
Semi-Automatic Approaches for Exploiting Shifter Patterns in Domain-Specific Sentiment Analysis
 , ,
, ,
Abstract
:1. Introduction
2. Related Work
2.1. Lexicon-Based Approaches
2.2. Employing Shifters in Sentiment Analysis
2.3. Deep-Learning-Based Approaches
2.4. Comparative Studies
2.5. Combined Approaches
2.6. Related Work on Negation Detection
3. Exploiting Symbolic and Deep NN Approaches in Sentiment Analysis
- Automatic generation of sentiment lexicon (Section 3.1).
- Shifter patterns (Section 3.2).
- Incorporating shifter patterns in the SA system (Section 3.3).
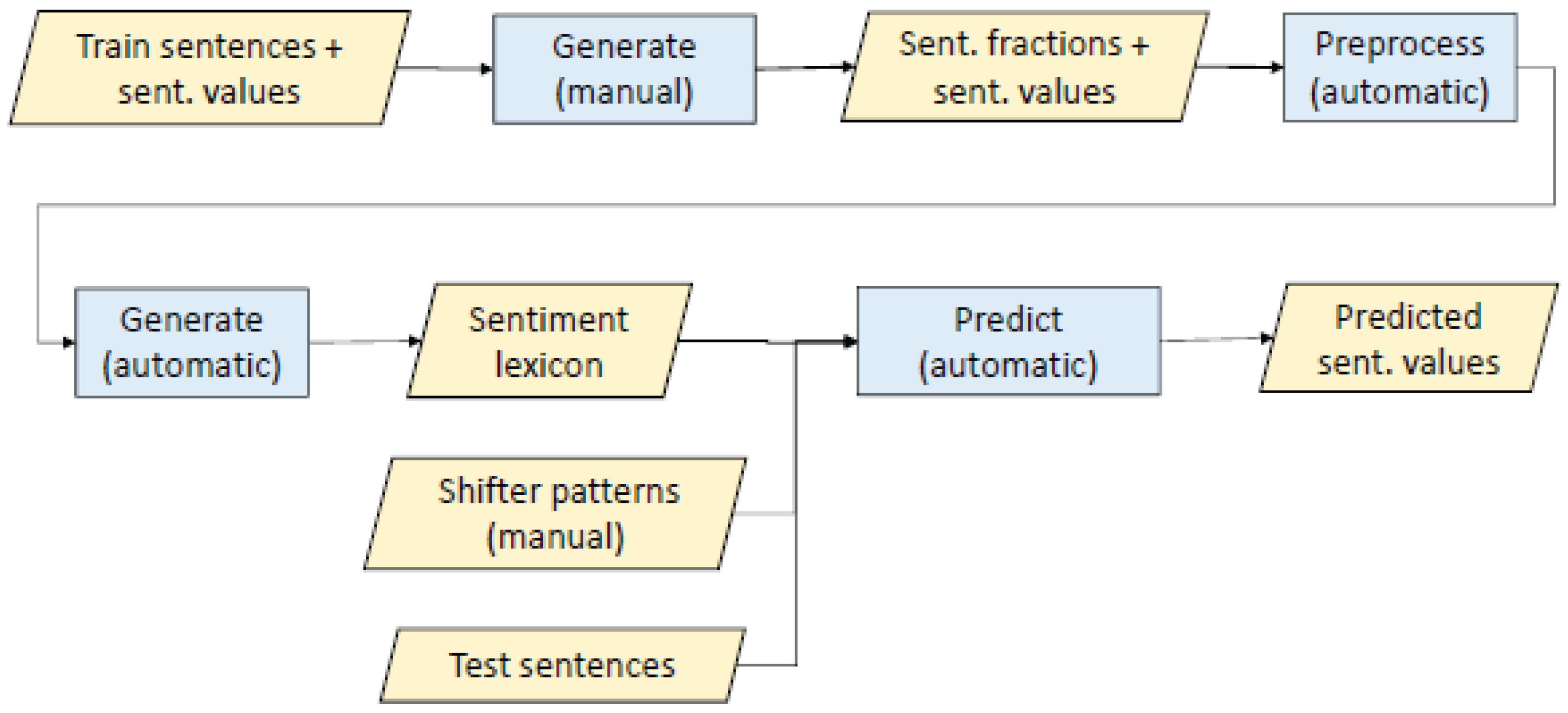
3.1. Automatic Generation of Sentiment Lexicon
- 1.
- Corpus used and its annotation.
- 2.
- Preprocessing.
- 3.
- Separating long sentences into short labeled fractions.
- 4.
- Generation of the sentiment values.
3.1.1. Corpus Used and Its Annotation
3.1.2. Preprocessing
3.1.3. Separating Long Sentences into Shorter Elements
- governar só para os mercados (govern only for the markets)/−1,
- défice (deficit)/−1,
- demonstrar que o défice está melhor (demonstrate that the deficit is better)/1.
