
Employing Fuzzy Logic to Analyze the Structure of Complex Biological and Epidemic Spreading Models


 ,
,  ,
,
Abstract
:1. Introduction
2. Theoretical Framework
2.1. Basic Definitions
2.2. Models of Complex Networks
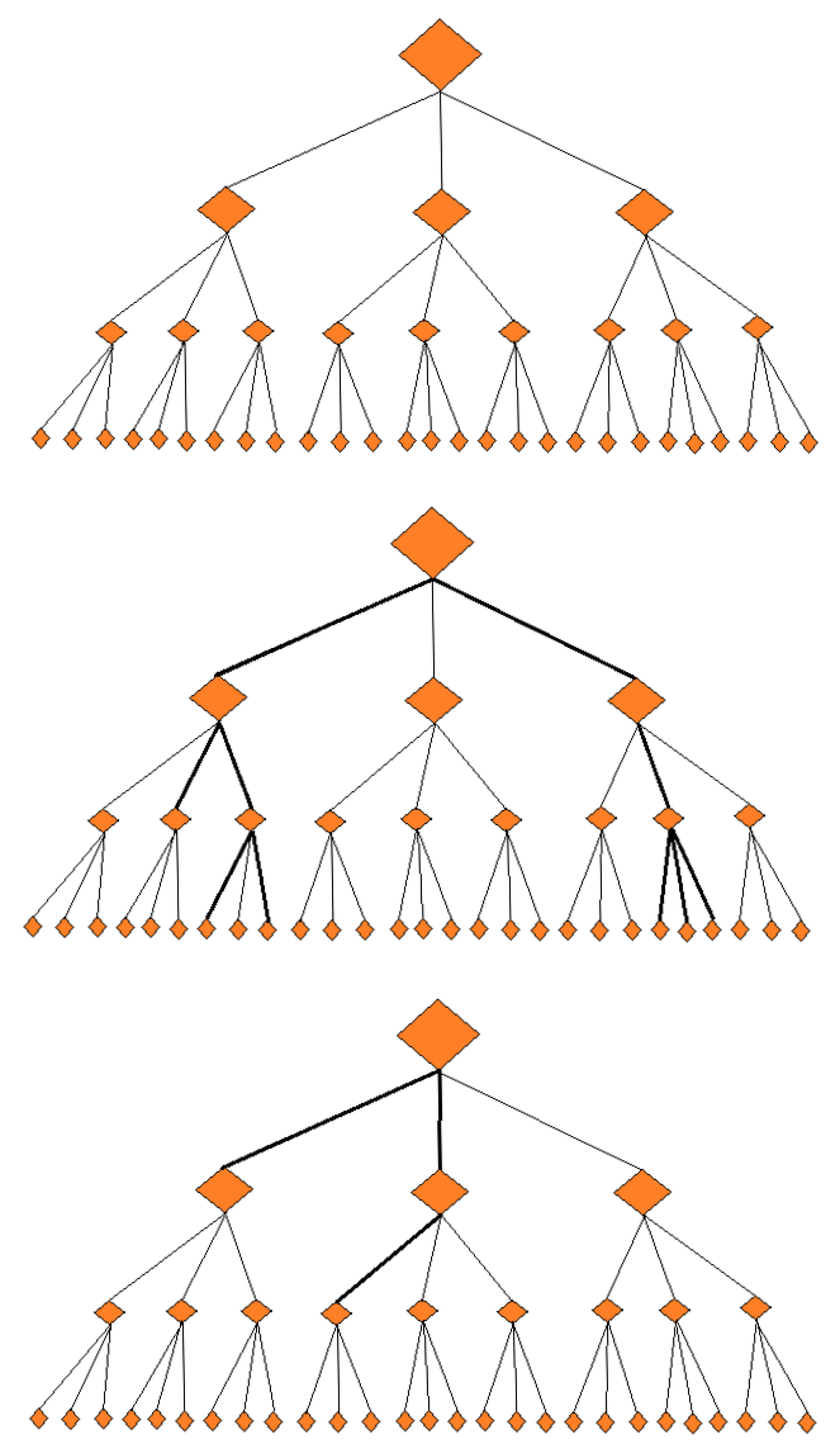
2.2.1. Erdös–Renyi Model
2.2.2. Barabási–Albert Model
2.3. Epidemic Models in Biological Networks
3. Fuzzy Epidemics
3.1. Transmitted Diseases in Networks
3.2. Branching Processes
3.3. Susceptible–Infectious–Susceptible Model (SIS)
3.4. Transient Contact Model
3.5. Network Fuzzy Logic
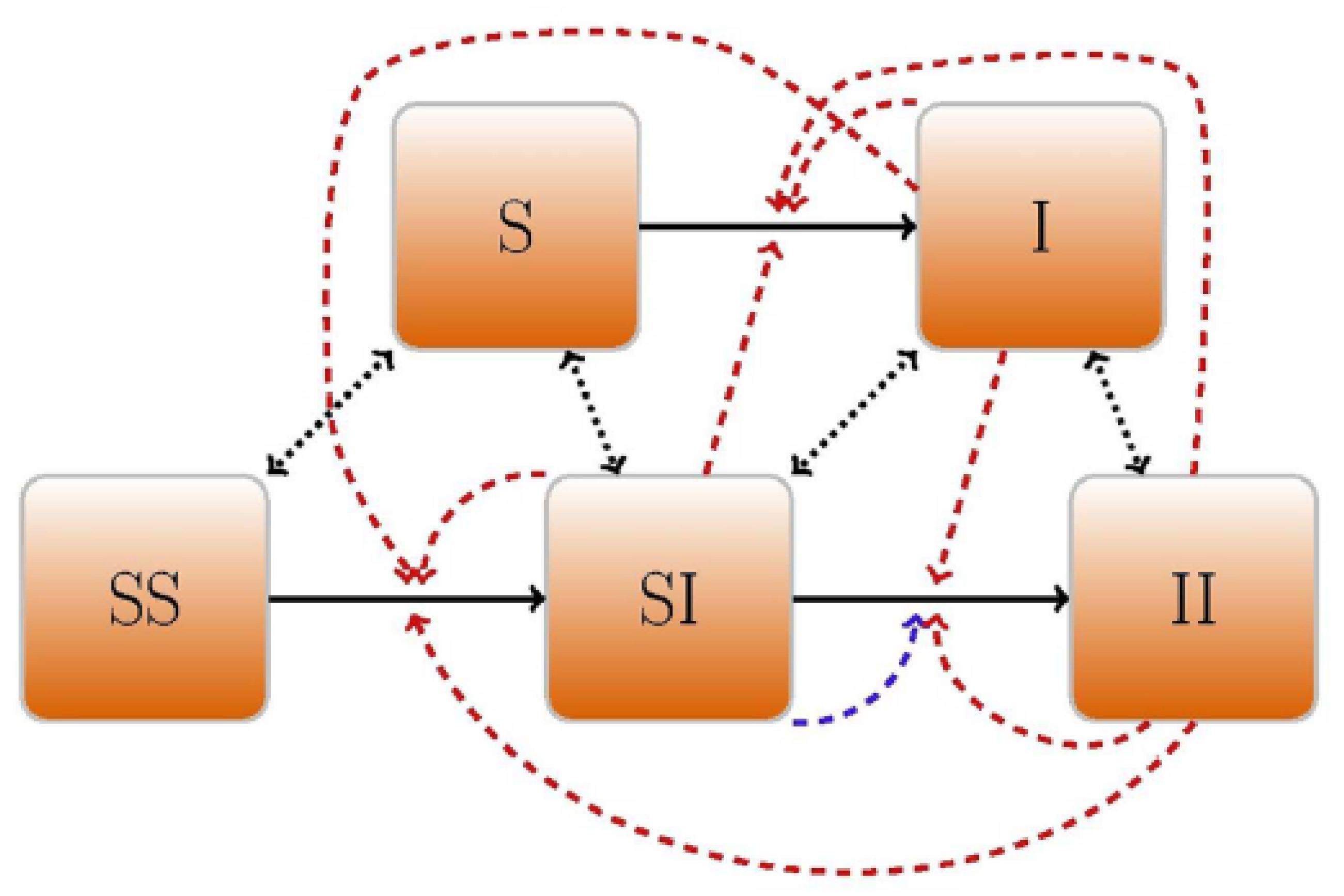
3.6. Contact Structure and Partnership Dynamics
- Single (uncoupled) susceptible (or sensitive) individuals (S);
- Single infected (or contaminated) individuals (I);
- Concordant negative couples (i.e., susceptible–susceptible, ) when both partners are susceptible;
- Discordant couples (i.e., susceptible–infected, );
- Concordant positive couples (i.e., infected–infected, ) when both partners are infectious.
4. HIV Transmission Simulation of Biological Network
4.1. Proposed Model
- Is the individual aware of carrying the infection or not?
- Has the syringe been given to more than one individual or not?
- Is the individual aware of being infected or not?
- For how long will the individual use the syringe?
- How many individuals will use clean (new) needles?
- How many individuals share simultaneously the same needle?
- How often are individuals tested by a physician?
