
An Overview of AI-Assisted Design-on-Simulation Technology for Reliability Life Prediction of Advanced Packaging


Abstract
:1. Introduction
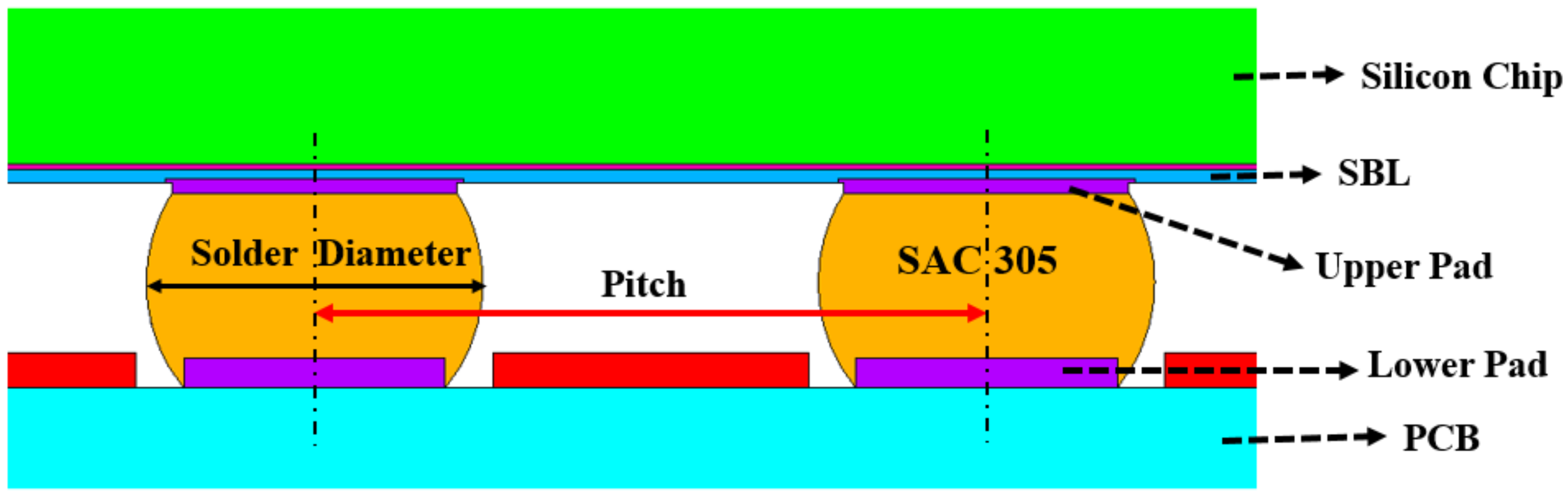
2. Finite Element Method for WLP
3. Machine Learning
3.1. Establishment of Dataset
3.2. ANN Model
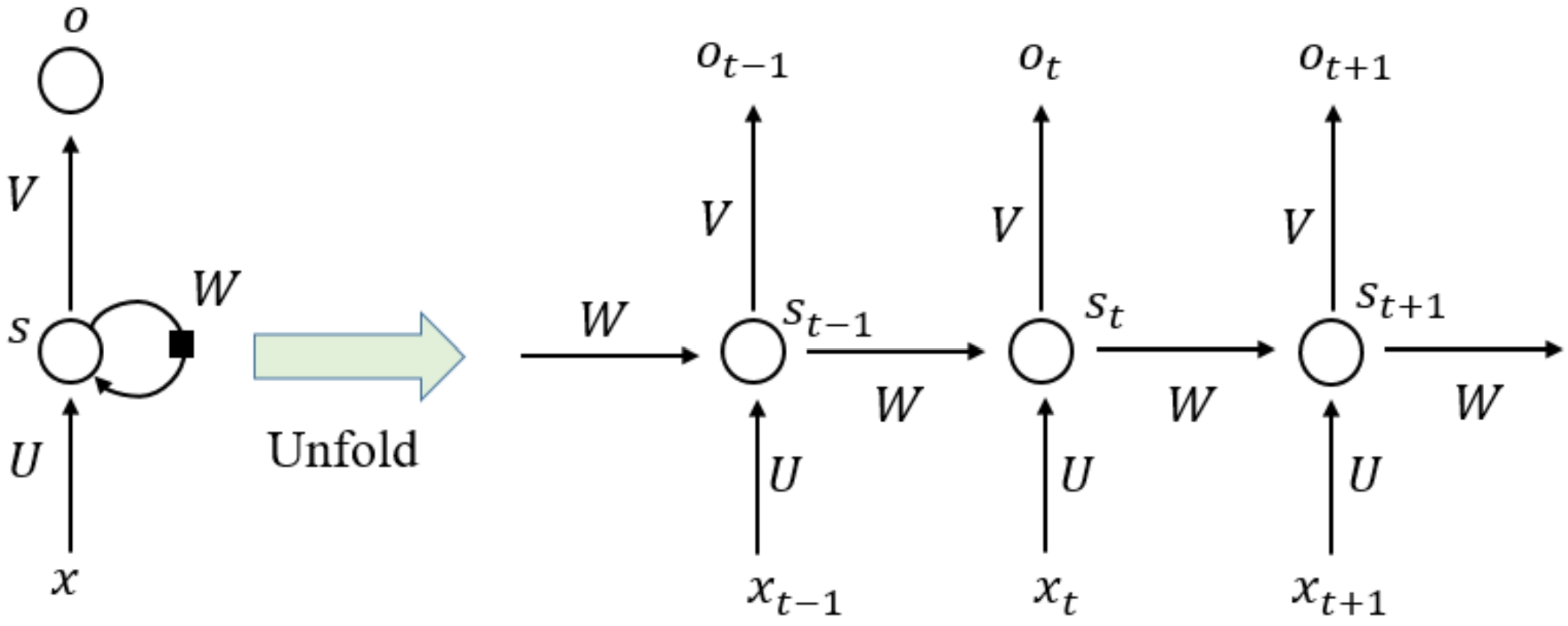
3.3. RNN Model
3.4. SVR Model
3.5. KRR Model
3.6. KNN Model
3.7. The RF Regression Model
3.8. Training Methodology
3.8.1. Data Preprocessing
3.8.2. Cross-Validation
3.8.3. Grid Search Technique
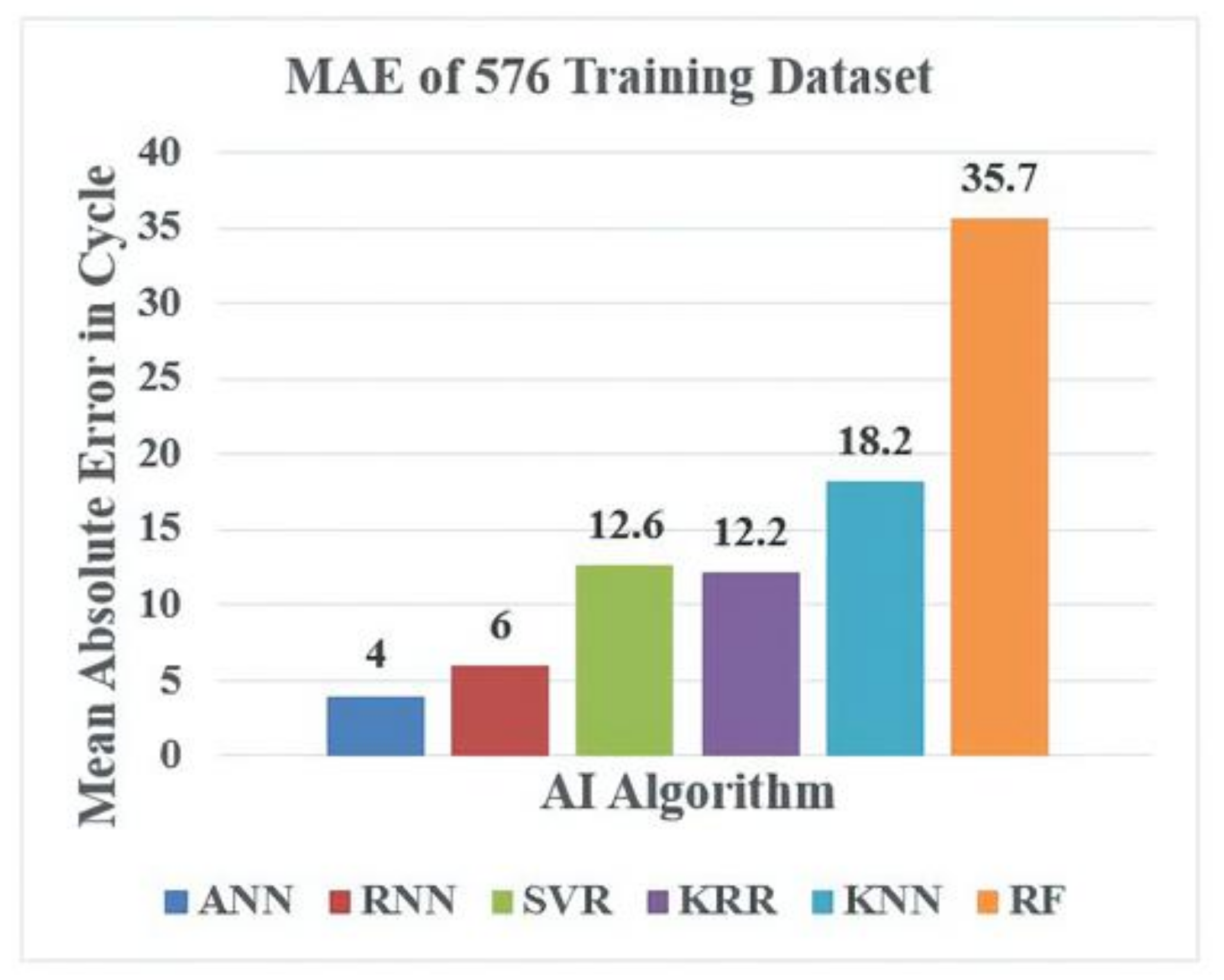
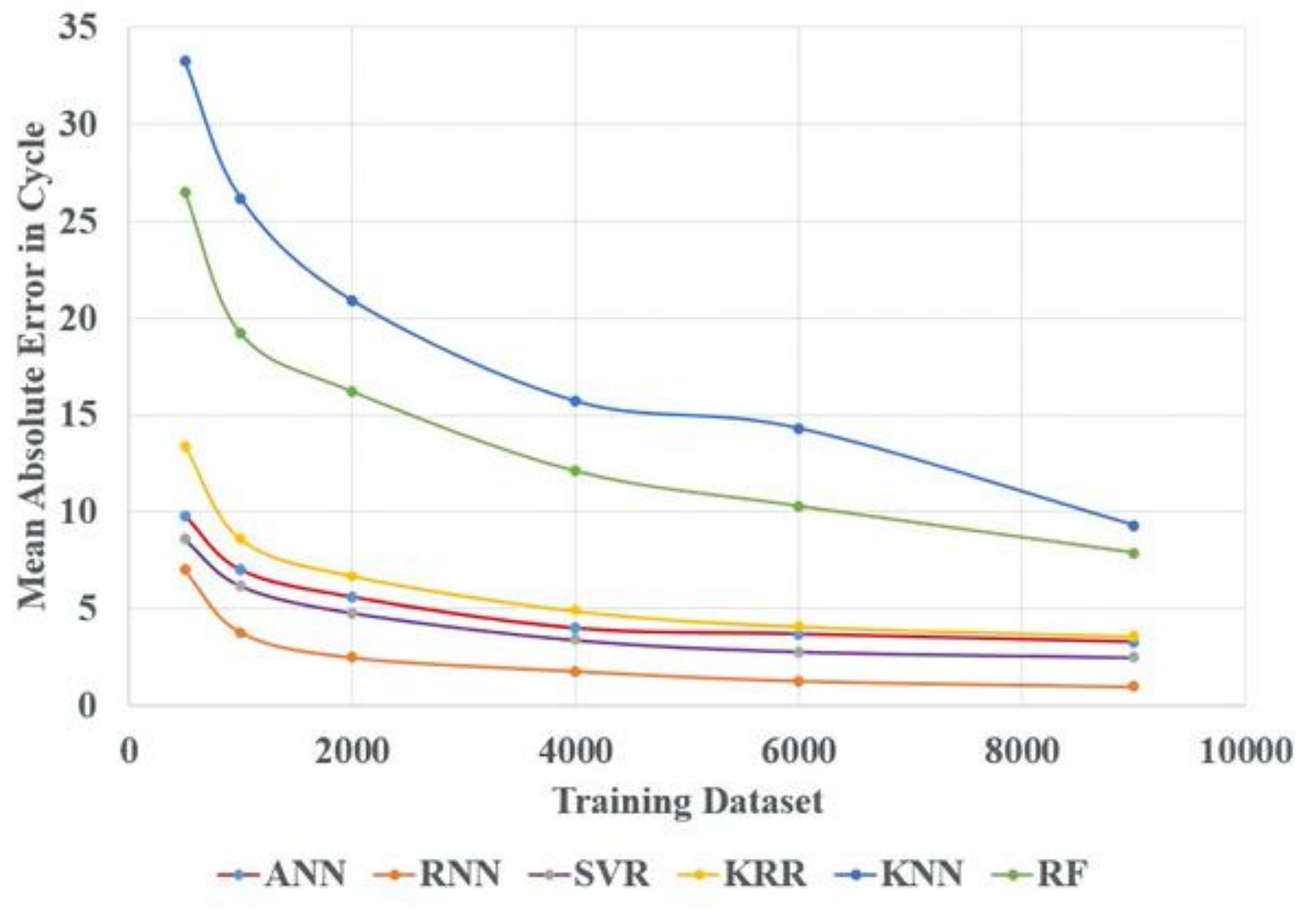
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Andriani, Y.; Wang, X.; Seng, D.H.L.; Teo, S.L.; Liu, S.; Lau, B.L.; Zhang, X. Effect of Boron Nitride Nanosheets on Properties of a Commercial Epoxy Molding Compound Used in Fan-Out Wafer-Level Packaging. IEEE Trans. Compon. Packag. Manuf. Technol. 2020, 10, 990–999. [Google Scholar] [CrossRef]
- Cheng, H.-C.; Chung, C.-H.; Chen, W.-H. Die shift assessment of reconstituted wafer for fan-out wafer-level packaging. IEEE Trans. Device Mater. Reliab. 2020, 20, 136–145. [Google Scholar] [CrossRef]
- Cheng, H.-C.; Wu, Z.-D.; Liu, Y.-C. Viscoelastic warpage modeling of fan-out wafer-level packaging during wafer-level mold cure process. IEEE Trans. Compon. Packag. Manuf. Technol. 2020, 10, 1240–1250. [Google Scholar] [CrossRef]
- Dong, H.; Chen, J.; Hou, D.; Xiang, Y.; Hong, W. A low-loss fan-out wafer-level package with a novel redistribution layer pattern and its measurement methodology for millimeter-wave application. IEEE Trans. Compon. Packag. Manuf. Technol. 2020, 10, 1073–1078. [Google Scholar] [CrossRef]
- Lau, J.H.; Li, M.; Li, Q.M.; Xu, I.; Chen, T.; Li, Z.; Tan, K.H.; Yong, Q.X.; Cheng, Z.; Wee, K.S. Design, materials, process, fabrication, and reliability of fan-out wafer-level packaging. IEEE Trans. Compon. Packag. Manuf. Technol. 2018, 8, 991–1002. [Google Scholar] [CrossRef]
- Lau, J.H.; Li, M.; Qingqian, M.L.; Chen, T.; Xu, I.; Yong, Q.X.; Cheng, Z.; Fan, N.; Kuah, E.; Li, Z. Fan-out wafer-level packaging for heterogeneous integration. IEEE Trans. Compon. Packag. Manuf. Technol. 2018, 8, 1544–1560. [Google Scholar] [CrossRef]
- Lee, T.-K.; Xie, W.; Tsai, M.; Sheikh, M.D. Impact of Microstructure Evolution on the Long-Term Reliability of Wafer-Level Chip-Scale Package Sn–Ag–Cu Solder Interconnects. IEEE Trans. Compon. Packag. Manuf. Technol. 2020, 10, 1594–1603. [Google Scholar] [CrossRef]
- Zhao, S.; Yu, D.; Zou, Y.; Yang, C.; Yang, X.; Xiao, Z.; Chen, P.; Qin, F. Integration of CMOS image sensor and microwell array using 3-D WLCSP technology for biodetector application. IEEE Trans. Compon. Packag. Manuf. Technol. 2019, 9, 624–632. [Google Scholar] [CrossRef]
- Chen, C.; Yu, D.; Wang, T.; Xiao, Z.; Wan, L. Warpage prediction and optimization for embedded silicon fan-out wafer-level packaging based on an extended theoretical model. IEEE Trans. Compon. Packag. Manuf. Technol. 2019, 9, 845–853. [Google Scholar] [CrossRef]
