
Influenza-like Illness Detection from Arabic Facebook Posts Based on Sentiment Analysis and 1D Convolutional Neural Network


Abstract
:1. Introduction
2. Background and Related Work
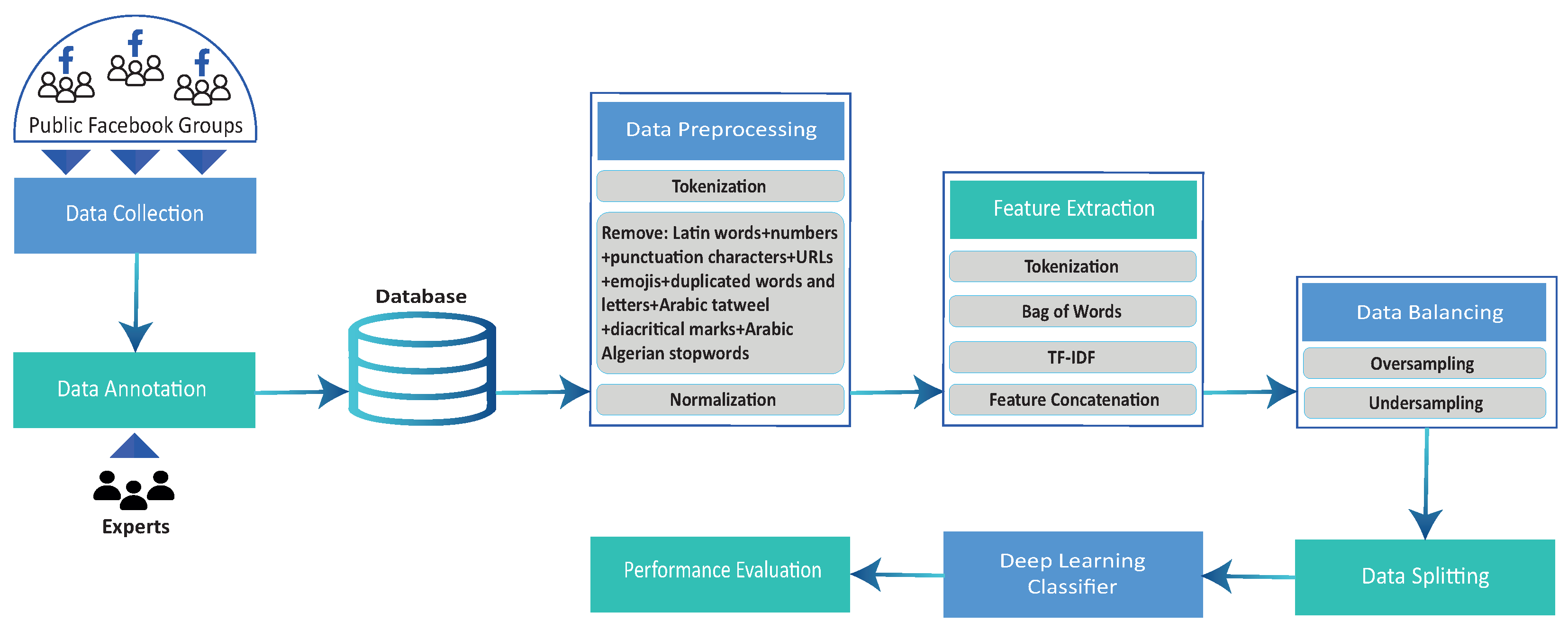
3. Methodology and Proposed Approach
3.1. Data Collection
3.2. Data Annotation
- Positive: This category contains the postings whose authors claim they are experiencing ILI symptoms (such as fever, cough, sore throat, runny or stuffy nose, headaches, muscle aches, etc.) or new symptoms connected with COVID-19 (e.g., loss of taste or smell, difficulty breathing, chest pain).
- Negative-related: This category covers posts that do not indicate that the person is ill, but do provide medical advice or information regarding ILI symptoms.
- Unrelated: This category contains posts that are not related to ILI.
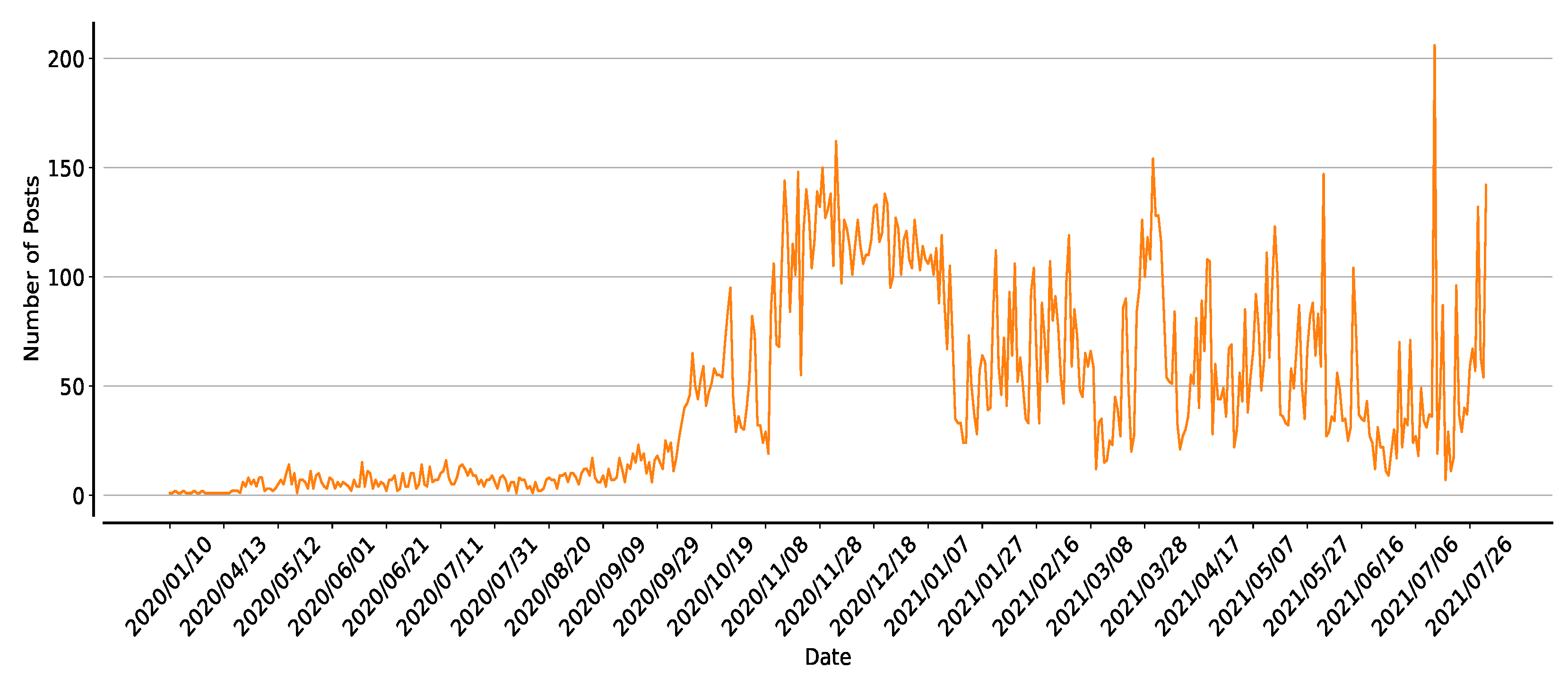
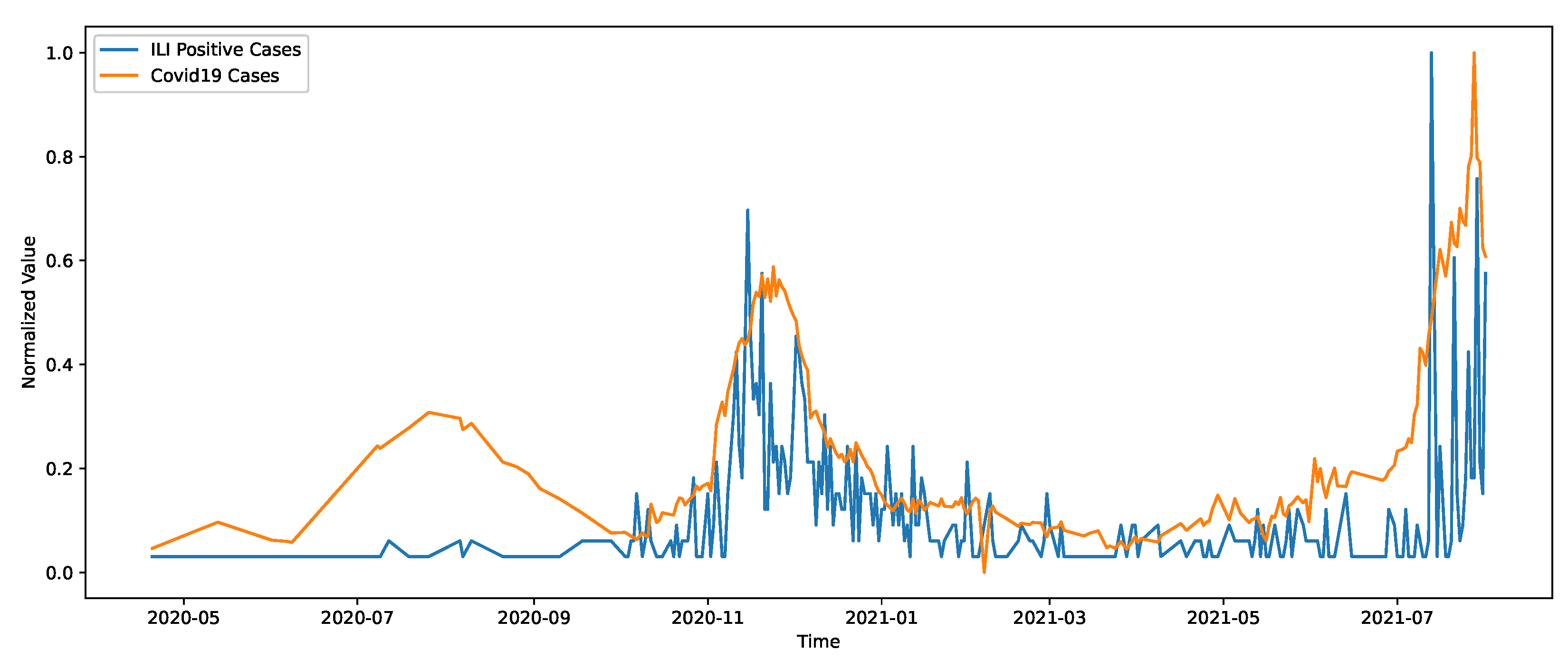
3.3. Data Analysis and Motivation
3.4. Data Preprocessing
3.5. Feature Engineering
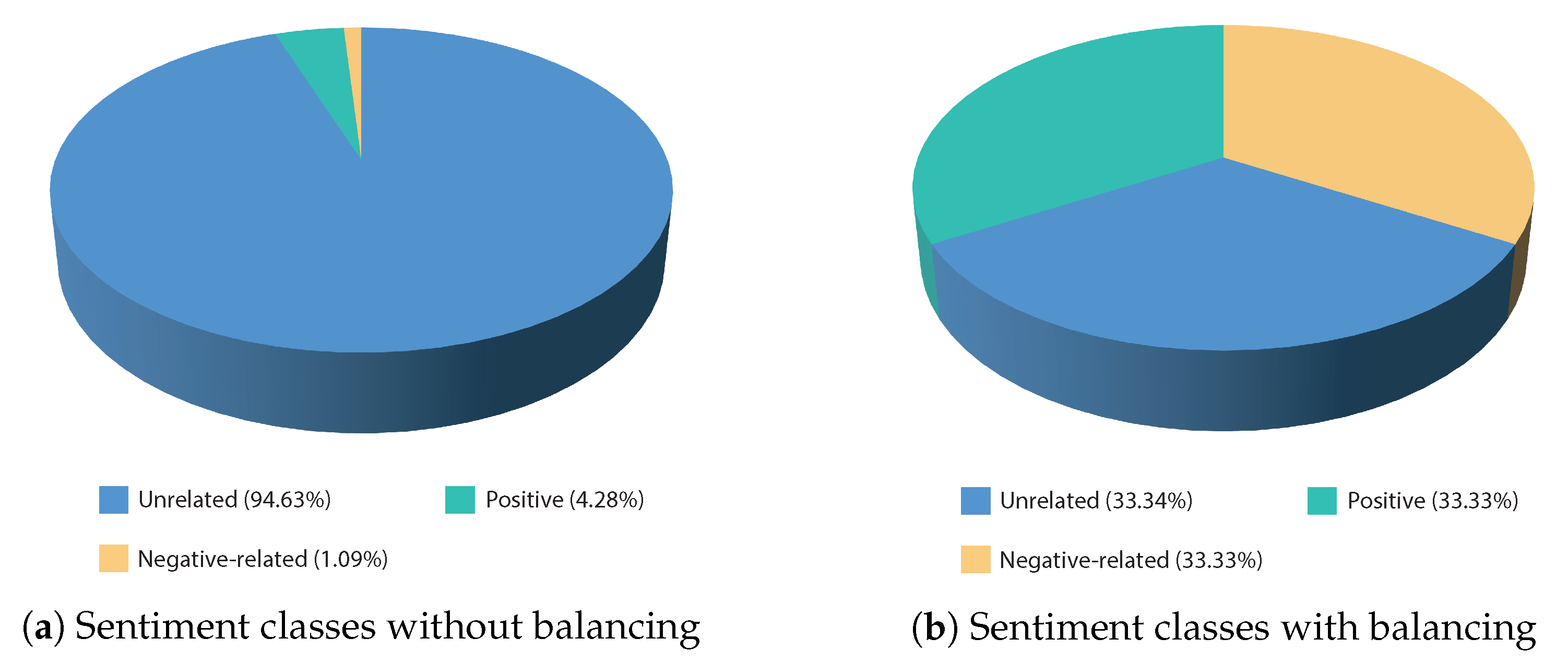
3.6. Data Balancing