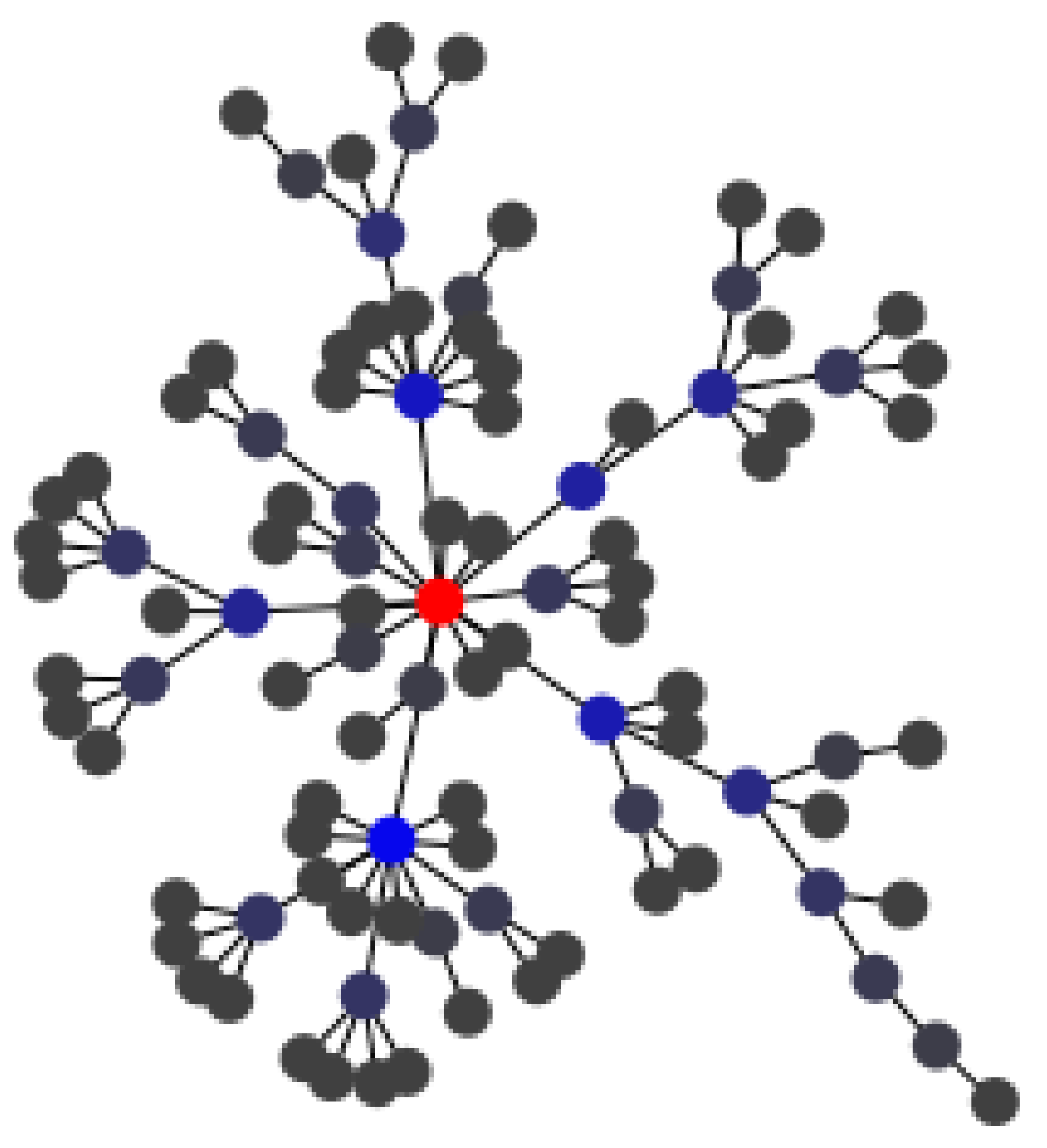
4.2. Random Graph
| Algorithm 1 Epidemic Transiently Contact Model. |
|
4.3. Implementation
5. Results
- AIDS-: users not infected by HIV.
- AIDS+: users infected by HIV and they know it (they have been tested).
- AIDS?: users who have no knowledge if they are (or not) infected by HIV and they have not passed the one year time limit in order to be tested.
5.1. Comparing All Four Scenarios
5.2. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- West, D.B. Introduction to Graph Theory; Prentice Hall: Upper Saddle River, NJ, USA, 2001; Volume 2. [Google Scholar]
- Newman, M.E.J. The Structure and Function of Complex Networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef] [Green Version]
- Boccaletti, S.; Latora, V.; Moreno, Y.; Chavez, M.; Hwang, D.U. Complex Networks: Structure and Dynamics. Phys. Rep. 2006, 424, 175–308. [Google Scholar] [CrossRef]
- Power, J.D.; Cohen, A.L.; Nelson, S.M.; Wig, G.S.; Barnes, K.A.; Church, J.A.; Vogel, A.C.; Laumann, T.O.; Miezin, F.M.; Schlaggar, B.L.; et al. Functional Network Organization of the Human Brain. Neuron 2011, 72, 665–678. [Google Scholar] [CrossRef] [Green Version]
- Shang, Y. Mixed SI (R) Epidemic Dynamics in Random Graphs with General Degree Distributions. Appl. Math. Comput. 2013, 219, 5042–5048. [Google Scholar] [CrossRef]
- Nowzari, C.; Preciado, V.; Pappas, G. Analysis and Control of Epidemics: A Survey of Spreading Processes on Complex Networks. IEEE Control. Syst. 2016, 36, 26–46. [Google Scholar]
- Pastor-Satorras, R.; Castellano, C.; Mieghem, P.V.; Vespignani, A. Epidemic Processes in Complex Networks. Rev. Mod. Phys. 2015, 87, 925–979. [Google Scholar] [CrossRef] [Green Version]
- Li, C.H.; Tsai, C.C.; Yang, S.Y. Analysis of Epidemic Spreading of an SIRS Model in Complex Heterogeneous Networks. Commun. Nonlinear Sci. Numer. Simul. 2014, 19, 1042–1054. [Google Scholar] [CrossRef]
- Fofana, A.M.; Hurford, A. Mechanistic Movement Models to Understand Epidemic Spread. Philos. Trans. R. Soc. Lond. Biol. Sci. 2017, 372, 20160086. [Google Scholar] [CrossRef]
- Wang, W.; Tang, M.; Stanley, E.; Braunstein, L.A. Unification of Theoretical Approaches for Epidemic Spreading on Complex Networks. Rep. Prog. Phys. 2017, 80, 036603. [Google Scholar] [CrossRef]
- Prettejohn, B.J.; Berryman, M.J.; McDonnell, M.D. Methods for Generating Complex Networks with Selected Structural Properties for Simulations: A Review and Tutorial for Neuroscientists. Front. Comput. Neurosci. 2011, 2011. [Google Scholar] [CrossRef] [Green Version]
- Faria, N.R.; Rambaut, A.; Suchard, M.A.; Baele, G.; Bedford, T.; Ward, M.J.; Tatem, A.J.; Sousa, J.D.; Arinaminpathy, N.; Pépin, J.; et al. The Early Spread and Epidemic Ignition of HIV-1 in Human Populations. Science 2014, 346, 56–61. [Google Scholar] [CrossRef] [Green Version]
- Massad, E.; Ortega, N.R.S.; Struchiner, C.J.; Burattini, M.N. Fuzzy Epidemics. Artif. Intell. Med. 2003, 29, 241–259. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy Sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Zimmermann, H.J. Fuzzy Set Theory and Its Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Goguen, J.A. The Logic of Inexact Concepts. Synthese 1969, 19, 325–373. [Google Scholar] [CrossRef]
