
Anchoring and Asymmetric Information in the Real Estate Market: A Machine Learning Approach
_Cheung.jpeg)


Abstract
:1. Introduction
2. Literature Review
3. Machine Learning for Classifying Names of Buyers and Sellers
4. Empirical Evidence: Non-Local Buyer Premium and Seller Discount
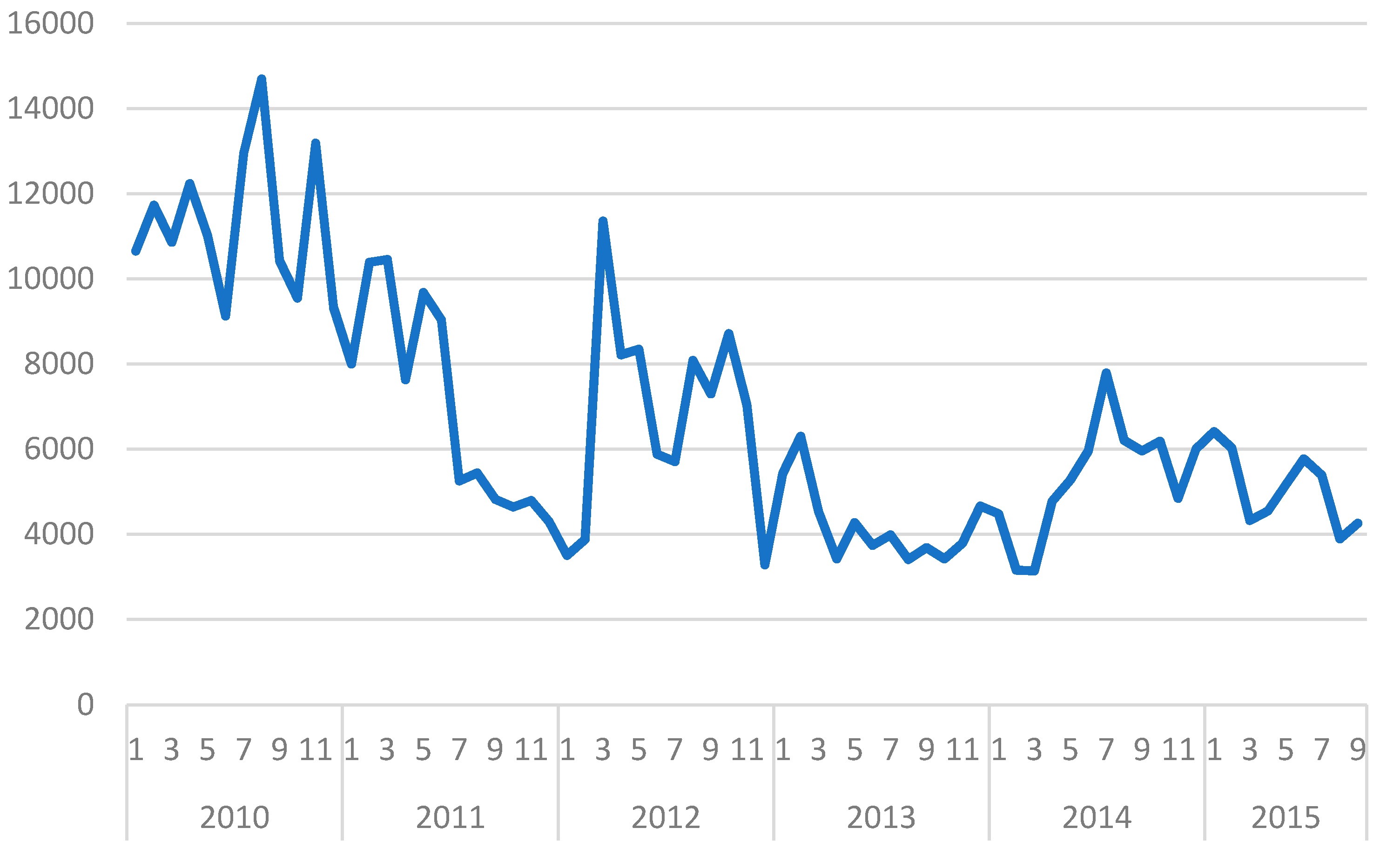
4.1. Research Data
4.2. Hedonic Pricing Model Analysis and Results
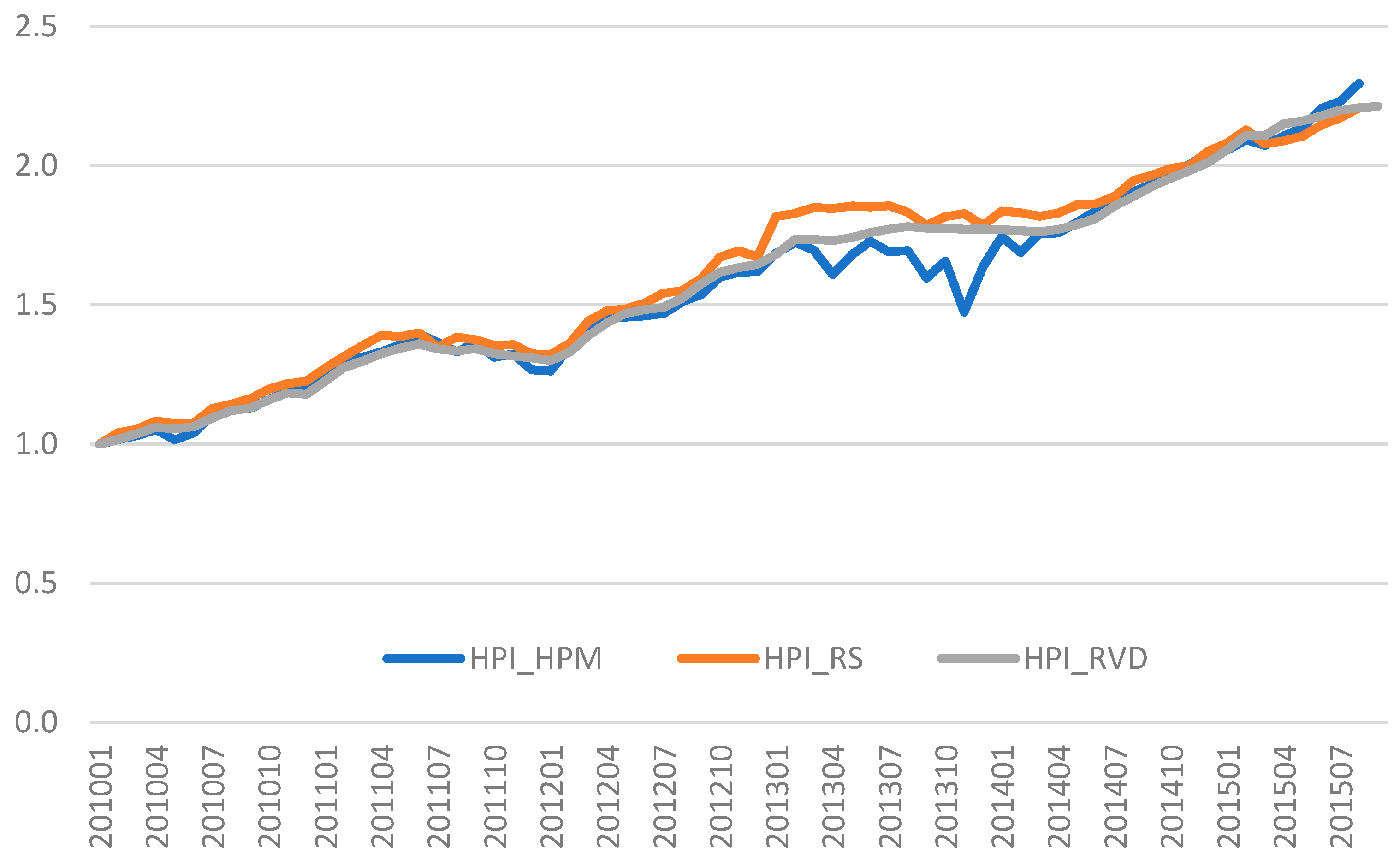
4.3. Repeat-Sales Method as a Robustness Check
5. A Critical Test for Information Asymmetry versus Anchoring Biases
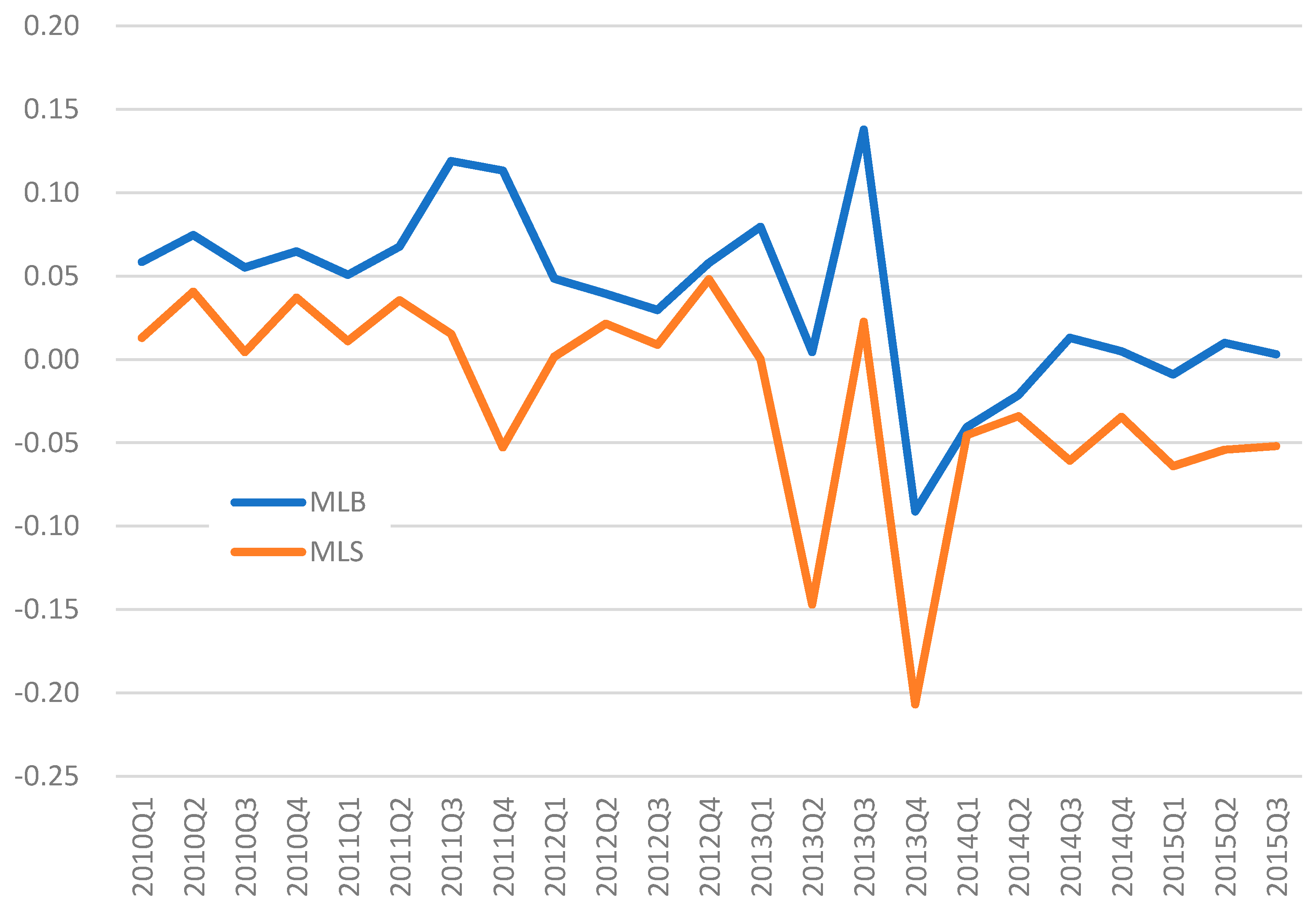
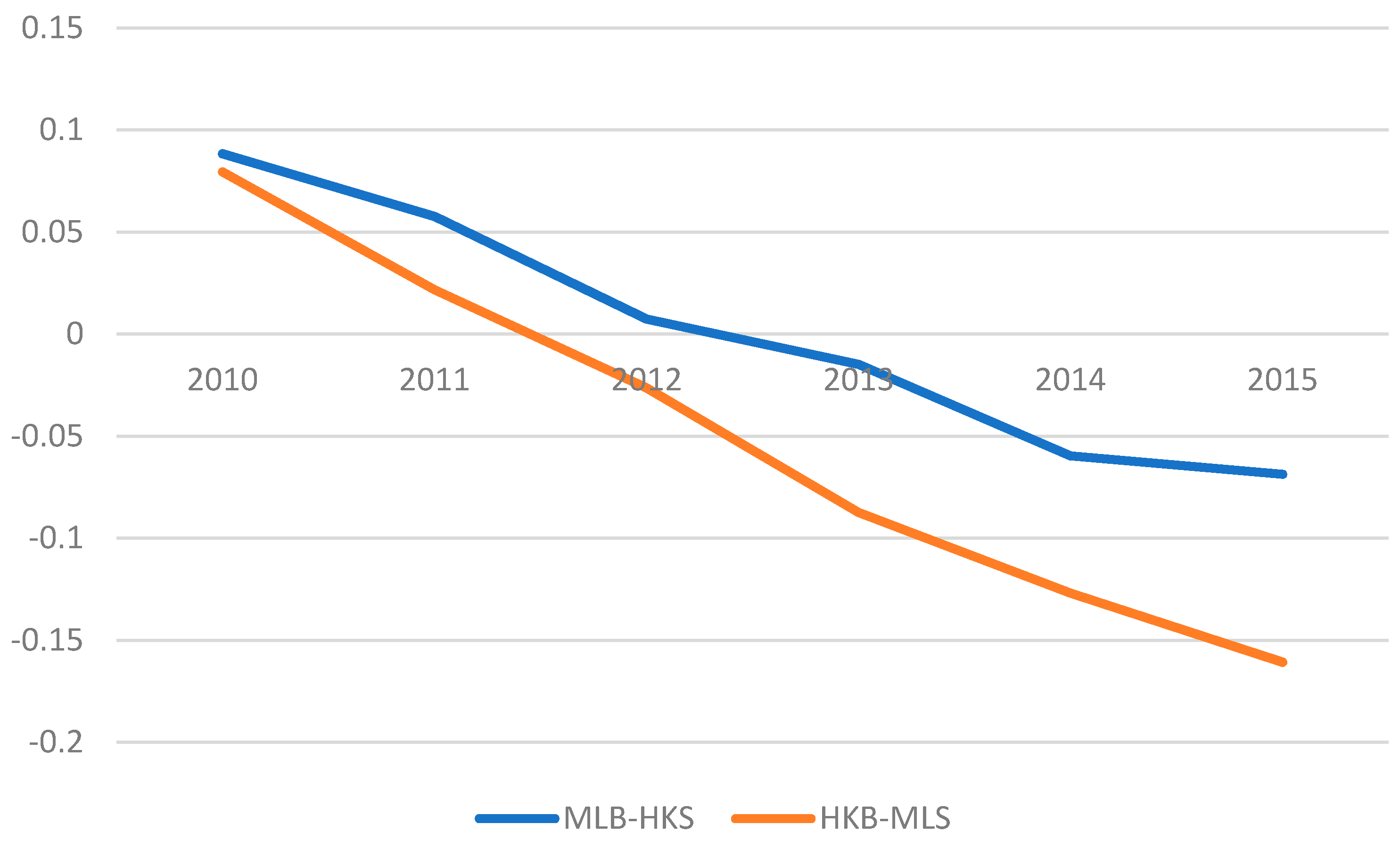
5.1. Difference-in-Differences Analysis and the Discussion on the Empirical Result
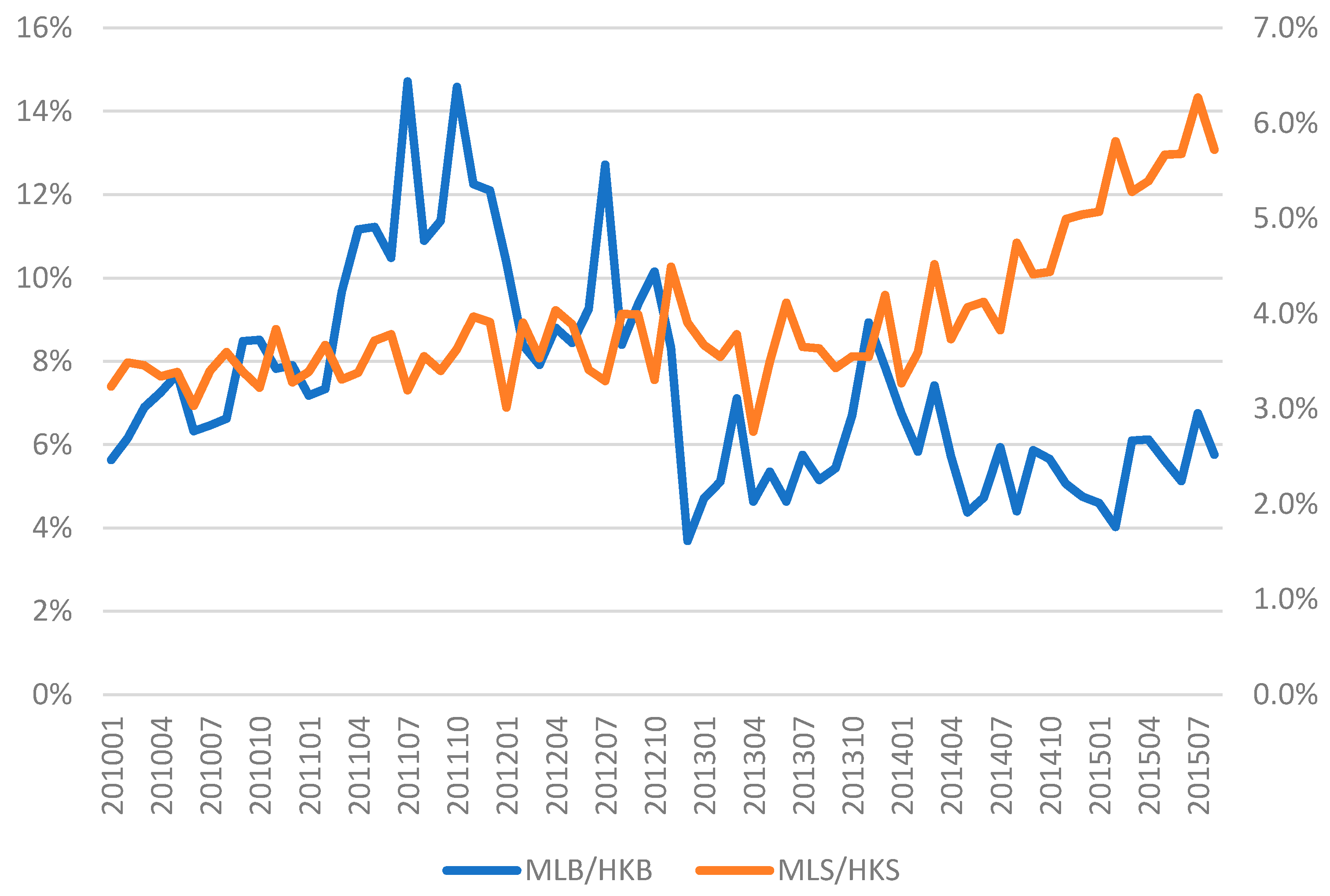
5.2. Difference-in-Differences Analysis and Discussion on the Results in the Repeat-Sales Setup
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
A Simple Model to Develop Hypotheses
Appendix B
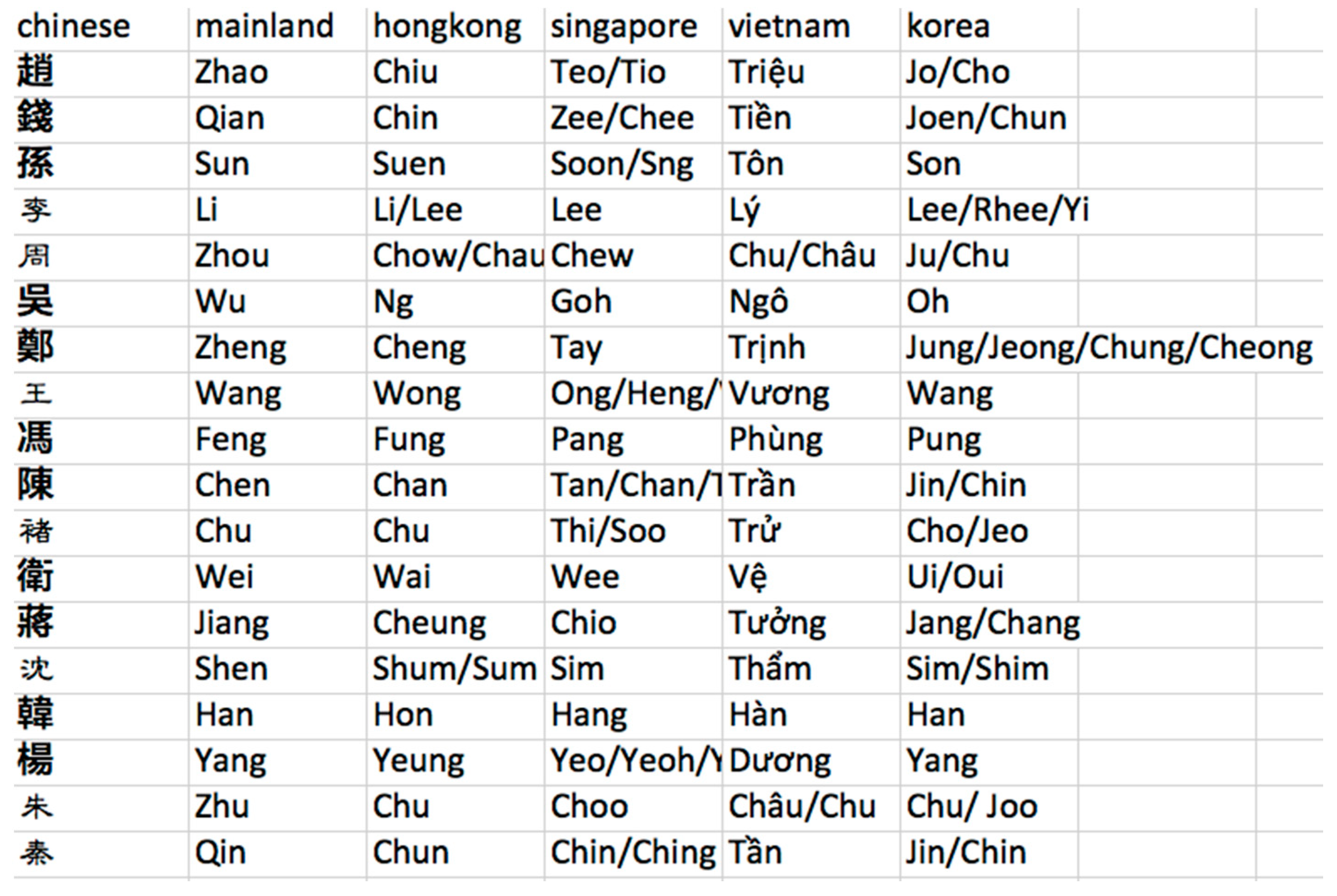
An Analysis of Naming Patterns among Mainland Chinese

Appendix C

| 1. | To test the effects of government policies on non-local buyers and sellers, we limit our sample period from 2010 to 2015. The special tax for non-local buyers (Buyers’ Stamp Duty) was implemented in October 2012, but the 2nd Double Stamp Duty of a uniform 15% rate applied on both local and non-local buyers did not apply till November 2016. Better still, the period can exclude the effect of the first and only development of sale restrictions on non-native buyers, One Kai Tak, as it was not open for sale until August 2016. |