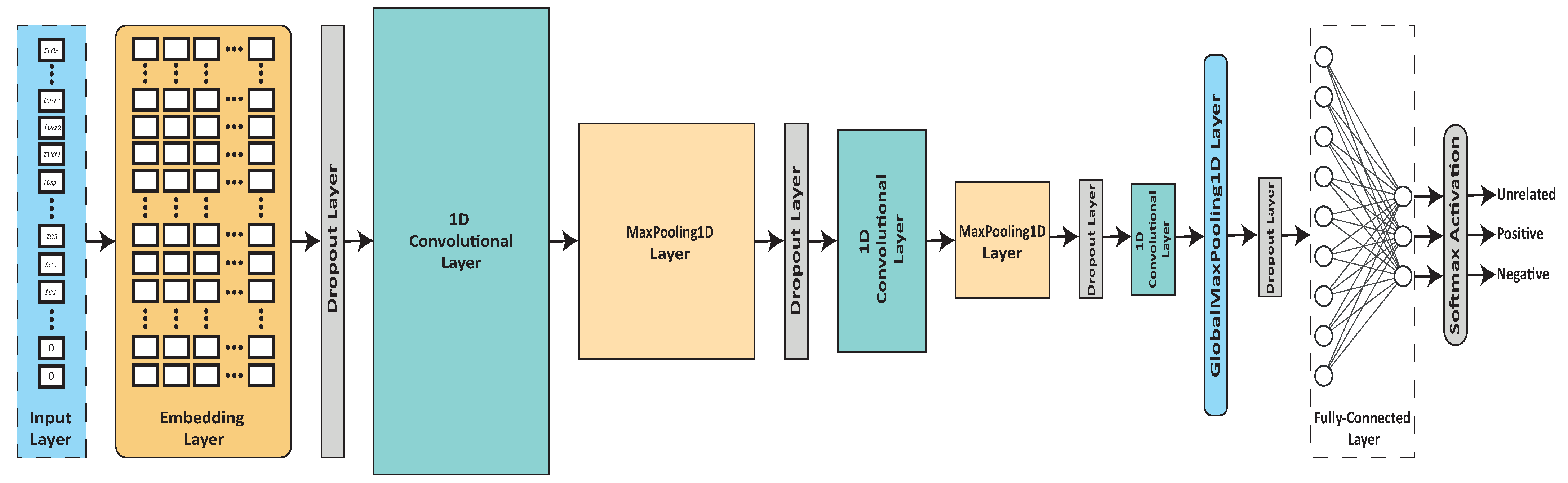
3.7. Sentiment Classification Using Deep Learning Model
4. Experiments and Analysis
4.1. Evaluation Metrics
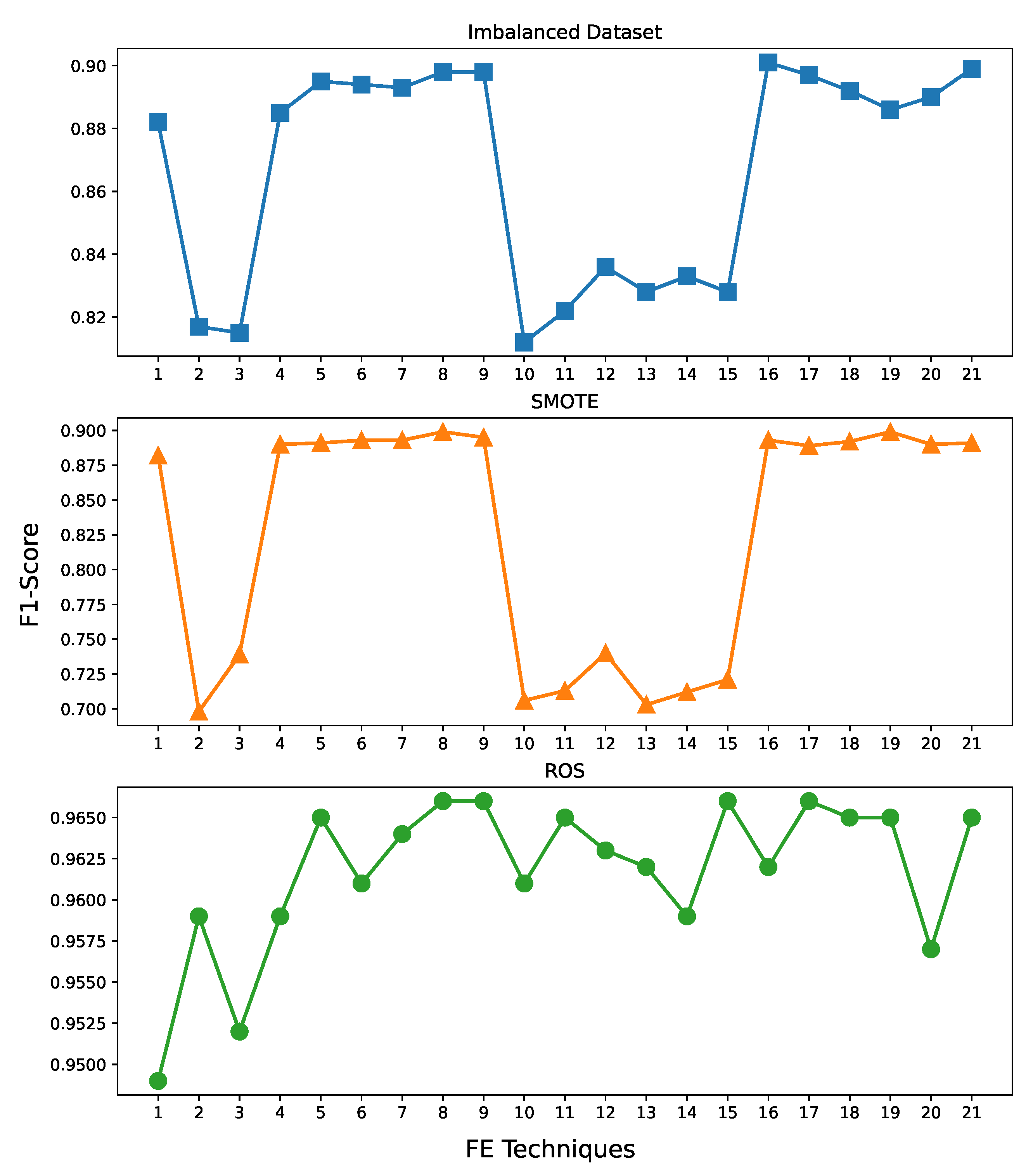
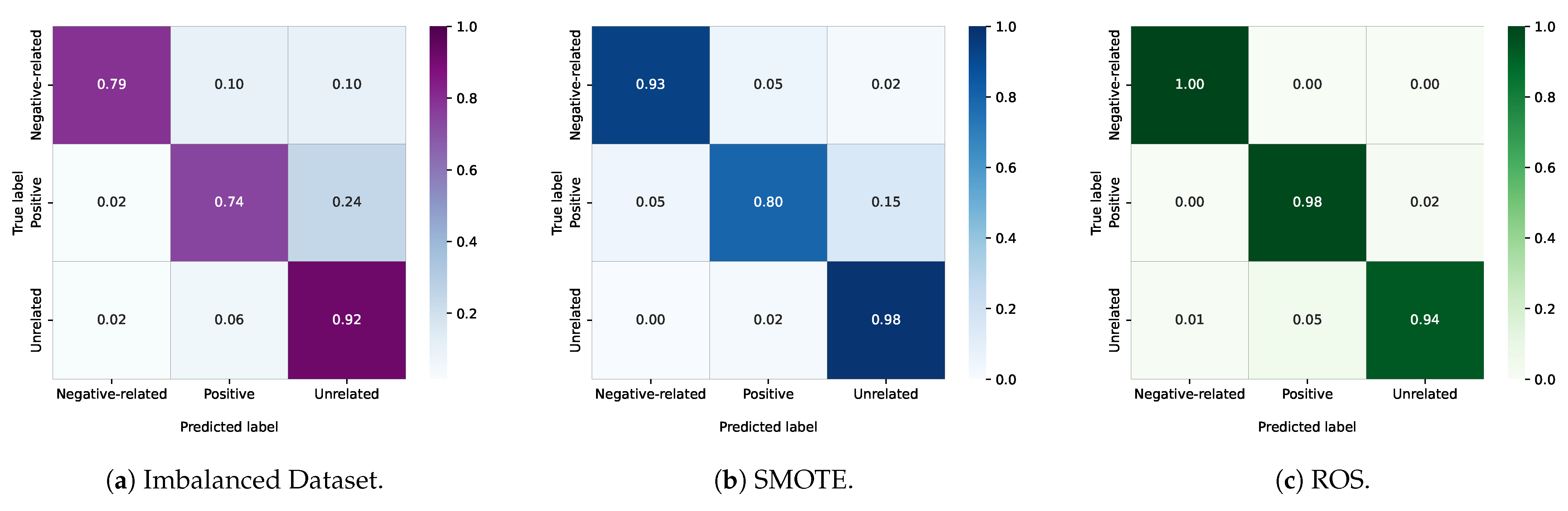
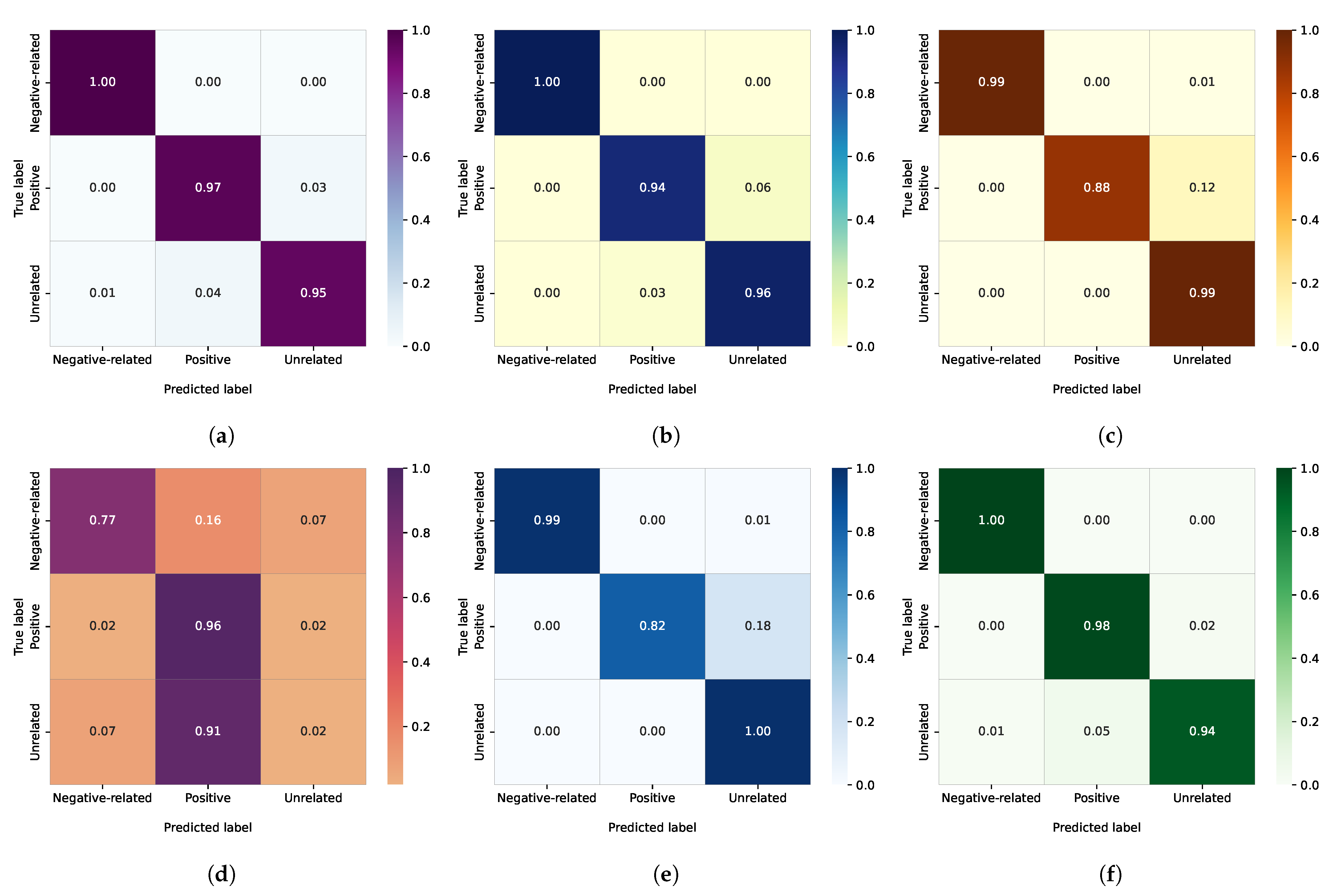
4.2. Performance Results and Analysis
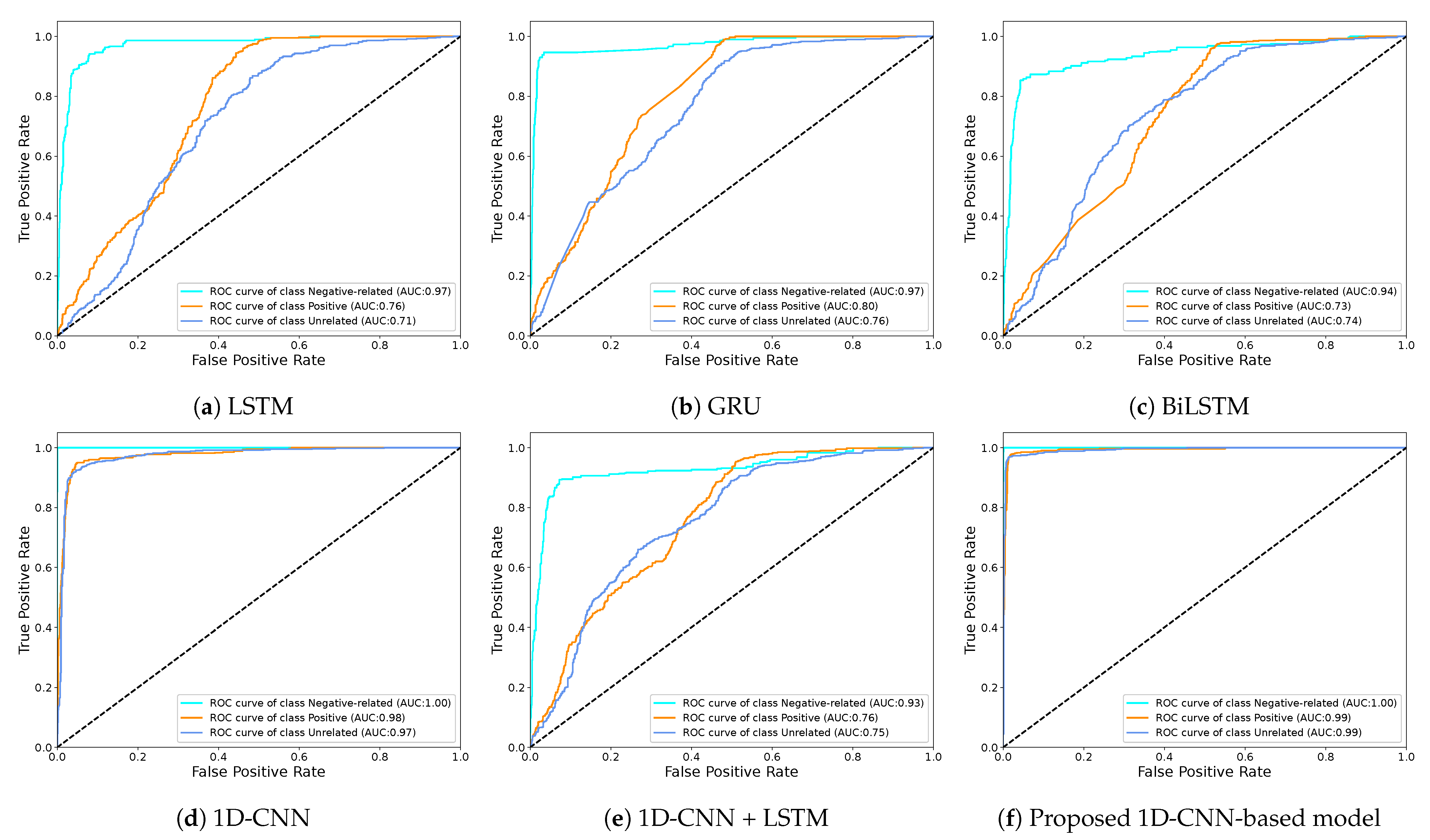
4.3. Comparison with Baselines
- LSTM is a type of recurrent neural network that uses different gates to learn long-term dependencies. It has been widely used for several sentiment classification tasks [81]. In this study, this model uses one LSTM layer with 128 neurons;
- GRU is a simpler and faster version of LSTM used widely in sequence problems. It consists of two gated functions: an update gate and a reset gate. The architecture of this model consists of one GRU layer with 64 neurons;
- BiLSTM is a sequence processing model with two LSTMs, one of which processes sequence data forward and the other backward. For this model, we use one bidirectional LSTM layer with 64 neurons;