- Lefevr, N.; Margariti, S.; Kanavos, A.; Tsakalidis, A. An Implementation of Disease Spreading over Biological Networks. In Proceedings of the 18th International Conference on Engineering Applications of Neural Networks (EANN), Athens, Greece, 25–27 August 2017; pp. 559–569. [Google Scholar]
- Easley, D.A.; Kleinberg, J.M. Networks, Crowds, and Markets-Reasoning about a Highly Connected World; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994; Volume 8. [Google Scholar]
- Dorogovtsev, S.N. Lectures on Complex Networks; Oxford University Press: New York, NY, USA, 2010; Volume 24. [Google Scholar]
- Newman, M.E.J. Networks: An Introduction; Oxford University Press Inc.: New York, NY, USA, 2010. [Google Scholar]
- Mao, G.; Zhang, N. Analysis of Average Shortest-Path Length of Scale-Free Network. J. Appl. Math. 2013, 2013, 865643:1–865643:5. [Google Scholar] [CrossRef]
- Ahuja, R.K.; Magnanti, T.L.; Orlin, J.B. Network Flows: Theory, Algorithms and Applications; Prentice Hall: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Crucitti, P.; Latora, V.; Marchiori, M. Model for Cascading Failures in Complex Networks. Phys. Rev. E 2004, 69, 045104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Shang, Y.; Yang, Y. Clustering Coefficients of Large Networks. Inf. Sci. 2017, 382–383, 350–358. [Google Scholar] [CrossRef]
- Watts, D.J. Small Worlds: The Dynamics of Networks between Order and Randomness; Princeton University Press: Princeton, NY, USA, 1999. [Google Scholar]
- Erdös, P.; Rényi, A. On Random Graphs I. Publ. Math. Debr. 1959, 6, 290–297. [Google Scholar]
- Adamic, L.A.; Lukose, R.M.; Puniyani, A.R.; Huberman, B.A. Search in Power-Law Networks. Phys. Rev. E 2001, 64, 046135. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barabási, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [Green Version]
- Pastor-Satorras, R.; Vespignani, A. Evolution and Structure of the Internet: A Statistical Physics Approach; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Anastasio, T.J. Tutorial on Neural Systems Modeling; Sinauer Associates Incorporated Publishers: Sunderland, MA, USA, 2009. [Google Scholar]
- Rothman, K.J.; Greenland, S.; Lash, T.L. Modern Epidemiology; Wolters Kluwer Health/Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2008. [Google Scholar]
- Zadeh, L.A. Fuzzy Sets as a Basis for a Theory of Possibility. Fuzzy Sets Syst. 1999, 100, 9–34. [Google Scholar] [CrossRef]
- Lee, C. Fuzzy Logic in Control Systems: Fuzzy Logic Controller I. IEEE Trans. Syst. Man, Cybern. 1990, 20, 404–418. [Google Scholar] [CrossRef] [Green Version]
- Lee, C. Fuzzy Logic in Control Systems: Fuzzy Logic Controller II. IEEE Trans. Syst. Man, Cybern. 1990, 20, 419–435. [Google Scholar] [CrossRef]
- Lin, C.; Lee, C.S.G. Neural-Network-Based Fuzzy Logic Control and Decision System. IEEE Trans. Comput. 1991, 40, 1320–1336. [Google Scholar] [CrossRef]
