
Roles of Physicochemical and Structural Properties of RNA-Binding Proteins in Predicting the Activities of Trans-Acting Splicing Factors with Machine Learning



Abstract
:1. Introduction
2. Results and Discussion
2.1. Comparing the Performance of Different Machine Learning Approaches
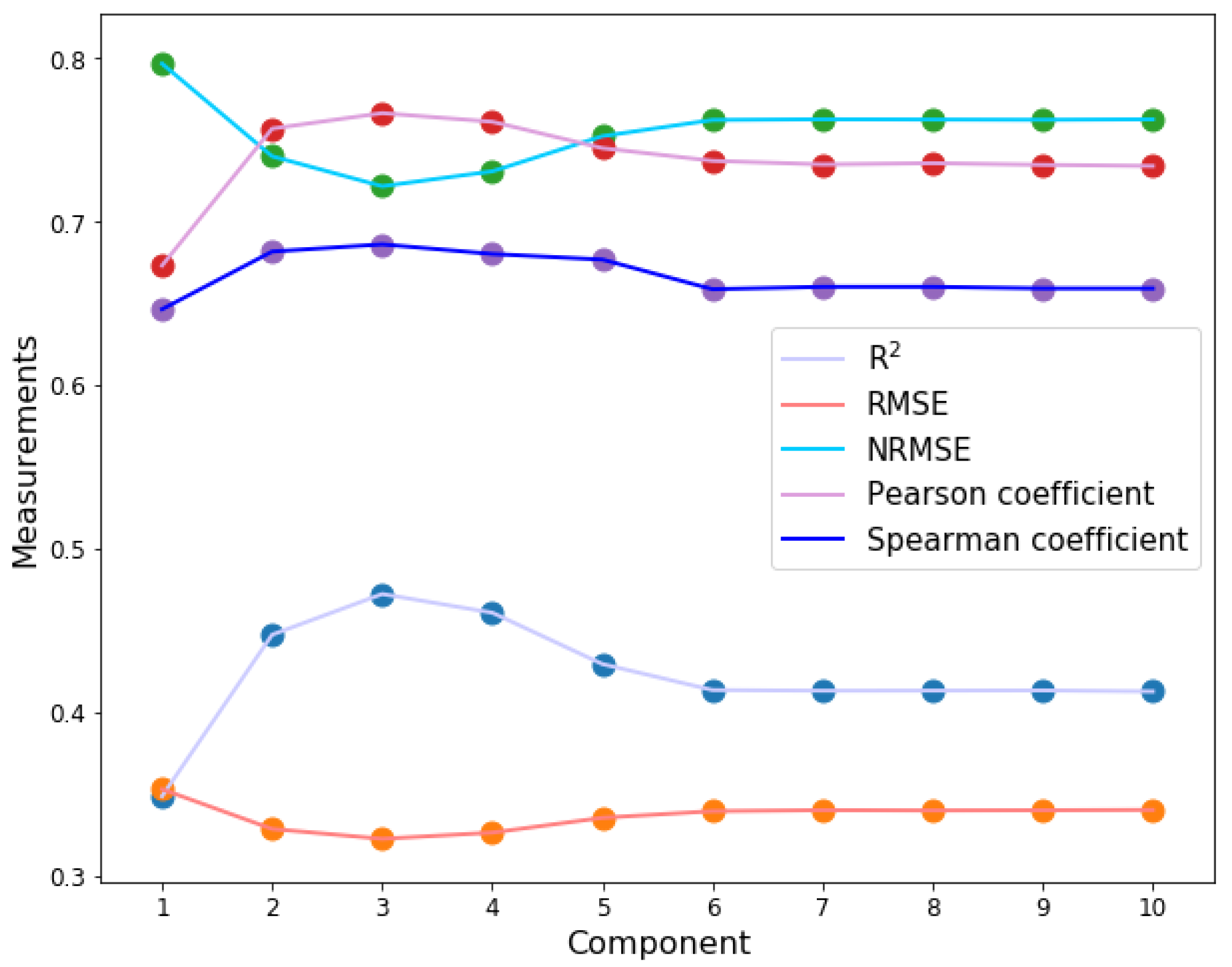
2.2. Determining the Parameters of PLSR for an Optimal Performance
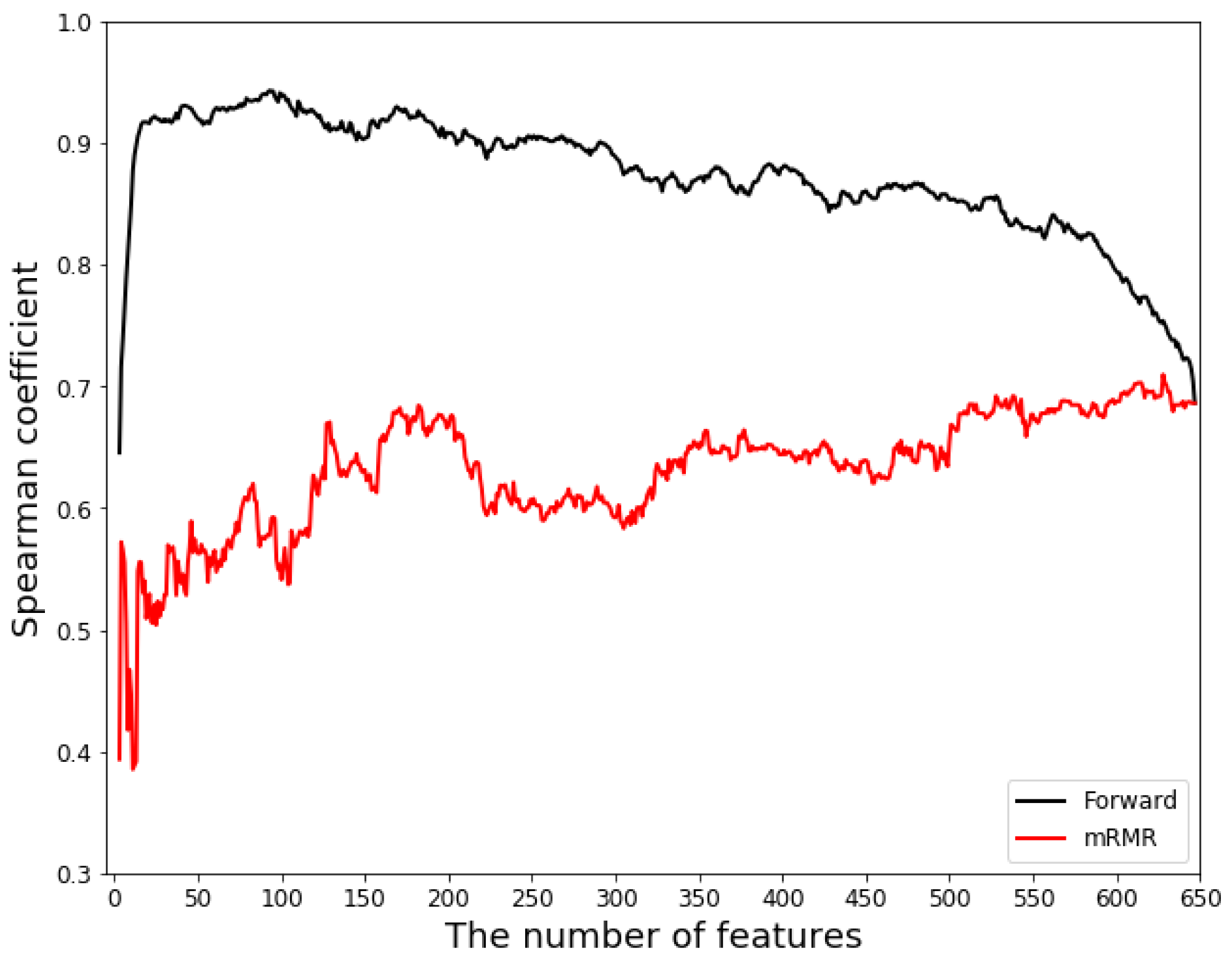
2.3. Feature Selection with mRMR Method
2.4. Feature Selection with Forward Feature Searching Strategy
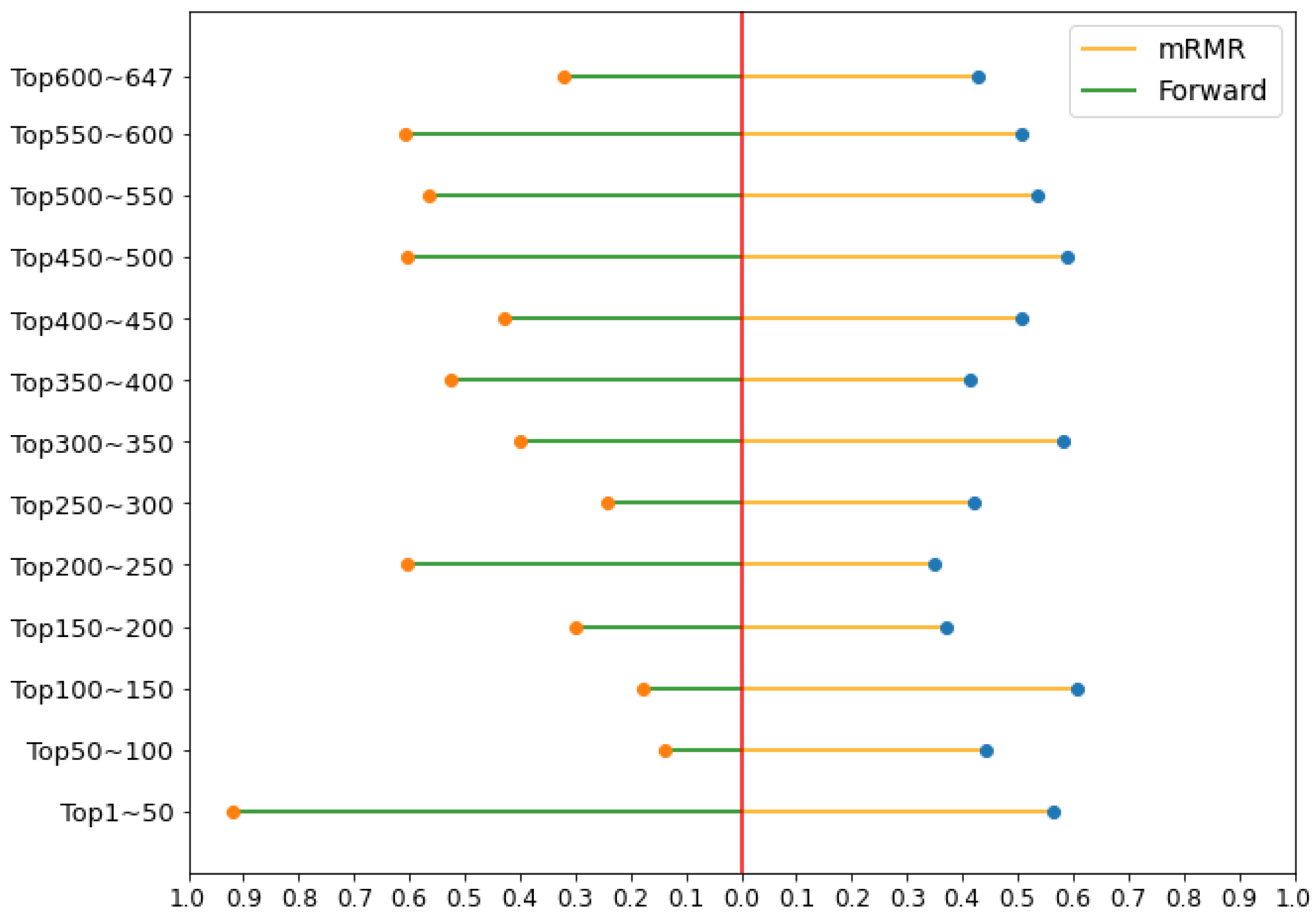
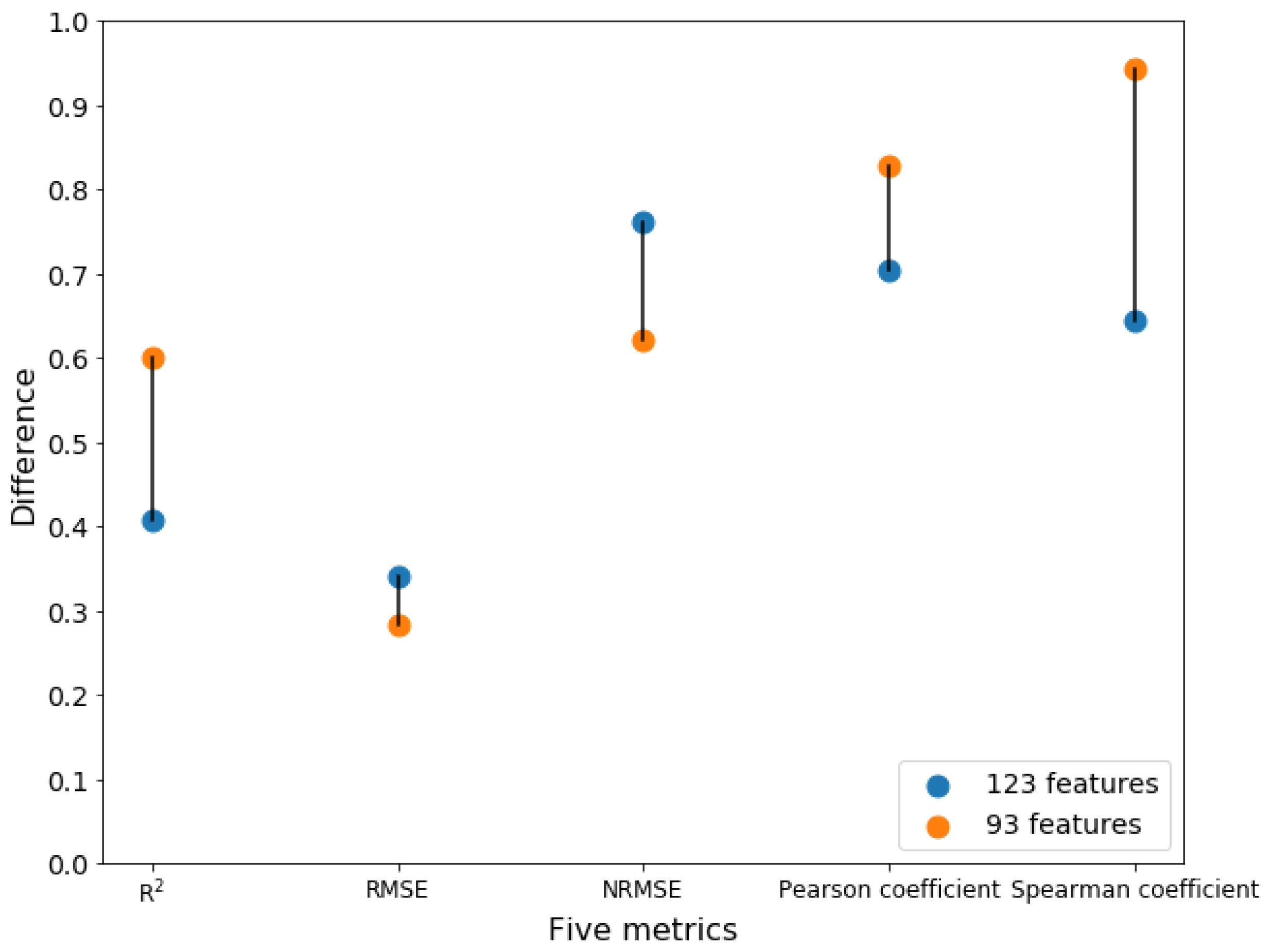
2.5. Comparison between mRMR Method and Forward Feature Searching Strategy
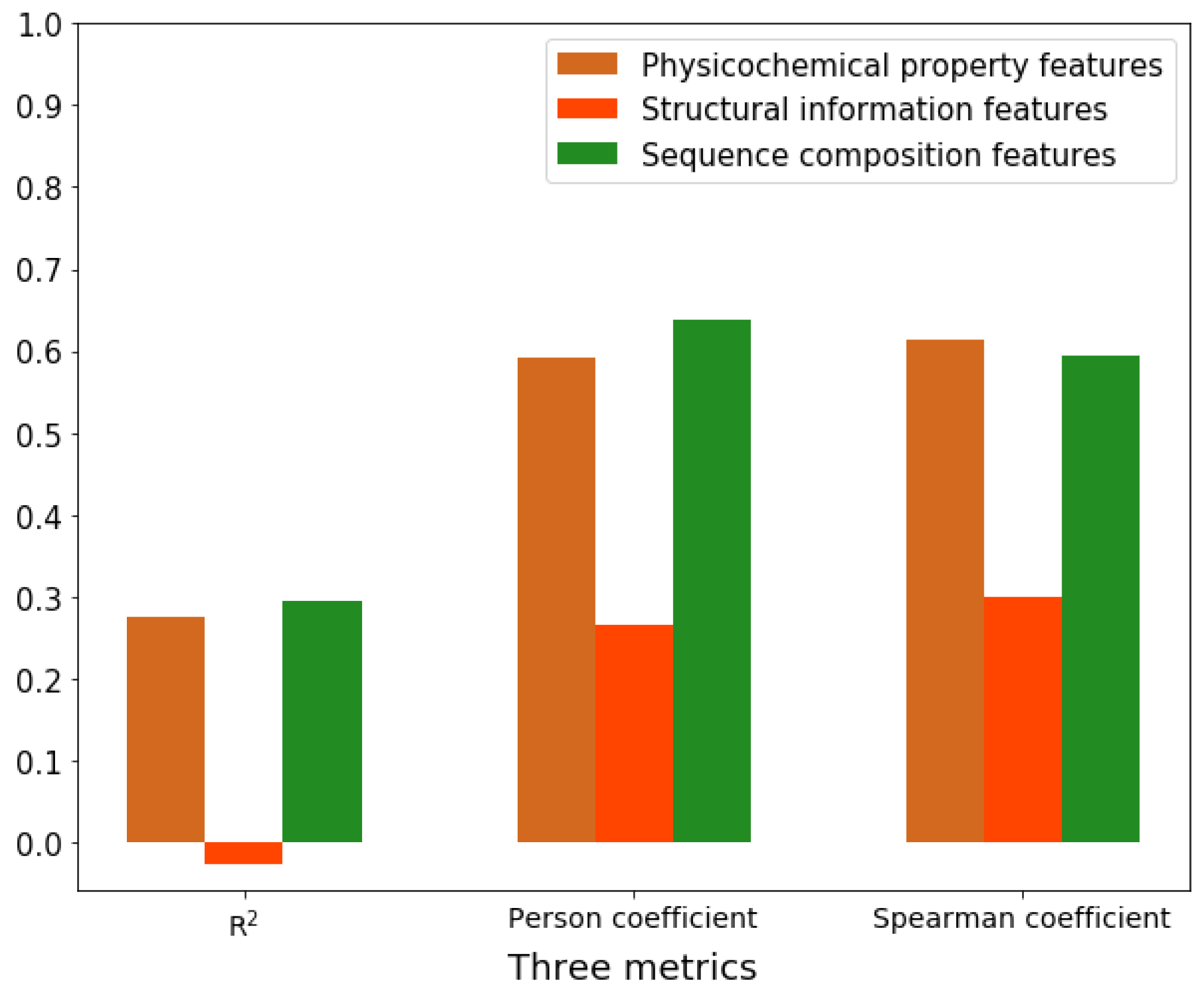
2.6. Feature Importance Analysis
2.7. Comparison with the Existing Model
3. Materials and Methods
3.1. Data Collection
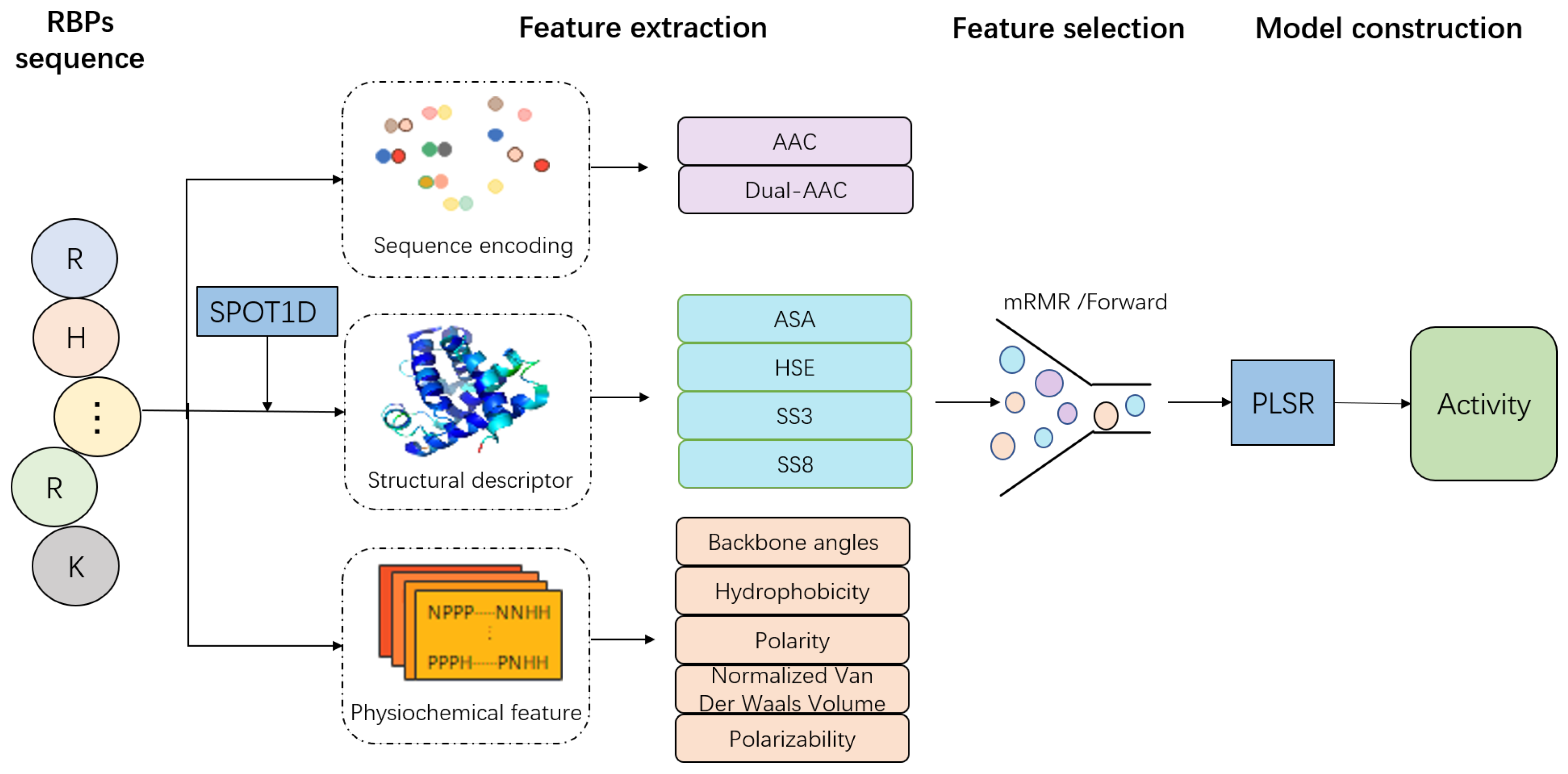
3.2. Feature Extraction
3.2.1. Sequence Composition Features
3.2.2. Physicochemical Property Features
3.2.3. Structural Descriptor
3.3. Feature Normalization
3.4. Feature Selection
3.5. Model Training
3.6. Cross-Validation
3.7. Performance Evaluation
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AS | Alternative Splicing |
| RBPs | RNA-binding proteins |
| mRMR | Minimum Redundancy, Maximum Relevance |
| PLSR | Partial Least Squares Regression |
| SVMR | Support vector machine regression |
| RFR | Random forest regression |
| SR | Splicing-regulatory |
| AAC | Amino acid composition |
| Dual-AAC | Dual amino acid composition |
| SS3 | 3-state secondary structural elements |
| SS8 | 8-state secondary structural elements |
| ASA | Solvent accessible surface area |
| HSE | Half-sphere exposure |
| CN | Contact numbers |
References
- Mao, M.; Hu, Y.; Yang, Y.; Qian, Y.; Wei, H.; Fan, W.; Yang, Y.; Li, X.; Wang, Z. Modeling and predicting the activities of trans-acting splicing factors with machine learning. Cell Syst. 2018, 7, 510–520. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Modrek, B.; Lee, C. A genomic view of alternative splicing. Nat. Genet. 2002, 30, 13–19. [Google Scholar] [CrossRef] [PubMed]
- Scotti, M.M.; Swanson, M.S. RNA mis-splicing in disease. Nat. Rev. Genet. 2016, 17, 19–32. [Google Scholar] [CrossRef] [PubMed]
- Matera, A.G.; Wang, Z. A day in the life of the spliceosome. Nat. Rev. Mol. Cell Biol. 2014, 15, 108–121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dominguez, D.; Tsai, Y.H.; Weatheritt, R.; Wang, Y.; Blencowe, B.J.; Wang, Z. An extensive program of periodic alternative splicing linked to cell cycle progression. Elife 2016, 5, e10288. [Google Scholar] [CrossRef]
- Fu, X.D.; Ares, M. Context-dependent control of alternative splicing by RNA-binding proteins. Nat. Rev. Genet. 2014, 15, 689–701. [Google Scholar] [CrossRef]
- Wang, E.T.; Ward, A.J.; Cherone, J.M.; Giudice, J.; Wang, T.T.; Treacy, D.J.; Lambert, N.J.; Freese, P.; Saxena, T.; Cooper, T.A.; et al. Antagonistic regulation of mRNA expression and splicing by CELF and MBNL proteins. Genome Res. 2015, 25, 858–871. [Google Scholar] [CrossRef] [Green Version]
