A Novel Approach to Working Memory Training Based on Robotics and AI


Department of Electronics Engineering, Pontificia Universidad Javeriana, Cra. 7 No. 40-62, Bogotá 110231, Colombia
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Information 2019, 10(11), 350; https://0-doi-org.brum.beds.ac.uk/10.3390/info10110350
Submission received: 28 September 2019
/
Revised: 4 November 2019
/
Accepted: 8 November 2019
/
Published: 12 November 2019
(This article belongs to the Section Information Applications)
Abstract
:Working memory is an important function for human cognition since several day-to-day activities are related to it, such as remembering a direction or developing a mental calculation. Unfortunately, working memory deficiencies affect performance in work or education related activities, mainly due to lack of concentration, and, with the goal to improve this, many software applications have been developed. However, sometimes the user ends up bored with these games and drops out easily. To cope with this, our work explores the use of intelligent robotics and dynamic difficulty adjustment mechanisms to develop a novel working memory training system. The proposed system, based on the Nao robotic platform, is composed of three main components: First, the N-back task allows stimulating the working memory by remembering visual sequences. Second, a BDI model implements an intelligent agent for decision-making during the progress of the game. Third, a fuzzy controller, as a dynamic difficulty adjustment system, generates customized levels according to the user. The experimental results of our system, when compared to a computer-based implementation of the N-back game, show a significant improvement on the performance of the user in the game, which might relate to an improvement in their working memory. Additionally, by providing a friendly and interactive interface, the participants have reported a more immersive and better game experience when using the robotic-based system.
1. Introduction
Nowadays, there are evident difficulties in the learning process of students, especially due to lack of attention, which sometimes is related to a poor short-term memory capacity, and, in that scenario, Working Memory (WM) plays a fundamental role. WM is responsible for keeping, managing and using the information during a short time, as well as for integrating knowledge to long-term memory [1]. Therefore, WM is paramount in activities such as reading comprehension, mental arithmetic and manage distractions.
Researchers from psychological studies have identified that children or teenagers with a limited WM tend to have a poor academic performance, presenting problems, such as withholding information, forgetting instructions, dissipating in the execution of tasks and inattention [2]. In addition, WM performance is compromised with age, since distraction becomes higher in adults [3]. According to Pugin et al. [4], WM training has demonstrated immediate and long-term effects on cognitive performance in children. In [5], the results show an improvement in fluid intelligence and processing speed tasks in adults after training the WM.
To cope with some of these problems, for several decades, the field of education has been incorporating new tools and technologies that favor the student’s learning processes, facilitate the acquisition of knowledge and mediate the transmission of information. These developments, in particular human-machine interfaces, are focused on achieving meaningful learning through interactive motivational strategies that in turn improve their cognitive process. As part of these initiatives, gamification applied to education is one of the strongest fields of innovation.
Experiences of educational gamification can be defined as environments that enhance learning processes based on the use of a game. These environments are effective because they awaken the student’s interest, curiosity and creativity. A human-machine interface generates immersion and interaction in the learning process, becoming a challenging task for customizing the learning process of the student. This customization means the possibility that an individual acquires knowledge through experience and experimentation (active learning) linked to situations or concrete facts of daily life. With that in mind, several games have been developed that aim to improve cognitive abilities, while also avoiding frustration, anxiety or boredom [6].
An interesting example of the combination between gamification and human-machine interfaces is robotics. Research about educational robotics has demonstrated that children and teenagers learn in the same way and sometimes better with robots [7]. Students achieve greater concentration and minimize downtime because those platforms are attractive and interesting to them.
Robots offer a concrete and tangible way to understand complex and abstract concepts and phenomena. Robot-based activities provide instant feedback that leads students to inquire for themselves and figure out how to solve the problems they are facing with the robots. Other special features that educational robotics provides are the ability to attract and maintain the attention and interest of students in the learning experience [8]. After reviewing the existing literature and related work, it was possible to identify that the WM problem has not been treated with new technological advances such as robotics and artificial intelligence.
Consequently, a robotic system is proposed as a novel way to develop a WM training game. The main contribution of our work is the development of a robotic-based system that is controlled by artificial intelligence algorithms, in order to provide a custom game experience to users, and, perhaps, contribute to the training process of WM. The user–robot interaction is through dialogue and the use of external devices that are able to sense and give feedback during the training.
The remainder of this paper is organized as follows. Section 2 presents a brief review of the related work. Section 3 introduces the proposed system. Section 4 describes the used methodology. Section 5 elaborates on the experimental setup and results. Section 6 presents the conclusions and future work.
2. Related Work
In this section, we present the most relevant work related to educational robotics, working memory, Belief–Desire–Intention (BDI) intelligent agents, and dynamic difficulty adjustment (DDA) systems.
2.1. Educational Robotics
Robotics has been introduced in different fields such as education. According to Brown and Howard [9], it was possible to engage children during high-demand cognitive tasks by using robotic-based engagement methods. This proposal was tested in a math quiz, reducing the completion time. Furthermore, in [7], the authors presented a robotic-learning system to motivate students to learn more, achieving positive effects.
Robotic systems have been used in schools [10] and at home [11] for STEM (Science, Technology, Engineering and Mathematics) education, promoting curiosity in science and engineering. Robotics provides important interactions with the user during an educational process, and, based on this, our proposal tries to emulate the aforementioned characteristics to obtain a useful robotic-based learning system.
2.2. Working Memory and the N-back Task
Working memory (WM) is developed mainly in early stages, so most of the research initiatives have been focused on young individuals. According to Gutiérrez-Martínez and Ramos [2], the academic performance of a child or teenager can be predicted depending on the WM. They used an amplitude test with high school students to analyze the correlation between WM and school scores. However, some research has also been performed with adults [12], showing that the WM training increased the cerebral cortex density of dopamine D1 receptors that mediate feelings of euphoria and reward.
The N-back task is a paradigm for evaluating and training the WM. In this test, the subject receives a sequence of stimuli that she can perceive through her senses. The user must recall the stimulus that was shown N steps before, but also remember a new stimulus. The N value will keep on increasing, which means the person needs to remember more and more stimuli as the game progresses. This task is recommended for experimental research of WM processes [13].
In [1], the authors mentioned that it is possible to improve the fluid intelligence (Gf) through WM training. Gf refers to the ability to cope with new situations regardless of prior knowledge. The N-back task was used and the authors figured out that the gain in intelligence depends directly on the amount of training.
In [6], the authors proved again that the N-back task is a good methodology to develop games for memory training. Based on this, in [14], a game based on N-back with a kinesthetic modality is proposed. The authors implemented a computer-based game with external devices so that users can perform physical movements during the training. However, to our knowledge, there is no robotic-based system oriented to train WM, so our proposal develops this new alternative.
