
Application of Artificial Intelligence Techniques to Predict Risk of Recurrence of Breast Cancer: A Systematic Review

Abstract
:1. Introduction
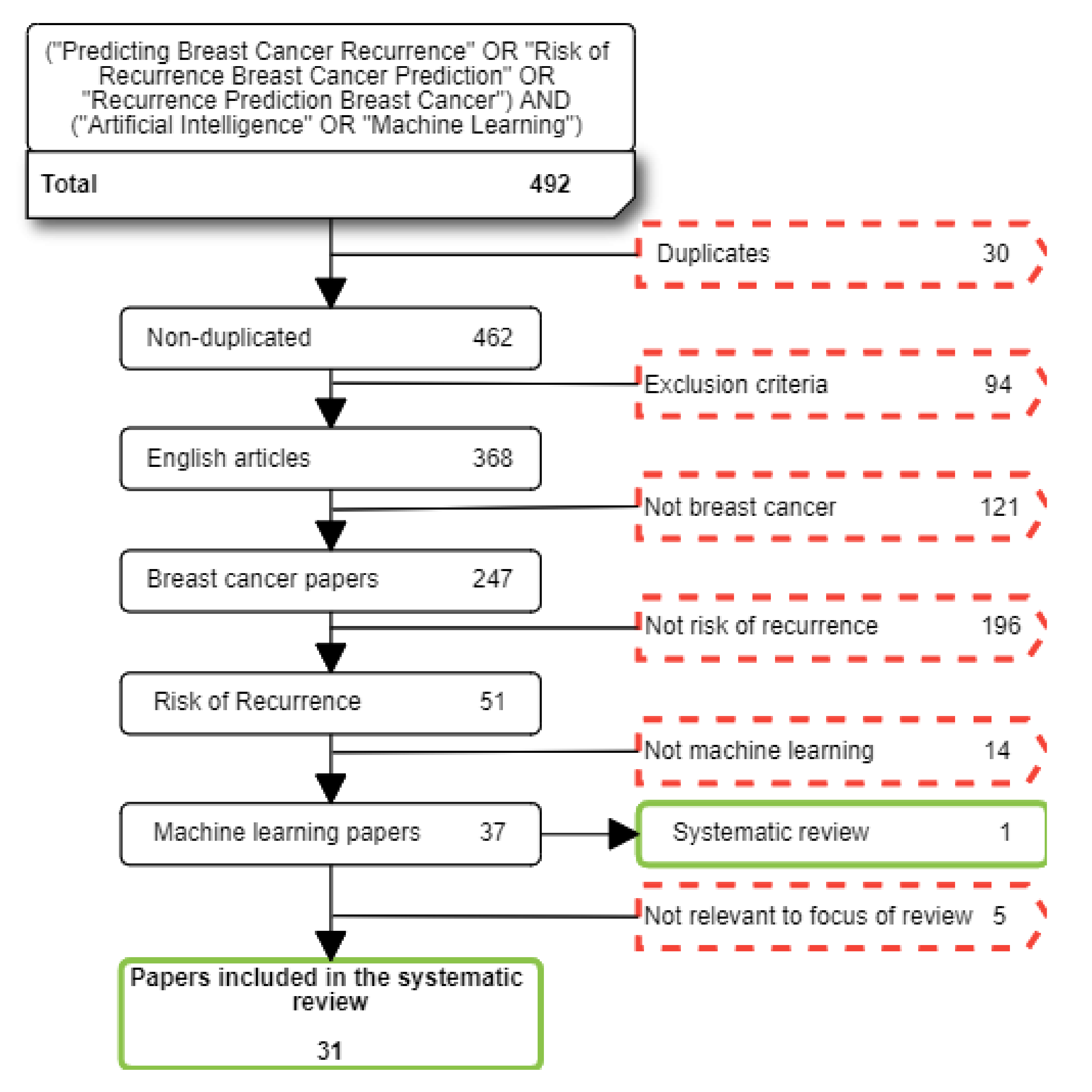
2. Method
2.1. Planning the Review
2.1.1. Related Works and Needs for the Review
2.1.2. Research Questions
- RQ1: What artificial intelligence techniques have been used to predict the risk of recurrence of breast cancer and what is their performance?
- RQ2: What type of features have been used?
- RQ3: What were the common training and testing methodologies used?
- RQ4: What model evaluation metrics have been used, and what are the advantages and disadvantages of these metrics?
- RQ5: What systems have been implemented in clinical practice, or validated in a real-world context?
2.2. Conducting the Review
2.2.1. Data Sources
2.2.2. Extracting Data and Synthesis
3. Results
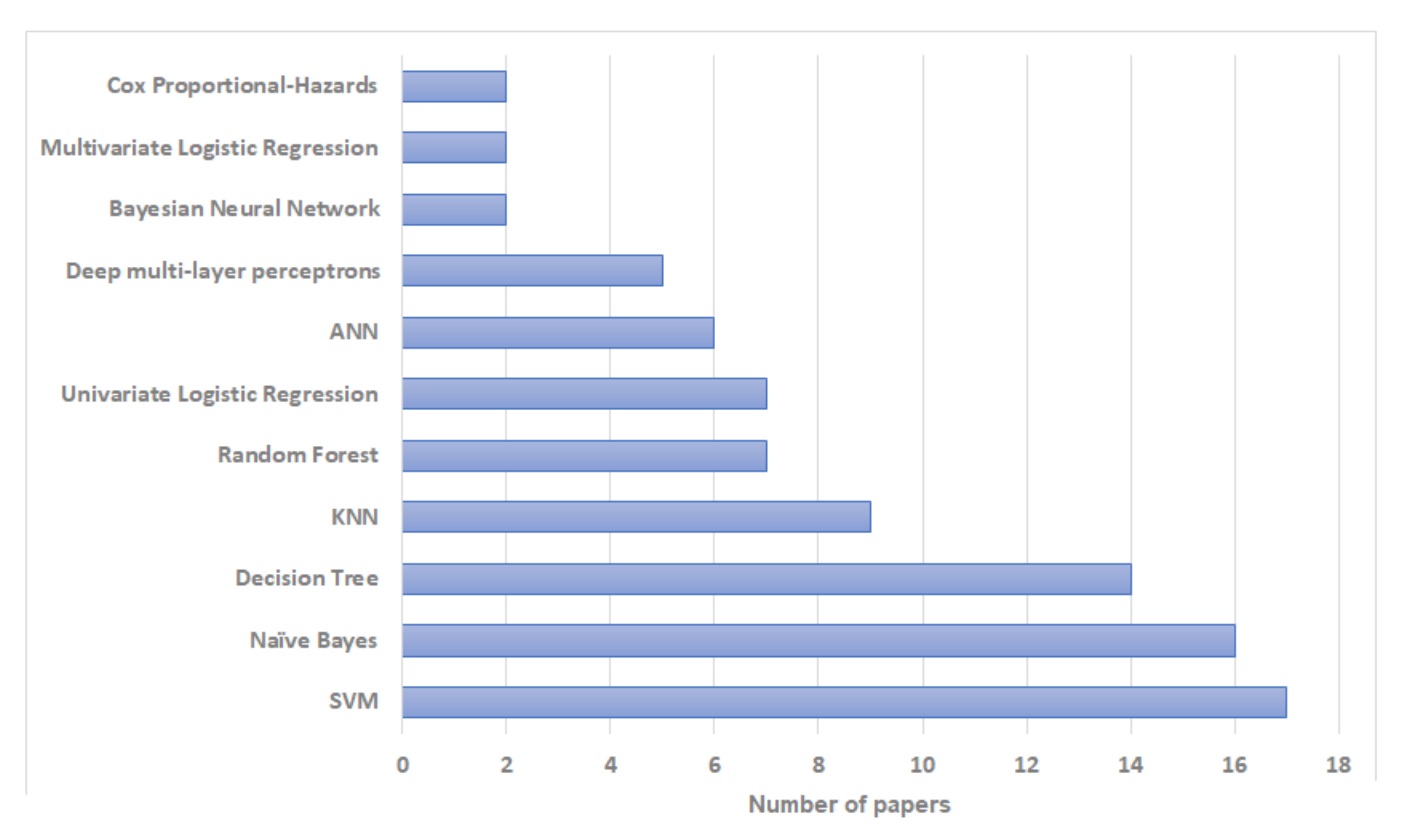
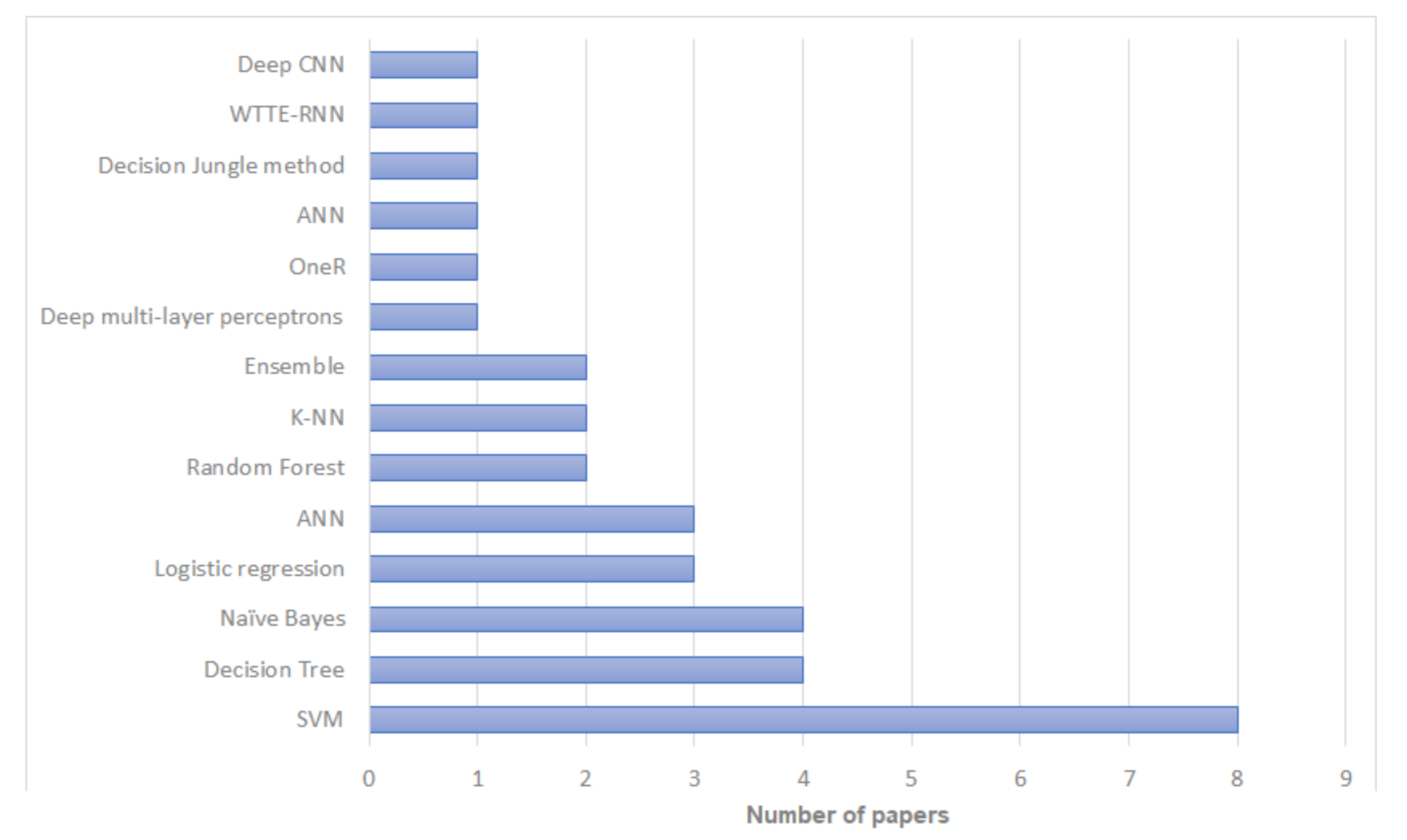
3.1. RQ1: What Artificial Intelligence Techniques Have Been Used to Predict the Risk of Recurrence of Breast Cancer and What Is Their Performance?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Publication | Algorithms | Training Set | Validation Set | Best Algorithm | Best Algorithm |
|---|---|---|---|---|---|
| (Total/Recurrence) | (Total/Recurrence) | Accuracy | |||
| Lg et al. [22] | Decision Tree C4.5, SVM, ANN | 547/117 | 10-fold Cross-Validation (CV) | SVM | Accuracy: 0.957, Sensitivity: 0.971, Specificity: 0.945 |
| Pritom et al. [23] | Naïve Bayes, Decision Tree C4.5, and SVM | 198/47 | 10-fold CV | SVM | 75.75% accuracy |
| Aline et al. [24] | Deep multi-layer perceptrons | 152/— | 168/— | Deep multi-layer perceptrons | AUC: 0.63 low, 0.59 intermediate, and 0.75 high risk |
| Mosayebi et al. [25] | Deep Multilayer Perceptron ANN, Bayesian Neural Network, LVQ neural network, KPCA-SVM, Random Forest, and Decision Tree C5.0 | 7874/5471 | nested 5-fold CV | Decision Tree C5.0 | Accuracy: 0.819, Sensitivity: 0.869, and Specificity: 0.777 |