| 2. | The statistics from the government audit’s report, Director of Audit’s Report No. 66: Chapter 4—Admission Schemes for Talent, Investors and Workers, Annex D: Statistics on entrants having acquired Hong Kong permanent resident status under various immigration policies/admission schemes, and having stayed in Hong Kong for seven years or more; retrieved from https://www.legco.gov.hk/yr15-16/english/pac/reports/66/app_13.pdf (accessed on 30 August 2021) indicate that the number of entrants who have acquired Hong Kong permanent resident status under various immigration policies remains low, fewer than 8000 per year. |
| 3. | Local movers are assumed to have their own uniform level of search costs. |
| 4. | The source code and model are publicly available at Github. |
| 5. | The examples could be from an external source. |
| 6. | Researchers can verify the accuracy using a hold-out sample known as testing data. We will discuss our procedure in this section. |
| 7. | Others include non-Hong Kong or mainland Chinese names and company names. |
| 8. | Dilution or dropout is a regularization technique that randomly omitting weights in a neural network model. |
| 9. | We acknowledge that there could be limitations to our method of identifying non-local sellers and buyers. First, many investors from Mainland China would buy housing units in Hong Kong via buying companies, and the pricing information of these company transactions is not reflected from normal housing transaction data. Second, some Chinese with Mainland Chinese’s last names may have lived in Hong Kong for some years and may be as experienced as local participants, but their number is small. However, the reversal of non-local price differential from premiums to discounts in our empirical findings implies that our machine-learning algorithm can successfully identify the non-locals given they are the only buyers who have to pay the foreign buyers’ stamp duties. |