- Lau, J.H.; Ko, C.-T.; Tseng, T.-J.; Yang, K.-M.; Peng, T.C.-Y.; Xia, T.; Lin, P.B.; Lin, E.; Chang, L.; Liu, H.N. Panel-level chip-scale package with multiple diced wafers. IEEE Trans. Compon. Packag. Manuf. Technol. 2020, 10, 1110–1124. [Google Scholar] [CrossRef]
- Lau, J.H.; Li, M.; Yang, L.; Li, M.; Xu, I.; Chen, T.; Chen, S.; Yong, Q.X.; Madhukumar, J.P.; Kai, W. Warpage measurements and characterizations of fan-out wafer-level packaging with large chips and multiple redistributed layers. IEEE Trans. Compon. Packag. Manuf. Technol. 2018, 8, 1729–1737. [Google Scholar] [CrossRef]
- Qin, C.; Li, Y.; Mao, H. Effect of Different PBO-Based RDL Structures on Chip-Package Interaction Reliability of Wafer Level Package. IEEE Trans. Device Mater. Reliab. 2020, 20, 524–529. [Google Scholar] [CrossRef]
- Qin, F.; Zhao, S.; Dai, Y.; Yang, M.; Xiang, M.; Yu, D. Study of warpage evolution and control for six-side molded WLCSP in different packaging processes. IEEE Trans. Compon. Packag. Manuf. Technol. 2020, 10, 730–738. [Google Scholar] [CrossRef]
- Wang, P.-H.; Huang, Y.-W.; Chiang, K.-N. Reliability Evaluation of Fan-Out Type 3D Packaging-On-Packaging. Micromachines 2021, 12, 295. [Google Scholar] [CrossRef]
- Yang, C.; Su, Y.; Liang, S.Y.; Chiang, K. Simulation of wire bonding process using explicit FEM with ALE remeshing technology. J. Mech. 2020, 36, 47–54. [Google Scholar] [CrossRef]
- Liu, C.-M.; Lee, C.-C.; Chiang, K.-N. Enhancing the reliability of wafer level packaging by using solder joints layout design. IEEE Trans. Compon. Packag. Technol. 2006, 29, 877–885. [Google Scholar] [CrossRef]
- Chiang, K.-N.; Chen, W.-H.; Cheng, H.-C. Large-scale three-dimensional area array electronic packaging analysis. J. Comput. Model. Simul. Eng. 1999, 4, 4–11. [Google Scholar]
- Tsou, C.; Chang, T.; Wu, K.; Wu, P.; Chiang, K. Reliability assessment using modified energy based model for WLCSP solder joints. In Proceedings of the International Conference on Electronics Packaging (ICEP), Yamagata, Japan, 19–22 April 2017; pp. 7–15. [Google Scholar]
- Liu, S.; Panigrahy, S.; Chiang, K. Prediction of fan-out panel level warpage using neural network model with edge detection enhancement. In Proceedings of the IEEE 70th Electronic Components and Technology Conference (ECTC), Orlando, FL, USA, 3–30 June 2020; pp. 1626–1631. [Google Scholar]
- Yuan, C.C.; Lee, C.-C. Solder joint reliability modeling by sequential artificial neural network for glass wafer level chip scale package. IEEE Access 2020, 8, 143494–143501. [Google Scholar] [CrossRef]
- Gupta, S.; Al-Obaidi, S.; Ferrara, L. Meta-Analysis and Machine Learning Models to Optimize the Efficiency of Self-Healing Capacity of Cementitious Material. Materials 2021, 14, 4437. [Google Scholar] [CrossRef]
