A Self-Care Prediction Model for Children with Disability Based on Genetic Algorithm and Extreme Gradient Boosting

 ,
,  , , and
, , and
Abstract
:1. Introduction
2. Literature Review
2.1. Self-Care Prediction Based on ICF-CY Dataset
2.2. Extreme Gradient Boosting (XGBoost) and Genetic Algorithms (GA)
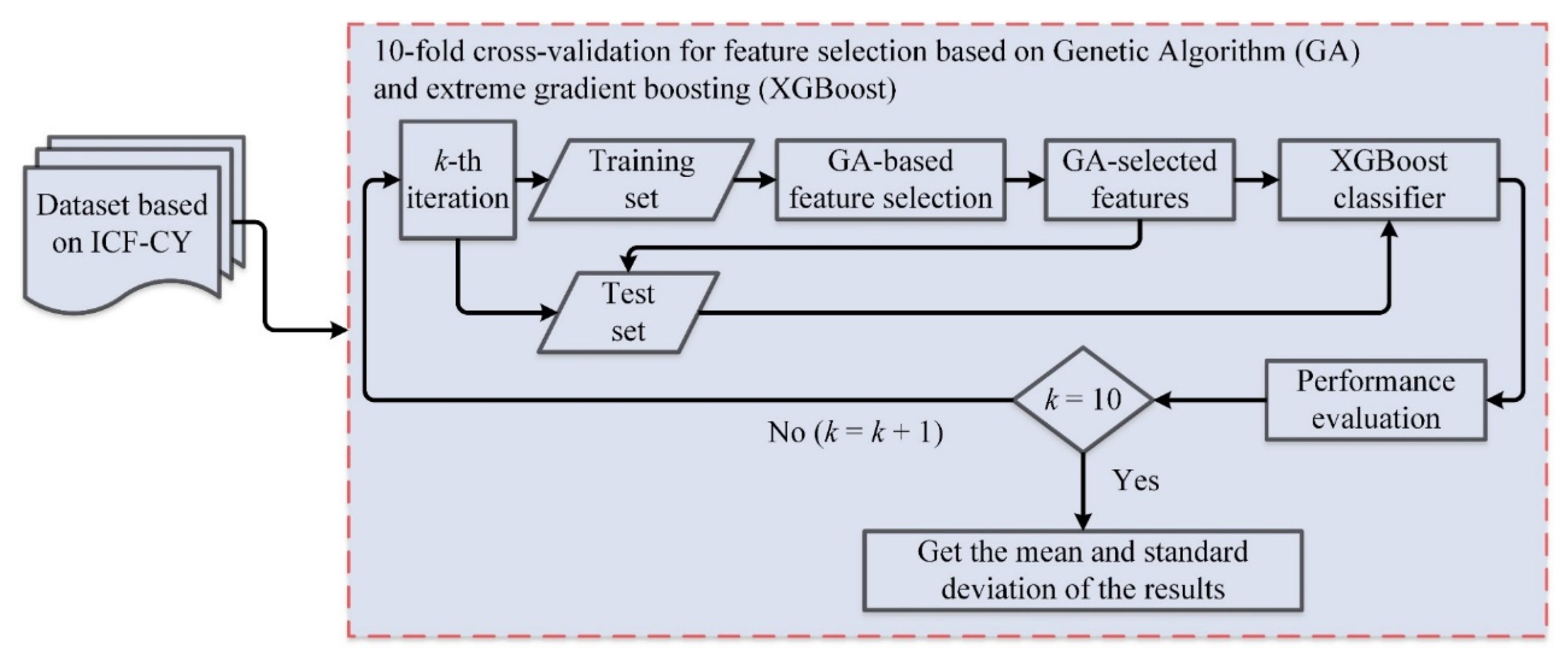
3. Methodology
3.1. Dataset
3.2. Design of Proposed Self-Care Prediction Model
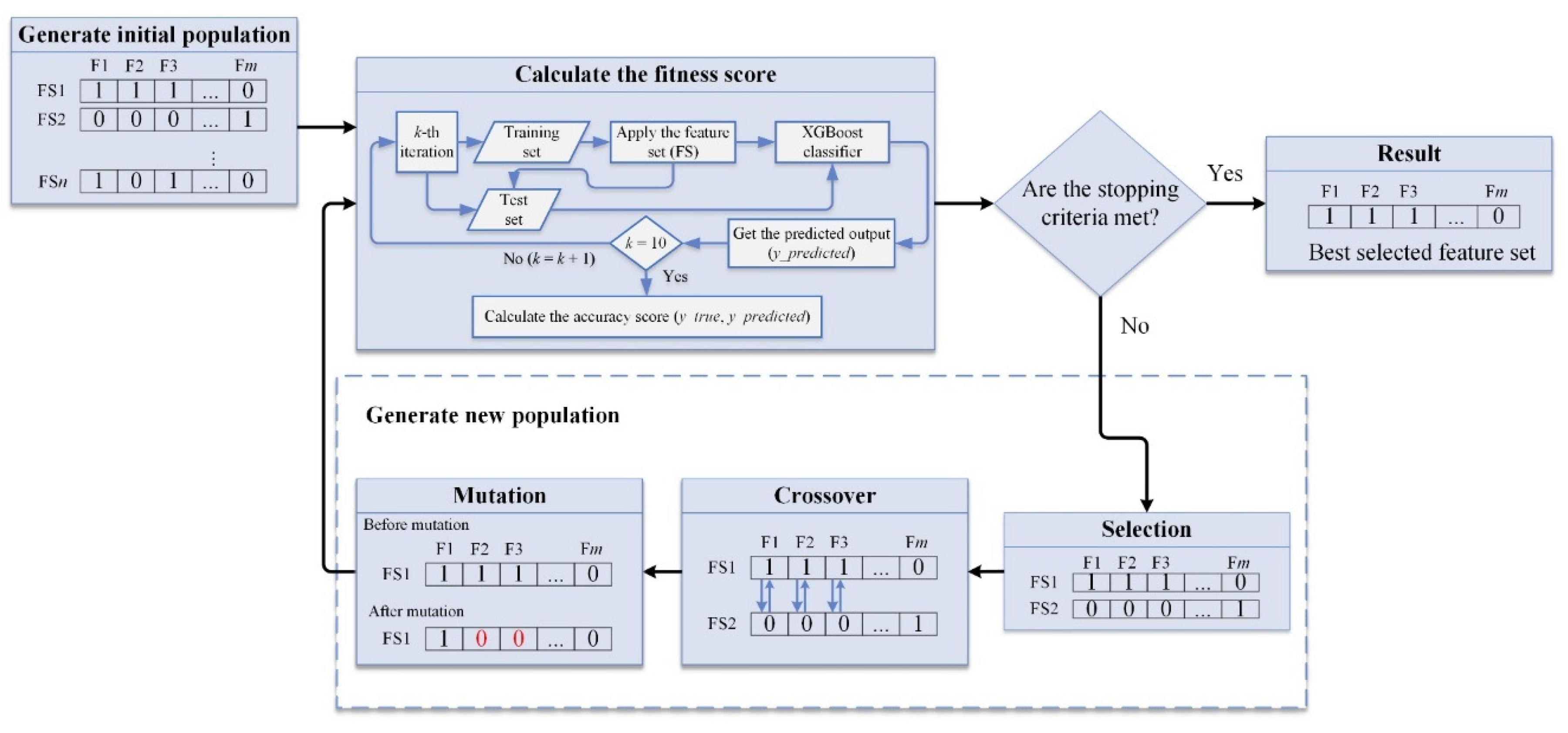
3.3. Genetic Algorithm (GA)
| Algorithm 1. Genetic Algorithms (GA)-based feature selection pseudocode | |
| Input: population size, pop-size; crossover probablity, cx-pb; mutation probability, mt-pb; number of generations, n-gen; | |
| Output: Best individual, best-ind; | |
| 1: | Generate initial population, pop |
| 2: | pop ← population(pop-size) |
| 3: | Calculate initial fitness score, fitnesses |
| 4: | fitnesses ← list(map(evaluate, pop)) |
| 5: | For individual ind, fitness value fit in zip(pop, fitnesses) do |
| 6: | Individual fitness score ind-fit ← fit |
| 7: | end for |
| 8: | For each generation g in range(n-gen) do |
| 9: | Select the next generation individuals, offspring |
| 10: | offspring ← select (pop, len(pop)) |
| 11: | Clone the selected individuals |
| 12: | offspring ← list(map(clone, offspring)) |
