Targeting: Logistic Regression, Special Cases and Extensions

Abstract
: Logistic regression is a classical linear model for logit-transformed conditional probabilities of a binary target variable. It recovers the true conditional probabilities if the joint distribution of predictors and the target is of log-linear form. Weights-of-evidence is an ordinary logistic regression with parameters equal to the differences of the weights of evidence if all predictor variables are discrete and conditionally independent given the target variable. The hypothesis of conditional independence can be tested in terms of log-linear models. If the assumption of conditional independence is violated, the application of weights-of-evidence does not only corrupt the predicted conditional probabilities, but also their rank transform. Logistic regression models, including the interaction terms, can account for the lack of conditional independence, appropriate interaction terms compensate exactly for violations of conditional independence. Multilayer artificial neural nets may be seen as nested regression-like models, with some sigmoidal activation function. Most often, the logistic function is used as the activation function. If the net topology, i.e., its control, is sufficiently versatile to mimic interaction terms, artificial neural nets are able to account for violations of conditional independence and yield very similar results. Weights-of-evidence cannot reasonably include interaction terms; subsequent modifications of the weights, as often suggested, cannot emulate the effect of interaction terms.1. Introduction
The objective of potential modeling or targeting [1] is to identify locations, i.e., pixels or voxels, for which the probability of an event spatially referenced in this way, e.g., a well-defined type of ore mineralization, is relatively maximum, i.e., is larger than in neighbor pixels or voxels. The major prerequisite for such predictions is a sufficient understanding of the causes of the target to be predicted. Conceptual models of ore deposits have been compiled by [2]. They may be read as factor models (in the sense of mathematical statistics), and a proper factor model may be turned into a regression-type model when using the factors as spatially-referenced predictors, which are favorable to or prohibitive of the target event. Thus, we may distinguish necessary or sufficient dependencies between the binary target T(x) indicating the presence or absence of the target at an areal or volumetric location x ⊂ D ⊂ ℝd, d = 1, 2, 3, and the spatially referenced predictors (B0(x), B1(x),…, Bm(x))T = B(x), which may be binary, discrete or continuous. Then, mathematical models and their numerical realizations are required to turn descriptive models into constructive ones, i.e., into quantitatively predictive models. Generally, a model considers the predictor B(x), with B0(x) ≡ 1 for all x ⊂ D, and assigns a parameter (θ0,…, θm)T = θ to them, which quantifies, by means of a link function , the extent of dependence of the conditional probability P (T(x) = 1|B(x)) on the predictors, i.e.,
Since the target T(x), as well as the predictor B(x) refer to areal or volumetric locations x ⊂ D, we may think of a two-dimensional digital map image of pixels or a three-dimensional digital geomodel of voxels. The pixels or voxels initially provide the physical support of the predictors and the target and will then be assigned the predicted conditional probability and the associated estimation errors, respectively. Then, the numerical results of targeting depend on the size of the objects, pixels or voxels, i.e., on the spatial resolution they provide. If the actual spatial reference of the target (or the predictors) is rather pointwise, i.e., if their physical support is rather of zero measure, then the dependence on the spatial resolution must not be ignored, because already, the estimate of the unconditional odds will be largely affected, as the total number of pixels or voxels depends on the spatial resolution, while the total number of pointwise occurrences is constant. If the spatial resolution provided by the pixels or voxels is poor with respect to the area or volume of the actual physical support of the predictors or target, then the numerical results of any kind of mathematical method of targeting are rather an artifact of the inappropriate spatial resolution.
To estimate the model parameters θ, data within a training region are required. The mathematical modeling assumption associated with a training dataset is complete knowledge, i.e., in particular, we assume that we know all occurrences of the target variable T = 1. However, in contrast to geostatistics [3], potential modeling does not consider spatially-induced dependencies between the predictors and the target. In fact, potential modeling applies the assumption of independently identically distributed random variables. Their distribution does not depend on the location. Therefore, any spatial reference can be dropped, and models of the form:
2. Mathematical Models
2.1. The Modeling Assumption of Conditional Independence
The random variables B1,…, Bm are conditionally independent given the random target variable T, if the joint conditional probability factorizes into the individual conditional probabilities:
Equivalently, but more instructively in terms of irrelevance, the random variables B1,…, Bm are conditionally independent given the random variable T, if knowing T renders all other Bj except Bi irrelevant for predicting Bi, i.e.,
It is emphasized that independence does not imply conditional independence and vice versa. The significant correlation of predictor variables does not imply that they are not conditionally independent. On the contrary, variables B1 and B2 may be significantly correlated and conditionally independent given the variable T, in particular when T can be interpreted to represent a common cause for B1 and B2, cf. the illustrative example [4]. In this way, conditional independence is a probabilistic approach to causality, while correlation is not. To relax the restrictive assumption that all predictor variables are conditionally independent given the target variable, the assumption of conditional independence of subsets of predictor variables, referred to as the Bayesian belief network, provides intermediate models that are less restrictive, but more tractable than general models [5]. A suitable choice of subsets are the cliques of the graphical model [6] representing the variables and their conditional independence relationships leading to interaction terms in logistic regression models [7].
2.2. Logistic Regression
A modern account of logistic regression is given by [8]. The conditional expectation of an indicator random target variable T given a (m + 1)-variate random predictor variable is equal to its conditional probability, i.e., for B = (B0, B1,…, Bm)T with B0 ≡ 1
Omitting the binomially distributed error term ([8]), as is done often, the ordinary logistic regression model without interaction terms for the conditional probability to be predicted can be written as [8]:
in terms of a logit:
in terms of a probability:
with the logistic function:
The ordinary logistic regression model is optimum, i.e., it agrees with the true conditional probability, if the predictor variables are discrete and conditionally independent given the target variable [7]. Here, the predictor variables are assumed to be discrete to ensure that the joint probability of B and T has a representation as a log-linear model, which is then subject to factorization, according to the Hammersley–Clifford theorem [7].
The logistic regression model can be generalized to include any interaction terms of the form , i.e., any product terms of predictors:
Lacking conditional independence can be exactly compensated for by corresponding interaction terms included in the logistic regression model, and the resulting logistic regression model with interaction terms is optimum for continuous predictor variables if the joint distribution of the target variable and the predictor variables is of a log-linear form. A log-linear form is ensured if the predictor variables are discrete. Thus, for discrete predictor variables, the logistic regression model, including appropriate interaction terms, is optimum [7].
Given m ≥ 2 predictor variables , ℓ = 1,…, m, there is a total of possible interaction terms. To be a feasible model, the total number 2m of all possible terms would have to be reasonably smaller than the sample size n. However, the interaction term , k ≤ m, is actually required if are not conditionally independent given T.
