
Modeling and Analysis of New Hybrid Clustering Technique for Vehicular Ad Hoc Network

 , and
, and
Abstract
:1. Introduction
- A new K-Means clustering model based on a covering rough set is proposed to improve the cluster stability with minimum vehicle speed differences within clusters.
- The hybrid algorithm includes a new K-value calculation model to randomly enhance the attribution of data points and select an optimal number of clusters based on the minimum within-cluster error rate and vehicle coverage range.
- Five unsupervised evaluation indexes (RMSE, DB, DI, SC, and the standard deviation of speed) were used directly to evaluate and analyze the results of the clustering.
- Comparative tests were designed and executed to show the effectiveness of RK-Means. We selected two highway topology scenarios (high-density and low-density) and eight datasets, with constraints on the simulation time and vehicle density.
2. Literature Study
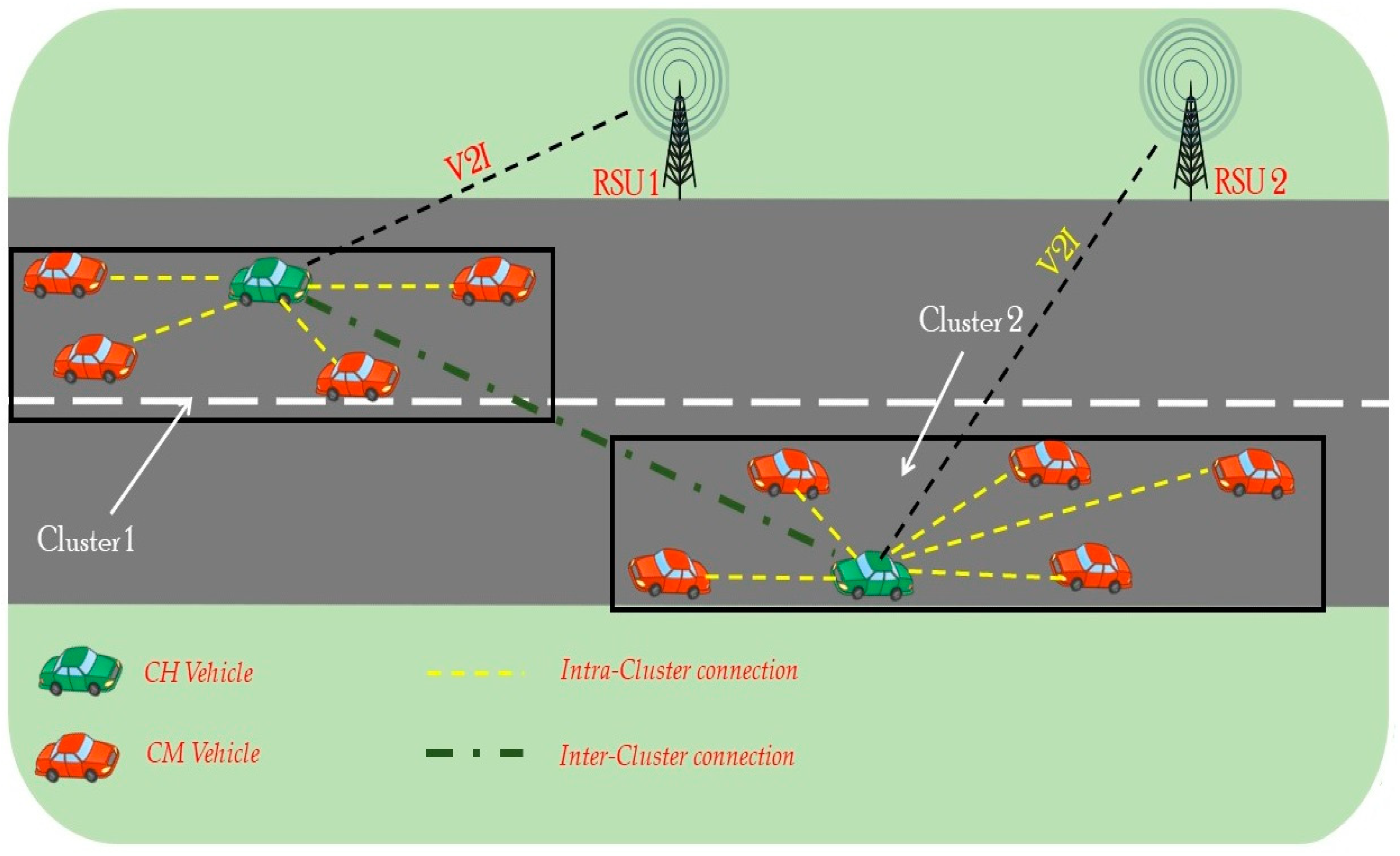
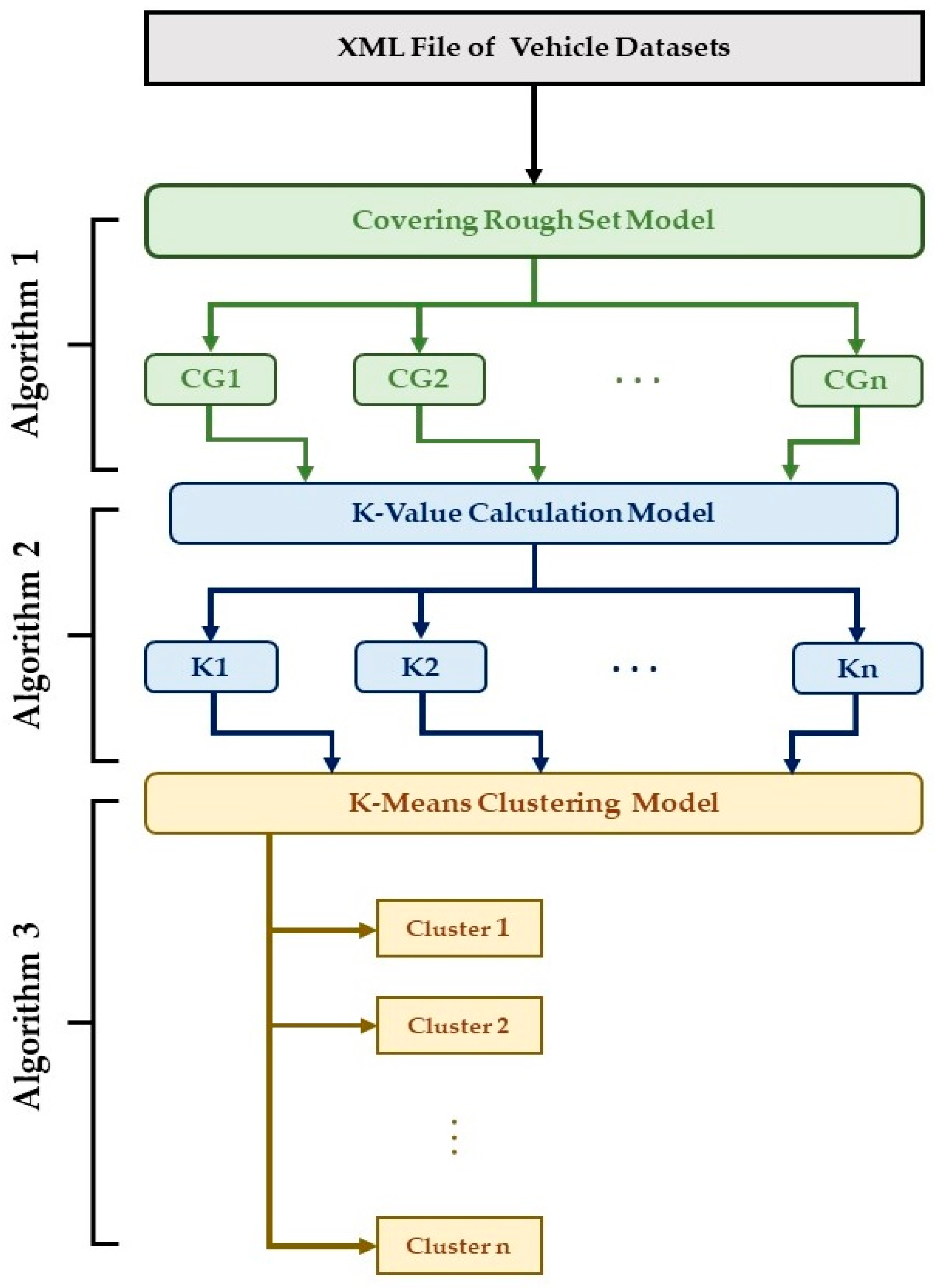
3. Clustering Model
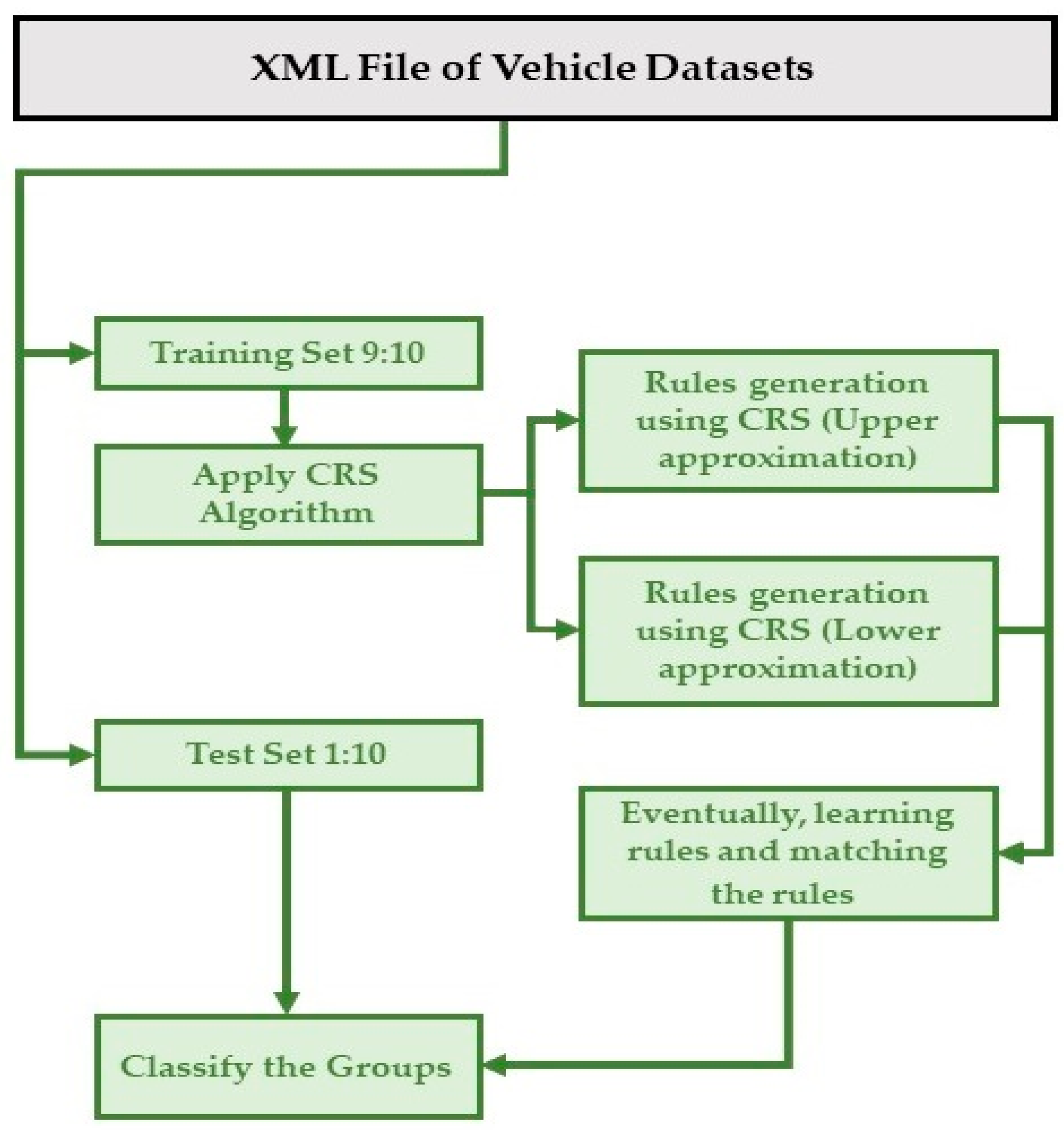
- Stage 1: The preparation of the datasets using SUMO software to collect the vehicle parameters at different timestamps. The XML file of the dataset describes the location, speed, direction, and steering angle. This study focused on a highway scenario, so the steering angle could not be used. To update this model for another scenario such as a city map, the steering angle would be a more important parameter to consider for covering table construction and clustering initialization. In this stage, the CRS algorithm works by considering all the vehicle parameters presented in the above table to initialize the covering groups. The covering groups divide the VANET datasets into multi-groups according to the approximation type. The output of the covering groups is CG1, CG2, CG3, …, and CGn. The number of covering groups depends on the vehicle status table and approximation types; in this paper, the number of groups was 10. The CRS model with descriptions of each step is illustrated in more detail in Section 3.1, where the main CRS algorithm includes the approximation calculation steps.
