
Enhancement: SiamFC Tracker Algorithm Performance Based on Convolutional Hyperparameters Optimization and Low Pass Filter

Abstract
:1. Introduction
- We propose an optimization strategy for the CNN block through the use of a simple but effective initialization and activation function in the first method.
- A new activation function (ModReLU) based on ReLU function is proposed to optimize the outputs of the CNN and improve the tracking precision in the second method.
- Introducing a low pass filter for noise and details reduction in the second method.
- The first proposed method surpasses the original fully convolutional Siamese networks (SiamFC) tracker performance with an increase of 15.42% in precision, 16.79% in AUPC, 15.93% in IOU.
- The second proposed technique also reveals remarkable advances over the original SiamFC with 18.07% precision increment, 17.01% AUPC improvement and an increase of 15.87% in IOU.
- Furthermore, both proposed techniques surpass other popular algorithms and top performers in relation to precision and speed.
2. Related Work
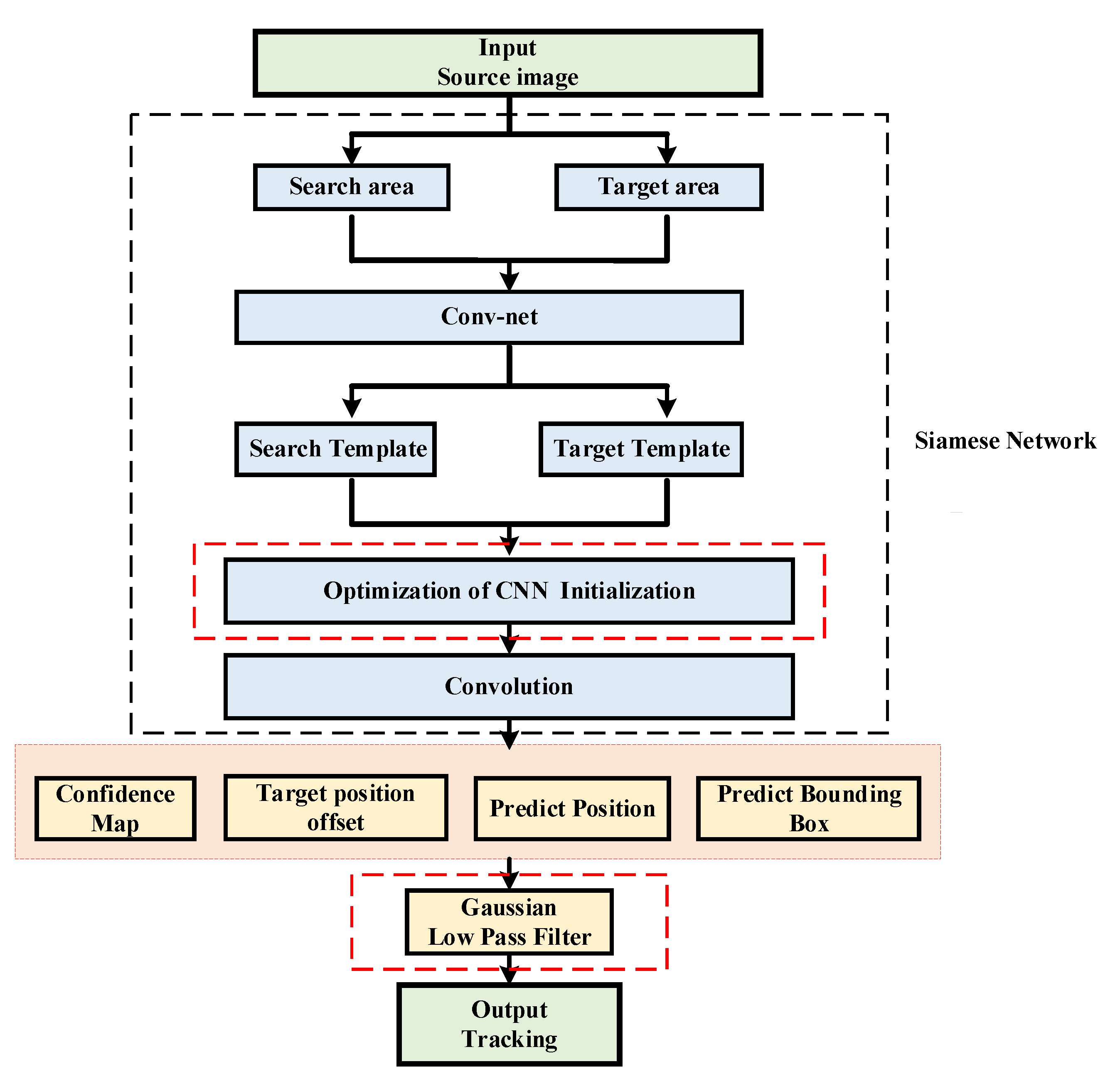
3. Implementation
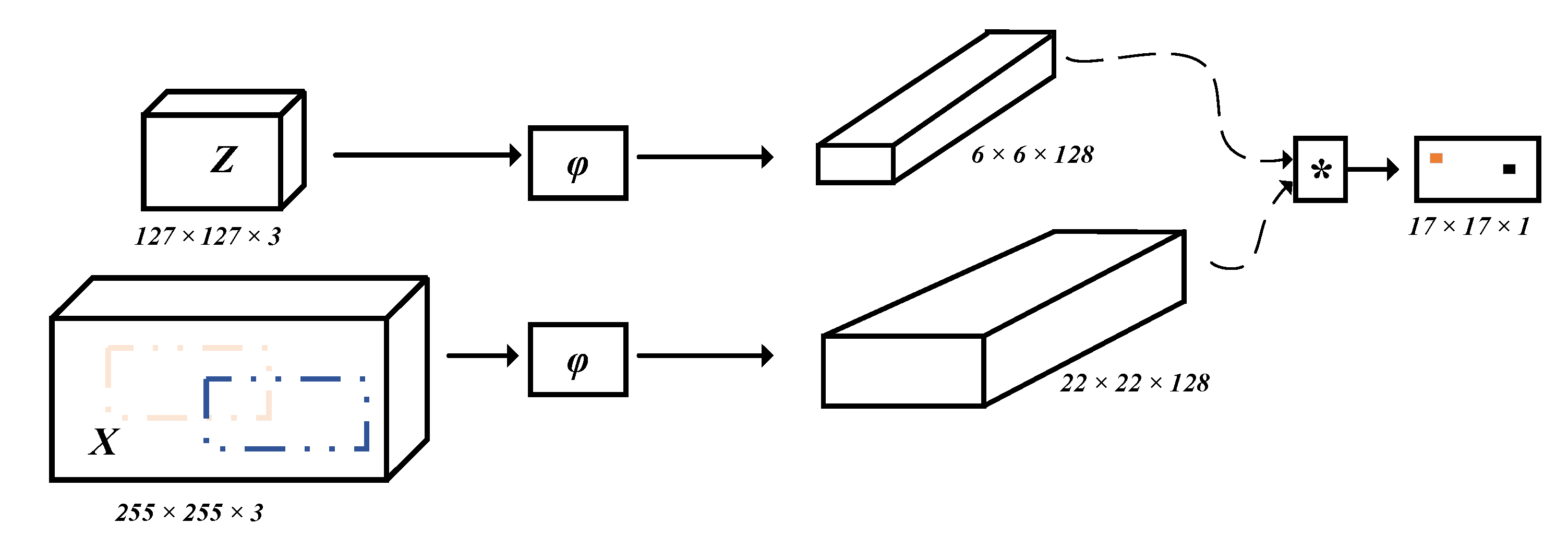
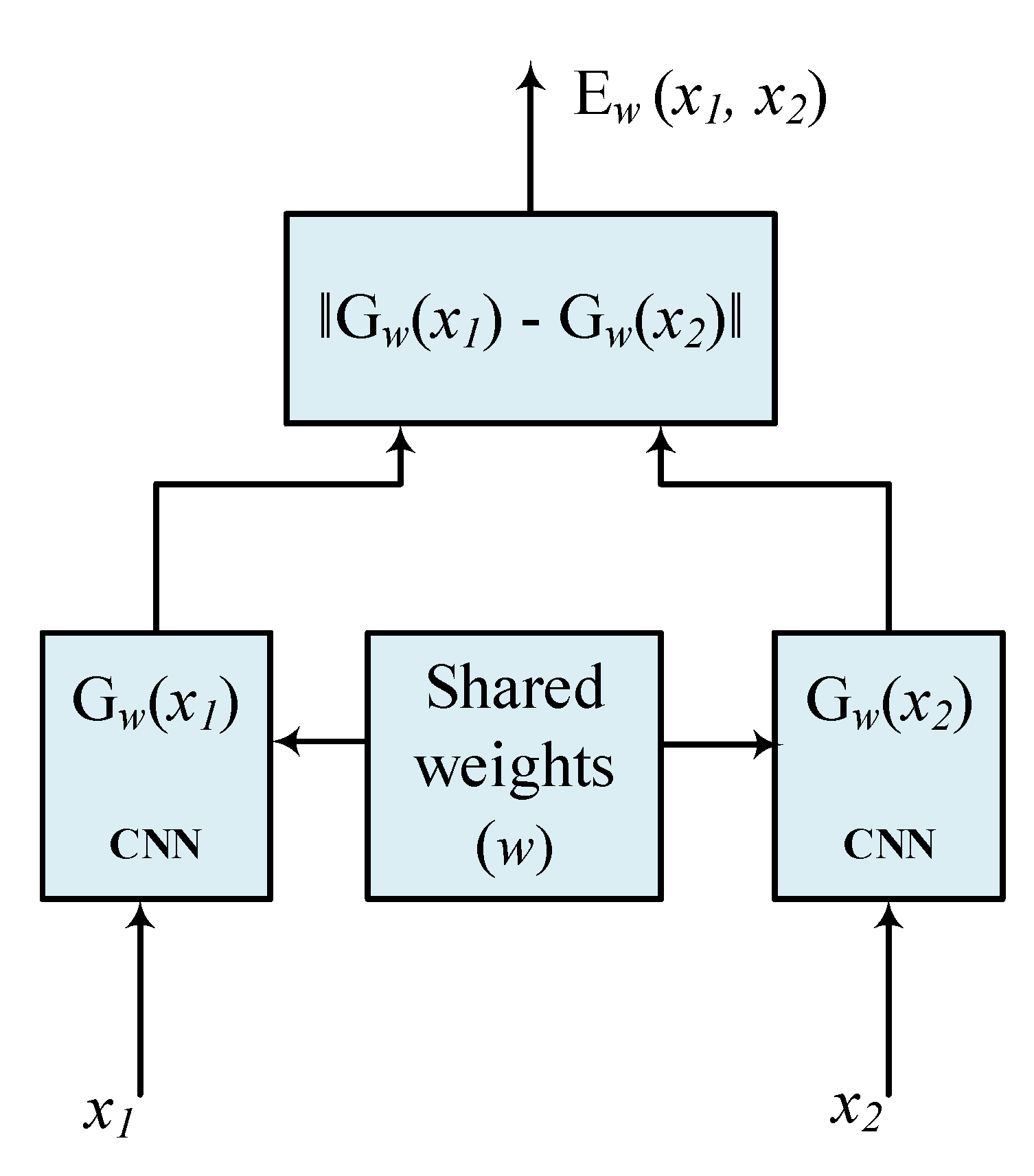
3.1. Siamese Network Model
3.2. Methods
- (1)
- Initialize the target area image. According to the file that contains the correct annotation of each frame image in the video clip, the target area in the first frame image is determined, and the target area image is acquired, so as to replace the process of manually selecting the tracking target.
- (2)
- Capture the image corresponding to the search area. Based on the location of the object in the present image predicted in the previous frame of the algorithm, the search area in the source image is determined according to the designed search area size, and the search area image is intercepted.
- (3)
- Recover the convolutional neural network. The same convolutional neural network Conv-Net used in pretraining is rebuilt, and the trained network parameters are imported from the model file to recover Conv-Net.
