1. Introduction
Log data analysis is a crucial task in cybersecurity, e.g., when monitoring and auditing systems, collecting threat intelligence, conducting forensic investigations of incidents, and pro-actively hunting threats [
1]. Currently available log analysis solutions, such as Security Information and Event Management (SIEM) systems, support the process by aggregating log data as well as storing and indexing log messages in a central relational database [
2]. With their strict schemas, however, such databases are limited in their ability to represent links between entities [
3]. This results in a lack of explicit links between heterogeneous log entries from dispersed log sources in turn makes it difficult to integrate the partial and isolated views on system states and activities reflected in the various logs. Furthermore, the central log aggregation model is also bandwidth-intensive and computationally demanding [
2,
4,
5], which limits its applicability in large-scale infrastructures. Without a dedicated centralized log infrastructure, however, the process necessary to acquire, integrate and query log data are tedious and inefficient, which poses a key challenge for security analysts who often face time critical tasks.
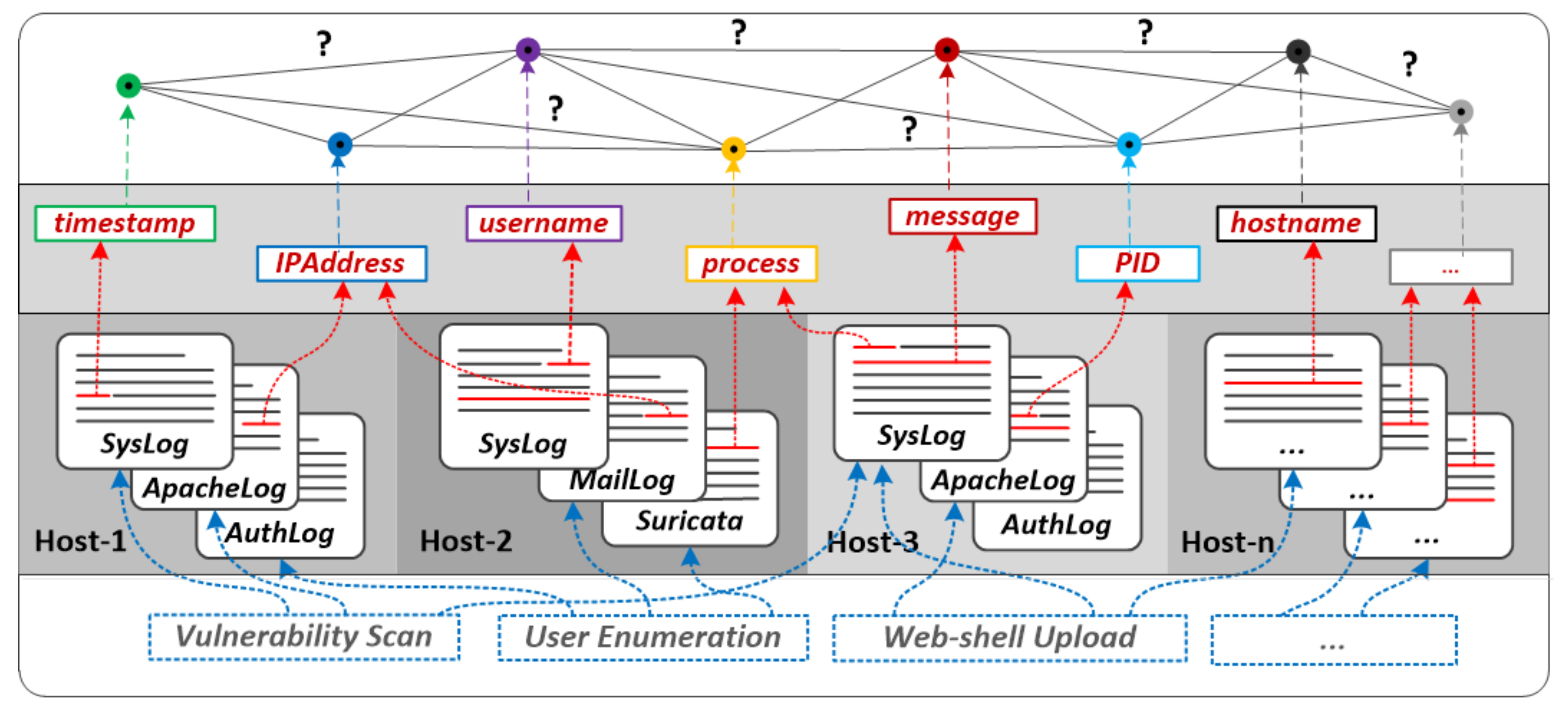
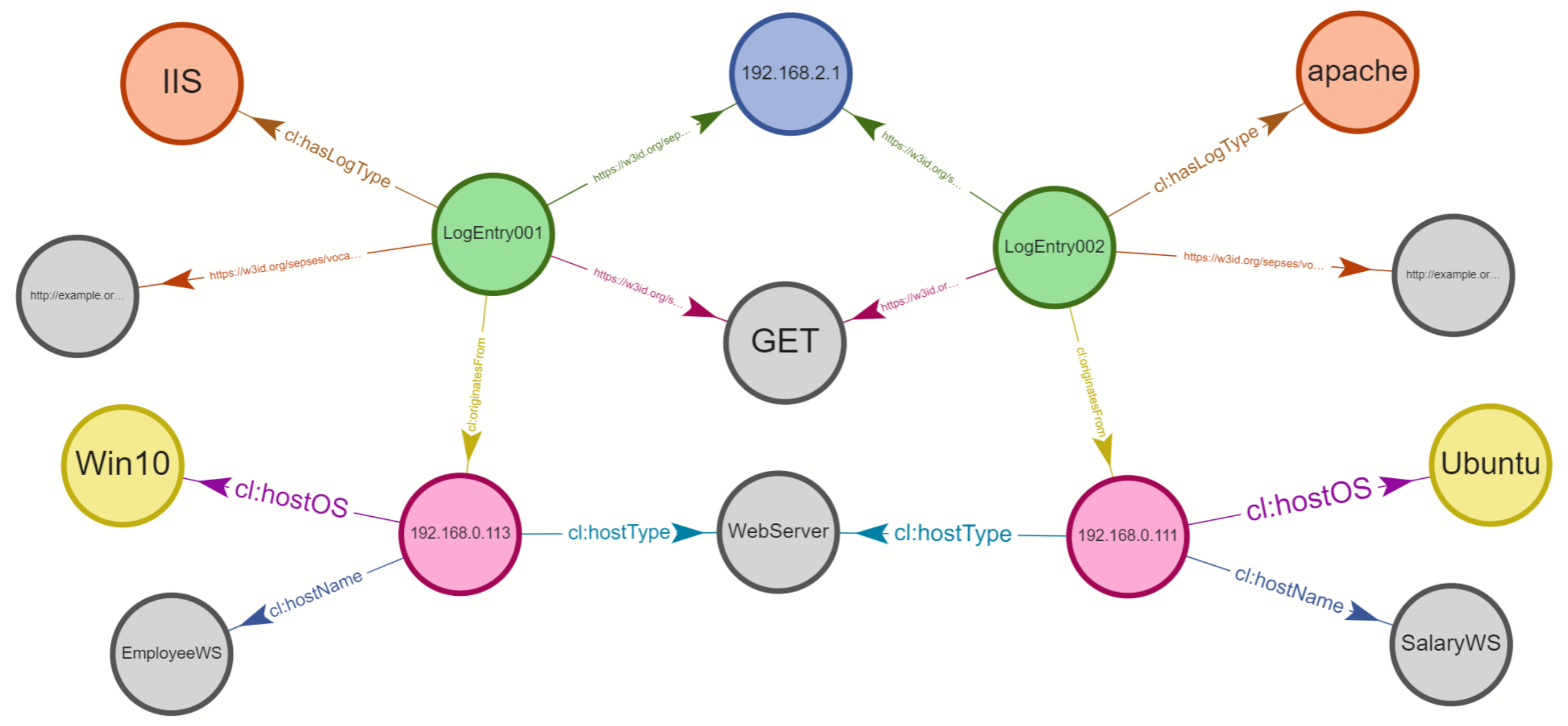
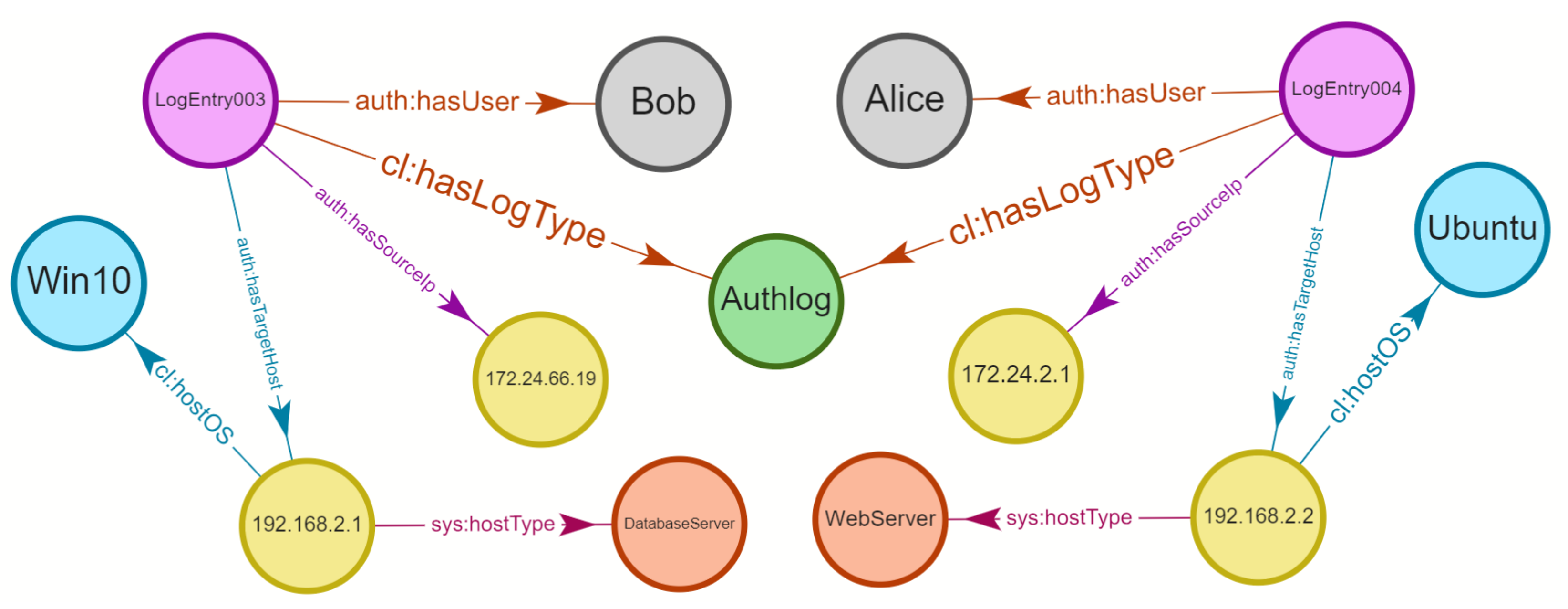
To illustrate the issue, consider the example in
Figure 1. It is based on log data produced by multi-step attacks as described in [
6]. These log data sets will also be used in a scenario in
Section 7. The various steps of the attack are reflected in a large number of log messages in a diverse set of log sources dispersed across multiple hosts and files (e.g.,
Syslog, ApacheLog, AuthLog, MailLog etc.).
