
An Experimental Analysis of Data Annotation Methodologies for Emotion Detection in Short Text Posted on Social Media


Abstract
:1. Introduction
- A natural language processor that handles the unique linguistic characteristics of social media posts in regard to lexical, syntax and annotation preferences and provides a uniform text in the annotated dataset.
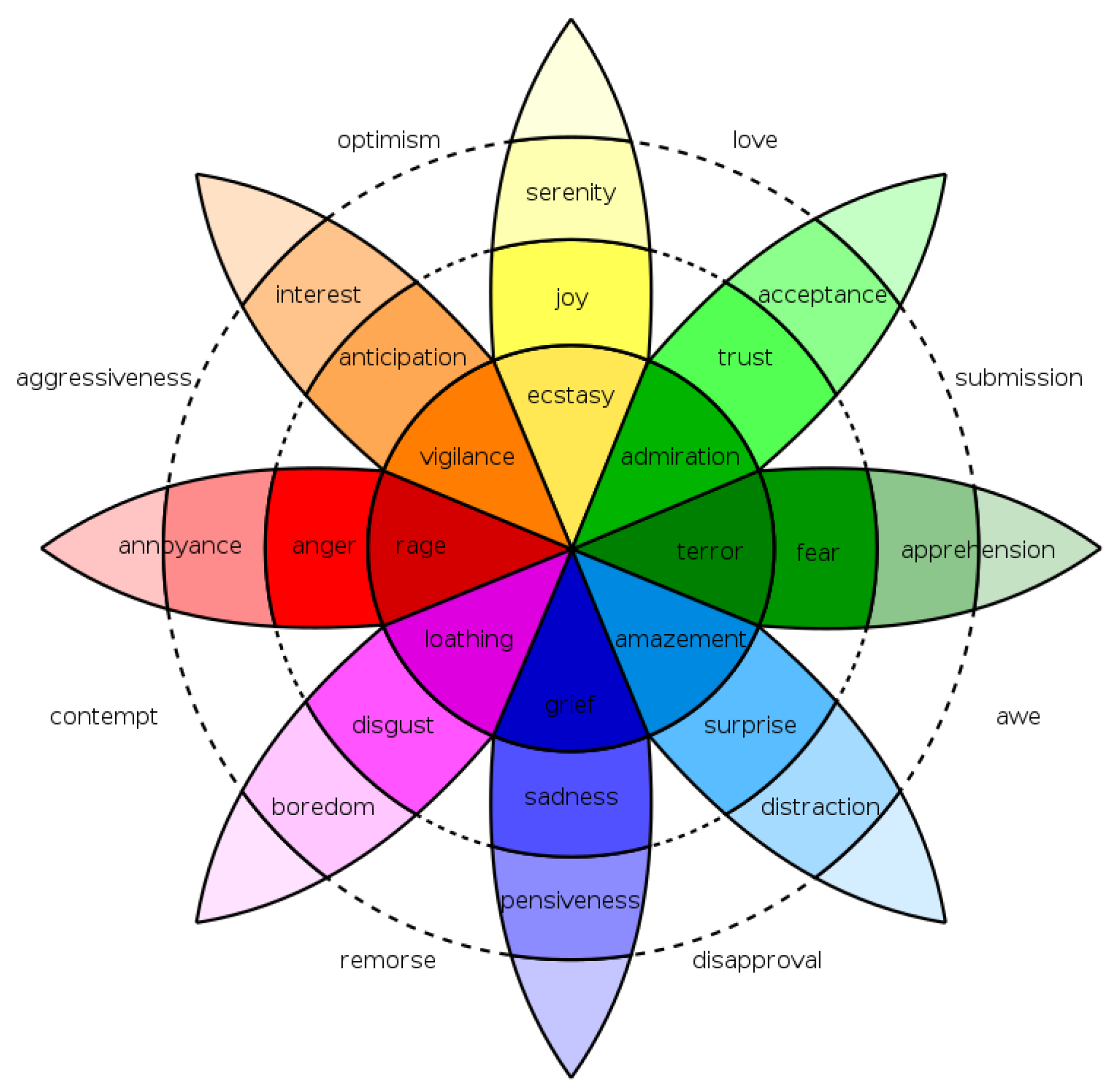
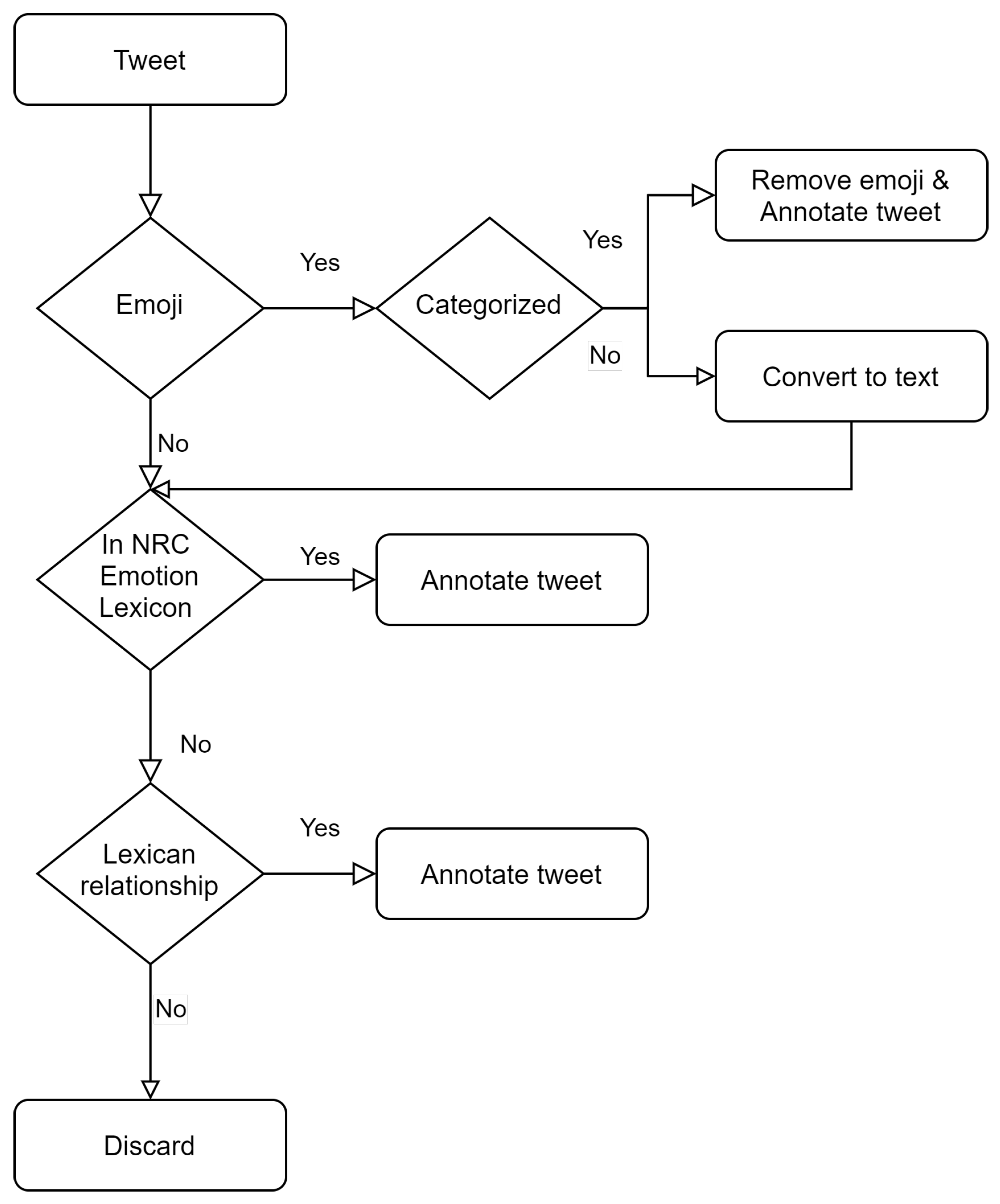
- A hybrid rule-based algorithm that supports the creation of an objectively classified dataset over the Plutchik’s eight basic emotions [12]. The algorithm takes into consideration the