
Online Support Vector Machine with a Single Pass for Streaming Data

1
Institute of Information Technology, Hebei University of Economics and Business, Shijiazhuang 050061, China
2
School of Computer Science and Technology, Qilu University of Technology (Shandong Academy of Sciences), Jinan 250353, China
3
Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China
*
Author to whom correspondence should be addressed.
Mathematics 2022, 10(17), 3113; https://0-doi-org.brum.beds.ac.uk/10.3390/math10173113
Submission received: 19 July 2022
/
Revised: 18 August 2022
/
Accepted: 25 August 2022
/
Published: 30 August 2022
(This article belongs to the Special Issue Artificial Intelligence and Machine Learning Based Methods and Applications)
Abstract
:In this paper, we focus on training a support vector machine (SVM) online with a single pass over streaming data.Traditional batch-mode SVMs require previously prepared training data; these models may be unsuitable for streaming data circumstances. Online SVMs are effective tools for solving this problem by receiving data streams consistently and updating model weights accordingly. However, most online SVMs require multiple data passes before the updated weights converge to stable solutions, and may be unable to address high-rate data streams. This paper presents OSVM_SP, a new online SVM with a single pass over streaming data, and three budgeted versions to bound the space requirement with support vector removal principles. The experimental results obtained with five public datasets show that OSVM_SP outperforms most state-of-the-art single-pass online algorithms in terms of accuracy and is comparable to batch-mode SVMs. Furthermore, the proposed budgeted algorithms achieve comparable predictive performance with only 1/3 of the space requirement.
1. Introduction
Support vector machine (SVMs) is a well-known binary classifier trained offline with supervised datasets [1]. The central idea is to find a hyperplane in the reproducing kernel Hilbert space (RKHS) that splits the data into different classes as well as possible and achieves a maximal margin. Based on the substantial foundations of the Vapnik–Chervonenkis (VC) dimension and the structural risk minimization (SRM) principle [2], SVM has shown its superiority in the literature [3,4,5,6].
For traditional batch-mode methods, the data for model training need to be prepared beforehand. This is mainly because once the training process starts, the optimization problem usually requires the cycling of training data many times in order to find the optimal solutions in the data space. In other words, traditional batch-mode models require the data to be prepared beforehand and to be accessible at any time. Traditional batch-mode models usually fail to deal with streaming data that arrive sequentially over time and usually never end. For scenarios in which data arrive in streams individually at a very high rate, every time new data arrive, a batch-mode SVM has to be retrained from scratch to exploit both the previous and new data. Because a batch-mode SVM is typically formulated as a quadratic programming problem with time complexity (where N represents the number of training data points), it is not suitable for streaming data due to the required time efficiency and computational capability [7,8]. Therefore, the training set increases consistently and changes dynamically, and is nearly unusable for learning with batch-mode methods. Fortunately, online SVM is an alternative type of algorithm that directly addresses the streaming data issue.
Thanks to the consistent interest of the online learning community, numerous online SVM algorithms have been proposed in the literature [9,10,11]. Online SVM algorithms do not initially hold all the data; instead, they receive streams of data one at a time and update the model weights with respect to specified instantaneous objective functions. Most online models adapt the streaming data scenario, in which samples arrive one by one. When one sample arrives as a representative of a new concept, the model can update itself to immediately account for this sample. One benefit of processing singular instead of multiple data is that the model can learn in a timely fashion without the need to wait until a fixed number of samples have been gathered. In addition, if the model is ideally updated in the right direction, a alrge number of samples arriving afterward can be avoided in the online learning process. Many online SVM algorithms [12,13,14] require multiple passes over the data before the updated weights converge to reasonable solutions. For instance, the algorithm in [12] continues passing through the training data to look for better solutions until a certain stopping criterion is met. In [13], a series of SVM models were trained periodically based on the training set extracted from historical streaming data; all of them needed many passes over the training data to find the appropriate solutions for each model. New data arriving during this period must wait until they can be processed. Therefore, the necessity of multiple passes over the training data hinders these algorithms from being timely and lightweight for fairly high data streaming rates. Recently, a handful of online SVM algorithms have been proposed that require only a single pass over the data [15,16,17,18]. Motivated by the work of [16], in this paper, we present a new single-pass online SVM based on the minimum enclosing ball (MEB) problem and three budgeted versions of the proposed algorithm to control the space requirement. We validated our methods on six public datasets, and our experimental results show the effectiveness and superiority of our methods compared to the present state-of-the-art.
The remainder of this paper is organized as follows: In Section 2, we review related works on online SVM algorithms; in Section 3, we provide a brief introduction to the formulation of batch-mode SVMs and MEBs, as well as their equivalence, which is closely related to our methods; in Section 4, we elaborate our proposed methods; in Section 5, we present experimental evaluations and analyses; finally, our conclusions are presented in Section 7.
2. Related Work
There are many online SVM algorithms that can handle streaming training data and achieve good results. Matsushima et al. [12] provided an algorithm for training linear SVMs that utilizes a dual coordinate descent procedure based on blocks of data. Their algorithm performs multiple passes through the training data until a certain stopping criterion is met. Wang et al. [13] presented an online algorithm that automatically extracts one representative set for each class from the historical stream of data and retrains the SVM periodically based on the data from these sets. Zheng et al. [14] provided an online incremental algorithm that learns prototypes and continuously adjusts to the streaming data, and that trains new SVMs periodically based on learned prototypes and old support vectors (SVs). These algorithms suffer from a similar issue in that a series of quadratic optimization problems must be solved in order to obtain intermediate solutions, which requires multiple passes of the chosen training data.
The optimization problem for SVM has several equivalent geometric formulations [19]. Moreover, many of these can be easily adapted to streaming learning scenarios. Several single-pass SVM algorithms have been studied in the literature. Liu et al. [15] presented a single-pass online algorithm based on the polytope distance problem in the computational geometry literature. The central idea of their algorithm is based on an interpretation in which finding the hyperplane with the maximum separating margin is equivalent to finding the shortest distance between two points on the convex hull of two classes of training data, and the latter is equivalent to finding the shortest distance between the origin and a point on the convex hull of the Minkowski difference [20] of two convex hulls. They provided theoretical guarantees regarding the constant time and space requirements of their algorithm. However, their algorithm was proposed for hard margin classification problems, and the data of the two classes ought to be completely separated; this requirement may not always be satisfied. Rai et al. [16] provided another single-pass online algorithm based on a geometric interpretation in which a ℓ2-SVM has an equivalent formulation in terms of the MEB problem. Therefore, solving the optimization problem for the ℓ2-SVM is equivalent to finding the ball of the minimum radius enclosing the feature vectors mapped by the training data. Their algorithm initializes a ball with radius zero for the first sample. For any incoming point outside of the ball, the algorithm moves the center towards it and simultaneously enlarges the radius in order to cover both the point and the previous ball. However, their algorithm may suffer due to the rapid expansion of the ball leading ti convergence on a suboptimal solution. Motivated by the above, we present a new single-pass online algorithm.
In addition to algorithms based on geometric formulations, Crammer et al. [17] provided an online algorithmic framework that formalizes the trade-off between the correct classification of new data with a sufficiently high margin and the amount of information retained from old data. In light of hard margins and soft margins with ℓ1 and ℓ2 losses, the authors provide three variants of online algorithms in such frameworks. Our work is compared with all three works in the experimental section, and empirically, our algorithm performs better in most cases.
3. Preliminaries
In this section, we introduce the primal and dual formulations of the batch-mode SVM and MEB, as well as their equivalence, all of which are closely related to our methods.
3.1. Support Vector Machine
Let be a training set with N labeled samples. The primal optimization problem for unbiased ℓ2-regularized ℓ2-loss SVMs for binary classification is provided in Equation (1):
Here, is a vector consisting of slack variables, C is a penalty parameter used to control the trade-off between ℓ2 regularization and ℓ2 loss, denotes the kernel mapping function, which maps into a higher-dimensional feature vector in RKHS, and corresponds to a chosen kernel function , with .
Note the variable in the optimization problem, which means that the boundaries of the margin are . The problem in Equation (1) is denoted as the “primal -SVM” in order to differentiate it from the corresponding batch-mode “SVM” with respect to StreamSVM in [16], which does not contain the variable and has the constant 1 instead. When parameter C is set to , -SVM shares a formulation with the unbiased ℓ2-regularized ℓ2-loss -SVM [21], with parameter being equal to 1. Because can be seen as the lower bound of the ratio of SVs, almost every sample in the training set is recognized as an SV for -SVM.
According to the Karush–Kuhn–Tucker (KKT) theorem [22], solving the primal -SVM is equivalent to solving the dual problem listed in Equation (2), which is denoted as the “dual -SVM”.
Here, is a vector consisting of Lagrange multipliers. The transformation of solutions of the dual -SVM to solutions , , and of the primal -SVM is provided in the following equation:
For a random sample , -SVM predicts its label as follows:
Derivations of Equations (3) and (4) have been listed in Appendix A for reference.
3.2. Minimum Enclosing Ball
An MEB is known as a hard margin support vector data description (SVDD) [23,24], the central idea of which is to find a minimum ball enclosing all the data. Let be a training set with N samples. The primal optimization problem of the MEB is denoted as the “primal MEB”, as follows [25]:
Here, we utilize to denote the kernel mapping function employed in the primal MEB. Likewise, denotes the kernel function corresponding to . A hypersphere is represented by , where the center is a high-dimensional feature vector in RKHS and denotes the radius.
According to the KKT theorem, the corresponding dual optimization problem is denoted as the “dual MEB”, as follows [25]:
The transformation of solutions of the dual MEB to solutions and r of the primal MEB is as follows [25]:
For a random sample , the MEB predicts whether it is inside or outside the ball according to the following inequality:
3.3. Equivalence of the SVM and MEB
The supervised -SVM classification problem can be equivalently reformulated as an unsupervised MEB problem by encoding the label of sample in feature vector . Specifically, the optimization problems of the dual -SVM in Equation (2) and the dual MEB in Equation (6) are equivalent to each other if the following two conditions are satisfied [16,25]:
Here, denotes the N-dimensional one-hot column vector in which the ith element is 1 and all other elements are 0, while denotes a constant related to the kernel mapping function .