Logistic regression parameters can be interpreted with respect to logits analogously to the parameters of linear regression model, e.g., βℓ represents the increment of logitP(T = 1|B) if Bℓℓis increased by one unit [8]. There are more involved interpretations to come, cf. Appendix B.
Given a sample bℓ,i, ti, i = 1,…, n, ℓ = 1,…, m, the parameters of the logistic regression model are estimated with the maximum likelihood method numerically realized in Fisher’s scoring algorithm (a form of Newton–Raphson, a special case of an iteratively reweighted least squares algorithm) and encoded in any major statistical software package.
2.3. Weights-of-Evidence
The model of weights-of-evidence is the special case of a logistic regression model without interaction terms, if all predictor variables are binary and conditionally independent given the target variable [9]. It reads, e.g., in terms of the conditional probability to be predicted:
Since the model of weights-of-evidence [10–14] is based on the naive Bayesian approach [5,14–17] assuming conditional independence of B given T, it can be derived in elementary terms from Bayes’ theorem for indicator random variables B0, B1, …, Bm:
Due to the simplifying assumption of conditional independence and in contrast to general logistic regression, the ratios of conditional probabilities involved in the definition of the weights of evidence, Equation (4), can be estimated by mere counting. Moreover, weights-of-evidence can easily be generalized to discrete random variables, as a discrete variable with s different states can be split into (s − 1) different binary random variables to be used in regression models.
2.4. Testing Conditional Independence
A straightforward test of conditional independence employs the relationship of weights-of-evidence and log-linear models. If predictor variables are discrete and conditionally independent given the target variable, then by virtue of the Hammersley–Clifford theorem, a correspondingly factorized simple log-linear model without interaction terms is sufficiently large to represent the joint distribution [7,9]. Thus, if the likelihood ratio test of this null-hypothesis with respect to an appropriate log-linear model leads to its reasonable rejection, then the assumption of conditional independence can be rejected, too. This test does not rely on any assumption involving the normal distribution, as the omnibus tests [18,19] do.
These omnibus tests use deviations of a characteristic of a fitted model from properties of the mathematical model (θ | B) known from probability and mathematical statistics, to interfere on the validity of the modeling assumption of conditional independence. The omnibus tests take as characteristic the mean of conditional probabilities over all objects, i.e., pixels or voxels, in the training dataset of sample size n,
Thus, for a proper (“true”) model, the mean of i = 1,…, n, is (approximately) equal to , estimated by the relative frequency of T = 1 in the training dataset. Deviations of the mean from would indicate that the model may not be true. For a weights-of-evidence model, deviations could be caused by a lack of conditional independence, while for a logistic regression model, is always satisfied (up to numerical accuracy). Based on Equation (7), [19] developed the omnibus test, and [18] the new omnibus test.
A more sophisticated statistical test for real predictor variables was recently suggested by [20].
2.5. Weights-of-Evidence vs. Logistic Regression
The parameters of ordinary logistic regression are equal to the contrasts of the weights, if all predictor variables are indicators and conditionally independent given the target variable. Thus, weights-of-evidence is the special case of ordinary logistic regression if the predictors B are indicator variables and conditional independent given T. The other way round, logistic regression is the canonical generalization of weights-of-evidence [14,17]. Note that the weights-of-evidence model cannot be enlarged to include interaction terms.
Generally, i.e., without assuming conditional independence, the relationship of ordinary logistic regression parameters and the contrast of weights of evidence is clearly non-linear [21,22]; see Appendix 2 for an explicit derivation.
When , i = 1, …, n, are estimated by maximum likelihood applied to the ordinary logistic regression model, Equation (7) always holds, because it is part of the maximum likelihood systems of equations. Having recognized weights-of-evidence as a special case of logistic regression, when predictors are indicator variables and conditionally independent given the target variable, the above comparison may now be seen as checking the statistics of different models. Analogously, the estimated contrasts of weights of evidence may be compared with the estimated logistic regression coefficients . Then, any deviation between them is indicative of violations of the modeling assumption of conditional independence.
2.6. Weights-of-Evidence vs. the τ- or ν-Model
The modeling assumption with respect to the factors of Equation (6) of the τ-model [23–25] is:
Then, modified weights are defined as:
The modeling assumption with respect to the factors of Equation (6) of the ν-model [26,27] is:
Then, modified weights are defined as:
A this point, we may conclude that there is no way to emulate the effect of interaction terms of logistic regression models by manipulating the weights of evidence or their contrasts.
2.7. Artificial Neural Nets
General regression models can be tackled by various approaches of statistical learning, including artificial neural nets [15]. With respect to artificial neural nets and statistical learning [5,15,16,28], the logistic regression model, Equation (1),
The basic multi-layer neural network model can be described as a sequence of functional transformations [15,29–31], often depicted as a graph:
input: predictor variables B;
first layer: linear combinations , j = 1, …, J, of the predictor variables B, referred to as input units or activations:
or:to mimic interaction terms:hidden layer: each of them is subject to a transformation applying a nonlinear differentiable activation function h usually of sigmoidal shape, referred to as hidden units:
second layer: linear combinations , k = 1, …, K of hidden units, referred to as output unit activations:
output: each of the output unit activations is subject to an activation function S, e.g., logistic function:
Then:
If K = 1 and S = Λ, h = id, J = 0, then we are of course back to ordinary logistic regression, Equation (1). On the other hand, in Equation (10), the linear combination of predictors, as given by Equation (8), can easily be replaced by the enlarged combination, including interaction terms, as given by Equation (9), where the consideration of interactions terms requires a more versatile net topology. The lack of the notion of significant parameters and, in turn, significant models is prohibitive of the successive construction of proper models. Instead, all variables and a sufficiently versatile net topology are plugged in, and coefficients for all variables are determined numerically with some gradient method. This procedure does not seem to meet the idea of parsimonious models.
2.8. Balancing
Methods of statistical learning are prone to fail if the odds O(T = 1) are too small, cf. [32–37]. Simple balancing mimics preferential sampling, i.e., a new balanced dataset is constructed by weighting all objects with T = 1 with a weight 1 < μ ∈ ℝ. This kind of balancing immediately results in:
Moreover, if:
It is emphasized that Equation (11) holds for mathematical models, if they are proper. Then, Equation (11) may be read as back transformation of balancing by weighting objects with T = 1 with weight μ. It may not hold for fitted models, i.e., estimation of the parameters of a poor model may corrupt the equation; then, . Note that the weights of evidence are not all affected by this kind of balancing.
2.9. Numerical Complexity of Logistic Regression
Potential modeling with logistic regression using a 3D training dataset of n voxels and (m + 1) predictor variables to fit the regression parameters requires to resolve a system of (m + 1) non-linear equations. Usually, the total number of predictor variables is much smaller than the total number of voxels. Statisticians’ numerical method of choice is iteratively reweighted least squares. The numerical complexity of one iteration step is of the order of 2n(m + 1)2 flops; the total number of iterations cannot generally be estimated. Considering the size of the problem for 3D geomodels with a reasonable spatial resolution clearly indicates that its numerical solution requires a highly efficient data management of 3D geomodels in voxel mode and very fast numerics based on massively parallel processing.
