
A Survey on Software Defect Prediction Using Deep Learning

 , ,
, ,
Abstract
:1. Introduction
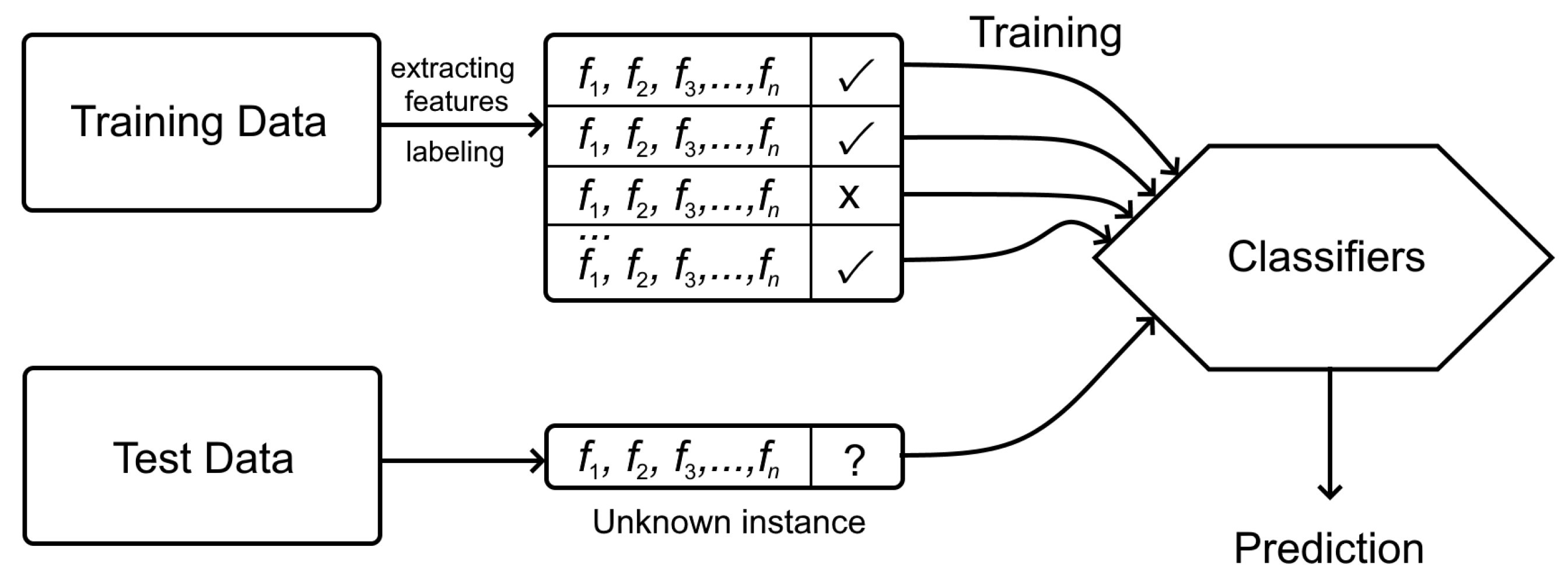
- Prepare the dataset by collecting the source code samples from repositories of the software projects (or choose the suitable existing dataset).
- Extract features from the source code.
- Train the model using the train dataset.
- Test the model using the test dataset and assess the performance using the quality metrics.
2. Methodology
2.1. Research Questions
- RQ1. What deep learning techniques have been applied to software defect prediction?
- RQ2. What are the key factors contributing to the difficulty of the problem?
- RQ3. What are the trends in the primary studies on the use of deep learning for the software defect prediction?
2.2. Literature Search and Inclusion or Exclusion Criteria
- The paper must describe a technique for automatic feature extraction using deep learning and apply it to the defect prediction problem.
- The paper length must not be less than six pages.
