster, Escene; End |
3.3. Acquisition of Individual Spatial Knowledge through Virtual Interactions
| Algorithm 2 Individual spatial knowledge acquisition algorithm (ISKA) |
| Input:Vraster, Escene, m, d Output:kind |
| Begin olist= According to the subjective perception of d, m places objects in Escene; groups = Group olist based on membership and sort the groups by membership value in ascending order; for i = 1 to length(groups) group = groups[i]; convex = Establish a minimum convex polygon based on the positions of the objects in the group; blocks = Find all ei that intersect with convex in Escene; rlist = Find the rasters in Vraster corresponding to blocks; All membership in rlist = membership value of the group; Update rlist in Vraster; Rind = All raster areas in Vraster such that membership≠0; kind = (m, d, Rind); Return kind; End |
3.4. Fuzzy Spatial Relation Knowledge Extraction
| Algorithm 3 Fuzzy spatial relation knowledge extraction algorithm (FSRKE) |
| Input: Kind, D, S Output:Kknowledge |
| Begin Kknowledge = ø; for i = 1 to length(D×S) (di, si) = (D×S)[i]; kgi = Select elements in Kind based on di and si; Rcmb = Calculate all Rind in kgi using Formula (1); Rknd = Calculate Rcmb using Formula (2); Kknowledge←(di, si, Rknd); End |
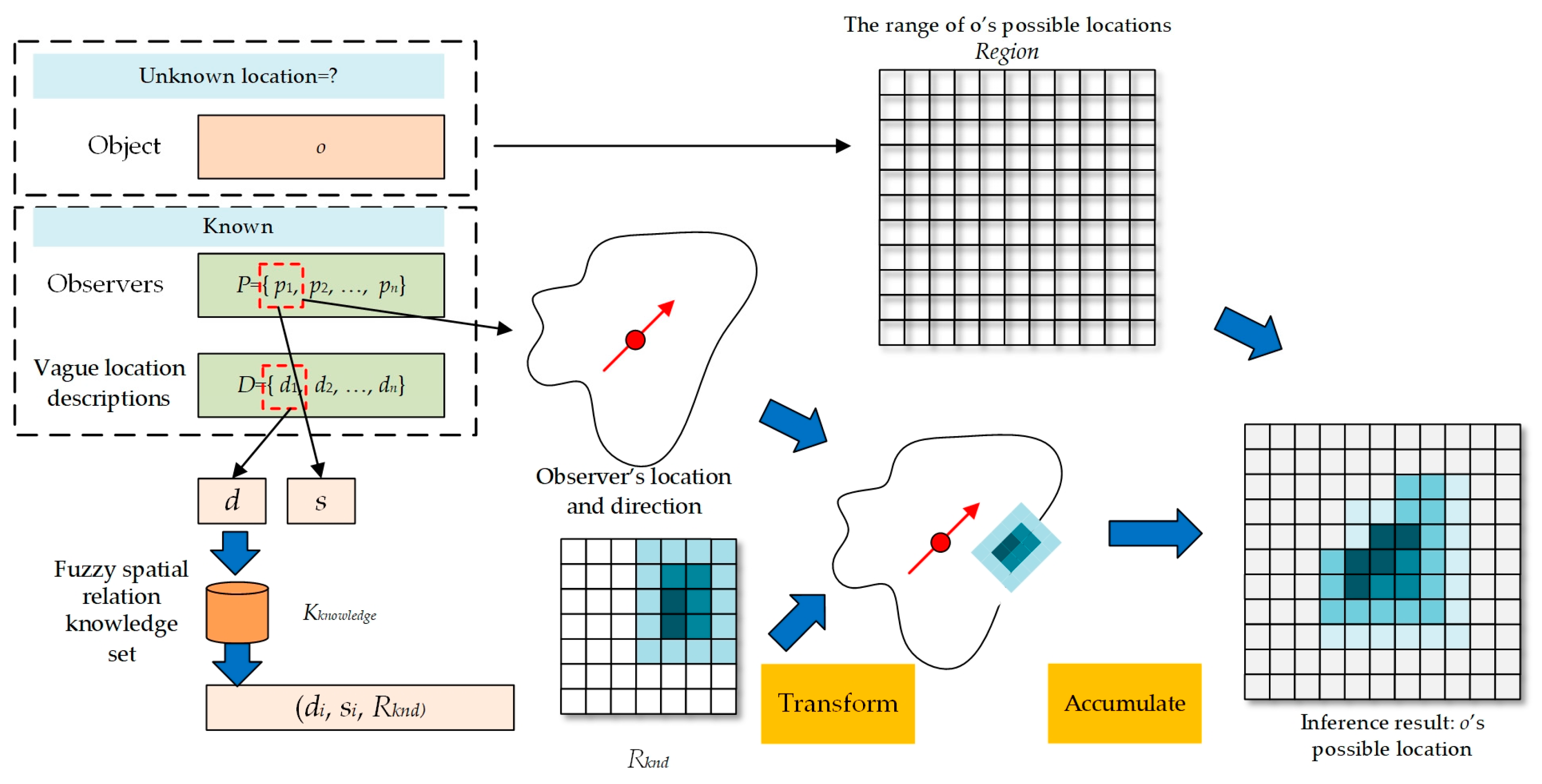
3.5. Vague Location Description Inference
| Algorithm 4 Fuzzy region inference (FRI) |
| Input: P, D, Kknowledge Output:Region |
| Begin Region = Initialize the inference result grid; R’ = ø; for i = 1 to length((P, D)) (pi, di) = (P, D)[i]; ki = Find knowledge in Kknowledge in accordance with pi.s and d; R’← Spatially transform ki.Rknd based on pi.l; for i = 1 to length(Region) ri= Region[i]; ri ← Accumulate R’ using Formula (3); Region = Normalize Region and filter out grids whose support is too low using Formulas (4) and (5); Return Region; End |
4. Experiments
4.1. Implementation and Execution of the Method
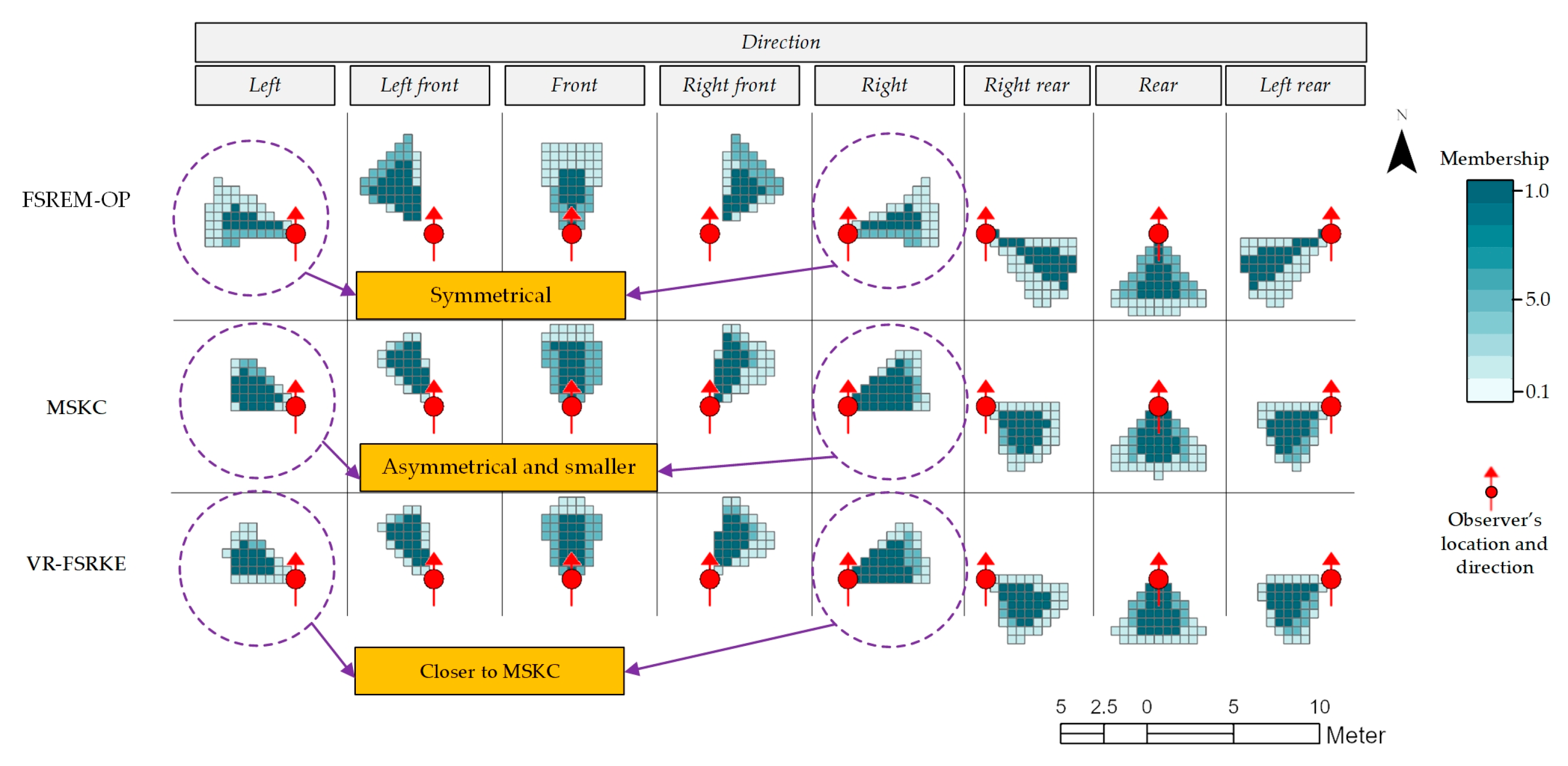
4.2. Comparison of Spatial Knowledge Collection Methods
4.3. Inference of Spatial Locations in a GIS
4.4. Analysis of the Spatial Knowledge Collection Strategies of the Three Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Juhász, A. A special GIS application-military historical reconstruction. Period. Polytechnica Civ. Eng. 2007, 51, 25–31. [Google Scholar] [CrossRef] [Green Version]
