
About the Data Analysis of Optical Emission Spectra of Reactive Ion Etching Processes—The Method of Spectral Redundancy Reduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Theory
2.1. Spectral Clustering
- Construction of the adjacency matrix.
- Computation of the (normalized) Laplacian matrix.
- Computation of the first k eigenvectors of the Laplacian matrix.
- Analysis of the eigenvectors.
2.2. Calculation of the Adjacency Matrix
2.3. Calculation of the Gaussian Similarity
3. Materials and Methods
3.1. Algorithms of the MSRR
3.1.1. Euclidean Distance
| Algorithm 1: Calculation of the Euclidean distance |
| Input : Data matrix with q columns and n rows Output: Distance matrix of dimension
|
3.1.2. Cosine and Sine Similarity
| Algorithm 2: Calculation of the cosine similarity matrix |
| Input : Data matrix with q columns and n rows Output: Similarity matrix of dimension |
| Algorithm 3: Calculation of the sine similarity |
| Input : Data matrix with q columns and n rows Output: Adjacency matrix of dimension |
3.1.3. Gaussian Similarity
| Algorithm 4: Calculation of the Gaussian similarity |
| Input : Data matrix with q columns and n rows Output: Adjacency matrix of dimension
|
3.1.4. Full Algorithm of MSRR
| Algorithm 5: Method of spectral redundancy reduction |
| Input : Data matrix with q columns and n rows Output: Reduced spectrum (a vector of length q)
|
3.2. Generation of Test Data Sets
3.3. Dry Etching Processes
