
An Explainable Deep Learning Framework for Detecting and Localising Smoke and Fire Incidents: Evaluation of Grad-CAM++ and LIME


Abstract
:1. Introduction
- The study utilises one of the largest available datasets, which is generated by merging image data from various repositories.
- The study highlights the Inception network, which demonstrated superior performance in distinguishing smoke and fire events from the images.
- The utilisation of explainability tools reveals that Inception seeks in the right direction and can be reliable.
2. Related Work
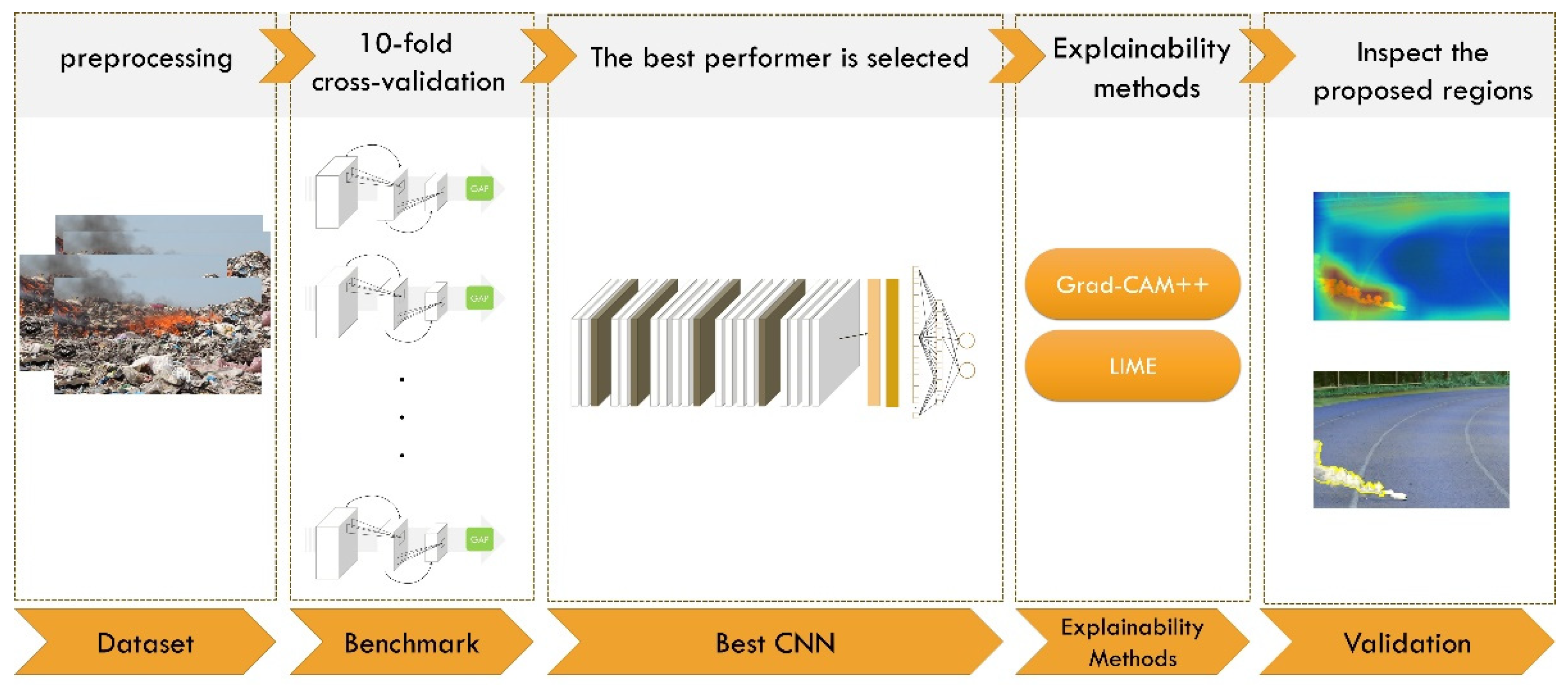
3. Materials and Methods
3.1. Deep Learning in a Nutshell
3.2. Dataset
- (a)
- Images from forest fires;
- (b)
- Image from fires caused by vehicle accidents;
- (c)
- Indoor incidents of smoke or small fire;
- (d)
- Fire incidents on the outside of buildings, as viewed by the streets;
- (e)
- Smoke incidents within large forests;
- (f)
- Smoke incidents on the road.
