Homogeneous Groups of Actors in an AHP-Local Decision Making Context: A Bayesian Analysis


Grupo Decisión Multicriterio Zaragoza (GDMZ), Facultad de Economía y Empresa, Universidad de Zaragoza, Gran Vía 2, 50005 Zaragoza, Spain
*
Author to whom correspondence should be addressed.
Mathematics 2019, 7(3), 294; https://0-doi-org.brum.beds.ac.uk/10.3390/math7030294
Submission received: 15 February 2019
/
Revised: 13 March 2019
/
Accepted: 16 March 2019
/
Published: 21 March 2019
(This article belongs to the Special Issue Optimization for Decision Making)
Abstract
:The two procedures traditionally followed for group decision making with the Analytical Hierarchical Process (AHP) are the Aggregation of Individual Judgments (AIJ) and the Aggregation of Individual Priorities (AIP). In both cases, the geometric mean is used to synthesise judgments and individual priorities into a collective position. Unfortunately, positional measures (means) are only representative if dispersion is reduced. It is therefore necessary to develop decision tools that allow: (i) the identification of groups of actors that present homogeneous and differentiated behaviours; and, (ii) the aggregation of the priorities of the near groups to reach collective positions with the greatest possible consensus. Following a Bayesian approach to AHP in a local context (a single criterion), this work proposes a methodology to solve these problems when the number of actors is not high. The method is based on Bayesian comparison and selection of model tools which identify the number and composition of the groups as well as their priorities. This information can be very useful to identify agreement paths among the decision makers that can culminate in a more representative decision-making process. The proposal is illustrated by a real-life case study.
1. Introduction
Two of the most outstanding characteristics of the Knowledge Society (KS), understood as a space for the talent, imagination and creativity of human beings, are [1]: (i) the collaborative predisposition of citizens in the resolution of complex problems, motivated by the existence of a more educated and participative society that wants to be involved in decision-making processes; and, (ii) the relevance of the human factor and the need for the formal models to incorporate the subjective, intangible and emotional aspects inherent to the human being, alongside the tangible and rational objectives of the traditional scientific method.
In order to take advantage of the characteristics of the KS and to provide an adequate response to new challenges and needs, it is necessary to develop appropriate analytical and computing decision-making tools to solve the complex problems characterised by the existence of multiple scenarios, actors and both tangible and intangible criteria. One of the most utilised multicriteria techniques that best incorporates intangible aspects and multiple actors is the Analytic Hierarchy Process (AHP) proposed by Thomas L. Saaty in the mid-1970s [2]. The methodology consists of three stages: (i) Hierarchical modelling; (ii) Valuation; (iii) Prioritisation and Synthesis.
AHP incorporates the intangible through the judgments issued when assessing the matrices of paired comparisons considered in the problem. The two most commonly used methods in AHP for the calculus of collective priorities in multi-actor decision making are [3,4,5]: the Aggregation of Individual Judgments (AIJ) and the Aggregation of Individual Priorities (AIP). They obtain, as averages (geometric mean), the collective judgments or collective priorities. The average is not a representative indicator of the collective when it is not homogeneous. It is therefore necessary to evaluate the compatibility (an objective measure obtained automatically) or the agreement (a subjective measure that requires personal intervention) between the individual positions of the actors and the position of the group.
If not all actors are compatible with the collective priority vector, the different positions and the actors that support them must be identified in order to initiate posterior negotiation processes to achieve final decisions that are as representative as possible. This paper presents a Bayesian procedure to solve this problem in a local context (a single criterion). The procedure adopts the Bayesian hierarchical approach (Stochastic AHP) proposed in reference [6]. It allows the estimation of the priorities of the group by incorporating restrictions on the maximum level of inconsistency of the actors involved in the problem. The procedure quantifies the homogeneity of the groups by means of the marginal density of the judgments elicited by their respective actors. The density evaluates the goodness of fit of the model and allows for comparisons between different partitions of the set of actors. The work further puts forward an algorithm for the exhaustive search of homogeneous groups with respect to their priorities based on the Bayesian comparison and selection of models. The methodology is illustrated by a practical example.
The paper is structured as follows: Section 2 presents the model used to determine the priorities of a group of homogeneous decision makers; Section 3 describes the algorithm that identifies decision groups with homogeneous preferences; Section 4 applies the methodology to a case study; and, Section 5 concludes by highlighting the most relevant aspects of the work and possible extensions.
2. Bayesian Local Priorities in an AHP-Multi-Actor Decision Making Context
This section deals with the problem of determining the total priorities of a group of actors with homogeneous opinions regarding a decision criterion. A Bayesian statistical approach based on the use of a log-linear model similar to that used in reference [6] is employed to describe the process of the issuing judgments by the decision makers of a group. The posterior distribution of the group’s priorities is calculated by means of Bayes’ Theorem; this is followed by a description of how to make inferences about the most preferred alternative (alpha problem—P.α) and the priority ranking (gamma problem—P.γ).
