Natural Test for Random Numbers Generator Based on Exponential Distribution


 ,
,
Abstract
:1. Introduction
2. Exponential Distribution of the Successive Difference Between Random Numbers
| → | • The interval A is equal from the previous event ti−1 to the event S |
| → | • The interval B is equal from the event S to the following event ti. |
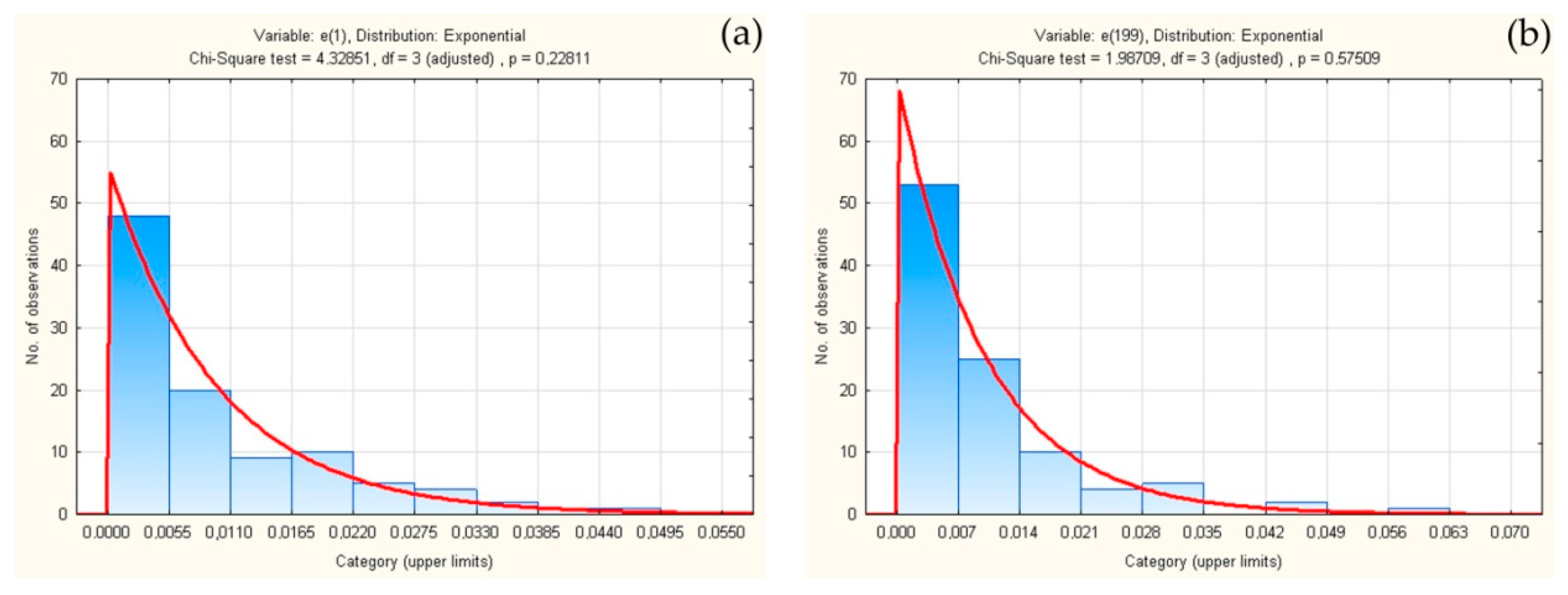
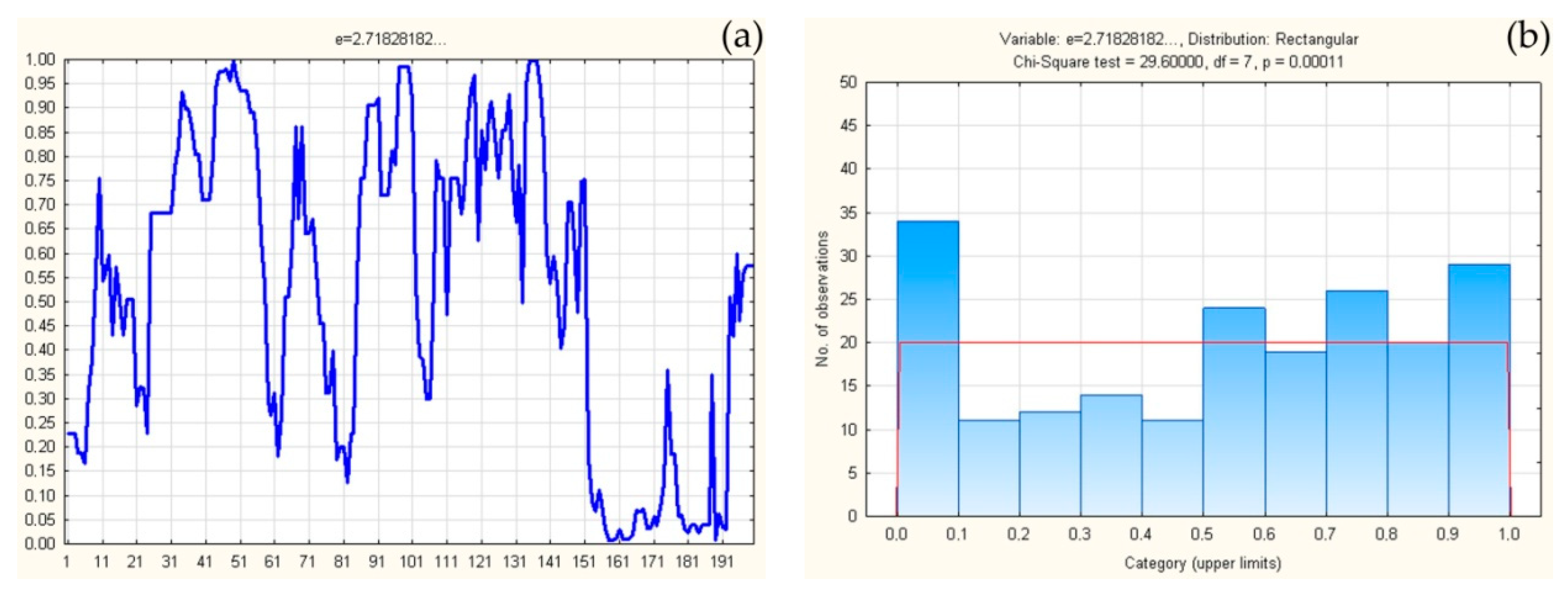
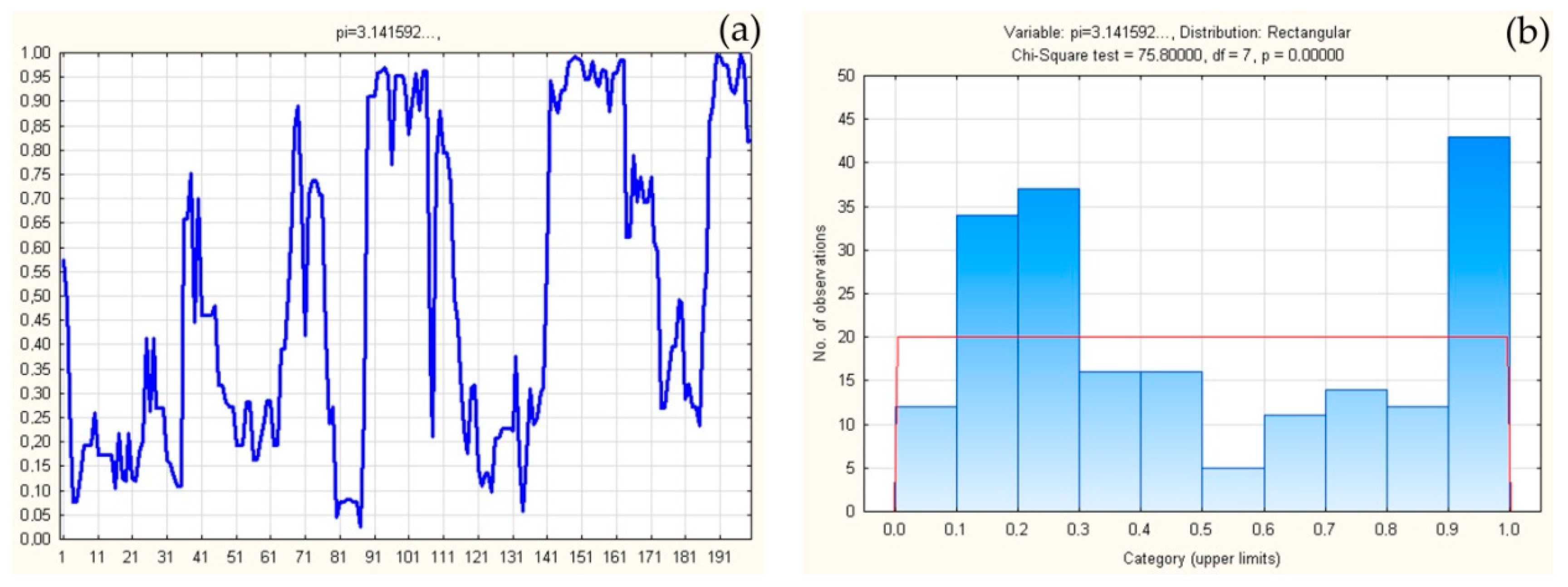
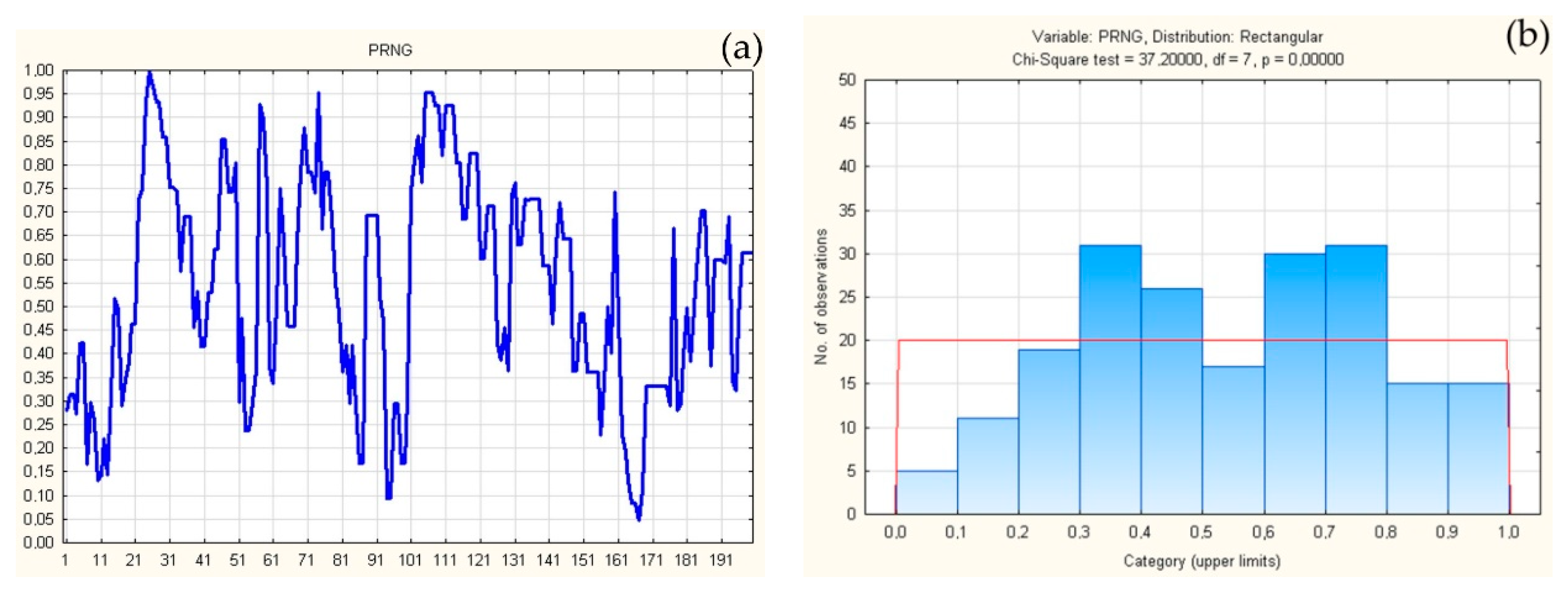
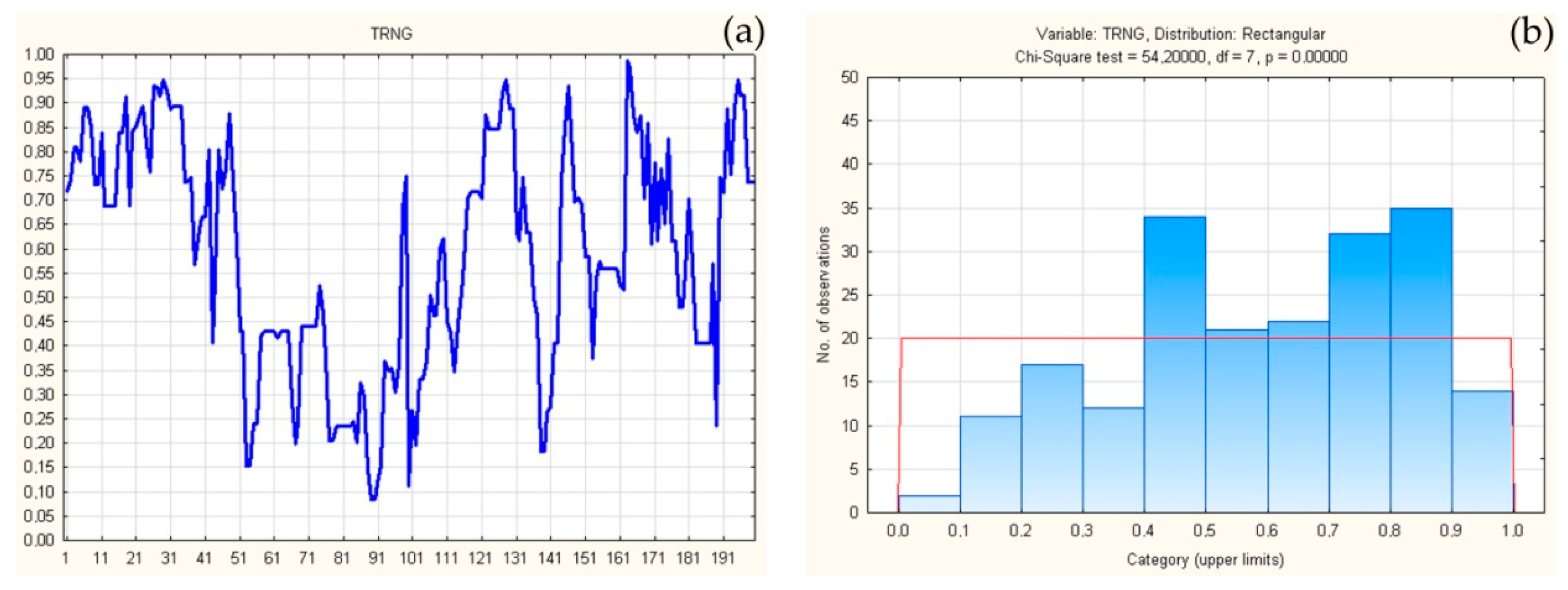
3. Application of Theorem
4. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gallager, R.G. Principles of Digital Communication, 1st ed.; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Ferguson, N.; Schneier, B.; Kohno, T. Cryptography Engineering: Design Principles and Practical Applications, 1st ed.; John Wiley & Sons: New York, NY, USA, 2010. [Google Scholar]
- Wang, J.; Liang, J.; Li, P.; Yang, L.; Wang, Y. All-optical random number generating using highly nonlinear fibers by numerical simulation. Opt. Commun. 2014, 321, 1–5. [Google Scholar] [CrossRef]