3. Examples
Both datasets are fabricated to serve certain purposes. The mathematical assumption associated with a training dataset is complete knowledge, i.e., in particular, we assume that we know all occurrences of the target variable T = 1. Otherwise, not even the odds or logits of T = 1 could be estimated properly. Thus, previously unknown occurrences or their probabilities cannot be predicted with respect to the training dataset. Comparing the estimated conditional probabilities with counted conditional frequencies provides a check of the appropriateness of the applied model. A more powerful check is to use only part of the data out of the training dataset to estimate the parameters of a model and, then, to validate the model with the remaining data that were not used before. All computations were done with the free statistical software, R [38].
3.1. Dataset RANKIT Revisited
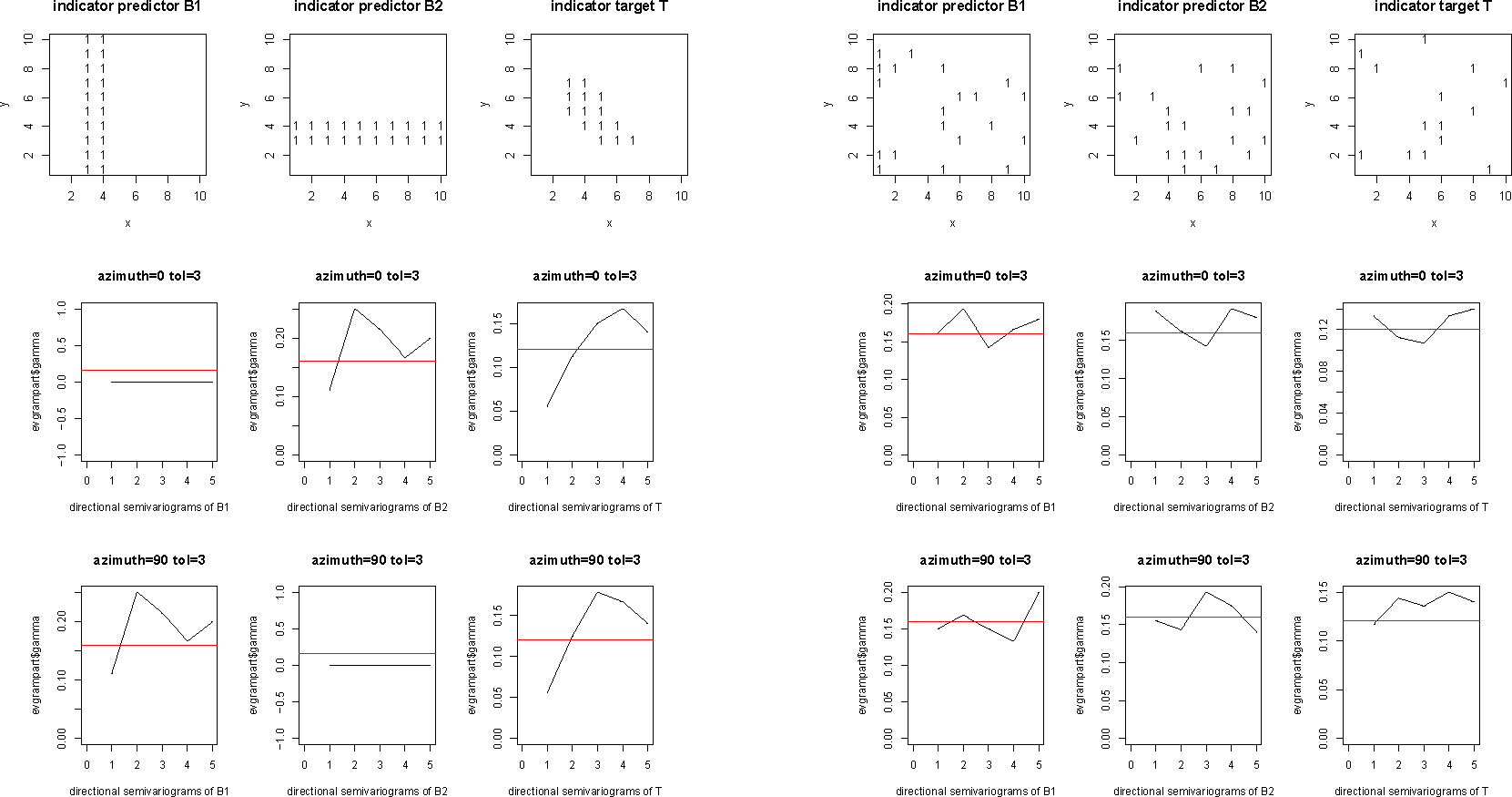
A first presentation and discussion of the dataset rankit (Figure 1) has been given in [9]. The rankit dataset comprises two predictor variables B1, B2 and a target variable T referring to pixels of a digital map image. The predictor variables B1, B2 are uncorrelated and not conditionally independent given the target variable T.
Here, the example is completed by considering a randomly rearranged dataset rankitmix (Figure 1), which originates from the dataset rankit by rearranging the pixel references (i, j) of triplets (bk1, bk2, tk), k = 1, …, n, of realizations of B1, B2 and T in the dataset at random. The uni-directional variograms of Figure 1 clearly indicate that the two datasets differ in their spatial statistics.
However, the datasets rankit and rankitmix have identical ordinary statistics like contingency tables, Tables 1 and 2, or a correlation matrix, Table 3, in common.
The indicator predictor variables B1 and B2 seem to be uncorrelated, while B1 and T, and B2 and T, respectively, are significantly correlated for all significance levels α > 0.002213 and α > 0.02101, respectively; cf. Table 3.