- Isoda, Y.; Tsukamoto, A.; Kosaka, Y.; Okumura, T.; Sawai, M.; Yano, K.; Nakata, S.; Tanaka, S. Reconstruction of Kyoto of the Edo era based on arts and historical documents: 3D urban model based on historical GIS data. Int. J. Humanit. Arts Comput. 2009, 3, 21–38. [Google Scholar] [CrossRef]
- Yang, X.; Koehl, M.; Grussenmeyer, P.; Macher, H. Complementarity of historic building information modelling and geographic information systems. In Proceedings of the XXIII ISPRS Congress, Prague, Czech Republic, 12–19 July 2016; pp. 437–444. [Google Scholar]
- Arnold, J.D.M.; Lafreniere, D. Creating a longitudinal, data-driven 3D model of change over time in a postindustrial landscape using GIS and CityEngine. J. Cult. Herit. Manag. Sustain. Dev. 2018, 8, 434–447. [Google Scholar] [CrossRef]
- Loglisci, C.; Ienco, D.; Roche, M.; Teisseire, M.; Malerba, D. An unsupervised framework for topological relations extraction from geographic documents. In Proceedings of the International Conference on Database and Expert Systems Applications, Vienna, Austria, 3–6 September 2012; pp. 48–55. [Google Scholar]
- Yang, Y.; Zhang, S.; Yang, J.; Chang, L.; Bu, K.; Xing, X. A review of historical reconstruction methods of land use/land cover. J. Geogr. Sci. 2014, 24, 746–766. [Google Scholar] [CrossRef]
- Carrion, D.; Migliaccio, F.; Minini, G.; Zambrano, C. From historical documents to GIS: A spatial database for medieval fiscal data in Southern Italy. Hist. Methods: A J. Quant. Interdiscip. Hist. 2016, 49, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Liu, K.; Shi, W. Computing the fuzzy topological relations of spatial objects based on induced fuzzy topology. Int. J. Geogr. Inf. Sci. 2006, 20, 857–883. [Google Scholar] [CrossRef]
- Hall, M.M.; Jones, C.B. Generating geographical location descriptions with spatial templates: A salient toponym driven approach. Int. J. Geogr. Inf. Sci. 2021, 1–32. Available online: https://0-www-tandfonline-com.brum.beds.ac.uk/doi/abs/10.1080/13658816.2021.1913498?journalCode=tgis20 (accessed on 25 November 2021). [CrossRef]
- Leach, J. Why people ‘freeze’in an emergency: Temporal and cognitive constraints on survival responses. Aviat. Space Environ. Med. 2004, 75, 539–542. [Google Scholar]