3.3. Data Processing
3.4. Deep Learning Fire Detection Framework
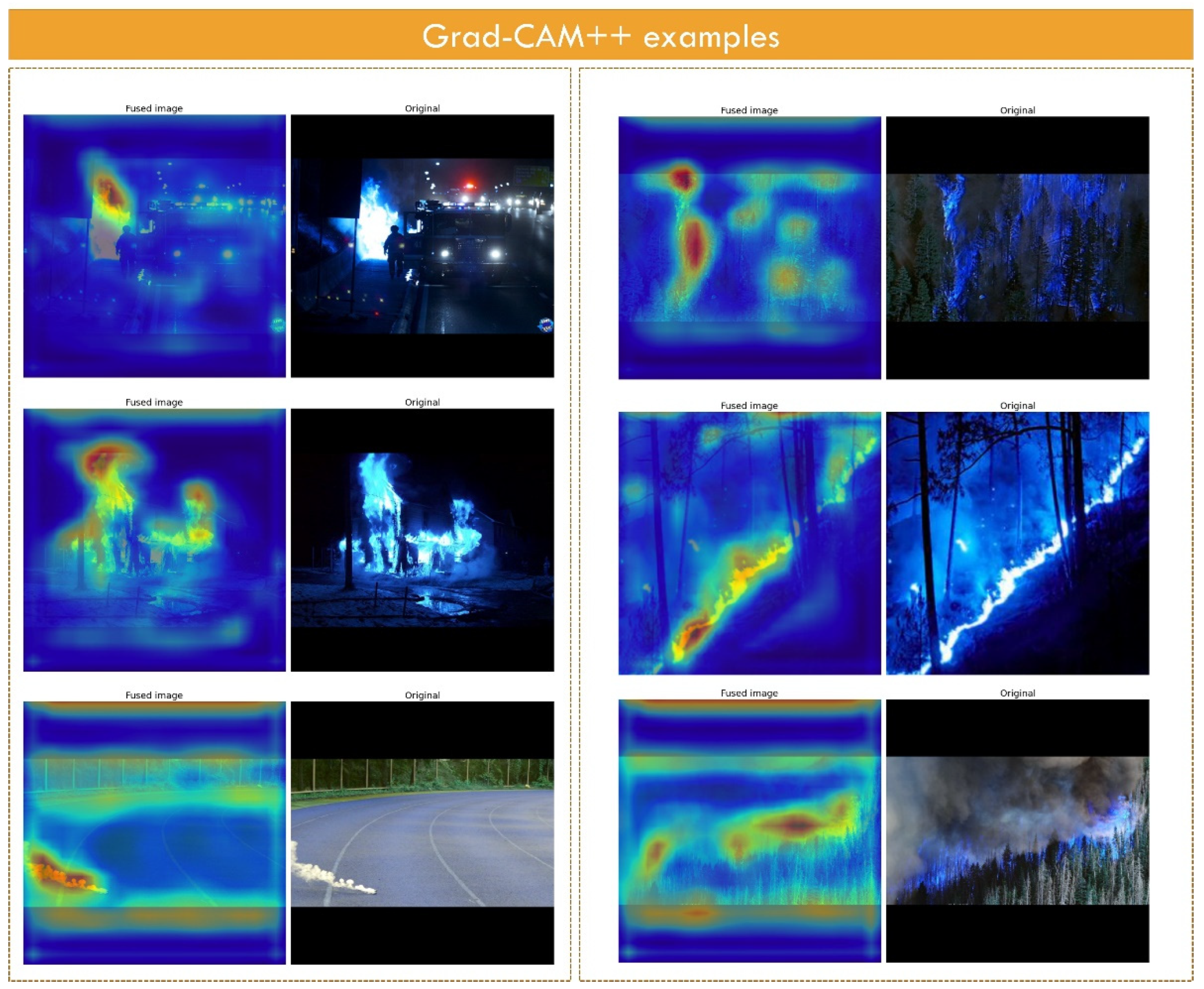
3.5. Explainability Methods
3.5.1. Grad-CAM++ Method
3.5.2. LIME Method
3.6. Experiment Setup
4. Results
4.1. Image Classification
4.2. Grad-CAM++ Outputs
4.3. LIME Outputs
4.4. Alternative Learning Methods
5. Discussion
6. Conclusions and Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Berrang-Ford, L.; Ford, J.D.; Paterson, J. Are We Adapting to Climate Change? Glob. Environ. Change 2011, 21, 25–33. [Google Scholar] [CrossRef]
- Ruddiman, W.F. How Did Humans First Alter Global Climate? Sci. Am. 2005, 292, 46–53. [Google Scholar] [CrossRef]
- Mitchell, J.F. The “Greenhouse” Effect and Climate Change. Rev. Geophys. 1989, 27, 115–139. [Google Scholar] [CrossRef]
- Xu, W.; He, H.S.; Huang, C.; Duan, S.; Hawbaker, T.J.; Henne, P.D.; Liang, Y.; Zhu, Z. Large Fires or Small Fires, Will They Differ in Affecting Shifts in Species Composition and Distributions under Climate Change? For. Ecol. Manag. 2022, 510, 120131. [Google Scholar] [CrossRef]
- Krikken, F.; Lehner, F.; Haustein, K.; Drobyshev, I.; van Oldenborgh, G.J. Attribution of the Role of Climate Change in the Forest Fires in Sweden 2018. Nat. Hazards Earth Syst. Sci. 2021, 21, 2169–2179. [Google Scholar] [CrossRef]
- Abram, N.J.; Henley, B.J.; Gupta, A.S.; Lippmann, T.J.R.; Clarke, H.; Dowdy, A.J.; Sharples, J.J.; Nolan, R.H.; Zhang, T.; Wooster, M.J.; et al. Connections of Climate Change and Variability to Large and Extreme Forest Fires in Southeast Australia. Commun Earth Environ. 2021, 2, 8. [Google Scholar] [CrossRef]
- Michetti, M.; Pinar, M. Forest Fires Across Italian Regions and Implications for Climate Change: A Panel Data Analysis. Environ. Resour. Econ. 2019, 72, 207–246. [Google Scholar] [CrossRef] [Green Version]
- Khan, F.; Xu, Z.; Sun, J.; Khan, F.M.; Ahmed, A.; Zhao, Y. Recent Advances in Sensors for Fire Detection. Sensors 2022, 22, 3310. [Google Scholar] [CrossRef]
- Allison, R.S.; Johnston, J.M.; Wooster, M.J. Sensors for Fire and Smoke Monitoring. Sensors 2021, 21, 5402. [Google Scholar] [CrossRef]
- Gaur, A.; Singh, A.; Kumar, A.; Kumar, A.; Kapoor, K. Video Flame and Smoke Based Fire Detection Algorithms: A Literature Review. Fire Technol. 2020, 56, 1943–1980. [Google Scholar] [CrossRef]
- Kim, B.; Lee, J. A Video-Based Fire Detection Using Deep Learning Models. Appl. Sci. 2019, 9, 2862. [Google Scholar] [CrossRef] [Green Version]