- Ince-Dunn, G.; Okano, H.J.; Jensen, K.B.; Park, W.Y.; Zhong, R.; Ule, J.; Mele, A.; Fak, J.J.; Yang, C.; Zhang, C.; et al. Neuronal Elav-like (Hu) proteins regulate RNA splicing and abundance to control glutamate levels and neuronal excitability. Neuron 2012, 75, 1067–1080. [Google Scholar] [CrossRef] [Green Version]
- Bhate, A.; Parker, D.J.; Bebee, T.W.; Ahn, J.; Arif, W.; Rashan, E.H.; Chorghade, S.; Chau, A.; Lee, J.H.; Anakk, S.; et al. ESRP2 controls an adult splicing programme in hepatocytes to support postnatal liver maturation. Nat. Commun. 2015, 6, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Martinez, N.M.; Pan, Q.; Cole, B.S.; Yarosh, C.A.; Babcock, G.A.; Heyd, F.; Zhu, W.; Ajith, S.; Blencowe, B.J.; Lynch, K.W. Alternative splicing networks regulated by signaling in human T cells. Rna 2012, 18, 1029–1040. [Google Scholar] [CrossRef] [Green Version]
- Baralle, F.E.; Giudice, J. Alternative splicing as a regulator of development and tissue identity. Nat. Rev. Mol. Cell Biol. 2017, 18, 437–451. [Google Scholar] [CrossRef] [PubMed]
- Gao, D.; Morini, E.; Salani, M.; Krauson, A.J.; Chekuri, A.; Sharma, N.; Ragavendran, A.; Erdin, S.; Logan, E.M.; Li, W.; et al. A deep learning approach to identify gene targets of a therapeutic for human splicing disorders. Nat. Commun. 2021, 12, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Kalsotra, A.; Xiao, X.; Ward, A.J.; Castle, J.C.; Johnson, J.M.; Burge, C.B.; Cooper, T.A. A postnatal switch of CELF and MBNL proteins reprograms alternative splicing in the developing heart. Proc. Natl. Acad. Sci. USA 2008, 105, 20333–20338. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Quesnel-Vallières, M.; Irimia, M.; Cordes, S.P.; Blencowe, B.J. Essential roles for the splicing regulator nSR100/SRRM4 during nervous system development. Genes Dev. 2015, 29, 746–759. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Xiao, X.; Zhang, J.; Choudhury, R.; Robertson, A.; Li, K.; Ma, M.; Burge, C.B.; Wang, Z. A complex network of factors with overlapping affinities represses splicing through intronic elements. Nat. Struct. Mol. Biol. 2013, 20, 36–45. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naik, N.; Rallapalli, Y.; Krishna, M.; Vellara, A.S.; KShetty, D.; Patil, V.; Hameed, B.Z.; Paul, R.; Prabhu, N.; Rai, B.P.; et al. Demystifying the Advancements of Big Data Analytics in Medical Diagnosis: An Overview. Eng. Sci. 2021, 19. [Google Scholar] [CrossRef]
- Feng, P.; Xiao, A.; Fang, M.; Wan, F.; Li, S.; Lang, P.; Zhao, D.; Zeng, J. A machine learning-based framework for modeling transcription elongation. Proc. Natl. Acad. Sci. USA 2021, 118, 5699–5732. [Google Scholar] [CrossRef]