| Alzubi et al. [26] | Decision Tree J48, Naïve Bayes, bagging, logistic regression, SVM, KNN, MLP, PART, and OneR | 142/— | 10-fold cross- validation | OneR | Accuracy: 0.1408, Sensitivity: 0.901, and Specificity: 0.72 |
| Witteveen et al. [27] | Logistic regression and Bayesian Networks | 72,638/37,230 | 24,063/12,308 | Logistic regression | C-statistic: 0.71 |
| Cirkovic et al. [28] | Naive Bayes, Decision tree C4.5, SVM polynomial kernel, logistic regression, K-NN, and ANN | 146/— | live-oneout CV | ANN | AUC: 0.847 |
| Ramkumar et al. [29] | SVM with linear and Radial kernel, Basis function kernel, Random Forest, Elastic Net, Multilayer perceptron, Normal mixture modeling | 298/— | 196/— | SVM Radial Kernel | AUC: 0.678 |
| Almuhaidib et al. [30] | Random Forest, Decision tree, and Naïve Bayes | 194/46 | 10-fold CV | Random Forest | Accuracy 0.6522, Sensitivity 0.6250, and Specificity 0.659 |
| Rosa Mendoza et al. [31] | Univariate and multivariate logistic regression | 215/— | —/— | Multivariate logistic regression | Sensitivity: 0.74 and Specificity 0.97 |
| Wang et al. [32] | Random Forest, SVM with linear kernel, logistic regression, Stochastic Gradient Descent Classifier (SGDC), Naïve Bayes, KNN | 4513/312 | 1934/134 | KNN | AUC: 0.888 |
| Chou et al. [33] | ANN, Decision trees, Logistic regression, Composite models of DT-ANN and DT-LR | 370/— | 387/— | ANN | Accuracy: 70.93 |
| Li et al. [34] | Linear regression | 84/— | —/— | Linear regression | AUC: 0.88 |
| Kim et al. [35] | Random Forest, Decision Jungle, NN, Naïve Bayes, and SVM | 301/— | 76/— | Decision Jungle | Accuracy: 0.90 |
| Kim et al. [36] | Weibull Time To Event Recurrent Neural Network (WTTE- RNN) | 10,494/— | 2623/— | WTTE- RNN | Accuracy: 0.90 |
| Chakradeo et al. [37] | Multiple Linear Regression, SVM (RBF kernel), and Decision Tree | 198/46 | CV | SVM | Accuracy: 0.97, Precision: 0.93, and Recall: 0.91 |
| Rana et al. [38] | SVM, Logistic Regression, KNN, and Naive Bayes | 194/46 | CV | KNN | Accuracy: 0.72 |