3.1.4. Generation of the Sentiment Values
- os impostos baixos (low taxes)/1
- impostos (taxes)/−1
3.1.5. Induced Lexicon: Ecolex
3.1.6. Combining Domain-Specific and General Purpose Lexicons
3.2. Shifter Patterns
3.2.1. Different Types of Shifter Patterns
Intensification
Attenuation/Downtoning
Reversal/Inversion
3.2.2. Methodology Used When Defining Shifter Patterns
- Examine the pattern of opposite polarity.The aim is to determine whether the same shifter can be added to the shifter pattern with opposite polarity. If we apply this strategy to our example, the question is whether the shifter anular (cancel) can also be associated with “RVN-”, as in anular a crise (cancel the crisis). As this seems admissible, we would add this shifter to this shifter pattern.
- Explore the knowledge relative to nominalization of verbs.There is a close relationship between verbal shifters (e.g., anular (cancel)) and other related counterparts, such as, nominalizations (e.g., anulação (cancelation)) and adjectives (e.g., nulo (null)). It would be useful to have a lexicon that lists these related forms; however, to the best of our knowledge, this does not yet exist, and hence this issue needs to be resolved manually. Thus, if one form (e.g., the verbal shifter) was introduced in one pattern, we need to make sure that other patterns include the other related forms.
- Extending shifters by introducing similar terms.This strategy involves searching for words with meaning similar to those introduced. If we consider our example with anular (cancel), we can use a dictionary to suggest other words (shifters) with a similar meaning. The on-line dictionary Priberam lists, for instance, aniquilar (aniquilate), destruir (destroy), exterminar (exterminate). In addition, Infopédia suggests inutilizar (turn unusable) and invalidar (invalidate). Thus, the steps discussed above (in Section 3.2.2) can be repeated with these new candidate shifters. This way, the shifter patterns and the associated shifters can grow rather rapidly, even though the process is manual.
3.3. Incorporating Shifter Patterns in the SA System
- 1.
- Process all portions of the given text (lines) one by one.
- 2.
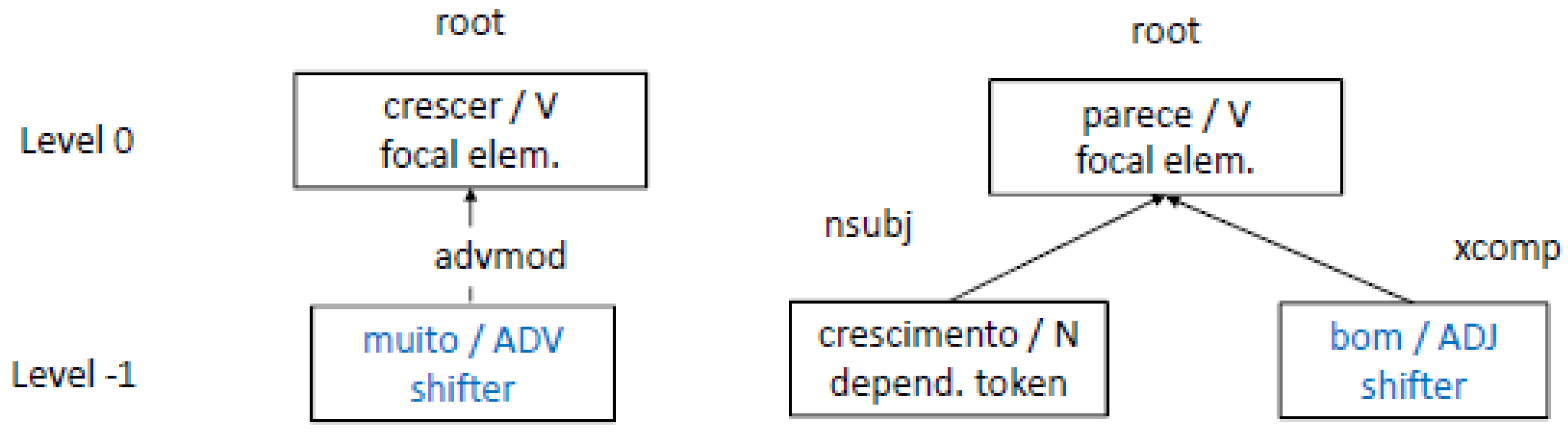
- For each line of text, process all sentences in it one by one. Suppose, for example, the sentence, for the sake of simplicity, is just crescer muito.
- 3.
- For each sentence, generate a dependency tree. The dependency tree for our example is shown in Figure 3.
- 4.
- For each dependency tree, identify all shifter words that appear in it. Then, it is necessary to determine how the order in which these should be processed. Section 3.3.3 provides more details regarding how this was conducted. Considering our example, the system identifies only one shifter—namely, the word muito.
- 5.
- For each identified shifter word, determine all definitions of shifter patterns associated with the respective shifter. Process all the pattern definitions one by one. Considering our example, the system would identify the definition shown in Table 5.
- 6.
- Determine whether the shifter is the head token or the dependent token. Take this information into account when searching for the focal element. Examine whether the focal element satisfies all the requirements stipulated in the definition of the shifter pattern. Check, for instance, whether the focal element is of the required class. Considering the pattern , it should be a verb (V). Our previous example with crescer/V satisfies this condition.