- Layer materials consisting of a single component were etched.
- The layer to be etched did not have density gradients.
- Ideally, the material was completely removed, i.e., no mask materials generated additional plasma species contributing to the spectrum.
- The precursor mixture included only components that allowed for the clear identification of depletion effects (the intensity loss or increase caused by variations in species consumption or generation).
4. Results
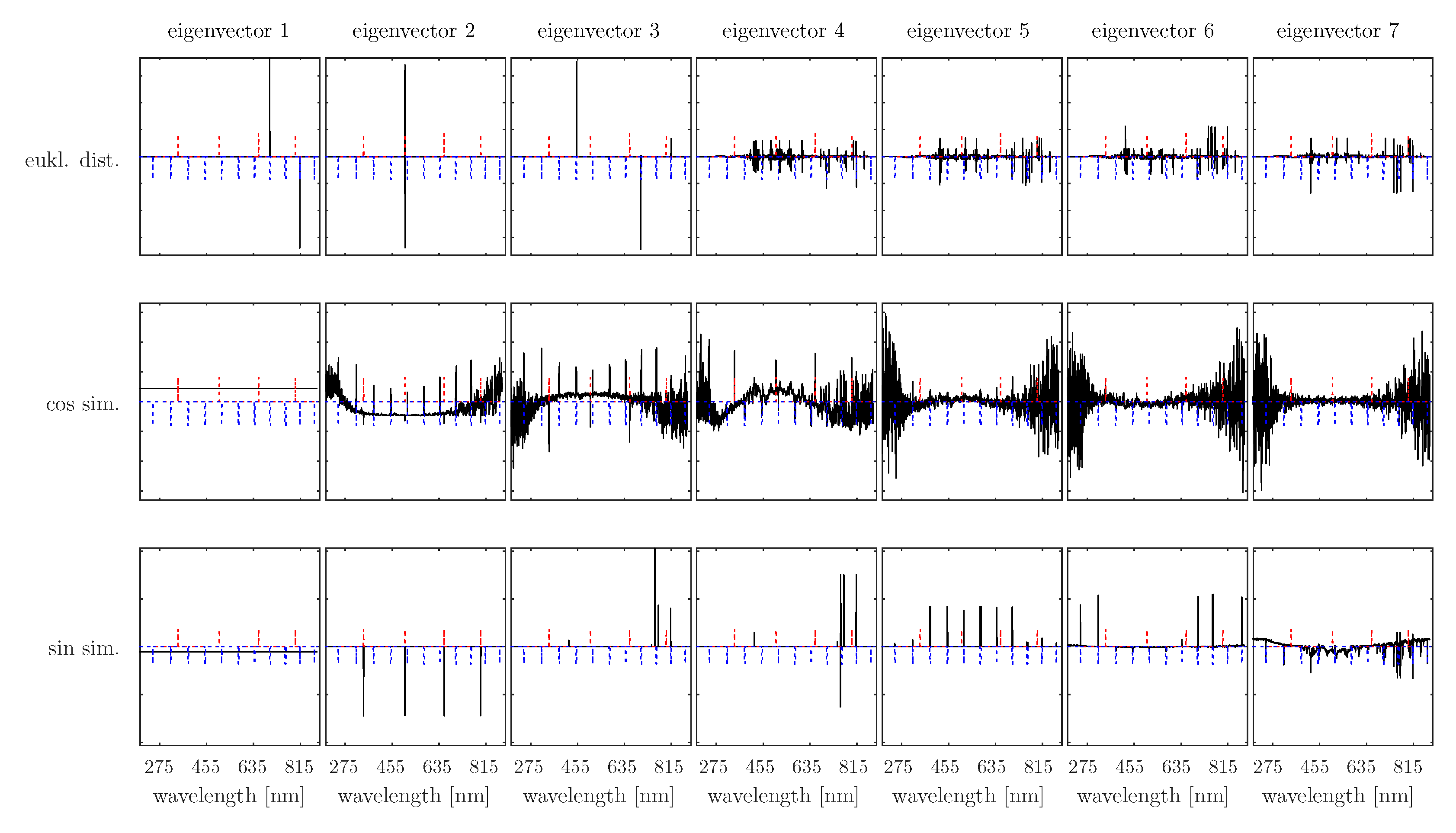
