
Head-Mounted Display-Based Augmented Reality for Image-Guided Media Delivery to the Heart: A Preliminary Investigation of Perceptual Accuracy



Abstract
:1. Introduction
1.1. Motivation
1.2. Related Work
1.3. Objectives
2. Materials and Methods
2.1. Display Device
2.2. Virtual Model Alignment
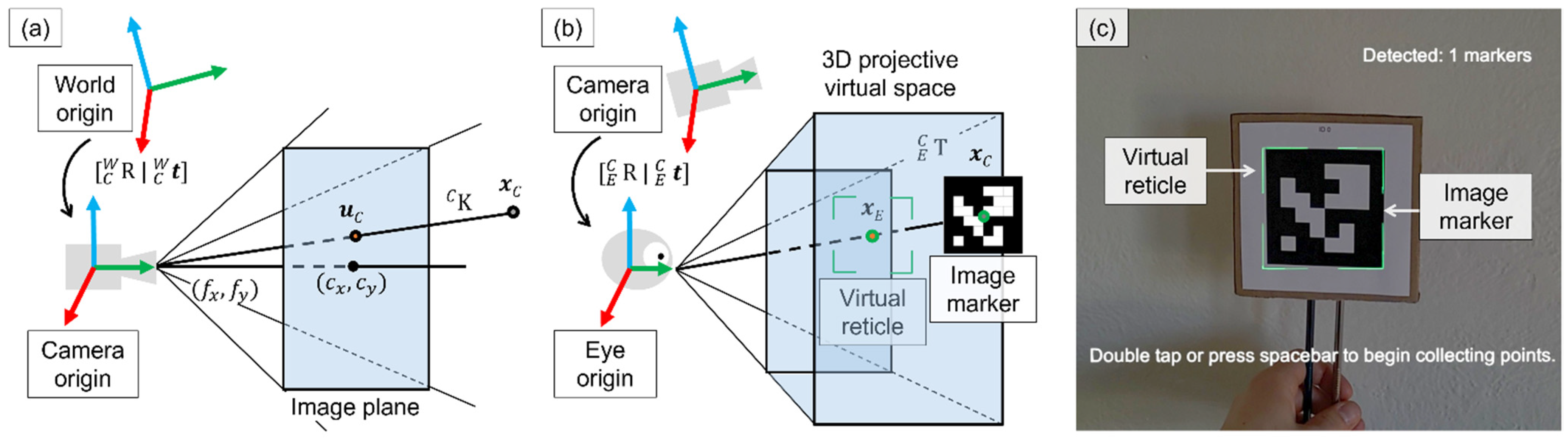
2.2.1. Sensor Calibration
2.2.2. Per-User Hsead-Mounted Display Calibration
2.2.3. Marker Tracking
2.3. User Study to Assess Perceptual Accuracy
2.3.1. Study Details
