
AI and Big Data in Healthcare: Towards a More Comprehensive Research Framework for Multimorbidity



Abstract
:1. Introduction
2. The Time for the Paradigm Change in Research on Multimorbidity
3. The Machine Learning/Big Data Approaches and Challenges in Research on Chronic Diseases and Multimorbidity
4. Current State and Future Perspective in Using Machine Learning/Big Data Analytics in Research on Multimorbidity
4.1. New Approaches in Multimorbidity Research Associated with Patterns and Clusters
4.2. The Ways to Improve Implementation of Machine Learning/Big Data Approaches in Research on Multimorbidity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Ogura, S.; Jakovljevic, M.M. Editorial, Global population aging—Health care, social and economic consequences. Front. Public Health 2018, 6, 335. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Urbanization and Health. Bull. World Health Org. 2010, 88, 241–320. [Google Scholar]
- Barnett, K.; Mercer, S.W.; Norbury, M.; Watt, G.; Wyke, S.; Guthrie, B. Epidemiology of multimorbidity and implications for health care, research and medical education, A cross-sectional study. Lancet 2012, 38, 37–43. [Google Scholar] [CrossRef] [Green Version]
- Sevick, M.A.; Trauth, J.; Ling, B.S.; Anderson, R.T.; Piatt, G.A.; Kilbourne, A.M.; Goodman, R.M. Patients with complex chronic diseases, perspectives on supporting self-management. J. Gen. Intern. Med. 2007, 22, 438–444. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wallace, E.; Salisbury, C.; Guthrie, B.; Lewis, C.; Fahey, T.; Smith, S.M. Managing patients with multimorbidity in primary care. BMJ 2015, 350, h176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boyd, C.; Smith, C.D.; Masoudi, F.A.; Blaum, C.S.; Dodson, J.A.; Green, A.R.; Kelley, A.; Matlock, D.; Ouellet, J.; Rich, M.W.; et al. Decision making for older adults with multiple chronic conditions, Executive Summary for the American Geriatrics Society Guiding Principles on the Care of Older Adults With Multimorbidity. J. Am. Geriatr. Soc. 2019, 67, 665–673. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heleno, B.; Silvério-Rodrigues, D. Multimorbidity and the challenge to deliver personalised and meaningful health care. Port. J. Public Health 2019, 37, I–III. [Google Scholar] [CrossRef]
- Onder, G.; Palmer, K.; Navickas, R.; Jurevičienė, E.; Mammarella, F.; Strandzheva, M.; Mannucci, P.; Pecorelli, S.; Marengoni, A. Time to face the challenge of multimorbidity. A European perspective from the joint action on chronic diseases and promoting healthy ageing across the life cycle (JA-CHRODIS). Eur. J. Intern. Med. 2015, 26, 157–159. [Google Scholar] [CrossRef]
- Gijsen, R.; Hoeymans, N.; Schellevis, F.G.; Ruwaard, D.; Satariano, W.A.; van den Bos, G.A. Causes and consequences of comorbidity. A review. J. Clin. Epidemiol. 2001, 54, 661–674. [Google Scholar] [CrossRef]
- Sinnige, J.; Braspenning, J.; Schellevis, F.; Stirbu-Wagner, I.; Westert, G.; Korevaar, J. The prevalence of disease clusters in older adults with multiple chronic diseases—A systematic literature review. PLoS ONE 2013, 8, e79641. [Google Scholar] [CrossRef]
- De Vries, N.M.; Staal, J.B.; van Ravensberg, C.D.; Hobbelen, J.S.M.; Olde Rikkert, M.G.M.; Nijhuis-van der Sanden, N.W.G. Outcome instruments to measure frailty: A systematic review. Ageing Res. Rev. 2011, 10, 104–114. [Google Scholar] [CrossRef] [PubMed]
- Stirland, L.E.; González-Saavedra, L.; Mullin, D.S.; Muniz-Terrera, D. Measuring multimorbidity beyond counting diseases, systematic review of community and population studies and guide to index choice. BMJ 2020, 368, m127. [Google Scholar] [CrossRef] [Green Version]
- Muth, C.; Blom, J.W.; Smith, S.M.; Johnell, K.; Gonzalez-Gonzalez, A.I.; Nguyen, T.S.; Brueckle, M.S.; Cesari, M.; Tinetti, M.E.; Valderas, J.M. Evidence supporting the best clinical management of patients with multimorbidity and polypharmacy, a systematic guideline review and expert consensus. J. Intern. Med. 2019, 285, 272–288. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fröhlich, H.; Balling, R.; Beerenwinkel, N.; Kohlbacher, O.; Kumar, S.; Lengauer, L.; Maathuis, M.H.; Moreau, Y.; Murphy, S.A.; Przytycka, T.M.; et al. From hype to reality: Data science enabling personalized medicine. BMC Med. 2018, 16, 150. [Google Scholar] [CrossRef] [PubMed]
- Read, J.R.; Sharpe, L.; Modini, M.; Dear, B.F. Multimorbidity and depression, A systematic review and meta-analysis. J. Affect. Dis 2017, 221, 36–46. [Google Scholar] [CrossRef] [PubMed]