| Mohebian et al. [39] | Bagged Decision Tree (BDT), SVM, Decision Tree, Multilayer perceptron neural network | 579/112 | 4-fold CV | Ensemble Learning | AUC: 0.90 |
| Eun et al. [40] | Random Forest, Decision Tree, KNN, Linear discriminant analysis (LDA), linear SVM, and Naïve Bayes | 130/21 | 5-fold CV | Random Forest | AUC: 0.94 |
| Bhargava et al. [41] | Decision Tree J48 | 286/85 | 10-fold cross validation | Decision Tree J48 | Precision: 0.76 |
| Adeyemi et al. [42] | Naïve Bayes, Decision trees C4.5, and SVM the stack ensemble models, Base (B) and Meta (M). B: Naïve Bayes, SVM and M: C4.5; B: Naïve Bayes, SVM and M: C4.5; B: SVM, C4.5 and M: Naïve Bayes | 201/85 | 10-fold CV | Ensemble method: B: Naïve Bayes, SVM and M: C4.5 | Precision Recurrence: 0.554 and No-Recurrence: 0.765 |
| Yang et al. [43] | AdaBoost and Cost sensitive learning | 1061/37 | 3-fold CV | Ensemble method | ROC: 0.907 |
| Massafra et al. [44] | Naïve Bayesian, Random Forest, and SVM | 256/— | 10-fold CV | SVM | Accuracy: 80.39 |
| Turkki et al. [45] | Deep CNN | 868/— | 431/— | Deep CNN | C-index: 0.60 |
| Kabiraj et al. [46] | Naïve Bayes | 275/85 | 10-fold CV | Naïve Bayes | Accuracy: 73.81 |
| Sakri et al. [47] | Naïve Bayes, Decisio Tree, and KNN | 198/47 | 10-fold CV | Naïve Bayes | Precision Recurrence: 0.814 and No-Recurrence: 0.381 |
| Lou et al. [48] | Multi-layer perceptron neural network ANN, KNN, SVM, and Naïve Bayesian | 798/— | 171/— | ANN | AUC: 0.998 |
| Ojha and Goel [49] | clustering algorithms: K-means, EM, PAM, and Fuzzy c-means classification algorithms: SVM, Decision Tree C5.0, Naïve bayes, and KNN | 194/46 | 10 fold cross validation | SVM and Decision Tree C5.0 | Accuracy: 0.81 |
| Kim et al. [50] | SVM, ANN, and Cox-proportional hazard regression model | 679/45 | 204 | SVM | AUC: 0.85 |
| Woojae et al. [51] | Naïve Bayesian | 475/31 | 204 | Naïve Bayesian | AUC: 0.81 |
| Zain et al. [52] | Naïve Bayes, KNN, and Fast Decision Tree (REPTree) | 198/47 | 10 fold cross validation | Naïve Bayes | F-Score: 0.721 |
