Performance Comparison of Parametric and Non-Parametric Regression Models for Uncertainty Analysis of Sheet Metal Forming Processes


 , , and
, , and 
Abstract
:1. Introduction
2. Metamodeling
2.1. Response Surface Method (RSM)
2.2. Polynomial Chaos Expansion (PCE)
2.3. Gaussian Process (GP)
2.4. Multi-Layer Perceptron (MLP)
2.5. Decision Trees (DTs) and Random Forest (RF)
2.6. k-Nearest Neighbors (kNN)
2.7. Support Vector Regression (SVR)
2.8. Kernel Ridge Regression (KRR)
3. Forming Simulations and Metamodeling Procedure
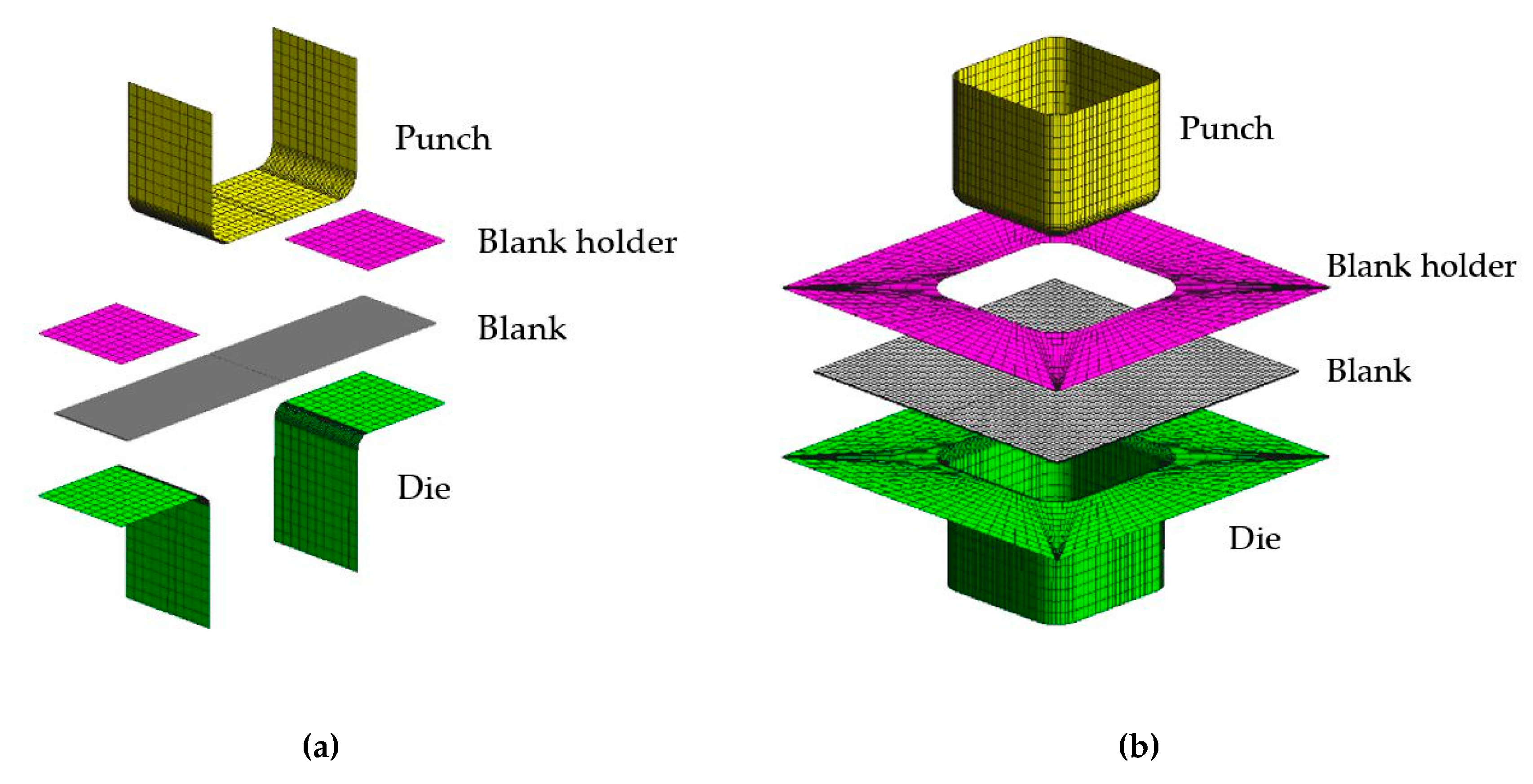
3.1. Numerical Models
3.2. Parameter Variability
3.3. Metamodel Generation and Evaluation
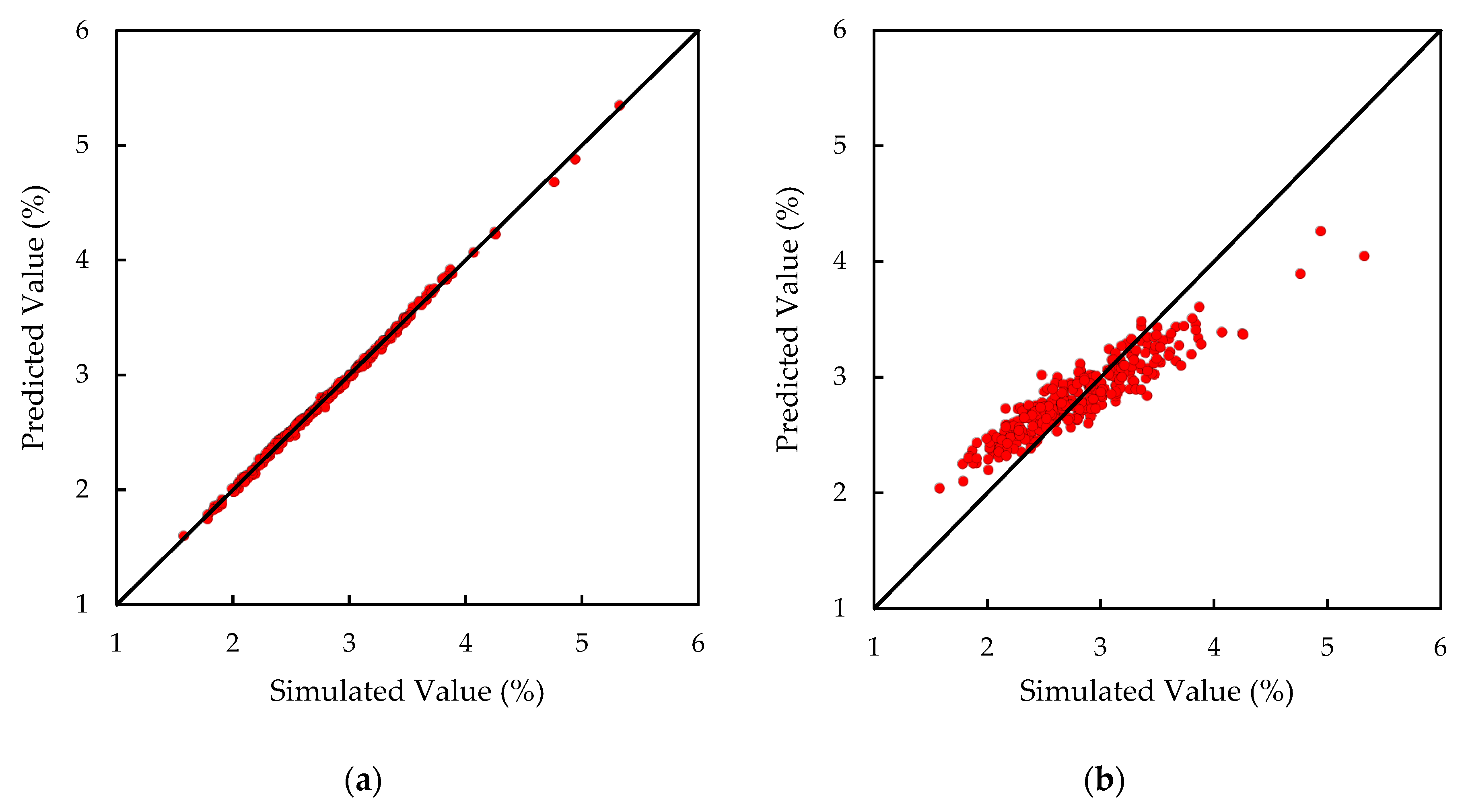