- Gould, C.E.; O’Hara, R.; Goldstein, M.K.; Beaudreau, S.A. Multimorbidity is associated with anxiety in older adults in the Health and Retirement Study. Int J. Geriatr. Psychiatry 2016, 31, 1105–1115. [Google Scholar] [CrossRef] [Green Version]
- Kohrt, B.A.; Griffith, J.L.; Patel, V. Chronic pain and mental health, integrated solutions for global problems. Pain 2018, 159, S85–S90. [Google Scholar] [CrossRef]
- Jank, R.; Gallee, A.; Boeckle, M.; Fiegl, S.; Pieh, C. Chronic pain and sleep disorders in primary care. Pain Res. Treat. 2017, 2, 9081802. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alexopoulos, G.S. The vascular depression hypothesis, 10 years later. Biol. Psychiatry 2006, 60, 1304–1305. [Google Scholar] [CrossRef]
- Valiengo, L.C.; Stella, F.; Forlenza, O.V. Mood disorders in the elderly, prevalence, functional impact, and management challenges. Neuropsychiatr. Dis. Treat. 2016, 12, 2105–2114. [Google Scholar]
- Moussavi, S.; Chatterji, S.; Verdes, E.; Tandon, A.; Patel, V.; Ustun, B. Depression, chronic diseases, and decrements in health, Results from the World Health Surveys. Lancet 2007, 370, 851–858. [Google Scholar] [CrossRef]
- Fiske, A.; Wetherell, J.L.; Gatz, M. Depression in older adults. Annu Rev. Clin. Psychol 2009, 5, 363–389. [Google Scholar] [CrossRef]
- Inouye, S.K.; Studenski, S.; Tinetti, M.E.; Kuchel, G.A. Geriatric syndromes, clinical, research and policy implications of a core geriatric concept. J. Am. Geriatr. Soc. 2007, 55, 780–791. [Google Scholar] [CrossRef] [PubMed]
- Calderόn-Larrañaga, A. Multimorbidity and functional impairment—Bidirectional interplay, synergistic effects and common pathways. J. Intern. Med. 2019, 285, 255–271. [Google Scholar] [CrossRef] [Green Version]
- Fried, L.P.; Qian-Li, X.; Cappola, A.R.; Ferucci, L.; Chaves, P.; Varadhan, R.; Guralnik, J.M.; Leng, S.X.; Semba, R.D.; Walston, J.D.; et al. Nonlinear multisystem physiological dysregulation associated with frailty in older women, Implications for etiology and treatment. J. Gerontol. A Biol. Sci. Med. Sci. 2009, 64, 1049–1057. [Google Scholar] [CrossRef] [Green Version]
- Hanlon, P.; Nicholl, B.I.; Jani, B.D.; Lee, D.; McQueenie, R.; Mair, F.S. Frailty and pre-frailty in middle-aged and older adults and its association with multimorbidity and mortality, A prospective analyses of 493 737 UK biobank participants. Lancet Public Health 2018, 3, e323–e332. [Google Scholar] [CrossRef]
- Rusanen, M.; Kivipelto, M.; Levälahti, E.; Laatikainen, T.; Tuomilehto, J.; Soininen, H.; Ngandu, T. Heart diseases and long-term risk of dementia and Alzheimer’s disease, a population-based CAIDE study. J. Alzheimers Dis 2014, 42, 183–191. [Google Scholar] [CrossRef] [PubMed]
- Canavelli, M.; Cesati, M.; van Kan, G.A. Frailty and cognitive decline, how do they relate? Curr. Opin. Clin. Nutr. Metab. Care 2015, 18, 43–50. [Google Scholar] [CrossRef]
- Raghupathi, W.; Raghupathi, V. Big data analytics in healthcare, promise and potential. Health Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef]
- Lee, C.H.; Yoon, H.J. Medical big data, promise and challenges. Kidney Res. Clin. Pract. 2017, 36, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Hassaine, A.; Salimi-Khorshidi, G.; Canoy, D.; Rahimi, K. Untangling the complexity of multimorbidity with machine learning. Mech. Ageing Dev. 2020, 190, 111325. [Google Scholar] [CrossRef] [PubMed]
- Hand, D.J. Statistics and data mining, intersecting disciplines. SIGKDD Explor. 1999, 1, 16–19. [Google Scholar] [CrossRef]
- Johnson, J.L. Probability and Statistics for Computer Science; Whiley: New York, NY, USA, 2011. [Google Scholar]
- Steyerberg, E.W.; van der Ploeg, T.; Van Calster, B. Risk prediction with machine learning and regression methods, risk prediction with machine learning and regression methods. Biom. J. 2014, 56, 601–606. [Google Scholar] [CrossRef]
- Trtica Majnaric, L. Complex thinking and Big Data. CPQ Neurol. Psychol. 2018, 2, 1–4. [Google Scholar]
- Morin, E. Complex thinking for a complex world—About reductionism, disjunction and systemism. Systema 2014, 2. [Google Scholar]
- Goldberger, A.L.; Peng, C.K.; Lipsitz, L.A. What is physiologic complexity and how does it change with aging and disease? Neurobiol. Aging 2002, 23, 23–26. [Google Scholar] [CrossRef]
- Holzinger, A.; Malle, B.; Saranti, A.; Pfeifer, B. Towards Multi-Modal Causability with Graph Neural Networks enabling Information Fusion for explainable AI. Inf. Fusion 2001, 71, 28–37. [Google Scholar] [CrossRef]