2.3. BDI Intelligent Agents
There is no universal definition of what an intelligent agent is, but a good attempt can be found in [15], where the authors defined an agent as a computer system in a specific environment, capable of taking autonomous actions in order to meet its objectives. The Belief–Desire–Intention (BDI) architecture is a particular methodology for developing agents, based on a model of human reasoning. This paradigm has been successful in different applications, because it reduces the human complex behavior to a very simple motivational model.
The main application of the BDI architecture is the development of intelligent agents that interact in real, complex and changing environments. This model was used to solve planning and decision-making problems, through the development of a high-level reasoning agent for the control of robots [16,17,18].
BDI models have also been used for human-robot interaction. In [19], the authors implemented a motivational agent that acts as a companion for children. In addition, the work in [20,21] presents well suited implementations of robotic systems for educational contexts.
The system proposed in this work uses the BDI approach to generate an agent capable of developing a customized memory training game, which takes advantage of the integration of decision-making tasks.
2.4. DDA Systems
Dynamic difficulty adjustment (DDA) systems were developed with the goal of adjusting the parameters, scenarios or behaviors of computer games. The main objective of these systems is to keep the user interested in the game and avoid frustrations or desertions when facing game challenges [22].
DDA systems have been applied to several famous games. In [23], the authors presented an approach based on neural networks for creating game opponents for Pac-Man, which is used to dynamically adjust the game difficulty to the player’s skill level. In [24], a fuzzy logic controller was implemented for DotA2, which adjusts the different game parameters depending on the user’s abilities.
These systems have also been used to develop games applied to other fields. The work in [25] presents a DDA system based on an evolutionary algorithm for a game on rehabilitation robotics. The system is used to change some parameters depending on the user’s performance. Another application is presented in [26], where a fuzzy neuro-adaptive inference system was used to balance a memory game. Users reached higher levels when compared to the classic approach. In our work, we present an extension of this approach, but we also include a human-robot interaction component.
3. Proposed System
Several memory games have been proposed with the goal to improve cognitive skills. However, most of the approaches are not interesting for the users, hence the challenge is to offer a more attractive tool to train working memory through the use of new technologies, which may avoid boredom or frustration, or even abandonment. In this section, we present a general overview of our proposal, a robotic system for memory training based on the N-back task.
3.1. Components
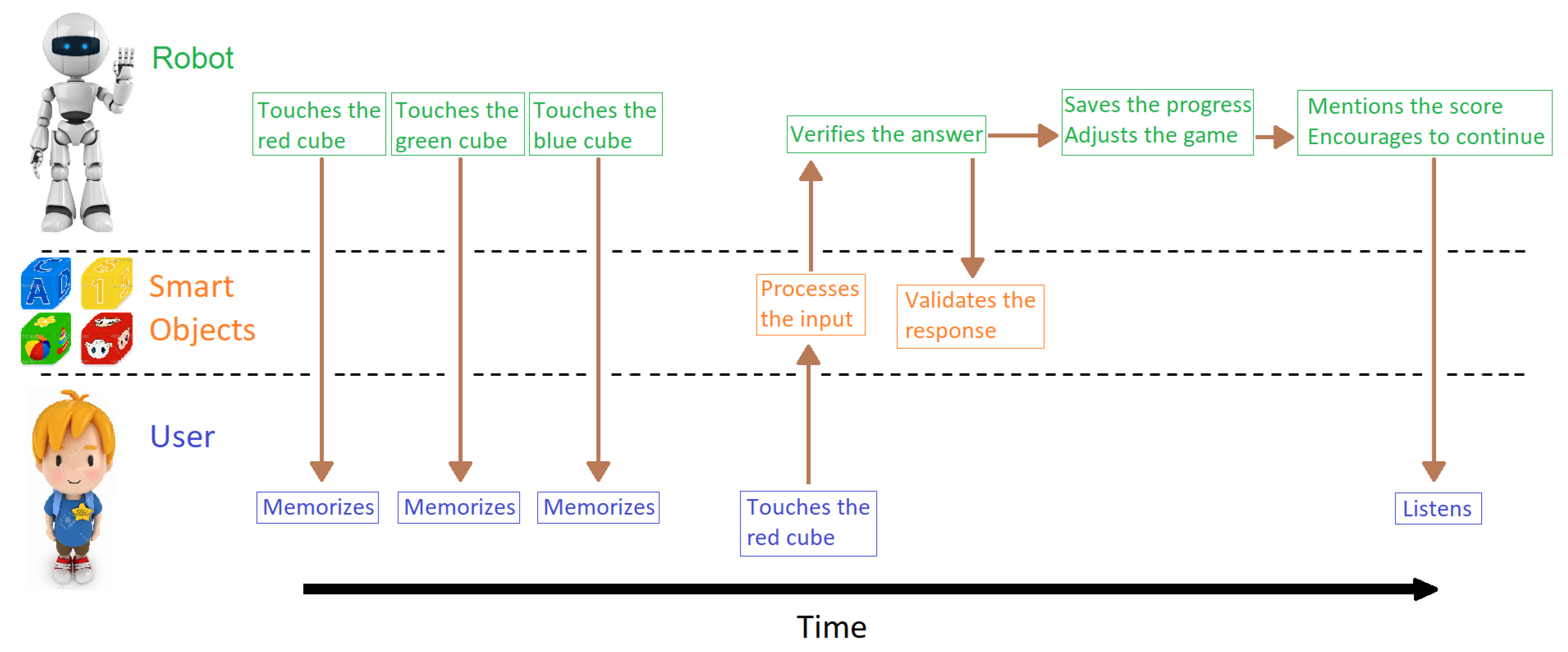
Figure 1 shows a representation of the environment of the proposed system. Following a context-aware approach [27], three different factors must be considered:
- User: Obviously the user/student is the center of our system. The user can receive instructions and feedback from the robot, and physically interact with the smart objects (electronic cubes) to provide inputs to the system.
- Robot: A Nao platform running our artificial intelligence algorithm, based on BDI agents, acts as the tutor in the N-back game. The robot has movement and speech capabilities, allowing it to command instructions and provide feedback.
- Smart Objects: Four cubes that are touch-sensitive provide inputs to the system and have actuators (LEDs and buzzer) as a feedback for the user during the game. By touching one of the cubes, the robot can generate a stimulus to the user, represented by the color of the LED of the cube (red, green, blue or yellow).
Additionally, an IoT platform is used to upload the collected progress information to a server to consolidate the results and further analyze the data.
3.2. Human–Robot Interaction
The user interacts with the game through dialogue with the robot and physical contact with the smart objects. Therefore, there is no physical interaction between the robot and the user, in order to avoid physical harm to the user and/or damage to the robot. We primarily used a robotic platform because, based on the work in [9], verbal and nonverbal interaction with a robot reduces boredom and maximizes enjoyment during a cognitive task. However, it could be possible to use another device that allows a similar human-computer interaction, such as screen, tablet, etc.
