
A New Goodness of Fit Test for Multivariate Normality and Comparative Simulation Study



1
Department of Applied Mathematics, Kaunas University of Technology, 51368 Kaunas, Lithuania
2
Department of Computer Sciences, Kaunas University of Technology, 51368 Kaunas, Lithuania
3
Department of Mathematical Modelling, Kaunas University of Technology, 51368 Kaunas, Lithuania
*
Author to whom correspondence should be addressed.
Mathematics 2021, 9(23), 3003; https://0-doi-org.brum.beds.ac.uk/10.3390/math9233003
Submission received: 12 October 2021
/
Revised: 18 November 2021
/
Accepted: 19 November 2021
/
Published: 23 November 2021
(This article belongs to the Special Issue Multivariate Statistics: Theory and Its Applications)
Abstract
:The testing of multivariate normality remains a significant scientific problem. Although it is being extensively researched, it is still unclear how to choose the best test based on the sample size, variance, covariance matrix and others. In order to contribute to this field, a new goodness of fit test for multivariate normality is introduced. This test is based on the mean absolute deviation of the empirical distribution density from the theoretical distribution density. A new test was compared with the most popular tests in terms of empirical power. The power of the tests was estimated for the selected alternative distributions and examined by the Monte Carlo modeling method for the chosen sample sizes and dimensions. Based on the modeling results, it can be concluded that a new test is one of the most powerful tests for checking multivariate normality, especially for smaller samples. In addition, the assumption of normality of two real data sets was checked.
1. Introduction
Much multivariate data is being collected by monitoring natural and social processes. IBM estimates that we all generate 175 zettabytes of data every day. To add, the data were collected at a rapidly increasing rate, i.e., it is estimated that 90% of data has been generated in the last two years. The need to extract useful information from continuously generated data sets drives demand for data specialists and the development of robust analysis methods.
Data analytics is inconceivable without testing the goodness of fit hypothesis. The primary task of a data analyst is to become familiar with the data sets received. This usually starts by identifying the distribution of the data. Then, the assumption that the data follow a normal distribution is usually tested. Since 1990, many tests have been developed to test this assumption, mostly for univariate data.
It is important to use the powerful tests for the goodness of fit hypothesis to test the assumption of normality because an alternative distribution is not known in general. Based on the outcome of normality verification, one can choose suitable analysis methods (parametric or non-parametric) for further investigation. From the end of the 20th century to the present day, multivariate tests for testing the goodness of fit hypothesis have been developed by a number of authors [1,2,3,4,5,6,7,8,9,10,11,12,13,14]. Some of the most popular and commonly used multivariate tests are Chi-Square [8], Cramer von Mises [2], Anderson-Darling [2], and Royston [3].
Checking the assumption of normality of multivariate data is more complex compared to univariate. Additional data processing is required (e.g., standardization). The development of multivariate tests is more complex because they require checking the properties of invariance and contingency. While for the univariate tests, the invariance property is always satisfied. The properties of invariance, contingency are presented in Section 2 and are discussed in more detail in [2,12,15].
The study aims to perform a power analysis of the multivariate goodness of fit hypothesis tests for the assumption of normality, to find out proposed test performances compared to other well-known tests and to apply the multivariate tests to the real data. The power estimation procedure is discussed in [16].
Scientific novelty. The power analysis of multivariate goodness of fit hypothesis testing for different data sets was performed. The goodness of fit tests were selected as representatives of popular techniques, which had been analyzed by other researchers experimentally. In addition, we proposed a new multivariate test based on the mean absolute deviation of the empirical distribution density from the theoretical distribution density. In this test, the density estimate is derived by using an inversion formula which is presented in Section 3.
The rest of the paper is organized as follows. Section 2 defines the tests for the comparative multivariate test power study. Section 3 presents details of our proposed test. Section 4 presents the data distributions used for experimental test power evaluation. Section 5 presents and discusses the results of simulation modeling. Section 6 discusses the application of multivariate goodness of fit hypothesis tests to real data. Finally, the conclusions and recommendations are given in Section 7.
2. Multivariate Tests for Normality
We denote the p-variate normal distribution as , where is an expectation vector and is the nonsingular covariance matrix. indicates a set of all possible p-variate normal distributions. Let where and , be a finite sample generated by a random p-variate (column) vector with distribution function . The mean vector is given by where is the sample size and the sample covariate matrix is
To assess multivariate normality of (based on the observed sample ) a lot of statistical tests have been developed. Before reviewing specific tests, selected for this study, let us consider two essential properties. The set is closed with respect to affine transformations, i.e.,
for any translation vector and any nonsingular matrix Thus, a reasonable statistic for checking the null hypothesis () of multivariate normality should have the same value for a sample and its affine transforms, that is
An invariant test has a statistic, which satisfies the condition (1). It might seem that a test based on a standardized sample
is invariant, however Henze and Zirkler [2] note that this is not always the case. In practice, for a given sample the alternative distribution is not know. In such a case it is important to use a test for which the probability of correctly rejecting tends to one as . Such a test is said to be consistent. For more elaborate discussion on these properties we refer the reader to [2]. Other important denotes are given in Appendix A.
2.1. Tests Based on Squared Radii
This section reviews the properties of several measures of squared radii concerning their use for assessing multivariate normality. Squared radii are defined as
have a distribution which, under normality, is times a distribution [9]. Under , the distribution of is approximately for large .
2.1.1. Chi-Squared (CHI2)
2.1.2. Cramer-Von Mises (CVM)
In 1982, Koziol proposed the use of Cramer-von Mises-type multivariate goodness of fit test based on order statistics [2]. This test statistic is defined as
where is order statistics.
2.1.3. Anderson-Darling (AD)
In 1987, Paulson, Roohan and Sullo proposed the Anderson-Darling type multivariate goodness of fit test based on order statistics [2]. The test statistic is defined as
2.2. Tests Based on Skewness and Kurtosis
This section reviews the properties of several measures of multivariate skewness and kurtosis regarding their use as statistics for assessing multivariate normality [2]. The skewness and kurtosis are defined as
where .
2.2.1. Doornik-Hansen (DH)
In 2008, Doornik-Hansen proposed a new multivariate goodness of fit test based on the skewness and kurtosis of multivariate data transformed to ensure independence [6]. The Doornik-Hansen test statistic is defined as the sum of squared transformations of the skewness and kurtosis. Approximately, the test statistic follows a distribution
where and are defined as
where
2.2.2. Royston (Roy)
In 1982, Royston proposed a test that uses the Shapiro-Wilk/Shapiro-Francia statistic to test multivariate normality. If the kurtosis of the sample is greater than 3, then it uses the Shapiro-Francia test for leptokurtic distributions. Otherwise it uses the Shapiro-Wilk test for platykurtic distributions [3,5]. Let be the Shapiro-Wilk/Shapiro-Francia test statistic for the th variable () and be the values obtained from the normality transformation [3,5].