available emoji in the text and used them as objective indicators of the expressed emotion thus efficiently tackling the challenge of the subjectivity of the emotion detection.
- An experimental analysis to select the proper machine learning solution, and its proper configuration, for identifying the expressed emotions in text.
2. Methodology
2.1. Emotion Categories
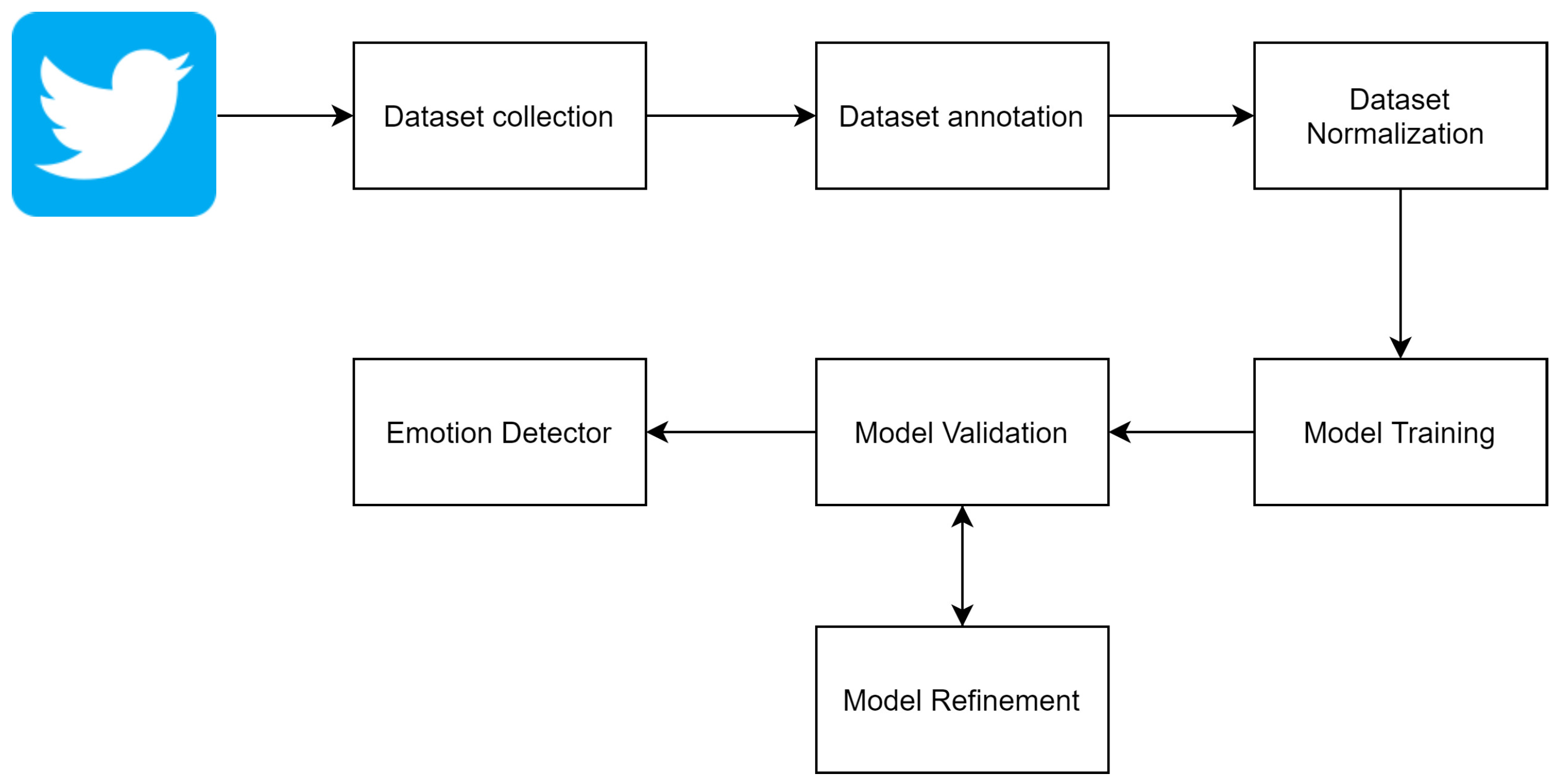
2.2. Dataset Acquisition
- Text size. Traditional NLP systems have been trained using large passages of text that have only one author. Social media posts have limited characters and are produced by multiple individuals.