- Franceschi, C.; Garagnani, P.; Morsiani, C.; Conte, M.; Santoro, A.; Grignolio, A.; Monti, D.; Capri, M.; Savioli, S. The continuum of aging and age-related diseases, common mechanisms but different rates. Front. Med. 2018, 5, 61. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lipsitz, L.A. Physiological complexity, aging and the path to frailty. Sci. Aging Knowl. Environ. 2004, 200, 16. [Google Scholar] [CrossRef]
- Sidey-Gibbons, J.; Sidey-Gibbons, C. Machine learning in medicine, a practical introduction. BMC Med. Res. Methodol. 2019, 19, 64. [Google Scholar] [CrossRef] [Green Version]
- Lan, K.; Wang, D.; Fong, S.; Liu, L.; Wong, K.K.L.; Dey, N. A survey of data mining and deep learning in bioinformatics. J. Med. Syst. 2018, 42, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Bellazzi, R. Big data and biomedical informatics, a challenging opportunity. Yearb. Med. Inform. 2014, 9, 8–13. [Google Scholar] [CrossRef] [Green Version]
- Moawad, N.G.; Elkhalil, J.; Klebanoff, J.S. Augmented Realities, Artificial Intelligence, and Machine Learning: Clinical Implications and How Technology Is Shaping the Future of Medicine. J. Clin. Med. 2020, 9, 3811. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.Y.; Cheng, C.W.; Kaddi, C.D.; Venugopalan, J.; Hoffman, R.; Wang, M.D. Omic and electronic health record Big Data analytics for Precision Medicine. IEEE Trans. Biomed. Eng. 2017, 64, 263–273. [Google Scholar]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago de Chile, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Ale, J.M.; Rossi, G.H. An Approach to Discovering Temporal Association Rules. In Proceedings of the 2000 ACM Symposium on Applied Computing, San Antonio, TX, USA, 19–21 March 2000; pp. 294–300. [Google Scholar]
- Tolles, J.; Meurer, W.J. Logistic Regression Relating Patient Characteristics to Outcomes. JAMA 2016, 316, 533–534. [Google Scholar] [CrossRef]
- Hand, D.J.; Yu, K. Idiot’s Bayes-not so stupid after all? Int. Stat. Rev. 2001, 69, 385–399. [Google Scholar]
- Murthy, K.S. Automatic construction of decision tress from data: A multidisciplinary survey. In Data Mining and Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 1997; pp. 345–389. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Hornik, K. Approximation capabilities of multilayer feedforward networks. Neural Netw. 1991, 4, 251–257. [Google Scholar] [CrossRef]
- Forgy, E.W. Cluster analysis of multivariate data: Efficiency versus interpretability of classifications. Biometrics 1965, 21, 768–769. [Google Scholar]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis; Springer Series in Statistics; Springer: New York, NY, USA, 2002. [Google Scholar]
- Kohonen, T. Self-Organized Formation of Topologically Correct Feature Maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Collins, L.M.; Lanza, S.T. Latent Class and Latent Transition Analysis: With Applications in the Social, Behavioral, and Health Sciences; Wiley: New York, NY, USA, 2010. [Google Scholar]
- Washio, T.; Motoda, H. State of the art of graph-based data mining. SIGKDD Exp. 2003, 5, 59–68. [Google Scholar] [CrossRef]
- Goldberg, Y. A Primer on Neural Network Models for Natural Language Processing. J. Artif. Intell. Res. 2016, 57, 345–420. [Google Scholar] [CrossRef] [Green Version]
- Cichocki, A.; Mørup, M.; Smaragdis, P.; Wang, W.; Zdunek, R. Advances in Nonnegative Matrix and Tensor Factorization. Comput. Intell. Neurosci. 2008, 2008, 852187. [Google Scholar] [CrossRef]
- Griffith, L.E.; Gruneir, A.; Fisher, K.A.; Nicholson, K.; Panjwani, D.; Patterson, C.; Markle-Reid, M.; Ploeg, J.; Bierman, A.S.; Hogan, D.B.; et al. Key factors to consider when measuring multimorbidity. Results from an expert panel and online survey. J. Comorb. 2018, 8. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A. Interactive machine learning for health informatics, when do we need the human-in-the-loop? Brain Inform. 2016, 3, 119–131. [Google Scholar] [CrossRef] [Green Version]
- Richtera, A.N.; Khoshgoftaara, T.M. A review of statistical and machine learning methods for modeling cancer risk using structured clinical data. Artif. Intell. Med. 2018, 90, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Rajan, J.R.; Prakash, J.J. Early diagnosis of lung cancer using a mining tool. In Proceedings of the National Conferenceon Architecture, Software systems and Green computing-2013(NCASG2013), Tamil Nadu, India, 3 May 2013. [Google Scholar]
