
A Comparative Ranking Model among Mexican Universities Using Pattern Recognition

 ,
,
Abstract
:1. Introduction
2. Technical Classification by Clustering
2.1. k-means Algorithm
- Begin
- 1. Randomly choose k cluster centers
- 2. While points stop changing assignment to centroids
- assign each data point to the nearest cluster center.
- Set the new cluster centroids based on the average (mean) position of each centroid point.
- 3. End While
- End
2.2. Gaussian Mixture Model
- Begin
- 1. Choose starting guesses for the location and shape
- 2. While the convergence is not reached:
- For each point, find weights encoding the probability of membership in each cluster.
- For each cluster, update its location, normalization, and shape based on all data points, making use of the weights.
- 3. End While
- End
2.3. Spectral Clustering
- Begin
- 1. Compute A, the n × n affinity matrix
- 2. Get the eigensystem of A:
- Compute the first k eigenvectors of its Laplacian matrix to define a feature vector for each object:
- Set U = n × k matrix containing the normalized eigenvectors of the k largest eigenvalues of A in its columns
- 3. Apply k-means on the row space of U to find the k cluster
- End
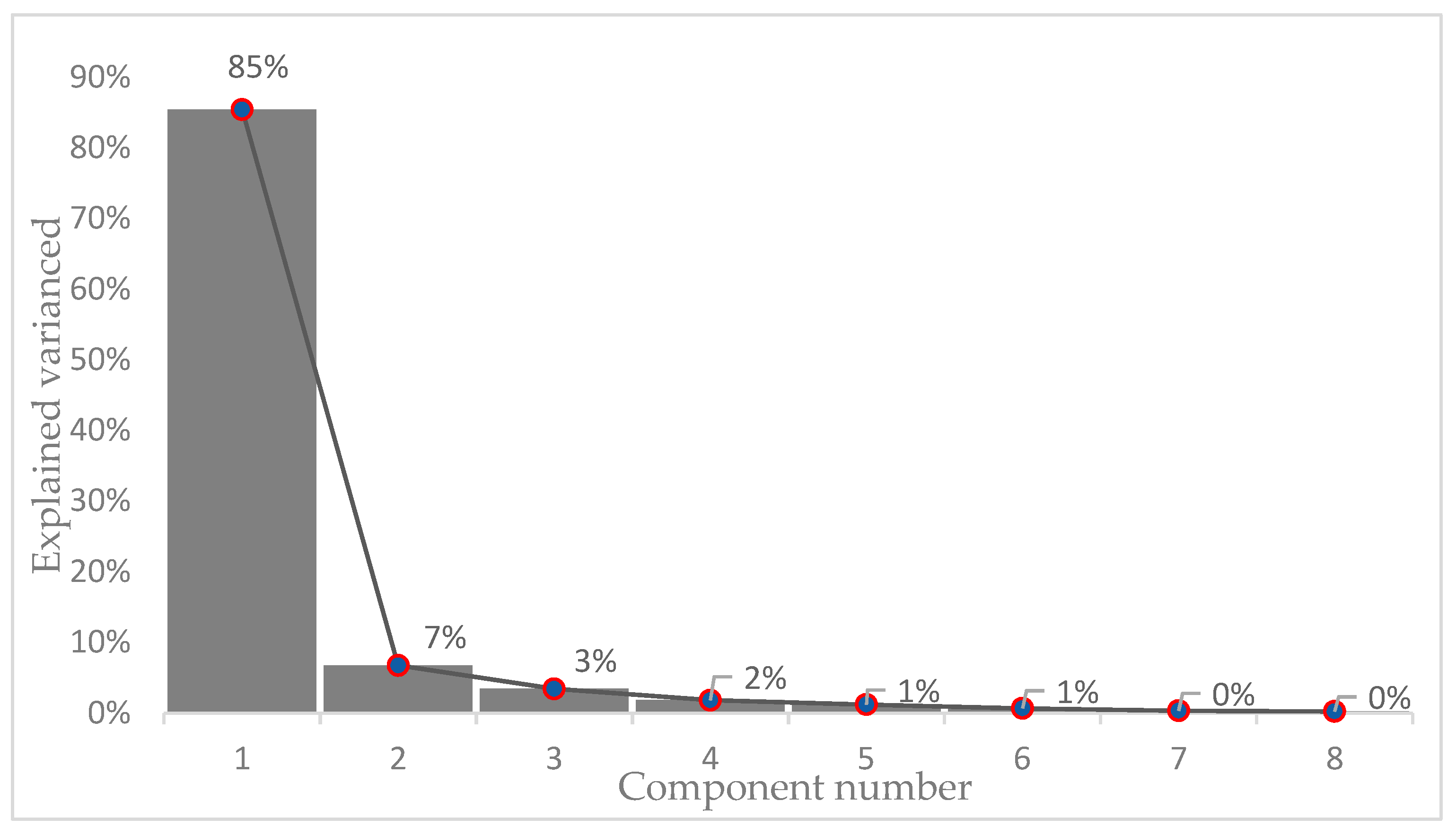
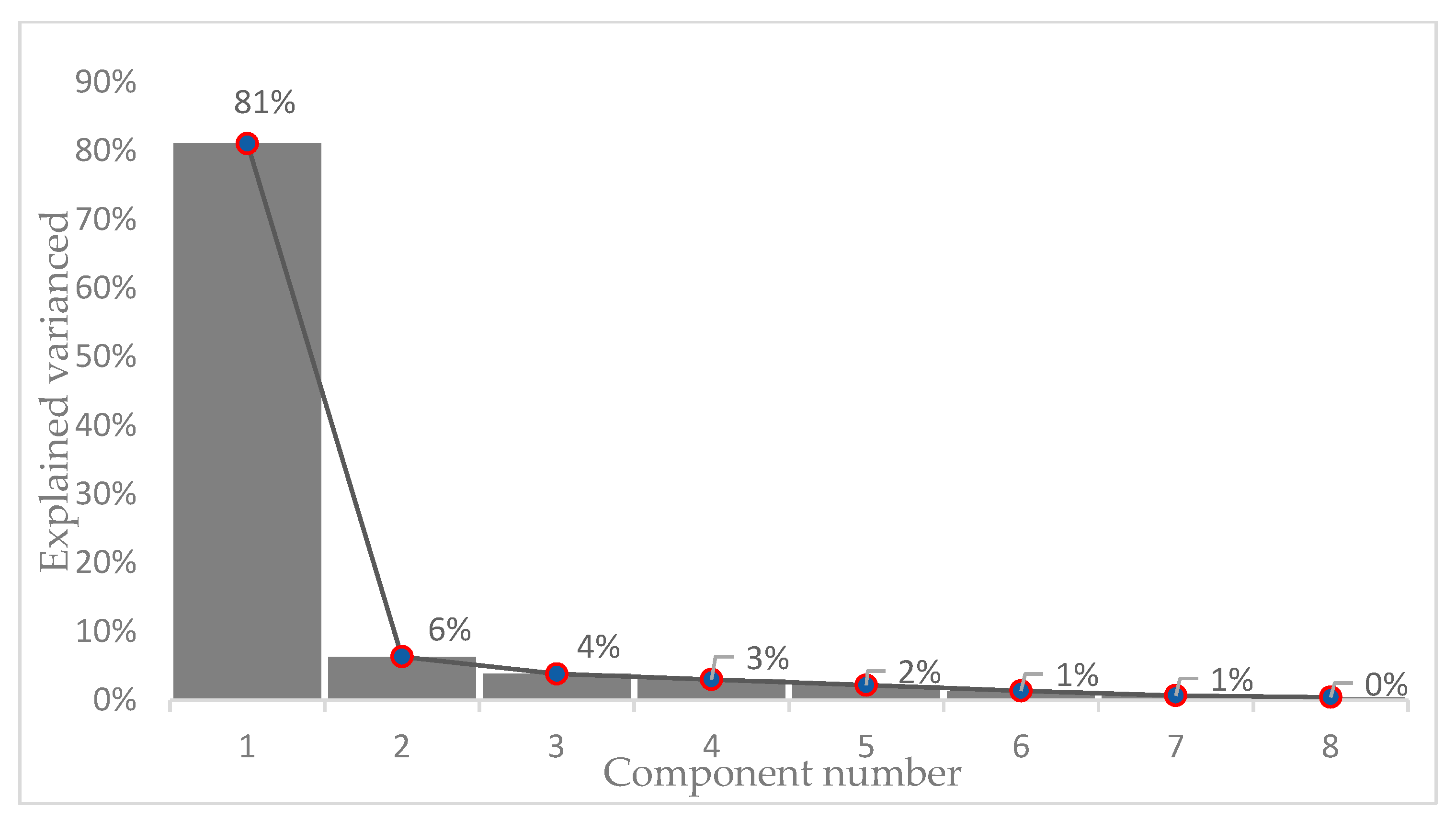
2.4. Principal Component Analysis
- Standardize the input data (or normalize the variables).
