Genetic Risk Profiling in Parkinson’s Disease and Utilizing Genetics to Gain Insight into Disease-Related Biological Pathways

 , , and
, , and 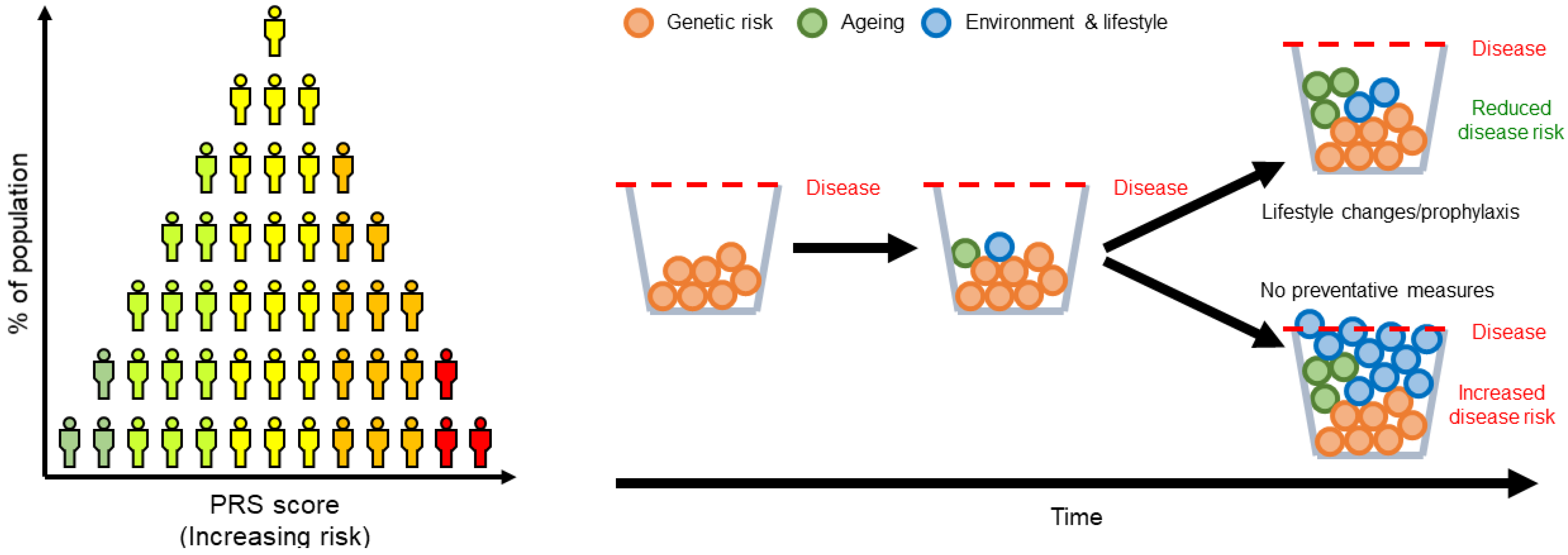{kind=link}
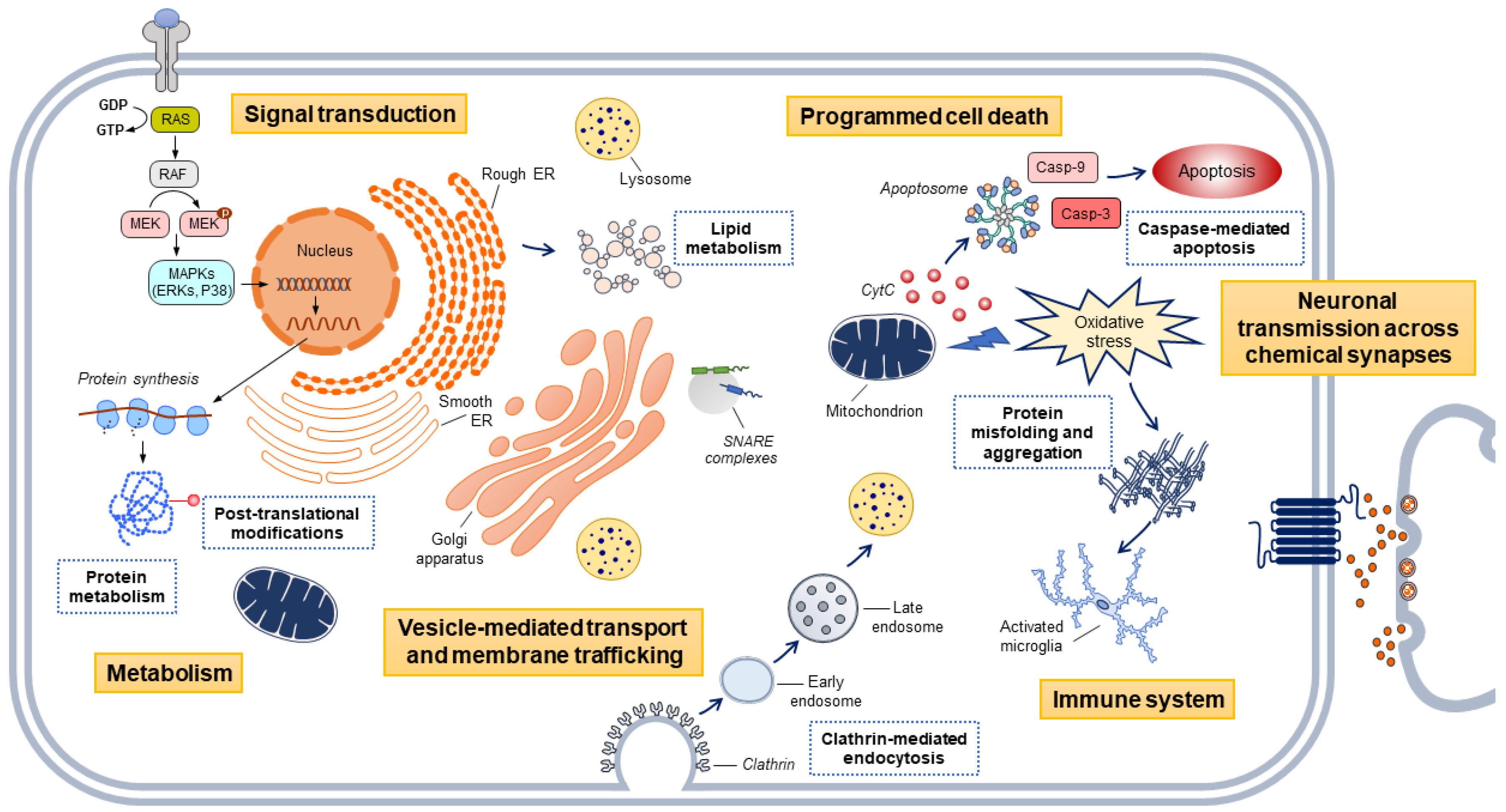{kind=link}
Abstract
:1. Parkinson’s Disease Genetics
2. Genetic risk Profiling in Parkinson’s Disease
3. Utilizing Genetic Risk Profiling to Identify Biological Pathways Involved in Disease
4. From Pathway to Possible Therapeutic Target: Analytical Methods for Gene Prioritization
5. The Limitations in Our Current Understanding of Parkinson’s Disease Genetics, Focusing on the Contribution of Structural Variants
6. Future Directions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PD | Parkinson’s Disease |
| REM | Rapid eye movement |
| GWA | Genome-wide association |
| PRS | Polygenic risk score |
| CDCV | Common disease common variant |
| SNV | Single nucleotide variants |
| LD | Linkage disequilibrium |
| AAO | Age at onset |
| EMTP | Endocytic membrane trafficking pathway |
| MSigDB | Molecular Signatures Database |
| KEGG | Kyoto Encyclopedia of Genes and Genomes |
| SE | Standard error |
| SMR | Summary-data-based Mendelian randomization |
| QTL | Quantitative trait loci |
| TWAS | Transcriptome-wide association studies |
| SV | Structural variants |
| CNV | Copy number variant |
| GP2 | Global Parkinson’s Genetics Program |
References
- Poewe, W.; Seppi, K.; Tanner, C.M.; Halliday, G.M.; Brundin, P.; Volkmann, J.; Schrag, A.E.; Lang, A.E. Parkinson disease. Nat. Rev. Dis Primers 2017, 3, 17013. [Google Scholar] [CrossRef] [PubMed]
- Chaudhuri, K.R.; Schapira, A.H. Non-motor symptoms of Parkinson’s disease: Dopaminergic pathophysiology and treatment. Lancet Neurol. 2009, 8, 464–474. [Google Scholar] [CrossRef]
- Dorsey, E.R.; Bloem, B.R. The Parkinson Pandemic-A Call to Action. JAMA Neurol. 2018, 75, 9–10. [Google Scholar] [CrossRef] [PubMed]
- Langston, J.W.; Ballard, P.; Tetrud, J.W.; Irwin, I. Chronic Parkinsonism in humans due to a product of meperidine-analog synthesis. Science 1983, 219, 979–980. [Google Scholar] [CrossRef] [Green Version]
- Eldridge, R.; Ince, S.E. The low concordance rate for Parkinson’s disease in twins: A possible explanation. Neurology 1984, 34, 1354–1356. [Google Scholar] [CrossRef]
- Lesage, S.; Brice, A. Parkinson’s disease: From monogenic forms to genetic susceptibility factors. Hum. Mol. Genet. 2009, 18, R48–R59. [Google Scholar] [CrossRef]
- Polymeropoulos, M.H.; Lavedan, C.; Leroy, E.; Ide, S.E.; Dehejia, A.; Dutra, A.; Pike, B.; Root, H.; Rubenstein, J.; Boyer, R.; et al. Mutation in the alpha-synuclein gene identified in families with Parkinson’s disease. Science 1997, 276, 2045–2047. [Google Scholar] [CrossRef] [Green Version]
- Kitada, T.; Asakawa, S.; Hattori, N.; Matsumine, H.; Yamamura, Y.; Minoshima, S.; Yokochi, M.; Mizuno, Y.; Shimizu, N. Mutations in the parkin gene cause autosomal recessive juvenile parkinsonism. Nature 1998, 392, 605–608. [Google Scholar] [CrossRef]
- Valente, E.M.; Bentivoglio, A.R.; Dixon, P.H.; Ferraris, A.; Ialongo, T.; Frontali, M.; Albanese, A.; Wood, N.W. Localization of a novel locus for autosomal recessive early-onset parkinsonism, PARK6, on human chromosome 1p35-p36. Am. J. Hum. Genet. 2001, 68, 895–900. [Google Scholar] [CrossRef] [Green Version]
- Bonifati, V.; Rizzu, P.; Squitieri, F.; Krieger, E.; Vanacore, N.; van Swieten, J.C.; Brice, A.; van Duijn, C.M.; Oostra, B.; Meco, G.; et al. DJ-1( PARK7), a novel gene for autosomal recessive, early onset parkinsonism. Neurol. Sci. 2003, 24, 159–160. [Google Scholar] [CrossRef] [Green Version]
- Zimprich, A.; Biskup, S.; Leitner, P.; Lichtner, P.; Farrer, M.; Lincoln, S.; Kachergus, J.; Hulihan, M.; Uitti, R.J.; Calne, D.B.; et al. Mutations in LRRK2 cause autosomal-dominant parkinsonism with pleomorphic pathology. Neuron 2004, 44, 601–607. [Google Scholar] [CrossRef] [Green Version]