Thus, it are observed that and change with the sample size. The transformed values of each random variable are obtained by [3,5]
where , and are derived from the polynomial approximations. The polynomial coefficients are provided for different [3,5]:
The Royston’s test statistic for multivariate normality is defined as
where is the equivalent degrees of freedom, is the cumulative distribution function for the standard normal distribution such that,
Let be the correlation matrix and is the correlation between th and th observations. Then, the extra term is found by
where
When and , then can be defined as
where , and are the unknown parameters, which are estimated by Ross modeling [4]. It was found that and for sample size and is a cubic function
2.2.3. Mardia (Mar1 and Mar2)
In 1970, K.V. Mardia proposed a new multivariate goodness of fit test based on skewness and kurtosis. The statistic for this test is defined as [17]
2.3. Other Tests
This section reviews the properties of several measures of non-negative functional distance, a covariance matrix and Energy distance concerning their use as statistics for assessing multivariate normality. A non-negative functional distance that measures the distance between two functions is defined as
where is the characteristic function of the multivariate standard normal, is the empirical characteristic function of the standardised observations, is a kernel (weighting) function
where and is a smoothing parameter that needs to be selected [10].
2.3.1. Energy (Energy)
In 2013, G. Szekely and M. Rizzo introduced a new multivariate goodness of fit test based on Energy distance between multivariate distributions. The statistic for this test is defined as [18]
where , is called scattering residues. and are independent randomly distributed vectors according to the normal distribution. , where is a Gamma function. The null hypothesis is rejected when acquires large values.
2.3.2. Lobato-Velasco (LV)
In 2004, I. Lobato and C. Velasco improved the Jarque and Bera test and applied it to stationary processes. The statistic for this test is defined as [19]
where is an auto-covariance function.
2.3.3. Henze-Zirkler (HZ)
In 1990, Henze and Zirkler introduced the HZ test [1]. The statistic for this test is defined as
where , .
gives the squared Mahalanobis distance of th observation to the centroid and gives the Mahalanobis distance between th and th observations. If the sample follows a multivariate normal distribution, the test statistic is approximately log-normally distributed with mean [1]
and variance [1]
where and Henze and Zirkler also proposed an optimal choice of the parameter in using in the p-variate case as [1]
A drawback of the Henze-Zirkler test is that, when is rejected, the possible violation of normality is generally not straightforward. Thus, many biomedical researchers would prefer a more informative and equally or more powerful test than the Henze-Zirkler test [5].
2.3.4. Nikulin-Rao-Robson (NRR) and Dzhaparidze-Nikulin (DN)
In 1981, Moore and Stubblebine suggested a multivariate Nikulin-Rao-Robson (NRR) goodness of fit test [7,8]. This test statistic for a covariance matrix of any dimension is defined as
where is a vector of standardized cell frequencies with components
where is the number of random vectors falling into . Then the limiting covariance matrix of standardized frequencies is , where is the matrix with elements
where is a r-vector with its entries as , 𝕞 is the number of unknown parameters, is the Fisher information matrix of size for one observation which evaluated as
where is the covariance matrix of (a vector of the entries of arranged column-wise by taking the upper triangular elements) [7]:
The second term of recovers information lost due to data grouping. Another useful decomposition of is defined as
where is the multivariate statistic defined by Dzhaparidze and Nikulin (1974) [7]. It is defined as
and in 1985, McCulloch presented a multivariate test statistic [7]:
If rank , then and are asymptotically independent and distributed in the limit as and , respectively.
3. The New Test
Our test is based on distribution distance and has been derived using an inversion formula. The estimation of a sample distribution density is based on application of the characteristic function and inversion formula. This method is known for its good properties (i.e., low sensitivity) and has been introduced in [20]. Marron and Wand [21] carried out an extensive comparison of density estimation methods (including the adapted kernel method) and concluded that density estimation based on application of characteristic function and inversion is more accurate for non-Gaussian data sets.
The random -variate vector , which follows a distribution of a mixture model has a density function
where is the number of clusters (i.e., components, classes) of the mixture, and is the a priori probability which satisfy
The is a distribution of the th class and is a set of parameters . We denote the -variate sample of independent and identically distributed random values .
When examining approximations of parametric methods, it should be emphasized that as the data dimension increases, the number of model parameters increases rapidly, making it more difficult to find accurate parameter estimates. It is much easier to find density of univariate data projections
than multivariate data density because of mutually unambiguous compliance.
It is quite natural to try to find the multivariate density using the density estimates of univariate observational projections [20]. In case of Gaussian mixture model, the projection of the observations (15) is also distributed according to the Gaussian mixture model:
where is univariate Gaussian density. The parameter set θ of the multivariate mixture and the distribution parameters of the data projections , are related by equations:
The inversion formula is used
where
where denotes the characteristic function of the random variable. Given that , and by changing the variables to a spherical coordinate system we obtain
where the first integral is the surface integral of the unit sphere. The characteristic function of the projection of the observed random variable is
and has the property
By selecting the set of uniform distributed directions on the sphere and replacing the characteristic function with its estimate, a density estimate is obtained [20,22]:
where denotes a size of set . Using the p-variate ball volume formula
the constant defined as
Computer simulation studies have shown that the density estimates obtained using the inversion formula are not smooth. Therefore, in Formula (24), an additional multiplier is used. This multiplier smoothes the estimate with the Gaussian kernel function. Moreover, this form of the multiplier allows the integral value to be calculated analytically. Monte Carlo studies have shown that its use significantly reduces the error of estimates. Formula (24) can be used to estimate the characteristic function of the projected data. Let us consider two approaches. The first one is based on the density approximation of the Gaussian distribution mixture model. In this case, the parametric estimate of the characteristic function is used:
By substituting in (24) by (27), we get
where
We note, that only the real part of the expression is considered here (the sum of the imaginary parts must be equal to zero) in other words, the density estimate can acquire only the real values. The chosen form of the smoothing multiplier allows relating the smoothing parameter with the variances of the projection clusters, i.e., in the calculations the variances are simply increased by . Next, the expression (29) is evaluated.