- Jianliang, S.; Mengqian, S.; Hesong, G.; Yan, P.; Jiang, J.; Lipu, X. Research on Edge Surface Warping Defect Diagnosis Based on Fusion Dimension Reduction Layer DBN and Contribution Plot Method. J. Mech. 2020, 36, 889–899. [Google Scholar] [CrossRef]
- Kuschmitz, S.; Ring, T.P.; Watschke, H.; Langer, S.C.; Vietor, T. Design and Additive Manufacturing of Porous Sound Absorbers—A Machine-Learning Approach. Materials 2021, 14, 1747. [Google Scholar] [CrossRef]
- Song, H.; Ahmad, A.; Ostrowski, K.A.; Dudek, M. Analyzing the Compressive Strength of Ceramic Waste-Based Concrete Using Experiment and Artificial Neural Network (ANN) Approach. Materials 2021, 14, 4518. [Google Scholar] [CrossRef]
- Farooq, F.; Czarnecki, S.; Niewiadomski, P.; Aslam, F.; Alabduljabbar, H.; Ostrowski, K.A.; Śliwa-Wieczorek, K.; Nowobilski, T.; Malazdrewicz, S. A Comparative Study for the Prediction of the Compressive Strength of Self-Compacting Concrete Modified with Fly Ash. Materials 2021, 14, 4934. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Wasouf, M.; Sresakoolchai, J.; Kaewunruen, S. Prediction of Healing Performance of Autogenous Healing Concrete Using Machine Learning. Materials 2021, 14, 4068. [Google Scholar] [CrossRef] [PubMed]
- Salazar, A.; Xiao, F. Design of Hybrid Reconstruction Scheme for Compressible Flow Using Data-Driven Methods. J. Mech. 2020, 36, 675–689. [Google Scholar] [CrossRef]
- Song, S.-H. A Comparison Study of Constitutive Equation, Neural Networks, and Support Vector Regression for Modeling Hot Deformation of 316L Stainless Steel. Materials 2020, 13, 3766. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Denoeux, T. A neural network classifier based on Dempster-Shafer theory. IEEE Trans. Syst. Man Cybern. Syst. 2000, 30, 131–150. [Google Scholar] [CrossRef] [Green Version]
- Tandel, G.S.; Biswas, M.; Kakde, O.G.; Tiwari, A.; Suri, H.S.; Turk, M.; Laird, J.R.; Asare, C.K.; Ankrah, A.A.; Khanna, N. A review on a deep learning perspective in brain cancer classification. Cancers 2019, 11, 111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Kulawik, A.; Wróbel, J.; Ikonnikov, A.M. Model of the Austenite Decomposition during Cooling of the Medium Carbon Steel Using LSTM Recurrent Neural Network. Materials 2021, 14, 4492. [Google Scholar] [CrossRef]
- Yuan, C.C.; Fan, J.; Fan, X. Deep machine learning of the spectral power distribution of the LED system with multiple degradation mechanisms. J. Mech. 2020, 37, 172–183. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Braun, A.C.; Weidner, U.; Hinz, S. Classification in high-dimensional feature spaces—Assessment using SVM, IVM and RVM with focus on simulated EnMAP data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 436–443. [Google Scholar] [CrossRef]
- Al-Sodani, K.A.A.; Adewumi, A.A.; Mohd Ariffin, M.A.; Maslehuddin, M.; Ismail, M.; Salami, H.O.; Owolabi, T.O.; Mohamed, H.D. Experimental and Modelling of Alkali-Activated Mortar Compressive Strength Using Hybrid Support Vector Regression and Genetic Algorithm. Materials 2021, 14, 3049. [Google Scholar] [CrossRef] [PubMed]