- Hernandez, D.G.; Reed, X.; Singleton, A.B. Genetics in Parkinson disease: Mendelian versus non-Mendelian inheritance. J. Neurochem. 2016, 139, 59–74. [Google Scholar] [CrossRef] [PubMed]
- Lohmueller, K.E.; Pearce, C.L.; Pike, M.; Lander, E.S.; Hirschhorn, J.N. Meta-analysis of genetic association studies supports a contribution of common variants to susceptibility to common disease. Nat. Genet. 2003, 33, 177–182. [Google Scholar] [CrossRef]
- Simón-Sánchez, J.; Schulte, C.; Bras, J.M.; Sharma, M.; Gibbs, J.R.; Berg, D.; Paisan-Ruiz, C.; Lichtner, P.; Scholz, S.W.; Hernandez, D.G.; et al. Genome-wide association study reveals genetic risk underlying Parkinson’s disease. Nat. Genet. 2009, 41, 1308–1312. [Google Scholar] [CrossRef]
- Kara, E.; Xiromerisiou, G.; Spanaki, C.; Bozi, M.; Koutsis, G.; Panas, M.; Dardiotis, E.; Ralli, S.; Bras, J.; Letson, C.; et al. Assessment of Parkinson’s disease risk loci in Greece. Neurobiol. Aging 2014, 35, 442.e9–442.e16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Satake, W.; Nakabayashi, Y.; Mizuta, I.; Hirota, Y.; Ito, C.; Kubo, M.; Kawaguchi, T.; Tsunoda, T.; Watanabe, M.; Takeda, A.; et al. Genome-wide association study identifies common variants at four loci as genetic risk factors for Parkinson’s disease. Nat. Genet. 2009, 41, 1303–1307. [Google Scholar] [CrossRef]
- Nalls, M.A.; Plagnol, V.; Hernandez, D.G.; Sharma, M.; Sheerin, U.M.; Saad, M.; Simón-Sánchez, J.; Schulte, C.; Lesage, S.; Sveinbjörnsdóttir, S.; et al. Imputation of sequence variants for identification of genetic risks for Parkinson’s disease: A meta-analysis of genome-wide association studies. Lancet 2011, 377, 641–649. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nalls, M.A.; Pankratz, N.; Lill, C.M.; Do, C.B.; Hernandez, D.G.; Saad, M.; DeStefano, A.L.; Kara, E.; Bras, J.; Sharma, M.; et al. Large-scale meta-analysis of genome-wide association data identifies six new risk loci for Parkinson’s disease. Nat. Genet. 2014, 46, 989–993. [Google Scholar] [CrossRef]
- Chang, D.; Nalls, M.A.; Hallgrímsdóttir, I.B.; Hunkapiller, J.; van der Brug, M.; Cai, F.; Kerchner, G.A.; Ayalon, G.; Bingol, B.; Sheng, M.; et al. A meta-analysis of genome-wide association studies identifies 17 new Parkinson’s disease risk loci. Nat. Genet. 2017, 49, 1511–1516. [Google Scholar] [CrossRef]
- Nalls, M.A.; Blauwendraat, C.; Vallerga, C.L.; Heilbron, K.; Bandres-Ciga, S.; Chang, D.; Tan, M.; Kia, D.A.; Noyce, A.J.; Xue, A.; et al. Identification of novel risk loci, causal insights, and heritable risk for Parkinson’s disease: A meta-analysis of genome-wide association studies. Lancet Neurol. 2019, 18, 1091–1102. [Google Scholar] [CrossRef]
- Grenn, F.P.; Kim, J.J.; Makarious, M.B.; Iwaki, H.; Illarionova, A.; Brolin, K.; Kluss, J.H.; Schumacher-Schuh, A.F.; Leonard, H.; Faghri, F.; et al. The Parkinson’s Disease Genome-Wide Association Study Locus Browser. Mov. Disord. 2020. [Google Scholar] [CrossRef] [PubMed]
- Purcell, S.M.; Wray, N.R.; Stone, J.L.; Visscher, P.M.; O’Donovan, M.C.; Sullivan, P.F.; Sklar, P.; Consortium, I.S. Common polygenic variation contributes to risk of schizophrenia and bipolar disorder. Nature 2009, 460, 748–752. [Google Scholar] [CrossRef] [PubMed]
- Chaudhury, S.; Patel, T.; Barber, I.S.; Guetta-Baranes, T.; Brookes, K.J.; Chappell, S.; Turton, J.; Guerreiro, R.; Bras, J.; Hernandez, D.; et al. Polygenic risk score in postmortem diagnosed sporadic early-onset Alzheimer’s disease. Neurobiol. Aging 2018, 62, 244.e241–244.e248. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ibanez, L.; Dube, U.; Saef, B.; Budde, J.; Black, K.; Medvedeva, A.; del-Aguila, J.L.; Davis, A.A.; Perlmutter, J.S.; Harari, O.; et al. Parkinson disease polygenic risk score is associated with Parkinson disease status and age at onset but not with alpha-synuclein cerebrospinal fluid levels. BMC Neurol. 2017, 17, 198. [Google Scholar] [CrossRef] [PubMed]
- Escott-Price, V.; Nalls, M.A.; Morris, H.R.; Lubbe, S.; Brice, A.; Gasser, T.; Heutink, P.; Wood, N.W.; Hardy, J.; Singleton, A.B.; et al. Polygenic risk of Parkinson disease is correlated with disease age at onset. Ann. Neurol. 2015, 77, 582–591. [Google Scholar] [CrossRef] [Green Version]