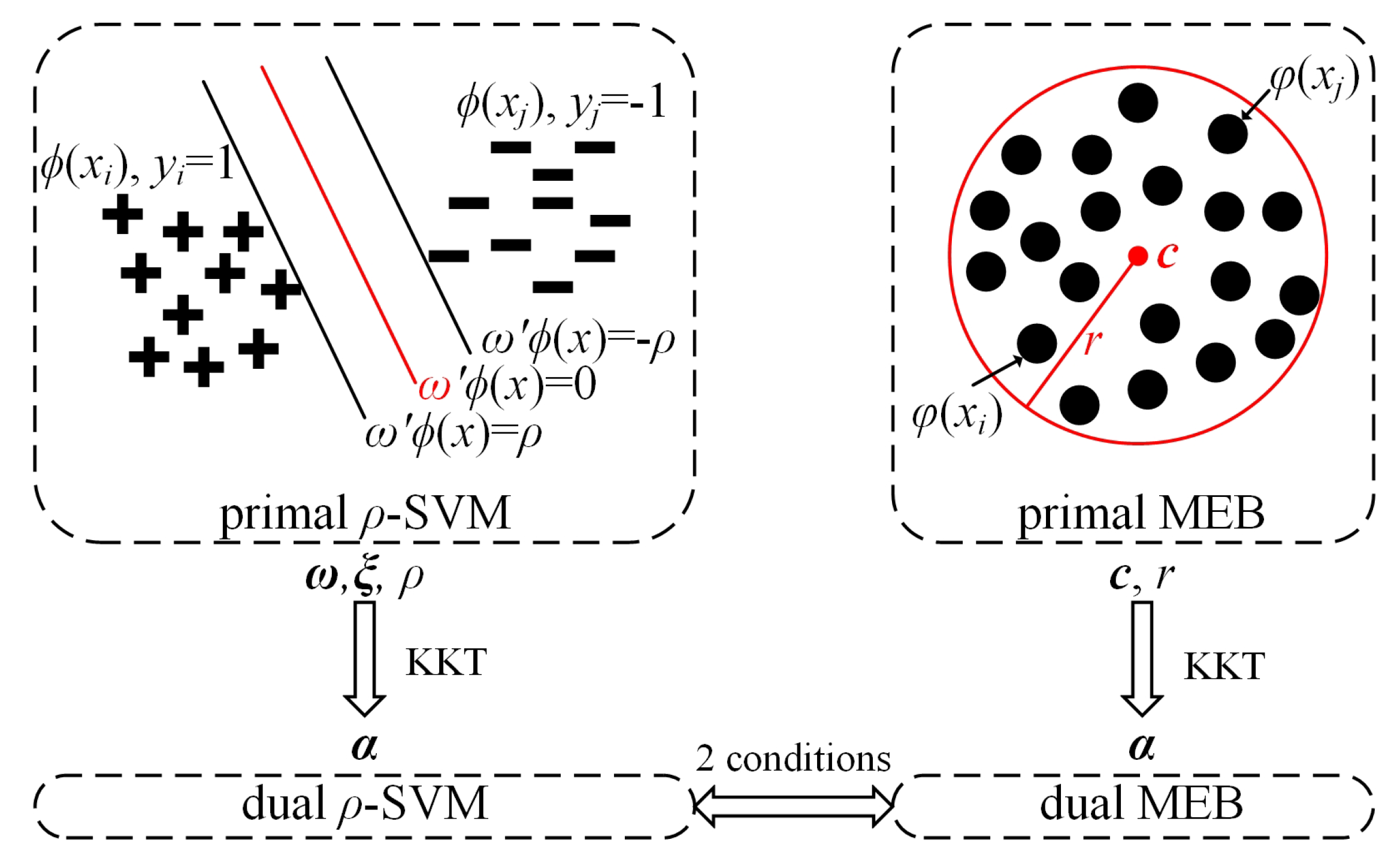
When the kernel utilized by the MEB is , the center and radius r of the MEB can be represented by and the mapping function according to Equation (7) in Section 3.2. Moreover, when these two conditions are satisfied, and can be substituted by another kernel and mapping function . Therefore, the center and radius r can be represented by and after substitution, as listed in Equation (9). In other words, for any , the center and radius r of the primal MEB can be represented by the solutions of -SVM. The equivalence of -SVM and the MEB are shown in Figure 1.
4. Methodology
4.1. Motivation
According to Section 3, when the two conditions (see Section 3.3) are satisfied, a batch-mode classifier learned offline by the supervised convex optimization of the SVM can be attained by solving an unsupervised convex optimization of the MEB. In other words, a classifier can be equivalently transformed by a minimum enclosing ball. In view of such equivalence, a series of online SVM/MEB methods have been proposed in the literature to deal with the data in streams.
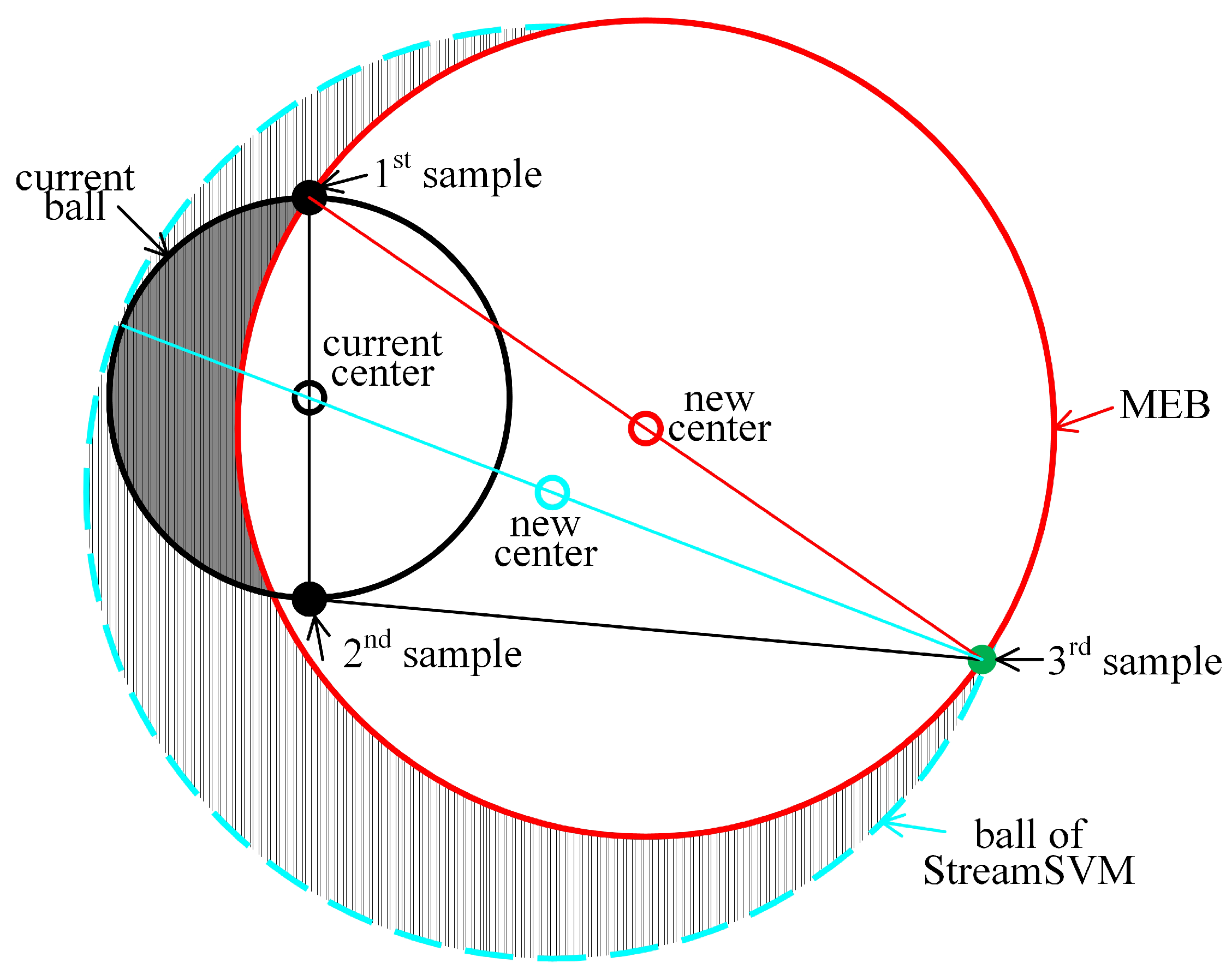
Taking the StreamSVM method in [16] as an example, a ball is constructed dynamically by enclosing all the streaming data. When a new sample arrives, StreamSVM learns a minimal ball enclosing both the sample and the current ball. Figure 2 illustrates the ball learned by StreamSVM when the third sample arrives outside. Although the enclosure of the whole current ball (the ball in black) instead of the old data (the first and second samples) prevents multiple passes of the data, it may lead to excessive enlargement of the ball (see the two colored balls for comparison). Because the ball of online methods often grows in an irreversible way, it ought to be enlarged cautiously in order to avoid enclosing any dispensable regions (e.g., the area with vertical lines as the background) as much as possible.
Therefore, we attempt to learn a new ball online under the constraint of a minimal radius with a single pass over the streaming data. To achieve this, we choose to relax the constraint of enclosing all data instead of the constraint of the minimal radius utilized by StreamSVM to avoid multiple passes. A new ball is required to enclose both the new sample and majority regions of the current ball, while the minority regions (e.g., the gray area in Figure 2) of the current ball are discarded, which are the regions most dissimilar to the new sample. On this basis, a new online method is proposed in the following section.
4.2. OSVM_SP
In Section 3.3, we introduce the equivalence between the MEB and -SVM and show that the solutions of the MEB can be equivalently represented by the solutions of the -SVM according to Equation (9). In other words, if we can find a way to learn the MEB online, we can obtain its corresponding online classifier. The online learning of a decision hyperplane is equivalently transformed into the online learning of an MEB.
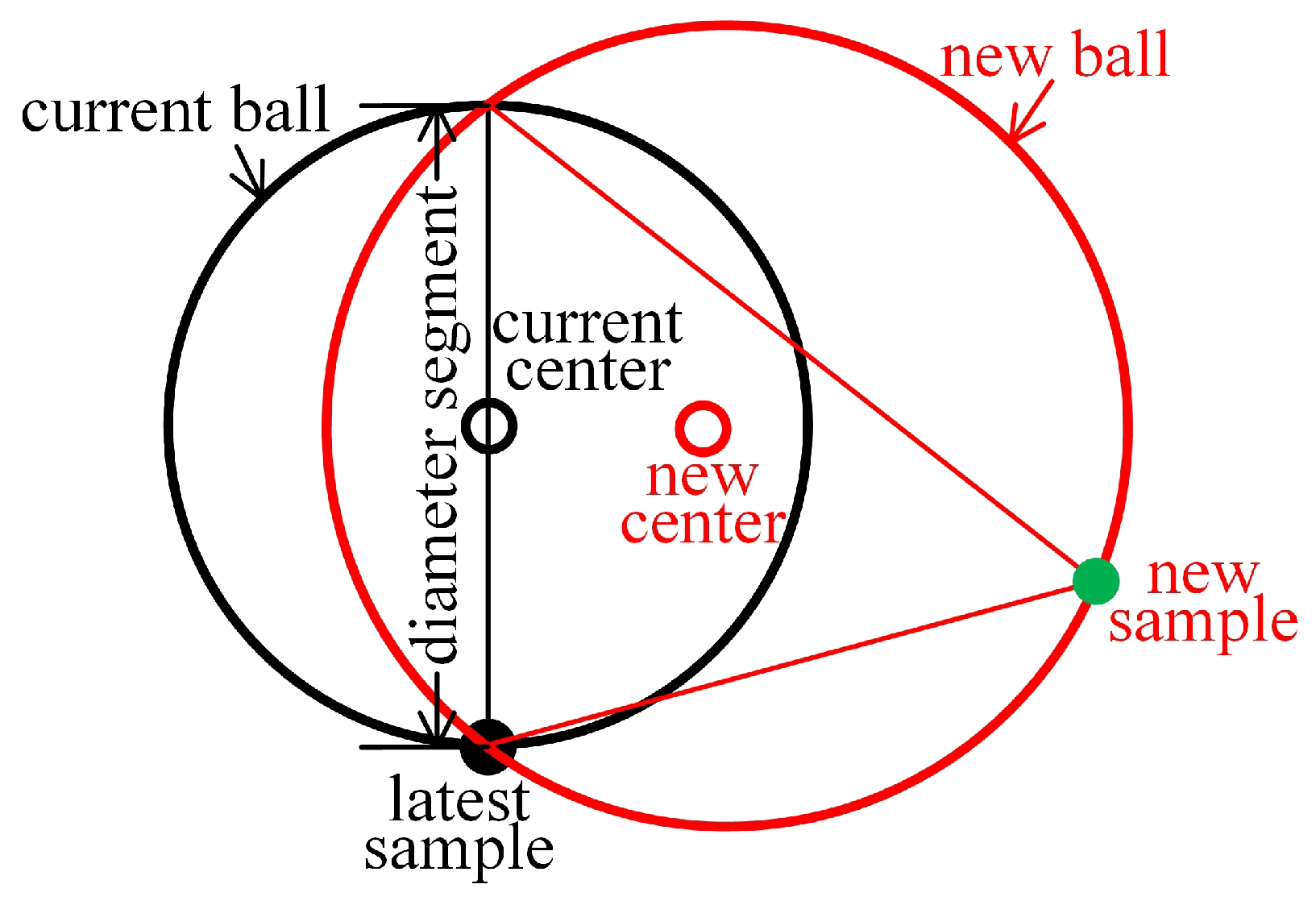
In this section, we present OSVM_SP, a new online SVM algorithm with a single pass over the streaming data. The basic idea of OSVM_SP is as follows: a ball is initialized by taking the first sample to arrive as the center and 0 as the radius; when a new sample arrives that is outside of the current ball, a new ball is learned to enclose both the sample and the majority of the region of the current ball with a radius increment that is as small as possible. To accomplish this, we record the latest sample that leads to the current ball being enlarged. Then, a diameter segment (see Figure 3) that crosses the recorded sample and the center of the current ball can be determined to represent the boundary of the majority of the region that must be enclosed in the new ball. Therefore, the new ball is created to enclose both the new sample and the diameter segment with a minimum radius.