Vulnerability Scan, for instance—which scans a system for known vulnerabilities—leaves some traces in multiple log sources such as
Syslog and
ApacheLog on
Host1 and
Host3, respectively.
User Enumeration—an activity that aims to guess or confirm valid users in a system—also leaves some traces in (
AuthLog, MailLog etc.) stored on
Host1 and
Host2. As this example shows, a single attack step typically results in a large number of log events that capture comprehensive information. This information can be used for log analysis and attack investigation, but correlating, tracing, and connecting the individual indicators of compromise—e.g., through timestamps, IP addresses, user names, processes and so forth—is typically a challenging and often time-consuming task. This is partly due to the weak structure of log sources and their inconsistent format and terminologies. Consequently, it is difficult to get a complete picture of suspicious activities and understand what happened in a given attack—particularly in the face of fast evolving, large volume, and highly scattered log data.
To tackle these challenges, we propose
VloGraph, a decentralized framework to contextualize, link, and query log data. We originally introduced this framework in [
7]; in this paper, we extend this prior work with a detailed requirements specification, evaluation with two additional application scenarios, and a section reflecting upon graph-based log integration and analysis, decentralization and virtualization, and discussing applications and limitations.
More specifically, we introduce a method to execute federated, graph pattern-based queries over dispersed, heterogeneous raw log data by dynamically constructing virtual knowledge graphs [
8,
9]. This knowledge-based approach is designed to be decentralized, flexible and scalable. To this end, it (i) federates graph-pattern based queries across endpoints, (ii) extracts only potentially relevant log messages, (iii) integrates the dispersed log events into a common graph, and (iv) links them to background knowledge.
All of these steps are executed at query time without any up-front ingestion and conversion of log messages.
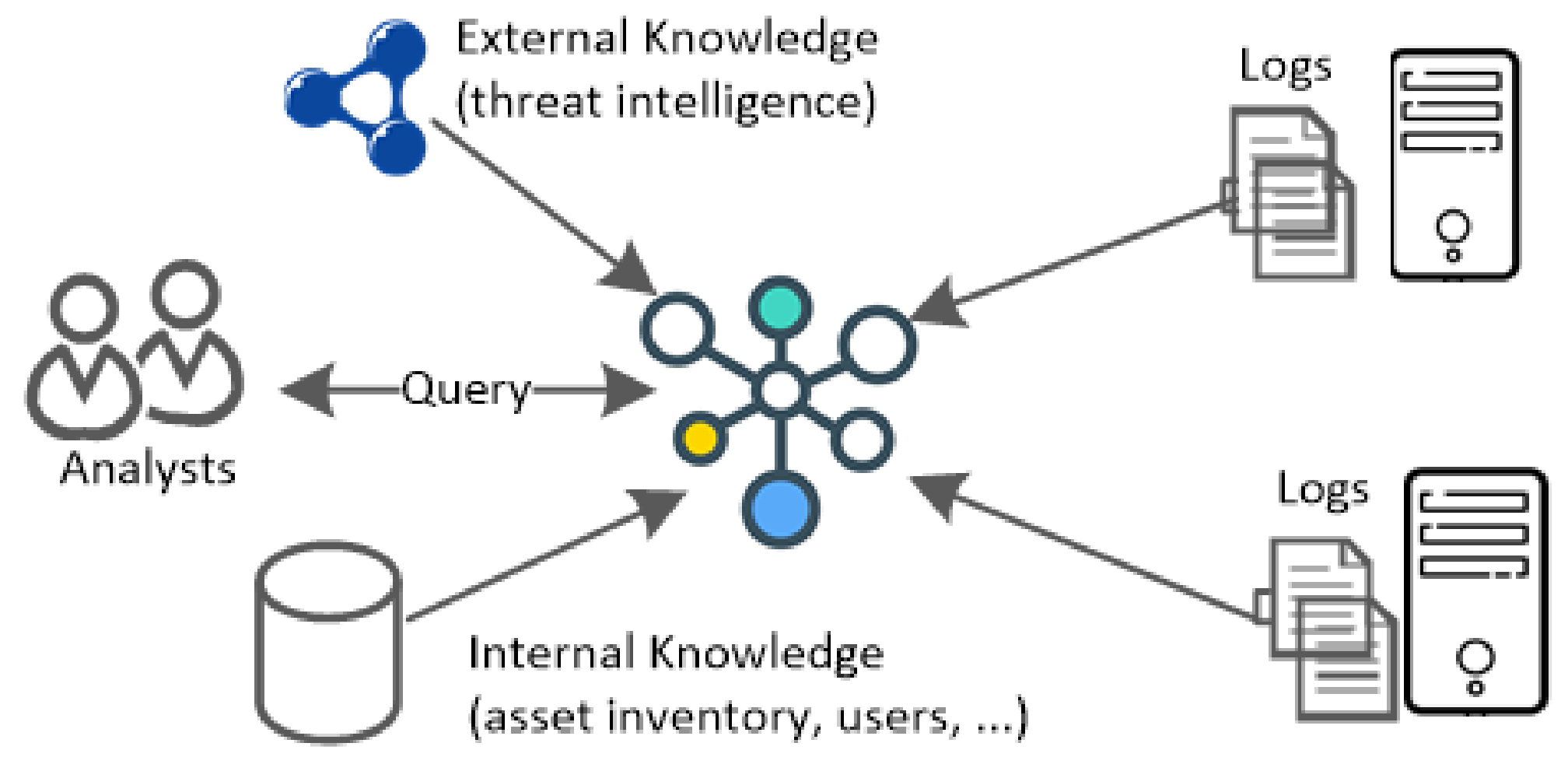
Figure 2 illustrates the proposed approach; the virtual log knowledge graph at the center of the figure is constructed dynamically from dispersed log sources based on analysts’ queries and linked to external and internal knowledge sources.
A key advantage of the graph-based model of this virtual knowledge graph is that it provides a concise, flexible, and intuitive abstraction for the representation of various relations such as, e.g., connections in networked systems, hierarchies of processes on endpoints, associations between users and services, and chains of indicators of compromise. These connections automatically link log messages that are related through common entities (such as users, hosts, and IP addresses); such links are crucial in cybersecurity investigations, as threat agent activities typically leave traces in various log files that are often spread across multiple endpoints in a network, particularly in discovery, lateral movement, and exfiltration stages of an attack ATT&CK Matrix for Enterprise [
10].
In contrast to traditional workflows that store log messages in a centralized repository, VloGraph shifts the log parsing workload from ingestion to analysis time. This makes it possible to directly access and dynamically integrate the most granular raw log data without any loss of information that would occur if the logs were pre-filtered and aggregated—typical steps performed before transferring them to a central archive.
VloGraph tackles a number of pressing challenges in security log analysis (discussed in
Section 4) and facilitates (i) ad-hoc integration and semantic analyses on raw log data without prior centralized materialization, (ii) the collection of evidence-based knowledge from heterogeneous log sources, (iii) automated linking of fragmented knowledge about system states and activities, and (iv) automated linking to external security knowledge (such as, e.g., attack patterns, threat implications, actionable advice).
The remainder of this paper is organized as follows:
Section 2 introduces background knowledge as conceptual foundation, including semantic standards and virtual knowledge graphs.