- Get the eigenvectors and eigenvalues of the covariance matrix.
- Sort eigenvalues from high to low and choose d eigenvectors that correspond to d higher eigenvalues (where d is the dimensionality of the new features subspace).
- Construct the projection matrix W with the d eigenvectors selected.
- Transform the original X standardized database via W to obtain the new d-dimensional characteristics.
- A measure of how each variable is associated with the others (covariance matrix)
- The direction in which our data is scattered (eigenvectors)
- The relative importance of these different directions (eigenvalues).
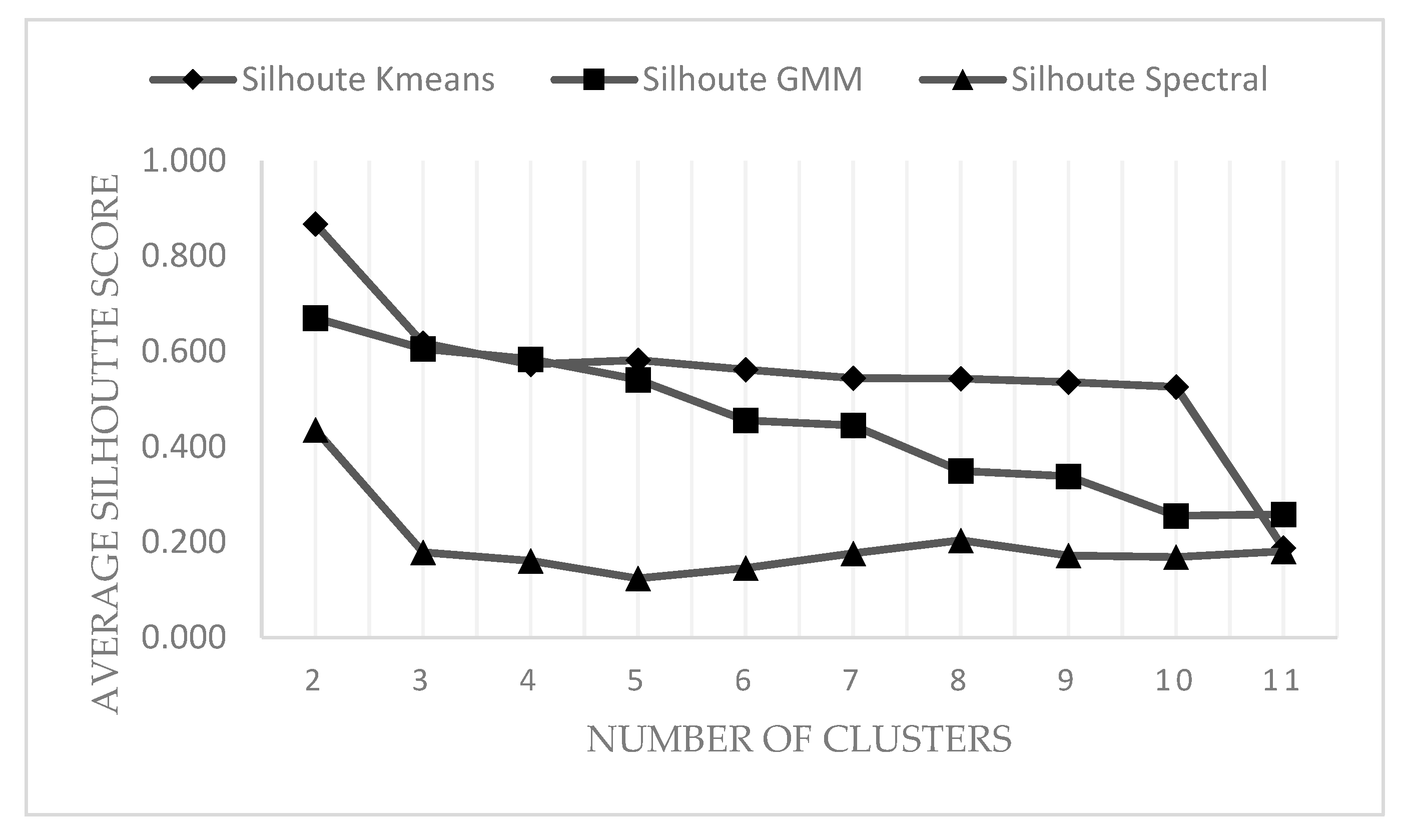
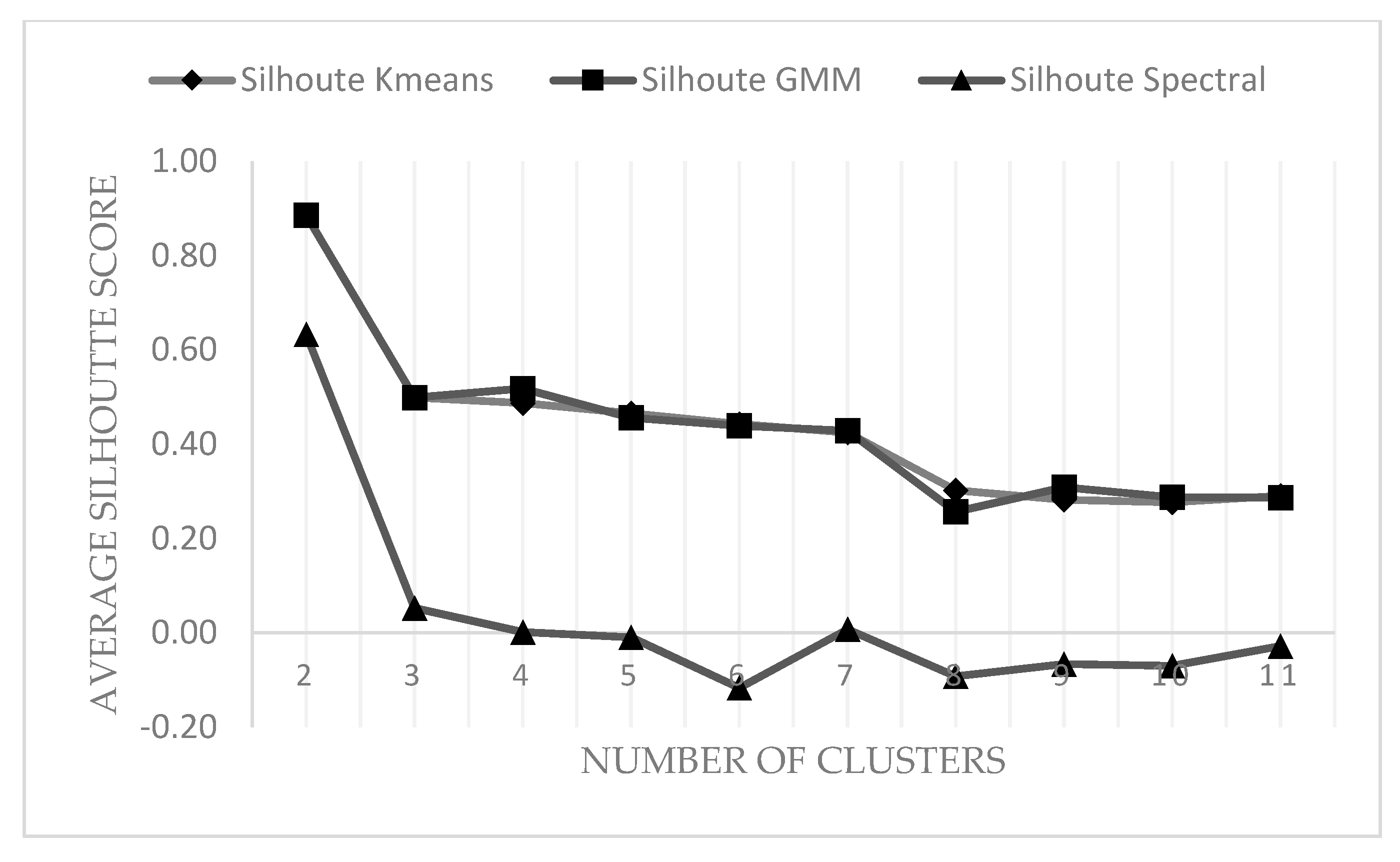
2.5. Determine the Number of Clusters and Evaluate Clustering Performance: Silhouette Coefficient
- Mean distance between the observation and all other data points in the same cluster. This distance can also be called a mean intra-cluster distance. This mean distance is denoted by
- Mean distance between the observation and all other data points of the next nearest cluster. This distance can also be called a mean nearest-cluster distance. The mean distance is denoted by
3. Materials & Methods
3.1. Comparative Study of Mexican Universities
- Teachers, tuition, and academic programs.