2.1. Problem Formulation
First, the log-linear model that is used to determine the priorities of the groups of decision makers is explained: in what follows, N (µ, σ) denotes the univariate normal distribution of mean µ and standard deviation σ; Np (µ, ∑) denotes the p-variant normal distribution of mean vector µ and the matrix of variances and covariances ∑; Tp (µ, ∑, υ) denotes the p-variant Student t distribution with mean vector µ, scale matrix ∑ and degrees of freedom υ; Gamma(p, a) denotes the gamma distribution with shape parameter p and scale parameter 1/a; denotes the chi-squared distribution with υ degrees of freedom; IA denotes the indicator function of set A; ∝ indicates ‘proportional to’ and [Y|X] denotes the density function of the conditional distribution of Y given X.
Let G = {D[1],…., D[K]} be a group of K homogeneous decision makers (k = 1, …, K), A = {A1,…, An} be a set of n alternatives and R(k) = ; k = 1,…, K be the nxn paired comparison matrices issued by each decision maker.
We assume, without loss of generality, that the matrices of judgments are complete—all paired comparisons have been made. If some of the rij comparisons are missing, the proposed methodology could be analogously adapted, as shown in reference [6].
We further assume that the decision makers of G have homogeneous opinions regarding the priorities of each of the alternatives of A so that:
with , where:
- (a)
- ; i = 1, …, n being the priority (without normalising) given to the alternative Ai by the members of the group G
- (b)
- (that is to say, ) to avoid identifiability problems
- (c)
- ; k = 1, …, K; 1 ≤ i < j ≤ n independents
The normalised priorities of the group will be given by the vector where ; i = 1, …, n. Likewise, the level of homogeneity will be determined by the standard deviation of the errors σ(G) that quantifies the inconsistency level of all decision makers in the group with the priority vector w(G).
2.2. Estimation of the Local Priorities for the Group
The estimation of the vector of group priorities w(G) uses a Bayesian approach that allows exact inferences about their values. We adopt, as a prior, a normal-gamma distribution given by:
that is the standard conjugate distribution used in Bayesian literature [7]. The constants c0, n0 and determine the degree of strength of the prior distribution. In the illustrative example we have taken c0 = 0.1 so that the influence of the prior distribution of µ(G) is not significant. The hyper-parameters n0 and are determined from the maximum levels of inconsistency allowed for each decision maker so that
being, 1 − α (0 < α < 1) the level of credibility that we want to achieve. The value of has been set using the consistency thresholds of the geometric consistency index (GCI) proposed by [8]. In our illustrative example, and given that n = 4, we take = 0.35 and α = 0.05, which resulted in n0 = 0.1 and = 0.0014.
Using Bayes’ theorem, and taking into account (1)–(3), we calculate the posterior distribution of (µ(G), τ(G)) whose density is given by:
where for k = 1, …, K and X = (xij) (J × (n − 1)) with is the regression matrix of model (1) so that:
- -
- xij = 1 if the ith judgement is yjk with k ≠ j;
- -
- xij = −1 if the ith judgement is ykj with k ≠ j;
- -
- xij = 0 in any other case.
It follows that:
where .
Therefore, it follows from (5) that:
where .
Integrating with respect to τ(G) in (5), it follows that:
From the posterior distributions (7) and (8), point estimates and credibility intervals of w(G) and σ(G) can be obtained using the posterior median and the corresponding quantiles.
In the case of σ2(G), and taking into account that from (7) , a 100 (1 − α)%, the Bayesian credibility interval for σ2(G) is given by where denotes the (1 − α)th quantile of the distribution .
To calculate a credibility interval for (1 ≤ i ≤ n) the Monte Carlo method is applied by extracting a sample from (8) and calculating a sample of the posterior distribution of w(G), with where . From this sample a credibility interval for is given by where is the αth quantile of the sample W(G).
Alpha distributions could also be calculated with:
and gamma distributions with:
where γh = (γh,1, …, γh,n) is the hth permutation of the elements of A sorted according to the lexicographical order. The approximate calculation of these probabilities is from the sample W(G) by means of the expressions:
These distributions report on preferences as well as the most preferred alternative and ranking for the group.
3. Identification of Homogeneous Groups of Actors
The procedure for estimating the priorities of a group, as detailed in the previous section, is based on the hypothesis of the similarity of the opinions of the decision makers. However, it is quite possible that there will be different opinions. In this case, and in order to facilitate a subsequent negotiation process, it is useful to identify the different opinions within the group and the actors that support them; this section presents a systematic procedure for doing this. It utilises a Bayesian oriented tool selection model based on the use of the Bayes factor as a selection element.
3.1. Problem Formulation
Let D = {D[1], …, D[K]} be a group of K decision makers, = {G1, …, Gm} be a partition of D, with ⊆ D; g = 1, …, m, Gg ∩ Gg′ = ∅ if g ≠ g′, . To avoid identifiability problems we impose that and if g < g′.