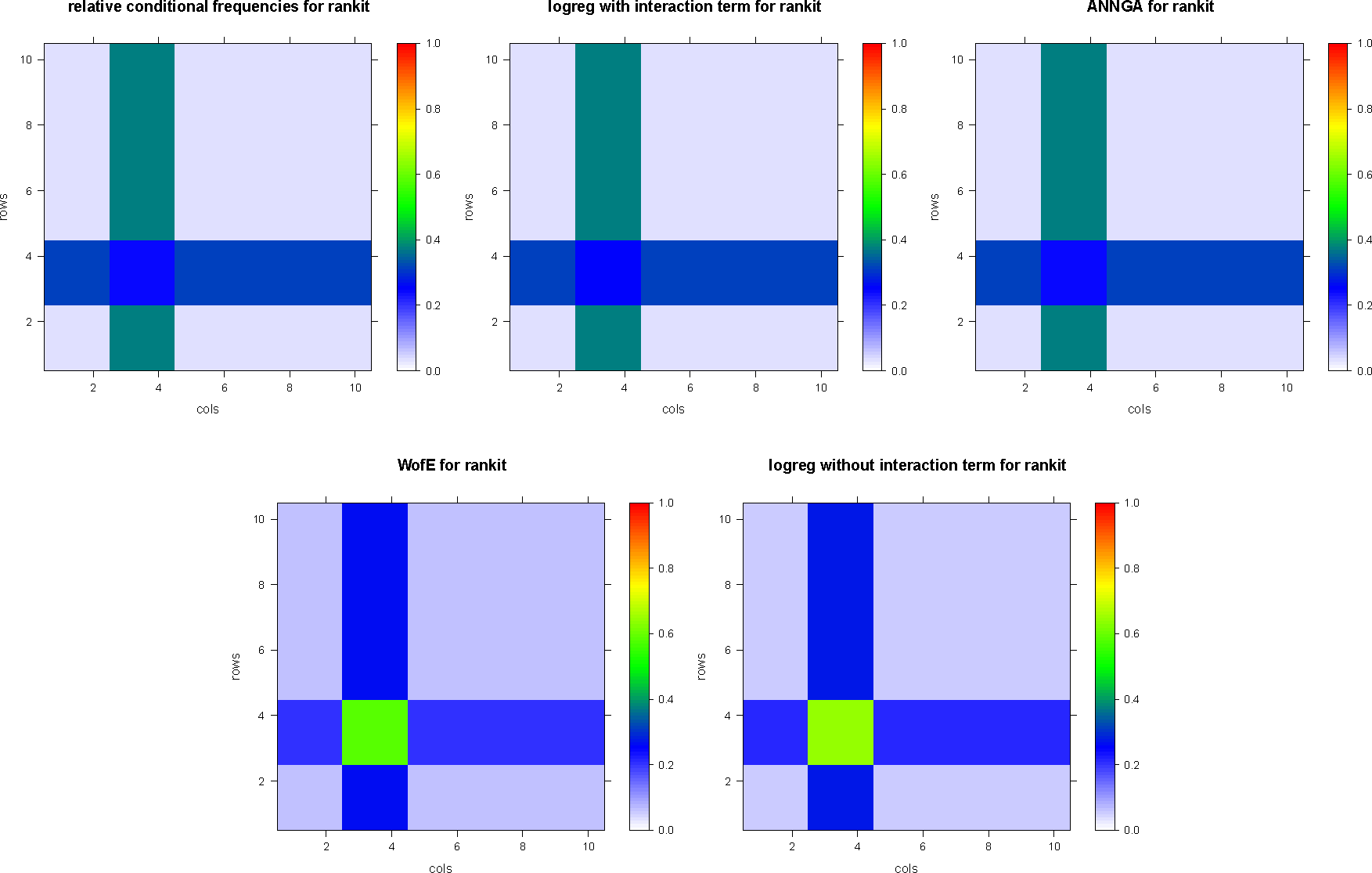
Therefore, for both the rankit and the rankitmix dataset, respectively, the models of weights-of-evidence, ordinary logistic regression without interaction term and enlarged logistic regression with the interaction term read explicitly:
Since the mathematical modeling assumption of conditional independence is violated, only logistic regression with interaction terms yields a proper model and predicts the conditional probabilities almost exactly.
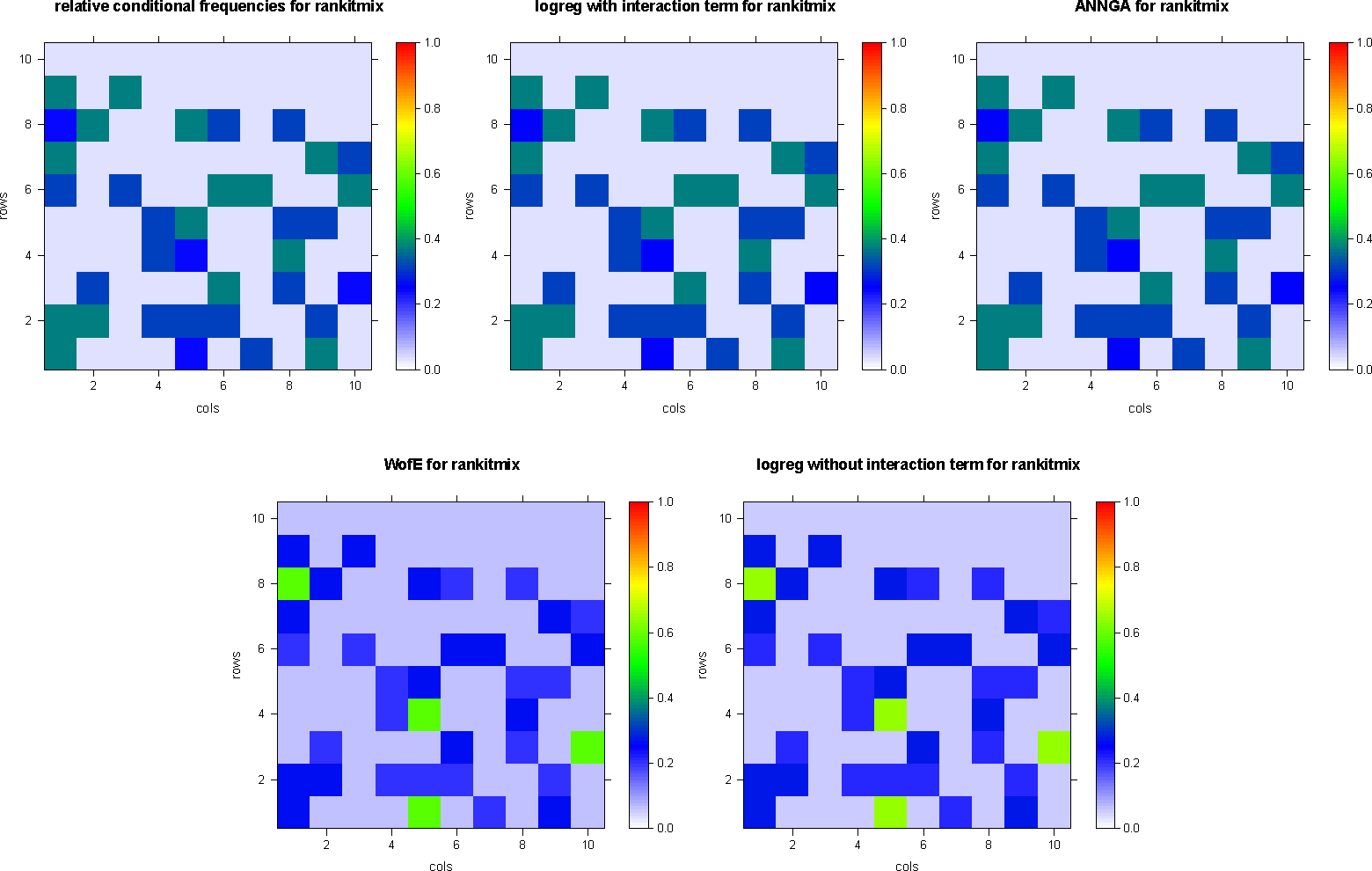
The results of weights-of-evidence, logistic regression with or without interaction terms and artificial neural net applied to the fabricated datasets rankit and the rankitmix dataset, respectively, are summarized in Table 4. Figure 2 depicts the results of dataset rankit, and Figure 3 depicts the results of dataset rankitmix.