| 13: | Apply crossover on the offspring |
| 14: | for child1, child2 in zip(offspring[::2], offspring[1::2]) do |
| 15: | if random() < cx-pb then |
| 16: | mate(child1, child2) |
| 17: | end if |
| 18: | end for |
| 19: | Apply mutation on the offspring |
| 20: | for mutant in offspring do |
| 21: | if random() < mt-pb then |
| 22: | mutate(mutant) |
| 23: | end if |
| 24: | end for |
| 25: | Evaluate the individuals with an invalid fitness score |
| 26: | Weak individual weak_ind ← [ind for ind in offspring if not individual with valid fitness score] |
| 27: | fitnesses ← list(map(evaluate, weak_ind)) |
| 28: | for ind, fit in zip(weak_ind, fitnesses) do |
| 29: | Individual fitness score ind-fit ← fit |
| 30: | end for |
| 31: | The population is fully replaced by the offspring |
| 32: | pop[:] ← offspring |
| 33: | end for |
| 34: | Gather all the fitnesses in one list, all-fitnesses |
| 35: | all-fitnesses ← [ind-fit[0] for ind in pop] |
| 36: | Select the best individual, best-ind |
| 37: | best-ind ← selectBest(pop, 1)[0] |
| 38: | returnbest-ind |
3.4. Extreme Gradient Boosting (XGBoost)
3.5. Performance Metrics and Experimental Setup
4. Results and Discussion
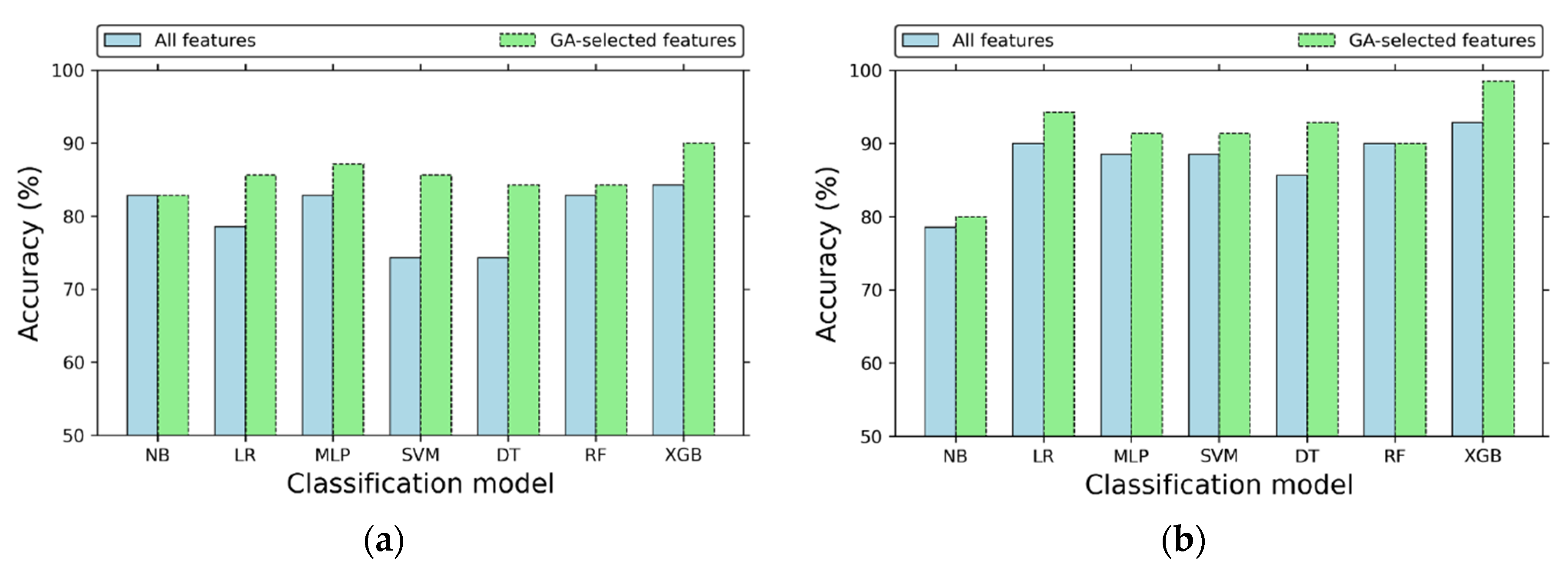
4.1. Performance Evaluation of Proposed Models
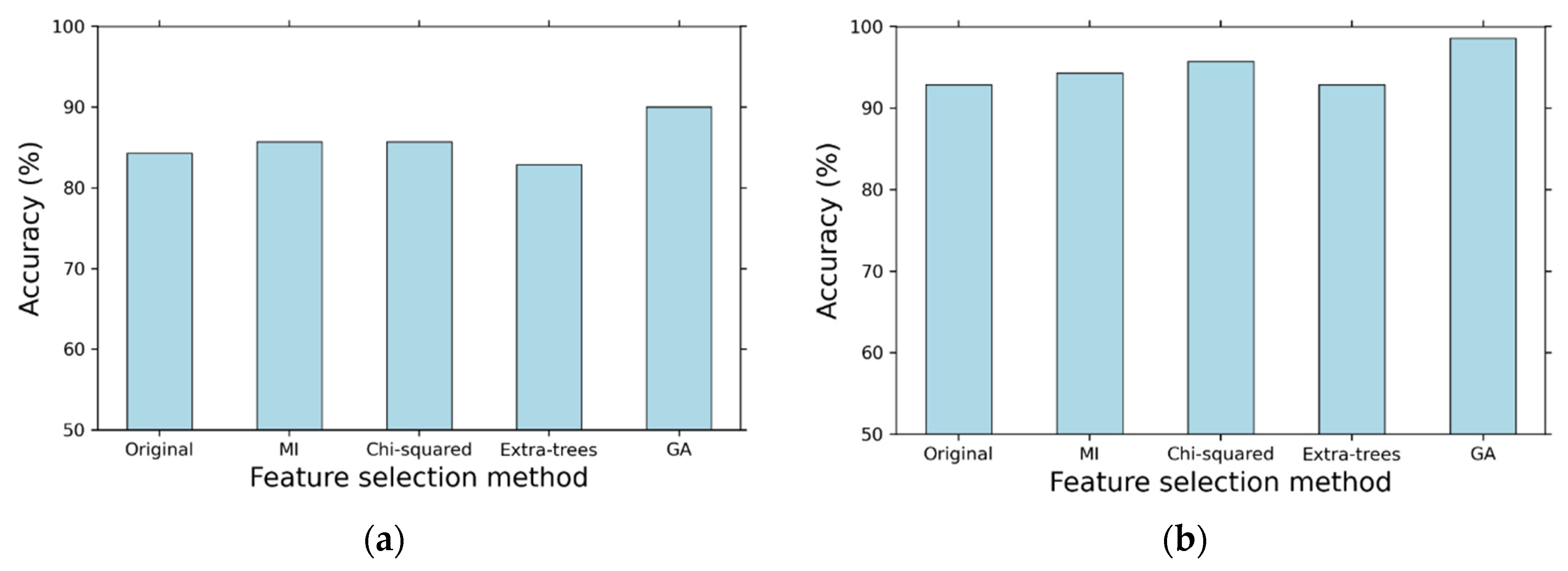