- Torrens, P.M. High-fidelity behaviours for model people on model streetscapes. Ann. GIS 2014, 20, 139–157. [Google Scholar] [CrossRef]
- Kracht, M. On the semantics of locatives. Linguist. Philos. 2002, 25, 157–232. [Google Scholar] [CrossRef]
- Hornsby, K.S.; Li, N. Conceptual framework for modeling dynamic paths from natural language expressions. Trans. GIS 2009, 13, 27–45. [Google Scholar] [CrossRef]
- Tenbrink, T. Reference frames of space and time in language. J. Pragmat. 2011, 43, 704–722. [Google Scholar] [CrossRef]
- Montello, D.R. Regions in geography: Process and content. Found. Geogr. Inf. Sci. 2003, 1, 173–189. [Google Scholar]
- Kronenfeld, B. Gradation as a communication device in area-class maps. Cartogr. Geogr. Inf. Sci. 2005, 32, 231–241. [Google Scholar] [CrossRef]
- Didelon, C.; Ruffray, S.d.; Boquet, M.; Lambert, N. A world of interstices: A fuzzy logic approach to the analysis of interpretative maps. Cartogr. J. 2011, 48, 100–107. [Google Scholar] [CrossRef]
- Kulik, L. A geometric theory of vague boundaries based on supervaluation. In Proceedings of the International Conference on Spatial Information Theory, Morro Bay, CA, USA, 19–23 September 2001; pp. 44–59. [Google Scholar]
- Vögele, T.; Schlieder, C.; Visser, U. Intuitive modelling of place name regions for spatial information retrieval. In Proceedings of the International Conference on Spatial Information Theory, Kartause Ittingen, Switzerland, 24–28 September 2003; pp. 239–252. [Google Scholar]
- Alani, H.; Jones, C.B.; Tudhope, D. Voronoi-based region approximation for geographical information retrieval with gazetteers. Int. J. Geogr. Inf. Sci. 2001, 15, 287–306. [Google Scholar] [CrossRef]
- Arampatzis, A.; van Kreveld, M.; Reinbacher, I.; Jones, C.; Vaid, S.; Clough, P.; Joho, H.; Sanderson, M. Web-based delineation of imprecise regions. Comput. Environ. Urban Systems. 2006, 30, 436–459. [Google Scholar] [CrossRef] [Green Version]
- Shariff, A.R.B.; Egenhofer, M.J.; Mark, D.M. Natural-language spatial relations between linear and areal objects: The topology and metric of English-language terms. Int. J. Geogr. Inf. Sci. 1998, 12, 215–245. [Google Scholar]
- Schwering, A. Evaluation of a semantic similarity measure for natural language spatial relations. In Proceedings of the International Conference on Spatial Information Theory, Melbourne, Australia, 19–23 September 2007; pp. 116–132. [Google Scholar]