- McClelland, J.L.; Cleeremans, A. Consciousness and Connectionist Models. Oxf. Companion Conscious. 2009, 5, 180–181. [Google Scholar]
- Park, S.W.; Bolker, B.M. Effects of Contact Structure on the Transient Evolution of HIV Virulence. PLoS Comput. Biol. 2017, 13, e1005453. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Champredon, D.; Bellan, S.; Dushoff, J. HIV Sexual Transmission is Predominantly Driven by Single Individuals Rather than Discordant Couples: A Model-Based Approach. PLoS ONE 2013, 8, e082906. [Google Scholar] [CrossRef] [PubMed]
- Patel, P.; Borkowf, C.B.; Brooks, J.T.; Lasry, A.; Lansky, A.; Mermin, J. Estimating Per-Act HIV Transmission Risk: A Systematic Review. Aids 2014, 28, 1509–1519. [Google Scholar] [CrossRef] [PubMed]
- Cannings, C.; Penman, D. Chapter 2: Models of Random Graphs and their Applications. Handb. Stat. 2003, 21, 51–91. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| k | Node’s Degree |
| Degree Distribution | |
| L | Average Shortest Path Length |
| b | Betweenness Node |
| T | Transitivity |
| C | Clustering Coefficient |
| Local Clustering Coefficient of Node i | |
| r | Probability Distribution Function related to Fuzzy Logic Setting |
| Universe of Discourse | |
| F | Fuzzy Set |
| u | Support Value |
| Membership Function | |
| x | Linguistic Variable |
| The Set of Names of x | |
| Semantic Rule |
| Scenario | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Number of Users | 300 | 300 | 500 | 500 |
| Number of Tests per Year | 1 | 2 | 1 | 2 |
| Features | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Percentage of Fuzziness | 0% Fuzzy | 10% Fuzzy | 30% Fuzzy | 50% Fuzzy | ||||||||
| Shared Syringe | 10 | 0 | 7 | 9 | 0 | 7 | 7 | 0 | 6 | 5 | 0 | 4 |
| New Syringe | 0 | 10 | 3 | 0 | 9 | 2 | 0 | 7 | 1 | 0 | 5 | 1 |
| Fuzzy | 0 | 0 | 0 | 1 | 1 | 1 | 3 | 3 | 3 | 5 | 5 | 5 |
| Option of Illness | 100 | 390 | 1390 | 2390 | 3930 |
|---|---|---|---|---|---|
| 0% Fuzzy—1st example | |||||
| AIDS- | 298 | 290 | 240 | 142 | 126 |
| AIDS+ | 0 | 2 | 41 | 138 | 174 |
| AIDS? | 2 | 8 | 19 | 20 | 0 |
| 0% Fuzzy—2nd example | |||||
| AIDS- | 298 | 298 | 298 | 298 | 298 |
| AIDS+ | 0 | 2 | 2 | 2 | 2 |
| AIDS? | 2 | 0 | 0 | 0 | 0 |
| 0% Fuzzy—3rd example | |||||
| AIDS- | 297 | 288 | 200 | 135 | 119 |
| AIDS+ | 0 | 5 | 63 | 156 | 181 |
| AIDS? | 3 | 7 | 37 | 9 | 0 |
| 10% Fuzzy—4th example | |||||
| AIDS- | 293 | 288 | 191 | 135 | 130 |
| AIDS+ | 3 | 5 | 74 | 162 | 170 |
| AIDS? | 4 | 7 | 35 | 3 | 0 |
| 10% Fuzzy—5th example | |||||
| AIDS- | 298 | 298 | 298 | 298 | 298 |
| AIDS+ | 0 | 2 | 2 | 2 | 2 |
| AIDS? | 2 | 0 | 0 | 0 | 0 |
| 10% Fuzzy—6th example | |||||
| AIDS- | 296 | 285 | 217 | 148 | 128 |
| AIDS+ | 0 | 9 | 55 | 141 | 172 |
| AIDS? | 4 | 6 | 28 | 11 | 0 |
| 30% Fuzzy—7th example | |||||
| AIDS- | 297 | 288 | 234 | 178 | 145 |
| AIDS+ | 0 | 4 | 54 | 109 | 155 |
| AIDS? | 3 | 8 | 12 | 13 | 0 |
| 30% Fuzzy—8th example | |||||
| AIDS- | 298 | 298 | 298 | 298 | 298 |
| AIDS+ | 0 | 2 | 2 | 2 | 2 |