Let
then (29) can be written as
By integrating in parts, we get
is expressed analogously. With respect to the limitations of the j index, the following recursive equations are obtained:
The initial function is founded by starting with the relation
From (35) and (38) it follows that satisfies the differential equation
which is solved by writing down as the Taylor series:
By equating the coefficients of the same powers, its values are obtained:
which gives us
is found from expression (30):
The value of the integral (24) then is
One of the disadvantages of the inversion formula method (defined by (24)) is that the Gaussian distribution mixture model (13) described by this estimate (for ) does not represent density accuratelly, except around observations. When approximating the density under study with a mixture of Gaussian distributions, the estimation of the density using the inversion formula often becomes complicated due to a large number of components. Thus, we merge components with small a priori probabilities into one noise cluster.
We have developed and examined a modification of the algorithm which is based on the use of a multivariate Gaussian distribution mixture model. The parametric estimate of the characteristic function of uniform distribution density is defined as
in the inversion Formula (19). In the density estimate calculation Formula (24), the estimation of the characteristic function is constructed as a union of the characteristic functions of a mixture of Gaussian distributions and uniform distribution with corresponding a priori probabilities:
where the second member describes uniformly distributed noise cluster, —noise cluster weight, , . Based on the established estimates of the parameters of the uniform distribution and data projections, it is possible to define the range
By inserting (46) to (24) we obtain
Using notations such as (28), we define the density estimate as
where is given in (29) which is evaluated by (44) and
By integrating, we get
where and are defined in (30) and (31). Then the integral (51) evaluates to
The above procedure is called a modified inversion formula density estimate. Our proposed normality test is based on the distance function
where is a standardized value, is an estimate of density function.
The choice of G(z) (54) is influenced by three aspects [23]:
- G(z) assigns high weight where |f(z)−| is large, f(z) pertaining to the alterative hypothesis. the distribution density is related to the alternative hypothesis.
- G(z) gives high weight where the is a relatively precise estimator of f(z).
- G(z) is such that the integral (54) has a closed form.
For the distribution free method, the first two aspects are fulfilled by adequately selecting the smoothness parameter , in addition it yields a closed (54) integral form
does not depend on a moderate sample volume (32) but depends on the data dimension. It is convenient to use the test statistics which had the lowest sensitivity based on the exploratory study. Under the null hypothesis statistic approximately follows the Johnson SU distribution which is specified by the shape (), scale (), location () parameters and has the density function
where , .
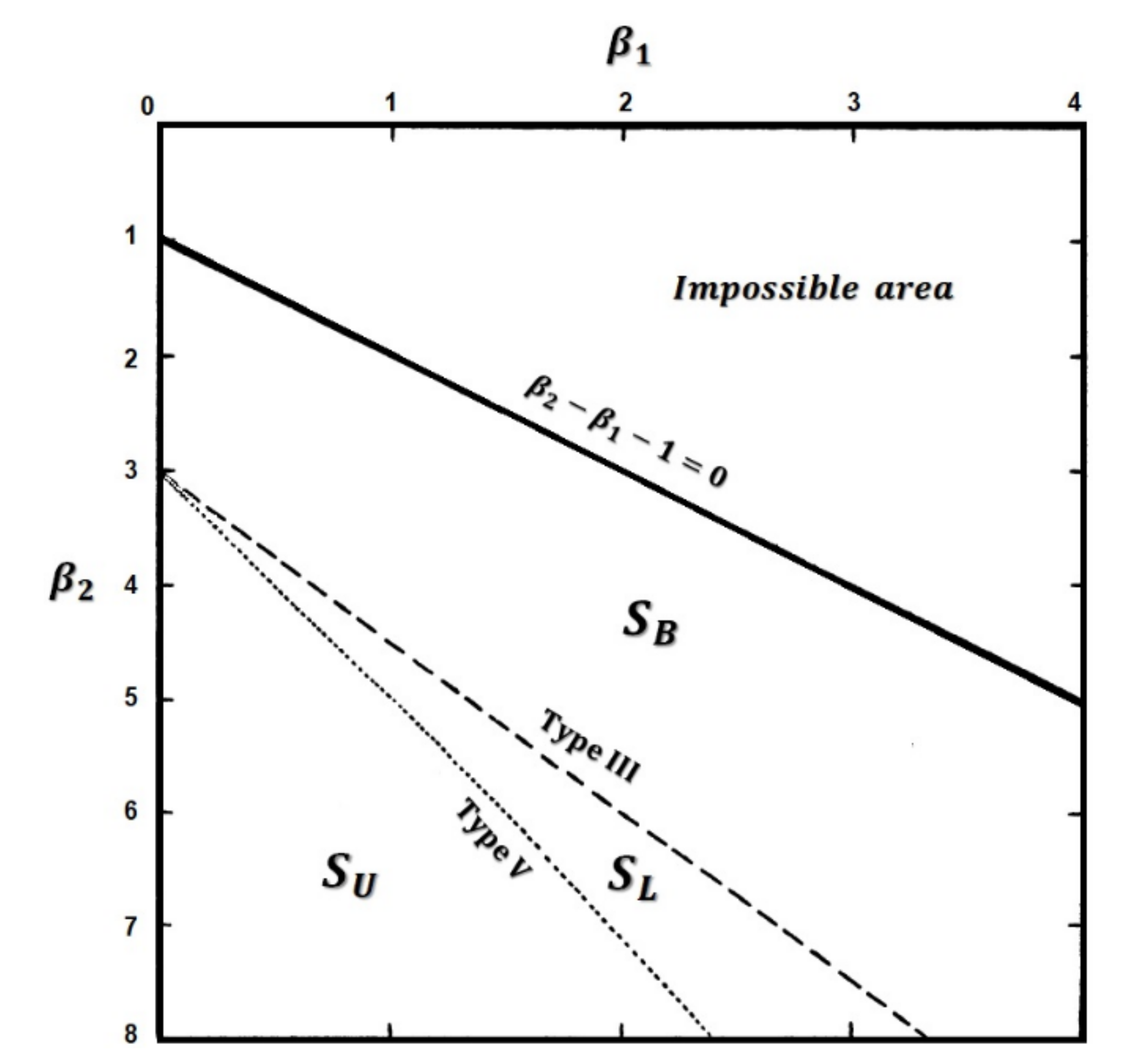
In the middle of the twentieth century, N. L. Johnson [24] proposed certain systems of curve derived by the method of translation, which, retain most of the advantages and eliminate some of the drawbacks of the systems first based on this method. Johnson introduced log-normal (SL), bounded (SB), and unbounded (SU) systems. The bounded system range of variation covers the area between the bounding line and the Pearson Type III distribution; where (, ) points are obtained from the distribution moments defined by Wicksell [25]:
It follows that
The SU system is bounded at one end only (Pearson Type V). The SL system is lying between SB and SU systems. These regions are indicated in Figure 1. The SU system is presented in detail in [24].
Estimates of statistic Johnson SU distribution parameters for different dimensions are given in Table 1.