3. RQ1. What Techniques Have Been Applied to This Problem?
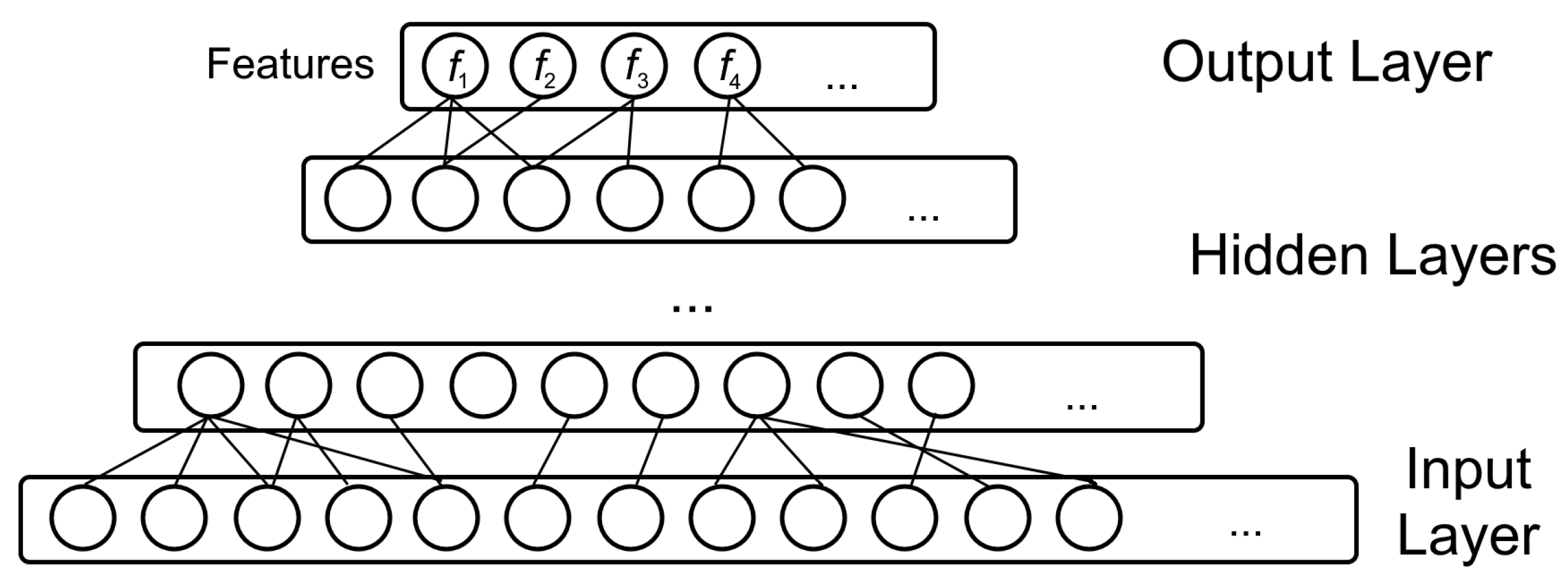
3.1. Deep Belief Networks
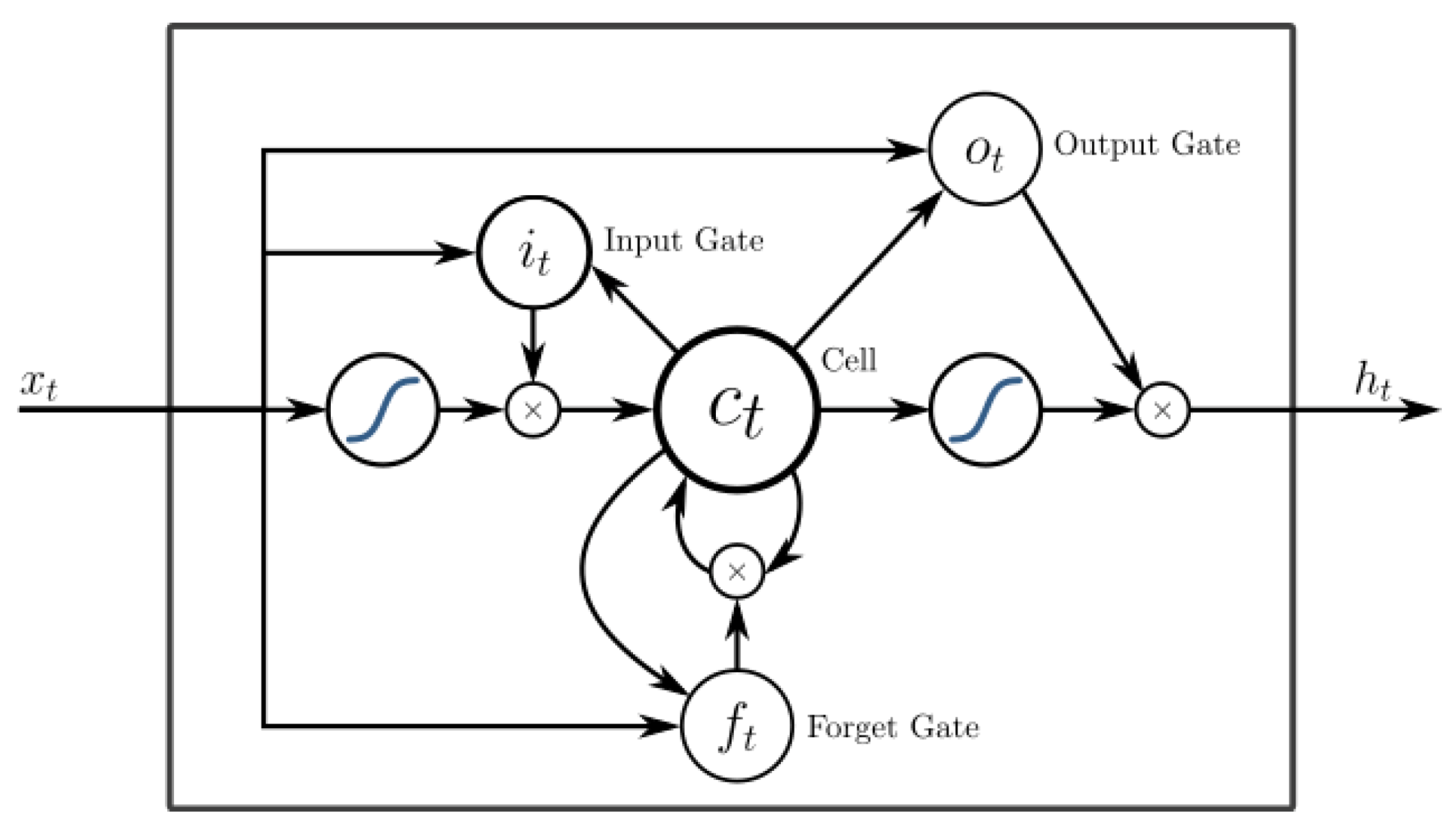
3.2. Long Short Term Memory
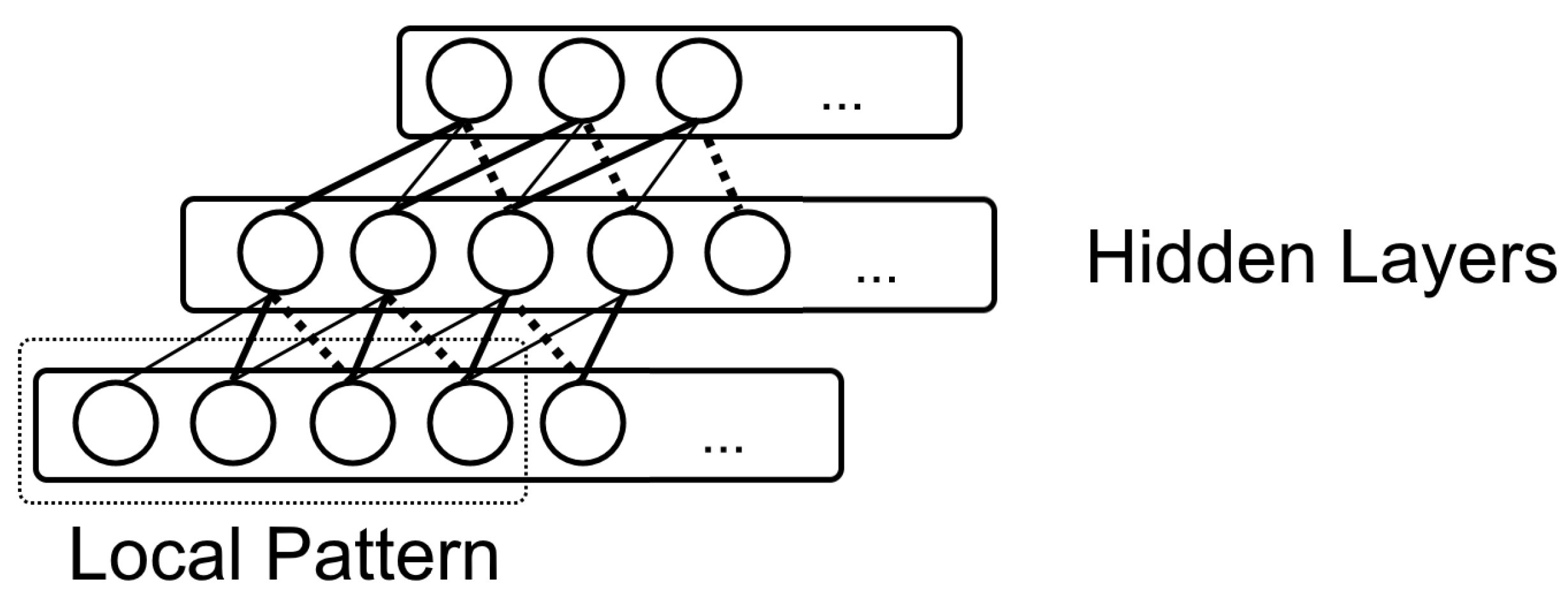
3.3. Convolutional Neural Networks
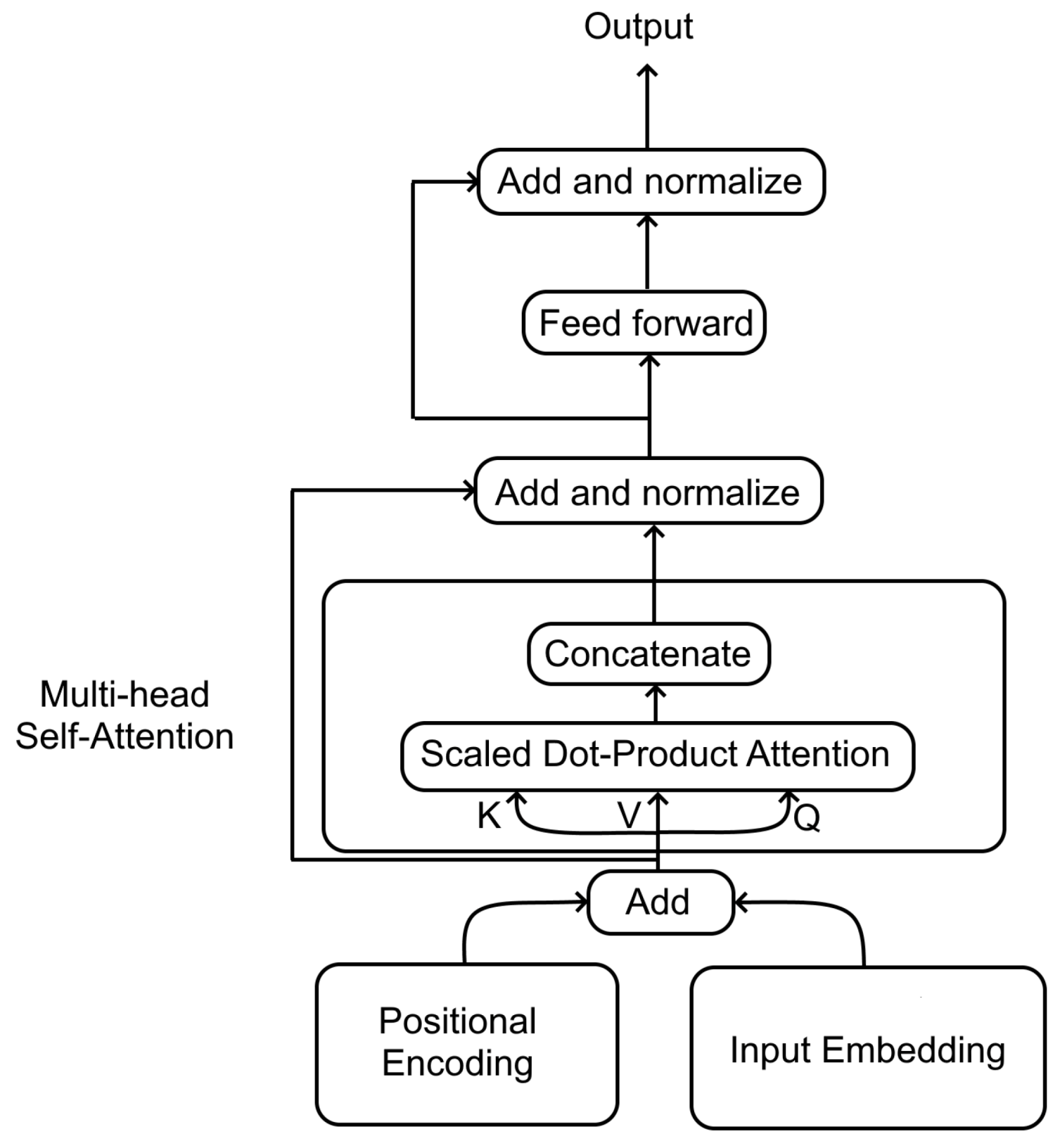
3.4. Transformer Models
3.5. Other Networks
4. RQ2. What Are the Key Factors Contributing to Difficulty of the Problem?
4.1. Lack of Data
4.2. Lack of Context
5. RQ3. What Are the Trends in the Primary Studies on the Use of Deep Learning for the Software Defect Prediction?
6. Conclusions
- To reduce the requirements for the size of the labeled datasets, one should use the self-supervised training on large corpora of the unlabeled data. In addition, it is necessary to use the unlabeled data for the pre-training of related tasks and to contribute to the fact that the trained models will have a deeper and more comprehensive understanding of the source code. This, in the turn, will allow one to find the deeper defects.
- To leverage the latest advances in the machine learning techniques in the natural language processing in the programming languages, we are already seeing the successful migration of these methods to solve various code understanding problems. For example, optimization of the self-attention mechanism for the transformers will allow one to use them for long sequences, which, in the turn, will lead to a more complete consideration of the code context for finding the defects.
- Often a defect is not limited to a single line of code or one function, and there are various ways to fix it. For example, a bug can be fixed either inside the function or at calling this function. Thus, the defect ceases to have specific coordinates inside the source file. In addition, not being an explicit defect, a line of code can become defective at a certain point in time. A changed context may lead to the fact that the purpose of the code changes, and, therefore, the old implementation no longer corresponds to the new requirements or specifications.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AST | Abstract Syntax Tree |