- Stage 2: In this stage, each covering group generated in stage 1 is input into the k-value calculation model to compute the number of clusters. At this stage, the optimal number of clusters is calculated based on two different models, and the minimum number of clusters is selected at the end. When the number of clusters has been calculated, the output represents the number of clusters in each covering group calculated in stage 1. The value of k1 represents the number of clusters in CG1, and the value of k2 is the number of clusters in CG2. For all covering groups in this work, the model generated the number of clusters. The cluster number calculation model is presented in detail in Section 3.2, with a description of the algorithm and each step.
- Stage 3: Finally, the cluster generation process is carried out by applying the classical K-Means clustering algorithm. The K-Means clustering algorithm creates the clusters of each covering group generated in stage 1 using the optimal cluster number calculated in stage 2. For example, if the value of k1 is 4, the K-Means algorithm creates four clusters from the CG1 datasets; if the k2 value is 6, it creates six clusters from CG2, and so on. This stage is explained in detail and the clustering algorithm is presented in Section 3.3.
3.1. Covering Rough Set Model
- Create an information table, which includes the general simulation parameters.
- Calculate the equivalence partition or relation for covering objects (denoted in this work by CG1, CG2, CG3,… CGn).
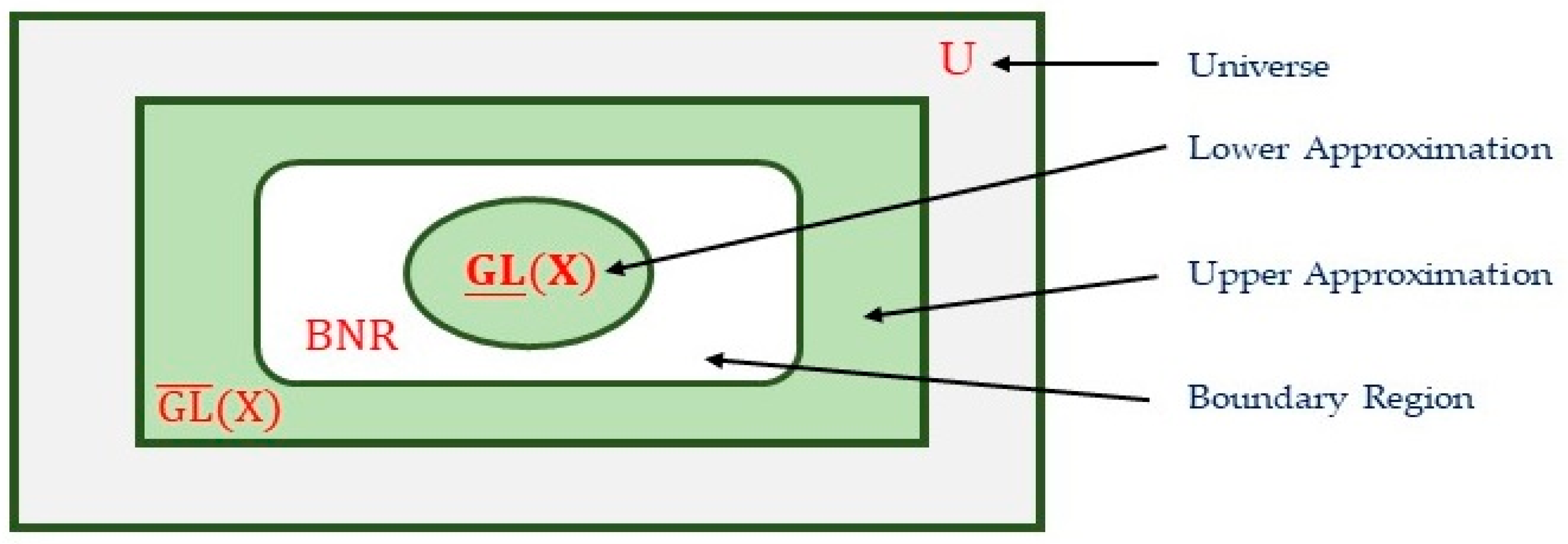
- Build the covering key of lower approximation for the given information table:
- Build the covering key of the upper approximation for the given information table:
- Use CRS to build a certain rule based on (1).
- Use CRS to build possible rules based on (2).
- Eliminate an equivalent rule for covering approximations based on (3):
- Finally, calculate the validation measures, choose an appropriate group, and select the road sector.
