1. A Quantitative Approach to Grammaticalization
Grammaticalization is the process whereby new grammar is created from erstwhile lexical material in specific constructions. A good example is the adverbial suffix -
ly in English, which derives from a noun meaning ‘shape’ or ‘body’ (Proto-Germanic *
līka-). In the vast literature on the topic that has accumulated over the years, the concept has at times been delineated more narrowly, e.g., by setting it off against lexicalization (e.g.,
Wischer 2000;
Brinton and Traugott 2005), and in other cases has been conceived more broadly as not only capturing the process from lexical to grammatical, but also encompassing the shift from grammatical to even-more-grammatical. Recent approaches have taken a constructional perspective and have integrated grammaticalization in a process of constructionalization (
Traugott and Trousdale 2013). This is not the place to review the various conceptions of grammaticalization (for good introductions and overviews, see
Hopper and Traugott 2003 and
Narrog and Heine 2011). Suffice it to say that the origin of the process need not necessarily be fully lexical, and the end product need not necessarily be a bound morpheme. Take, for instance, the grammaticalization of Old English
willan ‘wish’ to Present-day English
will as a future-marking auxiliary. It is often considered as a case of grammaticalization (see, e.g.,
Krug 2011, p. 554), but it is a less clear example than the adverbializing suffix -
ly, from *
līka-. As a marker of volition,
willan already had burgeoning auxiliary status, as it could be combined with an infinitive in Old English, as in (1). To argue that the ‘new’ function of
will is more grammaticalized, a number of changes in its morphosyntactic behavior can be pointed out, as well as changes on the semantic level. The morphosyntactic changes have to do with what
Hopper (
1991) has called
decategorialization: the future marker
will gradually loses the characteristics that betray its lexical origin as a run-of-the-mill verb, such as, e.g.,
do-support.
| (1) | sé | ðe | wyle | sóð | specan | (Beowulf, v. 2864) |
| | he | that | will | true | speak |
| ‘he who wants to speak the truth’ |
With cases of grammaticalization like Proto-Germanic *līka- to -ly, the shift is sufficiently clear and convincing: a free morpheme with lexical meaning transforms into a bound morpheme with grammatical meaning. In the case of the transformation of willan to will, however, things are less clear. Both are free morphemes, and they both hover between fully lexical and fully grammatical. How are we to assess that one is more grammatical(ized) than the other?
There seems to be a broad consensus in the literature that grammaticalization should not be considered as a binary feature, where a construction is either ‘grammaticalized’ or ‘not grammaticalized’, but rather as a continuum. Lexical constructions slowly shift into grammatical constructions, often imperceptibly (see
De Smet 2009,
2012;
Van de Velde and Van der Horst 2013;
Van der Horst and Van de Velde 2016, on the sneaky nature of language change), and once these constructions are in the grammar, they gradually worm their way further into the grammatical core. With regard to auxiliation, for instance,
Heine (
1993) observes that there is no clear boundary between lexical and auxiliary verbs.
Bolinger (
1980, p. 297) noted that “[t]he moment a verb is given an infinitival complement, that verb starts down the road of auxiliariness. It may make no more than a start or travel all the way”.
It would be helpful if we had some criteria to measure the degree of grammaticalization. In principle, the diagnostics in
Lehmann (
2002) (attrition, paradigmatization, obligatorification, condensation, coalescense, fixation),
Hopper (
1991) (layering, divergence, specialization, persistence, decategorialization), and
Himmelmann (
2004) (host-class expansion, syntactic expansion, semantic-pragmatic expansion) are amenable to quantify the degree of grammaticalization, though in practice, this is rarely done. Exceptions are the basic operationalizations in
Bybee et al. (
1994), the corpus-based approaches in
Cheshire (
2007) and
Brems (
2011), the more radically data-driven approach in Correia
Saavedra (
2019), and the rapprochement between variationist linguistics and grammaticalization theory in, among others,
Sankoff (
1990),
Schwenter (
1994),
Poplack and Tagliamonte (
1999),
Torres-Cacoullos (
1999),
Poplack (
2011),
Wolk et al. (
2013),
Rosemeyer and Grossman (
2017),
Denis and Tagliamonte (
2018), and
Petré and Van de Velde (
2018). Sankoff, Schwenter, Poplack and Tagliamonte, Cheshire, and Denis and Tagliamonte do not provide real-time diachronic data, however, and Poplack runs different regression analyses for different periods, and, like most other variationists studies (see
Wolk et al. 2013, for an exemplary study), uses semantic features as independent variables, restricting the formal (dependent) variable to the relative frequency of competing variants.