| CNN | Convolutional Neural Network |
| DBN | Deep Belief Network |
| DL | Deep Learning |
| LSTM | Long Short Term Memory |
| NLP | Natural Language Processing |
| SDP | Software Defect Prediction |
References
- IEEE Standard Classification for Software Anomalies. IEEE Standard 1044-2009 (Revision of IEEE Standard 1044-1993). 2010, pp. 1–23. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/document/5399061 (accessed on 17 December 2020). [CrossRef]
- Wang, S.; Liu, T.; Tan, L. Automatically Learning Semantic Features for Defect Prediction. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering (ICSE), Austin, TX, USA, 18–20 May 2016; pp. 297–308. [Google Scholar] [CrossRef]
- Omri, S.; Sinz, C. Deep Learning for Software Defect Prediction: A Survey. In Proceedings of the IEEE/ACM 42nd International Conference on Software Engineering Workshops, ICSEW ’20, Seoul, Korea, 6–11 July 2020; pp. 209–214. [Google Scholar] [CrossRef]
- Yang, Y.; Xia, X.; Lo, D.; Grundy, J. A Survey on Deep Learning for Software Engineering. arXiv 2020, arXiv:cs.SE/2011.14597. [Google Scholar]
- Shen, Z.; Chen, S. A Survey of Automatic Software Vulnerability Detection, Program Repair, and Defect Prediction Techniques. Secur. Commun. Netw. 2020, 2020, 8858010. [Google Scholar] [CrossRef]
- Bryksin, T.; Petukhov, V.; Alexin, I.; Prikhodko, S.; Shpilman, A.; Kovalenko, V.; Povarov, N. Using Large-Scale Anomaly Detection on Code to Improve Kotlin Compiler. In Proceedings of the 17th International Conference on Mining Software Repositories, MSR ’20, Seoul, Korea, 29–30 June 2020; pp. 455–465. [Google Scholar] [CrossRef]
- Phan, A.V.; Le Nguyen, M. Convolutional neural networks on assembly code for predicting software defects. In Proceedings of the 2017 21st Asia Pacific Symposium on Intelligent and Evolutionary Systems (IES), Hanoi, Vietnam, 15–17 November 2017; pp. 37–42. [Google Scholar] [CrossRef]