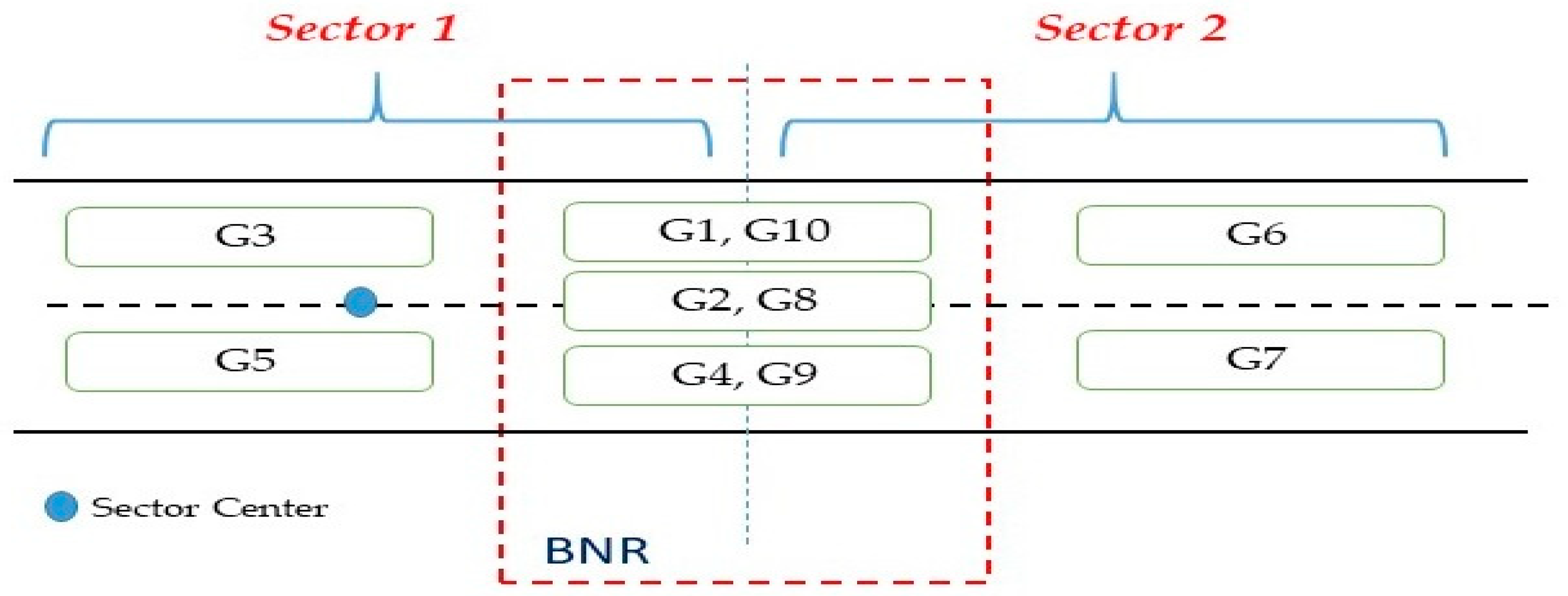
3.1.1. Group Formation
3.1.2. Group Implementation
| Algorithm 1 Implementation of CRS |
| Initialize v.id, v.location, v.speed ← read from the dataset v.direction ← {1,2}//1 for left, 2 for right L ← road length, c1 ← sector center RSU1 ← (xrsu1,yrsu1), RSU2 ← (xrsu2,yrsu2) begin for i = 1 to n do Distance (i) ← {near, far} based on the value of L and Formula (5) Compare v.speed(i) with the range of speed Speed (i) ← {high, medium, low} based on Formula (4) Direction (i) ← {left, right} based on v.direction input Calculate the distance between the vehicle and {RSU1, RSU2} then assign the decision-making {CS, NS} end for for i = 1 to n do Apply the rule in Table 1 to create G = {G1, G2, G3, …, Gn} end for for i = 1 to n do Create the covering groups using Formula (6)//CG1, CG2, CG3, …, and CGn Select the Upper and Lower Approximation using Formula (1) and Formula (2) Calculate the Boundary Region using Formula (3) end for Export the CG and Boundary Region end |
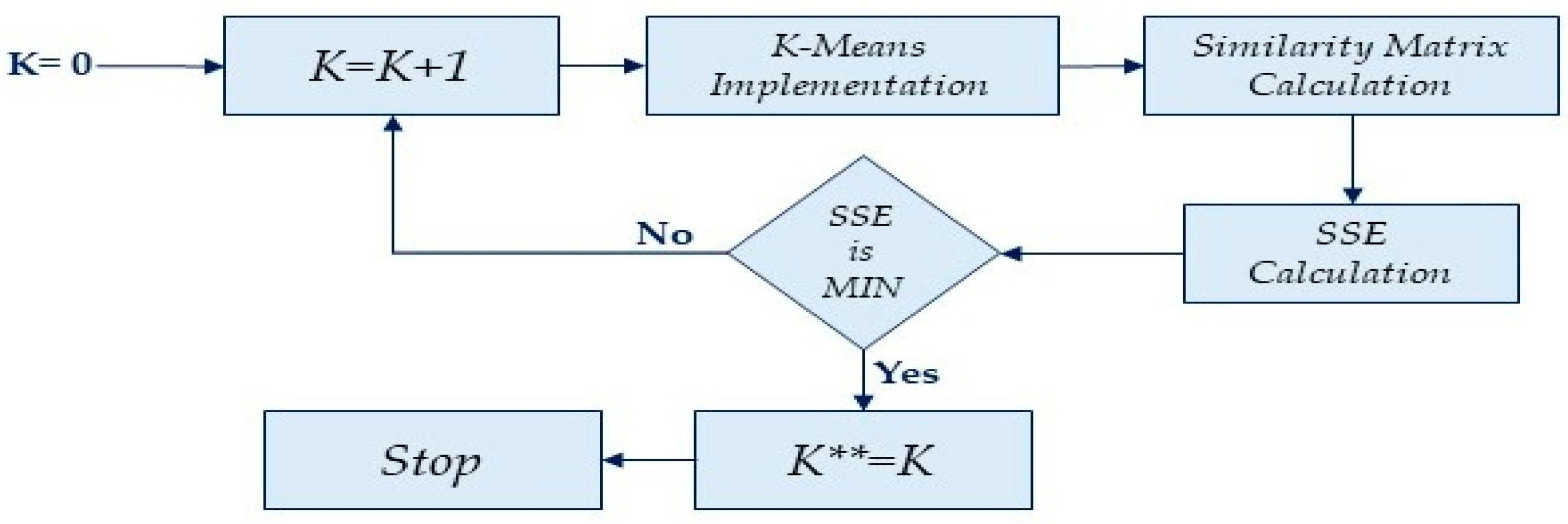
3.2. K-Value Calculation Model
- Calculate the initial value of K.
- Calculate the second value of K based on the similarity matrix.
- Select k = 0, then increase the value of k.
- Apply the K-Means clustering algorithm.
- Calculate the cluster similarity based on (12) and (13).
- Check the error rate value; if the value is at its minimum, then stop.
- For each high error value, increase the value of k and repeat steps 2 to 4.

- Compute the final value of K.
| Algorithm 2 K-value calculation |
| Initialize G, N, X, Y, R//G: a group of vehicles, n: number of vehicles in each group, X, Y: vehicle locations, CR: vehicle coverage area. begin for all nodes do Calculate the distance among all vehicles groups; dMax.← maximum distance//Calculate the group length end for Calculate K* as the nearest integer greater value using equation (11) Select a random number of k for S = 1 to K do K** = S + 1; for i = 1 to n do Initialize centroid Ci based on K** Assign other vehicles to Ci Apply Equations (12) and (13) to calculate SSE end for SSE(s) = SSE; // calculate SSE for each group. end for for S = 1 to K do Compute the minim value of SSE K** ← S; end for Use Equation (14) to select K Export K; end |
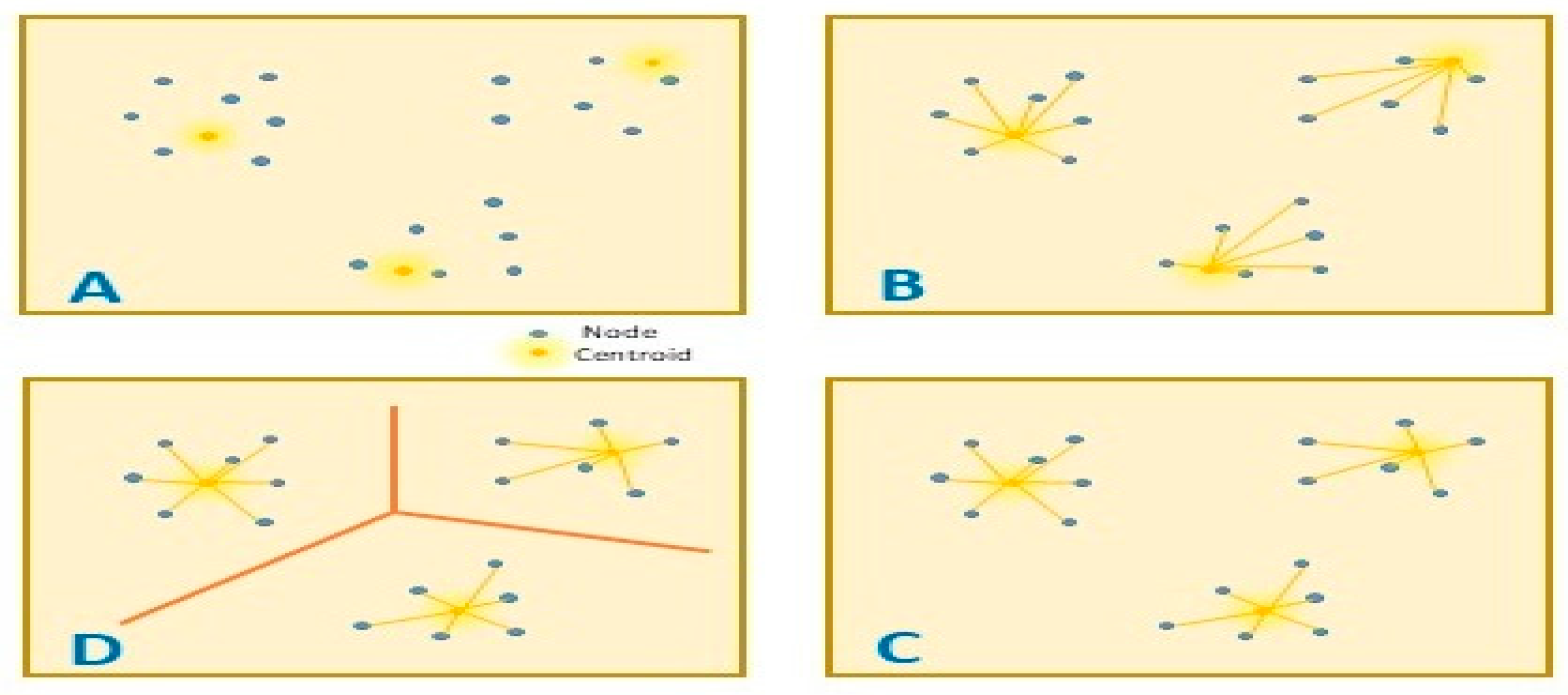
3.3. K-Means Model
| Algorithm 3 K-Means Implementation |
| Initialize Number of cluster centroids k; Set of vehicles N; List of cluster centroids assigned Ck begin Repeat for each vehicle in N do Compute the vehicles to the cluster centroid of ith cluster distance based on Equation (15) Assign each vehicle to the nearest cluster centroid. end for for each cluster do Compute the new cluster centroid position based on Equation (16). end for Until all vehicles belong to a cluster or the maximum number of iterations is reached end |
4. Problem Formulation and Evaluation Model
4.1. Problem Formulation
- Maximizing the intra-cluster similarity by minimizing the distances between vehicles in the same cluster.
