A New K-Nearest Neighbors Classifier for Big Data Based on Efficient Data Pruning

 ,
,  ,
,  and
and
Abstract
:1. Introduction
- Taking into account two new factors (cluster’s density and spread shape) in order to prune the training dataset more efficiently; and
- Implementing the proposed method and evaluating its classification accuracy and time cost in comparison to KNN, LC-KNN, and RFKNN methods.
2. Related Work
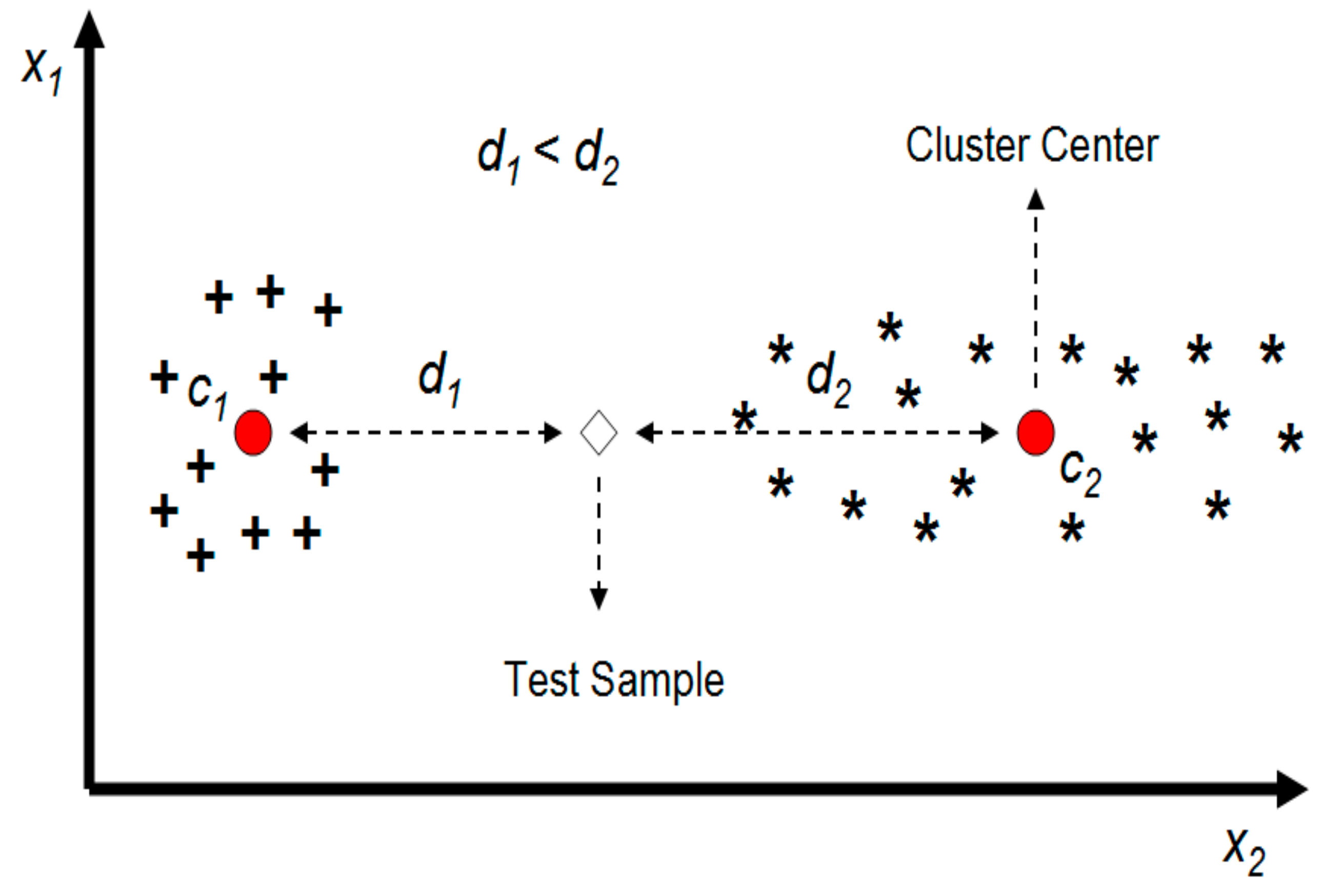
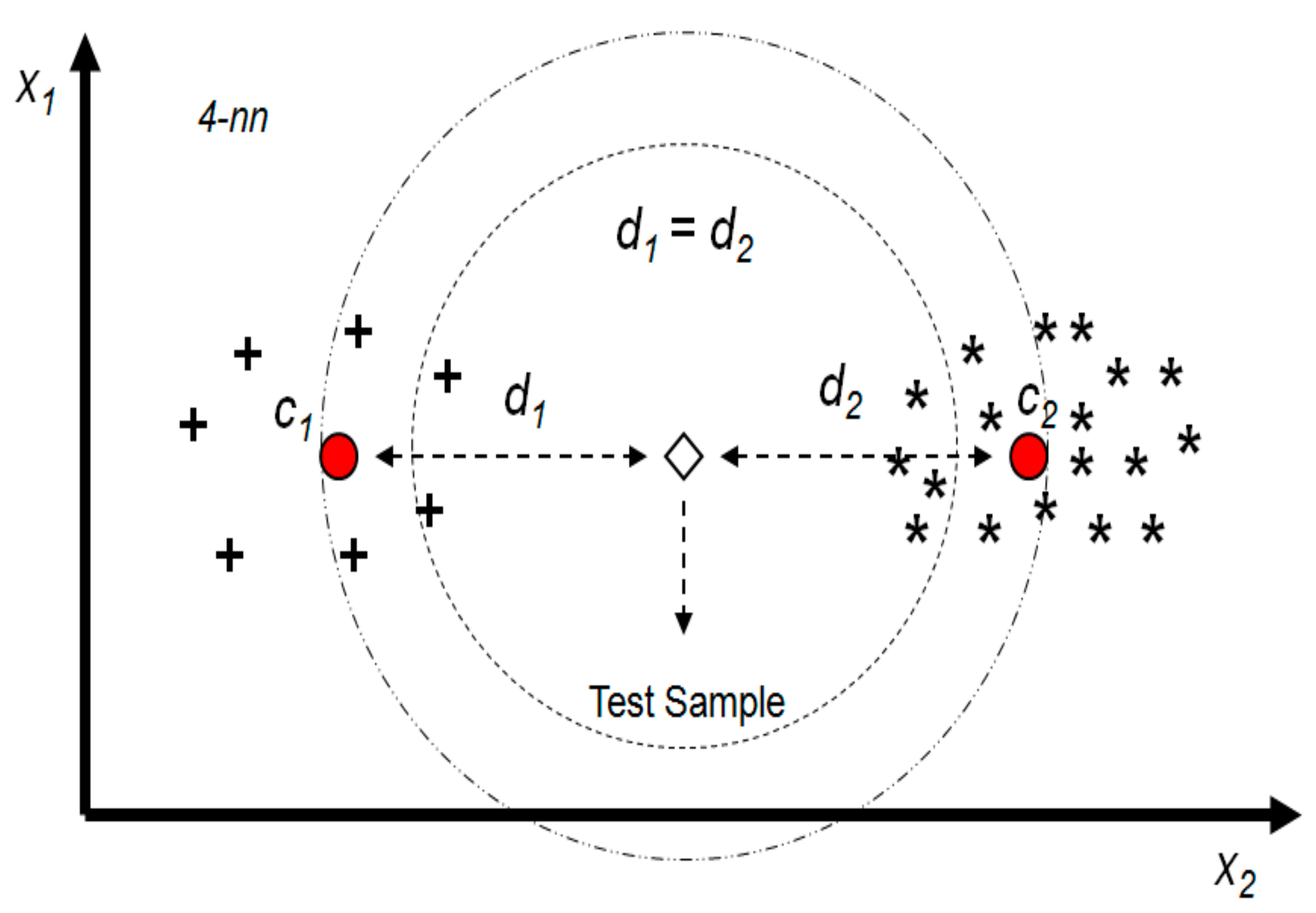
3. The Proposed KNN Algorithm for Big Data
| Algorithm 1. Choosing the proper cluster. |
| Input: a test sample () to be classified by KNN and clusters of data |
| Output: a data cluster which is used for finding the nearest neighbors |
| 1. Begin |
| 2. for |
| 3. Find the Euclidean distance between and cluster center () |
| 4. end for |
| 5. for |
| 6. if |
| 7. return |
| 8. for each cluster which |
| 9. Calculate the distance defined by Equation (2) () |
| 10. for each cluster which |
| 11. if |
| 12. return |
| 13. for each cluster which |
| 14. Calculate the density of the cluster using Equation (3) () |
| 15. Choose the cluster with maximum density |
| 16. End |
| Algorithm 2. The proposed KNN for big data. |
| Input: a large amount of data and a set of test samples that should be classified (data space has n dimension) |