- Allamanis, M.; Barr, E.T.; Devanbu, P.; Sutton, C. A Survey of Machine Learning for Big Code and Naturalness. ACM Comput. Surv. 2018, 51. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Monperrus, M. A Literature Study of Embeddings on Source Code. arXiv 2019, arXiv:cs.LG/1904.03061. [Google Scholar]
- Sharmin, S.; Arefin, M.R.; Wadud, M.A.; Nower, N.; Shoyaib, M. SAL: An effective method for software defect prediction. In Proceedings of the 2015 18th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 21–23 December 2015; pp. 184–189. [Google Scholar] [CrossRef]
- Dam, H.K.; Tran, T.; Pham, T.; Ng, S.W.; Grundy, J.; Ghose, A. Automatic Feature Learning for Predicting Vulnerable Software Components. IEEE Trans. Softw. Eng. 2018, 47, 67–85. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:cs.CL/1301.3781. [Google Scholar]
- Zhang, J.; Wang, X.; Zhang, H.; Sun, H.; Wang, K.; Liu, X. A Novel Neural Source Code Representation Based on Abstract Syntax Tree. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 783–794. [Google Scholar] [CrossRef]
- Pradel, M.; Sen, K. DeepBugs: A Learning Approach to Name-Based Bug Detection. Proc. ACM Program. Lang. 2018, 2. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y. Learning Deep Architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Yang, X.; Lo, D.; Xia, X.; Zhang, Y.; Sun, J. Deep Learning for Just-in-Time Defect Prediction. In Proceedings of the 2015 IEEE International Conference on Software Quality, Reliability and Security, Vancouver, BC, Canada, 3–5 August 2015; pp. 17–26. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Lo, D.; Xia, X.; Sun, J. TLEL: A two-layer ensemble learning approach for just-in-time defect prediction. Inf. Softw. Technol. 2017, 87, 206–220. [Google Scholar] [CrossRef]