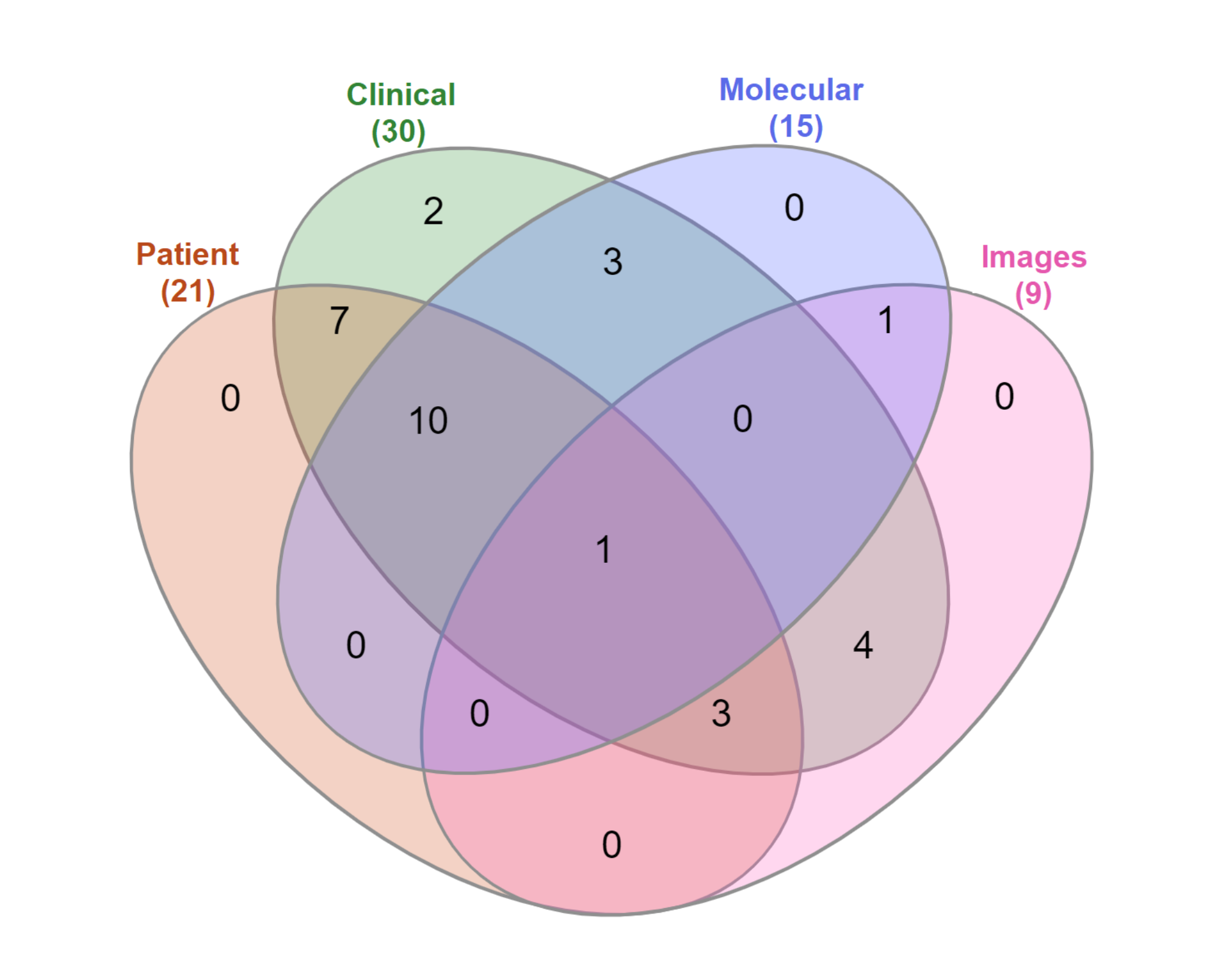
3.2. RQ2: What Type of Features Have Been Used?
3.3. RQ3: What Were the Common Training and Testing Methodologies Used?
3.3.1. Dataset Size and Class Balance
3.3.2. Sampling Strategies
3.3.3. Data Handling Strategies
3.3.4. Validation Strategies
3.3.5. Dataset Availability
3.4. RQ4: What Model Evaluation Metrics Have Been Used, and What Are the Advantages and Disadvantages of These Metrics?
3.5. RQ5: What Systems Have Been Implemented in Clinical Practice, or Validated in a Real-World Context?
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| pCR | pathological complete response |
| SVM | Support Vector Machines |
| SGDC | Stochastic Gradient Descent Classifier |
| WTTE- RNN | Weibull Time To Event Recurrent Neural Network |
| BDT | Bagged Decision Tree |
| LDA | Linear discriminant analysis |
| MRI | Magnetic Resonance Imaging |
| FNA | Fine Needle Aspirate |
| TMA | Tissue Microarray |
| XAI | Explainable Artificial Intelligence |
| FDA | Food and Drug Administration |
| EI | Enterprise Ireland |
| SFI | Science Foundation Ireland |
References
- American Cancer Society. Breast Cancer. 2018. Available online: https://www.cancer.org/cancer/breast-cancer.html (accessed on 29 July 2022).
- International Agency of Research Cancer. Breast Cancer. 2018. Available online: https://www.iarc.fr/index.php (accessed on 29 July 2022).
- Paraskevi, T. Quality of life outcomes in patients with breast cancer. Oncol. Rev. 2012, 6, e2. [Google Scholar] [CrossRef]
- Shachar, S.S.; Muss, H.B. Internet tools to enhance breast cancer care. Npj Breast Cancer 2016, 2, 16011. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, A. Pathways to Breast Cancer Recurrence. ISRN Oncol. 2013, 2013, 290568. [Google Scholar] [CrossRef]
- Hwang, E.J.; Park, S.; Jin, K.N.; Im Kim, J.; Choi, S.Y.; Lee, J.H.; Goo, J.M.; Aum, J.; Yim, J.J.; Cohen, J.G.; et al. Development and validation of a deep learning–based automated detection algorithm for major thoracic diseases on chest radiographs. JAMA Netw. Open 2019, 2, e191095. [Google Scholar] [CrossRef]
- Geras, K.J.; Wolfson, S.; Shen, Y.; Wu, N.; Kim, S.; Kim, E.; Heacock, L.; Parikh, U.; Moy, L.; Cho, K. High-resolution breast cancer screening with multi-view deep convolutional neural networks. arXiv 2017, arXiv:1703.07047. [Google Scholar]
- Chilamkurthy, S.; Ghosh, R.; Tanamala, S.; Biviji, M.; Campeau, N.G.; Venugopal, V.K.; Mahajan, V.; Rao, P.; Warier, P. Deep learning algorithms for detection of critical findings in head CT scans: A retrospective study. Lancet 2018, 392, 2388–2396. [Google Scholar] [CrossRef]
- Burbidge, R.; Trotter, M.; Buxton, B.; Holden, S. Drug design by machine learning: Support vector machines for pharmaceutical data analysis. Comput. Chem. 2001, 26, 5–14. [Google Scholar] [CrossRef]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef]
- Borchert, R.J.; Azevedo, T.; Badhwar, A.; Bernal, J.; Betts, M.; Bruffaerts, R.; Burkhart, M.C.; Dewachter, I.; Gellersen, H.; Low, A.; et al. Artificial intelligence for diagnosis and prognosis in neuroimaging for dementia; a systematic review. medRxiv 2021. [Google Scholar] [CrossRef]
- Sadoughi, F.; Kazemy, Z.; Hamedan, F.; Owji, L.; Rahmanikatigari, M.; Azadboni, T.T. Artificial intelligence methods for the diagnosis of breast cancer by image processing: A review. Breast Cancer 2018, 10, 219–230. [Google Scholar] [CrossRef]
- Jain, A.; Jain, A.; Jain, S.; Jain, L. Artificial Intelligence Techniques in Breast Cancer Diagnosis and Prognosis; World Scientific: Singapore, 2000. [Google Scholar] [CrossRef]
- Shi, P.; Zhong, J.; Hong, J.; Huang, R.; Wang, K.; Chen, Y. Automated Ki-67 Quantification of Immunohistochemical Staining Image of Human Nasopharyngeal Carcinoma Xenografts. Sci. Rep. 2016, 32127. [Google Scholar] [CrossRef]
- Tuominen, V.J.; Ruotoistenmäki, S.; Viitanen, A.; Jumppanen, M.; Isola, J. ImmunoRatio: A publicly available web application for quantitative image analysis of estrogen receptor (ER), progesterone receptor (PR), and Ki-67. Breast Cancer Res. 2010, 12, R56. [Google Scholar] [CrossRef]
- Mazo, C.; Orue-Etxebarria, E.; Zabalza, I.; Vivanco, M.d.M.; Kypta, R.M.; Beristain, A. In Silico Approach for Immunohistochemical Evaluation of a Cytoplasmic Marker in Breast Cancer. Cancers 2018, 10, 517. [Google Scholar] [CrossRef]
- Mazo, C.; Barron, S.; Mooney, C.; Gallagher, W. 257P—Multi-gene prognostic signatures and prediction of pathological complete response of ER-Positive HER2-negative breast cancer patients to neo-adjuvant chemotherapy. Ann. Oncol. 2019, 30, v86. [Google Scholar] [CrossRef]
- Mazo, C.; Barron, S.; Mooney, C.; Gallagher, W.M. Multi-Gene Prognostic Signatures and Prediction of Pathological Complete Response to Neoadjuvant Chemotherapy in ER-Positive, HER2-Negative Breast Cancer Patients. Cancers 2020, 12, 1133. [Google Scholar] [CrossRef]
- Abreu, P.H.; Santos, M.S.; Abreu, M.H.; Andrade, B.; Silva, D.C. Predicting Breast Cancer Recurrence Using Machine Learning Techniques: A Systematic Review. ACM Comput. Surv. 2016, 49. [Google Scholar] [CrossRef]
- Kitchenham, B.A.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Technical Report EBSE 2007-001; Keele University and Durham University Joint Report: Durham, UK, 2007. [Google Scholar]