- Joppich, G.; Däuper, J.; Dengler, R.; Johannes, S.; Rodriguez-Fornells, A.; Münte, T.F. Brain potentials index executive functions during random number generation. Neurosci. Res. 2004, 49, 57–164. [Google Scholar] [CrossRef] [PubMed]
- Bains, W. Random number generation and creativity. Med. Hypotheses 2008, 70, 186–190. [Google Scholar] [CrossRef] [PubMed]
- Brugger, P.; Monsch, A.U.; Salmon, D.P.; Butters, N. Random number generation in dementia of the Alzheimer type: A test of frontal executive functions. Neuropsychologia 1996, 34, 97–103. [Google Scholar] [CrossRef]
- Koike, S.; Takizawa, R.; Nishimura, Y.; Marumo, K.; Kinou, M.; Kawakubo, Y.; Rogers, M.A.; Kasai, K. Association between severe dorsolateral prefrontal dysfunction during random number generation random number generation and earlier onset in schizophrenia. Clin. Neurophysiol. 2011, 122, 1533–1540. [Google Scholar] [CrossRef]
- Anzak, A.; Gaynor, L.; Beigi, M.; Foltynie, T.; Limousin, P.; Zrinzo, L.; Brown, P.; Jahanshahi, M. Subthalamic nucleus gamma oscillations mediate a switch from automatic to controlled processing: A study of random number generation in Parkinson’s disease. NeuroImage 2013, 64, 284–289. [Google Scholar] [CrossRef] [PubMed]
- Linnebank, M.; Brugger, P. Random number generation deficits in patients with multiple sclerosis: Characteristics and neural correlates. Cortex 2016, 82, 237–243. [Google Scholar] [Green Version]