Each training day is called a session, and each session can have several rounds of different levels. At the beginning and the end of each session, the interaction is through speech because the robot asks something related to the user and the game. During a round, the robot provides instructions and expects an answer, and then the user must reply by touching the smart objects.
The game is a stimulus–response activity, because the robot shows a sequence of stimuli and the user must respond depending on the N-back factor that is working. Figure 1 also shows an example of the first iteration of a round with two-back level:
- First, the robot sends a red stimulus, then a green stimulus, and finally a blue stimulus, each generated by touching the corresponding cube (smart object) with its hand. The robot mentions that now it is the user’s turn.
- Since it is a two-back game, the user must touch the red smart object to answer correctly. The smart object processes the input and sends information to the computer when it is touched.
- The system receives the information and validates the response, and sends the validation to the smart objects.
- When the round ends, the score is saved and uploaded to a central server in order to analyze the data. The robot mentions the score to the user and asks if he wants to continue with another round.
- If the answer is positive, the system uses the DDA system, also running on the computer, to adjust the parameters for a new round. On the contrary, the robots says goodbye and goes into sleep mode.
4. Design and Implementation
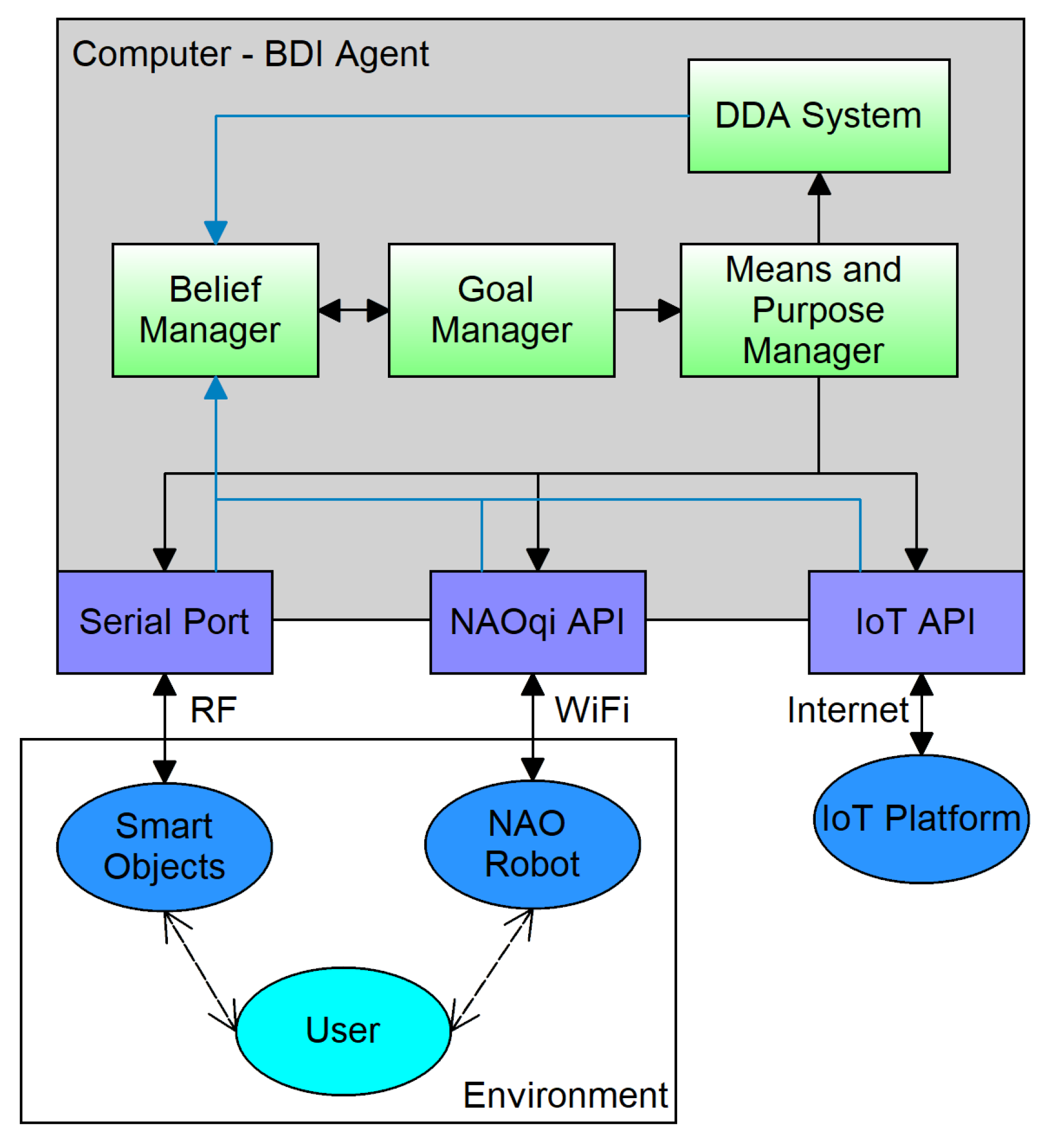
This section presents the design and implementation of the system. Figure 2 shows the general architecture of the proposed system and the interaction between the modules.
The system is composed of four main components:
- The External Devices are constituted by the smart objects that receive the inputs from the user and provide feedback, and the Nao robotic platform that interacts with the user.
- The BDI Agent is composed by the belief, goal and means and purpose managers, and is in charge of the development of the N-back game and the control of the other components.
- The Fuzzy DDA System is also part of the intelligent agent, and is used to balance the levels of the game.
- The IoT Platform is incorporated to collect data on the progress of the user.
The system runs on a computer which communicates with the Nao Robot and the smart objects via WiFi and RF, respectively. The algorithms running on the computer were implemented on Python and the smart objects were developed on an Arduino-based board. In the following paragraphs, the design and implementation of each component are described.
4.1. Smart Objects
In our system, four smart objects were implemented, each one composed by four modules: CPU, sensing, feedback and communication.
The CPU module is based on an AVR microcontroller and is responsible for receiving data from the sensors and controlling the actuators. In addition, it manages the communication with the robotic system. The Sensing module is responsible for providing touch sensitivity to the object. A force sensitive resistor was selected, which is composed by a polymer film that varies its resistance when a force is applied. The Feedback module, also known as the actuator module, provides feedback to the user through an LED array, used to identify each object and as an indicator of the game process (red, green, blue and yellow). A buzzer was also integrated to reinforce the feedback to the user. Finally, the Communication module sends the sensor data to the computer and receives feedback from the system. A low power 2.4 GHz RF hardware module was utilized for this purpose to provide an easy way to implement wireless communication with the computer.