| AIDS? | 2 | 0 | 0 | 0 | 0 |
| 30% Fuzzy—9th example | |||||
| AIDS- | 292 | 290 | 258 | 189 | 138 |
| AIDS+ | 2 | 4 | 32 | 88 | 162 |
| AIDS? | 4 | 6 | 10 | 23 | 0 |
| 50% Fuzzy—10th example | |||||
| AIDS- | 294 | 285 | 213 | 153 | 136 |
| AIDS+ | 2 | 5 | 64 | 134 | 164 |
| AIDS? | 4 | 10 | 23 | 13 | 0 |
| 50% Fuzz—11th example | |||||
| AIDS- | 298 | 298 | 298 | 298 | 298 |
| AIDS+ | 0 | 2 | 2 | 2 | 2 |
| AIDS? | 2 | 0 | 0 | 0 | 0 |
| 50% Fuzzy—12th example | |||||
| AIDS- | 296 | 294 | 277 | 264 | 210 |
| AIDS+ | 0 | 2 | 16 | 31 | 90 |
| AIDS? | 4 | 4 | 7 | 5 | 0 |
| Option of Illness | 100 | 390 | 1390 | 2390 | 3930 |
|---|---|---|---|---|---|
| 0% Fuzzy—1st example | |||||
| AIDS- | 295 | 294 | 290 | 284 | 284 |
| AIDS+ | 2 | 4 | 4 | 16 | 16 |
| AIDS? | 3 | 4 | 6 | 0 | 0 |
| 0% Fuzzy—2nd example | |||||
| AIDS- | 298 | 298 | 298 | 298 | 298 |
| AIDS+ | 0 | 2 | 2 | 2 | 2 |
| AIDS? | 2 | 0 | 0 | 0 | 0 |
| 0% Fuzzy—3rd example | |||||
| AIDS- | 295 | 292 | 291 | 291 | 291 |
| AIDS+ | 0 | 5 | 9 | 9 | 9 |
| AIDS? | 5 | 3 | 0 | 0 | 0 |
| 10% Fuzzy—4th example | |||||
| AIDS- | 295 | 290 | 258 | 254 | 254 |
| AIDS+ | 1 | 4 | 39 | 46 | 46 |
| AIDS? | 4 | 6 | 3 | 0 | 0 |
| 10% Fuzzy—5th example | |||||
| AIDS- | 298 | 298 | 298 | 298 | 298 |
| AIDS+ | 0 | 2 | 2 | 2 | 2 |
| AIDS? | 2 | 0 | 0 | 0 | 0 |
| 10% Fuzzy—6th example | |||||
| AIDS- | 296 | 292 | 273 | 273 | 273 |
| AIDS+ | 1 | 3 | 27 | 27 | 27 |
| AIDS? | 3 | 5 | 0 | 0 | 0 |
| 30% Fuzzy—7th example | |||||
| AIDS- | 296 | 288 | 261 | 244 | 244 |
| AIDS+ | 0 | 5 | 35 | 56 | 56 |
| AIDS? | 4 | 7 | 4 | 0 | 0 |
| 30% Fuzzy—8th example | |||||
| AIDS- | 298 | 298 | 298 | 298 | 298 |
| AIDS+ | 0 | 2 | 2 | 2 | 2 |
| AIDS? | 2 | 0 | 0 | 0 | 0 |
| 30% Fuzzy—9th example | |||||
| AIDS- | 294 | 288 | 278 | 278 | 278 |
| AIDS+ | 2 | 5 | 22 | 22 | 22 |
| AIDS? | 4 | 7 | 0 | 0 | 0 |
| 50% Fuzzy—10th example | |||||
| AIDS- | 295 | 288 | 259 | 253 | 253 |
| AIDS+ | 0 | 5 | 36 | 47 | 47 |
| AIDS? | 5 | 7 | 5 | 0 | 0 |
| 50% Fuzzy—11th example | |||||
| AIDS- | 298 | 298 | 298 | 298 | 298 |
| AIDS+ | 0 | 2 | 2 | 2 | 2 |
| AIDS? | 2 | 0 | 0 | 0 | 0 |
| 50% Fuzzy—12th example | |||||
| AIDS- | 296 | 294 | 293 | 293 | 293 |
| AIDS+ | 0 | 4 | 7 | 7 | 7 |
| AIDS? | 4 | 2 | 0 | 0 | 0 |
| Option of Illness | 100 | 390 | 1390 | 2390 | 3930 |
|---|---|---|---|---|---|
| 0% Fuzzy—1st example | |||||
| AIDS- | 491 | 489 | 385 | 260 | 211 |
| AIDS+ | 2 | 3 | 78 | 214 | 289 |
| AIDS? | 7 | 8 | 37 | 26 | 0 |
| 0% Fuzzy—2nd example | |||||
| AIDS- | 497 | 497 | 497 | 497 | 497 |
| AIDS+ | 0 | 3 | 3 | 3 | 3 |
| AIDS? | 3 | 0 | 0 | 0 | 0 |
| 0% Fuzzy—3rd example | |||||
| AIDS- | 491 | 483 | 312 | 190 | 172 |
| AIDS+ | 1 | 4 | 131 | 294 | 328 |
| AIDS? | 8 | 13 | 57 | 16 | 0 |
| 10% Fuzzy—4th example | |||||
| AIDS- | 492 | 482 | 384 | 235 | 219 |
| AIDS+ | 2 | 5 | 78 | 247 | 281 |
| AIDS? | 6 | 13 | 38 | 18 | 0 |
| 10% Fuzzy—5th example | |||||
| AIDS- | 497 | 497 | 497 | 497 | 497 |
| AIDS+ | 0 | 3 | 3 | 3 | 3 |
| AIDS? | 3 | 0 | 0 | 0 | 0 |
| 10% Fuzzy—6th example | |||||