- Wang, S.; Liu, T.; Nam, J.; Tan, L. Deep Semantic Feature Learning for Software Defect Prediction. IEEE Trans. Softw. Eng. 2018, 46, 1267–1293. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Dam, H.K.; Pham, T.; Ng, S.W.; Tran, T.; Grundy, J.; Ghose, A.; Kim, T.; Kim, C.J. Lessons Learned from Using a Deep Tree-Based Model for Software Defect Prediction in Practice. In Proceedings of the 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), Montreal, QC, Canada, 25–31 May 2019; pp. 46–57. [Google Scholar] [CrossRef]
- Habib, A.; Pradel, M. Neural Bug Finding: A Study of Opportunities and Challenges. arXiv 2019, arXiv:cs.SE/1906.00307. [Google Scholar]
- Shi, K.; Lu, Y.; Chang, J.; Wei, Z. PathPair2Vec: An AST path pair-based code representation method for defect prediction. J. Comput. Lang. 2020, 59, 100979. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 17 December 2020).
- Li, J.; He, P.; Zhu, J.; Lyu, M.R. Software Defect Prediction via Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Software Quality, Reliability and Security (QRS), Prague, Czech Republic, 25–29 July 2017; pp. 318–328. [Google Scholar] [CrossRef]
- Hoang, T.; Khanh Dam, H.; Kamei, Y.; Lo, D.; Ubayashi, N. DeepJIT: An End-to-End Deep Learning Framework for Just-in-Time Defect Prediction. In Proceedings of the 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), Montreal, QC, Canada, 25–31 May 2019; pp. 34–45. [Google Scholar] [CrossRef]
- Xu, Z.; Li, S.; Xu, J.; Liu, J.; Luo, X.; Zhang, Y.; Zhang, T.; Keung, J.; Tang, Y. LDFR: Learning deep feature representation for software defect prediction. J. Syst. Softw. 2019, 158, 110402. [Google Scholar] [CrossRef]
- Qiu, S.; Lu, L.; Cai, Z.; Jiang, S. Cross-Project Defect Prediction via Transferable Deep Learning-Generated and Handcrafted Features. In Proceedings of the 31st International Conference on Software Engineering & Knowledge Engineering (SEKE 2019), Lisbon, Portugal, 10–12 July 2019; pp. 1–6. Available online: http://ksiresearch.org/seke/seke19paper/seke19paper_70.pdf (accessed on 17 December 2020).