- Benkedjouh, T.; Medjaher, K.; Zerhouni, N.; Rechak, S. Health assessment and life prediction of cutting tools based on support vector regression. J. Intell. Manuf. 2015, 26, 213–223. [Google Scholar] [CrossRef] [Green Version]
- Dhanalakshmi, P.; Kanimozhi, T. Automatic segmentation of brain tumor using K-Means clustering and its area calculation. Int. J. Adv. Electr. Electron. Eng. 2013, 2, 130–134. [Google Scholar]
- Drineas, P.; Mahoney, M.W.; Cristianini, N. On the Nyström Method for Approximating a Gram Matrix for Improved Kernel-Based Learning. J. Mach. Learn. Res. 2005, 6, 2153–2175. [Google Scholar]
- Panigrahy, S.K.; Chiang, K.-N. Study on an Artificial Intelligence Based Kernel Ridge Regression Algorithm for Wafer Level Package Reliability Prediction. In Proceedings of the IEEE 71st Electronic Components and Technology Conference (ECTC), San Diego, CA, USA, 1 June–4 July 2021; pp. 1435–1441. [Google Scholar]
- Hamed, Y.; Alzahrani, A.I.; Mustaffa, Z.; Ismail, M.C.; Eng, K.K. Two steps hybrid calibration algorithm of support vector regression and K-nearest neighbors. Alex. Eng. J. 2020, 59, 1181–1190. [Google Scholar] [CrossRef]
- Tan, S. An effective refinement strategy for KNN text classifier. Expert Syst. Appl. 2006, 30, 290–298. [Google Scholar] [CrossRef]
- Ho, W.; Yu, F. Chiller system optimization using k nearest neighbour regression. J. Clean. Prod. 2021, 303, 127050. [Google Scholar] [CrossRef]
- Xia, J.; Zhang, J.; Wang, Y.; Han, L.; Yan, H. WC-KNNG-PC: Watershed clustering based on k-nearest-neighbor graph and Pauta Criterion. Pattern Recognit. 2021, 121, 108177. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hsiao, H.; Chiang, K. AI-assisted reliability life prediction model for wafer-level packaging using the random forest method. J. Mech. 2020, 37, 28–36. [Google Scholar] [CrossRef]
- Mohana, R.M.; Reddy, C.K.K.; Anisha, P.; Murthy, B.R. Random forest algorithms for the classification of tree-based ensemble. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Ortac, G.; Ozcan, G. Comparative study of hyperspectral image classification by multidimensional Convolutional Neural Network approaches to improve accuracy. Expert Syst. Appl. 2021, 182, 115280. [Google Scholar] [CrossRef]
- Petneházi, G. Quantile convolutional neural networks for Value at Risk forecasting. Mach. Learn. Appl. 2021, 6, 100096. [Google Scholar]
- Ramalho, L.; Belinha, J.; Campilho, R. A new crack propagation algorithm combined with the finite element method. J. Mech. 2020, 36, 405–422. [Google Scholar] [CrossRef]
- Hsieh, M.-C. Modeling correlation for solder joint fatigue life estimation in wafer-level chip scale packages. In Proceedings of the International Microsystems, Packaging, Assembly and Circuits Technology Conference (IMPACT), Taipei, Taiwan, 21–23 October 2015; pp. 65–68. [Google Scholar]