The problem is to select the partitions that best describe the opinions expressed by the decision makers about the alternative to be chosen from the judgments issued . To this end we extend the approach made in the previous section to the case of several groups, assuming that the decision makers of each group {Gg; g = 1, …, m} of the partition have homogeneous opinions regarding the priorities of each alternative of set A so that:
- (i)
- with g(k) ∈ {1, …, m} the group to which the decision maker D[k] belongs
- (ii)
- ; i = 1, …, n being the priority (without normalising) given to the alternative Ai by the members of the group Gg
- (iii)
- (that is to say, ) to avoid identifiability problems
- (iv)
- and independent
Finally, we take the following prior distributions for the parameters of the normal-gamma model:
independents for g = 1, …, m.
3.2. Goodness of Fit Evaluation of
The selection of the best partitions is made by an evaluation of their adjustment to the Y issued judgments. We use [Y|], the prior marginal density of the model (13)–(15), which is one of the tools utilised in the Bayesian inference to quantify it, so that, the higher the value, the greater the degree of fit of as a description of the existing opinions in D and the greater is the explanatory power of the Y issued judgments.
This density is given by:
Taking into account that:
from (6), (13), (14) and (15) it follows that
where . It follows that
where .
Substituting in (16) it follows that:
3.3. Location of Opinion Groups
Now that the evaluation of the adjustment of a partition to the issued judgements is completed, in this section we describe the process followed to determine the most representative partitions. We use Bayesian selection models and the Bayes factor, as a tool of comparison of two elements and ′ of ℘(D), the set of possible partitions of D.
We set a threshold β (0 < β < 1) to discriminate if there are significant differences in the data adjustment of the partitions and ′ so that if then the degree of fit of ′ is significantly worse than that of and, therefore, is more representative than ′. In this case, and in line with [9], we take β = 0.05.
The problem is to determine ∈ ℘(D) so that:
where and gives us the ‘Occam’s window’ of our problem [10]. The partitions could be taken as starting points for subsequent negotiation processes in order to reach an agreement among the decision makers that is as representative as possible. In our case, we look for the partitions of the window that have the least number of groups, since it can be foreseen that the fewer groups there will be, the easier it will be to reach more representative agreements because there are fewer disparate opinions. In order to do this, we use an exhaustive search algorithm that calculates the values of [Y|] for all the elements of ℘(D) using expression (19). Then max is determined and, from this, the partitions of Occam’s window that verify (20) are identified. Other methods for consensus searching in group decision making can be seen in references [11,12,13,14,15,16].
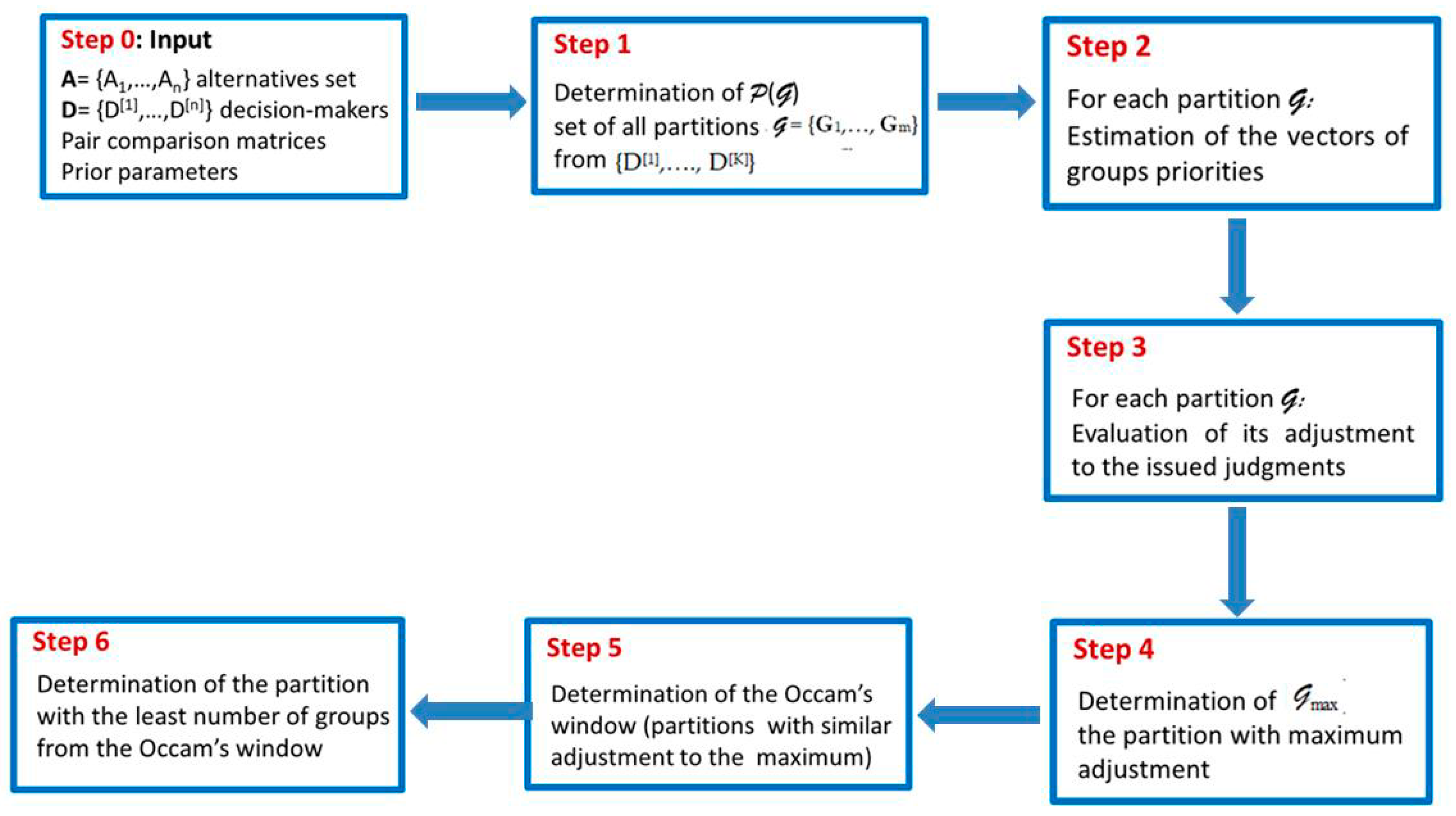
Figure 1 shows the main steps for determining the groups with homogeneous opinions.