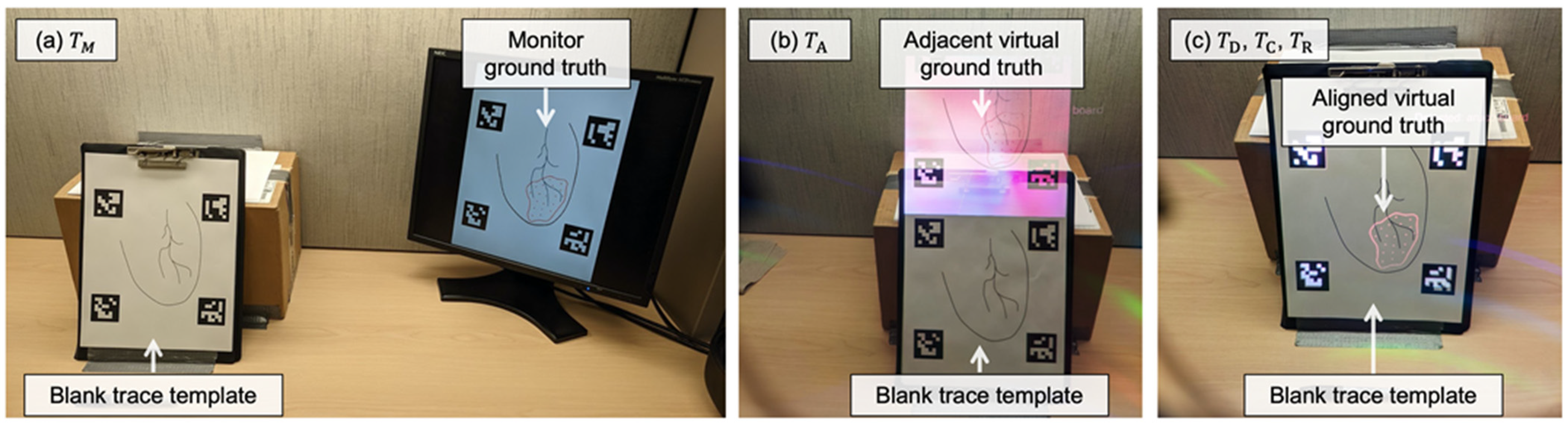
2.3.2. Display Paradigms
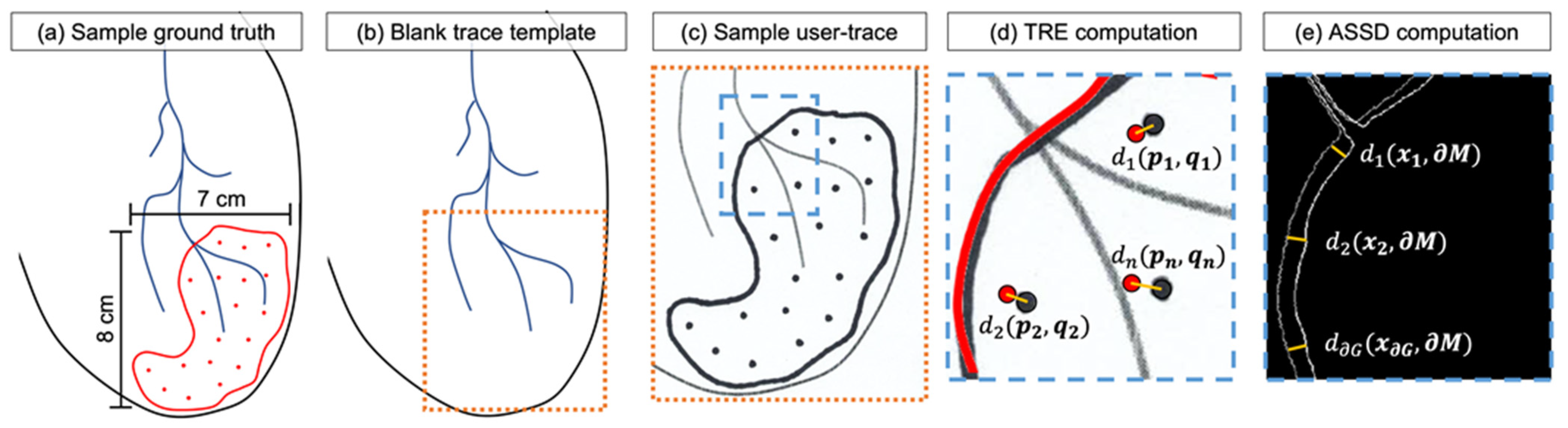
2.3.3. Point-and-Trace Tasks
2.3.4. Metrics for Evaluation
2.3.5. Statistical Analyses
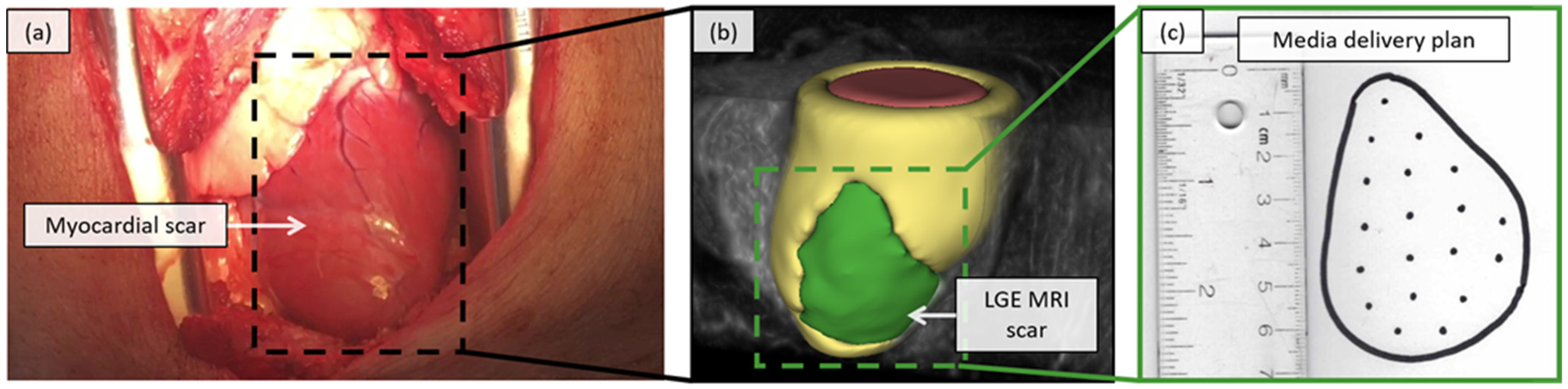
2.4. Feasability Assessment in a Porcine Model
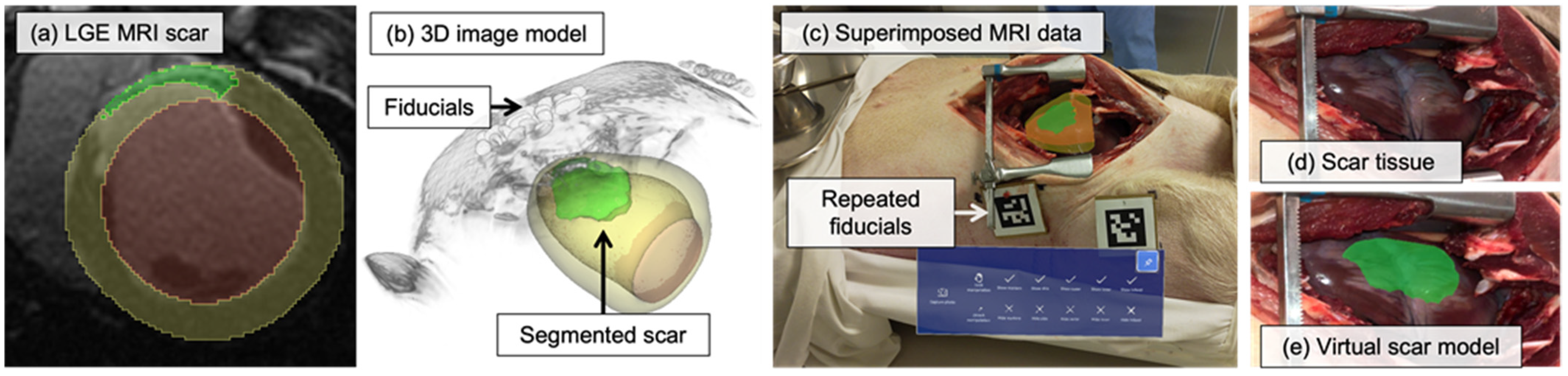
2.4.1. Virtual Scar Model
2.4.2. In-Situ Visualization
3. Results
3.1. User Study Results
3.1.1. User Details
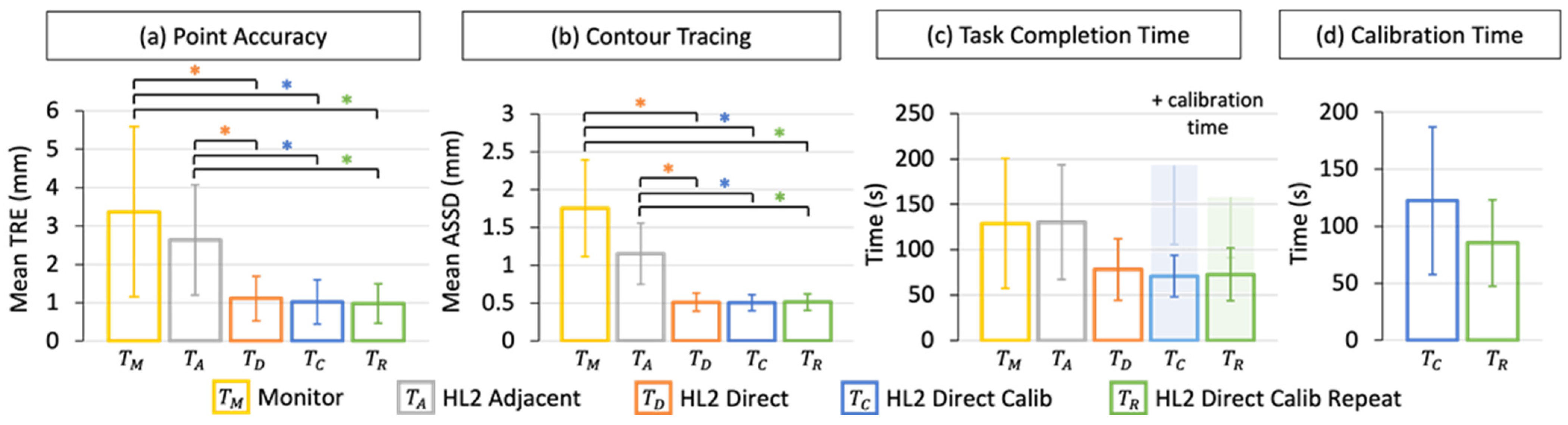
3.1.2. Point Accuracy