- 1D-CNN is a feed-forward artificial neural network [82] that has been successfully used in various tasks related to NLP due to its remarkable ability to extract syntactic and semantic features. The architecture of this baseline consists of one 1D-CNN layer with 64 neurons, MaxPooling1D layer, and Flatten layer;
- 1D-CNN + LSTM is a hybrid deep learning model constructed by CNN and LSTM networks and thus combines the advantages of these two networks. In this model, we use the same layers in a 1D-CNN baseline with 128 neurons, followed by an LSTM layer with 64 neurons.
4.4. Comparison with the State-of-the-Art Models

5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rathore, A.K.; Kar, A.K.; Ilavarasan, P.V. Social Media Analytics: Literature Review and Directions for Future Research. Decis. Anal. 2017, 14, 229–249. [Google Scholar] [CrossRef]
- Alalwan, A.A.; Rana, N.P.; Dwivedi, Y.K.; Algharabat, R. Social media in marketing: A review and analysis of the existing literature. Telemat. Inform. 2017, 34, 1177–1190. [Google Scholar] [CrossRef] [Green Version]
- Anstead, N.; O’Loughlin, B. Social Media Analysis and Public Opinion: The 2010 UK General Election. J. Comput.-Mediat. Commun. 2014, 20, 204–220. [Google Scholar] [CrossRef] [Green Version]
- Zeng, B.; Gerritsen, R. What do we know about social media in tourism? A review. Tour. Manag. Perspect. 2014, 10, 27–36. [Google Scholar] [CrossRef]
- Yang, F.C.; Lee, A.J.; Kuo, S.C. Mining Health Social Media with Sentiment Analysis. J. Med. Syst. 2016, 40, 236. [Google Scholar] [CrossRef]
- Haber, I.E.; Toth, M.; Hajdu, R.; Haber, K.; Pinter, G. Exploring Public Opinions on Renewable Energy by Using Conventional Methods and Social Media Analysis. Energies 2021, 14, 3089. [Google Scholar] [CrossRef]
- Corbett, J.; Savarimuthu, B.T.R. From tweets to insights: A social media analysis of the emotion discourse of sustainable energy in the United States. Energy Res. Soc. Sci. 2022, 89, 102515. [Google Scholar] [CrossRef]
- DataReportal. Digital 2022: Global Overview Report. 2022. Available online: https://datareportal.com/reports/digital-2022-global-overview-report (accessed on 1 September 2022).