- Chiba, S.; Lim, K.R.Q.; Sheri, N.; Anwar, S.; Erkut, E.; Shah, M.N.A.; Aslesh, T.; Woo, S.; Sheikh, O.; Maruyama, R.; et al. eSkip-Finder: A machine learning-based web application and database to identify the optimal sequences of antisense oligonucleotides for exon skipping. Nucleic Acids Res. 2021, 49, W193–W198. [Google Scholar] [CrossRef]
- Gerstberger, S.; Hafner, M.; Tuschl, T. A census of human RNA-binding proteins. Nat. Rev. Genet. 2014, 15, 829–845. [Google Scholar] [CrossRef]
- Wang, Y.; Cheong, C.G.; Hall, T.M.T.; Wang, Z. Engineering splicing factors with designed specificities. Nat. Methods 2009, 6, 825–830. [Google Scholar] [CrossRef]
- Fairbrother, W.G.; Yeh, R.F.; Sharp, P.A.; Burge, C.B. Predictive identification of exonic splicing enhancers in human genes. Science 2002, 297, 1007–1013. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xiong, H.Y.; Alipanahi, B.; Lee, L.J.; Bretschneider, H.; Merico, D.; Yuen, R.K.; Hua, Y.; Gueroussov, S.; Najafabadi, H.S.; Hughes, T.R.; et al. The human splicing code reveals new insights into the genetic determinants of disease. Science 2015, 347, 1254806. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rosenberg, A.B.; Patwardhan, R.P.; Shendure, J.; Seelig, G. Learning the sequence determinants of alternative splicing from millions of random sequences. Cell 2015, 163, 698–711. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Scalzitti, N.; Kress, A.; Orhand, R.; Weber, T.; Moulinier, L.; Jeannin-Girardon, A.; Collet, P.; Poch, O.; Thompson, J.D. Spliceator: Multi-species splice site prediction using convolutional neural networks. BMC Bioinform. 2021, 22, 561. [Google Scholar] [CrossRef]
- Desmet, F.O.; Hamroun, D.; Lalande, M.; Collod-Béroud, G.; Claustres, M.; Béroud, C. Human Splicing Finder: An online bioinformatics tool to predict splicing signals. Nucleic Acids Res. 2009, 37, e67. [Google Scholar] [CrossRef] [Green Version]
- Jaganathan, K.; Panagiotopoulou, S.K.; McRae, J.F.; Darbandi, S.F.; Knowles, D.; Li, Y.I.; Kosmicki, J.A.; Arbelaez, J.; Cui, W.; Schwartz, G.B.; et al. Predicting splicing from primary sequence with deep learning. Cell 2019, 176, 535–548. [Google Scholar] [CrossRef] [Green Version]
- Reese, M.G.; Eeckman, F.H.; Kulp, D.; Haussler, D. Improved splice site detection in Genie. J. Comput. Biol. 1997, 4, 311–323. [Google Scholar] [CrossRef]
- Hebsgaard, S.M.; Korning, P.G.; Tolstrup, N.; Engelbrecht, J.; Rouzé, P.; Brunak, S. Splice site prediction in Arabidopsis thaliana pre-mRNA by combining local and global sequence information. Nucleic Acids Res. 1996, 24, 3439–3452. [Google Scholar] [CrossRef] [Green Version]
- Korkuć, P.; Walther, D. Physicochemical characteristics of structurally determined metabolite-protein and drug-protein binding events with respect to binding specificity. Front. Mol. Biosci. 2015, 2, 51. [Google Scholar] [CrossRef] [Green Version]