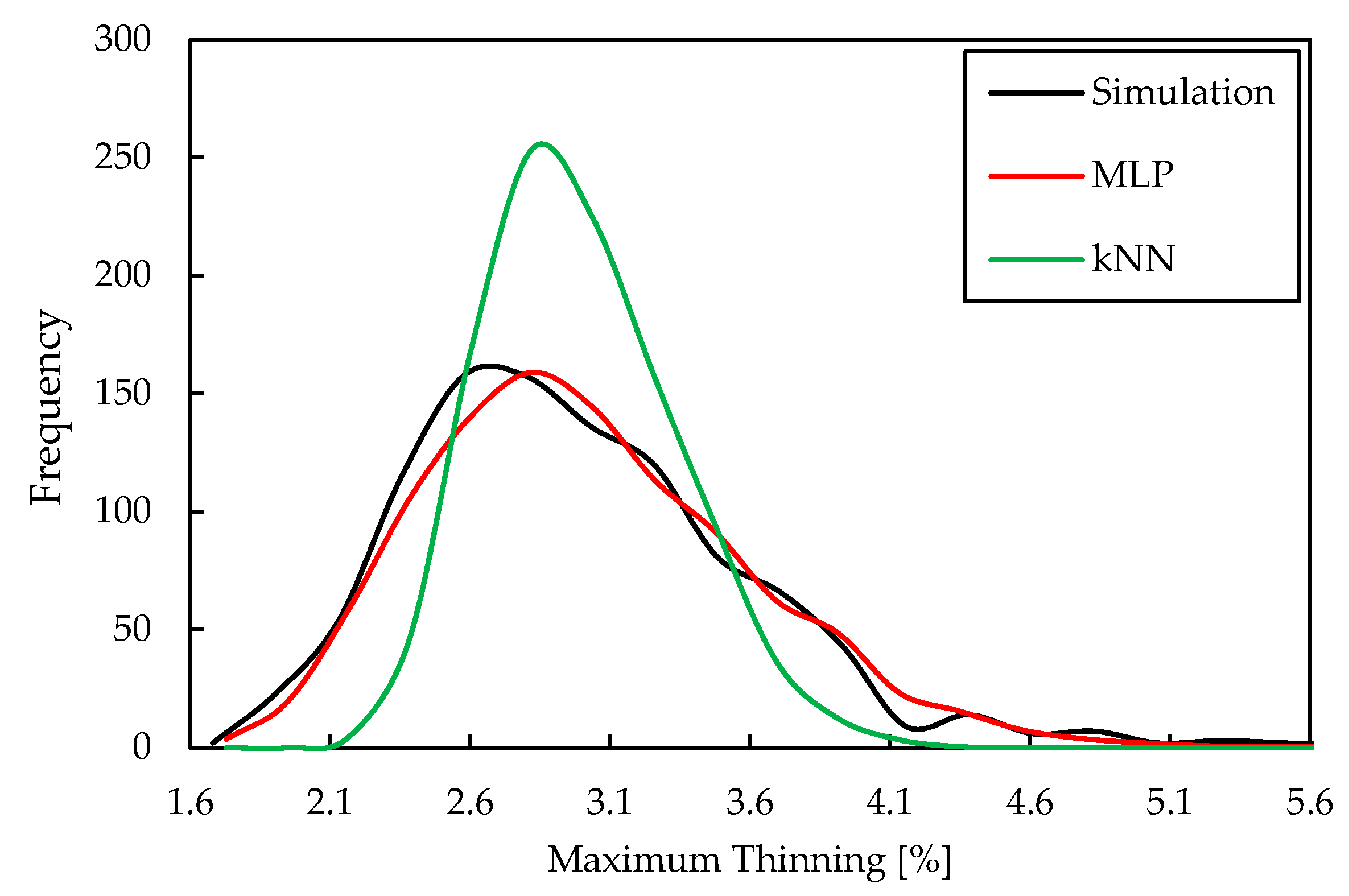
4. Results and Discussion
5. Conclusions
- The ML techniques can be divided into two groups in terms of performance:
- ○
- The first group consists of the DT, RF, and kNN metamodeling techniques, which generally showed poor performances, with kNN in particular producing the poorest predictions.