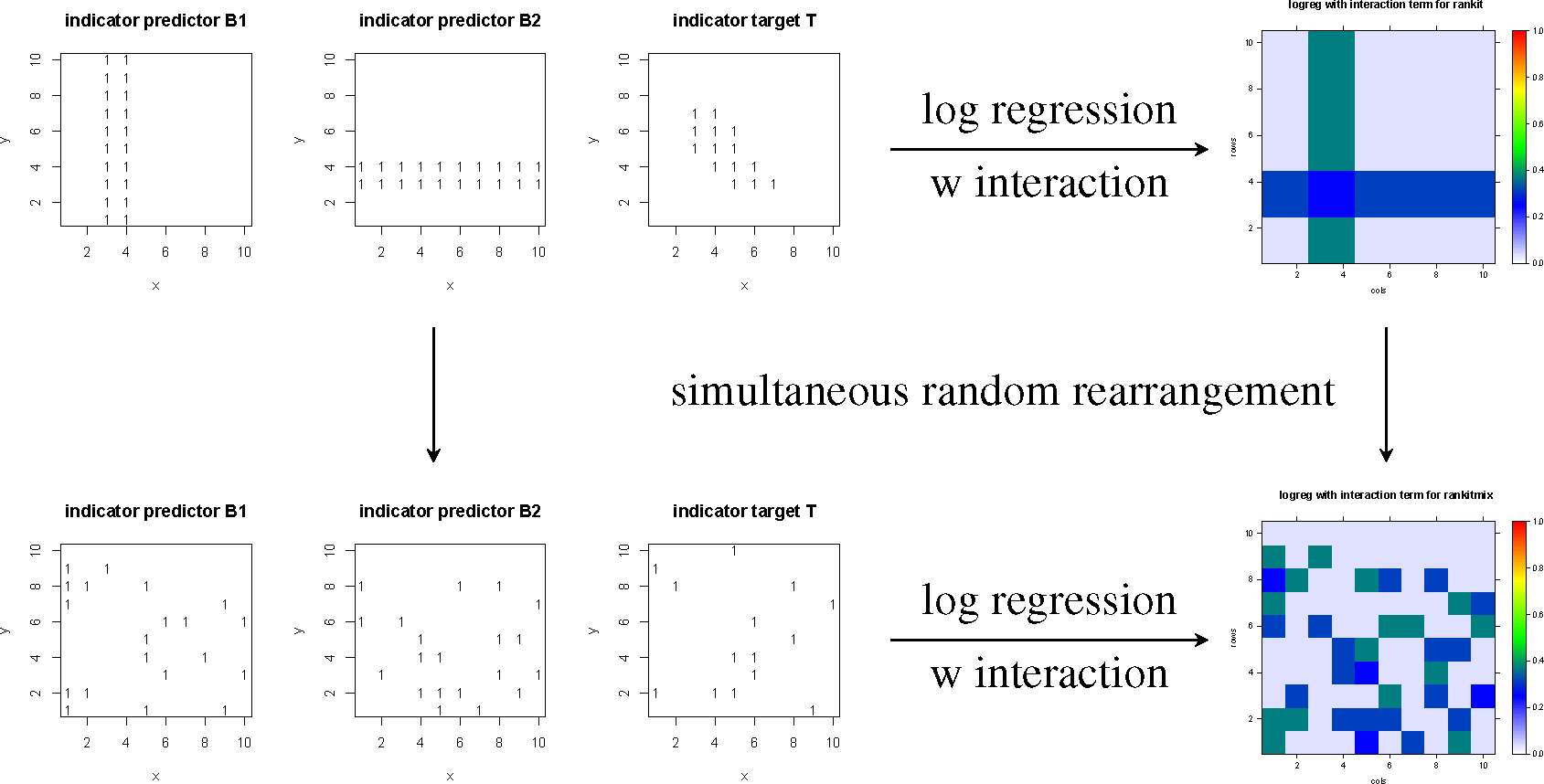
Obviously, the digital map images of Figures 2 and 3 are related to each other by the same rearrangement as the datasets rankit and rankitmix of the top row of Figure 1. This relationship can be depicted like a commutative diagram (Figure 4), for instance with respect to logistic regression, including interaction terms.
To state it explicitly, each of the methods of targeting considered here commutes with any random rearrangement applied simultaneously to all digital map images involved in or resulting from targeting. Thus, targeting and potential modeling, resp., are not spatial methods; they do not employ spatially-induced dependencies, which have been shown to be different by looking at the semi-variograms of the datasets; Figure 1.