- Paul, K.C.; Schulz, J.; Bronstein, J.M.; Lill, C.M.; Ritz, B.R. Association of Polygenic Risk Score With Cognitive Decline and Motor Progression in Parkinson Disease. JAMA Neurol. 2018, 75, 360–366. [Google Scholar] [CrossRef]
- Nalls, M.A.; McLean, C.Y.; Rick, J.; Eberly, S.; Hutten, S.J.; Gwinn, K.; Sutherland, M.; Martinez, M.; Heutink, P.; Williams, N.M.; et al. Diagnosis of Parkinson’s disease on the basis of clinical and genetic classification: A population-based modelling study. Lancet Neurol. 2015, 14, 1002–1009. [Google Scholar] [CrossRef] [Green Version]
- Crouch, D.J.M.; Bodmer, W.F. Polygenic inheritance, GWAS, polygenic risk scores, and the search for functional variants. Proc. Natl. Acad. Sci. USA 2020, 117, 18924–18933. [Google Scholar] [CrossRef]
- Torkamani, A.; Wineinger, N.E.; Topol, E.J. The personal and clinical utility of polygenic risk scores. Nat. Rev. Genet. 2018, 19, 581–590. [Google Scholar] [CrossRef]
- Chartier-Harlin, M.C.; Kachergus, J.; Roumier, C.; Mouroux, V.; Douay, X.; Lincoln, S.; Levecque, C.; Larvor, L.; Andrieux, J.; Hulihan, M.; et al. Alpha-synuclein locus duplication as a cause of familial Parkinson’s disease. Lancet 2004, 364, 1167–1169. [Google Scholar] [CrossRef]
- Singleton, A.B.; Farrer, M.; Johnson, J.; Singleton, A.; Hague, S.; Kachergus, J.; Hulihan, M.; Peuralinna, T.; Dutra, A.; Nussbaum, R.; et al. alpha-Synuclein locus triplication causes Parkinson’s disease. Science 2003, 302, 841. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blauwendraat, C.; Heilbron, K.; Vallerga, C.L.; Bandres-Ciga, S.; von Coelln, R.; Pihlstrøm, L.; Simón-Sánchez, J.; Schulte, C.; Sharma, M.; Krohn, L.; et al. Parkinson’s disease age at onset genome-wide association study: Defining heritability, genetic loci, and α-synuclein mechanisms. Mov. Disord. 2019, 34, 866–875. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Iwaki, H.; Blauwendraat, C.; Leonard, H.L.; Kim, J.J.; Liu, G.; Maple-Grødem, J.; Corvol, J.C.; Pihlstrøm, L.; van Nimwegen, M.; Hutten, S.J.; et al. Genomewide association study of Parkinson’s disease clinical biomarkers in 12 longitudinal patients’ cohorts. Mov. Disord. 2019, 34, 1839–1850. [Google Scholar] [CrossRef]
- Jacobs, B.M.; Belete, D.; Bestwick, J.; Blauwendraat, C.; Bandres-Ciga, S.; Heilbron, K.; Dobson, R.; Nalls, M.A.; Singleton, A.; Hardy, J.; et al. Parkinson’s disease determinants, prediction and gene-environment interactions in the UK Biobank. J. Neurol. Neurosurg. Psychiatry 2020, 91, 1046–1054. [Google Scholar] [CrossRef] [PubMed]
- Abeliovich, A.; Gitler, A.D. Defects in trafficking bridge Parkinson’s disease pathology and genetics. Nature 2016, 539, 207–216. [Google Scholar] [CrossRef]
- Bandres-Ciga, S.; Saez-Atienzar, S.; Bonet-Ponce, L.; Billingsley, K.; Vitale, D.; Blauwendraat, C.; Gibbs, J.R.; Pihlstrøm, L.; Gan-Or, Z.; Cookson, M.R.; et al. The endocytic membrane trafficking pathway plays a major role in the risk of Parkinson’s disease. Mov. Disord. 2019, 34, 460–468. [Google Scholar] [CrossRef]
- Billingsley, K.J.; Barbosa, I.A.; Bandrés-Ciga, S.; Quinn, J.P.; Bubb, V.J.; Deshpande, C.; Botia, J.A.; Reynolds, R.H.; Zhang, D.; Simpson, M.A.; et al. Mitochondria function associated genes contribute to Parkinson’s Disease risk and later age at onset. NPJ Parkinsons Dis. 2019, 5, 8. [Google Scholar] [CrossRef] [Green Version]
- Bandres-Ciga, S.; Saez-Atienzar, S.; Kim, J.J.; Makarious, M.B.; Faghri, F.; Diez-Fairen, M.; Iwaki, H.; Leonard, H.; Botia, J.; Ryten, M.; et al. Large-scale pathway specific polygenic risk and transcriptomic community network analysis identifies novel functional pathways in Parkinson disease. Acta Neuropathol. 2020, 140, 341–358. [Google Scholar] [CrossRef]