- Rogers, B.; Scanlan, C. Improving WLCSP reliability through solder joint geometry optimization. In Proceedings of the International Symposium on Microelectronics (IMAPS), Orlando, FL, USA, 30 September–3 October 2013; pp. 546–550. [Google Scholar]
- Chiang, K.-N.; Yuan, C.-A. An overview of solder bump shape prediction algorithms with validations. IEEE Trans. Adv. Packag. 2001, 24, 158–162. [Google Scholar] [CrossRef]
- Chang, J.; Wang, L.; Dirk, J.; Xie, X. Finite element modeling predicts the effects of voids on thermal shock reliability and thermal resistance of power device. Weld. J. 2006, 85, 63s–70s. [Google Scholar]
- JEDEC Solid State Technology Association. JEDEC Standard JESD22-A104D, Temperature Cycling. Jedec. Org 2005, 11, 2009. [Google Scholar]
- Coffin, L.F., Jr. A study of the effects of cyclic thermal stresses on a ductile metal. Trans. ASME 1954, 76, 931–950. [Google Scholar]
- Ramachandran, V.; Wu, K.; Chiang, K. Overview study of solder joint reliablity due to creep deformation. J. Mech. 2018, 34, 637–643. [Google Scholar] [CrossRef]
- Lee, C.-H.; Wu, K.-C.; Chiang, K.-N. A novel acceleration-factor equation for packaging-solder joint reliability assessment at different thermal cyclic loading rates. J. Mech. 2017, 33, 35–40. [Google Scholar] [CrossRef]
- Yanjun, X.; Liquan, W.; Fengshun, W.; Weisheng, X.; Hui, L. Effect of interface structure on fatigue life under thermal cycle with SAC305 solder joints. In Proceedings of the International Conference on Electronic Packaging Technology (ICEPT), Dalian, China, 11–14 August 2013; pp. 959–964. [Google Scholar]
- Wang, P.; Lee, Y.; Lee, C.; Chang, H.; Chiang, K. Solder Joint Reliability Assessment and Pad Size Studies of FO-WLP with Glass Substrate. IEEE Trans. Device Mater. Reliab. 2021, 21, 96–101. [Google Scholar] [CrossRef]
- Chou, P.; Chiang, K.; Liang, S.Y. Reliability assessment of wafer level package using artificial neural network regression model. J. Mech. 2019, 35, 829–837. [Google Scholar] [CrossRef]
- Tang, Z.; Fishwick, P.A. Feedforward neural nets as models for time series forecasting. ORSA J. Comput. 1993, 5, 374–385. [Google Scholar] [CrossRef]
- Zhang, D.; Han, X.; Deng, C. Review on the research and practice of deep learning and reinforcement learning in smart grids. CSEE J. Power Energy Syst. 2018, 4, 362–370. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Rui, J.; Zhang, H.; Zhang, D.; Han, F.; Guo, Q. Total organic carbon content prediction based on support-vector-regression machine with particle swarm optimization. J. Pet. Sci. Eng. 2019, 180, 699–706. [Google Scholar] [CrossRef]
- Welling, M.; Kernel Ridge Regression. Max Welling’s Class Notes in Machine Learning. 2013. Available online: https://web2.qatar.cmu.edu/~gdicaro/10315/additional/welling-notes-on-kernel-ridge.pdf (accessed on 6 August 2021).