- Cai, Z.; Lu, L.; Qiu, S. An Abstract Syntax Tree Encoding Method for Cross-Project Defect Prediction. IEEE Access 2019, 7, 170844–170853. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:cs.CL/1907.11692. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:cs.CL/1706.03762. [Google Scholar]
- Kanade, A.; Maniatis, P.; Balakrishnan, G.; Shi, K. Learning and Evaluating Contextual Embedding of Source Code. In Proceedings of the 37th International Conference on Machine Learning; Daumé, H., III, Singh, A., Eds.; PMLR, 2020; Volume 119, pp. 5110–5121. Available online: http://proceedings.mlr.press/v119/kanade20a.html (accessed on 17 December 2020).
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. arXiv 2020, arXiv:cs.CL/2002.08155. [Google Scholar]
- Humphreys, J.; Dam, H.K. An Explainable Deep Model for Defect Prediction. In Proceedings of the 22019 IEEE/ACM 7th International Workshop on Realizing Artificial Intelligence Synergies in Software Engineering (RAISE), Montreal, QC, Canada, 28 May 2019; pp. 49–55. [Google Scholar] [CrossRef]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. GraphCodeBERT: Pre-training Code Representations with Data Flow. arXiv 2021, arXiv:cs.SE/2009.08366. [Google Scholar]
- Tong, H.; Liu, B.; Wang, S. Software defect prediction using stacked denoising autoencoders and two-stage ensemble learning. Inf. Softw. Technol. 2018, 96, 94–111. [Google Scholar] [CrossRef]
- Tran, H.D.; Hanh, L.T.M.; Binh, N.T. Combining feature selection, feature learning and ensemble learning for software fault prediction. In Proceedings of the 2019 11th International Conference on Knowledge and Systems Engineering (KSE), Da Nang, Vietnam, 24–26 October 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Zhao, L.; Shang, Z.; Zhao, L.; Zhang, T.; Tang, Y.Y. Software defect prediction via cost-sensitive Siamese parallel fully-connected neural networks. Neurocomputing 2019, 352, 64–74. [Google Scholar] [CrossRef]
- Qiu, Y.; Liu, Y.; Liu, A.; Zhu, J.; Xu, J. Automatic Feature Exploration and an Application in Defect Prediction. IEEE Access 2019, 7, 112097–112112. [Google Scholar] [CrossRef]
- Zhou, T.; Sun, X.; Xia, X.; Li, B.; Chen, X. Improving defect prediction with deep forest. Inf. Softw. Technol. 2019, 114, 204–216. [Google Scholar] [CrossRef]
- Xu, J.; Wang, F.; Ai, J. Defect Prediction With Semantics and Context Features of Codes Based on Graph Representation Learning. IEEE Trans. Reliab. 2020, 1–13. [Google Scholar] [CrossRef]
- Raychev, V.; Bielik, P.; Vechev, M. Probabilistic Model for Code with Decision Trees. SIGPLAN Not. 2016, 51, 731–747. [Google Scholar] [CrossRef]
- Raychev, V.; Bielik, P.; Vechev, M.; Krause, A. Learning Programs from Noisy Data. SIGPLAN Not. 2016, 51, 761–774. [Google Scholar] [CrossRef]
- Alon, U.; Brody, S.; Levy, O.; Yahav, E. code2seq: Generating Sequences from Structured Representations of Code. arXiv 2019, arXiv:cs.LG/1808.01400. [Google Scholar]
- Allamanis, M.; Sutton, C. Mining source code repositories at massive scale using language modeling. In Proceedings of the 2013 10th Working Conference on Mining Software Repositories (MSR), San Francisco, CA, USA, 18–19 May 2013; pp. 207–216. [Google Scholar] [CrossRef] [Green Version]
- Iyer, S.; Konstas, I.; Cheung, A.; Zettlemoyer, L. Summarizing source code using a neural attention model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2073–2083. [Google Scholar]
- Allamanis, M.; Brockschmidt, M.; Khademi, M. Learning to Represent Programs with Graphs. arXiv 2018, arXiv:cs.LG/1711.00740. [Google Scholar]
- Mauša, G.; Galinac-Grbac, T.; Dalbelo-Bašić, B. A systematic data collection procedure for software defect prediction. Comput. Sci. Inf. Syst. 2016, 13, 173–197. [Google Scholar] [CrossRef] [Green Version]
- Sayyad Shirabad, J.; Menzies, T. The PROMISE Repository of Software Engineering Databases; School of Information Technology and Engineering, University of Ottawa: Ottawa, ON, Canada, 2005; Available online: http://promise.site.uottawa.ca/SERepository/ (accessed on 17 December 2020).
- Shepperd, M.; Song, Q.; Sun, Z.; Mair, C. NASA MDP Software Defects Data Sets. 2018. Available online: https://figshare.com/collections/NASA_MDP_Software_Defects_Data_Sets/4054940/1 (accessed on 17 December 2020).