4. Case Study
In September 2006 the Government of Aragón and the Zaragoza City Council advanced the ‘Zaragoza Plan for Sustainable Mobility’, which led to the construction of the city’s Tram Line 1 that was completed in 2013. The construction was controversial and in the following municipal elections, the political parties presented their proposals for improving transport in the city. Representatives of the main political parties (PSOE, PP and CHA) attended the university to explain their preferred alternative. The case study concerns a citizen participation project in a local community which contemplated alternatives put forward by the political parties during the municipal elections for the extension of the city tram network.
Eleven students (K = 11) from the ‘Electronic-Government and Public Decisions’ course of the Faculty of Economics and Business at the University of Zaragoza (Spain) were involved in its implementation.
There were 4 alternatives:
- A1
- Build a new tram line
- A2
- Use a tram and bus combination called Tranbus
- A3
- Use a tram combination with commuter lines
- A4
- Do nothing
As the construction of Line 1 had a high economic cost, and the selection of any of first three alternatives assumes a significant investment, a fourth alternative (no cost) was included. The selection problem was solved using the Analytic Hierarchy Process [2]. The hierarchical model comprised four levels (the goal, 3 criteria, 9 attributes and 4 alternatives).
The results of the Investment Cost attribute have been used to illustrate the proposed methodology. The prior distribution parameters were c0 = 0.1, n0 = 1 and = 0.0014 (corresponding to take = 0.35 and α = 0.05) and β = 0.05. The number of partitions was equal to the 678,570 that were processed in 98.84 s of CPU by a Toshiba Ultrabook KIRA with Intel (R) Core™ i7-4510U CPU @ 2.00GHz 2.60 GHz (64 bits) and 8 Gb of RAM.
The resulting number of groups was equal to five and the most probable composition was: G1 = {D1, D2, D3, D7}, G2 = {D4, D10}, G3 = {D5, D6}, G4 = {D9}, G5 = {D11}. The results obtained are shown in Table 1, Table 2 and Table 3. More specifically, Table 1 contains the posterior medians of the priorities of each alternative for each decision maker and each group. Table 2 shows the posterior probabilities that each alternative would be the most preferred, corresponding to the Pα distributions. Table 3 gives the probabilities for each ranking corresponding to the Pγ distributions. The values were calculated from (7)–(8) and (11)–(12), as described in Section 2.2, using S = 10,000 simulations.
So, for example, group G1 made up of decision makers D1, D2, D3 and D7, gives the highest priority (0.4502) to alternative A4, followed by the alternatives A2 (priority 0.3076), A3 (0.1518) and A1 (0.0879) (see Table 1). This ranking is also reflected by its Pα and Pγ distributions, which give the maximum posterior probabilities to the A4 alternative (97.31%, see Table 2) and the ranking 4231 (96.94%, see Table 3). Even though the individual opinion of D3 is different to the rest of the members of the group (their preferred alternative is A2 and the ranking is 2431), the consistency of the group G1 (0.2790) is good, being lower than the maximum level of inconsistency 0.35. This is due to the high priority of D3 for alternative A4 (0.2705) and the similarity of their priorities to alternatives A1 and A3 which means that G1 can be considered as a homogeneous group.
From the tables, it can be observed that the compositions of the groups are very much determined by their similarity to the most preferred alternative. The decision makers from groups G1 and G3 mostly prefer the alternative A4, those from group G2 prefer alternative A1, those from G3 prefer alternative A3 and those from G4 prefer alternative A2 (see Table 1 and Table 2). However, groups G1 and G3 differ in the rankings (see Table 3). The decision makers from the group G1 tend to prefer the 4231 ranking, while those from the group G3 prefer 4123. Nevertheless, preferences within each group are not completely homogeneous; in group G1, decision-maker D3 shows a greater preference for alternative A2. This opinion is shared with decision maker D11 of group G4, although it assigns a priority 0.2705 to alternative A4 that justifies its inclusion in group G1. Something similar happens in group G3, in which decision maker D5 shows a greater preference for alternative A1, although it assigns a non-negligible priority (0.3613) to alternative A4 and to the ranking 4123, hence its inclusion in group G3.