The smart objects are battery-powered in order to improve their usability and mobility. For this purpose, a 500 mAh lithium-ion battery with an integrated charger was included in the smart object
4.2. BDI Agent for the N-Back Game
The main purpose of the BDI agent is to perceive the environment through sensors and modify its beliefs about the world. Additionally, the agent must take decisions to interact with the world based on its beliefs and governed by its desires. Finally, the beliefs are transformed into goals that are materialized through a sequence of intentions.
In this work, a BDI concurrent architecture oriented to goal management [28] was used to develop an intelligent agent that can develop the N-back game. The model is composed of three main modules: belief manager, goal manager, and means and purpose manager.
4.2.1. Belief Manager
The most important objectives of this manager are to keep coherency in the belief system, to include information from the BDI mental processes, and to update the mechanisms of possible learning. In this case, a knowledge base was created, which stores the items presented in Table 1.
All these items are updated continuously, and, additionally, they are related with the agent actions, from an analysis of the goals.
4.2.2. Goal Manager
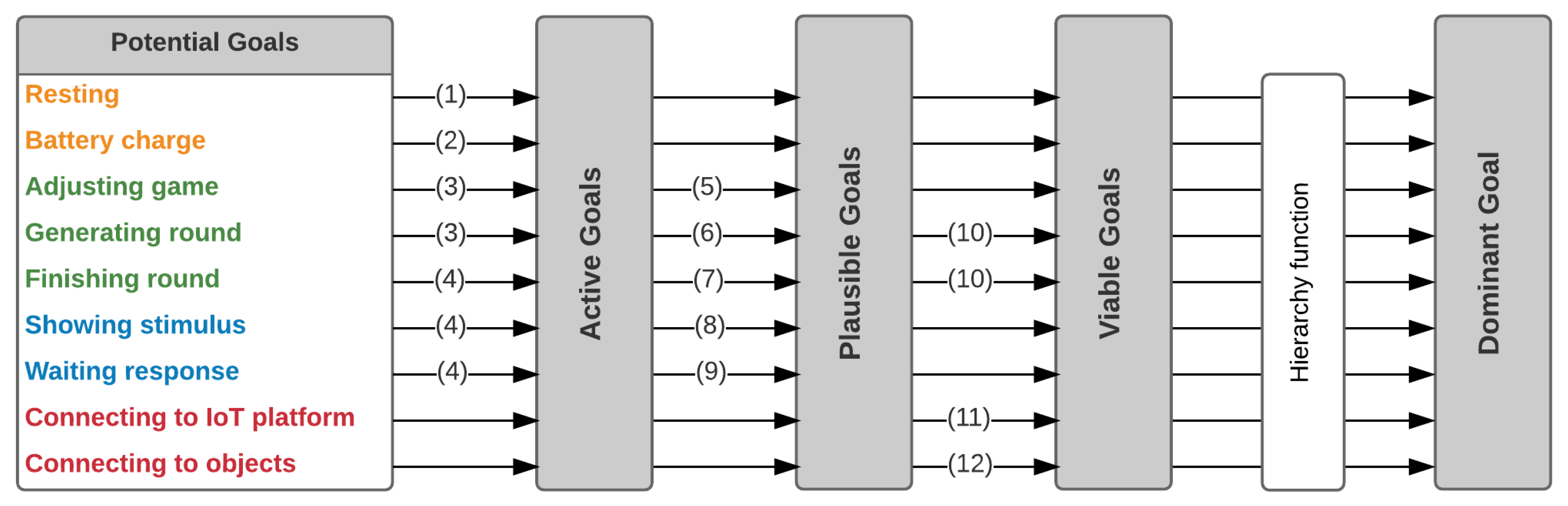
In this module, desires are now considered goals, which then evolve into intentions. The evolution of a goal into an intention is a process in which goals are detected, evaluated and activated/eliminated. Finally, active goals become intentions, which allows the planning of actions. The goals of the agent are classified as follows:
- Survival: Resting, Battery charge.
- Obligation: Adjusting game, Generating round and Finishing round.
- Requirement: Showing stimulus, Waiting for response.
- Needs: Connecting to IoT platform, Connecting to objects and Waiting for the presence of the user.
Figure 3 shows the cycle of evaluation of the goals to obtain the dominant goal. The process begins with all goals as potential goals, and through the conditional Equations (1)–(4), some potential goals can become active goals:
For instance, in Figure 3, the number in the arrow for the potential goal Showing Stimulus defines that we should evaluate Equation (4) in order to know if this potential goal becomes an active goal. Then, by using Equations (5)–(9) it is possible to eliminate some goals and define the plausible goals:
The emotional variable is calculated with Equation (13):
where is a percentage established when the system inquires “How are you doing?”, while is the percentage of rounds surpassed by the user.
Finally, using a hierarchical function, the dominant goal is obtained. The hierarchical function is based on the BDI goal hierarchy pyramid proposed in [28]. The priority defined by the evaluation process shown in Figure 3 is as follows (from high to low): the survival elements, the obligations, the requirements and the needs of the agent.
4.2.3. Means and Purpose Manager
Based on the dominant goal selected by the Goal Manager, in this module, a set of actions, through external actuators and internal processes, are taken to achieve that goal. The following list presents the actions that can be taken depending on each possible goal:
- Resting: The system deactivates all functions and the robot goes into idle mode.
- Battery charge: The robot mentions that its battery level is low, and requests to be plugged to a power supply if the user wants to continue playing.
- Adjusting game: The system inputs all the parameters of the last round into the DDA system to generate the new suitable parameters for the user.
- Generating round: The system takes the new parameters given by the DDA system and generates a new level.
- Finishing round: All game variables are reset and the progress of the user is uploaded to the central server.
- Showing stimulus: The robot moves its arms to touch a smart object, and the touched smart object reacts turning its LEDs on.
- Waiting for response: For a limited time, the robot waits for the user to touch one of the smart objects.
- Connecting to IoT platform: The system checks its Internet connection, and, if the connectivity is down, the robot requests the user to verify the connection.
- Connecting to objects: The system verifies its connection with the smart objects, and, if the link is down, the robot requests the user to verify the connection.
4.3. Fuzzy DDA System
As mentioned above, the DDA system is a component of the BDI agent as part of the process to generate a final action, and is based on a zero-order Sugeno fuzzy logic controller. The controller has two inputs, namely the user’s response time and the rate of positive responses, and three outputs, namely the number of stimuli to show, the sampling time and an indicator to suggest the level change.