After balancing with m = 10, the models of weights-of-evidence and enlarged logistic regression with interaction terms read explicitly:
3.2. Dataset DFQR
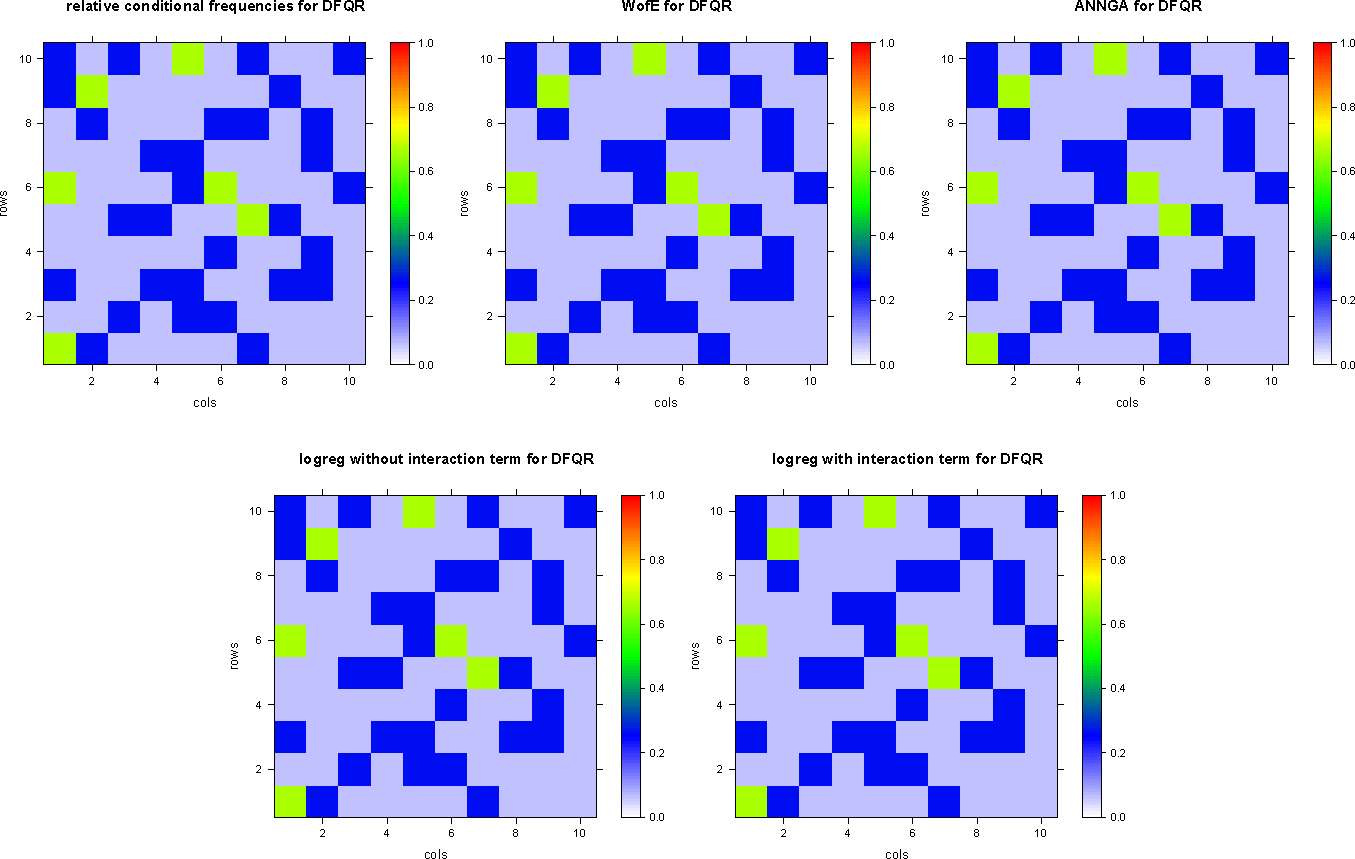
The dataset DFQR is visualized as a digital map image in Figure 5.
The contingencies are given in Tables 5 and 6.
The correlation matrix (Table 7) indicates that B1 and B2 are uncorrelated, and significantly correlated with T for all significance levels α > 0.001652.
The test of conditional independence referring to log-linear models (Table 8) shows that the null-hypothesis of conditional independence of B1 and B2 given T cannot reasonably be rejected.
The corresponding conditional relative frequencies factorize almost exactly, i.e.,
With , the weights-of-evidence model reads explicitly:
The ordinary logistic regression model without interaction terms reads explicitly:
β0 is significant for all α > 1.12e − 08, and
β1, β2 are significant for all α > 0.00651.
The two models are almost identical; small deviations of their parameters result from small violations of conditional independence. While the test with p = 0.999950 indicates that the null-hypothesis of conditional independence cannot reasonable be rejected, the conditional relative frequencies do not factorize perfectly, but only approximately. The conditional probabilities estimated with weights-of-evidence or ordinary logistic regression almost exactly recover the conditional probabilities estimated elementarily by counting conditional frequencies for the training dataset DFQR; cf. Table 9.
The logistic regression model with interaction terms reads explicitly:
β0 is significant for all α > 1.57e − 07,
β1, β2 are significant for all α > 0.0295, and
β12 is not at all significant as p = 0.9949.
The conditional probabilities estimated with logistic regression, including the interaction terms, exactly recover the conditional probabilities estimated elementarily by counting conditional frequencies for the training dataset DFQR, which is just the numerical confirmation, that the log-linear model with interaction terms is a perfect model for the training dataset DFQR; cf. Table 9 and Figure 6.
After balancing with m = 10, the models for the balanced dataset are:
4. Conclusions
Targeting or potential modeling applies regression or regression-like models to estimate the conditional probability of a target variable given predictor variables. All models considered here:
assume independently identical distributed random predictor and target variables, respectively, i.e., all models are non-spatial and do not consider spatially-induced dependencies, as, for instance, geostatistics; therefore, rearranging the dataset at random results in random map images or geomodels, but does not change the fitted models.
are not pointwise; they involve random variables referring to locations given in terms of areal pixels of 2D digital map images or volumetric voxels of 3D geomodels; thus, their results depend on the spatial resolution of the map image or the geomodel, respectively.
require a training region to fit the model parameters; that is to say that the mathematical modeling assumption associated with the training region is that it provides “ground truth”.
Then, the models can be put in a hierarchy, beginning with the naive Bayesian model of weights-of-evidence depending on the modeling assumption of conditional independence of all predictor variables given the target variable. It is the special case of the logistic regression model if the predictor variables (i) are indicator or discrete random variables and (ii) conditionally independent given the target variable. In this case, the contrasts of weights-of-evidence are identical to the logistic regression coefficients. Otherwise, there is no linear relationship between weights of evidence and logistic regression parameters.
The canonical generalization of the naive Bayesian model featuring weights of evidence to the case of lacking conditional independence is logistic regression, including interaction terms. If the interactions terms are chosen to correspond to violations of conditional independence, they are compensating exactly for these violations, if the predictor variables are discrete; for continuous predictor variables, they compensate exactly only if the joint probability is log-linear; otherwise, they may compensate approximately. Thus, in the case of discrete predictor variables, the logistic regression model is optimum.
Applying weights-of-evidence despite lacking conditional independence corrupts both the predicted conditional probabilities, as well as their rank-transforms. Their is no way to emulate the effect of interaction terms by “correcting” the weights of evidence subsequently, e.g., by powering or multiplying with some τ- or ν-coefficients.
To further enlarge the models, nesting logistic regression-like models is an option. Irrespective of the vocabulary, nesting giving rise to “hidden layers” is the hard core of artificial neural nets. If the configuration of the net topology is sufficiently versatile, artificial neural net models can compensate for the lack of conditional independence, much in the same way as logistic regression models, including interaction terms. When the odds of the target are too small, some “balancing” may be required. A simple balancing method was shown to leave the model parameters unchanged, if the model itself is proper.
The possibility to include interaction terms in logistic regression models or other models originating in statistical learning opens a promising route toward an effective means to abandon the severe modeling assumption of conditional independence and to cope with the lack of conditional independence in practice.