| 10. | On 4 November 2016, the Hong Kong Government amended the Stamp Duty Ordinance to increase the ad valorem stamp duty rates for all residential property transactions to a flat rate of 15 percent, with immediate effect. It is considered “a significant leap from the so-called [1st] “Double Stamp Duty” under the current regime, which stands at a range of 4.25 to 8.5 percent, being applicable to purchases by non-Hong Kong permanent residents and/or if the purchaser already owns another residential property at the time of the subsequent purchase.” (Yip 2016). |
| 11. | Equation (4) shows the typical repeat-sale model which subtracts the first-sale equation from the second-sale equation. Following the Hedonic Price Model (Equation (2)), we do not use Equation (3) is because most of the repeat-sales samples involve only one pair of repeat-sales in the study period, which does not provide information of the name of the seller in the first sale. |
| 12. | Even if the sellers are to share part of the new stamp duties under the market negotiation process, the average market sharing ratio should be the same for both the local and non-local sellers. |
| 13. | The three comparative statics are . |
References
- Akerlof, George A. 1970. The Market for “Lemons”: Quality Uncertainty and the Market Mechanism. The Quarterly Journal of Economics 84: 488–500. [Google Scholar] [CrossRef]
- Bailey, Martin J., Richard F. Muth, and Hugh O. Nourse. 1963. A Regression Model for Real Estate Price Index Construction. Journal of the American Statistical Association 58: 933–42. [Google Scholar] [CrossRef]
- Bucchianeri, Grace W., and Julia A. Minson. 2013. A homeowner’s dilemma: Anchoring in residential real estate transactions. Journal of Economic Behavior & Organization 89: 76–92. [Google Scholar] [CrossRef]