- Zou, Q.; Qu, K.; Luo, Y.; Yin, D.; Ju, Y.; Tang, H. Predicting Diabetes Mellitus with Machine Learning techniques. Front. Genet. 2018, 9, 515. [Google Scholar] [CrossRef]
- Sacchi, L.; Dagliati, A.; Segagni, D.; Leporati, P.; Chiovato, L.; Bellazi, R. Improving risk-stratification of Diabetes complications using temporal data mining. In Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 31 March 2015; pp. 2131–2134. [Google Scholar]
- Yousefi, L.; Swift, S.; Arzaky, M.; Saachi, L.; Chiovato, L.; Tucker, A. Opening the black box, personalizing type 2 diabetes patients based on their latent phenotype and temporal associated complication rules. Comput. Intell. 2020, 1–39. [Google Scholar] [CrossRef] [Green Version]
- Shaikhina, T.; Khovanova, N. Handling limited datasets with neural networks in medical applications, a small-data approach. Artef. Intell. Med. 2017, 75, 51–63. [Google Scholar] [CrossRef] [PubMed]
- Babič, F.; Pusztová, L.; Trtica Majnarić, L. Mild Cognitive Impairment detection using Association Rules Mining. Acta Inform. Prag. 2020, 9, 92–107. [Google Scholar] [CrossRef]
- Babič, F.; Trtica Majnarić, L.; Lukáčová, A.; Paralič, J.; Holzinger, A. On patient’s characteristics extraction for metabolic syndrome diagnosis, Predictive modelling based on machine learning. Information Technology. In Bio- and Medical Informatics; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8649, pp. 118–132. [Google Scholar]
- Rokošná, J.; Babič, F.; Trtica-Majnaric, L.; Pusztová, L. Cooperation between data analysts and medical experts, A case study. In Proceedings of the International Cross-Domain Conference, CD-MAKE 2020, Dublin, Ireland, 25–28 August 2020; pp. 173–190. [Google Scholar]
- Šabanović, Š.; Majnaric Trtica, L.; Babič, F.; Vadovský, M.; Paralič, J.; Včev, A.; Holzinger, A. Metabolic syndrome in hypertensive women in the age of menopause, a case study on data from general practice electronic health records. BMC Med. Inform. Decis. Mak. 2018, 18, 1–18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Majnaric Trtica, L.; Vitale, B. Systems biology as a conceptual framework for research in family medicine, use in predicting response to influenza vaccination. Prim. Health Care Res. Develop 2011, 12, 310–321. [Google Scholar] [CrossRef] [Green Version]
- Majnarić Trtica, L.; Babič, F.; Bosnić, Z.; Zekić-Sušac, M.; Wittlinger, T. The use of Artificial Intelligence in assessing glucose variability in individuals with Diabetes type 2 from routine primary care data. Int. J. Diabetes Clin. Res. 2020, 7, 121. [Google Scholar]
- Hund, M.; Böhm, D.; Sturm, W.; Sedlmair, M.; Schreck, T.; Ullrich, T.; Keim, D.A.; Majnaric, L.T.; Holzinger, A. Visual analytics for concept exploration in subspaces of patient groups. Brain Inform. 2016, 3, 233–247. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xiao, C.; Choi, E.; Sun, J. Opportunities and challenges in developing deep learning models using electronic health records data: A systematic review. J. Am. Med. Inform. Assoc. 2018, 25, 1419–1428. [Google Scholar] [CrossRef]
- Holder, L.B.; Haque, M.M.; Skinner, M.K. Machine learning for epigenetics and future medical applications. Epigenetics 2017, 12, 505–514. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shah, P.; Kendall, F.; Khozin, S.; Goosen, R.; Hu, J.; Laramie, J.; Ringel, M.; Schork, N. Artificial intelligence and machine learning in clinical development: A translational perspective. NPJ Digit. Med. 2019, 2, 69. [Google Scholar] [CrossRef] [Green Version]
- Alyass, A.; Turcotte, M.; Meyre, D. From big data analysis to personalized medicine for all: Challenges and opportunities. BMC Med. Genom. 2015, 8, 33. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krittanawong, C.; Bomback, A.S.; Baber, U.; Bangalore, S.; Messerli, F.H.; Tang, W.H.W. Future Direction for Using Artificial Intelligence to Predict and Manage Hypertension. Curr. Hypertens Rep. 2018, 20, 75. [Google Scholar] [CrossRef] [PubMed]
- van den Bussche, H.; Koller, D.; Kolonko, T.; Hansen, H.; Wegscheider, K.; Glaeske, G.; von Leitner, E.C.; Schäfer, I.; Schön, G. Which chronic diseases and disease combinations are specific to multimorbidity in the elderly? Results of a claims data based cross-sectional study in Germany. BMC Public Health 2011, 11, 101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Larsen, B.F.; Pedersen, H.M.; Friis, K.; Glümer, C.; Lasgaard, M. Latent class analysis of multimorbidity and the relationship to socio-demographic factors and health-related quality of life. A national population-based study of 162,283 Danish adults. PLoS ONE 2017, 12, e0169426. [Google Scholar] [CrossRef]