| Output: the estimated class of each test sample |
| 1. Begin |
| 2. Divide the large amount of data to separate clusters using k-means algorithm |
| 3. For each cluster |
| 4. Calculate the size of cluster (number of data samples) |
| 5. Calculate |
| 6. For each test sample |
| 7. Choose the proper cluster of data by using Algorithm 1. |
| 8. Employ the KNN algorithm on the selected cluster to find the estimatedclass of the test sample |
| 9. End |
4. Experimental Results
4.1. The Characteristic of the Datasets
4.2. Performance Evaluation with Different Values of the m Parameter
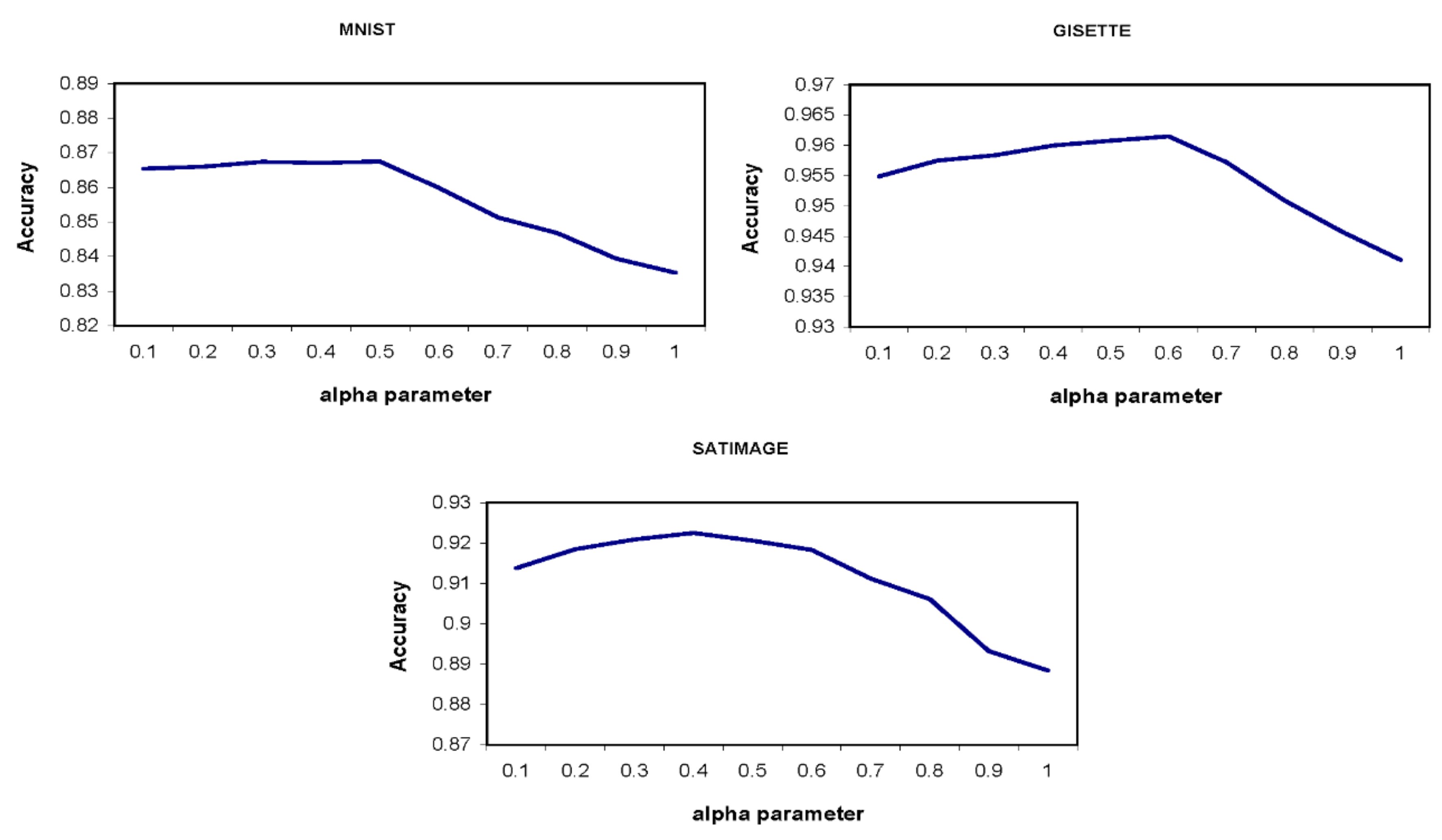
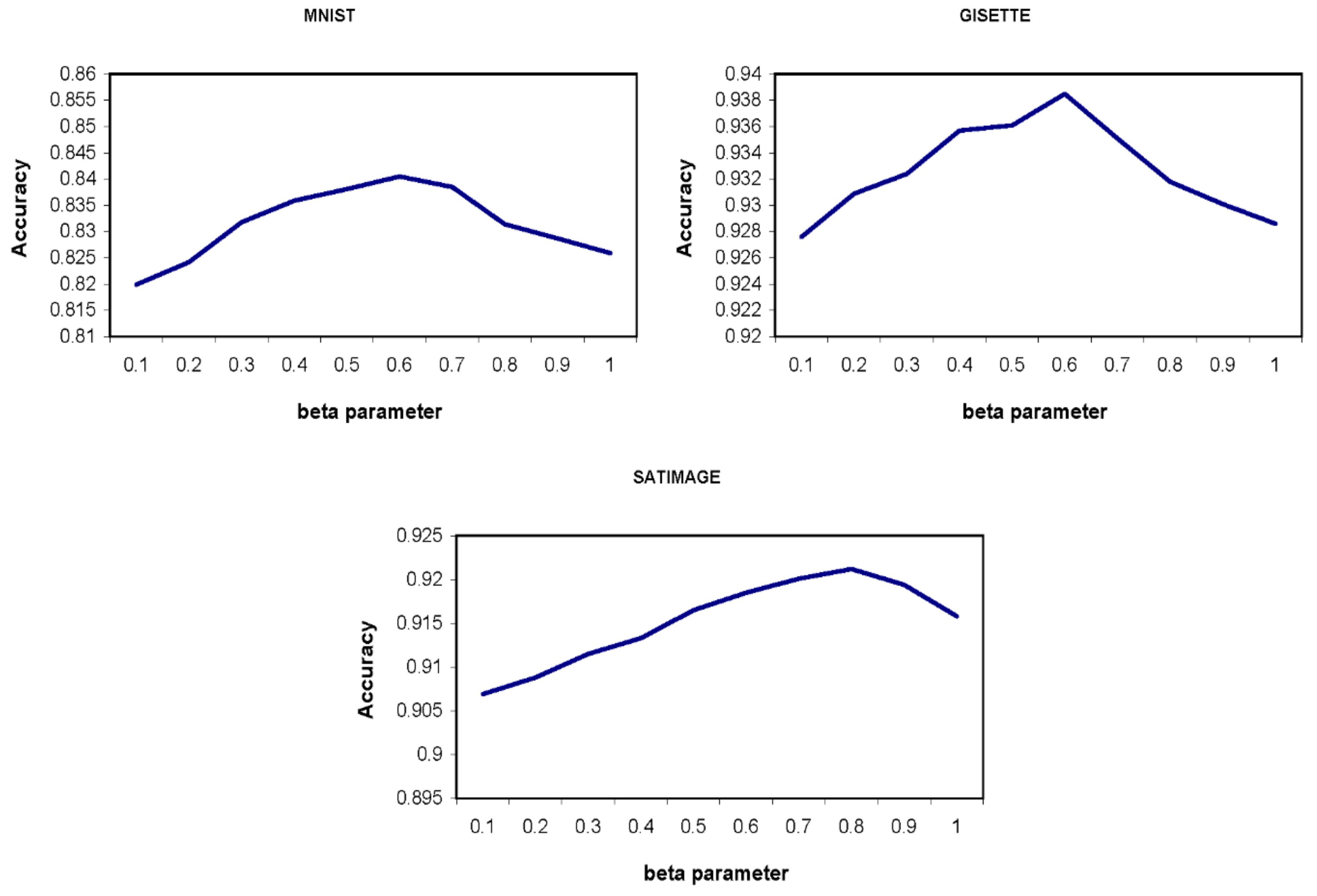
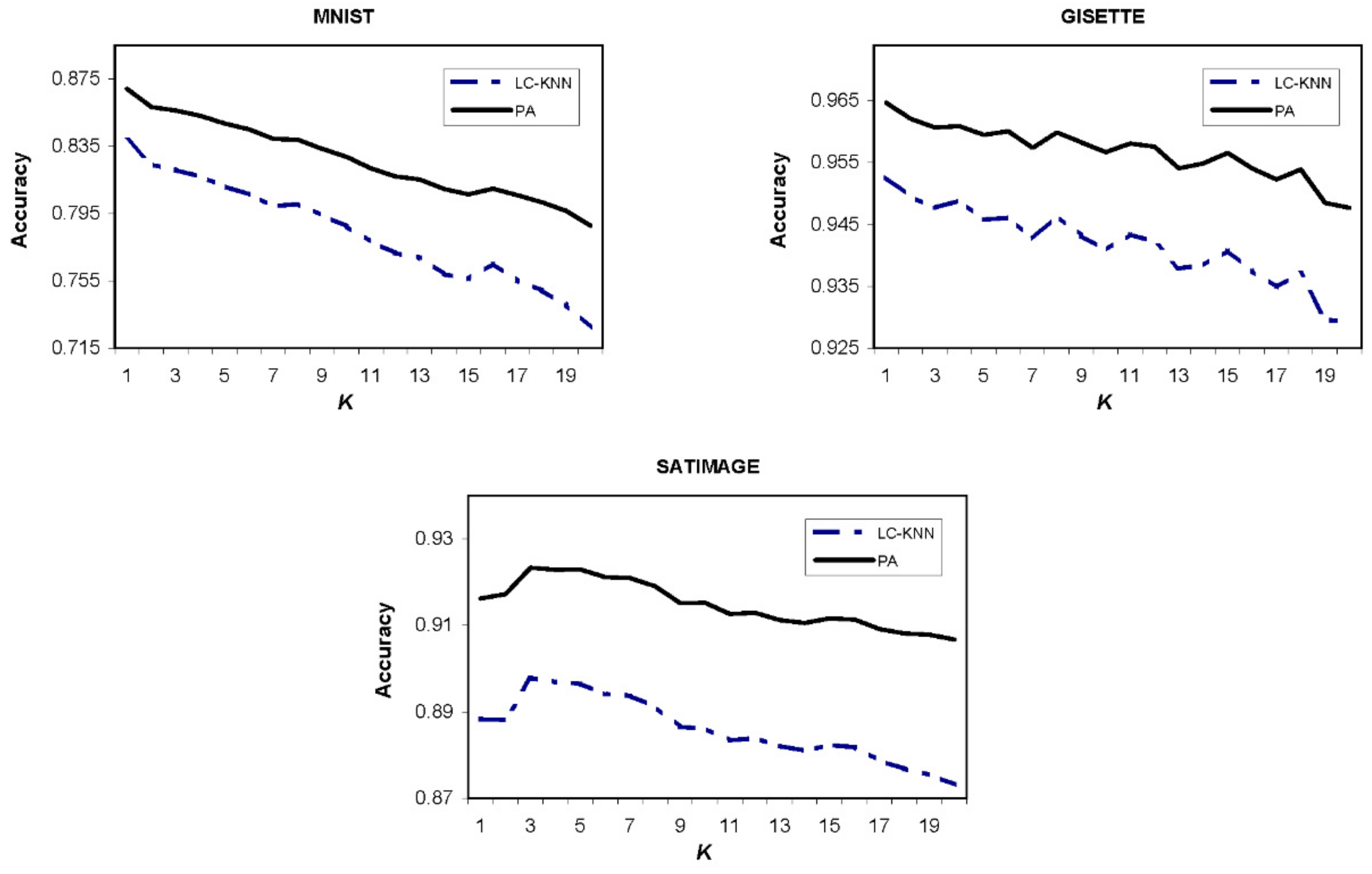
4.3. The Effect of and Parameters’ Values on the Accuracy of the Proposed Method
4.4. Classification Accuracy and Time Cost Comparisons
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wu, X.; Zhu, X.; Wu, G.Q.; Ding, W. Data mining with big data. IEEE Trans. Knowl. Data Eng. 2014, 26, 97–107. [Google Scholar]
- Anchalia, P.P.; Roy, K. The k-Nearest Neighbor Algorithm Using MapReduce Paradigm. In Proceedings of the 2014 5th International Conference on Intelligent Systems, Modelling and Simulation, Langkawi, Malaysia, 27–29 January 2014; pp. 513–518. [Google Scholar]