- Jiao, Z.; Zhang, Y.; Xin, J.; Mu, L.; Yi, Y.; Liu, H.; Liu, D. A Deep Learning Based Forest Fire Detection Approach Using UAV and YOLOv3. In Proceedings of the 2019 1st International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 23–27 July 2019; pp. 1–5. [Google Scholar]
- Seydi, S.T.; Saeidi, V.; Kalantar, B.; Ueda, N.; Halin, A.A. Fire-Net: A Deep Learning Framework for Active Forest Fire Detection. J. Sens. 2022, 2022, 8044390. [Google Scholar] [CrossRef]
- Xue, Z.; Lin, H.; Wang, F. A Small Target Forest Fire Detection Model Based on YOLOv5 Improvement. Forests 2022, 13, 1332. [Google Scholar] [CrossRef]
- priya, R.S.; Vani, K. Deep Learning Based Forest Fire Classification and Detection in Satellite Images. In Proceedings of the 2019 11th International Conference on Advanced Computing (ICoAC), Chennai, India, 18–20 December 2019; pp. 61–65. [Google Scholar]
- Khan, S.; Muhammad, K.; Hussain, T.; Ser, J.D.; Cuzzolin, F.; Bhattacharyya, S.; Akhtar, Z.; de Albuquerque, V.H.C. DeepSmoke: Deep Learning Model for Smoke Detection and Segmentation in Outdoor Environments. Expert Syst. Appl. 2021, 182, 115125. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, Y. Real-Time Forest Smoke Detection Using Hand-Designed Features and Deep Learning. Comput. Electron. Agric. 2019, 167, 105029. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional Networks for Images, Speech, and Time Series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y. Deep Learning Using Linear Support Vector Machines. arXiv 2013, arXiv:1306.0239. [Google Scholar]
- Le, Q.V.; Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Ng, A.Y. On optimization methods for deep learning. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Khan, A.; Hassan, B. Dataset for Forest Fire Detection. Mendeley Data V1 2020, 1, 2020. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Modeling the Shape of the Scene: A Holistic Representation of the Spatial Envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Y.; Zhang, Q.; Lin, G.; Wang, J. Domain Adaptation from Synthesis to Reality in Single-Model Detector for Video Smoke Detection. arXiv 2017, arXiv:1709.08142. [Google Scholar] [CrossRef]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-Margin Softmax Loss for Convolutional Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 2, p. 7. [Google Scholar]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Chattopadhyay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should i Trust You?” Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Apostolopoulos, I.D.; Papathanasiou, N.D.; Apostolopoulos, D.J. A Deep Learning Methodology for the Detection of Abnormal Parathyroid Glands via Scintigraphy with 99mTc-Sestamibi. Diseases 2022, 10, 56. [Google Scholar] [CrossRef] [PubMed]