- Van Oostrom, S.H.; Picavet, H.S.J.; van Gelder, B.M.; Lemmens, L.C.; Hoeymans, N.; Verheij, R.A.; Schellevis, F.G.; Baan, B.A. Multimorbidity and comorbidity in the Dutch population—data from general practices. BMC Public Health 2012, 12, 715. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Déruaz-Luyet, A.; N’Goran, A.A.; Senn, N.; Bodenmann, R.; Pasquier, O.; Widmer, D.; Tandjung, R.; Rosemann, T.; Frey, P.; Streit, S. Multimorbidity and patterns of chronic conditions in a primary care population in Switzerland, a cross-sectional study. BMJ Open 2017, 7, e013664. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roso-Llorach, A.; Violán, C.; Foguet-Boreu, Q.; Rodriguez-Blanco, T.; Pons-Vigués, M.; Pujol-Ribera, E.; Valderas, J.M. Comparative analysis of methods for identifying multimorbidity patterns, a study of ‘real-world’ data. BMJ Open 2018, 8, e018986. [Google Scholar] [CrossRef] [PubMed]
- Hernández, B.; Reilly, R.B.; Kenny, R.A. Investigation of multimorbidity and prevalent disease combinations in older Irish adults using network analysis and association rules. Sci. Rep. 2019, 9, 14567. [Google Scholar] [CrossRef]
- Yao, S.S.; Cao, G.Y.; Han, L.; Chen, Z.; Huang, Z.; Gong, P.; Hu, Y.; Xu, B. Prevalence and patterns of multimorbidity in a nationally representative sample of older Chinese: Results from CHARLS. J. Gerontol. 2020, 75, 1974–1980. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Kim, H.; Jeong, H.; Noh, Y. Patterns of Multimorbidity in Adults: An Association Rules Analysis Using the Korea Health Panel. Int. J. Environ. Res. Public Health 2020, 17, 2618. [Google Scholar] [CrossRef] [Green Version]
- Schiltz, N.K.; Warner, D.F.; Sun, J. Identifying specific combinations of multimorbidity that contribute to health care resource utilization: An analytic approach. Med. Care. 2017, 55, 276–284. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pedro, M.C.; Mercedes, M.P.; Ramón, L.H.; Borja, M.R. Subjective memory complaints in elderly: Relationship with health status, multimorbidity, medications, and use of services in a population-based study. Int. Psychogeriatr. 2016, 28, 1903–1916. [Google Scholar] [CrossRef] [PubMed]
- Bekić, S.; Babič, F.; Filipčić, I.; Majnarić Trtica, L. Clustering of mental and physical comorbidity and the risk of frailty in patients aged 60 years or more in primary care. Med. Sci. Monit. 2019, 25, 6820–6835. [Google Scholar] [CrossRef]
- Majnarić Trtica, L.; Bekić, S.; Babič, F.; Pusztová, Ľ.; Paralič, J. Cluster Analysis of the Associations among Physical Frailty, Cognitive Impairment and Mental Disorders. Med. Sci. Monit. 2020, 26, e924281. [Google Scholar]
- Marengoni, A.; Roso-Llorach, A.; Vetrano, D.L.; Fernández-Bertolín, S.; Guisado-Clavero, M.; Violán, C.; Calderón-Larrañaga, A. Patterns of multimorbidity in a population-based cohort of older people, sociodemographic, lifestyle, clinical, and functional differences. J. Gerontol. A Biol. 2020, 75, 798–805. [Google Scholar] [CrossRef]
- Gambhir, S.; Malik, S.K.; Kumar, Y. Role of soft computing approaches in healthcare domain, A mini review. J. Med. Syst. 2016, 40, 287. [Google Scholar] [CrossRef] [PubMed]
- Shickel, B.; Tighe, P.J.; Bihorac, A.; Rashidi, P. Deep EHR: A Survey of Recent Advances in Deep Learning Techniques for Electronic Health Record (EHR) Analysis. IEEE J. Biomed. Health Inform. 2018, 22, 1589–1604. [Google Scholar] [CrossRef]
- Li, Y.; Rao, S.; Solares, J.R.A.; Hassaine, A.; Ramakrishnan, R.; Canoy, D.; Zhu, Y.; Rahimi, K.; Salimi-Khorshidi, G. BEHRT: Transformer for Electronic Health Records. Sci. Rep. 2020, 10, 7155. [Google Scholar] [CrossRef] [PubMed]
- Meng, W.; Ou, W.; Chandwani, S.; Chen, X.; Black, W.; Cai, Z. Temporal phenotyping by mining healthcare data to derive lines of therapy for cancer. J. Biomed. Inform. 2019, 100, 103335. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Zhang, Y.; Schlueter, D.J.; Wu, P.; Kerchberger, V.E.; Rosenbloom, S.E.; Wells, Q.S.; Feng, Q.; Denny, J.C.; Wie, W. Detecting time-evolving phenotypic topics via tensor factorization on electronic health records, cardiovascular disease case study. J. Biomed. Inform. 2019, 98, 103270. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, P.; Tran, T.; Wickramasinghe, N.; Venkatesh, S. A convolutional net for medical records. IEEE J. Biomed. Health Inform. 2016, 21, 22–30. [Google Scholar] [CrossRef]