4.3.1. Inputs
The spline-based function was used to generate the membership functions of each fuzzy input set. The Response time input (RTI) is obtained by calculating the average time response of each level and falls into a range of 0–5 s. We employ three categories, namely Fast Response (FR), Normal Response (NR) and Slow Response (SR), and the respective fuzzy membership functions are shown in Equations (14)–(16):
The Positive rate input (PRI) is obtained by calculating the percentage of positive responses at each level, and falls into the range of 0–100%. In this case, five linguistic variables were defined, namely Low Percentage (LP), Mid-low percentage (MLP), Mid percentage (MP), Mid-high percentage (MHP) and High percentage (HP), and the respective fuzzy membership functions are shown in Equations (17)–(21):
4.3.2. Outputs
There are three linguistic output variables and their representations of consequence are through singleton. The Sample Time output has three possible values: High Time (HT) with 3 s, Middle Time (MT) with 2 s and Low Time (LT) with 1 s. The Stimuli Number output has three possible values: Few Stimuli (FS) with 9 units, Normal Stimuli (NS) with 12 units and Many Stimuli (MS) with 15 units. Lastly, the Change Level output can take three possible values: Level Down (LD) with number −1, Keep Level (KL) with number 0 and Level Up (LU) with number 1.
4.3.3. Fuzzy Rules
5. Experimental Results and Analysis
To test the proposed system, we executed different experiments with people using our system and a computer-based version of the N-back memory game, and compared the results obtain by both approaches.
5.1. Verification of the BDI Agent
As explained above, some actions of the BDI agent are executed by the robot. Since some experimental results are difficult to capture and visually present in this document, here we show some evidence of the Showing stimulus goal, which is a very common goal and one that generates an external and physical action by the robot.
Figure 4 presents four images where the Nao robot moves its arms in order to generate a set of stimuli by touching the smart objects. It is important to point out that, as the robot touches a smart object, the smart object turns its LEDs on in order to reinforce the stimulus. This is the main mechanism of interaction between the system and the user.
5.2. Experimental Setup
The N-back game is a repetitive process in which users have to play every day to overcome levels and reaching higher levels may be evidence on the improvement of their WM. When comparing the computer-based implementation of N-back and our system, we report the performance of the user as the maximum N-back level reached by the user.
A group of college students was exposed to the computer-based game (control group) and another group to the proposed robotic system (training group). The students, between the ages of 17 and 22, also received a gift card as a reward for their participation. Table 5 shows the detailed description for each group.
Although the computer-based implementation also uses visual stimuli and starts in one-back, there are some important differences with our robotic approach. On the one hand, the computer-based game only allows to leveling up when all the answers are correct, while the robotic system utilizing the DDA module, modifies the difficulty level depending on the progress of the user and not necessarily when all answers are correct.
Our experimental setup was based on the work in [1,26], which comprised 15 sessions (days) of training, each one of approximately 20–30 min, in which the user could perform various N-back levels. The work of Jaeggi et al. [1] concluded that, after at least 15 days of training, it is possible to obtain positive results in the WM capacity of the participants.
In our experiments, every participant had to attend a specific hour at a facility at the university, where the robotic system and the smart objects were installed and configured for the activity. The location was selected after looking for a calm and isolated place on the campus, to allow the user to play without interruptions or disturbances. To begin the training, users had to take a seat in front of the smart objects and the robot and familiarize with them. Then, when the game started, the participants interacted with the smart object after paying attention and understanding the actions of the robotic platform. The game interactions follow the steps presented in Figure 1, and Figure 4 shows an example of how the robot moves when it is in front of the participant. The users were allowed to have only one session per day, so as not to affect the experimental results. Next, we present a statistical analysis of the results of the experiments and an analysis of a survey conducted when the users finished the 15 days of training.
5.3. Training Results
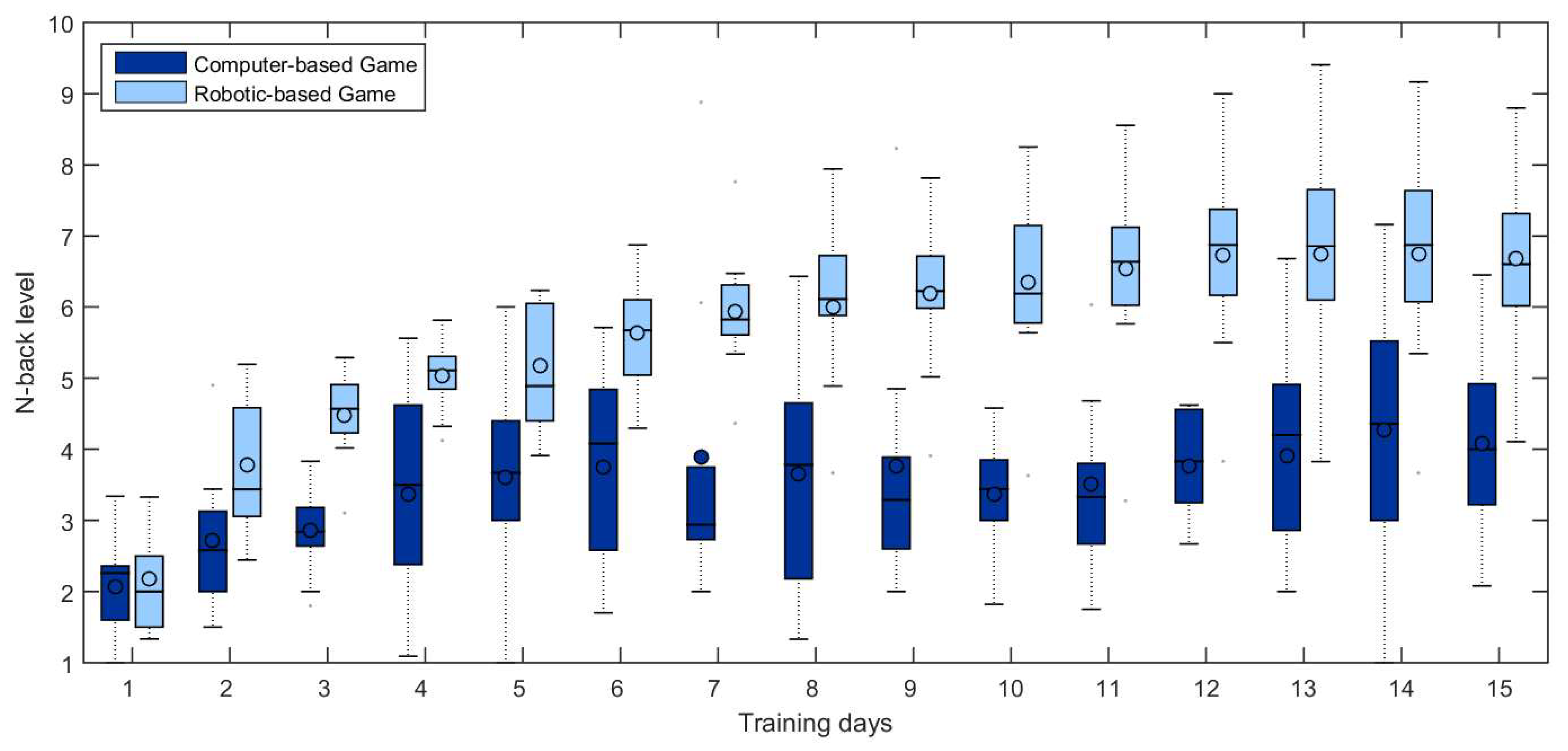
The average level graph of N-back is generally used to analyze the progress of WM training, but this paper presents a box-plot diagram, which was used to determine the differences between the two methods. The box-plot in Figure 5 presents relevant information such as extreme values, quartiles, median and mean.