- Qiu, W.R.; Jiang, S.Y.; Xu, Z.C.; Xiao, X.; Chou, K.C. iRNAm5C-PseDNC: Identifying RNA 5-methylcytosine sites by incorporating physical-chemical properties into pseudo dinucleotide composition. Oncotarget 2017, 8, 41178. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Xiao, X.; Yu, D.J.; Jia, J.; Qiu, W.R.; Chou, K.C. pRNAm-PC: Predicting N6-methyladenosine sites in RNA sequences via physical–chemical properties. Anal. Biochem. 2016, 497, 60–67. [Google Scholar] [CrossRef] [PubMed]
- Ladunga, I. PHYSEAN: PHYsical SEquence ANalysis for the identification of protein domains on the basis of physical and chemical properties of amino acids. Bioinformatics 1999, 15, 1028–1038. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Negi, S.S.; Braun, W. Statistical analysis of physical-chemical properties and prediction of protein-protein interfaces. J. Mol. Model. 2007, 13, 1157–1167. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, Z.C.; Wang, P.; Qiu, W.R.; Xiao, X. iss-pc: Identifying splicing sites via physical-chemical properties using deep sparse auto-encoder. Sci. Rep. 2017, 7, 1–12. [Google Scholar] [CrossRef]
- Cléry, A.; Krepl, M.; Nguyen, C.K.; Moursy, A.; Jorjani, H.; Katsantoni, M.; Okoniewski, M.; Mittal, N.; Zavolan, M.; Sponer, J.; et al. Structure of SRSF1 RRM1 bound to RNA reveals an unexpected bimodal mode of interaction and explains its involvement in SMN1 exon7 splicing. Nat. Commun. 2021, 12, 1–12. [Google Scholar] [CrossRef]
- Ding, Y.S.; Zhang, T.L.; Chou, K.C. Prediction of protein structure classes with pseudo amino acid composition and fuzzy support vector machine network. Protein Pept. Lett. 2007, 14, 811–815. [Google Scholar] [CrossRef]
- Zhu, L.; Davari, M.D.; Li, W. Recent advances in the prediction of protein structural classes: Feature descriptors and machine learning algorithms. Crystals 2021, 11, 324. [Google Scholar] [CrossRef]
- Liu, B.; Wang, S.; Wang, X. DNA binding protein identification by combining pseudo amino acid composition and profile-based protein representation. Sci. Rep. 2015, 5, 15479. [Google Scholar] [CrossRef] [Green Version]
- Diao, Y.; Ma, D.; Wen, Z.; Yin, J.; Xiang, J.; Li, M. Using pseudo amino acid composition to predict transmembrane regions in protein: Cellular automata and Lempel-Ziv complexity. Amino Acids 2008, 34, 111–117. [Google Scholar] [CrossRef]
- Lin, D.; Zhang, Q.; Xiao, L.; Huang, Y.; Yang, Z.; Wu, Z.; Tu, Z.; Qin, W.; Chen, H.; Wu, D.; et al. Effects of ultrasound on functional properties, structure and glycation properties of proteins: A review. Crit. Rev. Food Sci. Nutr. 2021, 61, 2471–2481. [Google Scholar] [CrossRef]
- Bonetta, R.; Valentino, G. Machine learning techniques for protein function prediction. Proteins: Struct. Funct. Bioinform. 2020, 88, 397–413. [Google Scholar] [CrossRef] [PubMed]
- Block, P.; Paern, J.; Huellermeier, E.; Sanschagrin, P.; Sotriffer, C.A.; Klebe, G. Physicochemical descriptors to discriminate protein–protein interactions in permanent and transient complexes selected by means of machine learning algorithms. PROTEINS: Struct. Funct. Bioinform. 2006, 65, 607–622. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Wang, M.; Zhang, P.; Huang, T. Classification of cancers based on copy number variation landscapes. Biochim. Et Biophys. Acta (BBA)-Gen. Subj. 2016, 1860, 2750–2755. [Google Scholar] [CrossRef] [PubMed]