- Topic diversity. Traditional sources provide content that presents specific topics within the same text, journal articles for example are expected to be focused on one single topic throughout. A single social media post can include multiple topics, and express opinions of different intensity, at the same time that multiple users are discussing a plethora of topics that are of interest.
- Vocabulary & Spellcheck. Formal text includes exclusively words that can be found in dictionaries, used following the proper spelling and the word capitalization rules. In social media posts, users often use words that are non-existing, either formed on the fly to emphasize a situation or due to incorrect spelling. There are also some habits of these users that deviate from the proper spelling rules, such as the usage of letter repetition to give emphasis, the use of capital letters to expressed the intensity of their emotions or the shortening of words to their sound for shorter messages, such as ’heyyyyy’, ’I am SAD’ or ’u’.
- Syntax & Grammar. Formal text follows all the syntax and grammar rules, including the use of punctuation marks. In social media posts, emphasis is prioritized over proper usage of the linguistic rules. The text includes incomplete phrases, non-existent grammar, phrases without verbs or subjects, incorrect and excessive use of punctuation marks.
- Text objectivity & originality. Formal sources are providing unique and objective text that contains properly presented facts and precise information with limited emotional expressions. On the other hand, social media posts are often repetitions or additions to already presented opinions. The posts aim to present specific views and arguments over recent events and topics of interest, often expressed under emotional excitement.