The consistency levels of the actors and most of the groups are acceptable (<0.35). The only exception is G3 whose consistency is estimated as 0.4071, but with a 95% credibility interval [0.20, 1.43] that does not reject the consistency hypothesis .
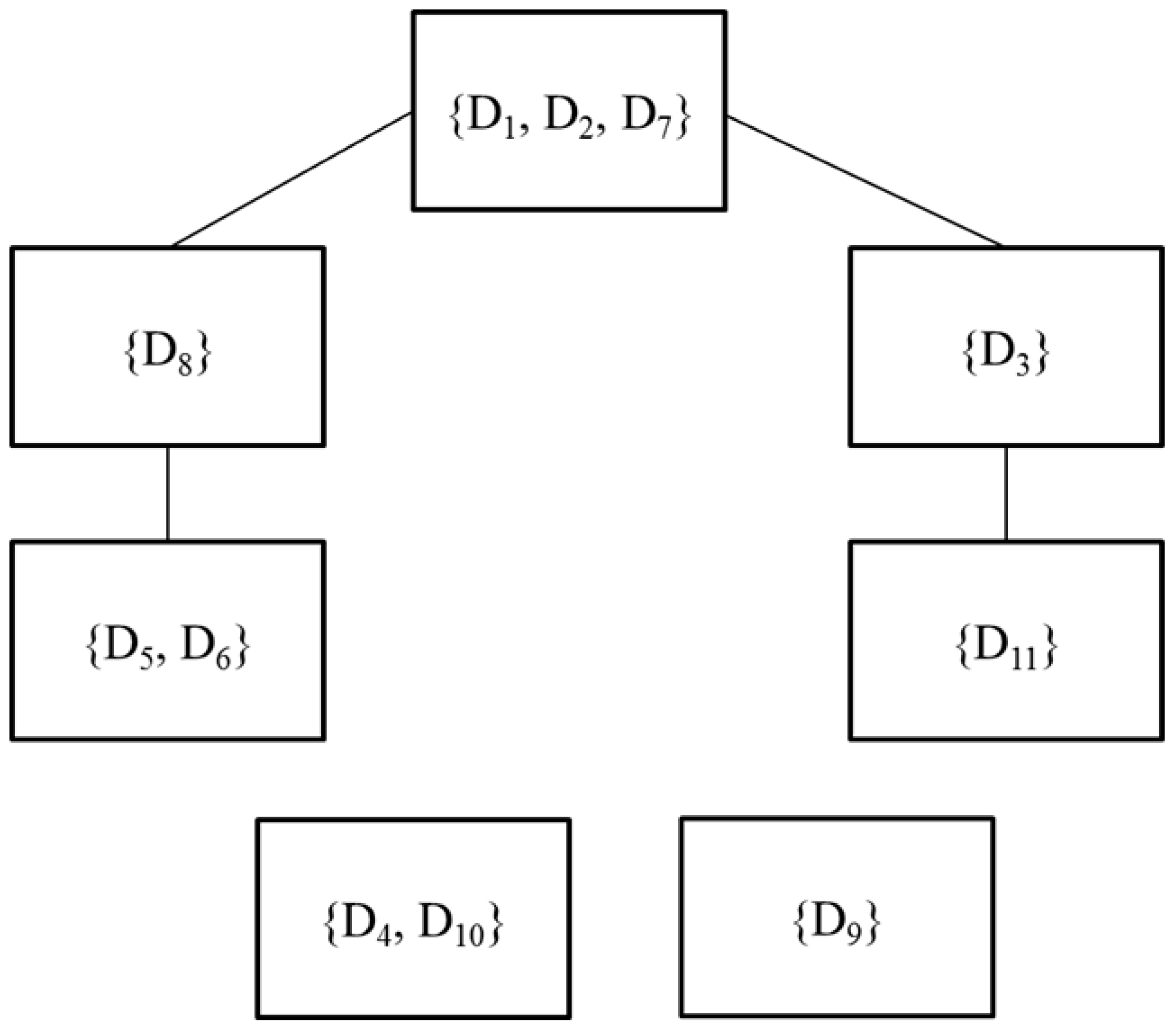
The ambiguities of the opinions are revealed if we analyse the partitions selected by Occam’s window with the smaller number of groups, included in Table 4 and Figure 2. Figure 2 incorporates, in each node, the groups of decision makers that are classified together in all the selected partitions and includes a link between two nodes if their components are classified together in some of the partitions. Most of the decision makers are linked because of their preferences for alternatives A2 and A4, the latter being the alternative which most decision makers support. Only D4, D9 and D10 are isolated because of their preferences for alternatives A1 (D4 and D10) and A3 (D9).