- Afric, P.; Sikic, L.; Kurdija, A.S.; Silic, M. REPD: Source code defect prediction as anomaly detection. J. Syst. Softw. 2020, 168, 110641. [Google Scholar] [CrossRef]
- Ferenc, R.; Gyimesi, P.; Gyimesi, G.; Tóth, Z.; Gyimóthy, T. An automatically created novel bug dataset and its validation in bug prediction. J. Syst. Softw. 2020, 169, 110691. [Google Scholar] [CrossRef]
- Tóth, Z.; Gyimesi, P.; Ferenc, R. A Public Bug Database of GitHub Projects and Its Application in Bug Prediction. In Proceedings of the Computational Science and Its Applications—ICCSA, Beijing, China, 4–7 July 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 625–638. [Google Scholar] [CrossRef] [Green Version]
- Ferenc, R.; Tóth, Z.; Ladányi, G.; Siket, I.; Gyimóthy, T. A public unified bug dataset for java and its assessment regarding metrics and bug prediction. Softw. Qual. J. 2020, 28, 1447–1506. [Google Scholar] [CrossRef]
- Tufano, M.; Watson, C.; Bavota, G.; Penta, M.D.; White, M.; Poshyvanyk, D. An Empirical Study on Learning Bug-Fixing Patches in the Wild via Neural Machine Translation. ACM Trans. Softw. Eng. Methodol. 2019, 28, 4:1–4:29. [Google Scholar] [CrossRef] [Green Version]
- Widyasari, R.; Sim, S.Q.; Lok, C.; Qi, H.; Phan, J.; Tay, Q.; Tan, C.; Wee, F.; Tan, J.E.; Yieh, Y.; et al. BugsInPy: A database of existing bugs in Python programs to enable controlled testing and debugging studies. In Proceedings of the ESEC/FSE ’20: 28th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, USA, 8–13 November 2020; Devanbu, P., Cohen, M.B., Zimmermann, T., Eds.; ACM: New York, NY, USA, 2020; pp. 1556–1560. [Google Scholar] [CrossRef]
- Russell, R.; Kim, L.; Hamilton, L.; Lazovich, T.; Harer, J.; Ozdemir, O.; Ellingwood, P.; McConley, M. Automated Vulnerability Detection in Source Code Using Deep Representation Learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 757–762. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Ahmed, U.Z.; Mechtaev, S.; Leong, B.; Roychoudhury, A. Re-factoring based Program Repair applied to Programming Assignments. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), IEEE/ACM, San Diego, CA, USA, 11–15 November 2019; pp. 388–398. [Google Scholar] [CrossRef]
- Just, R.; Jalali, D.; Ernst, M.D. Defects4J: A database of existing faults to enable controlled testing studies for Java programs. In Proceedings of the 2014 International Symposium on Software Testing and Analysis, San Jose, CA, USA, 21–25 July 2014; pp. 437–440. [Google Scholar] [CrossRef] [Green Version]
- Tomassi, D.A.; Dmeiri, N.; Wang, Y.; Bhowmick, A.; Liu, Y.; Devanbu, P.T.; Vasilescu, B.; Rubio-González, C. BugSwarm: Mining and Continuously Growing a Dataset of Reproducible Failures and Fixes; ICSE.IEEE/ACM: Montreal, QC, Canada, 2019; pp. 339–349. [Google Scholar] [CrossRef] [Green Version]
- Muvva, S.; Rao, A.E.; Chimalakonda, S. BuGL—A Cross-Language Dataset for Bug Localization. arXiv 2020, arXiv:cs.SE/2004.08846. [Google Scholar]
- Saha, R.K.; Lyu, Y.; Lam, W.; Yoshida, H.; Prasad, M.R. Bugs.Jar: A Large-Scale, Diverse Dataset of Real-World Java Bugs. In Proceedings of the 15th International Conference on Mining Software Repositories (MSR ’18), Gothenburg, Sweden, 28–29 May 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 10–13. [Google Scholar] [CrossRef]
- Alsawalqah, H.; Faris, H.; Aljarah, I.; Alnemer, L.; Alhindawi, N. Hybrid SMOTE-Ensemble Approach for Software Defect Prediction. In Software Engineering Trends and Techniques in Intelligent Systems; Silhavy, R., Silhavy, P., Prokopova, Z., Senkerik, R., Kominkova Oplatkova, Z., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 355–366. [Google Scholar]
- Agrawal, A.; Menzies, T. Is “Better Data” Better than “Better Data Miners”? On the Benefits of Tuning SMOTE for Defect Prediction. In Proceedings of the 40th International Conference on Software Engineering (ICSE ’18), Gothenburg, Sweden, 27 May–3 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1050–1061. [Google Scholar] [CrossRef] [Green Version]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient Transformers: A Survey. arXiv 2020, arXiv:cs.LG/2009.06732. [Google Scholar]
- Tay, Y.; Dehghani, M.; Abnar, S.; Shen, Y.; Bahri, D.; Pham, P.; Rao, J.; Yang, L.; Ruder, S.; Metzler, D. Long Range Arena: A Benchmark for Efficient Transformers. arXiv 2020, arXiv:cs.LG/2011.04006. [Google Scholar]
- Zaheer, M.; Guruganesh, G.; Dubey, A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; et al. Big Bird: Transformers for Longer Sequences. arXiv 2021, arXiv:cs.LG/2007.14062. [Google Scholar]
- Fiok, K.; Karwowski, W.; Gutierrez, E.; Davahli, M.R.; Wilamowski, M.; Ahram, T.; Al-Juaid, A.; Zurada, J. Text Guide: Improving the quality of long text classification by a text selection method based on feature importance. arXiv 2021, arXiv:cs.AI/2104.07225. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:cs.CL/2004.05150. [Google Scholar]