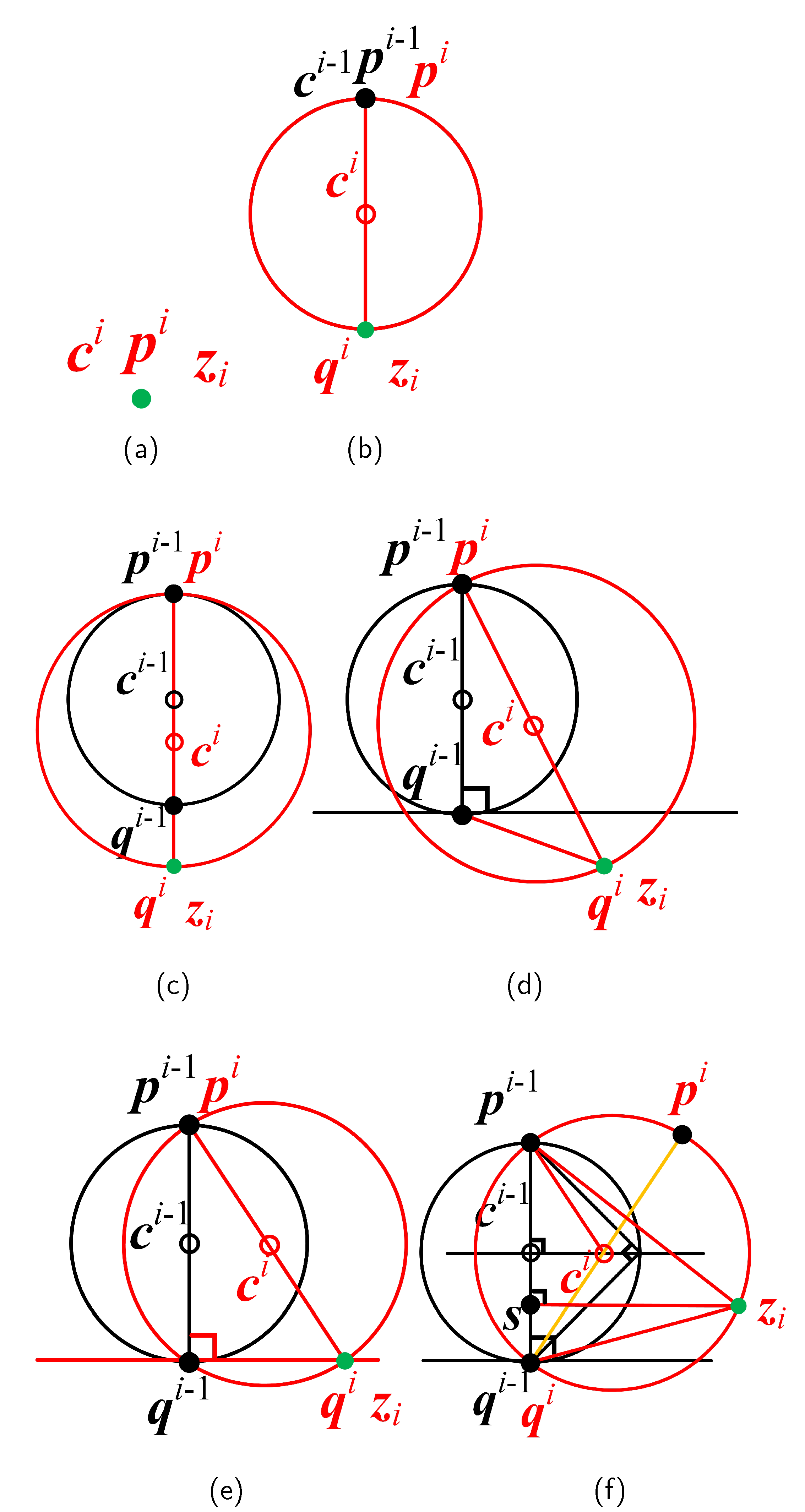
Before we elaborate on OSVM_SP, it is necessary to clarify the variables to be learned and the parameters required during the learning process. When the ith sample arrives, is first mapped into according to the first condition in Section 3.3. Let the current ball be and be the new ball to be learned. According to Equation (7a), the center can be represented as for each i. We use and to indicate two endpoints of the diameter segment (see Figure 4c–f), which can be universally expressed as and . Therefore, when the sample arrives, online learning of the new ball is equivalent to learning , , and based on , , , and sample .
When and is the first sample to arrive, we can easily initialize the MEB to enclose the sole point by letting the center coincide with and the radius equal 0 (see Figure 4a). In addition, is recorded by considering as the sole end point, and is not available at the moment. See Steps 5–6 in Algorithm 1 for details.
When the ith sample arrives for , we first calculate the distance in Equation (10) and compare it with the radius to determine whether is inside of the current ball . If it is, neither the ball nor the end points need to be adjusted, and they all inherit from the old ones (see Steps 24–26 in Algorithm 1); if not, a new ball should be learned that encloses sample as well as the current end point(s). Derivations of Equation (10) have been listed in Appendix B for reference.
If is an outsider and the end point is unavailable, the new ball must enclose two points of end point and sample , which can be easily learned by letting the center be the midpoint of these two points and letting equal half the distance between them (see Figure 4b). Additionally, sample is recorded by , and inherits from in preparation for the next update. In this case, , , and are computed by Equation (11).
| Algorithm 1 OSVM_SP |
| 1: Input: , regularization parameter C, kernel function with kernel parameter . |
| 2: Output: Lagrange multiplier . |
| 3: for to N do |
| 4: Map sample into according to . |
| 5: if then /*Initialization, see Figure 4a*/ |
| 6: , , , . |
| 7: else if then |
| 8: Compute , the distance of to the center of the current MEB, according to Equation (10). |
| 9: if then |
| 10: if then /*See Figure 4b*/ |
| 11: Compute , , and , , and according to Equation (11). |
| 12: else if then |
| 13: Compute and , the distances of to the two end points of and . |
| 14: if then /*Exchange and */ |
| 15: . |
| 16: end if |
| 17: Compute according to the cosine rule w.r.t. triangle with side lengths of , and . |
| 18: if then /*See Figure 4c–e*/ |
| 19: Compute , , and , , and according to Equation (11). |
| 20: else if then /*See Figure 4f*/ |
| 21: Compute , , and , , and according to Equation (12). |
| 22: end if |
| 23: end if |
| 24: end if then |
| 25: , , . , , , . |
| 26: end if |
| 27: end if |
| 28: end for |
| 29: return . |
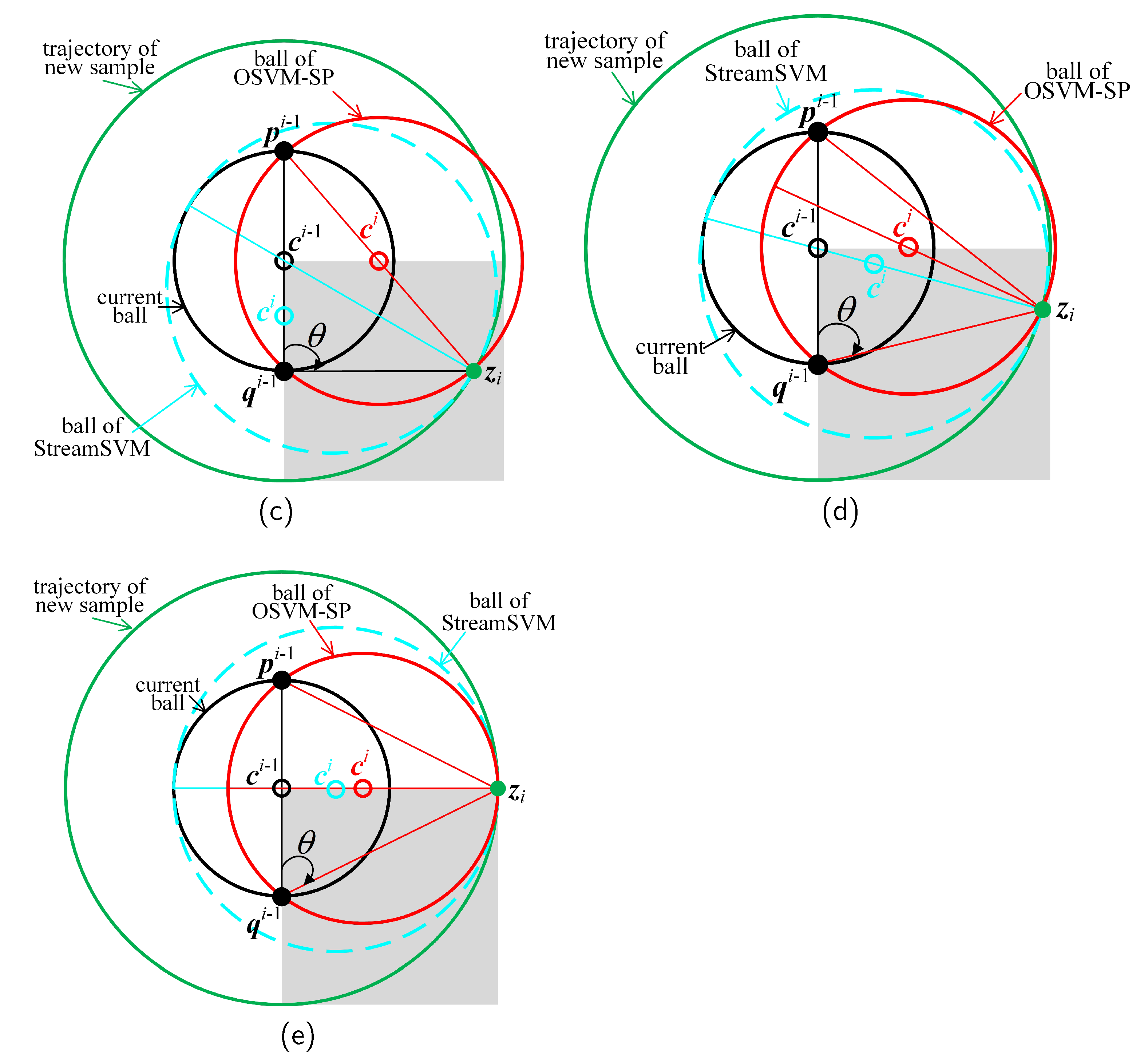
If is an outsider and the end point is available, the new ball must enclose all three points of , and . We assume that is the end point that is not less near sample than near . If otherwise, we exchange the values of and to satisfy the assumption. Let be , with . According to the value of , the construction of a new ball and the update process for the end points are divided into the following four subcases:
- . The three points are collinear, and is between them (see Figure 4c). Therefore, the new ball is constructed with the center being the midpoint of and , and with the radius being equal to half their distance. Then, sample is recorded by , and inherits from . All these steps are performed according to Equation (11).