- (4)
- Construct a full convolution twin network structure. The acquired image and search area are sent to Conv-Net recovered in step (3), and the target template and search area template obtained after feature extraction are output. The two templates are convoluted to get the similarity response graph.
- (5)
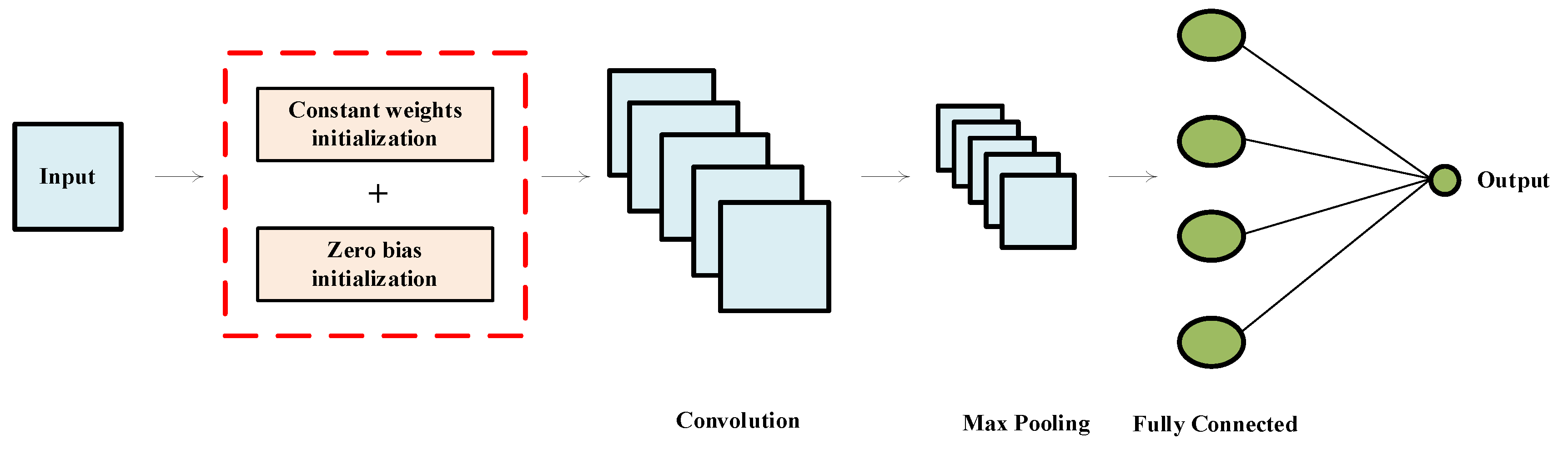
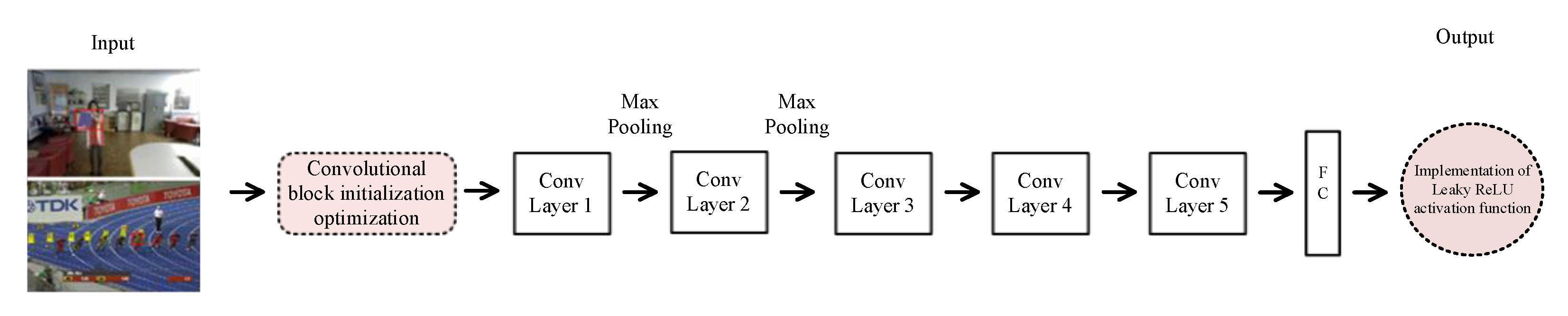
- With regard to the first method, in the convolutional neural network (CNN), we set the weights to constants and the bias to zero to implement a simple but very effective initialization. A Leaky ReLU activation is introduced in the activation layer according to the proposed initialization to accomplish the optimization of the CNN initialization.