For statistic , the invariance and contingency properties were checked. The invariance property is confirmed because standardized data was used. The contingency property is confirmed experimentally (see Section 5).
4. Statistical Distributions
The overviewed normality tests are assessed by the simulation study of 11 statistical distributions grouped into four groups: symmetric, asymmetric, mixed and normal mixture distributions [5]. A description of these distribution groups is given in the following subsections.
4.1. A Group of Symmetric Distributions
Symmetric multivariate distributions are taken from the research [5]:
- Three cases of the Beta(a,b) distribution − Beta(1,1),Beta(1,2) and Beta(2,2), where a and b are the shape parameters.
- One case of the Cauchy(t,s) distribution − Cauchy(0,1), where t and s are the location and scale parameters.
- One case of the Laplace(t,s) distribution − Laplace(0,1), where t and s are the location and scale parameters.
- One case of the Logistic(t,s) distribution − Logistic(0,1), where t and s are the location and scale parameters.
- Two cases of the t-Student(ν) distribution − t(2) and t(5), where ν is the number of degrees of freedom.
- One case of the standard normal N(0,1) distribution.
4.2. A Group of Asymmetric Distributions
Asymmetric multivariate distributions are taken from the research [5]:
- Five cases of the Chi-squared(ν) distribution − χ2 (1), χ2 (2), χ2 (5), χ2 (10) and χ2 (15), where ν is the number of degrees of freedom.
- Two cases of the Gamma(a,b) distribution − Gamma(0.5,1) and Gamma(5,1), where a and b are the shape and scale parameters.
- One case of the Gumbel(t,s) distribution − Gumbel(1,2), where t and s are the location and scale parameters.
- Two cases of the Lognormal(t,s) distribution − LN(0,1) and LN(0,0.25) where t and s are the location and scale parameters.
- Tree cases of the Weibull(β) distribution − Weibull(0.8), Weibull(1) and Weibull(1.5), where β is the shape parameter.
4.3. A Group of Mixed Distributions
The generated mixed data distribution
is such that the first m variates (i.e., Xk1, Xk2, …, Xkm) follow the standard normal distribution and distribution of the remaining variates is one of the non-normal distributions (Laplace(0,1), χ2(5), t(5), Beta(1,1), Beta(1,2), Beta(2,2)). The experimental research covers the cases for m = p − 1, m = p/2 and m = 1.
4.4. A Group of Normal Mixture Distributions
Normal mixture distributions are considered in this research [5]: nine cases of the multivariate normal mixture distribution MVNMIX (a,b,c,d) − MVNMIX (0.5,2,0,0), MVNMIX (0.5,4,0,0), MVNMIX (0.5,2,0.9,0), MVNMIX (0.5,0.5,0.9,0), MVNMIX (0.5,0.5,0.9,0.1), MVNMIX(0.5,0.5,0.9,0.9), MVNMIX(0.7,2,0.9,0.3), MVNMIX(0.3,1,0.9,0.1), MVNMIX(0.3,1,0.9,0.9). The multivariate normal mixture distribution with density:
where is the column vector with all elements being 1,
5. Simulation Study and Discussion
This section provides a modeling study that evaluates the power of selected multivariate normality tests. We used the Monte Carlo method to compare our proposed test with 13 multivariate tests described above for dimensions , with sample sizes at significance level . Power was estimated by applying the tests on 1 000 000 randomly drawn samples from the alternative distribution (Beta, Cauchy, Laplace, Logistic, Student, Standard normal, Chi-Square, Gamma, Gumbel, Lognormal, Weibull, Mixed, Normal mixture).
The values of the test smoothness parameter () were selected experimentally: from 0.1 to 5 with a step of 0.1. The value of the test parameter was determined for each dimension considered. It was found that the best results are obtained (i.e., maximum statistical value) for with , for with , and for with . These smoothness parameter values were used to carry out the numerical experiments.
The power of 13 (including our proposed test) multivariate goodness of fit hypothesis tests was estimated calculated for different sample sizes, distributions and mixtures. The mean power values for the groups for distributions (given in Section 4), for each test and sample sizes, have been computed and presented in Table 2, Table 3, Table 4 and Table 5. It can be determined that the new test for the groups of symmetric and mixed distributions is the most powerful one. In the group of asymmetric distributions, the new (for ) and Roy (for and ) tests are the most powerful ones. The new (for and ) and Roy (for with sample sizes ) tests are also the most powerful in the group of normal distribution mixtures. Comparing the Mardia (Mar1 and Mar2) tests, based on asymmetry and excess coefficients, it has been found that Mar1 is the most powerful only for the group of asymmetric distributions. For the group of symmetric distributions the power of this test is the lowest (compared to other tests).
In order to supplement and emphasize the results presented in Table 2, Table 3, Table 4 and Table 5, the generalized line diagrams were drawn using the Trellis display [26] multivariate data visualization method. The resulting graph is shown in Figure 2 which shows that the New test is significantly more powerful than the other tests. The power of the Mar1 tests is the lowest compared with the other tests. Figure 2 indicate that the power of the tests increases as the sample size increases. By increasing the dimensions of the power of 8 (AD, CHI2, CVM, Energy, HZ, New, Mar1 and NRR) tests decreases while the power of the other (DH, DN, LV, Mar2 and Roy) tests increases slightly. For small sample sizes, the most powerful tests are New, Roy and DH. For large sample sizes, the most powerful tests are New, Energy, HZ and LV.
6. Examples
6.1. Survival Data
The data set collected in 2001–2020 by the Head of the Department of Urology Clinic of the Lithuanian University of Health Sciences [27] illustrates the practical application. This dataset consists of study data from 2423 patients and two different continuous attributes (patient age and prostate-specific antigen (PSA)). The assumption of normality was verified by filtering patients’ age and PSA by year of death (i.e., deaths during the first 1, 2, 3, 4, 5, 6, 7, 10, and 15 years). The filtered data was standardized. The power and p-value were calculated for the multivariate tests. The significance level of was used for the study. Based on the obtained results, it was found that all the applied multivariate tests rejected the the hypothesis of normality. The power of tests CHI2, DH, Energy, HZ, LV, New, Mar, NRR and Roy was 0.999 and the p-value was <0.0001. Except for DN test, which power was 0.576 and the p-value was 0.026.