- Neeb, H.; Kurrus, C. Distributed K-Nearest Neighbors; Stanford University Publishing: Stanford, CA, USA, 2016. [Google Scholar]
- Yong, Z.; Youwen, L.; Shixiong, X. An improved KNN text classification algorithm based on clustering. J. Comput. 2009, 4, 230–237. [Google Scholar]
- Deng, Z.; Zhu, X.; Cheng, D.; Zong, M.; Zhang, S. Efficient kNN classification algorithm for big data. Neurocomputing 2016, 195, 143–148. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; Philip, S.Y. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Li, F.; Jestes, J. Efficient parallel kNN joins for large data in MapReduce. In Proceedings of the 15th International Conference on Extending Database Technology, Berlin, Germany, 26–30 March 2012; pp. 38–49. [Google Scholar]
- Sun, K.; Kang, H.; Park, H.-H. Tagging and classifying facial images in cloud environments based on KNN using MapReduce. Opt. Int. J. Light Electron Opt. 2015, 126, 3227–3233. [Google Scholar] [CrossRef]
- Chatzigeorgakidis, G.; Karagiorgou, S.; Athanasiou, S.; Skiadopoulos, S. FML-kNN: Scalable machine learning on Big Data using k-nearest neighbor joins. J. Big Data 2018, 5, 4. [Google Scholar] [CrossRef] [Green Version]