- 7.
- For the focal element found, retrieve its sentiment value from the sentiment lexicon and apply the respective rule to determine the sentiment value of the pattern. Suppose that the sentiment value of the token crescer is . Thus, the sentiment value of the phrase crescer muito is . This value is used as the modified value of this phrase.
- 8.
- Generate an explanation showing how the final sentiment value was calculated and output it on demand. Section 3.3.1 discusses the format of the explanations adopted here.
3.3.1. Explanations Provided by the System
crescer/*0.642/1.285/D muito/S/IAV+
- Sentiment values retrieved from the sentiment lexicon (here “*0.642”). The symbol “*” is used to identify the values retrieved from the sentiment lexicon.
- Sentiment values that have been derived from the values in the sentiment lexicon (here “1.285”).
- symbol “S” that accompanies each shifter identified (here it is associated with the token “muito”).
- Identifier of the shifter pattern(s) identified (here “IAV+”).
- Identification with symbol “D” all tokens that are in the scope of the shifter (here the token “crescer” is accompanied by “D”, as it is in the scope of the shifter “muito”).
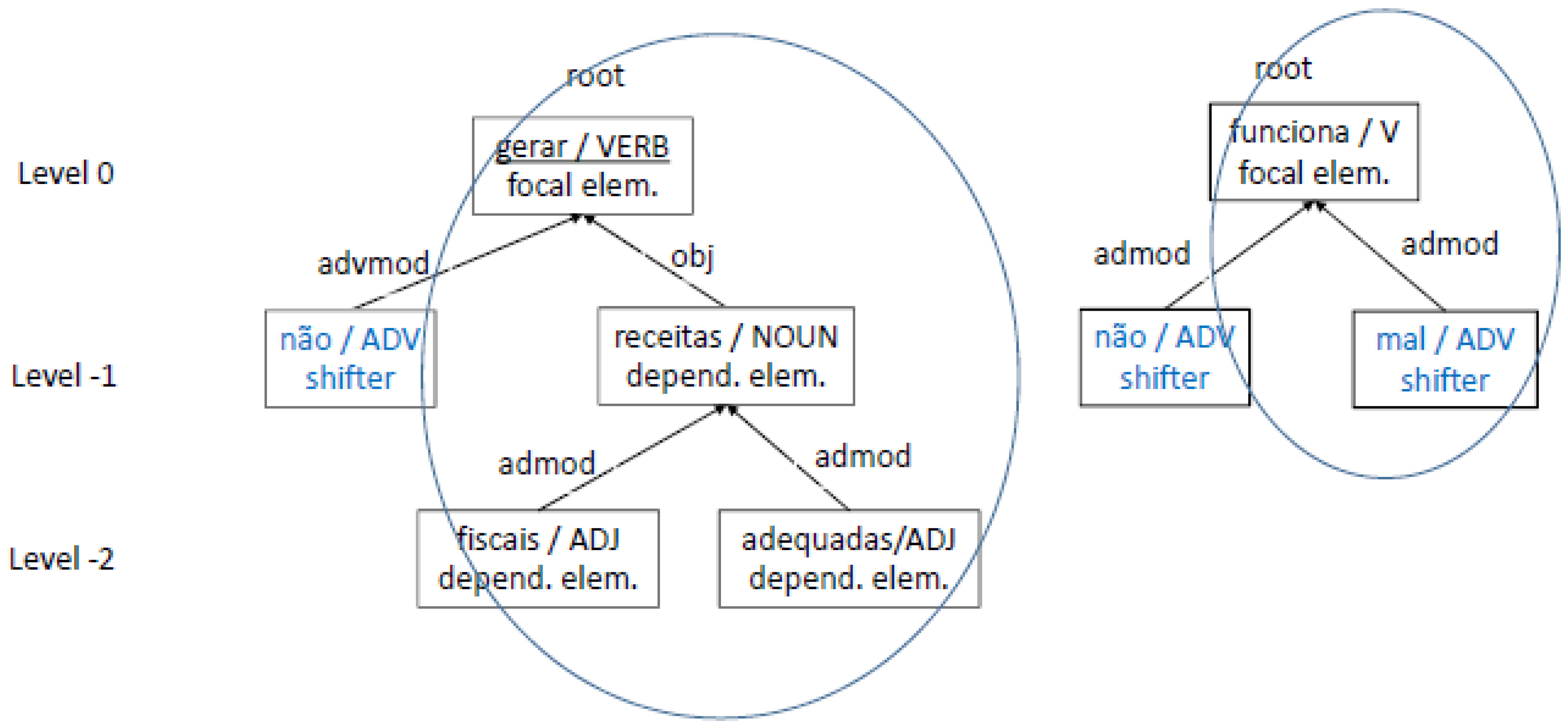
3.3.2. Dealing with Shifters That Affect Multiple Words in Their Scope
não gera receitas fiscais adequadas
(does not generate adequate fiscal income).
não/*−0.401/−0.627/S/RAV+ gera/*0.333/D receitas/D fiscais/D adequadas/*0.4/D
3.3.3. Processing Phrases with Multiple Shifters
não/*−0.401/0.001/S/RAV- funciona/*0.625/D mal/*−0.286/D/RAV+
inverter/*0.4/−1.151/M/RVN+ crescimento/*0.598/D/INN+ economia/*0.445/D
3.4. Applying a Deep Learning Approach to Sentiment Analysis
4. Experimental Setup, Evaluation and Results
4.1. Experimental Setups
- Sentence fractions used for training.