- Abbreviations. Shortened text is really used in official documents, unless it has been clearly defined, is related to a well-established term that is used throughout the document and is properly explained. The users of the social media are creating abbreviations continuously, giving them multiple interpretations based on the overall context and fail to explain their meaning.
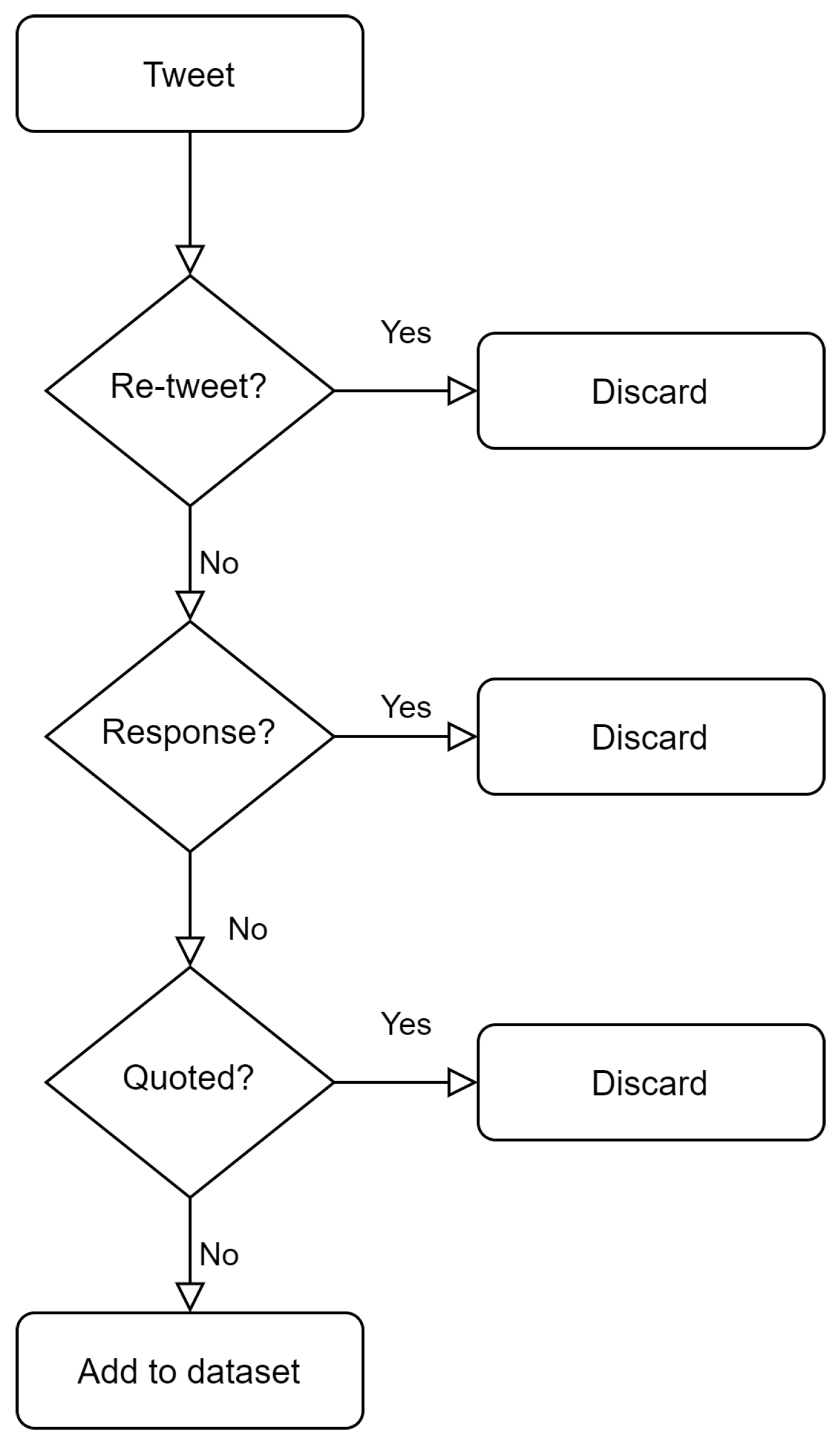
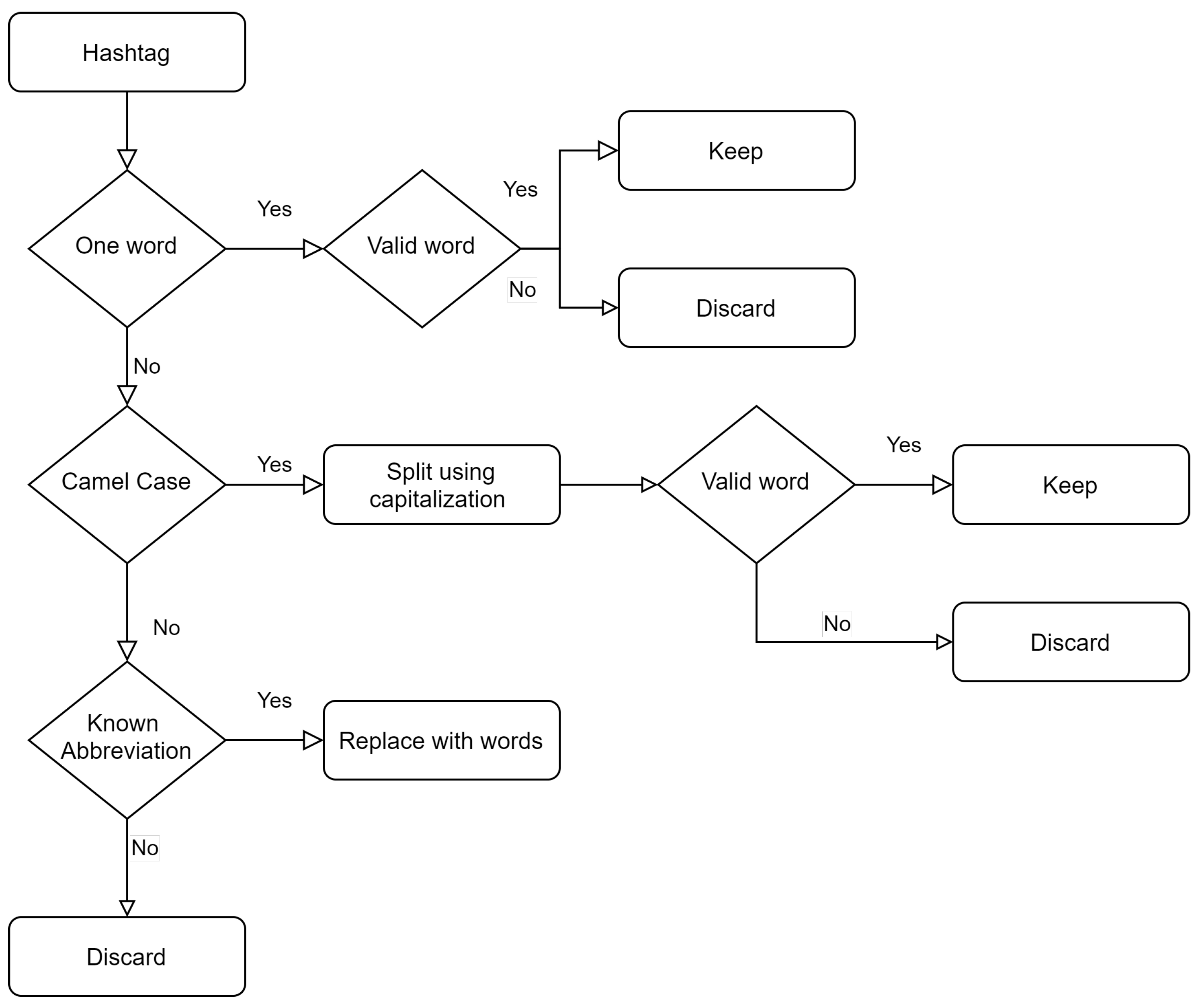
2.2.1. Dataset Collection and Harmonization
2.2.2. Dataset Annotation
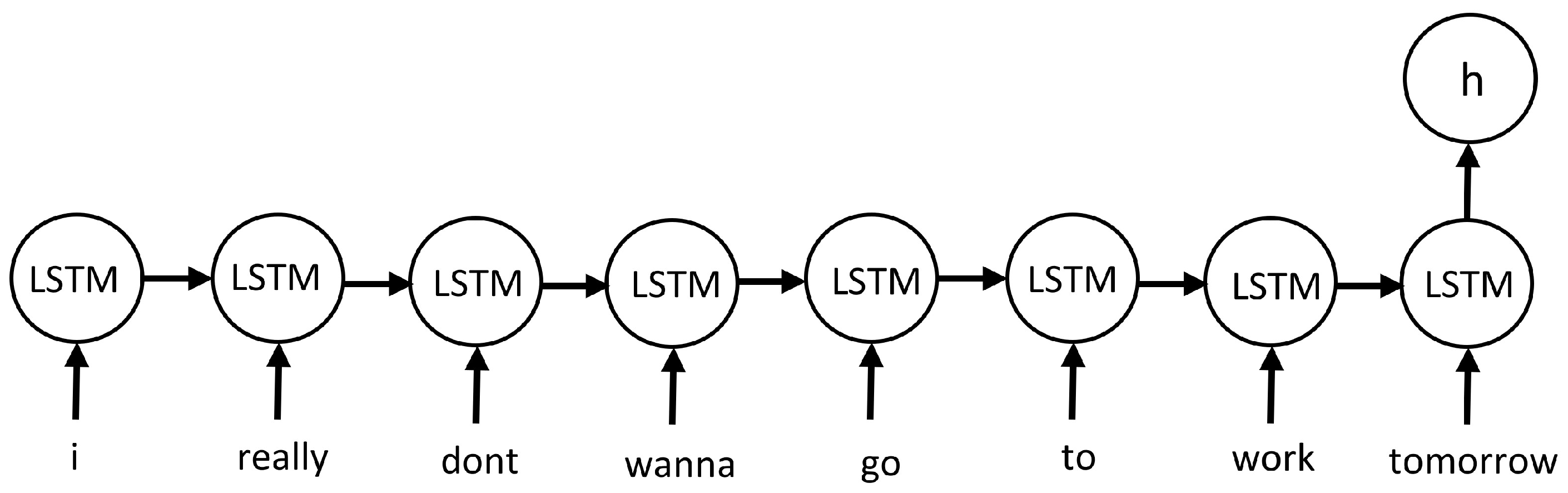
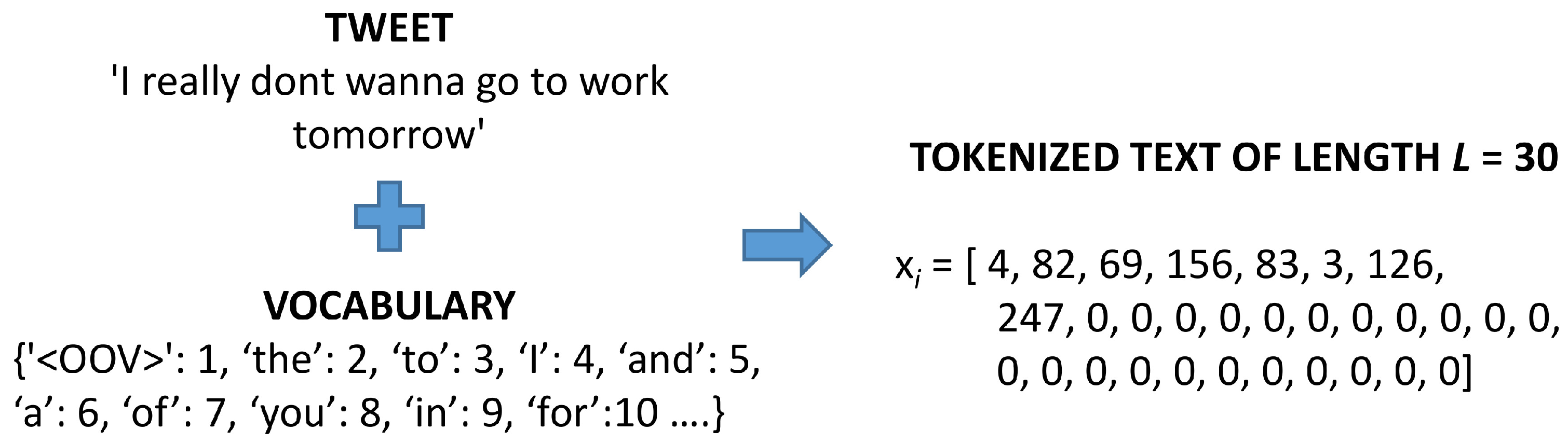
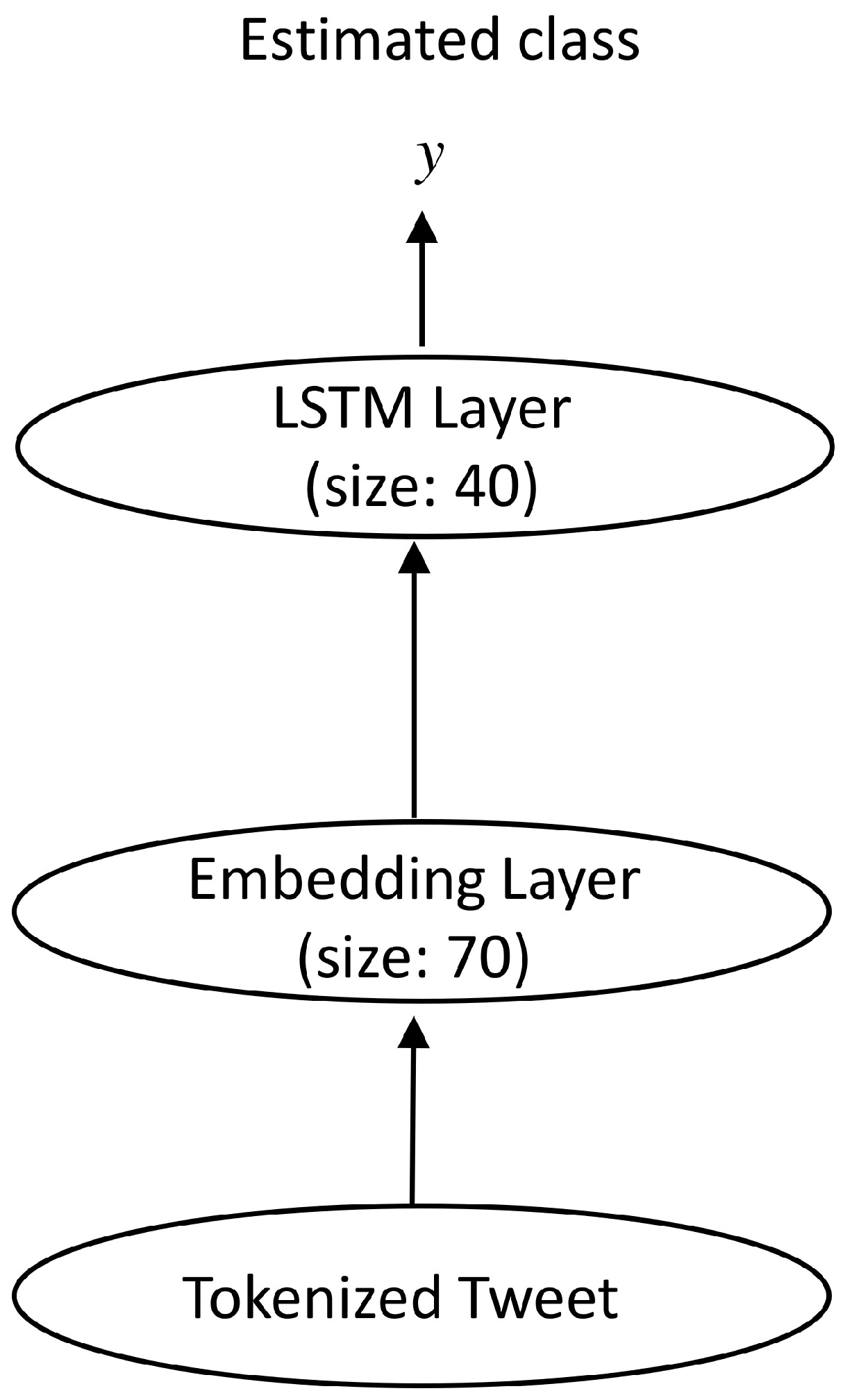
2.3. Classification Model Development
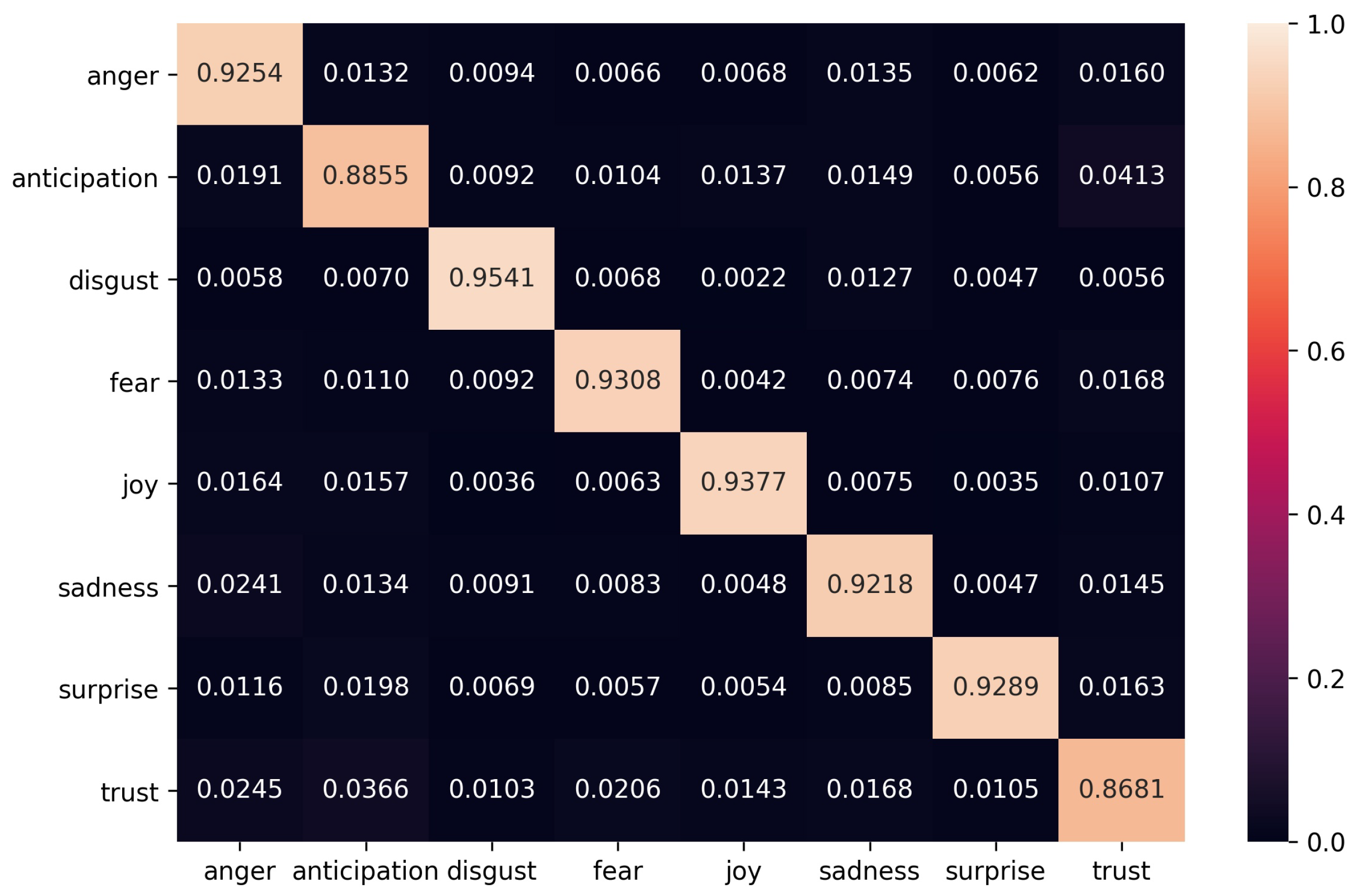
3. Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| API | Application programming interface |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
| LIWC | Linguistic Inquiry and Word Count |
| LSTM | Long Short-Term Memory |
| NLP | Natural Language Processing |
| OOV | Out Of Vocabulary |
| POMS | Profile of Mood States |
| RAM | Random Access Memory |
| SGD | Stochastic Gradient Descent |
| SVM | Support Vector Machine |
| URL | Uniform Resource Locator |
References