- Kato, A.; Nakai, S. Hydrophobicity determined by a fluorescence probe method and its correlation with surface properties of proteins. Biochim. Et Biophys. Acta (BBA)-Protein Struct. 1980, 624, 13–20. [Google Scholar] [CrossRef]
- Wimley, W.C.; White, S.H. Experimentally determined hydrophobicity scale for proteins at membrane interfaces. Nat. Struct. Biol. 1996, 3, 842–848. [Google Scholar] [CrossRef] [PubMed]
- Bigelow, C.C. On the average hydrophobicity of proteins and the relation between it and protein structure. J. Theor. Biol. 1967, 16, 187–211. [Google Scholar] [CrossRef]
- Hanson, J.; Paliwal, K.; Litfin, T.; Yang, Y.; Zhou, Y. Improving prediction of protein secondary structure, backbone angles, solvent accessibility and contact numbers by using predicted contact maps and an ensemble of recurrent and residual convolutional neural networks. Bioinformatics 2019, 35, 2403–2410. [Google Scholar] [CrossRef]
- Manavalan, B.; Basith, S.; Shin, T.H.; Lee, D.Y.; Wei, L.; Lee, G. 4mCpred-EL: An ensemble learning framework for identification of DNA N4-methylcytosine sites in the mouse genome. Cells 2019, 8, 1332. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Xu, C.; Huang, J.; Liu, W.; Zhang, L.; Wan, W.; Tao, H.; Li, L.; Lin, S.; Harrison, A.; et al. Prediction and identification of the effectors of heterotrimeric G proteins in rice (Oryza sativa L.). Briefings Bioinform. 2017, 18, 270–278. [Google Scholar]
- Chen, Z.; Zhou, Y.; Song, J.; Zhang, Z. hCKSAAP_UbSite: Improved prediction of human ubiquitination sites by exploiting amino acid pattern and properties. Biochim. Et Biophys. Acta (BBA)-Proteins Proteom. 2013, 1834, 1461–1467. [Google Scholar] [CrossRef]
- Wang, X.B.; Wu, L.Y.; Wang, Y.C.; Deng, N.Y. Prediction of palmitoylation sites using the composition of k-spaced amino acid pairs. Protein Eng. Des. Sel. 2009, 22, 707–712. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Yang, B.; An, Y.; Marquez-Lago, T.; Leier, A.; Wilksch, J.; Hong, Q.; Zhang, Y.; Hayashida, M.; Akutsu, T.; et al. Systematic analysis and prediction of type IV secreted effector proteins by machine learning approaches. Briefings Bioinform. 2019, 20, 931–951. [Google Scholar] [CrossRef] [PubMed]
- Dubchak, I.; Muchnik, I.; Holbrook, S.R.; Kim, S.H. Prediction of protein folding class using global description of amino acid sequence. Proc. Natl. Acad. Sci. USA 1995, 92, 8700–8704. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dubchak, I.; Muchnik, I.; Mayor, C.; Dralyuk, I.; Kim, S.H. Recognition of a protein fold in the context of the SCOP classification. Proteins Struct. Funct. Bioinform. 1999, 35, 401–407. [Google Scholar] [CrossRef]
- Li, W.; Lin, K.; Feng, K.; Cai, Y. Prediction of protein structural classes using hybrid properties. Mol. Divers. 2008, 12, 171–179. [Google Scholar] [CrossRef] [Green Version]