Section 3 provides an overview of related work in this area, and in
Section 4, we discuss challenges in log analysis and derive requirements for our approach.
Section 5 introduces the proposed
VloGraph architecture and describes the components for virtual log knowledge graph construction in detail. In
Section 6 we present a prototypical implementation of the architecture and illustrate its use in three application scenarios. We evaluate our approach on a systematically generated log dataset in
Section 7 and discuss benefits and limitations of the presented approach in
Section 8. Finally, we conclude with an outlook on future work in
Section 9.
2. Background
In this section, we first provide a brief background on log files and formats and then introduce knowledge graphs as a conceptual foundation of our approach.
Log File Formats
Typically, software systems (operating systems, applications, network devices, etc.) produce time-sequenced log files to keep track of relevant events. These logs are used by roles such as administrators, security analysts, and software developers to identify and diagnose issues. Various logging standards are in use today, often focused on a specific application domain, such as operating system logs (e.g., syslogd [
11] and Windows Event Logs [
12]), web server logs (e.g., W3C Extended log file format [
13], NGINX logging [
14]), database logs, firewall logs, etc.
Log entries are often stored as semi-structured lines of text, comprising structured parts (e.g., timestamp and severity level) and unstructured fields such as a message. While the structured parts are typically standardized, the content of the unstructured fields contains context specific information and lacks uniformity. Before plain text log lines can be (automatically) analyzed, they must be split into their relevant parts, e.g., into a key-value based representation. This pre-processing step often relies on predefined regular expressions. Other standards, such as the Windows Event Log (EVTX), are already highly structured and support XML or JSON. Despite standardization attempts, heterogeneous log formats are still often an impediment to effective analysis. Current research also strives to automatically detect structure in log files [
15] and to establish a semantic understanding of log contents such as [
16,
17].
Knowledge Graphs
A knowledge graph is a directed, edge-labelled graph where V is a set of vertices (nodes) and E is a set of edges (properties). A single graph is usually represented as a collection of triples T = <spo> where s is a subject, p is a predicate, and o is an object.
RDF, RDF-S, OWL
Resource Description Framework (RDF) is a standardized data model that has been recommended by the W3C [
18] to represent directed edge-labelled graphs. In RDF, a
subject is a resource identified by a unique identifier (URI) or a blank-node, an
object can be a resource, blank-node or literal (e.g., String, number), and
predicate is a property defined in an ontology and must be a URI.
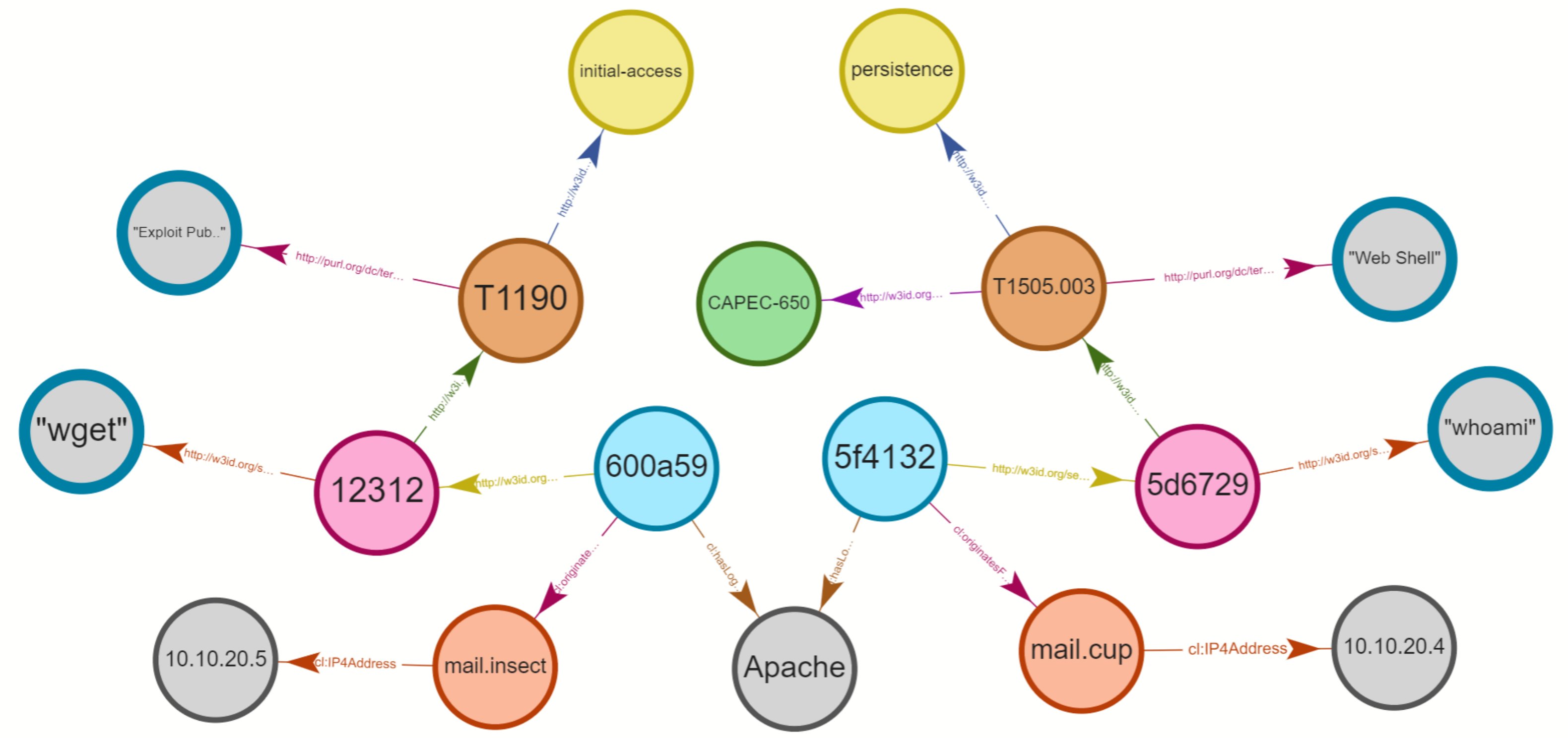
Figure 3 shows an excerpt of a log knowledge graph that expresses a single Apache log event in RDF. To the left, it shows a graphical representation of this log event and to the right a representation of the same graph in TURTLE [
19] serialization. The subject
:logEntry-24e is characterized by a number of properties that specify its type (
cl:ApacheLog), the timestamp of creation, the originate host of the log event, the client that made the request, and the request string. Furthermore, the highlighted IP-Address (in the visualization) indicate that the objects link to other entities in the graph.
RDF-S (Resource Description Framework Schema) [
20] is a W3C standard data model for knowledge representation. It extends the basic RDF vocabulary with a set of classes and RDFS entailment (inference patterns) [
21]. OWL (Ontology Web Language) [
22] is also a W3C standard for authoring ontologies.
SPARQL
SPARQL [
23] is a W3C query language to retrieve and manipulate data stored in RDF. It offers rich expressivity for complex queries such as aggregation, subqueries, and negation. Furthermore, SPARQL provides capabilities to express queries across multiple distributed data sources through SPARQL query federation [
24]. In the security context, this is a major benefit, as security-relevant information is typically dispersed across different systems and networks and requires the consideration of e.g., different log sources, IT repositories, and cyberthreat intelligence sources [
25].
Virtual Knowledge Graph
The Virtual Knowledge Graph (VKG) paradigm for data integration is typically used to provide integrated access to heterogeneous relational data. The approach—also known in the literature as Ontology-based Data Access—aims to replace the rigid structure of tables in traditional data integration layers with the flexibility of graphs. This makes it possible to connect data silos by means of conceptual graph representations that provide an integrated view on the data. To this end, VKGs integrate three main ideas [
9]:
Data Virtualization (V), i.e., they provide a conceptual view that avoids exposing end users to the actual data sources. This conceptual view is typically not materialized in order to make it possible to query the data without paying a price in terms of storage and time for the data to be made accessible.
Domain Knowledge (K), i.e., the graphs can be enriched and contextualized with domain knowledge that makes it possible to derive new implicit knowledge from the asserted facts at the time a query is executed.
Graph Representation (G), i.e., the data are represented as graph where object and data values are represented as nodes, and properties of those object are represented as edges. Compared to traditional relational integration tables, the graph representation provides flexibility and through mapping and merging makes it easier to link and integrate data.
In this paper, we follow these principles and generalize the VKG paradigm to weakly structured log data.
3. Related Work
In this section, we organize the related literature—from general to specific—into three categories:
Log Management and Analytics
The rising number, volume and variety of logs has created the need for systematic computer security log management [
26] and motivated the development of a wide range of log-analytic techniques to derive knowledge from these logs [
27], including anomaly detection [
28,
29], clustering [
30], and rule-base intrusion detection [
31].
In the context of our work, approaches that aim to integrate and analyze log data across multiple sources are particularly relevant. Security Information and Event Management (SIEM) are widely used to provide a centralized view on security-relevant events inside an organization and focus on data aggregation, correlation, and typically rule-based alerting. These ideas are outlined in numerous guidelines and industrial best practices such as the NIST Cybersecurity Framework [
32] and NIST SP 800-92 Guide to Computer Security Log Management [
33]. In this current state of practice, various commercial offerings provide centralized solutions, e.g., Gartner Magic Quadrant for SIEM 2021 [
34].