At first glance, it is possible to appreciate that the robotic system performs better during N-back training when compared to the computer-based implementation. After the 15 training days (sessions), the control group reached an average level of four-back, while the training group utilizing the robotic approach reached an average level of seven-back, a significant improvement.
Our previous work presented in [26], which considers the same experimental setup, showed that including a similar improvement to the computer-based game helped the participants achieve better results. In these previous experiments, including the DDA system in the computer-based game allowed the control group to reach an average level of six-back, an improvement when compared to the average level of four-back achieved with the basic computer-based implementation. Therefore, it is possible to conclude that by utilizing external devices users could improve their training experience.
To verify the previous hypothesis, a mixed repeated measure ANOVA was conducted analyzing time-method and only method. The training data of the users were aggregated into a t-score distribution and the weekly WM performance was on average five days. The ANOVA results indicate a significant interaction between time and training method for the N-back variable (), which implies a strong difference in the performance of the user when using different training methods. In addition, there is a significant effect in the N-back performance due to the training method, regardless of the time (). In other words, the robotic approach is always better than the computer-based implementation regardless of how long the user plays.
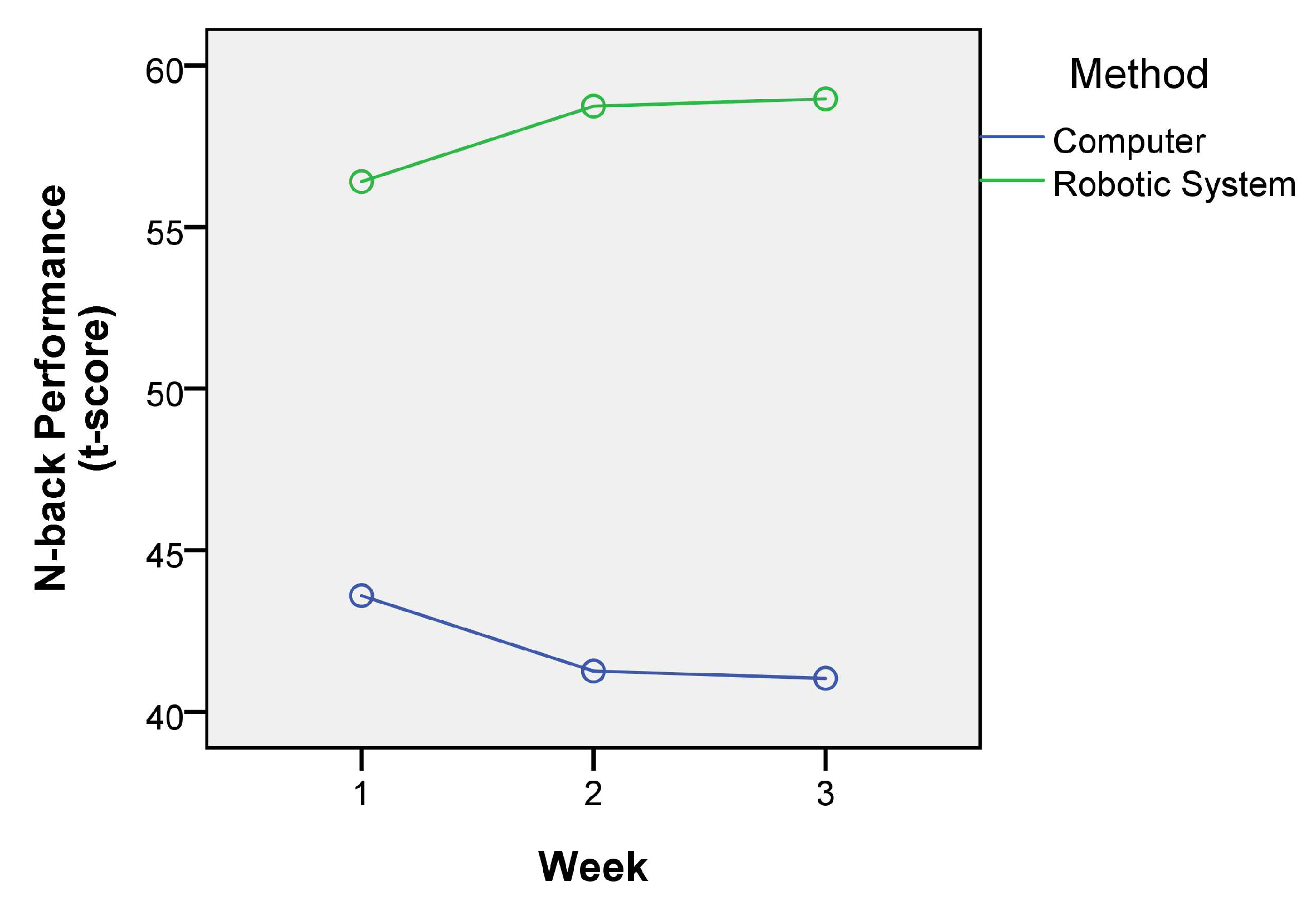
Additionally, Figure 6 shows the graph of marginal means of N-back performance. On the one hand, the participants in the control group who used the computer-based implementation started on below-average performance and continued to decline. On the other hand, the training group who used the robotic system began on a performance above-average and kept increasing over the next few weeks.
5.4. Survey Results
Three important questions were inquired in the survey in order to find out the users’ opinion on the tested training games. The first question was: How difficult is the game at the beginning? In the control group, of the participants using the computer-based approach indicated that it was easy, but, in the training group, of the participants using the robotic system indicated that it was easy. These results may be related to the implemented DDA system that tries to balance the levels according to the user.
The second question was: How immersed were you during the activity?. In this question, people had to choose a rating from 1 to 3, where 3 was the highest level of immersion. Users of the robotic system had a mean of , while the computer users had a mean of . The usage of the robot and the smart objects may be linked to these responses because those elements might have generated more attraction to the user during training.
The third question was: Do you consider that the system has helped you to improve your memory?. In this case, for both groups, of the participants had a positive answer. It is a fact that the N-back task is responsible for these results, and, in both cases, an improvement in the WM was expected. This question is slightly subjective, but the real purpose of this was to assess whether the user found the training process useful.