There are 4 homogeneous groups: {D1, D2, D7} that prefer alternative A4 and the ranking 4231; {D5, D6} position alternatives A2 and A3 in the last places and they show a non-negligible preference for A4; {D4, D10} prefer alternative A1 and put A3 in last place; decision maker {D9} prefers A3. Decision makers D3, D8, D11 are in more intermediate and ambiguous positions. In the case of D3, this is due to the greater preference for A2 (shared with D11) and the non-negligible preference for A4 (which places them close to the group {D1, D2, D7}). In the case of D8, the intermediate position is due to their preferences for A4 and A2, in that order, which places them close to the group {D1, D2, D7}, as well as to the rejection of A3, which places them close to the group {D5, D6}.
In order to achieve as broad an agreement as possible, alternative A4 could be suggested, given that a majority of decision makers (in groups G1 and G3) showed a preference for it. The negotiation should be aimed at convincing decision makers D4, D9, D10 and D11.
With regards to the practical implications of the Bayesian procedure proposed in this work, it is worth mentioning that, as in AHP, these applications are numerous, especially in matters of strategic planning where the number of actors is not usually very high.
5. Conclusions
This paper has proposed a methodology for the identification of homogenous opinion groups with AHP in a local context. The methodology is based on the use of Bayesian processes for the selection of hierarchical models that describe the judgments issued by each decision maker in their matrices of pairwise comparisons based on a set of priorities common to each of the members of the group.
Using an exhaustive search method of the most compatible partitions with the judgments issued, the Occam’s window of the compared models is defined. From these models it has been shown how it is possible to describe the existing opinions in the groups, information that can be very useful to identify consensus paths among the decision makers that can culminate in a more representative decision-making process.
The search method works in a local AHP context, but has some limitations. First, it functions if the number of decision makers is not very high (≤11). The total number of partitions of the set of decision makers is equal to the Bell number with B0 = 1, B1 = 1. The larger the number of decision makers, the more computationally infeasible is the problem. In our case (K = 11), the number of possible partitions is 687,570, which is computationally feasible. For instance, if K = 22 the number is 4507 × 1015, then it is necessary to use algorithms that approximately determine Occam’s window.
We are currently experimenting with stochastic search algorithms and the results obtained will be published in a future work. A second limitation is that it is necessary that the groups constitute a partition of the set of decision makers and this implies that a decision maker cannot belong to more than one group. Even though this requirement decreases the computational time of the algorithm, it also reduces the flexibility of the method. The development of search strategies that eliminate this unrealistic assumption is worthy of consideration. Finally, it would be interesting to extend the methodology to a global context in which a hierarchy of criteria and sub-criteria is used.
Author Contributions
The paper has been elaborated jointly by the four authors.
Funding
This research was funded by the Spanish Ministry of Economy and Competitiveness and FEDER funding, projects ECO2015-66673-R (first and third authors) and ECO2016-79392-P (second and fourth authors).
Acknowledgments
The authors would like to acknowledge the work of English translation professional David Jones in preparing the final text.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Moreno-Jiménez, J.M.; Vargas, L.G. Cognitive Multicriteria Decision Making and the Legacy of AHP. Estud. Econ. Apl. 2018, 36, 67–80. [Google Scholar]
- Saaty, T.L. The Analytic Hierarchy Process; Mc Graw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Saaty, T.L. Group decision making and the AHP. In The Analytic Hierarchy Process; Golden, B.L., Wasil, E.A., Harker, P.T., Eds.; Springer: Berlin/Heidelberg, Germany, 1989; pp. 59–67. [Google Scholar]
- Ramanathan, R.; Ganesh, L.S. Group preference aggregation methods employed in AHP: An evaluation and intrinsic process for deriving members’ weightages. Eur. J. Oper. Res. 1994, 79, 249–265. [Google Scholar] [CrossRef]
- Forman, E.; Peniwati, K. Aggregating individual judgements and priorities with the analytic hierarchy process. Eur. J. Oper. Res. 1998, 108, 165–169. [Google Scholar] [CrossRef]
- Altuzarra, A.; Moreno-Jiménez, J.M.; Salvador, M. A Bayesian priorization procedure for AHP-group decision making. Eur. J. Oper. Res. 2007, 182, 367–382. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.; Stern, H.; Dunson, D.; Vehtary, A.; Rubin, D. Bayesian Data Analysis, 3rd ed.; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Aguarón, J.; Moreno-Jiménez, J.M. The geometric consistency index: Approximate thresholds. Eur. J. Oper. Res. 2003, 147, 137–145. [Google Scholar] [CrossRef]
- Kass, R.E.; Raftery, A.E. Bayes factors. J. Am. Stat. Assoc. 1995, 90, 773–795. [Google Scholar] [CrossRef]
- Madigan, D.; Raftery, A.E. Model Selection and Accounting for Model Uncertainty in Graphical Models Using Occam’s Window. J. Am. Stat. Assoc. 1994, 89, 1535–1546. [Google Scholar] [CrossRef]
- Altuzarra, A.; Moreno-Jiménez, J.M.; Salvador, M. A Consensus building in AHP-group decision making: A Bayesian approach. Oper. Res. 2010, 58, 1755–1773. [Google Scholar] [CrossRef]
- Chen, S.M.; Lin, T.E.; Lee, L.W. Group Decision Making using incomplete fuzzy preference relations based on the additive consistency and the order consistency. Inf. Sci. 2014, 259, 1–15. [Google Scholar] [CrossRef]
- Herrera-Viedma, E.; Cabrerizo, F.J.; Kacprzyk, J.; Pedrycz, W. A review of soft consensus models in a fuzzy environment. Inf. Fusion 2014, 17, 4–13. [Google Scholar] [CrossRef]
- Wang, Z.J.; Lin, J. Ratio-based similarity analysis and consensus building for group decision making with interval reciprocal preference relations. Appl. Soft Comput. 2016, 42, 260–275. [Google Scholar] [CrossRef]
- Dong, Y.C.; Ding, Z.G.; Martínez, L.; Herrera, F. Managing consensus based on leadership in opinion dynamics. Inf. Sci. 2017, 397, 187–205. [Google Scholar] [CrossRef]
- Wu, Z.B.; Xu, J. A consensus model for large-scale group decision making with hesitant fuzzy information and changeable clusters. Inf. Fusion 2018, 41, 217–231. [Google Scholar] [CrossRef]
Figure 1.