- Kitchenham, B. Procedures for Performing Systematic Reviews; Technical Report tr/se-0401; Department of Computer Science, Keele University: Newcastle, UK, 2004. [Google Scholar]
- Lg, A.; Eshlaghy, A.T.; Poorebrahimi, A.; Ebrahimi, M.; Ar, R. Using Three Machine Learning Techniques for Predicting Breast Cancer Recurrence. J. Health Med. Inform. 2013, 4, 1–3. [Google Scholar] [CrossRef]
- Pritom, A.I.; Munshi, M.A.R.; Sabab, S.A.; Shihab, S. Predicting breast cancer recurrence using effective classification and feature selection technique. In Proceedings of the 2016 19th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2016; pp. 310–314. [Google Scholar]
- Aline, B.; Zeina, A.M.; Ryad, Z.; Severine, V.D.; Laurent, A.; Noureddine, Z.; Christine, D. Prediction of Oncotype DX recurrence score using deep multi-layer perceptrons in estrogen receptor-positive, HER2-negative breast cancer. Breast Cancer 2020, 27, 1007–1016. [Google Scholar] [CrossRef]
- Mosayebi, A.; Mojaradi, B.; Bonyadi Naeini, A.; Khodadad Hosseini, S.H. Modeling and comparing data mining algorithms for prediction of recurrence of breast cancer. PLoS ONE 2020, 15, e237658. [Google Scholar] [CrossRef]
- Alzubi, A.; Najadat, H.; Doulat, W.; Al-Shari, O.; Zhou, L. Predicting the recurrence of breast cancer using machine learning algorithms. Multimed. Tools Appl. 2021, 80, 13787–13800. [Google Scholar] [CrossRef]
- Witteveen, A.; Nane, G.; Vliegen, I.; Siesling, S.; IJzerman, M. Comparison of Logistic Regression and Bayesian Networks for Risk Prediction of Breast Cancer Recurrence. Med Decis. Mak. 2018, 38, 822–833. [Google Scholar] [CrossRef] [PubMed]
- Cirkovic, B.R.A.; Cvetkovic, A.M.; Ninkovic, S.M.; Filipovic, N.D. Prediction models for estimation of survival rate and relapse for breast cancer patients. In Proceedings of the 2015 IEEE 15th International Conference on Bioinformatics and Bioengineering (BIBE), Belgrade, Serbia, 2–4 November 2015; pp. 1–6. [Google Scholar]
- Ramkumar, C.; Buturovic, L.; Malpani, S.; Attuluri, A.K.; Basavaraj, C.; Prakash, C.; Madhav, L.; Doval, D.C.; Mehta, A.; Bakre, M.M. Development of a Novel Proteomic Risk-Classifier for Prognostication of Patients with Early-Stage Hormone Receptor–Positive Breast Cancer. Biomark. Insights 2018, 13, 1177271918789100. [Google Scholar] [CrossRef] [PubMed]
- Almuhaidib, D.A.; Albusayyis, F.M.; Shaiba, H.A.; Alzaid, M.A.; Alharbi, N.G.; Almadhi, R.M.; Alotaibi, S.M. Ensemble Learning Method for the Prediction of Breast Cancer Recurrence. In Proceedings of the 2018 1st International Conference on Computer Applications Information Security (ICCAIS), Riyadh, Saudi Arabia, 4–6 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Rosa Mendoza, E.S.; Moreno, E.; Caguioa, P.B. Predictors of early distant metastasis in women with breast cancer. J. Cancer Res. Clin. Oncol. 2013, 139, 645–652. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y.; Khan, S.A.; Luo, Y. Prediction of breast cancer distant recurrence using natural language processing and knowledge-guided convolutional neural network. Artif. Intell. Med. 2020, 110, 101977. [Google Scholar] [CrossRef]
- Chou, H.L.; Yao, C.T.; Su, S.L.; Lee, C.Y.; Hu, K.Y.; Terng, H.J.; Shih, Y.W.; Chang, Y.T.; Lu, Y.F.; Chang, C.W.; et al. Gene expression profiling of breast cancer survivability by pooled cDNA microarray analysis using logistic regression, artificial neural networks and decision trees. BMC Bioinform. 2013, 14, 101977. [Google Scholar] [CrossRef]
- Li, H.; Zhu, Y.; Burnside, E.S.; Drukker, K.; Hoadley, K.A.; Fan, C.; Conzen, S.D.; Whitman, G.J.; Sutton, E.J.; Net, J.M.; et al. MR Imaging Radiomics Signatures for Predicting the Risk of Breast Cancer Recurrence as Given by Research Versions of MammaPrint, Oncotype DX, and PAM50 Gene Assays. Radiology 2016, 281, 382–391. [Google Scholar] [CrossRef] [PubMed]
- Kim, I.; Choi, H.J.; Ryu, J.M.; Lee, S.K.; Yu, J.H.; Kim, S.W.; Nam, S.J.; Lee, J.E. A predictive model for high/low risk group according to oncotype DX recurrence score using machine learning. Eur. J. Surg. Oncol. 2019, 45, 134–140. [Google Scholar] [CrossRef]
- Kim, J.Y.; Lee, Y.S.; Yu, J.; Park, Y.; Lee, S.K.; Lee, M.; Lee, J.E.; Kim, S.W.; Nam, S.J.; Park, Y.H.; et al. Deep Learning-Based Prediction Model for Breast Cancer Recurrence Using Adjuvant Breast Cancer Cohort in Tertiary Cancer Center Registry. Front. Oncol. 2021, 4, 655. [Google Scholar] [CrossRef]
- Chakradeo, K.; Vyawahare, S.; Pawar, P. Breast Cancer Recurrence Prediction using Machine Learning. In Proceedings of the 2019 IEEE Conference on Information and Communication Technology, Allahabad, India, 6–8 December 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Rana, M.; Chandorkar, P.; Dsouza, A.; Kazi, N. Breast cancer diagnosis and recurrence prediction using machine learning techniques. Int. J. Res. Eng. Technol. 2015, 04, 372–376. [Google Scholar]
- Mohebian, M.R.; Marateb, H.R.; Mansourian, M.; Mananas, M.A.; Mokarian, F. A Hybrid Computer-aided-diagnosis System for Prediction of Breast Cancer Recurrence (HPBCR) Using Optimized Ensemble Learning. Comput. Struct. Biotechnol. J. 2017, 15, 75–85. [Google Scholar] [CrossRef]