- Minimizing inter-cluster similarity by maximizing the distances between vehicle clusters.
4.2. Similarity Measurement
4.3. Silhouette Coefficient (SC)
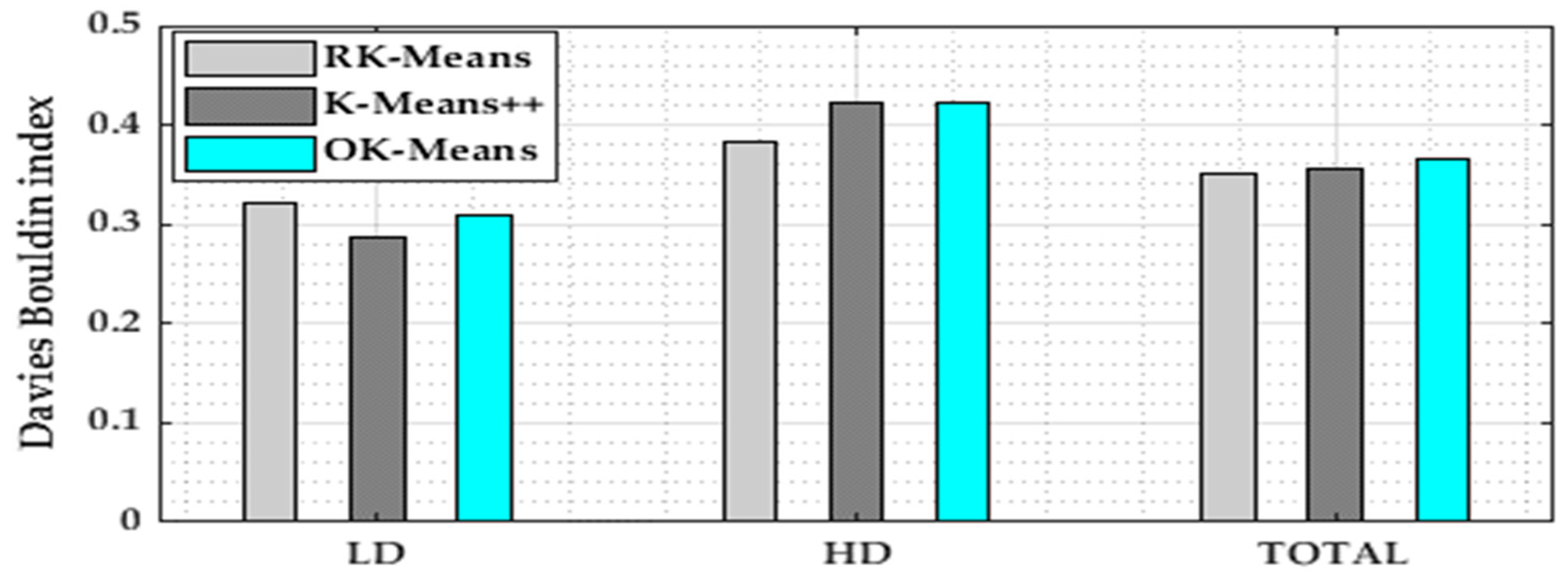
4.4. Davies–Bouldin Index
- : Number of total clusters;
- : Number of vehicles in the ith cluster;
- : Value of the center of the ith cluster;
- : Euclidean distance between two centers;
- : Two vehicles in the ith cluster.
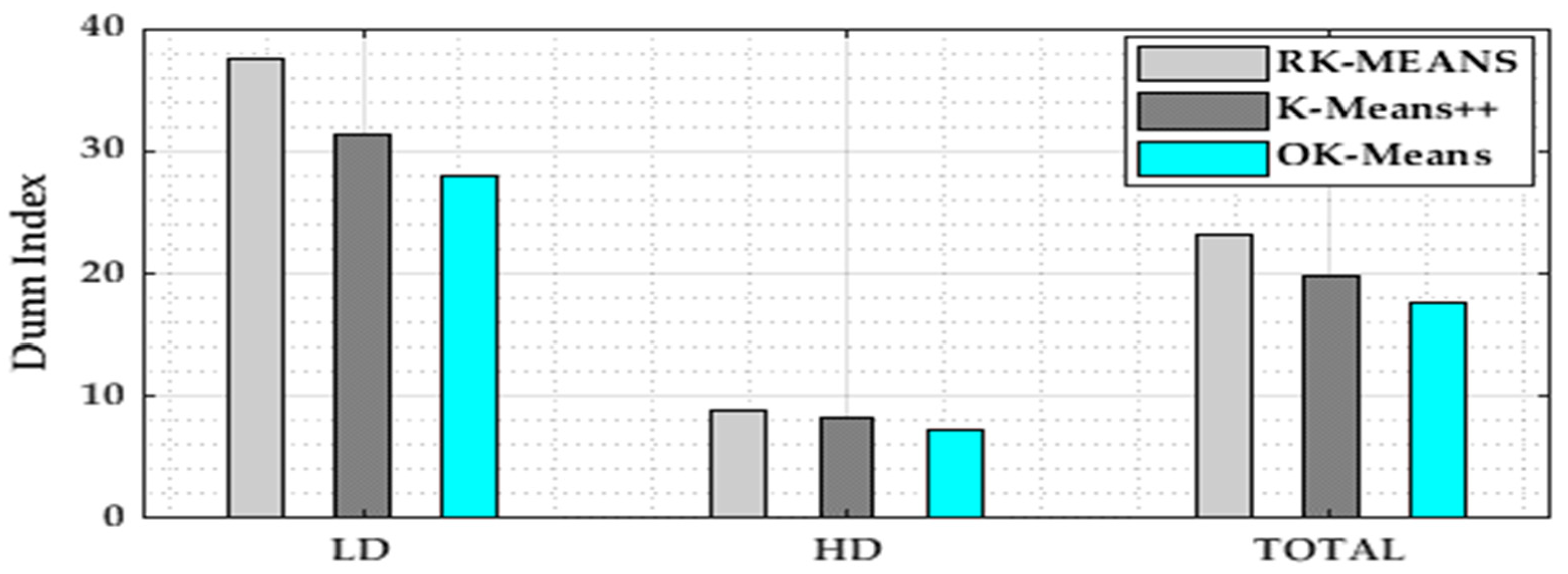
4.5. Dunn Index
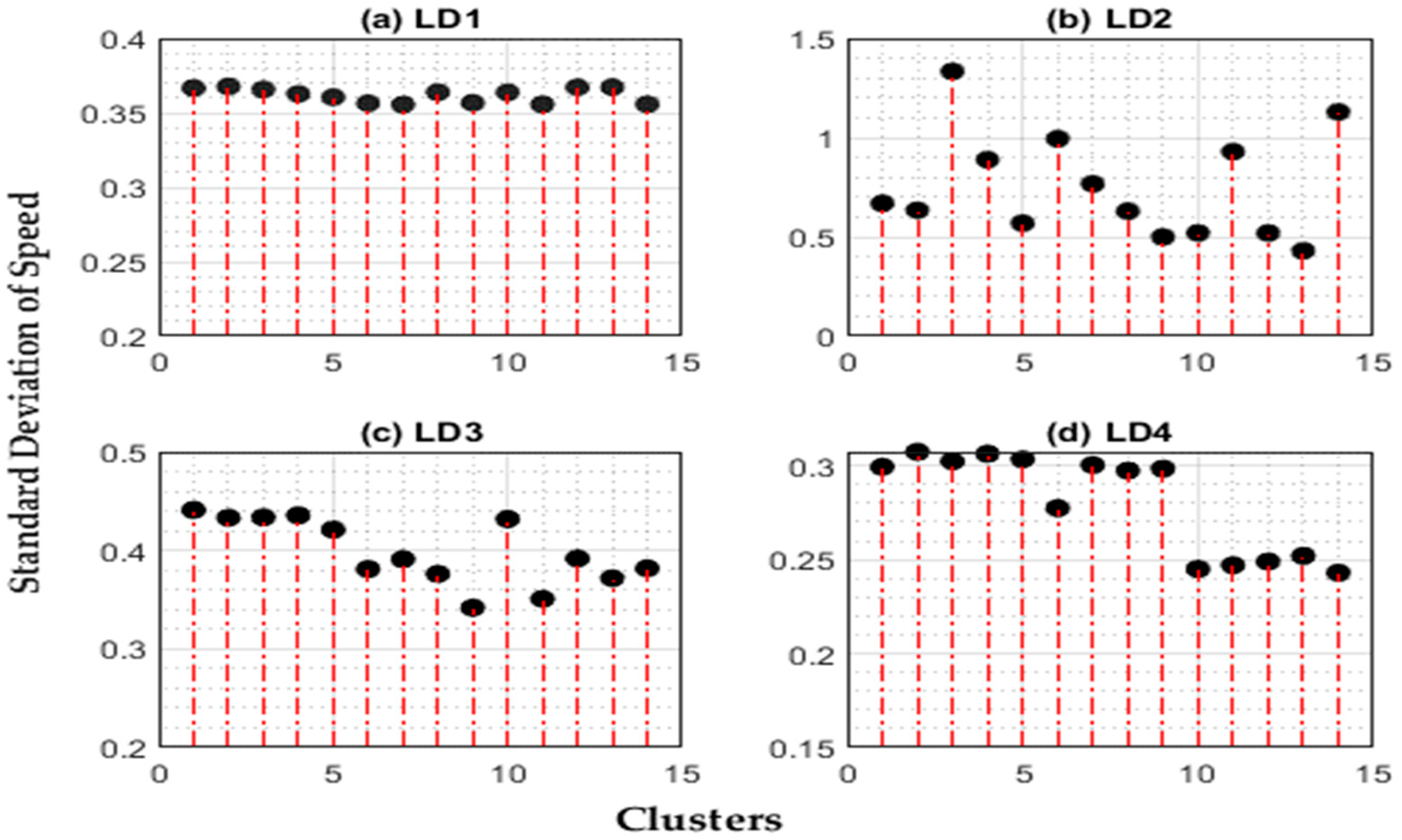
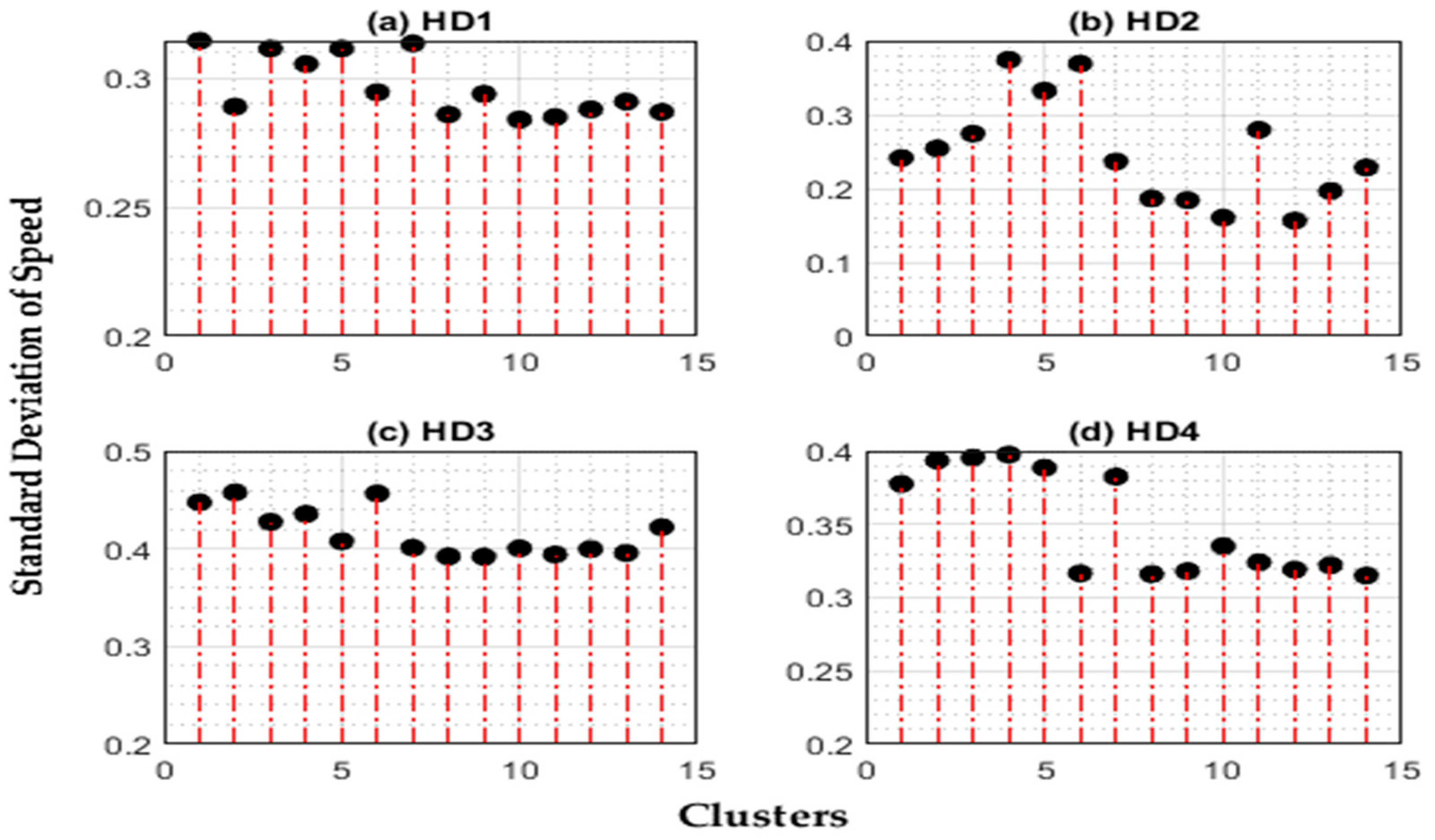
4.6. Cluster Speed Stability
5. Simulation and Result
5.1. Vehicle Dataset Initialization
5.2. Simulation Environment and Parameter Setting
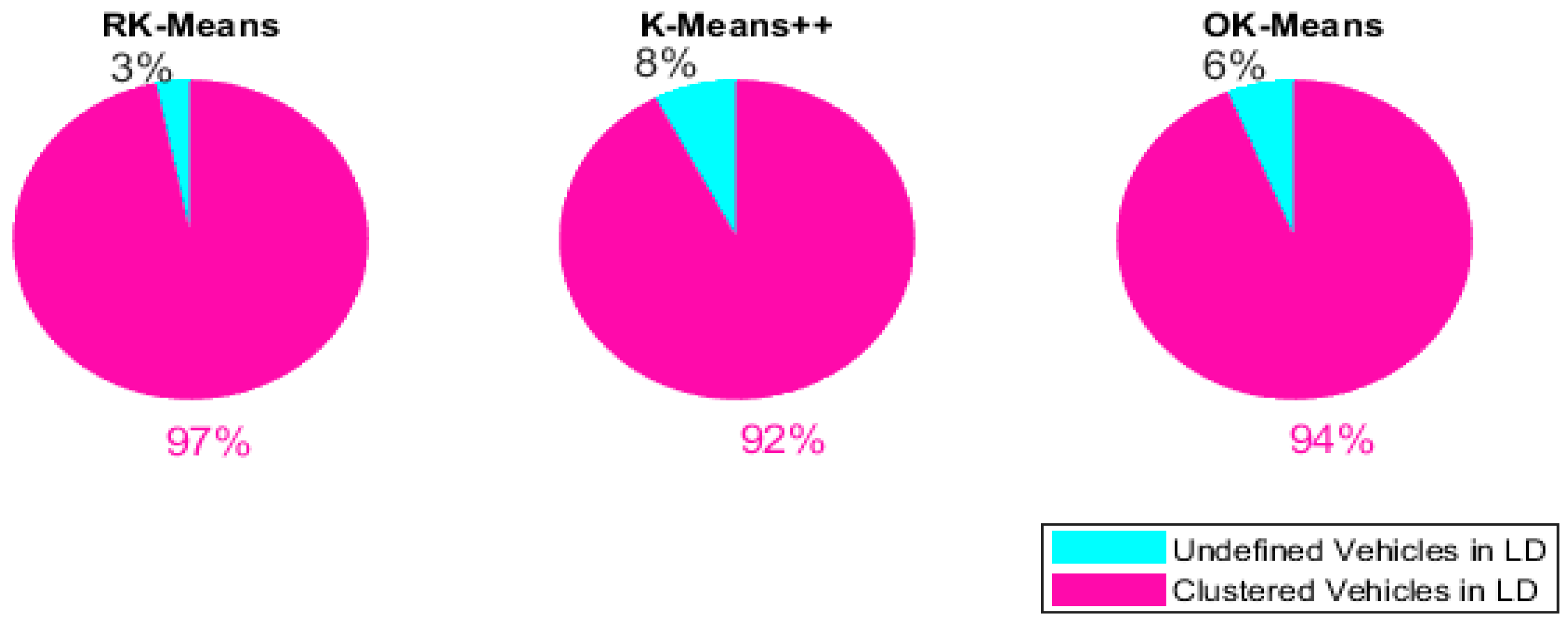
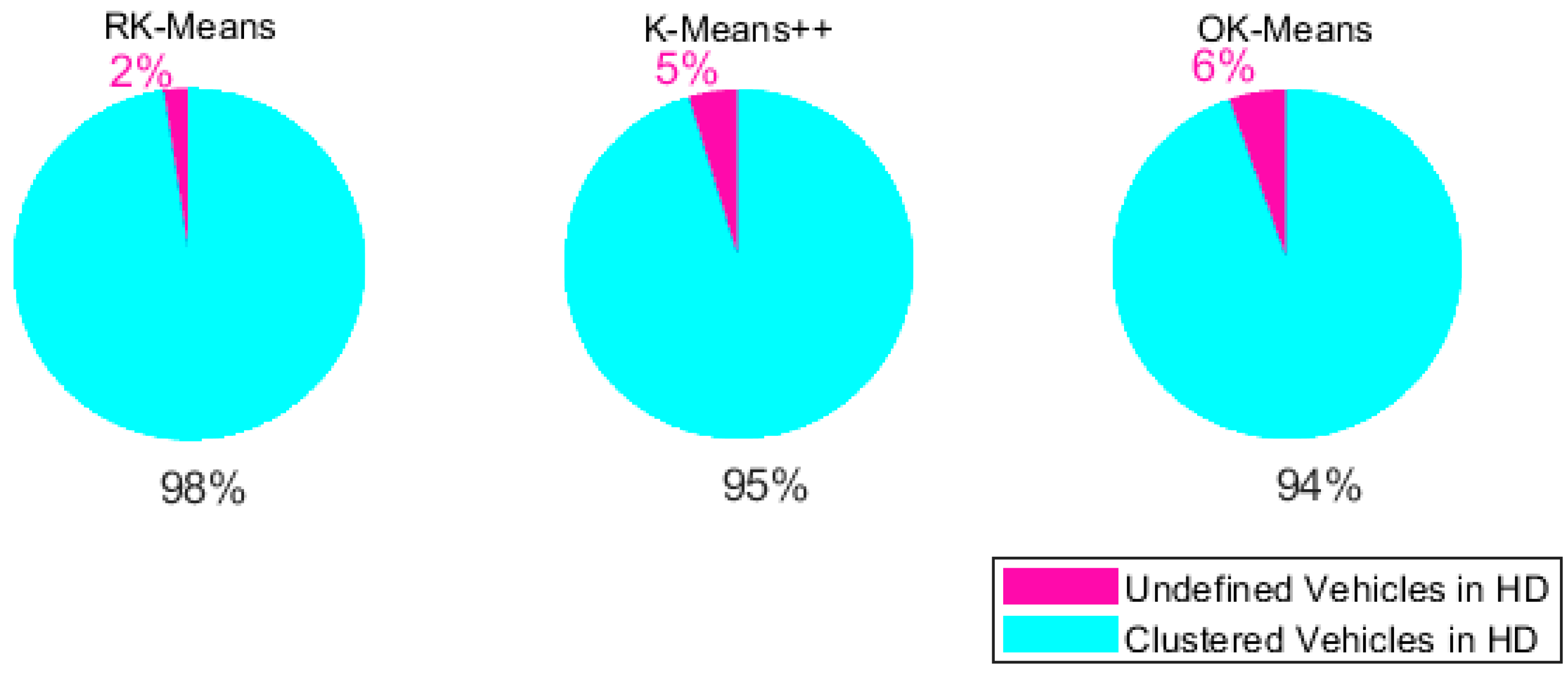
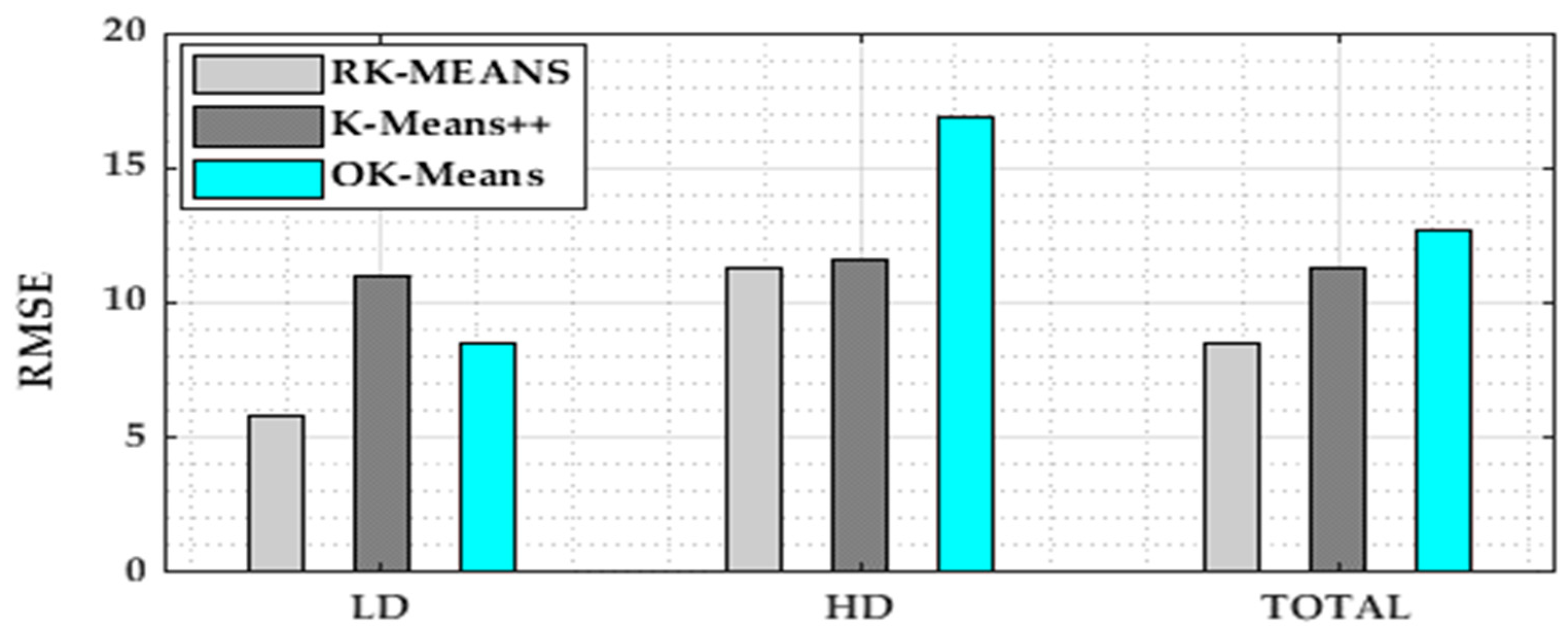
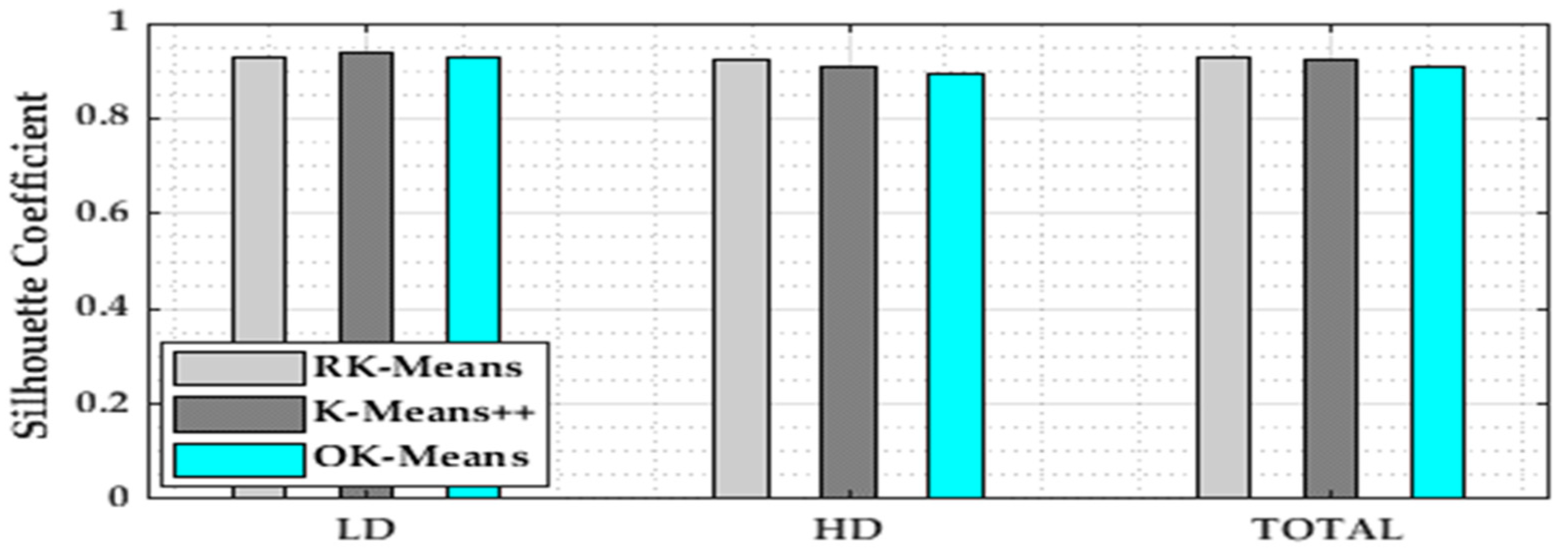
5.3. Numerical Results and Comparison
5.4. Stability Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jabbar, M.K.; Trabelsi, H. A Novelty of Hypergraph Clustering Model (HGCM) for Urban Scenario in VANET. IEEE Access 2022, 10, 66672–66693. [Google Scholar] [CrossRef]
- Cheng, X.; Huang, B. A Center-Based Secure and Stable Clustering Algorithm for VANETs on Highways. Wirel. Commun. Mob. Comput. 2019. [Google Scholar] [CrossRef] [Green Version]
- Abdulrazzak, H.N.; Tan, N.M.L.; Radzi, N.A. M Minimizing Energy Consumption in Roadside Unit of Zigzag Distribution Based on RS-LS Technique. In Proceedings of the 2021 IEEE International Conference on Automatic Control & Intelligent Systems, Shah Alam, Malaysia, 26 June 2021; 2021; pp. 69–173. [Google Scholar] [CrossRef]
- Aadil, F.; Raza, A.; Khan, M.F.; Maqsood, M.; Mehmood, I.; Rho, S. Energy Aware Cluster-Based Routing in Flying Ad-Hoc Networks. Sensors 2018, 18, 1413. [Google Scholar] [CrossRef] [Green Version]
- Aissa, M.; Bouhdid, B.; Ben Mnaouer, A.; Belghith, A.; AlAhmadi, S. SOFCluster: Safety-Oriented, Fuzzy Logic-Based Clustering Scheme for Vehicular Ad Hoc Networks. Trans. Emerg. Telecommun. Technol. 2022, 33. [Google Scholar] [CrossRef]
- Mukhtaruzzaman, M.; Atiquzzaman, M. Junction-Based Stable Clustering Algorithm for Vehicular Ad Hoc Network. Ann. Telecommun. Telecommun. 2021, 76, 777–786. [Google Scholar] [CrossRef]
- Montero, J.; Yáñez, J.; Gómez, D. A Divisive Hierarchical K-Means Based Algorihtm for Image Segmentation. In Proceedings of the 2010 IEEE International Conference on Intelligent Systems and Knowledge Engineering, ISKE 2010, Hangzhou, China, 15–16 November 2010; pp. 300–304. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough Sets. Int. J. Comput. Inf. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, Y. Feature Subset Selection Based on Variable Precision Neighborhood Rough Sets. Int. J. Comput. Intell. Syst. 2021, 14, 572–581. [Google Scholar] [CrossRef]
- Jinila, B.; Komathy, K. Rough Set Based Fuzzy Scheme for Clustering and Cluster Head Selection in VANET. Elektron. Elektrotech. 2015, 21, 54–59. [Google Scholar] [CrossRef]
- Sathish Kumar, S.; Manimegalai, P.; Karthik, S. A Rough Set Calibration Scheme for Energy Effective Routing Protocol in Mobile Ad Hoc Networks. Cluster Comput. 2019, 22, 13957–13963. [Google Scholar] [CrossRef]