Indeed, when approached from a quantitative perspective, the formal side of grammaticalization is often measured by the simple proxy of token frequency. The use of token frequency comes basically in two guises: either the rise of construction is traced through normalized frequency (the number of instances per fixed number of tokens, most often 10,000 or 1,000,000), or two competing constructions are set off against each other, and the shifting proportion of their respective token frequencies is seen as a new form encroaching on an older one, which is gradually ousted. The latter approach takes its inspiration from variationist linguistics (see
Pintzuk 2003), and its preferred method is logistic regression. The underlying idea in both approaches is that increased grammatical status goes hand in hand with increased frequency (pace some cases where rapid or instant grammaticalization occurs on the basis of analogy; see
Hoffmann 2004 and
Aaron 2016). While informative, this is a brutally restricted view on how to approach language change quantitatively (see
Szmrecsanyi 2016 and
Hilpert 2017, for well-taken considerations). The wrong way to go about this is to abandon the quantitative approach altogether. Instead, we are better off looking beyond mere tallying how often a construction occurs per million words or how often a construction occurs vis-à-vis a competing construction. This will allow us to get a better view on the different changes that transpire in the process of grammaticalization. We do not deny the pertinence of the language-internal and language-external variables that variationist studies have included in their studies, of course, but we put forward a more encompassing view on grammaticalization by looking at other formal correlates of grammaticalization. The formal behavioral and coding properties (see
Haspelmath 2010, for this terminological pair) are then treated as
dependent variables in their own right. This approach diverges from adding semantic-pragmatic (e.g., animacy, topicality), contextual (main clauses vs. subordinate clauses), and language-external variables (age, gender) as
independent variables in a multivariate approach. The advantage of our approach is that we can pick up on subtle trends, i.e., those grammaticalization processes in which token frequency is not visibly on the rise in the time window under investigation. In this proof-of-concept article, we will look at a particular change in which we also have traditional token frequency measures. In that way, we can compare the rise in the token frequency with other measures. Our quantitative approach to grammaticalization focuses on Dutch binominals with
soort ‘sort’. In contrast to earlier studies on the development of this Dutch construction, we will adduce quantitative diachronic evidence on the changing syntax, using frequency measures, including ‘dispersion’, a valuable metric in quantitative approaches to grammaticalization, but one not very commonly used at present.
2. The Construction at Hand
As in many other European languages, Dutch ‘binominal’ noun phrases (NPs) with
soort ‘sort’ as first noun (N
1) are remarkably prone to grammaticalization and subjectification (see, e.g., contributions in
Brems et al. 2016). The examples in (2)–(6) illustrate various uses of
soort that coexist in Present-day Dutch, representing different stages of grammaticalization.
1| (2) | Ze | eet | maar | twee | soorten | brood. | (CGN, fv400275) |
| | she | eats | only | two | sorts | bread | |
| | ‘She only eats two types of bread.’ |
| (3) | Hij | wordt | gewoon | met | een | smoes | naar | de | Cambrinus | gehaald | en | dan |
| | he | is | just | with | an | excuse | to | the | Cambrinus | lured | and | then |
| is | d’r | een | soort | van | ja | afscheidsfeestje. | (CGN, fn000261) | |
| is | there | a | sort | of | yes | farewell_party |
| ‘He’s just lured to the Cambrinus with an excuse and then there’s a kind of farewell party.’ |
| | | | | | | | | | | | | | |
| (4) | Dus | alle | tegeltjes | d’raf | en | de | pot | d’ruit | en | zo | en | dat | soort |
| | so | all | tiles | off_it | and | the | pot | out_it | and | so | and | that | sort |
| dingen | allemaal | […]. | (CGN, fn000259) |
| things | all | |
| ‘So remove all the tiles and the pot and so on and all that kind of stuff.’ |
| (5) | En | daarna | is | ‘t | gewoon | soort | van | onmogelijk | geworden. | (CGN, fn000435) |
| | and | after_that | is | it | just | sort | of | impossible | become | |
| ‘And after that it sort of just became impossible.’ |
| (6) | A: | Is | ‘t | ijs | of | niet? | (CGN, fn000438) |
| | | is | it | ice | or | not | |
| B: | Ja | soort | van. | |
| | yes | sort | of |
| A: ‘Is it ice or not?’ B: ‘Yes, sort of.’ |
In (2),
soort is clearly used as the syntactic head, and the second noun (N
2,
brood) as its dependent. The construction still has its fully lexical meaning of ‘subclass’: it is used to profile two members of the superordinate category ‘bread’ that the person in question may eat. This is not the case in (3), where the N
2 (
afscheidsfeestje) is the head, and the chunk
(een) soort (van) is a qualifying modifier. Here,
soort does not refer to some class of entities, but it is used as a hedge (downtoner, approximator), signaling that the entity the construction refers to is a less (proto)typical member of the category designated by the second noun (cf.