- Eun, N.L.; Kang, D.; Son, E.J.; Youk, J.H.; Kim, J.A.; Gweon, H.M. Texture analysis using machine learning-based 3-T magnetic resonance imaging for predicting recurrence in breast cancer patients treated with neoadjuvant chemotherapy. Eur. Radiol. 2021, 31, 6916–6928. [Google Scholar] [CrossRef] [PubMed]
- Bhargava, N.; Sharma, S.; Purohit, R.; Rathore, P.S. Prediction of recurrence cancer using J48 algorithm. In Proceedings of the 2017 2nd International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 19–20 October 2017; pp. 386–390. [Google Scholar] [CrossRef]
- Adeyemi, O.; Adebayo, V.O.; Olaniyi, O.; Olayinka, O.; Sekoni, I.P.A. A Stack Ensemble Model for the Risk of Breast Cancer Recurrence. Int. J. Res. Stud. Comput. Sci. Eng. 2019, 6, 8–21. [Google Scholar] [CrossRef]
- Yang, P.T.; Wu, W.S.; Wu, C.C.; Shih, Y.N.; Hsieh, C.H.; Hsu, J.L. Breast cancer recurrence prediction with ensemble methods and cost-sensitive learning. Open Med. 2021, 16, 754–768. [Google Scholar] [CrossRef]
- Massafra, R.; Latorre, A.; Fanizzi, A.; Bellotti, R.; Didonna, V.; Giotta, F.; Forgia, D.L.; Nardone, A.; Pastena, M.; Ressa, C.M.; et al. A Clinical Decision Support System for Predicting Invasive Breast Cancer Recurrence: Preliminary Results. Front. Oncol. 2021, 11, 576007. [Google Scholar] [CrossRef]
- Turkki, R.; Byckhov, D.; Lundin, M.; Isola, J.; Nordling, S.; Kovanen, P.E.; Verrill, C.; von Smitten, K.; Joensuu, H.; Lundin, J.; et al. Breast cancer outcome prediction with tumour tissue images and machine learning. Breast Cancer Res. Treat. 2019, 177, 41–52. [Google Scholar] [CrossRef] [PubMed]
- Kabiraj, S.; Akter, L.; Raihan, M.; Diba, N.J.; Podder, E.; Hassan, M.M. Prediction of Recurrence and Non-recurrence Events of Breast Cancer using Bagging Algorithm. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Sakri, S.B.; Abdul Rashid, N.B.; Muhammad Zain, Z. Particle Swarm Optimization Feature Selection for Breast Cancer Recurrence Prediction. IEEE Access 2018, 6, 29637–29647. [Google Scholar] [CrossRef]
- Lou, S.J.; Hou, M.F.; Chang, H.T.; Chiu, C.C.; Lee, H.H.; Yeh, S.C.J.; Shi, H.Y. Machine Learning Algorithms to Predict Recurrence within 10 Years after Breast Cancer Surgery: A Prospective Cohort Study. Cancers 2020, 12, 3817. [Google Scholar] [CrossRef]
- Ojha, U.; Goel, S. A study on prediction of breast cancer recurrence using data mining techniques. In Proceedings of the 2017 7th International Conference on Cloud Computing, Data Science Engineering—Confluence, Noida, India, 12–13 January 2017; pp. 527–530. [Google Scholar] [CrossRef]
- Kim, W.; Kim, K.S.; Lee, J.E.; Noh, D.Y.; Kim, S.W.; Jung, Y.S.; Park, M.Y.; Park, R.W. Development of Novel Breast Cancer Recurrence Prediction Model Using Support Vector Machine. Breast Cancer 2012, 15, 230–238. [Google Scholar] [CrossRef]
- Woojae, K.; Sang, K.K.; Woong, P.R. Nomogram of Naive Bayesian Model for Recurrence Prediction of Breast Cancer. Healthc. Inform. Res. 2016, 22, 89–94. [Google Scholar] [CrossRef]
- Zain, Z.; Alshenaifi, M.; Aljaloud, A.; Albednah, T.; Alghanim, R.; Alqifari, A.; Alqahtani, A. Predicting breast cancer recurrence using principal component analysis as feature extraction: An unbiased comparative analysis. Int. J. Adv. Intell. Inform. 2020, 6, 313–327. [Google Scholar] [CrossRef]
- Mange, J. Effect of Training Data Order for Machine Learning. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 406–407. [Google Scholar] [CrossRef]
- Amin, M.B.; Greene, F.L.; Edge, S.B.; Compton, C.C.; Gershenwald, J.E.; Brookland, R.K.; Meyer, L.; Gress, D.M.; Byrd, D.R.; Winchester, D.P. The Eighth Edition AJCC Cancer Staging Manual: Continuing to build a bridge from a population-based to a more personalized approach to cancer staging. CA A Cancer J. Clin. 2017, 67, 93–99. [Google Scholar] [CrossRef] [PubMed]
- Kalli, S.; Semine, A.; Cohen, S.; Naber, S.P.; Makim, S.S.; Bahl, M. American Joint Committee on Cancer’s Staging System for Breast Cancer, Eighth Edition: What the Radiologist Needs to Know. RadioGraphics 2018, 38, 1921–1933. [Google Scholar] [CrossRef] [PubMed]
- Shokouh, T.Z.; Ezatollah, A.; Barand, P. Interrelationships Between Ki67, HER2/neu, p53, ER, and PR Status and Their Associations With Tumor Grade and Lymph Node Involvement in Breast Carcinoma Subtypes: Retrospective-Observational Analytical Study. Medicine (Baltimore) 2015, 94, e1359. [Google Scholar] [CrossRef] [PubMed]
- Singh, V.; Pencina, M.; Einstein, A.J.; Liang, J.X.; Berman, D.S.; Slomka, P. Impact of train/test sample regimen on performance estimate stability of machine learning in cardiovascular imaging. Sci. Rep. 2021, 11, 14490. [Google Scholar] [CrossRef]
- Antoniadi, A.M.; Du, Y.; Guendouz, Y.; Wei, L.; Mazo, C.; Becker, B.A.; Mooney, C. Current Challenges and Future Opportunities for XAI in Machine Learning-Based Clinical Decision Support Systems: A Systematic Review. Appl. Sci. 2021, 11, 5088. [Google Scholar] [CrossRef]
- Katharopoulos, A.; Fleuret, F. Not All Samples Are Created Equal: Deep Learning with Importance Sampling. arXiv 2019, arXiv:cs.LG/1803.00942. [Google Scholar]
- The European Parliament and the Council of the European Union. General Data Protection Regulation. 2016. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32016R0679 (accessed on 26 January 2022).