4.2. Impacts of Features Selections on the Classification Performance
4.3. Comparison of the Proposed Model with Previous Works
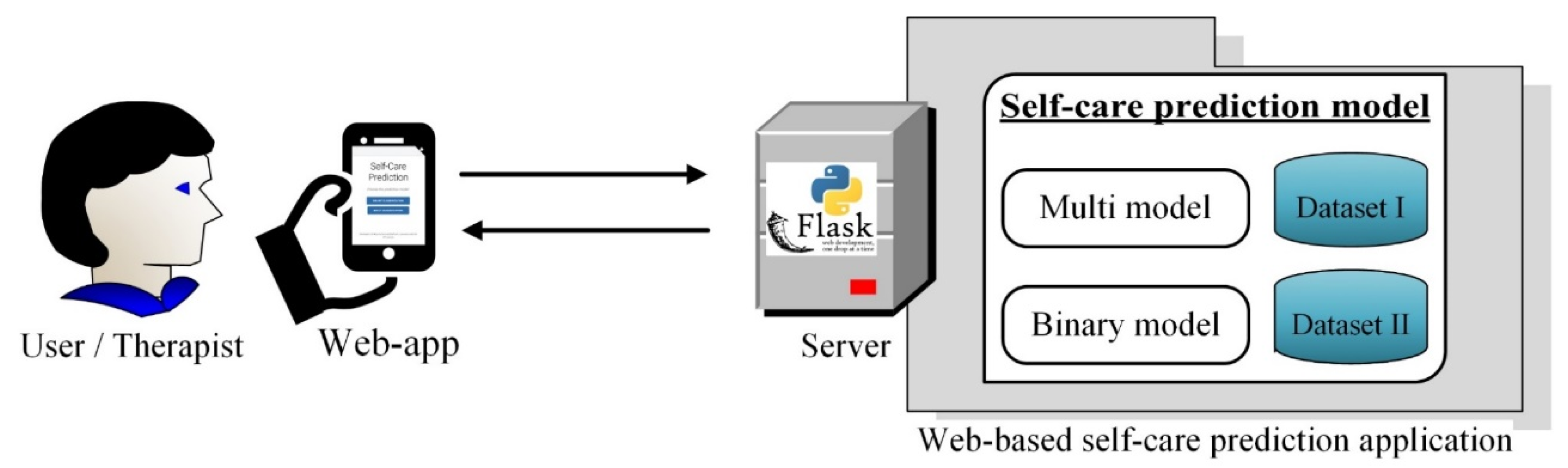
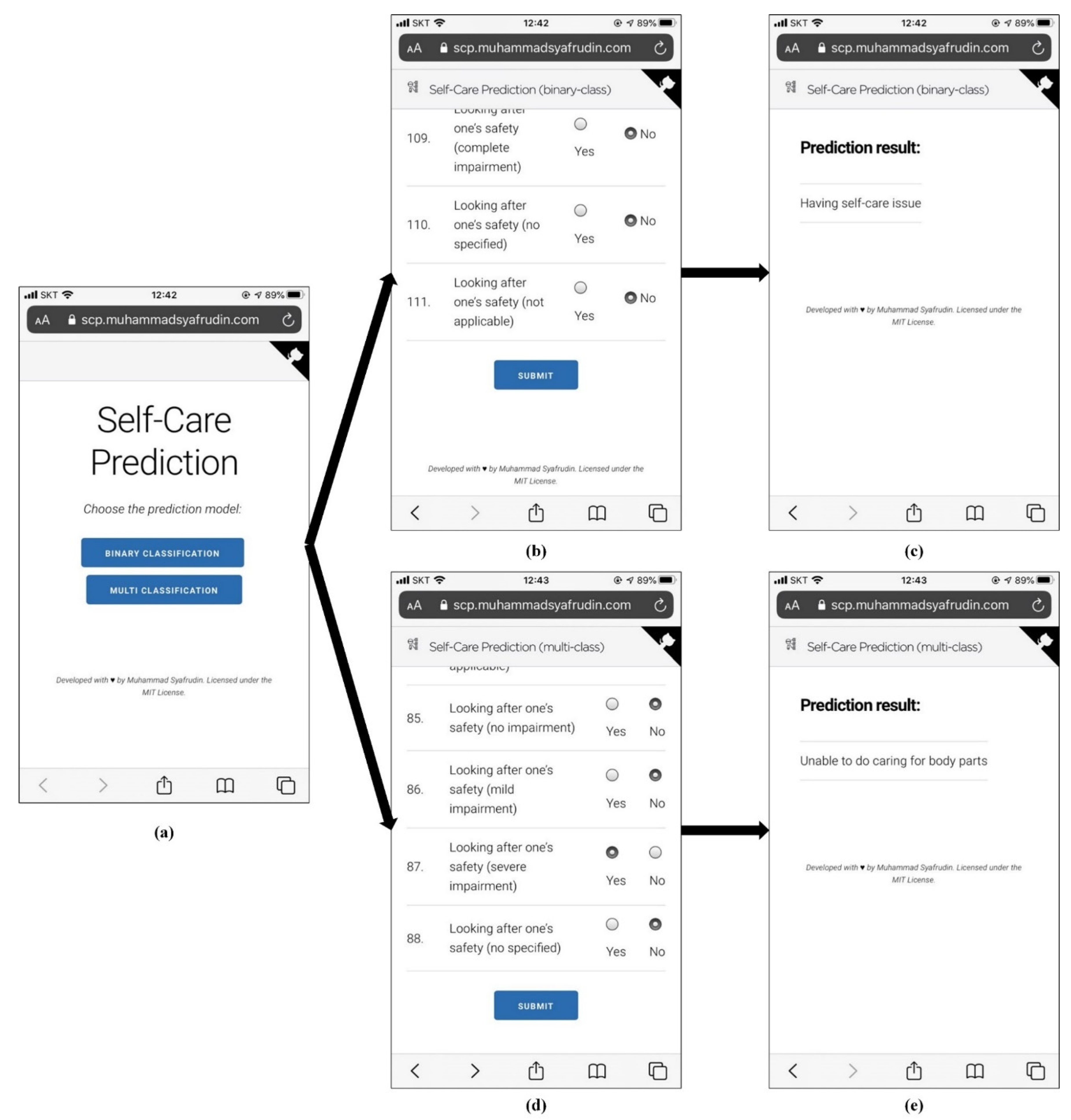
5. Practical Application of the Proposed Self-Care Prediction Model
6. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym/Abbreviation | Definition |
|---|---|
| GA | Genetic algorithms |
| XGBoost | Extreme gradient boosting |
| WHO | World health organization |
| ICF-CY | International classification of functioning, disability, and health: children and youth version |
| SCADI | Self-care activities dataset based on ICF-CY |
| MLAs | Machine learning algorithms |
| ANN | Artificial neural network |
| KNN | K-nearest neighbor |
| NB | Naïve bayes |
| FNN | Fuzzy neural networks |
| DNN | Deep neural networks |
| LR | Logistic regression |
| MLP | Multi-layer perceptron |
| SVM | Support vector machine |
| DT | Decision tree |
| RF | Random forest |
| T1D | Type 1 diabetes |
| CACS | Coronary artery calcium score |
| COVID-19 | Coronavirus disease |
| CV | Cross-validation |
| PCA | Principal component analysis |
| IGRCFS | Information gain regression curve feature selection |
| SMOTE | Synthetic minority over sampling technique |
| ELM | Extreme learning machines |
| FS | Feature’s subset |