- Yadolah, D. A Natural Random Number Generator. Int. Stat. Rev. 1996, 64, 329–344. [Google Scholar]
- Yadolah, D.; Melfi, G. Random numbergenerators and rare events in the continued fraction of π. J. Stat. Comput. Simul. 2005, 75, 189–197. [Google Scholar]
- Kanter, I.; Aviad, Y.; Reidler, I.; Cohen, E.; Rosenbluh, M. An optical ultrafast random bit generator. Nat. Photonics 2010, 4, 58–61. [Google Scholar] [CrossRef]
- Lucian, L. FPGA optimized cellular automaton random number generator. J. Parallel Distrib. Comput. 2018, 111, 251–259. [Google Scholar]
- Panneton, F.; L’Ecuyer, P. Resolution-stationary random number generators. Math. Comput. Simul. 2010, 80, 1096–1103. [Google Scholar] [CrossRef]
- Fleischer, K. Two tests of pseudo random number generators for independence and uniform distribution. J. Stat. Comput. Simul. 1995, 52, 311–322. [Google Scholar] [CrossRef]
- Geisseler, O.; Pflugshaupt, T.; Buchmann, A.; Bezzola, L.; Reuter, K.; Schuknecht, B.; Weller, D.; L’Ecuyer, P. Tests based on sum-functions of spacings for uniform random numbers. J. Stat. Comput. Simul. 1997, 59, 251–269. [Google Scholar]