- Agarwal, D.; Sandor, C.; Volpato, V.; Caffrey, T.; Monzon-Sandoval, J.; Bowden, R.; Alegre-Abarrategui, J.; Wade-Martins, R.; Webber, C. A human single-cell atlas of the Substantia nigra reveals novel cell-specific pathways associated with the genetic risk of Parkinson’s disease and neuropsychiatric disorders. bioRxiv 2020. [Google Scholar] [CrossRef]
- Bryois, J.; Skene, N.G.; Hansen, T.F.; Kogelman, L.J.A.; Watson, H.J.; Liu, Z.; Brueggeman, L.; Breen, G.; Bulik, C.M.; Arenas, E.; et al. Genetic identification of cell types underlying brain complex traits yields insights into the etiology of Parkinson’s disease. Nat. Genet. 2020, 52, 482–493. [Google Scholar] [CrossRef]
- Wang, D.; Liu, S.; Warrell, J.; Won, H.; Shi, X.; Navarro, F.C.P.; Clarke, D.; Gu, M.; Emani, P.; Yang, Y.T.; et al. Comprehensive functional genomic resource and integrative model for the human brain. Science 2018, 362. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Won, H.; de la Torre-Ubieta, L.; Stein, J.L.; Parikshak, N.N.; Huang, J.; Opland, C.K.; Gandal, M.J.; Sutton, G.J.; Hormozdiari, F.; Lu, D.; et al. Chromosome conformation elucidates regulatory relationships in developing human brain. Nature 2016, 538, 523–527. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sey, N.Y.A.; Hu, B.; Mah, W.; Fauni, H.; McAfee, J.C.; Rajarajan, P.; Brennand, K.J.; Akbarian, S.; Won, H. A computational tool (H-MAGMA) for improved prediction of brain-disorder risk genes by incorporating brain chromatin interaction profiles. Nat. Neurosci. 2020, 23, 583–593. [Google Scholar] [CrossRef] [PubMed]
- Keo, A.; Mahfouz, A.; Ingrassia, A.M.T.; Meneboo, J.P.; Villenet, C.; Mutez, E.; Comptdaer, T.; Lelieveldt, B.P.F.; Figeac, M.; Chartier-Harlin, M.C.; et al. Transcriptomic signatures of brain regional vulnerability to Parkinson’s disease. Commun. Biol. 2020, 3, 101. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Zheng, Z.; Visscher, P.M.; Yang, J. Quantifying the mapping precision of genome-wide association studies using whole-genome sequencing data. Genome Biol. 2017, 18, 86. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, Z.; Zhang, F.; Hu, H.; Bakshi, A.; Robinson, M.R.; Powell, J.E.; Montgomery, G.W.; Goddard, M.E.; Wray, N.R.; Visscher, P.M.; et al. Integration of summary data from GWAS and eQTL studies predicts complex trait gene targets. Nat. Genet. 2016, 48, 481–487. [Google Scholar] [CrossRef] [PubMed]
- Cruts, M.; Gijselinck, I.; van der Zee, J.; Engelborghs, S.; Wils, H.; Pirici, D.; Rademakers, R.; Vandenberghe, R.; Dermaut, B.; Martin, J.J.; et al. Null mutations in progranulin cause ubiquitin-positive frontotemporal dementia linked to chromosome 17q21. Nature 2006, 442, 920–924. [Google Scholar] [CrossRef]
- Smith, K.R.; Damiano, J.; Franceschetti, S.; Carpenter, S.; Canafoglia, L.; Morbin, M.; Rossi, G.; Pareyson, D.; Mole, S.E.; Staropoli, J.F.; et al. Strikingly different clinicopathological phenotypes determined by progranulin-mutation dosage. Am. J. Hum. Genet. 2012, 90, 1102–1107. [Google Scholar] [CrossRef] [Green Version]
- Giambartolomei, C.; Zhenli Liu, J.; Zhang, W.; Hauberg, M.; Shi, H.; Boocock, J.; Pickrell, J.; Jaffe, A.E.; Pasaniuc, B.; Roussos, P.; et al. A Bayesian framework for multiple trait colocalization from summary association statistics. Bioinformatics 2018, 34, 2538–2545. [Google Scholar] [CrossRef] [Green Version]
- Kia, D.A.; Zhang, D.; Guelfi, S.; Manzoni, C.; Hubbard, L.; United; (UKBEC), K.B.E.C.; Disease, I.P.s.; (IPDGC), G.C.; Reynolds, R.H.; et al. Integration of eQTL and Parkinson’s disease GWAS data implicates 11 disease genes. bioRxiv 2019, 627216. [Google Scholar] [CrossRef] [Green Version]