A promising future perspective is regression accounting for spatially-induced dependencies to get rid of (i) the training region partitioned in pixels or voxels and the dependence on the spatial resolution that they provide; and (ii) the modeling assumption of independently identical distributed random variables.
Acknowledgments
The author gratefully acknowledges partial financial funding by Bundesministerium für Wirtschaft und Technologie (BMWi) within the frame of “Zentrales Innovationsprogramm Mittelstand” (ZIM), Kooperationsprojekt KF3212102KM3. Emphatic discussions with Gerald van den Boogaart, Helmholtz Institute Freiberg for Resource Technology and Technische Universität Bergakademie Freiberg, and Raimon Tolosana-Delgado, Helmholtz Institute Freiberg for Resource Technology, have always been greatly appreciated.
A. Appendix
A.1. Derivation of Weights-of-Evidence in Elementary Terms
If T, B are indicator random variables with P (T = j) > 0, P (B = i) > 0, i, j = 0, 1, then Bayes’ theorem states:
Then, the ratio of the conditional probabilities of T = 1 and T = 0, respectively, given B, referred to as the log-linear form of Bayes’ theorem,
Now, the naive Bayes’ assumption of conditional independence of all predictor variables B given the target variable T leads to the most efficient simplification:
in terms of a logit (“log-linear form of Bayes’ formula”):
and:in terms of a probability:
with , , if Equation (5) holds. Then, the weights-of-evidence model in terms of contrasts, Equation (2), is derived from its initial representation in terms of weights as follows:
To avoid the restrictive condition, Equation (5), the weights-of-evidence model in terms of odds, Equation (12), is rewritten as:
To distinguish different cases, we set = {1,…, m}, m ∈ ℕ, and then:
Eventually, the naive Bayes’ model in terms of logits reads:
Thus, for the slightly more general Equation (15) than Equation (13), the initial correspondence Equation (3) becomes a little bit more involved, i.e., with the notation of Equation (14):
A.2. Explicit Derivation of the Generally Non-Linear Relationship of Logistic Regression Coefficients and Weights of Evidence
For indicator predictor variables (B0,… Bm)T = B with realizations (b0,…, bm)T = b with b0 =1, bℓ = 0, 1, for ℓ = 1,…, m,, the ordinary logistic regression model reads explicitly:
There are 2m different realization b; hence, there are 2m different logits. Now, keeping all Bj = bj fixed, except Bℓ, Equation (16), implies that the logarithmic odds ratio:
With respect to the ordinary logistic regression model, the 2m marginal log odds cℓk are defined by:
Equation (18) establishes the non-linear relationship of contrasts and regression parameters. The trivial case m = 1 leads immediately to C1 = β1. For m = 2, Equation (18) simplifies to:
Mistaking the logit transform as linear leads to the erroneous linear relationship of contrasts and logistic regression parameters given by Deng (2009); cf. [22].
Conflicts of Interest
The author declares no conflict of interest.
References
- Hronsky, J.M.A.; Groves, D.I. Science of targeting: Definition, strategies, targeting and performance measurement. Aust. J. Earth Sci. 2008, 55, 3–12. [Google Scholar]
- Cox, D.P.; Singer, D.A. Mineral Deposit Models; U.S. Geological Survey Bulletin 1693; US Government Printing Office: Washington, DC, USA, 1986. [Google Scholar]
- Chilès, J.-P.; Delfiner, P. Geostatistics—Modeling Spatial Uncertainty, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Independence and Conditional Independence, Available online: http://www.eecs.qmul.ac.uk/norman/BBNs/Independence_and_conditional_independence.htm accessed on 10 October 2014.
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Højsgaard, S.; Edwards, D.; Lauritzen, S. Graphical Models with R.; Springer: New York, NY, USA, 2012. [Google Scholar]
- Schaeben, H. A mathematical view of weights-of-evidence, conditional independence, and logistic regression in terms of markov random fields. Math. Geosci. 2014, 46, 691–709. [Google Scholar]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression, 2nd ed.; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Schaeben, H. Potential modeling: Conditional independence matters. Int. J. Geomath. 2014, 5, 99–116. [Google Scholar]
- Agterberg, F.P.; Bonham-Carter, G.F.; Wright, D.F. Statistical pattern integration for mineral exploration. In Computer Applications in Resource Estimation Prediction and Assessment for Metals and Petroleum; Gaál, G., Merriam, D.F., Eds.; Pergamon Press: Oxford, NY, USA, 1990; pp. 1–21. [Google Scholar]
- Bonham-Carter, G.F.; Agterberg, F.P. Application of a microcomputer based geographic information system to mineral-potential mapping. In Microcomputer—Based Applications in Geology II, Petroleum; Hanley, J.T., Merriam, D.F., Eds.; Pergamon Press: New York, NY, USA, 1990; pp. 49–74. [Google Scholar]
- Good, I.J. Probability and the Weighing of Evidence; Griffin: London, UK, 1950. [Google Scholar]
- Good, I.J. The Estimation of Probabilities: An Essay on Modern Bayesian Methods; Research Monograph No. 30; The MIT Press: Cambridge, MA, USA, 1968. [Google Scholar]
- Hand, D.J.; Yu, K. Idiot’s bayes—Not so stupid after all? Int. Stat. Rev. 2001, 69, 385–398. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2001. [Google Scholar]
- Smola, A.J.; Vishwanathan, S.V.N. Introduction to Machine Learning; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Sutton, C.; McCallum, A. An introduction to conditional random fields for relational learning. In Introduction to Statistical Relational Learning; Getoor, L., Taskar, B., Eds.; MIT Press: London, UK, 2007; pp. 93–127. [Google Scholar]
- Agterberg, F.P.; Cheng, Q. Conditional independence test for weights-of-evidence modeling. Nat. Resour. Res. 2002, 11, 249–255. [Google Scholar]
- Bonham-Carter, G.F. Geographic Information Systems for Geoscientists; Pergamon Press: Oxford, NY, USA, 1994. [Google Scholar]
- Zhang, K.; Peters, J.; Janzing, D.; Schölkopf, B. Kernel-based conditional independence test and application in causal discovery, Proceedings of the 27th Conference on Uncertainty in Artificial Intelligence (UAI 2011), Barcelona, Spain, 14–17 July 2011; Cozman, F.G., Pfeffer, A., Eds.; AUAI Press: Corvallis, OR, USA, 2011; pp. 804–813.