- ○
- The second group consists of the MLP, GP, SVR, and KRR techniques. For almost all cases studied, the best predictive performance corresponded to one of these techniques, with MLP showing the best performance in more cases than any other. It is also of note that the performance of these techniques is comparable and, as such, the usage of any of them can be recommended.
- The parametric modeling techniques, RSM and PCE, showed competitive performances when compared with the second group of ML techniques and should be considered as valid alternatives.
- The performance of both types of modeling techniques depends on the response under analysis. For the particular case of the maximum thinning, GP shows better performance compared to the other techniques.
- When training metamodels to predict forming process results for different materials, the usage of just one dataset containing the training data of all materials should be considered, instead of training a different model for each material.
Author Contributions
Funding
Conflicts of Interest
Notations
| Symbol | Description |
| Set of pre-selected multi-index | |
| Number of RSM coefficients | |
| , , | Swift hardening law parameters |
| E | Young’s modulus |
| , , , , , | Anisotropy parameters |
| GP random variable | |
| , | Vector of GP predictions, covariance of GP outputs |
| Linear system matrix | |
| , , | Index variables |
| Identity matrix | |
| KRR cost function | |
| Covariance matrix | |
| k | Selected number of nearest training points in the kNN model |
| Number of sources of variability | |
| , | Number of training and testing points, respectively |
| , , | Anisotropy coefficients |
| Initial sheet thickness | |
| SVR trade-off variable | |
| Normal weight vector | |
| , | Weight parameter, bias |
| Vector of design variables (Inputs) | |
| , | Training matrix, testing matrix |
| , | Vector of design variables of a training and a testing point, respectively |
| Flow stress | |
| Vector of simulation responses | |
| Simulation response for set of inputs | |
| Metamodel response for set of inputs | |
| , | Output of the current MLP node, output of a node at the prior layer |
| Multi-index | |
| Vector of unknowns for the RSM model | |
| , , , , | RSM and PCE coefficients |
| SVR threshold parameter | |
| Noise variable | |
| Equivalent plastic strain | |
| Regularization term | |
| µ | Friction coefficient |
| ν | Poisson coefficient |
| , | SVR slack variables |
| , , , , , | Components of the Cauchy stress tensor |
| Noise variance | |
| Orthogonal polynomial basis | |
| Activation Function in MLP |
References
- Wei, D.; Cui, Z.; Chen, J. Optimization and tolerance prediction of sheet metal forming process using response surface model. Comput. Mater. Sci. 2008, 42, 228–233. [Google Scholar] [CrossRef]
- Naceur, H.; Ben-Elechi, S.; Batoz, J.L.; Knopf-Lenoir, C. Response surface methodology for the rapid design of aluminum sheet metal forming parameters. Mater. Des. 2008, 29, 781–790. [Google Scholar] [CrossRef]
- Sun, G.; Li, G.; Li, Q. Variable fidelity design based surrogate and artificial bee colony algorithm for sheet metal forming process. Finite Elem. Anal. Des. 2012, 59, 76–90. [Google Scholar] [CrossRef]