| Borderline-SMOTE | Borderline-Synthetic minority oversampling technique |
| AUC | Area under the receiver operating characteristic curves |
| GDM | Gestational diabetes mellitus |
| PH | Prediction horizon |
| RMSE | Root mean square error |
| CT | Computed tomography |
| cx-pb | Crossover probability |
| mt-pb | Mutation probability |
| pop-size | Population size |
| n-gen | Number of generations |
| GBDT | Gradient boosting decision trees |
| MI | Mutual information |
| Web-app | Web-based application |
References
- Tung-Kuang, W.; Shian-Chang, H.; Ying-Ru, M. Identifying and Diagnosing Students with Learning Disabilities using ANN and SVM. In Proceedings of the The 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006; IEEE: Vancouver, BC, Canada, 2006; pp. 4387–4394. [Google Scholar] [CrossRef]
- Haley, S.; Andrellos, P.J.; Coster, W.; Haltiwanger, J.T.; Ludlow, L.H. Pediatric Evaluation of Disability Inventory™ (PEDI™). Available online: https://eprovide.mapi-trust.org/instruments/pediatric-evaluation-of-disability-inventory (accessed on 5 June 2020).
- World Health Organization. International Classification of Functioning, Disability and Health: Children and Youth Version: ICF-CY. World Health Organization. 2007. Available online: https://apps.who.int/iris/handle/10665/43737 (accessed on 10 June 2020).