- . The three points constitute an obtuse triangle (see Figure 4d). A ball that encloses the two points and can enclose as well. Therefore, we can replicate the steps in the first subcase to fulfill the task.
- . The three points constitute a right triangle (see Figure 4e). The ball constructed in the first subcase is simply the circumscribed sphere of the right triangle. Therefore, we can replicate the steps in the first subcase to fulfill the task.
- . The three points constitute an acute triangle (see Figure 4f), and the new ball should be its circumscribed sphere. Therefore, and are set as the circumcenter and circumradius, respectively. Then, sample is recorded by . As must be the midpoint of and , can be obtained accordingly. Therefore, , , and are computed by Equation (12).
The online learning process of OSVM_SP is provided in Algorithm 1. Whenever there is a label prediction requirement, an optimal hyperplane equivalent to the current ball can be generated accordingly by Equation (4).
The most time-consuming steps in Algorithm 1 are the distance computations in Steps 8 and 13. Among them, the distance to center in Step 8 must be computed for every upcoming , whereas and in Step 13 need to be computed only under certain conditions (see Steps 9 and 12). Note that the space requirement of OSVM_SP grows without limit as the data continue to arrive, which might be infeasible in high-rate data streams.
4.3. Budgeted OSVM_SP
For the aforementioned reason, we propose three budgeted versions of OSVM_SP to decrease the boundless space requirement. Specifically, a budget of fixed size is utilized as the upper bound of the storage space. When this budget is exceeded, it is necessary to remove an SV learned beforehand to make space for the new SV. Therefore, our budgeted algorithms all have constant space complexity. The core of budgeted algorithms is the method of choosing the SV to remove. We employ three widely used SV removal principles [26,27] to remove either a randomly selected SV (-Ran), the oldest SV (-Old), or the least important SV (-Min). Here, the importance of an SV is measured by the value of its corresponding multiplier. Accordingly, the three proposed budgeted versions of OSVM_SP are denoted OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min.
4.4. Complexity Analysis
The respective time and space complexities of OSVM_SP are and . Let B be the size of the budget; then, the time complexity of our three budgeted algorithms (OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min) is and the space complexity is , a constant unrelated to the number of samples N.
Note that when the linear kernel is employed in OSVM_SP, both the center and the two end points can be explicitly computed and stored for computing the distances in Steps 8 and 13. In such a case, OSVM_SP has space complexity, which is unrelated to the sample number N or time complexity . Table 1 lists the computational complexity of all the methods.
4.5. Comparison of OSVM-SP with StreamSVM
When the first training sample arrives, OSVM-SP and StreamSVM both initialize a ball of . When the first sample arrives and is outside of the current ball, OSVM-SP and StreamSVM both construct a new ball of to replace the current ball. When the third or later sample arrives outside, however, the balls of OSVM-SP and StreamSVM may coincide with each other in certain cases, although most of the time they differ from each other.
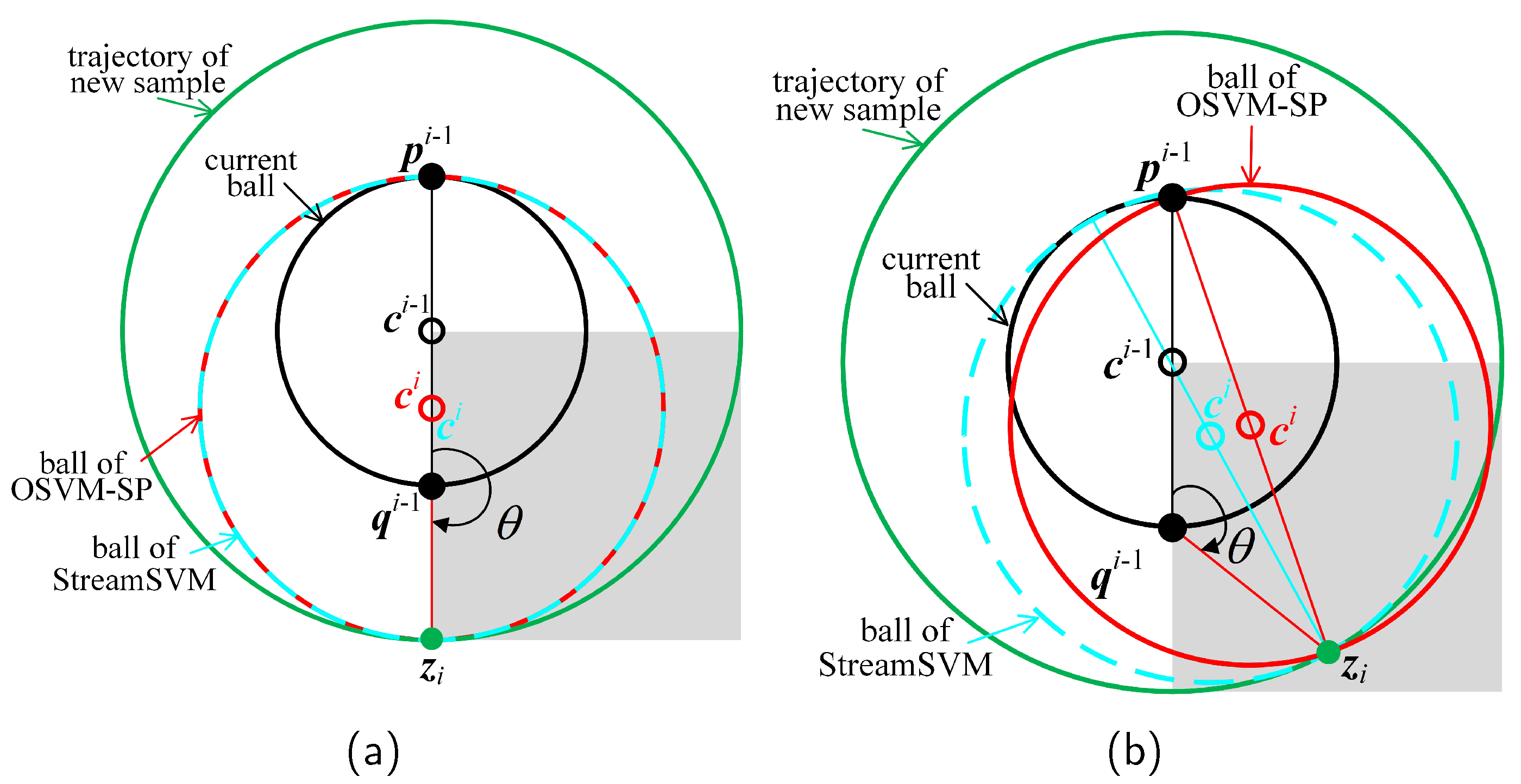
Figure 5 illustrates a comparison of OSVM-SP with StreamSVM in the construction of new balls, while denotes the third or later sample coming outside of the current ball (the ball in black); hence, . For convenience of analysis, the distance is equal to a constant ; therefore, the trajectory of all the possible is a ball denoted (the ball in green). Because the trajectory is bilaterally symmetric, only the left or right half of the trajectory must be considered. Moreover, if we continue to assume that is the end point closer to sample than , then only a quarter of the trajectory (the green ball with the gray background) is distinguished for consideration.
Figure 5a–e illustrates five different cases in which the new sample may appear in the trajectory, divided according to the value of angle . When and sample is co-linear to the endpoints (see Figure 5a), new balls of OSVM-SP (the ball in red) and StreamSVM (the ball in dotted blue) coincide with each other; otherwise, these two balls are different (see Figure 5b–d). In particular, when and the distances from sample to those end points are equal (see Figure 5e), the new ball of OSVM-SP is enclosed by the new ball of StreamSVM.
5. Experiments
5.1. Benchmark Datasets
Six binary datasets (australian, fourclass, banknote, svmguide1, EGSSD, and occupation) were employed to validate the performance of our methods; they are all publicly available from the following websites (https://archive.ics.uci.edu/ml/datasets, accessed on 1 January 2022; https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets, accessed on 1 January 2022). Each dataset had already been scaled featurewise to (−1,1) according to min–max normalization. All of the datasets contained only one set of data, except for svmguide1, which contained two sets of training and testing data. We merged these two sets into a single set for unified management during the following experiments, making svmguide1 the same as the remaining datasets. The specifications of the datasets are listed in Table 2, showing the number of features, sample size, and percentage of the majority class contained in each dataset. The missing data issue does not exist in these six datasets as the online methods we focus on in this paper are not able to handle the missing data problem, although this might be an interesting and promising research direction in future work.
5.2. Baseline Methods
The proposed method is denoted as OSVM_SP, while OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min are three budgeted versions of OSVM_SP that respectively remove a randomly selected SV, the oldest SV, and the least important SV when the budget is exceeded. The methods for comparison can be divided into three groups: “nonbudgeted online”, “budgeted online”, and “offline”. The nonbudgeted online group consists of five methods (StreamSVM, PA, PA-I, PA-II, and AMM-online), which are mainly compared with the proposed OSVM_SP. Meanwhile, the two budgeted online representatives (BSGD and BPA-S) are compared with OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min. The two offline batch methods (SVM and -SVM) are listed as the baselines. Nine comparable methods are briefly introduced below.
- -
- StreamSVM [16]: StreamSVM is a nonbudgeted online method that leverages the equivalence of SVM and MEB (see Section 3.3), which is similar to our OSVM_SP method. For any incoming point outside of the ball, the StreamSVM algorithm moves the center towards it and simultaneously enlarges the radius to cover both the point and the previous ball. OSVM_SP is different from StreamSVM in that the center moves in different directions and the radius grows according to different strategies; see Figure 4d–f. Taking Figure 4e as an example, the two directions to (in StreamSVM) and to (in OSVM_SP) are very different from each other.
- -
- PA, PA-I, and PA-II [17]: PA, PA-I, and PA-II are three nonbudgeted online algorithms operating under the same framework provided in [17], which formalizes the trade-off between the correct classification of new data with a sufficiently high margin and the amount of information retained from old data. Among them, PA is a hard margin classifier while PA-I and PA-II are soft margin classifiers with losses of ℓ1 and ℓ2, respectively.