- Tomassini, M.; Sipper, M.; Zolla, M.; Perrenoud, M. Generating high-quality random numbers in parallel by cellular automata. Future Gener. Comput. Syst. 1999, 16, 291–305. [Google Scholar] [CrossRef]
- Díaz, N.C.; Gil, A.V.; Vargas, M.J. Assessment of the suitability of different random number generators for Monte Carlo simulations in gamma-ray spectrometry. Appl. Radiat. Isot. 2010, 68, 469–473. [Google Scholar] [CrossRef] [PubMed]
- Van Bever, G. Simplicial bivariate tests for randomness. Stat. Probab. Lett. 2016, 112, 20–25. [Google Scholar] [CrossRef]
- Knuth, D. The Art of Computer Programming: Seminumerical Algorithms, 3rd ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1997. [Google Scholar]
- Marsaglia, G.; Tsang, W. Some Difficult-to-pass Tests of Randomness. J. Stat. Softw. 2002, 7, 1–9. [Google Scholar] [CrossRef]
- McCullough, B.D. A Review of TestU01. J. Appl. Econ. 2006, 21, 677–682. [Google Scholar] [CrossRef]
- Rukhin, A.; Soto, J.; Nechvatal, J.; Smid, M.; Barker, E.; Leigh, S.; Levenson, M.; Vangel, M.; Banks, D.; Heckert, A.; et al. A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications; National Institute of Standards and Technology; U.S. Department of Commerce: Washington, DC, USA, 2010.