- Choi, E.; Bahadori, M.; Schuetz, A.; Stewart, W.F.; Sun, J. Doctor AI, predicting clinical events via recurrent neural networks. Mach. Learn. Healthc. Conf. 2016, 56, 301–318. [Google Scholar]
- Jonsson, A. Deep Reinforcement Learning in Medicine. Kidney Dis. (Basel) 2019, 5, 18–22. [Google Scholar] [CrossRef]
- Weng, C.; Shah, N.H.; Hripcsak, G. Deep phenotyping, Embracing complexity and temporality-Towards scalability, portability, and interoperability. J. Biomed. Inform. 2020, 105, 103433. [Google Scholar] [CrossRef]
- Stenholm, S.; Westerlund, H.; Head, J.; Hyde, M.; Kawachi, I.; Pentti, J.; Kivimäki, M.; Vahtera, J. Comorbidity and functional trajectories from midlife to old age. J. Gerontol. A. Biol 2014, 70, 332–338. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lappenschaar, M.; Hommersom, A.; Lucas, P.J.; Lagro, J.; Visscher, S.; Korevaar, J.C.; Schellevis, F.G. Multilevel temporal Bayesian networks can model longitudinal change in multimorbidity. J. Clin. Epidemiol. 2013, 66, 1405–1416. [Google Scholar] [CrossRef] [Green Version]
- Hassaine, A.; Canoy, D.; Ayala Solares, R.A.; Zhu, Y.; Rao, S.; Li, Y.; Zottoli, M.; Rahimi, K.; Salimi-Khorshidi, G. Learning multimorbidity patterns from electronic health records using non-negative matrix factorisation. J. Biomed. Inform. 2020, 112, 103606. [Google Scholar] [CrossRef]
- Akugizibwe, R.; Calderón-Larrañaga, A.; Roso-Llorach, A.; Onder, G.; Marengoni, A.; Zucchelli, A.; Rizzuto, D.; Vetrano, D.L. Multimorbidity Patterns and Unplanned Hospitalisation in a Cohort of Older Adults. J. Clin. Med. 2020, 9, 4001. [Google Scholar] [CrossRef]
- Rizzo, L.; Majnaric Trtica, L.; Dondio, P.; Longo, L. An investigation of Argumentation Theory for the prediction of survival in elderly using biomarkers. In Artificial Intelligence Applications and Innovations; Iliadis, L., Maglogiannis, I., Plagianakos, V., Eds.; Springer: Cham, Switzerland, 2018; Volume 519. [Google Scholar]
- Liang, Z.; Zhang, G.; Huang, J.X.; Hu, Q.V. Deep learning for healthcare decision making with EMRs. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Belfast, UK, 2–5 November 2014; pp. 556–559. [Google Scholar]
- Norgeot, B.; Glicksberg, B.S.; Trupin, L.; Lituiev, D.; Gianfrancesco, M.; Oskotsky, B.; Schmajuk, G.; Yazdany, J.; Butte, A.J. Assessment of a Deep Learning Model Based on Electronic Health Record Data to Forecast Clinical Outcomes in Patients with Rheumatoid Arthritis. JAMA Netw. Open 2019, 2, e190606. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miotto, R.; Li, L.; Kidd, B.A.; Dudley, J.T. Deep Patient: An Unsupervised Representation to Predict the Future of Patients from the Electronic Health Records. Sci. Rep. 2016, 17, 26094. [Google Scholar] [CrossRef] [PubMed]
- Peng, L.N.; Hsiao, F.Y.; Lee, W.J.; Huang, S.T.; Chen, L.K. Comparisons Between Hypothesis- and Data-Driven Approaches for Multimorbidity Frailty Index: A Machine Learning Approach. J. Med. Internet Res. 2020, 22, e16213. [Google Scholar] [CrossRef]
- Searle, S.D.; Mitnitski, A.; Gahbauer, E.A.; Gill, T.M.; Rockwood, K. A standard procedure for creating a frailty index. BMC Geriatr. 2008, 8, 24. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Chen, R.; Tang, J.; Stewart, W.F.; Sun, J. LEAP: Learning to prescribe effective and safe treatment combinations for multimorbidity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2017; pp. 1315–1324. [Google Scholar]
- Pham, T.; Tran, T.; Phung, D.; Venkatesh, S. Predicting healthcare trajectories from medical records: A deep learning approach. J. Biomed. Inform. 2017, 69, 218–229. [Google Scholar] [CrossRef]
- Violán, C.; Foguet-Boreu, Q.; Fernández-Bertolín, S.; Guisado-Clavero, M.; Cabrera-Bean, M.; Formiga, F.; Valderas, J.M.; Roso-Llorach, A. Soft clustering using real-world data for the identification of multimorbidity patterns in an elderly population: Cross-sectional study in a Mediterranean population. BMJ Open 2019, 9, e029594. [Google Scholar]