- Sudhakar, T.; Hannah Inbarani, H.; Senthil Kumar, S. Route Classification Scheme Based on Covering Rough Set Approach in Mobile Ad Hoc Network (CRS-MANET). Int. J. Intell. Unmanned Syst. 2020, 8, 85–96. [Google Scholar] [CrossRef]
- Senthil Kumar, S.; Hannah Inbarani, H.; Azar, A.T.; Polat, K. Covering-Based Rough Set Classification System. Neural Comput. Appl. 2017, 28, 2879–2888. [Google Scholar] [CrossRef]
- Kumar, S.U.; Inbarani, H.H. A Novel Neighborhood Rough Set Based Classification Approach for Medical Diagnosis. Procedia Comput. Sci. 2015, 47, 351–359. [Google Scholar] [CrossRef] [Green Version]
- Sengupta, S.; Das, A.K. Dimension Reduction Using Clustering Algorithm and Rough Set Theory. In Swarm, Evolutionary, and Memetic Computing. SEMCCO 2012, LNCS 7677; Lecture Notes in Computer Science; Panigrahi, B.K., Das, S., Suganthan, P.N., Nanda, P.K., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 705–712. [Google Scholar]
- Rivoirard, L.; Wahl, M.; Sondi, P. Multipoint Relaying versus Chain-Branch-Leaf Clustering Performance in Optimized Link State Routing-Based Vehicular Ad Hoc Networks. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1034–1043. [Google Scholar] [CrossRef] [Green Version]
- Ali, I.; Ur Rehman, A.; Khan, D.M.; Khan, Z.; Shafiq, M.; Choi, J.G. Model Selection Using K-Means Clustering Algorithm for the Symmetrical Segmentation of Remote Sensing Datasets. Symmetry 2022, 14, 1149. [Google Scholar] [CrossRef]
- Huang, J.; Cui, H.; Chen, C. Cluster-Based Radio Resource Management in Dynamic Vehicular Networks. IEEE Access 2022, 10, 43562–43570. [Google Scholar] [CrossRef]
- Hajlaoui, R.; Alsolami, E.; Moulahi, T.; Guyennet, H. An Adjusted K-Medoids Clustering Algorithm for Effective Stability in Vehicular Ad Hoc Networks. Int. J. Commun. Syst. 2019, 32, 3995. [Google Scholar] [CrossRef]
- Ran, X.; Zhou, X.; Lei, M.; Tepsan, W.; Deng, W. A Novel K-Means Clustering Algorithm with a Noise Algorithm for Capturing Urban Hotspots. Appl. Sci. 2021, 11, 1202. [Google Scholar] [CrossRef]
- Kandali, K.; Bennis, L.; Bennis, H. A New Hybrid Routing Protocol Using a Modified K-Means Clustering Algorithm and Continuous Hopfield Network for VANET. IEEE Access 2021, 9, 47169–47183. [Google Scholar] [CrossRef]
- Yang, X.; Yu, T.; Chen, Z.; Yang, J.; Hu, J.; Wu, Y. An Improved Weighted and Location-Based Clustering Scheme for Flying Ad Hoc Networks. Sensors 2022, 22, 3236. [Google Scholar] [CrossRef]
- Pandey, P.K.; Kansal, V.; Swaroop, A. OCSR: Overlapped Cluster-Based Scalable Routing Approach for Vehicular Ad Hoc Networks (VANETs). Wirel. Commun. Mob. Comput. 2022, 2022, 6815. [Google Scholar] [CrossRef]
- Sinaga, K.P.; Hussain, I.; Yang, M.S. Entropy K-Means Clustering with Feature Reduction under Unknown Number of Clusters. IEEE Access 2021, 9, 67736–67751. [Google Scholar] [CrossRef]
- Herawan, T.; Deris, M.M.; Abawajy, J.H. A Rough Set Approach for Selecting Clustering Attribute. Knowl. Based Syst. 2010, 23, 220–231. [Google Scholar] [CrossRef]
- Nawrin, S.; Rahatur, M.; Akhter, S. Exploreing K-Means with Internal Validity Indexes for Data Clustering in Traffic Management System. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 337. [Google Scholar] [CrossRef] [Green Version]
- Yuan, C.; Yang, H. Research on K-Value Selection Method of K-Means Clustering Algorithm. J 2019, 2, 226–235. [Google Scholar] [CrossRef] [Green Version]