- Plaku, E.; Kavraki, L.E. Distributed Computation of the knn Graph for Large High-Dimensional Point Sets. J. Parallel Distrib. Comput. 2007, 67, 346–359. [Google Scholar] [CrossRef] [Green Version]
- Kim, W.; Kim, Y.; Shim, K. Parallel computation of k-nearest neighbor joins using MapReduce. In Proceedings of the 2016 IEEE International Conference on Big Data, Washington, DC, USA, 5–8 December 2016; pp. 696–705. [Google Scholar]
- Garcia, V.; Debreuve, E.; Barlaud, M. Fast k Nearest Neighbor Search using GPU. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008; pp. 1–6. [Google Scholar]
- Garcia, V.; Debreuve, E.; Nielsen, F.; Barlaud, M. K-nearest neighbor Search: Fast gpu-based implementations and application to high-dimensional feature matching. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 12–15 September 2010; pp. 3757–3760. [Google Scholar]
- Lu, W.; Shen, Y.; Chen, S.; Chin Ooi, B. Efficient Processing of k Nearest Neighbor Joins using MapReduce. Proc. VLDB Endow. 2012, 5, 1016–1027. [Google Scholar] [CrossRef] [Green Version]
- Connor, M.; Piyush, K. Fast construction of k-nearest neighbor graphs for point clouds. IEEE Trans. Vis. Comput. Gr. 2010, 16, 599–608. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Valero-Mas, J.J.; Calvo-Zaragoza, J.; Rico-Juan, J.R. On the suitability of Prototype Selection methods for kNN classification with distributed data. Neurocomputing 2016, 203, 150–160. [Google Scholar] [CrossRef] [Green Version]