- Prados-Torres, A.; Poblador-Plou, B.; Calderón-Larrañaga, A.; Gimeno-Feliu, L.A.; González-Rubio, F.; Poncel-Falcó, A.; Sicras-Mainar, A.; Alcalá-Nalvaiz, J.T. Multimorbidity patterns in primary care: Interactions among chronic diseases using factor analysis. PLoS ONE 2012, 7, e32190. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Violán, C.; Fernández-Bertolín, S.; Guisado-Clavero, M.; Foguet-Boreu, Q.; Valderas, J.M.; Manzano, J.V.; Roso-Lhorach, A.; Cabreara-Bean, M. Five-year trajectories of multimorbidity patterns in an elderly Mediterranean population using Hidden Markov Models. Sci Rep. 2020, 10, 16879. [Google Scholar] [CrossRef] [PubMed]
- Anker, D.; Santos-Eggimann, B.; Zwahlen, M.; Santschi, V.; Rodondi, N.; Wolfson, C.; Chiolero, A. Blood Pressure in Relation to Frailty in Older Adults: A Population-Based Study. J. Clin. Hypertens. 2019, 21, 1895–1904. [Google Scholar] [CrossRef]
- Vetrano, D.L.; Rizzuto, D.; Calderón-Larrañaga, A.; Onder, G.; Welmer, A.K.; Bernabei, R.; Marengoni, A.; Fratiglioni, L. Trajectories of functional decline in older adults with neuropsychiatric and cardiovascular multimorbidity: A Swedish cohort study. PLoS Med. 2018, 15, e1002503. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Calderón-Larrañaga, A.; Vetrano, D.L.; Onder, G.; Gimeno-Feliu, L.A.; Coscollar-Santaliestra, C.; Carfí, A.; Pisciotta, M.S.; Angleman, S.; Melis, R.J.F.; Santoni, G. Assessing and measuring chronic multimorbidity in the older population: A proposal for its operationalization. J. Gerontol. Ser. A Biol. Sci. Med. Sci. 2017, 72, 1417–1423. [Google Scholar] [CrossRef]
- Ng, S.K.; Tawiah, R.; Sawyer, M.; Scuffham, P. Patterns of multimorbid health conditions: A systematic review of analytical methods and comparison analysis. Int. J. Epidemiol. 2018, 47, 1687–1704. [Google Scholar] [CrossRef] [Green Version]
- Peterson, E.D. Machine Learning, predictive analytics, and clinical practice, Can the past inform the present? JAMA 2019, 322, 2283–2284. [Google Scholar] [CrossRef] [PubMed]
- Panicacci, S.; Donati, M.; Fanucci, L.; Bellin, I.; Profili, F.; Francesconi, P. Population Health Management Exploiting Machine Learning Algorithms to Identify High-Risk Patients. In Proceedings of the IEEE 31st International Symposium on Computer-Based Medical Systems (CBMS), Karlstad, Sweden, 18–21 June 2018; pp. 298–303. [Google Scholar]
- Boulton, C.; Wilkinson, M. Use of public datasets in the examination of multimorbidity, Opportunities and challenges. Mech. Aging Dev. 2020, 190, 111310. [Google Scholar] [CrossRef]
- Coorevits, P.; Sundgren, M.; Klein, G.O.; Bahr, A.; Claerhout, A.; Daniel, C.; Dugas, M.; Dupont, D.; Schmidt, A.; Singleton, P.; et al. Electronic health records, new opportunities for clinical research. J. Intern. Med. 2013, 274, 547–560. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carrington, A.M.; Fieguth, P.W.; Qazi, H.; Holzinger, A.; Chen, H.H.; Mayr, F.; Manuel, D.G. A new concordant partial AUC and partial c statistic for imbalanced data in the evaluation of machine learning algorithms. BMC Med. Inform. Decis. Mak. 2020, 20, 1–12. [Google Scholar] [CrossRef]
- Hassler, A.P.; Menasalvas, E.; García-García, F.J.; Rodríguez-Mañas, L.; Holzinger, A. Importance of medical data preprocessing in predictive modeling and risk factor discovery for the frailty syndrome. BMC Med. Inform. Decis. Mak. 2019, 19, 33. [Google Scholar] [CrossRef] [PubMed]
- Lindsell, C.J.; Stead, W.W.; Johnson, K.B. Action-informed Artificial Intelligence-matching the algorithm to the problem. JAMA 2020, 323, 2141–2142. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
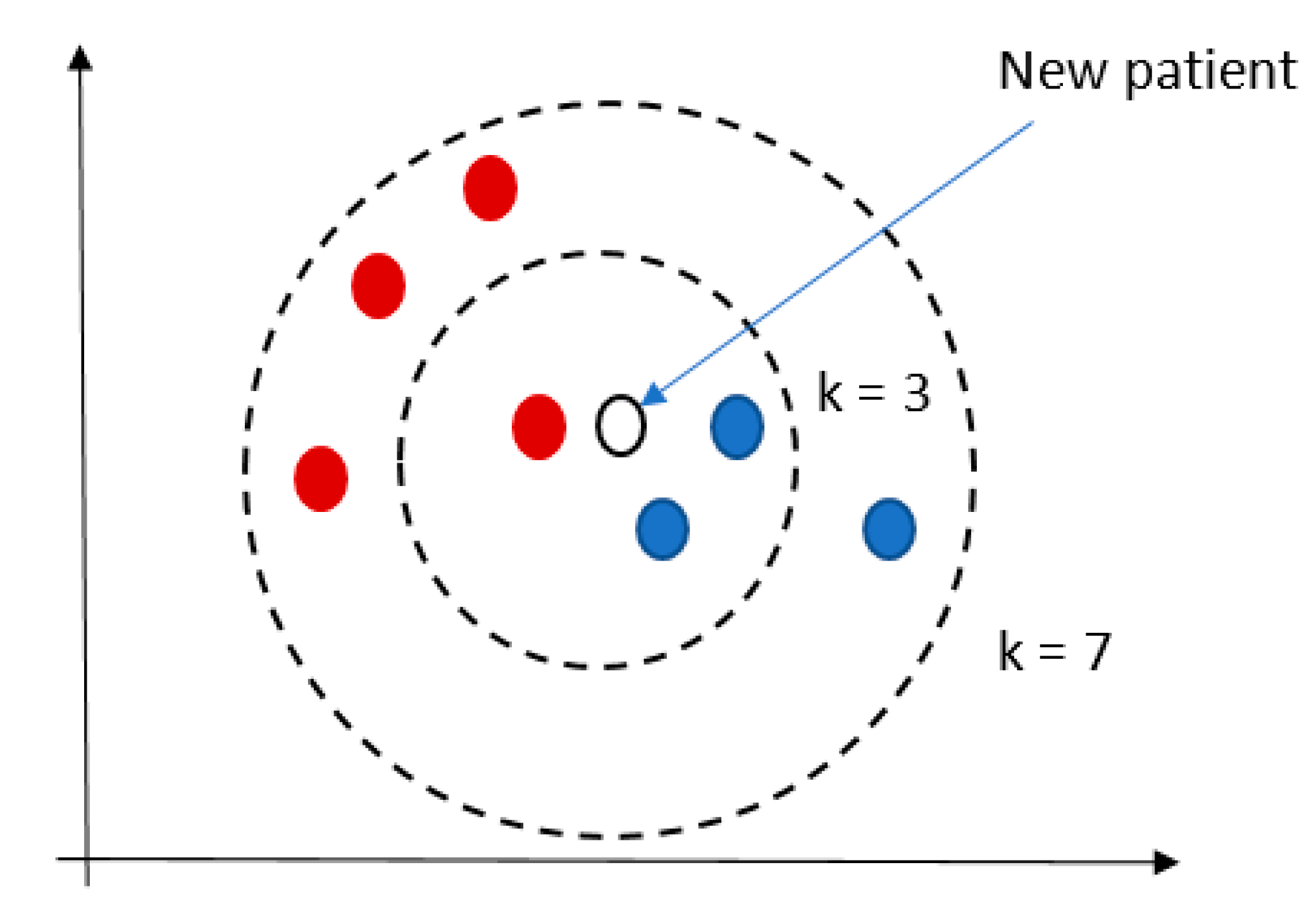{kind=link}
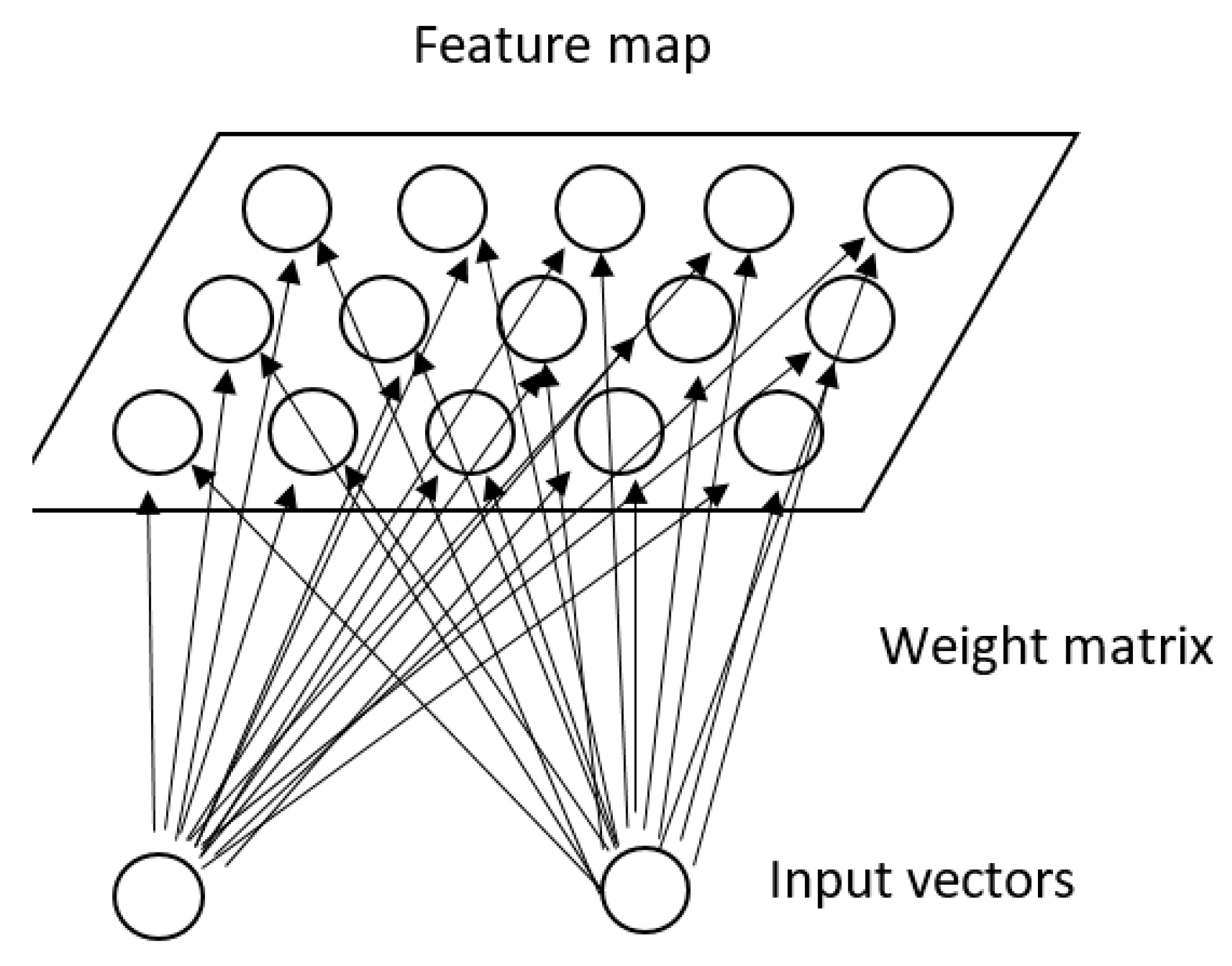{kind=link}
| Key Term | Description |
|---|---|
| Knowledge Discovery (KD) | A multiple-step process in data analysis, often managed using CRISP-DM methodology including steps: (1) business understanding; (2) data understanding; (3) data preparation; (4) modelling–decision models generation, patterns extraction; (5) evaluation and (6) deployment-the new knowledge implementation in practice. |
| Data Mining (DM) | Some experts use it to name the knowledge discovery process. Other experts view data mining as an essential step in the process of knowledge discovery = modelling. |
| Machine Learning (ML) | The engine within the framework of AI; the collection of techniques allowing computers to undertake complicated tasks by implementation of learning on data (by training and validating the data). The main ML categories are Supervised (SV) Learning, Un-Supervised (USV) Learning and Reinforcement Learning. |