6.2. IQOS Data
In 2017, the data set of pollution research with IQOS and traditional cigarettes [28] was used by Kaunas University of Technology, Faculty of Chemical Technology, and Department of Environmental Technology for practical application. This data set consists of 33 experiments (with different conditions) in which the numerical (Pn10) and mass concentrations (Pm2.5, Pm10) of particles were measured. The assumption of normality was checked by filtering Pn10, Pm2.5, Pm10 according to the number of the experiment in the smoking phase. The filtered data was standardized. The power and p-values of multivariate tests with a significance level of were calculated. Based on the obtained results, it was found that all the applied multivariate tests show that the assumption of normality is rejected. Most of the multivariate tests used (CHI2, DH, Energy, HZ, LV, New, Mar, NRR, and Roy) had a power of 0.999 and p-value of <0.0001. The power of the other tests was also close to 0.99 and the p-value was about 0.0001.
7. Conclusions
In this study, the comprehensive comparison of the power of 13 multivariate goodness of fit tests was performed for groups of symmetric, asymmetric, mixed, and normal mixture distributions. Two-dimensional, five-dimensional, and ten-dimensional data sets were generated to estimate the test power empirically.
A new multivariate goodness of fit test based on inversion formula was proposed. Based on the obtained modeling results, it was determined that the most powerful tests for the groups of symmetric, asymmetric mixed and normal mixture distributions are the proposed test and Roy multivariate test. From two real data examples, it was concluded that our proposed test is stable, even when applied to real data sets.
Author Contributions
Data curation, J.A., T.R.; Formal analysis, J.A., T.R.; Investigation, J.A., T.R.; Methodology, J.A., T.R.; Software, J.A., T.R.; Supervision, T.R.; Writing—original draft, J.A., M.B.; writing—review and editing, J.A., M.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Generated data sets were used in the study (see in Section 4).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
| is p-variate set of real numbers, |
| is p-variate vector, |
| #T denotes a size of set T, |
| is dimension, |
| is smoothness parameter, |
| are ordered statistics, |
| is the probability distribution function of , |
| is skewness, |
| is kurtosis, |
| is sample size, |
| is sample mean, |
| is sample variance, |
| is a standardized value, |
| is number of variables, |
| is the equivalent degrees of freedom, |
| is the cumulative distribution function for the standard normal distribution, |
| is the correlation matrix, |
| is the correlation between and observations, |
| is a vector of standardized cell frequencies, |
| is the number of random vectors, |
| is the Fisher information matrix, |
| is the covariance matrix of , |
| is the characteristic function of the multivariate standard normal, |
| is the empirical characteristic function of the standardised observations, |
| is a kernel (weighting) function, |
| is a Gamma function, |
| is an auto-covariance function, |
| is Mahalanobis distance between and observations, |
| is the normality transformations, |
| is a distribution of the class, |
| is a set of parameters , |
| is the characteristic function of the random variable. |
| is the a priori probability, |
| is the radius of the ball (bounded sphere), |
| is a quantile of standardized normal distribution |
| and are shape parameters, |
| is scale parameter, |
| is location parameter. |
References
- Henze, N.; Zirkler, B. A class of invariant consistent tests for multivariate normality. Commun. Stat. Theory Methods 1990, 19, 3595–3617. [Google Scholar] [CrossRef]
- Henze, N. Invariant tests for multivariate normality: A critical review. Stat. Pap. 2002, 43, 467–506. [Google Scholar] [CrossRef]
- Royston, J.P. An extension of Shapiro and Wilk’s W test for normality to large samples. Appl. Stat. 1982, 31, 115–124. [Google Scholar] [CrossRef]
- Ross, G.J.S.; Hawkins, D. MLP: Maximum Likelihood Program; Rothamsted Experimental Station: Harpenden, UK, 1980. [Google Scholar]
- Korkmaz, S.; Goksuluk, D.; Zararsiz, G. MVN: An R Package for Assessing Multivariate Normality. R J. 2014, 6, 151–162. [Google Scholar] [CrossRef] [Green Version]
- Doornik, J.A.; Hansen, H. An Omnibus Test for Univariate and Multivariate Normality. Oxf. Bull. Econ. Stat. 2008, 70, 927–939. [Google Scholar]
- Voinov, V.; Pya, N.; Makarov, R.; Voinov, Y. New invariant and consistent chi-squared type goodness-of-fit tests for multivariate normality and a related comparative simulation study. Commun. Stat. Theory Methods 2016, 45, 3249–3263. [Google Scholar] [CrossRef]
- Moore, D.S.; Stubblebine, J.B. Chi-square tests for multivariate normality with application to common stock prices. Commun. Stat. Theory Methods 1981, A10, 713–738. [Google Scholar] [CrossRef]
- Gnanadesikan, R.; Kettenring, J.R. Robust estimates, residuals, and outlier detection with multiresponse data. Biometrics 1972, 28, 81–124. [Google Scholar]
- Górecki, T.; Horváth, L.; Kokoszka, P. Tests of Normality of Functional Data. Int. Stat. Rev. 2020, 88, 677–697. [Google Scholar] [CrossRef]
- Pinto, L.P.; Mingoti, S.A. On hypothesis tests for covariance matrices under multivariate normality. Pesqui. Operacional. 2015, 35, 123–142. [Google Scholar] [CrossRef] [Green Version]
- Dörr, P.; Ebner, B.; Henze, N. A new test of multivariate normality by a double estimation in a characterizing PDE. Metrika 2021, 84, 401–427. [Google Scholar] [CrossRef]
- Zhoua, M.; Shao, Y. A Powerful Test for Multivariate Normality. J. Appl Stat. 2014, 41, 351–363. [Google Scholar] [CrossRef] [Green Version]
- Kolkiewicz, A.; Rice, G.; Xie, Y. Projection pursuit based tests of normality with functional data. J. Stat. Plan. Inference 2021, 211, 326–339. [Google Scholar] [CrossRef]
- Ebner, B.; Henze, N. Tests for multivariate normality-a critical review with emphasis on weighted L^2-statistics. TEST 2020, 29, 845–892. [Google Scholar] [CrossRef]
- Arnastauskaitė, J.; Ruzgas, T.; Bražėnas, M. An Exhaustive Power Comparison of Normality Tests. Mathematics 2021, 9, 788. [Google Scholar] [CrossRef]
- Mardia, K. Measures of Multivariate Skewness and Kurtosis with Applications. Biometrika 1970, 57, 519–530. [Google Scholar] [CrossRef]
- Szekely, J.G.; Rizzo, L.M. Energy statistics: A class of statistics based on distances. J. Stat. Plan. Inference 2013, 143, 1249–1272. [Google Scholar] [CrossRef]
- Lobato, I.; Velasco, C. A simple Test of Normality for Time Series. Econom. Theory 2004, 20, 671–689. [Google Scholar] [CrossRef] [Green Version]
- Ruzgas, T. The Nonparametric Estimation of Multivariate Distribution Density Applying Clustering Procedures. Ph.D. Thesis, Institute of Mathematics and Informatics, Vilnius, Lithuania, 2007; p. 161. [Google Scholar]
- Marron, J.S.; Wand, M.P. Exact mMean Integrated Squared Error. Ann. Stat. 1992, 20, 712–736. [Google Scholar] [CrossRef]
- Kavaliauskas, M.; Rudzkis, R.; Ruzgas, T. The Projection-based Multivariate Distribution Density Estimation. Acta Comment. Univ. Tartu. Math. 2004, 8, 135–141. [Google Scholar]
- Epps, T.W.; Pulley, L.B. A test for normality based on the empirical characteristic function. Biometrika 1983, 70, 723–726. [Google Scholar] [CrossRef]
- Johnson, N.L. Systems of Frequency Curves Generated by Methods of Translation. Biometrika 1949, 36, 149–176. [Google Scholar] [CrossRef] [PubMed]
- Wicksell, S.D. The construction of the curves of equal frequency in case of type A correlation. Ark. Mat. Astr. Fys. 1917, 12, 1–19. [Google Scholar]
- Theus, M. High Dimensional Data Visualization. In Handbook of Data Visualization; Springer: Berlin/Heidelberg, Germany, 2008; pp. 5–7. [Google Scholar]
- Milonas, D.; Ruzgas, T.; Venclovas, Z.; Jievaltas, M.; Joniau, S. The significance of prostate specific antigen persistence in prostate cancer risk groups on long-term oncological outcomes. Cancers 2021, 13, 2453. [Google Scholar] [CrossRef]
- Martuzevicius, D.; Prasauskas, T.; Setyan, A.; O’Connell, G.; Cahours, X.; Julien, R.; Colard, S. Characterization of the Spatial and Temporal Dispersion Differences Between Exhaled E-Cigarette Mist and Cigarette Smoke. Nicotine Tob. Res. 2019, 21, 1371–1377. [Google Scholar] [CrossRef]
Figure 1.