- Camerer, Colin F., and George Loewenstein. 2003. Behavioral economics: Past, present, future. In Advances in Behavioral Economics. Princeton: Princeton University Press. [Google Scholar]
- Chang, Chuang-Chang, Ching-Hsiang Chao, and Jin-Huei Yeh. 2016. The role of buy-side anchoring bias: Evidence from the real estate market. Pacific-Basin Finance Journal 38: 34–54. [Google Scholar] [CrossRef]
- Cho, Kyunghyun, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv arXiv:1406.1078. [Google Scholar]
- Clauretie, Terrence M., and Paul D. Thistle. 2007. The Effect of Time-on-Market and Location on Search Costs and Anchoring: The Case of Single-Family Properties. The Journal of Real Estate Finance and Economics 35: 181–96. [Google Scholar] [CrossRef]
- Diaz, Julian, III, and Marvin L. Wolverton. 1998. A Longitudinal Examination of the Appraisal Smoothing Hypothesis. Real Estate Economics 26: 349–58. [Google Scholar] [CrossRef]
- Edelstein, Robert, and Wenlan Qian. 2014. Short-Term Buyers and Housing Market Dynamics. The Journal of Real Estate Finance and Economics 49: 654–89. [Google Scholar] [CrossRef] [Green Version]
- Elder, Harold W., Leonard V. Zumpano, and Edward A. Baryla. 1999. Buyer Search Intensity and the Role of the Residential Real Estate Broker. The Journal of Real Estate Finance and Economics 18: 351–68. [Google Scholar] [CrossRef]
- Garmaise, Mark J., and Tobias J. Moskowitz. 2004. Confronting information asymmetries: Evidence from real estate markets. The Review of Financial Studies 17: 405–37. [Google Scholar] [CrossRef]
- Haley, Alex. 1983. Ethnic Genealogy: A Research Guide. Santa Barbara: ABC-CLIO. [Google Scholar]