- Beilina, A.; Rudenko, I.N.; Kaganovich, A.; Civiero, L.; Chau, H.; Kalia, S.K.; Kalia, L.V.; Lobbestael, E.; Chia, R.; Ndukwe, K.; et al. Unbiased screen for interactors of leucine-rich repeat kinase 2 supports a common pathway for sporadic and familial Parkinson disease. Proc. Natl. Acad. Sci. USA 2014, 111, 2626–2631. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fujimoto, T.; Kuwahara, T.; Eguchi, T.; Sakurai, M.; Komori, T.; Iwatsubo, T. Parkinson’s disease-associated mutant LRRK2 phosphorylates Rab7L1 and modifies trans-Golgi morphology. Biochem. Biophys. Res. Commun. 2018, 495, 1708–1715. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Bryant, N.; Kumaran, R.; Beilina, A.; Abeliovich, A.; Cookson, M.R.; West, A.B. LRRK2 phosphorylates membrane-bound Rabs and is activated by GTP-bound Rab7L1 to promote recruitment to the trans-Golgi network. Hum. Mol. Genet. 2018, 27, 385–395. [Google Scholar] [CrossRef] [PubMed]
- Purlyte, E.; Dhekne, H.S.; Sarhan, A.R.; Gomez, R.; Lis, P.; Wightman, M.; Martinez, T.N.; Tonelli, F.; Pfeffer, S.R.; Alessi, D.R. Rab29 activation of the Parkinson’s disease-associated LRRK2 kinase. EMBO J. 2018, 37, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Gusev, A.; Ko, A.; Shi, H.; Bhatia, G.; Chung, W.; Penninx, B.W.; Jansen, R.; de Geus, E.J.; Boomsma, D.I.; Wright, F.A.; et al. Integrative approaches for large-scale transcriptome-wide association studies. Nat. Genet. 2016, 48, 245–252. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.I.; Wong, G.; Humphrey, J.; Raj, T. Prioritizing Parkinson’s disease genes using population-scale transcriptomic data. Nat. Commun. 2019, 10, 994. [Google Scholar] [CrossRef] [Green Version]
- Catanesi, M.; d’Angelo, M.; Tupone, M.G.; Benedetti, E.; Giordano, A.; Castelli, V.; Cimini, A. MicroRNAs Dysregulation and Mitochondrial Dysfunction in Neurodegenerative Diseases. Int. J. Mol. Sci. 2020, 21. [Google Scholar] [CrossRef]
- Kern, F.; Fehlmann, T.; Violich, I.; Alsop, E.; Hutchins, E.; Kahraman, M.; Grammes, N.L.; Guimarães, P.; Backes, C.; Poston, K.; et al. Deep sncRNA-seq of the PPMI cohort to study Parkinson’s disease progression. bioRxiv 2020. [Google Scholar] [CrossRef]
- Ohnmacht, J.; May, P.; Sinkkonen, L.; Krüger, R. Missing heritability in Parkinson’s disease: The emerging role of non-coding genetic variation. J. Neural Transm. 2020, 127, 729–748. [Google Scholar] [CrossRef] [Green Version]
- Bandres-Ciga, S.; Diez-Fairen, M.; Kim, J.J.; Singleton, A.B. Genetics of Parkinson’s disease: An introspection of its journey towards precision medicine. Neurobiol. Dis. 2020, 137, 104782. [Google Scholar] [CrossRef]
- Sudmant, P.H.; Rausch, T.; Gardner, E.J.; Handsaker, R.E.; Abyzov, A.; Huddleston, J.; Zhang, Y.; Ye, K.; Jun, G.; Fritz, M.H.; et al. An integrated map of structural variation in 2,504 human genomes. Nature 2015, 526, 75–81. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jeffares, D.C.; Jolly, C.; Hoti, M.; Speed, D.; Shaw, L.; Rallis, C.; Balloux, F.; Dessimoz, C.; Bähler, J.; Sedlazeck, F.J. Transient structural variations have strong effects on quantitative traits and reproductive isolation in fission yeast. Nat. Commun. 2017, 8, 14061. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, L.; Zhao, X.; Benton, M.L.; Perumal, T.; Collins, R.L.; Hoffman, G.E.; Johnson, J.S.; Sloofman, L.; Wang, H.Z.; Stone, M.R.; et al. Functional annotation of rare structural variation in the human brain. Nat. Commun. 2020, 11, 2990. [Google Scholar] [CrossRef] [PubMed]
- Iafrate, A.J.; Feuk, L.; Rivera, M.N.; Listewnik, M.L.; Donahoe, P.K.; Qi, Y.; Scherer, S.W.; Lee, C. Detection of large-scale variation in the human genome. Nat. Genet. 2004, 36, 949–951. [Google Scholar] [CrossRef] [Green Version]
- Redon, R.; Ishikawa, S.; Fitch, K.R.; Feuk, L.; Perry, G.H.; Andrews, T.D.; Fiegler, H.; Shapero, M.H.; Carson, A.R.; Chen, W.; et al. Global variation in copy number in the human genome. Nature 2006, 444, 444–454. [Google Scholar] [CrossRef] [Green Version]
- Tuzun, E.; Sharp, A.J.; Bailey, J.A.; Kaul, R.; Morrison, V.A.; Pertz, L.M.; Haugen, E.; Hayden, H.; Albertson, D.; Pinkel, D.; et al. Fine-scale structural variation of the human genome. Nat. Genet. 2005, 37, 727–732. [Google Scholar] [CrossRef]
- Kidd, J.M.; Cooper, G.M.; Donahue, W.F.; Hayden, H.S.; Sampas, N.; Graves, T.; Hansen, N.; Teague, B.; Alkan, C.; Antonacci, F.; et al. Mapping and sequencing of structural variation from eight human genomes. Nature 2008, 453, 56–64. [Google Scholar] [CrossRef]