Regions of Johnson’s systems.

Figure 2.
The summary of average empirical power of all examined distribution groups by sample size and dimensionality.
Figure 2.
The summary of average empirical power of all examined distribution groups by sample size and dimensionality.


{kind=link}
{kind=link}
Table 1.
Statistic Johnson SU distribution parameter estimates.
| Parameter | Symbol | Estimate |
|---|---|---|
| p = 2 | ||
| Location | 4.342807 | |
| Scale | 0.585038 | |
| Shape | 1.498293 | |
| Shape | 0.764906 | |
| p = 5 | ||
| Location | 7.025845 | |
| Scale | 0.088023 | |
| Shape | 0.895003 | |
| Shape | 0.400035 | |
| p = 10 | ||
| Location | 5.195174 | |
| Scale | 1.578613 | |
| Shape | 2.24856 | |
| Shape | −1.83037 | |
Table 2.
An average empirical power for a group of symmetric distributions.
| AD | CHI2 | CVM | DH | DN | Energy | HZ | LV | New | Mar1 | Mar2 | NRR | Roy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| p = 2 | |||||||||||||
| n = 32 | 0.651 | 0.57 | 0.652 | 0.677 | 0.565 | 0.65 | 0.644 | 0.696 | 0.999 | 0.532 | 0.605 | 0.608 | 0.703 |
| n = 64 | 0.778 | 0.692 | 0.779 | 0.809 | 0.671 | 0.77 | 0.765 | 0.815 | 0.999 | 0.617 | 0.751 | 0.736 | 0.819 |
| n = 128 | 0.867 | 0.798 | 0.868 | 0.892 | 0.768 | 0.86 | 0.853 | 0.893 | 0.999 | 0.681 | 0.857 | 0.842 | 0.891 |
| n = 256 | 0.92 | 0.873 | 0.92 | 0.932 | 0.847 | 0.914 | 0.906 | 0.932 | 0.999 | 0.721 | 0.917 | 0.91 | 0.929 |
| n = 512 | 0.939 | 0.912 | 0.94 | 0.945 | 0.903 | 0.941 | 0.936 | 0.945 | 0.999 | 0.743 | 0.942 | 0.941 | 0.944 |
| n = 1024 | 0.945 | 0.932 | 0.945 | 0.949 | 0.937 | 0.948 | 0.947 | 0.949 | 0.999 | 0.758 | 0.95 | 0.949 | 0.95 |
| p = 5 | |||||||||||||
| n = 32 | 0.644 | 0.531 | 0.624 | 0.735 | 0.585 | 0.632 | 0.622 | 0.763 | 0.985 | 0.523 | 0.637 | 0.602 | 0.784 |
| n = 64 | 0.791 | 0.656 | 0.775 | 0.864 | 0.7 | 0.758 | 0.755 | 0.871 | 0.989 | 0.621 | 0.792 | 0.739 | 0.875 |
| n = 128 | 0.883 | 0.773 | 0.876 | 0.924 | 0.806 | 0.863 | 0.856 | 0.925 | 0.988 | 0.696 | 0.89 | 0.851 | 0.924 |
| n = 256 | 0.929 | 0.864 | 0.926 | 0.941 | 0.886 | 0.921 | 0.91 | 0.941 | 0.987 | 0.735 | 0.934 | 0.916 | 0.941 |
| n = 512 | 0.942 | 0.916 | 0.942 | 0.946 | 0.932 | 0.945 | 0.94 | 0.946 | 0.981 | 0.752 | 0.948 | 0.944 | 0.947 |
| n = 1024 | 0.946 | 0.941 | 0.946 | 0.949 | 0.949 | 0.949 | 0.949 | 0.949 | 0.985 | 0.764 | 0.95 | 0.95 | 0.95 |
| p = 10 | |||||||||||||
| n = 32 | 0.557 | 0.473 | 0.534 | 0.754 | 0.599 | 0.598 | 0.604 | 0.791 | 0.997 | 0.458 | 0.65 | 0.599 | 0.834 |
| n = 64 | 0.754 | 0.604 | 0.728 | 0.884 | 0.704 | 0.709 | 0.71 | 0.893 | 0.998 | 0.592 | 0.802 | 0.719 | 0.905 |
| n = 128 | 0.878 | 0.726 | 0.865 | 0.934 | 0.817 | 0.821 | 0.831 | 0.935 | 0.998 | 0.676 | 0.899 | 0.844 | 0.934 |
| n = 256 | 0.928 | 0.824 | 0.922 | 0.941 | 0.896 | 0.906 | 0.901 | 0.941 | 0.998 | 0.733 | 0.94 | 0.913 | 0.943 |
| n = 512 | 0.942 | 0.891 | 0.941 | 0.945 | 0.936 | 0.943 | 0.937 | 0.945 | 0.991 | 0.747 | 0.951 | 0.942 | 0.946 |
| n = 1024 | 0.945 | 0.928 | 0.945 | 0.948 | 0.949 | 0.948 | 0.949 | 0.948 | 0.991 | 0.756 | 0.95 | 0.949 | 0.95 |
Table 3.