- Karkkainen, I.; Franti, P. Minimization of the Value of Davies-Bouldin Index. In Proceedings of the IASTED International Conference on Signal Processing and communications, Banff, AB, Canada, 24–26 July 2000; pp. 426–432. [Google Scholar]
- Feng, M.; Yao, H.; Ungurean, I. A Roadside Unit Deployment Optimization Algorithm for Vehicles Serving as Obstacles. Mathematics 2022, 10, 3282. [Google Scholar] [CrossRef]
- Lim, K.G.; Lee, C.H.; Chin, R.K.Y.; Beng Yeo, K.; Teo, K.T.K. SUMO Enhancement for Vehicular Ad Hoc Network (VANET) Simulation. In Proceedings of the 2017 IEEE 2nd International Conference on Automatic Control and Intelligent Systems (I2CACIS), Kota Kinabalu, Malaysia, 21–21 October 2017; pp. 86–91. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronyms | Definition |
|---|---|
| CBL | Chain-Branch-Leaf |
| CG | Covering Group |
| CH | Cluster Head |
| CM | Cluster Member |
| CRS | Covering Rough Set |
| DB | Davies–Bouldin Index |
| DI | Dunn Index |
| DSRC | Dedicated Short-Range Communication |
| MANET | Mobile Ad Hoc Network |
| ML | Machine Learning |
| MPR | Multi-Point Relay Node |
| NSC | Number of Status Changes |
| OK-Means | Overlapping K-Means |
| OLSR | Optimized Link State Routing Protocol |
| RMSE | Root Mean Square Error |
| RSU | Road Side Unit |
| SC | Silhouette Coefficient |
| SUMO | Simulation of Urban Mobility |
| UAV | Unmanned Aerial Vehicle |
| V2I | Vehicle-to-Infrastructure Communications |
| V2V | Vehicle-to-Vehicle Communications |
| VANET | Vehicular Ad Hoc Network |
| Proposed Model | Algorithm Type | Network Scenario | Effective Parameters | ||||
|---|---|---|---|---|---|---|---|
| Location | Speed | Direction | Distance | Transmission Range | |||
| CBL [16] | Single | Highway | √ | √ | ˟ | √ | ˟ |
| K-Means [17] | Single | Satellite image | √ | ˟ | ˟ | √ | ˟ |
| Radio Resource [18] | Single | Highway | √ | √ | ˟ | √ | √ |
| Modified K-Means [21] | Hybrid | Highway | √ | ˟ | ˟ | √ | √ |
| K-Means++ [22] | Single | UAV | √ | ˟ | √ | √ | √ |
| OK-Means [23] | Single | Highway | √ | ˟ | √ | √ | √ |
| RK-Means (proposed herein) | Hybrid | Highway | √ | √ | √ | √ | √ |
| Speed | Direction | Distance | Sector | |
|---|---|---|---|---|
| G1 | Medium | Right | Far | NS |
| G2 | Low | Left | Near | CS |
| G3 | Medium | Right | Near | CS |
| G4 | High | Left | Near | CS |
| G5 | High | Right | Near | CS |
| G6 | Medium | Left | Far | NS |
| G7 | Low | Right | Far | NS |
| G8 | Low | Left | Near | NS |
| G9 | High | Left | Near | NS |
| G10 | Medium | Right | Far | CS |
| Density | SUMO Running Time | Timestamp Period | Scenario |
|---|---|---|---|
| Low-density (60 vehicles) | 200 s | 1 to 50 s | LD1 |
| 51 to 100 s | LD2 | ||
| 101 to 150 s | LD3 | ||
| 151 to 200 s | LD4 | ||
| High-density (120 vehicles) | 380 s | 1 to 95 s | HD1 |
| 96 to 190 s | HD2 | ||
| 191 to 285 s | HD3 | ||
| 286 to 380 s | HD4 |
| Parameter | Value |
|---|---|
| Network topology | Highway (2 Km road length, 4 lanes) |
| Mobility simulator | SUMO |
| Direction | Two directions |
| Mobility simulation time | 200 s, 380 s |
| Vehicle density | HD = 120, LD = 60 |
| Vehicle speed | 0–120 Km/h |
| Vehicle coverage range | 200 m |
| Vehicle Density | Algorithm | No. of Clusters | Average No. of CMs/Clusters |
|---|---|---|---|
| Low-density (60 vehicles) | RK-Means | 14 | 4.14 |
| K-Means++ | 15 | 3.67 | |