- Sentence fractions used for testing.
- Sentences used for testing.
4.2. Method Used to Construct the Train and Test Sentence Fractions
4.3. Evaluation Measures
4.4. Experiments with the Symbolic Approach
- Ecolex: The induced sentiment lexicon (see Section 3.1.4 and Section 3.1.5).
- Sentilex’ (see Section 3.1.6).
- Eco-Senti-lex: Combination of Ecolex and Sentilex’ (see Section 3.1.6).
4.4.1. Experiments Involving Sentence Fractions
4.4.2. Experiments Involving Sentences
4.5. Deep Learning Approach Experiment
4.6. Limitations of the Symbolic and Deep Learning Approaches
4.6.1. Analysis of Some Errors of the Symbolic Approach
- 1.
- devemos reduzir a dívida (we should reduce the debt) (+),
- 2.
- podemos reduzir a dívida (we can reduce the debt) (+),
- 3.
- é imprescindível reduzir a dívida (it is necessary to reduce the debt) (+) and
- 4.
- quem nos dera a dívida menor (who could arrange us a smaller debt) (−).
4.6.2. Analysis of Some Errors of the Deep-Learning Approach
5. Future Work and Conclusions
5.1. Future Work
5.2. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schulder, M.; Wiegand, M.; Ruppenhofer, J. Automatic generation of lexica for sentiment polarity shifters. Nat. Lang. Eng. 2021, 27, 153–179. [Google Scholar] [CrossRef]
- Yadav, A.; Vishwakarma, D.K. Sentiment analysis using deep learning architectures: A review. Artif. Intell. Rev. 2020, 53, 4335–4385. [Google Scholar] [CrossRef]
- Schulder, M.; Wiegand, M.; Ruppenhofer, J.; Roth, B. Towards bootstrapping a polarity shifter lexicon using linguistic features. In Proceedings of the International Joint Conference on Natural Language Processing (IJCNLP), Taipei, Taiwan, 27 November–1 December 2017; Asian Federation of Natural Language Processing: Taipei, Taiwan, 2017; pp. 624–633. [Google Scholar]
- Trnavac, R.; Das, D.; Taboada, M. Discourse relations and evaluation. Corpora 2016, 11, 169–190. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Forte, A.C.; Brazdil, P.B. Determining the level of clients’ dissatisfaction from their commentaries. In Proceedings of the International Conference on Computational Processing of the Portuguese Language, Tomar, Portugal, 13–15 July 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 74–85. [Google Scholar]
- Silva, F.; Silvano, P.; Leal, A.; Oliveira, F.; Brazdil, P.; Cordeiro, J.; Oliveira, D. Análise de sentimento em artigos de opinião. Linguíst. Rev. Estud. Linguíst. Univ. Porto 2018, 13, 79–114. [Google Scholar]
- Moreno-Ortiz, A.; Fernández-Cruz, J.; Hernández, C.P.C. Design and evaluation of SentiEcon: A fine-grained economic/financial sentiment lexicon from a corpus of business news. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 5065–5072. [Google Scholar]
- Almatarneh, S.; Gamallo, P. Automatic construction of domain-specific sentiment lexicons for polarity classification. In Proceedings of the International Conference on Practical Applications of Agents and Multi-Agent Systems, Porto, Portugal, 21–23 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 175–182. [Google Scholar]
- Muhammad, S.H.; Brazdil, P.; Jorge, A. Incremental Approach for Automatic Generation of Domain-Specific Sentiment Lexicon. In Proceedings of the Advances in Information Retrieval, LNCS, Lisbon, Portugal, 14–17 April 2020; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12036, pp. 619–623. [Google Scholar]
- Brazdil, P.; Silvano, P.; Silva, F.; Muhammad, S.; Oliveira, F.; Cordeiro, J.; Leal, A. Extending General Sentiment Lexicon to Specific Domains in (Semi-)Automatic Manner. In Proceedings of the SALLD-1: Proceedings of the Workshop on Sentiment Analysis & Linguistic Linked Data, Zaragoza, Spain, 1 September 2021; Volume 3064. [Google Scholar]