- Bakshi, R.K.; Kaur, N.; Kaur, R.; Kaur, G. Opinion mining and sentiment analysis. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 452–455. [Google Scholar]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R.J. Sentiment analysis of twitter data. In Proceedings of the Workshop on Language in Social Media (LSM 2011), Portland, OR, USA, 23 June 2011; pp. 30–38. [Google Scholar]
- Feldman, R. Techniques and applications for sentiment analysis. Commun. ACM 2013, 56, 82–89. [Google Scholar] [CrossRef]
- Acheampong, F.A.; Wenyu, C.; Nunoo-Mensah, H. Text-based emotion detection: Advances, challenges, and opportunities. Eng. Rep. 2020, 2, e12189. [Google Scholar] [CrossRef]
- Bollen, J.; Pepe, A.; Mao, H. Modeling public mood and emotion: Twitter sentiment and socio-economic phenomena. arXiv 2009, arXiv:cs.CY/0911.1583. [Google Scholar]
- Larsen, M.E.; Boonstra, T.W.; Batterham, P.J.; O’Dea, B.; Paris, C.; Christensen, H. We feel: Mapping emotion on Twitter. IEEE J. Biomed. Health Informat. 2015, 19, 1246–1252. [Google Scholar] [CrossRef]
- Wang, W.; Chen, L.; Thirunarayan, K.; Sheth, A.P. Harnessing twitter “big data” for automatic emotion identification. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust and 2012 International Confernece on Social Computing, Amsterdam, The Netherlands, 3–5 September 2012; pp. 587–592. [Google Scholar]
- Felbo, B.; Mislove, A.; Søgaard, A.; Rahwan, I.; Lehmann, S. Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm. arXiv 2017, arXiv:1708.00524. [Google Scholar]
- Balabantaray, R.C.; Mohammad, M.; Sharma, N. Multi-class twitter emotion classification: A new approach. Int. J. Appl. Inf. Syst. 2012, 4, 48–53. [Google Scholar]
- Alm, C.O.; Roth, D.; Sproat, R. Emotions from text: Machine learning for text-based emotion prediction. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 579–586. [Google Scholar]