| OK-Means | 12 | 4.67 | |
| High-density (120 vehicles) | RK-Means | 14 | 8.36 |
| K-Means++ | 16 | 7.13 | |
| OK-Means | 10 | 11.3 |
| Scenario | Algorithm | Maximum | Average | Minimum |
|---|---|---|---|---|
| LD1 | RK-Means | 10.0281 | 7.1953 | 2.8043 |
| K-Means++ | 22.3953 | 13.0426 | 9.7661 | |
| OK-Means | 10.0102 | 7.5284 | 2.9302 | |
| LD2 | RK-Means | 6.1243 | 3.7182 | 1.9843 |
| K-Means++ | 11.7042 | 10.1505 | 9.8902 | |
| OK-Means | 13.3535 | 3.7293 | 2.9646 | |
| LD3 | RK-Means | 8.4965 | 7.8033 | 6.8341 |
| K-Means++ | 15.0121 | 13.3145 | 11.7047 | |
| OK-Means | 16.6213 | 13.6447 | 11.1972 | |
| LD4 | RK-Means | 7.9712 | 4.5561 | 3.5431 |
| K-Means++ | 9.7351 | 7.4745 | 6.4503 | |
| OK-Means | 11.3739 | 8.9334 | 6.7684 | |
| HD1 | RK-Means | 15.0285 | 11.5614 | 8.0535 |
| K-Means++ | 17.4779 | 13.0422 | 9.7661 | |
| OK-Means | 22.7448 | 16.4297 | 11.4612 | |
| HD2 | RK-Means | 10.7905 | 9.8075 | 7.8421 |
| K-Means++ | 11.8499 | 10.0278 | 8.5043 | |
| OK-Means | 17.4678 | 17.0153 | 16.4298 | |
| HD3 | RK-Means | 18.0311 | 8.8341 | 1.8682 |
| K-Means++ | 13.7679 | 9.7783 | 4.0764 | |
| OK-Means | 16.5879 | 14.3458 | 12.2135 | |
| HD4 | RK-Means | 17.4466 | 14.8739 | 11.4529 |
| K-Means++ | 16.5129 | 13.3536 | 7.8224 | |
| OK-Means | 21.1495 | 19.7686 | 16.4615 |
| Scenario | Algorithm | Maximum | Average | Minimum |
|---|---|---|---|---|
| LD1 | RK-Means | 0.9884 | 0.9672 | 0.9511 |
| K-Means++ | 0.9793 | 0.9559 | 0.9143 | |
| OK-Means | 0.9595 | 0.9489 | 0.9093 | |
| LD2 | RK-Means | 0.9944 | 0.9515 | 0.9463 |
| K-Means++ | 0.9861 | 0.9572 | 0.9489 | |
| OK-Means | 0.9877 | 0.9498 | 0.9398 | |
| LD3 | RK-Means | 0.9387 | 0.9184 | 0.8963 |
| K-Means++ | 0.9539 | 0.9275 | 0.8827 | |
| OK-Means | 0.8979 | 0.8837 | 0.8625 | |
| LD4 | RK-Means | 0.9698 | 0.8826 | 0.8801 |
| K-Means++ | 0.9491 | 0.9109 | 0.8593 | |
| OK-Means | 0.9585 | 0.9276 | 0.8746 | |
| HD1 | RK-Means | 0.9895 | 0.9227 | 0.7542 |
| K-Means++ | 0.9861 | 0.8931 | 0.7633 | |
| OK-Means | 0.9488 | 0.8839 | 0.7437 | |
| HD2 | RK-Means | 0.9892 | 0.9623 | 0.9382 |
| K-Means++ | 0.9723 | 0.9631 | 0.9553 | |
| OK-Means | 0.9715 | 0.9599 | 0.9451 | |
| HD3 | RK-Means | 0.8664 | 0.8548 | 0.8492 |
| K-Means++ | 0.8212 | 0.8156 | 0.8003 | |
| OK-Means | 0.8151 | 0.8028 | 0.7948 | |
| HD4 | RK-Means | 0.9583 | 0.9499 | 0.9271 |
| K-Means++ | 0.9745 | 0.9567 | 0.9355 | |
| OK-Means | 0.9313 | 0.9186 | 0.9082 |
| Scenario | Algorithm | Maximum | Average | Minimum |
|---|---|---|---|---|
| LD1 | RK-Means | 0.3901 | 0.2061 | 0.0977 |
| K-Means++ | 0.4466 | 0.3913 | 0.3777 | |
| OK-Means | 0.4554 | 0.3208 | 0.1787 | |
| LD2 | RK-Means | 0.0806 | 0.0663 | 0.0543 |
| K-Means++ | 0.1804 | 0.0344 | 0.0138 | |
| OK-Means | 0.3852 | 0.2752 | 0.1504 | |
| LD3 | RK-Means | 0.5057 | 0.4197 | 0.2838 |
| K-Means++ | 0.4018 | 0.3018 | 0.2852 | |
| OK-Means | 0.5238 | 0.4328 | 0.2733 | |
| LD4 | RK-Means | 0.7129 | 0.5925 | 0.4697 |
| K-Means++ | 0.4734 | 0.3248 | 0.2725 | |
| OK-Means | 0.4533 | 0.2082 | 0.1471 | |
| HD1 | RK-Means | 0.4274 | 0.3391 | 0.2165 |
| K-Means++ | 0.5644 | 0.5002 | 0.4825 | |
| OK-Means | 0.4878 | 0.3106 | 0.2098 | |
| HD2 | RK-Means | 0.6412 | 0.4352 | 0.3348 |
| K-Means++ | 0.6825 | 0.5901 | 0.4729 | |
| OK-Means | 0.5689 | 0.5138 | 0.2246 | |
| HD3 | RK-Means | 0.4524 | 0.3402 | 0.2204 |