- Leidner, J.L.; Lieberman, M.D. Detecting geographical references in the form of place names and associated spatial natural language. Sigspatial Spec. 2011, 3, 5–11. [Google Scholar] [CrossRef]
- Stock, K.; Yousaf, J. Context-aware automated interpretation of elaborate natural language descriptions of location through learning from empirical data. Int. J. Geogr. Inf. Sci. 2018, 32, 1087–1116. [Google Scholar] [CrossRef]
- Adams, B.; Janowicz, K. On the geo-indicativeness of non-georeferenced text. In Proceedings of the Sixth International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–8 June 2012. [Google Scholar]
- Zhang, W.; Gelernter, J. Geocoding location expressions in Twitter messages: A preference learning method. J. Spat. Inf. Sci. 2014, 2014, 37–70. [Google Scholar]
- Hu, Y.; Mao, H.; McKenzie, G. A natural language processing and geospatial clustering framework for harvesting local place names from geotagged housing advertisements. Int. J. Geogr. Inf. Sci. 2019, 33, 714–738. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, F.; Kang, C.; Gao, Y.; Lu, Y. Analyzing Relatedness by Toponym Co-O ccurrences on Web Pages. Trans. GIS 2014, 18, 89–107. [Google Scholar] [CrossRef]
- Hall, M.; Smart, P.; Jones, C. Interpreting spatial language in image captions. Cogn. Process. 2011, 12, 67–94. [Google Scholar] [CrossRef]
- Du, S.; Wang, X.; Feng, C.-C.; Zhang, X. Classifying natural-language spatial relation terms with random forest algorithm. Int. J. Geogr. Inf. Sci. 2017, 31, 542–568. [Google Scholar] [CrossRef]
- Tan, L.; Wu, L.; Lin, H. An individual cognitive evacuation behaviour model for agent-based simulation: A case study of a large outdoor event. Int. J. Geogr. Inf. Sci. 2015, 29, 1552–1568. [Google Scholar] [CrossRef]
- Manley, E.; Filomena, G.; Mavros, P. A spatial model of cognitive distance in cities. Int. J. Geogr. Inf. Sci. 2021, 35, 2316–2338. [Google Scholar] [CrossRef]
- Teknomo, K. Application of microscopic pedestrian simulation model. Transp. Res. Part F Traffic Psychol. Behav. 2006, 9, 15–27. [Google Scholar] [CrossRef]
- Kwan, M.-P. Beyond space (as we knew it): Toward temporally integrated geographies of segregation, health, and accessibility: Space–time integration in geography and GIScience. Ann. Assoc. Am. Geogr. 2013, 103, 1078–1086. [Google Scholar] [CrossRef]