- Hamed, Y.; Mustaffa, Z.B.; Idris, N.R.B. Comparative Calibration of Corrosion Measurements Using K-Nearest Neighbour Based Techniques. In Proceedings of the MATEC Web of Conferences, Amsterdam, The Netherlands, 23–25 March 2016; Volume 52, p. 02001. [Google Scholar]
- Hamed, Y.; Mustaffa, Z.B.; Idris, N.R.B. An application of K-Nearest Neighbor interpolation on calibrating corrosion measurements collected by two non-destructive techniques. In Proceedings of the International Conference on Smart Instrumentation, Measurement and Applications (ICSIMA), Kuala Lumpur, Malaysia, 24–25 November 2015; pp. 1–5. [Google Scholar]
- Härdle, W.; Linton, O. Applied nonparametric methods. Handb. Econom. 1994, 4, 2295–2339. [Google Scholar]
- Atkeson, C.G.; Moore, A.W.; Schaal, S. Locally weighted learning for control. Artif. Intell. Rev. 1997, 11, 75–113. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Material | TV1 (mm) | TV2 (mm) |
|---|---|---|
| Si Chip | 5.3 × 5.3 × 0.33 | 4 × 4 × 0.33 |
| Cu RDL | 0.26 × 0.008 | 0.26 × 0.008 |
| UBM | -- | 0.24 × 0.0086 |
| Cu Pad | 0.22 × 0.025 | 0.22 × 0.025 |
| SBL1 | 5.3 × 5.3 × 0.0075 | 4 × 4 × 0.0075 |
| SBL2 | 0.01 | 0.004 |
| PCB | 10.6 × 10.6 × 1 | 8 × 8 × 1 |
| Low-k | 5.3 × 0.005 | 4 × 0.005 |
| Ball Diameter (mm) | 0.25 | 0.25 |
| Ball Pitch (mm) | 0.4 | 0.4 |
| Ball Counts | 121 | 100 |
| MTTF (cycles) | 318 | 1013 |
| Material | TV3 (mm) | TV4 (mm) | TV5 (mm) |
|---|---|---|---|
| Si Chip | 4 × 4 × 0.33 | 4 × 4 × 0.33 | 6 × 6 × 0.33 |
| Cu RDL | 0.18 × 0.004 | 0.2 × 0.004 | 0.25 × 0.0065 |
| UBM | 0.17 × 0.0086 | 0.19 × 0.0086 | 0.24 × 0.0075 |
| Cu Pad | 0.22 × 0.025 | 0.22 × 0.025 | 0.22 × 0.04 |
| SBL1 | 4 × 4 × 0.0075 | 4 × 4 × 0.0075 | 6 × 6 × 0.008 |
| SBL2 | 0.004 | 0.004 | 0.0065 |
| PCB | 8 × 8 × 1 | 8 × 8 × 1 | 12 × 12 × 1 |
| Low-k | 4 × 0.005 | 4 × 0.005 | -- |
| Ball Diameter (mm) | 0.18 | 0.2 | 0.25 |
| Ball Pitch (mm) | 0.3 | 0.3 | 0.4 |
| Ball Counts | 144 | 144 | 196 |
| MTTF (cycles) | 587 | 876 | 904 |
| Material | Young’s Modulus (Gpa) | Poisson’s Ratio | CTE (ppm/°C) |
|---|---|---|---|
| Solder joint | Temperature-dependent | 0.35 | 25 |
| Silicon chip | 150 | 0.28 | 2.62 |
| Copper | 68.9 | 0.34 | 16.7 |
| Low-k | 10 | 0.16 | 5 |
| Solder mask | 6.87 | 0.35 | 19 |
| PCB | 18.2 | 0.19 | 16 |
| Temperature | Young’s Modulus (GPa) |
|---|---|
| 233 K | 45.74 |
| 253 K | 42.22 |
| 313 K | 31.66 |
| 353 K | 24.62 |
| 398 K | 16.70 |
| Test Vehicle | Experimental Reliability (Cycles) | Simulation Reliability (Cycles) | Difference |
|---|---|---|---|
| TV1 | 318 | 313 | −5 |
| TV2 | 1013 | 982 | −31 |
| TV3 | 587 | 587 | 0 |
| TV4 | 876 | 804 | 72 |
| TV5 | 904 | 885 | 19 |
| Feature Name | Level (mm) |
|---|---|
| Upper Pad Diameter | 0.18, 0.20, 0.22, 0.24 |
| Lower Pad Diameter | 0.18, 0.20, 0.22, 0.24 |
| Chip Thickness | 0.20, 0.25, 0.30, 0.35, 0.40, 0.45 |
| Stress Buffer Layer Thickness | 0.0075, 0.0125, 0.0175, 0.0225, 0.0275, 0.0325 |
| Total Number | 576 |
| Feature Name | Level (mm) |
|---|---|
| Upper Pad Diameter | 0.18, 0.19, 0.20, 0.21, 0.22, 0.23 |
| Lower Pad Diameter | 0.18, 0.19, 0.20, 0.21 0.22, 0.23 |
| Chip Thickness | 0.20, 0.25, 0.30, 0.35, 0.40, 0.45 |
| Stress Buffer Layer Thickness | 0.0075, 0.0125, 0.0175, 0.0225, 0.0275, 0.0325 |
| Total Number | 1296 |
| Hidden Layer (2) | Hidden Layer (5) | Hidden Layer (10) | Hidden Layer (20) | |||||
|---|---|---|---|---|---|---|---|---|
| Number of Neurons | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle |
| 10 | 57 | 148 | 62 | 157 | 65 | 182 | 51 | 138 |