Schermer-Vermeer 2008, pp. 20–21).
2 In (4), the binominal with
soort is used as a so-called ‘general extender’ (GE) (
Overstreet 1999,
2014; also see
Van der Wouden 2014 for a discussion of GEs in Dutch), which is typically introduced by a conjunction (
en), features a non-specific N
2 (
dingen), and occurs usually at the end of a list. They function as “indexical expressions encoding explicit reference to further [potential members] that share with the explicit elements a common context-dependent property P” (
Mauri and Sansò 2018, p. 13).
In addition to these three ‘binominal’ uses,
soort can also occur outside the NP. In (5), for instance, the sequence
soort van does not modify a noun, but an adjective (
onmogelijk). Finally, in (6),
soort van does not modify another constituent, but it occurs ‘independently’ at the clausal level, hedging the entire proposition uttered by speaker A. It is not clear whether these two uses of
soort instantiate autonomous developments in Dutch or whether they are calques from English, where similar constructions with
sort/
kind of are (much) more prevalent (cf. e.g.,
Aijmer 2002, pp. 173–209). The ‘independent use’ is colloquial and, as such, is unlikely to crop up in corpora of written language, which makes its rise hard to pin down in time. If it is indeed a calque from English, it ought to have risen after World War II, when Dutch underwent drastic lexical influence from English (
Van den Toorn 1997, pp. 559–60;
Van der Sijs 2019, pp. 204–6). Our view on the matter is further complicated by the fact that native developments can be catalyzed by kindred constructions in English (see
Zenner et al. 2018). This may well have been the case with the independent use of
soort (van) as well: it may be an indigenous development, but with support from English. One argument in favor of the indigenous development account is that we see similar developments in
verre van (far-from), which can be used more comfortably in independent use in Dutch than in English (see
Van Goethem et al. 2018).
3 We refrain from taking a strong stance with regard to the borrowed nature of this construction.
Soort has received quite some attention in the literature on Dutch nominal syntax, because of several syntactic and semantic properties that set it off against other binominals in Dutch (
Van der Lubbe 1958;
Vos 1999;
Schermer-Vermeer 2008;
Broekhuis and den Dikken 2012, pp. 631–37).
4 However, something that has received only short shrift is the fact that, in Dutch, the preposition linking the two nouns of the binominal appears to be optional: in addition to a prepositional schema [
soort van N], as in (3) above, Dutch sports another variant where there is no preposition, [
soort N], as in (2) and (4).
If binominal constructions with
soort undergo grammaticalization, as in English, we may expect decategorialization (cf. supra). Over time,
soort may be expected to lose its characteristics of a typical noun, as the binominal aggregate will experience a loss in transparency (see
Ten Wolde 2018 for extensive illustrations in various binominal constructions in English). The question then arises what this means for the use of the prepositional ‘relator’ between N
1 and N
2 (see
Van de Velde 2009, Chp. 3 for this term). We cannot fall back on previous studies on the English sort-kind-type (SKT) construction, as English does not allow the preposition-less combinations of N
1 and N
2 in binominal construction. Dutch does allow such combinations, but not across the board (see
Van de Velde 2009, Chp. 3).
Two scenarios can be envisaged. Either the bare construction [
soort N] is pressured into the mould of a construction with a prepositional postmodifier: [
soort van N]. This would bring the construction in line with other postmodifiers introduced with a relator. In this scenario, the use of the preposition would increase over time. Alternatively
soort (van) may develop into some kind of premodifier, and it may then lose its preposition. This process has been witnessed for
miljoen ‘million’ in the course of its development from noun to cardinal (see
Van der Horst and Van de Velde 2016, pp. 412–13). If we are dealing with grammaticalization, the latter scenario is more plausible, but our case would be stronger if we additionally have other indications of increasing grammaticalization. Ideally, we want those indication to be quantitatively measureable.