- Zarchi, M.S.; Fatemi Bushehri, S.M.M.; Dehghanizadeh, M. SCADI: A standard dataset for self-care problems classification of children with physical and motor disability. Int. J. Med. Inform. 2018, 114, 81–87. [Google Scholar] [CrossRef] [PubMed]
- Islam, B.; Ashafuddula, N.I.M.D.; Mahmud, F. A Machine Learning Approach to Detect Self-Care Problems of Children with Physical and Motor Disability. In Proceedings of the 2018 21st International Conference of Computer and Information Technology (ICCIT), Amsterdam, The Netherlands, 10–11 December 2018; IEEE: Dhaka, Bangladesh, 2018; pp. 1–4. [Google Scholar]
- Liu, L.; Zhang, B.; Wang, S.; Li, S.; Zhang, K.; Wang, S. Feature selection based on feature curve of subclass problem. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Le, T.; Baik, S. A Robust Framework for Self-Care Problem Identification for Children with Disability. Symmetry 2019, 11, 89. [Google Scholar] [CrossRef] [Green Version]
- Souza, P.V.C.; dos Reis, A.G.; Marques, G.R.R.; Guimaraes, A.J.; Araujo, V.J.S.; Araujo, V.S.; Rezende, T.S.; Batista, L.O.; da Silva, G.A. Using hybrid systems in the construction of expert systems in the identification of cognitive and motor problems in children and young people. In Proceedings of the 2019 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), New Orleans, LA, USA, 23–26 June 2019; IEEE: New Orleans, LA, USA, 2019; pp. 1–6. [Google Scholar]
- Akyol, K. Comparing of deep neural networks and extreme learning machines based on growing and pruning approach. Expert Syst. Appl. 2020, 140, 112875. [Google Scholar] [CrossRef]
- Putatunda, S. Care2Vec: A hybrid autoencoder-based approach for the classification of self-care problems in physically disabled children. Neural. Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Yeh, Y.-L.; Hou, T.-H.; Chang, W.-Y. An intelligent model for the classification of children’s occupational therapy problems. Expert Syst. Appl. 2012, 39, 5233–5242. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: San Francisco, CA, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Du, Z.; Lawrence, W.R.; Huang, Y.; Deng, Y.; Hao, Y. Predicting Hepatitis B Virus Infection Based on Health Examination Data of Community Population. IJERPH 2019, 16, 4842. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Li, J.; Leng, J.; Wang, H.; Liu, J.; Li, W.; Liu, H.; Wang, S.; Ma, J.; Chan, J.C.; et al. Machine learning risk score for prediction of gestational diabetes in early pregnancy in Tianjin, China. Diabetes Metab. Res. Rev. 2020. [Google Scholar] [CrossRef]
- Alfian, G.; Syafrudin, M.; Rhee, J.; Anshari, M.; Mustakim, M.; Fahrurrozi, I. Blood Glucose Prediction Model for Type 1 Diabetes based on Extreme Gradient Boosting. IOP Conf. Ser. Mater. Sci. Eng. 2020, 803, 012012. [Google Scholar] [CrossRef]
- Lee, J.; Lim, J.-S.; Chu, Y.; Lee, C.H.; Ryu, O.-H.; Choi, H.H.; Park, Y.S.; Kim, C. Prediction of Coronary Artery Calcium Score Using Machine Learning in a Healthy Population. JPM 2020, 10, 96. [Google Scholar] [CrossRef]
- Fitriyani, N.L.; Syafrudin, M.; Alfian, G.; Rhee, J. HDPM: An Effective Heart Disease Prediction Model for a Clinical Decision Support System. IEEE Access 2020, 8, 133034–133050. [Google Scholar] [CrossRef]
- Tsai, C.-J. New feature selection and voting scheme to improve classification accuracy. Soft Comput 2019, 23, 12017–12030. [Google Scholar] [CrossRef]
- Panay, B.; Baloian, N.; Pino, J.A.; Peñafiel, S.; Sanson, H.; Bersano, N. Feature Selection for Health Care Costs Prediction Using Weighted Evidential Regression. Sensors 2020, 20, 4392. [Google Scholar] [CrossRef] [PubMed]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Aggarwal, C.C. (Ed.) Data Classification; Chapman and Hall/CRC: Boca Raton, FL, USA, 2014; ISBN 978-1-4665-8675-8. [Google Scholar] [CrossRef]
- Jain, D.; Singh, V. Feature selection and classification systems for chronic disease prediction: A review. Egypt. Inform. J. 2018, 19, 179–189. [Google Scholar] [CrossRef]
- Fitriyani, N.L.; Syafrudin, M.; Alfian, G.; Rhee, J. Development of Disease Prediction Model Based on Ensemble Learning Approach for Diabetes and Hypertension. IEEE Access 2019, 7, 144777–144789. [Google Scholar] [CrossRef]
- Vafaie, H.; De Jong, K. Genetic algorithms as a tool for feature selection in machine learning. In Proceedings of the Proceedings Fourth International Conference on Tools with Artificial Intelligence TAI ’92, Arlington, VA, USA, 10–13 November 1992; pp. 200–203. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Prado-Cumplido, M.; Pérez-Cruz, F.; Bousoño-Calzón, C. Feature Selection via Genetic Optimization. In Artificial Neural Networks—ICANN 2002; Dorronsoro, J.R., Ed.; Lecture Notes in Computer Science; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 2002; Volume 2415, pp. 547–552. ISBN 978-3-540-44074-1. [Google Scholar] [CrossRef]