- (6)
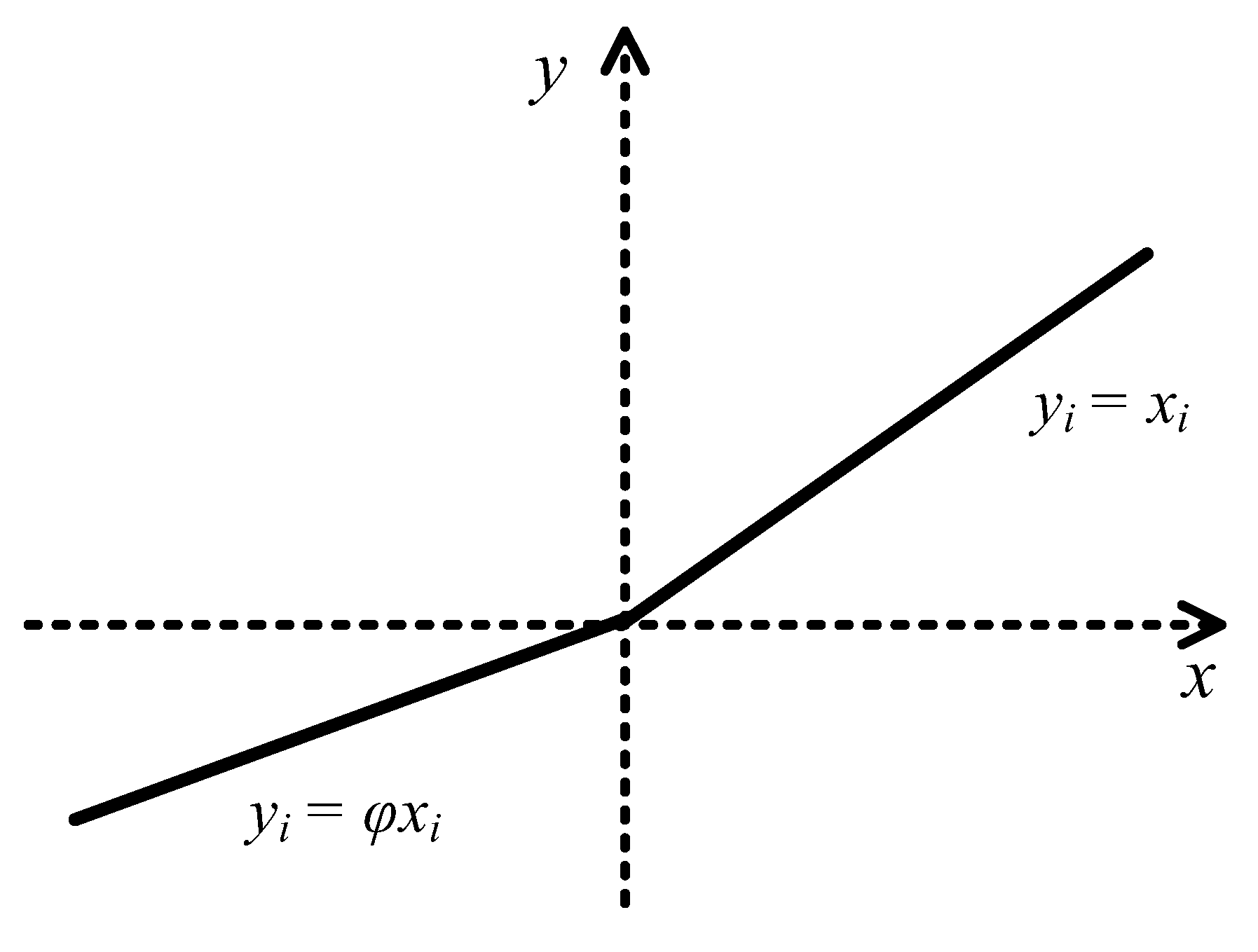
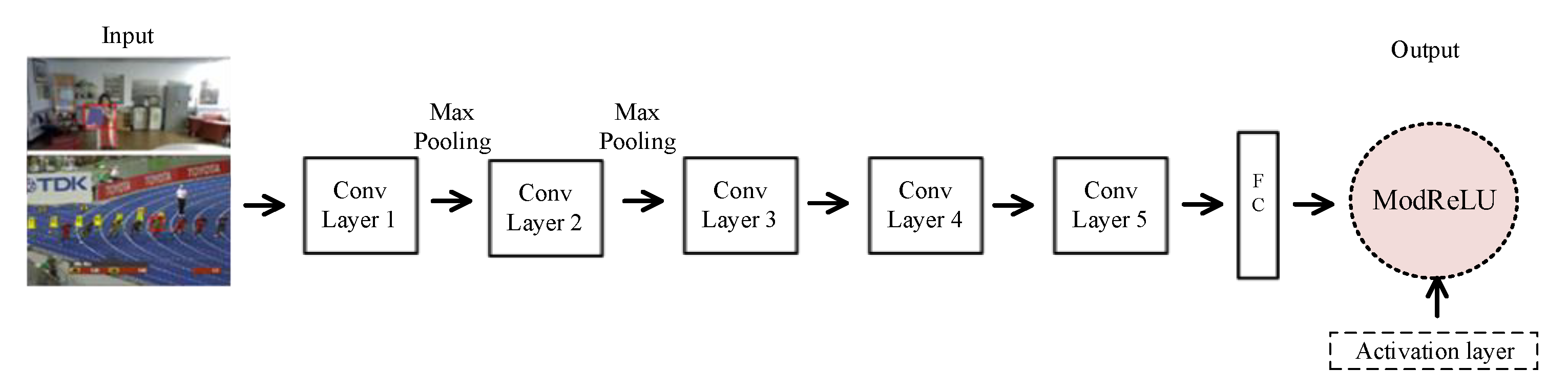
- With respect to the second method, we realize the optimization of the CNN initialization by proposing and introducing a new activation function, ModReLU.
- (7)
- Predict the target position in the next image. Bicubic interpolation is used to adjust the size of the similarity response graph to the size of the search area and find out the maximum response position in the similarity response graph. The image block corresponding to the position is the image block with the largest similarity to the image in the search area. Since the search area is determined by taking the target position in the current frame image predicted by the algorithm in the previous frame as the center, the maximum response position obtained at this time is the offset relative to the position of the target in the present frame image. This offset is used as the update parameter of the target position predicted by the algorithm, so as to update the target position predicted by the algorithm and obtain the target position in the next image predicted by the algorithm. Finally, according to the boundary frame parameters of the first frame, the image area of the target in the next frame predicted by the algorithm in the current frame is obtained. In the process of implementation, since the convolution neural network used for two inputs in the twin network is identical, only one Conv-Net is built for the common use of two input image data.