- Angiulli, F. Fast condensed nearest neighbor rule. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 25–32. [Google Scholar]
- Seidl, T.; Kriegel, H.-P. Optimal multi-step k-nearest neighbor search. ACM SIGMOD Rec. 1998, 27, 154–165. [Google Scholar] [CrossRef]
- Li, R.-L.; Hu, Y. A density-based method for reducing the amount of training data in kNN text classification. J. Comput. Res. Dev. 2004, 41, 539–545. [Google Scholar]
- Chen, Y.; Hu, X.; Fan, W.; Shen, L.; Zhang, Z.; Liu, X.; Li, H. Fast density peak clustering for large scale data based on kNN. Knowl. Based Syst. 2020, 187, 104824. [Google Scholar] [CrossRef]
- Mahfouz, M. Rfknn: Rough-Fuzzy Knn for Big Data Classification. Int. J. Adv. Res. Comput. Sci. 2018, 9, 274. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, M.; Zha, Z.J.; Shen, J.; Li, X.; Wu, X. Visual-textual joint relevance learning for tag-based social image search. IEEE Trans. Image Process. 2013, 22, 363–376. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Wang, M.; Tao, D.; Ji, R.; Dai, Q. 3-D object retrieval and recognition with hypergraph analysis. IEEE Trans. Image Process. 2012, 21, 4290–4303. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Zhang, H.; Tao, D.; Wang, Y.; Lu, K. Large-scale paralleled sparse principal component analysis. Multimed. Tools Appl. 2016, 75, 1481–1493. [Google Scholar] [CrossRef]