- DataReportal. Digital 2022: Algeria. 2022. Available online: https://datareportal.com/reports/digital-2022-algeria (accessed on 1 September 2022).
- CDC. Overview of Influenza Surveillance in United States. USA: Department of Health and Human Services, Center for Disease Control. 2020. Available online: https://www.cdc.gov/flu/weekly/overview.htm (accessed on 8 February 2021).
- Guan, W.-J.; Ni, Z.-Y.; Hu, Y.; Liang, W.-H.; Ou, C.-Q.; He, J.-X.; Liu, L.; Shan, H.; Lei, C.-L.; Hui, D.S.; et al. Clinical Characteristics of Coronavirus Disease 2019 in China. N. Engl. J. Med. 2020, 382, 1708–1720. [Google Scholar] [CrossRef]
- Murtas, R.; Decarli, A.; Russo, A.G. Trend of pneumonia diagnosis in emergency departments as a COVID-19 surveillance system: A time series study. BMJ Open 2021, 11, e044388. [Google Scholar] [CrossRef]
- Rustam, F.; Khalid, M.; Aslam, W.; Rupapara, V.; Mehmood, A.; Choi, G.S. A performance comparison of supervised machine learning models for Covid-19 tweets sentiment analysis. PLOS ONE 2021, 16, e0245909. [Google Scholar] [CrossRef]
- Chakraborty, K.; Bhatia, S.; Bhattacharyya, S.; Platos, J.; Bag, R.; Hassanien, A.E. Sentiment Analysis of COVID-19 tweets by Deep Learning Classifiers—A study to show how popularity is affecting accuracy in social media. Appl. Soft Comput. 2020, 97, 106754. [Google Scholar] [CrossRef] [PubMed]
- Naseem, U.; Razzak, I.; Khushi, M.; Eklund, P.W.; Kim, J. COVIDSenti: A Large-Scale Benchmark Twitter Data Set for COVID-19 Sentiment Analysis. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1003–1015. [Google Scholar] [CrossRef] [PubMed]
- Lim, S.; Tucker, C.S.; Kumara, S. An unsupervised machine learning model for discovering latent infectious diseases using social media data. J. Biomed. Inform. 2017, 66, 82–94. [Google Scholar] [CrossRef] [PubMed]
- García-Díaz, J.A.; Apolinario-Arzube, Ó.; Medina-Moreira, J.; Luna-Aveiga, H.; Lagos-Ortiz, K.; Valencia-García, R. Sentiment Analysis on Tweets related to infectious diseases in South America. In Proceedings of the Euro American Conference on Telematics and Information Systems, Fortaleza, Brazil, 12–15 November 2018. [Google Scholar] [CrossRef]
- Babu, N.V.; Kanaga, E.G.M. Sentiment Analysis in Social Media Data for Depression Detection Using Artificial Intelligence: A Review. SN Comput. Sci. 2021, 3, 74. [Google Scholar] [CrossRef]
- Hassan, A.U.; Hussain, J.; Hussain, M.; Sadiq, M.; Lee, S. Sentiment analysis of social networking sites (SNS) data using machine learning approach for the measurement of depression. In Proceedings of the 2017 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 18–20 October 2017. [Google Scholar] [CrossRef]
- Joshi, M.L.; Kanoongo, N. Depression detection using emotional artificial intelligence and machine learning: A closer review. Mater. Today Proc. 2022, 58, 217–226. [Google Scholar] [CrossRef]
- Hinduja, S.; Afrin, M.; Mistry, S.; Krishna, A. Machine learning-based proactive social-sensor service for mental health monitoring using twitter data. Int. J. Inf. Manag. Data Insights 2022, 2, 100113. [Google Scholar] [CrossRef]
- Sumathy, B.; Kumar, A.; Sungeetha, D.; Hashmi, A.; Saxena, A.; Shukla, P.K.; Nuagah, S.J. Machine Learning Technique to Detect and Classify Mental Illness on Social Media Using Lexicon-Based Recommender System. Comput. Intell. Neurosci. 2022, 2022, 5906797. [Google Scholar] [CrossRef]
- Jain, V.K.; Kumar, S. Effective surveillance and predictive mapping of mosquito-borne diseases using social media. J. Comput. Sci. 2018, 25, 406–415. [Google Scholar] [CrossRef]
- Gabarron, E.; Dechsling, A.; Skafle, I.; Nordahl-Hansen, A. Discussions of Asperger Syndrome on Social Media: Content and Sentiment Analysis on Twitter. JMIR Form. Res. 2022, 6, e32752. [Google Scholar] [CrossRef]
- Amin, S.; Uddin, M.I.; Hassan, S.; Khan, A.; Nasser, N.; Alharbi, A.; Alyami, H. Recurrent Neural Networks With TF-IDF Embedding Technique for Detection and Classification in Tweets of Dengue Disease. IEEE Access 2020, 8, 131522–131533. [Google Scholar] [CrossRef]
- Yousefinaghani, S.; Dara, R.; Poljak, Z.; Bernardo, T.M.; Sharif, S. The Assessment of Twitter’s Potential for Outbreak Detection: Avian Influenza Case Study. Sci. Rep. 2019, 9, 18147. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, F.; Luo, J.; Li, C.; Wang, X.; Zhao, Z. Detecting and Analyzing Influenza Epidemics with Social Media in China. In Advances in Knowledge Discovery and Data Mining; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 90–101. [Google Scholar] [CrossRef]
- Alessa, A.; Faezipour, M. A review of influenza detection and prediction through social networking sites. Theor. Biol. Med. Model. 2018, 15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jain, V.K.; Kumar, S. An Effective Approach to Track Levels of Influenza-A (H1N1) Pandemic in India Using Twitter. Procedia Comput. Sci. 2015, 70, 801–807. [Google Scholar] [CrossRef] [Green Version]
- Zuccon, G.; Khanna, S.; Nguyen, A.; Boyle, J.; Hamlet, M.; Cameron, M. Automatic detection of tweets reporting cases of influenza like illnesses in Australia. Health Inf. Sci. Syst. 2015, 3, S4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alkouz, B.; Aghbari, Z.A.; Al-Garadi, M.A.; Sarker, A. Deepluenza: Deep learning for influenza detection from Twitter. Expert Syst. Appl. 2022, 198, 116845. [Google Scholar] [CrossRef]
- Asiri, E.; Khalifa, M.; Shabir, S.A.; Hossain, M.N.; Iqbal, U.; Househ, M. Sharing sensitive health information through social media in the Arab world. Int. J. Qual. Health Care 2016, 29, 68–74. [Google Scholar] [CrossRef]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl.-Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Binkheder, S.; Aldekhyyel, R.N.; AlMogbel, A.; Al-Twairesh, N.; Alhumaid, N.; Aldekhyyel, S.N.; Jamal, A.A. Public Perceptions around mHealth Applications during COVID-19 Pandemic: A Network and Sentiment Analysis of Tweets in Saudi Arabia. Int. J. Environ. Res. Public Health 2021, 18, 13388. [Google Scholar] [CrossRef]
- Aljameel, S.S.; Alabbad, D.A.; Alzahrani, N.A.; Alqarni, S.M.; Alamoudi, F.A.; Babili, L.M.; Aljaafary, S.K.; Alshamrani, F.M. A Sentiment Analysis Approach to Predict an Individual’s Awareness of the Precautionary Procedures to Prevent COVID-19 Outbreaks in Saudi Arabia. Int. J. Environ. Res. Public Health 2020, 18, 218. [Google Scholar] [CrossRef]
- Essam, N.; Moussa, A.M.; Elsayed, K.M.; Abdou, S.; Rashwan, M.; Khatoon, S.; Hasan, M.M.; Asif, A.; Alshamari, M.A. Location Analysis for Arabic COVID-19 Twitter Data Using Enhanced Dialect Identification Models. Appl. Sci. 2021, 11, 11328. [Google Scholar] [CrossRef]
- Addawood, A. Coronavirus: Public Arabic Twitter Data Set. 2020. Available online: https://openreview.net/forum?id=ZxjFAfD0pSy (accessed on 22 October 2022).