| The Big Data analytical approach | Enables managing data of the big size and high diversity and complexity; its emergency is due to the rapid advances of high-throughput (-omics) technologies and a wide adoption of eHRs; it is able to challenge the paradigm shift in research on multimorbidity towards the logic of the precision medicine. |
| Precision medicine | Marked with 4P: Personalized, Predictive, Preventive and Participatory-individualized evaluation and treatments-in contrast to the paradigm “one-size-fits-all”. |
| The black box concept | Refers to models that use nonlinear transformations to facilitate feature identification; it is used in complex algorithms, such as Artificial Neural Networks (ANN) or a new concept called Deep Learning (DL). |
| Method | Description |
|---|---|
| SV Learning algorithms | A model is trained on a range of input data that are associated with a known outcome (but there is no knowledge on predictors). |
| USV Learning algorithms | Does not involve the knowledge of the outcome; they are usually used to find undefined patterns or clusters in datasets or to reduce the number of features. |
| Reinforcement Learning | The algorithms do not need to know the outcome; they use the estimated errors as rewards or penalties. |
| Association Rule Mining (ARM) | Techniques aim to observe frequently occurring patterns, correlations, or associations in the data; how items are associated to each other. |
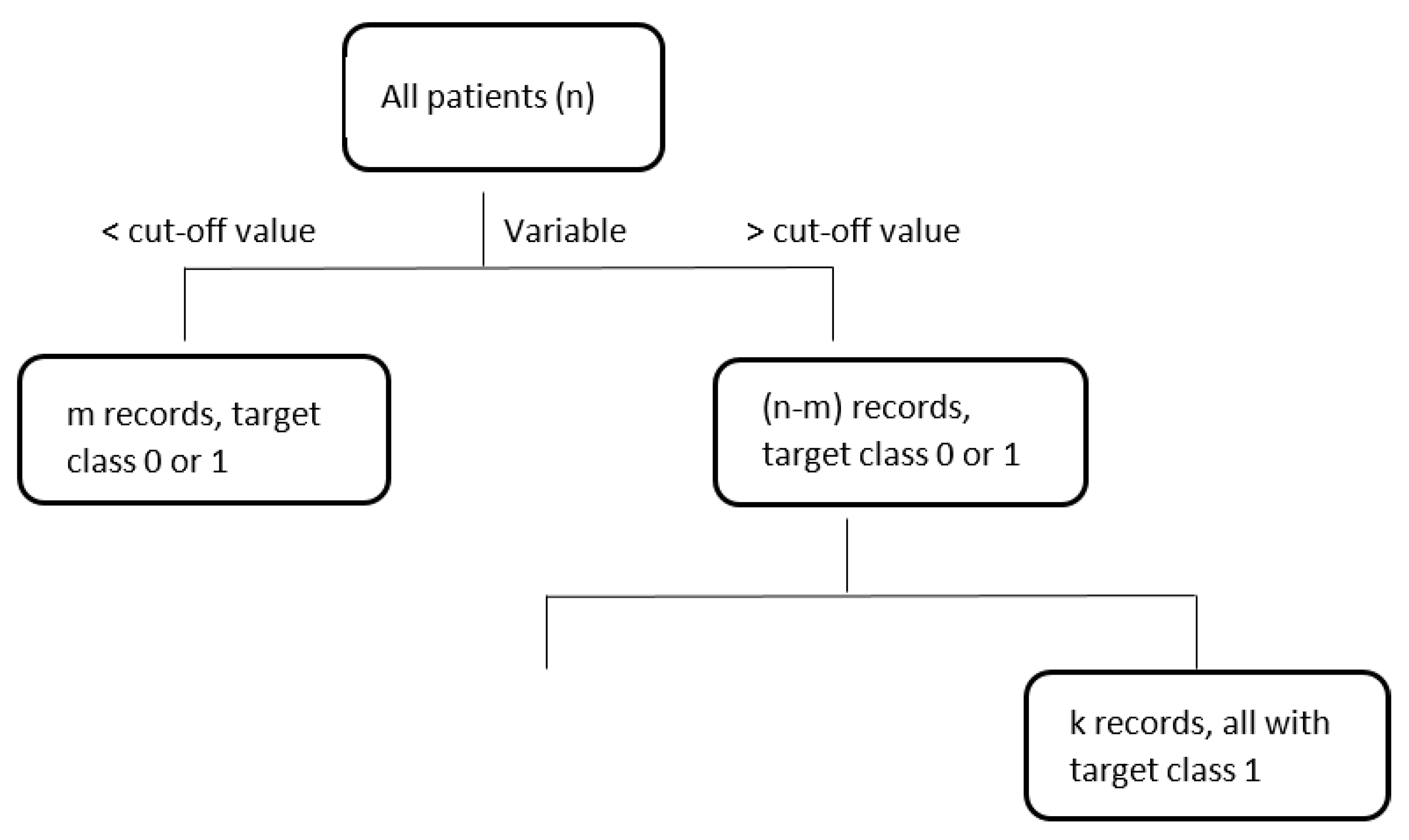
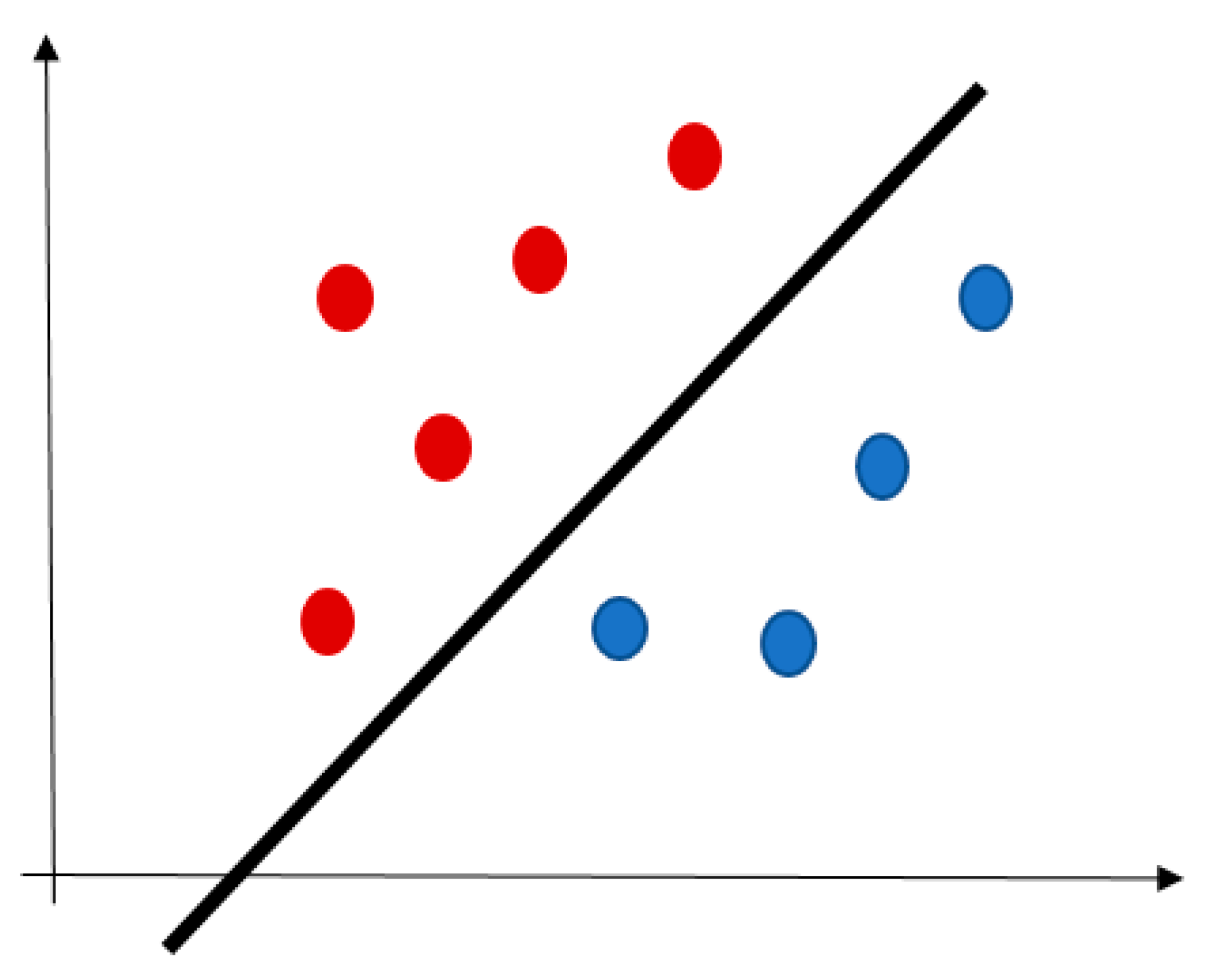
| Classification techniques | The objects are assigned to one of a pre-specified set of classes. Some classification techniques are:
|
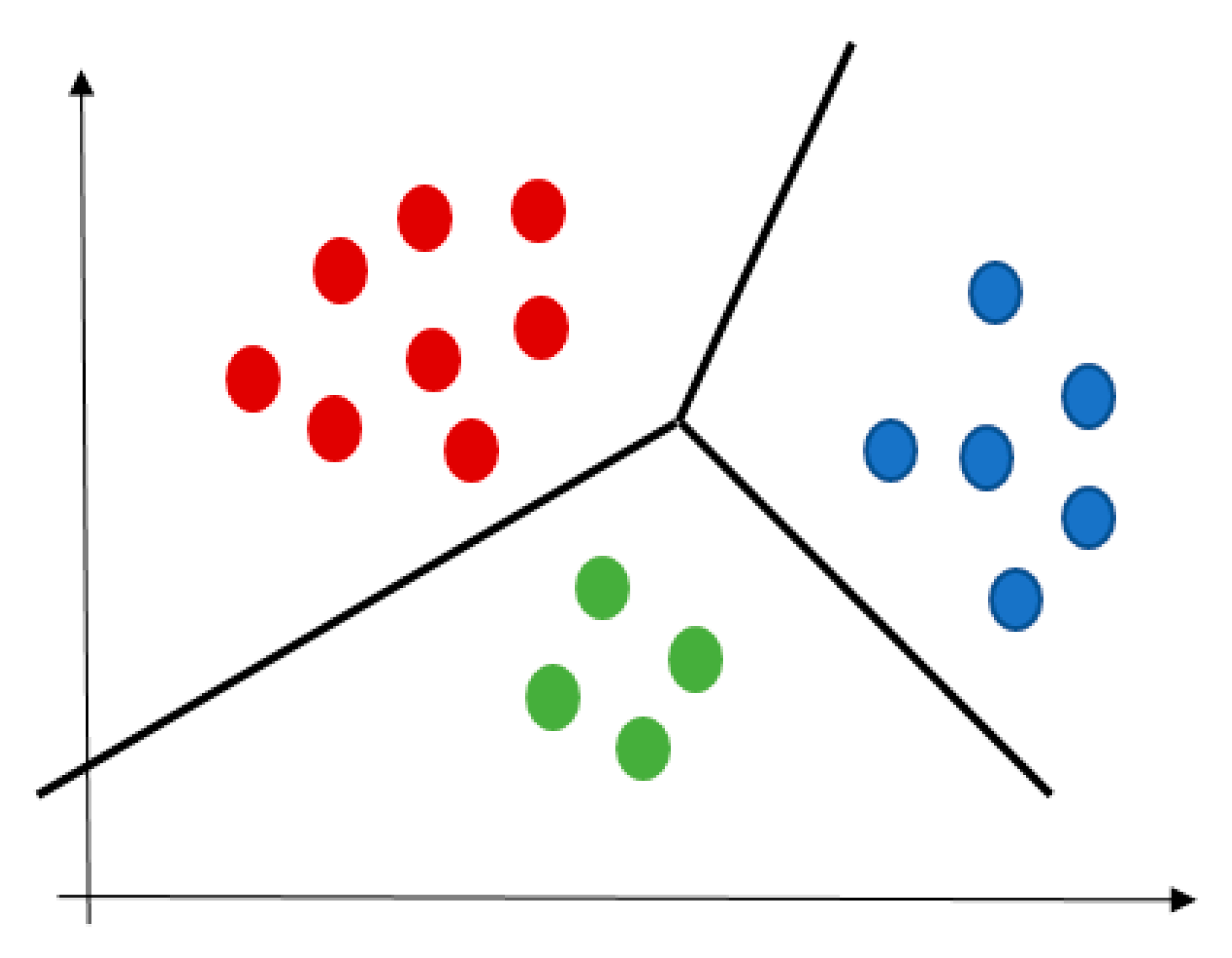
| Clustering techniques | The objects are grouped without any pre-specified knowledge on the rule of their grouping (based on using the distance metrics). Some clustering techniques are:
|
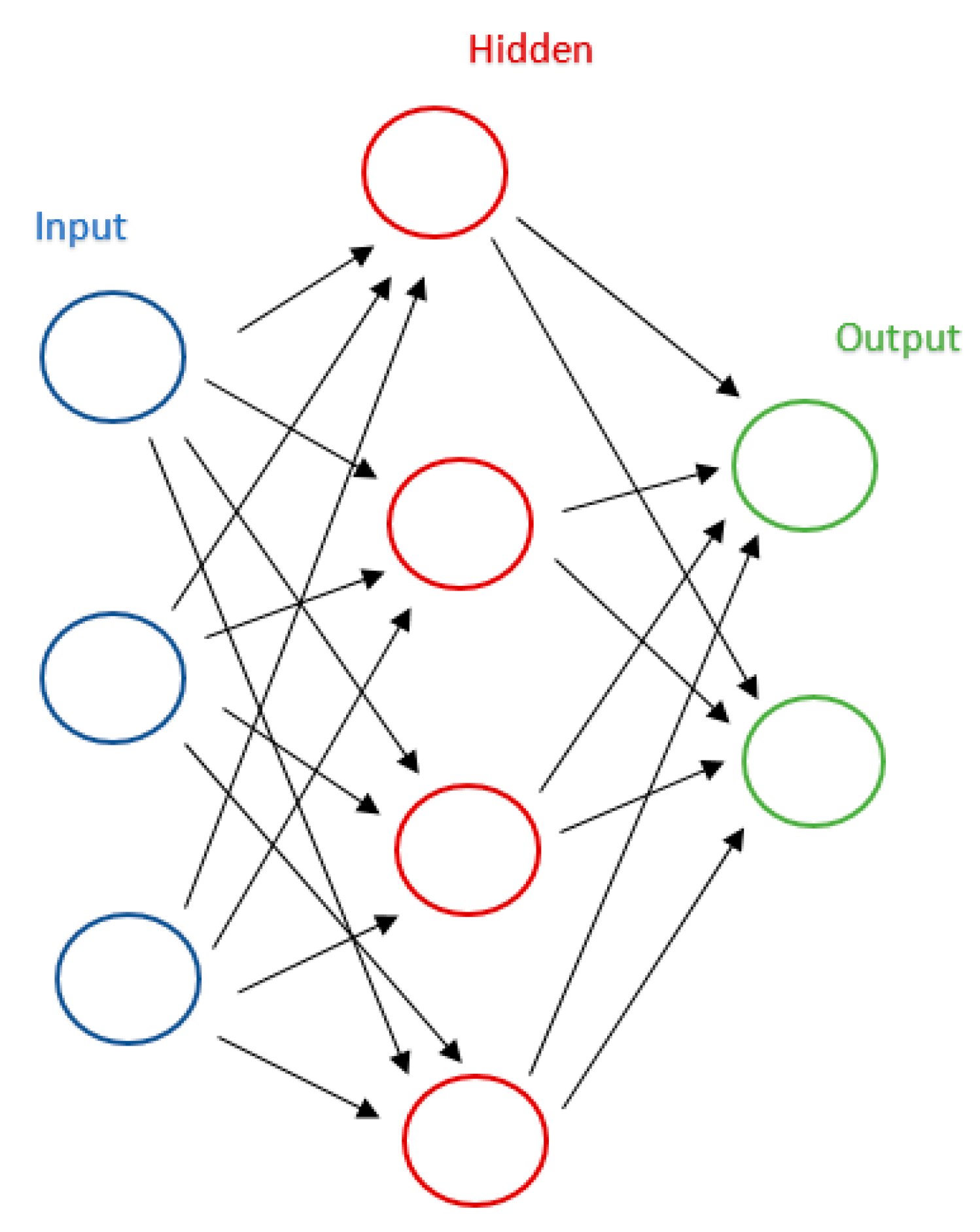
| Deep Learning | More recent concept of ML; has much better ability of feature representation in the abstract level; has an ability to translate the information from the high level of an abstraction to the level that is more understandable for human reasoning; uses complex algorithms, such as ANN. |
| Advanced computer-based methods | Techniques that can be used to organize highly complex or unstructured data or to find temporal trends in data:
|
| Arguments |
|---|
| Managing data of different grades of diversity and complexity. |
| Allowing for hidden knowledge to be extracted from data. |
| The potential to represent real world phenomena. |
| Linking data of different types and of multiple data sources. |
| Clinical research tasks determine research methods, which is opposite to what is nowadays when clinical projects meet the criteria of the established research methods. |
| In predicting the behavior of the system, the method learns from data. |
| Making sense of all accumulated data (including data from routine medical practice). |
| Patterns identification or identification of temporal trends in patterns. |
| The crucial role of a domain expert (knowledge) in data analyzing and in interpreting the results. |
Application in different areas of research on multimorbidity, including:
|
| Statements |
|---|
| Typically, require massive data samples for training. |
| High data quality without missing or biased values. |
| Enough time for model’s generation in combination of training and testing. |
| Insufficient prediction performance for clinical practice |
| Results interpretation, transparency and explainability. |
| More accurate quantitative measures to evaluate the utility and privacy preservation. |
| Insufficient validation for clinical practice |
| High error-susceptibility. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Majnarić, L.T.; Babič, F.; O’Sullivan, S.; Holzinger, A. AI and Big Data in Healthcare: Towards a More Comprehensive Research Framework for Multimorbidity. J. Clin. Med. 2021, 10, 766. https://0-doi-org.brum.beds.ac.uk/10.3390/jcm10040766
Majnarić LT, Babič F, O’Sullivan S, Holzinger A. AI and Big Data in Healthcare: Towards a More Comprehensive Research Framework for Multimorbidity. Journal of Clinical Medicine. 2021; 10(4):766. https://0-doi-org.brum.beds.ac.uk/10.3390/jcm10040766
Chicago/Turabian StyleMajnarić, Ljiljana Trtica, František Babič, Shane O’Sullivan, and Andreas Holzinger. 2021. "AI and Big Data in Healthcare: Towards a More Comprehensive Research Framework for Multimorbidity" Journal of Clinical Medicine 10, no. 4: 766. https://0-doi-org.brum.beds.ac.uk/10.3390/jcm10040766