- Wang, Y.; Zhang, Y.; Liu, B. Sentiment lexicon expansion based on neural PU learning, double dictionary lookup, and polarity association. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Muhammad, A.; Wiratunga, N.; Lothian, R.; Glassey, R. Domain-Based Lexicon Enhancement for Sentiment Analysis. In Proceedings of the BCS SGAI Workshop on Social Media Analysis, Cambridge, UK, 10 December 2013; Citeseer: Gaithersburg, MD, USA, 2013; pp. 7–18. [Google Scholar]
- Hamilton, W.L.; Clark, K.; Leskovec, J.; Jurafsky, D. Inducing domain-specific sentiment lexicons from unlabeled corpora. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 595–605. [Google Scholar]
- Mukhtar, N.; Khan, M.A.; Chiragh, N. Lexicon-based approach outperforms Supervised Machine Learning approach for Urdu Sentiment Analysis in multiple domains. Telemat. Inform. 2018, 35, 2173–2183. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning Based Text Classification: A Comprehensive Review. arXiv 2021, arXiv:2004.03705. [Google Scholar] [CrossRef]
- Dogra, V.; Verma, S.; Kavita; Chatterjee, P.; Shafi, J.; Choi, J.; Ijaz, M. A Complete Process of Text Classification System Using State-of-the-Art NLP Models. Comput. Intell. Neurosci. 2022, 2022. [Google Scholar] [CrossRef] [PubMed]
- Sharfuddin, A.A.; Tihami, M.N.; Islam, M.S. A deep recurrent neural network with BiLSTM model for sentiment classification. In Proceedings of the 2018 International Conference on Bangla Speech and Language Processing (ICBSLP), Sylhet, Bangladesh, 21–22 September 2018; pp. 1–4. [Google Scholar]
- Muhammad, P.F.; Kusumaningrum, R.; Wibowo, A. Sentiment analysis using Word2vec and long short-term memory (LSTM) for Indonesian hotel reviews. Procedia Comput. Sci. 2021, 179, 728–735. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Ouyang, X.; Zhou, P.; Li, C.H.; Liu, L. Sentiment analysis using convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Computer and Information Technology, Ubiquitous Computing and Communications Dependable, Autonomic and Secure Computing, Pervasive Intelligence and Computing, Liverpool, UK, 26–28 October 2015; pp. 2359–2364. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Grote, H.; Schmidt, F. MAD-X-an upgrade from MAD8. In Proceedings of the 2003 Particle Accelerator Conference, Portland, OR, USA, 12–16 May 2003; Volume 5, pp. 3497–3499. [Google Scholar]
- Muhammad, S.H.; Adelani, D.I.; Ahmad, I.S.; Abdulmumin, I.; Bello, B.S.; Choudhury, M.; Emezue, C.C.; Aremu, A.; Abdul, S.; Brazdil, P. NaijaSenti: A Nigerian Twitter Sentiment Corpus for Multilingual Sentiment Analysis. arXiv 2022, arXiv:2201.08277. [Google Scholar]
- van Atteveldt, W.; van der Velden, M.A.; Boukes, M. The Validity of Sentiment Analysis: Comparing Manual Annotation, Crowd-Coding, Dictionary Approaches, and Machine Learning Algorithms. Commun. Methods Meas. 2021, 15, 121–140. [Google Scholar] [CrossRef]
- Tavares, C.; Ribeiro, R.; Batista, F. Sentiment Analysis of Portuguese Economic News. In Proceedings of the tenth Symposium on Languages, Applications and Technologies (SLATE 2021), Vila do Conde/Póvoa de Varzim, Portugal, 1–2 July 2021; Schloss Dagstuhl-Leibniz-Zentrum für Informatik: Wadern, Germany, 2021; Volume 94, pp. 17:1–17:13. [Google Scholar]
- Mudinas, A.; Zhang, D.; Levene, M. Combining lexicon and learning based approaches for concept-level sentiment analysis. In Proceedings of the first International Workshop on Issues of Sentiment Discovery and Opinion Mining, Beijing, China, 12–16 August 2012; pp. 1–8. [Google Scholar]
- Zou, Y.; Gui, T.; Zhang, Q.; Huang, X.J. A lexicon-based supervised attention model for neural sentiment analysis. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 868–877. [Google Scholar]
- Hitzler, P.; Sarker, M.K. Neuro-Symbolic Artificial Intelligence: State of the Art; IOS Press: Dordrecht, The Netherlands, 2022. [Google Scholar]