- Conrad, D.F.; Pinto, D.; Redon, R.; Feuk, L.; Gokcumen, O.; Zhang, Y.; Aerts, J.; Andrews, T.D.; Barnes, C.; Campbell, P.; et al. Origins and functional impact of copy number variation in the human genome. Nature 2010, 464, 704–712. [Google Scholar] [CrossRef] [Green Version]
- Pang, A.W.; MacDonald, J.R.; Pinto, D.; Wei, J.; Rafiq, M.A.; Conrad, D.F.; Park, H.; Hurles, M.E.; Lee, C.; Venter, J.C.; et al. Towards a comprehensive structural variation map of an individual human genome. Genome Biol. 2010, 11, R52. [Google Scholar] [CrossRef] [Green Version]
- Bandrés-Ciga, S.; Ruz, C.; Barrero, F.J.; Escamilla-Sevilla, F.; Pelegrina, J.; Vives, F.; Duran, R. Structural genomic variations and Parkinson’s disease. Minerva Med. 2017, 108, 438–447. [Google Scholar] [CrossRef]
- La Cognata, V.; Morello, G.; D’Agata, V.; Cavallaro, S. Copy number variability in Parkinson’s disease: Assembling the puzzle through a systems biology approach. Hum. Genet. 2017, 136, 13–37. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ibáñez, P.; Lesage, S.; Janin, S.; Lohmann, E.; Durif, F.; Destée, A.; Bonnet, A.M.; Brefel-Courbon, C.; Heath, S.; Zelenika, D.; et al. Alpha-synuclein gene rearrangements in dominantly inherited parkinsonism: Frequency, phenotype, and mechanisms. Arch. Neurol. 2009, 66, 102–108. [Google Scholar] [CrossRef] [PubMed]
- Farrer, M.; Kachergus, J.; Forno, L.; Lincoln, S.; Wang, D.S.; Hulihan, M.; Maraganore, D.; Gwinn-Hardy, K.; Wszolek, Z.; Dickson, D.; et al. Comparison of kindreds with parkinsonism and alpha-synuclein genomic multiplications. Ann. Neurol. 2004, 55, 174–179. [Google Scholar] [CrossRef]
- Sekine, T.; Kagaya, H.; Funayama, M.; Li, Y.; Yoshino, H.; Tomiyama, H.; Hattori, N. Clinical course of the first Asian family with Parkinsonism related to SNCA triplication. Mov. Disord. 2010, 25, 2871–2875. [Google Scholar] [CrossRef]
- Keyser, R.J.; Lombard, D.; Veikondis, R.; Carr, J.; Bardien, S. Analysis of exon dosage using MLPA in South African Parkinson’s disease patients. Neurogenetics 2010, 11, 305–312. [Google Scholar] [CrossRef]
- Kojovic, M.; Sheerin, U.M.; Rubio-Agusti, I.; Saha, A.; Bras, J.; Gibbons, V.; Palmer, R.; Houlden, H.; Hardy, J.; Wood, N.W.; et al. Young-onset parkinsonism due to homozygous duplication of α-synuclein in a consanguineous family. Mov. Disord. 2012, 27, 1827–1829. [Google Scholar] [CrossRef] [Green Version]
- Olgiati, S.; Thomas, A.; Quadri, M.; Breedveld, G.J.; Graafland, J.; Eussen, H.; Douben, H.; de Klein, A.; Onofrj, M.; Bonifati, V. Early-onset parkinsonism caused by alpha-synuclein gene triplication: Clinical and genetic findings in a novel family. Parkinsonism Relat. Disord. 2015, 21, 981–986. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferese, R.; Modugno, N.; Campopiano, R.; Santilli, M.; Zampatti, S.; Giardina, E.; Nardone, A.; Postorivo, D.; Fornai, F.; Novelli, G.; et al. Four Copies of SNCA Responsible for Autosomal Dominant Parkinson’s Disease in Two Italian Siblings. Parkinsons Dis. 2015, 2015, 546462. [Google Scholar] [CrossRef] [Green Version]
- Byers, B.; Cord, B.; Nguyen, H.N.; Schüle, B.; Fenno, L.; Lee, P.C.; Deisseroth, K.; Langston, J.W.; Pera, R.R.; Palmer, T.D. SNCA triplication Parkinson’s patient’s iPSC-derived DA neurons accumulate α-synuclein and are susceptible to oxidative stress. PLoS ONE 2011, 6, e26159. [Google Scholar] [CrossRef]
- Fuchs, J.; Nilsson, C.; Kachergus, J.; Munz, M.; Larsson, E.M.; Schüle, B.; Langston, J.W.; Middleton, F.A.; Ross, O.A.; Hulihan, M.; et al. Phenotypic variation in a large Swedish pedigree due to SNCA duplication and triplication. Neurology 2007, 68, 916–922. [Google Scholar] [CrossRef]
- Konno, T.; Ross, O.A.; Puschmann, A.; Dickson, D.W.; Wszolek, Z.K. Autosomal dominant Parkinson’s disease caused by SNCA duplications. Parkinsonism Relat. Disord. 2016, 22, S1–S6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ibáñez, P.; Bonnet, A.M.; Débarges, B.; Lohmann, E.; Tison, F.; Pollak, P.; Agid, Y.; Dürr, A.; Brice, A. Causal relation between alpha-synuclein gene duplication and familial Parkinson’s disease. Lancet 2004, 364, 1169–1171. [Google Scholar] [CrossRef]