- Hellendoorn, V.J.; Sutton, C.; Singh, R.; Maniatis, P.; Bieber, D. Global Relational Models of Source Code. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, 26 April–1 May 2020. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Karampatsis, R.M.; Sutton, C. SCELMo: Source Code Embeddings from Language Models. arXiv 2020, arXiv:cs.SE/2004.13214. [Google Scholar]
- Herbold, S.; Trautsch, A.; Grabowski, J. A Comparative Study to Benchmark Cross-Project Defect Prediction Approaches. IEEE Trans. Softw. Eng. 2018, 44, 811–833. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Content | Size | Used in Tasks |
|---|---|---|---|
| Bigquery github repos [31] | Python source code | 4 M files | Pre-training CuBERT model |
| Py150 [41] | Python source code, AST | 8423 repos, 149,993 files | Fine-tuning CuBERT model |
| Js150 [42] | Javascript source code, AST | 150,000 source files | Code Summarization; Defect Prediction |
| Datasets for [43] | Java source code | 9500 projects, 16 M samples in the largest one | Code summarization |
| GitHub Java Corpus [44] | Java source code | 11,000 projects | Language Modeling |
| CodeNN Dataset [45] | C# source code and summaries | 66,015 fragments | Code Captioning |
| Dataset for [6] | Kotlin source code, AST, bytecode | 47,751 repos, 932,548 files, 4,044,790 functions | Anomaly detection, defect prediction |
| Dataset for [46] | C# source code | 29 projects, 2.9 M lines of code | Variable Misuse detection |
| Dataset | Content | Size | Used in Tasks |
|---|---|---|---|
| SEIP Lab Software Defect Prediction Data [47] | Complexity metrics | 5 subsequent releases of 3 projects from the Java Eclipse community | Data collection and linking |
| PROMISE Software Engineering Repository [48] | Numeric metrics; reported defects (false/true) | 15,000 modules | Defect prediction |
| NASA Defect Dataset [49] | Numeric metrics; reported defects (false/true) | 51,000 modules | Defect prediction |
| REPD datasets [50] | Numeric metrics, semantic features, reported defects | 10,885 fragments in the largest one | Defect prediction |
| GPHR [40] | Java code and metrics | 3526 pairs of fragments, buggy and fixed, code metrics | Defect prediction |
| BugHunter [51] | Java source code; metrics; fix-inducing commit; number of reported bugs | 159 k pairs for 3 granularity levels (file/class/method), 15 projects | Analyzing the importance of complexity metrics |
| GitHub Bug DataSet [52] | Java source code; code metrics; number of reported bugs and vulnerabilities | 15 projects; 183 k classes | Bug prediction |
| Unified Bug Dataset [53] | Java source code; code metrics; number of reported bugs | 47,618 classes; 43,744 files | Bug prediction |
| Neural Code Translator Dataset [54] | Pairs of buggy and fixed abstracted method-level fragments | 46 k pairs of small fragments (under 50 tokens), 50 k pairs of medium fragments (under 100 tokens) | Code refinement |
| BugsInPy [55] | Pair of buggy and fixed Python snippets, manually processed | 493 bugs from 17 projects | Benchmark for testing and debugging tools |
| Draper VDISC Dataset [56] | C and C++ source code, labeled for potential vulnerabilities | 1.27 M functions | Vulnerability Detection |
| Refactory Dataset [57] | Python source code | 2442 correct and 1783 buggy program | Program repair |
| Defect4J [58] | Java source code | 835 pairs of buggy and fixed fragments | Software testing research |
| BugSwarm [59] | Java and Python source code | 3232 pairs of buggy and fixed fragments | Software testing research |
| BuGL [60] | C, C++, Java, and Python source code; issues; pull requests | 54 projects; 151 k closed issues; 10,187 pull requests | Bug localization |
| Bugs.jar [61] | Java source code | 1158 pairs of buggy and and fixed fragments | Program repair |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akimova, E.N.; Bersenev, A.Y.; Deikov, A.A.; Kobylkin, K.S.; Konygin, A.V.; Mezentsev, I.P.; Misilov, V.E. A Survey on Software Defect Prediction Using Deep Learning. Mathematics 2021, 9, 1180. https://0-doi-org.brum.beds.ac.uk/10.3390/math9111180
Akimova EN, Bersenev AY, Deikov AA, Kobylkin KS, Konygin AV, Mezentsev IP, Misilov VE. A Survey on Software Defect Prediction Using Deep Learning. Mathematics. 2021; 9(11):1180. https://0-doi-org.brum.beds.ac.uk/10.3390/math9111180
Chicago/Turabian StyleAkimova, Elena N., Alexander Yu. Bersenev, Artem A. Deikov, Konstantin S. Kobylkin, Anton V. Konygin, Ilya P. Mezentsev, and Vladimir E. Misilov. 2021. "A Survey on Software Defect Prediction Using Deep Learning" Mathematics 9, no. 11: 1180. https://0-doi-org.brum.beds.ac.uk/10.3390/math9111180