- Production of patents by Mexican institutions. It includes data on patents applied for and granted, according to the records of the Mexican Institute of Industrial Protection (MIIP).
- Participation of institutions in documents, articles and citations indexed in international bibliographic databases: ISI, Web of Knowledge, SciVerse, Scopus, etc.
- Participation of institutions in documents and articles indexed in the regional databases (Latin American citations in social sciences and humanities) and Periódica (index of Latin American journals in science).
- Academics of the institutions in the National System of Researchers (SNI) of the National Council of Science and Technology (CONACYT).
- Research journals indexed by Latindex (Latin American Index of Serial Scientific Publications) and the CONACYT Index.
- Academic bodies recognized in the National Program for the Improvement of Teachers (PROMEP), currently known as the Program for Teacher Professional Development (PRODEP) of the Ministry of Public Education (SEP).
- Postgraduate programs recognized in CONACYT’s National Register of Quality Postgraduate Programs (PNPC).
- Higher education programs evaluated by the Inter-Institutional Committees for the Evaluation of Higher Education (CIEES) and programs accredited by agencies recognized by the Council for the Accreditation of Higher Education (COPAES).
3.2. Application Instance: 60 ExECUM Universities
- Contract: Full time, 3/4-time, 1/2-time, hourly hired.
- Academic degree: Higher Technical University, bachelor’s degree, specialty, master’s degree, doctorate.
- Level: Bachelor’s degree, specialty, master’s degree, doctorate.
- Level: Bachelor’s degree, specialty, master’s degree, doctorate.
- Researchers: Candidate, level I, level II, level III
- Consolidated, in consolidation, in formation.
- Articles: Institutional production, analysis by author, collaborators, citations.
- Documents: Institutional production, analysis by author, collaborators, citations.
- Articles: Institutional production, analysis by author, collaborators, citations.
- Documents: Institutional production, analysis by author, collaborators, citations.
- Pending or granted journals.
- Latindex or CONACYT index
- Doctorate: International competence, consolidated, developing, newly created
- Master’s Degree: International competence, consolidated, developing, newly created.
- Specialty: International competence, consolidated, developing, newly created