- Bache, K.; Lichman, M. UCI Machine Learning Repository 2013. University of California, School of Information and Computer Science. Available online: http://archive.ics.uci.edu/ml (accessed on 26 November 2019).
- Shabani, S.; Samadianfard, S.; Sattari, M.T.; Mosavi, A.; Shamshirband, S.; Kmet, T.; Várkonyi-Kóczy, A.R. Modeling Pan Evaporation Using Gaussian Process Regression K-Nearest Neighbors Random Forest and Support Vector Machines; Comparative Analysis. Atmosphere 2020, 11, 66. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Number of Instances | Number of Attributes | Number of Class Labels |
|---|---|---|---|
| USPS | 7291 | 256 | 10 |
| MNIST | 60,000 | 780 | 10 |
| GISETTE | 13,500 | 5000 | 2 |
| LETTER | 20,000 | 16 | 26 |
| PENDIGITS | 10,992 | 16 | 10 |
| SATIMAGE | 6430 | 36 | 6 |
| ADNC | 427 | 93 | 2 |
| psMCI | 242 | 93 | 2 |
| MCINC | 509 | 93 | 2 |
| m | USPS | MNIST | GISETTE | LETTER | PENDIGITS | SATIMAGE | ADNC | psMCI | MCINC | |
|---|---|---|---|---|---|---|---|---|---|---|
| 10 | LC-KNN | 0.9355 | 0.8389 | 0.9526 | 0.9495 | 0.9721 | 0.8883 | 0.7667 | 0.5833 | 0.6159 |