- Apostolopoulos, I.D.; Pintelas, E.G.; Livieris, I.E.; Apostolopoulos, D.J.; Papathanasiou, N.D.; Pintelas, P.E.; Panayiotakis, G.S. Automatic classification of solitary pulmonary nodules in PET/CT imaging employing transfer learning techniques. Med. Biol. Eng. Comput. 2021, 59, 1299–1310. [Google Scholar] [CrossRef]
- Huh, M.; Agrawal, P.; Efros, A.A. What makes ImageNet good for transfer learning? arXiv 2016, arXiv:1608.08614. [Google Scholar]
- Apostolopoulos, I.D.; Groumpos, P.P. Non-Invasive Modelling Methodology for the Diagnosis of Coronary Artery Disease Using Fuzzy Cognitive Maps. Comput. Methods Biomech. Biomed. Eng. 2020, 23, 879–887. [Google Scholar] [CrossRef]
- Apostolopoulos, I.D.; Tzani, M.A. Industrial Object and Defect Recognition Utilizing Multilevel Feature Extraction from Industrial Scenes with Deep Learning Approach. J Ambient Intell Hum. Comput 2022, 1–14. [Google Scholar] [CrossRef]
- Vassiliki, M.; Peter, G.P. Increasing the energy efficiency of buildings using human cognition; via fuzzy cognitive maps. IFAC-Pap. 2018, 51, 727–732. [Google Scholar] [CrossRef]
- Targetti, S.; Schaller, L.L.; Kantelhardt, J. A Fuzzy Cognitive Mapping Approach for the Assessment of Public-Goods Governance in Agricultural Landscapes. Land Use Policy 2021, 107, 103972. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | DOI or LINK |
|---|---|
| FOREST FIRE IMAGE DATASET | https://www.kaggle.com/datasets/cristiancristancho/forest-fire-image-dataset, accessed on 13 September 2022 |
| Fire-Detection-Image-Dataset | https://github.com/cair/Fire-Detection-Image-Dataset.git, accessed on 13 September 2022 |
| YOLOv3-for-custum-objects | https://github.com/amineHY/YOLOv3-for-custum-objects, accessed on 13 September 2022 |
| Fire Images Database | https://www.kaggle.com/datasets/gondimjoaom/fire-images-database, accessed on 13 September 2022 |
| Forest Fire | https://www.kaggle.com/datasets/kutaykutlu/forest-fire, accessed on 13 September 2022 |
| Wildfire Detection Image Data | https://www.kaggle.com/datasets/brsdincer/wildfire-detection-image-data, accessed on 13 September 2022 |
| Fire Dataset | https://www.kaggle.com/datasets/phylake1337/fire-dataset, accessed on 13 September 2022 |