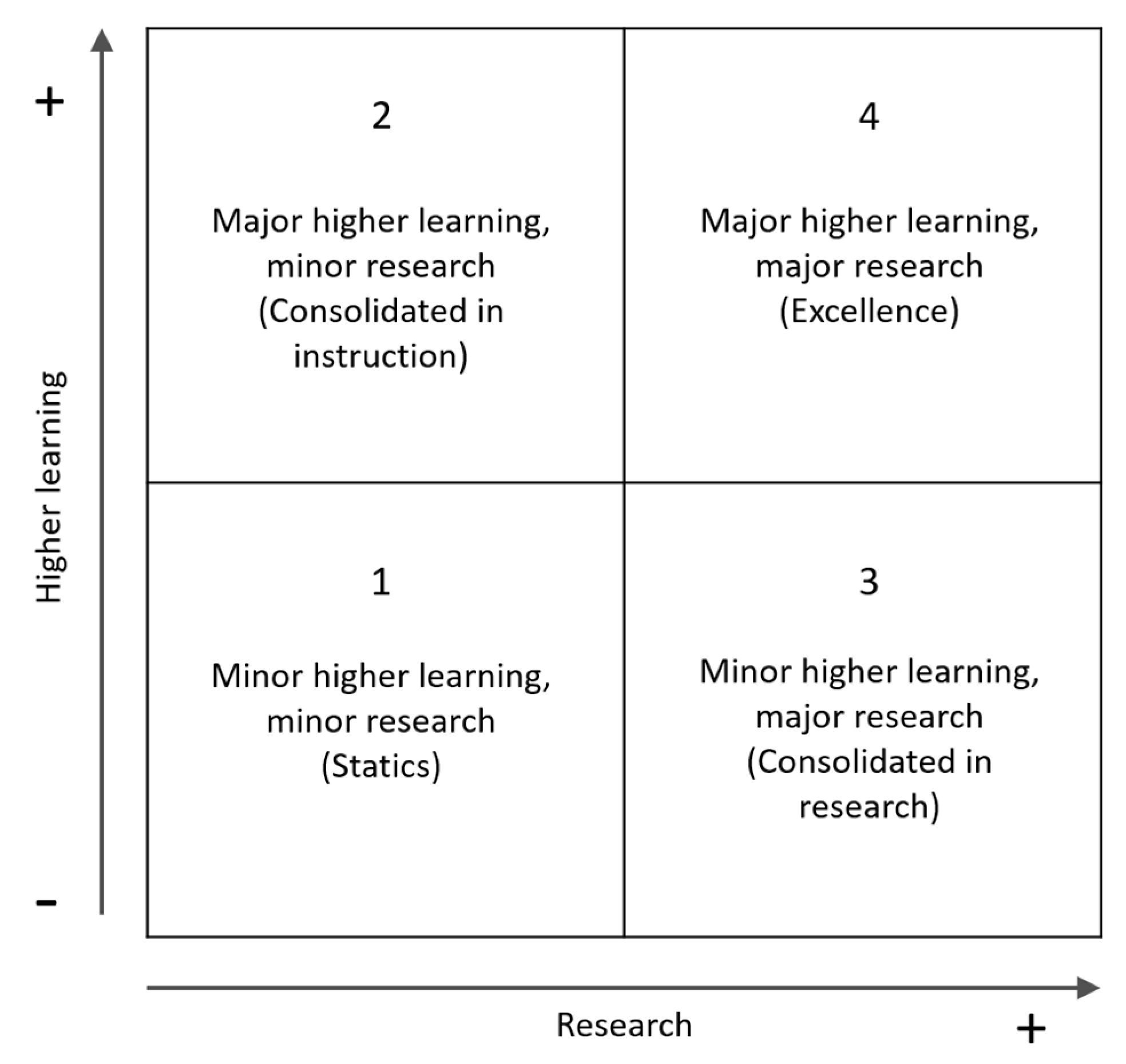
3.3. Proposed Matrix Model
4. Results and Analysis
4.1. k-means Results
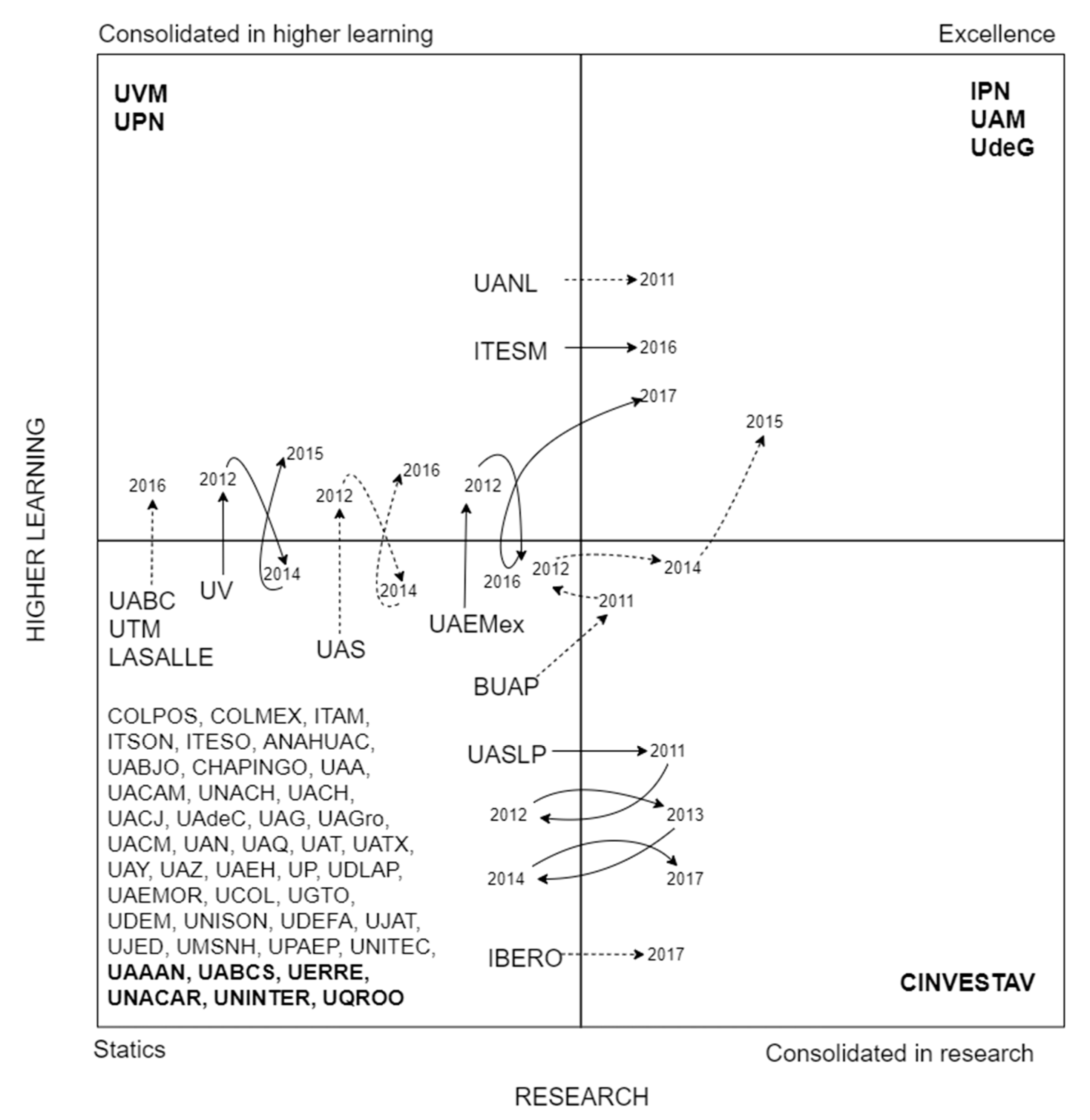
4.1.1. Invariable Universities in k-Means Analysis
- Excellence
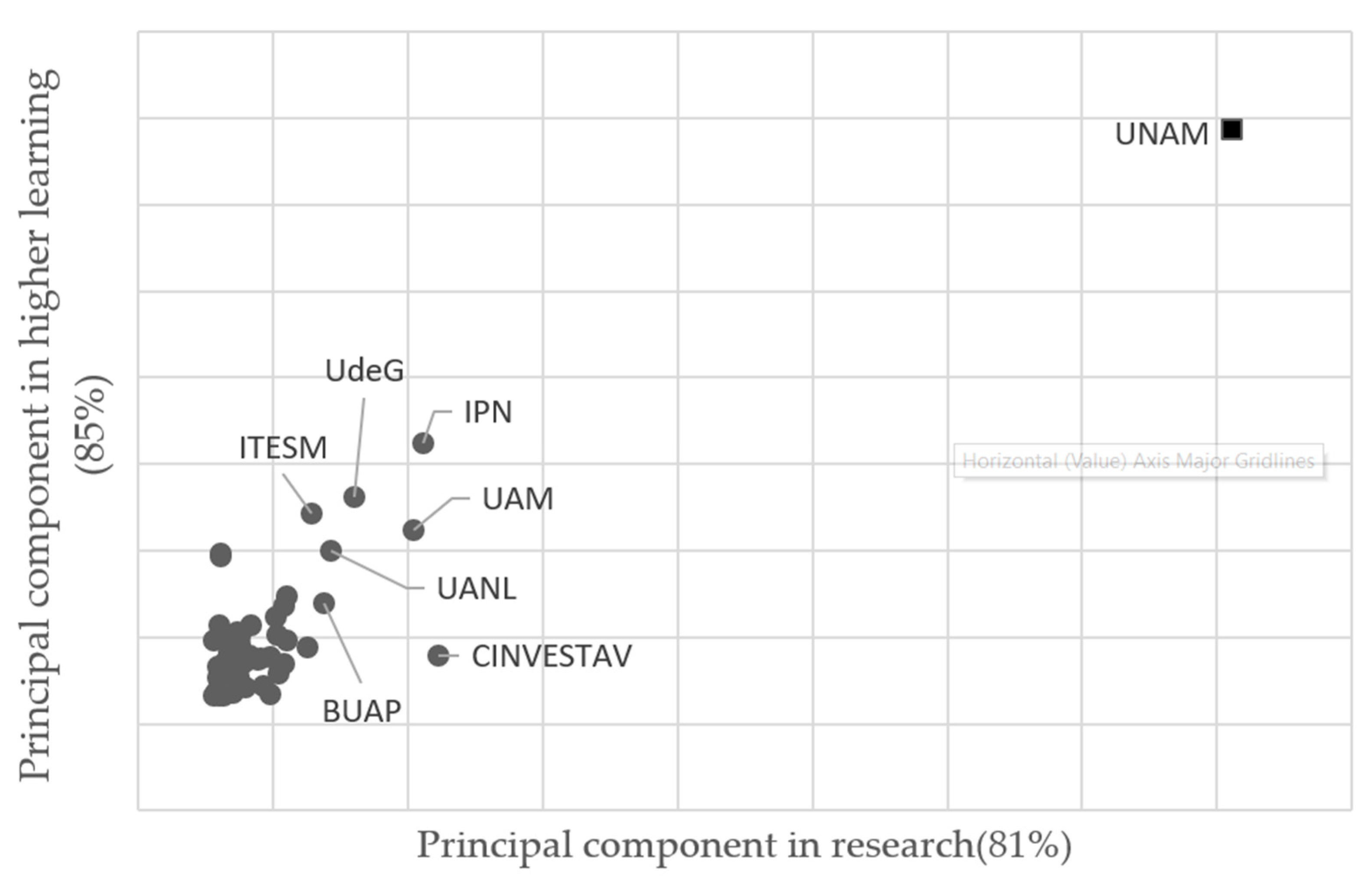
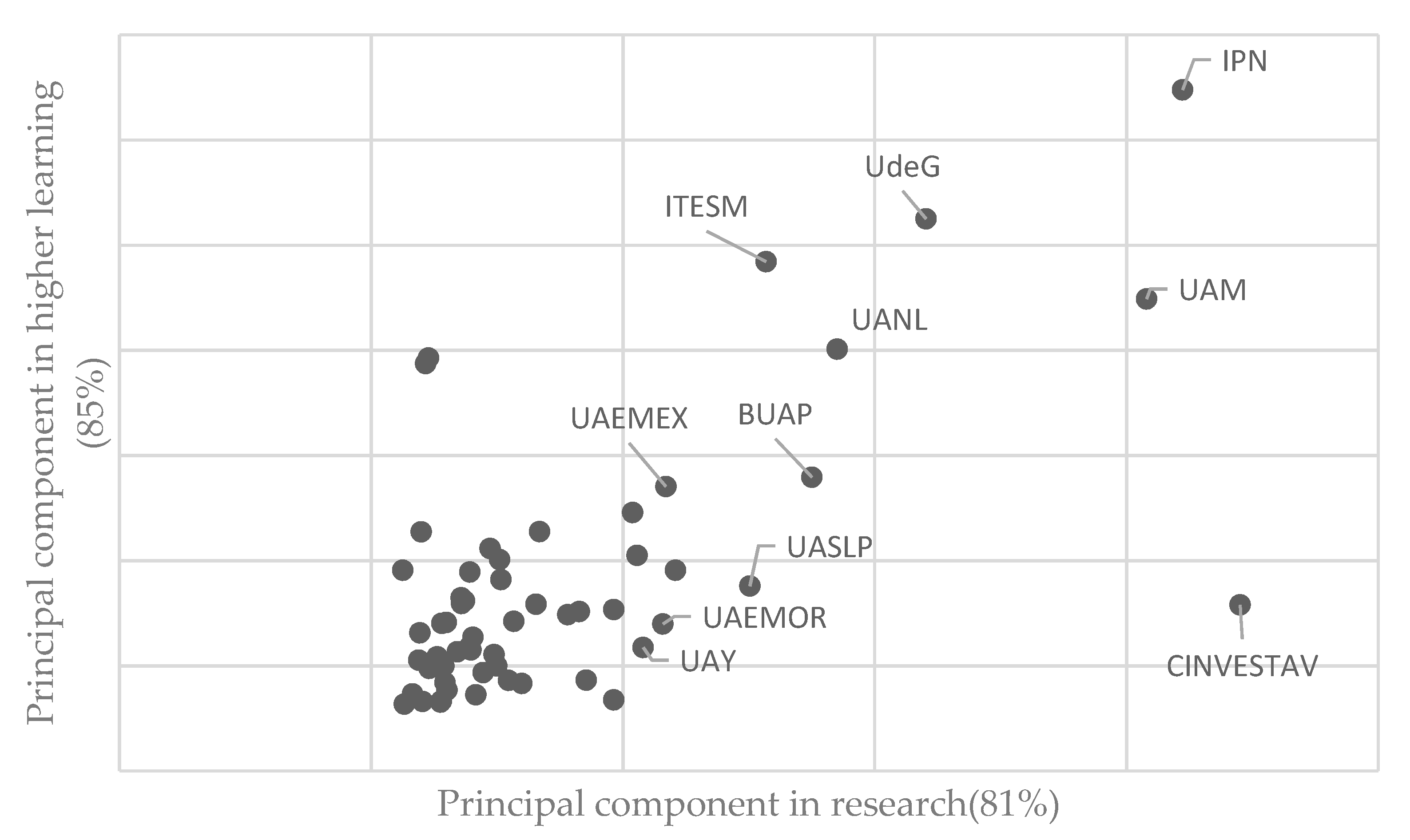
- The invariable universities consolidated in excellence are those that, throughout the analyzed period, that is, from 2009 to 2017, excel in both higher learning and research. These are: The National Polytechnic Institute (IPN), the Metropolitan Autonomous University (UAM) and the University of Guadalajara (UdeG).
- Consolidated only in higher learning.
- The invariable universities consolidated in higher learning are: The University of the Mexican Valley (UVM) and the National Pedagogical University (UPN).
- Consolidated in research.
- The only institution considered invariably consolidated in research is the Center for Research and Advanced of the IPN (CINVESTAV).
- Static.
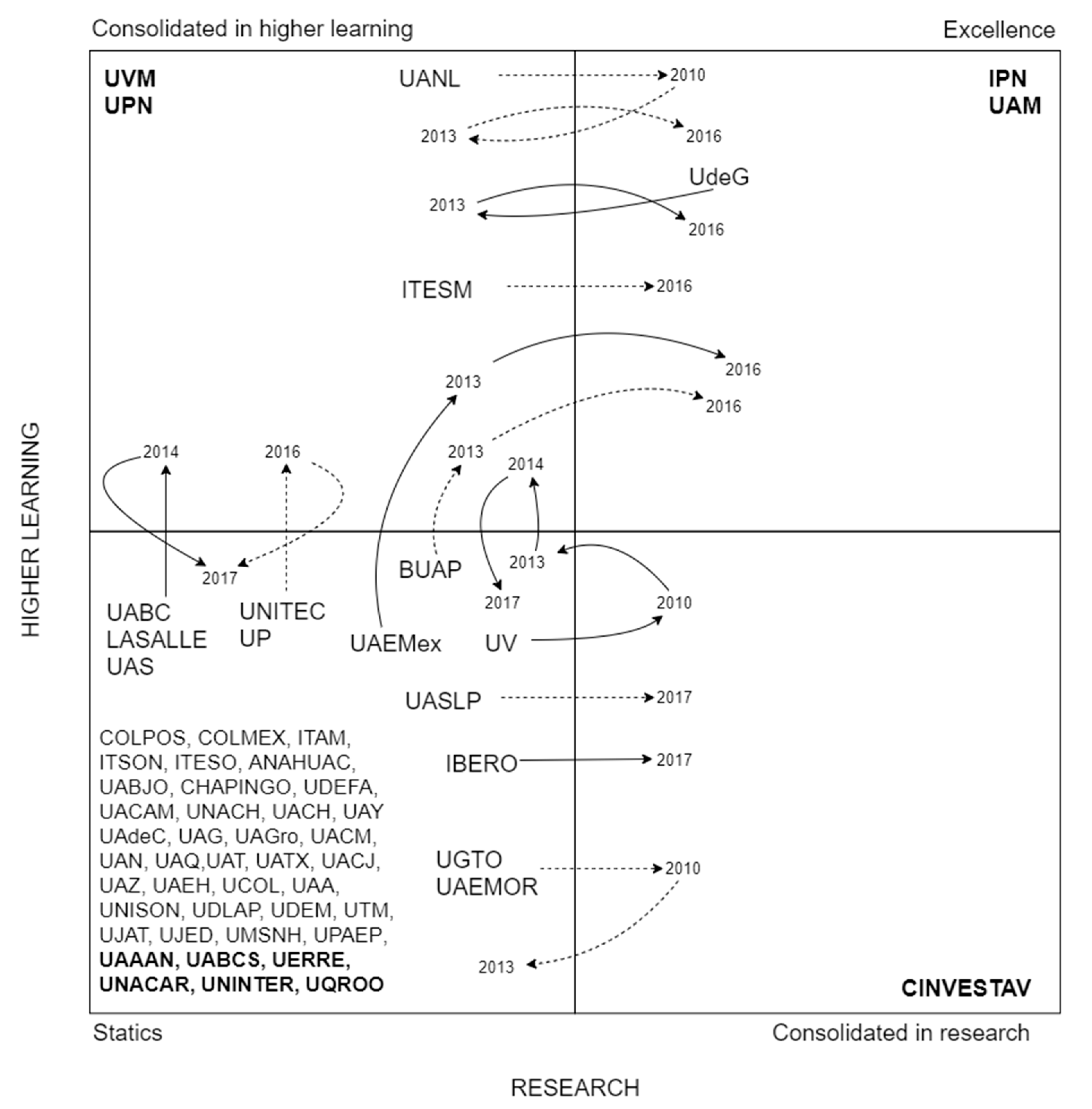
- According to k-means classification, approximately 70 percent of educational institutions fall into this category (41 of them). Their names are shown in the lower left of Figure 6.