- Steffensen, J.F. Some Recent Research in the Theory of Statistics and Actuarial Science; Cambridge University Press: Cambridge, UK, 1930. [Google Scholar]
- Kinzer, J.P. Application of The Theory of Probability to Problems of Highway Traffic, B.C.E. Doctoral Thesis, Polytechnic Institute of Brooklyn, New York, NY, USA, 1933. [Google Scholar]
- Teissier, F. Researches sur le vieillissement et sur les lios se mortalit. Ann. Phys. Biol. Phys. Chemestry 1934, 10, 237–264. [Google Scholar]
- Adams, W.F. Road Traffic Considered as a Random Series. J. Inst. Civ. Eng. 1936, 4, 121–130. [Google Scholar] [CrossRef]
- Weibull, W. The phenomenon of rupture in solids. Ingeniorsvetenskapsakademienshandlingar 1939, 153, 1–55. [Google Scholar]
- Kendall, M.G.; Smith, B.; Babington, B. Randomness and Random Sampling Numbers. J. R. Stat. Soc. 1938, 101, 147–166. [Google Scholar] [CrossRef]
- Kjos-Hanssen, B.; Taveneaux, A.; Thapen, N. How much randomness is needed for statistics? Ann. Pure Appl. Log. 2014, 165, 1470–1483. [Google Scholar] [CrossRef] [Green Version]
- Vukadinović, S. Queueing Systems; NaučnaKnjiga: Beograd, Serbia, 1988. [Google Scholar]
- Random Sequence Generator. Available online: https://www.random.org/sequences (accessed on 19 May 2019).