- Besold, T.R.; d’Avila Garcez, A.; Bader, S.; Bowman, H.; Domingos, P.; Hitzler, P.; Kühnberger, K.U.; Lamb, L.C.; Lima, P.M.V.; de Penning, L.; et al. Neural-Symbolic Learning and Reasoning: A Survey and Interpretation. In Neuro-symbolic Artificial intelligence: State of the Art; Hitzler, P., Sarker, M.K., Eds.; IOS Press: Dordrecht, The Netherlands, 2022; pp. 1–51. [Google Scholar]
- Solarte, O.; Montenegro, O.; Torrente, M.; González, A.R.; Provencio, M.; Menasalvas, E. Negation and uncertainty detection in clinical texts written in Spanish: A deep learning-based approach. PeerJ Comput. Sci. 2022, 8, e913. [Google Scholar]
- Schöne, J.P.; Parkinson, B.; Goldenberg, A. Negativity spreads more than positivity on Twitter after both positive and negative political situations. Affect. Sci. 2021, 2, 379–390. [Google Scholar] [PubMed]
- Martin, J.R.; White, P.R. The Language of Evaluation: Appraisal in English; Palgrave Macmillan: London, UK, 2005. [Google Scholar]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based methods for sentiment analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar]
- Silva, M.J.; Carvalho, P.; Sarmento, L. Building a sentiment lexicon for social judgement mining. In Proceedings of the International Conference on Computational Processing of the Portuguese Language (PROPOR), Coimbra, Portugal, 17–20 April 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 218–228. [Google Scholar]
- Carvalho, P.; Silva, M.J. SentiLex-PT: Principais características e potencialidades. Oslo Stud. Lang. 2015, 7, 425–438. [Google Scholar] [CrossRef]
- Polanyi, L.; Zaenen, A. Contextual valence shifters. In Computing Attitude and Affect in Text: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–10. [Google Scholar]
- van Rijsbergen, C. Information Retrieval, 2nd ed.; Butterworth-Heinemann: Woburn, MA, USA, 1979. [Google Scholar]
- Souza, F.; Nogueira, R.; Lotufo, R. BERTimbau: Pretrained BERT Models for Brazilian Portuguese. In Proceedings of the Brazilian Conference on Intelligent Systems, Rio Grande, Brazil, 20–23 October 2010; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2020; Volume 12319. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentence | Translation | Val. |
|---|---|---|
| Portugal não pode estar a governar só para os mercados, ou seja, para tentar demonstrar que o défice está melhor. | Portugal cannot govern only for the markets, that is, try to demonstrate that the deficit is better. | −1 |
| Governo mostra-se mais inseguro e débil, e sem um rumo definido. | Government appears more insecure and weak and without a defined direction. | −2 |
| Quem lida com a exportação de serviços sabe que a falta de qualificação dos portugueses é uma falsa questão. | Anyone who deals with the export of services knows that the lack of qualifications of the Portuguese is a false issue. | 1 |
| O saldo positivo das nossas trocas compensa largamente o financiamento das atividades do país. | The positive balance of our exchanges largely compensates for the financing of the country’s activities. | 2 |
| Ecolex | Sentilex’ | |||
|---|---|---|---|---|
| Word | SV | Class | Word/Idiom | SV |
| resolver (resolve) | 0.909 | V | - | - |
| bom (good) | 0.897 | ADJ | bom | 1 |
| felizmente (luckily) | 0.889 | ADV | - | - |
| corrigir (correct) | 0.880 | V | corrigir | 1 |
| qualidade (quality) | 0.857 | N | - | - |
| amenizar (soften) | 0.854 | V | - | - |
| responsabilidade (responsability) | 0.851 | N | responsabilidade | −1 |
| importante (important) | 0.845 | ADJ | - | - |
| ganhar (win) | 0.835 | V | ganhar | 1 |
| capacidade (capacity) | 0.824 | N | - | - |
| Class | Count | % |
|---|---|---|
| N (noun) | 595 | 47.8 |
| V (verb) | 329 | 26.5 |