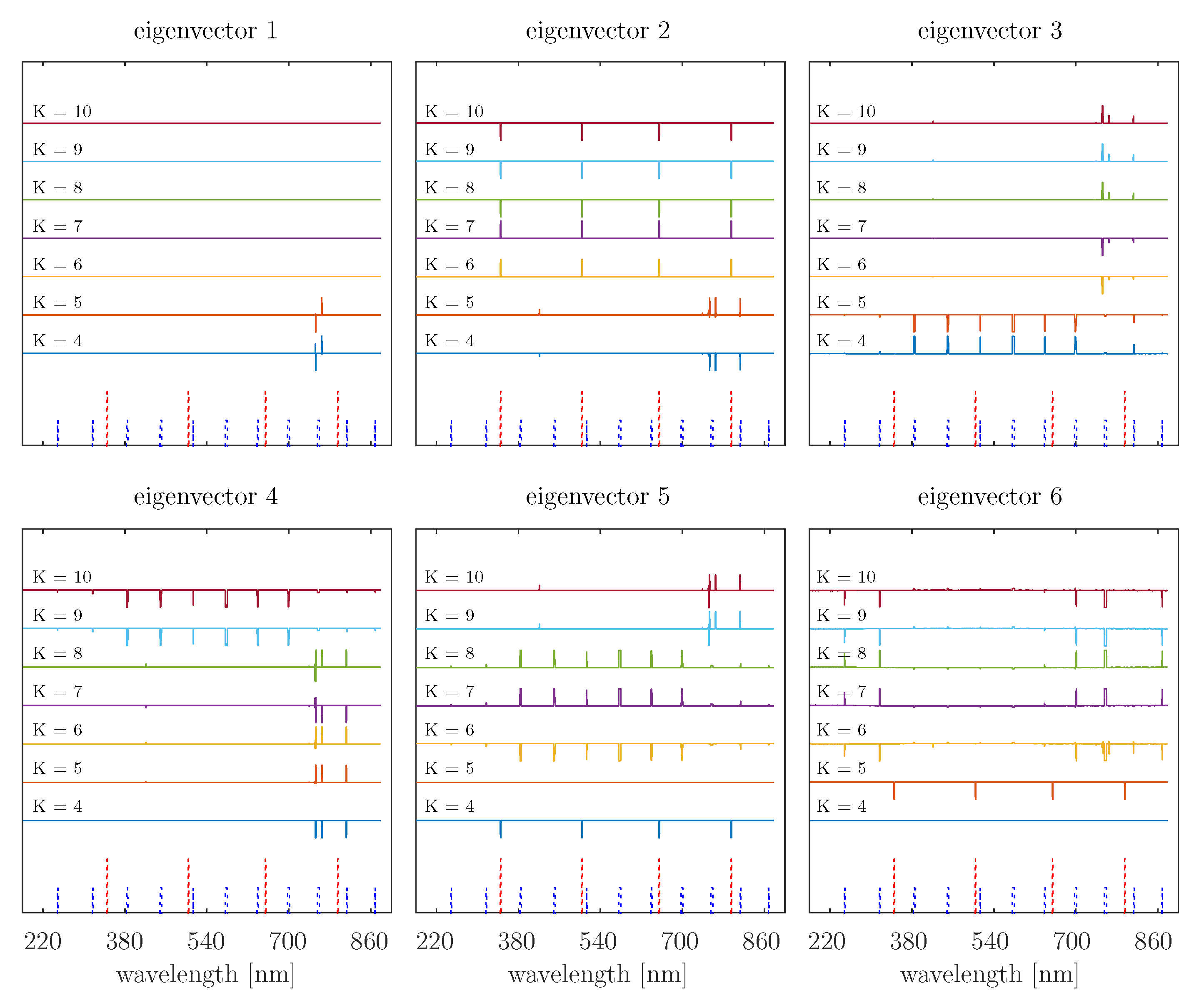
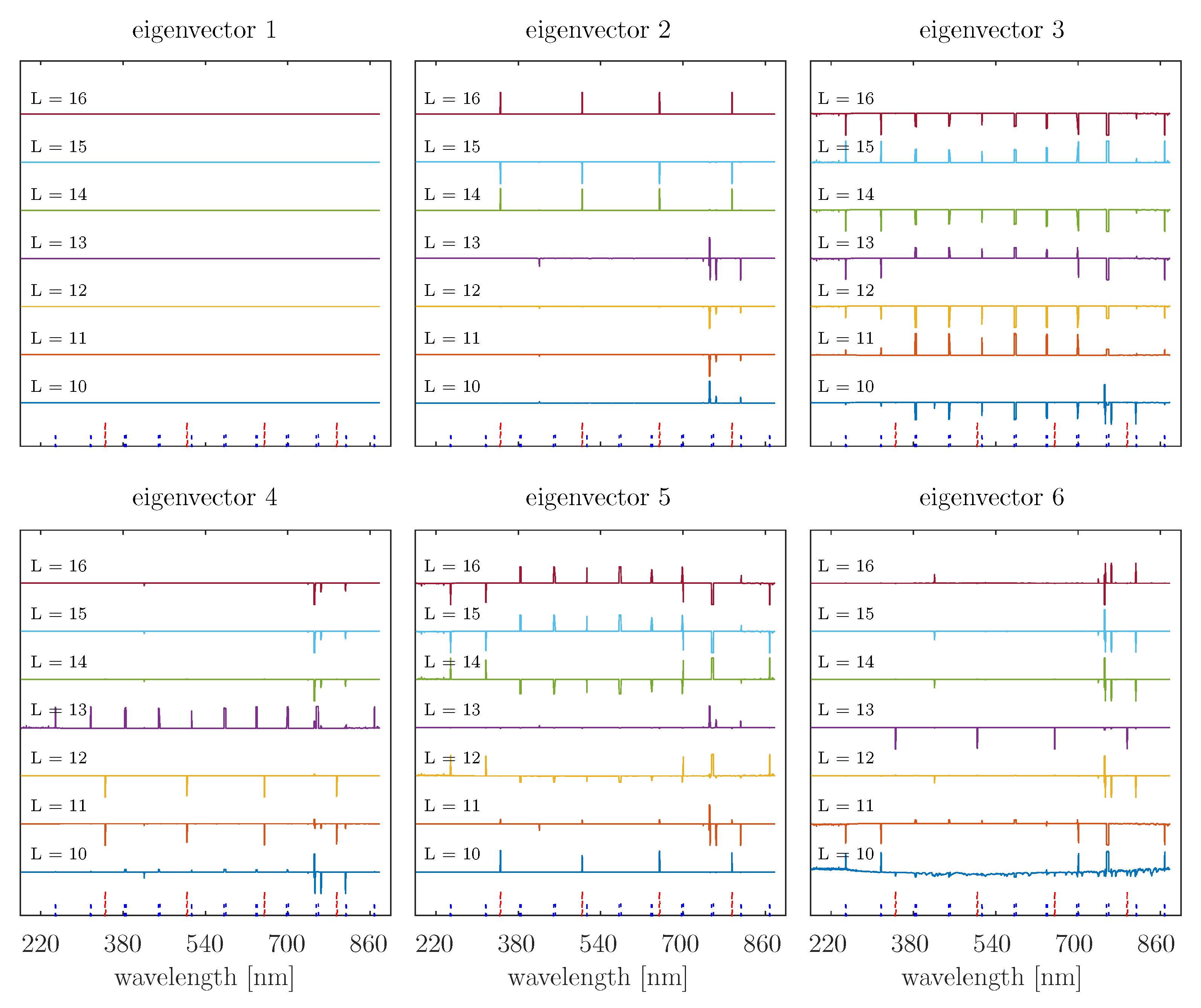
4.1. Eigenvector Analyses
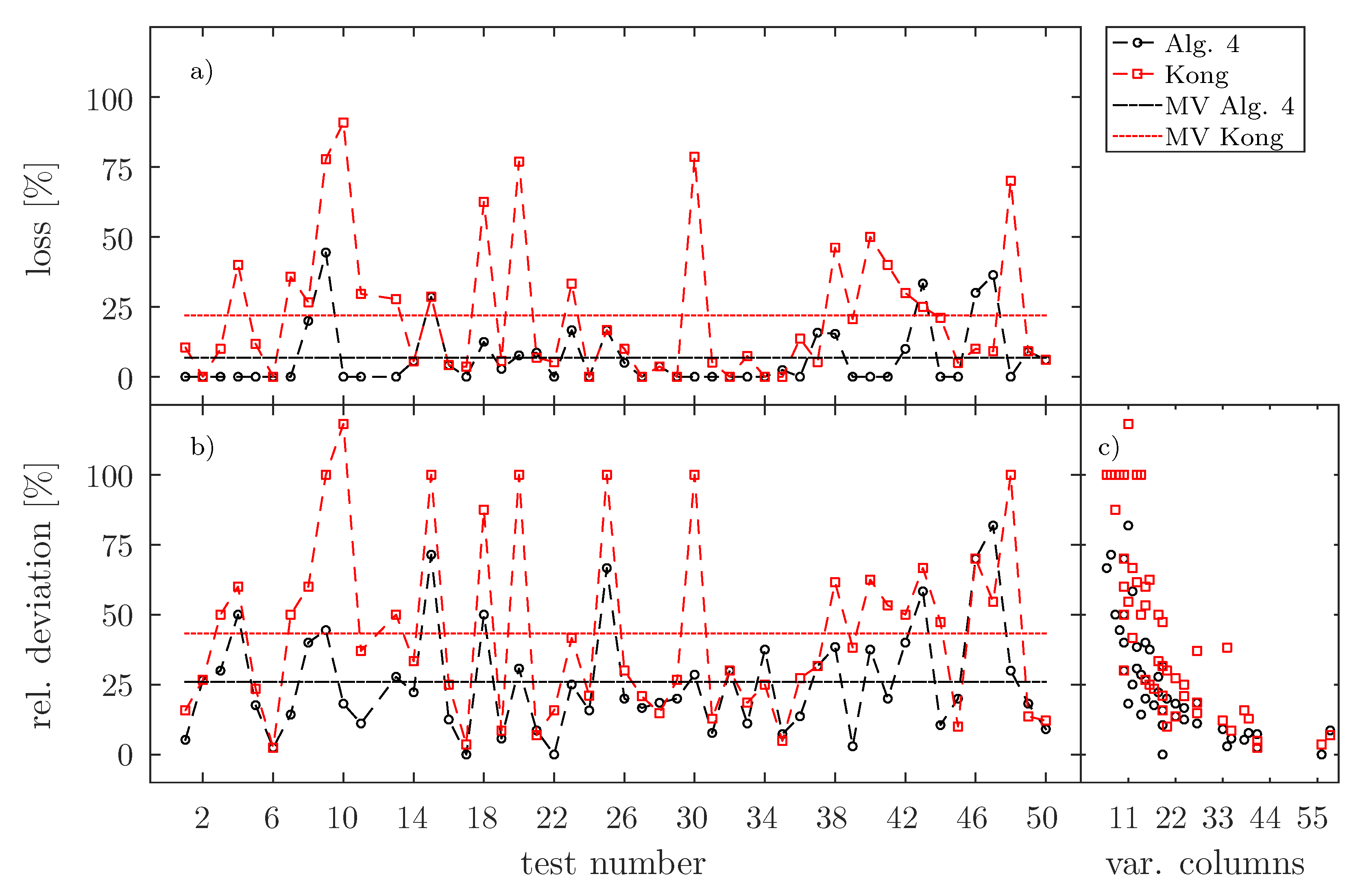
4.2. Application of the Proposed Calculation of the Gaussian Similarity Matrix
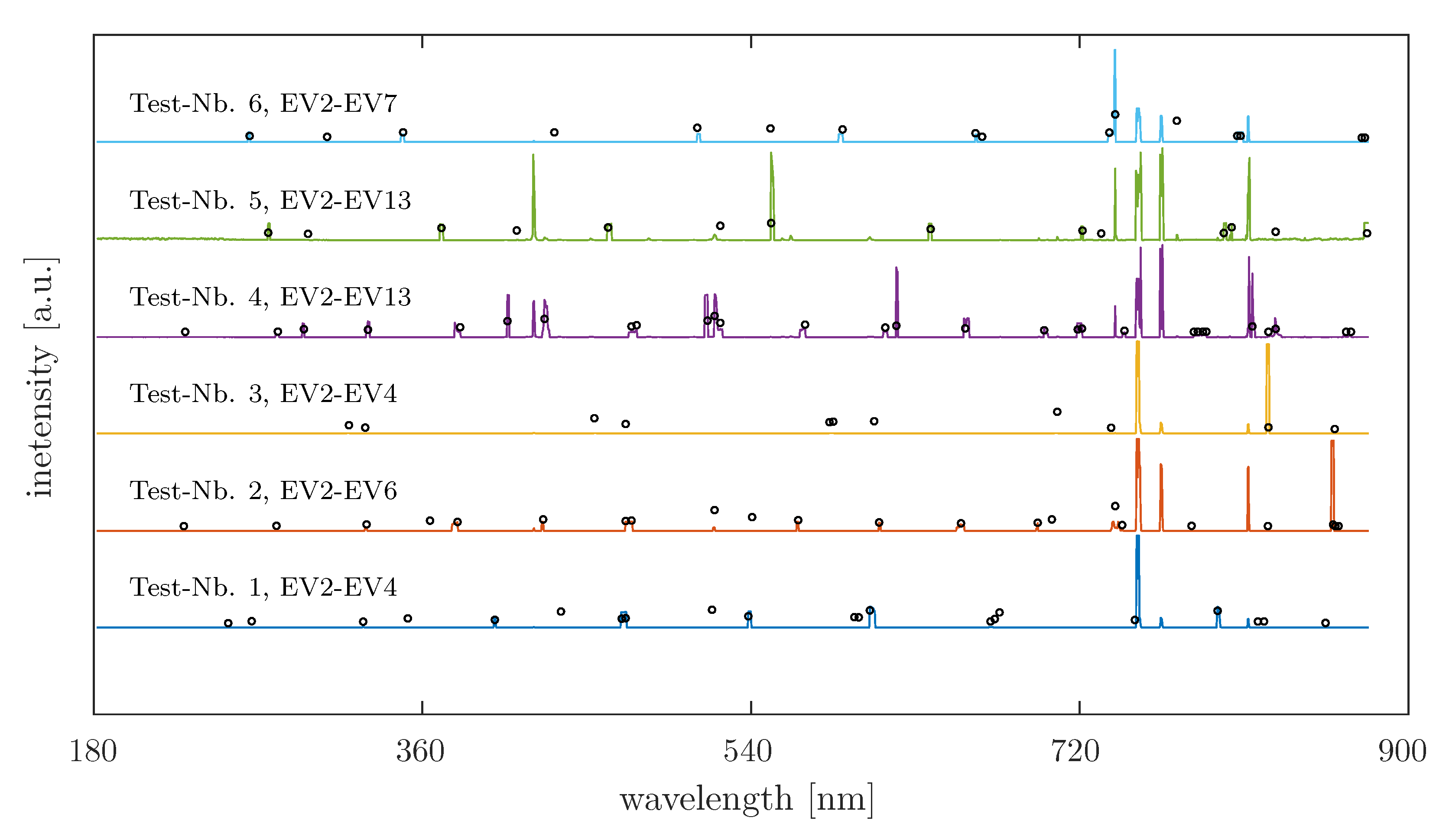
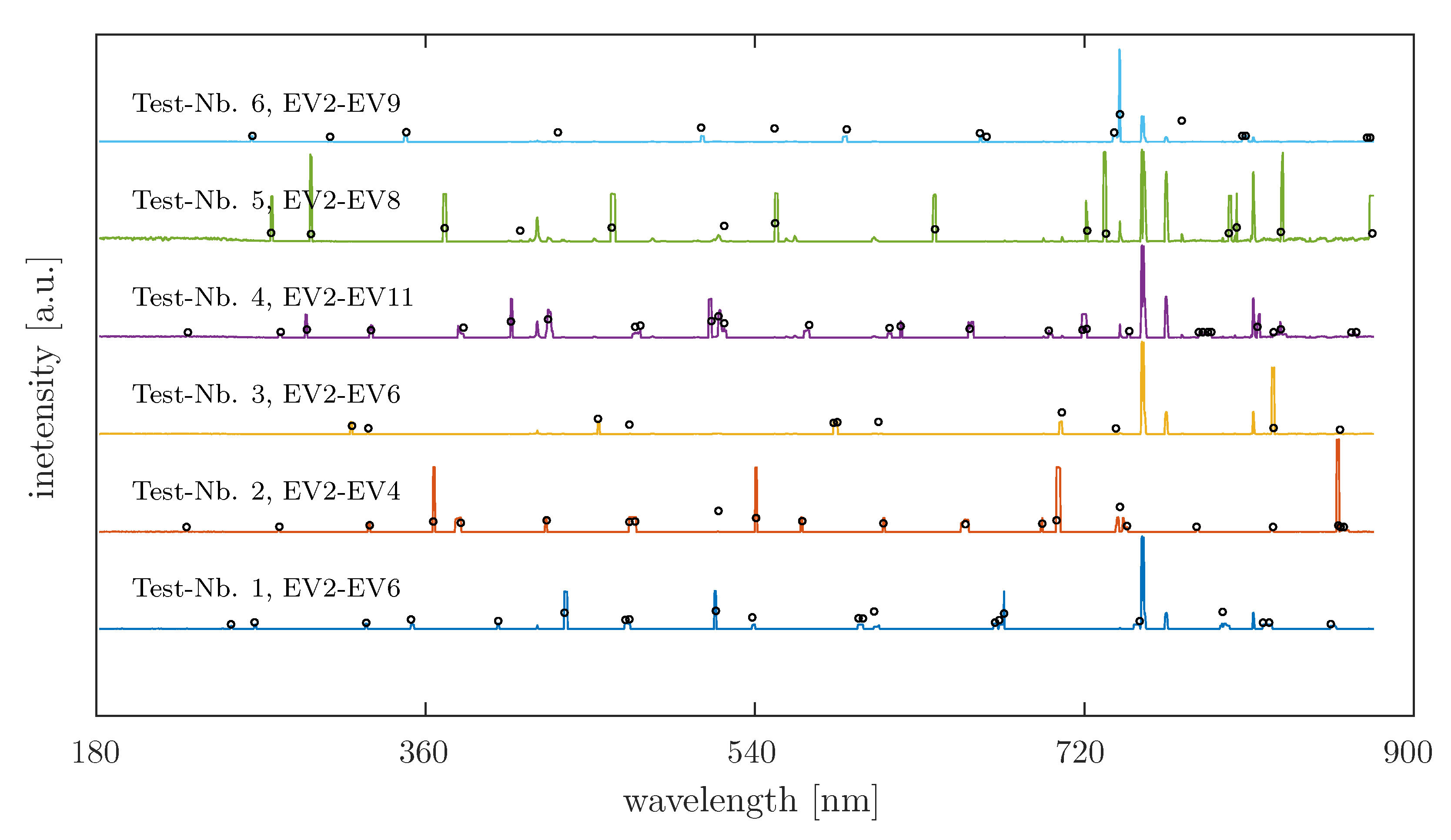
4.3. The Reduced Spectrum of Artificial Generated Data
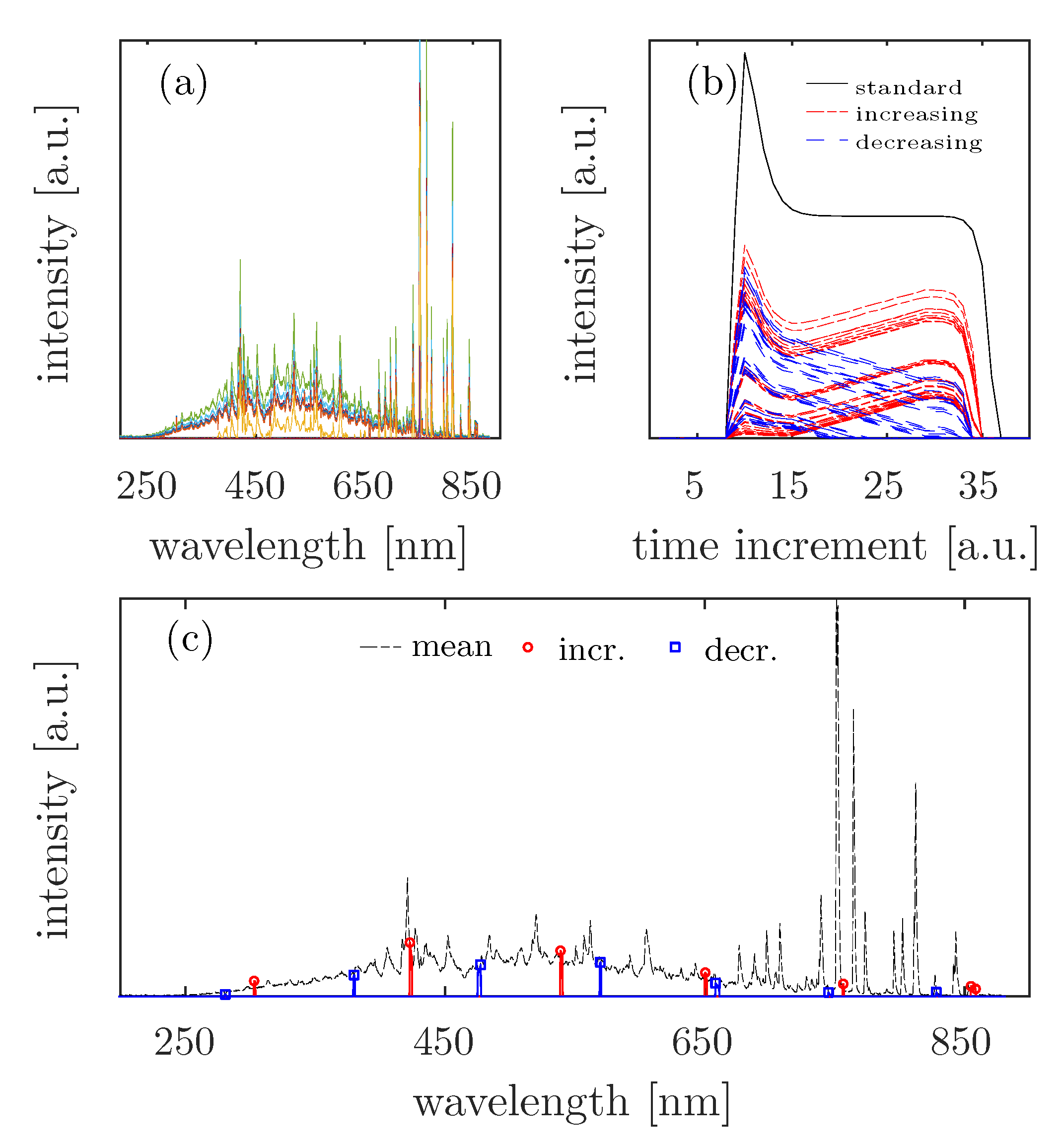
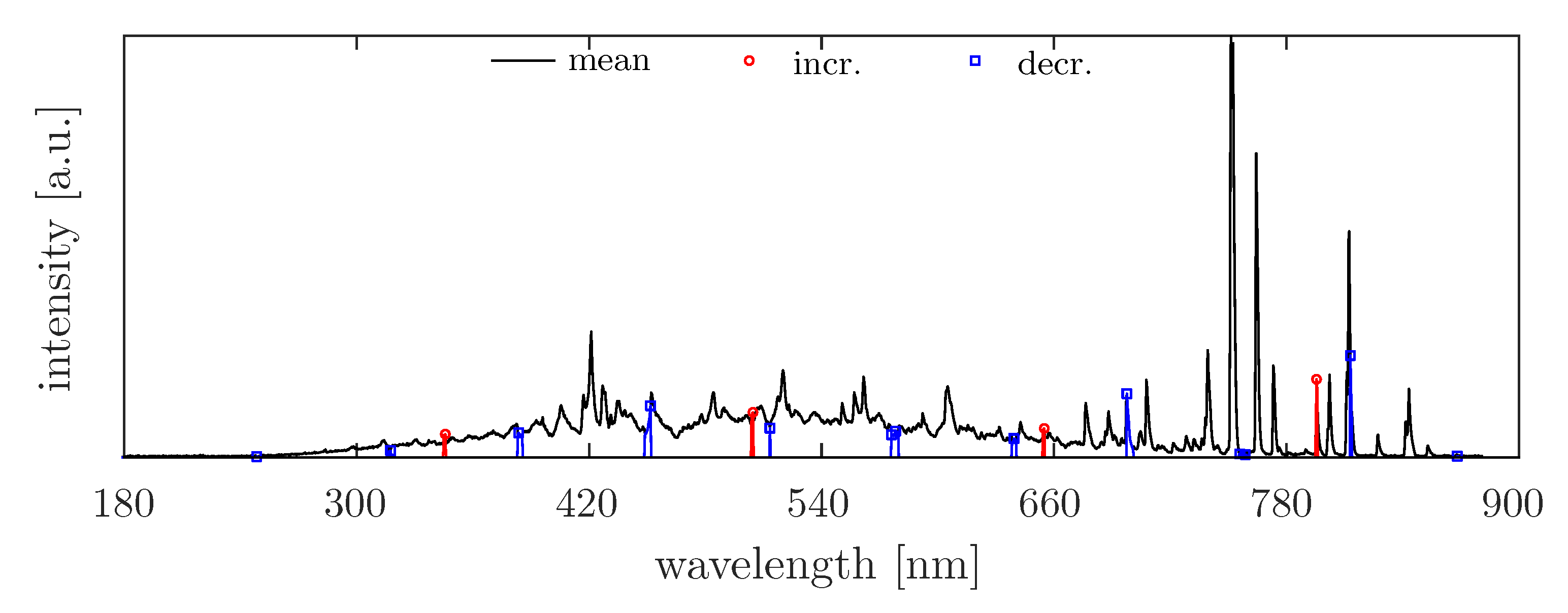