- Girstmair, K. Jacobi symbols and Euler′s number e. J. Number Theory 2014, 135, 155–166. [Google Scholar] [CrossRef]
- Khodabin, M. Some Wonderful Statistical Properties of Pi-number decimal digits. J. Math. Sci. Adv. Appl. 2011, 11, 69–77. [Google Scholar]
- Ganc, E.R. The Decimal Expansion of π Is Not Statistically Random. Exp. Math. 2014, 23, 99–104. [Google Scholar]
- Marsaglia, G. On the randomness of pi and other decimal expansions. InterStat: Statistics on the Internet, p. 17, October 2005. ISSN 1941-689X. Available online: http://interstat.statjournals.net/YEAR/2005/articles/ 0510005.pdf (accessed on 25 September 2019).
- Tanackov, I.; Jevtić, Ž.; Stojić, G.; Feta, S.; Ercegovac, P. Rare events queueing system. Oper. Res. Eng. Sci. Theory Appl. 2019, 2, 1–11. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| “e” decimals | 271828182845904523536028747135266249775724709369995957496696762772407663035354759457138217852516642742746639193200305992181741359662904357290033429526059563073813232862794349076323382988075319525101901157383418793070215408914993488416750924476146066808226480016847741185374234544243710753907774499206955… |
| “π” decimals | 314159265358979323846264338327950288419716939937510582097494459230781640628620899862803482534211706798214808651328230664709384460955058223172535940812848111745028410270193852110555964462294895493038196442881097566593344612847564823378678316527120190914564856692346034861045432664821339360726024914127372… |
| PRNG | 7259227051902899760820653695717034400802758150121933828161585021229157597171018544683160397426233882495837244083781905313129529407819631027568084023355456995655961036454261291377117301740011443026315431314350950726053529878643963583104666483673482473576217179604102739202744182506031608391653276202184739… |
| TRNG | 5702321834924319698039224328949632170253798713293486165903367803756808794325594419963116773060031715966487336963199719730183382190863756390073297420987570798457304675443797726780701009434479393354064614498365777658458194195989924883287287212182011407782292143460981825932571746610515092283157440087522747… |
| e(1) | e(2) | e(3) | e(4) | e(5) | e(6) | … | e(199) | e(200) | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.271828 | 0.718281 | 0.182818 | 0.828182 | 0.281828 | 0.818284 | … | 0.901157 | 0.011573 |
| 2 | 0.718281 | 0.182818 | 0.828182 | 0.281828 | 0.818284 | 0.182845 | … | 0.011573 | 0.115738 |
| 3 | 0.182818 | 0.828182 | 0.281828 | 0.818284 | 0.182845 | 0.828459 | … | 0.115738 | 0.157383 |
| 4 | 0.828182 | 0.281828 | 0.818284 | 0.182845 | 0.828459 | 0.284590 | … | 0.157383 | 0.573834 |
| 5 | 0.281828 | 0.818284 | 0.182845 | 0.828459 | 0.284590 | 0.845904 | … | 0.573834 | 0.738341 |
| 6 | 0.818284 | 0.182845 | 0.828459 | 0.284590 | 0.845904 | 0.459045 | … | 0.738341 | 0.383418 |
| 7 | 0.182845 | 0.828459 | 0.284590 | 0.845904 | 0.459045 | 0.590452 | … | 0.383418 | 0.834187 |
| 8 | 0.828459 | 0.284590 | 0.845904 | 0.459045 | 0.590452 | 0.904523 | … | 0.834187 | 0.341879 |
| 9 | 0.284590 | 0.845904 | 0.459045 | 0.590452 | 0.904523 | 0.045235 | … | 0.341879 | 0.418793 |