| ADJ | 251 | 20.1 |
| ADV | 64 | 5.1 |
| PRON | 3 | 0.2 |
| Other | 4 | 0.3 |
| Total | 1246 | 100 |
| sno | token_id | token | upos | head token_id | dep_rel |
|---|---|---|---|---|---|
| 1 | 1 | crescer | V | 0 | root |
| 1 | 2 | muito | ADV | 1 | advmod |
| 2 | 1 | crescimento | N | 2 | nsubj |
| 2 | 2 | parece | V | 0 | root |
| 2 | 3 | bom | ADJ | 2 | xcomp |
| Id | Shifter Pat. | Token 1 | Token 2 | |S| | Use |
|---|---|---|---|---|---|
| IAV+ | (F = crescer (grow)) | S = muito (very much) | 28 | 2.7 | |
| IAV- | (F = prejudicar (harm)) | S = muito (very much) | 10 | 1.5 | |
| IAJ+ | S = muito (very) | (F = satisfatório (satisfactory)) | 29 | 6.8 | |
| IAJ- | S = muito (very) | (F = negativo (negative)) | 11 | 4.3 | |
| IJN+ | S = bom (good) | (F = crescimento (growth)) | 23 | 9.5 | |
| IJN- | S = mau (bad) | (F = crise (crisis)) | 10 | 3.3 | |
| IV’N+ | S = reforçar (reinforce) | (F = crescimento (growth)) | 20 | 2.3 | |
| IV’N- | S = ampliar (amplify) | (F = crise (crisis)) | 15 | 1.8 | |
| IVN+ | (F = crescimento (growth)) | S = reforçado (reinforced) | 20 | 0.8 | |
| IVN- | (F = crise (crisis) | S = ampliado (amplified) | 15 | 0.3 | |
| IN’N+ | S = aumento (increase of) | (F = crescimento (growth)) | 11 | 0.7 | |
| IN’N- | S = aumento (increase of) | (F = despesa (expenditure)) | 8 | 0.8 | |
| INN+ | (S = crescimento (growth)) | F = aumentado (increased) | 11 | 0.8 | |
| INN- | (S = despesa (expenditure)) | F = aumentado (increased) | 8 | 1.0 |
| Id | Shifter Pat. | Token 1 | Token 2 | |S| | Use |
|---|---|---|---|---|---|
| AAV+ | (F = crescer (grow)) | S = pouco (not much) | 5 | 0.8 | |
| AAV- | (F = prejudicar (harm)) | S = pouco (not much) | 4 | 0.7 | |
| AAJ+ | S = pouco (not much) | (F = satisfatório (satisfactory)) | 4 | 1.8 | |
| AAJ- | S = pouco (not much) | (F = negativo (negative)) | 4 | 0.8 | |
| AJN+ | S = fraco (weak) | (F = crescimento (growth)) | 12 | 1.2 | |
| AJN- | S = fraca (weak) | (F = crise (crisis)) | 7 | 1.3 | |
| AV’N+ | S = diminuir (decrease) | (F = crescimento (growth)) | 8 | 0.7 | |
| AV’N- | S = controlar (control) | (F = despesa (expenditure)) | 23 | 1.5 | |
| AVN+ | (F = crescimento (growth)) | S = diminuído (decreased) | 8 | 0.7 | |
| AVN- | (F = crise (crisis)) | S = controlado (controled) | 23 | 1.5 | |
| AN’N+ | S = diminuição (decrease of) | (F = crescimento (growth)) | 5 | 0.0 | |
| AN’N- | S = diminuição (decrease of) | (F = despesa (expenditure)) | 5 | 0.2 | |
| ANN+ | (S = crescimento (growth)) | F = diminuido (decreased) | 5 | 0.8 | |
| ANN- | (S = despesa (expenditure)) | F = diminuido (decreased) | 5 | 1.0 |
| Id | Shifter Pat. | Token 1 | Token 2 | |S| | Use |
|---|---|---|---|---|---|
| RAV+ | S = não (not) | (F = crescer (grow)) | 12 | 0.7 | |
| RAV- | S = não (not) | (F = prejudicar (harm)) | 12 | 6.2 | |
| RAJ+ | S = não (not) | (F = satisfatório (satisfactory)) | 6 | 1.0 | |
| RAJ- | S = não (not) | (F = mau (bad)) | 6 | 1.0 | |
| RAN+ | S = não (no) | (F = crescimento (growth)) | 7 | 3.7 | |
| RAN- | S = não (no) | (F = crise (crisis)) | 7 | 3.3 | |
| RV’N+ | S = inverter (reverse) | (F = crescimento (growth)) | 22 | 1.7 | |
| RV’N- | S = inverter (reverse) | (F = crise (crisis)) | 13 | 0.7 | |
| RVN+ | (F = crescimento (growth)) | S = invertido (reversed) | 22 | 0.3 | |
| RVN- | (F = crise (crisis)) | S = reduzida (reduced) | 13 | 0.0 | |
| RN’N+ | S = inversão (reversal) | (F = crescimento (growth)) | 21 | 0.3 | |
| RN’N- | S = redução (reduction) | (F = despesa (expenditure)) | 12 | 0.2 | |
| RNN+ | (S = crescimento (growth)) | F = reduzido (reduced) | 5 | 0.8 | |
| RNN- | (S = dívida (debt)) | F = reduzido (reduced) | 5 | 1.0 | |
| RVV+ | S = faltar (fail to) | (F = crescer (grow)) | 1 | 0.2 |
| Setup | 1 | 2 | 3 | 4 | 5 | 6 | Mean |