- Shon, D.; Im, K.; Park, J.-H.; Lim, D.-S.; Jang, B.; Kim, J.-M. Emotional Stress State Detection Using Genetic Algorithm-Based Feature Selection on EEG Signals. IJERPH 2018, 15, 2461. [Google Scholar] [CrossRef] [Green Version]
- Wutzl, B.; Leibnitz, K.; Rattay, F.; Kronbichler, M.; Murata, M.; Golaszewski, S.M. Genetic algorithms for feature selection when classifying severe chronic disorders of consciousness. PLoS ONE 2019, 14, e0219683. [Google Scholar] [CrossRef] [Green Version]
- García-Dominguez, A.; Galván-Tejada, C.E.; Zanella-Calzada, L.A.; Gamboa-Rosales, H.; Galván-Tejada, J.I.; Celaya-Padilla, J.M.; Luna-García, H.; Magallanes-Quintanar, R. Feature Selection Using Genetic Algorithms for the Generation of a Recognition and Classification of Children Activities Model Using Environmental Sound. Mob. Inf. Syst. 2020, 2020, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Uzma, A.F.; Tubaishat, A.; Shah, B.; Halim, Z. Gene encoder: A feature selection technique through unsupervised deep learning-based clustering for large gene expression data. Neural. Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Parisi, L.; RaviChandran, N. Evolutionary feature transformation to improve prognostic prediction of hepatitis. Knowl.-Based Syst. 2020, 200, 10601. [Google Scholar] [CrossRef]
- Shaban, W.M.; Rabie, A.H.; Saleh, A.I.; Abo-Elsoud, M.A. A new COVID-19 Patients Detection Strategy (CPDS) based on hybrid feature selection and enhanced KNN classifier. Knowl.-Based Syst. 2020, 205, 106270. [Google Scholar] [CrossRef] [PubMed]
- Qu, Y.; Lin, Z.; Li, H.; Zhang, X. Feature Recognition of Urban Road Traffic Accidents Based on GA-XGBoost in the Context of Big Data. IEEE Access 2019, 7, 170106–170115. [Google Scholar] [CrossRef]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Taylor, T.; Altares Sarik, D.; Salyakina, D. Development and Validation of a Web-Based Pediatric Readmission Risk Assessment Tool. Hosp. Pediatrics 2020, 10, 246–256. [Google Scholar] [CrossRef]
- Yu, C.-S.; Lin, Y.-J.; Lin, C.-H.; Lin, S.-Y.; Wu, J.L.; Chang, S.-S. Development of an Online Health Care Assessment for Preventive Medicine: A Machine Learning Approach. J. Med. Internet. Res. 2020, 22, e18585. [Google Scholar] [CrossRef]
- Krebs, J.; Negatsch, V.; Berg, C.; Aigner, A.; Opitz-Welke, A.; Seidel, P.; Konrad, N.; Voulgaris, A. Applicability of two violence risk assessment tools in a psychiatric prison hospital population. Behav. Sci. Law 2020, bsl.2474. [Google Scholar] [CrossRef]
- Sansen, L.M.; Saupe, L.B.; Steidl, A.; Fegert, J.M.; Hoffmann, U.; Neuner, F. Development and randomized-controlled evaluation of a web-based training in evidence-based trauma therapy. Prof. Psychol. Res. Pract. 2020, 51, 115–124. [Google Scholar] [CrossRef]
- Blum, A.L.; Langley, P. Selection of relevant features and examples in machine learning. Artif. Intell. 1997, 97, 245–271. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning, 1st ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1989; ISBN 0-201-15767-5. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Friedman, M. The Use of Ranks to Avoid the Assumption of Normality Implicit in the Analysis of Variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Holm, S. A Simple Sequentially Rejective Multiple Test Procedure. Scand. J. Stat. 1979, 6, 65–70. [Google Scholar]
- Guyon, I.; Elisseeff, A. An Introduction to Feature Extraction. In Feature Extraction; Guyon, I., Nikravesh, M., Gunn, S., Zadeh, L.A., Eds.; Studies in Fuzziness and Soft Computing; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 2006; Volume 207, pp. 1–25. ISBN 978-3-540-35487-1. [Google Scholar]
- Miao, J.; Niu, L. A Survey on Feature Selection. Procedia Comput. Sci. 2016, 91, 919–926. [Google Scholar] [CrossRef] [Green Version]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Santos, M.S.; Soares, J.P.; Abreu, P.H.; Araujo, H.; Santos, J. Cross-Validation for Imbalanced Datasets: Avoiding Overoptimistic and Overfitting Approaches [Research Frontier]. IEEE Comput. Intell. Mag. 2018, 13, 59–76. [Google Scholar] [CrossRef]







| Study | Method | Feature Selection | Validation Method | Classification Type | Statistical Test | Practical Application |
|---|---|---|---|---|---|---|
| Zarchi et al., 2018 [4] | ANN | No | 10-fold CV | Multi-class | No | No |
| Islam et al., 2018 [5] | KNN | Yes | 5-fold CV | Multi-class | No | No |