Steps of the proposed methodology.

Figure 2.
Relations of opinions existing in D.


{kind=link}
{kind=link}
Table 1.
Priorities and consistency for each decision maker and each group.
| Decision Maker | Priorities | Consistency | |||
|---|---|---|---|---|---|
| w1 | w2 | w3 | w4 | ||
| D1 | 0.1285 | 0.2860 | 0.1275 | 0.4511 | 0.1412 |
| D2 | 0.0899 | 0.2500 | 0.1418 | 0.5110 | 0.2042 |
| D3 | 0.0900 | 0.4759 | 0.1582 | 0.2705 | 0.1363 |
| D7 | 0.0587 | 0.2501 | 0.1839 | 0.5026 | 0.1405 |
| G1 | 0.0879 | 0.3076 | 0.1518 | 0.4502 | 0.2790 |
| D4 | 0.5748 | 0.1406 | 0.1086 | 0.1721 | 0.1214 |
| D10 | 0.6318 | 0.1809 | 0.0797 | 0.1044 | 0.1046 |
| G2 | 0.6139 | 0.1600 | 0.0926 | 0.1318 | 0.1602 |
| D5 | 0.4021 | 0.1570 | 0.0758 | 0.3613 | 0.0888 |
| D6 | 0.2131 | 0.1057 | 0.0542 | 0.6194 | 0.2849 |
| D8 | 0.1388 | 0.2763 | 0.0578 | 0.5197 | 0.2186 |
| G3 | 0.2321 | 0.1676 | 0.0617 | 0.5338 | 0.4071 |
| D9 | 0.2846 | 0.0871 | 0.5503 | 0.0720 | 0.2186 |
| G4 | 0.2846 | 0.0871 | 0.5503 | 0.0720 | 0.2186 |
| D11 | 0.1228 | 0.4684 | 0.2736 | 0.1294 | 0.1261 |
| G5 | 0.1228 | 0.4684 | 0.2736 | 0.1294 | 0.1261 |
in bold the highest priority.
Table 2.
Alpha distributions for each decision maker and each group.
| Decision Maker | Alternatives | |||
|---|---|---|---|---|
| A1 | A2 | A3 | A4 | |
| D1 | 0.30 | 6.11 | 0.00 | 93.59 |
| D2 | 0.19 | 2.71 | 0.04 | 97.06 |
| D3 | 0.00 | 96.75 | 0.00 | 3.25 |
| D7 | 0.01 | 1.75 | 0.04 | 98.20 |
| G1 | 0.00 | 2.69 | 0.00 | 97.31 |
| D4 | 99.23 | 0.03 | 0.00 | 0.74 |
| D10 | 99.92 | 0.02 | 0.00 | 0.06 |
| G2 | 99.96 | 0.00 | 0.00 | 0.04 |
| D5 | 63.16 | 0.01 | 0.00 | 36.83 |
| D6 | 5.24 | 0.00 | 0.00 | 94.76 |
| D8 | 1.09 | 3.92 | 0.00 | 94.99 |
| G3 | 2.96 | 0.00 | 0.00 | 97.04 |
| D9 | 5.49 | 0.00 | 94.51 | 0.00 |
| G4 | 5.49 | 0.00 | 94.51 | 0.00 |
| D11 | 0.01 | 98.75 | 1.20 | 0.04 |
| G5 | 0.01 | 98.75 | 1.20 | 0.04 |
in bold the probabilities higher than 20%.
Table 3.
Gamma distributions for each decision maker (Di) and each group (Gj) (probabilities higher than 20% are in bold).
Table 3.