|---|---|---|---|---|---|---|---|
| Train set (fractions) | 1422 | 1452 | 1577 | 1570 | 1475 | 1246 | 1457.0 |
| % of negative | 51.0 | 49.9 | 48.3 | 48.1 | 48.7 | 53.4 | 49.9 |
| Test set (fractions) | 332 | 291 | 183 | 188 | 269 | 497 | 292.3 |
| % of negative | 44.6 | 49.1 | 62.3 | 63.8 | 55.8 | 40.4 | 52.7 |
| Test set (sentences) | 59 | 68 | 66 | 70 | 68 | 67 | 66.3 |
| % of negative | 66.1 | 75.0 | 69.7 | 67.1 | 85.3 | 35.8 | 66.5 |
| Setup | 1 | 2 | 3 | 4 | 5 | 6 | Mean |
|---|---|---|---|---|---|---|---|
| Ecolex | 1246 | 1230 | 1280 | 1220 | 1227 | 1162 | 1227.5 |
| Sentilex’ | 5496 | 5496 | 5496 | 5496 | 5496 | 5496 | 5496 |
| Eco-Senti-lex | 6561 | 6561 | 6583 | 6541 | 6551 | 6480 | 6546.2 |
| Setup | 1 | 2 | 3 | 4 | 5 | 6 | Mean |
|---|---|---|---|---|---|---|---|
| SA-Ecolex | 68.6 | 68.8 | 67.4 | 70.5 | 62.9 | 66.9 | 67.5 |
| SAP-Ecolex | 66.7 | 69.9 | 68.9 | 69.5 | 65.0 | 64.6 | 67.6 |
| SA-Sentilex’ | 51.1 | 47.0 | 66.4 | 60.5 | 57.6 | 46.3 | 55.0 |
| SAP-Sentilex’ | 46.6 | 47.8 | 68.1 | 60.5 | 57.6 | 43.9 | 54.1 |
| SA-Eco-Senti-lex | 71.8 | 68.5 | 68.6 | 69.1 | 65.9 | 68.6 | 68.8 |
| SAP-Eco-Senti-lex | 71.3 | 70.8 | 68.6 | 68.6 | 68.5 | 67.0 | 69.5 |
| Setup | 1 | 2 | 3 | 4 | 5 | 6 | Mean |
|---|---|---|---|---|---|---|---|
| SA-Ecolex | 54.7 | 65.6 | 62.1 | 60.9 | 61.7 | 63.4 | 61.4 |
| SAP-Ecolex | 68.5 | 65.3 | 69.0 | 60.0 | 72.4 | 61.7 | 66.2 |
| SA-Sentilex’ | 71.0 | 70.3 | 62.8 | 63.0 | 70.9 | 61.6 | 66.2 |
| SAP-Sentilex’ | 69.8 | 72.8 | 66.1 | 55.5 | 32.1 | 63.2 | 59.9 |
| SA-Eco-Senti-lex | 56.2 | 68.0 | 65.1 | 63.7 | 59.4 | 62.0 | 62.4 |
| SAP-Eco-Senti-lex | 61.7 | 60.2 | 76.5 | 68.1 | 67.3 | 64.7 | 66.4 |
| Run|Setup | 1 | 2 | 3 | 4 | 5 | 6 | Mean |
|---|---|---|---|---|---|---|---|
| 1 | 82.6 | 78.4 | 74.1 | 73.9 | 78.1 | 73.9 | 76.8 |
| 2 | 77.8 | 77.5 | 76.2 | 75.7 | 79.9 | 75.7 | 77.1 |
| 3 | 81.9 | 69.6 | 66.5 | 74.0 | 78.1 | 74.0 | 74.0 |
| 4 | 81.6 | 74.9 | 71.7 | 74.8 | 75.8 | 76.3 | 75.9 |
| 5 | 80.2 | 81.9 | 74.2 | 71.2 | 76.3 | 71.2 | 75.3 |
| Mean | 80.4 | 76.5 | 72.5 | 73.9 | 77.6 | 74.2 | 75.9 |
| Run|Setup | 1 | 2 | 3 | 4 | 5 | 6 | Mean |
|---|---|---|---|---|---|---|---|
| 1 | 78.4 | 77.8 | 74.0 | 52.8 | 79.3 | 52.8 | 69.2 |
| 2 | 77.5 | 76.7 | 76.2 | 40.9 | 75.2 | 40.9 | 60.3 |
| 3 | 69.6 | 72.0 | 66.5 | 52.8 | 79.7 | 54.8 | 65.9 |
| 4 | 74.9 | 74.7 | 75.3 | 54.6 | 81.6 | 54.6 | 69.3 |
| 5 | 81.9 | 77.9 | 72.1 | 37.8 | 84.7 | 37.8 | 51.2 |
| Mean | 76.5 | 75.8 | 72.8 | 47.8 | 80.1 | 47.8 | 66.8 |
| No | Term/Phrase | True | Pred. |
|---|---|---|---|
| 1 | custo (cost) | − | + |
| 2 | desajustada (maladjusted) | − | + |
| 3 | limpar (clean) | + | − |
| 4 | rentável (profitable) | + | − |
| 5 | resolver problema (resolve the problem) | + | − |
| 6 | não é um problema económico (it is not an economic problem) | + | − |
| 7 | têm de ser resolvidos (have to be resolved) | + | − |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brazdil, P.; Muhammad, S.H.; Oliveira, F.; Cordeiro, J.; Silva, F.; Silvano, P.; Leal, A. Semi-Automatic Approaches for Exploiting Shifter Patterns in Domain-Specific Sentiment Analysis. Mathematics 2022, 10, 3232. https://0-doi-org.brum.beds.ac.uk/10.3390/math10183232
Brazdil P, Muhammad SH, Oliveira F, Cordeiro J, Silva F, Silvano P, Leal A. Semi-Automatic Approaches for Exploiting Shifter Patterns in Domain-Specific Sentiment Analysis. Mathematics. 2022; 10(18):3232. https://0-doi-org.brum.beds.ac.uk/10.3390/math10183232
Chicago/Turabian StyleBrazdil, Pavel, Shamsuddeen H. Muhammad, Fátima Oliveira, João Cordeiro, Fátima Silva, Purificação Silvano, and António Leal. 2022. "Semi-Automatic Approaches for Exploiting Shifter Patterns in Domain-Specific Sentiment Analysis" Mathematics 10, no. 18: 3232. https://0-doi-org.brum.beds.ac.uk/10.3390/math10183232