| Proposed approach | 0.9501 | 0.8691 | 0.9647 | 0.9484 | 0.9798 | 0.9162 | 0.7711 | 0.6165 | 0.6198 | |
| 15 | LC-KNN | 0.9338 | 0.8364 | 0.9494 | 0.9469 | 0.9711 | 0.9468 | 0.7500 | 0.6042 | 0.5633 |
| Proposed approach | 0.9512 | 0.8680 | 0.9623 | 0.9467 | 0.9790 | 0.9374 | 0.7680 | 0.6427 | 0.5802 | |
| 20 | LC-KNN | 0.9300 | 0.8353 | 0.9411 | 0.9451 | 0.9700 | 0.8884 | 0.7143 | 0.6500 | 0.6500 |
| Proposed approach | 0.9495 | 0.8675 | 0.9608 | 0.9457 | 0.9781 | 0.9206 | 0.7628 | 0.7013 | 0.6833 | |
| 25 | LC-KNN | 0.9284 | 0.8338 | 0.9321 | 0.9423 | 0.9687 | 0.9421 | 0.7071 | 0.6417 | 0.5746 |
| Proposed approach | 0.9482 | 0.8669 | 0.9567 | 0.9448 | 0.9775 | 0.9456 | 0.7601 | 0.7025 | 0.6147 | |
| 30 | LC-KNN | 0.9275 | 0.8313 | 0.9192 | 0.9403 | 0.9683 | 0.8878 | 0.7190 | 0.6125 | 0.5984 |
| Proposed approach | 0.9475 | 0.8658 | 0.9513 | 0.9439 | 0.9761 | 0.9258 | 0.7608 | 0.6784 | 0.6421 |
| Dataset | KNN | LC-KNN | RFKNN | Proposed Approach | ||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Time | Accuracy | Time | Accuracy | Time | Accuracy | Time | |
| USPS | 0.9503 | 44.8120 | 0.9300 | 4.9874 | 0.9471 | 7.3458 | 0.9495 | 5.1213 |
| MNIST | 0.8768 | 35.0211 | 0.8353 | 4.6309 | 0.8534 | 6.9142 | 0.8675 | 4.8757 |
| GISETTE | 09660 | 296.4012 | 0.9411 | 37.5111 | 0.9631 | 51.2430 | 0.9608 | 40.6560 |