An average empirical power for a group of asymmetric distributions.
| AD | CHI2 | CVM | DH | DN | Energy | HZ | LV | New | Mar1 | Mar2 | NRR | Roy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| p = 2 | |||||||||||||
| n = 32 | 0.634 | 0.631 | 0.639 | 0.852 | 0.55 | 0.832 | 0.811 | 0.87 | 0.999 | 0.813 | 0.63 | 0.639 | 0.877 |
| n = 64 | 0.744 | 0.767 | 0.744 | 0.956 | 0.657 | 0.93 | 0.906 | 0.961 | 0.999 | 0.941 | 0.776 | 0.759 | 0.962 |
| n = 128 | 0.827 | 0.861 | 0.822 | 0.995 | 0.724 | 0.985 | 0.968 | 0.995 | 0.999 | 0.992 | 0.876 | 0.841 | 0.995 |
| n = 256 | 0.897 | 0.931 | 0.892 | 0.999 | 0.774 | 0.999 | 0.995 | 0.999 | 0.999 | 0.999 | 0.947 | 0.915 | 0.999 |
| n = 512 | 0.954 | 0.977 | 0.949 | 0.999 | 0.816 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.988 | 0.968 | 0.999 |
| n = 1024 | 0.985 | 0.996 | 0.982 | 0.999 | 0.864 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.993 | 0.999 |
| p = 5 | |||||||||||||
| n = 32 | 0.614 | 0.6 | 0.608 | 0.915 | 0.551 | 0.854 | 0.798 | 0.932 | 0.982 | 0.803 | 0.623 | 0.61 | 0.945 |
| n = 64 | 0.763 | 0.779 | 0.761 | 0.99 | 0.675 | 0.958 | 0.907 | 0.992 | 0.989 | 0.954 | 0.791 | 0.763 | 0.993 |
| n = 128 | 0.869 | 0.892 | 0.869 | 0.999 | 0.748 | 0.996 | 0.974 | 0.999 | 0.997 | 0.997 | 0.908 | 0.869 | 0.999 |
| n = 256 | 0.946 | 0.965 | 0.947 | 0.999 | 0.812 | 0.999 | 0.998 | 0.999 | 0.997 | 0.999 | 0.978 | 0.95 | 0.999 |
| n = 512 | 0.984 | 0.994 | 0.985 | 0.999 | 0.872 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.997 | 0.989 | 0.999 |
| n = 1024 | 0.995 | 0.999 | 0.995 | 0.999 | 0.926 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 |
| p = 10 | |||||||||||||
| n = 32 | 0.483 | 0.443 | 0.459 | 0.944 | 0.532 | 0.829 | 0.744 | 0.96 | 0.922 | 0.693 | 0.573 | 0.532 | 0.98 |
| n = 64 | 0.707 | 0.712 | 0.7 | 0.998 | 0.679 | 0.956 | 0.861 | 0.998 | 0.947 | 0.931 | 0.746 | 0.722 | 0.999 |
| n = 128 | 0.863 | 0.87 | 0.859 | 0.999 | 0.776 | 0.997 | 0.954 | 0.999 | 0.98 | 0.997 | 0.898 | 0.86 | 0.999 |
| n = 256 | 0.955 | 0.96 | 0.953 | 0.999 | 0.858 | 0.999 | 0.994 | 0.999 | 0.995 | 0.999 | 0.978 | 0.952 | 0.999 |
| n = 512 | 0.99 | 0.994 | 0.989 | 0.999 | 0.93 | 0.999 | 0.999 | 0.999 | 0.996 | 0.999 | 0.998 | 0.992 | 0.999 |
| n = 1024 | 0.996 | 0.999 | 0.996 | 0.999 | 0.975 | 0.999 | 0.999 | 0.999 | 0.996 | 0.999 | 0.999 | 0.999 | 0.999 |
Table 4.
An average empirical power for a group of mixed distributions.
| AD | CHI2 | CVM | DH | DN | Energy | HZ | LV | New | Mar1 | Mar2 | NRR | Roy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| p = 2 | |||||||||||||
| n = 32 | 0.469 | 0.408 | 0.463 | 0.436 | 0.439 | 0.582 | 0.572 | 0.453 | 0.999 | 0.476 | 0.412 | 0.444 | 0.451 |
| n = 64 | 0.572 | 0.476 | 0.567 | 0.51 | 0.511 | 0.703 | 0.697 | 0.547 | 0.999 | 0.577 | 0.527 | 0.533 | 0.513 |
| n = 128 | 0.683 | 0.571 | 0.679 | 0.591 | 0.59 | 0.809 | 0.807 | 0.667 | 0.999 | 0.659 | 0.651 | 0.641 | 0.572 |
| n = 256 | 0.78 | 0.667 | 0.778 | 0.66 | 0.674 | 0.872 | 0.871 | 0.749 | 0.999 | 0.717 | 0.762 | 0.741 | 0.643 |
| n = 512 | 0.848 | 0.763 | 0.847 | 0.746 | 0.763 | 0.895 | 0.894 | 0.808 | 0.999 | 0.76 | 0.843 | 0.827 | 0.72 |
| n = 1024 | 0.883 | 0.842 | 0.883 | 0.826 | 0.835 | 0.902 | 0.901 | 0.857 | 0.999 | 0.78 | 0.884 | 0.878 | 0.764 |
| p = 5 | |||||||||||||
| n = 32 | 0.626 | 0.466 | 0.585 | 0.545 | 0.538 | 0.703 | 0.706 | 0.553 | 0.982 | 0.584 | 0.584 | 0.551 | 0.47 |
| n = 64 | 0.749 | 0.582 | 0.726 | 0.631 | 0.684 | 0.788 | 0.815 | 0.628 | 0.989 | 0.675 | 0.723 | 0.694 | 0.524 |
| n = 128 | 0.805 | 0.67 | 0.791 | 0.695 | 0.771 | 0.845 | 0.864 | 0.692 | 0.995 | 0.722 | 0.791 | 0.769 | 0.589 |
| n = 256 | 0.852 | 0.729 | 0.841 | 0.747 | 0.825 | 0.88 | 0.885 | 0.751 | 0.998 | 0.75 | 0.838 | 0.822 | 0.669 |
| n = 512 | 0.88 | 0.763 | 0.875 | 0.777 | 0.865 | 0.894 | 0.895 | 0.81 | 0.999 | 0.766 | 0.864 | 0.863 | 0.73 |
| n = 1024 | 0.894 | 0.789 | 0.893 | 0.795 | 0.891 | 0.9 | 0.899 | 0.883 | 0.999 | 0.778 | 0.889 | 0.889 | 0.764 |
| p = 10 | |||||||||||||
| n = 32 | 0.688 | 0.477 | 0.642 | 0.58 | 0.669 | 0.719 | 0.745 | 0.592 | 0.916 | 0.614 | 0.731 | 0.679 | 0.475 |
| n = 64 | 0.753 | 0.579 | 0.744 | 0.69 | 0.753 | 0.744 | 0.78 | 0.69 | 0.942 | 0.68 | 0.796 | 0.753 | 0.529 |
| n = 128 | 0.775 | 0.651 | 0.771 | 0.736 | 0.776 | 0.777 | 0.821 | 0.735 | 0.94 | 0.722 | 0.795 | 0.774 | 0.602 |
| n = 256 | 0.802 | 0.709 | 0.795 | 0.761 | 0.793 | 0.823 | 0.87 | 0.76 | 0.968 | 0.745 | 0.811 | 0.79 | 0.689 |
| n = 512 | 0.833 | 0.746 | 0.821 | 0.778 | 0.818 | 0.875 | 0.892 | 0.776 | 0.995 | 0.764 | 0.84 | 0.814 | 0.745 |
| n = 1024 | 0.866 | 0.763 | 0.853 | 0.791 | 0.842 | 0.897 | 0.899 | 0.79 | 0.997 | 0.779 | 0.861 | 0.837 | 0.769 |
Table 5.