Whereas SIEMs facilitate centralized log aggregation and management, however, they lack a semantic foundation for the managed log data and consequently typically do not make it easy to link, contextualize, and interpret events against the background of domain knowledge. To tackle these challenges, Ref. [
35] creates a foundation for semantic SIEMs that introduces a Security Strategy Meta-Model to enable interrelating information from different domains and abstraction levels. In a similar vein, Ref. [
2] proposes a hybrid relational-ontological architecture to overcome cross-domain modeling, schema complexity, and scalability limitations in SIEMs. This approach combines existing relational SIEM data repositories with external vulnerability information, i.e., Common Vulnerabilities and Exposures (CVE) [
36].
Graph-Based Log Integration and Analysis
More closely related to the VloGraph approach proposed in this paper, a stream of literature has emerged that recognizes the interrelated nature of log data and conceives log events and their connections as graphs—i.e., labeled property graphs (LPGs) or semantically explicit RDF knowledge graphs.
In the former category, LPGs are stored in graph databases and queried through specialized graph query languages. For network log files, for instance, Ref. [
37] proposes an approach that materializes the log in a Neo4J graph database and makes it available for querying and visualization. The approach is limited to a single log source and focuses exclusively on network log analysis. Similar to this, CyGraph [
38] is a framework that integrates isolated data and events in a unified graph-based cybersecurity model to assist decision making and improve situational awareness. It is based on a domain-specific language CyQL to express graph patterns and uses a third-party tool for visualization.
Another stream of literature transforms logs into RDF knowledge graphs that can be queried with SPARQL, a standardized query language. Early work such as [
39] has illustrated that the use of explicit semantics can help to avoid ambiguity, impose meaning on raw log data, and facilitate correlation in order to lower the barrier for log interpretation and analysis. In this case, however, the log source considered is limited to a firewall log. Approaches like this do not directly transform log data into a graph, but impose semantics to existing raw log data or log data stored in a relational database. More recently, approaches have been developed that aim to transform log data from multiple sources into an integrated log knowledge graph.
For structured log files, Ref. [
40] discusses an approach that analyzes their schema to generate a semantic representation of their contents in RDF. Similar to our work, the approach links log entities to external background knowledge (e.g., DBPedia), but the log source processed is limited to a single log type. Ref. [
41] leverages an ontology to correlate alerts from multiple Intrusion Detection Systems (IDSs) with the goal of reducing the number of false-positive and false-negative alerts. It relies on a shared vocabulary to facilitate security information exchange (e.g., IDMEF, STIX, TAXII), but does not facilitate linking to other log sources that may contain indicators of attacks.
LEKG [
42] provides a log extraction approach to construct knowledge graphs using inference rules and validates them from a background knowledge graph. It uses local inference rules to create graph elements (triples) which can later be used to identify and generate causal relations between events. Compared to
VloGraph, the approach does not aim to provide integration and interlinking over multiple heterogeneous log sources.
To facilitate log integration, contextualization and linking to background knowledge, Ref. [
17] proposes a modular log vocabulary that enables log harmonization and integration between heterogeneous log sources. A recent approach proposed in [
25] introduces a vocabulary and architecture to collect, extract, and correlate heterogeneous low-level file access events from Linux and Windows event logs.
Compared to the approach in this paper, the approaches discussed so far rely on a centralized repository. A methodologically similar approach for log analysis outside of the security domain has also been introduced in [
43], which leverages ontology-based data access to support log extraction and data preparation on legacy information systems for process mining. In contrast to this paper, the focus is on log data from legacy systems in existing relational schemas and on ontology-based query translation.
Decentralized Security Log Analysis
Decentralized event correlation for intrusion detection was introduced in early work such as [
44], where the authors propose a specification language to describe intrusions in a distributed pattern and use a peer-to-peer system to detect attacks. In this decentralized approach, the focus is on individual IDS events only. To address scalability limitations of centralized log processing, Ref. [
4] distributes correlation workloads across networks to the event-producing hosts. Similar to this approach, we aim to tackle challenges of centralized log analysis. However, we leverage semantic web technologies to also provide contextualization and linking to external background knowledge. In the cloud environment, Ref. [
45] proposes a distributed and parallel security log analysis framework that provides analyses of a massive number of systems, networks, and transaction logs in a scalable manner. It utilizes the two-level master-slave model to distribute, execute, and harvest tasks for log analysis. The framework is specific to cloud-based infrastructures and lacks the graph-oriented data model and contextualization and querying capabilities of our approach.
4. Requirements
Existing log management systems typically ingest log sources from multiple log-producing endpoints and store them in a central repository for further processing. Before they can be analyzed, such systems typically parse and index these logs, which typically requires considerable amounts of disk space to store the data as well as computational power for log analysis. The concentrated network bandwidth, CPU, memory, and disk space needs limit the scalability of such centralized approaches.
Decentralized log analysis, by contrast, (partly) shifts the computational workloads involved in log pre-processing (e.g., acquisition, extraction, and parsing) and analysis to the log-producing hosts [
4]. This model has the potential for higher scalability and applicability in large-scale settings where the scope of the infrastructure prohibits effective centralization of all potentially relevant log sources in a single repository.
Existing approaches for decentralized log processing, however, primarily aim to provide correlation and alerting capabilities, rather than the ability to query dispersed log data in a decentralized manner. Furthermore, they lack effective means for semantic integration, contextualization, and linking, i.e., dynamically creating connections between entities and potentially involving externally available security information. They also typically have to ingest all log data continuously on the local endpoints, which increases continuous resource consumption across the infrastructure.
In this paper, we tackle these challenges and propose a distributed approach for security log integration and analysis. Thereby, we facilitate ad-hoc querying of dispersed raw log sources without prior ingestion and aggregation in order to address the following requirements (R):
R.1—Resource-efficiency Traditional log management systems, such as SIEMs, perform continuous log ingestion and preprocessing, typically from multiple monitoring endpoints, before analyzing the log data. This requires considerable resources as all data needs to be extracted and parsed in advance. A key requirement for distributed security log analysis is to avoid unnecessary ex-ante log preprocessing (acquisition, extraction, and parsing), thus minimizing resource requirements in terms of centralized storage space and network bandwidth. This should make log analysis both more efficient and more scalable.
R.2—Aggregation and integration over multiple endpoints As discussed in the context of the motivating example in
Section 1, a single attack may leave traces in multiple log sources, which can be scattered across different systems and hosts. To detect sophisticated attacks, it is therefore necessary to identify and connect such isolated indicators of compromise [
17]. The proposed solution should therefore provide the ability to execute federated queries across multiple monitoring endpoints concurrently and deliver integrated results. This makes it possible to detect not only potential attack actions, but also to obtain an integrated picture of the overall attack (e.g., through linking of log entries).
R.3—Integration, Contextualization & Background-Linking the interpretation of log information for attack investigation depends highly on the context; isolated indicators on their own are, however, often inconspicuous in their local context. Therefore, the proposed approach should provide the ability to contextualize disparate log information, integrate it, and link it to internal background knowledge and external security information.
R.4—Standards-based query language The proposed approach should provide an expressive, standards-based query language for log analysis. This should make it easier for analysts to formulate queries (e.g., define rules) during attack investigation in an intuitive and declarative manner.
5. VloGraph Framework Architecture
Based on the requirements set out in
Section 4, we propose
VloGraph, an approach and architecture for security log analytics based on the concept of Virtual Knowledge Graphs (VKGs). The proposed approach leverages Semantic Web Technologies that provide (i) a standardized graph-based representation to describe data and their relationships flexibly using RDF [
46], (ii) semantic linking and alignment to integrate multiple heterogeneous log data and other resources (e.g., internal/external background knowledge), and (iii) a standardized semantic query language (i.e., SPARQL [
23]) to retrieve and manipulate RDF data.
To address R.1, our approach does not rely on centralized log processing, i.e., we only extract relevant log events based on the temporal scope and structure of a given query and its query parameters. Specifically, we only extract lines in a log file that: (i) are within the temporal scope of the query, and (ii) may contain relevant information based on the specified query parameters and filters.