3.1.3. Contour Tracing
3.1.4. Task Completion Time
3.1.5. Calibration Time
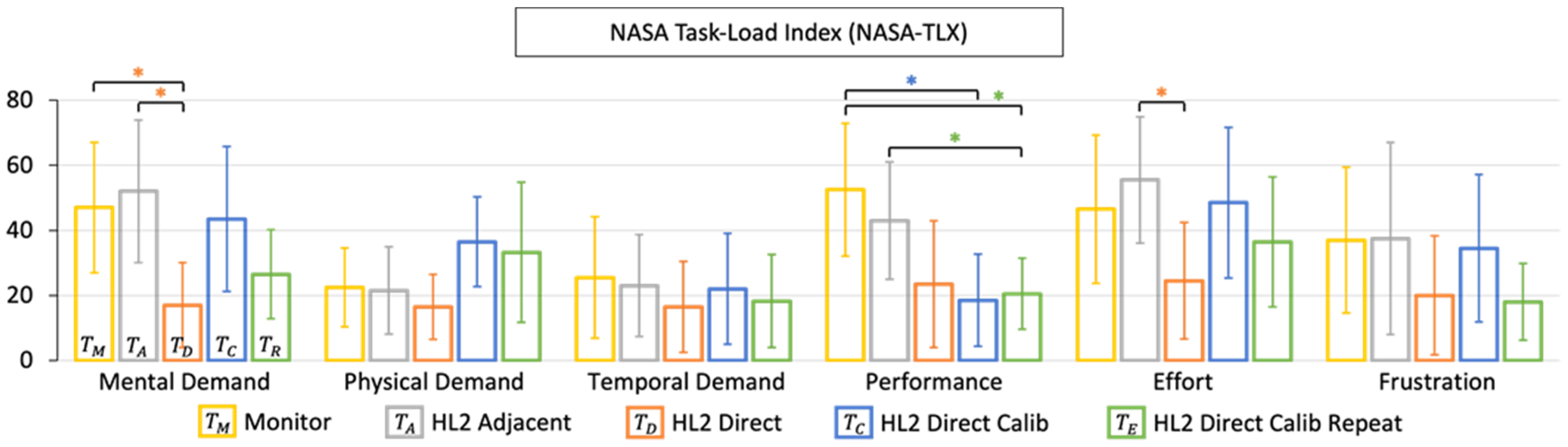
3.1.6. NASA-TLX Results
3.2. Porcine Study Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Benjamin, E.J.; Virani, S.S.; Chair, C.-V.; Callaway, C.W.; Chamberlain, A.M.; Chang, A.R.; Cheng, S.; Chiuve, S.E.; Cushman, M.; Delling, F.N.; et al. Heart Disease and Stroke Statistics—2018 Update: A Report From the American Heart Association. Circulation 2018, 137, 426. [Google Scholar] [CrossRef]
- Heart and Stroke, The Burden of Heart Failure. 2016. Available online: https://www.heartandstroke.ca/-/media/pdf-files/canada/2017-heart-month/heartandstroke-reportonhealth-2016.ashx?la=en (accessed on 9 March 2018).
- Canadian Organ Replacement Register Annual Report: Treatment of End-Stage Organ Failure in Canada, 2004 to 2013. Heart Transplant. p. 6. Available online: https://globalnews.ca/wp-content/uploads/2015/04/2015_corr_annualreport_enweb.pdf (accessed on 28 December 2021).