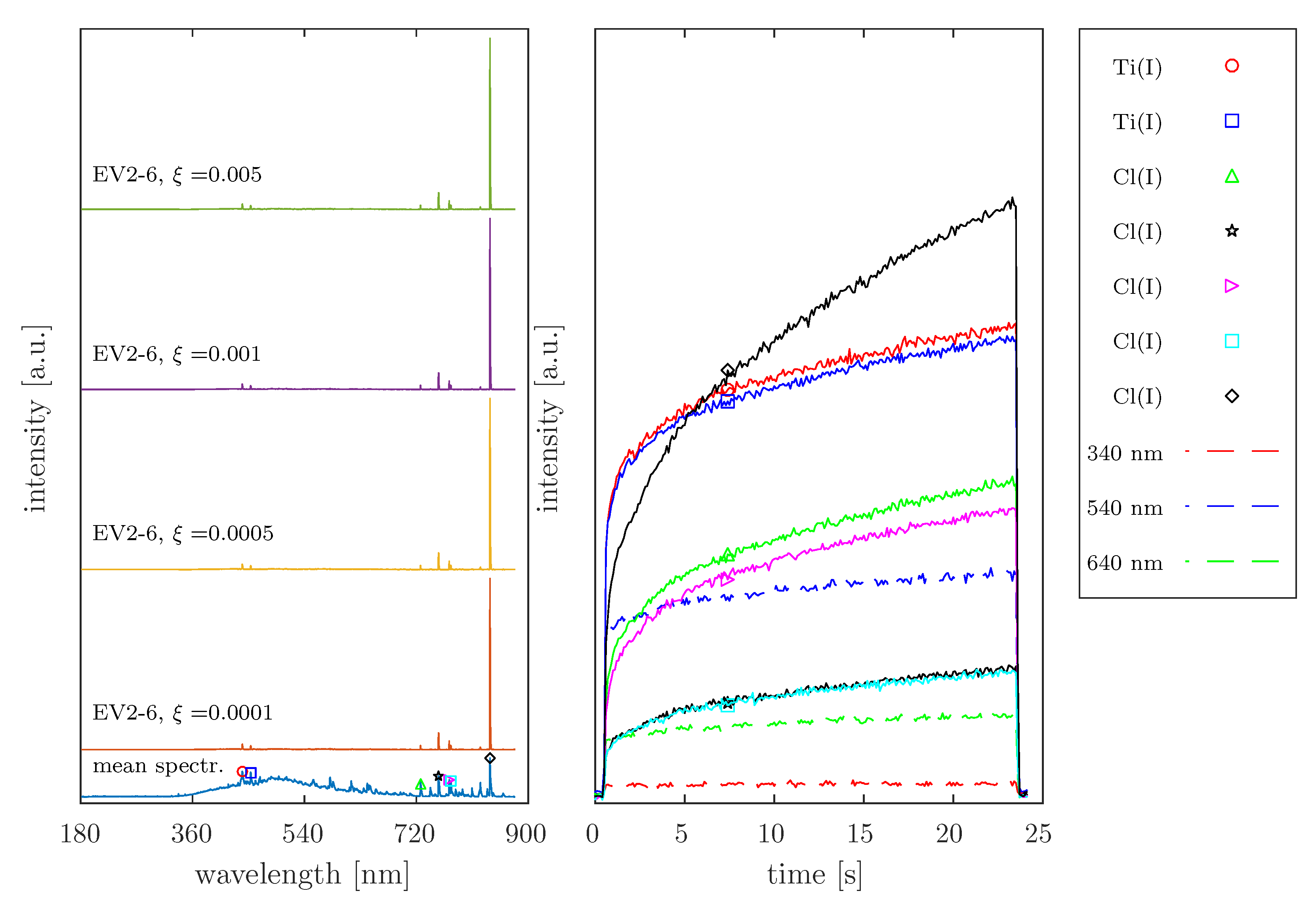
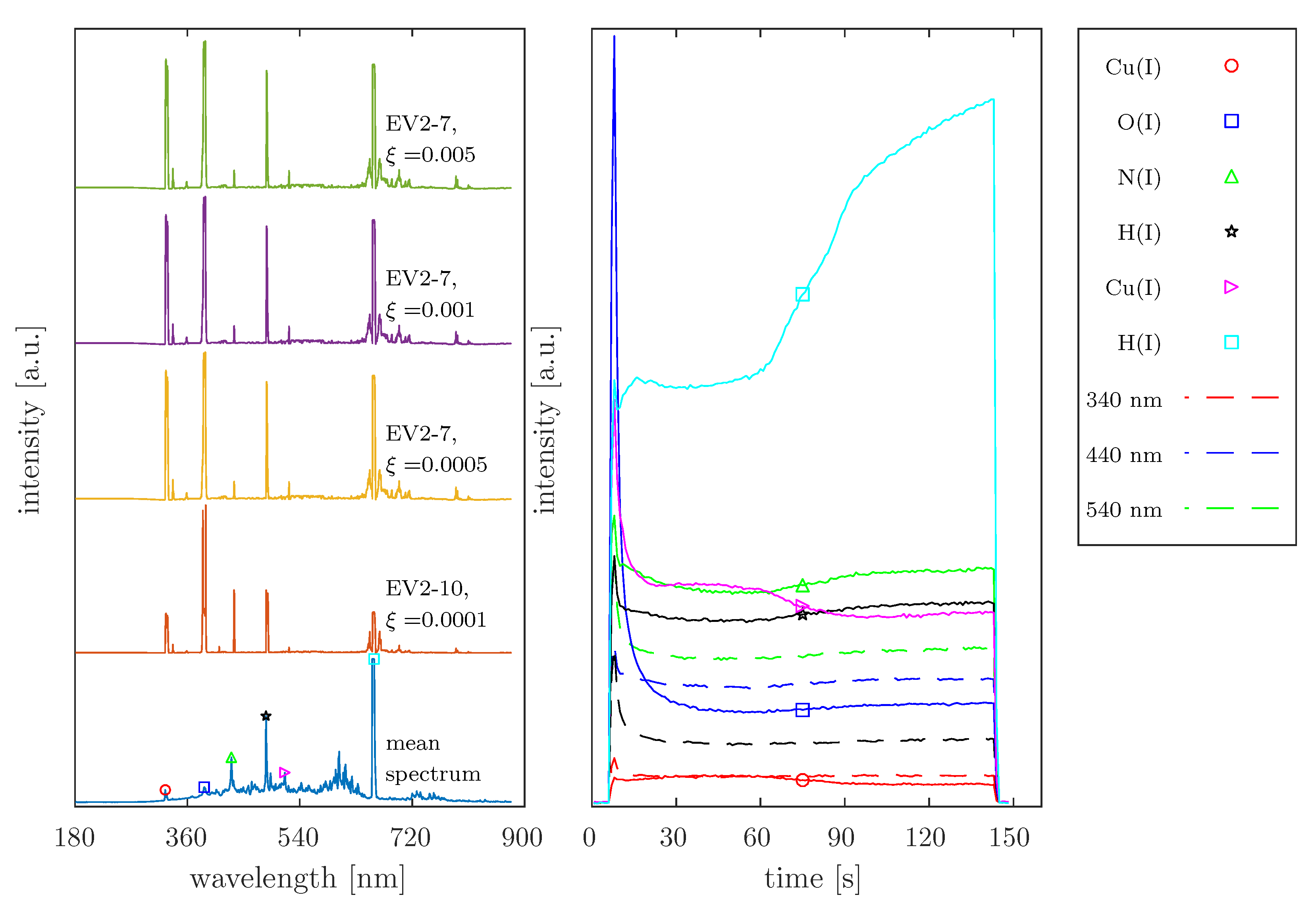
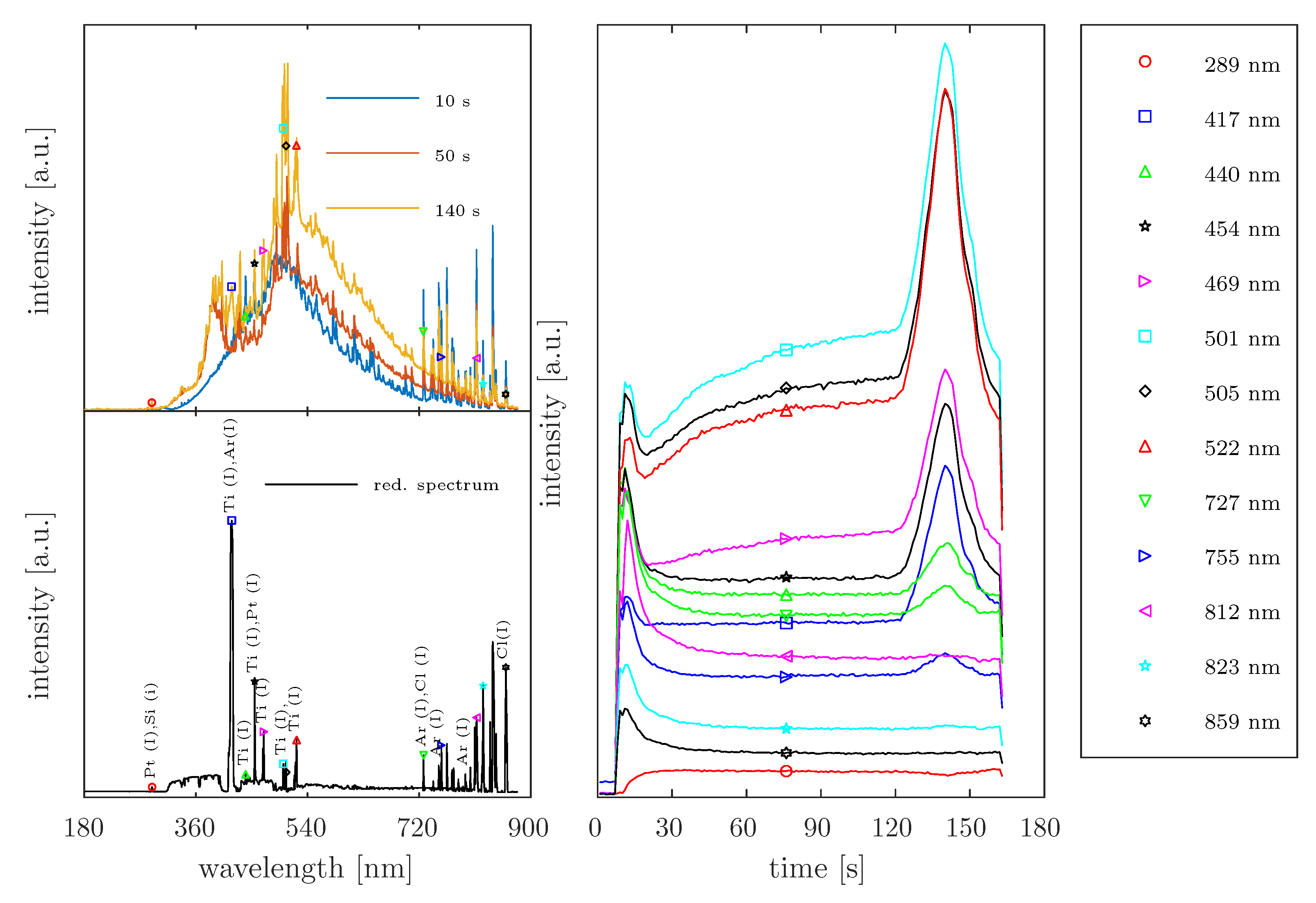
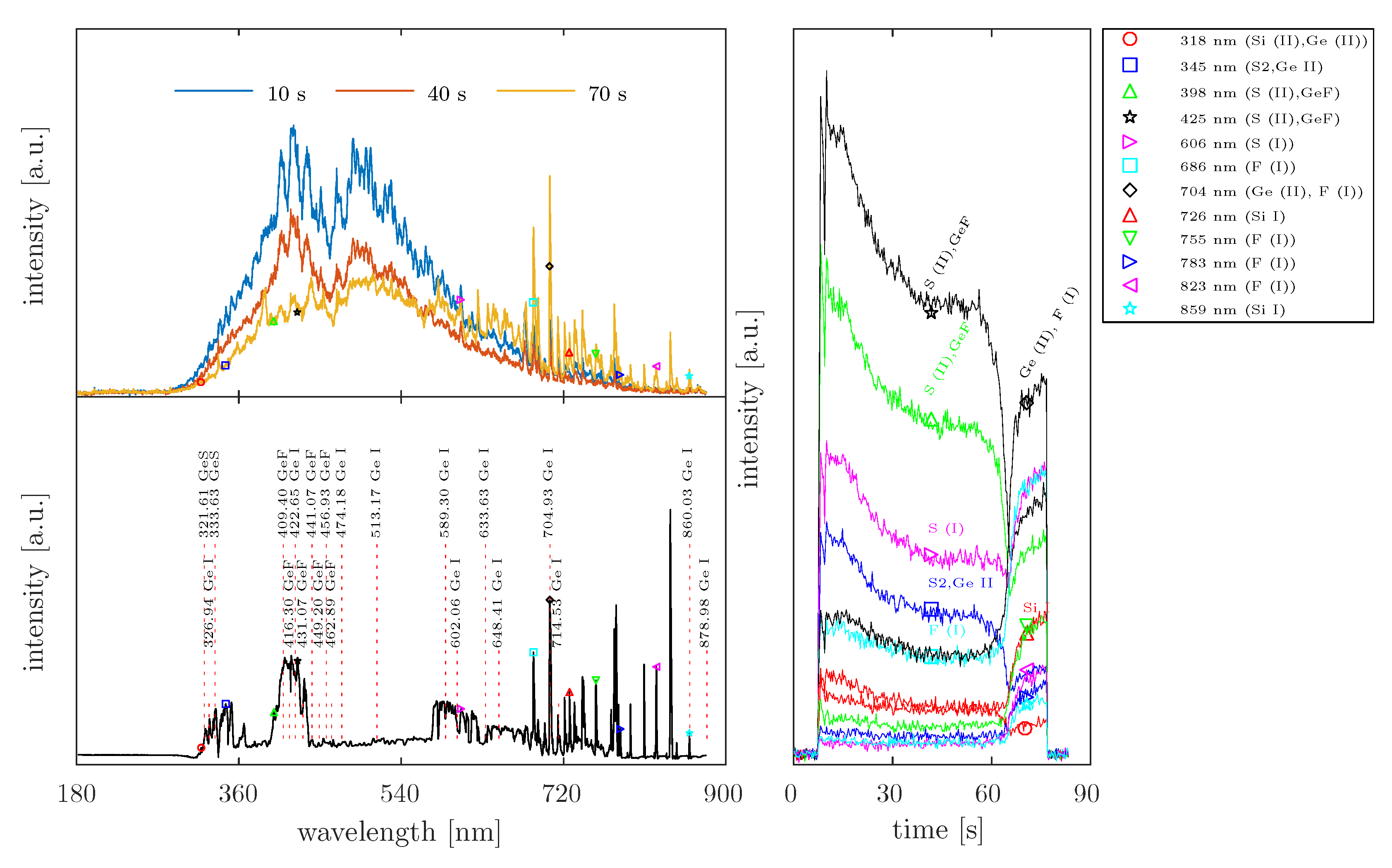
4.4. Analysis of Real OES Data
 ). When considering the intensity variation in the Fluorine emission (686 nm, 755 nm, and 823 nm), an increase in intensities is only observed after the complete removal of Ge. The peak at 704 nm, which was assigned to both the plasma species Germanium and Fluorine, shows an equivalent temporal intensity behavior to the other emission lines associated with Fluorine. Based on this background, the emission of Germanium at this position would be excluded, which disagrees with the findings in the database entries. This aspect is not interpreted in the present study. In addition, a complete assignment of the emission lines found to plasma species is not attempted, because in this study, the OES data sets were used exclusively to test the developed Method of Spectral Redundancy Reduction.