- (8)
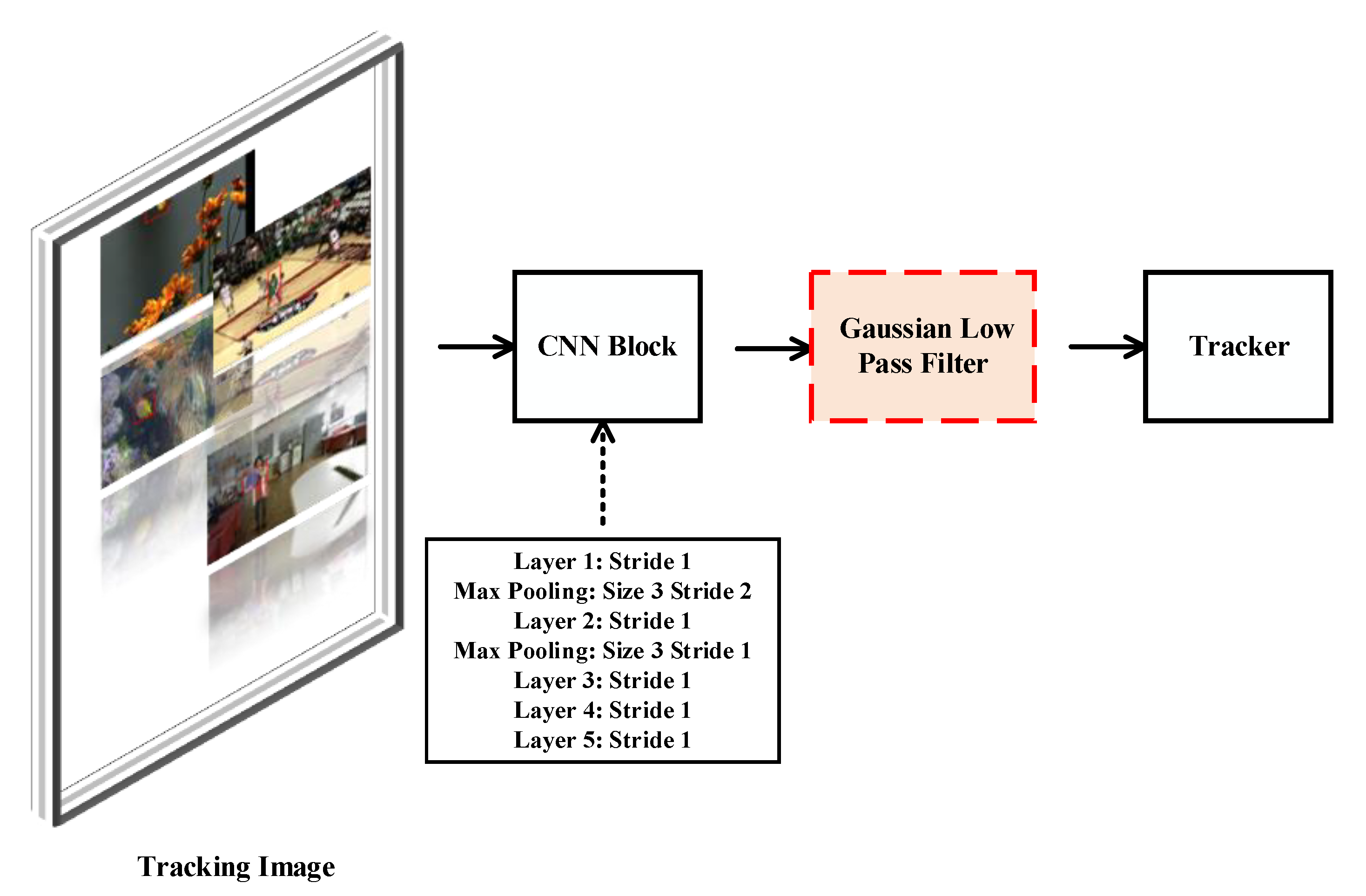
- Introduce Gaussian low pass filter for noise and details reduction.
- (9)
- Tracking process.
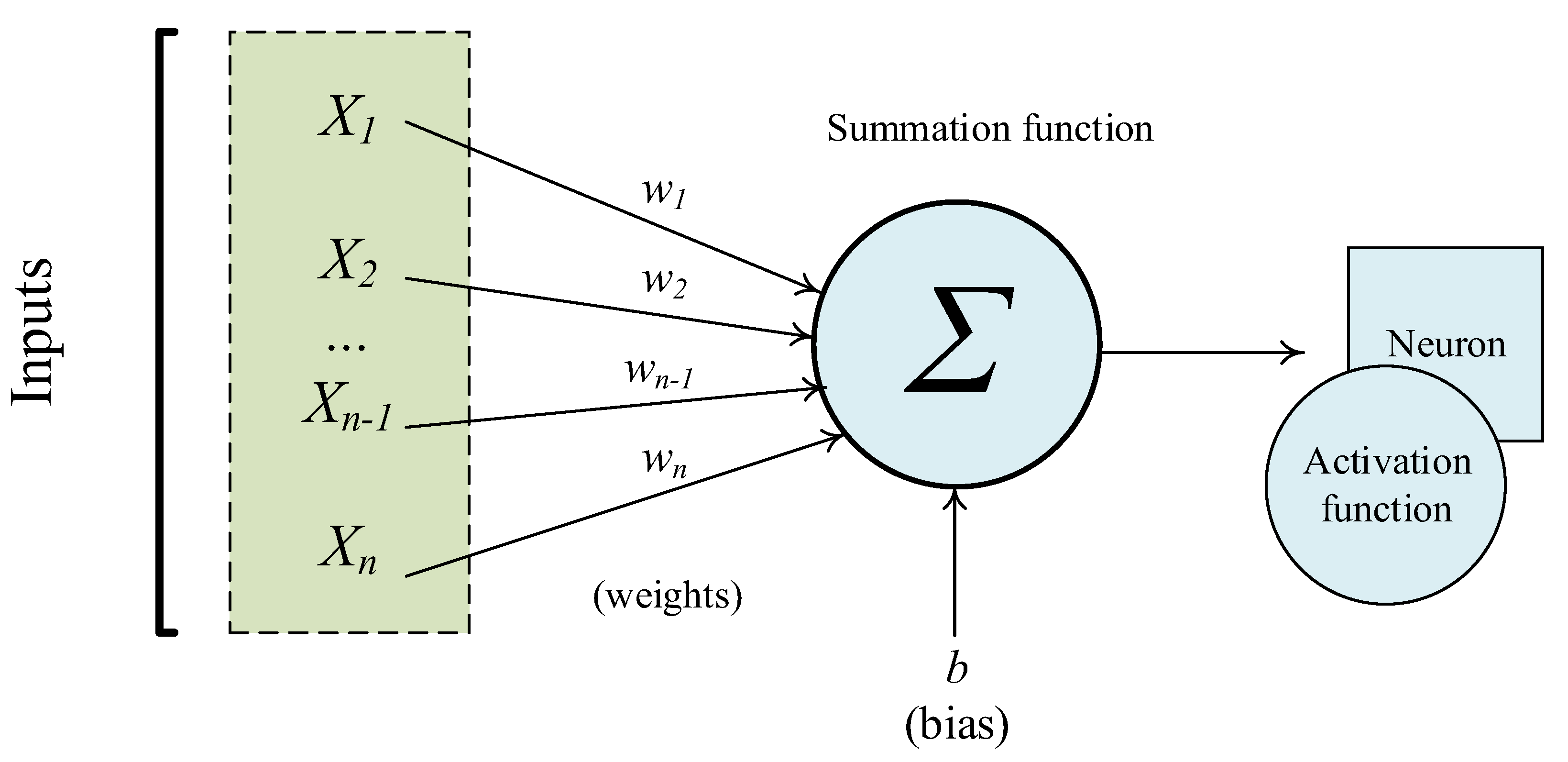
3.2.1. Initialization Optimization and Activation Layer
Initialization Optimization
Activation Layer
3.2.2. New Activation Function and Gaussian Low Pass Filter
New Activation Function
- (1)
- The new activation function can aid in avoiding the problem of dying ReLU because it selectively activates a large number of negative values, which further assist the network in squeezing weights and bias in the proper direction.