- Pawlik, M.; Hutter, T.; Kocher, D.; Mann, W.; Augsten, N. A Link is not Enough—Reproducibility of Data. Datenbank-Spektrum 2019, 19, 107–115. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M. A Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process (IJDKP) 2019, 5, 1–11. [Google Scholar] [CrossRef]
- Jia, P.; Zhang, L.; Chen, J.; Zhao, P.; Zhang, M. The Effects of Clinical Decision Support Systems on Medication Safety: An Overview. PLoS ONE 2016, 11, e167683. [Google Scholar] [CrossRef]
- Mazo, C.; Kearns, C.; Mooney, C.; Gallagher, W.M. Clinical Decision Support Systems in Breast Cancer: A Systematic Review. Cancers 2020, 12, 369. [Google Scholar] [CrossRef]
- Couture, H.D.; Williams, L.A.; Geradts, J.; Nyante, S.J.; Butler, E.N.; Marron, J.S.; Perou, C.M.; Troester, M.A.; Niethammer, M. Image analysis with deep learning to predict breast cancer grade, ER status, histologic subtype, and intrinsic subtype. NPJ Breast Cancer 2018, 4, 30. [Google Scholar] [CrossRef] [PubMed]
- Whitney, J.; Corredor, G.; Janowczyk, A.; Ganesan, S.; Doyle, S.; Tomaszewski, J.; Feldman, M.; Gilmore, H.; Madabhushi, A. Quantitative nuclear histomorphometry predicts oncotype DX risk categories for early stage ER+ breast cancer. BMC Cancer 2018, 18, 610. [Google Scholar] [CrossRef] [PubMed]
- Sunarti, S.; Fadzlul Rahman, F.; Naufal, M.; Risky, M.; Febriyanto, K.; Masnina, R. Artificial intelligence in healthcare: Opportunities and risk for future. Gac. Sanit. 2021, 35, S67–S70. [Google Scholar] [CrossRef]
- Bajwa, J.; Munir, U.; Nori, A.; Williams, B. Artificial intelligence in healthcare: Transforming the practice of medicine. Future Healthc. J. 2021, 8, e188–e194. [Google Scholar] [CrossRef]
- Yin, J.; Ngiam, K.Y.; Teo, H.H. Role of Artificial Intelligence Applications in Real-Life Clinical Practice: Systematic Review. J. Med. Internet Res. 2021, 23, e25759. [Google Scholar] [CrossRef] [PubMed]
- Latif, J.; Xiao, C.; Imran, A.; Tu, S. Medical Imaging using Machine Learning and Deep Learning Algorithms: A Review. In Proceedings of the 2019 2nd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 30–31 January 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.A.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef]
- Demicheli, R.; Bonadonna, G.; Hrushesky, W.J.; Retsky, M.W.; Valagussa, P. Menopausal status dependence of the timing of breast cancer recurrence after surgical removal of the primary tumour. Breast Cancer Res. 2004, 6, 1–8. [Google Scholar] [CrossRef]
- Lao, C.; Elwood, M.; Kuper-Hommel, M.; Campbell, I.; Lawrenson, R.; Health, D.C. Impact of menopausal status on risk of metastatic recurrence of breast cancer. Menopause 2021, 28, 1085–1092. [Google Scholar] [CrossRef]
- Sree, S.V.; Ng, E.Y.K.; Acharya, R.U.; Faust, O. Breast imaging: A survey. World J. Clin. Oncol. 2011, 2, 1085–1092. [Google Scholar] [CrossRef]
- Dutta, S.; Prakash, P.; Matthews, C.G. Impact of data augmentation techniques on a deep learning based medical imaging task. In Proceedings of the Medical Imaging 2020: Imaging Informatics for Healthcare, Research, and Applications; Chen, P.H., Deserno, T.M., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2020; Volume 11318, pp. 168–177. [Google Scholar] [CrossRef]
- Chen, R.J.; Lu, M.Y.; Chen, T.Y.; Williamson, D.F.K.; Mahmood, F. Synthetic data in machine learning for medicine and healthcare. Nat. Biomed. Eng. 2021, 5, 493–497. [Google Scholar] [CrossRef]
- Mohr, D.C.; Burns, M.N.; Schueller, S.M.; Clarke, G.; Klinkman, M. Behavioral Intervention Technologies: Evidence review and recommendations for future research in mental health. Gen. Hosp. Psychiatry 2013, 35, 332–338. [Google Scholar] [CrossRef] [PubMed]
- Iliashenko, O.; Bikkulova, Z.; Dubgorn, A. Opportunities and challenges of artificial intelligence in healthcare. E3S Web Conf. 2019, 110, 02028. [Google Scholar] [CrossRef]
- Bartoletti, I. AI in Healthcare: Ethical and Privacy Challenges. In Proceedings of the Artificial Intelligence in Medicine; Ria no, D., Wilk, S., ten Teije, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 7–10. [Google Scholar]
- Allen, T.C. Regulating Artificial Intelligence for a Successful Pathology Future. Arch. Pathol. Lab. Med. 2019, 143, 1175–1179. [Google Scholar] [CrossRef] [PubMed]
- Campanella, G.; Hanna, M.G.; Geneslaw, L.; Miraflor, A.; Werneck Krauss Silva, V.; Busam, K.J.; Brogi, E.; Reuter, V.E.; Klimstra, D.S.; Fuchs, T.J. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images. Nat. Med. 2019, 25, 1301–1309. [Google Scholar] [CrossRef]
- da Silva, L.M.; Pereira, E.M.; Salles, P.G.; Godrich, R.; Ceballos, R.; Kunz, J.D.; Casson, A.; Viret, J.; Chandarlapaty, S.; Ferreira, C.G.; et al. Independent real-world application of a clinical-grade automated prostate cancer detection system. J. Pathol. 2021, 254, 147–158. [Google Scholar] [CrossRef]
- Philips. Philips and Paige Team up to Bring Artificial Intelligence (AI) to Clinical Pathology Diagnostics. 2019. Available online: https://www.philips.com/a-w/about/news/archive/standard/news/press/2019/20190512-philips-and-paige-team-up-to-bring-artificial-intelligence-ai-to-clinical-pathology-diagnostics.html (accessed on 13 April 2021).