- Turner, A. From axial to road-centre lines: A new representation for space syntax and a new model of route choice for transport network analysis. Environ. Plan. B: Plan. Des. 2007, 34, 539–555. [Google Scholar] [CrossRef] [Green Version]
- Derrible, S.; Kennedy, C. The complexity and robustness of metro networks. Phys. A Stat. Mech. Its Appl. 2010, 389, 3678–3691. [Google Scholar] [CrossRef]
- Matuszka, T.; Kiss, A.; Woo, W. A formal model for context-aware semantic augmented reality systems. In Proceedings of the International Conference on Distributed, Ambient, and Pervasive Interactions, Toronto, ON, Canada, 17–22 July 2016; pp. 91–102. [Google Scholar]
- Seo, D.; Yoo, B. Interoperable information model for geovisualization and interaction in XR environments. Int. J. Geogr. Inf. Sci. 2020, 34, 1323–1352. [Google Scholar] [CrossRef]
- Havenith, H.-B.; Cerfontaine, P.; Mreyen, A.-S. How virtual reality can help visualise and assess geohazards. Int. J. Digit. Earth 2019, 12, 173–189. [Google Scholar] [CrossRef]
- Guo, Y.; Zhu, J.; Wang, Y.; Chai, J.; Li, W.; Fu, L.; Xu, B.; Gong, Y. A Virtual Reality Simulation Method for Crowd Evacuation in a Multiexit Indoor Fire Environment. ISPRS Int. J. Geo-Inf. 2020, 9, 750. [Google Scholar] [CrossRef]
- Huang, L.; Gong, J.; Li, W. A Perception Model for Optimizing and Evaluating Evacuation Guidance Systems. ISPRS Int. J. Geo-Inf. 2021, 10, 54. [Google Scholar] [CrossRef]
- Huang, J.; Lucash, M.S.; Scheller, R.M.; Klippel, A. Walking through the forests of the future: Using data-driven virtual reality to visualize forests under climate change. Int. J. Geogr. Inf. Sci. 2021, 35, 1155–1178. [Google Scholar] [CrossRef]
- Levin, E.; Shults, R.; Habibi, R.; An, Z.; Roland, W. Geospatial virtual reality for cyberlearning in the field of topographic surveying: Moving towards a cost-effective mobile solution. ISPRS Int. J. Geo-Inf. 2020, 9, 433. [Google Scholar] [CrossRef]
- Halik, Ł.; Kent, A.J. Measuring user preferences and behaviour in a topographic immersive virtual environment (TopoIVE) of 2D and 3D urban topographic data. Int. J. Digit. Earth 2021, 1–33. Available online: https://0-www-tandfonline-com.brum.beds.ac.uk/doi/full/10.1080/17538947.2021.1984595 (accessed on 25 November 2021). [CrossRef]