| fire smoke dataset | https://www.kaggle.com/datasets/hhhhhhdoge/fire-smoke-dataset, accessed on 13 September 2022 |
| Dataset for Forest Fire Detection | [26] |
| Fire and Smoke | [27] |
| Smoke | [28] |
| Dataset Feature | Description |
|---|---|
| Incidents of smoke/fire | forest, vehicle, building, indoor, road, industrial buildings and machinery |
| Image acquisition devices | UAV, smartphone cameras, satellite images, surveillance cameras |
| Image Formats | jpg, png, tiff, gif |
| Image sizes | Width: 600 to 1200 pixels Height: 500 to 1080 pixels |
| Network | Trainable Layers | Dense Layers at the Top |
|---|---|---|
| Xception | None | 1500-500-2 |
| VGG16 | None | 1500-500-2 |
| VGG19 | None | 1500-500-2 |
| ResNet152 | None | 1500-500-2 |
| ResNet152V2 | None | 1500-500-2 |
| InceptionV3 | None | 1500-500-2 |
| InceptionResNetV2 | None | 1500-500-2 |
| MobileNet | None | 1500-500-2 |
| MobileNetV2 | None | 1500-500-2 |
| DenseNet169 | None | 1500-500-2 |
| DenseNet201 | None | 1500-500-2 |
| NASNetMobile | None | 1500-500-2 |
| EfficientNetB6 | None | 1500-500-2 |
| EfficientNetB7 | None | 1500-500-2 |
| EfficientNetV2B3 | None | 1500-500-2 |
| ConvNeXtLarge | None | 1500-500-2 |
| ConvNeXtXLarge | None | 1500-500-2 |
| Network | ACC | PRE | REC | TNR | FPR | FNR | NPV | F1 | AUC |
|---|---|---|---|---|---|---|---|---|---|
| Xception | 0.9881 | 0.9948 | 0.9833 | 0.9938 | 0.0062 | 0.0167 | 0.9803 | 0.9890 | 0.9886 |
| VGG16 | 0.9822 | 0.9918 | 0.9755 | 0.9903 | 0.0097 | 0.0245 | 0.9711 | 0.9835 | 0.9829 |
| VGG19 | 0.9745 | 0.9918 | 0.9613 | 0.9904 | 0.0096 | 0.0387 | 0.9551 | 0.9763 | 0.9759 |
| ResNet152 | 0.9484 | 0.9819 | 0.9225 | 0.9796 | 0.0204 | 0.0775 | 0.9132 | 0.9513 | 0.9511 |
| ResNet152V2 | 0.9516 | 0.9756 | 0.9346 | 0.9719 | 0.0281 | 0.0654 | 0.9252 | 0.9547 | 0.9533 |
| InceptionV3 | 0.9534 | 0.9605 | 0.9538 | 0.9528 | 0.0472 | 0.0462 | 0.9449 | 0.9571 | 0.9533 |
| InceptionResNetV2 | 0.9762 | 0.9736 | 0.9830 | 0.9680 | 0.0320 | 0.0170 | 0.9793 | 0.9783 | 0.9755 |
| MobileNet | 0.8923 | 0.9730 | 0.8256 | 0.9725 | 0.0275 | 0.1744 | 0.8227 | 0.8933 | 0.8990 |
| MobileNetV2 | 0.9790 | 0.9924 | 0.9689 | 0.9911 | 0.0089 | 0.0311 | 0.9637 | 0.9805 | 0.9800 |
| DenseNet169 | 0.9695 | 0.9865 | 0.9571 | 0.9843 | 0.0157 | 0.0429 | 0.9503 | 0.9716 | 0.9707 |
| DenseNet201 | 0.9385 | 0.9494 | 0.9372 | 0.9400 | 0.0600 | 0.0628 | 0.9257 | 0.9433 | 0.9386 |
| NASNetMobile | 0.7904 | 0.8385 | 0.7628 | 0.8235 | 0.1765 | 0.2372 | 0.7428 | 0.7989 | 0.7931 |