- -
- AMM-online [28]: another nonbudgeted algorithm, AMM-online is an online version of AMM that consists of a set of hyperplanes; each hyperplane is assigned to one class. We employ the implementation of AMM-online in the BudgetedSVM toolbox [29]. Note that the default setting of AMM-online in the toolbox is required to run five training epochs, which deviates from the restriction of single-pass online learning. In fact, we tried to run AMM-online in one epoch; however, its performance declined rapidly. Therefore, the performance of AMM-online with five epochs is listed in all the following experimental results.
- -
- BSGD [27]: BSGD is a class of budgeted versions of online SVM algorithms that belong to the SGD family. We employ the implementation of BSGD in the same BudgetedSVM toolbox with two budget maintenance strategies, “-removal” and “-merging”, which are based on the removal and merging of support vectors during the training process. The experimental results based on our six datasets show that there is a minor difference between these methods.
- -
- BPA-S [26]: BPA-S is a budgeted version of PA-I. When the budget is exceeded, BPA-S removes an SV to make room for the new sample, while the multipliers of the remaining SV remain unchanged.
- -
- ρ-SVM & SVM: -SVM is the respective offline batch method corresponding to our OSVM_SP, introduced in Section 3.1. We implemented the dual -SVM in Equation (2) with convex optimization (CVX) [30,31], a package for specifying and solving convex programs. The SVM indicates the corresponding offline model of StreamSVM, which is a transformation of -SVM in which the variable is set to a constant value of 1.
5.3. User-Specified Parameters
For simplicity, we utilize the Gaussian kernel for all the kernelized methods, as it satisfies the 2nd condition in Section 3.3. Therefore, the penalty parameter C and kernel parameter must be set for StreamSVM, PA, PA-I, PA-II, SVM, -SVM, and the proposed OSVM_SP, OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min. As the SVM and -SVM are the corresponding batch versions of StreamSVM and OSVM_SP, they share the same objective functions. Therefore, SVM is utilized to choose the optimal parameter values for StreamSVM as well as itself, and -SVM is utilized both for itself and the proposed four methods. The optimal group is chosen by performing a grid search with . Because there is no explicit batch-mode optimization problem for PA, PA-I, or PA-II, there is no corresponding batch model in the experiments. The values of parameters C and within these three methods are set according to the SVM.
The parameter values corresponding to the best performance were chosen as the optimal values, and are listed in Table 3 for each dataset. Each dataset was randomly divided into training and testing sets according to two-fold cross-validation. A series of SVM and -SVM models were learned based on the training set with different parameter values, and their classification accuracies were measured based on the testing set.
The experiments in the following subsections were all conducted as follows: each dataset was randomly divided into equal-sized training and testing sets; every method in Section 5.2 was trained with the former set and validated with the latter set; we ran each method five times with randomized permutations, and reported the mean results (along with the standard deviation in several subsections) from the experiments.
5.4. Classification Accuracy
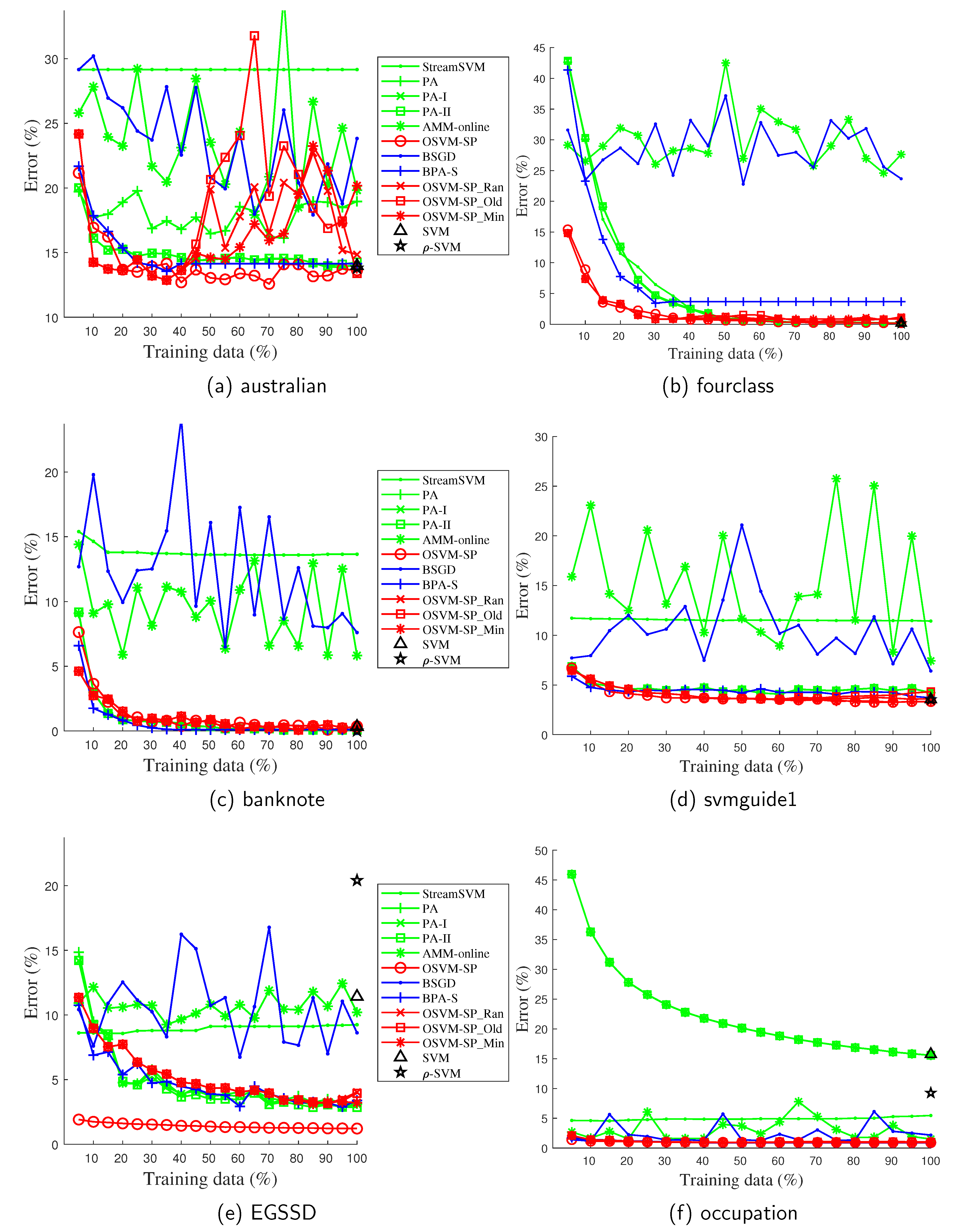
First, we validated the predictive performance of all the methods based on six datasets. This paper focuses on training online models over streaming data, which means that training samples arrive one by one or chunk by chunk. Whenever a new sample arrives, the current model may require a timely update to fit the new sample. Therefore, online models usually change dynamically and frequently during the whole training process. The trend in the performance of an online model is of great importance, as it clearly reflects whether, or even how, the model adapts to the new data. The performance comparison of online models with respect to different sizes of training data is an easy way of displaying the trends, and is widely utilized by many state-of-the-art online learning-related methods [32,33,34,35]. Figure 6 shows the classification error with respect to different amounts of training data, while Table 4 lists the classification accuracy attained at the end of the training process.
OSVM_SP obtains the highest accuracy among the six nonbudgeted online methods for nearly all the datasets, with the exception of banknote, for which it is surpassed by PA, PA-I, and PA-II with a slight accuracy loss (0.2%). In addition, PA, PA-I, and PA-II share the highest accuracy with OSVM_SP based on the fourclass dataset. The budgeted versions of OSVM_SP, OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min converge steadily to OSVM_SP in predictive performance for all six datasets. In fact, there is a slight accuracy loss for OSVM_SP-Min based on fourclass and EGSSD compared with OSVM_SP, which seems reasonable as OSVM_SP-Min must occasionally remove SVs in order to make room for the new sample. Despite the accuracy loss, OSVM_SP-Min surpasses the other budgeted online methods (BSGD and BPA-S) most of the time. OSVM_SP-Old beats OSVM_SP-Min and even OSVM_SP based on the australian dataset, achieving the best performance only this once. The superiority of OSVM_SP-Ran does not appear obvious, indicating that an SV removal principle with more explicit intentionality might be more helpful than randomization. The difference in accuracy between the two batch-mode algorithms, the SVM and -SVM, is negligible for most of the datasets. The error of PA increases and then decreases for the australian dataset, while PA-I and PA-II behave much more steadily for all six datasets. PA-I and PA-II are soft margin classifiers that enable misclassification of several training samples, whereas the hard margin classifier, PA, does not. Therefore, we suspect that PA might be sensitive to noise in the data. StreamSVM obtains the best results for fourclass, although it fails for the remaining datasets. Moreover, the performance of StreamSVM remains at a nearly static level, with no further improvement during the training process for the remaining five datasets. This result is analyzed in Section 5.5.
5.5. Percentage of Support Vectors
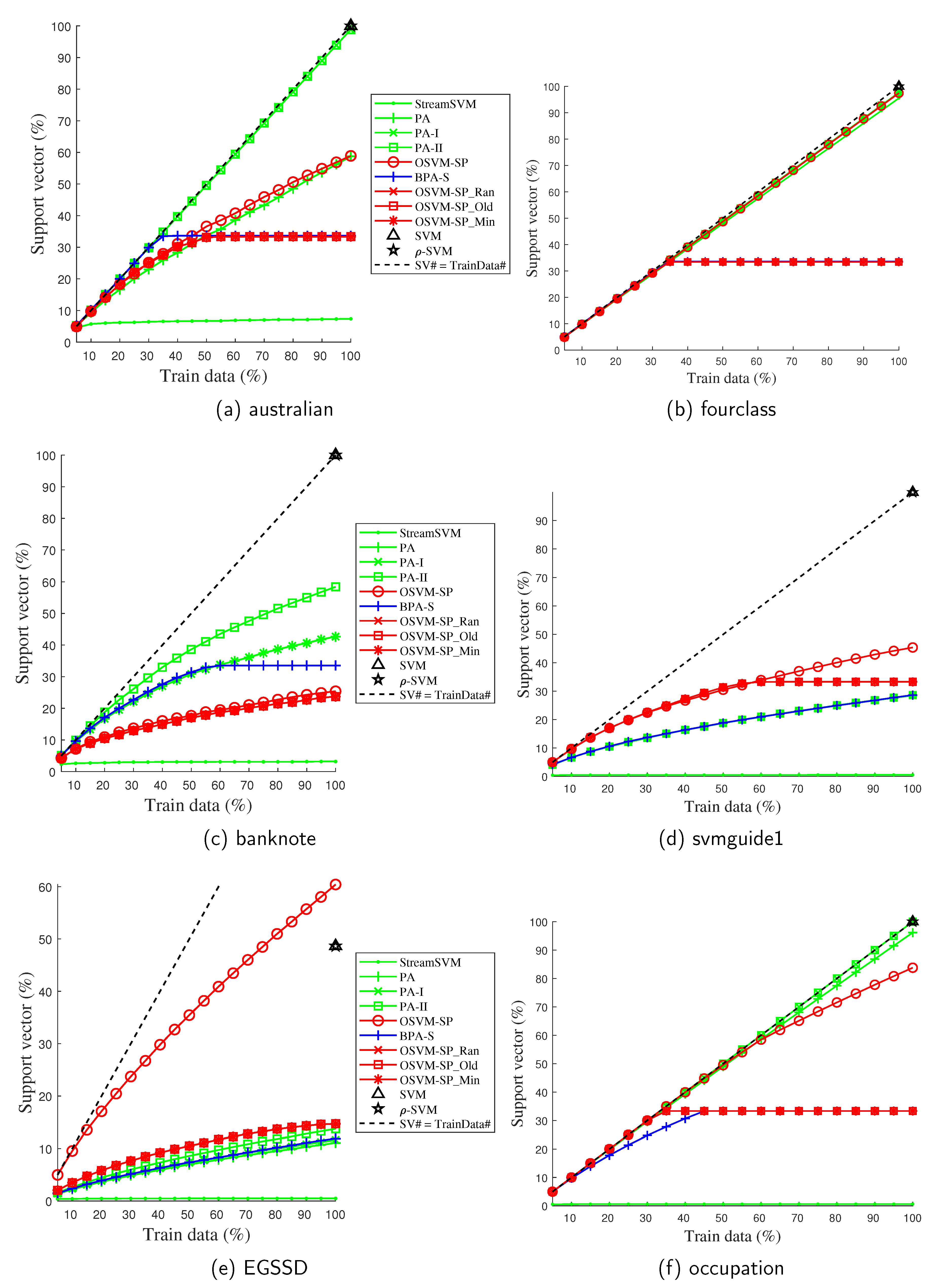
Our second experiment examined the computation and memory requirements of each method by counting the percentage of SVs in the training data during the whole training process. As the proposed OSVM_SP and its three budgeted versions along with the majority of the compared methods are kernelized, the number of SVs can be considered one of the most important indicators of computation and memory consumption. Here, an SV is denoted as a training sample with a nonempty Lagrange multiplier. Figure 7 depicts the number of SVs with respect to different amounts of training data.