- Harding, John P., John R. Knight, and C. F. Sirmans. 2003a. Estimating bargaining effects in hedonic models: Evidence from the housing market. Real Estate Economics 31: 601–22. [Google Scholar] [CrossRef]
- Harding, John P., John R. Knight, and C. F. Sirmans. 2003b. Estimating bargaining power in the market for existing homes. The Review of Economics and Statistics 85: 178–88. [Google Scholar] [CrossRef]
- Humphreys, Brad R., Adam Nowak, and Yang Zhou. 2019. Superstition and real estate prices: Transaction-level evidence from the US housing market. Applied Economics 51: 2818–41. [Google Scholar] [CrossRef]
- Ihlanfeldt, Keith, and Tom Mayock. 2009. Price Discrimination in the Housing Market. Journal of Urban Economics 66: 125–40. [Google Scholar] [CrossRef]
- Ihlanfeldt, Keith, and Tom Mayock. 2012. Information, Search, and House Prices: Revisited. Journal of Real Estate Finance and Economics 44: 90–115. [Google Scholar] [CrossRef]
- Lambson, Val E., Grant R. McQueen, and Barrett A. Slade. 2004. Do Out-of-State Buyers Pay More for Real Estate? An Examination of Anchoring-Indexed Bias and Search Costs. Real Estate Economics 32: 85–126. [Google Scholar] [CrossRef]
- Lichtenstein, Sarah, and Paul Slovic. 1971. Reversal of Preferences between Bids and Choices in Gambling Decisions. Journal of Experimental Psychology 89: 46–55. [Google Scholar] [CrossRef] [Green Version]
- Ling, David C., Andy Naranjo, and Milena T. Petrova. 2018. Search Costs, Behavioral Biases, and Information Intermediary Effects. The Journal of Real Estate Finance and Economics 57: 114–51. [Google Scholar] [CrossRef]
- Liu, Yu, Paul Gallimore, and Jonathan A. Wiley. 2015. Non-local investors: Anchored by their markets and impaired by their distance. The Journal of Real Estate Finance and Economics 50: 129–49. [Google Scholar] [CrossRef]
- Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space. arXiv arXiv:1301.3781. [Google Scholar]
- Mullainathan, Sendhil, and Jann Spiess. 2017. Machine learning: An applied econometric approach. Journal of Economic Perspectives 31: 87–106. [Google Scholar] [CrossRef] [Green Version]
- Neo, Poh Har, Seow Eng Ong, and Yong Tu. 2008. Buyer exuberance and price premium. Urban Studies 45: 331–45. [Google Scholar]
- Northcraft, Gregory B., and Margaret A. Neale. 1987. Expert, Amateurs, and Real Estate: An Anchoring-and-Adjustment Perspective on Property Pricing Decisions. Organizational Behavior and Human Decision Processes 39: 84–97. [Google Scholar] [CrossRef]
- OECD. 2013. Repeat Sales Methods. In Handbook on Residential Property Price Indices. Luxembourg: Eurostat, chp. 6. [Google Scholar] [CrossRef]
- Pace, R. Kelley, and Darren Hayunga. 2020. Examining the Information Content of Residuals from Hedonic and Spatial Models Using Trees and Forests. The Journal of Real Estate Finance and Economics 60: 170–80. [Google Scholar] [CrossRef]
- Platt, John R. 1964. Strong Inference. Science 146: 347–53. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rosen, Sherwin. 1974. Hedonic prices and implicit markets: Product differentiation in pure competition. Journal of Political Economy 82: 34–55. [Google Scholar] [CrossRef]
- Salehinejad, Hojjat, Sharan Sankar, Joseph Barfett, Errol Colak, and Shahrokh Valaee. 2017. Recent advances in recurrent neural networks. arXiv arXiv:1801.01078. [Google Scholar]
- Scott, Peter J., and Colin Lizieri. 2012. Consumer house price judgements: New evidence of anchoring and arbitrary coherence. Journal of Property Research 29: 49–68. [Google Scholar] [CrossRef]