- Nishioka, K.; Hayashi, S.; Farrer, M.J.; Singleton, A.B.; Yoshino, H.; Imai, H.; Kitami, T.; Sato, K.; Kuroda, R.; Tomiyama, H.; et al. Clinical heterogeneity of alpha-synuclein gene duplication in Parkinson’s disease. Ann. Neurol. 2006, 59, 298–309. [Google Scholar] [CrossRef] [PubMed]
- Nishioka, K.; Ross, O.A.; Ishii, K.; Kachergus, J.M.; Ishiwata, K.; Kitagawa, M.; Kono, S.; Obi, T.; Mizoguchi, K.; Inoue, Y.; et al. Expanding the clinical phenotype of SNCA duplication carriers. Mov. Disord. 2009, 24, 1811–1819. [Google Scholar] [CrossRef] [PubMed]
- Ikeuchi, T.; Kakita, A.; Shiga, A.; Kasuga, K.; Kaneko, H.; Tan, C.-F.; Idezuka, J.; Wakabayashi, K.; Onodera, O.; Iwatsubo, T.; et al. Patients Homozygous and Heterozygous for SNCA Duplication in a Family With Parkinsonism and Dementia. Arch. Neurol. 2008, 65, 514–519. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nuytemans, K.; Meeus, B.; Crosiers, D.; Brouwers, N.; Goossens, D.; Engelborghs, S.; Pals, P.; Pickut, B.; Van den Broeck, M.; Corsmit, E.; et al. Relative contribution of simple mutations vs. copy number variations in five Parkinson disease genes in the Belgian population. Hum. Mutat 2009, 30, 1054–1061. [Google Scholar] [CrossRef]
- Sironi, F.; Trotta, L.; Antonini, A.; Zini, M.; Ciccone, R.; della Mina, E.; Meucci, N.; Sacilotto, G.; Primignani, P.; Brambilla, T.; et al. alpha-Synuclein multiplication analysis in Italian familial Parkinson disease. Parkinsonism Relat. Disord. 2010, 16, 228–231. [Google Scholar] [CrossRef] [PubMed]
- Bonifati, V.; Rohé, C.F.; Breedveld, G.J.; Fabrizio, E.; De Mari, M.; Tassorelli, C.; Tavella, A.; Marconi, R.; Nicholl, D.J.; Chien, H.F.; et al. Early-onset parkinsonism associated with PINK1 mutations: Frequency, genotypes, and phenotypes. Neurology 2005, 65, 87–95. [Google Scholar] [CrossRef]
- Bragg, D.C.; Mangkalaphiban, K.; Vaine, C.A.; Kulkarni, N.J.; Shin, D.; Yadav, R.; Dhakal, J.; Ton, M.-L.; Cheng, A.; Russo, C.T.; et al. Disease onset in X-linked dystonia-parkinsonism correlates with expansion of a hexameric repeat within an SVA retrotransposon in TAF1. Proc. Natl. Acad. Sci. USA 2017, 114, E11020–E11028. [Google Scholar] [CrossRef] [Green Version]
- Makino, S.; Kaji, R.; Ando, S.; Tomizawa, M.; Yasuno, K.; Goto, S.; Matsumoto, S.; Tabuena, M.D.; Maranon, E.; Dantes, M.; et al. Reduced neuron-specific expression of the TAF1 gene is associated with X-linked dystonia-parkinsonism. Am. J. Hum. Genet. 2007, 80, 393–406. [Google Scholar] [CrossRef] [Green Version]
- Aneichyk, T.; Hendriks, W.T.; Yadav, R.; Shin, D.; Gao, D.; Vaine, C.A.; Collins, R.L.; Domingo, A.; Currall, B.; Stortchevoi, A.; et al. Dissecting the Causal Mechanism of X-Linked Dystonia-Parkinsonism by Integrating Genome and Transcriptome Assembly. Cell 2018, 172, 897–909. [Google Scholar] [CrossRef] [Green Version]
- McDonald-McGinn, D.M.; Sullivan, K.E.; Marino, B.; Philip, N.; Swillen, A.; Vorstman, J.A.; Zackai, E.H.; Emanuel, B.S.; Vermeesch, J.R.; Morrow, B.E.; et al. 22q11.2 deletion syndrome. Nat. Rev. Dis. Primers 2015, 1, 15071. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krahn, L.E.; Maraganore, D.M.; Michels, V.V. Childhood-onset schizophrenia associated with parkinsonism in a patient with a microdeletion of chromosome 22. Mayo Clin. Proc. 1998, 73, 956–959. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Booij, J.; van Amelsvoort, T.; Boot, E. Co-occurrence of early-onset Parkinson disease and 22q11.2 deletion syndrome: Potential role for dopamine transporter imaging. Am. J. Med. Genet. 2010, 152A, 2937–2938. [Google Scholar] [CrossRef] [PubMed]