For most unbudgeted online methods, the number of SVs increases with the amount of training data. The curve for OSVM-SP varies greatly between different datasets. When the amount of training data approaches 100%, however, the number of SVs for OSVM-SP remains less than (see Figure 7a,c,d,f) or as much as (see Figure 7b) the SV numbers of the SVM and -SVM in most cases. In combination with the accuracy results in Table 4, the effective predictive performance of SVM and -SVM is acquired at a cost of nearly 100% of the training data, as the SVs (see Figure 7a–d) can consume enormous amounts of memory and time latency in both the model training and label prediction processes. Compared with SVM and -SVM, OSVM-SP is more lightweight while attaining a comparable predictive performance. Sometimes, OSVM-SP even achieves higher accuracy (10.2–19.2%, see Table 4) than the batch methods, although at the cost of more SVs (see Figure 7e). PA generates fewer SVs than PA-II and/or PA-I most of the time (see Figure 7a,c,e,f), which is to be expected as the SVs of the hard margin method PA consist of only the misclassified data, while the SVs of the soft margin methods PA-I and PA-II are constructed using both the misclassified data and those that are classified correctly and are within the margin. StreamSVM maintains a small number of SVs based on five datasets, with the exception of fourclass. In combination with the accuracy results of StreamSVM in Table 4, the reason for this might be that the corresponding MEB of StreamSVM expands excessively to cover most of the training data arriving afterwards without triggering any further updates.
For the budgeted online methods, the number of SVs initially increases with the amount of training data. When it grows to the size of the budget (one-third of the training size), it remains constant through the various SV removal principles utilized. The number of SVs for OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min is controlled in keeping with the size of the budget. Compared with the nonbudgeted OSVM_SP, it can bes observed that decreasing the memory requirement by approximately two-thirds leads to only a 0.6–2.0% loss in accuracy. In other words, OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min offer great potential for efficiency and effectiveness in budgeted online learning.
5.6. Radius of the Minimum Enclosing Ball
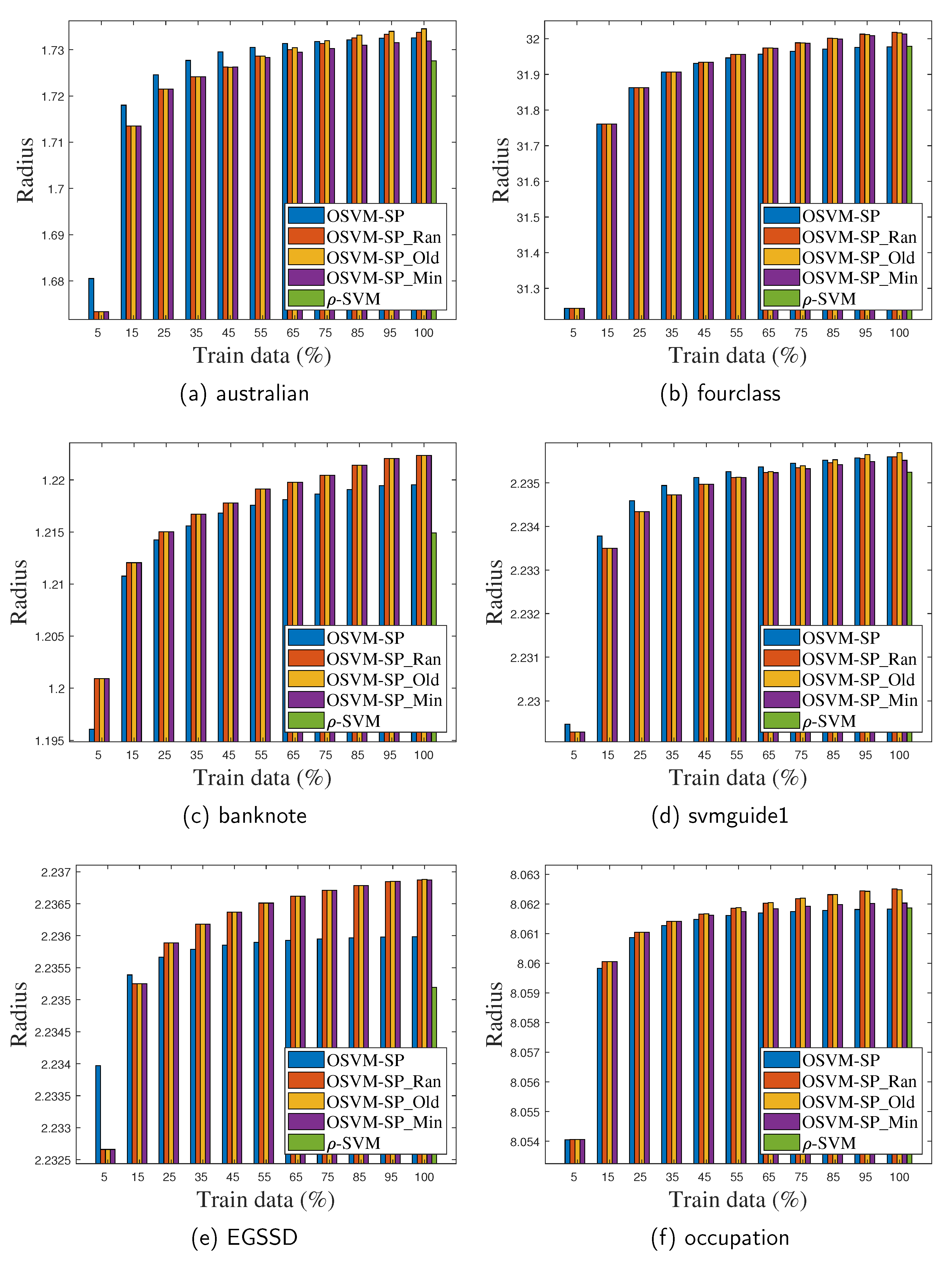
Our third experiment compared the radii of the MEBs corresponding to the proposed nonbudgeted online method (OSVM_SP), the three budgeted online methods (OSVM_SP-Ran, OSVM_SP-Old and OSVM_SP-Min), and the corresponding batch-mode method (-SVM). Figure 8 shows the radii with respect to different amounts of training data.
The methods can be sorted in ascending order of radii, that is, -SVM, OSVM_SP, OSVM_SP-Min, OSVM_SP-Old, and OSVM_SP-Ran, on each dataset. The batch-mode method, -SVM, achieves the minimum radius, as it can iteratively search for the smallest ball among those covering all the training data. OSVM_SP falls between the batch-mode -SVM and the three budgeted online methods. In Figure 4f, the ball with respect to OSVM_SP can be determined by three points represented by two real samples ( and ) and one fake sample (), which we believe incurs an expanding radius as well as a loss in accuracy. The budgeted online methods obtain a larger radius than OSVM_SP, as one SV must be removed whenever the budget is exceeded. Because the center of the ball is linearly represented by the SVs, the center drifts away from the location it had after the removal. Therefore, these methods have to enlarge their radii to cover the new data. In addition, the degree of drift varies for different removal principles. Among these budgeted online methods, OSVM_SP-Min achieves the minimal radius mostly by removing the least important SV, while OSVM_SP-Ran or OSVM_SP-Old achieves the maximal radius by removing a randomized SV or the oldest SV. There is occasionally a minor difference in their radius lengths.