4.1.2. Universities in Transition in k-Means Analysis
- Universities that have improved in higher learning:
- In 2016 La Salle University (LASALLE), the Autonomous University of Baja California (UABC) and the Technological University of Mexico (UNITEC) became part of the consolidated universities in higher learning.
- The Autonomous University of Sinaloa (UAS) shows a tendency to consolidate higher learning because it begins hovering between static universities at the beginning of the study, and although for 2012 it is consolidated into higher learning, in 2014 it returns to the place where it started; finally, in 2016 it was consolidated again in higher learning and remained on the site until the last year analyzed.
- Universities that have improved in research:
- During the first years of analysis, though the Autonomous University of San Luis Potosí (UASLP) is a static institution, in 2011 it was consolidated in research, the following year it was once again part of the static ones; and this behavior is repeated in the following two years until it remains from 2014 to 2016 as a static institution and during the last year analyzed it is consolidated again in research. This behavior of constant transitions makes evident their interest in consolidating in research.
- The Iberoamerican University (IBERO) remains among the static institutions for almost the entire period analyzed and it is not until the last year that this institution is consolidated in research.
- Universities that became of excellence:
- There are institutions such as the Autonomous University of Nuevo León (UANL) and the Monterrey Institute of Technology and Higher Education (ITESM) which begin the study as consolidated in higher learning, the study shows their interest in being of excellence, achieving their goal for the year 2011 and 2016, respectively.
- The Meritorious Autonomous University of Puebla (BUAP) went from being a static university to one with a better research quality in 2011; However, by 2012 it was once again part of the static institutions, where it remained until 2013. During 2014 its research quality improved again and for the following year it was able to be part of the excellence institutions, maintaining that position until the last year of analysis.
- The Autonomous University of Mexico State (UAMEX) is another institution that begins located among the static universities, but in 2012 it became consolidated in higher learning and only became static again during 2016, because for the following year it passes to be part of the excellence group.
4.2. GMM Results
4.2.1. Invariable Universities in GMM Analysis
- Excellence
- Two of the invariable universities consolidated in excellence by the GMM method coincide with those obtained by k-means.
- For this method, there are two invariable universities consolidated in excellence, these are: IPN and UAM.
- Consolidated in higher learning
- The results of the invariable universities consolidated in higher learning coincide with the results obtained by k-means since they only have UVM and NUP.
- Consolidated in research
- As with the k-means, the only institution regarded as invariable consolidated research is the CINVESTAV.
- Static
- Using GMM, the list of institutions is rather similar to the one provided by k-means; the only changes are UAMOR, UGTO, UP and UNITEC. The first two leaves the first quadrant in 2010 and return in 2013; while the last two leave in 2016 to return in the following year.
4.2.2. Universities in Transition in GMM Analysis
- Universities that have improved in research.
- In this analysis, the IBERO and the UASLP begin being static and during 2017 they were consolidated in research.
- Universities that became of excellence:
- Even though UdeG begins as part of the universities of excellence, it does not remain unchanged in its position, because during the period from 2013 to 2015, it is located with the consolidated institutions in higher learning, and it is until 2016 when it finally returns to be part of the excellence institutions.
- The ITESM begins as a consolidated university in higher learning, but its interest focuses on being part of the group of excellence; thus, by 2016 it achieves its goal and becomes a fourth quadrant institution.
- The UANL is a university with a behavior that shows its interest in being part of the g excellence group because it begins being consolidated in higher learning, for 2010 it becomes of excellence and although for the following year until 2015 it returns to the group where it started, in 2016 it is once again part of the group of excellence.
- The BUAP and UAMEX are institutions that, despite starting out as static, focused first on consolidating themselves in higher learning, a group to which they belonged from 2013 to 2015, and then gave the highest to the universities of the fourth quadrant in 2016.
- Universities that became static:
- The UABC, LASALLE and the UAS are institutions that begin as part of the static group, but there is an interest in consolidating themselves in higher learning, and although they achieve their goal in the period from 2013 to 2016; finally, in the last year of analysis, these institutions became static again.
- The UNITEC and UP are in a similar case, with the only difference that the period in which they are consolidated into higher learning corresponds only to 2016 and return to the static group in 2017.
- The University of Guanajuato (UGTO) and the Autonomous University of Morelos State (UAMOR) are institutions that are initially part of the static group and are consolidated in research, in the period that corresponds from 2010 to 2012; after this period, they return to be static institutions until the last year analyzed.
- The Veracruzana University (UV) is characterized by its constant transitions; in 2010 it went from being a static university to a consolidated one in research, in 2013 it returned to its starting point; the following year it consolidated its higher learning position, a place where it remained until 2016 and during 2017 it became static again.
4.3. Spectral Clustering Results
4.3.1. Universities in Transition in Spectral Clustering Analysis
4.3.2. Static Universities in Spectral Clustering Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANAHUAC | Anahuac University (Sistema Universidad Anahuac) |
| BUAP | Meritorious Autonomous University of Puebla (Benemérita Universidad Autónoma de Puebla) |
| CINVESTAV | IPN Center for Research and Advanced Studies (Centro De Investigación y de Estudios Avanzados del IPN) |
| COLMEX | The School of Mexico (El Colegio De México) |
| COLPOS | Postgraduate College (Colegio de Posgraduados) |
| CHAPINGO | Chapingo Autonomous University (Universidad Autónoma Chapingo) |
| IBERO | Iberoamerican University System (Sistema Universidad Iberoamericana) |
| IPN | National Polytechnic Institute (Instituto Politécnico Nacional) |
| ITAM | Autonomous Technological Institute of Mexico (Instituto Tecnológico Autónomo De México) |
| ITESM | Monterrey Institute of Technology and Higher Education (Sistema Instituto Tecnológico y de Estudios Superiores de Monterrey) |
| ITESO | Estudios Superiores de Occidente) |
| ITSON | Technological Institute of Sonora (Instituto Tecnológico de Sonora) |
| LASALLE | La Salle University (Sistema Universidad La Salle, AC) |
| UAA | Autonomous University of Aguascalientes (Universidad Autónoma de Aguascalientes) |
| UAAAN | Autonomous Agrarian University Antonio Narro (Universidad Autónoma Agraria Antonio Narro) |