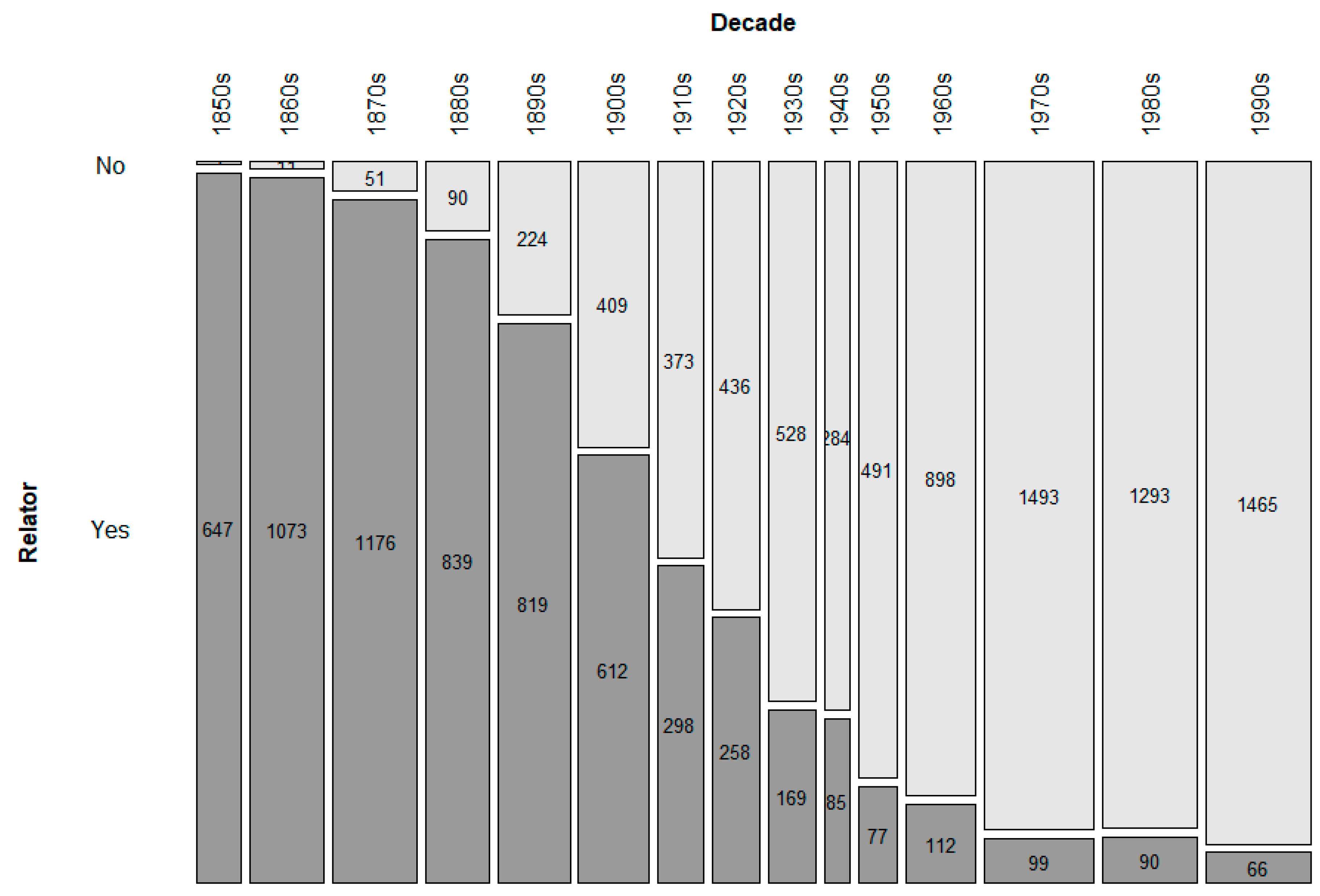
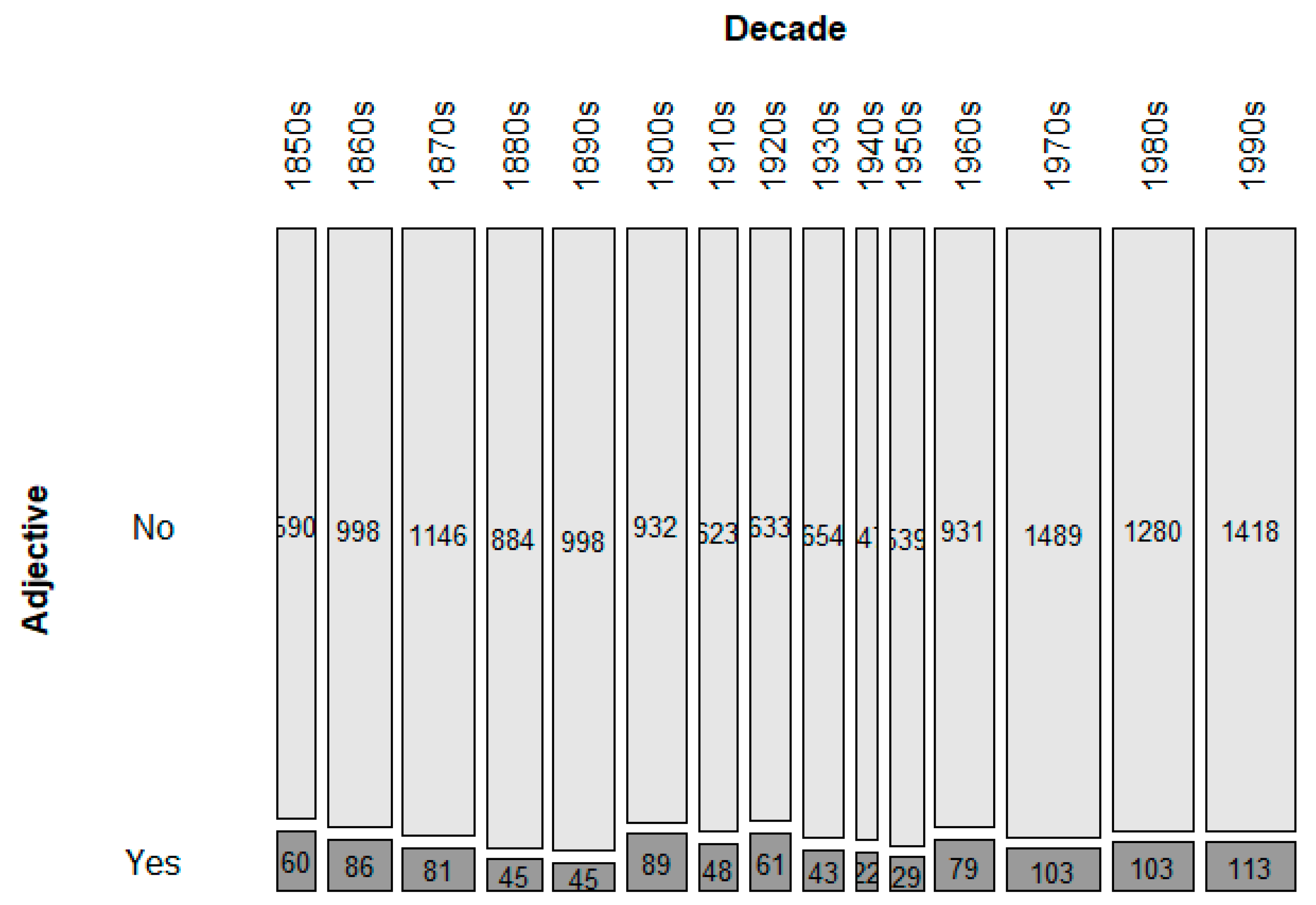
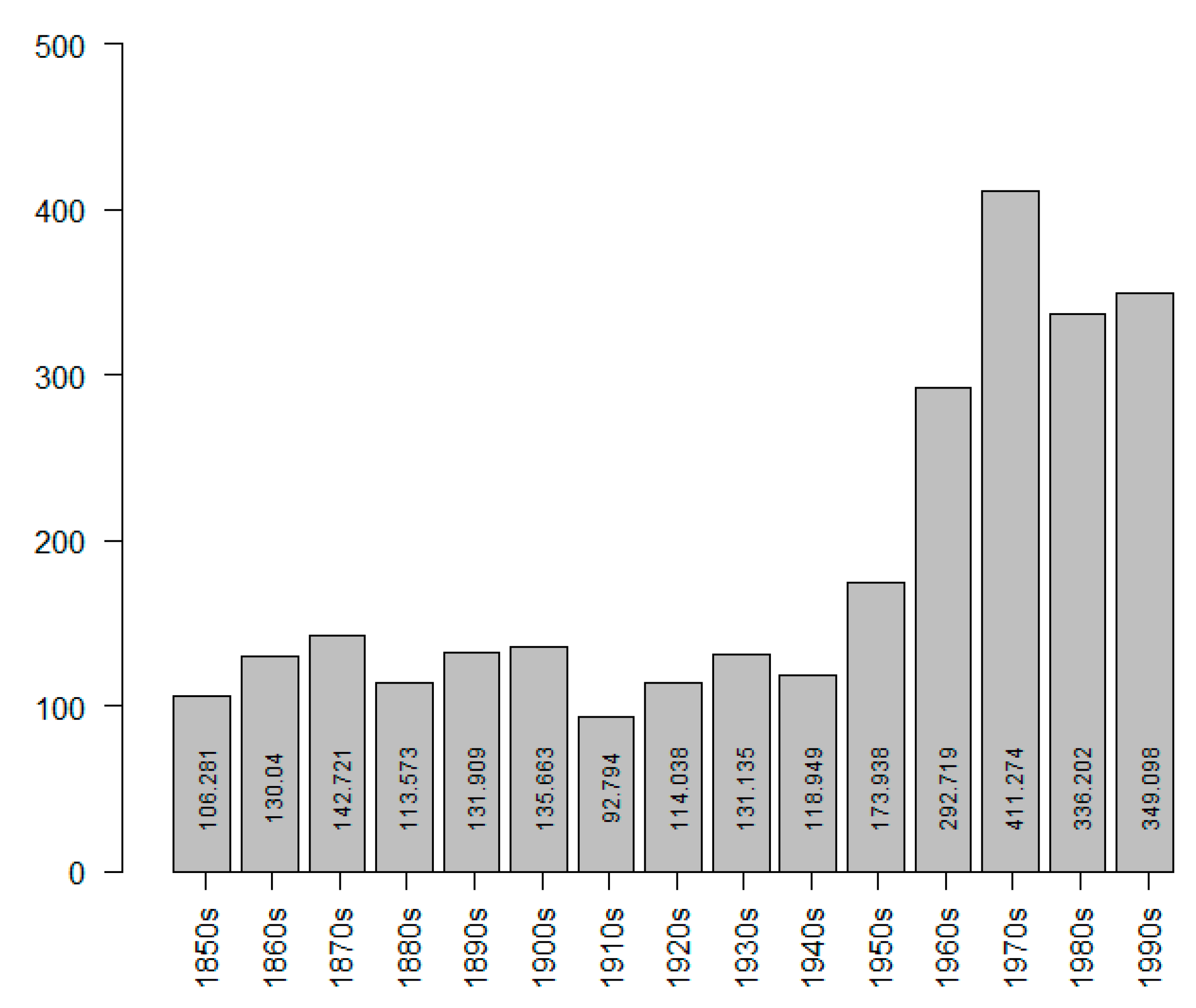
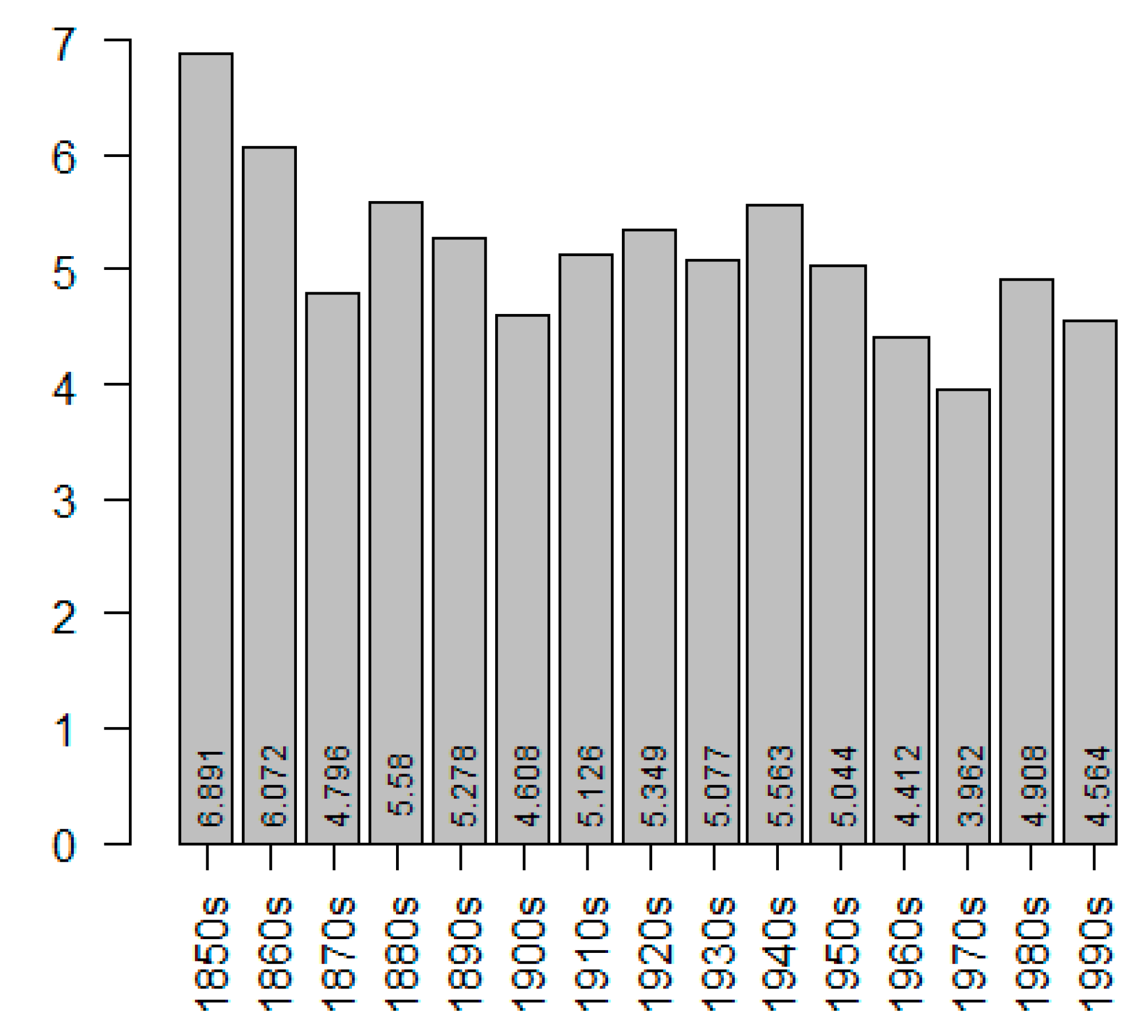
What might these indications be? One additional indication is the loss of premodification of soort and the possibility for it to be used in the plural form. Again, this can be considered a case of decategorialization: if soort grammaticalizes into a premodifier of what was originally a dependent noun, then it will lose its head status and will be less likely to be premodified or be used in the plural. Second, with increasing grammaticalization, we not only expect a rise in the relative frequency of soort, but also a drop in its dispersion. Dispersion is a technical term for how equal the distribution of the construction is in a (sub)corpus. The more grammatical an element is, the less clustered it occurs, and the lower its dispersion will be.
Before we proceed to our analysis of what happens to soort in its ongoing grammaticalization in Late Modern Dutch, we first look into the historical provenance of the construction.
4. Data
For the data collection, we turned to a newly compiled corpus of historical Dutch that covers the period between 1837 and 1999, totaling approximately 200 million tokens in size. This
Dutch Corpus of Contemporary and Late Modern Periodicals (Dutch C-CLAMP), comprises materials from a range of cultural and literary periodicals published in Flanders and the Netherlands (
Piersoul et al. 2020). It is intended as representative of standard Dutch as used by the cultural and literary elite in the period at hand.
7 For the present study, we restricted ourselves to the 1850–1999 issues of the periodical
De Gids, which makes up almost half of the Dutch C-CLAMP.