- Schaeben, H. Comparison of mathematical methods of potential modeling. Math. Geosci. 2012, 44, 101–129. [Google Scholar]
- Schaeben, H.; van den Boogaart, K.G. Comment on “A conditional dependence adjusted weights of evidence model” by Minfeng Deng in Natural Resources Research 18(2009), 249–258. Nat. Resour. Res. 2011, 29, 401–406. [Google Scholar]
- Journel, A.G. Combining knowledge from diverse sources: An alternative to traditional data independence hypotheses. Math. Geol. 2002, 34, 573–596. [Google Scholar]
- Krishnan, S.; Boucher, A.; Journel, A.G. Evaluating information redundancy through the τ-model. In Geostatistics Banff 2004; Leuangthong, O., Deutsch, C.V., Eds.; Springer: Dordrecht, The Netherlands, 2005; pp. 1037–1046. [Google Scholar]
- Krishnan, S. The τ-model for data redundancy and information combination in earth sciences: Theory and Application. Math. Geosci. 2008, 40, 705–727. [Google Scholar]
- Polyakova, E.I.; Journel, A.G. The ν-model for probabilistic data integration, IAMG’2006, Proceedings of the XIth International Congress of the International Association for Mathematical Geology: Quantitative Geology from Multiple Sources, Liège, Belgium, 3–8 September 2006.
- Polyakova, E.I.; Journel, A.G. The ν-expression for probabilistic data integration. Math. Geol. 2007, 39, 715–733. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory, 2nd ed.; Springer: New York, NY, USA, 2000. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence, A Modern Approach, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Skabar, A. Modeling the spatial distribution of mineral deposits using neural networks. Nat. Resour. Model. 2007, 20, 435–450. [Google Scholar]
- Adam, A.; Ibrahim, Z.; Shapiai, M.I.; Chew, L.C.; Jau, L.W.; Khalid, M.; Watada, J. A two-stwp supervised learning artificial neural network for imbalanced dataset problems. Int. J. Innov. Comput. Inf. Control. 2012, 8, 3163–3172. [Google Scholar]
- Adam, A.; Shapiai, M.I.; Ibrahim, Z.; Khalid, M.; Jau, L.W. development of a hybrid artificial neural network—Naive bayes classifier for binary classification problem of imbalanced datasets. ICIC Express Lett. 2011, 5, 3171–3175. [Google Scholar]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. SIGKDD Explor. Spec. Issue Learn. Imbalanced Datasets. 2004, 6, 20–29. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. Smote: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Handling imbalanced datasets: A review. GESTS Int. Trans. Comput. Sci. Eng. 2006, 30, 25–36. [Google Scholar]
- Zhao, Z.-Q. A novel modular neural network for imbalanced classification problems. Pattern Recognit. Lett. 2008, 30, 783–788. [Google Scholar]
- R Development Core Team. R—A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. Available online: http://www.R-project.org/ accessed on 10 October 2014.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| B2 = 0 | B2 = 1 | |
|---|---|---|
| B1 = 0 | 64 | 16 |
| B1 = 1 | 16 | 4 |
| T = 0 | B2 = 0 | B2 = 1 |
|---|---|---|
| B1 = 0 | 62 | 11 |
| B1 = 1 | 10 | 3 |
| T = 1 | B2 = 0 | B2 = 1 |
|---|---|---|
| B1 = 0 | 2 | 5 |
| B1 = 1 | 6 | 1 |
| B2 = 0 | B2 = 1 | |
|---|---|---|
| T = 0 | 73 | 13 |
| T = 1 | 7 | 7 |
| B2 = 0 | B2 = 1 | |
|---|---|---|
| T = 0 | 72 | 14 |
| T = 1 | 8 | 6 |
| B1 | B2 | T | |
|---|---|---|---|
| B1 | 1.0000000 | −0.0000000 | 0.3026050 |
| B2 | −0.0000000 | 1.0000000 | 0.2305562 |
| T | 0.3026050 | 0.2305562 | 1.0000000 |
| Counting | WofE | oLogReg | LogRegwI | ANNGA | |
|---|---|---|---|---|---|
| B1 = 1, B2 = 1 | 0.25000 | 0.58636 | 0.64055 | 0.25000 | 0.24992 |
| B1 = 1, B2 = 0 | 0.37500 | 0.26875 | 0.27736 | 0.37500 | 0.37502 |
| B1 = 0, B2 = 1 | 0.31250 | 0.20156 | 0.21486 | 0.31250 | 0.31250 |
| B1 = 0, B2 = 0 | 0.03125 | 0.06142 | 0.05565 | 0.03125 | 0.03124 |
| B2 = 0 | B2 = 1 | |
|---|---|---|
| B1 = 0 | 64 | 15 |
| B1 = 1 | 15 | 6 |
| T = 0 | B2 = 0 | B2 = 1 |
|---|---|---|
| B1 = 0 | 60 | 11 |
| B1 = 1 | 11 | 2 |
| T = 1 | B2 = 0 | B2 = 1 |
|---|---|---|
| B1 = 0 | 4 | 4 |
| B1 = 1 | 4 | 4 |
| B1 = 0 | B1 = 1 | |
|---|---|---|
| T= 0 | 71 | 13 |
| T= 1 | 8 | 8 |
| B2 = 0 | B2 = 1 | |
|---|---|---|
| T= 0 | 71 | 13 |
| T= 1 | 8 | 8 |
| B1 | B2 | T | |
|---|---|---|---|
| B1 | 1.0000000 | 0.0958409 | 0.3107386 |
| B2 | 0.0958409 | 1.0000000 | 0.3107386 |
| T | 0.3107386 | 0.3107386 | 1.0000000 |
| Statistics
| |||
|---|---|---|---|
| χ2 | df | P(> χ2) | |
| Likelihood Ratio | 9.872996e-05 | 2 | 0.9999506 |
| Pearson | 9.859977e-05 | 2 | 0.9999507 |
| Counting | WofE | oLogReg | LogRegwI | ANNGA | |
|---|---|---|---|---|---|
| B1 = 1, B2 = 1 | 0.66666 | 0.66534 | 0.66585 | 0.66666 | 0.66666 |
| B1 = 1, B2 = 0 | 0.26666 | 0.26687 | 0.26699 | 0.26666 | 0.26666 |
| B1 = 0, B2 = 1 | 0.26666 | 0.26687 | 0.26699 | 0.26666 | 0.26666 |
| B1 = 0, B2 = 0 | 0.06250 | 0.06248 | 0.06242 | 0.06250 | 0.06250 |
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schaeben, H. Targeting: Logistic Regression, Special Cases and Extensions. ISPRS Int. J. Geo-Inf. 2014, 3, 1387-1411. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi3041387
Schaeben H. Targeting: Logistic Regression, Special Cases and Extensions. ISPRS International Journal of Geo-Information. 2014; 3(4):1387-1411. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi3041387
Chicago/Turabian StyleSchaeben, Helmut. 2014. "Targeting: Logistic Regression, Special Cases and Extensions" ISPRS International Journal of Geo-Information 3, no. 4: 1387-1411. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi3041387