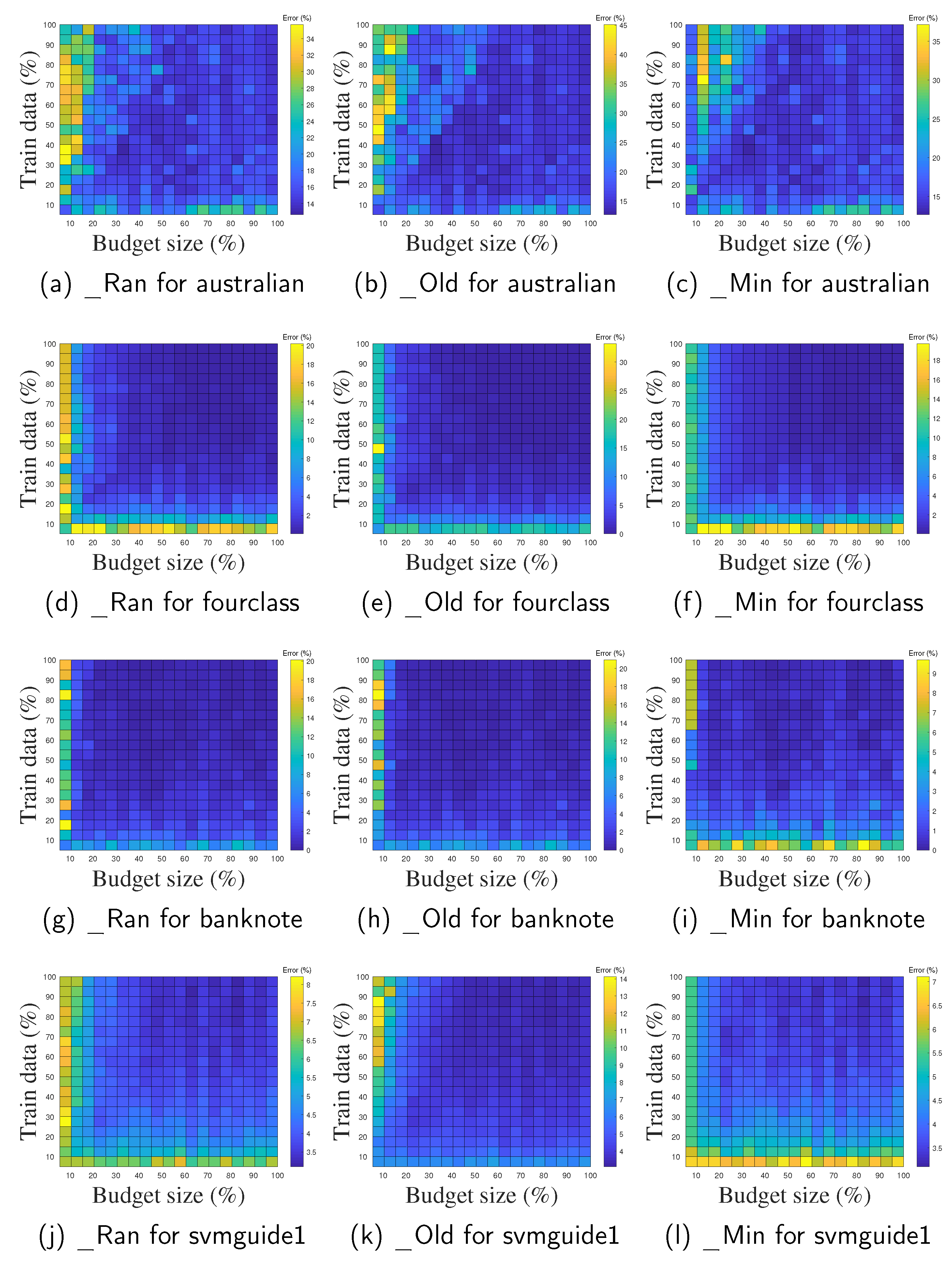
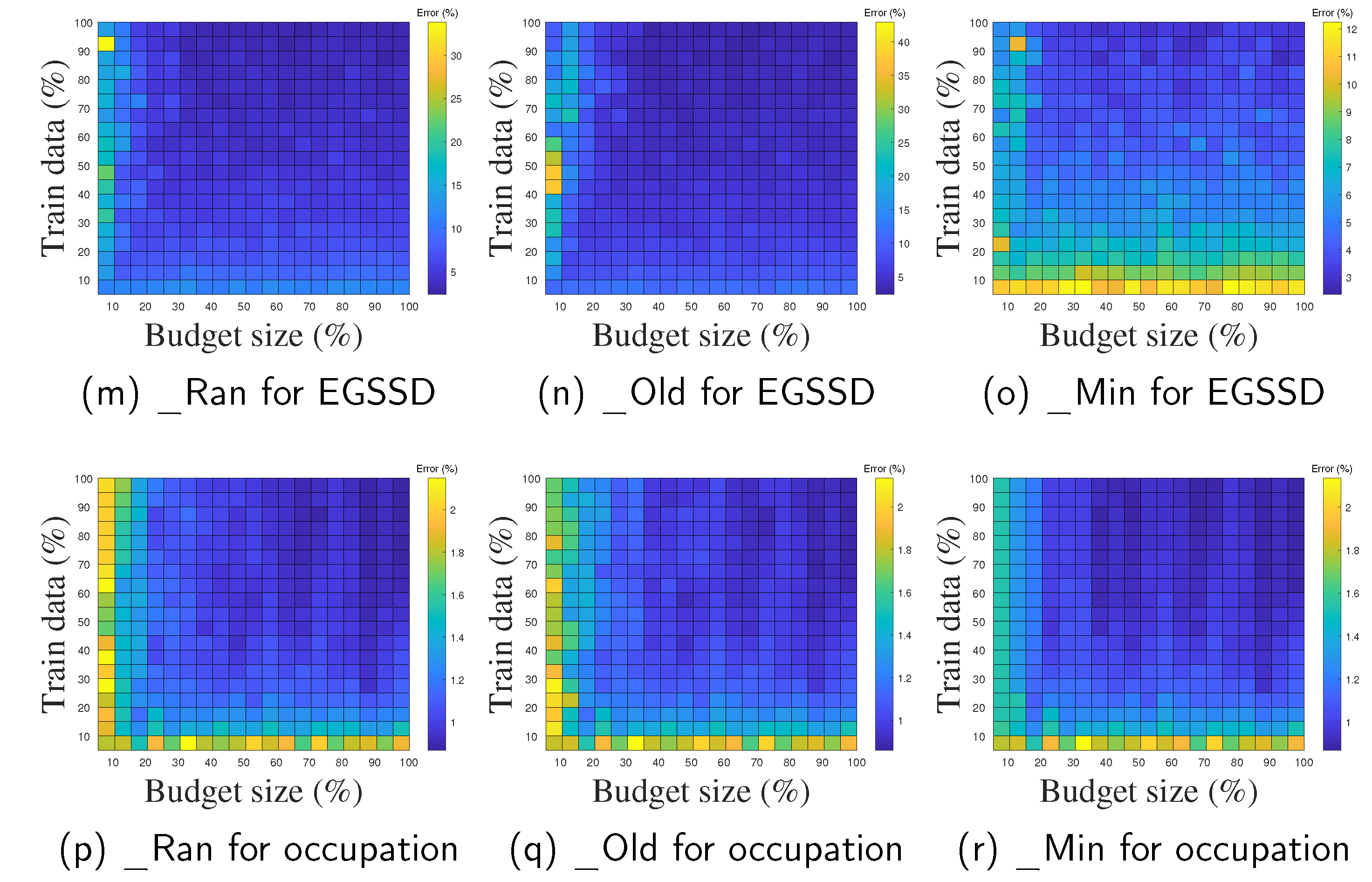
5.7. Effect of Budget Size
Our last experiment verified the effect of different budget sizes on the performance of the three proposed budgeted methods, OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min. The size of the budget was set to be a range of percentages of the training data, with the percentage chosen by a grid search with . Note that when the percentage equals 100%, OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min are identical to OSVM_SP, which means that the budget is able to store all the training data without any SVs needing to be removed.
Figure 9 depicts the classification error with respect to different budget sizes as well as different amounts of training data. The error decreases with increasing the budget size percentage, and ultimately converges to the error of OSVM_SP. First, the error of the budgeted methods decreases much more quickly when the percentage is small (e.g., less than 20%), which means that a few new data points are not sufficient for learning; the performance of our proposed algorithms can thus be greatly improved by remembering more data. The rate of decrease slows when the percentage is above 40%, which implies that it is not necessary to remember all the old SVs in order to achieve comparable predictive performance. The experimental results in the above section show that when the budget size is set to one-third, the three budgeted algorithms can achieve predictive performance comparable to that of a classifier as well as a radius length comparable to that of the MEB.
6. Discussion
This paper presents OSVM_SP, a single-pass online algorithm for streaming data. Moreover, OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min are proposed as three budgeted online algorithms to bound the space requirement using support vector removal principles. This section discusses the superiority and limitations of the proposed methods.
The proposed methods are superior in three distinct ways:
- OSVM_SP has the most effective predictive performance in the family of nonbudgeted online methods and is lightweight compared to batch-mode methods.
- The budgeted OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min all converge steadily to the nonbudgeted OSVM_SP in their predictive performance. Compared with OSVM_SP, a decrease in the memory requirement of approximately two-thirds leads to a loss in accuracy of only about 2.0%.
- For OSVM_SP-Ran, OSVM_SP-Old, and OSVM_SP-Min, the error decreases with the increase in the budget size, and ultimately converges to the error of OSVM_SP. Moreover, the error decreases quickly/slowly when the budget size is small/large; 20–40% of the training size seems to be a proper range for the budget size.
The limitations are three-fold as well:
- Similar to the other kernelized methods, the proposed OSVM_SP has to save all of the SVs during the whole online learning process, which can become a heavy burden in restricted memory scenarios.
- OSVM_SP and its three budgeted versions are all proposed for binary classification problems. For multiple classification problems, it is possible to build a series of binary models according to one-versus-one or one-versus-rest techniques. In other words, when new samples arrive, several models have to be learned to maintain updates, which may be computationally burdensome.
- Class imbalance and missing data issues are not fully considered in this paper. Ways of adapting the proposed methods to streaming data with missing features/labels from imbalanced classes is an interesting and promising direction for future research.
7. Conclusions
In this paper, we present OSVM_SP, a new online SVM algorithm for streaming data, and three budgeted versions of OSVM_SP to bound the space requirement. All of these approaches are based on the online MEB problem and require a single pass over the streaming data. The experimental results obtained for five public datasets show that OSVM_SP outperforms most state-of-the-art single-pass online algorithms in terms of accuracy and is comparable to batch-mode SVMs and MEBs in both accuracy and radius. Our budgeted algorithms reduce the space requirement by two-thirds with only a slight loss in accuracy (0.7–5.7%).
Author Contributions
Conceptualization, L.H.; Methodology, L.H. and C.H.; Validation, L.H. and C.H.; Writing, L.H. and Z.H.; Formal Analysis, X.J.; Supervision, S.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China (grant numbers 62002187, 62002098, and 61902379), the Natural Science Foundation of Hebei Province (grant numbers F2020207001, and F2021207005), the Scientific Research and Development Program Fund Project of Hebei University of Economics and Business (grant number 2022ZD10), and Youth Innovation Promotion Association CAS.
Conflicts of Interest
The authors declare that they have no conflict of interest.
Appendix A. Derivation of Equations (3) and (4)
The Lagrange function of Equation (1) is listed as follows:
According to the KKT Theorem: (a) the partial derivative of the Lagrange function with respect to all the variables , , and of Equation (1) is required to be zero; and (b) , which leads to the following solutions.
(a.1) ; thus, Equation (3a) holds.
(a.2) ; thus, Equation (3b) holds.
(a.3) .
(a.4) ; with Equations (3a) and (3b), . Thus, Equation (3c) holds.
Becuase the SVM in this paper indicates the unbiased linear function in RKHS, the classifier learned by SVM can be represented by . In conjunction with Equation (3a), we can find that , as listed in Equation (4).
Appendix B. Derivation of Equation (10)
, according to the definition of .
, according to the first condition in Section 3.2.
, according to Equation (9a).
, according to the definition of d.
,
,
,
, according to the second condition in Section 3.2.
. Thus, Equation (10) holds.