| K-Means++ | 0.5254 | 0.5021 | 0.3358 | |
| OK-Means | 0.3098 | 0.2191 | 0.1604 | |
| HD4 | RK-Means | 0.5393 | 0.4183 | 0.2912 |
| K-Means++ | 0.4852 | 0.3801 | 0.3012 | |
| OK-Means | 0.4694 | 0.3592 | 0.2781 |
| Scenario | Algorithm | Maximum | Average | Minimum |
|---|---|---|---|---|
| LD1 | RK-Means | 85.8927 | 33.6926 | 3.2534 |
| K-Means++ | 72.1376 | 35.8044 | 5.8996 | |
| OK-Means | 80.8281 | 31.7001 | 2.3408 | |
| LD2 | RK-Means | 180.8782 | 106.0554 | 18.5412 |
| K-Means++ | 165.1512 | 82.4533 | 14.3342 | |
| OK-Means | 174.6099 | 72.2308 | 19.0643 | |
| LD3 | RK-Means | 4.4773 | 3.4773 | 2.2075 |
| K-Means++ | 1.9242 | 1.5312 | 1.2292 | |
| OK-Means | 6.6109 | 2.9776 | 1.4617 | |
| LD4 | RK-Means | 11.9315 | 6.4332 | 0.5564 |
| K-Means++ | 12.5944 | 5.8871 | 1.3079 | |
| OK-Means | 10.5521 | 5.0209 | 1.6851 | |
| HD1 | RK-Means | 10.7695 | 8.7729 | 7.3401 |
| K-Means++ | 10.5944 | 8.9973 | 4.3972 | |
| OK-Means | 8.4049 | 7.2903 | 5.5639 | |
| HD2 | RK-Means | 14.7284 | 12.5428 | 7.8825 |
| K-Means++ | 13.3297 | 12.3372 | 6.0038 | |
| OK-Means | 10.1819 | 8.9921 | 5.7791 | |
| HD3 | RK-Means | 9.0338 | 7.2291 | 6.3301 |
| K-Means++ | 7.4296 | 7.0062 | 6.8871 | |
| OK-Means | 8.7701 | 6.2207 | 3.5209 | |
| HD4 | RK- Means | 8.7705 | 6.8892 | 4.4719 |
| K-Means++ | 5.5482 | 4.4402 | 3.2733 | |
| OK-Means | 6.9058 | 6.3081 | 4.6704 |
| Scenario | Algorithm | Maximum | Minimum |
|---|---|---|---|
| LD1 | RK-Means | 0.367654729 | 0.355499648 |
| K-Means++ | 3.79731923 | 3.276113551 | |
| OK-Means | 4.150443082 | 3.059492927 | |
| LD2 | RK-Means | 1.333829075 | 0.429344109 |
| K-Means++ | 3.934093954 | 3.566997337 | |
| OK-Means | 3.306255255 | 3.126828608 | |
| LD3 | RK-Means | 0.441085438 | 0.34182981 |
| K-Means++ | 3.393721654 | 3.017891096 | |
| OK-Means | 4.140321739 | 2.71766411 | |
| LD4 | RK-Means | 0.307420352 | 0.243036348 |
| K-Means++ | 3.089658018 | 3.080243497 | |
| OK-Means | 4.46502773 | 3.59913184 | |
| HD1 | RK-Means | 0.314635087 | 0.284018779 |
| K-Means++ | 3.329564536 | 2.984212427 | |
| OK-Means | 3.872622844 | 3.549938092 | |
| HD2 | RK-Means | 0.374165739 | 0.156418243 |
| K-Means++ | 3.18453398 | 2.148264416 | |
| OK-Means | 4.632240821 | 3.13175631 | |
| HD3 | RK-Means | 0.457573309 | 0.392045916 |
| K-Means++ | 3.415059785 | 2.724496284 | |
| OK-Means | 4.024010542 | 3.64913583 | |
| HD4 | RK-Means | 0.397510108 | 0.31507142 |
| K-Means++ | 3.344377656 | 3.210557584 | |
| OK-Means | 3.11267672 | 2.720969446 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulrazzak, H.N.; Hock, G.C.; Mohamed Radzi, N.A.; Tan, N.M.L.; Kwong, C.F. Modeling and Analysis of New Hybrid Clustering Technique for Vehicular Ad Hoc Network. Mathematics 2022, 10, 4720. https://0-doi-org.brum.beds.ac.uk/10.3390/math10244720
Abdulrazzak HN, Hock GC, Mohamed Radzi NA, Tan NML, Kwong CF. Modeling and Analysis of New Hybrid Clustering Technique for Vehicular Ad Hoc Network. Mathematics. 2022; 10(24):4720. https://0-doi-org.brum.beds.ac.uk/10.3390/math10244720
Chicago/Turabian StyleAbdulrazzak, Hazem Noori, Goh Chin Hock, Nurul Asyikin Mohamed Radzi, Nadia M. L. Tan, and Chiew Foong Kwong. 2022. "Modeling and Analysis of New Hybrid Clustering Technique for Vehicular Ad Hoc Network" Mathematics 10, no. 24: 4720. https://0-doi-org.brum.beds.ac.uk/10.3390/math10244720