- Cleland, J.G.; Teerlink, J.R.; Senior, R.; Nifontov, E.M.; Mc Murray, J.J.; Lang, C.C.; Tsyrlin, V.A.; Greenberg, B.H.; Mayet, J.; Francis, D.P.; et al. The effects of the cardiac myosin activator, omecamtiv mecarbil, on cardiac function in systolic heart failure: A double-blind, placebo-controlled, crossover, dose-ranging phase 2 trial. Lancet 2011, 378, 676–683. [Google Scholar] [CrossRef]
- Bar, A.; Cohen, S. Inducing Endogenous Cardiac Regeneration: Can Biomaterials Connect the Dots? Front. Bioeng. Biotechnol. 2020, 8, 126. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gerbin, K.A.; Murry, C.E. The winding road to regenerating the human heart. Cardiovasc. Pathol. 2015, 24, 133–140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naumova, A.V.; Modo, M.; Moore, A.; Murry, C.E.; Frank, J.A. Clinical imaging in regenerative medicine. Nat. Biotechnol. 2014, 32, 804–818. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chong, J.J.H.; Yang, X.; Don, C.W.; Minami, E.; Liu, Y.-W.; Weyers, J.J.; Mahoney, W.M.; Van Biber, B.; Cook, S.M.; Palpant, N.J.; et al. Human Embryonic Stem Cell-Derived Cardiomyocytes Regenerate Non-Human Primate Hearts. Nature 2014, 510, 273–277. [Google Scholar] [CrossRef] [PubMed]
- Roche, E.T.; Hastings, C.L.; Lewin, S.A.; Shvartsman, D.; Brudno, Y.; Vasilyev, N.V.; O’Brien, F.J.; Walsh, C.J.; Duffy, G.P.; Mooney, D.J. Comparison of biomaterial delivery vehicles for improving acute retention of stem cells in the infarcted heart. Biomaterials 2014, 35, 6850–6858. [Google Scholar] [CrossRef] [Green Version]
- Ghugre, N.R.; Pop, M.; Barry, J.; Connelly, K.A.; Wright, G.A. Quantitative magnetic resonance imaging can distinguish remodeling mechanisms after acute myocardial infarction based on the severity of ischemic insult: Remodeling Mechanisms After AMI With Quantitative MRI. Magn. Reson. Med. 2013, 70, 1095–1105. [Google Scholar] [CrossRef]
- Cleary, K.; Peters, T.M. Image-Guided Interventions: Technology Review and Clinical Applications. Annu. Rev. Biomed. Eng. 2010, 12, 119–142. [Google Scholar] [CrossRef]
- Liu, D.; Jenkins, S.A.; Sanderson, P.M.; Fabian, P.; Russell, W.J. Monitoring with Head-Mounted Displays in General Anesthesia: A Clinical Evaluation in the Operating Room. Anesth. Analg. 2010, 110, 1032–1038. [Google Scholar] [CrossRef] [Green Version]
- Rahman, R.; Wood, M.E.; Qian, L.; Price, C.L.; Johnson, A.A.; Osgood, G.M. Head-Mounted Display Use in Surgery: A Systematic Review. Surg. Innov. 2020, 27, 88–100. [Google Scholar] [CrossRef] [PubMed]
- Meola, A.; Cutolo, F.; Carbone, M.; Cagnazzo, F.; Ferrari, M.; Ferrari, V. Augmented reality in neurosurgery: A systematic review. Neurosurg. Rev. 2017, 40, 537–548. [Google Scholar] [CrossRef] [PubMed]
- Jud, L.; Fotouhi, J.; Andronic, O.; Aichmair, A.; Osgood, G.; Navab, N.; Farshad, M. Applicability of augmented reality in orthopedic surgery—A systematic review. BMC Musculoskelet. Disord. 2020, 21, 103. [Google Scholar] [CrossRef] [PubMed]
- Bernhardt, S.; Nicolau, S.A.; Soler, L.; Doignon, C. The status of augmented reality in laparoscopic surgery as of 2016. Med. Image Anal. 2017, 37, 66–90. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Kim, H.; Kim, Y.O. Virtual Reality and Augmented Reality in Plastic Surgery: A Review. Arch. Plast. Surg. 2017, 44, 179–187. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Condino, S.; Carbone, M.; Piazza, R.; Ferrari, M.; Ferrari, V. Perceptual Limits of Optical See-Through Visors for Augmented Reality Guidance of Manual Tasks. IEEE Trans. Biomed. Eng. 2020, 67, 411–419. [Google Scholar] [CrossRef]