| Liu et al., 2019 [6] | NB | Yes | 10-fold CV | Multi-class | No | No |
| Le and Baik, 2019 [7] | SMOTE + XGBoost | No | 10-fold CV | Multi-class | No | No |
| Souza et al., 2019 [8] | FNN | No | k-fold * | Binary-class | No | No |
| Akyol, 2020 [9] | DNN | No | Hold-out | Multi-class | No | No |
| Putatunda, 2020 [10] | Hybrid autoencoder | No | 10-fold CV | Multi-class, Binary-class | No | No |
| Our proposed study | GA + XGBoost | Yes | 10-fold CV | Multi-class, Binary-class | Yes, with two-step statistical test | Yes |
| Self-Care | No. | Activity Description | Feature Code | Impairment Extension Code |
|---|---|---|---|---|
| I. Washing oneself | 1 | Washing body parts | d 5100 | 0, 1, 2, 3, 4, 8, 9 |
| 2 | Washing whole body | d 5101 | ||
| 3 | Drying oneself | d 5102 | ||
| II. Caring for body parts | 4 | Caring for skin | d 5200 | 0, 1, 2, 3, 4, 8, 9 |
| 5 | Caring for teeth | d 5201 | ||
| 6 | Caring for hair | d 5202 | ||
| 7 | Caring for fingernails | d 5203 | ||
| 8 | Caring for toenails | d 5204 | ||
| 9 | Caring for nose | d 5205 | ||
| III. Toileting | 10 | Indicating need for urination | d 53000 | 0, 1, 2, 3, 4, 8, 9 |
| 11 | Carrying out urination appropriately | d 53001 | ||
| 12 | Indicating need for defecation | d 53010 | ||
| 13 | Carrying out defecation appropriately | d 53011 | ||
| 14 | Menstrual care | d 5302 | ||
| IV. Dressing | 15 | Putting clothes | d 5400 | 0, 1, 2, 3, 4, 8, 9 |
| 16 | Taking off clothes | d 5401 | ||
| 17 | Putting on footwear | d 5402 | ||
| 18 | Taking off footwear | d 5403 | ||
| 19 | Choosing appropriate clothing | d 5404 | ||
| V. Eating | 20 | Indicating need for eating | d 5500 | 0, 1, 2, 3, 4, 8, 9 |
| 21 | Carrying out eating appropriately | d 5501 | ||
| VI. Drinking | 22 | Indicating need for drinking | d 5600 | 0, 1, 2, 3, 4, 8, 9 |
| 23 | Carrying out feeding from bottle | d 5602 | ||
| VII. Looking after one’s health | 24 | Ensuring one’s physical comfort | d 5700 | 0, 1, 2, 3, 4, 8, 9 |
| 25 | Managing diet and fitness | d 5701 | ||
| 26 | Managing medications and following health advice | d 57020 | ||
| 27 | Seeking advice or assistance from caregivers or professionals | d 57021 | ||
| 28 | Avoiding risks of abuse of drugs or alcohol | d 57022 | ||
| VIII. Looking after one’s safety | 29 | Looking after one’s safety | d 571 | 0, 1, 2, 3, 4, 8, 9 |
| Dataset | Target Class | Description | # of Subject |
|---|---|---|---|
| I (multi-class) | 1 | Unable to do caring for body parts | 2 |
| 2 | Unable to do toileting | 7 | |
| 3 | Unable to do dressing | 1 | |
| 4 | Unable to do washing and caring for body parts and dressing | 12 | |
| 5 | Unable to do washing, caring for body parts, toileting, and dressing | 3 | |
| 6 | Unable to do eating, drinking, washing, caring for body parts, toileting, and dressing | 29 | |
| 7 | No issues | 16 | |
| II (binary-class) | 0 | No issues | 16 |
| 1 | Having self-care issues | 54 |
| Dataset | GA Parameter | # of Feature | Best Selected Feature | ||||
|---|---|---|---|---|---|---|---|
| pop-size | cx-pb | mt-pb | n-gen | Original (%) | Selected (%) | ||
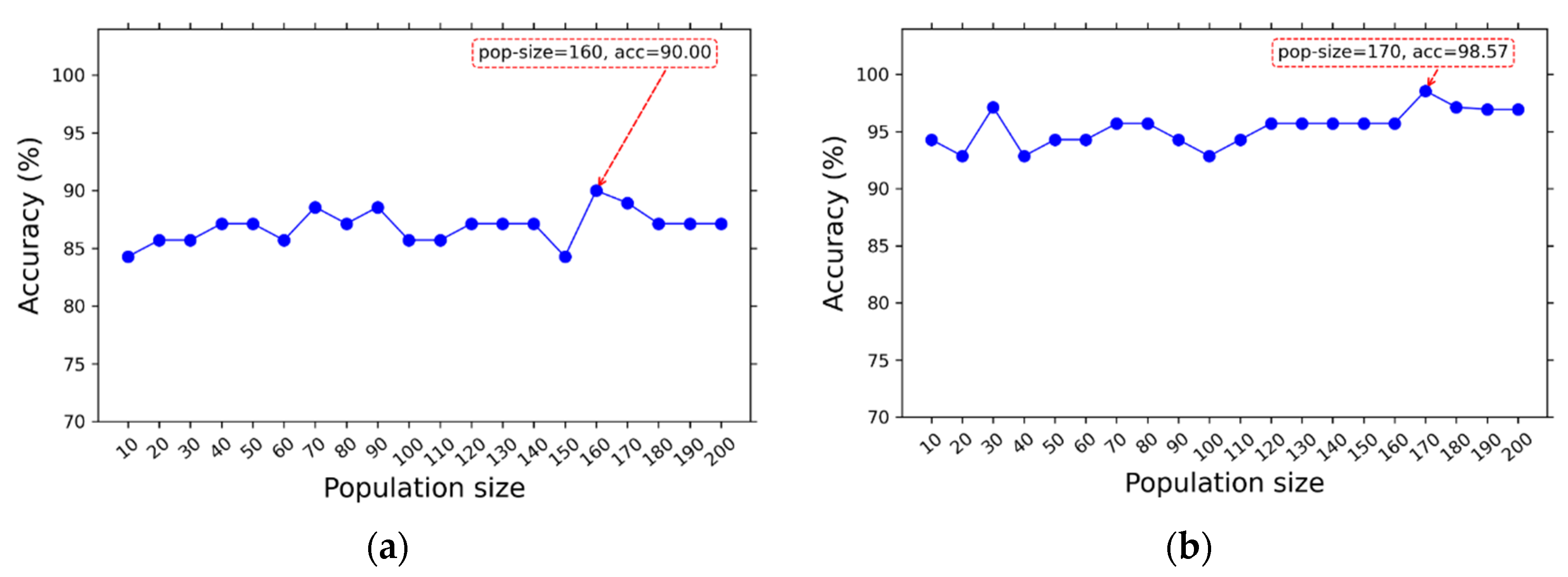
| I (multi-class) | 160 | 0.7 | 0.19 | 30 | 205 (100%) | 88 (42.93%) | d 5100-3, d 5101-1, d 5101-2, d 5101-4, d 5101-8, d 5101-9, d 5102-0, d 5102-2, d 5102-4, d 5200-0, d 5200-1, d 5200-3, d 5200-4, d 5201-3, d 5201-8, d 5202-9, d 5203-9, d 5204-1, d 5204-4, d 5204-9, d 5205-0, d 5205-1, d 5205-3, d 5205-8, d 53000-1, d 53000-4, d 53000-8, d 53000-9, d 53001-0, d 53001-2, d 53001-3, d 53001-4, d 53001-9, d 53010-2, d 53010-4, d 53010-9, d 53011-3, d 53011-4, d 5302-4, d 5400-0, d 5400-1, d 5400-2, d 5400-8, d 5401-1, d 5401-3, d 5401-4, d 5401-8, d 5401-9, d 5402-0, d 5403-0, d 5403-2, d 5403-9, d 5404-0, d 5404-1, d 5404-4, d 5404-8, d 5404-9, d 5500-0, d 5500-2, d 5500-3, d 5500-4, d 5500-9, d 5501-8, d 5600-4, d 5600-9, d 5602-3, d 5602-4, d 5602-9, d 5700-0, d 5700-2, d 5700-3, d 5701-0, d 5701-1, d 5701-3, d 5701-4, d 5701-8, d 57020-2, d 57020-3, d 57020-4, d 57020-8, d 57021-2, d 57022-3, d 57022-8, d 57022-9, d 571-1, d 571-2, d 571-3, d 571-8 |