| LETTER | 0.9518 | 26.3548 | 0.9451 | 4.3528 | 0.9489 | 6.5956 | 0.9457 | 4.7016 |
| PENDIGITS | 0.9793 | 9.6935 | 0.9700 | 3.2756 | 0.9772 | 5.0158 | 0.9781 | 3.5584 |
| SATIMAGE | 0.9315 | 4.7499 | 0.8884 | 1.7377 | 0.9281 | 2.7885 | 0.9206 | 1.9511 |
| ADNC | 07906 | 0.0473 | 0.7143 | 0.0450 | 0.7709 | 0.0459 | 0.7628 | 0.0453 |
| psMCI | 0.7195 | 0.0240 | 0.6500 | 0.0234 | 0.6964 | 0.0236 | 0.7013 | 0.0236 |
| MCINC | 0.7201 | 0.0766 | 0.6500 | 0.0690 | 0.6916 | 0.0713 | 0.6833 | 0.0694 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saadatfar, H.; Khosravi, S.; Joloudari, J.H.; Mosavi, A.; Shamshirband, S. A New K-Nearest Neighbors Classifier for Big Data Based on Efficient Data Pruning. Mathematics 2020, 8, 286. https://0-doi-org.brum.beds.ac.uk/10.3390/math8020286
Saadatfar H, Khosravi S, Joloudari JH, Mosavi A, Shamshirband S. A New K-Nearest Neighbors Classifier for Big Data Based on Efficient Data Pruning. Mathematics. 2020; 8(2):286. https://0-doi-org.brum.beds.ac.uk/10.3390/math8020286
Chicago/Turabian StyleSaadatfar, Hamid, Samiyeh Khosravi, Javad Hassannataj Joloudari, Amir Mosavi, and Shahaboddin Shamshirband. 2020. "A New K-Nearest Neighbors Classifier for Big Data Based on Efficient Data Pruning" Mathematics 8, no. 2: 286. https://0-doi-org.brum.beds.ac.uk/10.3390/math8020286