- Qian, L.; Song, T.; Unberath, M.; Kazanzides, P. AR-Loupe: Magnified Augmented Reality by Combining an Optical See-Through Head-Mounted Display and a Loupe. IEEE Trans. Vis. Comput. Graph. 2020, 1. [Google Scholar] [CrossRef]
- Fischer, M.; Leuze, C.; Perkins, S.; Rosenberg, J.; Daniel, B.; Martin-Gomez, A. Evaluation of Different Visualization Techniques for Perception-Based Alignment in Medical AR. In Proceedings of the 2020 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Recife, Brazil, 9–13 November 2020; pp. 45–50. [Google Scholar]
- Fotouhi, J.; Song, T.; Mehrfard, A.; Taylor, G.; Wang, Q.; Xian, F.; Martin-Gomez, A.; Fuerst, B.; Armand, M.; Unberath, M.; et al. Reflective-AR Display: An Interaction Methodology for Virtual-to-Real Alignment in Medical Robotics. IEEE Robot. Autom. Lett. 2020, 5, 2722–2729. [Google Scholar] [CrossRef]
- Eckert, M.; Volmerg, J.S.; Friedrich, C.M. Augmented Reality in Medicine: Systematic and Bibliographic Review. JMIR MHealth UHealth 2019, 7, e10967. [Google Scholar] [CrossRef]
- Sielhorst, T.; Feuerstein, M.; Navab, N. Advanced Medical Displays: A Literature Review of Augmented Reality. J. Disp. Technol. 2008, 4, 451–467. [Google Scholar] [CrossRef] [Green Version]
- Kramida, G. Resolving the Vergence-Accommodation Conflict in Head-Mounted Displays. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1912–1931. [Google Scholar] [CrossRef] [PubMed]
- Doughty, M.; Singh, K.; Ghugre, N.R. SurgeonAssist-Net: Towards Context-Aware Head-Mounted Display-Based Augmented Reality for Surgical Guidance. In Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI), Strasbourg, France, 27 September–1 October 2021; Springer: Cham, Switzerland, 2021; pp. 667–677. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Grubert, J.; Itoh, Y.; Moser, K.; Swan II, J.E. A Survey of Calibration Methods for Optical See-Through Head-Mounted Displays. IEEE Trans. Vis. Comput. Graph. 2018, 24, 2649–2662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tuceryan, M.; Navab, N. Single point active alignment method (SPAAM) for optical see-through HMD calibration for AR. In Proceedings of the IEEE and ACM International Symposium on Augmented Reality (ISAR 2000), Munich, Germany, 5–6 October 2000; pp. 149–158. [Google Scholar]
- Owen, C.B.; Zhou, J.; Tang, A.; Xiao, F. Display-Relative Calibration for Optical See-Through Head-Mounted Displays. In Proceedings of the Third IEEE and ACM International Symposium on Mixed and Augmented Reality, Arlington, VA, USA, 5 November 2004; pp. 70–78. [Google Scholar]
- Plopski, A.; Itoh, Y.; Nitschke, C.; Kiyokawa, K.; Klinker, G.; Takemura, H. Corneal-Imaging Calibration for Optical See-Through Head-Mounted Displays. IEEE Trans. Vis. Comput. Graph. 2015, 21, 481–490. [Google Scholar] [CrossRef] [PubMed]
- Azimi, E.; Qian, L.; Navab, N.; Kazanzides, P. Alignment of the Virtual Scene to the Tracking Space of a Mixed Reality Head-Mounted Display. arXiv 2017, arXiv:170305834. [Google Scholar]
- Arun, K.S.; Huang, T.S.; Blostein, S.D. Least-Squares Fitting of Two 3-D Point Sets. IEEE Trans. Pattern Anal. Mach. Intell. 1987, PAMI-9, 698–700. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schönemann, P.H. A generalized solution of the orthogonal procrustes problem. Psychometrika 1966, 31, 1–10. [Google Scholar] [CrossRef]
- Garrido-Jurado, S.; Muñoz-Salinas, R.; Madrid-Cuevas, F.J.; Marín-Jiménez, M.J. Automatic generation and detection of highly reliable fiducial markers under occlusion. Pattern Recognit. 2014, 47, 2280–2292. [Google Scholar] [CrossRef]