- Butcher, N.J.; Kiehl, T.R.; Hazrati, L.N.; Chow, E.W.; Rogaeva, E.; Lang, A.E.; Bassett, A.S. Association between early-onset Parkinson disease and 22q11.2 deletion syndrome: Identification of a novel genetic form of Parkinson disease and its clinical implications. JAMA Neurol. 2013, 70, 1359–1366. [Google Scholar] [CrossRef] [PubMed]
- Mok, K.Y.; Sheerin, U.; Simón-Sánchez, J.; Salaka, A.; Chester, L.; Escott-Price, V.; Mantripragada, K.; Doherty, K.M.; Noyce, A.J.; Mencacci, N.E.; et al. Deletions at 22q11.2 in idiopathic Parkinson’s disease: A combined analysis of genome-wide association data. Lancet Neurol. 2016, 15, 585–596. [Google Scholar] [CrossRef] [Green Version]
- Sebat, J.; Lakshmi, B.; Malhotra, D.; Troge, J.; Lese-Martin, C.; Walsh, T.; Yamrom, B.; Yoon, S.; Krasnitz, A.; Kendall, J.; et al. Strong association of de novo copy number mutations with autism. Science 2007, 316, 445–449. [Google Scholar] [CrossRef] [Green Version]
- Weiss, L.A.; Shen, Y.; Korn, J.M.; Arking, D.E.; Miller, D.T.; Fossdal, R.; Saemundsen, E.; Stefansson, H.; Ferreira, M.A.; Green, T.; et al. Association between microdeletion and microduplication at 16p11.2 and autism. New Engl. J. Med. 2008, 358, 667–675. [Google Scholar] [CrossRef] [Green Version]
- Turner, T.N.; Coe, B.P.; Dickel, D.E.; Hoekzema, K.; Nelson, B.J.; Zody, M.C.; Kronenberg, Z.N.; Hormozdiari, F.; Raja, A.; Pennacchio, L.A.; et al. Genomic Patterns of De Novo Mutation in Simplex Autism. Cell 2017, 171, 710–722.e712. [Google Scholar] [CrossRef] [Green Version]
- Walsh, T.; McClellan, J.M.; McCarthy, S.E.; Addington, A.M.; Pierce, S.B.; Cooper, G.M.; Nord, A.S.; Kusenda, M.; Malhotra, D.; Bhandari, A.; et al. Rare structural variants disrupt multiple genes in neurodevelopmental pathways in schizophrenia. Science 2008, 320, 539–543. [Google Scholar] [CrossRef] [Green Version]
- Consortium, I.S. Rare chromosomal deletions and duplications increase risk of schizophrenia. Nature 2008, 455, 237–241. [Google Scholar] [CrossRef] [Green Version]
- McCarthy, S.E.; Makarov, V.; Kirov, G.; Addington, A.M.; McClellan, J.; Yoon, S.; Perkins, D.O.; Dickel, D.E.; Kusenda, M.; Krastoshevsky, O.; et al. Microduplications of 16p11.2 are associated with schizophrenia. Nat. Genet. 2009, 41, 1223–1227. [Google Scholar] [CrossRef]
- Marshall, C.R.; Howrigan, D.P.; Merico, D.; Thiruvahindrapuram, B.; Wu, W.; Greer, D.S.; Antaki, D.; Shetty, A.; Holmans, P.A.; Pinto, D.; et al. Contribution of copy number variants to schizophrenia from a genome-wide study of 41,321 subjects. Nat. Genet. 2017, 49, 27–35. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Collins, R.L.; Brand, H.; Karczewski, K.J.; Zhao, X.; Alföldi, J.; Francioli, L.C.; Khera, A.V.; Lowther, C.; Gauthier, L.D.; Wang, H.; et al. A structural variation reference for medical and population genetics. Nature 2020, 581, 444–451. [Google Scholar] [CrossRef]
- Mahmoud, M.; Gobet, N.; Cruz-Dávalos, D.I.; Mounier, N.; Dessimoz, C.; Sedlazeck, F.J. Structural variant calling: The long and the short of it. Genome Biol. 2019, 1, 246. [Google Scholar] [CrossRef] [PubMed]


© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hall, A.; Bandres-Ciga, S.; Diez-Fairen, M.; Quinn, J.P.; Billingsley, K.J. Genetic Risk Profiling in Parkinson’s Disease and Utilizing Genetics to Gain Insight into Disease-Related Biological Pathways. Int. J. Mol. Sci. 2020, 21, 7332. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms21197332
Hall A, Bandres-Ciga S, Diez-Fairen M, Quinn JP, Billingsley KJ. Genetic Risk Profiling in Parkinson’s Disease and Utilizing Genetics to Gain Insight into Disease-Related Biological Pathways. International Journal of Molecular Sciences. 2020; 21(19):7332. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms21197332
Chicago/Turabian StyleHall, Ashley, Sara Bandres-Ciga, Monica Diez-Fairen, John P. Quinn, and Kimberley J. Billingsley. 2020. "Genetic Risk Profiling in Parkinson’s Disease and Utilizing Genetics to Gain Insight into Disease-Related Biological Pathways" International Journal of Molecular Sciences 21, no. 19: 7332. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms21197332