| AIDS- | 491 | 477 | 292 | 183 | 171 |
| AIDS+ | 1 | 5 | 141 | 311 | 329 |
| AIDS? | 8 | 18 | 67 | 6 | 0 |
| 30% Fuzzy—7th example | |||||
| AIDS- | 491 | 479 | 283 | 169 | 173 |
| AIDS+ | 1 | 4 | 140 | 322 | 329 |
| AIDS? | 8 | 17 | 77 | 9 | 0 |
| 30% Fuzzy—8th example | |||||
| AIDS- | 497 | 497 | 497 | 497 | 497 |
| AIDS+ | 0 | 3 | 3 | 3 | 3 |
| AIDS? | 3 | 0 | 0 | 0 | 0 |
| 30% Fuzzy—9th example | |||||
| AIDS- | 492 | 475 | 294 | 231 | 223 |
| AIDS+ | 1 | 8 | 151 | 261 | 275 |
| AIDS? | 7 | 17 | 55 | 8 | 0 |
| 50% Fuzzy—10th example | |||||
| AIDS- | 491 | 483 | 312 | 190 | 172 |
| AIDS+ | 1 | 4 | 131 | 294 | 328 |
| AIDS? | 8 | 13 | 57 | 16 | 0 |
| 50% Fuzzy—11th example | |||||
| AIDS- | 497 | 497 | 497 | 497 | 497 |
| AIDS+ | 0 | 3 | 3 | 3 | 3 |
| AIDS? | 3 | 0 | 0 | 0 | 0 |
| 50% Fuzzy—12th example | |||||
| AIDS- | 494 | 487 | 326 | 241 | 221 |
| AIDS+ | 0 | 3 | 114 | 246 | 279 |
| AIDS? | 6 | 10 | 60 | 13 | 0 |
| Option of Illness | 100 | 390 | 1390 | 2390 | 3930 |
|---|---|---|---|---|---|
| 0% Fuzzy—1st example | |||||
| AIDS- | 487 | 477 | 417 | 391 | 376 |
| AIDS+ | 3 | 13 | 74 | 106 | 123 |
| AIDS? | 10 | 10 | 9 | 2 | 0 |
| 0% Fuzzy—2nd example | |||||
| AIDS- | 497 | 497 | 497 | 497 | 497 |
| AIDS+ | 0 | 3 | 3 | 3 | 3 |
| AIDS? | 3 | 0 | 0 | 0 | 0 |
| 0% Fuzzy—3rd example | |||||
| AIDS- | 486 | 481 | 413 | 343 | 318 |
| AIDS+ | 4 | 14 | 70 | 141 | 182 |
| AIDS? | 10 | 5 | 17 | 16 | 0 |
| 10% Fuzzy—4th example | |||||
| AIDS- | 488 | 487 | 446 | 412 | 395 |
| AIDS+ | 4 | 9 | 45 | 80 | 105 |
| AIDS? | 8 | 4 | 9 | 8 | 0 |
| 10% Fuzzy—5th example | |||||
| AIDS- | 497 | 497 | 497 | 497 | 497 |
| AIDS+ | 0 | 3 | 3 | 3 | 3 |
| AIDS? | 3 | 0 | 0 | 0 | 0 |
| 10% Fuzzy—6th example | |||||
| AIDS- | 493 | 485 | 435 | 365 | 331 |
| AIDS+ | 0 | 10 | 57 | 115 | 169 |
| AIDS? | 7 | 5 | 8 | 17 | 0 |
| 30% Fuzzy—7th example | |||||
| AIDS- | 488 | 485 | 448 | 422 | 400 |
| AIDS+ | 5 | 10 | 43 | 73 | 100 |
| AIDS? | 7 | 5 | 9 | 5 | 0 |
| 30% Fuzzy—8th example | |||||
| AIDS- | 497 | 497 | 497 | 497 | 497 |
| AIDS+ | 0 | 3 | 3 | 3 | 3 |
| AIDS? | 3 | 0 | 0 | 0 | 0 |
| 30% Fuzzy—9th example | |||||
| AIDS- | 489 | 486 | 420 | 352 | 340 |
| AIDS+ | 3 | 9 | 62 | 140 | 160 |
| AIDS? | 8 | 5 | 18 | 8 | 0 |
| 50% Fuzzy—10th example | |||||
| AIDS- | 492 | 478 | 417 | 392 | 380 |
| AIDS+ | 2 | 14 | 74 | 105 | 120 |
| AIDS? | 6 | 8 | 9 | 3 | 0 |
| Fuzzy—11th example | |||||
| AIDS- | 497 | 497 | 497 | 497 | 497 |
| AIDS+ | 0 | 3 | 3 | 3 | 3 |
| AIDS? | 3 | 0 | 0 | 0 | 0 |
| 50% Fuzzy—12th example | |||||
| AIDS- | 492 | 486 | 461 | 454 | 443 |
| AIDS+ | 0 | 9 | 36 | 45 | 57 |
| AIDS? | 8 | 5 | 3 | 1 | 0 |
| Option of Illness | 100 | 390 | 1390 | 2390 | 3930 | 100 | 390 | 1390 | 2390 | 3930 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1st scenario—1 test—300 users | 3rd scenario—1 test—500 users | |||||||||
| AIDS- | 297 | 288 | 200 | 135 | 119 | 491 | 483 | 312 | 190 | 172 |
| AIDS+ | 0 | 5 | 63 | 156 | 181 | 1 | 4 | 131 | 294 | 328 |
| AIDS? | 3 | 7 | 37 | 9 | 0 | 8 | 13 | 57 | 16 | 0 |