| UABC | Autonomous University of Baja California (Universidad Autónoma de Baja California) |
| UABCS | Autonomous University of Baja California Sur (Universidad Autónoma de Baja California Sur) |
| UABJO | Autonomous University Benito Juarez of Oaxaca (Universidad Autónoma Benito Juárez de Oaxaca) |
| UACAM | Autonomous University of Campeche (Universidad Autónoma de Campeche) |
| UACJ | Autonomous University of Juarez City (Universidad Autónoma de Ciudad Juárez) |
| UACM | Autonomous University of Mexico City (Universidad Autónoma de la Ciudad de México) |
| UACH | Autonomous University of Chihuahua (Universidad Autónoma de Chihuahua) |
| UAdeC | Autonomous University of Coahuila (Universidad Autónoma de Coahuila) |
| UAEH | Autonomous University of Hidalgo State (Universidad Autónoma del Estado de Hidalgo) |
| UAG | Autonomous University of Guadalajara (Universidad Autónoma de Guadalajara) |
| UAGRO | Autonomous University of Guerrero (Universidad Autónoma de Guerrero) |
| UAM | Metropolitan Autonomous University (Universidad Autónoma Metropolitana) |
| UAEMEX | Autonomous University of Mexico State (Universidad Autónoma del Estado de México) |
| UAEMOR | Autonomous University of Morelos State (Universidad Autónoma del Estado de Morelos) |
| UAN | Autonomous University of Nayarit (Universidad Autónoma de Nayarit) |
| UANL | Autonomous University of Nuevo Leon (Universidad Autónoma de Nuevo León) |
| UAQ | Autonomous University of Queretaro (Universidad Autónoma de Querétaro) |
| UAS | Autonomous University of Sinaloa (Universidad Autónoma de Sinaloa) |
| UASLP | Autonomous University of San Luis Potosi (Universidad Autónoma de San Luis Potosí) |
| UAT | Autonomous University of Tamaulipas (Universidad Autónoma de Tamaulipas) |
| UATX | Autonomous University of Tlaxcala (Universidad Autónoma de Tlaxcala) |
| UAY | Autonomous University of Yucatan (Universidad Autónoma de Yucatán) |
| UAZ | Autonomous University of Zacatecas (Universidad Autónoma de Zacatecas) |
| UCOL | University of Colima (Universidad de Colima) |
| UDEFA | University of The Mexican Army and Air force (Universidad del Ejército y Fuerza Aérea Mexicana) |
| UdeG | University of Guadalajara (Universidad de Guadalajara) |
| UDEM | University of Monterrey (Universidad de Monterrey) |
| UDLAP | University of The Americas Puebla (Universidad de Las Américas Puebla, AC) |
| UERRE | Regiomontana University (Universidad Regiomontana, AC) |
| UGTO | University of Guanajuato (Universidad de Guanajuato) |
| UIC | Intercontinental University (Universidad Intercontinental) |
| UJAT | Juarez Autonomous University of Tabasco (Universidad Juárez Autónoma de Tabasco) |
| UJED | Juarez University of Durango State (Universidad Juárez del Estado de Durango) |
| UMSNH | Michoacana University of San Nicolas from Hidalgo (Universidad Michoacana de San Nicolás de Hidalgo) |
| UN | Naval University (Universidad Naval) |
| UNACAR | Autonomous University Del Carmen (Universidad Autónoma del Carmen) |
| UNACH | Autonomous University of Chiapas (Universidad Autónoma de Chiapas) |
| UNAM | National Autonomous University of Mexico (Universidad Nacional Autónoma de México) |
| UNISON | University of Sonora (Universidad de Sonora) |
| UNITEC | Technological University of Mexico (Universidad Tecnológica de México) |
| UP | Panamerican University (Universidad Panamericana) |
| UPAEP | Popular Autonomous University of Puebla State (Universidad Popular Autónoma del Estado de Puebla) |
| UPN | National Pedagogical University (Universidad Pedagógica Nacional) |
| UQROO | University of Quintana Roo (Universidad de Quintana Roo) |
| UTM | Technological University of La Mixteca (Universidad Tecnológica de la Mixteca) |
| UV | Veracruz University (Universidad Veracruzana) |
| UVM | University of The Mexican Valley (Sistema Universidad del Valle de México) |
References
- Palma, E. Percepción y Valoración de la Calidad Educativa de Alumnos y Padres en 14 Centros Escolares de la Región Metropolitana de Santiago de Chile. REICE Rev. Iberoam. Sobre Calid. Efic. Cambio Educ. 2016, 6, 1. Available online: http://www.redalyc.org/articulo.oa?id=55160106 (accessed on 5 January 2020).
- Jiménez Galán, M.; Hernández Jaime, M.; Ortega Pacheco, M. ¿Forman los programas de formación docente? Rev. Investig. Educ. 2014, 19, 1–27. [Google Scholar] [CrossRef]
- Espinosa, E.M.; Gutiérrez, F.C.; Muñoz, V.M.R. Estudiantes Frente al Espejo: Percepciones de la Calidad Educativa en Programas de Licenciatura y Posgrado en México. Universidad de Guadalajara. 2015. Available online: http://www.sinectica.iteso.mx/index.php?cur=38&art=38_07 (accessed on 7 January 2020).
- Montes, E.; Mora, R.A.; Obregón, B.; de-los-Cobos, S.G.; Rincón, E.A.; Lara, P.; Gutiérrez, M.Á. Mexican University Ranking Based on Maximal Clique. In Educational Networking; Peña-Ayala, A., Ed.; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 327–395. [Google Scholar] [CrossRef]
- Van der Plas, J. Python Data Science Handbook: Essential Tools for Working with Data; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2016; ISBN 9781491912058. [Google Scholar]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- MacQueen, J.B. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 27 December 1965–7 January 1966; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. Available online: https://projecteuclid.org/euclid.bsmsp/1200512992 (accessed on 7 January 2020).
- Drineas, P.; Frieze, A.M.; Kannan, R.; Vempala, S.; Vinay, V. Clustering in Large Graphs and Matrices. In Proceedings of the SODA’99: Proceedings of the Tenth Annual ACM-SIAM Symposium on Discrete Algorithms, Baltimor, MA, USA, 17–19 January 1999; Available online: https://0-dl-acm-org.brum.beds.ac.uk/doi/10.5555/314500.314576 (accessed on 7 January 2020).
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1988; Available online: https://0-dl-acm-org.brum.beds.ac.uk/doi/book/10.5555/46712 (accessed on 7 January 2020).
- Mao, J.; Jain, A.K. A self-organizing network for hyperellipsoidal clustering (HEC). IEEE Trans. Neural Netw. 1996, 7, 16–29. [Google Scholar] [CrossRef] [PubMed]
- Bilmes, J.A. A Gentle Tutorial of the EM Algorithm and Its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models; International Computer Science Institute: Berkeley, CA, USA, 1998. [Google Scholar]
- Bishop, P. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; p. 430. Available online: https://0-search-ebscohost-com.brum.beds.ac.uk/login.aspx?direct=true&db=cat07429a&AN=ulpgc.547268&lang=es&site=eds-live&scope=site (accessed on 6 January 2020).
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Jin, R.; Kang, F.; Ding, C.H. A Probabilistic Approach for Optimizing Spectral Clustering. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2006; pp. 571–578. Available online: http://papers.nips.cc/paper/2952-a-probabilistic-approach-for-optimizing-spectral-clustering.pdf (accessed on 5 January 2020).
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2001, 14, 849–856. [Google Scholar]
- Yin, W.; Zhu, E.; Zhu, X.; Yin, J. Landmark-Based Spectral Clustering with Local Similarity Representation. In Theoretical Computer Science; Du, D., Li, L., Zhu, E., He, K., Eds.; Springer: Singapore, 2017; Volume 768, pp. 198–207. [Google Scholar] [CrossRef]
- Estudio Comparativo de las Universidades Mexicanas—Explorador de datos (ExECUM). 2017. Available online: http://www.execum.unam.mx/ (accessed on 7 January 2020).