| II (binary-class) | 170 | 0.9 | 0.36 | 30 | 205 (100%) | 111 (54.15%) | Gender, d 5100-0, d 5100-3, d 5100-4, d 5100-9, d 5101-0, d 5101-1, d 5101-2, d 5102-0, d 5102-8, d 5102-9, d 5200-0, d 5200-1, d 5200-2, d 5200-3, d 5200-4, d 5201-0, d 5201-1, d 5201-2, d 5201-3, d 5201-8, d 5202-2, d 5202-8, d 5203-1, d 5203-2, d 5203-3, d 5203-9, d 5204-0, d 5204-1, d 5204-2, d 5204-3, d 5204-9, d 5205-2, d 5205-3, d 5205-8, d 53000-1, d 53000-4, d 53000-8, d 53001-4, d 53001-9, d 53010-2, d 53010-4, d 53011-3, d 53011-4, d 5302-1, d 5302-2, d 5302-4, d 5400-0, d 5400-1, d 5400-9, d 5401-0, d 5401-3, d 5401-4, d 5401-8, d 5402-1, d 5402-2, d 5402-4, d 5402-8, d 5403-0, d 5403-1, d 5403-8, d 5403-9, d 5404-0, d 5404-3, d 5404-9, d 5500-8, d 5501-0, d 5501-1, d 5501-4, d 5501-8, d 5501-9, d 5600-0, d 5600-1, d 5600-2, d 5600-4, d 5600-8, d 5600-9, d 5602-0, d 5602-1, d 5602-3, d 5602-8, d 5602-9, d 5700-0, d 5700-4, d 5700-8, d 5700-9, d 5701-0, d 5701-2, d 5701-3, d 5701-4, d 5701-8, d 5701-9, d 57020-3, d 57020-8, d 57020-9, d 57021-2, d 57021-4, d 57021-5, d 57021-6, d 57022-0, d 57022-1, d 57022-2, d 57022-3, d 57022-4, d 57022-8, d 57022-9, d 571-0, d 571-3, d 571-4, d 571-8, d 571-9 |
| Metric | Formula |
|---|---|
| Average accuracy | |
| Metric | Formula |
|---|---|
| Accuracy | |
| Precision | |
| Recall | |
| F1 score |
| Method | Feature Selection | # of Features (%) | Performance Metric (%) | |||
|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | |||
| NB | None | 205 (100%) | 82.86 ± 10.69 | 65.25 ± 22.36 | 73.25 ± 18.10 | 67.70 ± 20.35 |
| LR | 78.57 ± 14.64 | 63.08 ± 24.81 | 70.58 ± 21.88 | 65.31 ± 23.27 | ||
| MLP | 82.86 ± 10.69 | 67.58 ± 22.08 | 74.00 ± 18.03 | 69.13 ± 20.33 | ||
| SVM | 74.29 ± 12.45 | 53.92 ± 13.07 | 63.08 ± 15.21 | 57.23 ± 13.70 | ||
| DT | 74.29 ± 20.00 | 58.50 ± 21.74 | 61.58 ± 22.02 | 58.81 ± 22.10 | ||
| RF | 82.86 ± 10.69 | 67.83 ± 21.31 | 74.08 ± 18.71 | 69.31 ± 20.22 | ||
| Proposed Model | GA | 88 (42.93%) | 90.00 ± 9.15 | 79.92 ± 20.18 | 84.75 ± 15.43 | 81.21 ± 18.43 |
| Method | Feature Selection | # of Features (%) | Performance Metric (%) | |||
|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | |||
| NB | None | 205 (100%) | 78.57 ± 17.20 | 91.31 ± 11.14 | 83.00 ± 19.75 | 85.16 ± 12.48 |
| LR | 90.00 ± 11.16 | 93.81 ± 9.94 | 95.00 ± 10.67 | 93.61 ± 7.19 | ||
| MLP | 88.57 ± 14.00 | 93.81 ± 9.94 | 93.33 ± 15.28 | 92.27 ± 10.20 | ||
| SVM | 88.57 ± 10.69 | 87.86 ± 10.93 | 100.00 ± 0.00 | 93.17 ± 6.29 | ||
| DT | 85.71 ± 12.78 | 92.38 ± 9.98 | 91.33 ± 15.58 | 90.39 ± 9.47 | ||
| RF | 90.00 ± 14.36 | 95.48 ± 9.43 | 93.33 ± 15.28 | 93.18 ± 10.44 | ||
| Proposed Model | GA | 111 (54.15%) | 98.57 ± 4.29 | 98.33 ± 5.00 | 100.00 ± 0.00 | 99.09 ± 2.73 |
| Method | Friedman Rank | p-Value |
|---|---|---|
| NB | 9.37 | 4.89 × 10−19 |
| LR | 8.44 | |
| MLP | 7.92 | |
| SVM | 10.09 | |
| DT | 9.63 | |
| RF | 7.50 | |
| Proposed Model | 5.02 |
| Comparison | Post-Hoc p-Value | Significant? |
|---|---|---|
| Proposed vs. NB | 0.000055 | Yes |
| Proposed vs. LR | 0.001908 | Yes |
| Proposed vs. MLP | 0.007504 | Yes |
| Proposed vs. SVM | 0.000002 | Yes |
| Proposed vs. DT | 0.000021 | Yes |
| Proposed vs. RF | 0.012983 | Yes |
| Method | Year | Feature Selection | # of Features (%) | Validation Method | Classification Type | Accuracy (%) | Statistical Test | Practical Application |
|---|---|---|---|---|---|---|---|---|
| ANN [4] | 2018 | - | 205 (100%) | 10-fold CV | Multi-class | 83.1 | No | No |
| KNN [5] | 2018 | PCA | 53 (25.85%) | 5-fold CV | Multi-class | 84.29 | No | No |
| NB [6] | 2019 | IGRCFS | 12 (5.85%) | 10-fold CV | Multi-class | 78.32 | No | No |
| SMOTE + XGBoost [7] | 2019 | - | 31 (15.12%) | 10-fold CV | Multi-class | 85.4 | No | No |
| FNN [8] | 2019 | - | 205 (100%) | k-fold * | Binary-class | 85.11 | No | No |
| DNN [9] | 2019 | - | 205 (100%) | Hold-out | Multi-class | 97.45 | No | No |
| Hybrid autoencoder [10] | 2020 | - | 205 (100%) | 10-fold CV | Multi-class | 84.29 | No | No |
| Binary-class | 91.43 | |||||||
| Proposed Model (GA + XGBoost) | 2020 | GA | 88 (42.93%) | 10-fold CV | Multi-class | 90.00 | Yes, with two-step statistical test | Yes |
| 111 (54.15%) | Binary-class | 98.57 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Syafrudin, M.; Alfian, G.; Fitriyani, N.L.; Anshari, M.; Hadibarata, T.; Fatwanto, A.; Rhee, J. A Self-Care Prediction Model for Children with Disability Based on Genetic Algorithm and Extreme Gradient Boosting. Mathematics 2020, 8, 1590. https://0-doi-org.brum.beds.ac.uk/10.3390/math8091590
Syafrudin M, Alfian G, Fitriyani NL, Anshari M, Hadibarata T, Fatwanto A, Rhee J. A Self-Care Prediction Model for Children with Disability Based on Genetic Algorithm and Extreme Gradient Boosting. Mathematics. 2020; 8(9):1590. https://0-doi-org.brum.beds.ac.uk/10.3390/math8091590
Chicago/Turabian StyleSyafrudin, Muhammad, Ganjar Alfian, Norma Latif Fitriyani, Muhammad Anshari, Tony Hadibarata, Agung Fatwanto, and Jongtae Rhee. 2020. "A Self-Care Prediction Model for Children with Disability Based on Genetic Algorithm and Extreme Gradient Boosting" Mathematics 8, no. 9: 1590. https://0-doi-org.brum.beds.ac.uk/10.3390/math8091590