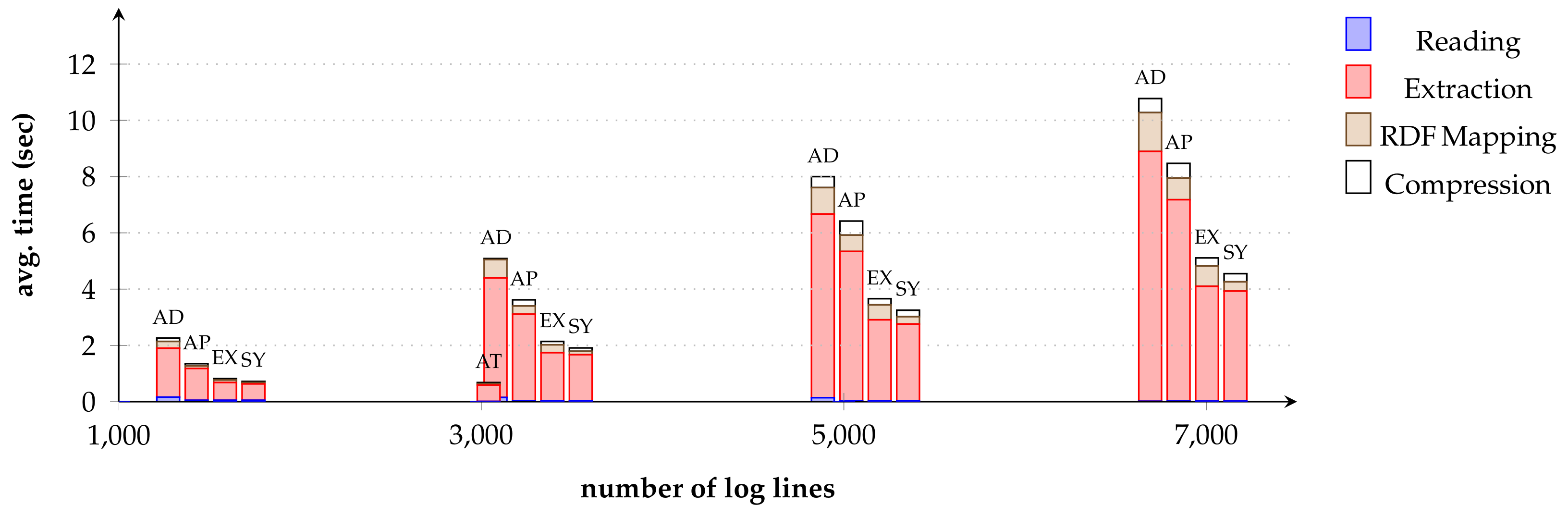
The identified log lines are extracted, parsed, lifted to RDF, compressed, and temporarily stored in a local cache on the respective endpoint. This approach implements the concept of data virtualization and facilitates on-demand log processing. By shifting computational loads to individual monitoring agents and only extracting log entries that are relevant for a given query, this approach can significantly reduce unnecessary log data processing. Furthermore, due to the use of RDF compression techniques, the transferred data are rather small; we discuss this further in
Section 7.
To address R.2, we distribute queries over multiple log sources across distributed endpoints and combine the results in a single integrated output via query federation [
24].
To address R.3, we interlink and contextualize our extracted log data with internal and external background knowledge—such as, e.g., IT asset information and cybersecurity knowledge—via semantic linking and alignment. Finally, we use SPARQL to formulate queries and perform log analyses, which addresses R.4. We will illustrate SPARQL query federation and contextualization in multiple application scenarios for in
Section 6.
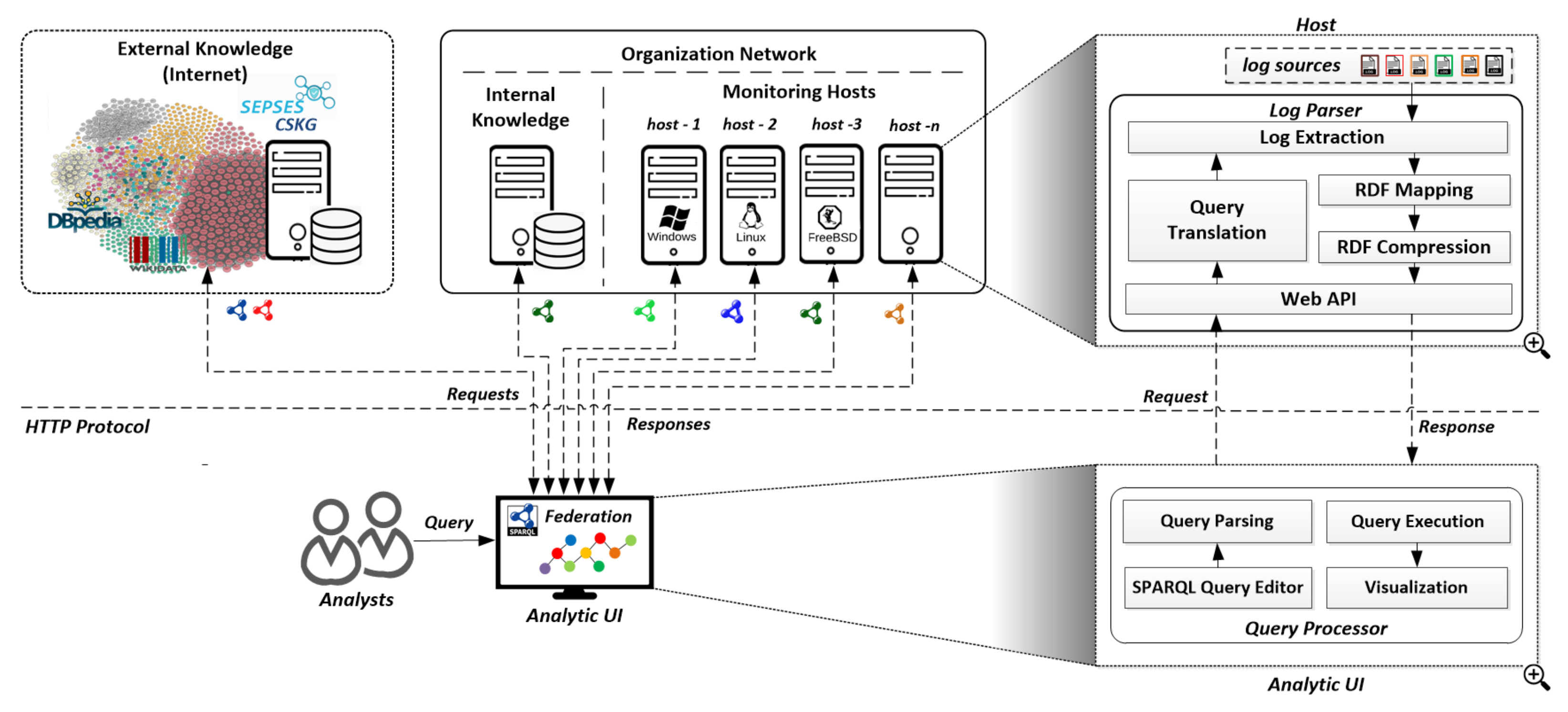
Figure 4 illustrates the
VloGraph virtual log graph and query federation architecture for log analysis; (i) a
Log Parser on each host, which receives and translates queries, extracts raw log data from hosts, parses the extracted log data into an RDF representation, compresses the resulting RDF data into a binary format, and sends the results back to a (ii)
Query Processor, which provides an interface to formulate SPARQL queries and distributes the queries among individual endpoints; furthermore, it retrieves the individual log graphs from the endpoints, integrates them, and presents the resulting integrated graph.
In the following, we explain the individual components in detail.
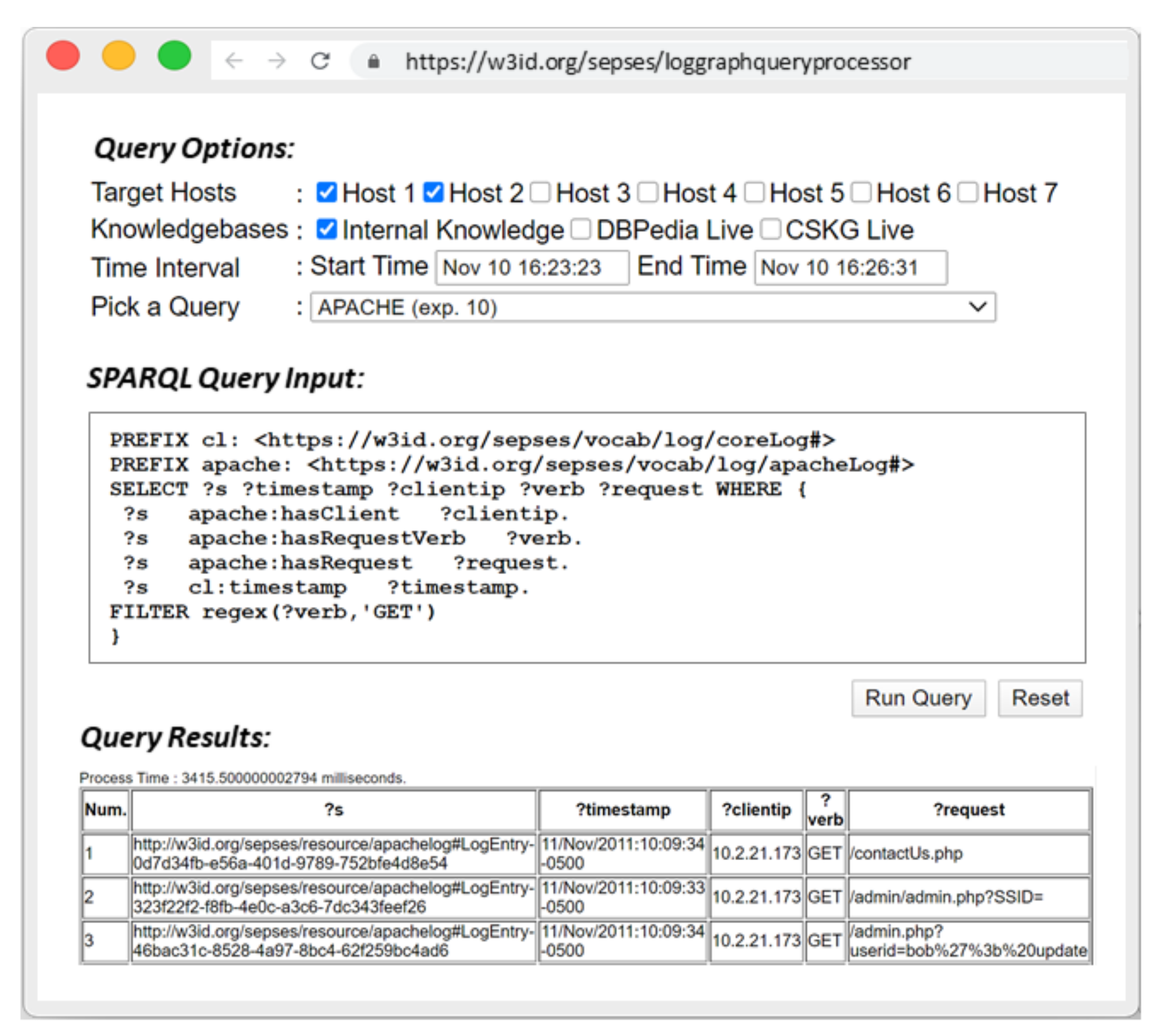
SPARQL Query Editor
This Sub-Component is Part of the Query Processor and allows analysts to define settings for query execution, including: (i) Target Hosts: a set of endpoints to be included in the log analysis, (ii) Knowledge bases: a collection of internal and/or external sources of background knowledge that should be included in the query execution (e.g., IT infrastructure, cyber threat intelligence knowledge bases, etc.), (iii) Time Interval: the time range of interest for the log analysis (i.e., start time and end time).