References
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Wang, H.; Zhang, L.; Yao, L. Application of genetic algorithm based support vector machine in selection of new EEG rhythms for drowsiness detection. Expert Syst. Appl. 2021, 171, 114634. [Google Scholar] [CrossRef]
- Huang, C.; Zhou, J.; Chen, J.; Yang, J.; Clawson, K.; Peng, Y. A feature weighted support vector machine and artificial neural network algorithm for academic course performance prediction. Neural Comput. Appl. 2021, 1–13. [Google Scholar] [CrossRef]
- Ding, C.; Bao, T.Y.; Huang, H.L. Quantum-inspired support vector machine. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–13. [Google Scholar] [CrossRef]
- Che, Z.; Liu, B.; Xiao, Y.; Cai, H. Twin Support Vector Machines with Privileged Information. Inf. Sci. 2021, 573, 141–153. [Google Scholar] [CrossRef]
- Nguyen, H.L.; Woon, Y.K.; Ng, W.K. A survey on data stream clustering and classification. Knowl. Inf. Syst. 2015, 45, 535–569. [Google Scholar] [CrossRef]
- Lawal, I.A. Incremental SVM learning. In Learning from Data Streams in Evolving Environments; Springer: Berlin/Heidelberg, Germany, 2019; pp. 279–296. [Google Scholar]
- Guo, H.; Zhang, A.; Wang, W. An accelerator for online SVM based on the fixed-size KKT window. Eng. Appl. Artif. Intell. 2020, 92, 103637. [Google Scholar] [CrossRef]
- Mello, A.R.; Stemmer, M.R.; Koerich, A.L. Incremental and decremental fuzzy bounded twin support vector machine. Inf. Sci. 2020, 526, 20–38. [Google Scholar] [CrossRef]
- Soula, A.; Tbarki, K.; Ksantini, R.; Said, S.B.; Lachiri, Z. A novel incremental kernel nonparametric SVM model (iKN-SVM) for data classification: An application to face detection. Eng. Appl. Artif. Intell. 2020, 89, 103468. [Google Scholar] [CrossRef]
- Matsushima, S.; Vishwanathan, S.; Smola, A.J. Linear support vector machines via dual cached loops. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 177–185. [Google Scholar]
- Wang, X.; Xing, Y. An online support vector machine for the open-ended environment. Expert Syst. Appl. 2019, 120, 72–86. [Google Scholar] [CrossRef]
- Zheng, J.; Shen, F.; Fan, H.; Zhao, J. An online incremental learning support vector machine for large-scale data. Neural Comput. Appl. 2013, 22, 1023–1035. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, J. One-pass online SVM with extremely small space complexity. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3482–3487. [Google Scholar]
- Rai, P.; Daumé, H.; Venkatasubramanian, S. Streamed learning: One-pass SVMs. In Proceedings of the International Jont Conference on Artifical Intelligence, Hainan Island, China, 25–26 April 2009; pp. 1211–1216. [Google Scholar]
- Crammer, K.; Dekel, O.; Keshet, J.; Shalev-Shwartz, S.; Singer, Y. Online passive aggressive algorithms. J. Mach. Learn. Res. 2006, 7, 551–585. [Google Scholar]
- Ñanculef, R.; Allende, H.; Lodi, S.; Sartori, C. Two one-pass algorithms for data stream classification using approximate MEBs. In Proceedings of the International Conference on Adaptive and Natural Computing Algorithms, Ljubljana, Slovenia, 14–16 April 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 363–372. [Google Scholar]
- Tukan, M.; Baykal, C.; Feldman, D.; Rus, D. On coresets for support vector machines. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Changsha, China, 18–20 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 287–299. [Google Scholar]
- Gärtner, B.; Jaggi, M. Coresets for polytope distance. In Proceedings of the Annual Symposium on Computational Geometry, Aarhus, Denmark, 8–10 June 2009; pp. 33–42. [Google Scholar]
- Chang, C.C.; Lin, C.J. Training v-support vector classifiers: Theory and algorithms. Neural Comput. 2001, 13, 2119–2147. [Google Scholar] [CrossRef]
- Kuhn, H.W.; Tucker, A.W. Nonlinear programming. In Traces and Emergence of Nonlinear Programming; Springer: Berlin/Heidelberg, Germany, 2014; pp. 247–258. [Google Scholar]
- Tax, D.M.; Duin, R.P. Support vector domain description. Pattern Recognit. Lett. 1999, 20, 1191–1199. [Google Scholar] [CrossRef]
- Tax, D.M.; Duin, R.P. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Tsang, I.W.; Kwok, J.T.; Cheung, P.M.; Cristianini, N. Core vector machines: Fast SVM training on very large data sets. J. Mach. Learn. Res. 2005, 6, 363–392. [Google Scholar]
- Wang, Z.; Vucetic, S. Online passive-aggressive algorithms on a budget. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 908–915. [Google Scholar]
- Wang, Z.; Crammer, K.; Vucetic, S. Breaking the curse of kernelization: Budgeted stochastic gradient descent for large-scale svm training. J. Mach. Learn. Res. 2012, 13, 3103–3131. [Google Scholar]
- Wang, Z.; Djuric, N.; Crammer, K.; Vucetic, S. Trading representability for scalability: Adaptive multi-hyperplane machine for nonlinear classification. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 24–32. [Google Scholar]
- Djuric, N.; Lan, L.; Vucetic, S.; Wang, Z. Budgetedsvm: A toolbox for scalable svm approximations. J. Mach. Learn. Res. 2013, 14, 3813–3817. [Google Scholar]
- Grant, M.; Boyd, S. CVX: Matlab Software for Disciplined Convex Programming, Version 2.1; 2014. Available online: http://cvxr.com/cvx (accessed on 1 January 2022).
- Grant, M.; Boyd, S. Graph implementations for nonsmooth convex programs. In Recent Advances in Learning and Control; Springer: Berlin/Heidelberg, Germany, 2008; pp. 95–110. [Google Scholar]
- Zhao, P.; Zhang, Y.; Wu, M.; Hoi, S.C.; Tan, M.; Huang, J. Adaptive cost-sensitive online classification. IEEE Trans. Knowl. Data Eng. 2018, 31, 214–228. [Google Scholar] [CrossRef]
- Sahoo, D.; Pham, Q.; Lu, J.; Hoi, S.C. Online Deep Learning: Learning Deep Neural Networks on the Fly. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Gözüaçık, Ö.; Can, F. Concept learning using one-class classifiers for implicit drift detection in evolving data streams. Artif. Intell. Rev. 2021, 54, 3725–3747. [Google Scholar] [CrossRef]
- Din, S.U.; Shao, J.; Kumar, J.; Mawuli, C.B.; Mahmud, S.; Zhang, W.; Yang, Q. Data stream classification with novel class detection: A review, comparison and challenges. Knowl. Inf. Syst. 2021, 63, 2231–2276. [Google Scholar] [CrossRef]
Figure 1.
Equivalence of the SVM and MEB.

Figure 2.
Motivation from StreamSVM [16] in learning the MEB.
Figure 2.
Motivation from StreamSVM [16] in learning the MEB.

Figure 3.
Basic idea of OSVM_SP.

Figure 4.
Update of the MEB according to OSVM_SP. A ball is initialized when the first sample comes in (a), and enlarged when the second sample comes in (b). When the ith sample comes outside later, the ball is enlarged with respect to different values of . (c) ; (d) ; (e) ; (f) .
Figure 4.
Update of the MEB according to OSVM_SP. A ball is initialized when the first sample comes in (a), and enlarged when the second sample comes in (b). When the ith sample comes outside later, the ball is enlarged with respect to different values of . (c) ; (d) ; (e) ; (f) .

Figure 5.
Comparison of OSVM-SP and StreamSVM in the MEB update [16] with respect to different values of . (a) ; (b) ; (c) ; (d) ; (e) .
Figure 5.
Comparison of OSVM-SP and StreamSVM in the MEB update [16] with respect to different values of . (a) ; (b) ; (c) ; (d) ; (e) .


Figure 6.
Classification error with varying amounts of training data.

Figure 7.
Number of SVs with varying amounts of training data.

Figure 8.
Radius with varying amounts of training data.

Figure 9.
Error with varying budget size and training data.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Computational complexity of the proposed methods.
| Method | Time | Space |
|---|---|---|
| OSVM_SP | ||
| Three Budgeted OSVM_SPs | ||
| OSVM_SP with linear kernel |
Table 2.
Specifications of the public datasets.
| Dataset | # Features | #Instances | Majority% |
|---|---|---|---|
| australian | 14 | 690 | 55.51 |
| fourclass | 2 | 862 | 64.39 |
| banknote | 4 | 1372 | 55.54 |
| svmguide1 | 4 | 7089 | 56.43 |
| EGSSD | 13 | 10,000 | 63.80 |
| occupation | 5 | 20,560 | 76.90 |
Table 3.
Optimal parameter values after grid search.
| SVM | -SVM | |||
|---|---|---|---|---|
| australian | ||||
| fourclass | ||||
| banknote | ||||
| svmguide1 | ||||
| EGSSD | ||||
| occupation | ||||
Table 4.
Classification accuracy (mean ± STD, %) with best results shown in bold.
| Methods | Datasets | ||||||
|---|---|---|---|---|---|---|---|
| Australian | Fourclass | Banknote | Svmguide1 | EGSSD | Occupation | ||
| non-budgeted online | StreamSVM | 70.8 ± 8.0 | 99.8 ± 0.2 | 86.4 ± 11.0 | 88.6 ± 2.3 | 90.8 ± 0.8 | 94.5 ± 1.6 |
| PA | 81.0 ± 2.9 | 99.8 ± 0.2 | 99.9 ± 0.1 | 95.8 ± 0.3 | 96.9 ± 0.4 | 84.4 ± 0.3 | |
| PA-I | 86.0 ± 0.5 | 99.8 ± 0.2 | 99.9 ± 0.1 | 95.8 ± 0.3 | 96.9 ± 0.7 | 84.4 ± 0.3 | |
| PA-II | 85.7 ± 0.7 | 99.8 ± 0.2 | 99.9 ± 0.1 | 95.8 ± 0.3 | 97.1 ± 0.5 | 84.4 ± 0.3 | |
| AMM-online | 80.2 ± 8.3 | 72.4 ± 7.1 | 94.2 ± 2.8 | 92.6 ± 1.5 | 89.8 ± 2.0 | 98.5 ± 0.3 | |
| OSVM-SP | 86.4 ± 0.9 | 99.8 ± 0.2 | 99.7 ± 0.2 | 96.7 ± 0.1 | 98.8 ± 0.1 | 99.1 ± 0.0 | |
| budgeted online | BSGD | 76.2 ± 13.1 | 76.3 ± 3.0 | 92.4 ± 3.7 | 93.6 ± 1.8 | 91.4 ± 4.8 | 97.8 ± 2.1 |
| BPA-S | 85.9 ± 2.0 | 96.3 ± 1.5 | 99.9 ± 0.1 | 96.3 ± 0.2 | 96.6 ± 1.6 | 99.1 ± 0.1 | |
| OSVM-SP_Ran | 85.2 ± 2.5 | 98.8 ± 0.9 | 99.7 ± 0.3 | 96.4 ± 0.4 | 96.0 ± 2.1 | 99.0 ± 0.1 | |
| OSVM-SP_Old | 86.6 ± 1.4 | 98.9 ± 0.9 | 99.7 ± 0.3 | 95.7 ± 0.5 | 96.1 ± 1.3 | 99.0 ± 0.1 | |
| OSVM-SP_Min | 79.8 ± 5.3 | 99.2 ± 0.7 | 99.7 ± 0.3 | 96.7 ± 0.4 | 96.8 ± 0.8 | 99.1 ± 0.1 | |
| offline | SVM | 86.0 ± 1.6 | 99.8 ± 0.2 | 99.7 ± 0.3 | 96.5 ± 0.3 | 88.6 ± 1.1 | 84.3 ± 0.4 |
| -SVM | 86.2 ± 1.9 | 99.9 ± 0.2 | 100.0 ± 0.0 | 96.5 ± 0.2 | 79.6 ± 1.5 | 90.7 ± 0.3 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hu, L.; Hu, C.; Huo, Z.; Jiang, X.; Wang, S. Online Support Vector Machine with a Single Pass for Streaming Data. Mathematics 2022, 10, 3113. https://0-doi-org.brum.beds.ac.uk/10.3390/math10173113
AMA Style
Hu L, Hu C, Huo Z, Jiang X, Wang S. Online Support Vector Machine with a Single Pass for Streaming Data. Mathematics. 2022; 10(17):3113. https://0-doi-org.brum.beds.ac.uk/10.3390/math10173113
Chicago/Turabian StyleHu, Lisha, Chunyu Hu, Zheng Huo, Xinlong Jiang, and Suzhen Wang. 2022. "Online Support Vector Machine with a Single Pass for Streaming Data" Mathematics 10, no. 17: 3113. https://0-doi-org.brum.beds.ac.uk/10.3390/math10173113
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.