- Plutchik, R. The Emotions; University Press of America: Lanham, MD, USA, 1991. [Google Scholar]
- Roseman, I.J. Cognitive determinants of emotion: A structural theory. Rev. Personal. Soc. Psychol. 1984, 5, 11–36. [Google Scholar]
- Darwin, C.; Prodger, P. The Expression of the Emotions in Man and Animals; Oxford University Press: New York, NY, USA, 1998. [Google Scholar]
- Ekman, P. A methodological discussion of nonverbal behavior. J. Psychol. 1957, 43, 141–149. [Google Scholar] [CrossRef]
- Tomkins, S.S. Affect Imagery Consciousness: Volume I: The Positive Affects; Springer Publishing Company: Berlin/Heidelberg, Germany, 1962; Volume 1. [Google Scholar]
- Ekman, P.; Keltner, D. Universal facial expressions of emotion. In Nonverbal Communication: Where Nature Meets Culture; Segerstrale, U.P., Molnar, P., Eds.; University Of California: San Francisco, CA, USA, 1997; pp. 27–46. [Google Scholar]
- Plutchik, R. A general psychoevolutionary theory of emotion. In Theories of Emotion; Elsevier: Amstedam, The Netherlands, 1980; pp. 3–33. [Google Scholar]
- Deep Learning for NLP: An Overview of Recent Trends. Available online: https://medium.com/dair-ai/deep-learning-for-nlp-an-overview-of-recent-trends-d0d8f40a776d (accessed on 7 November 2020).
- Jurafsky, D. Speech & Language Processing; Pearson Education India: Chennai, India, 2000. [Google Scholar]