| 10 | 0.845904 | 0.718281 | 0.182818 | 0.828182 | 0.281828 | 0.818284 | … | 0.418793 | 0.187930 |
| … | … | … | … | … | … | … | … | … | … |
| 92 | 0.525166 | 0.251664 | 0.516642 | 0.166427 | 0.664274 | 0.642742 | … | 0.077744 | 0.777449 |
| 93 | 0.251664 | 0.516642 | 0.166427 | 0.664274 | 0.642742 | 0.427427 | … | 0.777449 | 0.774499 |
| 94 | 0.516642 | 0.166427 | 0.664274 | 0.642742 | 0.427427 | 0.274274 | … | 0.774499 | 0.744992 |
| 95 | 0.166427 | 0.664274 | 0.642742 | 0.427427 | 0.274274 | 0.742746 | … | 0.744992 | 0.449920 |
| 96 | 0.664274 | 0.642742 | 0.427427 | 0.274274 | 0.742746 | 0.427466 | … | 0.449920 | 0.499206 |
| 97 | 0.642742 | 0.427427 | 0.274274 | 0.742746 | 0.427466 | 0.274663 | … | 0.499206 | 0.992069 |
| 98 | 0.427427 | 0.274274 | 0.742746 | 0.427466 | 0.274663 | 0.746639 | … | 0.992069 | 0.920695 |
| 99 | 0.274274 | 0.742746 | 0.427466 | 0.274663 | 0.746639 | 0.466391 | … | 0.920695 | 0.206955 |
| 100 | 0.742746 | 0.427466 | 0.274663 | 0.746639 | 0.466391 | 0.663919 | … | 0.206955 | 0.069551 |
| 101 | 0.427466 | 0.274663 | 0.746639 | 0.466391 | 0.663919 | 0.639193 | … | 0.069551 | 0.695517 |
| ↓[e(1)] | ↓[e(2)] | ↓[e(3)] | ↓[e(4)] | ↓[e(5)] | ↓[e(6)] | … | ↓[e(199)] | ↓[e(200)] | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.028747 | 0.028747 | 0.028747 | 0.028747 | 0.028747 | 0.028747 | … | 0.001684 | 0.001684 |
| 2 | 0.035354 | 0.035354 | 0.035354 | 0.035354 | 0.035354 | 0.035354 | … | 0.011573 | 0.011573 |
| 3 | 0.045235 | 0.045235 | 0.045235 | 0.045235 | 0.045235 | 0.045235 | … | 0.016847 | 0.016847 |
| 4 | 0.076630 | 0.076630 | 0.076630 | 0.076630 | 0.076630 | 0.076630 | … | 0.021540 | 0.021540 |
| 5 | 0.093699 | 0.093699 | 0.093699 | 0.093699 | 0.093699 | 0.093699 | … | 0.066808 | 0.066808 |
| 6 | 0.135266 | 0.135266 | 0.135266 | 0.135266 | 0.135266 | 0.135266 | … | 0.069551 | 0.069551 |
| 7 | 0.138217 | 0.138217 | 0.138217 | 0.138217 | 0.138217 | 0.138217 | … | 0.070215 | 0.070215 |
| 8 | 0.166427 | 0.166427 | 0.166427 | 0.166427 | 0.166427 | 0.166427 | … | 0.075390 | 0.075390 |
| 9 | 0.178525 | 0.178525 | 0.178525 | 0.178525 | 0.178525 | 0.178525 | … | 0.077744 | 0.077744 |
| 10 | 0.182818 | 0.182818 | 0.182818 | 0.182845 | 0.182845 | 0.182845 | … | 0.082264 | 0.082264 |
| … | … | … | … | … | … | … | … | … | … |
| 92 | 0.904523 | 0.904523 | 0.904523 | 0.904523 | 0.904523 | 0.904523 | … | 0.891499 | 0.884167 |
| 93 | 0.936999 | 0.936999 | 0.936999 | 0.936999 | 0.936999 | 0.936999 | … | 0.901157 | 0.891499 |
| 94 | 0.945713 | 0.945713 | 0.945713 | 0.945713 | 0.945713 | 0.945713 | … | 0.907774 | 0.907774 |
| 95 | 0.957496 | 0.957496 | 0.957496 | 0.957496 | 0.957496 | 0.957496 | … | 0.914993 | 0.914993 |
| 96 | 0.959574 | 0.959574 | 0.959574 | 0.959574 | 0.959574 | 0.959574 | … | 0.920695 | 0.920695 |
| 97 | 0.966967 | 0.966967 | 0.966967 | 0.966967 | 0.966967 | 0.966967 | … | 0.924476 | 0.924476 |
| 98 | 0.967627 | 0.967627 | 0.967627 | 0.967627 | 0.967627 | 0.967627 | … | 0.930702 | 0.930702 |
| 99 | 0.977572 | 0.977572 | 0.977572 | 0.977572 | 0.977572 | 0.977572 | … | 0.934884 | 0.934884 |
| 100 | 0.995957 | 0.995957 | 0.995957 | 0.995957 | 0.995957 | 0.995957 | … | 0.992069 | 0.992069 |