An average empirical power for a group of normal mixture distributions.
| AD | CHI2 | CVM | DH | DN | Energy | HZ | LV | New | Mar1 | Mar2 | NRR | Roy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| p = 2 | |||||||||||||
| n = 32 | 0.465 | 0.422 | 0.468 | 0.56 | 0.428 | 0.537 | 0.529 | 0.588 | 0.999 | 0.433 | 0.437 | 0.442 | 0.607 |
| n = 64 | 0.576 | 0.508 | 0.581 | 0.74 | 0.503 | 0.682 | 0.672 | 0.752 | 0.999 | 0.544 | 0.563 | 0.544 | 0.778 |
| n = 128 | 0.71 | 0.618 | 0.715 | 0.893 | 0.582 | 0.836 | 0.823 | 0.895 | 0.999 | 0.633 | 0.707 | 0.664 | 0.908 |
| n = 256 | 0.844 | 0.738 | 0.848 | 0.974 | 0.685 | 0.938 | 0.926 | 0.974 | 0.999 | 0.701 | 0.84 | 0.805 | 0.978 |
| n = 512 | 0.943 | 0.845 | 0.945 | 0.998 | 0.791 | 0.986 | 0.977 | 0.998 | 0.999 | 0.733 | 0.931 | 0.924 | 0.998 |
| n = 1024 | 0.987 | 0.917 | 0.988 | 0.999 | 0.882 | 0.999 | 0.998 | 0.999 | 0.999 | 0.757 | 0.977 | 0.985 | 0.999 |
| p = 5 | |||||||||||||
| n = 32 | 0.45 | 0.399 | 0.441 | 0.594 | 0.443 | 0.503 | 0.485 | 0.632 | 0.98 | 0.384 | 0.46 | 0.442 | 0.672 |
| n = 64 | 0.574 | 0.491 | 0.563 | 0.782 | 0.51 | 0.64 | 0.621 | 0.795 | 0.994 | 0.516 | 0.59 | 0.539 | 0.828 |
| n = 128 | 0.699 | 0.598 | 0.689 | 0.916 | 0.594 | 0.781 | 0.761 | 0.92 | 0.997 | 0.619 | 0.728 | 0.655 | 0.934 |
| n = 256 | 0.806 | 0.702 | 0.798 | 0.979 | 0.691 | 0.894 | 0.877 | 0.979 | 0.999 | 0.694 | 0.832 | 0.766 | 0.984 |
| n = 512 | 0.889 | 0.787 | 0.883 | 0.998 | 0.782 | 0.963 | 0.95 | 0.998 | 0.999 | 0.736 | 0.905 | 0.857 | 0.998 |
| n = 1024 | 0.946 | 0.857 | 0.942 | 0.999 | 0.859 | 0.992 | 0.985 | 0.999 | 0.999 | 0.758 | 0.954 | 0.925 | 0.999 |
| p = 10 | |||||||||||||
| n = 32 | 0.402 | 0.392 | 0.396 | 0.62 | 0.495 | 0.476 | 0.487 | 0.667 | 0.989 | 0.287 | 0.547 | 0.487 | 0.735 |
| n = 64 | 0.556 | 0.47 | 0.537 | 0.8 | 0.536 | 0.599 | 0.581 | 0.815 | 0.984 | 0.472 | 0.634 | 0.55 | 0.855 |
| n = 128 | 0.709 | 0.587 | 0.692 | 0.915 | 0.629 | 0.723 | 0.708 | 0.919 | 0.977 | 0.582 | 0.758 | 0.674 | 0.939 |
| n = 256 | 0.801 | 0.688 | 0.79 | 0.973 | 0.723 | 0.834 | 0.815 | 0.974 | 0.971 | 0.669 | 0.834 | 0.771 | 0.98 |
| n = 512 | 0.853 | 0.76 | 0.846 | 0.995 | 0.8 | 0.912 | 0.887 | 0.995 | 0.971 | 0.711 | 0.885 | 0.833 | 0.997 |
| n = 1024 | 0.893 | 0.818 | 0.886 | 0.999 | 0.85 | 0.96 | 0.939 | 0.999 | 0.973 | 0.739 | 0.924 | 0.875 | 0.999 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Arnastauskaitė, J.; Ruzgas, T.; Bražėnas, M. A New Goodness of Fit Test for Multivariate Normality and Comparative Simulation Study. Mathematics 2021, 9, 3003. https://0-doi-org.brum.beds.ac.uk/10.3390/math9233003
AMA Style
Arnastauskaitė J, Ruzgas T, Bražėnas M. A New Goodness of Fit Test for Multivariate Normality and Comparative Simulation Study. Mathematics. 2021; 9(23):3003. https://0-doi-org.brum.beds.ac.uk/10.3390/math9233003
Chicago/Turabian StyleArnastauskaitė, Jurgita, Tomas Ruzgas, and Mindaugas Bražėnas. 2021. "A New Goodness of Fit Test for Multivariate Normality and Comparative Simulation Study" Mathematics 9, no. 23: 3003. https://0-doi-org.brum.beds.ac.uk/10.3390/math9233003
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.