- Manning, C.; Schutze, H. Foundations of Statistical Natural Language Processing; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Farzindar, A.; Inkpen, D. Natural language processing for social media. Synth. Lect. Hum. Lang. Technol. 2015, 8, 1–166. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Canales, L.; Martínez-Barco, P. Emotion detection from text: A survey. In Proceedings of the Workshop on Natural Language Processing in the 5th Information Systems Research Working Days (JISIC), Quito, Ecuador, 20–24 October 2014; pp. 37–43. [Google Scholar]
- Twitter. Available online: https://twitter.com/home?lang=en (accessed on 17 November 2020).
- Twitter Developer Docs. Available online: https://developer.twitter.com/en/docs (accessed on 7 November 2020).
- Roesslein, J. Tweepy: Twitter for Python! Available online: Https://github.com/tweepy/tweepy (accessed on 17 November 2020).
- Filter realtime Tweets. Available online: https://developer.twitter.com/en/docs/twitter-api/v1/tweets/filter-realtime/guides/basic-stream-parameters (accessed on 10 March 2020).
- The 500 Most Frequently Used Words on Twitter. Available online: https://techland.time.com/2009/06/08/the-500-most-frequently-used-words-on-twitter/ (accessed on 14 February 2021).
- NLTP Corpus. Available online: http://www.nltk.org/howto/corpus.html (accessed on 17 November 2020).
- Abbreviations. Available online: https://www.abbreviations.com/ (accessed on 17 November 2020).
- Tweet Preprocessor. Available online: https://pypi.org/project/tweet-preprocessor/ (accessed on 17 November 2020).
- Emoji. Available online: https://github.com/carpedm20/emoji/ (accessed on 28 October 2020).
- Emoji Tracker. Available online: http://emojitracker.com/ (accessed on 17 November 2020).