| 20 | 60 | 164 | 65 | 179 | 14 | 69 | 10 | 60 |
| 50 | 63 | 159 | 11 | 51 | 8 | 54 | 11 | 67 |
| 100 | 66 | 173 | 7 | 51 | 5 | 31 | 9 | 40 |
| 200 | 64 | 173 | 7 | 47 | 5 | 28 | 5 | 40 |
| 500 | 10 | 62 | 5 | 43 | 7 | 35 | 7 | 46 |
| Hidden Layer (2) | Hidden Layer (5) | Hidden Layer (10) | Hidden Layer (20) | |||||
|---|---|---|---|---|---|---|---|---|
| Number of Neurons | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle |
| 10 | 51 | 142 | 47 | 137 | 47 | 125 | 14 | 57 |
| 20 | 47 | 140 | 47 | 143 | 12 | 50 | 9 | 57 |
| 50 | 47 | 127 | 22 | 35 | 7 | 42 | 5 | 43 |
| 100 | 23 | 104 | 6 | 35 | 4 | 24 | 5 | 27 |
| 200 | 13 | 70 | 4 | 31 | 3 | 22 | 4 | 27 |
| 500 | 6 | 43 | 3 | 18 | 3 | 20 | 3 | 19 |
| Training Data Set (ANN) | Neuron Number | Hidden Layer | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | CPU Time in Second |
|---|---|---|---|---|---|
| 576 | 200 | 10 | 5 | 28 | 151 |
| 1296 | 500 | 5 | 3 | 18 | 235 |
| Hidden Layer (2) | Hidden Layer (5) | Hidden Layer (10) | Hidden Layer (20) | |||||
|---|---|---|---|---|---|---|---|---|
| Number of Neuron | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle |
| 10 | 65 | 166 | 61 | 178 | 61 | 159 | 26 | 101 |
| 20 | 63 | 163 | 62 | 168 | 13 | 54 | 16 | 64 |
| 50 | 65 | 157 | 29 | 71 | 8 | 57 | 10 | 43 |
| 100 | 65 | 159 | 12 | 71 | 7 | 37 | 8 | 65 |
| 200 | 17 | 79 | 8 | 50 | 9 | 53 | 10 | 65 |
| 500 | 12 | 69 | 6 | 36 | 6 | 37 | 9 | 50 |
| Hidden Layer (2) | Hidden Layer (5) | Hidden Layer (10) | Hidden Layer (20) | |||||
|---|---|---|---|---|---|---|---|---|
| Number of Neuron | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle |
| 10 | 125 | 355 | 44 | 141 | 11 | 61 | 6 | 44 |
| 20 | 69 | 215 | 21 | 103 | 10 | 54 | 10 | 57 |
| 50 | 33 | 154 | 5 | 28 | 4 | 30 | 4 | 30 |
| 100 | 10 | 51 | 3 | 28 | 4 | 32 | 4 | 32 |
| 200 | 4 | 36 | 4 | 32 | 6 | 43 | 4 | 32 |
| 500 | 3 | 27 | 3 | 39 | 159 | 506 | 159 | 506 |
| Training Data Set (RNN) | Neuron Number | Hidden Layer | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | CPU Time in Second |
|---|---|---|---|---|---|
| 576 | 500 | 5 | 6 | 36 | 173 |
| 1296 | 500 | 2 | 3 | 27 | 698 |
| SVR Kernel Function | RBF Kernel | Sigmoid Kernel | Polynomial Kernel Degree 3 |
|---|---|---|---|
| Hyperparameter (C) | 2250.97 | 540.31 | 2563 |
| Hyperparameter (γ) | 0.86 | 1.7 | 4 |
| Hyperparameter (ε) | 10 | 10 | 10 |
| Training Score () | 0.996 | 0.97 | 0.976 |
| Cross-Validation Score () | 0.964 | 0.936 | 0.954 |
| Maximum Absolute Error (cycle) Train Data | 68 | 125 | 142 |
| Mean Absolute Error (cycle) Train Data | 10 | 30 | 25 |
| Maximum Absolute Error (cycle) Test Data | 55 | 93 | 94 |
| Mean Absolute Error (cycle) Test Data | 13 | 29 | 20 |
| CPU Time In Second | 0.093 | 0.119 | 0.153 |
| SVR Training Dataset | 576 | 1296 |
|---|---|---|
| Hyperparameter (C) | 2250.97 | 3000.51 |
| Hyperparameter (γ) | 0.86 | 2.37 |
| Hyperparameter (ε) | 10 | 10 |
| Training Score () | 0.996 | 0.998 |
| Cross-Validation Score () | 0.964 | 0.981 |
| Maximum Absolute Error (cycle) Train Data | 68 | 46 |
| Mean Absolute Error (cycle) Train Data | 10 | 7.3 |
| Maximum Absolute Error (cycle) Test Data | 55 | 30 |
| Mean Absolute Error (cycle) Test Data | 13 | 8 |
| CPU Time In Second | 0.093 | 6.00 |
| KRR Kernel Function | RBF Kernel | Sigmoid Kernel | Polynomial Kernel Degree 3 |
|---|---|---|---|
| Hyperparameter (α) | 0.01 | 8.16 | 0.1 |
| Hyperparameter (γ) | 1 | 0.09 | 3.9 |
| Maximum Absolute Error (Cycle) Train Data | 57 | 149 | 75 |
| Mean Absolute Error (Cycle) Train Data | 8.4 | 38.7 | 18.9 |