| 2nd scenario—2 tests—300 users | 4th scenario—2 tests—500 users | |||||||||
| AIDS- | 295 | 292 | 291 | 291 | 291 | 486 | 481 | 413 | 343 | 318 |
| AIDS+ | 0 | 5 | 9 | 9 | 9 | 4 | 14 | 70 | 141 | 182 |
| AIDS? | 5 | 3 | 0 | 0 | 0 | 10 | 5 | 17 | 16 | 0 |
| Option of Illness | 100 | 390 | 1390 | 2390 | 3930 | 100 | 390 | 1390 | 2390 | 3930 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1st scenario—1 test—300 users | 3rd scenario—1 test—500 users | |||||||||
| AIDS- | 296 | 285 | 217 | 148 | 128 | 491 | 477 | 292 | 183 | 171 |
| AIDS+ | 0 | 9 | 55 | 141 | 172 | 1 | 5 | 141 | 311 | 329 |
| AIDS? | 4 | 6 | 28 | 11 | 0 | 8 | 18 | 67 | 6 | 0 |
| 2nd scenario—2 tests—300 users | 4th scenario—2 tests—500 users | |||||||||
| AIDS- | 296 | 292 | 273 | 273 | 273 | 493 | 485 | 435 | 365 | 331 |
| AIDS+ | 1 | 3 | 27 | 27 | 27 | 0 | 10 | 57 | 115 | 169 |
| AIDS? | 3 | 5 | 0 | 0 | 0 | 7 | 5 | 8 | 17 | 0 |
| Option of Illness | 100 | 390 | 1390 | 2390 | 3930 | 100 | 390 | 1390 | 2390 | 3930 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1st scenario—1 test—300 users | 3rd scenario—1 test—500 users | |||||||||
| AIDS- | 292 | 290 | 258 | 189 | 138 | 492 | 475 | 294 | 231 | 223 |
| AIDS+ | 2 | 4 | 32 | 88 | 162 | 1 | 8 | 151 | 261 | 275 |
| AIDS? | 4 | 6 | 10 | 23 | 0 | 7 | 17 | 55 | 8 | 0 |
| 2nd scenario—2 tests—300 users | 4th scenario—2 tests—500 users | |||||||||
| AIDS- | 294 | 288 | 278 | 278 | 278 | 489 | 486 | 420 | 352 | 340 |
| AIDS+ | 2 | 5 | 22 | 22 | 22 | 3 | 9 | 62 | 140 | 160 |
| AIDS? | 4 | 7 | 0 | 0 | 0 | 8 | 5 | 18 | 8 | 0 |
| Option of Illness | 100 | 390 | 1390 | 2390 | 3930 | 100 | 390 | 1390 | 2390 | 3930 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1st scenario—1 test—300 users | 3rd scenario—1 test—500 users | |||||||||
| AIDS- | 296 | 294 | 277 | 264 | 210 | 494 | 487 | 326 | 241 | 221 |
| AIDS+ | 0 | 2 | 16 | 31 | 90 | 0 | 3 | 114 | 246 | 279 |
| AIDS? | 4 | 4 | 7 | 5 | 0 | 6 | 10 | 60 | 13 | 0 |
| 2nd scenario—2 tests—300 users | 4th scenario—2 tests—500 users | |||||||||
| AIDS- | 296 | 294 | 293 | 293 | 293 | 492 | 486 | 461 | 454 | 443 |
| AIDS+ | 0 | 4 | 7 | 7 | 7 | 0 | 9 | 36 | 45 | 57 |
| AIDS? | 4 | 2 | 0 | 0 | 0 | 8 | 5 | 3 | 1 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lefevr, N.; Kanavos, A.; Gerogiannis, V.C.; Iliadis, L.; Pintelas, P. Employing Fuzzy Logic to Analyze the Structure of Complex Biological and Epidemic Spreading Models. Mathematics 2021, 9, 977. https://0-doi-org.brum.beds.ac.uk/10.3390/math9090977
Lefevr N, Kanavos A, Gerogiannis VC, Iliadis L, Pintelas P. Employing Fuzzy Logic to Analyze the Structure of Complex Biological and Epidemic Spreading Models. Mathematics. 2021; 9(9):977. https://0-doi-org.brum.beds.ac.uk/10.3390/math9090977
Chicago/Turabian StyleLefevr, Nickie, Andreas Kanavos, Vassilis C. Gerogiannis, Lazaros Iliadis, and Panagiotis Pintelas. 2021. "Employing Fuzzy Logic to Analyze the Structure of Complex Biological and Epidemic Spreading Models" Mathematics 9, no. 9: 977. https://0-doi-org.brum.beds.ac.uk/10.3390/math9090977