- (2)
- The new activation function has some attributes of ReLU. It does not simultaneously activate all of the neurons.
Gaussian Low Pass Filter
4. Experimental Results and Discussion
4.1. Convolutional Block Optimization Results
4.2. ModReLU Activation and Gaussian Low Pass Filter Implementation Results
5. Comparison of Implemented Approaches with Original SiamFC Tracker Performance on VOT 2016 Dataset
6. Comparison with the State-of-the-Art Trackers
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013; pp. 2411–2418. [Google Scholar]
- Marvasti-Zadeh, S.M.; Cheng, L.; Ghanei-Yakhdan, H.; Kasaei, S. Deep learning for visual tracking: A comprehensive survey. IEEE Trans. Intell. Transp. Syst. 2021, 1–26. [Google Scholar] [CrossRef]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 6268–6276. [Google Scholar]
- Wu, F.; Zhang, J.; Xu, Z. Stably adaptive anti-occlusion Siamese region proposal network for realtime object tracking. IEEE Access 2020, 8, 161349–161360. [Google Scholar] [CrossRef]
- Sosnovik, I.; Moskalev, A.; Smeulders, A. Scale equivariance improves Siamese tracking. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2021; pp. 2764–2773. [Google Scholar]
- Abbass, M.Y.; Kwon, K.-C.; Kim, N.; Abdelwahab, S.A.; El-Samie, F.E.A.; Khalaf, A.A.M. A survey on online learning for visual tracking. Vis. Comput. 2021, 37, 1–22. [Google Scholar] [CrossRef]
- Li, D.; Yu, Y. Foreground information guidance for Siamese visual tracking. IEEE Access 2020, 8, 55905–55914. [Google Scholar] [CrossRef]
- Rao, Y.; Cheng, Y.; Xue, J.; Pu, J.; Wang, Q.; Jin, R.; Wang, Q. FPSiamRPN: Feature pyramid Siamese network with region proposal network for target tracking. IEEE Access 2020, 8, 176158–176169. [Google Scholar] [CrossRef]
- Luo, Y.; Cai, Y.; Wang, B.; Wang, J.; Wang, Y. SiamFF: Visual tracking with a Siamese network combining information fusion with rectangular window filtering. IEEE Access 2020, 8, 119899–119910. [Google Scholar] [CrossRef]
- Zhao, F.; Zhang, T.; Wu, Y.; Tang, M.; Wang, J. Antidecay LSTM for Siamese tracking with adversarial learning. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4475–4489. [Google Scholar] [CrossRef]
- Zhao, F.; Zhang, T.; Song, Y.; Tang, M.; Wang, X.; Wang, J. Siamese regression tracking with reinforced template updating. IEEE Trans. Image Process. 2021, 30, 628–640. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [Green Version]
- Lu, L.; Fei, M.; Wang, H.; Hu, H. A new meanshift target tracking algorithm by combining feature points from gray and depth images. In Advanced Computational Methods in Life System Modeling and Simulation; Fei, M., Ma, S., Li, X., Sun, X., Jia, L., Su, Z., Eds.; Springer: Singapore, 2017; pp. 545–555. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.T.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Brookner, E. Tracking and Kalman Filtering Made Easy; Wiley-Blackwell: New York, NY, USA, 1998. [Google Scholar]
- Bruno, A.; Ardizzone, E.; Vitabile, S.; Midiri, M. A Novel Solution Based on Scale Invariant Feature Transform Descriptors and Deep Learning for the Detection of Suspicious Regions in Mammogram Images. J. Med. Signals Sens. 2020, 10, 158–173. [Google Scholar]
- Zhao, Y.; Yu, L.; Zheng, X. A Deep Hyper Siamese Network for Real-Time Object Tracking. Trans. Mach. Learn. Artif. Intell. 2020, 8, 35–46. [Google Scholar] [CrossRef]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-Learning-Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; LeCun, Y.; Moore, C.; Säckinger, E.; Shah, R. Signature verification using a “Siamese” time delay neural network. In Proceedings of the 6th International Conference on Neural Information Processing Systems, Denver, CO, USA, 29 November–2 December 1993; pp. 737–744. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Wang, Y.; Li, Y.; Song, Y.; Rong, X. The Influence of the Activation Function in a Convolution Neural Network Model of Facial Expression Recognition. Appl. Sci. 2020, 10, 1897. [Google Scholar] [CrossRef] [Green Version]