- Teimouri, R.; Baseri, H.; Rahmani, B.; Bakhshi-Jooybari, M. Modeling and optimization of spring-back in bending process using multiple regression analysis and neural computation. Int. J. Mater. Form. 2014, 7, 167–178. [Google Scholar] [CrossRef]
- Wessing, S.; Rudolph, G.; Turck, S.; Klimmek, C.; Schäfer, S.C.; Schneider, M.; Lehmann, U. Replacing FEA for sheet metal forming by surrogate modeling. Cogent Eng. 2012, 1. [Google Scholar] [CrossRef]
- Ambrogio, G.; Ciancio, C.; Filice, L.; Gagliardi, F. Innovative metamodelling-based process design for manufacturing: an application to Incremental Sheet Forming. Int. J. Mater. Form. 2017, 10, 279–286. [Google Scholar] [CrossRef]
- Feng, Y.; Hong, Z.; Gao, Y.; Lu, R.; Wang, Y.; Tan, J. Optimization of variable blank holder force in deep drawing based on support vector regression model and trust region. Int. J. Adv. Manuf. 2019, 105, 4265–4278. [Google Scholar] [CrossRef]
- Lin, J.D.; Huang, L.; Zhou, H.B. Forming defects prediction for sheet metal forming using Gaussian process regression. In Proceedings of the 29th Chinese Control and Decision Conference, Chongqing, China, 28–30 May 2017. [Google Scholar] [CrossRef]
- Wiebenga, J.H.; Atzema, E.H.; An, Y.G.; Vegter, H.; van den Boogaard, A.H. Effects of material scatter on the plastic behavior and stretchability in sheet metal forming. J. Mater. Process. Technol. 2014, 214, 238–252. [Google Scholar] [CrossRef]
- Blatman, G. Adaptive Sparse Polynomial Chaos Expansions for Uncertainty Propagation and Sensitivity Analysis. Ph.D. Thesis, Université Blaise Pascal, Clermont-Ferrand, France, 8 October 2009. [Google Scholar] [CrossRef]
- Kaur, D.; Wilson, D.; Forrest, M.; Feng, L. Regression tree and neuro-fuzzy approach to system identification of laser lap welding. In Proceedings of the 2005 Annual Meeting of the North American Fuzzy Information Processing Society, Detroit, MI, USA, 26–28 June 2005. [Google Scholar] [CrossRef]
- Segal, M.R. Machine Learning Benchmarks and Random Forest Regression. In UCSF: Center for Bioinformatics and Molecular Biostatistics; 2004; Available online: https://escholarship.org/uc/item/35x3v9t4 (accessed on 30 January 2020).
- Cook, B.; Huber, M. Balanced k-Nearest Neighbors. In Proceedings of the Thirty-Second International Flairs Conference, Florida, FL, USA, 19–22 May 2019. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Welling, M. Kernel ridge regression. Max Welling’s Classnotes in Machine Learning. 2013. Available online: https://www.ics.uci.edu/~welling/classnotes/papers_class/Kernel-Ridge.pdf (accessed on 30 January 2020).
- Menezes, L.F.; Teodosiu, C. Three-dimensional numerical simulation of the deep-drawing process using solid finite elements. J. Mater. Process. Technol. 2000, 97, 100–106. [Google Scholar] [CrossRef] [Green Version]
- Neto, D.M.; Oliveira, M.C.; Menezes, L.F. Surface Smoothing Procedures in Computational Contact Mechanics. Arch. Comput. Meth. Eng. 2017, 24, 37–87. [Google Scholar] [CrossRef]
- Alves, J.L. Simulação Numérica do Processo de Estampagem de Chapas Metálicas. Ph.D. Thesis, University of Minho, Guimarães, Portugal, 7 November 2003. [Google Scholar]