- Gnad, F.; Ren, S.; Cox, J.; Olsen, J.V.; Macek, B.; Oroshi, M.; Mann, M. PHOSIDA (phosphorylation site database): Management, structural and evolutionary investigation, and prediction of phosphosites. Genome Biol. 2007, 8, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Mizianty, M.J.; Stach, W.; Chen, K.; Kedarisetti, K.D.; Disfani, F.M.; Kurgan, L. Improved sequence-based prediction of disordered regions with multilayer fusion of multiple information sources. Bioinformatics 2010, 26, i489–i496. [Google Scholar] [CrossRef] [Green Version]
- Bellman, R. Dynamic programming. Science 1966, 153, 34–37. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Ni, Q.; Chen, L. A feature and algorithm selection method for improving the prediction of protein structural class. Comb. Chem. High Throughput Screen. 2017, 20, 612–621. [Google Scholar] [CrossRef]
- Li, B.Q.; Huang, T.; Liu, L.; Cai, Y.D.; Chou, K.C. Identification of colorectal cancer related genes with mRMR and shortest path in protein-protein interaction network. PLoS ONE 2012, 7, e33393. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- You, Z.H.; Zhu, L.; Zheng, C.H.; Yu, H.J.; Deng, S.P.; Ji, Z. Prediction of protein-protein interactions from amino acid sequences using a novel multi-scale continuous and discontinuous feature set. BMC Bioinform. 2014, 15, S9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Ding, C.; Li, T. Gene selection algorithm by combining reliefF and mRMR. BMC Genom. 2008, 9, S27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, B.Q.; Hu, L.L.; Niu, S.; Cai, Y.D.; Chou, K.C. Predict and analyze S-nitrosylation modification sites with the mRMR and IFS approaches. J. Proteom. 2012, 75, 1654–1665. [Google Scholar] [CrossRef]
- Wold, S.; Sjöström, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Höskuldsson, A. PLS regression methods. J. Chemom. 1988, 2, 211–228. [Google Scholar] [CrossRef]
- Wang, Y.; Boysen, R.I.; Wood, B.R.; Kansiz, M.; McNaughton, D.; Hearn, M.T. Determination of the secondary structure of proteins in different environments by FTIR-ATR spectroscopy and PLS regression. Biopolym. Orig. Res. Biomol. 2008, 89, 895–905. [Google Scholar] [CrossRef]
- Tenenhaus, A.; Guillemot, V.; Gidrol, X.; Frouin, V. Gene association networks from microarray data using a regularized estimation of partial correlation based on PLS regression. IEEE/ACM Trans. Comput. Biol. Bioinform. 2008, 7, 251–262. [Google Scholar] [CrossRef]
- Roman, M.; Wrobel, T.P.; Panek, A.; Efeoglu, E.; Wiltowska-Zuber, J.; Paluszkiewicz, C.; Byrne, H.J.; Kwiatek, W.M. Exploring subcellular responses of prostate cancer cells to X-ray exposure by Raman mapping. Sci. Rep. 2019, 9, 8715. [Google Scholar] [CrossRef]
- Chakraborty, S. Use of partial least squares improves the efficacy of removing unwanted variability in differential expression analyses based on RNA-Seq data. Genomics 2019, 111, 893–898. [Google Scholar] [CrossRef]