Query Parsing
The SPARQL query specification [
47] provides a number of alternative syntaxes to formulate queries. For uniform access to the properties and variables inside the query, we therefore parse the raw SPARQL syntax into a structured format prior to transferring the query to the monitoring hosts. The prepared SPARQL query is then sent as a parameter to the
Query Translator via the
Web API in the
Log Parser Component.
Query Translation
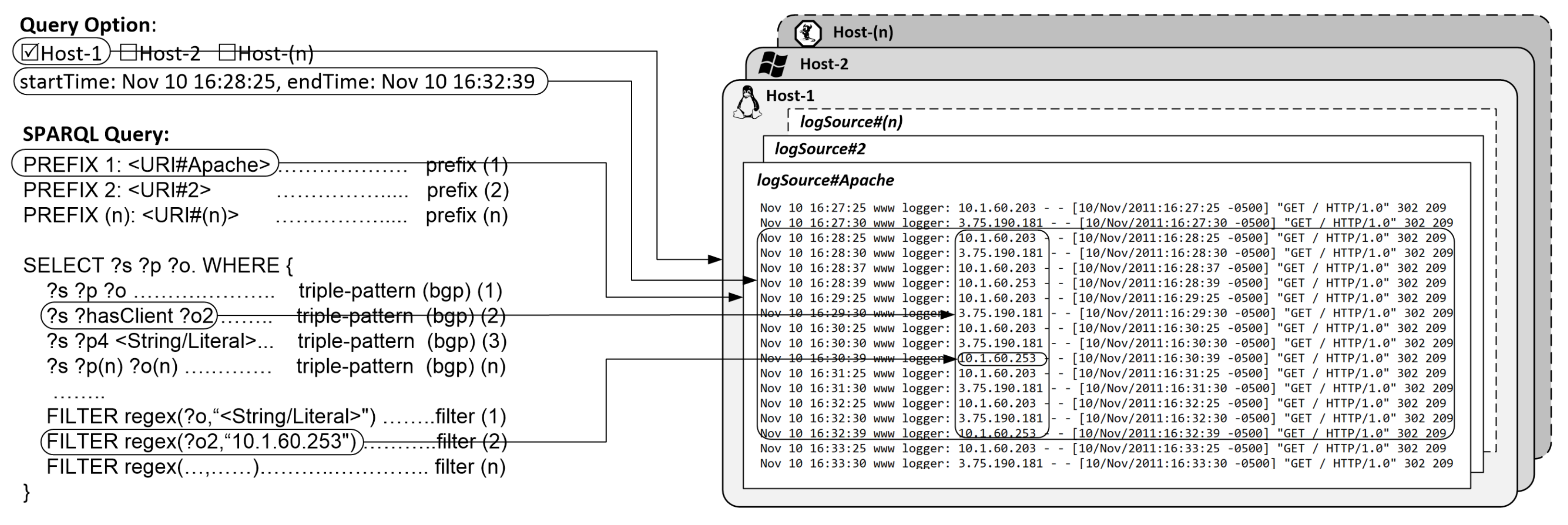
This sub-component decomposes the SPARQL query to identify relevant properties for log source selection and log line matching. 1 outlines the general query translation procedure, which identifies relevant log sources and log lines based on three criteria, i.e., (i) prefixes used in the query; (ii) triples; and (iii) filters.
is a set of log vocabulary prefixes that appear in a given query
Q. In each query, the contained prefixes will be used by the query translator to identify relevant log sources. Available prefixes can be configured for the respective log sources in the
Log Parser configuration on each client, including, e.g., the path to the local location of the log file. As an example,
PREFIX auth: http://w3id.org/authLog is the prefix for
; its presence in a query indicates that the
on the selected hosts will be included in the log processing.
is a set of triples that appear in a query, each represented as Triple Pattern or a Basic Graph Pattern (BGP) (i.e., <Subject> <Predicate> <Object>).
We match these triples to log lines (e.g., hosts and users) as follows: Function collects the triple patterns T contained within the query Q. For each triple statement in a query, we identify the type of Object . If the type is , we identify the as well. For example, for the triple {?Subject cl:originatesFrom "Host1"}, the function identifies "Host1", and additionally, looks up the property range provided in .
links property terms in a vocabulary to the terms in a log entry and the respective regular expression pattern. For example, the property is linked to the concept "hostname" in , which has a connected regex pattern for the extraction of host names. The output of the function is a set of <, > key-value pairs.
Similar to triples, we also include
that appear in a query
Q for log-line matching. Filter statements contain the term
FILTER and a set of pairs (i.e.,
and
), therefore each
statement
has the members
and
. Currently, we support FILTER clauses with simple pattern matching and regular expressions such as
,
.
| Algorithm 1: Query translation. |
![Make 04 00016 i001]() |
The function
is used to retrieve these filter statements from the query and to identify the type of
. If it is a Literal, the
function will look for the connected
. Similar to the technique used in triples, we use
to retrieve the regular expression defined in
. Finally, the collected prefixes and retrieved key-value pairs, both from triples and filters, will be stored in
for further processing.
Figure 5 depicts a SPARQL query translation example.
Log Extraction
This component is part of the
Log Parser that extracts the selected raw log lines and splits them into a key-value pair representation by means of predefined regular expression patterns. As outlined in Algorithm 2, Log sources
are included based on the prefixes that appear in the query.
| Algorithm 2: Log Extraction and RDF Mapping. |
![Make 04 00016 i002]() |
For each log line in a log source, we check whether the log timestamp is within the defined TimeFrame . We leverage the monotonicity assumption that is common in the log context by stopping the log parsing once the end of the temporal window of interest is reached in a log file (i.e., we assume that log lines do not appear out of order). This can be adapted, if required for a specific log source. If this condition is satisfied, the function checks the logline property against the set of queried triples and filters . If the log line matches the requirements, the selected log line will be parsed using based on predefined regular expression patterns. The resulting parsed queries will be accumulated and cached in a temporary file for subsequent processing.
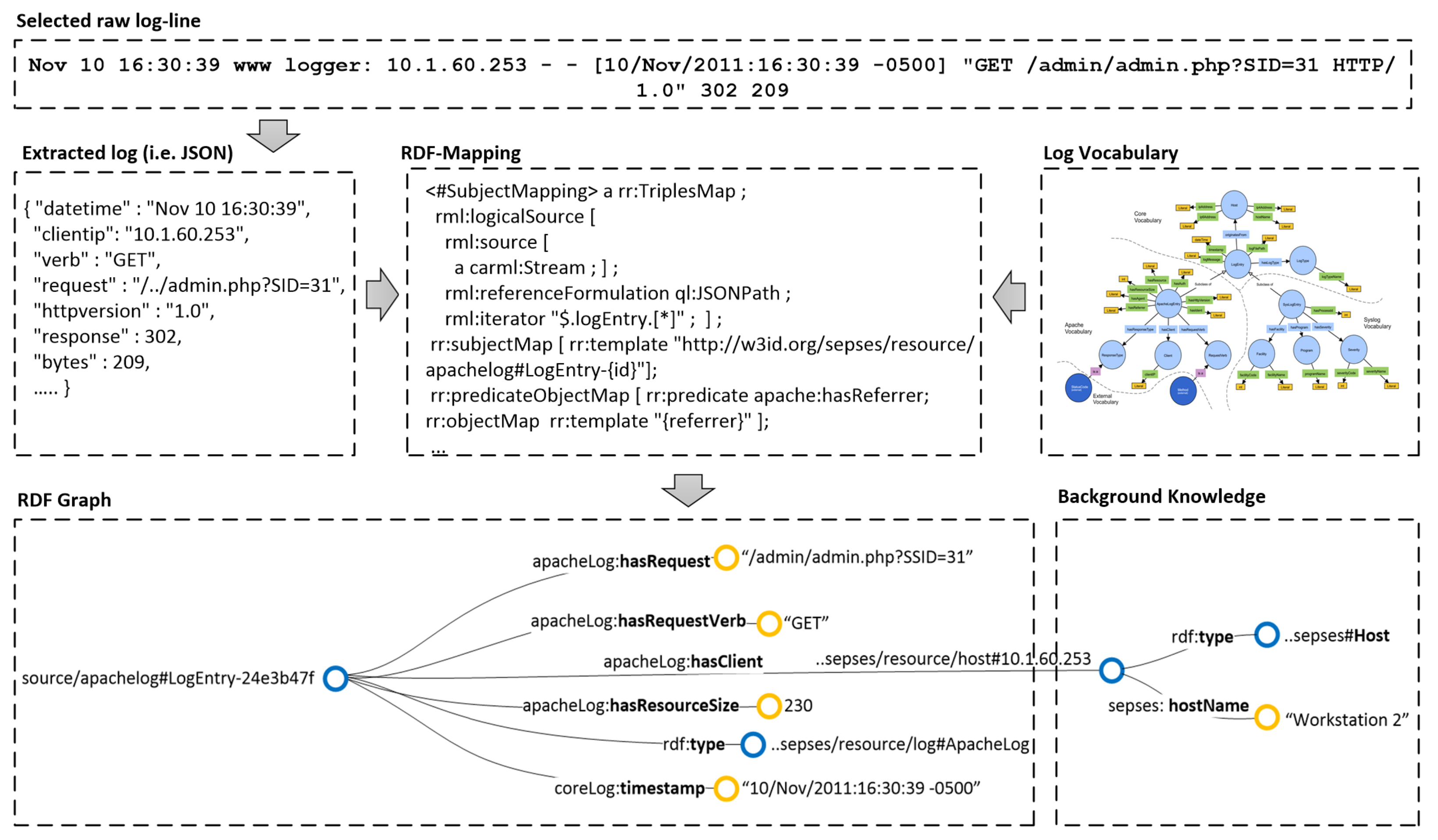
RDF Mapping
This sub-component of the
Log Parser maps and parses the extracted log data into RDF. It uses the standard RDF mapping language to map between the log data and the vocabulary. Different log sources use a common core log vocabulary (e.g., SEPSES coreLog [
48]) for common terms (e.g., host, user, message) and can define extensions for specific terms (e.g., the
request term in ApacheLog). The RDF Mapping also maps terms from a log entry to specific background knowledge (e.g., hosts in a log entry are linked to their host
type according to the background knowledge).