- Zaidan, O.; Callison-Burch, C. The arabic online commentary dataset: An annotated dataset of informal arabic with high dialectal content. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 37–41. [Google Scholar]
- Alabrah, A.; Alawadh, H.M.; Okon, O.D.; Meraj, T.; Rauf, H.T. Gulf Countries’ Citizens’ Acceptance of COVID-19 Vaccines—A Machine Learning Approach. Mathematics 2022, 10, 467. [Google Scholar] [CrossRef]
- Alqurashi, S.; Hamoui, B.; Alashaikh, A.; Alhindi, A.; Alanazi, E. Eating Garlic Prevents COVID-19 Infection: Detecting Misinformation on the Arabic Content of Twitter. arXiv 2021, arXiv:2101.05626. [Google Scholar]
- Albalawi, Y.; Nikolov, N.S.; Buckley, J. Pretrained Transformer Language Models Versus Pretrained Word Embeddings for the Detection of Accurate Health Information on Arabic Social Media: Comparative Study. JMIR Form. Res. 2022, 6, e34834. [Google Scholar] [CrossRef] [PubMed]
- Al-Laith, A.; Alenezi, M. Monitoring People’s Emotions and Symptoms from Arabic Tweets during the COVID-19 Pandemic. Information 2021, 12, 86. [Google Scholar] [CrossRef]
- Ghanem, A.; Asaad, C.; Hafidi, H.; Moukafih, Y.; Guermah, B.; Sbihi, N.; Zakroum, M.; Ghogho, M.; Dairi, M.; Cherqaoui, M.; et al. Real-Time Infoveillance of Moroccan Social Media Users’ Sentiments towards the COVID-19 Pandemic and Its Management. Int. J. Environ. Res. Public Health 2021, 18, 12172. [Google Scholar] [CrossRef]
- Alturayeif, N.; Luqman, H. Fine-Grained Sentiment Analysis of Arabic COVID-19 Tweets Using BERT-Based Transformers and Dynamically Weighted Loss Function. Appl. Sci. 2021, 11, 10694. [Google Scholar] [CrossRef]
- Almouzini, S.; khemakhem, M.; Alageel, A. Detecting Arabic Depressed Users from Twitter Data. Procedia Comput. Sci. 2019, 163, 257–265. [Google Scholar] [CrossRef]
- Musleh, D.A.; Alkhales, T.A.; Almakki, R.A.; Alnajim, S.E.; Almarshad, S.K.; Alhasaniah, R.S.; Aljameel, S.S.; Almuqhim, A.A. Twitter Arabic Sentiment Analysis to Detect Depression Using Machine Learning. Comput. Mater. Contin. 2022, 71, 3463–3477. [Google Scholar] [CrossRef]
- ElDin, D.M.; Hamed, M.; Eldeen, N. SentiNeural: A Depression Clustering Technique for Egyptian Women Sentiments. Int. J. Adv. Comput. Sci. Appl. 2019, 10. [Google Scholar] [CrossRef] [Green Version]
- Yafooz, W.M.; Alsaeedi, A. Sentimental Analysis on Health-Related Information with Improving Model Performance using Machine Learning. J. Comput. Sci. 2021, 17, 112–122. [Google Scholar] [CrossRef]
- Baker, Q.; Shatnawi, F.; Rawashdeh, S.; Al-Smadi, M.; Jararweh, Y. Detecting Epidemic Diseases Using Sentiment Analysis of Arabic Tweets. JUCS J. Univers. Comput. Sci. 2020, 26, 50–70. [Google Scholar] [CrossRef]
- Saeed, F.; Yafooz, W.M.S.; Al-Sarem, M.; Abdullah, E. Detecting Health-Related Rumors on Twitter using Machine Learning Methods. Int. J. Adv. Comput. Sci. Appl. 2020, 11. [Google Scholar] [CrossRef]
- Lounis, M. Epdemiology of coronavirus disease 2020 (COVID-19) in Algeria. New Microbes New Infect. 2021, 39, 100822. [Google Scholar] [CrossRef] [PubMed]
- Al-Twairesh, N.; Al-Khalifa, H.; Al-Salman, A.; Al-Ohali, Y. AraSenTi-Tweet: A Corpus for Arabic Sentiment Analysis of Saudi Tweets. Procedia Comput. Sci. 2017, 117, 63–72. [Google Scholar] [CrossRef]
- Dong, E.; Du, H.; Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect. Dis. 2020, 20, 533–534. [Google Scholar] [CrossRef]
- Amin, M.T.; Fatema, K.; Arefin, S.; Hussain, F.; Bhowmik, D.R.; Hossain, M.S. Obesity, a major risk factor for immunity and severe outcomes of COVID-19. Biosci. Rep. 2021, 41, BSR20210979. [Google Scholar] [CrossRef]
- Kumar, R.; Arora, R.; Bansal, V.; Sahayasheela, V.J.; Buckchash, H.; Imran, J.; Narayanan, N.; Pandian, G.N.; Raman, B. Accurate Prediction of COVID-19 using Chest X-Ray Images through Deep Feature Learning model with SMOTE and Machine Learning Classifiers. medRxiv 2020. [Google Scholar] [CrossRef] [Green Version]
- Symeonidis, S.; Effrosynidis, D.; Arampatzis, A. A comparative evaluation of pre-processing techniques and their interactions for twitter sentiment analysis. Expert Syst. Appl. 2018, 110, 298–310. [Google Scholar] [CrossRef]
- Sidorov, G.; Velasquez, F.; Stamatatos, E.; Gelbukh, A.; Chanona-Hernández, L. Syntactic N-grams as machine learning features for natural language processing. Expert Syst. Appl. 2014, 41, 853–860. [Google Scholar] [CrossRef]
- El-Khair, I.A. Effects of stop words elimination for Arabic information retrieval: A comparative study. Int. J. Comput. Inf. Sci. 2006, 4, 119–133. [Google Scholar]
- PyArabic. PyPI. Available online: https://pypi.org/project/PyArabic/ (accessed on 1 September 2021).