). When considering the intensity variation in the Fluorine emission (686 nm, 755 nm, and 823 nm), an increase in intensities is only observed after the complete removal of Ge. The peak at 704 nm, which was assigned to both the plasma species Germanium and Fluorine, shows an equivalent temporal intensity behavior to the other emission lines associated with Fluorine. Based on this background, the emission of Germanium at this position would be excluded, which disagrees with the findings in the database entries. This aspect is not interpreted in the present study. In addition, a complete assignment of the emission lines found to plasma species is not attempted, because in this study, the OES data sets were used exclusively to test the developed Method of Spectral Redundancy Reduction.5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shadmehr, R.; Angell, D.; Chou, P.B.; Oehrlein, G.S.; Jaffe, R.S. Principal Component Analysis of Optical Emission Spectroscopy and Mass Spectrometry: Application to Reactive Ion Etch Process Parameter Estimation Using Neural Networks. J. Electrochem. Soc. 1992, 139, 907. [Google Scholar] [CrossRef]
- Park, J.H.; Cho, J.H.; Yoon, J.S.; Song, J.H. Machine Learning Prediction of Electron Density and Temperature from Optical Emission Spectroscopy in Nitrogen Plasma. Coatings 2021, 11, 1221. [Google Scholar] [CrossRef]
- Jang, H.; Lee, H.; Lee, H.; Kim, C.K.; Chae, H. Sensitivity Enhancement of Dielectric Plasma Etching Endpoint Detection by Optical Emission Spectra With Modified K -Means Cluster Analysis. IEEE Trans. Semicond. Manuf. 2017, 30, 17–22. [Google Scholar] [CrossRef]
- Lee, S.; Jang, H.; Kim, Y.; Kim, S.J.; Chae, H. Sensitivity Enhancement of SiO2 Plasma Etching Endpoint Detection Using Modified Gaussian Mixture Model. IEEE Trans. Semicond. Manuf. 2020, 33, 252–257. [Google Scholar] [CrossRef]
- Flynn, B.; McLoone, S. Max Separation Clustering for Feature Extraction From Optical Emission Spectroscopy Data. IEEE Trans. Semicond. Manuf. 2011, 24, 480–488. [Google Scholar] [CrossRef]
- Yang, J.; McArdle, C.; Daniels, S. Dimension Reduction of Multivariable Optical Emission Spectrometer Datasets for Industrial Plasma Processes. Sensors 2014, 14, 52–67. [Google Scholar] [CrossRef] [PubMed]
- Puggini, L.; McLoone, S. Feature Selection for Anomaly Detection Using Optical Emission Spectroscopy. IFAC-PapersOnLine 2016, 49, 132–137. [Google Scholar] [CrossRef]
- von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Mohar, B. Some applications of Laplace eigenvalues of graphs. In Graph Symmetry: Algebraic Methods and Applications; Springer: Dordrecht, The Netherlands, 1997; pp. 225–275. [Google Scholar] [CrossRef]
- Zelnik-Manor, L.; Perona, P. Self-Tuning Spectral Clustering. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2005; pp. 1601–1608. [Google Scholar]
- Kong, W.; Hu, S.; Zhang, J.; Dai, G. Robust and smart spectral clustering from normalized cut. Neural Comput. Appl. 2013, 23, 1503–1512. [Google Scholar] [CrossRef]
- Kramida, A.; Ralchenko, Y.; Reader, J.; NIST ASD Team. NIST Atomic Spectra Database (ver. 5.9); National Institute of Standards and Technology: Gaithersburg, MD, USA, 2021. Available online: https://physics.nist.gov/asd (accessed on 26 November 2021).
- Puggini, L.; McLoone, S. An enhanced variable selection and Isolation Forest based methodology for anomaly detection with OES data. Eng. Appl. Artif. Intell. 2018, 67, 126–135. [Google Scholar] [CrossRef]
- Zakour, S.B.; Taleb, H. Shift Endpoint Trace Selection Algorithm and Wavelet Analysis to Detect the Endpoint Using Optical Emission Spectroscopy. Photonic Sens. 2016, 6, 158–168. [Google Scholar] [CrossRef]
- Kyounghoon, H.; Kun, J.P.; Heeyeop, C.; En, S.Y. Modified PCA algorithm for the end point monitoring of the small open area plasma etching process using the whole optical emission spectra. In Proceedings of the ICCAS 2007—International Conference on Control, Automation and Systems, Seoul, Republic of Korea, 17–20 October 2007; pp. 869–873. [Google Scholar] [CrossRef]
- White, D.A.; Goodlin, B.E.; Gower, A.E.; Boning, D.S.; Chen, H.; Sawin, H.H.; Dalton, T.J. Low open-area endpoint detection using a PCA-based T statistic and Q statistic on optical emission spectroscopy measurements. IEEE Trans. Semicond. Manuf. 2000, 13, 193–207. [Google Scholar] [CrossRef]
- Lee, S.; Choi, H.; Kim, J.; Chae, H. Spectral clustering algorithm for real-time endpoint detection of silicon nitride plasma etching. Plasma Process. Polym. 2023, 20, e2200238. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haase, M.; Sayyed, M.A.; Langer, J.; Reuter, D.; Kuhn, H. About the Data Analysis of Optical Emission Spectra of Reactive Ion Etching Processes—The Method of Spectral Redundancy Reduction. Plasma 2024, 7, 258-283. https://0-doi-org.brum.beds.ac.uk/10.3390/plasma7010015
Haase M, Sayyed MA, Langer J, Reuter D, Kuhn H. About the Data Analysis of Optical Emission Spectra of Reactive Ion Etching Processes—The Method of Spectral Redundancy Reduction. Plasma. 2024; 7(1):258-283. https://0-doi-org.brum.beds.ac.uk/10.3390/plasma7010015
Chicago/Turabian StyleHaase, Micha, Mudassir Ali Sayyed, Jan Langer, Danny Reuter, and Harald Kuhn. 2024. "About the Data Analysis of Optical Emission Spectra of Reactive Ion Etching Processes—The Method of Spectral Redundancy Reduction" Plasma 7, no. 1: 258-283. https://0-doi-org.brum.beds.ac.uk/10.3390/plasma7010015