We used an untagged version of the corpus, from which all instances of the noun
soort and its morphological and orthographic variants were automatically retrieved, yielding 18,964 hits. Next, false positives and doubles were manually weeded out, as were instances inside citations from other works. Incidentally, these often manifested instances of
soort from earlier language stages, as in (14)—from Constantijn Huygens’
Koren-bloemen (1658) quoted in an article from 1889—which demonstrates that formerly,
soort and N
2 (in this case,
geraecktheit) could appear discontinuously, suggesting a stronger syntactic independence (cf. Section 3 supra, and
Van de Velde 2009).
| (14) | Jan gaet aen een blaeuw oogh, en seght m’ hem niet geraeckt heit;/Maer dat het (en ’t is waer) |
| | een | soort | is | van | geraecktheit. |
| | a | sort | is | of | injury |
| | ‘a sort of injury’ |
We also removed a number of instances that featured dialectal or colloquial language (e.g., in short stories by the Flemish naturalist author Cyriel Buysse), as well as a handful of instances where there is no variation with regard to the appearance of the preposition
van. In (15), the coordination of the nouns
vormen and
soorten all but blocks the omission of
van, as the noun
vorm obligatorily requires a
van-complement (cf. *
zovele vormen muzikaliteit). In (16), N
2 is preceded by the indefinite article
een, which similarly renders a construction without
van ungrammatical (cf. *
een soort een bocht).
| (15) | Er | zijn | zovele | vormen | en | soorten | van | muzikaliteit […]. |
| | there | are | so_many | forms | and | sorts | of | musicality |
| | (De Gids, 1950) |
| | ‘There are so many forms and sorts of musicality.’ |
| (16) | De | kust | maakt | daar | bij | Hilligermond | een | soort | van | een | bocht. |
| | the | coast | makes | there | by | Hilligermond | a | sort | of | a | turn |
| | (De Gids, 1881) |
| | ‘Near Hilligermond, the coastal line makes a sort of turn.’ |
After the manual clean-up, we were left with 14,469 valid instances. These were all cases of binominal uses of
soort, i.e., classifying and premodifying uses as in (2)–(4) supra. We did not encounter NP-external uses such as (5) or (6), which, as mentioned in
Section 2, are more typical of colloquial language and, as such, are shunned in the prose of the authors represented in the Dutch C-CLAMP.
Table 1 gives the distribution of the instances per decade.
6. Conclusions
As the prototypical member of the Dutch SKT construction,
soort is gradually grammaticalizing into a hedge or approximator. This shift entails a rebracketing (
Hopper and Traugott 2003, p. 51) from a transparent, compositional binominal construction into a premodified NP, in which the original postmodifier is now the head noun and
soort, together with its prepositional relator
van, is reanalyzed as a premodifier. In this process of grammaticalization,
soort undergoes ‘decategorialization’ and loses more and more of its nominal syntax. This process spans an extensive period and happens very gradually, and the semantic nature of the shift in head status is invisible on the surface. All this makes it hard to catch the reanalysis in the act. We set out to use different quantitative measures. Rather than merely looking at token frequency, taking an observed rise to be a straightforward indication of grammaticalization, we looked at several formal diagnostics.
In our data, ranging from the 1850s to the 1990s, we can observe a clear trend of dropping van and a (somewhat weaker but still significant) trend of losing the possibility of it occurring in the plural, which are both indications of decategorialization, one of the defining diagnostics of grammaticalization. Another expected decategorialization trend, namely the loss of modification possibilities, was not supported by our data. The decategorialization trends turned out to be somewhat equivocal: of the three expected trends, one manifested itself clearly, the other weakly, and the third not at all. In order to support the idea that soort is indeed undergoing grammaticalization, we turned to two other measures that rely on frequency; namely, relative frequency and dispersion. Both trends are in line with the scenario of increasing grammaticalization: relative frequency goes up through the years and dispersion goes down.
In sum, gathering a substantial number of observations, we were able to pick up a subtle grammaticalization trend that would otherwise have been hard to detect. A possible objection (and maybe an explanation for the unequivocal results for some of the expected trends) is that we did not separate the data on the basis of semantics, more specifically whether
soort has a classifying or premodifying function, and that our aggregate results may be obfuscated by a ‘layering’ effect (in the sense of
Hopper 1991), in which the pattern in the old non-grammaticalized function continues to be used alongside the new function. However, this is counterbalanced, we feel, by the objectivity of our methods. Categorizing data according to the function they have, in a non-circular way, is a subjective enterprise.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}