- Qin, Z.; Cong, Y.; Wan, T. Topic modeling of Chinese language beyond a bag-of-words. Comput. Speech Lang. 2016, 40, 60–78. [Google Scholar] [CrossRef] [Green Version]
- HaCohen-Kerner, Y.; Miller, D.; Yigal, Y. The influence of preprocessing on text classification using a bag-of-words representation. PLoS ONE 2020, 15, e0232525. [Google Scholar] [CrossRef] [PubMed]
- Passalis, N.; Tefas, A. Learning bag-of-embedded-words representations for textual information retrieval. Pattern Recognit. 2018, 81, 254–267. [Google Scholar] [CrossRef]
- Zhang, W.; Yoshida, T.; Tang, X. A comparative study of TF* IDF, LSI and multi-words for text classification. Expert Syst. Appl. 2011, 38, 2758–2765. [Google Scholar] [CrossRef]
- Lauriola, I.; Lavelli, A.; Aiolli, F. An introduction to Deep Learning in Natural Language Processing: Models, techniques, and tools. Neurocomputing 2022, 470, 443–456. [Google Scholar] [CrossRef]
- Kumar, V.; Recupero, D.R.; Riboni, D.; Helaoui, R. Ensembling Classical Machine Learning and Deep Learning Approaches for Morbidity Identification From Clinical Notes. IEEE Access 2021, 9, 7107–7126. [Google Scholar] [CrossRef]
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A Systematic Review on Imbalanced Data Challenges in Machine Learning. ACM Comput. Surv. 2019, 52, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Singla, Z.; Randhawa, S.; Jain, S. Sentiment analysis of customer product reviews using machine learning. In Proceedings of the 2017 International Conference on Intelligent Computing and Control (I2C2), Coimbatore, India, 23–24 June 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Tolba, M.; Ouadfel, S.; Meshoul, S. Hybrid ensemble approaches to online harassment detection in highly imbalanced data. Expert Syst. Appl. 2021, 175, 114751. [Google Scholar] [CrossRef]
- Ramos-Pérez, I.; Arnaiz-González, Á.; Rodríguez, J.J.; García-Osorio, C. When is resampling beneficial for feature selection with imbalanced wide data? Expert Syst. Appl. 2022, 188, 116015. [Google Scholar] [CrossRef]
- Liang, D.; Yi, B.; Cao, W.; Zheng, Q. Exploring ensemble oversampling method for imbalanced keyword extraction learning in policy text based on three-way decisions and SMOTE. Expert Syst. Appl. 2022, 188, 116051. [Google Scholar] [CrossRef]
- Houssein, E.H.; Hassaballah, M.; Ibrahim, I.E.; AbdElminaam, D.S.; Wazery, Y.M. An automatic arrhythmia classification model based on improved Marine Predators Algorithm and Convolutions Neural Networks. Expert Syst. Appl. 2022, 187, 115936. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Elreedy, D.; Atiya, A.F. A Comprehensive Analysis of Synthetic Minority Oversampling Technique (SMOTE) for handling class imbalance. Inf. Sci. 2019, 505, 32–64. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Giménez, M.; Palanca, J.; Botti, V. Semantic-based padding in convolutional neural networks for improving the performance in natural language processing. A case of study in sentiment analysis. Neurocomputing 2020, 378, 315–323. [Google Scholar] [CrossRef]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very Deep Convolutional Networks for Text Classification. arXiv 2016, arXiv:1606.01781. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Sharma, A.K.; Chaurasia, S.; Srivastava, D.K. Sentimental Short Sentences Classification by Using CNN Deep Learning Model with Fine Tuned Word2Vec. Procedia Comput. Sci. 2020, 167, 1139–1147. [Google Scholar] [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Joseph, J.; Vineetha, S.; Sobhana, N. A survey on deep learning based sentiment analysis. Mater. Today Proc. 2022, 58, 456–460. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Li, J.; Wu, Y. A Global Optimization Approach to Multi-Polarity Sentiment Analysis. PLoS ONE 2015, 10, e0124672. [Google Scholar] [CrossRef] [PubMed]
- AlBadani, B.; Shi, R.; Dong, J. A Novel Machine Learning Approach for Sentiment Analysis on Twitter Incorporating the Universal Language Model Fine-Tuning and SVM. Appl. Syst. Innov. 2022, 5, 13. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Articles | Model | Disease | Social Network | #Instances | #Classes | Result |
|---|---|---|---|---|---|---|
| [34] | SVM with AraVec Embeddings | COVID-19 | 4719 | 3 | 85.00% F1 | |
| [35] | SVM with Bigram in TF-IDF | COVID-19 | 242,525 | 3 | 85.00% F1 | |
| [43] | LSTM | COVID-19 | Twitter, Facebook, Youtube | 747,018 | 6 | 70.00% Acc |
| [42] | LSTM | COVID-19 | 5.5 M | 6 | 83.00% F1 | |
| [39] | ML Classifiers based on LSTM deep features | COVID-19 | 685 | 2 | 94.01% Acc | |
| [36] | BERT-based Models | COVID-19 | 1.8 M | 4 | 97.36% Acc | |
| [40] | ML Classifiers | COVID-19 | 8786 | 2 | 87.80% Acc | |
| [41] | AraBERT-based Model | General | 779 | 2 | 87.70% Acc | |
| [44] | BERT-based Models | COVID-19, Mental Health | 10,000 | 11 | 72.50% F1 | |
| [46] | ML Classifiers | Depression | 4542 | 3 | 82.39% Acc | |
| [45] | ML Classifiers | Depression | 2722 | 2 | 87.50% Acc | |
| [47] | LSTM | Depression | 10,000 | >3 | 85.00% Acc | |
| [48] | ML Classifiers with SMOTE | Diabetes | YouTube | 4111 | 2 | 95.00% Acc |
| [50] | ML Classifiers | Cancer | 208 | 2 | 83.50% Acc | |
| [49] | ML Classifiers | Influenza | 6300 | 2 | 89.06% Acc |
| Class | Post in Arabic (Algerian Dialect) | Translated Post to English |
|---|---|---|
| Unrelated | نحتاج طبيب جلد مليح لنزع الشعر بالليزر تكون نتيجة مليحة شكون يعرف ولا تعرف | I need a good dermatologist for laser hair removal, with a good result, who knows a good doctor. |
| Negative-related | الكحة هي واحدة مِن الأعراض المُصاحبة لمرضٍ ما كالإنفلونزا والرشح وغيرها من الأمراض المُنتشرة بالأخص في فصل الشتاء وقد تكون علامةً وإشارة للشخص لينتبه لوجود أمرٍ خطير في جسده | Cough is one of the symptoms that accompanies a disease such as influenza, cold and other diseases that are prevalent, especially in the winter season, and it may be a sign and signal for a person to be aware of the presence of something dangerous in his body. |
| Positive | السلام عليكم عندي السعال نسعل بزاف عندها يومين كاش دوا تع السعلة الله يجازيكم | Peace be upon you. I have a cough and I have been coughing a lot for two days. Is there a medicine for the cough, thank you. |
| Before Data Preprocessing Phase |
|---|
| انا, عندي, فقدان, حساسة, الشم, والذوق, مع, انو, معنديش, حرارة, مرتفعة, هل, انا, مصاب? |
| (I, have, loss, sense, smell, and taste, with, that, I don’t have, high, temperature, |
| is, I, injured?) |
| After Data Preprocessing Phase |
| فقدان, حساسة, شم, ذوق, حرارة, مرتفعة, مصاب |
| (Loss, sensitivity, smell, taste, temperature, high, injured) |
| Positive | Negative-Related | Unrelated | Total | |
|---|---|---|---|---|
| Imbalanced | 927 | 238 | 3000 | 4165 |
| SMOTE | 3000 | 3000 | 3000 | 9000 |
| ROS | 3000 | 3000 | 3000 | 9000 |
| Hyperparameter | Values Range | Optimal Value |
|---|---|---|
| Embedding dimension (E) | 10, 20, 32, 64, 128 | 20 |
| Batch size | 32, 50, 64,128 | 128 |
| Dropout rate | 0.1, 0.2, 0.3, 0.4, 0.5 | 0.2 |
| Optimizer | ‘SGD’, ‘RMSprop’, ‘adam’, ‘Nadam’ | ‘adam’ |
| Early stopping patience | 1, 5, 10, 15, 20, 30 | 20 |