Gamma distributions for each decision maker (Di) and each group (Gj) (probabilities higher than 20% are in bold).
| Decision Maker | Rankings | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1234 † | 1243 | 1324 | 1342 | 1432 | 1423 | 2134 | 2143 | 2314 | 2341 | 2431 | 2413 | 3214 | 3241 | 3124 | 3142 | 3412 | 3421 | 4231 | 4213 | 4321 | 4312 | 4132 | 4123 | |
| D1 | 0.02 | 0.17 | 0.00 | 0.00 | 0.00 | 0.11 | 0.01 | 0.64 | 0.00 | 0.01 | 0.51 | 4.94 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 49.20 | 43.98 | 0.09 | 0.01 | 0.01 | 0.30 |
| D2 | 0.05 | 0.10 | 0.00 | 0.00 | 0.00 | 0.04 | 0.01 | 0.23 | 0.00 | 0.00 | 0.87 | 1.60 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.03 | 86.05 | 8.68 | 2.10 | 0.05 | 0.03 | 0.15 |
| D3 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.43 | 0.57 | 0.21 | 1.05 | 91.49 | 3.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 3.20 | 0.02 | 0.03 | 0.00 | 0.00 | 0.00 |
| D7 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.02 | 0.04 | 1.55 | 0.09 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.03 | 89.78 | 0.07 | 8.33 | 0.00 | 0.01 | 0.01 |
| G1 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 2.28 | 0.41 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 96.94 | 0.36 | 0.01 | 0.00 | 0.00 | 0.00 |
| D4 | 1.75 | 20.98 | 0.23 | 0.40 | 8.64 | 67.23 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.01 | 0.02 | 0.41 | 0.29 |
| D10 | 8.90 | 88.84 | 0.01 | 0.01 | 0.06 | 2.10 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.01 | 0.00 | 0.00 | 0.04 |
| G2 | 2.46 | 80.42 | 0.00 | 0.02 | 0.15 | 16.91 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.03 |
| D5 | 0.00 | 0.29 | 0.00 | 0.00 | 0.04 | 62.83 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.08 | 0.00 | 0.00 | 0.06 | 36.69 |
| D6 | 0.01 | 0.15 | 0.00 | 0.00 | 0.09 | 4.99 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.36 | 3.63 | 0.16 | 0.16 | 1.99 | 88.46 |
| D8 | 0.01 | 0.64 | 0.01 | 0.00 | 0.00 | 0.43 | 0.00 | 0.57 | 0.00 | 0.00 | 0.00 | 3.35 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 2.27 | 90.83 | 0.00 | 0.01 | 0.01 | 1.87 |
| G3 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 2.93 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 11.32 | 0.00 | 0.00 | 0.00 | 85.72 |
| D9 | 0.00 | 0.00 | 5.37 | 0.12 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.03 | 66.57 | 26.61 | 1.08 | 0.17 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| G4 | 0.00 | 0.00 | 5.37 | 0.12 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.03 | 66.57 | 26.61 | 1.08 | 0.17 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| D11 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.14 | 0.00 | 43.39 | 53.94 | 0.28 | 0.00 | 0.28 | 0.88 | 0.00 | 0.00 | 0.00 | 0.04 | 0.03 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 |
| G5 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.14 | 0.00 | 43.39 | 53.94 | 0.28 | 0.00 | 0.28 | 0.88 | 0.00 | 0.00 | 0.00 | 0.04 | 0.03 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 |
† 1234 denotes the ranking A1 > A2 > A3 > A4.
Table 4.
Partitions selected by the Occam window.
| Partition | D1 | D2 | D3 | D4 | D5 | D6 | D7 | D8 | D9 | D10 | D11 | Ratio † |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 2 | 3 | 3 | 1 | 3 | 4 | 2 | 5 | 1.00 |
| 2 | 1 | 1 | 2 | 3 | 4 | 4 | 1 | 4 | 5 | 3 | 2 | 0.48 |
| 3 | 1 | 1 | 1 | 2 | 3 | 3 | 1 | 1 | 4 | 2 | 5 | 0.42 |
| 4 | 1 | 1 | 2 | 3 | 4 | 4 | 1 | 1 | 5 | 3 | 2 | 0.15 |
† The ratio calculates the quotient of the posterior probability for the most probable model and that for the model corresponding to each partition.
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Altuzarra, A.; Gargallo, P.; Moreno-Jiménez, J.M.; Salvador, M. Homogeneous Groups of Actors in an AHP-Local Decision Making Context: A Bayesian Analysis. Mathematics 2019, 7, 294. https://0-doi-org.brum.beds.ac.uk/10.3390/math7030294
AMA Style
Altuzarra A, Gargallo P, Moreno-Jiménez JM, Salvador M. Homogeneous Groups of Actors in an AHP-Local Decision Making Context: A Bayesian Analysis. Mathematics. 2019; 7(3):294. https://0-doi-org.brum.beds.ac.uk/10.3390/math7030294
Chicago/Turabian StyleAltuzarra, Alfredo, Pilar Gargallo, José María Moreno-Jiménez, and Manuel Salvador. 2019. "Homogeneous Groups of Actors in an AHP-Local Decision Making Context: A Bayesian Analysis" Mathematics 7, no. 3: 294. https://0-doi-org.brum.beds.ac.uk/10.3390/math7030294
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.