| Maximum Absolute Error (Cycle) Test Data | 39 | 84 | 57 |
| Mean Absolute Error (Cycle) Test Data | 12.2 | 25.4 | 17.9 |
| CPU Time In Second | 0.093 | 0.117 | 0.157 |
| KRR Kernel Function | RBF Kernel | Sigmoid Kernel | Polynomial Kernel Degree 3 |
|---|---|---|---|
| Hyperparameter (α) | 1 | 3 | 1 |
| Hyperparameter (γ) | 0.19 | 0.02 | 2 |
| Maximum Absolute Error (Cycle) Train Data | 40 | 46 | 107 |
| Mean Absolute Error (Cycle) Train Data | 5.3 | 7.2 | 16 |
| Maximum Absolute Error (Cycle) Test Data | 24 | 29 | 45 |
| Mean Absolute Error (Cycle) Test Data | 5.6 | 7 | 14.5 |
| CPU Time In Second | 0.422 | 1.495 | 0.787 |
| KRR Training Dataset | 576 | 1296 |
|---|---|---|
| Hyperparameter (α) | 0.01 | 1 |
| Hyperparameter (γ) | 1 | 0.19 |
| Maximum Absolute Error (Cycle) Train Data | 57 | 40 |
| Mean Absolute Error (Cycle) Train Data | 8.4 | 5.3 |
| Maximum Absolute Error (Cycle) Test Data | 39 | 24 |
| Mean Absolute Error (Cycle) Test Data | 12.2 | 5.6 |
| CPU Time In Second | 0.093 | 0.422 |
| Number Nearest Neighbor (K) | Euclidean Distance | Manhattan Distance | ||
|---|---|---|---|---|
| Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | |
| 1 | 53.7 | 172 | 63 | 172 |
| 2 | 59.3 | 128 | 56.9 | 124 |
| 3 | 38.2 | 115 | 37.9 | 83 |
| 4 | 28.9 | 81 | 28.1 | 81 |
| 5 | 25.5 | 74 | 24.2 | 66 |
| 6 | 27.6 | 71 | 25.6 | 67 |
| 7 | 22.3 | 71 | 21.4 | 63 |
| 8 | 21.6 | 77 | 20.5 | 77 |
| 9 | 18.9 | 83 | 18.2 | 72 |
| 10 | 21.4 | 81 | 18.7 | 77 |
| Number Nearest Neighbor (K) | Euclidean Distance | Manhattan Distance | ||
|---|---|---|---|---|
| Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | |
| 1 | 2626.37 | 172 | 26.3 | 74 |
| 2 | 18.2 | 55 | 14.3 | 51 |
| 3 | 13 | 46 | 7.55 | 23 |
| 4 | 20.2 | 54 | 11.62 | 41 |
| 5 | 17.8 | 43 | 11.15 | 51 |
| 6 | 14.5 | 44 | 11.86 | 44 |
| 7 | 12.7 | 37 | 13.87 | 52 |
| 8 | 11.5 | 38 | 13.78 | 42 |
| 9 | 11.4 | 28 | 11.93 | 41 |
| 10 | 13.7 | 36 | 11.02 | 42 |
| Number Nearest Neighbor (K) | Weight as Uniform with Euclidean | Weight as Distance with Euclidean | ||
|---|---|---|---|---|
| Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | |
| 9 | 2618.9 | 8374 | 18.2 | 72 |
| Training Dataset(KNN) | Nearest Neighbor Value (K) | Mean Absolute Error in Cycle | Maximum Absolute Error in Cycle | CPU Time in Second |
|---|---|---|---|---|
| 576 | 9 | 18.2 | 72 | 0.03 |
| 1296 | 3 | 7.5 | 23 | 0.034 |
| Random Forest Training Dataset | 576 | 1296 |
|---|---|---|
| Random State | 1 | 1 |
| Number of Tree | 81 | 81 |
| Maximum Absolute Error (Cycle) Train Data | 56 | 28 |
| Mean Absolute Error (Cycle) Train Data | 12 | 6.3 |
| Maximum Absolute Error (Cycle) Test Data | 133 | 103 |
| Mean Absolute Error (Cycle) Test Data | 36 | 26.3 |
| CPU Time In Second | 3.5 | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panigrahy, S.K.; Tseng, Y.-C.; Lai, B.-R.; Chiang, K.-N. An Overview of AI-Assisted Design-on-Simulation Technology for Reliability Life Prediction of Advanced Packaging. Materials 2021, 14, 5342. https://0-doi-org.brum.beds.ac.uk/10.3390/ma14185342
Panigrahy SK, Tseng Y-C, Lai B-R, Chiang K-N. An Overview of AI-Assisted Design-on-Simulation Technology for Reliability Life Prediction of Advanced Packaging. Materials. 2021; 14(18):5342. https://0-doi-org.brum.beds.ac.uk/10.3390/ma14185342
Chicago/Turabian StylePanigrahy, Sunil Kumar, Yi-Chieh Tseng, Bo-Ruei Lai, and Kuo-Ning Chiang. 2021. "An Overview of AI-Assisted Design-on-Simulation Technology for Reliability Life Prediction of Advanced Packaging" Materials 14, no. 18: 5342. https://0-doi-org.brum.beds.ac.uk/10.3390/ma14185342