- Zhang, Z.; Demšar, U.; Wang, S.; Virrantaus, K. A spatial fuzzy influence diagram for modelling spatial objects’ dependencies: A case study on tree-related electric outages. Int. J. Geogr. Inf. Sci. 2018, 32, 349–366. [Google Scholar] [CrossRef]
- Dilo, A.; De By, R.A.; Stein, A. A system of types and operators for handling vague spatial objects. Int. J. Geogr. Inf. Sci. 2007, 21, 397–426. [Google Scholar] [CrossRef]
- Xu, J.; Pan, X. A Fuzzy Spatial Region Extraction Model for Object’s Vague Location Description from Observer Perspective. ISPRS Int. J. Geo-Inf. 2020, 9, 703. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Total Time Required to Collect 8 Directions for 20 People (Minutes) | ||
|---|---|---|---|
| Distance = Adjacent | Distance = Not far | Distance = Slightly far | |
| FSREM-OP | 321 | 335 | 367 |
| MSKC | 1040 | 1631 | Unable to collect |
| VR-FSRKE | 568 | 579 | 603 |
| Observer | Description |
|---|---|
| Observer1 | Object1 is adjacent to and in front of me. |
| Observer2 | In the adjacent area to the left in front of me, I saw Object1. |
| Observer3 | At a distance not far from me, Object1 is to the right and in front ofme. |
| Observer4 | At a distance slightly far from me, Object1 is to the left and in front of me. |
| Observer5 | Object 1 is in front of me, and the distance is slightly far. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Pan, X.; Zhao, J.; Fu, H. Virtual Reality-Based Fuzzy Spatial Relation Knowledge Extraction Method for Observer-Centered Vague Location Descriptions. ISPRS Int. J. Geo-Inf. 2021, 10, 833. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10120833
Xu J, Pan X, Zhao J, Fu H. Virtual Reality-Based Fuzzy Spatial Relation Knowledge Extraction Method for Observer-Centered Vague Location Descriptions. ISPRS International Journal of Geo-Information. 2021; 10(12):833. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10120833
Chicago/Turabian StyleXu, Jun, Xin Pan, Jian Zhao, and Haohai Fu. 2021. "Virtual Reality-Based Fuzzy Spatial Relation Knowledge Extraction Method for Observer-Centered Vague Location Descriptions" ISPRS International Journal of Geo-Information 10, no. 12: 833. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10120833