| EfficientNetB6 | 0.9288 | 0.8967 | 0.9828 | 0.8640 | 0.1360 | 0.0172 | 0.9766 | 0.9378 | 0.9234 |
| EfficientNetB7 | 0.9561 | 0.9390 | 0.9833 | 0.9233 | 0.0767 | 0.0167 | 0.9788 | 0.9607 | 0.9533 |
| EfficientNetV2B3 | 0.9720 | 0.9924 | 0.9561 | 0.9912 | 0.0088 | 0.0439 | 0.9494 | 0.9739 | 0.9737 |
| ConvNeXtLarge | 0.9543 | 0.9881 | 0.9274 | 0.9866 | 0.0134 | 0.0726 | 0.9187 | 0.9568 | 0.9570 |
| ConvNeXtXLarge | 0.9672 | 0.9826 | 0.9569 | 0.9796 | 0.0204 | 0.0431 | 0.9497 | 0.9695 | 0.9682 |
| Network | Training Time | Test Time |
|---|---|---|
| Xception | 1313 | 0.09 |
| VGG16 | 1427 | 0.08 |
| VGG19 | 1587 | 0.08 |
| ResNet152 | 1457 | 0.08 |
| ResNet152V2 | 1493 | 0.08 |
| InceptionV3 | 1342 | 0.09 |
| InceptionResNetV2 | 1477 | 0.1 |
| MobileNet | 1105 | 0.05 |
| MobileNetV2 | 1126 | 0.06 |
| DenseNet169 | 1274 | 0.05 |
| DenseNet201 | 1355 | 0.05 |
| NASNetMobile | 1304 | 0.04 |
| EfficientNetB6 | 1227 | 0.04 |
| EfficientNetB7 | 1364 | 0.04 |
| EfficientNetV2B3 | 1290 | 0.04 |
| ConvNeXtLarge | 1434 | 0.04 |
| ConvNeXtXLarge | 1651 | 0.04 |
| Method | ACC | PRE | REC | TNR | FPR | FNR | NPV | F1 | AUC |
|---|---|---|---|---|---|---|---|---|---|
| CNN: Training from scratch | 0.6530 | 0.6346 | 0.6750 | 0.3250 | 0.3654 | 0.7012 | 0.6059 | 0.6663 | 0.6548 |
| Neural Network | 0.7418 | 0.6853 | 0.8098 | 0.1902 | 0.3147 | 0.8123 | 0.6816 | 0.7434 | 0.7475 |
| Transfer Learning | 0.9881 | 0.9948 | 0.9833 | 0.9938 | 0.0062 | 0.0167 | 0.9803 | 0.9890 | 0.9886 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Apostolopoulos, I.D.; Athanasoula, I.; Tzani, M.; Groumpos, P.P. An Explainable Deep Learning Framework for Detecting and Localising Smoke and Fire Incidents: Evaluation of Grad-CAM++ and LIME. Mach. Learn. Knowl. Extr. 2022, 4, 1124-1135. https://0-doi-org.brum.beds.ac.uk/10.3390/make4040057
Apostolopoulos ID, Athanasoula I, Tzani M, Groumpos PP. An Explainable Deep Learning Framework for Detecting and Localising Smoke and Fire Incidents: Evaluation of Grad-CAM++ and LIME. Machine Learning and Knowledge Extraction. 2022; 4(4):1124-1135. https://0-doi-org.brum.beds.ac.uk/10.3390/make4040057
Chicago/Turabian StyleApostolopoulos, Ioannis D., Ifigeneia Athanasoula, Mpesi Tzani, and Peter P. Groumpos. 2022. "An Explainable Deep Learning Framework for Detecting and Localising Smoke and Fire Incidents: Evaluation of Grad-CAM++ and LIME" Machine Learning and Knowledge Extraction 4, no. 4: 1124-1135. https://0-doi-org.brum.beds.ac.uk/10.3390/make4040057