Figure 6 provides an overview of the log graph generation process.
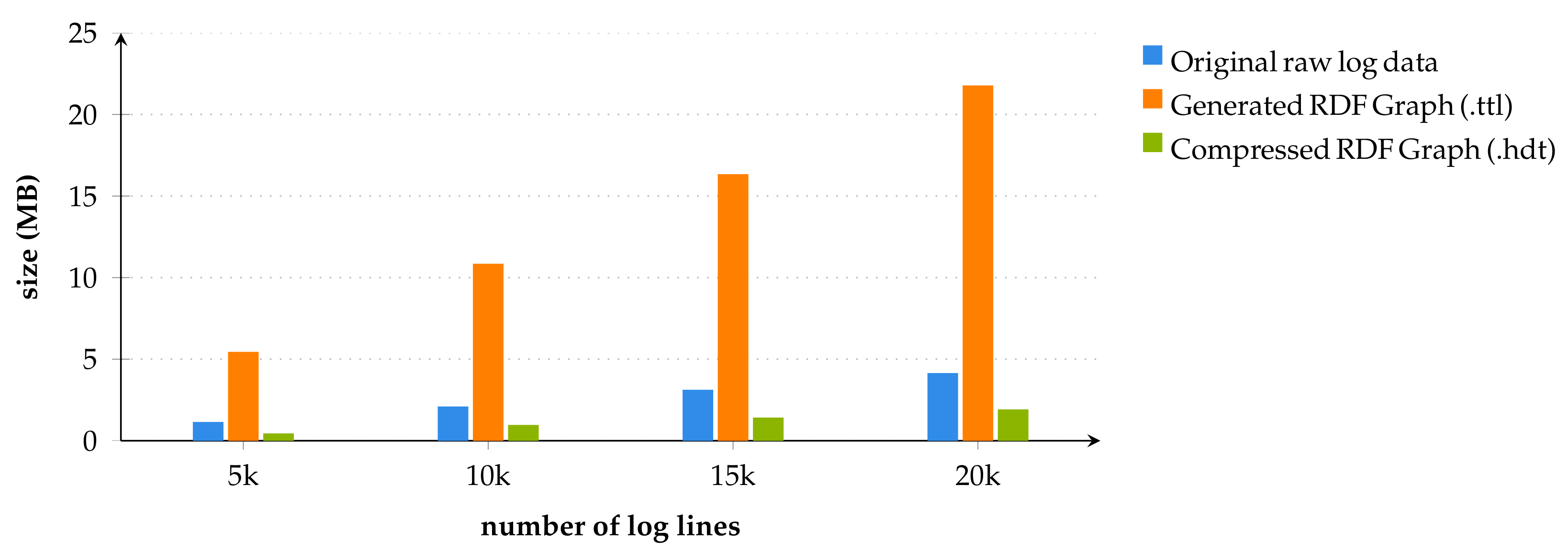
RDF Compression
This sub-component is part of the
Log Parser, which transforms the resulting RDF output produced by the
RDF Mapper into a compact version of RDF. This compression results in a size reduction by an order of magnitude, which has significant advantages in our
VloGraph framework: (i) it enables fast data transfer to the
Query Processor component and thereby reduces latency; (ii) it makes the query execution itself more efficient as the compressed RDF version enables query operations without prior decompression directly on the binary representation [
49].
We discuss the implementation of this component based on existing libraries in
Section 6 and evaluate the effect of compression on the query execution performance on virtual log graphs in
Section 7.
Query Execution
Once the pre-processing on each target host has been completed and the compressed RDF data results have been successfully sent back to the Query Processor, a query engine executes the given queries against the compressed RDF data. If multiple hosts were defined in the query, the query engine will perform query federation over multiple compressed RDF data from those individual hosts and combine the query results into an integrated output.
Furthermore, due to semantic query federation, external data sources are automatically linked in the query results in case they were referenced in the query (cf.
Section 6 for an example that links IDS messages to the SEPSES-CSKG [
50]).
Visualization
Finally, this component presents the query results to the user; depending on the SPARQL query form [
51], e.g.,: (i) SELECT—returns the variables bound in the query pattern, (ii) CONSTRUCT—returns an RDF graph specified by a graph template, and (iii) ASK—returns a Boolean indicating whether a query pattern matches.
The returned result can be either in JSON or RDF format, and the resulting data can be presented to the user as an HTML table, chart, graph visualization, or it can be downloaded as a file.
8. Discussion
In this section, we reflect upon benefits, limitations, and possible applications of the proposed virtual log knowledge graph framework.
Graph-Based Log Integration and Analysis
Representing log data in semantic graph structures opens up new possibilities, such as handling log data in a uniform representation, exploring connections between disparate entities, and applying graph-based queries to search for abstract or concrete patterns of log events. Compared to text-based search, graph-pattern based queries are more expressive and make it possible to link entities that appear in log lines to background knowledge. Furthermore, the ability to provide query results as a graph enables new workflows for analysts and may help them to be more efficient in exploring log data and ultimately improving their situational awareness faster.
In our evaluation, we find that SPARQL as a standardized RDF query language provides powerful means for graph pattern-based ad-hoc log analyses. A challenge, however, is that analysts are typically not familiar with the language and require some training. This may improve in the future, as SPARQL is often already part of computer science curricula and is increasingly being adopted in many industries [
58]. Furthermore, intuitive general-purpose visual query building and exploration tools such as [
59,
60] could be used and possibly adapted for security applications to abstract the complexity of writing queries directly in SPARQL.
Decentralization and Virtualization
Decentralized ad-hoc extraction on the endpoints at query execution time is a particularly useful approach in scenarios where log acquisition, aggregation, and storage are difficult or impractical. This includes scenarios with a large number of distributed hosts and log sources. Pushing log analysis towards the endpoints is also particularly interesting in settings where bandwidth constraints do not permit continuous transmission of log streams to a central log archive.
Whereas these considerations apply generally, the decentralized approach also has benefits that are specific to our knowledge-graph based approach for log integration and analysis. Specifically, the federated execution distributes the computational load of extraction, transformation, and (partly) query execution towards the endpoints. This will be useful in many practical settings where the scale of the log data that is constantly generated in a distributed environment is prohibitively large and it is not feasible to transform the complete log data into a Knowledge Graph (KG) presentation. In such settings, the decentralized approach facilitates ad-hoc graph-based analyses without the need to set up, configure and maintain sophisticated log aggregation systems.
Our evaluation showed that this ad-hoc extraction, transformation, and federated query execution works efficiently for temporally restricted queries over dispersed log data without prior aggregation and centralized storage. Consequently, the approach is particularly useful for iterative investigations over smaller subsets of distributed log data that start from initial indicators of interest. It supports diagnostics, root cause analyses etc. and can leverage semantic connections in the graph that would otherwise make manual exploration tedious. An inherent limitation, however, is that the computational costs become exceedingly large for queries without any temporal restrictions or property-based filters—i.e., the approach is less useful for large-scale exploratory queries over long time intervals without any initial starting point.