6. Conclusions and Future Work
The design of interfaces for human-machine interaction in the context of learning should include elements that allow the student to have an educational immersion in a natural way, seeking to maintain the student’s attention and motivation while working with the system. The use of robots in the educational context offers the student new effective learning strategies in spaces of human-machine interaction through a personalized and unique experience. With the proposed robotic-based system, it was possible to validate that the usage of simple and coherent interaction schemes and visually immersive resources improve the participants performance.
Particularly, it was possible to generate a novel system for WM training using robotics and artificial intelligence. These paradigms allowed the performance of users to be superior when compared to a traditional computer-based game. People were more interested in using the proposed system because of an attractive human-machine interface, implemented with the robot and smart objects. According to the opinion of the participants, during the game, a greater level of satisfaction and immersion was achieved.
Context-awareness was obtained by integrating a BDI agent, which, in conjunction with the DDA system, allows the system to have some degree of rationality during the development of the game, adapting its difficulty to the user’s evolution. The collection of information about the environment of the game is very important to this adaptability, which is achieved through the utilization of external elements, more specifically, with the smart objects.
From a quantitative perspective, the experimental results presented here are very promising, as the process of memory formation had better results using the robotic system, which could be verified with the statistical analysis performed. The results show that from the beginning of the training the users of the robotic system reached a higher level of N-back that kept increasing as the game developed.
As part of our ongoing work, the integration of artificial vision is being considered in order to allow the robot to identify external elements and manipulate them in a better way, as well as be able to detect emotions through facial recognition. Finally, although our main focus is the improvement of WM on teenagers, the proposed system could be evaluated with different populations, for instance kids and adults, for a comparative analysis of the results.
Author Contributions
Conceptualization, D.M.; Formal analysis, V.A.; Investigation, V.A.; Methodology, D.M. and A.G.; Software, V.A.; Supervision, D.M. and A.G.; Validation, V.A.; Writing—original draft, D.M.; Writing—review & editing, D.M. and A.G.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jaeggi, S.M.; Buschkuehl, M.; Jonides, J.; Perrig, W.J. Improving fluid intelligence with training on working memory. Proc. Natl. Acad. Sci. USA 2008, 105, 6829–6833. [Google Scholar] [CrossRef] [PubMed]
- Gutiérrez-Martínez, F.; Ramos, M. La memoria operativa como capacidad predictora del rendimiento escolar. Estudio de adaptación de una medida de memoria operativa para niños y adolescentes. Psicología Educativa 2014, 20, 1–10. [Google Scholar] [CrossRef]
- McNab, F.; Zeidman, P.; Rutledge, R.B.; Smittenaar, P.; Brown, H.R.; Adams, R.A.; Dolan, R.J. Age-related changes in working memory and the ability to ignore distraction. Proc. Natl. Acad. Sci. USA 2015, 112, 6515–6518. [Google Scholar] [CrossRef] [PubMed]
- Pugin, F.; Metz, A.J.; Stauffer, M.; Wolf, M.; Jenni, O.G.; Huber, R. Working memory training shows immediate and long-term effects on cognitive performance in children. F1000 Res. 2015. [Google Scholar] [CrossRef]
- Borella, E.; Carretti, B.; Riboldi, F.; De Beni, R. Working memory training in older adults: evidence of transfer and maintenance effects. Psychol. Aging 2010, 25, 767–778. [Google Scholar] [CrossRef] [PubMed]
- Deveau, J.; Jaeggi, S.M.; Zordan, V.; Phung, C.; Seitz, A.R. How to build better memory training games. Front. Syst. Neurosci. 2015, 8, 243. [Google Scholar] [CrossRef] [PubMed]
- Chin, K.Y.; Hong, Z.W.; Chen, Y.L. Impact of Using an Educational Robot-Based Learning System on Students’; Motivation in Elementary Education. IEEE Trans. Learn. Technol. 2014, 7, 333–345. [Google Scholar] [CrossRef]
- Bravo Sánchez, F.A.; González Correal, A.M.; Guerrero, E.G. Interactive Drama with Robots for Teaching Non-technical Subjects. J. Hum.-Robot Interact. 2017, 6, 48–69. [Google Scholar] [CrossRef]
- Brown, L.; Howard, A. Engaging children in math education using a socially interactive humanoid robot. In Proceedings of the 2013 13th IEEE-RAS International Conference on Humanoid Robots (Humanoids), Atlanta, GA, USA, 15–17 October 2013; pp. 183–188. [Google Scholar] [CrossRef]
- Phamduy, P.; LeGrand, R.; Porfiri, M. Robotic Fish: Design and Characterization of an Interactive iDevice-Controlled Robotic Fish for Informal Science Education. IEEE Robot. Autom. Mag. 2015, 22, 86–96. [Google Scholar] [CrossRef]
- Plaza, P.; Sancristobal, E.; Carro, G.; Castro, M. Home-made robotic education, a new way to explore. In Proceedings of the 2017 IEEE Global Engineering Education Conference (EDUCON), Athens, Greece, 26–28 April 2017; pp. 132–136. [Google Scholar] [CrossRef]
- McNab, F.; Varrone, A.; Farde, L.; Jucaite, A.; Bystritsky, P.; Forssberg, H.; Klingberg, T. Changes in Cortical Dopamine D1 Receptor Binding Associated with Cognitive Training. Science 2009, 323, 800–802. [Google Scholar] [CrossRef] [PubMed]
- Jaeggi, S.M.; Buschkuehl, M.; Perrig, W.J.; Meier, B. The concurrent validity of the N-back task as a working memory measure. Memory 2010, 18, 394–412. [Google Scholar] [CrossRef] [PubMed]
- Bouker, J.; Scarlatos, A. Investigating the impact on fluid intelligence by playing N-Back games with a kinesthetic modality. In Proceedings of the 2013 10th International Conference and Expo on Emerging Technologies for a Smarter World (CEWIT), Melville, NY, USA, 21–22 October 2013; pp. 1–3. [Google Scholar] [CrossRef]
- Wooldridge, M.; Jennings, N.R. Intelligent Agents: Theory and Practice. Knowl. Eng. Rev. 1995, 10, 115–152. [Google Scholar] [CrossRef]
- Gottifredi, S.; Tucat, M.; Corbatta, D.; García, A.; Simari, G.R. A BDI Architecture for High Level Robot Deliberation. Inteligencia Artificial: Revista Iberoamericana de Inteligencia Artificial 2010, 14, 74–83. [Google Scholar] [CrossRef]