- Linte, C.A.; White, J.; Eagleson, R.; Guiraudon, G.M.; Peters, T.M. Virtual and Augmented Medical Imaging Environments: Enabling Technology for Minimally Invasive Cardiac Interventional Guidance. IEEE Rev. Biomed. Eng. 2010, 3, 25–47. [Google Scholar] [CrossRef] [PubMed]
- Fitzpatrick, J.M.; West, J.B.; Maurer, C.R. Predicting error in rigid-body point-based registration. IEEE Trans. Med. Imaging 1998, 17, 694–702. [Google Scholar] [CrossRef]
- Hart, S.G.; Staveland, L.E. Development of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research. In Advances in Psychology; Hancock, P.A., Meshkati, N., Eds.; Human Mental Workload: Amsterdam, The Netherlands, 1988; Volume 52, pp. 139–183. [Google Scholar]
- Shapiro, S.S.; Wilk, M.B. An Analysis of Variance Test for Normality (Complete Samples). Biometrika 1965, 52, 591. [Google Scholar] [CrossRef]
- Dastidar, A.G.; Rodrigues, J.C.; Baritussio, A.; Bucciarelli-Ducci, C. MRI in the assessment of ischaemic heart disease. Heart 2016, 102, 239–252. [Google Scholar] [CrossRef] [PubMed]
- Kikinis, R.; Pieper, S.D.; Vosburgh, K.G. 3D Slicer: A Platform for Subject-Specific Image Analysis, Visualization, and Clinical Support. In Intraoperative Imaging and Image-Guided Therapy; Jolesz, F.A., Ed.; Springer: New York, NY, USA, 2014; pp. 277–289. ISBN 978-1-4614-7657-3. [Google Scholar]
- Ballestin, G.; Chessa, M.; Solari, F. Assessment of Optical See-Through Head Mounted Display Calibration for Interactive Augmented Reality. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 4452–4460. [Google Scholar]
- Kunz, C.; Genten, V.; Meißner, P.; Hein, B. Metric-based evaluation of fiducial markers for medical procedures. In Proceedings of the Medical Imaging 2019: Image-Guided Procedures, Robotic Interventions, and Modeling, San Diego, CA, USA, 16–21 February 2019; Volume 10951, p. 109512O. [Google Scholar]
- Nousiainen, K.; Mäkelä, T. Measuring geometric accuracy in magnetic resonance imaging with 3D-printed phantom and nonrigid image registration. Magn. Reson. Mater. Phys. Biol. Med. 2020, 33, 401–410. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lemma, M.; Mangini, A.; Redaelli, A.; Acocella, F. Do cardiac stabilizers really stabilize? Experimental quantitative analysis of mechanical stabilization. Interact. Cardiovasc. Thorac. Surg. 2005, 4, 222–226. [Google Scholar] [CrossRef] [PubMed]
- Perkins, S.L.; Daniel, B.L.; Hargreaves, B.A. MR imaging of magnetic ink patterns via off-resonance sensitivity. Magn. Reson. Med. 2018, 80, 2017–2023. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Participants | Sex | Age (Years) | Glasses | Experience with AR |
|---|---|---|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Doughty, M.; Ghugre, N.R. Head-Mounted Display-Based Augmented Reality for Image-Guided Media Delivery to the Heart: A Preliminary Investigation of Perceptual Accuracy. J. Imaging 2022, 8, 33. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging8020033
Doughty M, Ghugre NR. Head-Mounted Display-Based Augmented Reality for Image-Guided Media Delivery to the Heart: A Preliminary Investigation of Perceptual Accuracy. Journal of Imaging. 2022; 8(2):33. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging8020033
Chicago/Turabian StyleDoughty, Mitchell, and Nilesh R. Ghugre. 2022. "Head-Mounted Display-Based Augmented Reality for Image-Guided Media Delivery to the Heart: A Preliminary Investigation of Perceptual Accuracy" Journal of Imaging 8, no. 2: 33. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging8020033