Log Parsing and Extraction
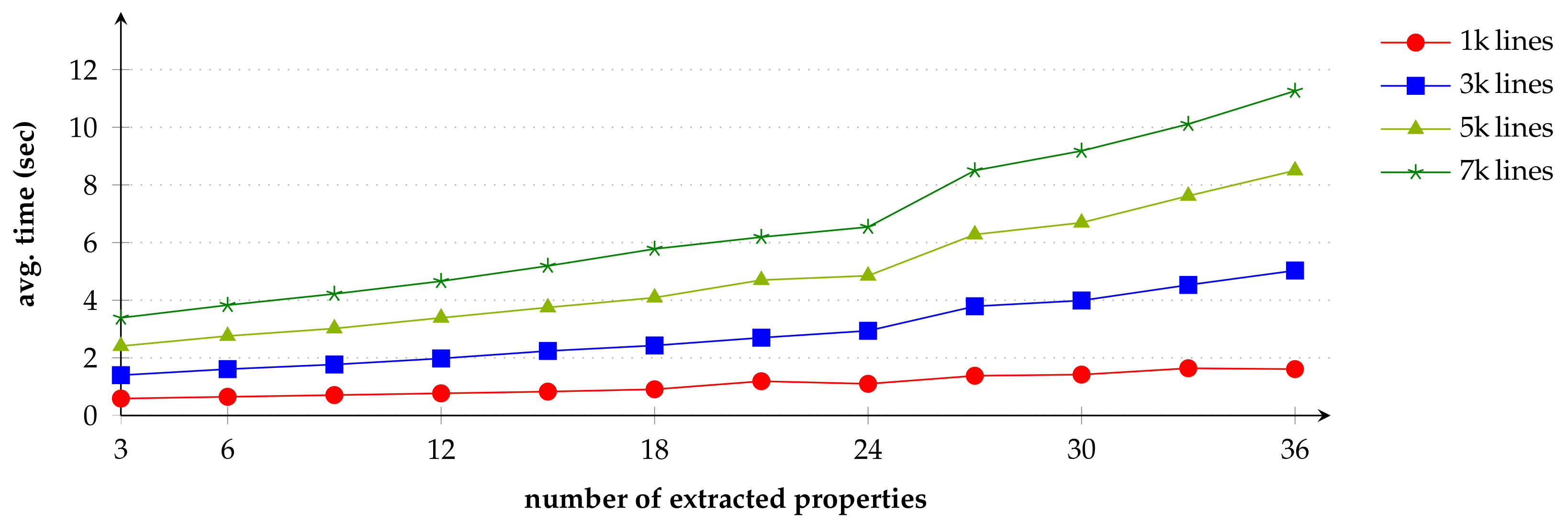
The identification and mapping of relevant concepts in log messages is currently based on regular expression patterns. Extracted log lines are filtered and only lines that potentially match the query are transferred from the local endpoint, which minimizes bandwidth usage and processing load at the querying client. A limitation of this approach is that for complex queries, the execution of a large set of regular expression patterns on each log line raises scalability issues.
An approach based on templates, similar to [
16], could be applied to learn the structure and content of common log messages and then only extract the expected elements from those log messages. Furthermore, repeated application of regular expression patterns on each log line could also be avoided by building a local index on each endpoint. Such techniques should improve query performance, but these improvements have to be traded off against the additional complexity and storage requirements they introduce.
Applications and Limitations
The illustrative scenarios in
Section 6 highlighted the applicability of the approach in web access log analysis, intrusion detection, network monitoring, and threat detection and ATT&CK linking.
In these settings, ad-hoc integration of dispersed heterogeneous log data and graph-based integration can be highly beneficial to connect isolated indicators. Moreover, we found that the virtual log knowledge graph is highly useful in diagnostic applications such as troubleshooting or service management more generally and we are currently working on a framework for instrumenting containers with virtual knowledge graph interfaces to support such scenarios.
In the security domain—the focus in this paper—we found that virtual knowledge graphs can complement existing log analytic tools in order to quickly gain visibility in response to security alerts or to support security analysts in threat hunting based on an initial set of indicators or hypotheses.
Key limitations, however, include that the virtual integration approach is not directly applicable for (i) repeated routine analyses over large amounts of log data, i.e., in scenarios where up-front materialization into a KG is feasible and amortizes due to repeated queries over the same large data set or; (ii) continuous monitoring applications, i.e., scenarios where log data has to be processed in a streaming manner, particularly in the context of low latency requirements.
The latter would require the extension of the approach to streaming settings, which we plan to address in future work.
Evasion and Log Retention
A typical motivation for shipping log data to dedicated central servers is to reduce the risk of undetected log tampering when hosts in the network are compromised. This reduces the attack surface, but makes securing the central log archive against tampering all the more critical. Relying on data extracted at the endpoints, by contrast, comes with the risk of local log tampering. File integrity features could help to spot manipulations of log files, but for auditing purposes, the proposed approach has to be complemented with secure log retention policies and mechanisms. Finally, the communication channel between the query processor in the analytic user interface and the local log parsers also represents an attack vector that has to be secured.
9. Conclusions
In this article, we presented VloGraph, a novel approach for distributed ad-hoc log analysis. It extends the Virtual Knowledge Graph (VKG) concept and provides integrated access to (partly) unstructured log data. In particular, we proposed a federated method to dynamically extract, semantically lift and link named entities directly from raw log files. In contrast to traditional approaches, this method only transforms the information that is relevant for a given query, instead of processing all log data centrally in advance. Thereby, it avoids scalability issues associated with the central processing of large amounts of rarely accessed log data.
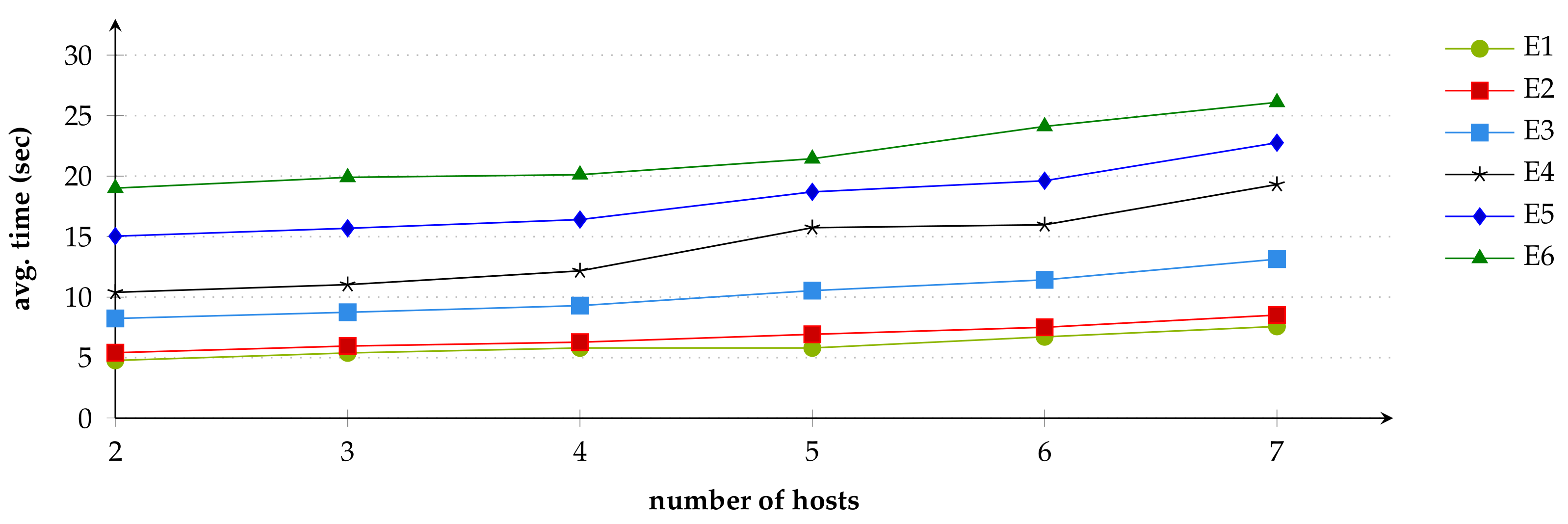
To explore the feasibility of this approach, we developed a prototype and demonstrated its application in three log analysis tasks in security analytics. These scenarios demonstrate federated queries over multiple log sources across different systems. Furthermore, they highlight the use of semantic concepts inside queries and the possibility of linking contextual information from background knowledge. We also conducted a performance evaluation which indicates that the total log processing time is primarily a function of the number of extracted (relevant) log lines and queried hosts, rather than the size of the raw log files. Our prototypical implementation of the approach provides scalability when facing larger log files and an increasing number of monitoring hosts.
Although this distributed ad-hoc querying has multiple advantages, we also discussed a number of limitations. First, log files are always parsed on demand in our prototype. By introducing a template-based approach to learn the structure of common log messages and by building an index on each endpoint to store the results of already parsed messages, query performance could be improved. Second, the knowledge-based ad-hoc analysis approach presented in this article is intended to complement, but does not replace traditional log processing techniques. Finally, while out of scope for the proof of concept implementation, the deployment of the concept in real environments requires traditional software security measures such as vulnerability testing, authentication, secure communication channels, and so forth.
In future work, we plan to improve the query analysis, e.g., to automatically select relevant target hosts based on the query and asset background knowledge. Furthermore, we will explore the ability to incrementally build larger knowledge graphs based on a series of consecutive queries in a step-by-step process. Finally, an interesting direction for research that would significantly extend the scope of potential use cases is a streaming mode that could execute continuous queries, e.g., for monitoring and alerting purposes. We plan to investigate this aspect and integrate and evaluate stream processing engines in this context.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}