- Shen, Lily, and Stephen Ross. 2021. Information value of property description: A machine learning approach. Journal of Urban Economics 121: 103299. [Google Scholar] [CrossRef]
- South China Morning Post. 2017. Plunging Chinese Rental Yields Point to Property Bubbles in Major Cities. South China Morning Post. July 18. Available online: https://www.scmp.com/business/china-business/article/2103116/plunging-chinese-rental-yields-point-property-bubbles-major (accessed on 30 August 2021).
- Sun, Hua, and Seow Eng Ong. 2014. Bidding Heterogeneity, Signaling Effect and its Implications on House Seller’s Pricing Strategy. The Journal of Real Estate Finance and Economics 49: 568–97. [Google Scholar] [CrossRef]
- Turnbull, Geoffrey K., and Casey F. Sirmans. 1993. Information, Search, and House Prices. Regional Science and Urban Economics 23: 545–57. [Google Scholar] [CrossRef]
- Watkins, Craig. 1998. Are New Entrants to the Residential Property Market Informationally Disadvantaged? Journal of Property Research 15: 57–70. [Google Scholar] [CrossRef]
- Wong, Kai On, Osmar R. Zaïane, Faith G. Davis, and Yutaka Yasui. 2020. A machine learning approach to predict ethnicity using personal name and census location in Canada. PLoS ONE 15: e0241239. [Google Scholar] [CrossRef] [PubMed]
- Wright, Danika, and María B. Yanotti. 2019. Home advantage: The preference for local residential real estate investment. Pacific-Basin Finance Journal 57: 101167. [Google Scholar] [CrossRef] [Green Version]
- Yip, Alan. 2016. HK Residential Property Stamp Duty Jump to 15%. Industry Insights, Hong Kong Lawyer, December. Available online: http://www.hk-lawyer.org/content/hk-residential-property-stamp-duty-jump-15 (accessed on 30 August 2021).