- Maguolo, G.; Nanni, L.; Ghidoni, S. Ensemble of Convolutional Neural Networks Trained with Different Activation Functions. Expert Syst. Appl. 2019, 166, 114048. [Google Scholar] [CrossRef]
- Dubey, A.K.; Jain, V. Comparative study of convolution neural network’s ReLu and Leaky-ReLu activation functions. In Applications of Computing, Automation and Wireless Systems in Electrical Engineering; Springer: Singapore, 2019; pp. 873–880. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-convolutional Siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 15–17 June 2010; pp. 2544–2550. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Ma, C.; Huang, J.-B.; Yang, X.; Yang, M.-H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Danelljan, M.; Hager, G.; Khan, F.S.; Felsberg, M. Convolutional features for correlation filter based visual tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 58–66. [Google Scholar]
- Wang, N.; Li, S.; Gupta, A.; Yeung, D.-Y. Transferring rich feature hierarchies for robust visual tracking. arXiv 2015, arXiv:1501.04587. [Google Scholar]
- Kashiani, H.; Shokouhi, S.B. Visual object tracking based on adaptive Siamese and motion estimation network. Image Vis. Comput. 2019, 83–84, 17–28. [Google Scholar] [CrossRef] [Green Version]
- Zhai, M.; Roshtkhari, M.J.; Mori, G. Deep learning of appearance models for online object tracking. In Proceedings of the European Conference on Computer Vision Workshops (ECCVW), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 472–488. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 749–765. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. End-to-end representation learning for correlation filter-based tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2805–2813. [Google Scholar]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning dynamic siamese network for visual object tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1763–1771. [Google Scholar]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A twofold siamese network for real-time object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4834–4843. [Google Scholar]
- Yu, Y.; Xiong, Y.; Huang, W.; Scott, M.R. Deformable Siamese attention networks for visual object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, Online, USA, 13–19 June 2020; pp. 6727–6736. [Google Scholar]
- Yan, Y.; Huo, W.; Ou, J.; Liu, Z.; Li, T. Improved SiamFC Target Tracking Algorithm Based on Anti-Interference Module. J. Sens. 2022, 2022, 2804114. [Google Scholar] [CrossRef]
- Cui, Z.; An, J.; Ye, Q.; Cui, T. Siamese Cascaded Region Proposal Networks with Channel-Interconnection-Spatial Attention for Visual Tracking. IEEE Access 2020, 8, 154800–154815. [Google Scholar] [CrossRef]
- Madrigal, F.; Maurice, C.; Lerasle, F. Hyper-parameter optimization tools comparison for multiple object tracking applications. Mach. Vis. Appl. 2019, 30, 269–289. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. J. Mach. Learn. Res. 2010, 9, 249–256. [Google Scholar]
- Ding, B.; Qian, H.; Zhou, J. Activation functions and their characteristics in deep neural networks. In Proceedings of the Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 1836–1841. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Misra, S.; Wu, Y. Machine learning assisted segmentation of scanning electron microscopy images of organic-rich shales with feature extraction and feature ranking. In Machine Learning for Subsurface Characterization; Elsevier: Cambridge, MA, USA, 2020; pp. 289–314. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Čehovin Zajc, L.; Vojir, T.; Hager, G.; Lukezic, A.; Eldesokey, A.; et al. The visual object tracking VOT 2016 challenge results. In Proceedings of the European Conference on Computer Vision Workshops (ECCVW), Amsterdam, The Netherlands, 8–16 October 2016; pp. 191–217. [Google Scholar]