- Kamboj, U.; Guha, P.; Mishra, S. Comparison of PLSR, MLR, SVM regression methods for determination of crude protein and carbohydrate content in stored wheat using near Infrared spectroscopy. Mater. Today Proc. 2022, 48, 576–582. [Google Scholar] [CrossRef]
- Zeng, W.; Zhang, D.; Fang, Y.; Wu, J.; Huang, J. Comparison of partial least square regression, support vector machine, and deep-learning techniques for estimating soil salinity from hyperspectral data. J. Appl. Remote Sens. 2018, 12, 1–16. [Google Scholar] [CrossRef]
- Naguib, I.A.; Abdelaleem, E.A.; Hassan, E.S.; Ali, N.W.; Gamal, M. Partial least squares and linear support vector regression chemometric models for analysis of Norfloxacin and Tinidazole with Tinidazole impurity. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 239, 118513. [Google Scholar] [CrossRef]
- Fernández-Habas, J.; Cañada, M.C.; Moreno, A.M.G.; Leal-Murillo, J.R.; González-Dugo, M.P.; Oar, B.A.; Gómez-Giráldez, P.J.; Fernández-Rebollo, P. Estimating pasture quality of Mediterranean grasslands using hyperspectral narrow bands from field spectroscopy by Random Forest and PLS regressions. Comput. Electron. Agric. 2022, 192, 106614. [Google Scholar] [CrossRef]
- Chou, K.C. Progress in protein structural class prediction and its impact to bioinformatics and proteomics. Curr. Protein Pept. Sci. 2005, 6, 423–436. [Google Scholar] [CrossRef]
- Kawashima, S.; Kanehisa, M. AAindex: Amino acid index database. Nucleic Acids Res. 2000, 28, 374. [Google Scholar] [CrossRef] [PubMed]
- Kawashima, S.; Pokarowski, P.; Pokarowska, M.; Kolinski, A.; Katayama, T.; Kanehisa, M. AAindex: Amino acid index database, progress report 2008. Nucleic Acids Res. 2007, 36, D202–D205. [Google Scholar] [CrossRef] [Green Version]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A.; et al. Highly accurate protein structure prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef]
- Baek, M.; DiMaio, F.; Anishchenko, I.; Dauparas, J.; Ovchinnikov, S.; Lee, G.R.; Wang, J.; Cong, Q.; Kinch, L.N.; Schaeffer, R.D.; et al. Accurate prediction of protein structures and interactions using a three-track neural network. Science 2021, 373, 871–876. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition. Adv. Comput. 1993, 37, 119–166. [Google Scholar]
- Dayhoff, J.E.; DeLeo, J.M. Artificial neural networks: Opening the black box. Cancer Interdiscip. Int. J. Am. Cancer Soc. 2001, 91, 1615–1635. [Google Scholar] [CrossRef]
- Musunuri, B.; Shetty, S.; Shetty, D.K.; Vanahalli, M.K.; Pradhan, A.; Naik, N.; Paul, R. Acute-on-chronic liver failure mortality prediction using an artificial neural network. Eng. Sci. 2021, 15, 187–196. [Google Scholar] [CrossRef]
- Xu, J.; Li, H. Adarank: A boosting algorithm for information retrieval. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 391–398. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Order | Name | Descriptions | Spearman |
|---|---|---|---|