| Exclusion | Inclusion |
|---|---|
| Papers that were not written in English | Breast cancer risk of recurrence prediction studies |
| Papers that were not peer-reviewed conference or journal papers (e.g., theses, dissertations, books, book chapters, pre-prints, posters, PowerPoint presentations, or other archived articles) | Studies using machine learning techniques (regression, instance-based, regularization, decision tree, Bayesian, clustering, association rule learning, artificial neural network, deep learning, dimensionality reduction, and ensemble algorithms) |
| Not human studies | |
| Surveys |
| Feature | Number (n) | Percentage (%) |
|---|---|---|
| Patient demographics | ||
| Marital status | 2 | 6.5 |
| Demographic information | 2 | 6.5 |
| Race/ethnicity | 1 | 3.2 |
| Years of education | 1 | 3.2 |
| Personal Medical History | ||
| Age at diagnosis | 17 | 54.8 |
| Menopausal status | 7 | 22.6 |
| Age at menarche | 2 | 6.5 |
| Smoking status | 2 | 6.5 |
| History of infertility | 2 | 6.5 |
| Alcohol usage | 2 | 6.5 |
| Death (related to breast cancer or unrelated) | 2 | 6.5 |
| History of other cancers | 1 | 3.2 |
| History of other chronic diseases | 1 | 3.2 |
| Breastfeeding | 1 | 3.2 |
| Body mass index | 1 | 3.2 |
| Charlson comorbidity index | 1 | 3.2 |
| Family history | ||
| Breast cancer | 4 | 12.9 |
| Other cancers | 2 | 6.5 |
| Feature | Number (n) | Percentage (%) | |
|---|---|---|---|
| Anatomic staging | 1. Clinical staging | ||
| 1.1 Diagnostic imaging | |||
| MRI scans | 12 | 38.7 | |
| Ultrasonography | 1 | 3.2 | |
| 1.2 Core biopsy | 2 | 6.5 | |
| 2. Pathologic staging TNM | |||
| Nodal status | 29 | 93.5 | |
| Tumour | 28 | 90.3 | |
| Metastasis | 7 | 22.6 | |
| 3. Post-therapy staging | |||
| 3.1 Clinical Information | |||
| Radiation | 10 | 32.3 | |
| Hormone therapy | 8 | 25.8 | |
| Chemotherapy | 8 | 25.8 | |
| Type of surgery | 7 | 22.6 | |
| Therapy | 4 | 12.9 | |
| NAC | 1 | 3.2 | |
| Anti-HER2 therapy | 1 | 3.2 | |
| 3.2 Pathological information | |||
| Response to neoadjuvant therapy | 2 | 6.5 | |
| Complete pathologic response | 1 | 3.2 | |
| 4. Restaging in the event of tumour recurrence | |||
| Outcome (recurrence/not) | 7 | 22.6 | |
| Recurrence time | 6 | 19.4 | |
| Prognostic stage | Tumour grade | 21 | 67.7 |
| Hormone receptor | 15 | 48.4 | |
| Tumour invasion | 13 | 41.9 | |
| HER2 | 8 | 25.8 | |
| Tumour type | 7 | 22.6 | |
| Ki-67 | 5 | 16.1 | |
| Oncogene expression | 2 | 6.5 | |
| Multigene panels testing | 1 | 3.2 | |
| Other molecular markets | |||
| Stromal TILs | 1 | 3.2 | |
| CD44 | 1 | 3.2 | |
| ABCC4 | 1 | 3.2 | |
| ABCC11 | 1 | 3.2 | |
| N-cadherin | 1 | 3.2 | |
| Pan-cadherin | 1 | 3.2 | |
| Cytokeratin 5/6 (CK5/6) | 1 | 3.2 | |
| Epidermal Growth Factor Receptor (EGFR) | 1 | 3.2 |
| Rank | Feature | Number (n) | Percentage (%) |
|---|---|---|---|
| 3 | Magnetic Resonance Imaging (MRI) | 12 | 38.7 |
| 1 | Fine Needle Aspirate (FNA) | 6 | 19.4 |
| 4 | TMA samples | 1 | 3.2 |
| Publication | Publicly | Years of | Balanced | Validation | Sampling | Data Handling |
|---|---|---|---|---|---|---|
| Available | Recurrence | Classes | Strategy | Strategy | Strategy | |
| Lg et al. [22] | No | 2 | No | Cross validation | Simple | Expectation |
| maximization | ||||||
| Pritom et al. [23] | Yes | — | No | Cross validation | Simple | — |
| Aline et al. [24] | No | 5 | No | Validation set | Stratified | — |
| Mosayebi et al. [25] | No | 5 | No | Cross validation | Stratified | Excluding |
| Alzubi et al. [26] | No | — | No | Cross validation | Stratified | Excluding |
| Witteveen et al. [27] | No | 5 | No | Validation set | Stratified | — |
| Cirkovic et al. [28] | No | 5 | No | Cross validation | Stratified | — |
| Ramkumar et al. [29] | No | 5 | No | Validation set | Stratified | Excluding |
| Almuhaidib et al. [30] | Yes | — | No | Cross validation | Simple | Excluding |
| Rosa Mendoza et al. [31] | No | 2 | No | — | Stratified | Excluding |
| Wang et al. [32] | No | 5 | No | 70-30 | Simple | Excluding |
| Chou et al. [33] | Yes | 5 | No | Validation set | Simple | Excluding |
| Li et al. [34] | Yes | — | No | — | Simple | Excluding |
| Kim et al. [35] | No | — | No | Validation set | Simple | Excluding |
| Kim et al. [36] | No | 5 | No | 80-20 | Simple | Excluding |
| Chakradeo et al. [37] | Yes | — | No | Cross validation | Simple | Excluding |
| Rana et al. [38] | Yes | — | No | Cross validation | Simple | Excluding |
| Mohebian et al. [39] | No | 5 | No | Cross validation | Simple | Excluding |
| Eun et al. [40] | No | 7 | No | Cross validation | Systematic | Excluding |
| Bhargava et al. [41] | Yes | — | No | Cross validation | Simple | Excluding |
| Adeyemi et al. [42] | Yes | — | No | Cross validation | Simple | Excluding |
| Yang et al. [43] | No | 5 | No | Cross validation | Simple | Excluding |
| Massafra et al. [44] | Yes | 5–10 | No | Cross validation | Simple | Predictive |
| Turkki et al. [45] | No | 15 | No | Validation set | Simple | Excluding |
| Kabiraj et al. [46] | Yes | — | No | Cross validation | Simple | Excluding |
| Sakri et al. [47] | Yes | 4 | No | Cross validation | Simple | Excluding |
| Lou et al. [48] | No | 10 | No | Validation set | Simple | Excluding |
| Ojha and Goel [49] | Yes | — | No | Cross validation | Cluster | Excluding |
| Kim et al. [50] | No | 5 | No | Validation set | Systematic | Excluding |
| Woojae et al. [51] | No | 5 | No | 70-30 | Stratified | Excluding |
| Zain et al. [52] | Yes | — | No | Cross validation | Simple | Excluding |
| Rank | Feature | Number (n) | Percentage (%) |
|---|---|---|---|
| 1 | Specificity | 20 | 64.5 |
| 2 | Sensitivity | 19 | 61.3 |
| 3 | Accuracy | 18 | 58.1 |
| 4 | AUC | 16 | 51.6 |
| 5 | F-Score | 8 | 25.8 |
| 6 | Precision | 7 | 22.6 |
| 7 | Positive predictive value | 4 | 12.9 |
| 8 | Negative predictive value | 4 | 12.9 |
| 9 | Recall | 4 | 12.9 |
| 10 | Kappa statistic | 2 | 6.5 |
| 11 | Mean absolute error | 1 | 3.2 |
| 12 | Root mean squared error | 1 | 3.2 |
| 13 | Relative absolute error | 1 | 3.2 |
| 14 | Root relative squared error | 1 | 3.2 |
| 15 | Error rate | 1 | 3.2 |
| 16 | Youden’s J statistic | 1 | 3.2 |
| 17 | Standard error | 1 | 3.2 |
| 18 | Gini index | 1 | 3.2 |
| 19 | Entropy | 1 | 3.2 |
| 20 | Information gain | 1 | 3.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazo, C.; Aura, C.; Rahman, A.; Gallagher, W.M.; Mooney, C. Application of Artificial Intelligence Techniques to Predict Risk of Recurrence of Breast Cancer: A Systematic Review. J. Pers. Med. 2022, 12, 1496. https://0-doi-org.brum.beds.ac.uk/10.3390/jpm12091496
Mazo C, Aura C, Rahman A, Gallagher WM, Mooney C. Application of Artificial Intelligence Techniques to Predict Risk of Recurrence of Breast Cancer: A Systematic Review. Journal of Personalized Medicine. 2022; 12(9):1496. https://0-doi-org.brum.beds.ac.uk/10.3390/jpm12091496
Chicago/Turabian StyleMazo, Claudia, Claudia Aura, Arman Rahman, William M. Gallagher, and Catherine Mooney. 2022. "Application of Artificial Intelligence Techniques to Predict Risk of Recurrence of Breast Cancer: A Systematic Review" Journal of Personalized Medicine 12, no. 9: 1496. https://0-doi-org.brum.beds.ac.uk/10.3390/jpm12091496