- Taillandier, P.; Therond, O.; Gaudou, B. A new BDI agent architecture based on the belief theory. Application to the modelling of cropping plan decision-making. In Proceedings of the International Environmental Modelling and Software Society (iEMSs), Leipzig, Germany, 1–5 July 2012. [Google Scholar]
- Lin, Y.; Min, H.; Zhou, H.; Pei, F. A Human–Robot-Environment Interactive Reasoning Mechanism for Object Sorting Robot. IEEE Trans. Cogn. Dev. Syst. 2018, 10, 611–623. [Google Scholar] [CrossRef]
- Liu, L.; Li, B.; Chen, I.; Goh, T.J.; Sung, M. Interactive robots as social partner for communication care. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2231–2236. [Google Scholar] [CrossRef]
- Ayerbe, M.A.B.; Gonzalez, D.S.A.; Jiménez, F.A.M.; Guerrero, E.G.; Correal, A.M.G. AIO robot: A EDI modular robotic dramatization platform. In Proceedings of the 2017 18th International Conference on Advanced Robotics (ICAR), Hong Kong, China, 10–12 July 2017; pp. 262–268. [Google Scholar] [CrossRef]
- Kaptein, F.; Broekens, J.; Hindriks, K.; Neerincx, M. Personalised self-explanation by robots: The role of goals versus beliefs in robot-action explanation for children and adults. In Proceedings of the 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, Portugal, 28–31 August 2017; pp. 676–682. [Google Scholar] [CrossRef]
- Silva, M.P.; do Nascimento Silva, V.; Chaimowicz, L. Dynamic Difficulty Adjustment through an Adaptive AI. In Proceedings of the 2015 14th Brazilian Symposium on Computer Games and Digital Entertainment (SBGames), Piauí, Brazil, 11–13 November 2015; pp. 173–182. [Google Scholar] [CrossRef]
- Sun, Q.; He, S. Artificial neural network using the training set of DTS for Pacman game. In Proceedings of the 2014 11th International Computer Conference on Wavelet Actiev Media Technology and Information Processing(ICCWAMTIP), Chengdu, China, 19–21 December 2014; pp. 209–213. [Google Scholar] [CrossRef]
- Pratama, N.P.H.; Nugroho, S.M.S.; Yuniarno, E.M. Fuzzy controller based AI for dynamic difficulty adjustment for defense of the Ancient 2 (DotA2). In Proceedings of the 2016 International Seminar on Intelligent Technology and Its Applications (ISITIA), Lombok, Indonesia, 28–30 July 2016; pp. 95–100. [Google Scholar] [CrossRef]
- Andrade, K.D.O.; Pasqual, T.B.; Caurin, G.A.P.; Crocomo, M.K. Dynamic difficulty adjustment with Evolutionary Algorithm in games for rehabilitation robotics. In Proceedings of the 2016 IEEE International Conference on Serious Games and Applications for Health (SeGAH), Orlando, FL, USA, 11–13 May 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Araujo, V.; Gonzalez, A.; Mendez, D. Dynamic Difficulty Adjustment for a Memory Game. In Communications in Computer and Information Science; Springer International Publishing: New York, NY, USA, 2018; pp. 605–616. [Google Scholar] [CrossRef]
- Wang, K.; Liu, X. Particle Filtering-based tracking and localization on context-aware robotic system. In Proceedings of the 2014 9th International Conference on Computer Science Education (ICCSE), Vancouver, BC, Canada, 22–24 August 2014; pp. 229–234. [Google Scholar] [CrossRef]
- González, A.; Angel, R.; González, E. BDI concurrent architecture orientedto goal managment. In Proceedings of the 2013 8th Computing Colombian Conference (8CCC), Armenia, Colombia, 21–23 August 2013; pp. 1–6. [Google Scholar] [CrossRef]
Figure 1.
Graphical representation of the interaction among the user, the robot and the smart objects. As an example, the first iteration of the two-back case is shown.
Figure 1.
Graphical representation of the interaction among the user, the robot and the smart objects. As an example, the first iteration of the two-back case is shown.

Figure 2.
General modular diagram of the system.

Figure 3.
Dominant goal evaluation process, based on the BDI goal hierarchy pyramid proposed in [28].
Figure 3.
Dominant goal evaluation process, based on the BDI goal hierarchy pyramid proposed in [28].

Figure 4.
Robot Nao showing stimulus.

Figure 5.
Box-plot showing the performance of both approaches (computer- and robotic-based) for the N-back level reached in each session.
Figure 5.
Box-plot showing the performance of both approaches (computer- and robotic-based) for the N-back level reached in each session.

Figure 6.
Mean WM performance across three weeks.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Items considered in the knowledge base.
| Item | Type | |
|---|---|---|
| Sensors | Battery level () | percentage |
| Robot’s motors high temperature () | boolean | |
| User’s presence sensor () | boolean | |
| Objects connection () | boolean | |
| IoT platform connection () | boolean | |
| Process | Game over () | boolean |
| Round initiated () | boolean | |
| Stimuli number () | integer | |
| Continue game () | boolean | |
| Game turn () | assignment | |
| Loops () | integer | |
| Game balanced () | boolean | |
| Emotional | Mood () | percentage |
Table 2.
The rule table for the Sample Time output.
| RTI/PRI | LP | MLP | MP | MHP | HP |
|---|---|---|---|---|---|
| FR | HT | HT | MT | LT | LT |
| NR | HT | MT | MT | MT | LT |
| HP | HT | HT | MT | MT | LT |
Table 3.
The rule table for the Stimuli Number output.
| RTI/PRI | LP | MLP | MP | MHP | HP |
|---|---|---|---|---|---|
| FR | FS | NS | NS | MS | MS |
| NR | FS | NS | NS | NS | MS |
| HP | FS | FS | FS | NS | NS |
Table 4.
The rule table for the Change Level output.
| RTI/PRI | LP | MLP | MP | MHP | HP |
|---|---|---|---|---|---|
| FR | LD | KL | KL | KL | LU |
| NR | LD | KL | KL | KL | LU |
| HP | LD | LD | KL | KL | KL |
Table 5.
Characteristics of the training and control groups.
| Training Group (n = 9) | Control Group (n = 9) | |
|---|---|---|
| Average age | 20.25 | 20.4 |
| Gender | 55.5% Female | 55.5% Female |
| Average years of education | 15.25 | 15.4 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Araujo, V.; Mendez, D.; Gonzalez, A. A Novel Approach to Working Memory Training Based on Robotics and AI. Information 2019, 10, 350. https://0-doi-org.brum.beds.ac.uk/10.3390/info10110350
AMA Style
Araujo V, Mendez D, Gonzalez A. A Novel Approach to Working Memory Training Based on Robotics and AI. Information. 2019; 10(11):350. https://0-doi-org.brum.beds.ac.uk/10.3390/info10110350
Chicago/Turabian StyleAraujo, Vladimir, Diego Mendez, and Alejandra Gonzalez. 2019. "A Novel Approach to Working Memory Training Based on Robotics and AI" Information 10, no. 11: 350. https://0-doi-org.brum.beds.ac.uk/10.3390/info10110350
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.