- Yiu, Chung Yim. 2009. Disentanglement of Age, Time, and Vintage Effects on Housing Price by Forward Contracts. Journal of Real Estate Literature 17: 273–91. [Google Scholar] [CrossRef]
- Zhou, Xiaorong, Karen Gibler, and Velma Zahirovic-Herbert. 2015. Asymmetric Buyer Information Influence on Price in a Homogenous Housing Market. Urban Studies 52: 891–905. [Google Scholar] [CrossRef]
- Zumpano, Leonard V., Harold W. Elder, and Edward A. Baryla. 1996. Buying a house and the decision to use a real estate broker. The Journal of Real Estate Finance and Economics 13: 169–81. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Panel A—Hyperparameters of the Machine Learning Model | |||
| Sequence | Layer | Hyperparameter | Value |
| 1st layer | Word Embedding | Max length | 50 |
| Number of embeddings | 30 | ||
| 2nd layer | GRU | Number of layers | 3 |
| Number of neurons | 30 | ||
| 3rd layer | Activation | Functional form | tanh |
| 4th layer | Dropout | Probability of dropout | 20% |
| 5th layer | MLP | Number of layers | 2 |
| Number of neurons | 10 | ||
| Activation | Sigmoid | ||
| Panel B—Performance of the Machine Learning Model | |||
| Training Sample | Validation Sample | Testing Sample | |
| 99.14% | 98.94% | 99.00% | |
| Variable | Description | Mean/ Count | S.D. | Min. | Max. |
|---|---|---|---|---|---|
| P | Sales Price (in HK$ Million) | 4.01 | 3.57 | 0.10 | 236 |
| AGE | Building Age (in years) | 20.40 | 10.40 | −3.25 | 58 |
| FLR | Floor Level (in Storey) | 16.95 | 12.15 | 0.00 | 86 |
| GFA | Gross Floor Area (in sq ft) | 655.49 | 242.2 | 134 | 6315 |
| U_RATIO | Utility Ratio = Saleable to Gross Floor Area (in sq ft) | 0.78 | 0.06 | 0.32 | 0.99 |
| BW | Bay Window Area (in sq ft) | 15.31 | 15.73 | 0.00 | 250 |
| LEASE | Remaining land lease period (in years) | 111.47 | 223.55 | 12 | 890 |
| PRESALE | Pre-sale Dummies | 238 | - | 0 | 1 |
| MLS | Mainland Seller (1, or 0 otherwise) | 5265 | - | 0 | 1 |
| MLB | Mainland Buyer (1, or 0 otherwise) | 7632 | - | 0 | 1 |
| Direction Dummies | 8 | ||||
| Time Dummies | 69 | 2010M1–2015M9 | |||
| District Dummies | 59 | Appendix C | |||
| Equation (1) Baseline | Equation (2) | Equation (3) | |
|---|---|---|---|
| Dep. Var. | The Logarithm of Sales Prices ln(P) | ||
| MLB | - | 0.049 | 0.049 |
| (0.003) *** | (0.003) *** | ||
| MLS | - | - | −0.010 |
| (0.004) *** | |||
| |AGE| × PRESALE | 0.135 | −0.128 | −0.124 |
| (0.100) | (0.100) | (0.100) | |
| AGE × (1 − PRESALE) | −0.012 | −0.012 | −0.012 |
| (0.000) *** | (0.000) *** | (0.000) *** | |
| FLR | 0.003 | 0.003 | 0.003 |
| (0.000) *** | (0.000) *** | (0.000) *** | |
| GFA | 0.001 | 0.001 | 0.001 |
| (0.000) *** | (0.000) *** | (0.000) *** | |
| U_RATIO | 1.680 | 1.681 | 1.681 |
| (0.020) *** | (0.020) *** | (0.020) *** | |
| BW | 0.003 | 0.003 | 0.003 |
| (0.000) *** | (0.000) *** | (0.000) *** | |
| LEASE | 0.000 | 0.000 | 0.000 |
| (0.000) *** | (0.000) *** | (0.000) *** | |
| Constant | −0.862 | −0.865 | −0.865 |
| (0.016) *** | (0.016) *** | (0.016) *** | |
| Direction Fixed Effect | Included (8 Directions) | ||
| Time Fixed Effect | Included (2010M1–2015M9) | ||
| Neighbourhood Fixed Effect | Included (59 Subdistricts) | ||
| Observations: | 93,726 | 93,726 | 93,726 |
| R-squared: | 0.851 | 0.852 | 0.852 |
| Description | Mean/ Count | S.D. | Min | Max | |
|---|---|---|---|---|---|
| P1 | Price of the first sale in a repeat-sale | 2.93 | 3.36 | 0.10 | 344.88 |
| P2 | Price of the second sale in a repeat-sale | 3.89 | 3.83 | 0.10 | 528.80 |
| MLB | Mainland Buyer (1, or 0 otherwise) | 2860 | |||
| MLS | Mainland Seller (1, or 0 otherwise) | 2895 |
| Dep. Var: | |||
|---|---|---|---|
| Variable | Model (4) | Model (5) | Model (6) |
| 0.0283 (0.0037) *** | |||
| 0.0067 (0.0053) | 0.0025 (0.0055) *** | ||
| −0.0499 (0.0053) *** | −0.0381 (0.0055) *** | ||
| Time Fixed Effects | Yes (2010M1–2015M9) | Yes (2010–2015) | |
| Observations | 54,794 | 54,794 | 54,794 |
| R-squared | 0.2288 | 0.2302 | 0.1741 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheung, K.S.; Chan, J.T.; Li, S.; Yiu, C.Y. Anchoring and Asymmetric Information in the Real Estate Market: A Machine Learning Approach. J. Risk Financial Manag. 2021, 14, 423. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm14090423
Cheung KS, Chan JT, Li S, Yiu CY. Anchoring and Asymmetric Information in the Real Estate Market: A Machine Learning Approach. Journal of Risk and Financial Management. 2021; 14(9):423. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm14090423
Chicago/Turabian StyleCheung, Ka Shing, Julian TszKin Chan, Sijie Li, and Chung Yim Yiu. 2021. "Anchoring and Asymmetric Information in the Real Estate Market: A Machine Learning Approach" Journal of Risk and Financial Management 14, no. 9: 423. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm14090423