| #FE | FE Technique | Level | N-Grams | Performance Metrics | ||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | |||||
| Imbalanced Dataset | 1 | Tokenization | Character | 1 | 0.878 | 0.881 | 0.875 | 0.882 |
| 2 | Tokenization | Word | 1 | 0.811 | 0.811 | 0.810 | 0.817 | |
| 3 | Tokenization | Character + Word | 1 | 0.807 | 0.808 | 0.807 | 0.815 | |
| 4 | Tokenization + BoW | Character | 1 | 0.883 | 0.886 | 0.881 | 0.885 | |
| 5 | Tokenization + BoW | Character | 1-2 | 0.892 | 0.895 | 0.888 | 0.895 | |
| 6 | Tokenization + BoW | Character | 1-3 | 0.891 | 0.894 | 0.888 | 0.894 | |
| 7 | Tokenization + TF-IDF | Character | 1 | 0.889 | 0.892 | 0.887 | 0.893 | |
| 8 | Tokenization + TF-IDF | Character | 1-2 | 0.896 | 0.898 | 0.893 | 0.898 | |
| 9 | Tokenization + TF-IDF | Character | 1-3 | 0.894 | 0.897 | 0.891 | 0.898 | |
| 10 | Tokenization + BoW | Word | 1 | 0.807 | 0.808 | 0.807 | 0.812 | |
| 11 | Tokenization + BoW | Word | 1-2 | 0.815 | 0.815 | 0.815 | 0.822 | |
| 12 | Tokenization + BoW | Word | 1-3 | 0.829 | 0.829 | 0.828 | 0.836 | |
| 13 | Tokenization + TF-IDF | Word | 1 | 0.822 | 0.825 | 0.821 | 0.828 | |
| 14 | Tokenization + TF-IDF | Word | 1-2 | 0.827 | 0.827 | 0.827 | 0.833 | |
| 15 | Tokenization + TF-IDF | Word | 1-3 | 0.821 | 0.822 | 0.820 | 0.828 | |
| 16 | Tokenization + BoW | Character + Word | 1 | 0.899 | 0.902 | 0.895 | 0.901 | |
| 17 | Tokenization + BoW | Character + Word | 1-2 | 0.894 | 0.896 | 0.891 | 0.897 | |
| 18 | Tokenization + BoW | Character + Word | 1-3 | 0.888 | 0.894 | 0.886 | 0.892 | |
| 19 | Tokenization + TF-IDF | Character + Word | 1 | 0.883 | 0.887 | 0.879 | 0.886 | |
| 20 | Tokenization + TF-IDF | Character + Word | 1-2 | 0.887 | 0.892 | 0.884 | 0.890 | |
| 21 | Tokenization + TF-IDF | Character + Word | 1-3 | 0.897 | 0.900 | 0.891 | 0.899 | |
| SMOTE | 1 | Tokenization | Character | 1 | 0.884 | 0.886 | 0.883 | 0.882 |
| 2 | Tokenization | Word | 1 | 0.706 | 0.710 | 0.702 | 0.698 | |
| 3 | Tokenization | Character + Word | 1 | 0.746 | 0.749 | 0.742 | 0.739 | |
| 4 | Tokenization + BoW | Character | 1 | 0.888 | 0.890 | 0.886 | 0.890 | |
| 5 | Tokenization + BoW | Character | 1-2 | 0.893 | 0.895 | 0.891 | 0.891 | |
| 6 | Tokenization + BoW | Character | 1-3 | 0.891 | 0.893 | 0.889 | 0.893 | |
| 7 | Tokenization + TF-IDF | Character | 1 | 0.888 | 0.890 | 0.885 | 0.893 | |
| 8 | Tokenization + TF-IDF | Character | 1-2 | 0.894 | 0.896 | 0.892 | 0.899 | |
| 9 | Tokenization + TF-IDF | Character | 1-3 | 0.895 | 0.897 | 0.892 | 0.895 | |
| 10 | Tokenization + BoW | Word | 1 | 0.719 | 0.722 | 0.714 | 0.706 | |
| 11 | Tokenization + BoW | Word | 1-2 | 0.721 | 0.723 | 0.718 | 0.713 | |
| 12 | Tokenization + BoW | Word | 1-3 | 0.738 | 0.745 | 0.735 | 0.740 | |
| 13 | Tokenization + TF-IDF | Word | 1 | 0.709 | 0.712 | 0.705 | 0.703 | |
| 14 | Tokenization + TF-IDF | Word | 1-2 | 0.727 | 0.733 | 0.721 | 0.712 | |
| 15 | Tokenization + TF-IDF | Word | 1-3 | 0.727 | 0.731 | 0.720 | 0.721 | |
| 16 | Tokenization + BoW | Character + Word | 1 | 0.893 | 0.894 | 0.890 | 0.893 | |
| 17 | Tokenization + BoW | Character + Word | 1-2 | 0.893 | 0.895 | 0.891 | 0.889 | |
| 18 | Tokenization + BoW | Character + Word | 1-3 | 0.891 | 0.893 | 0.888 | 0.892 | |
| 19 | Tokenization + TF-IDF | Character + Word | 1 | 0.898 | 0.900 | 0.896 | 0.899 | |
| 20 | Tokenization + TF-IDF | Character + Word | 1-2 | 0.894 | 0.897 | 0.893 | 0.890 | |
| 21 | Tokenization + TF-IDF | Character + Word | 1-3 | 0.893 | 0.894 | 0.890 | 0.891 | |
| ROS | 1 | Tokenization | Character | 1 | 0.950 | 0.951 | 0.950 | 0.949 |
| 2 | Tokenization | Word | 1 | 0.958 | 0.958 | 0.958 | 0.959 | |
| 3 | Tokenization | Character + Word | 1 | 0.950 | 0.951 | 0.950 | 0.952 | |
| 4 | Tokenization + BoW | Character | 1 | 0.960 | 0.960 | 0.960 | 0.959 | |
| 5 | Tokenization + BoW | Character | 1-2 | 0.963 | 0.963 | 0.963 | 0.965 | |
| 6 | Tokenization + BoW | Character | 1-3 | 0.958 | 0.959 | 0.958 | 0.961 | |
| 7 | Tokenization + TF-IDF | Character | 1 | 0.963 | 0.964 | 0.963 | 0.964 | |
| 8 | Tokenization + TF-IDF | Character | 1-2 | 0.964 | 0.964 | 0.964 | 0.966 | |
| 9 | Tokenization + TF-IDF | Character | 1-3 | 0.963 | 0.964 | 0.963 | 0.966 | |
| 10 | Tokenization + BoW | Word | 1 | 0.958 | 0.958 | 0.958 | 0.961 | |
| 11 | Tokenization + BoW | Word | 1-2 | 0.963 | 0.963 | 0.963 | 0.965 | |
| 12 | Tokenization + BoW | Word | 1-3 | 0.961 | 0.961 | 0.961 | 0.963 | |
| 13 | Tokenization + TF-IDF | Word | 1 | 0.961 | 0.962 | 0.961 | 0.962 | |
| 14 | Tokenization + TF-IDF | Word | 1-2 | 0.956 | 0.957 | 0.956 | 0.959 | |
| 15 | Tokenization + TF-IDF | Word | 1-3 | 0.964 | 0.964 | 0.963 | 0.966 | |
| 16 | Tokenization + BoW | Character + Word | 1 | 0.960 | 0.961 | 0.960 | 0.962 | |
| 17 | Tokenization + BoW | Character + Word | 1-2 | 0.966 | 0.966 | 0.965 | 0.966 | |
| 18 | Tokenization + BoW | Character + Word | 1-3 | 0.963 | 0.963 | 0.963 | 0.965 | |
| 19 | Tokenization + TF-IDF | Character + Word | 1 | 0.963 | 0.963 | 0.962 | 0.965 | |
| 20 | Tokenization + TF-IDF | Character + Word | 1-2 | 0.955 | 0.956 | 0.955 | 0.957 | |
| 21 | Tokenization + TF-IDF | Character + Word | 1-3 | 0.962 | 0.963 | 0.962 | 0.965 | |
| Model | Performance Metrics | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | |
| LSTM | 0.801 | 0.858 | 0.741 | 0.761 |
| GRU | 0.778 | 0.870 | 0.666 | 0.685 |
| BiLSTM | 0.617 | 0.840 | 0.464 | 0.490 |
| 1D-CNN | 0.953 | 0.953 | 0.953 | 0.955 |
| 1D-CNN+LSTM | 0.789 | 0.866 | 0.685 | 0.713 |
| Proposed 1D-CNN-based model | 0.966 | 0.966 | 0.965 | 0.966 |
| Model | Performance Metrics | ||||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | ||
| ROS | LSTM [42] | 0.948 | 0.949 | 0.948 | 0.951 |
| SVM Bigram-TF-IDF [35] | 0.967 | 0.968 | 0.967 | 0.967 | |
| SVM Trigram-TF-IDF [48] | 0.955 | 0.960 | 0.955 | 0.955 | |
| NB [49] | 0.582 | 0.516 | 0.582 | 0.498 | |
| RF [50] | 0.937 | 0.947 | 0.937 | 0.937 | |
| Proposed 1D-CNN-based model | 0.966 | 0.966 | 0.965 | 0.966 | |
| Imbalanced Dataset | LSTM [42] | 0.823 | 0.825 | 0.821 | 0.828 |
| SVM Bigram-TF-IDF [35] | 0.802 | 0.819 | 0.802 | 0.766 | |
| SVM Trigram-TF-IDF [48] | 0.753 | 0.797 | 0.753 | 0.673 | |
| NB [49] | 0.270 | 0.526 | 0.270 | 0.143 | |
| RF [50] | 0.738 | 0.799 | 0.738 | 0.639 | |
| Proposed 1D-CNN-based model | 0.894 | 0.896 | 0.891 | 0.897 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boulesnane, A.; Meshoul, S.; Aouissi, K. Influenza-like Illness Detection from Arabic Facebook Posts Based on Sentiment Analysis and 1D Convolutional Neural Network. Mathematics 2022, 10, 4089. https://0-doi-org.brum.beds.ac.uk/10.3390/math10214089
Boulesnane A, Meshoul S, Aouissi K. Influenza-like Illness Detection from Arabic Facebook Posts Based on Sentiment Analysis and 1D Convolutional Neural Network. Mathematics. 2022; 10(21):4089. https://0-doi-org.brum.beds.ac.uk/10.3390/math10214089
Chicago/Turabian StyleBoulesnane, Abdennour, Souham Meshoul, and Khaoula Aouissi. 2022. "Influenza-like Illness Detection from Arabic Facebook Posts Based on Sentiment Analysis and 1D Convolutional Neural Network" Mathematics 10, no. 21: 4089. https://0-doi-org.brum.beds.ac.uk/10.3390/math10214089