- Márquez, A. Estudio comparativo de universidades mexicanas (ECUM): Otra mirada a la realidad universitaria. Rev. Iberoam. Educ. Super. 2010, I, 148–156. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Does It Belong to the Outstanding Group in Higher Learning? (Part 1) | Does It Belong to the Outstanding Group in Research? (Part 2) | Quadrant Where It Will Be Located |
|---|---|---|
| No | No | 1 |
| Yes | No | 2 |
| No | Yes | 3 |
| Yes | Yes | 4 |
| k-Means Results Summary | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | |
| Major higher learning, major research | IPN, UAM, UdeG | IPN, UAM, UdeG | IPN, UAM, UANL, UdeG | IPN, UAM, UANL, UdeG | IPN, UAM, UANL, UdeG | IPN, ITESM, UAM, UANL, UdeG | BUAP, IPN, ITESM, UAM, UANL, UdeG | BUAP, IPN, ITESM, UAM, UANL, UdeG | BUAP, IPN, ITESM, UAEMex, UAM, UANL, UdeG |
| Major higher learning, minor research | ITESM, UANL, UPN, UVM | ITESM, UANL, UPN, UVM | ITESM, UPN, UVM | BUAP, ITESM, LASALLE, UABC, UAEMex, UAS, UP, UPN, UV, UVM | ITESM, UABC, UAEMex, UAS, UPN, UV, UVM | UAEMex, UPN, UVM | UABC, UAEMex, UPN, UV, UVM | LASALLE, UABC, UAS, UP, UPN, UTM, UV, UVM | LASALLE, UABC, UAS, UPN, UTM, UV, UVM |
| Minor higher learning, major research | CINVESTAV | CINVESTAV | BUAP, CINVESTAV, UASLP | CINVESTAV | CINVESTAV, UASLP | BUAP, CINVESTAV, UASLP | CINVESTAV | CINVESTAV | UASLP, IBERO, CINVESTAV |
| GMM Results Summary | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | |
| Major higher learning, major research | IPN, UAM, UdeG | IPN, UAM, UANL, UdeG | IPN, UAM, UANL, UdeG | IPN, UAM, UANL, UdeG | IPN, UAM | IPN, UAM | IPN, UAM | IPN, UAM, BUAP, ITESM, UAEMex, UANL, UdeG | IPN, UAM, BUAP, ITESM, UAEMex, UANL, UdeG |
| Major higher learning, minor research | ITESM, UANL, UPN, UVM | ITESM, UPN, UVM | ITESM, UPN, UVM | ITESM, UPN, UVM | BUAP, ITESM, UANL, UPN, UAEMex, UVM, UdeG | BUAP, ITESM, LASALLE, UABC, UAEMex, UANL, UAS, UPN, UV, UVM, UdeG | BUAP, ITESM, LASALLE, UABC, UAEMex, UANL, UAS, UPN, UV, UVM, UdeG | LASALLE, UABC, UAS, UNITEC, UP, UPN, UV, UVM | |
| Minor higher learning, major research | CINVESTAV | CINVESTAV, UAEMOR, UGTO, UV | CINVESTAV, UAEMOR, UGTO, UV | CINVESTAV, UAEMOR, UGTO, UV | CINVESTAV | CINVESTAV | CINVESTAV | CINVESTAV | CINVESTAV, IBERO, UASLP |
| Spectral Clustering Results Summary | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | |
| Major higher learning, major research | ANAHUAC, ITSON, LASALLE, UAA, UABJO, UACH, UAG, UAdeC, UDEFA, UJAT, UJED, UNACH, UNITEC, UPN, UVM | ANAHUAC, ITSON, LASALLE, UABJO, UACH, UAG, UAN, UAdeC, UDEFA, UJAT, UJED, UNACH, UNITEC, UP, UPAEP, UPN, UVM | ANAHUAC, ITSON, LASALLE, UABJO, UACH, UAG, UAN, UAdeC, UDEFA, UJAT, UJED, UNACH, UNITEC, UP, UPAEP, UPN, UVM | ANAHUAC, ITSON, LASALLE, UAA, UABJO, UACH, UAG, UAGro, UAN, UATx, UAZ, UAdeC, UDEFA, UDEM, UJAT, UJED, UNACH, UNITEC, UP, UPAEP, UPN, UVM | ANAHUAC, IBERO, ITSON, LASALLE, UAA, UABJO, UACH, UAEH, UAG, UAGro, UAN, UAS, UAT, UATx, UAZ, UAdeC, UCOL, UDEFA, UDEM, UJAT, UJED, UNACH, UNITEC, UP, UPAEP, UPN, UVM | ITSON, LASALLE, UAA, UABJO, UAG, UAGro, UAN, UAT, UATx, UAdeC, UDEFA, UDEM, UJAT, UJED, UNACH, UNITEC, UP, UPAEP, UPN, UVM | ANAHUAC, LASALLE, UABJO, UAG, UAdeC, UDEM, UNACH, UNITEC, UPAEP, UPN, UVM | ANAHUAC, LASALLE, UABJO, UACH, UACJ, UAG, UAN, UAT, UATx, UAY, UAZ, UAdeC, UDEFA, UDEM, UJAT, UJED, UNACH, UNITEC, UP, UPAEP, UPN, UVM | ITESO, LASALLE, UAA, UABJO, UACJ, UAG, UAN, UATx, UAdeC, UDEM, UJED, UNACH, UNITEC, UP, UPAEP, UPN, UVM |
| Minor higher learning, major research | COLMEX, COLPOS, ITAM, UACAM, UACM, UDLAP | CHAPINGO, COLMEX, COLPOS, ITAM, UACAM, UACM, UDLAP | CHAPINGO, COLMEX, COLPOS, ITAM, UACAM, UACM, UDLAP | COLMEX, COLPOS, ITAM, UDLAP | COLPOS, ITAM | CHAPINGO, COLMEX, COLPOS, ITAM, UACM, UDLAP | CHAPINGO, COLMEX, COLPOS, ITAM, UACM, UAY, UCOL | CHAPINGO, COLPOS, UTM, ITAM, UCOL | |
| Minor higher learning, minor research | CHAPINGO, ITESO, UAAAN, UABCS, UAN, UATx, UDEM, UERRE, UNACAR, UNINTER, UQROO | ITESO, UAAAN, UABCS, UATx, UTM, UDEM, UERRE, UNACAR, UNINTER, UQROO | ITESO, UAAAN, UABCS, UATx, UTM, UDEM, UERRE, UNACAR, UNINTER, UQROO | CHAPINGO, ITESO, UAAAN, UABCS, UTM, UACAM, UACM, UERRE, UNACAR, UNINTER, UQROO | CHAPINGO, COLMEX, ITESO, UAAAN, UABCS, UTM, UACAM, UACM, UDLAP, UERRE, UNACAR, UNINTER, UQROO | ITESO, UAAAN, UABCS, UTM, UACAM, UERRE, UNACAR, UNINTER, UQROO | ITESO, ITSON, UAA, UAAAN, UABCS, UTM, UACAM, UAGro, UAN, UATx, UDEFA, UDLAP, UERRE, UJED, UNACAR, UNINTER, UQROO | CHAPINGO, COLMEX, COLPOS, ITAM, ITESO, ITSON, UTM, UAA, UAGro, UAAAN, UABCS, UACAM, UACM, UCOL, UDLAP, UERRE, UNACAR, UNINTER, UQROO | COLMEX, ITSON, UAAAN, UABCS, UACAM, UACM, UDEFA, UDLAP, UERRE, UNACAR, UNINTER, UQROO |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Urueta, D.E.; Lara, P.; Gutiérrez, M.Á.; de-los-Cobos, S.G.; Rincón, E.A.; Mora, R.A. A Comparative Ranking Model among Mexican Universities Using Pattern Recognition. Mathematics 2021, 9, 1615. https://0-doi-org.brum.beds.ac.uk/10.3390/math9141615
Urueta DE, Lara P, Gutiérrez MÁ, de-los-Cobos SG, Rincón EA, Mora RA. A Comparative Ranking Model among Mexican Universities Using Pattern Recognition. Mathematics. 2021; 9(14):1615. https://0-doi-org.brum.beds.ac.uk/10.3390/math9141615
Chicago/Turabian StyleUrueta, Daniel Edahi, Pedro Lara, Miguel Ángel Gutiérrez, Sergio Gerardo de-los-Cobos, Eric Alfredo Rincón, and Román Anselmo Mora. 2021. "A Comparative Ranking Model among Mexican Universities Using Pattern Recognition" Mathematics 9, no. 14: 1615. https://0-doi-org.brum.beds.ac.uk/10.3390/math9141615