- GPy: A Gaussian Process Framework in Python. Available online: http://github.com/SheffieldML/GPy (accessed on 22 January 2020).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Materials | C (MPa) | n | Y0 (MPa) | E (GPa) | ν | µ | r0 | r45 | r90 | t0 (mm) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DC06 | Mean | 565.32 | 0.259 | 157.12 | 206 | 0.3 | 0.144 | 1.790 | 1.510 | 2.270 | 0.780 |
| SD | 26.85 | 0.018 | 7.16 | 3.85 | 0.015 | 0.029 | 0.051 | 0.037 | 0.121 | 0.013 | |
| DP600 | Mean | 1093.0 | 0.187 | 330.30 | 210 | 0.3 | 0.144 | 1.010 | 0.760 | 0.980 | 0.780 |
| SD | 52.46 | 0.02 | 9.64 | 7.35 | 0.015 | 0.029 | 0.04 | 0.03 | 0.06 | 0.01 | |
| HSLA340 | Mean | 673.0 | 0.131 | 365.30 | 210 | 0.3 | 0.144 | 0.820 | 1.070 | 1.040 | 0.780 |
| SD | 32.30 | 0.011 | 10.67 | 7.35 | 0.015 | 0.029 | 0.033 | 0.039 | 0.061 | 0.005 |
| U-Channel | Springback | Maximum Thinning | ||||||
| DC06 | DP600 | HSLA340 | Mixed | DC06 | DP600 | HSLA340 | Mixed | |
| RSM | 2.223 | 1.084 | 1.117 | 1.574 | 0.905 | 1.046 | 0.970 | 2.146 |
| PCE | 2.111 | 1.084 | 1.184 | 2.098 | 0.861 | 1.058 | 1.144 | 1.563 |
| GP | 2.132 | 1.060 | 1.023 | 1.572 | 0.849 | 1.025 | 0.875 | 1.017 |
| MLP | 1.986 | 1.113 | 1.019 | 1.476 | 0.772 | 1.242 | 0.782 | 1.097 |
| SVR | 2.230 | 1.056 | 1.090 | 1.538 | 0.883 | 1.048 | 0.864 | 1.083 |
| DT | 4.620 | 4.004 | 3.448 | 4.776 | 5.742 | 4.290 | 3.992 | 6.047 |
| RF | 2.876 | 2.726 | 2.298 | 3.545 | 4.022 | 2.815 | 2.796 | 4.104 |
| kNN | 4.068 | 3.777 | 2.950 | 4.542 | 10.846 | 5.599 | 5.585 | 6.877 |
| KRR | 2.168 | 1.057 | 1.072 | 1.546 | 0.851 | 1.035 | 0.865 | 1.060 |
| Square Cup | Maximum Equivalent Plastic Strain | Maximum Thinning | ||||||
| DC06 | DP600 | HSLA340 | Mixed | DC06 | DP600 | HSLA340 | Mixed | |
| RSM | 0.519 | 1.741 | 0.744 | 1.523 | 0.688 | 1.607 | 2.258 | 1.687 |
| PCE | 0.514 | 1.741 | 0.750 | 1.201 | 0.688 | 1.577 | 2.242 | 1.748 |
| GP | 0.493 | 1.618 | 0.666 | 1.230 | 0.672 | 1.538 | 2.195 | 1.529 |
| MLP | 0.607 | 1.653 | 0.952 | 1.416 | 0.661 | 1.553 | 2.233 | 1.633 |
| SVR | 0.533 | 1.606 | 0.836 | 1.231 | 0.688 | 1.585 | 2.221 | 1.556 |
| DT | 1.210 | 2.415 | 1.688 | 2.009 | 2.499 | 2.582 | 3.612 | 3.550 |
| RF | 0.823 | 1.830 | 1.308 | 1.490 | 1.734 | 1.850 | 2.682 | 2.527 |
| kNN | 1.322 | 2.754 | 2.253 | 2.899 | 2.481 | 2.419 | 3.084 | 4.188 |
| KRR | 0.518 | 1.689 | 0.665 | 1.321 | 0.673 | 1.545 | 2.147 | 1.532 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marques, A.E.; Prates, P.A.; Pereira, A.F.G.; Oliveira, M.C.; Fernandes, J.V.; Ribeiro, B.M. Performance Comparison of Parametric and Non-Parametric Regression Models for Uncertainty Analysis of Sheet Metal Forming Processes. Metals 2020, 10, 457. https://0-doi-org.brum.beds.ac.uk/10.3390/met10040457
Marques AE, Prates PA, Pereira AFG, Oliveira MC, Fernandes JV, Ribeiro BM. Performance Comparison of Parametric and Non-Parametric Regression Models for Uncertainty Analysis of Sheet Metal Forming Processes. Metals. 2020; 10(4):457. https://0-doi-org.brum.beds.ac.uk/10.3390/met10040457
Chicago/Turabian StyleMarques, Armando E., Pedro A. Prates, André F. G. Pereira, Marta C. Oliveira, José V. Fernandes, and Bernardete M. Ribeiro. 2020. "Performance Comparison of Parametric and Non-Parametric Regression Models for Uncertainty Analysis of Sheet Metal Forming Processes" Metals 10, no. 4: 457. https://0-doi-org.brum.beds.ac.uk/10.3390/met10040457