- Krommyda, M.; Rigos, A.; Bouklas, K.; Amditis, A. Emotion detection in Twitter posts: A rule-based algorithm for annotated data acquisition. In Proceedings of the 2020 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 16–18 December 2020. [Google Scholar]
- Mohammad, S.M.; Turney, P.D. Nrc Emotion Lexicon; National Research Council Canada: Ottawa, ON, Canada, 2013; Volume 2. [Google Scholar]
- Fellbaum, C. WordNet. In The Encyclopedia of Applied Linguistics; John Wiley and Sons, Inc.: Hoboken, NJ, USA, 2012. [Google Scholar]
- Krommyda, M.; Kantere, V. Understanding SPARQL Endpoints through Targeted Exploration and Visualization. In Proceedings of the 2019 First International Conference on Graph Computing (GC), Laguna Hills, CA, USA, 25–27 September 2019; pp. 21–28. [Google Scholar] [CrossRef]
- Krommyda, M.; Kantere, V. A Framework for Exploration and Visualization of SPARQL Endpoint Information. Int. J. Graph Comput. 2020, 1, 39–69. [Google Scholar] [CrossRef]
- Krommyda, M.; Kantere, V. Improving the Quality of the Conversational Datasets through Extensive Semantic Analysis. In Proceedings of the 2019 IEEE International Conference on Conversational Data Knowledge Engineering (CDKE), San Diego, CA, USA, 9–11 December 2019; pp. 1–8. [Google Scholar]
- Krommyda, M.; Kantere, V. Semantic analysis for conversational datasets: Improving their quality using semantic relationships. Int. J. Semant. Comput. 2020, 14, 395–422. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Nowak, J.; Taspinar, A.; Scherer, R. LSTM recurrent neural networks for short text and sentiment classification. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 11–15 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 553–562. [Google Scholar]
- Olah, C. Understanding lstm networks. 2015. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs (accessed on 17 November 2020).
- Sagheer, A.; Kotb, M. Time series forecasting of petroleum production using deep LSTM recurrent networks. Neurocomputing 2019, 323, 203–213. [Google Scholar] [CrossRef]
- Karevan, Z.; Suykens, J.A. Transductive LSTM for time-series prediction: An application to weather forecasting. Neural Netw. 2020, 125, 1–9. [Google Scholar] [CrossRef]
- Miao, K.C.; Han, T.T.; Yao, Y.Q.; Lu, H.; Chen, P.; Wang, B.; Zhang, J. Application of LSTM for Short Term Fog Forecasting based on Meteorological Elements. Neurocomputing 2020, 408, 285–291. [Google Scholar] [CrossRef]
- Rao, G.; Huang, W.; Feng, Z.; Cong, Q. LSTM with sentence representations for document-level sentiment classification. Neurocomputing 2018, 308, 49–57. [Google Scholar] [CrossRef]
- Wang, J.; Peng, B.; Zhang, X. Using a stacked residual LSTM model for sentiment intensity prediction. Neurocomputing 2018, 322, 93–101. [Google Scholar] [CrossRef]
- Rao, A.; Spasojevic, N. Actionable and political text classification using word embeddings and lstm. arXiv 2016, arXiv:1607.02501. [Google Scholar]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Kibriya, A.M.; Frank, E.; Pfahringer, B.; Holmes, G. Multinomial naive bayes for text categorization revisited. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Cairns, QLD, Australia, 4–6 December 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 488–499. [Google Scholar]
- Zuo, Z. Sentiment Analysis of Ateam Review Datasets Using Naive Bayes and Decision Tree Classifier. 2018. Available online: http://hdl.handle.net/2142/100126 (accessed on 14 February 2021).
- Al Amrani, Y.; Lazaar, M.; El Kadiri, K.E. Random forest and support vector machine based hybrid approach to sentiment analysis. Procedia Comput. Sci. 2018, 127, 511–520. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 14 February 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Testing Accuracy |
|---|---|
| LSTM | 91.90% |
| SVM-SGD | 86.86% |
| XGBoost | 84.45% |
| Naive Bayes | 77.01% |
| Decision Tree | 84.69% |
| Random forest | 80.35% |
| # | Correctly Classified Tweets | Annotated as | Classified as |
|---|---|---|---|
| (1) | Nothing hurt more than loyalty coming from one side in a relationship. | anger | anger |
| (2) | What a vibe This song made my day | joy | joy |
| (3) | How you gonna find a knockoff version of me that welcomes commitment that’s gross | disgust | disgust |
| (4) | The greatest day of the year has finally begun | anticipation | anticipation |
| (5) | How to cope with parents who regret your existence | sadness | sadness |
| (6) | can we cancel 2020? im so done | sadness | sadness |
| (7) | god bless the ability to mute people on instagram | anticipation | anticipation |
| (8) | I cant wait to live alone in the mountains. | anticipation | anticipation |
| (9) | I hate this fucking song | anger | anger |
| Incorrectly Classified Tweets | |||
| (10) | 40 minutes till i can play tomb raider again | sadness | joy |
| (11) | Man I hate my life | disgust | anger |
| (12) | allergy highs | disgust | joy |
| (13) | CHANGE MY PIC TO ALL THOSE DIRTY HACKERS AND SCAMMERS TRYING TO USE MY FB, INSTAGRAM PG, THANK YOU MONIE FOR THE LOOKOUT CHICK!!! #CLASS OF ’88 | joy | anger |
| (14) | I love not being loved by my friends | joy | sadness |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krommyda, M.; Rigos, A.; Bouklas, K.; Amditis, A. An Experimental Analysis of Data Annotation Methodologies for Emotion Detection in Short Text Posted on Social Media. Informatics 2021, 8, 19. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8010019
Krommyda M, Rigos A, Bouklas K, Amditis A. An Experimental Analysis of Data Annotation Methodologies for Emotion Detection in Short Text Posted on Social Media. Informatics. 2021; 8(1):19. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8010019
Chicago/Turabian StyleKrommyda, Maria, Anastasios Rigos, Kostas Bouklas, and Angelos Amditis. 2021. "An Experimental Analysis of Data Annotation Methodologies for Emotion Detection in Short Text Posted on Social Media" Informatics 8, no. 1: 19. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8010019