- Zhou, L.; Zhang, J. Combined kalman filter and multifeature fusion siamese network for real-time visual tracking. Sensors 2019, 19, 2201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Size of Activation | ||||||
|---|---|---|---|---|---|---|
| Layer | Support | Channel Map | Stride | Exemplar | Search | Channels |
| 127 × 127 | 255 × 255 | ×3 | ||||
| Conv1 | 11 × 11 | 96 × 3 | 2 | 59 × 59 | 123 × 123 | ×96 |
| Max Pool1 | 3 × 3 | 2 | 29 × 29 | 61 × 61 | ×96 | |
| Conv2 | 5 × 5 | 256 × 48 | 1 | 25 × 25 | 57 × 57 | ×256 |
| Max Pool2 | 3 × 3 | 2 | 12 × 12 | 28 × 28 | ×256 | |
| Conv3 | 3 × 3 | 384 × 256 | 1 | 10 × 10 | 26 × 26 | ×192 |
| Conv4 | 3 × 3 | 384 × 192 | 1 | 8 × 8 | 24 × 24 | ×192 |
| Conv5 | 3 × 3 | 256 × 192 | 1 | 6 × 6 | 22 × 22 | ×192 |
| Algorithm | Precision (%) | AUPC (%) | IOU (%) | Speed (FPS) |
|---|---|---|---|---|
| Optimized bias initialization-based SiamFC | 53.39 | 18.85 | 35.43 | 46.46 |
| Convolutional block optimization-based SiamFC | 59.34 | 21.14 | 39.29 | 45.23 |
| Algorithm | Precision (%) | AUPC (%) | IOU (%) | Speed (FPS) |
|---|---|---|---|---|
| ModReLU–Gaussian low pass filter-based SiamFC | 60.69 | 21.18 | 39.27 | 44.20 |
| Algorithm | Precision (%) | AUPC (%) | IOU (%) | Speed (FPS) |
|---|---|---|---|---|
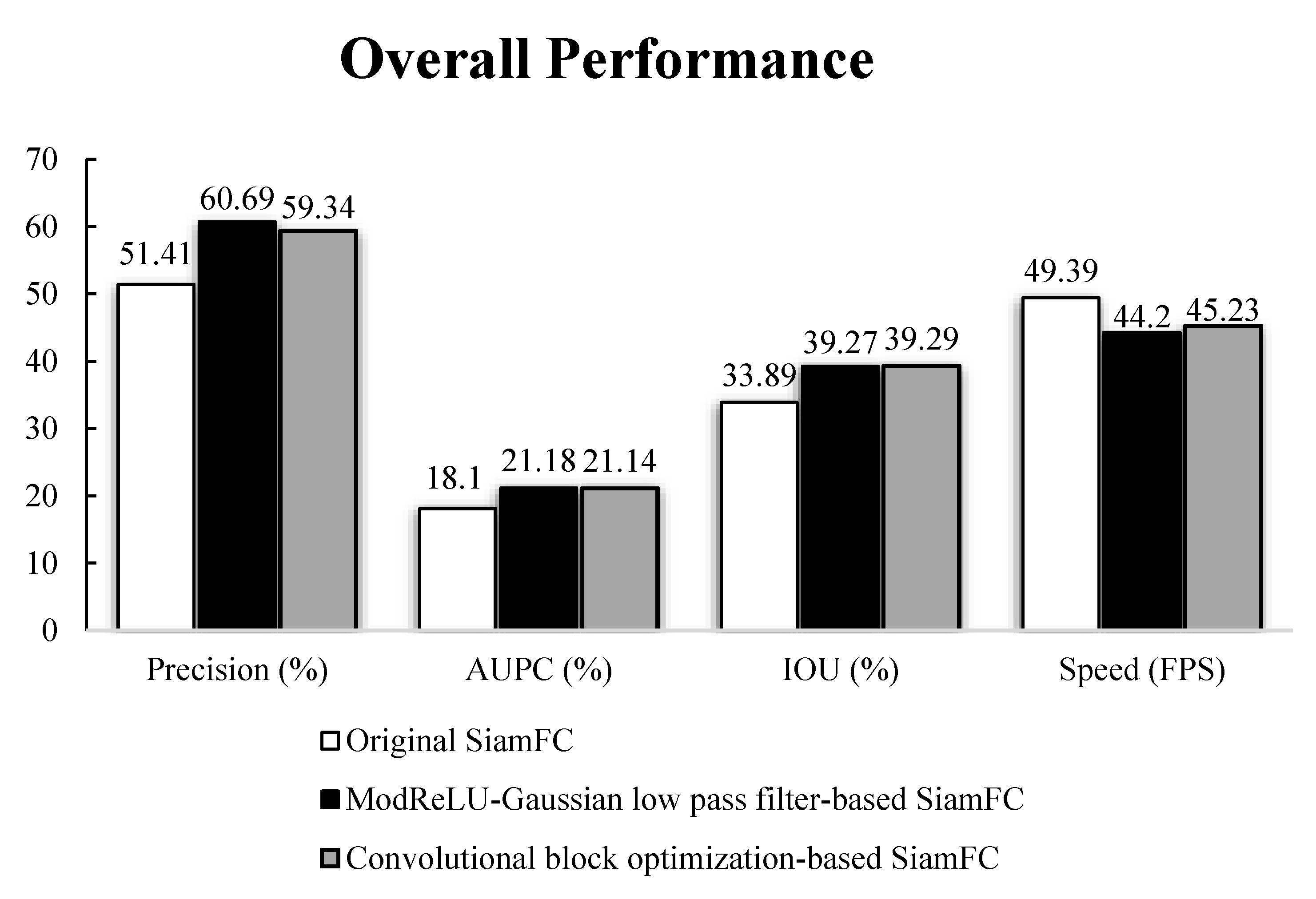
| Original SiamFC | 51.41 | 18.10 | 33.89 | 49.39 |
| Convolutional block optimization-based SiamFC | 59.34 | 21.14 | 39.29 | 45.23 |
| Algorithm | Precision (%) | AUPC (%) | IOU (%) | Speed (FPS) |
|---|---|---|---|---|
| Original SiamFC | 51.41 | 18.10 | 33.89 | 49.39 |
| ModReLU–Gaussian low pass filter-based SiamFC | 60.69 | 21.18 | 39.27 | 44.20 |
| Algorithm | Precision (%) | AUPC (%) | IOU (%) | Speed (FPS) |
|---|---|---|---|---|
| Original SiamFC | 51.41 | 18.10 | 33.89 | 49.39 |
| Convolutional block optimization-based SiamFC | 59.34 | 21.14 | 39.29 | 45.23 |
| ModReLU–Gaussian low pass filter-based SiamFC | 60.69 | 21.18 | 39.27 | 44.20 |
| Tracker | Precision | Speed (FPS) |
|---|---|---|
| STAPLEp | 0.557 | 44.8 |
| CCOT | 0.539 | 0.5 |
| TCNN | 0.554 | 1.1 |
| SSKCF | 0.54 | >25 |
| DPT | 0.49 | >25 |
| Staple | 0.544 | 11 |
| DNT | 0.515 | 1.1 |
| DeepSRDCF | 0.528 | 0.38 |
| MDNet_N | 0.541 | 0.989 |
| KCF | 0.48 | 172 |
| SiamRPN | 0.560 | 23.0 |
| SSAT | 0.577 | 0.5 |
| MLDF | 0.490 | 1.2 |
| SRBT | 0.496 | 3.7 |
| FlowTrack | 0.58 | - |
| ECO | 0.55 | - |
| Convolutional block optimization-based SiamFC (ours) | 0.593 | 45.23 |
| ModReLU–Gaussian low pass filter-based SiamFC (ours) | 0.606 | 44.20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kanza, R.; Zhao, Y.; Huang, Z.; Huang, C.; Li, Z. Enhancement: SiamFC Tracker Algorithm Performance Based on Convolutional Hyperparameters Optimization and Low Pass Filter. Mathematics 2022, 10, 1527. https://0-doi-org.brum.beds.ac.uk/10.3390/math10091527
Kanza R, Zhao Y, Huang Z, Huang C, Li Z. Enhancement: SiamFC Tracker Algorithm Performance Based on Convolutional Hyperparameters Optimization and Low Pass Filter. Mathematics. 2022; 10(9):1527. https://0-doi-org.brum.beds.ac.uk/10.3390/math10091527
Chicago/Turabian StyleKanza, Rogeany, Yu Zhao, Zhilin Huang, Chenyu Huang, and Zhuoming Li. 2022. "Enhancement: SiamFC Tracker Algorithm Performance Based on Convolutional Hyperparameters Optimization and Low Pass Filter" Mathematics 10, no. 9: 1527. https://0-doi-org.brum.beds.ac.uk/10.3390/math10091527