| 1 | Backbone angle_tau-3th | the measurement of the residue-wise torsion | - |
| 2 | Hydrophobicity_distrib-ution_H-0.0 | the first distribution value for H | - |
| 3 | Polarity_composition_P | the percentage of physiochemical property P | 0.65 |
| 4 | Dual-AAC_GT | the percentage of dual amino acid GT | 0.72 |
| 5 | Dual-AAC_HK | the percentage of dual amino acid HK | 0.74 |
| 6 | Dual-AAC_KK | the percentage of dual amino acid KK | 0.76 |
| 7 | Dual-AAC_FN | the percentage of dual amino acid FN | 0.79 |
| 8 | Dual-AAC_HY | the percentage of dual amino acid HY | 0.81 |
| 9 | Dual-AAC_TA | the percentage of dual amino acid TA | 0.83 |
| 10 | Dual-AAC_RT | the percentage of dual amino acid RT | 0.85 |
| 11 | Dual-AAC_TT | the percentage of dual amino acid TT | 0.88 |
| 12 | SS8_Dual_GG | the percentage of dual G | 0.89 |
| 13 | Dual-AAC_AA | the percentage of dual amino acid AA | 0.90 |
| 14 | Dual-AAC_DP | the percentage of dual amino acid DP | 0.91 |
| 15 | Dual-AAC_IY | the percentage of dual amino acid IY | 0.91 |
| 16 | Dual-AAC_YQ | the percentage of dual amino acid YQ | 0.92 |
| 17 | Dual-AAC_VH | the percentage of dual amino acid VH | 0.92 |
| 18 | SS8_distribution_C-1.0 | the fifth distribution of coil in SS8 | 0.92 |
| 19 | SS3_distribution_C-1.0 | the fifth distribution of coil in SS3 | 0.92 |
| 20 | Hydrophobicity_distrib-ution_N-1.0 | the fifth distribution of N | 0.92 |
| 21 | Dual-AAC_CG | the percentage of dual amino acid CG | 0.92 |
| 22 | Dual-AAC_CE | the percentage of dual amino acid CE | 0.92 |
| 23 | Dual-AAC_WS | the percentage of dual amino acid WS | 0.92 |
| 24 | SS8_Dual_GS | the percentage of pair G and high-curvature loop S | 0.92 |
| Feature Type | Overview of the Features |
|---|---|
| Amino acid composition | 20 |
| Dual amino acid composition | 400 |
| Hydrophobicity | 21 |
| Normalized Van Der Waal volume | 21 |
| Polarity | 21 |
| Polarizability | 21 |
| SS3 | 36 |
| SS8 | 136 |
| Others (ASA, HSE—up and down, CN and backbone angles) | 24 |
| Total | 700 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, L.; Li, W. Roles of Physicochemical and Structural Properties of RNA-Binding Proteins in Predicting the Activities of Trans-Acting Splicing Factors with Machine Learning. Int. J. Mol. Sci. 2022, 23, 4426. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms23084426
Zhu L, Li W. Roles of Physicochemical and Structural Properties of RNA-Binding Proteins in Predicting the Activities of Trans-Acting Splicing Factors with Machine Learning. International Journal of Molecular Sciences. 2022; 23(8):4426. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms23084426
Chicago/Turabian StyleZhu, Lin, and Wenjin Li. 2022. "Roles of Physicochemical and Structural Properties of RNA-Binding Proteins in Predicting the Activities of Trans-Acting Splicing Factors with Machine Learning" International Journal of Molecular Sciences 23, no. 8: 4426. https://0-doi-org.brum.beds.ac.uk/10.3390/ijms23084426