| 101 | 0.999595 | 0.999595 | 0.999595 | 0.999595 | 0.999595 | 0.999595 | … | 0.993488 | 0.993488 |
| Δ↓[e(1)] | Δ↓[e(2)] | Δ↓[e(3)] | Δ↓[e(4)] | Δ↓[e(5)] | Δ↓[e(6)] | … | Δ↓[e(199)] | ↓[e(200)] | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.006607 | 0.006607 | 0.006607 | 0.006607 | 0.006607 | 0.006607 | … | 0.009889 | 0.009889 |
| 2 | 0.009881 | 0.009881 | 0.009881 | 0.009881 | 0.009881 | 0.009881 | … | 0.005274 | 0.005274 |
| 3 | 0.031395 | 0.031395 | 0.031395 | 0.031395 | 0.031395 | 0.031395 | … | 0.004693 | 0.004693 |
| 4 | 0.017069 | 0.017069 | 0.017069 | 0.017069 | 0.017069 | 0.017069 | … | 0.045268 | 0.045268 |
| 5 | 0.041567 | 0.041567 | 0.041567 | 0.041567 | 0.041567 | 0.041567 | … | 0.002743 | 0.002743 |
| 6 | 0.002951 | 0.002951 | 0.002951 | 0.002951 | 0.002951 | 0.002951 | … | 0.000664 | 0.000664 |
| 7 | 0.028210 | 0.028210 | 0.028210 | 0.028210 | 0.028210 | 0.028210 | … | 0.005175 | 0.005175 |
| 8 | 0.012098 | 0.012098 | 0.012098 | 0.012098 | 0.012098 | 0.012098 | … | 0.002354 | 0.002354 |
| 9 | 0.004293 | 0.004293 | 0.004293 | 0.004320 | 0.004320 | 0.004320 | … | 0.004520 | 0.004520 |
| 10 | 0.000027 | 0.000027 | 0.000027 | 0.035007 | 0.035007 | 0.035007 | … | 0.009889 | 0.009889 |
| … | … | … | … | … | … | … | … | … | … |
| 91 | 0.029810 | 0.029810 | 0.029810 | 0.029810 | 0.029810 | 0.029810 | … | 0.009658 | 0.007332 |
| 92 | 0.032476 | 0.032476 | 0.032476 | 0.032476 | 0.032476 | 0.032476 | … | 0.006617 | 0.016275 |
| 93 | 0.008714 | 0.008714 | 0.008714 | 0.008714 | 0.008714 | 0.008714 | … | 0.007219 | 0.007219 |
| 94 | 0.011783 | 0.011783 | 0.011783 | 0.011783 | 0.011783 | 0.011783 | … | 0.005702 | 0.005702 |
| 95 | 0.002078 | 0.002078 | 0.002078 | 0.002078 | 0.002078 | 0.002078 | … | 0.003781 | 0.003781 |
| 96 | 0.007393 | 0.007393 | 0.007393 | 0.007393 | 0.007393 | 0.007393 | … | 0.006226 | 0.006226 |
| 97 | 0.000660 | 0.000660 | 0.000660 | 0.000660 | 0.000660 | 0.000660 | … | 0.004182 | 0.004182 |
| 98 | 0.009945 | 0.009945 | 0.009945 | 0.009945 | 0.009945 | 0.009945 | … | 0.057185 | 0.057185 |
| 99 | 0.018385 | 0.018385 | 0.018385 | 0.018385 | 0.018385 | 0.018385 | … | 0.001419 | 0.001419 |
| 100 | 0.003638 | 0.003638 | 0.003638 | 0.003638 | 0.003638 | 0.003638 | … | 0.009658 | 0.007332 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tanackov, I.; Sinani, F.; Stanković, M.; Bogdanović, V.; Stević, Ž.; Vidić, M.; Mihaljev-Martinov, J. Natural Test for Random Numbers Generator Based on Exponential Distribution. Mathematics 2019, 7, 920. https://0-doi-org.brum.beds.ac.uk/10.3390/math7100920
Tanackov I, Sinani F, Stanković M, Bogdanović V, Stević Ž, Vidić M, Mihaljev-Martinov J. Natural Test for Random Numbers Generator Based on Exponential Distribution. Mathematics. 2019; 7(10):920. https://0-doi-org.brum.beds.ac.uk/10.3390/math7100920
Chicago/Turabian StyleTanackov, Ilija, Feta Sinani, Miomir Stanković, Vuk Bogdanović, Željko Stević, Mladen Vidić, and Jelena Mihaljev-Martinov. 2019. "Natural Test for Random Numbers Generator Based on Exponential Distribution" Mathematics 7, no. 10: 920. https://0-doi-org.brum.beds.ac.uk/10.3390/math7100920